一种车辆CAN总线数据分类方法及装置与流程
本发明涉及车联网
技术领域:
,特别涉及一种车辆can总线数据分类方法及装置。
背景技术:
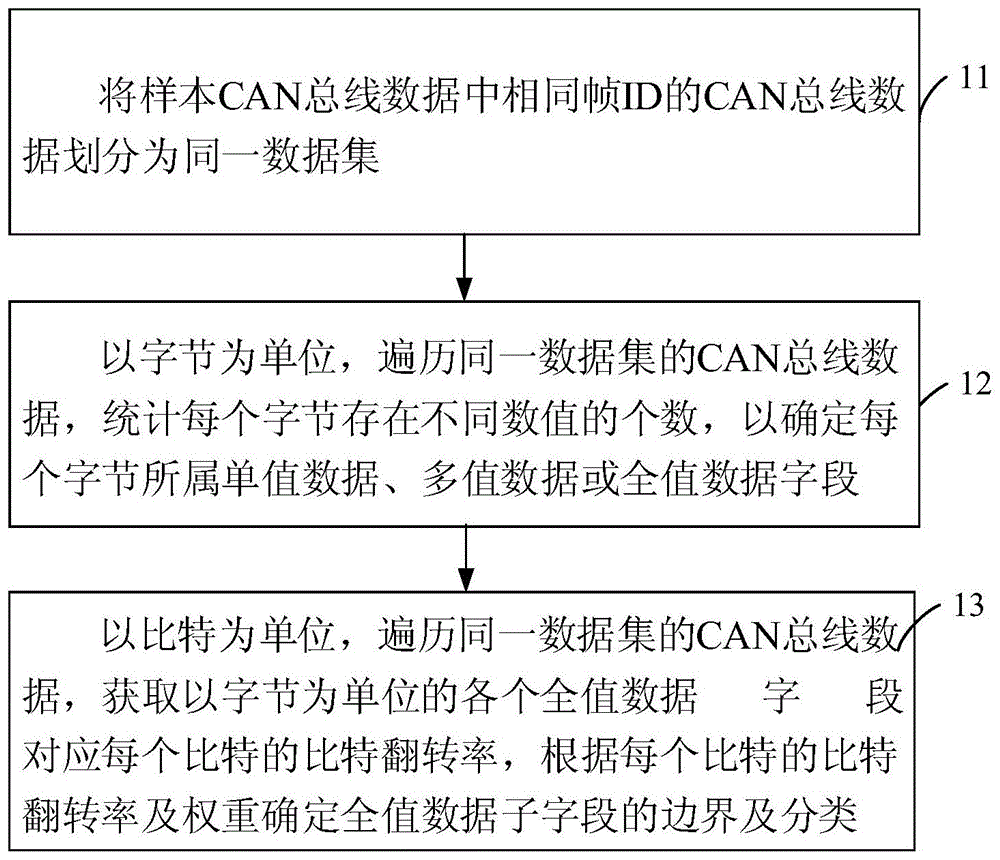
:控制器局域网络(controllerareanetwork,can)总线协议是目前应用于车联网车载网络最广泛的协议。用户操纵车辆,比如点火启动,开关车门等操作,本质上都是相应电控元件(ecu)向can总线中发送了对应的控制命令使然的。掌握can总线协议的细节,不仅有助于新手学习车辆控制逻辑,还有助于第三方对车辆进行安全检测。然而can总线协议标准是公开的,但是can总线协议的细节,不同的厂商有各自的实现方式,且对外保密。因此,can总线协议逆向技术就发展起来。目前主流的两种can总线协议逆向方案,一是通过拔插ecu,对比观察can总线中的数据流量变化,将缺失的流量与拔出的ecu相关联;二是对每个ecu设置网关,监控进出ecu的数据,直接将数据与ecu相对应。上述这两种can总线协议逆向方案,前者可能会误判,因为不同的ecu之间可能会有数据关联,拔出某个ecu,可能与之关联的另一ecu也会停止发送数据;而后者虽然相对准确,但需要对每个ecu都加装网关,监控流量,不仅费用高昂,而且效率低下。同时,这两种can总线协议逆向方案还有以下几点共同的缺点:(1)操作繁琐前者需要拔插ecu,后者需要给ecu加装网关,这就意味着这两种协议逆向的方案都需要将整车拆开,暴露出总线。并且前者对每个ecu进行逆向,都需要拔出ecu,统计一段时间数据,然后插回ecu,再统计一段时间数据,最后对比两段数据的差异。而后者对每个ecu进行逆向,都需要调整网关的加装位置,统计一段时间数据,然后根据网关的监控数据进行分析。两者的操作都非常麻烦。(2)逆向的粒度粗两者协议逆向方案都是将数据与ecu对应起来,没有把具体功能也对应进来。根据两者最后输出的结果,我们只能知道某些数据,是对应某个ecu的,但并不知道这些数据的具体功能含义。技术实现要素:有鉴于此,本发明的发明目的是:推断并切割can总线数据字段,对can总线数据字段进行准确分类。为达到上述目的,本发明的技术方案具体是这样实现的:本发明提供了一种车辆can总线数据分类方法,该方法包括:将样本can总线数据中相同帧id的can总线数据划分为同一数据集;以字节为单位,遍历同一数据集的can总线数据,统计每个字节存在不同数值的个数,以确定每个字节所属单值数据、多值数据或全值数据字段;以比特为单位,遍历同一数据集的can总线数据,获取以字节为单位的各个全值数据字段对应每个比特的比特翻转率,根据每个比特的比特翻转率及权重确定全值数据子字段的边界及分类。本发明还提供了一种车辆can总线数据分类装置,该装置包括:划分模块,将样本can总线数据中相同帧id的can总线数据划分为同一数据集;第一切割模块,以字节为单位,遍历同一数据集的can总线数据,统计每个字节存在不同数值的个数,以确定每个字节所属单值数据、多值数据或全值数据字段;第二切割模块,以比特为单位,遍历同一数据集的can总线数据,获取以字节为单位的各个全值数据字段对应每个比特的比特翻转率,根据每个比特的比特翻转率及权重确定全值数据子字段的边界及分类。由上述的技术方案可见,本发明将样本can总线数据中相同帧id的can总线数据划分为同一数据集;先粗略切割数据字段,以字节为单位,遍历同一数据集的can总线数据,统计每个字节存在不同数值的个数,以确定每个字节所属单值数据、多值数据或全值数据字段;再精确切割数据字段,对于确认出的每个字节所属全值数据字段,合并相邻字节的全值数据字段,在上一步的基础上,对合并后的全值数据字段进行子字段切割,进一步切割成状态值、计数器值和校验值字段,步骤是以比特为单位,遍历全值数据字段,根据每个比特的比特翻转率以及权重确定全值数据子字段的边界及分类。本发明实施例根据can总线数据特征,对数据字段由粗略到细致进行多次切割,从而能够准确切割can总线数据字段,对can总线数据字段进行准确分类。附图说明图1为本发明实施例提出的车辆can总线数据分类方法的流程示意图。图2为本发明另一实施例提出的车辆can总线数据分类方法的流程示意图。图3为本发明另一实施例提出的车辆can总线数据分类装置的结构示意图。具体实施方式为使本发明的目的、技术方案、及优点更加清楚明白,以下参照附图并举实施例,对本发明进一步详细说明。由于can总线协议的专有性,各车厂can总线协议的实现方式都各不相同,且对外保密。一条can总线数据可能是控制命令,也可能是反映车辆状态信息,或者只是周期性地反馈心跳数据(也可能是多种情况杂糅)。在一条can总线数据中,数据部分最多有8个字节(64个bit)。协议设计者可能使用了其中某些字节,甚至只使用其中某几个bit来设计功能。想要顺利地进行协议逆向,就必须准确地切割数据字段。如果在不知道数据边界的情况下就对can总线数据进行协议逆向,这样分析的难度无疑是非常大的。如果盲目地切割数据,来推断功能,效果是很差的。比如以1个字节为单位,将8字节数据切割成了8个数据字段,那么可能有的功能会被划分在了多个数据字段中;如果以2个字节为单位,又可能有些功能划分在一个数据字段中。而且很难用一个统一的长度对数据切割,因为协议设计师不太可能将每个功能都设计成同样长度(比如车门开和关,使用1个bit来表示就行了,但是反映车速信息,1个bit是不够用的,至少得用上多个字节)。因此,对盲目切割的数据字段进行功能推断,是没有意义的。因此,对can总线数据准确地切割数据字段,对于后续can总线协议逆向,使用准确的数据字段推断具体功能,具有非常重要的意义。本发明can总线协议逆向方案,根据can总线数据特征,对数据字段进行多次准确切割,从而对can总线数据字段进行准确分类。本发明根据can总线数据特征,将can总线数据划分为三类:单值数据字段、多值数据字段、全值数据字段。其中全值数据字段可以进一步细分为状态值字段、计数器值字段、校验值字段三类。单值数据字段,就是至始至终都为同一个数值的数据,这样的数据往往是用作填充,没有推断功能的必要。多值数据字段,就是只可能在某几个数值中变化的数据,这样的数据往往是用作控制,状态显示等表示某些状态离散的车辆信息。比如车门的开和关;比如雨刷的状态:静止、慢刷、快刷等。全值数据字段,就是能够遍历一个范围数值的数据,这样的数据往往是表示某些状态连续的车辆信息,比如车速、燃油量等;或者是计数器,比如用作心跳数据;又或者只是用作校验值。在can总线数据字段类别中,单值数据字段和多值数据字段很好判断。难点主要在于区分出全值数据字段中的状态值字段、计数器值字段和校验值字段这三类。而全值数据字段中,计数器值字段和校验值字段的特征相对明显,所以使用排除法的方式来区分出状态值字段,即如果数据不属于计数器值字段,也不属于校验值字段,则认为是状态值字段。下面详细介绍计数器值字段与校验值字段的特征。计数器值字段的特征:随时间递增或递减,最低有效位的比特反转率(bit从0变为1,或者从1变为0的概率)为1,并且低有效位的比特反转率是更高一级有效位的两倍。下面举例解释,比如使用两个字节来表示计数器值,即一共使用了16个bit。这个数值将从0x0000累加到0xffff,然后进入下一次循环。假设我们拿到了一个循环的数据,共65536条,则第16个bit值(最低有效位)一共反转了65535次,比特反转率为1;第15个bit值一共反转了32767次,比特反转率为0.5;第14个bit的反转率为0.25,以此类推。当然,我们不一定能获取一整个循环的数据;但是没有关系,只要数据出现了计数器的特征,就能够分割出计数器的边界。右边界(最低有效位)在比特反转率为1的位置,标定右边界之后再往左推断左边界,只要高bit的反转率是低bit反转率的一半,则说明高bit还在计数器数据的边界内,还能继续往左推断左边界。迭代执行,逐bit往左推断,直到高bit的反转率不再是低bit的一半,此时的低bit则作为计数器字段的左边界(最高有效位)。校验值字段的特征:与反应车辆状态信息的数据,还有计数器字段相比,校验值字段具有明显的随机数特征。理论上,校验值字段的每个bit,都具有0.5的比特反转率。在数据足量的情况下,校验值字段所有bit的比特反转率分布应该呈现以0.5为期望的正态分布。基于上述分析,本发明实施例提出的一种车辆can总线数据分类方法,其流程示意图如图1所示,该方法包括:步骤11、将样本can总线数据中相同帧id的can总线数据划分为同一数据集;一可选实施例中,一个车辆有多个控制元件,不同帧id表示不同控制元件的数据特征。假设样本can总线数据有10000条,以其中的20条can总线数据进行示例,如表1所示。帧id数据14886a5c64041e5cff4323c93247f0e62171000033b8e6dfcbffcbcc9000460803ac0c000900500053c93246f0c521750000655201f8dbcb00037430760803600c000900500083c93244f08c2174000093c93243f057217d00001048887fb64041e81ff47115924468002f9c11501d12208192033004c34353513208191036004c35363614208198034004c363535153b8e6c7cbffcbcb00001655201f8c983000374301720818f035004c343333183b8e71fcaffcacbe000………99993b8e6b7ccffcbcb0000100003b8e6efc9ffcac9f000表1上述表1数据为16进制表示法。为解析can总线数据,根据帧id对样本can总线数据进行分类,将相同帧id的数据划分到同一数据集,以便进行后续解析。例如,在表1的10000条数据中,帧id为666的数据有1000条,因此,将帧id为666,表示车灯的数据特征的1000条can总线数据划分到同一数据集。显然,样本数据越多,数据字段划分的越准确。步骤12、以字节为单位,遍历同一数据集的can总线数据,统计每个字节存在不同数值的个数,以确定每个字节所属单值数据、多值数据或全值数据字段;一可选实施例中,在一条can总线数据中,数据部分最多有8个字节(64个bit)。本步骤将同一数据集的can总线数据以字节为单位进行第一次切割,可以确定出每个字节所属单值数据、多值数据或全值数据字段。需要注意的是,可能全值数据字段有的功能会被划分在了多个数据字段中,所以需要对全值数据字段进行进一步地合并和切割。步骤13、以比特为单位,遍历同一数据集的can总线数据,获取以字节为单位的各个全值数据字段对应每个比特的比特翻转率,根据每个比特的比特翻转率及权重确定全值数据子字段的边界及分类。一可选实施例中,对于全值数据字段,本步骤将同一数据集的can总线数据以比特为单位进行第二次切割,根据每个比特的比特翻转率及权重确定全值数据子字段的边界及分类。本发明实施例提供的车辆can总线数据分类方法,根据can总线数据特征,对数据字段进行多次准确切割,从而能够对can总线数据字段进行准确分类。与现有技术相比,本发明的分类方法操作简单易实现,能够准确对can总线数据字段进行准确分类。一可选实施例中,步骤12中所述统计每个字节存在不同数值的个数,以确定每个字节所属单值数据、多值数据或全值数据字段,具体包括:当字节存在不同数值的个数为1时,确定所述字节为单值数据字段;当字节存在不同数值的个数不大于预定个数时,确定所述字节为多值数据字段;当字节存在不同数值的个数大于预定个数时,确定所述字节为全值数据字段。一可选实施例中,步骤13中所述根据每个比特的比特翻转率及权重确定全值数据子字段的边界及分类,具体包括:将相邻字节的全值数据字段进行合并后,计算各合并后的全值数据字段对应每个比特的比特翻转率权重;根据所述权重对各合并后的全值数据字段进行子字段切割,以确定每个全值数据子字段的边界;根据切割后各个全值数据子字段对应每个比特的比特翻转率特征,对各个全值数据子字段进行分类。进一步地,根据所述权重对各合并后的全值数据字段进行子字段切割,以确定每个全值数据子字段的边界,具体包括:当前一比特的比特翻转率权重小于后一比特的比特翻转率权重,则确定所述前一比特和后一比特属于不同的全值数据子字段;当前一比特的比特翻转率权重不小于后一比特的比特翻转率权重,则确定所述前一比特和后一比特属于同一全值数据子字段。进一步地,根据切割后各个全值数据子字段对应每个比特的比特翻转率特征,对各个全值数据子字段进行分类,具体包括:根据低有效位的比特翻转率是高有效位比特翻转率的两倍,确定所述全值数据子字段为计数器值字段;或者,根据全值数据子字段每个比特的比特翻转率分布呈现以0.5为期望的正态分布,确定所述全值数据子字段为校验值字段;或者,如果所述全值数据子字段既不属于计数器值字段,也不属于校验值字段,则确定所述全值数据子字段为状态值字段。图2为本发明另一实施例提供的车辆can总线数据分类方法流程图,其具体步骤如下:步骤21、将样本can总线数据中相同帧id的can总线数据划分为同一数据集。本实施例中,将帧id为666,表示车灯的数据特征的j条can总线数据划分到同一数据集。每条can总线数据包含n个字节。例如,同一数据集的can总线数据为1000条,每条can总线数据包含8个字节,如表2所示。帧id数据16664204038100004d372666420402820001f2d93666420403830002f828466642040384000323645666420403850004ab916666420404840005aafd7666420403840006816f8666420403830007d9c79666420404840008627e10666420405830009b6d01166642040683000a7af91266642040683000b355b1366642040683000c56e21466642040783000dae18………10006664204189200e7cf0e表2步骤22、以字节为单位,遍历同一数据集的can总线数据,统计每个字节存在不同数值的个数,以确定每个字节所属单值数据、多值数据或全值数据字段。在相同数据集中,遍历j条can总线数据,统计每个字节存在不同数值的个数,每条can总线数据包含n个字节,当数组arr[n]=1时,表示第n个字节至始至终都为同一个数值,则将其划分为单值数据字段;当数组arr[n]≤25时,表示第n个字节不同数值的个数不到字节范围的10%,则将其划分为多值数据字段;当数组arr[n]>25时,将其划分为全值数据字段。其中,一个字节=8bit,8个bit表示的范围为0-255,共256个数值。由于多值数据字段,就是只可能在某几个数值中变化的数据,这样的数据往往是用作控制,或者是表示某些状态离散的车辆信息。比如车门的开和关;比如雨刷的状态:静止、慢刷、快刷等。所以本实施例中,根据经验将本字节数值变化的个数不到256个数值的10%的字节定义为多值数据字段。具体的,也可以根据实际应用调整预定个数的限定。例如,对于每条can总线数据包含8个字节,第一字节存在不同数值的个数为1,属于单值数据字段;第二字节存在不同数值的个数为1,属于单值数据字段;第5字节存在不同数值的个数为20,属于多值数据字段。第三、四字节存在不同数值的个数分别为100和120,则第三、四字节属于全值数据字段;第六、七、八字节存在不同数值的个数分别为120、130和140,则第六、七、八字节属于全值数据字段。步骤23、以比特为单位,遍历同一数据集的can总线数据,获取以字节为单位的各个全值数据字段对应每个比特的比特翻转率。本实施例中,遍历相同数据集中,j条can总线数据,将步骤22确定出的全值数据字段,计算全值数据字段每个bit的比特翻转率。这里,全值数据字段以字节为单位,但是可能全值数据字段有的功能会被划分在了多个字节中,所以需要对全值数据字段进行进一步地合并和切割,以准确定义全值数据字段的字节数。对于以字节为单位的全值数据字段中的任一第i个比特,遍历j条can总线数据,如果第j条can总线数据第i个比特的值不同于第j-1条can总线数据,则将比特翻转次数+1,在遍历j条can总线数据结束后,所得的比特反转次数除以总条数j,则得到第i个比特的比特翻转率。例如,第三字节对应第17至24比特,每个比特对应的比特翻转率分别为0、0、0.002、0.013、0.086、0.155、0.296、0.612。其中,以第19比特的比特翻转率0.002为例,遍历1000条can总线数据后,比特翻转次数为2,比特翻转率=2/1000=0.002。第四字节对应第25至32比特,每个比特对应的比特翻转率分别为0、0、0.004、0.025、0.082、0.178、0.332、0.69。第六字节对应第41至48比特,每个比特对应的比特翻转率分别为0.007、0.015、0.031、0.062、0.125、0.25、0.5、1。第七字节对应第49至56比特,每个比特对应的比特翻转率分别为0.494、0.513、0.493、0.513、0.501、0.495、0.49、0.484。第八字节对应第57至64比特,每个比特对应的比特翻转率分别为0.498、0.523、0.53、0.505、0.503、0.494、0.503、0.504。步骤24、将相邻字节的全值数据字段进行合并得到长度为m的比特翻转率数组。例如,将相邻的三四字节合并,得到比特翻转率数组brr[0、0、0.002、0.013、0.086、0.155、0.296、0.612、0、0、0.004、0.025、0.082、0.178、0.332、0.69],数组长度m为16;将相邻的六七八字节合并,得到比特翻转率数组brr[0.007、0.015、0.031、0.062、0.125、0.25、0.5、1、0.494、0.513、0.493、0.513、0.501、0.495、0.49、0.484、0.498、0.523、0.53、0.505、0.503、0.494、0.503、0.504],数组长度m为24。步骤25、计算各合并后的全值数据字段对应每个比特的比特翻转率权重。比特权重数组w[],举例4bit的计数器值字段的比特反转率数组brr[]=[0.125,0.25,0.5,1],故其比特权重数组w[]=[3,2,1,0]。举例4bit的校验值字段的比特反转率数组可能为brr[]=[0.54,0.39,0.44,0.51],故其比特权重数组w[]=[1,1,1,1]。同理,三四字节对应的长度为16的比特权重数组,以及六七八字节对应的长度为24的比特权重数组,计算原理与上述相同。步骤26、根据所述权重对各合并后的全值数据字段进行子字段切割,以确定每个全值数据子字段的边界。当w[i]<w[i+1],说明第i+1个比特属于另一全值数据字段,是另一全值数据字段的最高有效位;当w[i]≥w[i+1],则说明第i个bit和第i+1个bit属于同一全值数据字段。例如,第3字节的24比特对应的比特翻转率为0.612,第4字节的25比特对应的比特翻转率为0,则w[24]=1,w[25]=∞,因此,第3字节的24比特和第4字节的25比特属于不同的全值数据子字段。第3字节和第4字节属于不同的全值数据子字段。再例如,第6字节的48比特对应的比特翻转率为1,第7字节的49比特对应的比特翻转率为0.494,则w[48]=0,w[49]=1,因此,第6字节的48比特和第7字节的49比特属于不同的全值数据子字段。第6字节和第7字节属于不同的全值数据子字段。但是,第7字节和第8字节每个比特的比特翻转率分布呈现以0.5为期望的正态分布,每个比特对应的权重都为1,因此,第7字节和第8字节属于同一全值数据子字段。步骤27、根据切割后各个全值数据子字段对应每个比特的比特翻转率特征,对各个全值数据子字段进行分类。全值数据子字段进一步划分为三类:如果低有效位的比特翻转率是高有效位比特翻转率的两倍,则确定所述全值数据子字段为计数器值字段;如果全值数据子字段每个比特的比特翻转率分布呈现以0.5为期望的正态分布,则确定所述全值数据子字段为校验值字段。如果既不属于计数器值字段,也不属于校验值字段则确定所述全值数据子字段为状态值字段。例如,字节3为一个状态值字段,字节4为一个状态值字段,字节6为一个计数器值字段,字节7-8合并为一个校验值字段。基于相同的发明构思,本发明实施例提出了一种车辆can总线数据分类装置,其结构示意图如图3所示,该装置包括:划分模块31,将样本can总线数据中相同帧id的can总线数据划分为同一数据集;第一切割模块32,以字节为单位,遍历同一数据集的can总线数据,统计每个字节存在不同数值的个数,以确定每个字节所属单值数据、多值数据或全值数据字段;第二切割模块33,以比特为单位,遍历同一数据集的can总线数据,获取以字节为单位的各个全值数据字段对应每个比特的比特翻转率,根据每个比特的比特翻转率及权重确定全值数据子字段的边界及分类。所述第一切割模块32,统计每个字节存在不同数值的个数,以确定每个字节所属单值数据、多值数据或全值数据字段,具体用于:当字节存在不同数值的个数为1时,确定所述字节为单值数据字段;当字节存在不同数值的个数不大于预定个数时,确定所述字节为多值数据字段;当字节存在不同数值的个数大于预定个数时,确定所述字节为全值数据字段。所述第二切割模块33,根据每个比特的比特翻转率及权重确定全值数据子字段的边界及分类,具体用于:将相邻字节的全值数据字段进行合并后,计算各合并后的全值数据字段对应每个比特的比特翻转率权重;根据所述权重对各合并后的全值数据字段进行子字段切割,以确定每个全值数据子字段的边界;根据切割后各个全值数据子字段对应每个比特的比特翻转率特征,对各个全值数据子字段进行分类。所述第二切割模块33,根据所述权重对各合并后的全值数据字段进行子字段切割,以确定每个全值数据子字段的边界,具体用于:当前一比特的比特翻转率权重小于后一比特的比特翻转率权重,则确定所述前一比特和后一比特属于不同的全值数据子字段;当前一比特的比特翻转率权重不小于后一比特的比特翻转率权重,则确定所述前一比特和后一比特属于同一全值数据子字段。所述第二切割模块33,根据切割后各个全值数据子字段对应每个比特的比特翻转率特征,对各个全值数据子字段进行分类,具体用于:根据低有效位的比特翻转率是高有效位比特翻转率的两倍,确定所述全值数据子字段为计数器值字段;或者,根据全值数据子字段每个比特的比特翻转率分布呈现以0.5为期望的正态分布,确定所述全值数据子字段为校验值字段;或者,如果所述全值数据子字段既不属于计数器值字段,也不属于校验值字段,则确定所述全值数据子字段为状态值字段。综上,本发明的有益效果为:一、本发明车辆can总线数据分类方法,操作简单易实现,能够准确推断并切割can总线数据字段,对can总线数据字段进行准确分类。二、本发明能够将车辆can总线数据准确划分为三类:单值数据字段、多值数据字段、全值数据字段。其中,全值数据字段可以进一步划分为状态值字段、计数器值字段、校验值字段。以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换以及改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1