一种基于深度学习的防啸叫扩声方法及系统与流程
本发明属于扩声应用领域,涉及一种基于深度学习的防啸叫扩声方法及系统,特别涉及一种基于深度学习的防啸叫教育扩声方法及系统。
背景技术:
在如学校教室等环境中,由于房间较大,通常需要扩声系统,才能让最后一排学生也能听清楚讲台老师的讲课。尽管扩声系统可以有助于教师讲课,但处理不当,会引入新的问题。
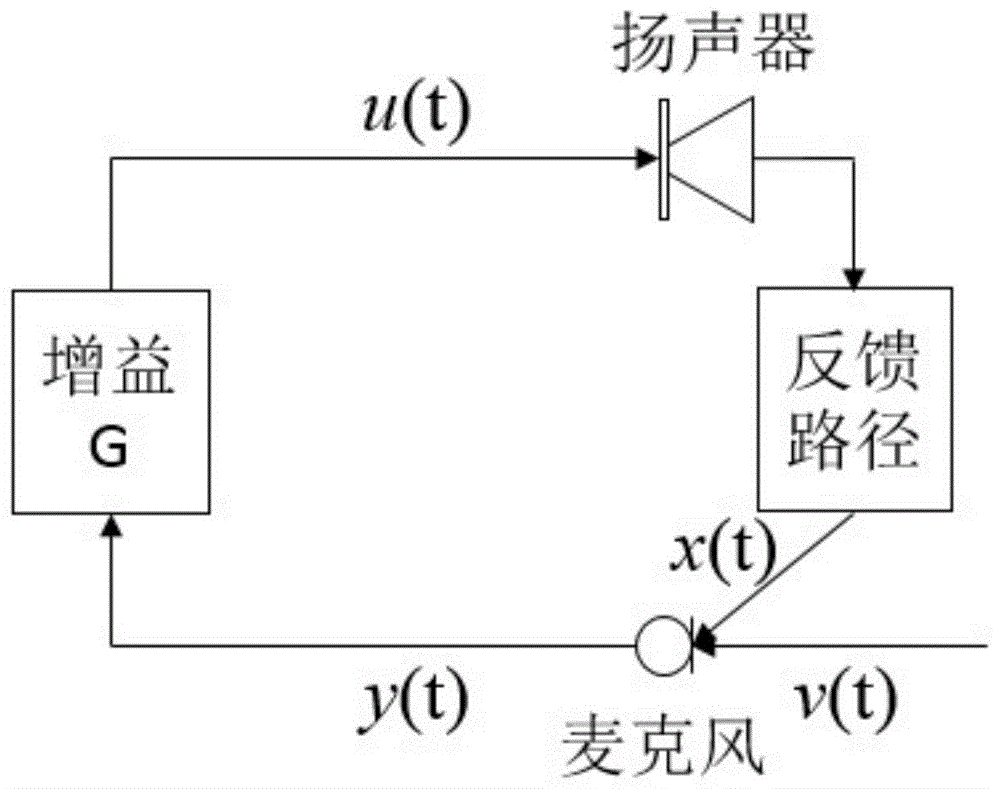
如图1所示,在教育扩声系统中,音频信号经过扬声器系统输出,由传声器拾音后由功率放大器放大后再由扬声器系统输出,形成扬声器系统-传声器-放大器-扬声器系统之间的正反馈,在满足振幅平衡和相位平衡的条件下,此循环会导致整个闭环系统自激振荡产生啸叫现象。啸叫声不仅会造成输出信号失真,恶化主观听音感受,阻碍正常的语音交流,同时有可能会因为输出功率过高而烧坏功率放大器,造成器件损坏。
教育扩声系统中常见的啸叫抑制方法主要有:(1)移频移相;(2)陷波法;(3)自适应滤波器。其中,移频移相对系统音质损伤较大,且提高增益有限;自适应滤波器理论上可以提高无穷大增益,且语音损伤较小,但其对系统非线性敏感度较高,且计算复杂度高,降低成本比较困难。而陷波法在语音损伤和计算复杂度之间取得了一个较好的平衡,因此被广泛应用。
陷波法包括啸叫检测和抑制两部分,其中检测部分通过各种特征判断是否存在啸叫频率点,抑制部分根据检测部分的结果,对相应的啸叫频率成份进行抑制。然而,传统的陷波法中,需要通过人工选择特征向量。
技术实现要素:
本发明的目的是提供一种基于深度学习的防啸叫扩声方法及系统,利用深度学习模型,可以直接从原始数据中获取啸叫频率点,避免了传统方法需要通过人工选择特征向量的缺陷,可以进一步提高啸叫检测准确度。
为达到上述目的,本发明采用的一种技术方案为:
一种基于深度学习的防啸叫扩声方法,包括如下步骤:
a、对采集的语音信号进行预加重;
b、对步骤a预加重后的输入音源信号进行分帧、fft变换、取频谱幅度值的对数并对连续多帧按顺序进行拼接组合,作为深度学习模型的输入;
c、利用训练完的深度学习模型,对步骤b中的输入进行计算,并输出向量;
d、取所述输出向量的最大值,若其为所述输出向量中的最后一个元素,则不存在啸叫;否,则存在啸叫,执行下一步骤;
e、精确定位啸叫频率;
f、根据精确定位的啸叫频率,进行抑制。
优选地,所述步骤c中的深度学习模型由如下步骤训练或所述防啸叫扩声方法还包括如下步骤:
a、提供预采集的声音作为训练音源信号,并进行预加重;
b、对步骤a预加重后的训练音源信号进行分帧、fft变换并取频谱幅度值的对数;
c、将连续多帧信号组成一组输入向量x,判断这组信号是否存在啸叫信号并记录啸叫信号位置,若不存在啸叫信号,则标记为
d、当输入向量为非啸叫信号时,则标记输出向量
e、将步骤c的输入向量x和步骤d的输出向量y作为训练集,使用后向传播算法对深度学习模型进行训练。
更优选地,所述步骤a或步骤a中,预加重滤波器为h(z)=1-αz-1,其中,z为延时单元,α为调节参数。
更优选地,所述步骤b或步骤b中,对分帧后的每帧信号做fft变换y(ωi,n),ωi为数字频率,i=0,1,…(i-1),n为帧数,对fft频谱取绝对值y1(ωi,n)=|y(ωi,n)|,并按10为底数并取其对数y2(ωi,n)=20*log10y1(ωi,n);
所述步骤c中,将连续n帧信号组成一组输入向量x;所述步骤d中,采用dnn深度学习模型,包含输入层向量大小为(i×n)×1,三层隐藏层大小都为m×1,输出大小为(i+1)×1,输入层为n帧频谱信号y2(ωi,n)按顺序拼成的(ixn)x1向量x,隐藏层激活函数σ(x)为relu,其表达式为σ(x)=max(x,0),其中max(·,·)为取两个数的最大数,输出层激活函数采用softmax,其表达式为:
其中si为输出层的第i个输出,xi为输出层的第i个输入,xj为输出层的第j个输入;
误差函数err采用交叉熵,其表达式为:
优选地,所述步骤a中,采用麦克风阵列采集声音,并划分频带,将不同的麦克风分配给不同的频带,对同一频带内的各麦克风进行滤波,并分别赋予不同的增益,对同一频带内的各麦克风的输出进行叠加形成当前频带输出,并最终对所有频带输出叠加形成总输出;其中,所述麦克风阵列包括多个麦克风,所述多个麦克风沿一弧形间隔排列。采用麦克风阵列,可以进一步降低反馈路径增益,降低啸叫发生的概率;利用弧形麦克风阵列,具有天然聚焦性,进一步增强指向性。
更优选地,所述麦克风阵列对称设置,除位于弧形中间位置的麦克风外,任一麦克风与其靠近弧形中间位置一侧的相邻麦克风之间的弧长d1小于与其远离弧形中间位置一侧的相邻麦克风的之间的弧长d2。麦克风阵列采用非均匀分布,可以在同等引径下,减少麦克风个数,降低硬件成本;同时利用子带分析和非均匀分布,可以达到宽带指向性一致的效果,并利用模拟电路实现,进一步降低硬件成本。
进一步地,弧长d2为弧长d1的两倍。
本发明采用的另一种技术方案为:
一种基于深度学习的防啸叫扩声系统,包括:
麦克风阵列,其用于采集待扩声区域的声音;
麦克风驱动电路,其用于驱动所述麦克风系统工作,所述麦克风驱动电路和所述麦克风阵列电性连接;
宽带波束形成电路,其用于进行波束形成,所述宽带波束形成电路和所述麦克风驱动电路电性连接;
ad转换装置,其用于将模拟信号转换为数字信号,所述ad转换装置和所述宽带波束形成电路电性连接;
dsp处理器,其用于执行如上所述的防啸叫扩声方法,所述dsp处理器和所述ad转换装置电性连接;
da转换装置,其用于将数字信号转换为模拟信号,所述da转换装置和所述dsp处理器电性连接;及
扬声器驱动电路,其用于驱动扬声器将电信号转化为声信号,所述扬声器驱动电路和所述da转换装置及所述扬声器电性连接。
优选地,所述麦克风阵列包括多个麦克风,所述多个麦克风沿一弧形间隔排列,所述麦克风阵列对称设置,除位于弧形中间位置的麦克风外,任一麦克风与其靠近弧形中间位置一侧的相邻麦克风之间的弧长d1小于与其远离弧形中间位置一侧的相邻麦克风的之间的弧长d2。采用麦克风阵列,可以进一步降低反馈路径增益,降低啸叫发生的概率;利用弧形麦克风阵列,具有天然聚焦性,进一步增强指向性;麦克风阵列采用非均匀分布,可以在同等引径下,减少麦克风个数,降低硬件成本;同时利用子带分析和非均匀分布,可以达到宽带指向性一致的效果,并利用模拟电路实现,进一步降低硬件成本。
优选地,所述多个麦克风划分为多组,每组麦克风对应一个频带,所述宽带波束形成电路包括多组麦克风通道、多个第一加法电路及一个第二加法电路,每个麦克风通道分别包括相互串接的带通滤波电路和增益电路,每个带通滤波电路分别和一个麦克风连接,每组所述麦克风通道对应一个频带并由对应该频带的多个麦克风通道组成,各所述第一加法电路分别与对应的一组麦克风通道的增益电路连接以对同一频带内的各麦克风的输出进行叠加形成当前频带输出,所述第二加法电路与所述多个第一加法电路连接以对所有频带输出叠加形成总输出。
本发明采用以上方案,相比现有技术具有如下优点:
利用深度学习模型,自动从原始频域数据中学习啸叫规律,避免了人工进行特征选择和判断,降低了调试难度,可以进一步提高啸叫检测准确度。
附图说明
为了更清楚地说明本发明的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为扩声系统的声反馈示意图;
图2、3分别为发生啸叫时的时域图和时频图;
图4为防啸叫扩声方法的运行过程示意图;
图5为实施例的防啸叫扩声系统的结构框图;
图6为麦克风阵列的间距示意图;
图7为频带划分及波束输出的示意图;
图8为宽带波束形成电路的结构框图;
图9为带通滤波电路的电路图;
图10为增益电路的电路图;
图11为第一加法电路的电路图。
具体实施方式
下面结合附图对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域的技术人员理解。在此需要说明的是,对于这些实施方式的说明用于帮助理解本发明,但并不构成对本发明的限定。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以互相结合。
本实施例提供一种基于深度学习的防啸叫教育扩声方法,其分为训练和运行两部分,在运行之前需要先对所采用的深度学习模型训练。在另外一些实施例中,可直接采用训练好的深度学习模型运行防啸叫扩声方法。
本实施例中,深度学习模型通过如下步骤训练:
1、利用教育扩声系统装置(此时dsp处理器中的程序为直通程序,并将原始录音数据上传至上位机进行记录),在不同大小、不同教室环境中进行记录原始录音数据预加重并进行分帧,数据采样率为16khz,每帧信号长度为1024点(64ms),帧与帧之间的移位为256点(16ms),其中,预加重滤波器为h(z)=1-αz-1,z为延时单元,α为调节参数,本实施例中取值为0.9,用于抬高高频成份,降低低频权重。
2、对每帧信号做fft变换y(ωi,n),ωi为数字频率,i=0,1,…512(由于对称性,只取前述一半),n为帧数,对fft频谱取绝对值y1(ωi,n)=|y(ωi,n)|,并按10为底数并取其对数y2(ωi,n)=20*log10y1(ωi,n)。其中发生啸叫时的时域图和时频图分别如图2和图3所示。
3、将连续7帧信号组成一组输入向量x,通过人工判断这组向量x是否存在啸叫信号和啸叫信号位置,并做相应标记,如果不存在啸叫信号,则标记为
4、深度学习模型为dnn,包含输入层向量大小为(513x7)3591x1,三层隐藏层大小都为2048x1,输出大小为514x1。
5、dnn采用全连接方式,输入层为7帧频谱信号y2(ωi,n),按顺序拼成的(513x7)x1向量,隐藏层激活函数σ(x)为relu,其表达式为σ(x)=max(x,0),其中max(·,·)为取两个数的最大数,输出层激活函数采用softmax,其表达式为:
其中si为输出层的第i个输出,xi为输出层的第i个输入,xj为输出层的第j个输入。
6、误差函数err采用交叉熵,其表达式为:
令y=[y0,y1,…,y513],当输入的7帧信号对应为非啸叫信号时,则标记输出向量
7、将输入向量x和输出向量y作为训练集,使用后向传播算法对深度学习模型进行训练,本实施例中使用pytorch、tensorflow等开源软件进行深度学习训练。
结合图4所示,该防啸叫扩声方法的运行过程如下:
a、对输入信号进行预加重,与训练时的预加重表达式一样。
b、对步骤a中预加重后的信号进行分帧,并做fft变换,再取频谱幅度值的对数,最后对连续7帧按顺序进行拼接组合,作为深度学习模型的输入。下一次的组合与上一次的组合间距为1帧。
c、利用训练完的模型参数,对步骤b中的输入进行计算,输出向量y大小为514x1。
d、取步骤c中输出向量的最大值,如果对应的下标为y中的最后一个元素,则不存在啸叫,否则存在啸叫。
e、如果存在啸叫,则针对啸叫频率点附近的区间,利用czt(chirpz-transform)变换进一步细化频率分辨率,精确定位啸叫频率。
f、根据步骤e中的啸叫频率,在啸叫抑制中利用陷波器进行抑制。
本实施例还提供一种用于执行上述防啸叫扩声方法的防啸叫扩声系统。参照图5所示,该防啸叫扩声系统包括:
麦克风阵列,其用于采集待扩声区域的声音;
麦克风驱动电路,其用于驱动所述麦克风系统工作,所述麦克风驱动电路和所述麦克风阵列电性连接;
宽带波束形成电路,其用于进行波束形成,所述宽带波束形成电路和所述麦克风驱动电路电性连接;
ad转换装置,其用于将模拟信号转换为数字信号,所述ad转换装置和所述宽带波束形成电路电性连接;
dsp处理器,其用于执行如上所述的防啸叫扩声方法,所述dsp处理器和所述ad转换装置电性连接;
da转换装置,其用于将数字信号转换为模拟信号,所述da转换装置和所述dsp处理器电性连接;及
扬声器驱动电路,其用于驱动扬声器将电信号转化为声信号,所述扬声器驱动电路和所述da转换装置及所述扬声器电性连接。
结合图5和图6所示,麦克风阵列包括多个麦克风,所述多个麦克风沿一弧形间隔排列。所述麦克风阵列对称设置,除位于弧形中间位置的麦克风外,任一麦克风与其靠近弧形中间位置一侧的相邻麦克风之间的弧长d1小于与其远离弧形中间位置一侧的相邻麦克风的之间的弧长d2。本实施例中,弧长d2为弧长d1的两倍。应用在教育扩声系统中,麦克风阵列用于接收教师讲课声音,通过利用麦克风阵列的指向性降低反馈路径增益,降低啸叫发生的概率;麦克风阵列非均匀分布在圆弧上,在利用较大张径的同时减少麦克风个数,较大的张径可以取得更好的低频指向性效果,而非均匀分布可以减少麦克风个数,降低硬件成本。非均匀分布麦克风的弧度间距从中间开始按照倍数增长。本实施例中麦克风阵列具体设置如下:
a、划分频带,教育系统主要考虑人声扩声,人声频率主要分布在[300,4000]hz之间,同时为提高语音质量,系统采样率设为16khz。按照倍频程划分频带为中心频率500hz([353hz、707hz])、1khz([707hz、1414hz])、2khz([1414hz、2828hz])、4khz([2828hz、5657hz])和6khz([5657hz、8000hz])的五个区间。
b、如图6所示,根据频带划分将不同的麦克分配给不同的频带,其中[0,1,2]分配给6khz,麦克风间距为1cm,[0,2,3]分配给4khz,麦克风间距为2cm,[0,3,4]分配给2khz,麦克风间距为4cm,[0,4,5]分配给1khz,麦克风间距为8cm,[0,5,6]分配给500hz,麦克风间距为16cm。
c、最后根据实际长度大小,将图6中的线阵弯曲成圆弧阵,线阵本身具有正前方指向性,形成圆弧阵后,由于圆弧天然的聚焦性,圆弧阵会有更好的指向性。因为教师一般在讲台区域活动,将圆弧阵指向讲台区域即可。
麦克风驱动电路用于提供麦克风偏置电压,使麦克风可以正常工作。
宽带波束形成电路用于在模拟域中进行波束形成。具体如下:
i、根据上述步骤a中的划分,每一组频带由5个麦克风组成;
ii、针对某一频带,先对其中的5个麦克风根据相应的频带带宽进行滤波,滤完波以后,对不同的麦克风通道赋于不同的增益,增益由hamming窗决定,按从左到右顺序为:[0.0800,0.5400,1.0000,0.5400,0.0800],进一步增强正前方指向性,最后对5个麦克风的输出进行叠加形成当前频带输出;如图7即示出了500hz频带的波束输出;
iii、对所有频带都执行步骤ii,最后将所有输出的频带进行叠加,作为最终的输出。
图8示出了本实施例采用的宽带波束形成电路,所述宽带波束形成电路包括多组麦克风通道、多个第一加法电路及一个第二加法电路,每个麦克风通道分别包括相互串接的一个带通滤波电路和一个增益电路,每个带通滤波电路分别和一个麦克风连接,每组所述麦克风通道对应一个频带并由对应该频带的多个麦克风通道组成,各所述第一加法电路分别与对应的一组麦克风通道的增益电路连接以对同一频带内的各麦克风的输出进行叠加形成当前频带输出,所述第二加法电路与所述多个第一加法电路连接以对所有频带输出叠加形成总输出。
图9示出了图8中的一个带通滤波电路。参照图9所示,带通滤波电路包括一个第一电容c1、一个第二电容c2、一个第一电阻r1、一个第二电阻r2、一个第三电阻r3及一个运算放大器u1。第一电阻r1连接带通滤波电路的输入端mic_in,其为相应麦克风的输出;第二电容c2连接于第一电阻r1和运算放大器u1的反相输入端之间;第一电容c1的一端连接于第一电阻r1和第二电容c2之间,另一端连接于运算放大器u1的输出端v12;第三电阻r3的一端连接于第二电容c2和运算放大器u1的反相输入端之间,另一端连接于运算放大器u1的输出端v12;第二电阻r2的一端连接于第一电阻r1和第二电容c2之间,另一端接地;运算放大器u1的同相输入端接地。该带通滤波电路具体为负反馈双二次型带通滤波电路。
图10示出了图8中的一个增益电路。参照图10所示,该增益电路和图9所示的带通滤波电路连接,带通滤波电路的输出v12即作为该增益电路的输入端v12。该增益电路包括一个第四电阻r4和一个运算放大器u2,第四电阻r4连接输入端v12,运算放大器u2的反向输入端连接第四电阻r4,运算放大器u2的同相输入端接地。该增益电路还包括并联于运算放大器u2的反相输入端和输出端v23_1之间的第五电阻r5。该增益电路的输出即为某一麦克风通道的输出。
图11示出了图8中的一个第一加法电路。参照图11所示,该第一加法电路具有多个输入端v23_1、v23_2、v23_3、v23_4及v23_5,分别为某一频带的5个麦克风通道的输出。该第一加法电路包括多个电阻及一个运算放大器u3,其中,输入端v23_1和第六电阻r6串接后连接于运算放大器u3的反相输入端,输入端v23_2和第七电阻r7串接后连接于运算放大器u3的反相输入端,输入端v23_3和第八电阻r8串接后连接于运算放大器u3的反相输入端,输入端v23_4和第九电阻r9串接后连接于运算放大器u3的反相输入端,输入端v23_5和第十电阻r10串接后连接于运算放大器u3的反相输入端。运算放大器u3的同相输入端接地。该第一加法电路还包括并联于所述运算放大器u3的反相输入端和输出端v34_1之间的第十一电阻r11。该第一加法电路的输出即为某一频带的所有麦克风的输出。
第二加法电路的结构基本同图11所示的第一加法电路,区别在于,第二加法电路的多个输入端和各第一加法电路的输出端连接,即将各第一加法电路输出的所有频带的输出作为输入,并对其进行叠加,形成宽带波束形成电路的总输出。
ad转换装置是将宽带波束形成电路的输出转化为数字信号,dsp处理器利用深度学习模型进行啸叫判断,并根据啸叫情况,对输入信号进行相应的抑制并输出至da转换装置,da转换装置将数字信号转换为模拟信号输出至扬声器驱动电路。扬声器驱动电路将da的输出通过扬声器将电信号转化为声信号后在空间中进行播放。
通过非均匀分布和宽带波束形成,在同等长度条件下,可以减少麦克风个数,同时利子带分配,可以在不同的频带内取得同样的指向性,即宽带指向性效果一样,同时只利用了硬件模拟电路,避免了数字信号处理,需要多通道ad解码器,降低了硬件成本。
本实施例的防啸叫扩声方法及防啸叫扩声系统具有如下优点:
(1)利用深度学习模型,自动从原始频域数据中学习啸叫规律,避免了人工进行特征选择和判断,降低了调试难度;
(2)采用麦克风阵列,可以进一步降低反馈路径增益,降低啸叫发生的概率;
(3)采用非均匀分布,可以在同等引径下,减少麦克风个数,降低硬件成本;同时利用子带分析和非均匀分布,可以达到宽带指向性一致效果,并利用模拟电路实现,进一步降低硬件成本;
(4)利用弧形麦克风阵列,具有天然聚焦性,进一步增强指向性。
上述实施例只为说明本发明的技术构思及特点,是一种优选的实施例,其目的在于熟悉此项技术的人士能够了解本发明的内容并据以实施,并不能以此限定本发明的保护范围。凡根据本发明的精神实质所作的等效变换或修饰,都应涵盖在本发明的保护范围之内。
-
 0188554... 来自[中国] 2021年12月09日 16:23最近也在研究啸叫,可以麻烦博主把对应模型发给参考一下吗
0188554... 来自[中国] 2021年12月09日 16:23最近也在研究啸叫,可以麻烦博主把对应模型发给参考一下吗