与通过蛋白诱导的体内细胞重编程的细胞转化相关的方法、系统和组合物与流程
本发明是在由国立卫生研究院/国立癌症研究所授予的基金No.1 R01 CA172480-01A1的政府支持下完成的。政府对本发明享有某些权利。
技术领域
本发明总体上涉及在需要其的受试者中治疗病理学病症的方法、系统和组合物。在具体的方面,本发明涉及用于蛋白诱导的体内细胞转化的方法、系统和组合物,用于在需要其的受试者中治疗病理学病症。
背景技术:
尽管近来医学进步,但存在对用于治疗疾病和损伤的方法和组合物的持续需求。
技术实现要素:
根据本发明的方面,提供了治疗需要其的受试者的方法,其包括将包含蛋白转导试剂修饰的重编程蛋白的药物组合物给予所述受试者,其中所述蛋白转导试剂与所述重编程蛋白非共价结合并且其中所述蛋白转导试剂包含阳离子试剂和脂质。
根据本发明的方面,提供了治疗需要其的受试者的方法,其包括将包含蛋白转导试剂修饰的重编程蛋白的药物组合物给予所述受试者,其中所述蛋白转导试剂与所述重编程蛋白非共价结合并且其中所述蛋白转导试剂包含阳离子试剂和脂质,其中所述受试者患有选自如下的疾病:癌症;胰腺疾病或损伤;心脏病或心脏损伤,例如急性心肌梗塞、慢性心肌梗塞和心力衰竭;肝损伤或肝病,例如家族性高胆固醇血症(FH)、Crigler-Najjar综合征和遗传性的酪氨酸血症I;动脉粥样硬化;神经系统疾病或损伤,例如脊髓损伤、外伤性脑损伤、肌萎缩侧索硬化、脊髓性肌萎缩和帕金森氏病;关节炎;关节疾病或损伤;血液病;糖尿病;肥胖症;肌肉疾病或损伤;软骨疾病或损伤;乳腺疾病或损伤;和血管疾病或损伤。
根据本发明的方面,提供了治疗患有以受损的细胞和/或有缺陷的细胞为表征的病症的受试者的方法,其包括将包含蛋白转导试剂修饰的重编程蛋白的药物组合物给予所述受试者,其中所述蛋白转导试剂与所述重编程蛋白非共价结合并且其中所述蛋白转导试剂包含阳离子试剂和脂质。
治疗患有癌症的受试者的方法,其包括:将包含蛋白转导试剂修饰的重编程蛋白的药物组合物给予所述受试者,其中所述蛋白转导试剂与所述重编程蛋白非共价结合并且其中所述蛋白转导试剂包含阳离子试剂和脂质。
根据本发明的方面,提供了治疗患有癌症的受试者的方法,其包括给予包含蛋白转导试剂修饰的重编程蛋白——其选自蛋白转导试剂修饰的Sox2、蛋白转导试剂修饰的Oct4和蛋白转导试剂修饰的Nanog——的药物组合物。
根据本发明的方面,提供了治疗患有癌症的受试者的方法,其包括给予包含蛋白转导试剂修饰的Sox2、蛋白转导试剂修饰的Oct4和蛋白转导试剂修饰的Nanog的药物组合物。
根据本发明的方面,提供了治疗患有脑肿瘤或乳腺癌的受试者的方法,其包括给予包含蛋白转导试剂修饰的重编程蛋白——其选自蛋白转导试剂修饰的Sox2、蛋白转导试剂修饰的Oct4和蛋白转导试剂修饰的Nanog——的药物组合物。
根据本发明的方面,提供了治疗患有脑肿瘤或乳腺癌的受试者的方法,其包括给予包含蛋白转导试剂修饰的Sox2、蛋白转导试剂修饰的Oct4和蛋白转导试剂修饰的Nanog的药物组合物。
根据本发明的方面,提供了治疗患有以受损的细胞和/或有缺陷的细胞为表征的病症的受试者的方法,其包括:将包含蛋白转导试剂修饰的重编程蛋白的药物组合物给予所述受试者,其中所述蛋白转导试剂与所述重编程蛋白非共价结合并且其中所述蛋白转导试剂包含阳离子试剂和脂质,其中所述病症为心脏病或心脏损伤并且所述药物组合物包含如下中的一种或多种:蛋白转导试剂修饰的Gata4、蛋白转导试剂修饰的Hand2、蛋白转导试剂修饰的MEF2c和蛋白转导试剂修饰的Tbox5;其中所述病症为肝病或肝损伤并且所述药物组合物包含如下中的一种或多种:蛋白转导试剂修饰的Hnf1a、蛋白转导试剂修饰的Foxa1、蛋白转导试剂修饰的Foxa2和蛋白转导试剂修饰的Foxa3;其中所述病症为肝病或肝损伤并且所述药物组合物包含如下中的一种或多种:蛋白转导试剂修饰的Gata4、蛋白转导试剂修饰的Hnf1a和蛋白转导试剂修饰的Foxa3;其中所述病症为动脉粥样硬化并且所述药物组合物包含如下中的一种或多种:蛋白转导试剂修饰的CEBPα、蛋白转导试剂修饰的CEBPβ和蛋白转导试剂修饰的PU.1;其中所述病症为神经退行性疾病或神经元组织损伤并且所述药物组合物包含如下中的一种或多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Sox2和蛋白转导试剂修饰的Foxg1;如下中的一种或多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Lmx1a、蛋白转导试剂修饰的Nurr1、蛋白转导试剂修饰的Brn2和蛋白转导试剂修饰的Mytl1;如下中的一种或多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Mytl1和蛋白转导试剂修饰的NeuroD1;蛋白转导试剂修饰的Ngn2;如下中的一种或两者:蛋白转导试剂修饰的Sox2和蛋白转导试剂修饰的NeuroD1;如下中的一种或多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Ascl1、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lhx3和蛋白转导试剂修饰的Hb9;如下中的一种或多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Ascl1、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lhx3、蛋白转导试剂修饰的Hb9、蛋白转导试剂修饰的Lsl1和蛋白转导试剂修饰的Ngn2;蛋白转导试剂修饰的Dlx2;蛋白转导试剂修饰的Dlx2和蛋白转导试剂修饰的Ascl1;如下中的一种或多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lmx1a和蛋白转导试剂修饰的Foxa2;或如下中的一种或多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Lmx1a和蛋白转导试剂修饰的Nurr1;其中所述病症为血液疾病或障碍并且所述药物组合物包含:蛋白转导试剂修饰的Oct4;其中所述病症为糖尿病、胰腺疾病或胰腺组织损伤并且所述药物组合物包含如下中的一种或多种:蛋白转导试剂修饰的Ngn3、蛋白转导试剂修饰的Pdx1和蛋白转导试剂修饰的Pax4,或如下中的一种或多种:蛋白转导试剂修饰的Ngn3、蛋白转导试剂修饰的Pdx1和蛋白转导试剂修饰的MafA;其中所述病症为肥胖症并且所述药物组合物包含如下中的一种或多种:蛋白转导试剂修饰的Prdm16和蛋白转导试剂修饰的C/EBPb;其中所述病症为肌肉疾病或肌肉损伤并且所述药物组合物包含蛋白转导试剂修饰的MyoD;其中所述病症为关节炎或关节疾病或关节损伤并且所述药物组合物包含如下中的一种或多种:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Runx2、蛋白转导试剂修饰的Sox5和蛋白转导试剂修饰的Sox6;其中所述病症为乳腺疾病或乳腺组织损伤并且所述药物组合物包含如下中的一种或多种:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Slug、蛋白转导试剂修饰的Stat5a、蛋白转导试剂修饰的Gata3和蛋白转导试剂修饰的Brca-1l;其中所述病症为血管疾病或血管损伤并且所述药物组合物包含如下中的一种或多种:蛋白转导试剂修饰的Erg1、蛋白转导试剂修饰的Er71、蛋白转导试剂修饰的Fli1和蛋白转导试剂修饰的Gata2,或如下中的一种或多种:蛋白转导试剂修饰的Hey1、蛋白转导试剂修饰的Hey2、蛋白转导试剂修饰的FoxC1和蛋白转导试剂修饰的FoxC2,或如下中的一种或两种:蛋白转导试剂修饰的Sox7和蛋白转导试剂修饰的Sox18。
根据本发明的方面,提供了包含一种或多种选自如下的蛋白转导试剂-重编程蛋白的药物组合物:蛋白转导试剂修饰的Gata4、蛋白转导试剂修饰的Hand2、蛋白转导试剂修饰的MEF2c、蛋白转导试剂修饰的Tbox、蛋白转导试剂修饰的Hnf1a、蛋白转导试剂修饰的Foxa1、蛋白转导试剂修饰的Foxa2和蛋白转导试剂修饰的Foxa3,蛋白转导试剂修饰的Hnf1a、蛋白转导试剂修饰的CEBPα、蛋白转导试剂修饰的CEBPβ、蛋白转导试剂修饰的PU.1、蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Sox2和蛋白转导试剂修饰的Foxg1、蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Lmx1a、蛋白转导试剂修饰的Nurr1、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的NeuroD1、蛋白转导试剂修饰的Ngn2、蛋白转导试剂修饰的Lhx3、蛋白转导试剂修饰的Hb9、蛋白转导试剂修饰的Lsl1、蛋白转导试剂修饰的Dlx2、蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Oct4、蛋白转导试剂修饰的Ngn3、蛋白转导试剂修饰的Pdx1、蛋白转导试剂修饰的Pax4、蛋白转导试剂修饰的MafA、蛋白转导试剂修饰的Prdm16、蛋白转导试剂修饰的MyoD、蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Runx2、蛋白转导试剂修饰的Sox5和蛋白转导试剂修饰的Sox6,蛋白转导试剂修饰的Slug、蛋白转导试剂修饰的Stat5a、蛋白转导试剂修饰的Gata3、蛋白转导试剂修饰的Brca-1l、蛋白转导试剂修饰的Erg1、蛋白转导试剂修饰的Er71、蛋白转导试剂修饰的Fli1、蛋白转导试剂修饰的Gata2、蛋白转导试剂修饰的Hey1、蛋白转导试剂修饰的Hey2、蛋白转导试剂修饰的FoxC1和蛋白转导试剂修饰的FoxC2、蛋白转导试剂修饰的Sox7和蛋白转导试剂修饰的Sox18。
根据本发明的方面,提供了包含两种或更多种选自如下的蛋白转导试剂修饰的重编程蛋白的药物组合物:蛋白转导试剂修饰的Gata4、蛋白转导试剂修饰的Hand2、蛋白转导试剂修饰的MEF2c和蛋白转导试剂修饰的Tbox5;如下中的两种或更多种:蛋白转导试剂修饰的Hnf1a、蛋白转导试剂修饰的Foxa1、蛋白转导试剂修饰的Foxa2和蛋白转导试剂修饰的Foxa3;如下中的两种或更多种:蛋白转导试剂修饰的Gata4、蛋白转导试剂修饰的Hnf1a和蛋白转导试剂修饰的Foxa3;蛋白转导试剂修饰的CEBPα、蛋白转导试剂修饰的CEBPβ和蛋白转导试剂修饰的PU.1;如下中的两种或更多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Sox2和蛋白转导试剂修饰的Foxg1;如下中的两种或更多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Lmx1a、蛋白转导试剂修饰的Nurr1、蛋白转导试剂修饰的Brn2和蛋白转导试剂修饰的Mytl1;如下中的两种或更多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Mytl1和蛋白转导试剂修饰的NeuroD1;蛋白转导试剂修饰的Ngn2;蛋白转导试剂修饰的Sox2和蛋白转导试剂修饰的NeuroD1;如下中的两种或更多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Asc11、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lhx3和蛋白转导试剂修饰的Hb9;如下中的两种或更多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Asc11、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lhx3、蛋白转导试剂修饰的Hb9、蛋白转导试剂修饰的Lsl1和蛋白转导试剂修饰的Ngn2;蛋白转导试剂修饰的Dlx2;蛋白转导试剂修饰的Dlx2和蛋白转导试剂修饰的Asc11;如下中的两种或更多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lmx1a和蛋白转导试剂修饰的Foxa2;如下的两种或更多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Lmx1a和蛋白转导试剂修饰的Nurr1;蛋白转导试剂修饰的Ngn3、蛋白转导试剂修饰的Pdx1和蛋白转导试剂修饰的Pax4;如下中的两种或更多种:蛋白转导试剂修饰的Ngn3、蛋白转导试剂修饰的Pdx1和蛋白转导试剂修饰的MafA;蛋白转导试剂修饰的Prdm16和蛋白转导试剂修饰的C/EBPβ;如下中的两种或更多种:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Runx2、蛋白转导试剂修饰的Sox5和蛋白转导试剂修饰的Sox6;如下中的两种或更多种:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Slug、蛋白转导试剂修饰的Stat5a、蛋白转导试剂修饰的Gata3和蛋白转导试剂修饰的Brca-1l;如下中的两种或更多种:蛋白转导试剂修饰的Erg1、蛋白转导试剂修饰的Er71、蛋白转导试剂修饰的Fli1和蛋白转导试剂修饰的Gata2;如下中的两种或更多种:蛋白转导试剂修饰的Hey1、蛋白转导试剂修饰的Hey2、蛋白转导试剂修饰的FoxC1和蛋白转导试剂修饰的FoxC2;或蛋白转导试剂修饰的Sox7和蛋白转导试剂修饰的Sox18。
本发明的方法使得能够将蛋白转导试剂修饰的重编程蛋白递送至癌细胞(如肿瘤细胞)以及病变组织的病变细胞。
根据本发明的方面的方法提供了病变细胞通过蛋白诱导的原位细胞重编程向正常细胞的体内转化。根据本发明的方面的方法提供了癌细胞通过蛋白诱导的原位细胞重编程向正常细胞的体内转化。
根据本发明的方面,提供了蛋白转导试剂修饰的重编程蛋白用于将癌细胞或病变细胞原位重编程为随后被诱导分化为所述癌细胞或病变细胞所处的组织中的正常细胞的干细胞或瞬时蛋白诱导的多能干细胞的用途。
根据本发明的方面,提供了治疗癌症的方法,其不通过杀死癌细胞,而是通过给予(例如全身给药或局部给药)一种或多种蛋白转导试剂修饰的重编程蛋白将癌细胞转化为非癌细胞来体内治疗癌症。
附图说明
图1A是携带9L-颅内肿瘤的大鼠的脑的代表性MRI图像,示出了在9L脑肿瘤中QQ-铁蛋白的增强的渗透性和保留效应,表明经静脉内(i.v.)注射的QQ-铁蛋白通过增强的渗透性和保留效应被递送至9L脑肿瘤中,引起在携带9L-脑肿瘤的大鼠中的脑肿瘤的增强的负MRI图像;
图1B是携带9L-颅内肿瘤的大鼠的脑的代表性MRI图像,示出了在9L脑肿瘤中未经QQ修饰的铁蛋白没有增强的渗透性和保留效应,表明经静脉内注射的铁蛋白未进入9L脑肿瘤中并且在携带9L-脑肿瘤的大鼠中未观察到脑肿瘤的增强的负MRI图像;
图2A为携带4T1乳腺肿瘤的小鼠在尾静脉注射QQ-铁蛋白之前的代表性MRI图像;
图2B为携带4T1乳腺肿瘤的小鼠在尾静脉注射QQ-铁蛋白后0.5h的代表性MRI图像;
图2C为携带4T1乳腺肿瘤的小鼠在尾静脉注射QQ-铁蛋白后2h的代表性MRI图像;
图2D为携带4T1乳腺肿瘤的小鼠在尾静脉注射QQ-铁蛋白后3.5h的代表性MRI图像;
图2E为携带4T1乳腺肿瘤的小鼠在尾静脉注射QQ-铁蛋白后8h的代表性MRI图像;
图2F为携带4T1乳腺肿瘤的小鼠在尾静脉注射QQ-铁蛋白后18h的代表性MRI图像;
图3A是示出了通过Ki67测定监测的U251细胞和U251-piPSC的增殖的图;
图3B是示出了患者来源的原发性人GBM(12-14)细胞(正方形)和GBM(12-14)-piPSC(圆形)对烷化剂替莫唑胺的剂量依赖性的化疗药物敏感性的图;
图3C是示出了9L-细胞(正方形)和9L-piPSC(圆形)对卡铂的剂量依赖性的化疗药物敏感性的图;
图4A是示出了U251细胞和U251-piPSC的几种上皮和间质的标志物(包括E-钙黏着蛋白(E-cad)、β-连环蛋白(β-cat)、波形蛋白(VMT))的Western印迹的图,表明在细胞重编程过程中的间质至上皮的转化(MET)。此外,9L-细胞细胞重编程为9L-piPSC也引起胶质细胞原纤维酸性蛋白(GFAP)——星形细胞的标志物——的增强的表达。
图4B是示出了通过U251细胞和U251-piPSC的细胞迁移的体外测定确认U251细胞在根据本发明的方面的细胞重编程后致瘤性降低的图,表明体外U251-piPSC的迁移显著减少(p<0.01);
图4C是示出了通过U251细胞和U251-piPSC的侵入的体外测定确认U251细胞在根据本发明的方面的细胞重编程后致瘤性降低的图,表明体外U251-piPSC的侵入显著减少(p<0.01);
图4D是示出了与亲代4T1细胞和67NR细胞的那些特性相比的4T1-piPSC和67NR-piPSC的增殖减少的图,表明4T1细胞和67NR细胞在体外细胞重编程为4T1-piPSC和67NR-piPSC后致瘤性显著降低;
图4E是示出了与亲代4T1细胞的那些特性相比的4T1-piPSC的乳腺球形成减少的图,表明4T1细胞在体外细胞重编程为4T1-piPSC后致瘤性显著降低;
图4F是示出了与亲代4T1细胞的那些特性相比的4T1-piPSC的迁移减少的图,表明4T1细胞在体外细胞重编程为4T1-piPSC后致瘤性显著降低;
图4G是示出了与亲代4T1细胞的那些特性相比的4T1-piPSC的侵入减少的图,表明4T1细胞在体外细胞重编程为4T1-piPSC后致瘤性显著降低;
图5A是示出了U251细胞的细胞形态的图像;
图5B是示出了间接与U251-piPSC共培养40-64小时的U251细胞的细胞形态的变化的图像,指示了间质至上皮的转化并证明了U251-piPSC对U251细胞的旁观者效应;
图5C是示出了以U251-piPSC和U251细胞1∶1的比率间接与U25 1-piPSC共培养的U251-piPSC和U251细胞的增殖显著减少的图,表明经共培养的U251细胞的致瘤性显著降低并且支持了旁观者效应的观察结果;
图5D是示出了以1∶1和8∶1(U251∶U251-piPSC)的比率间接与U251-piPSC共培养的U251-piPSC和U251细胞的迁移显著减少(P<0.005)的图,表明经共培养的U251细胞的致瘤性显著降低并支持了旁观者效应的观察结果;
图5E是示出了以1∶1和8∶1(U251∶U251-piPSC)的比率间接与U251-piPSC共培养的U251-piPSC和U251细胞的侵入显著减少(P<0.005)的图,表明经共培养的U251细胞的致瘤性显著降低并支持了旁观者效应的观察结果;
图5F是示出了与4T1-piPSC共培养40小时的4T1细胞的增殖显著减少的图,表明经共培养的4T1细胞的致瘤性显著降低并支持了旁观者效应的观察结果;
图5G是示出了与4T1-piPSC共培养40小时的4T1细胞的迁移显著减少的图,表明经共培养的4T1细胞的致瘤性显著降低并支持了旁观者效应的观察结果;
图5H是示出了与4T1-piPSC共培养40小时的4T1细胞的侵入显著减少的图,表明经共培养的4T1细胞的致瘤性显著降低并支持了旁观者效应的观察结果;
图6A是示出了颅内植入9L细胞或9L-piPSC(n=10)的大鼠在第14天的肿瘤体积(mm3)以及示出了与9L-肿瘤的那些相比的颅内9L-piPSC肿瘤体积显著减少的图,表明9L细胞在体内细胞重编程为9L-piPSC后致瘤性显著降低;
图6B是示出了皮下植入9L细胞和9L-piPSC的大鼠在植入后第25天的肿瘤质量(g)(n=6)以及示出了与9L-肿瘤的那些相比的皮下9L-piPSC肿瘤重量显著减少的图,表明9L细胞在体内细胞重编程为9L-piPSC后体内致瘤性显著降低;
图6C是示出了在4T1-和4T1-piPSC植入后25天内使用肿瘤体积所测量的4T1-和4T1-piPSC肿瘤生长曲线的图,表明4T1细胞在体内细胞重编程为4T1-piPSC后显著的体内肿瘤停滞;
图6D是在4T1-和4T1-piPSC植入后第25天使用肿瘤重量所测量的4T1-和4T1-piPSC肿瘤生长曲线的图,表明4T1细胞在体内细胞重编程为4T1-piPSC后显著的体内肿瘤停滞;
图6E是示出了植入4T1细胞或4T1-piPSC的小鼠在植入后第25天的肺转移的图,表明由4T1细胞体内细胞重编程为4T1-piPSC引起的主要体内转移抑制作用;将肺分成200个区,对转移的数目进行计数并在y轴报告;
图6F是在#4脂肪垫植入4T1细胞和4T1-piPSC的小鼠的Kaplan-Meier存活曲线,表明在该250天存活实验期间,4T1-piPSC的存活显著延长,表明恶性癌细胞细胞重编程为piPSC显著降低亲代癌细胞的致瘤性和转移特性;
图7A是示出了在用溶于PBS缓冲液的QQ-试剂(n=10)、QQ-SON蛋白1μg/天(n=5)、QQ-SON蛋白5μg/天(n=5)和QQ-SON蛋白10μg/天(n=10)治疗持续每日治疗18天的大鼠中通过肿瘤体积测量的剂量依赖性的9L肿瘤生长曲线的图,其中治疗开始于9L细胞植入后第5天并在第23天处死大鼠;
图7B是示出了在用溶于PBS缓冲液的QQ-试剂(n=10)、QQ-SON蛋白1μg/天(n=5)、QQ-SON蛋白5μg/天(n=5)和QQ-SON蛋白10μg/天(n=10)治疗持续每日治疗18天的大鼠中的9L肿瘤重量的图,其中治疗开始于9L细胞植入后第5天并在第23天处死大鼠;
图7C是用溶于PBS缓冲液的QQ-试剂(实线,n=6;中值存活时间=21天)或QQ-SON蛋白(虚线,10μg/天,n=8;中值存活时间=127天)治疗持续每日治疗30天的患有皮下9L肿瘤的大鼠的Kaplan-Meier存活曲线(130天),终点是肿瘤体积达到12cm3的时候;
图7D是示出了在25天的时程内通过乳腺中的肿瘤体积所监测的多种QQ-SON蛋白剂量对4T1-肿瘤生长的影响的图;
图7E是示出了在第25天多种QQ-SON蛋白剂量对乳腺中的4T1-肿瘤重量的影响的图;
图7F是示出了通过MRI成像确定的用QQ-SON蛋白(n=8)或作为对照的QQ-PBS(n=8)治疗的携带4T1-肿瘤的小鼠的肿瘤体积在不同时间点的变化的图,表明未经原发性肿瘤切除的主要肿瘤停滞;
图7G是示出了用QQ-SON蛋白(n=8)或作为对照的QQ-PBS(n=8)治疗的携带4T1-肿瘤的小鼠在第35天的肿瘤重量的图,表明未经原发性肿瘤切除的主要肿瘤停滞;
图7H是在未经原发性4T1乳腺癌切除的60天存活实验期间,用QQ-PBS(对照,虚线)和QQ-SON蛋白(治疗,实线)治疗的携带4T1-乳腺癌的小鼠的Kaplan-Meier存活曲线,如图7H所示。治疗开始于4T1-细胞植入后第5天。处死到达终点——包括肿瘤大小负荷、吃力的呼吸、无法控制的疼痛等——的小鼠;
图7I是示出了未经原发性肿瘤切除、在肺中具有转移病灶的经QQ-SON或QQ-PBS治疗的携带4T1肿瘤的小鼠的百分比的图,如在指定天通过MRI所观察到的,表明由未经原发性肿瘤切除的QQ-SON蛋白治疗导致的在携带4T1的小鼠中的主要转移抑制作用;
图7J是示出了未经原发性肿瘤切除、在淋巴结中具有转移病灶的经QQ-SON或QQ-PBS治疗的携带4T1肿瘤的小鼠的百分比的图,如在指定天通过MRI所观察到的,表明由未经原发性肿瘤切除的QQ-SON蛋白治疗导致的在携带4T1的小鼠中的主要转移抑制作用;
图7K是示出了未经原发性肿瘤切除、在肝中具有转移病灶的经QQ-SON或QQ-PBS治疗的携带4T1肿瘤的小鼠的百分比的图,如在指定天通过MRI所观察到的,表明由未经原发性肿瘤切除的QQ-SON蛋白治疗导致的在携带4T1的小鼠中的主要转移抑制作用;
图7L是示出了未经原发性肿瘤切除、在脾中具有转移病灶的经QQ-SON或QQ-PBS治疗的携带4T1肿瘤的小鼠的百分比的图,如在指定天通过MRI所观察到的,表明由未经原发性肿瘤切除的QQ-SON蛋白治疗导致的在携带4T1的小鼠中的主要转移抑制作用;
图7M是示出了未经原发性肿瘤切除、在肺中具有转移病灶的经QQ-SON或QQ-PBS治疗的携带4T1肿瘤的小鼠中的每只小鼠的平均数目的图,如在指定天通过MRI所观察到的,表明由未经原发性肿瘤切除的QQ-SON蛋白治疗导致的在携带4T1的小鼠中的主要转移抑制作用;
图7N是示出了未经原发性肿瘤切除、在淋巴结中具有转移病灶的经QQ-SON或QQ-PBS治疗的携带4T1肿瘤的小鼠中的每只小鼠的平均数目的图,如在指定天通过MRI所观察到的,表明由未经原发性肿瘤切除的QQ-SON蛋白治疗导致的在携带4T1的小鼠中的主要转移抑制作用;
图7O是示出了未经原发性肿瘤切除、在肝中具有转移病灶的经QQ-SON或QQ-PBS治疗的携带4T1肿瘤的小鼠中的每只小鼠的平均数目的图,如在指定天通过MRI所观察到的,表明由未经原发性肿瘤切除的QQ-SON蛋白治疗导致的在携带4T1的小鼠中的主要转移抑制作用;
图7P是示出了未经原发性肿瘤切除、在脾中具有转移病灶的经QQ-SON或QQ-PBS治疗的携带4T1肿瘤的小鼠中的每只小鼠的平均数目的图,如在指定天通过MRI所观察到的,表明由未经原发性肿瘤切除的QQ-SON蛋白治疗导致的在携带4T1的小鼠中的主要转移抑制作用;
图8是携带4T1-乳腺癌的小鼠在第18天手术切除原发性4T1-乳腺癌后的Kaplan-Meier存活曲线(250天存活期),QQ-SON蛋白治疗开始于第6天。
具体实施方式
本文使用的科技术语旨在具有本领域普通技术人员所通常理解的含义。发现这些术语在多篇标准参考文献的上下文中被定义和使用,所述参考文献示例性地包括J.Sambrook和D.W.Russell,Molecular Cloning:A Laboratory Manual,Cold Spring Harbor Laboratory Press;第三版,2001;F.M.Ausubel,Ed.,Short Protocols in Molecular Biology,Current Protocols;第五版,2002;B.Alberts等人,Molecular Biology of the Cell,第四版,Garland,2002;D.L.Nelson和M.M.Cox,Lehninger Principles of Biochemistry,第四版,W.H.Freeman&Company,2004;Engelke,D.R.,RNA Interference(RNAi):Nuts and Bolts of RNAi Technology,DNA Press LLC,Eagleville,PA,2003;Herdewijn,P.(Ed.),Oligonucleotide Synthesis:Methods and Applications,Methods in Molecular Biology,Humana Press,2004;A.Nagy,M.Gertsenstein,K.Vintersten,R.Behringer,Manipulating the Mouse Embryo:A Laboratory Manual,第三版,Cold Spring Harbor Laboratory Press;2002-12-15,ISBN-10:0879695919;Kursad Turksen(Ed.),Embryonic stem cells:methods and protocols in Methods Mol Biol.2002;185,Humana Press;Current Protocols in Stem Cell Biology,ISBN:9780470151808。
除非另外明确说明或上下文中另外清楚说明,单数术语“一(a)”、“一(an)”和“所述(the)”不意为限制性的,并包括复数个指示物。
根据本发明的方面的方法、系统和组合物提供了体内蛋白诱导的细胞重编程以治疗需要其的受试者。
根据本发明的方面的方法、系统和组合物提供用于通过引入一种或多种QQ修饰的重编程蛋白到体内病变细胞或损伤细胞中,而不引入编码所述一种或多种重编程蛋白的核酸,将所述病变细胞或损伤细胞转化成正常细胞。
根据本发明的方面的方法、系统和组合物提供用于通过引入一种或多种QQ修饰的重编程蛋白到体内癌细胞中,而不引入编码所述一种或多种重编程蛋白的核酸,将所述癌细胞转化成非癌细胞。
根据本发明的方面,提供了治疗需要其的受试者的方法,其包括将包含蛋白转导试剂修饰的重编程蛋白的药物组合物全身地和/或局部地给予所述受试者,其中所述蛋白转导试剂与所述重编程蛋白非共价结合并且其中所述蛋白转导试剂包含阳离子试剂和脂质。
根据本发明的方面,提供了包含蛋白转导试剂修饰的重编程蛋白的药物组合物。
“蛋白转导试剂修饰的重编程蛋白”为已用蛋白转导试剂——在本文中也称为“QQ试剂”——处理的重编程蛋白。术语“蛋白转导试剂”是指有效地使与蛋白转导试剂非共价结合的蛋白被递送到哺乳动物细胞中并且一旦存在于哺乳动物细胞中就与该蛋白解离以将该蛋白适当递送到其适当的亚细胞位置的组合物。所述蛋白转导试剂——在本文中也称为“QQ试剂”——包括至少一种阳离子试剂、至少一种脂质和任选的增强剂。本文使用的术语“QQ修饰的重编程蛋白”及其语法变体等同于本文使用的“蛋白转导试剂修饰的重编程蛋白”及其语法变体。类似地,称为“QQ”蛋白的一种或多种蛋白表示蛋白通过用蛋白转导试剂处理而被修饰并且为“蛋白转导试剂修饰的重编程蛋白”。例如,术语“QQ-SON”是指通过用本文所述的蛋白转导试剂处理而被修饰以产生蛋白转导试剂修饰的重编程Sox2蛋白、Oct4蛋白和Nanog蛋白的Sox2蛋白、Oct4蛋白和Nanog蛋白的混合物。
合适的阳离子试剂的一个实例是聚乙烯亚胺(PEI),例如,但不限于,PEI Mw 1,200(PEI 1.2K)、PEI Mw 2000(PEI 2K)、PEI Mw 4000(PEI 4K)和PEI Mw 8000(PEI 8K)。脂质可以是本领域技术人员已知的具有与本文列出的那些脂质相同的一般特性的任何脂质。这样的脂质的实例包括,但不限于,DOTMA(N-1(-(2,3-二油酰氧基)丙基-N,N,N-三甲基氯化铵;DOGS(二十八基酰胺基-甘氨酰精胺);DOTAP,1,2-二油酰基-3-三甲基铵-丙烷;DOPE,1,2-二油酰基-sn-甘油-3-磷酸乙醇胺;POPC,1-棕榈酰-2-油酰-sn-甘油-3-磷酸胆碱;和DMPE 1,2-二肉豆蔻酰-sn-甘油-3-磷酸胆碱。
任选地,所述蛋白转导试剂包括作为阳离子试剂的聚乙烯亚胺,并且所述脂质为DOTAP或DOTMA和DOPE或DOGS;POPC和DMPE;或DOTAP或DOTMA、DOPE或DOGS、POPC和DMPE。任选地,所述蛋白转导试剂为表1所述的QQ1a、QQ2a、QQ3a、QQ4a、QQ5a、QQ6a、QQ7a、QQ8a、QQ9a。
任选的增强剂可以是显著增强阳离子蛋白质的细胞负载的任何增强剂。在细胞培养物中的这样的增强剂的实例包括,但不限于MG132、蛋白酶抑制剂、CaCl2、DMSO和生长因子。也可使用其他增强剂,包括但不限于细胞膜表面活性剂。所述试剂还可以包括不影响该试剂功能的稳定剂和其他惰性载体。如表1所示,可以改变使用的浓度和具体化合物。
本文使用的术语“重编程蛋白”是指DNA结合转录因子蛋白或其有效部分,其影响基因的转录并且诱导由第一分化细胞类型至第二、不同的分化细胞类型的改变。由第一分化细胞类型至第二、不同的分化细胞类型的改变通常历经一个中间的、更少分化的细胞类型(例如包括蛋白诱导的多能干细胞的瞬时干细胞)。已经从人类和其他物种中分离出重编程蛋白和编码它们的核酸。重编程蛋白包括,但不限于,Asc1、Ascl1、Brca-1l、Brn2、C/EBPα、CEBPβ、c-MYC、Dlx2、EKLF、Erg1、Er71、Fli1、Foxa1、Foxa2、Foxa3、FoxC1、FoxC2、FOXG1、FOXP3、Gata1、Gata2、Gata3、Gata4、Gata6、GFI1、Hand2、Hb9、Hey1、Hey2、HNF4A、Hnf1a、Klf4、Lhx3、LIN28A、Lmx1a、Lsl1、MafA、MEF2c、Mytl1、MYF5、MyoD、NAB2、Nanog、NeuroD1、NEUROG2、NEUROG3、Nurr1、Oct4、Pdx1、Pax4、PAX5、Pax6、Prdm16、PU.1、RORγ、Runx2、SLC7A10、Slug、Sox2、Sox5、Sox6、Sox7、Sox9、Sox18、Stat5a、T-bet和Tbox5。这样的重编程蛋白的氨基酸序列是已知的,如在本文示为SEQ ID NOs:1-63的序列所示例的,以及在本文示为SEQ ID NOs:65-127的编码它们的核酸。
待被QQ修饰的重编程蛋白通过例如分离、合成或重组表达编码所述重编程蛋白的核酸的方法来获得。这样的蛋白也可是市售可得的。
术语“核酸”是指具有如下任意形式的多于一个核苷酸的RNA或DNA分子:包括单链、双链、寡核苷酸或多核苷酸。术语“核苷酸序列”是指单链形式的核酸的寡核苷酸或多核苷酸中的排序。
待被QQ修饰的重编程蛋白的重组表达包括编码所述蛋白的核酸的表达,其中所述核酸被包含在表达构建体中。
宿主细胞可以用编码所需的重编程蛋白的表达构建体转染,以使所述重编程蛋白在细胞中表达。
术语“表达构建体”和“表达盒”在本文中用于指含有所需的待表达的重编程因子的核酸编码序列并含有一种或多种表达可操作地连接的编码序列所必需或期望的调控元件的双链重组DNA分子。
可操作地用于表达所需蛋白的表达构建体包括,例如,处于可操作连接的启动子、编码所需蛋白的DNA序列和转录终止位点。
本文使用的术语“调控元件”是指控制核酸序列表达的一些方面的核苷酸序列。示例性的调控元件说明性地包括增强子、内部核糖体进入位点(IRES)、内含子;复制起点、多腺苷酸化信号(多聚A)、启动子、转录终止序列和有助于核酸序列的复制、转录、转录后加工的上游调控区。本领域普通技术人员仅利用常规实验即能够选择上述和其他调控元件并将其使用在表达构建体中。可使用公知的方法通过重组或合成产生表达构建体。
本文使用的术语“可操作地连接”是指一个核酸与第二个核酸处于功能性关系中。
在具体的方面,包含在表达盒中的调控元件为启动子。
术语“启动子”在本领域中是公知的,是指一种或多种与待转录的核酸序列可操作地连接并结合RNA聚合酶且允许转录开始的DNA序列。启动子通常位于编码待表达的肽或蛋白的核酸的上游(5′)。
内含启动子可以是组成型启动子或可提供可诱导的表达。本领域技术人员熟悉各种公知的启动子,并且能够选择适用于在特定环境中(例如在具体指明的细胞类型中)表达肽或蛋白的启动子。
对于在酵母宿主细胞中的表达,合适的启动子包括,但不限于,ADH1启动子、PGK1启动子、ENO启动子、PYK1启动子等;或可调控的启动子,例如GAL1启动子、GAL 10启动子、ADH2启动子、PH05启动子、CUP1启动子、GAL7启动子、MET25启动子、MET3启动子、CYC1启动子、HIS 3启动子、ADH1启动子、PGK启动子、GAPDH启动子、ADC1启动子、TRP1启动子、URA3子、LEU2启动子、ENO启动子、TP1启动子和AOX1。
对于在原核宿主细胞中的表达,合适的启动子包括,但不限于,噬菌体T7 RNA聚合酶启动子;trp启动子;乳糖操纵子启动子;trc启动子;tac启动子;araBAD启动子;ssaG启动子;pagC启动子、σ70启动子、dps启动子、spv启动子、SPI-2启动子;actA启动子、rps M启动子;四环素启动子、SP6启动子、细菌噬菌体T3启动子、gpt启动子和细菌噬菌体λP启动子。
其他合适的细菌启动子和真核启动子是公知的,例如,如在Sambrook等人,Molecular Cloning,A Laboratory Manual,1989第二版;和第三版,2001;Kriegler,Gene Transfer and Expression:A Laboratory Manual(1990);和Ausubel等人,Current Protocols in Molecular Biology,2014中所记载的。
对于在真核细胞中的表达,可包括在表达构建体中的启动子包括,但不限于,巨细胞病毒立即早期启动子;单纯疱疹病毒胸苷激酶启动子;早期和晚期SV40启动子;磷酸甘油酸激酶(PGK)启动子;存在于来自反转录病毒的长末端重复序列的启动子;和小鼠金属硫蛋白-I启动子、β-肌动蛋白启动子、ROSA26启动子、热休克蛋白70(Hsp70)启动子、编码延伸因子1α(EF1)的EF-1α基因启动子、真核起始因子4A(eIF-4A1)启动子、氯霉素乙酰转移酶(CAT)启动子和Rous Sarcoma病毒的长末端重复区(RSV启动子)。
除了启动子,可包括一种或多种增强子序列,例如,但不限于,巨细胞病毒(CMV)早期增强子元件和SV40增强子元件。
其他内含序列包括内含子序列,例如β球蛋白内含子或通用内含子、转录终止序列和mRNA多聚腺苷酸化(pA)序列,例如,但不限于SV40-pA、β-球蛋白-pA和SCF-pA。
表达构建体可包括在细菌细胞中扩增所必需的序列,例如选择标记物(例如卡那霉素抗性基因或氨苄西林抗性基因)和复制子。
内部核糖体进入位点(IRES)为任选的内含核酸序列,其允许翻译起始于mRNA中的内部位点。IRES是本领域公知的,例如如Pelletier,J.等人,Nature,334:320-325,1988;Vagner,S.等人,EMBO Rep.,2:893-898,2001;和Hellen,C.U.等人,Genes Dev.15:1593-1612,2001中所记载的。
术语“转录终止位点”是指可操作地通过RNA聚合酶终止转录的DNA序列。转录终止位点通常位于编码待表达的肽或蛋白的核酸的下游(3′)。
在表达构建体中任选地包括前导序列。
编码所需蛋白的核酸的密码子优化可用于改善在特定的表达系统中的表达,例如通过提高翻译效率。编码所需蛋白的经选择的核酸可经密码子优化以用于在任何指定的宿主细胞中表达,所述细胞为原核的或真核的,例如,但不限于,细菌、昆虫细胞、酵母、真菌、鸟卵和哺乳动物细胞。
经表达的蛋白任选地包括N末端元件,如前导序列和/或N-末端蛋氨酸。
除了编码所需重编程蛋白的一种或多种核酸,在表达载体中还可包括一种或多种编码额外蛋白的核酸序列。例如,任选地包括编码报道子——包括,但不限于,β-半乳糖苷酶、绿色荧光蛋白和抗生素抗性报道子——的核酸序列。在其他实例中,任选地包括his-标签、GST-标签或MBP-标签。
可将编码重编程蛋白的核酸克隆到用于转化至原核细胞或真核细胞并表达所编码的肽和/或蛋白的表达载体中。本文使用的“表达载体”被定义为当被引入合适的宿主细胞、表达系统中时,可被转录和翻译而产生所编码的多肽的多核苷酸。
表达载体是本领域已知的,例如,包括质粒、粘粒、病毒和噬菌体。表达载体可以是,例如,原核载体、昆虫载体或真核载体。
例如,包括处于可操作连接的启动子、编码所需蛋白的DNA序列和转录终止位点的表达构建体包括在质粒、粘粒、病毒或噬菌体表达载体中。
特定的载体是本领域已知的,并且本领域技术人员会知晓用于特定目的的适当载体。
根据本发明的各方面,任何合适的表达载体/宿主细胞系统可用于给予受试者的转录因子的表达。
使用重组表达载体的重编程蛋白的表达通过将表达载体引入到真核或原核宿主细胞表达系统(例如昆虫细胞、哺乳动物细胞、酵母细胞、真菌、鸟卵、细菌细胞或本领域中公认的任何其他单细胞生物体或多细胞生物体)中来实现。
含有重组表达载体的宿主细胞被维持在所需蛋白在其中产生的条件下。可以使用已知的细胞培养技术来培养或维持宿主细胞,例如,在Celis,Julio主编,1994,Cell Biology Laboratory Handbook,Academic Press,N.Y中记载的。可以由本领域技术人员选择并优化这些细胞的各种培养条件,包括与特定的营养成分、氧、张力、二氧化碳和降低的血清水平相关的培养基配方。
可将细菌细胞用作宿主细胞以产生重编程蛋白。在细菌细胞中的重编程蛋白表达和所产生的蛋白的纯化可以使用已知方案进行,例如在Paulina Balbás,Argelia Lorence主编,2004,Recombinant Gene Expression:Reviews and Protocols,Humana Press,New Jersey;Peter E.Vaillancourt,2003,E.Coli Gene Expression Protocols,Springer Science&Business Media中所记载的。
任选地,当使用产生内毒素的宿主细胞类型时,纯化经重组产生的重编程蛋白以除去内毒素。例如,在蛋白纯化阶段,可增加使用10个柱体积的0.2%Triton X114以从细菌表达的重组重编程蛋白中除去内毒素的额外的洗涤步骤。
或者,为了产生在人类细胞中不引发内毒素反应的重组重编程蛋白,可将经遗传修饰的细菌菌株ClearColiTM BL21(DE3)用作宿主细胞,以使不需要去除内毒素。
对于在宿主细胞中的表达,可以使用任何用于将重组核酸引入到宿主细胞中的公知方法,例如磷酸钙转染、聚凝胺、原生质体融合、电穿孔、声致穿孔、脂质体和显微注射法,其实例记载于Sambrook等人,Molecular Cloning:A Laboratory Manual,Cold Spring Harbor Laboratory Press,2001;和Ausubel,F.等人,(主编),Current Protocols in Molecular Biology,2014中。
无细胞表达系统任选地用于表达重编程蛋白,如在Ausubel,F.等人,(主编),Current Protocols in Molecular Biology,2014中所记载的。
可将在本文示为SEQ ID NOs:1-63并由SEQ ID NOs:65-127的核酸序列编码的人类重编程蛋白及其变体用于根据本文所述的方面的方法中。
本文使用的术语“变体”是指编码重编程蛋白的核酸序列的变异,或其中一种或多种核苷酸或氨基酸残基已通过核苷酸或氨基酸取代、添加或缺失被修饰且保留参照核酸序列或重编程蛋白功能的重编程蛋白的变异。相比于相应的核酸序列或重编程蛋白,本文所述的核酸序列或重编程蛋白的变体以保守的功能特性为表征。
可以使用标准分子生物学技术,例如化学合成、位点定向诱变和PCR介导的诱变来引入突变。
本领域技术人员会理解,可引入一种或多种氨基酸突变而不改变所需重编程蛋白的功能特性。例如,可以进行一种或多种氨基酸取代、添加或缺失而不改变所需重编程蛋白的功能特性。
本领域技术人员可容易地确定重编程蛋白变体的生物学活性,例如使用本文所述的任何功能测定法或本领域中已知的其他功能测定法。
相比于相应的重编程蛋白,本文所述的重编程蛋白的变体以保守的功能特性为表征并且与参照重编程蛋白的氨基酸序列具有75%、80%、85%、90%、95%、96%、97%、98%、99%或更大的同一性。
当将参照重编程蛋白与变体比较时,除了在氨基酸序列中相应位置处的氨基酸的同一性,还可以考虑氨基酸相似性。“氨基酸相似性”是指相比于在参照蛋白中的相应氨基酸位置,在推定的同源物中的氨基酸同一性和保守性氨基酸取代。
相比于相应的重编程蛋白,本文所述的重编程蛋白的变体以保守的功能特性为表征并且与参照重编程蛋白的氨基酸序列具有75%、80%、85%、90%、95%、96%、97%、98%、99%或更大的相似性。
可以在参照蛋白中进行保守性氨基酸取代以制备变体。
保守性氨基酸取代是本领域公认的一个氨基酸被另一个具有相似特性的氨基酸取代。例如,每个氨基酸可被描述为具有如下特征中的一种或多种:带正电的、带负电的、脂肪族的、芳香族的、极性的、疏水性的和亲水性的。保守性取代是一个具有具体指定结构或功能特征的氨基酸被另一种具有相同特征的氨基酸取代。酸性氨基酸包括天冬氨酸、谷氨酸;碱性氨基酸包括组氨酸、赖氨酸、精氨酸;脂肪族氨基酸包括异亮氨酸、亮氨酸和缬氨酸;芳香族氨基酸包括苯丙氨酸、甘氨酸、酪氨酸和色氨酸;极性氨基酸包括天冬氨酸、谷氨酸、组氨酸、赖氨酸、天冬酰胺、谷氨酰胺、精氨酸、丝氨酸、苏氨酸和酪氨酸;和疏水氨基酸包括丙氨酸、半胱氨酸、苯丙氨酸、甘氨酸、异亮氨酸、亮氨酸、蛋氨酸、脯氨酸、缬氨酸和色氨酸;和保守性取代包括在每组内氨基酸之间的取代。还可以根据相对大小来描述氨基酸,丙氨酸、半胱氨酸、天冬氨酸、甘氨酸、天冬酰胺、脯氨酸、苏氨酸、丝氨酸、缬氨酸通常都被认为是小氨基酸。
变体可包括合成的氨基酸类似物、氨基酸衍生物和/或非标准氨基酸,举例说明性地包括但不限于,α-氨基丁酸、瓜氨酸、刀豆氨酸、氰丙氨酸、二氨基丁酸、二氨基庚二酸、二羟基-苯丙氨酸、黎豆氨酸、高精氨酸、羟脯氨酸、正亮氨酸、正缬氨酸、3-磷酸丝氨酸、高丝氨酸、5-羟色氨酸、1-甲基组氨酸、3-甲基组氨酸和鸟氨酸。
同一性百分比通过比较氨基酸序列或核酸序列——包括参照氨基酸序列或核酸序列和推定的同源物氨基酸序列或核酸序列——来确定。为了确定两个氨基酸序列或两个核酸序列的同一性百分比,对所述序列进行比对用于最佳比较目的(例如,可在第一氨基酸序列或核酸序列中引入空位,以与第二氨基酸序列或核酸序列进行最佳比对)。然后比较相应的氨基酸位置或核苷酸位置上的氨基酸残基或核苷酸。当所述第一序列上的位置被与所述第二序列中对应位置的相同的氨基酸残基或核苷酸占据时,所述分子在此位置上是相同的。所述两个序列之间的同一性百分比是所述序列共有的相同位置的数量的函数(即,同一性百分比(%)=相同重叠位置的数量/位置总数×100%)。所比较的两个序列通常具有相同的长度或几乎相同的长度。
确定两个序列之间的同一性百分比也可使用数学算法来完成。用于测定同一性百分比的算法示例性地包括S.Karlin和S.Altshul,PNAS,90:5873-5877,1993;T.Smith和M.Waterman,Adv.Appl.Math.2:482-489,1981,S.Needleman和C.Wunsch,J.Mol.Biol.,48:443-453,1970,W.Pearson和D.Lipman,PNAS,85:2444-2448,1988的算法,以及其他纳入计算机化实现形式(computerized implementations)的算法,例如但不限于,GAP、BESTFIT、FASTA TFASTA;以及,例如纳入在Wisconsin Genetics Software Package,Genetics Computer Group,575Science Drive,Madison,Wis.中并可从国立生物技术信息中心(National Center for Biotechnology Information)公开获得的BLAST。
用于比较两个序列的数学算法的非限制性实例是Karlin和Altschul,1990,PNAS 87:2264-2268,在Karlin和Altschul,1993,PNAS.90:5873-5877中被改良。这样的算法被纳入Altschul等人,1990,J.Mol.Biol.215:403中的NBLAST和XBLAST程序。利用NBLAST核苷酸程序参数组(例如,得分=100、字长=12)进行BLAST核苷酸搜索,以获得与本发明的核酸分子同源的核苷酸序列。利用XBLAST程序参数组(例如,得分=50,字长=3)进行BLAST蛋白搜索,以获得与本发明的蛋白分子同源的氨基酸序列。为了获得用于比较目的的空位比对,按照Altschul等人,1997,Nucleic Acids Res.25:3389-3402中所述使用Gapped BLAST。或者,使用PSI BLAST进行迭代检索——其检测分子间的远缘关系。当利用BLAST、Gapped BLAST和PSI Blast程序时,使用各个程序的(例如XBLAST和NBLAST的)默认参数。用于序列比较所使用的数学算法的另一个优选的非限制性实例是Myers和Miller,1988,CABIOS 4:11-17中的算法。此样的算法被纳入ALIGN程序(2.0版本)——其为GCG序列比对软件包的一部分。当利用所述ALIGN程序比较氨基酸序列时,其使用PAM120权重残基表、空位长度罚分为12且空位罚分为4。
在允许或不允许空位的情况下,使用与上述那些类似的技术来确定两个序列之间的同一性百分比。在计算同一性百分比时,通常仅计数精确的匹配。
本领域技术人员会认识到,可分别引入一种或多种核酸或氨基酸突变而不改变给定的核酸或蛋白的功能特性。
如前所述,在本文示为SEQ ID NOs:1-63的人类重编程蛋白由SEQ ID NOs:65-127的核酸序列编码。应理解,由于遗传密码的简并性,替代的核酸序列编码特定的重编程蛋白,并且这类替代核酸可被表达以产生所需重编程蛋白。
术语“互补”是指核苷酸之间的Watson-Crick碱基配对,并且具体是指核苷酸彼此氢键合——胸腺嘧啶或尿嘧啶残基与腺嘌呤残基通过两个氢键连接;并且胞嘧啶残基和鸟嘌呤残基通过三个氢键连接。通常,一个核酸包括被描述为与具体指定的第二核苷酸序列具有“互补性百分比”的核苷酸序列。例如,一个核苷酸序列可与具体指定的第二核苷酸序列具有80%、90%或100%的互补性,表明在序列的10个核苷酸中有8、9或10个核苷酸与所述具体指定的第二核苷酸序列互补。例如,核苷酸序列3′-TCGA-5′与核苷酸序列5′-AGCT-3′是100%互补的。此外,核苷酸序列3′-TCGA-5′与核苷酸序列5′-TTAGCTGG-3′的一个区域是100%互补的。
术语“杂交”是指互补核酸的配对和结合。如本领域众所公知的,两个核酸之间发生不同程度的杂交,这取决于例如核酸互补的程度、核酸的解链温度(Tm)和杂交条件的严格性的因素。术语“杂交条件的严格性”是指杂交介质的温度、离子强度和组成(针对具体的常用添加剂,例如甲酰胺和Denhardt溶液)的条件。对具体指定的核酸的特定杂交条件的确定是常规的且是本领域中公知的,例如,如在J.Sambrook和D.W.Russell,Molecular Cloning:A Laboratory Manual,Cold Spring Harbor Laboratory Press;第三版,2001;和F.M.Ausubel主编,Short Protocols in Molecular Biology,Current Protocols;第五版,2002中所记载的。高严格杂交条件是仅允许基本上互补的核酸杂交的那些。通常,具有约85-100%互补性的核酸被认为是高度互补的,并在高严格条件下杂交。中等严格杂交条件的实例是这样的条件,在该条件下具有中度互补性(约50-84%互补性)的核酸,以及具有高度互补性的核酸发生杂交。相比之下,低严格杂交条件是其中具有低度互补性程度的核酸发生杂交的那些。
术语“特异性杂交”和“特异性地杂交”是指特定的核酸与靶核酸的杂交,而基本上不与样品中除了靶核酸以外的核酸杂交。
如本领域技术人员所公知的,杂交和洗涤条件的严格性取决于若干因素,包括探针和靶点的Tm,以及所述杂交和洗涤条件的离子强度。实现所需杂交严格性的杂交和条件记载于例如Sambrook等人,Molecular Cloning:A Laboratory Manual,Cold Spring Harbor Laboratory Press,2001;和Ausubel,F.等人,(主编),Short Protocols in Molecular Biology,Wiley,2002中。
高严格杂交条件的实例是,在含有6X SSC、5X Denhardt溶液、30%甲酰胺和100μg/ml退行性的鲑鱼精子的溶液中,长度超过约100个核苷酸的核酸于37℃下过夜杂交,然后在0.1×SSC和0.1%SDS的溶液中在60℃下洗涤15分钟。SSC是0.15M NaCl/0.015M柠檬酸钠。Denhardt溶液是0.02%牛血清白蛋白/0.02%FICOLL/0.02%聚乙烯吡咯烷酮。
根据本发明的方面,通过QQ修饰的重编程蛋白是经分离的蛋白。术语“经分离的蛋白”表示蛋白已经从生物材料(例如可存在于蛋白在其中产生的系统中的细胞、细胞碎片和其他蛋白)中分离。术语“经分离的蛋白”可以,但不必然表示蛋白是经纯化的。包括在本发明的方法和组合物中的经纯化的蛋白含有所包括的蛋白的质量的至少约1-100重量%,例如约25重量%、50重量%、75重量%、85重量%、95重量%、99重量%或大于约99重量%。
术语“受试者”是指需要治疗响应于细胞重编程的有益效果的疾病或损伤的个体,并且通常包括哺乳动物和鸟类,例如,但不限于,人类、其他灵长类动物、猫、狗、绵羊、牛、山羊、马、猪、家禽、兔和啮齿类(如大鼠、小鼠和豚鼠)。根据本发明的方面,所述受试者是人。
病症以受损的细胞和/或有缺陷的细胞为表征。
术语“治疗”用于指治疗由受损的和/或有缺陷的细胞为表征的病症(例如,受试者的疾病或损伤),其包括:在受试者中抑制或改善疾病或损伤,例如减缓疾病的进展和/或减少或改善疾病或损伤的征象或症状。
以血管生成为表征的病症根据本发明的方法的方面治疗,并且以QQ修饰的重编程蛋白通过血管生成性血管的增强的渗透性和保留效应(EPR效应)的有效递送为表征。
根据本发明的方面治疗的以受损的细胞和/或有缺陷的细胞为表征的病症为多种人类病症,包括但不限于:癌症;心血管疾病或损伤例如急性和慢性心肌梗塞,局部缺血,心脏损伤,冠状动脉病,先天性心脏病,心肌病例如酒精性心肌病、致心律失常性右室心肌病、高血压性心肌病、扩张型心肌病、肥厚性心肌病、炎症性心肌病、缺血性心肌病、继发于全身代谢性疾病的心肌病、营养不良性心肌病(myocardiodystrophy)、致密化不全心肌病、限制性心肌病和瓣膜性心肌病;血管疾病或血管损伤;贫血;缺血性和出血性中风;代谢性疾病或病症,例如I型糖尿病和II型糖尿病,和肥胖症;神经系统疾病和损伤例如脊髓损伤,外伤性脑损伤,Huntington氏病,精神分裂症,Alzheimer病,肌萎缩性侧索硬化,共济失调,自闭症,Lyme病,脑膜炎,偏头痛,运动神经元病,运动障碍例如帕金森氏病,神经病,疼痛,神经性疼痛,脊髓病症,外周和中枢神经疾病,自主神经系统疾病,疾病发作例如癫痫,睡眠障碍,痴呆例如Alzheimer病,肌营养不良症,Charcot-Marie-Tooth神经病1A型和脱髓鞘疾病例如急性播散性脑脊髓炎、肾上腺脑白质营养不良、肾上腺脊髓神经病、多发性硬化、视神经脊髓炎、视神经炎和横贯性脊髓炎;创伤;炎症性病症;肝疾病和损伤例如肝疾病例如家族性高胆固醇血症(FH),Crigler-Najjar综合征,遗传性酪氨酸血症I,暴发性肝衰竭,病毒性肝炎,药物诱发的肝损伤,肝硬化,遗传性肝功能不全例如由于Wilson病、Gilbert综合征或a1-抗胰蛋白酶缺乏症,肝胆管癌,自身免疫性肝病例如自身免疫性慢性肝炎或原发性胆汁性肝硬化;自身免疫疾病;骨关节炎;类风湿性关节炎;软骨疾病或损伤例如由于关节疾病,骨关节炎,软骨损伤,外伤性破裂或脱离,软骨发育不全,肋软骨炎,椎间盘脱出症,复发性多软骨炎(polychonritis),肿瘤,软骨瘤,软骨肉瘤和多形性腺瘤;Crohn病和遗传异常。
使用本文所述的方法和组合物治疗的特定的癌症以异常的细胞增殖为表征,包括但不限于,肿瘤前期过度增殖、原位癌、肿瘤和转移。术语“治疗”用于指在受试者中治疗癌症,包括:在受试者中抑制或改善癌症,例如减缓癌症的进展和/或减少或改善癌症的征象或症状。
包括本发明的抗癌组合物的组合物的治疗有效量是在被治疗的受试者中具有有益作用的量。在患有癌症(例如以异常的细胞增殖为表征的病症,包括但不限于,肿瘤前期过度增殖、原位癌、肿瘤、转移、肿瘤、良性生长物或其他响应于本发明的组合物的病症)的受试者中,治疗有效量的QQ修饰的蛋白有效改善一种或多种癌症的征象和/或症状。例如,治疗有效量的组合物对于可检测地降低以异常的细胞增殖为表征的癌细胞的增殖是有效的,所述异常的细胞增殖包括但不限于肿瘤前期过度增殖、原位癌、肿瘤、转移、肿瘤、良性生长物或其他响应于所给予的QQ修饰的蛋白的病症。
这样的癌症包括实体癌和非实体癌,例如膀胱癌;乳腺癌;结肠直肠癌;子宫颈癌;食道癌;头颈癌;肾癌;肺癌;神经系统癌症,例如胶质母细胞瘤、星形细胞瘤、室管膜瘤、神经母细胞瘤、视网膜母细胞瘤、脑膜瘤、颗粒细胞瘤和神经鞘瘤;卵巢癌;胰腺癌;前列腺癌;皮肤癌;胃癌;睾丸癌;喉癌;脐尿管癌;或阴道癌。
根据本发明的方面的药物组合物包括QQ修饰的重编程蛋白和可药用的载体。
本文使用的术语“可药用的载体”是指对预期接收者通常是无毒的,并且不会显著抑制QQ修饰的蛋白或其他包括在组合物中的活性剂的活性的载体或稀释剂。
本发明的组合物通常包括约0.1-99%的QQ修饰的重编程蛋白。
适合递送至受试者的药物组合物可以各种示例性地包括如下的形式来制备:生理上可接受的无菌水溶液或非水溶液、分散液、悬浮液或乳液,和用于复水成无菌可注射溶液或分散液的无菌粉末。
药物组合物任选地包含缓冲剂、溶剂或稀释剂。
合适的水性和非水性载体的实例包括水,乙醇,多元醇例如丙二醇、聚乙二醇和甘油;植物油例如橄榄油;和可注射的有机酯例如油酸乙酯;以及它们中的任意两种或更多种的合适的混合物。
这样的制剂通过包括肠胃外给药的合适的途径给药。任选地,给药包括全身给药或局部给药。
这些组合物还可含有佐剂,例如防腐剂、湿润剂、乳化剂和分散剂。微生物作用的预防可通过各种抗细菌剂和抗真菌剂(例如对羟苯甲酸类、三氯叔丁醇、苯酚、山梨酸等)来确保。一种或多种任选地包括等渗剂,例如,糖类和或盐类例如氯化钠。
在具体的方面,将QQ-修饰的蛋白通过局部施用给药。
在具体的方面,局部制剂可以是软膏剂、洗剂、霜剂或凝胶剂。局部剂型例如软膏剂、洗剂、霜剂或凝胶剂基质记载于Remington:The Science and Practice of Pharmacy,第二十一版,Lippincott Williams&Wilkins,2006,p.880-882和p.886-888;和Allen,L.V.等人,Ansel’s Pharmaceutical Dosage Forms and Drug Delivery Systems,第八版,Lippincott Williams&Wilkins,2005,p.277-297中。
药物组合物的可药用的载体和制剂是本领域已知的,示例性地包括,但不限于,如在Remington:The Science and Practice of Pharmacy,第21版,Lippincott,Williams&Wilkins,Philadelphia,PA,2006;和Allen,L.V.等人,Ansel’s Pharmaceutical Dosage Forms and Drug Delivery Systems,第八版,Lippincott,Williams&Wilkins,Philadelphia,PA,2005中所记载的。
包括QQ修饰的蛋白的药物组合物适于通过多种全身途径和/或局部途径——包括但不限于:肠胃外、口腔、直肠、鼻、肺、硬膜外、眼、耳、动脉内、心脏内、脑室内、颅内、真皮内、静脉内、肌肉内、腹膜内、骨内、鞘内、瘤内、膀胱内、皮下、局部、经皮和经粘膜,例如通过舌下、颊、阴道和吸入给药途径——给予受试者。
药物组合物的给药
本发明的组合物可以急性给药或慢性给药。例如,如本文所述的组合物可以作为单一剂量或以多个剂量在相对有限的时间段(例如数秒-数年)内给药。在其他实施方案中,给药可包括在数天-数年的时期内给药多个剂量,例如用于慢性治疗癌症。
治疗有效量的QQ修饰的蛋白会根据给药途径和所给予的组合物的形式和所给予的特定组合物、在受试者中所治疗的病症的严重性和类型、受试者的物种、受试者的年龄和性别以及待治疗的受试者的总体身体特征而改变。根据本公开内容和本领域公知常识,本领域技术人员可基于医疗实践中典型的这些和其他考虑事项来确定治疗有效量,而无需过多实验。通常,认为治疗有效量会在约0.001ng/kg体重-100mg/kg体重的范围内,任选地在约0.01ng/kg-1mg/kg的范围内,并且还任选地在约0.1ng/kg-0.1mg/kg的范围内。此外,可根据治疗是否会是急性的或持续的来调整剂量。
尽管可给予更多个剂量,通常给予1-100个剂量的QQ修饰的蛋白以治疗需要其的受试者。为了延续1天、1周、2周、4周、1个月、2个月、3-6个月或更长的疗程,可以一天两次、每天、每周两次、每周、每隔一周、每月或以一些其他间隔给予QQ修饰的蛋白。任选地重复疗程,并且如果需要的话可延长为长期治疗。
根据本发明的方面的方法的QQ修饰的蛋白的给药包括按照给药方案给药,以产生所需的响应。合适的剂量给药方案(schedual)取决于几个因素,例如包括受试者的年龄、体重、性别、病史和健康状况,所用的组合物的类型和给药途径。本领域技术人员能够容易地确定用于特定受试者的给药剂量和给药方案。
本发明的实施方案的方法包括给予作为药物制剂的QQ修饰的蛋白,例如通过全身给药或局部给药。示例性的给药途径包括,但不限于,肠胃外、口腔、直肠、鼻、肺、硬膜外、眼、耳、动脉内、心脏内、脑室内、颅内、真皮内、静脉内、肌肉内、腹膜内、骨内、鞘内、瘤内、膀胱内、皮下、局部、经皮和经粘膜,例如通过舌下、颊、阴道和吸入给药途径。
QQ修饰的蛋白可经肠胃外给药,例如,通过注射,例如静脉内注射、肌内注射、腹膜内注射、皮下注射、经皮注射、鞘内注射、颅内注射、脑脊髓内注射,和/或连续输注,例如通过静脉连续输注设备或脑脊髓内连续输注设备。
根据各方面,蛋白转导试剂修饰的重编程蛋白为DNA结合转录因子。根据本文所述的方面,给予蛋白转导试剂修饰的重编程蛋白对于在疾病或损伤部位原位重编程一种或多种细胞类型以体内治疗疾病或损伤是有效的。根据本文所述的方面,给予蛋白转导试剂修饰的重编程蛋白对于在疾病或损伤部位原位重编程一种或多种细胞类型,产生随后在疾病或损伤部位体内原位分化成正常细胞的瞬时干细胞以治疗疾病或损伤是有效的。
根据本发明的方面的治疗癌症的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Sox2、蛋白转导试剂修饰的Oct4和蛋白转导试剂修饰的Nanog。根据本发明的方面的治疗癌症的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Sox2、蛋白转导试剂修饰的Oct4和蛋白转导试剂修饰的Nanog。根据本发明的方面的治疗癌症的方法包括给予:蛋白转导试剂修饰的Sox2、蛋白转导试剂修饰的Oct4和蛋白转导试剂修饰的Nanog。这样的方法通过在癌症位点重编程癌细胞而在该位点产生新的正常细胞。
根据本发明的方面的治疗脑肿瘤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Sox2、蛋白转导试剂修饰的Oct4和蛋白转导试剂修饰的Nanog。根据本发明的各方面的治疗脑肿瘤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Sox2、蛋白转导试剂修饰的Oct4和蛋白转导试剂修饰的Nanog。根据本发明的方面的治疗脑肿瘤的方法包括给予:蛋白转导试剂修饰的Sox2、蛋白转导试剂修饰的Oct4和蛋白转导试剂修饰的Nanog。这样的方法通过在脑肿瘤位点重编程脑肿瘤细胞而在该位点产生新的正常细胞。
根据本发明的方面的治疗脑肿瘤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Sox2和蛋白转导试剂修饰的NeuroD。根据本发明的方面的治疗脑肿瘤的方法包括给予:蛋白转导试剂修饰的Sox2和蛋白转导试剂修饰的NeuroD。这样的方法通过在胰腺癌位点重编程脑肿瘤细胞而在该位点产生新的正常细胞。
根据本发明的方面的治疗乳腺癌的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Sox2、蛋白转导试剂修饰的Oct4和蛋白转导试剂修饰的Nanog。根据本发明的方面的治疗乳腺癌的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Sox2、蛋白转导试剂修饰的Oct4和蛋白转导试剂修饰的Nanog。根据本发明的方面的治疗乳腺癌的方法包括给予:蛋白转导试剂修饰的Sox2、蛋白转导试剂修饰的Oct4和蛋白转导试剂修饰的Nanog。这样的方法通过在乳腺癌位点重编程乳腺癌细胞而在该位点产生新的正常细胞。
根据本发明的方面的治疗乳腺癌的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Slug、蛋白转导试剂修饰的Gata3、蛋白转导试剂修饰的Brca-1和蛋白转导试剂修饰的State5a。根据本发明的方面的治疗乳腺癌的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Slug、蛋白转导试剂修饰的Gata3、蛋白转导试剂修饰的Brca-1和蛋白转导试剂修饰的State5a。根据本发明的方面的治疗乳腺癌的方法包括给予如下中的三种或更多种:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Slug、蛋白转导试剂修饰的Gata3、蛋白转导试剂修饰的Brca-1和蛋白转导试剂修饰的State5a。根据本发明的方面的治疗乳腺癌的方法包括给予如下中的四种或更多种:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Slug、蛋白转导试剂修饰的Gata3、蛋白转导试剂修饰的Brca-1和蛋白转导试剂修饰的State5a。根据本发明的方面的治疗乳腺癌的方法包括给予:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Slug、蛋白转导试剂修饰的Gata3、蛋白转导试剂修饰的Brca-1和蛋白转导试剂修饰的State5a。这样的方法通过在乳腺癌位点重编程乳腺癌细胞而在该位点产生新的正常细胞。
根据本发明的方面的治疗胰腺癌的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Sox2、蛋白转导试剂修饰的Oct4和蛋白转导试剂修饰的Nanog。根据本发明的方面的治疗胰腺癌的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Sox2、蛋白转导试剂修饰的Oct4和蛋白转导试剂修饰的Nanog。根据本发明的方面的治疗胰腺癌的方法包括给予:蛋白转导试剂修饰的Sox2、蛋白转导试剂修饰的Oct4和蛋白转导试剂修饰的Nanog。这样的方法通过在胰腺癌位点重编程胰腺癌细胞而在该位点产生新的正常细胞。
根据本发明的方面的治疗胰腺癌的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的PDX1、蛋白转导试剂修饰的PAX4、蛋白转导试剂修饰的MafA和蛋白转导试剂修饰的Ngn3。根据本发明的方面的治疗胰腺癌的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的PDX1、蛋白转导试剂修饰的PAX4、蛋白转导试剂修饰的MafA和蛋白转导试剂修饰的Ngn3。根据本发明的方面的治疗胰腺癌的方法包括给予如下中的三种或更多种:蛋白转导试剂修饰的PDX1、蛋白转导试剂修饰的PAX4、蛋白转导试剂修饰的MafA和蛋白转导试剂修饰的Ngn3。根据本发明的方面的治疗胰腺癌的方法包括给予:蛋白转导试剂修饰的PDX1、蛋白转导试剂修饰的PAX4、蛋白转导试剂修饰的MafA和蛋白转导试剂修饰的Ngn3。这样的方法通过在胰腺癌位点重编程胰腺癌细胞而在该位点产生新的正常细胞。
根据本发明的方面的治疗心脏病或心脏损伤(例如由于急性或慢性心肌梗塞造成的损伤)的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Gata4、蛋白转导试剂修饰的Hand2、蛋白转导试剂修饰的MEF2c和蛋白转导试剂修饰的Tbox5。根据本发明的方面的治疗心脏病或心脏损伤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Gata4、蛋白转导试剂修饰的Hand2、蛋白转导试剂修饰的MEF2c和蛋白转导试剂修饰的Tbox5。根据本发明的方面的治疗心脏病或心脏损伤的方法包括给予如下中的三种或更多种:蛋白转导试剂修饰的Gata4、蛋白转导试剂修饰的Hand2、蛋白转导试剂修饰的MEF2c和蛋白转导试剂修饰的Tbox5。根据本发明的方面的治疗心脏病或心脏损伤的方法包括给予:蛋白转导试剂修饰的Gata4、蛋白转导试剂修饰的Hand2、蛋白转导试剂修饰的MEF2c和蛋白转导试剂修饰的Tbox5。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的心肌细胞、平滑肌细胞和内皮细胞。
根据本发明的方面的治疗肝病或肝损伤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Gata4、蛋白转导试剂修饰的Hnf1a和蛋白转导试剂修饰的Foxa3。根据本发明的方面的治疗肝病或肝损伤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Gata4、蛋白转导试剂修饰的Hnf1a和蛋白转导试剂修饰的Foxa3。根据本发明的方面的治疗肝病或肝损伤的方法包括给予:蛋白转导试剂修饰的Gata4、蛋白转导试剂修饰的Hnf1a和蛋白转导试剂修饰的Foxa3。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的肝细胞。这样的肝病或肝损伤的实例包括:家族性高胆固醇血症(FH)、Crigler-Najjar综合征和遗传性的酪氨酸血症I。
根据本发明的方面的治疗肝病或肝损伤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Hnf1a、蛋白转导试剂修饰的Foxa1、蛋白转导试剂修饰的Foxa2和蛋白转导试剂修饰的Foxa3。根据本发明的方面的治疗肝病或肝损伤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Hnf1a、蛋白转导试剂修饰的Foxa1、蛋白转导试剂修饰的Foxa2和蛋白转导试剂修饰的Foxa3。根据本发明的方面的治疗肝病或肝损伤的方法包括给予:蛋白转导试剂修饰的Hnf1a、蛋白转导试剂修饰的Foxa1、蛋白转导试剂修饰的Foxa2和蛋白转导试剂修饰的Foxa3。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的肝细胞。这样的肝病或肝损伤的实例包括:家族性高胆固醇血症(FH)、Crigler-Najjar综合征和遗传性的酪氨酸血症I。
根据本发明的方面的治疗动脉粥样硬化的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的CEBP/α/β和蛋白转导试剂修饰的PU.1。根据本发明的方面的治疗动脉粥样硬化的方法包括给予CEBP/α/β和蛋白转导试剂修饰的PU.1。这样的方法通过在动脉粥样硬化位点重编程成纤维细胞而在该位点产生新的泡沫细胞和巨噬细胞。
根据本发明的方面的治疗神经退行性疾病或神经元组织损伤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Sox2和蛋白转导试剂修饰的Foxg1。根据本发明的方面的治疗神经退行性疾病或神经元组织损伤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Sox2和蛋白转导试剂修饰的Foxg1。根据本发明的方面的治疗神经退行性疾病或神经元组织损伤的方法包括给予:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Sox2和蛋白转导试剂修饰的Foxg1。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的神经元。
根据本发明的方面的治疗神经退行性疾病或神经元组织损伤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Lmx1a、蛋白转导试剂修饰的Nurr1、蛋白转导试剂修饰的Brn2和蛋白转导试剂修饰的Mytl1。根据本发明的方面的治疗神经退行性疾病或神经元组织损伤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Lmx1a、蛋白转导试剂修饰的Nurr1、蛋白转导试剂修饰的Brn2和蛋白转导试剂修饰的Mytl1。根据本发明的方面的治疗神经退行性疾病或神经元组织损伤的方法包括给予如下中的三种或更多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Lmx1a、蛋白转导试剂修饰的Nurr1、蛋白转导试剂修饰的Brn2和蛋白转导试剂修饰的Mytl1。根据本发明的方面的治疗神经退行性疾病或神经元组织损伤的方法包括给予如下中的四种或更多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Lmx1a、蛋白转导试剂修饰的Nurr1、蛋白转导试剂修饰的Brn2和蛋白转导试剂修饰的Mytl1。根据本发明的方面的治疗神经退行性疾病或神经元组织损伤的方法包括给予:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Lmx1a、蛋白转导试剂修饰的Nurr1、蛋白转导试剂修饰的Brn2和蛋白转导试剂修饰的Mytl1。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的谷氨酸能神经元。
根据本发明的方面的治疗神经退行性疾病或神经元组织损伤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Mytl1和蛋白转导试剂修饰的NeuroD1。根据本发明的方面的治疗神经退行性疾病或神经元组织损伤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Mytl1和蛋白转导试剂修饰的NeuroD1。根据本发明的方面的治疗神经退行性疾病或神经元组织损伤的方法包括给予如下中的三种或更多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Mytl1和蛋白转导试剂修饰的NeuroD1。根据本发明的方面的治疗神经退行性疾病或神经元组织损伤的方法包括给予:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Mytl1和蛋白转导试剂修饰的NeuroD1。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的谷氨酸能神经元。
根据本发明的方面的治疗神经退行性疾病或神经元组织损伤的方法包括给予:蛋白转导试剂修饰的Ngn2。这样的方法通过在疾病或损伤位点重编程星形细胞而在该位点产生新的谷氨酸能神经元。
根据本发明的方面的治疗神经退行性疾病或神经元组织损伤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Sox2和蛋白转导试剂修饰的NeuroD1。根据本发明的方面的治疗神经退行性疾病或神经元组织损伤的方法包括给予:蛋白转导试剂修饰的Sox2和蛋白转导试剂修饰的NeuroD1。这样的方法在疾病或损伤的位点产生新的神经干细胞。
根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Ascl1、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lhx3和蛋白转导试剂修饰的Hb9。根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Ascl1、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lhx3和蛋白转导试剂修饰的Hb9。根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予如下中的三种或更多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Ascl1、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lhx3和蛋白转导试剂修饰的Hb9。根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予如下中的四种或更多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Ascl1、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lhx3和蛋白转导试剂修饰的Hb9。根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Ascl1、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lhx3和蛋白转导试剂修饰的Hb9。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的运动神经元。这样的神经性疾病的实例包括肌萎缩侧索硬化症(ALS)。
根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Ascl1、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lhx3、蛋白转导试剂修饰的Hb9、蛋白转导试剂修饰的Lsl1和蛋白转导试剂修饰的Ngn2。根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Ascl1、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lhx3、蛋白转导试剂修饰的Hb9、蛋白转导试剂修饰的Lsl1和蛋白转导试剂修饰的Ngn2。根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予如下中的三种或多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Ascl1、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lhx3、蛋白转导试剂修饰的Hb9、蛋白转导试剂修饰的Lsl1和蛋白转导试剂修饰的Ngn2。根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予如下中的四种或更多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Ascl1、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lhx3、蛋白转导试剂修饰的Hb9、蛋白转导试剂修饰的Lsl1和蛋白转导试剂修饰的Ngn2。根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予如下中的五种或更多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Ascl1、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lhx3、蛋白转导试剂修饰的Hb9、蛋白转导试剂修饰的Lsl1和蛋白转导试剂修饰的Ngn2。根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予如下中的六种或更多种:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Ascl1、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lhx3、蛋白转导试剂修饰的Hb9、蛋白转导试剂修饰的Lsl1和蛋白转导试剂修饰的Ngn2。根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予:蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Ascl1、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lhx3、蛋白转导试剂修饰的Hb9、蛋白转导试剂修饰的Lsl1和蛋白转导试剂修饰的Ngn2。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的运动神经元。这样的神经性疾病的实例包括肌萎缩侧索硬化症(ALS)。
根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予蛋白转导试剂修饰的。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的GABA神经元。这样的神经性疾病的实例包括脊髓性肌萎缩(SMA)。
根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予蛋白转导试剂修饰的Dlx2。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的GABA神经元。这样的神经性疾病的实例包括肌萎缩侧索硬化症(ALS)、脊髓性肌萎缩(SMA)和帕金森氏病。
根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予:蛋白转导试剂修饰的Dlx2和蛋白转导试剂修饰的Ascl1。这样的方法通过在疾病或损伤位点重编程星形细胞而在该位点产生新的GABA神经元。这样的神经性疾病的实例包括脊髓性肌萎缩(SMA)。
根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lmx1a和蛋白转导试剂修饰的Foxa2。根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lmx1a和蛋白转导试剂修饰的Foxa2。根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予如下中的三种或更多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lmx1a和蛋白转导试剂修饰的Foxa2。根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予如下中的四种或更多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lmx1a和蛋白转导试剂修饰的Foxa2。根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Brn2、蛋白转导试剂修饰的Mytl1、蛋白转导试剂修饰的Lmx1a和蛋白转导试剂修饰的Foxa2。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的多巴胺神经元。这样的神经性疾病的实例包括帕金森氏病。
根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Lmx1a和蛋白转导试剂修饰的Nurr1。根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Lmx1a和蛋白转导试剂修饰的Nurr1。根据本发明的方面的治疗神经性疾病或神经元组织损伤的方法包括给予:蛋白转导试剂修饰的Asc1、蛋白转导试剂修饰的Lmx1a和蛋白转导试剂修饰的Nurr1。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的神经元。这样的神经性疾病的实例包括帕金森氏病。
根据本发明的方面的治疗血液疾病或血液障碍的方法包括给予:蛋白转导试剂修饰的Oct4。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的造血细胞。
根据本发明的方面的治疗糖尿病、胰腺疾病或胰腺组织损伤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Ngn3、蛋白转导试剂修饰的Pdx1和蛋白转导试剂修饰的Pax4。根据本发明的方面的治疗糖尿病、胰腺疾病或胰腺组织损伤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Ngn3、蛋白转导试剂修饰的Pdx1和蛋白转导试剂修饰的Pax4。根据本发明的方面的治疗糖尿病、胰腺疾病或胰腺组织损伤的方法包括给予:蛋白转导试剂修饰的Ngn3、蛋白转导试剂修饰的Pdx1和蛋白转导试剂修饰的Pax4。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的胰腺β细胞。
根据本发明的方面的治疗糖尿病、胰腺疾病或胰腺组织损伤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Ngn3、蛋白转导试剂修饰的Pdx1和蛋白转导试剂修饰的MafA。根据本发明的方面的治疗糖尿病、胰腺疾病或胰腺组织损伤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Ngn3、蛋白转导试剂修饰的Pdx1和蛋白转导试剂修饰的MafA。根据本发明的方面的治疗糖尿病、胰腺疾病或胰腺组织损伤的方法包括给予:蛋白转导试剂修饰的Ngn3、蛋白转导试剂修饰的Pdx1和蛋白转导试剂修饰的MafA。这样的方法通过在疾病或损伤位点重编程胰腺外分泌细胞而在该位点产生新的胰腺β细胞。
根据本发明的方面的治疗肥胖症的方法包括给予如下中的一种或两者:蛋白转导试剂修饰的Prdm16和蛋白转导试剂修饰的C/EBPb。根据本发明的方面的治疗肥胖症的方法包括给予蛋白转导试剂修饰的Prdm16和蛋白转导试剂修饰的C/EBPb。这样的方法通过在疾病或损伤位点重编程白色脂肪细胞而在该位点产生新的棕色脂肪细胞。
根据本发明的方面的治疗肌肉疾病或肌肉损伤的方法包括给予:蛋白转导试剂修饰的MyoD。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的肌肉细胞。
根据本发明的方面的治疗关节炎、骨关节炎、软骨退变和/或软骨损伤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Runx2、蛋白转导试剂修饰的Sox5和蛋白转导试剂修饰的Sox6。根据本发明的方面的治疗关节炎、骨关节炎、软骨退变和/或软骨损伤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Runx2、蛋白转导试剂修饰的Sox5和蛋白转导试剂修饰的Sox6。根据本发明的方面的治疗关节炎、骨关节炎、软骨退变和/或软骨损伤的方法包括给予如下中的三种或更多种:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Runx2、蛋白转导试剂修饰的Sox5和蛋白转导试剂修饰的Sox6。根据本发明的方面的治疗关节炎、骨关节炎、软骨退变和/或软骨损伤的方法包括给予:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Runx2、蛋白转导试剂修饰的Sox5和蛋白转导试剂修饰的Sox6。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的软骨细胞。
根据本发明的方面的治疗乳腺疾病或乳腺组织损伤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Slug、蛋白转导试剂修饰的Stat5a、蛋白转导试剂修饰的Gata3和蛋白转导试剂修饰的Brca-1。根据本发明的方面的治疗乳腺疾病或乳腺组织损伤的方法包括给予蛋白转导试剂修饰的Brca-1。根据本发明的方面的治疗乳腺疾病或乳腺组织损伤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Slug、蛋白转导试剂修饰的Stat5a、蛋白转导试剂修饰的Gata3和蛋白转导试剂修饰的Brca-1。根据本发明的方面的治疗乳腺疾病或乳腺组织损伤的方法包括给予蛋白转导试剂修饰的Sox9和蛋白转导试剂修饰的Slug。根据本发明的方面的治疗乳腺疾病或乳腺组织损伤的方法包括给予蛋白转导试剂修饰的Stat5a和蛋白转导试剂修饰的Gata3。根据本发明的方面的治疗乳腺疾病或乳腺组织损伤的方法包括给予如下中的三种或更多种:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Slug、蛋白转导试剂修饰的Stat5a、蛋白转导试剂修饰的Gata3和蛋白转导试剂修饰的Brca-1。根据本发明的方面的治疗乳腺疾病或乳腺组织损伤的方法包括给予如下中的四种或更多种:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Slug、蛋白转导试剂修饰的Stat5a、蛋白转导试剂修饰的Gata3和蛋白转导试剂修饰的Brca-1。根据本发明的方面的治疗乳腺疾病或乳腺组织损伤的方法包括给予:蛋白转导试剂修饰的Sox9、蛋白转导试剂修饰的Slug、蛋白转导试剂修饰的Stat5a、蛋白转导试剂修饰的Gata3和蛋白转导试剂修饰的Brca-1。这样的方法通过在疾病或损伤位点重编程成纤维细胞而在该位点产生新的乳腺导管细胞。
根据本发明的方面的治疗血管疾病或血管损伤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Erg1、蛋白转导试剂修饰的Er71、蛋白转导试剂修饰的Fli1和蛋白转导试剂修饰的Gata2。根据本发明的方面的治疗血管疾病或血管损伤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Erg1、蛋白转导试剂修饰的Er71、蛋白转导试剂修饰的Fli1和蛋白转导试剂修饰的Gata2。根据本发明的方面的治疗血管疾病或血管损伤的方法包括给予如下中的三种或更多种:蛋白转导试剂修饰的Erg1、蛋白转导试剂修饰的Er71、蛋白转导试剂修饰的Fli1和蛋白转导试剂修饰的Gata2。根据本发明的方面的治疗血管疾病或血管损伤的方法包括给予:蛋白转导试剂修饰的Erg1、蛋白转导试剂修饰的Er71、蛋白转导试剂修饰的Fli1和蛋白转导试剂修饰的Gata2。这样的方法通过在疾病或损伤位点重编程细胞而在该位点产生新的内皮细胞。
根据本发明的方面的治疗血管疾病或血管损伤的方法包括给予如下中的一种或多种:蛋白转导试剂修饰的Hey1、蛋白转导试剂修饰的Hey2、蛋白转导试剂修饰的FoxC1和蛋白转导试剂修饰的FoxC2。根据本发明的方面的治疗血管疾病或血管损伤的方法包括给予如下中的两种或更多种:蛋白转导试剂修饰的Hey1、蛋白转导试剂修饰的Hey2、蛋白转导试剂修饰的FoxC1和蛋白转导试剂修饰的FoxC2。根据本发明的方面的治疗血管疾病或血管损伤的方法包括给予如下中的三种或更多种:蛋白转导试剂修饰的Hey1、蛋白转导试剂修饰的Hey2、蛋白转导试剂修饰的FoxC1和蛋白转导试剂修饰的FoxC2。根据本发明的方面的治疗血管疾病或血管损伤的方法包括给予:蛋白转导试剂修饰的Hey1、蛋白转导试剂修饰的Hey2、蛋白转导试剂修饰的FoxC1和蛋白转导试剂修饰的FoxC2。这样的方法通过在疾病或损伤位点重编程细胞而在该位点产生新的动脉内皮细胞。
根据本发明的方面的治疗血管疾病或血管损伤的方法包括给予如下中的一种或两者:蛋白转导试剂修饰的Sox7和蛋白转导试剂修饰的Sox18。根据本发明的方面的治疗血管疾病或血管损伤的方法包括给予蛋白转导试剂修饰的Sox7和蛋白转导试剂修饰的Sox18。这样的方法通过在疾病或损伤位点重编程细胞而在该位点产生新的静脉内皮细胞。
联合治疗
根据本发明的方面给予治疗剂的结合物。
在一些方面,将两种或更多种QQ修饰的蛋白给予受试者以在需要其的受试者中治疗病症。
在其他方面,将至少一种QQ修饰的蛋白和至少一种额外的治疗剂给予受试者以在需要其的受试者中治疗病症。
在其他方面,将至少一种QQ修饰的蛋白和至少两种额外的治疗剂给予受试者以在需要其的受试者中治疗病症。
在一些方面,将两种或更多种QQ修饰的蛋白给予受试者以在需要其的受试者中治疗癌症。在其他方面,将至少一种QQ修饰的蛋白和至少一种额外的治疗剂给予受试者以在需要其的受试者中治疗癌症。在其他方面,将至少一种QQ修饰的蛋白和至少两种额外的治疗剂给予受试者以在需要其的受试者中治疗癌症。
术语“额外的治疗剂”在本文中用于指示化合物、化合物的混合物、生物大分子(例如核酸、抗体、蛋白质或其部分例如肽)或从生物材料例如细菌、植物、真菌或动物(特别是哺乳类动物)细胞或组织制备的提取物,所述提取物是在受试者中局部或全身起作用的一种或多种生物学、生理学或者药理学活性物质。
本发明的方法和组合物的方面所包括的额外的治疗剂包括,但不限于,抗生素、抗病毒剂、抗肿瘤剂、镇痛剂、退热剂、抗抑郁剂、抗精神病药物、抗癌剂、抗组胺剂、抗骨质疏松剂、抗骨坏死剂、抗炎剂、抗焦虑药、化疗剂、利尿剂、生长因子、激素类、非甾族类抗炎剂、类固醇和血管活性剂。
利用一种或多种QQ修饰的蛋白质和一种或多种额外的治疗剂的联合疗法可显示协同效应,例如,比单独使用一种或多种QQ修饰的蛋白质或一种或多种额外的治疗剂作为单一疗法可观察到的更大的治疗效果。
根据各方面,联合疗法包括:(1)包括一种或多种QQ修饰的蛋白以及一种或多种额外的治疗剂的药物组合物;和(2)一种或多种QQ修饰的蛋白与一种或多种额外的治疗剂的共给药,其中所述一种或多种QQ修饰的蛋白和所述一种或多种额外的治疗剂未被配制在同一组合物中。当使用单独的制剂时,相对于一种或多种额外的治疗剂的给药,一种或多种QQ修饰的蛋白可同时、在间歇的时间、在错开的时间、之前、之后或其组合给药。
联合治疗可使得用于本发明的方法中的一种或多种QQ修饰的蛋白和一种或多种额外的治疗剂的有效剂量降低以及它们的治疗指数增加。
任选地,治疗患有癌症或处于患癌风险的受试者的方法还包括辅助的抗癌治疗。辅助的抗癌治疗可以是抗癌剂的给药。
抗癌剂记载于例如在Goodman等人,Goodman and Gilman′s The Pharmacological Basis of Therapeutics,第八版,Macmillan Publishing Co.,1990中。
抗癌剂示例性地包括异恶唑乙酸(acivicin)、阿柔比星(aclarubicin)、阿考达唑(acodazole)、阿克罗宁(acronine)、阿多来新(adozelesin)、阿地白介素(aldesleukin)、阿利维A酸(alitretinoin)、别嘌醇(allopurinol)、六甲蜜胺(altretamine)、安波霉素(ambomycin)、阿美蒽醌(ametantrone)、氨磷汀(amifostine)、氨鲁米特(aminoglutethimide)、安吖啶(amsacrine)、阿那曲唑(anastrozole)、氨茴霉素(anthramycin)、白砒(arsenic trioxide)、门冬酰胺酶(asparaginase)、曲林菌素(asperlin)、阿扎胞苷(azacitidine)、阿扎替派(azetepa)、阿佐霉素(azotomycin)、巴马司他(batimastat)、苯佐替派(benzodepa)、比卡鲁胺(bicalutamide)、比生群(bisantrene)、双奈法德(bisnafide dimesylate)、比折来新(bizelesin)、博莱霉素(bleomycin)、布喹那(brequinar)、溴匹立明(bropirimine)、马利兰(busulfan)、放线菌素(cactinomycin)、卡普睾酮(calusterone)、卡培他滨(capecitabine)、卡醋胺(caracemide)、卡贝替姆(carbetimer)、卡铂(carboplatin)、卡莫司汀(carmustine)、卡柔比星(carubicin)、卡折来新(carzelesin)、西地芬戈(cedefingol)、塞来昔布(celecoxib)、苯丁酸氮齐(chlorambucil)、西罗霉素(cirolemycin)、顺铂(cisplatin)、克拉屈滨(cladribine)、克立那托(crisnatol mesylate)、环磷酰胺(cyclophosphamide)、阿糖胞苷(cytarabine)、达卡巴嗪(dacarbazine)、更生霉素(dactinomycin)、柔红霉素(daunorubicin)、地西他滨(decitabine)、右奥马铂(dexormaplatin)、地扎胍宁(dezaguanine)、甲磺酸地扎胍宁(dezaguanine mesylate)、地吖醌(diaziquone)、多西他赛(docetaxel)、多柔比星(doxorubicin)、屈洛昔芬(droloxifene)、屈他雄酮(dromostanolone)、达佐霉素(duazomycin)、依达曲沙(edatrexate)、依氟鸟氨酸(eflomithine)、依沙芦星(elsamitrucin)、恩洛铂(enloplatin)、恩普氨酯(enpromate)、依匹哌啶(epipropidine)、表柔比星(epirubicin)、厄布洛唑(erbulozole)、依索比星(esorubicin)、雌氮芥(estramustine)、依他硝唑(etanidazole)、依托泊苷(etoposide)、氯苯乙嘧胺(etoprine)、法倔唑(fadrozole)、法扎拉滨(fazarabine)、芬维A胺(fenretinide)、氟尿苷(floxuridine)、氟达拉滨(fludarabine)、氟尿嘧啶(fluorouracil)、氟西他滨(flurocitabine)、磷喹酮(fosquidone)、福司曲星(fostriecin)、氟维司群(fulvestrant)、吉西他滨(gemcitabine)、羟基脲(hydroxyurea)、伊达比星(idarubicin)、异环磷酰胺(ifosfamide)、伊莫福新(ilmofosine)、白细胞介素II(interleukin II;IL-2;包括重组白细胞介素II或rIL2)、干扰素α-2a、干扰素α-2b、干扰素α-n1、干扰素β-n3、干扰素β-Ia、干扰素y-Ib、异丙铂(iproplatin)、伊立替康(irinotecan)、兰瑞肽(lanreotide)、来曲唑(letrozole)、亮丙瑞林(leuprolide)、利阿唑(liarozole)、洛美曲索(lometrexol)、洛莫司汀(lomustine)、洛索蒽酿(losoxantrone)、马索罗酚(masoprocol)、美登素(maytansine)、盐酸氮芥(mechlorethamine hydrochloride)、甲地孕酮(megestrol)、美仑孕酮乙酸盐(melengestrol acetate)、马法兰(melphalan)、美诺立尔(menogaril)、巯基嘌吟(mercaptopurine)、甲氨蝶呤(methotrexate)、氯苯氨啶(metoprine)、美妥替哌(meturedepa)、米丁度胺(mitindomide)、米托卡星(mitocarcin)、丝裂红素(mitocromin)、米托洁林(mitogillin)、米托马星(mitomalcin)、丝裂霉素(mitomycin)、米托司培(mitosper)、米托坦(mitotane)、米托蒽醌(mitoxantrone)、霉酚酸(mycophenolic acid)、奈拉滨(nelarabine)、诺考达唑(nocodazole)、诺拉霉素(nogalamycin)、奥马铂(ormnaplatin)、奥昔舒仑(oxisuran)、紫杉醇(paclitaxel)、培门冬酶(pegaspargase)、培利霉素(peliomycin)、戊氮芥(pentamustine)、培洛霉素(peplomycin)、培磷酰胺(perfosfamide)、哌泊溴烷(pipobroman)、嗪消安(piposulfan)、盐酸吡罗蒽醌(piroxantrone hydrochloride)、普卡霉素(plicamycin)、普洛美坦(plomestane)、卟吩姆钠(porfimer)、泊非霉素(porfiromycin)、泼尼莫司汀(prednimustine)、甲基苄肼(procarbazine)、嘌呤霉素(puromycin)、吡唑呋喃菌素(pyrazofurin)、利波腺苷(riboprine)、罗谷亚胺(rogletimide)、沙芬戈(safingol)、司莫司汀(semustine)、辛曲秦(simtrazene)、磷乙酰天冬氨酸(sparfosate)、稀疏霉素(sparsomycin)、锗螺胺(spirogermanium)、螺莫司汀(spiromustine)、螺铂(spiroplatin)、链黑菌素(streptonigrin)、链脲佐菌素(streptozocin)、磺氯苯脲(sulofenur)、他利霉素(talisomycin)、他莫昔芬(tamoxifen)、替可加兰(tecogalan)、替加氟(tegafur)、替洛蒽醌(teloxantrone)、替莫泊芬(temoporfin)、替尼泊苷(teniposide)、替罗昔隆(teroxirone)、睾内醋(testolactone)、硫味嘌吟(thiamiprine)、硫鸟嘌吟(thioguanine)、塞替派(thiotepa)、噻唑羧胺核苷(tiazofurin)、替拉扎明(tirapazamine)、拓扑替康(topotecan)、托瑞米芬(toremifene)、曲托龙(trestolone)、曲西立滨(triciribine)、三甲曲沙(trimetrexate)、曲普瑞林(triptorelin)、妥布氯唑(tubulozole)、尿嘧啶齐末(uracil mustard)、乌瑞替派(uredepa)、伐普肽(vapreotide)、维替泊芬(verteporfin)、长春碱(vinblastine)、硫酸长春新碱(vincristine sulfate)、长春地辛(vindesine)、长春匹定(vinepidine)、长春甘醋(vinglycinate)、长春罗新(vinleurosine)、长春瑞滨(vinorelbine)、长春罗定(vinrosidine)、长春利定(vinzolidine)、伏氯唑(vorozole)、折尼铂(zeniplatin)、净司他丁(zinostatin)、唑来膦酸(zoledronate)和佐柔比星(zorubicin)。
辅助的抗癌治疗可以是受试者或受试者身体的患病区域的放射治疗。
在以下实施例中对本发明的组合物和方法的实施方案进行举例说明。提供这些实施例是为了举例说明的目的,并且不应被认为是对本发明的组合物和方法的范围的限制。
实施例
实施例1
重编程蛋白表达和制备
质粒构建
分别将编码Oct4、Sox2、Klf4和c-Myc、Nanog、GATA4、Hand2、Mef2c和Tbox5重编程蛋白的各DNA亚克隆到sHT-pET30a细菌表达载体中,其中短的his-标签:‘HHHHHHSS’(SEQ ID NO:64)替换了来自Novagen的pET30a表达载体中的长的his-标签。因子Xa(IEGR)切割位点位于短的his标签和编码基因之间。细菌表达载体的序列通过DNA测序确认。
蛋白表达和纯化
将重编程蛋白的DNA构建体分别转化到大肠杆菌菌株BL-21(DE3)或ClearColiTMBL21(DE3)细菌细胞中。ClearColiTM BL21(DE3)细菌细胞用于生产无内毒素的重组重编程蛋白。选择单个菌落用于细菌蛋白表达。在简单的优化后,根据不同的蛋白用0.5-1.2mM IPTG诱导蛋白表达并在18℃下继续培养12-16小时。在含有6M尿素的结合缓冲液中收集细胞并超声处理几次以提取蛋白。根据关于修饰的手册,使用组氨酸结合树脂柱(Novagen公司)纯化所述重组重编程蛋白。通常将蛋白提取上清液上柱两次,用5×柱体积的结合缓冲液洗涤。当使用常规的细菌菌株BL21(DE3)制备重组重编程蛋白时,在蛋白纯化阶段可增加使用10倍柱体积的0.2%Triton X-114的额外的洗涤步骤,以从细菌表达的重组重编程蛋白中除去内毒素。将加载有重组蛋白的柱再次用10×柱体积的含有15-50mM咪唑的洗涤缓冲液洗涤。将纯化的蛋白用含有500mM咪唑的洗脱缓冲液从柱中洗脱。将纯化的蛋白用水充分透析并冻干成蛋白粉末。
实施例2
QQ修饰:表达的重编程蛋白用蛋白转导试剂修饰以产生蛋白转导试剂修饰的重编程蛋白
可通过改变组合物使其包括表1所示的试剂来调整蛋白转导试剂(QQ试剂),以获得对于特定重编程蛋白和细胞类型的最佳蛋白转导效率。
对于体内施用,使总体积为1ml:
储液的聚乙烯亚胺(PEI)浓度:
储液的脂质浓度:
用包含溶于1-6M尿素的重编程蛋白和指定的PEI、脂质的PBS缓冲液使总体积为1ml。
根据蛋白溶解度,首先将重编程蛋白以0.5-10mg/ml的浓度溶解在磷酸钠缓冲液(pH7.0,NaCl 50mM)中。发现蛋白溶解度影响阳离子化效率。为了完全溶解蛋白,将蛋白溶液在室温下过夜搅拌(有或没有3mM的DTT持续过夜,取决于所述重编程蛋白是否具有半胱氨酸残基)。也可将蛋白溶解在1-6M尿素中以提高蛋白溶解度。
使用如下的方法制备脂质DOTAP/DOPE(1∶1)乳液:将1mg的DOTAP/DOPE(0.5mg∶0.5mg=1∶1)混合物溶解在氯仿中并在N2气体下干燥。然后将干燥的脂质膜溶解于pH 7.0的PBS缓冲液中,并将脂质溶液在购自Fisher Scientific(Sonic Dismembrator,Model 100)的具有微探针的超声波仪上使用7-8的功率超声处理3×30s。将脂质溶液在37℃再孵育2小时,直至悬浮液变成半澄清的。将所制备的乳液储存在4℃下,其在一个月内是稳定的。
根据上述配方,将QQ试剂的其他成分(不包括脂质乳剂或任选的Ca或DMSO)在管中混合。然后将QQ试剂在搅拌的同时非常缓慢地滴加到蛋白溶液中,然后加入脂质乳液。一旦完成,将所得的蛋白溶液在使用前于室温下放置4小时。在此期间,必须温和搅拌以将QQ试剂与蛋白溶液混合,并且也使蛋白修饰反应完成。如果观察到沉淀,可将蛋白溶液以14,000rpm离心15分钟以除去沉淀物。如果出现沉淀物,将使用上清液进行BCA蛋白测定以检查溶液中剩余的蛋白量。为了确保蛋白转移到细胞内的效率,经修饰的蛋白的浓度必须足够高,为>0.1mg/ml。
通常,对于体内给药,根据蛋白溶解度以0.5-1.5mg/ml的浓度制备QQ修饰的蛋白。
可对每个蛋白单独进行QQ修饰,或对待被一起给予受试者的蛋白混合物进行QQ修饰。
任选地,对每个蛋白单独进行QQ修饰,将QQ修饰的蛋白一起混合数小时,然后以1ml/管等分到小管中,并储存在-20℃下——在该温度下所述蛋白在数月内是稳定的。
如果大多数重编程蛋白沉淀,可将另外的QQ试剂用于蛋白修饰。QQ系列试剂涵盖广泛的阳离子化试剂以及不同的脂质和增强剂,因而任何沉淀问题都得到解决。可重复上述过程以制备更高浓度的蛋白转导试剂修饰的重编程蛋白。
将蛋白转导试剂修饰的重编程蛋白通过脱盐柱以将蛋白转导试剂修饰的重编程蛋白与剩余的未反应原料分开。将经纯化的蛋白通过过滤器(截留值为0.22μm,用于在体内给药前灭菌)。可将经纯化的蛋白级分在灭菌前或灭菌后浓缩,例如通过使用自旋柱浓缩;所述蛋白级分是稳定的并可在-20℃下储存几周到几个月。
为了蛋白转移的最佳效率以及最小细胞毒性,也可使用不同的QQ试剂。此外,为了蛋白转移入细胞的最佳效率,将不同的蛋白用不同的QQ试剂修饰。通常,为了更好的体内递送效率,使用QQ5a-QQ9a。然而,这可能会引起更高的体内毒性。当使用QQ5a-QQ9a时,强调使用更低浓度的更大的PEI和脂质。
为了良好的体内递送效率,使用具有更少体内毒性的QQ1a-QQ4a。可以使用具有更高脂质浓度的QQ1-QQ4。
实施例3
将重编程蛋白溶解在具有2M尿素的50mM pH 7.4的磷酸钠中。根据配方新鲜配置蛋白转导试剂(QQ试剂)。用于该实施例中的QQ试剂为聚乙烯亚胺(PEI)1200(1.2K,0.05-1.0mg/ml)和DOTAP/DOPE(25-100μg/ml)的混合物。通过将QQ试剂与一种或多种重编程蛋白(例如Oct4/Sox2/Nanog:1mg/ml)在室温下混合4小时或在冷室过夜混合来进行重编程蛋白的QQ修饰。
实施例4
QQ蛋白通过静脉内注射递送至大鼠中的脑肿瘤中
铁蛋白为可用作磁共振成像(MRI)的阴性对照试剂的普遍存在的含铁蛋白。
在该实施例中,将铁蛋白或用QQ试剂处理以制备QQ-铁蛋白的铁蛋白静脉内注射至通过植入大鼠神经胶质肉瘤细胞系9L细胞而产生的患有脑肿瘤的大鼠中。
新鲜制备大鼠神经胶质肉瘤细胞系9L的细胞并在植入前调整到1×106细胞/ml。根据标准方案制备颅内异种移植物。麻醉Fisher大鼠并将其置于立体定位框架中,并暴露头骨。在向右侧3mm和前囟点的1mm前打孔,并使用具有安装在立体定位器(Bonaduz,GR,Switzerland)中的26s号针头的10-μl Hamilton注射器注射9L细胞(5μl中5×104个细胞)。将注射器降低到3.5mm的深度,然后升高至3.0mm的深度。以0.5μl/10s的速率注射肿瘤细胞,并且用Horsley的骨蜡覆盖颅骨切开术。9L细胞植入12天后,经大鼠尾静脉注射QQ-修饰的铁蛋白或单独的铁蛋白,100μg/100μl/只大鼠。注射4小时后,麻醉大鼠并将大鼠脑部通过MRI成像。MRI后,处死所述动物。将所提取的脑在4%多聚甲醛中固定过夜,然后包埋在石蜡中用于进一步分析。从每个块切下6μm薄切片并用苏木精和伊红染色。脑肿瘤的大小通过显微镜测定。
图1A和1B示出了QQ-铁蛋白靶向递送至大鼠中的9L-脑肿瘤中的MRI证据,并且在用单独的铁蛋白注射的大鼠的9L-脑肿瘤中没有可检测的铁蛋白。图1A是经尾静脉用QQ-铁蛋白注射的患有9L-脑肿瘤的大鼠的代表性MRI图像。箭头指向9L-脑肿瘤,黑色指示递送至该肿瘤的铁蛋白。图1B:用未经QQ修饰的铁蛋白注射的患有9L-脑肿瘤的大鼠的代表性MRI图像。虽然处死大鼠并确认其具有大的9L-脑肿瘤,但是在这种情况下在脑肿瘤中没有观察到铁蛋白。
使用血管标志物的抗体CD31和铁蛋白的抗体来进行经QQ-铁蛋白注射的9L-脑肿瘤组织切片的双重免疫染色。用DAPI染色切片中的9L-癌细胞的细胞核。在脑肿瘤的血管中观察到CD31和铁蛋白的重叠免疫染色,表明QQ-铁蛋白通过与脑肿瘤相关的血管生成性血管的增强的通透性和保留效应(EPR效应)而从血管中渗出。在经QQ-铁蛋白治疗的动物中,在靠近或紧邻血管的肿瘤细胞的细胞液内观察到铁蛋白的免疫染色,表明QQ-铁蛋白渗透到肿瘤细胞中。相比之下,在用未经QQ-修饰的铁蛋白处理的9L-肿瘤切片中的铁蛋白免疫染色表明未经QQ修饰的铁蛋白没有渗透到肿瘤细胞中,虽然免疫染色表明该未经修饰的铁蛋白也渗出肿瘤相关的血管生成性血管。在细胞之间观察到这些未经修饰的铁蛋白纳米颗粒,并且可能由于在组织内的细胞之间的流体而没有积聚,使得通过MRI没有观察到肿瘤中有未经QQ修饰的铁蛋白。
这些数据提供了铁蛋白通过QQ-蛋白递送技术靶向递送至大鼠中的脑肿瘤中的MRI证据,其通过组织学分析和脑组织切片的免疫染色来确认。
实施例5
QQ蛋白通过静脉内注射递送至小鼠中的乳腺癌中。
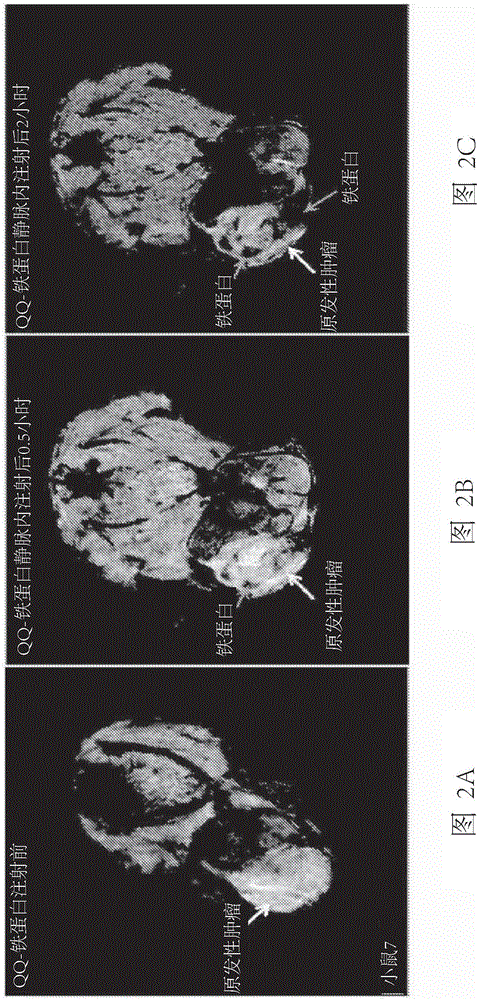
在该实施例中,将铁蛋白或用QQ试剂处理以产生QQ-铁蛋白的铁蛋白静脉内注射到通过植入小鼠转移性乳腺癌细胞系4T1细胞而产生的患有转移性乳腺癌的小鼠中。在小鼠中的小鼠转移性乳腺癌细胞系4T1细胞的植入是自发转移性乳腺癌的小鼠模型。
将4T1细胞植入到2月龄雌性BALB/c小鼠的乳腺(#4脂肪垫)中(在50μl/只小鼠中20000个4T1细胞)。在4T1细胞植入18天后,4T1肿瘤在小鼠乳腺中已经生长到直径为~1.0-1.5cm的大小。经尾静脉注射QQ-修饰的铁蛋白(100μg/50μl/只小鼠)。麻醉小鼠并在注射经QQ-修饰的铁蛋白之前和注射后0.5小时、2小时、3.5小时、8小时和18小时进行MRI成像。
图2A-F为该时程的代表性MRI图像,示出了在携带乳腺癌的小鼠的原发性肿瘤中的QQ-递送的铁蛋白为在原发性肿瘤中变暗的区域。该原发性肿瘤暗度是时间依赖性的并且在8小时达到最大值,然后强度开始下降。
使用普鲁士蓝染色和铁蛋白免疫染色通过组织学分析确认MRI结果。在QQ-铁蛋白注射后18小时对携带4T1-乳腺癌的小鼠的原发性肿瘤组织切片的免疫组织化学染色和普鲁士蓝染色示出了原发性肿瘤内阳性的铁蛋白和普鲁士蓝染色。该组织学结果确认了对携带4T1-肿瘤的小鼠的原发性肿瘤内的QQ递送的铁蛋白的MRI观察结果。
实施例6
Oct4和Klf4蛋白至携带4T1乳腺癌的小鼠的原发性肿瘤中的4T1-乳腺癌细胞的细胞核的QQ-蛋白递送
将4T1细胞(2×104个细胞/50μl/只小鼠)植入到雌性BALB/c小鼠中。肿瘤细胞植入15天后,制备Alexa Fluor594标记的Klf4。然后制备QQ-修饰的未标记的Oct4(QQ-Oct4)和QQ-修饰的Alexa Fluor594标记的Klf4。瘤内注射50μg QQ-Oct4蛋白和QQ-Alexa Fluor594标记的Klf4蛋白。在注射后5小时处死小鼠并制备用于免疫染色和荧光显微镜的肿瘤组织切片。在原发性4T1-乳腺癌组织切片中的Oct4的免疫染色证明Oct4在4T1-癌细胞中的核定位以及与DAPI的共定位。荧光显微成像也示出了Klf4在原发性4T1-乳腺癌组织切片中的核定位以及与DAPI的共定位。
实施例7
GATA4、OCT4和SOX2到急性心肌梗塞后大鼠的受损心脏的QQ蛋白递送
通过腹膜内注射对心肌梗塞后的大鼠给药QQ-修饰的和荧光标记的GATA4、Sox2和Oct4,并将经QQ-修饰的蛋白和荧光标记的蛋白递送至动物的受损心脏组织。
根据制造商指定的方法,将GATA4、Sox2和Oct4各自用Alexa Fluor488标记。将经标记的GATA4、Sox2和Oct4蛋白用小的自旋柱纯化。然后将Alexa Fluor488-GATA4、Alexa Fluor488-Sox2和Alexa Fluor488-Oct4进行QQ修饰以生成QQ-修饰的Alexa Fluor488-GATA4、QQ-修饰的Alexa Fluor488-Sox2和QQ-修饰的Alexa Fluor488-Oct4。
麻醉Lewis大鼠并进行冠状动脉结扎手术以在Lewis大鼠中引起心肌梗塞。冠状动脉结扎手术24小时后,将QQ-修饰的Alexa Fluor488标记的GATA4、QQ-修饰的Alexa Fluor488标记的Sox2和QQ-修饰的Alexa Fluor488标记的Oct4(200μg/100μl/鼠)腹膜内注射到Lewis大鼠中。荧光标记的蛋白注射后7小时,处死大鼠并制备用于梗塞面积的Trichrome染色或用于使用α-肌动蛋白抗体——其为指示成熟心肌细胞的心肌标志物——的免疫染色的心脏组织切片。
荧光显微分析示出了Alexa Fluor488-GATA4蛋白与α-肌动蛋白免疫荧光的共定位,表明在冠状动脉结扎后腹膜内注射QQ-荧光标记的GATA4导致GATA4蛋白递送至受损心脏组织的创伤区。类似地,对Alexa Fluor488-Sox2和α-肌动蛋白免疫荧光的荧光显微分析表明在冠状动脉结扎后腹膜内注射QQ-修饰的Alexa Fluor488标记的Sox2导致Sox2蛋白在受损心脏组织的边缘区域的定位。最终,Alexa Fluor488-Oct4的荧光图像示出了注射的QQ-修饰的Alexa Fluor488-Oct4在较远的正常心脏组织区的定位。这些结果表明,通过腹膜内注射给药的荧光标记的和QQ-修饰的GATA4、Sox2和Oct4到达创伤区的受损心脏组织。这些数据证明了QQ-蛋白递送将这些蛋白靶向递送至受损心脏组织中。
实施例8
使用QQ-修饰的Sox2、Oct4和Nanog(SON)蛋白如下所述将包括9L-细胞系、U251-细胞系、U87-细胞系和来自患者的原发性GBM细胞系的恶性神经胶质瘤细胞重编程为蛋白诱导的多能干细胞(piPSC):在第0天,接种神经胶质瘤细胞24小时以使它们在50mm的培养皿中生长。在第2天,将QQ-SON蛋白以0.5-2.0μg/ml添加到培养基中并培养24小时。次日,将新鲜的QQ-SON蛋白添加到新的培养基中并培养24小时。根据用于细胞重编程的神经胶质瘤细胞,将这样的循环重复5-7次。在细胞重编程的最后,将培养基更换为维持培养基持续2天。在细胞重编程过程中,出现piPSC菌落。在第8天,将整个培养皿传代以扩增所产生的piPSC。使用多能性标志物(包括细胞核标志物Oct4、Nanog、Rex-1和表面标志物ALP、Tra1-60和Tra1-81)对包括9L-piPSC的单层细胞和菌落的整个培养皿传代的神经胶质瘤-piPSC的免疫染色显示几乎所有细胞对这些多能性标志物都是阳性的。相比之下,对9L-细胞的免疫染色示出了对这些标志物的阴性染色。这些数据表明使用QQ-SON蛋白将9L-细胞细胞重编程为9L-piPSC的高转化效率。
这通过使用Nanog和Oct4的9L-piPSC的全孔(96孔)免疫染色来确认。当计数与阴性克隆相比的阳性9L-piPSC克隆时,发现平均96±2%的转化效率,见表2。对9L细胞的对照免疫染色示出对于Nanog和Oct4这两个多能性标志物的阴性染色。使用由EVOS自动荧光显微镜提供的软件通过阳性染色的菌落和单层9L-piPSC对比用DAPI染色的总菌落和单层细胞来计算由9L细胞到9L-piPSC的转化效率。将重复的96孔的9L-piPSC的免疫染色用于计算平均转化效率和标准偏差。
使用QQ-SON蛋白细胞重编程9L细胞以产生9L-piPSC(0.5ug/ml,Sox2∶Oct4∶Nanog=1∶1∶1,连续循环五次)。
使用类似的细胞重编程方案,由4T1小鼠乳腺癌细胞产生4T1-piPSC。使用相同的全孔计数法(96孔),4T1细胞到4T1-piPSC的重编程转化效率为96±1.3%,参见表3。
实施例9
使用QQ-修饰的Sox2、Oct4和Nanog(SON)蛋白如下所述将人类胶质母细胞瘤细胞系U251的细胞重编程为U251-piPSC:在第0天,接种U251胶质母细胞瘤细胞24小时以使它们在50mm的培养皿中生长。在第2天,将QQ-SON蛋白以0.5-2.0μg/ml添加到培养基中并培养24小时。次日,将新鲜的QQ-SON蛋白添加到新的培养基中并培养24小时。将这样的循环重复5-7次。在细胞重编程的最后,将培养基更换为维持培养基持续2天。在细胞重编程过程中,出现U251-piPSC菌落。在第8天,将整个培养皿传代以扩增所产生的U251-piPSC。
通过测定Ki67-阳性细胞的数目来测定U251和U251-piPSC的增殖活性。图3A为示出该测定结果的图,表明神经胶质瘤细胞细胞重编程为piPSC显著降低了它们的增殖,误差线代表三次独立实验的标准误差。
实施例10
使用QQ-修饰的Sox2、Oct4和Nanog(SON)蛋白如下所述将患者来源的原发性人多形性成胶质母细胞瘤(GBM)细胞系GBM(12-14)的细胞重编程为GBM-piPSC:在第0天,接种GBM细胞24小时以使它们在50mm的培养皿中生长。在第2天,将QQ-SON蛋白以0.5-2.0μg/ml添加到培养基中并培养24小时。次日,将新鲜的QQ-SON蛋白添加到新的培养基中并培养24小时。将这样的循环重复5-7次。在细胞重编程的最后,将培养基更换为维持培养基持续2天。在细胞重编程过程中,出现GBM1-piPSC菌落。在第8天,将整个培养皿传代以扩增所产生的GBM1-piPSC。
测定了患者来源的原发性人GBM(12-14)细胞(正方形)和GBM(12-14)-piPSC(圆形)对烷化剂替莫唑胺的剂量依赖性的化疗药物敏感性,结果示于图3B中。实验重复3次,平均值±SD,p<0.01。与亲代胶质母细胞瘤细胞相比,GBM-piPSC对替莫唑胺的药物敏感性显著增强。
实施例11
使用QQ-修饰的Sox2、Oct4和Nanog(SON)蛋白如下所述将大鼠胶质母细胞瘤细胞系9L的细胞重编程为9L-piPSC:在第0天,接种9L神经胶质瘤细胞24小时以使它们在50mm的培养皿中生长。在第2天,将QQ-SON蛋白以0.5-2.0μg/ml添加到培养基中并培养24小时。次日,将新鲜的QQ-SON蛋白添加到新的培养基中并培养24小时。将这样的循环重复5-7次。在细胞重编程的最后,将培养基更换为维持培养基持续2天。在细胞重编程过程中,出现9L-piPSC菌落。在第8天,将整个培养皿传代以扩增所产生的9L-piPSC。
通过MTT测定法测定了9L细胞(正方形)和9L-piPSC(圆形)对卡铂的剂量依赖性的化疗药物敏感性,结果示于图3C中。实验重复3次,平均值±SD,P<0.01。与亲代9L细胞相比,9L-piPSC对卡铂的药物敏感性显著增强。
实施例12
使用QQ-修饰的Sox2、Oct4和Nanog(SON)蛋白如下所述将小鼠乳腺肿瘤细胞系4T1的细胞重编程为4T1-piPSC:在第0天,接种4T1细胞24小时以使它们在50mm的培养皿中生长。在第2天,将QQ-SON蛋白以0.5-2.0μg/ml添加到培养基中并培养24小时。次日,将新鲜的QQ-SON蛋白添加到新的培养基中并培养24小时。将这样的循环重复5-7次。在细胞重编程的最后,将培养基更换为维持培养基持续2天。在细胞重编程过程中,出现4T1-piPSC菌落。在第8天,将整个培养皿传代以扩增所产生的4T1-piPSC。
通过测定Ki67-阳性细胞的数量来测定4T1-细胞和4T1-piPSC的增殖活性并发现4T1乳腺肿瘤细胞细胞重编程为4T1-piPSC显著降低了它们的增殖。
与4T1细胞的乳腺球形成相比,4T1-piPSC的乳腺球形成减少。
通过MTT测定法测定了4T1-细胞和4T1-piPSC对多柔比星和紫衫醇的剂量依赖性的化疗药物敏感性。与亲代4T1细胞相比,4T1-piPSC对多柔比星和紫衫醇的药物敏感性显著增强。
实施例13
神经胶质瘤细胞衍生的piPSC到三个胚层的体外分化
使用悬滴法制备用于神经胶质瘤-piPSC的胚体(EB)。将神经胶质瘤-piPSC EB置于自发的分化培养基中10天,然后使用外胚层、中胚层和内胚层的标志物免疫染色,示出了对于外胚层的PAX6的阳性免疫染色、对于中胚层的结蛋白的阳性免疫染色和对于内胚层的α-甲胎蛋白(AFP)的阳性免疫染色。对照9L细胞的免疫染色对这些标志物是阴性的。对于4T1-piPSC也获得了类似的结果,表明4T1-piPSC也分化成三个胚层。
实施例14
神经胶质瘤细胞衍生的piPSC到神经细胞谱系的体外分化
将神经胶质瘤-piPSC EB置于特定的神经细胞谱系诱导分化培养基中14天,然后使用神经细胞谱系标志物免疫染色,示出了对于神经元的Tuj I的阳性免疫染色、对于星形细胞的GFAP的阳性免疫染色和对于神经干细胞的巢蛋白的阳性免疫染色。这些神经-特异性分化细胞也显示了神经细胞形态。对照9L细胞的免疫染色对这些标志物是阴性的。
实施例15
细胞重编程导致间质至上皮的转化(MET)和体外致瘤性的降低。
对U251细胞和U251-piPSC的几个上皮和间质的标志物(包括E-钙黏着糖蛋白(E-cad)、β-连环蛋白(β-cat)、波形蛋白(VMT))的Western印迹分析结果(参见图4A)表明在细胞重编程过程中的MET,其通过细胞形态变化和qRT-PCR结果确认。在U251细胞细胞重编程为U251-piPSC后,GFAP蛋白水平也显著增强,表明在细胞重编程过程中,细胞重编程引起U251细胞体外致瘤性的显著降低。将肌动蛋白表达用作内部对照。使用抗GFAP抗体对U251细胞和U251-piPSC的免疫染色确认了如在Western印迹中所示的在U251-piPSC中的GFAP蛋白表达的上调。此外,表达GFAP的细胞显示神经细胞的形态。
在细胞重编程后U251细胞的致瘤性降低已经通过U251细胞和U251-piPSC的细胞迁移(图4B)和侵入(图4C)的体外测定而确认,表明U251-piPSC的迁移和侵入显著减少(p<0.01)。
类似地,比较了使用上皮的标志物:E-钙黏着糖蛋白和间质的标志物纤连蛋白对41-piPSC和4T1细胞的免疫染色,并表明尽管4T1细胞显示阳性的E-钙黏着糖蛋白免疫染色,但是4T1-piPSC显示更强的E-钙黏着糖蛋白免疫染色。相比之下,4T1细胞显示更强的纤连蛋白免疫染色并且4T1-piPSC表现出几乎阴性的纤连蛋白免疫染色。该结果确认4T1细胞在细胞重编程为4T1-piPSC的过程中的MET。此外,相比于亲代4T1细胞的那些特性,4T1-piPSC也表现出减少的增殖(图4D)、减少的乳腺球形成(图4E)、减少的迁移(图4F)和减少的侵入(图4G),表明4T1细胞在体外细胞重编程为4T1-piPSC后显著降低的致瘤性。
实施例16
神经胶质瘤细胞和神经胶质瘤-piPSC之间的共培养表明,神经胶质瘤-piPSC显示出改变他们周围的神经胶质瘤细胞的表型的旁观者效应和降低的体外致瘤性。
观察到间接与U251-piPSC共培养40-64小时的U251细胞的细胞形态变化,表明经共培养的神经胶质瘤细胞的间质至上皮的转化(MET)。图5A为示出了U251细胞的细胞形态的图像,图5B为示出了间接与U251-piPSC共培养40-64小时的U251细胞的细胞形态的变化的图像。
使用抗-泛-钙粘着蛋白抗体通过对U251细胞、U251-piPSC、第一次(1st)共培养的U251细胞和第二次(2nd)共培养的U251细胞的免疫染色确认了该MET,表明泛-钙粘着蛋白在U251细胞中的细胞液/细胞核定位以及U251-piPSC和1st/2nd共培养的U251细胞的细胞膜/细胞核定位,暗示了在U251-piPSC中以及在1st/2nd共培养的U251细胞中的细胞-细胞粘附的重大增强。这指示在细胞重编程过程中和1st/2nd共培养的U251细胞的MET。2nd共培养是将经1st共培养的细胞置于跨孔插件(transwell insert)中,并将新鲜的U251细胞置于基底外侧室中的间接共培养实验。使用经区别标记的抗-GFAP和抗-Tuj1抗体对U251细胞和间接共培养的U251细胞的双重免疫染色示出了具有神经形态的共培养的U251细胞中的显著的GFAP蛋白表达,而U251细胞(纺锤体形态)不表达GFAP。
U251细胞、U251-piPSC和间接共培养的U251细胞通过Ki-67免疫染色的增殖测定的结果表明U251-piPSC和经共培养的U251细胞的增殖显著减少(图5C)。U251细胞、U251-piPSC以及以1∶1和8∶1的比例(U251∶U251-piPSC)直接共培养的U251细胞的迁移测定的结果(图5D)和侵入测定的结果(图5E)表明在与U251-piPSC共培养之后U251细胞的迁移和侵入显著减少(p<0.005)。
在类似的共培养实验后,观察到与4T1-piPSC共培养的4T1细胞的MET。共培养的4T1细胞和4T1-piPSC的免疫染色表明这两种细胞具有E-钙黏着糖蛋白的高蛋白表达和纤连蛋白的更低的蛋白表达,确认了经共培养的4T1细胞的MET。此外,经共培养的4T1细胞也显示显著减少的增殖(图5F)、迁移(图5G)和侵入(图5H),表明在与4T1-piPSC共培养40小时后4T1细胞的致瘤性显著降低。
患者来源的原发性脑肿瘤细胞GBM(12-14)与U251-piPSC的共培养也导致经共培养的患者来源的原发性脑肿瘤细胞的间质至上皮的转化和降低的致瘤性——U251-piPSC的旁观者效应。
这些结果表明piPSC的旁观者效应改变周围癌细胞的表型以降低致瘤性和恶性肿瘤。该旁观者效应表明更小数目的piPSC可通过该旁观者效应改变大量周围肿瘤细胞的恶性表型,提供了细胞转化癌症疗法的细胞机制。
实施例17
由恶性癌细胞产生的piPSC的显著降低的致瘤性和体内转移/浸润抑制作用。
在第一组的动物中,将相同数量的9L细胞或9L-piPSC(5×104个细胞/5μL)颅内植入Fisher大鼠中。在第二组的动物中,将相同数量的9L细胞或9L-piPSC(1×106个细胞/100μL)皮下植入Fisher大鼠中。
在第14天测量颅内植入9L细胞或9L-piPSC的大鼠(n=10)的肿瘤体积(mm3),参见图6A。在4T1-细胞植入25天后测量皮下植入9L细胞或9L-piPSC的大鼠(n=6)以克计的肿瘤重量,参见图6B。结果示出了与9L-肿瘤的那些相比的颅内9L-piPSC肿瘤的体积显著降低和皮下9L-piPSC肿瘤的重量显著降低,表明9L细胞在细胞重编程为9L-piPSC后的致瘤性显著降低。该结果也通过对来自经9L细胞和9L-piPSC植入的动物的肿瘤的苏木精和伊红(H&E)染色得到确认,表明9L-细胞浸润的主要抑制作用,因为9L-piPSC颅内肿瘤显示出清楚的完整边界,而9L-颅内肿瘤显示出破碎的边界,且9L-肿瘤细胞主要浸润到正常脑组织中。
实施例18
由恶性乳腺癌细胞产生的piPSC的显著降低的致瘤性和体内转移/浸润抑制作用。
将相同数量的4T1细胞和4T1-piPSC(2×104个细胞/50μL)植入到2-3月龄的雌性BALB/c小鼠(20克)的#4脂肪垫中。在细胞植入后第5-7天观察4T1乳腺肿瘤。每天监测小鼠的肿瘤体积和体重。在第25天,处死小鼠并称重肿瘤。对于存活实验,一旦动物达到肿瘤负荷就将它们处死。
在4T1-和4T1-piPSC植入后第25天,通过肿瘤体积(图6C)和肿瘤重量(图6D)测量4T1和4T1-piPSC肿瘤生长,表明4T1细胞在细胞重编程为4T1-piPSC后显著的肿瘤停滞。
在细胞植入后第25天分析植入有4T1细胞和4T1-piPSC的小鼠的肺转移。在细胞植入后第25天,虽然植入有4T1细胞的所有小鼠显示出很多转移病灶,但是在植入有4T1-piPSC的小鼠中没有观察到肺转移(图6E),表明由4T1细胞细胞重编程为4T1-piPSC引起的重大的转移抑制作用。该结果通过对携带4T1的小鼠和携带4T1-piPSC的小鼠的肺组织切片的H&E染色确认,表明在植入有4T1-piPSC的小鼠中没有肺转移。
在#4脂肪垫中植入4T1细胞和4T1-piPSC的小鼠的Kaplan-Meier存活曲线(图6F)证明携带4T1-piPSC的小鼠在该250天存活实验过程中的显著延长的存活。这些结果证明,恶性癌细胞到piPSC的细胞预编程显著地降低亲代癌细胞的致瘤性和转移特性,因此显著地延长了植入有4T1-piPSC的小鼠的存活。
实施例19
根据不同分化组织环境,肿瘤细胞衍生的piPSC体内分化成不同的正常组织。
对9L-颅内植入的大鼠的脑组织切片的H&E染色显示出主要神经胶质瘤血管生成至正常脑组织中以及脑肿瘤内严重出血,而在9L-piPSC颅内植入的大鼠中观察到更少的血管生成和出血。此外,9L-piPSC颅内植入的大鼠在大脑中的肿瘤附近也显示出新分化的神经细胞团(neural rosettes)。此外,对皮下植入9L-piPSC的大鼠的肿瘤组织载玻片的H&E染色示出了在肿瘤内的具有立方的且矮柱状的上皮细胞的未成熟汗腺和具有褐色黑色素的黑素细胞。对皮下植入9L-piPSC的大鼠的肿瘤组织载玻片的H&E染色也示出了具有两层上皮的皮肤上皮细胞以及具有更长形状和位于细胞基底部的细胞核的早期简单的柱状上皮细胞。
类似地,对携带4T1-piPSC的小鼠的肿瘤团块的H&E染色显示植入的4T1-piPSC体内分化成包括脂肪细胞(包括褐色和白色脂肪细胞)的正常乳腺组织以及成熟和未成熟的乳腺导管。
这些结果表明,根据不同分化组织环境,肿瘤细胞衍生的piPSC体内分化成不同的正常组织细胞。
实施例20
谱系追踪显示肿瘤细胞衍生的piPSC分化成正常组织。
为了确保肿瘤细胞衍生的piPSC分化成正常组织,制备表达GFP的9L-细胞和4T1-细胞。
制备GFP-9L-piPSC和GFP-4T1-piPSC。
用两种细胞类型进行谱系追踪实验。对于GFP-9L-piPSC,将细胞皮下植入到Fisher大鼠的左侧面。对于GFP-4T1-piPSC,将细胞植入到雌性BALB/c小鼠的#4脂肪垫。对于GFP-9L-piPSC植入的大鼠,在第10-15天观察到小肿瘤团块;对于GFP-4T1-piPSC植入的小鼠,在第20-25天观察到小肿瘤团块。在细胞植入后,将动物在不同天数时处死并收集肿瘤团块,用于制备用于H&E染色和免疫染色的组织切片。使用差异化的可检测标记物进行使用Tuj I和Nestin神经标志物抗体,脂连蛋白(脂肪细胞标志物),角蛋白8、14、18(CK8,14,18)或角蛋白5、8(CK5,8)(乳腺导管标志物)的免疫染色。
对携带4T1-piPSC的小鼠的肿瘤团块的中心和边缘的H&E染色均显示在肿瘤团块中出现潜在的脂肪细胞和未成熟乳腺导管。
对从使用抗-Tuj I抗体的谱系追踪实验获得的GFP-9L-piPSC肿瘤团块的组织切片的免疫染色显示阳性的Tuj I免疫染色,其与相同组织切片的表达GFP的细胞的GFP荧光重叠。在组织切片中仅观察到重叠的Tuj I和GFP荧光图像,表明这些Tuj I阳性细胞源自表达GFP的9L-piPSC。Tuj I/GFP-阳性细胞显示出神经元细胞形态。该数据证明了表达GFP的9L-piPSC体内分化成Tuj I阳性神经元谱系细胞。
对从使用抗-巢蛋白抗体的谱系追踪实验获得的GFP-9L-piPSC肿瘤团块的组织切片的免疫染色显示出阳性的巢蛋白免疫染色,其与相同组织切片的表达GFP的细胞的GFP荧光重叠。在组织切片中仅观察到重叠的巢蛋白和GFP荧光图像,表明这些巢蛋白阳性细胞源自表达GFP的9L-piPSC。该数据证明了表达GFP的9L-piPSC体内分化成巢蛋白阳性神经元谱系细胞。
使用抗-脂联素抗体对携带4T1-piPSC的小鼠的肿瘤组织切片的免疫染色显示脂联素阳性免疫染色,其与来自表达GFP的细胞的绿色荧光重叠。在具有脂肪细胞形态的细胞的组织切片中仅观察到重叠的脂联素和GFP荧光,表明在携带4T1-piPSC的小鼠的肿瘤团块的中间存在脂肪细胞并且这些脂肪细胞源自植入的GFP-4T1-piPSC的分化,因为这些脂肪细胞表达GFP。
使用抗-CK8,18,14和抗-CK5,8抗体对携带4T1-piPSC的小鼠的肿瘤组织切片的免疫染色显示CK8,18,14-阳性免疫染色和抗CK5,8-阳性免疫染色,其与来自表达GFP的细胞的绿色荧光重叠。在具有乳腺导管形态的细胞的组织切片中仅观察到重叠的CK8,18,14-阳性荧光或抗-CK5,8-阳性荧光和GFP荧光,表明源自植入的GFP-4T1-piPSC的分化的未成熟的乳腺导管的存在,因为这些乳腺导管表达GFP。
实施例21
QQ-SON蛋白-诱导的肿瘤的体内细胞重编程治疗
为了产生携带9L-肿瘤的大鼠,将9L细胞(1×106个细胞/100μL)皮下植入到Fisher大鼠中。9L-植入后5天,每天以1μg/天(n=5)、5μg/天(n=5)或10μg/天(n=10)通过肿瘤内注射给予QQ-SON蛋白,持续每日治疗18天。通过肿瘤内注射给予溶于PBS缓冲液的QQ-试剂以控制大鼠(n=10)。每天监测大鼠的肿瘤体积和体重。在第23天,处死大鼠并称重肿瘤。
通过体积测量肿瘤生长(参见图7A)和以克计的肿瘤重量(参见图7B)。在23天处死大鼠并称重肿瘤。该数据表明QQ-SON治疗诱导原位细胞重编程——其导致肿瘤停滞。
为了确定QQ-SON蛋白治疗对于皮下植入9L细胞的大鼠的存活的影响,在9L细胞植入后第5天,用溶于PBS的QQ-试剂(n=8;中值存活时间=21天)或用QQ-SON蛋白(10μg/天,n=8;中值存活时间=127天)治疗大鼠,持续每日治疗30天。一旦动物达到肿瘤负荷(<12cm3)就处死它们。Kaplan-Meier存活曲线(130天)示于图7C中。该数据表明QQ-SON蛋白治疗显著延长携带9L肿瘤的大鼠的存活。
实施例22
QQ-SON蛋白诱导的肿瘤的体内细胞重编程治疗
为了产生携带原位4T1乳腺癌的小鼠,将4T1细胞(2×104个细胞/50μL)植入到2-3月龄雌性BALB/c小鼠(20克)的#4脂肪垫中。在细胞植入后5-7天观察到4T1乳腺肿瘤。每天监测小鼠的肿瘤体积和体重。在第25天,处死小鼠并称重肿瘤。对于存活实验,一旦动物达到包括肿瘤负荷(<2g)、导致呼吸吃力的转移、无法控制的疼痛等的终点就将它们处死。
给予不同剂量的QQ-SON蛋白(0.5μg QQ-修饰的SON蛋白/只小鼠、1.25μg QQ-修饰的SON蛋白/只小鼠或2.5μg QQ-修饰的SON蛋白/只小鼠),并与QQ-PBS对照比较。通过在25天的时程内测量肿瘤体积(图7D)以及在第25天测量以克计的肿瘤重量(图7E)来测定功效。
在进一步的实验中,通过MRI测定在35天的时程期间用QQ-SON蛋白(n=8)或作为对照的QQ-PBS(n=8)治疗的小鼠的肿瘤体积(参见图7F),并通过在第35天称重来测定两组的肿瘤重量(参见图7G)。QQ-SON蛋白治疗导致未经原发性肿瘤切除的主要肿瘤停滞。
分析小鼠以测定如在指定天数时通过MRI所观察到的在经QQ-SON和QQ-PBS治疗的未经原发性肿瘤切除的携带4T1的小鼠的肺(图7I和7M)、淋巴结(图7J和7N)、肝(图7K和7O)和脾(图7L和7P)中的转移病灶的数量和百分比。这些结果表明,与经QQ-PBS治疗的小鼠相比,经QQ-SON治疗的小鼠在4T1-细胞植入后更晚的时期显示出转移,在肺、淋巴结中显示更少的转移病灶并且在肝和脾中没有观察到转移病灶。该数据表明由未经原发性肿瘤切除的QQ-SON蛋白治疗导致的携带4T1的小鼠中的主要转移抑制作用。
实施例23
对用QQ-PBS和QQ-SON蛋白治疗的未经原发性肿瘤切除的肿瘤组织切片的组织学分析。
对使用溶于PBS缓冲液的QQ-试剂治疗(持续每日治疗18天)的大鼠的9L-肿瘤组织载玻片的H&E染色示出了具有大量血管生成的均质肿瘤细胞。使用抗-VE-钙黏着蛋白抗体对附近的组织载玻片的免疫染色确认了血管生成。在皮下9L细胞植入后第26天处死具有13.5cm3(约15.5g)的肿瘤的该大鼠。相比之下,对使用QQ-SON蛋白治疗(持续每日治疗18天)的大鼠的肿瘤组织载玻片的H&E染色示出了不同的细胞区,包括肿瘤细胞区、结缔组织区和成纤维细胞区。在皮下9L细胞植入后第49天处死该鼠,其肿瘤大小显著减少到0.2cm3(约0.6g)。使用抗-a-原胶原、成纤维细胞标志物、抗体对同一大鼠的附近肿瘤组织载玻片的成纤维细胞区的免疫染色确认了成纤维细胞区(阳性染色)和肿瘤细胞区(阴性染色)。使用抗-GFAP抗体和抗Tuj1抗体对用QQ-SON蛋白治疗(持续每日治疗18天)的同一大鼠的肿瘤组织载玻片的免疫染色显示这两种标志物的阳性染色,形成了神经元细胞形态和神经细胞团。该数据表明所注射的QQ-SON蛋白诱导瞬时9L-piPSC的原位产生,所述瞬时9L-piPSC分化成包括神经元谱系细胞的非癌细胞。
类似地,对用QQ-SON蛋白治疗的小鼠的4T1-肿瘤组织载玻片的H&E染色也示出了脂肪细胞和乳腺导管——其为脂连素和角蛋白5/8/14免疫染色阳性的,表明所注射的QQ-SON蛋白也诱导原发性肿瘤内的4T1-肿瘤细胞原位重编程为4T1-piPSC——其分化成乳腺组织。
实施例24
QQ-SON治疗显著增强经治疗的9L细胞的体内基因组稳定性。
对两只携带皮下9L-肿瘤的大鼠——两者均用QQ-SON蛋白治疗18天——的外植细胞的SKY基因组进行分析。一只大鼠(#12)对QQ-SON治疗表现出主要响应并且肿瘤开始收缩。在肿瘤消失之前,处死该大鼠并收集肿瘤用于外植体和肿瘤组织载玻片。另一只大鼠(#15)对QQ-SON蛋白治疗没有响应并且肿瘤继续增长至达到终点(>12cm3)。也处死该鼠并制备外植体和肿瘤组织载玻片。
来自#15大鼠外植体的细胞迅速生长并在3天内达到汇合。细胞显示出典型的9L-细胞纺锤体形态。然而,来自#12大鼠外植体的细胞生长非常缓慢并且仅在两周后观察到一些具有神经形态的细胞以及一些菌落。对于在#12大鼠中显示神经形态的那些细胞,使用GFAP和Tuj I对肿瘤组织载玻片的免疫染色对这两种标志物显示出阳性染色,但是对于#15大鼠,对这两种标志物为阴性染色。使用β-连环蛋白、CK5/6、E-钙黏着糖蛋白、Lefty、Nodal和Cripto-1的额外的免疫染色对于#12和#15大鼠显示出相反的结果。尽管#12大鼠的肿瘤组织载玻片示出CK5/6、E-钙黏着糖蛋白、Lefty和β-连环蛋白的阳性染色,但是在#15大鼠的肿瘤组织载玻片中观察到阴性染色。有趣的是,Lefty和E-钙黏着糖蛋白以及CK5/6和E-钙黏着糖蛋白在肿瘤组织切片的相同区域中共染色。相比之下,#15大鼠的肿瘤组织载玻片示出对Nodal和Cripto-1的阳性染色,但#12的那些组织切片示出对这两种标志物的阴性染色。这些结果表明在#12大鼠的组织切片中肿瘤细胞转化成非癌细胞,而#15大鼠的组织切片仍然是9L-肿瘤细胞。
为评估外植体细胞的基因组稳定性,进行了分子细胞遗传学分析。对于大鼠#15和大鼠#12的每个外植体收集20个有丝分裂的图像并分析大鼠#15和大鼠#12的平均染色体数目。表4示出了对大鼠#15和大鼠#12染色体畸变的比较。分子细胞遗传学分析表明大鼠#12的35%非克隆性染色体畸变(NCCA)和20%的克隆性染色体畸变(CCA)以及大鼠#15的70%的NCCA和15%CCA(表4)。由于NCCA的频率代表基因组不稳定性水平,而CCA代表相对稳定性,这些数据表明不响应QQ-SON蛋白治疗的肿瘤(大鼠#15)显示出与对QQ-SON治疗显示良好的响应的肿瘤(大鼠#12)的那些相比更高水平的基因组异质性。该结果表明蛋白诱导的原位细胞重编程显著增强经治疗的癌细胞的基因组稳定性,表明恶性癌细胞到非癌细胞的细胞转化。
实施例25
通过蛋白诱导的原位细胞重编程介导的QQ-SON诱导的细胞转化的癌症疗法使得携带皮下9L-肿瘤的大鼠和携带晚期4T1的小鼠在手术切除原发性肿瘤后癌症治愈。
进行9L-细胞到Fisher大鼠的皮下植入以产生荷瘤大鼠。肿瘤细胞植入后五天,进行QQ-修饰的SON(QQ-SON)蛋白的每日瘤内注射。还进行溶于PBS的QQ-试剂(QQ-PBS)的适当的对照。在使用QQ-SON蛋白以10μg/只小鼠/天的18天每日瘤内治疗方案后,进行90天的存活实验。在治疗过程中,在所有治疗的大鼠中观察到显著降低的肿瘤生长。在18天的每日治疗之后,50%的经治疗的大鼠随着时间的推移显示出减少的肿瘤体积并且在这些动物中不存在可触及的肿瘤。剩余的经治疗的大鼠显示出显著更慢的肿瘤生长。治疗组的中值存活时间为49±20天(n=8),而对照组中的存活时间为21±4天(n=6)。在第32天、43天和62天,在三只经治疗的大鼠中观察到肿瘤复发,具有45±13天的中值存活时间。复发肿瘤生长非常积极并且在5-7天内达到>12cm3的体积(表5,治疗1)。第四个神经胶质瘤治愈的大鼠保持无瘤超过30个月,没有畸胎瘤形成的证据。
当所述每日肿瘤内治疗方案延长到30天时,在400天的存活实验(n=8)期间,在头73天内获得100%神经胶质瘤治愈的大鼠。此外,在第73天、78天和92天(中值复发时间:81±8天)观察到三只经治疗的大鼠的肿瘤复发,其远远晚于在仅治疗18天的大鼠中观察到的肿瘤复发。剩余的5只大鼠保持无瘤400天。将具有复发肿瘤的三只大鼠额外治疗30天(每日瘤内注射,10μg/天QQ-SON)。在三只大鼠中,两只具有非常缓慢的进展并且额外存活了66天(在第78天肿瘤发生)或68天(在第92天肿瘤复发)。仅一只大鼠显示出缓慢的肿瘤生长并当肿瘤体积达到12cm3时在第109天(确定为肿瘤复发后36天)被处死。与对照组(n=6)的21±4天相比,经治疗的大鼠的中值存活时间为280±155天(n=8)(表5,治疗2)。
为了确保该结果是可重复的,重复上述30天的每日治疗实验并在头79天内获得80%的神经胶质瘤治愈的大鼠。两只大鼠显示出缓慢的肿瘤生长,但是分别在第29天和第48天已经达到12cm3的肿瘤体积(表5,治疗3)。然而,两只神经胶质瘤治愈的大鼠在第79天和第111天显示出肿瘤复发(中值复发时间:95±16天)。将这两只大鼠用QQ-SON蛋白(10μg/天)额外治疗30天。两只大鼠之一显示出缓慢的肿瘤生长并且在第79天肿瘤复发后30天内达到12cm3的体积。另一只大鼠额外存活了69天。经治疗的大鼠的中值存活时间为276±156天(n=10),而用QQ-PBS治疗的对照大鼠在肿瘤植入后仅存活23±3天(n=6)。来自治疗2和治疗3的肿瘤治愈的大鼠目前存活超过15个月,而无肿瘤复发并且不形成畸胎瘤。
对于经QQ-PBS和QQ-SON治疗的小鼠,在4T1细胞植入后第18天手术切除原发性肿瘤后的携带晚期4T1-乳腺癌的小鼠中观察到类似的结果。在第5天进行每日肿瘤内QQ-SON蛋白治疗并持续40天。此前,证明了肺转移开始于第7天。在第18天,观察到每只小鼠的MRI可观察到的肺转移病灶。进行250天的存活实验。所得到的数据(表6)表明尽管QQ-PBS对照小鼠死于第25-47天,但是经QQ-SON治疗的小鼠存活更长的时间并且61%(n=11)的经QQ-SON治疗的小鼠存活整个250天,而无肿瘤复发和畸胎瘤形成(n=18),参见图8。MRI结果显示肺转移病灶消失。这些数据证明该QQ-SON诱导的细胞转化癌症疗法的高治疗效力。
图8是在第18天手术切除原发性4T1-乳腺癌后的携带4T1-乳腺癌的小鼠的Kaplan-Meier存活曲线(250天存活期)。在将4T1-细胞植入到雌性BALB/c小鼠的#4脂肪垫中6天后用QQ-PBS(对照)和QQ-SON蛋白(治疗)治疗这些携带4T1乳腺癌的小鼠。约在第5天,原发性肿瘤是可触及的并在第18天手术切除。通过瘤内注射(5μg/只小鼠/天)和腹膜内注射(25μg/只小鼠/天)每日进行QQ-PBS/QQ-SON治疗。
图8的Kaplan-Meier存活曲线中的第0天为在第18天进行手术时的天数。少数的小鼠由于不完全的肿瘤切除而出现肿瘤复发。将这些小鼠用QQ-SON蛋白或QQ-PBS通过瘤内注射治疗并且也比较它们的存活时间(虚线的存活曲线)。对于没有肿瘤复发的那些小鼠,它们的存活曲线以实线示出。在该整个250天的存活实验之后仍存活的没有肿瘤复发的小鼠被认为是肿瘤治愈的小鼠。已经在61%的经治疗的小鼠种群中实现肿瘤治愈。
因此,证明了QQ-SON诱导的癌细胞在肿瘤内的原位细胞重编程产生在那个组织中分化为不同的非癌细胞的瞬时piPSC。所分化的非癌细胞的类型取决于具体的组织环境。QQ-SON诱导的原位细胞重编程和组织环境诱导的分化之间的该相互作用精确地调节在肿瘤内的瞬时piPSC的产生和诱导的分化,防止了肿瘤和畸胎瘤形成。这种安全的蛋白诱导的原位细胞重编程技术原位生成干细胞,干细胞随后分化为由组织环境诱导的正常细胞以替代病变细胞,用于治疗许多疾病和损伤。
序列
人类SRY(性别决定区Y)-盒2(SOX2)(NM_003106)SEQ ID NO:1(蛋白质)和SEQ ID NO:65(DNA)
MYNMMETELKPPGPQQTSGGGGGNSTAAAAGGNQKNSPDRVKRPMNAFMVWSRGQRRKMAQENPKMHNSEISKRLGAEWKLLSETEKRPFIDEAKRLRALHMKEHPDYKYRPRRKTKTLMKKDKYTLPGGLLAPGGNSMASGVGVGAGLGAGVNQRMDSYAHMNGWSNGSYSMMQDQLGYPQHPGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVVKSEASSSPPVVTSSSHSRAPCQAGDLRDMISMYLPGAEVPEPAAPSRLHMSQHYQSGPVPGTAINGTLPLSHM(SEQ ID NO:1)
atgtacaacatgatggagacggagctgaagccgccgggcccgcagcaaacttcggggggcggcggcggcaactccaccgcggcggcggccggcggcaaccagaaaaacagcccggaccgcgtcaagcggcccatgaatgccttcatggtgtggtcccgcgggcagcggcgcaagatggcccaggagaaccccaagatgcacaactcggagatcagcaagcgcctgggcgccgagtggaaacttttgtcggagacggagaagcggccgttcatcgacgaggctaagcggctgcgagcgctgcacatgaaggagcacccggattataaataccggccccggcggaaaaccaagacgctcatgaagaaggataagtacacgctgcccggcgggctgctggcccccggcggcaatagcatggcgagcggggtcggggtgggcgccggcctgggcgcgggcgtgaaccagcgcatggacagttacgcgcacatgaacggctggagcaacggcagctacagcatgatgcaggaccagctgggctacccgcagcacccgggcctcaatgcgcacggcgcagcgcagatgcagcccatgcaccgctacgacgtgagcgccctgcagtacaactccatgaccagctcgcagacctacatgaacggctcgcccacctacagcatgtcctactcgcagcagggcacccctggcatggctcttggctccatgggttcggtggtcaagtccgaggccagctccagcccccctgtggttacctcttcctcccactccagggcgccctgccaggccggggacctccgggacatgatcagcatgtatctccccggcgccgaggtgccggaacccgccgcccccagcagacttcacatgtcccagcactaccagagcggcccggtgcccggcacggccattaacggcacactgcccctctcacacatgtga(SEQ ID NO:65)
人类POU 5类同源异型框1(POU5F1),也称为Oct4(NM_002701)SEQ ID NO:2(蛋白质)和SEQ ID NO:66(DNA)
MAGHLASDFAFSPPPGGGGDGPGGPEPGWVDPRTWLSFQGPPGGPGIGPGVGPGSEVWGIPPCPPPYEFCGGMAYCGPQVGVGLVPQGGLETSQPEGEAGVGVESNSDGASPEPCTVTPGAVKLEKEKLEQNPEESQDIKALQKELEQFAKLLKQKRITLGYTQADVGLTLGVLFGKVFSQTTICRFEALQLSFKNMCKLRPLLQKWVEEADNNENLQEICKAETLVQARKRKRTSIENRVRGNLENLFLQCPKPTLQQISHIAQQLGLEKDVVRVWFCNRRQKGKRSSSDYAQREDFEAAGSPFSGGPVSFPLAPGPHFGTPGYGSPHFTALYSSVPFPEGEAFPPVSVTTLGSPMHSN(SEQ ID NO:2)
atggcgggacacctggcttcggatttcgccttctcgccccctccaggtggtggaggtgatgggccaggggggccggagccgggctgggttgatcctcggacctggctaagcttccaaggccctcctggagggccaggaatcgggccgggggttgggccaggctctgaggtgtgggggattcccccatgccccccgccgtatgagttctgtggggggatggcgtactgtgggccccaggttggagtggggctagtgccccaaggcggcttggagacctctcagcctgagggcgaagcaggagtcggggtggagagcaactccgatggggcctccccggagccctgcaccgtcacccctggtgccgtgaagctggagaaggagaagctggagcaaaacccggaggagtcccaggacatcaaagctctgcagaaagaactcgagcaatttgccaagctcctgaagcagaagaggatcaccctgggatatacacaggccgatgtggggctcaccctgggggttctatttgggaaggtattcagccaaacgaccatctgccgctttgaggctctgcagcttagcttcaagaacatgtgtaagctgcggcccttgctgcagaagtgggtggaggaagctgacaacaatgaaaatcttcaggagatatgcaaagcagaaaccctcgtgcaggcccgaaagagaaagcgaaccagtatcgagaaccgagtgagaggcaacctggagaatttgttcctgcagtgcccgaaacccacactgcagcagatcagccacatcgcccagcagcttgggctcgagaaggatgtggtccgagtgtggttctgtaaccggcgccagaagggcaagcgatcaagcagcgactatgcacaacgagaggattttgaggctgctgggtctcctttctcagggggaccagtgtcctttcctctggccccagggccccattttggtaccccaggctatgggagccctcacttcactgcactgtactcctcggtccctttccctgagggggaagcctttccccctgtctccgtcaccactctgggctctcccatgcattcaaactga(SEQ ID NO:66)
人类Nanog同源异型框(NANOG)(NM_024865)SEQ ID NO:3(蛋白质)和SEQ ID NO:67(DNA)
MSVDPACPQSLPCFEASDCKESSPMPVICGPEENYPSLQMSSAEMPHTETVSPLPSSMDLLIQDSPDSSTSPKGKQPTSAEKSVAKKEDKVPVKKQKTRTVFSSTQLCVLNDRFQRQKYLSLQQMQELSNILNLSYKQVKTWFQNQRMKSKRWQKNNWPKNSNGVTQKASAPTYPSLYSSYHQGCLVNPTGNLPMWSNQTWNNSTWSNQTQNIQSWSNHSWNTQTWCTQSWNNQAWNSPFYNCGEESLQSCMQFQPNSPASDLEAALEAAGEGLNVIQQTTRYFSTPQTMDLFLNYSMNMQPEDV(SEQ ID NO:3)
atgagtgtggatccagcttgtccccaaagcttgccttgctttgaagcatccgactgtaaagaatcttcacctatgcctgtgatttgtgggcctgaagaaaactatccatccttgcaaatgtcttctgctgagatgcctcacacggagactgtctctcctcttccttcctccatggatctgcttattcaggacagccctgattcttccaccagtcccaaaggcaaacaacccacttctgcagagaagagtgtcgcaaaaaaggaagacaaggtcccggtcaagaaacagaagaccagaactgtgttctcttccacccagctgtgtgtactcaatgatagatttcagagacagaaatacctcagcctccagcagatgcaagaactctccaacatcctgaacctcagctacaaacaggtgaagacctggttccagaaccagagaatgaaatctaagaggtggcagaaaaacaactggccgaagaatagcaatggtgtgacgcagaaggcctcagcacctacctaccccagcctttactcttcctaccaccagggatgcctggtgaacccgactgggaaccttccaatgtggagcaaccagacctggaacaattcaacctggagcaaccagacccagaacatccagtcctggagcaaccactcctggaacactcagacctggtgcacccaatcctggaacaatcaggcctggaacagtcccttctataactgtggagaggaatctctgcagtcctgcatgcagttccagccaaattctcctgccagtgacttggaggctgccttggaagctgctggggaaggccttaatgtaatacagcagaccactaggtattttagtactccacaaaccatggatttattcctaaactactccatgaacatgcaacctgaagacgtgtga(SEQ ID NO:67)
人类的lin-28同源物A(秀丽线虫(C.elegans))(LIN28A)(NM_024674)SEQ ID NO:4(蛋白质)和SEQ ID NO:68(DNA)
MGSVSNQQFAGGCAKAAEEAPEEAPEDAARAADEPQLLHGAGICKWFNVRMGFGFLSMTARAGVALDPPVDVFVHQSKLHMEGFRSLKEGEAVEFTFKKSAKGLESIRVTGPGGVFCIGSERRPKGKSMQKRRSKGDRCYNCGGLDHHAKECKLPPQPKKCHFCQSISHMVASCPLKAQQGPSAQGKPTYFREEEEEIHSPTLLPEAQN(SEQ ID NO:4)
atgggctccgtgtccaaccagcagtttgcaggtggctgcgccaaggcggcagaagaggcgcccgaggaggcgccggaggacgcggcccgggcggcggacgagcctcagctgctgcacggtgcgggcatctgtaagtggttcaacgtgcgcatggggttcggcttcctgtccatgaccgcccgcgccggggtcgcgctcgaccccccagtggatgtctttgtgcaccagagtaagctgcacatggaagggttccggagcttgaaggagggtgaggcagtggagttcacctttaagaagtcagccaagggtctggaatccatccgtgtcaccggacctggtggagtattctgtattgggagtgagaggcggccaaaaggaaagagcatgcagaagcgcagatcaaaaggagacaggtgctacaactgtggaggtctagatcatcatgccaaggaatgcaagctgccaccccagcccaagaagtgccacttctgccagagcatcagccatatggtagcctcatgtccgctgaaggcccagcagggccctagtgcacagggaaagccaacctactttcgagaggaagaagaagaaatccacagccctaccctgctcccggaggcacagaattga(SEQ ID NO:68)
人类Krueppel样因子4(Klf4)(NP_004226)SEQ ID NO:5(蛋白质)和SEQ ID NO:69(DNA)
MRQPPGESDMAVSDALLPSFSTFASGPAGREKTLRQAGAPNNRWREELSHMKRLPPVLPGRPYDLAAATVATDLESGGAGAACGGSNLAPLPRRETEEFNDLLDLDFILSNSLTHPPESVAATVSSSASASSSSSPSSSGPASAPSTCSFTYPIRAGNDPGVAPGGTGGGLLYGRESAPPPTAPFNLADINDVSPSGGFVAELLRPELDPVYIPPQQPQPPGGGLMGKFVLKASLSAPGSEYGSPSVISVSKGSPDGSHPVVVAPYNGGPPRTCPKIKQEAVSSCTHLGAGPPLSNGHRPAAHDFPLGRQLPSRTTPTLGLEEVLSSRDCHPALPLPPGFHPHPGPNYPSFLPDQMQPQVPPLHYQELMPPGSCMPEEPKPKRGRRSWPRKRTATHTCDYAGCGKTYTKSSHLKAHLRTHTGEKPYHCDWDGCGWKFARSDELTRHYRKHTGHRPFQCQKCDRAFSRSDHLALHMKRHF(SEQ ID NO:5)
atgaggcagccacctggcgagtctgacatggctgtcagcgacgcgctgctcccatctttctccacgttcgcgtctggcccggcgggaagggagaagacactgcgtcaagcaggtgccccgaataaccgctggcgggaggagctctcccacatgaagcgacttcccccagtgcttcccggccgcccctatgacctggcggcggcgaccgtggccacagacctggagagcggcggagccggtgcggcttgcggcggtagcaacctggcgcccctacctcggagagagaccgaggagttcaacgatctcctggacctggactttattctctccaattcgctgacccatcctccggagtcagtggccgccaccgtgtcctcgtcagcgtcagcctcctcttcgtcgtcgccgtcgagcagcggccctgccagcgcgccctccacctgcagcttcacctatccgatccgggccgggaacgacccgggcgtggcgccgggcggcacgggcggaggcctcctctatggcagggagtccgctccccctccgacggctcccttcaacctggcggacatcaacgacgtgagcccctcgggcggcttcgtggccgagctcctgcggccagaattggacccggtgtacattccgccgcagcagccgcagccgccaggtggcgggctgatgggcaagttcgtgctgaaggcgtcgctgagcgcccctggcagcgagtacggcagcccgtcggtcatcagcgtcagcaaaggcagccctgacggcagccacccggtggtggtggcgccctacaacggcgggccgccgcgcacgtgccccaagatcaagcaggaggcggtctcttcgtgcacccacttgggcgctggaccccctctcagcaatggccaccggccggctgcacacgacttccccctggggcggcagctccccagcaggactaccccgaccctgggtcttgaggaagtgctgagcagcagggactgtcaccctgccctgccgcttcctcccggcttccatccccacccggggcccaattacccatccttcctgcccgatcagatgcagccgcaagtcccgccgctccattaccaagagctcatgccacccggttcctgcatgccagaggagcccaagccaaagaggggaagacgatcgtggccccggaaaaggaccgccacccacacttgtgattacgcgggctgcggcaaaacctacacaaagagttcccatctcaaggcacacctgcgaacccacacaggtgagaaaccttaccactgtgactgggacggctgtggatggaaattcgcccgctcagatgaactgaccaggcactaccgtaaacacacggggcaccgcccgttccagtgccaaaaatgcgaccgagcattttccaggtcggaccacctcgccttacacatgaagaggcatttttaa(SEQ ID NO:69)
人类c-MYC(NP_002458)SEQ ID NO:6(蛋白质)和SEQ ID NO:70(DNA)
MDFFRVVENQQPPATMPLNVSFTNRNYDLDYDSVQPYFYCDEEENFYQQQQQSELQPPAPSEDIWKKFELLPTPPLSPSRRSGLCSPSYVAVTPFSLRGDNDGGGGSFSTADQLEMVTELLGGDMVNQSFICDPDDETFIKNIIIQDCMWSGFSAAAKLVSEKLASYQAARKDSGSPNPARGHSVCSTSSLYLQDLSAAASECIDPSVVFPYPLNDSSSPKSCASQDSSAFSPSSDSLLSSTESSPQGSPEPLVLHEETPPTTSSDSEEEQEDEEEIDVVSVEKRQAPGKRSESGSPSAGGHSKPPHSPLVLKRCHVSTHQHNYAAPPSTRKDYPAAKRVKLDSVRVLRQISNNRKCTSPRSSDTEENVKRRTHNVLERQRRNELKRSFFALRDQIPELENNEKAPKVVILKKATAYILSVQAEEQKLISEEDLLRKRREQLKHKLEQLRNSCA(SEQ ID NO:6)
atggatttttttcgggtagtggaaaaccagcagcctcccgcgacgatgcccctcaacgttagcttcaccaacaggaactatgacctcgactacgactcggtgcagccgtatttctactgcgacgaggaggagaacttctaccagcagcagcagcagagcgagctgcagcccccggcgcccagcgaggatatctggaagaaattcgagctgctgcccaccccgcccctgtcccctagccgccgctccgggctctgctcgccctcctacgttgcggtcacacccttctcccttcggggagacaacgacggcggtggcgggagcttctccacggccgaccagctggagatggtgaccgagctgctgggaggagacatggtgaaccagagtttcatctgcgacccggacgacgagaccttcatcaaaaacatcatcatccaggactgtatgtggagcggcttctcggccgccgccaagctcgtctcagagaagctggcctcctaccaggctgcgcgcaaagacagcggcagcccgaaccccgcccgcggccacagcgtctgctccacctccagcttgtacctgcaggatctgagcgccgccgcctcagagtgcatcgacccctcggtggtcttcccctaccctctcaacgacagcagctcgcccaagtcctgcgcctcgcaagactccagcgccttctctccgtcctcggattctctgctctcctcgacggagtcctccccgcagggcagccccgagcccctggtgctccatgaggagacaccgcccaccaccagcagcgactctgaggaggaacaagaagatgaggaagaaatcgatgttgtttctgtggaaaagaggcaggctcctggcaaaaggtcagagtctggatcaccttctgctggaggccacagcaaacctcctcacagcccactggtcctcaagaggtgccacgtctccacacatcagcacaactacgcagcgcctccctccactcggaaggactatcctgctgccaagagggtcaagttggacagtgtcagagtcctgagacagatcagcaacaaccgaaaatgcaccagccccaggtcctcggacaccgaggagaatgtcaagaggcgaacacacaacgtcttggagcgccagaggaggaacgagctaaaacggagcttttttgccctgcgtgaccagatcccggagttggaaaacaatgaaaaggcccccaaggtagttatccttaaaaaagccacagcatacatcctgtccgtccaagcagaggagcaaaagctcatttctgaagaggacttgttgcggaaacgacgagaacagttgaaacacaaacttgaacagctacggaactcttgtgcgtaa(SEQ ID NO:70
人类GATA结合蛋白4(GATA4)(NM_002052)SEQ ID NO:7(蛋白质)和SEQ ID NO:71(DNA)
MYQSLAMAANHGPPPGAYEAGGPGAFMHGAGAASSPVYVPTPRVPSSVLGLSYLQGGGAGSASGGASGGSSGGAASGAGPGTQQGSPGWSQAGADGAAYTPPPVSPRFSFPGTTGSLAAAAAAAAAREAAAYSSGGGAAGAGLAGREQYGRAGFAGSYSSPYPAYMADVGASWAAAAAASAGPFDSPVLHSLPGRANPAARHPNLDMFDDFSEGRECVNCGAMSTPLWRRDGTGHYLCNACGLYHKMNGINRPLIKPQRRLSASRRVGLSCANCQTTTTTLWRRNAEGEPVCNACGLYMKLHGVPRPLAMRKEGIQTRKRKPKNLNKSKTPAAPSGSESLPPASGASSNSSNATTSSSEEMRPIKTEPGLSSHYGHSSSVSQTFSVSAMSGHGPSIHPVLSALKLSPQGYASPVSQSPQTSSKQDSWNSLVLADSHGDIITA(SEQ ID NO:7)
atgtatcagagcttggccatggccgccaaccacgggccgccccccggtgcctacgaggcgggcggccccggcgccttcatgcacggcgcgggcgccgcgtcctcgccagtctacgtgcccacaccgcgggtgccctcctccgtgctgggcctgtcctacctccagggcggaggcgcgggctctgcgtccggaggcgcctcgggcggcagctccggtggggccgcgtctggtgcggggcccgggacccagcagggcagcccgggatggagccaggcgggagccgacggagccgcttacaccccgccgccggtgtcgccgcgcttctccttcccggggaccaccgggtccctggcggccgccgccgccgctgccgcggcccgggaagctgcggcctacagcagtggcggcggagcggcgggtgcgggcctggcgggccgcgagcagtacgggcgcgccggcttcgcgggctcctactccagcccctacccggcttacatggccgacgtgggcgcgtcctgggccgcagccgccgccgcctccgccggccccttcgacagcccggtcctgcacagcctgcccggccgggccaacccggccgcccgacaccccaatctcgatatgtttgacgacttctcagaaggcagagagtgtgtcaactgtggggctatgtccaccccgctctggaggcgagatgggacgggtcactatctgtgcaacgcctgcggcctctaccacaagatgaacggcatcaaccggccgctcatcaagcctcagcgccggctgtccgcctcccgccgagtgggcctctcctgtgccaactgccagaccaccaccaccacgctgtggcgccgcaatgcggagggcgagcctgtgtgcaatgcctgcggcctctacatgaagctccacggggtccccaggcctcttgcaatgcggaaagaggggatccaaaccagaaaacggaagcccaagaacctgaataaatctaagacaccagcagctccttcaggcagtgagagccttcctcccgccagcggtgcttccagcaactccagcaacgccaccaccagcagcagcgaggagatgcgtcccatcaagacggagcctggcctgtcatctcactacgggcacagcagctccgtgtcccagacgttctcagtcagtgcgatgtctggccatgggccctccatccaccctgtcctctcggccctgaagctctccccacaaggctatgcgtctcccgtcagccagtctccacagaccagctccaagcaggactcttggaacagcctggtcttggccgacagtcacggggacataatcactgcgtaa(SEQ ID NO:71)
人类心脏和神经嵴表达衍生物2(HAND2)(NM_021973)SEQ ID NO:8(蛋白质)和SEQ ID NO:72(DNA)
MSLVGGFPHHPVVHHEGYPFAAAAAAAAAAAASRCSHEENPYFHGWLIGHPEMSPPDYSMALSYSPEYASGAAGLDHSHYGGVPPGAGPPGLGGPRPVKRRGTANRKERRRTQSINSAFAELRECIPNVPADTKLSKIKTLRLATSYIAYLMDLLAKDDQNGEAEAFKAEIKKTDVKEEKRKKELNEILKSTVSSNDKKTKGRTGWPQHVWALELKQ(SEQ ID NO:8)
atgagtctggtaggtggttttccccaccacccggtggtgcaccacgagggctacccgtttgccgccgccgccgccgcagctgccgccgccgccgccagccgctgcagccatgaggagaacccctacttccatggctggctcatcggccaccccgagatgtcgccccccgactacagcatggccctgtcctacagccccgagtatgccagcggcgccgccggcctggaccactcccattacgggggggtgccgccgggcgccgggcccccgggcctgggggggccgcgcccggtgaagcgccgaggcaccgccaaccgcaaggagcggcgcaggactcagagcatcaacagcgccttcgccgaactgcgcgagtgcatccccaacgtacccgccgacaccaaactctccaaaatcaagaccctgcgcctggccaccagctacatcgcctacctcatggacctgctggccaaggacgaccagaatggcgaggcggaggccttcaaggcagagatcaagaagaccgacgtgaaagaggagaagaggaagaaggagctgaacgaaatcttgaaaagcacagtgagcagcaacgacaagaaaaccaaaggccggacgggctggccgcagcacgtctgggccctggagctcaagcagtga(SEQ ID NO:72)
人类肌细胞强化因子2C(MEF2C)(NM_001193350)SEQ ID NO:9(蛋白质)和SEQ ID NO:73(DNA)
MGRKKIQITRIMDERNRQVTFTKRKFGLMKKAYELSVLCDCEIALIIFNSTNKLFQYASTDMDKVLLKYTEYNEPHESRTNSDIVETLRKKGLNGCDSPDPDADDSVGHSPESEDKYRKINEDIDLMISRQRLCAVPPPNFEMPVSIPVSSHNSLVYSNPVSSLGNPNLLPLAHPSLQRNSMSPGVTHRPPSAGNTGGLMGGDLTSGAGTSAGNGYGNPRNSPGLLVSPGNLNKNMQAKSPPPMNLGMNNRKPDLRVLIPPGSKNTMPSVSEDVDLLLNQRINNSQSAQSLATPVVSVATPTLPGQGMGGYPSAISTTYGTEYSLSSADLSSLSGFNTASALHLGSVTGWQQQHLHNMPPSALSQLGACTSTHLSQSSNLSLPSTQSLNIKSEPVSPPRDRTTTPSRYPQHTRHEAGRSPVDSLSSCSSSYDGSDREDHRNEFHSPIGLTRPSPDERESPSVKRMRLSEGWAT(SEQ ID NO:9)
atggggagaaaaaagattcagattacgaggattatggatgaacgtaacagacaggtgacatttacaaagaggaaatttgggttgatgaagaaggcttatgagctgagcgtgctgtgtgactgtgagattgcgctgatcatcttcaacagcaccaacaagctgttccagtatgccagcaccgacatggacaaagtgcttctcaagtacacggagtacaacgagccgcatgagagccggacaaactcagacatcgtggagacgttgagaaagaagggccttaatggctgtgacagcccagaccccgatgcggacgattccgtaggtcacagccctgagtctgaggacaagtacaggaaaattaacgaagatattgatctaatgatcagcaggcaaagattgtgtgctgttccacctcccaacttcgagatgccagtctccatcccagtgtccagccacaacagtttggtgtacagcaaccctgtcagctcactgggaaaccccaacctattgccactggctcacccttctctgcagaggaatagtatgtctcctggtgtaacacatcgacctccaagtgcaggtaacacaggtggtctgatgggtggagacctcacgtctggtgcaggcaccagtgcagggaacgggtatggcaatccccgaaactcaccaggtctgctggtctcacctggtaacttgaacaagaatatgcaagcaaaatctcctcccccaatgaatttaggaatgaataaccgtaaaccagatctccgagttcttattccaccaggcagcaagaatacgatgccatcagtgtctgaggatgtcgacctgcttttgaatcaaaggataaataactcccagtcggctcagtcattggctaccccagtggtttccgtagcaactcctactttaccaggacaaggaatgggaggatatccatcagccatttcaacaacatatggtaccgagtactctctgagtagtgcagacctgtcatctctgtctgggtttaacaccgccagcgctcttcaccttggttcagtaactggctggcaacagcaacacctacataacatgccaccatctgccctcagtcagttgggagcttgcactagcactcatttatctcagagttcaaatctctccctgccttctactcaaagcctcaacatcaagtcagaacctgtttctcctcctagagaccgtaccaccaccccttcgagatacccacaacacacgcgccacgaggcggggagatctcctgttgacagcttgagcagctgtagcagttcgtacgacgggagcgaccgagaggatcaccggaacgaattccactcccccattggactcaccagaccttcgccggacgaaagggaaagtccctcagtcaagcgcatgcgactttctgaaggatgggcaacatga(SEQ ID NO:73)
人类转录因子TBX5(U80987)SEQ ID NO:10(蛋白质)和SEQ ID NO:74(DNA)
MADADEGFGLAHTPLEPDAKDLPCDSKPESALGAPSKSPSSPQAAFTQQGMEGIKVFLHERELWLKFHEVGTEMIITKAGRRMFPSYKVKVTGLNPKTKYILLMDIVPADDHRYKFADNKWSVTGKAEPAMPGRLYVHPDSPATGAHWMRQLVSFQKLKLTNNHLDPFGHIILNSMHKYQPRLHIVKADENNGFGSKNTAFCTHVFPETAFIAVTSYQNHKITQLKIENNPFAKGFRGSDDMELHRMSRMQSKEYPVVPRSTVRQKVASNHSPFSSESRALSTSSNLGSQYQCENGVSGPSQDLLPPPNPYPLPQEHSQIYHCTKRKGECDHPWSICFLSYLFLSLGWG(SEQ ID NO:10)
atggccgacgcagacgagggctttggcctggcgcacacgcctctggagcctgacgcaaaagacctgccctgcgattcgaaacccgagagcgcgctcggggcccccagcaagtccccgtcgtccccgcaggccgccttcacccagcagggcatggagggaatcaaagtgtttctccatgaaagagaactgtggctaaaattccacgaagtgggcacggaaatgatcataaccaaggctggaaggcggatgtttcccagttacaaagtgaaggtgacgggccttaatcccaaaacgaagtacattcttctcatggacattgtacctgccgacgatcacagatacaaattcgcagataataaatggtctgtgacgggcaaagctgagcccgccatgcctggccgcctgtacgtgcacccagactcccccgccaccggggcgcattggatgaggcagctcgtctccttccagaaactcaagctcaccaacaaccacctggacccatttgggcatattattctaaattccatgcacaaataccagcctagattacacatcgtgaaagcggatgaaaataatggatttggctcaaaaaatacagcgttctgcactcacgtctttcctgagactgcgtttatagcagtgacttcctaccagaaccacaagatcacgcaattaaagattgagaataatccctttgccaaaggatttcggggcagtgatgacatggagctgcacagaatgtcaagaatgcaaagtaaagaatatcccgtggtccccaggagcaccgtgaggcaaaaagtggcctccaaccacagtcctttcagcagcgagtctcgagctctctccacctcatccaatttggggtcccaataccagtgtgagaatggtgtttccggcccctcccaggacctcctgcctccacccaacccatacccactgccccaggagcatagccaaatttaccattgtaccaagaggaaaggtgagtgtgatcacccctggtcaatttgctttctttcttaccttttcctttccttgggttgggggtga(SEQ ID NO:74)
人类神经原素3(NEUROG3)(NM_020999.3)SEQ ID NO:11(蛋白质)和SEQ ID NO:75(DNA)
MTPQPSGAPTVQVTRETERSFPRASEDEVTCPTSAPPSPTRTRGNCAEAEEGGCRGAPRKLRARRGGRSRPKSELALSKQRRSRRKKANDRERNRMHNLNSALDALRGVLPTFPDDAKLTKIETLRFAHNYIWALTQTLRIADHSLYALEPPAPHCGELGSPGGSPGDWGSLYSPVSQAGSLSPAASLEERPGLLGATFSACLSPGSLAFSDFL(SEQ ID NO:11)
atgacgcctcaaccctcgggtgcgcccactgtccaagtgacccgtgagacggagcggtccttccccagagcctcggaagacgaagtgacctgccccacgtccgccccgcccagccccactcgcacacgggggaactgcgcagaggcggaagagggaggctgccgaggggccccgaggaagctccgggcacggcgcgggggacgcagccggcctaagagcgagttggcactgagcaagcagcgacggagtcggcgaaagaaggccaacgaccgcgagcgcaatcgaatgcacaacctcaactcggcactggacgccctgcgcggtgtcctgcccaccttcccagacgacgcgaagctcaccaagatcgagacgctgcgcttcgcccacaactacatctgggcgctgactcaaacgctgcgcatagcggaccacagcttgtacgcgctggagccgccggcgccgcactgcggggagctgggcagcccaggcggttcccccggggactgggggtccctctactccccagtctcccaggctggcagcctgagtcccgccgcgtcgctggaggagcgacccgggctgctgggggccaccttttccgcctgcttgagcccaggcagtctggctttctcagattttctgtga(SEQ ID NO:75)
人类配对盒4(PAX4)(NM_006193.2)SEQ ID NO:12(蛋白质)和SEQ ID NO:76(DNA)
MNQLGGLFVNGRPLPLDTRQQIVRLAVSGMRPCDISRILKVSNGCVSKILGRYYRTGVLEPKGIGGSKPRLATPPVVARIAQLKGECPALFAWEIQRQLCAEGLCTQDKTPSVSSINRVLRALQEDQGLPCTRLRSPAVLAPAVLTPHSGSETPRGTHPGTGHRNRTIFSPSQAEALEKEFQRGQYPDSVARGKLATATSLPEDTVRVWFSNRRAKWRRQEKLKWEMQLPGASQGLTVPRVAPGIISAQQSPGSVPTAALPALEPLGPSCYQLCWATAPERCLSDTPPKACLKPCWGHLPPQPNSLDSGLLCLPCPSSHCHLASLSGSQALLWPGCPLLYGLE(SEQ ID NO:12)
atgaaccagcttggggggctctttgtgaatggccggcccctgcctctggatacccggcagcagattgtgcggctagcagtcagtggaatgcggccctgtgacatctcacggatccttaaggtatctaatggctgtgtgagcaagatcctagggcgttactaccgcacaggtgtcttggagccaaagggcattgggggaagcaagccacggctggctacaccccctgtggtggctcgaattgcccagctgaagggtgagtgtccagccctctttgcctgggaaatccaacgccagctttgtgctgaagggctttgcacccaggacaagactcccagtgtctcctccatcaaccgagtcctgcgggcattacaggaggaccagggactaccgtgcacacggctcaggtcaccagctgttttggctccagctgtcctcactccccatagtggctctgagactccccggggtacccacccagggaccggccaccggaatcggactatcttctccccaagccaagcagaggcactggagaaagagttccagcgtgggcagtatcctgattcagtggcccgtggaaagctggctactgccacctctctgcctgaggacacggtgagggtctggttttccaacagaagagccaaatggcgtcggcaagagaagctcaagtgggaaatgcagctgccaggtgcttcccaggggctgactgtaccaagggttgccccaggaatcatctctgcacagcagtcccctggcagtgtgcccacagcagccctgcctgccctggaaccactgggtccctcctgctatcagctgtgctgggcaacagcaccagaaaggtgtctgagtgacaccccacctaaagcctgtctcaagccctgctggggccacttgcccccacagccgaattccctggactcaggactgctttgccttccttgcccttcctcccactgtcacctggccagtcttagtggctctcaggccctgctctggcctggctgcccactactgtatggcttggaatga(SEQ ID NO:76)
人类胰脏和十二指肠同源异型框1(PDX1)(NM_000209.3)SEQ ID NO:13(蛋白质)和SEQ ID NO:77(DNA)
MNGEEQYYAATQLYKDPCAFQRGPAPEFSASPPACLYMGRQPPPPPPHPFPGALGALEQGSPPDISPYEVPPLADDPAVAHLHHHLPAQLALPHPPAGPFPEGAEPGVLEEPNRVQLPFPWMKSTKAHAWKGQWAGGAYAAEPEENKRTRTAYTRAQLLELEKEFLFNKYISRPRRVELAVMLNLTERHIKIWFQNRRMKWKKEEDKKRGGGTAVGGGGVAEPEQDCAVTSGEELLALPPPPPPGGAVPPAAPVAAREGRLPPGLSASPQPSSVAPRRPQEPR(SEQ ID NO:13)
atgaacggcgaggagcagtactacgcggccacgcagctttacaaggacccatgcgcgttccagcgaggcccggcgccggagttcagcgccagcccccctgcgtgcctgtacatgggccgccagcccccgccgccgccgccgcacccgttccctggcgccctgggcgcgctggagcagggcagccccccggacatctccccgtacgaggtgccccccctcgccgacgaccccgcggtggcgcaccttcaccaccacctcccggctcagctcgcgctcccccacccgcccgccgggcccttcccggagggagccgagccgggcgtcctggaggagcccaaccgcgtccagctgcctttcccatggatgaagtctaccaaagctcacgcgtggaaaggccagtgggcaggcggcgcctacgctgcggagccggaggagaacaagcggacgcgcacggcctacacgcgcgcacagctgctagagctggagaaggagttcctattcaacaagtacatctcacggccgcgccgggtggagctggctgtcatgttgaacttgaccgagagacacatcaagatctggttccaaaaccgccgcatgaagtggaaaaaggaggaggacaagaagcgcggcggcgggacagctgtcgggggtggcggggtcgcggagcctgagcaggactgcgccgtgacctccggcgaggagcttctggcgctgccgccgccgccgccccccggaggtgctgtgccgcccgctgcccccgttgccgcccgagagggccgcctgccgcctggccttagcgcgtcgccacagccctccagcgtcgcgcctcggcggccgcaggaaccacgatga(SEQ ID NO:77)
人类SOX9蛋白(1-509)(Z46629.1)SEQ ID NO:14(蛋白质)和SEQ ID NO:78(DNA)
MNLLDPFMKMTDEQEKGLSGAPSPTMSEDSAGSPCPSGSGSDTENTRPQENTFPKGEPDLKKESEEDKFPVCIREAVSQVLKGYDWTLVPMPVRVNGSSKNKPHVKRPMNAFMVWAQAARRKLADQYPHLHNAELSKTLGKLWRLLNESEKRPFVEEAERLRVQHKKDHPDYKYQPRRRKSVKNGQAEAEEATEQTHISPNAIFKALQADSPHSSSGMSEVHSPGEHSGQSQGPPTPPTTPKTDVQPGKADLKREGRPLPEGGRQPPIDFRDVDIGELSSDVISNIETFDVNEFDQYLPPNGHPGVPATHGQVTYTGSYGISSTAATPASAGHVWMSKQQAPPPPPQQPPQAPPAPQAPPQPQAAPPQQPAAPPQQPQAHTLTTLSSEPGQSQRTHIKTEQLSPSHYSEQQQHSPQQIAYSPFNLPHYSPSYPPITRSQYDYTDHQNSSSYYSHAAGQGTGLYSTFTYMNPAQRPMYTPIADTSGVPSIPQTHSPQHWEQPVYTQLTRP(SEQ ID NO:14)
atgaatctcctggaccccttcatgaagatgaccgacgagcaggagaagggcctgtccggcgcccccagccccaccatgtccgaggactccgcgggctcgccctgcccgtcgggctccggctcggacaccgagaacacgcggccccaggagaacacgttccccaagggcgagcccgatctgaagaaggagagcgaggaggacaagttccccgtgtgcatccgcgaggcggtcagccaggtgctcaaaggctacgactggacgctggtgcccatgccggtgcgcgtcaacggctccagcaagaacaagccgcacgtcaagcggcccatgaacgccttcatggtgtgggcgcaggcggcgcgcaggaagctcgcggaccagtacccgcacttgcacaacgccgagctcagcaagacgctgggcaagctctggagacttctgaacgagagcgagaagcggcccttcgtggaggaggcggagcggctgcgcgtgcagcacaagaaggaccacccggattacaagtaccagccgcggcggaggaagtcggtgaagaacgggcaggcggaggcagaggaggccacggagcagacgcacatctcccccaacgccatcttcaaggcgctgcaggccgactcgccacactcctcctccggcatgagcgaggtgcactcccccggcgagcactcggggcaatcccagggcccaccgaccccacccaccacccccaaaaccgacgtgcagccgggcaaggctgacctgaagcgagaggggcgccccttgccagaggggggcagacagccccctatcgacttccgcgacgtggacatcggcgagctgagcagcgacgtcatctccaacatcgagaccttcgatgtcaacgagtttgaccagtacctgccgcccaacggccacccgggggtgccggccacgcacggccaggtcacctacacgggcagctacggcatcagcagcaccgcggccaccccggcgagcgcgggccacgtgtggatgtccaagcagcaggcgccgccgccacccccgcagcagcccccacaggccccgccggccccgcaggcgcccccgcagccgcaggcggcgcccccacagcagccggcggcacccccgcagcagccacaggcgcacacgctgaccacgctgagcagcgagccgggccagtcccagcgaacgcacatcaagacggagcagctgagccccagccactacagcgagcagcagcagcactcgccccaacagatcgcctacagccccttcaacctcccacactacagcccctcctacccgcccatcacccgctcacagtacgactacaccgaccaccagaactccagctcctactacagccacgcggcaggccagggcaccggcctctactccaccttcacctacatgaaccccgctcagcgccccatgtacacccccatcgccgacacctctggggtcccttccatcccgcagacccacagcccccagcactgggaacaacccgtctacacacagctcactcgaccttga(SEQ ID NO:78)
人类锌指蛋白SLUG(SLUG)基因(AF084243.1)SEQ ID NO:15(蛋白质)和SEQ ID NO:79(DNA)
MPRSFLVKKHFNASKKPNYSELDTHTVIISPYLYESYSMPVIPQPEILSSGAYSPITVWTTAAPFHAQLPNGLSPLSGYSSSLGRVSPPPPSDTSSKDHSGSESPISDEEERLQSKLSDPHAIEAEKFQCNLCNKTYSTFSGLAKHKQLHCDAQSRKSFSCKYCDKEYVSLGALKMHIRTHTLPCVCKICGKAFSRPWLLQGHIRTHTGEKPFSCPHCNRAFADRSNLRAHLQTHSDVKKYQCKNCSKTFSRMSLLHKHEESGCCVAH(SEQ ID NO:15)
atgccgcgctccttcctggtcaagaagcatttcaacgcctccaaaaagccaaactacagcgaactggacacacatacagtgattatttccccgtatctctatgagagttactccatgcctgtcataccacaaccagagatcctcagctcaggagcatacagccccatcactgtgtggactaccgctgctccattccacgcccagctacccaatggcctctctcctctttccggatactcctcatctttggggcgagtgagtccccctcctccatctgacacctcctccaaggaccacagtggctcagaaagccccattagtgatgaagaggaaagactacagtccaagctttcagacccccatgccattgaagctgaaaagtttcagtgcaatttatgcaataagacctattcaactttttctgggctggccaaacataagcagctgcactgcgatgcccagtctagaaaatctttcagctgtaaatactgtgacaaggaatatgtgagcctgggcgccctgaagatgcatattcggacccacacattaccttgtgtttgcaagatctgcggcaaggcgttttccagaccctggttgcttcaaggacacattagaactcacacgggggagaagcctttttcttgccctcactgcaacagagcatttgcagacaggtcaaatctgagggctcatctgcagacccattctgatgtaaagaaataccagtgcaaaaactgctccaaaaccttctccagaatgtctctcctgcacaaacatgaggaatctggctgctgtgtagcacactga(SEQ ID NO:79)
人类v-maf禽肌腱膜纤维肉瘤致癌基因同源物A(MafA)(NM_201589.3)SEQ ID NO:16(蛋白质)和SEQ ID NO:80(DNA)
MAAELAMGAELPSSPLAIEYVNDFDLMKFEVKKEPPEAERFCHRLPPGSLSSTPLSTPCSSVPSSPSFCAPSPGTGGGGGAGGGGGSSQAGGAPGPPSGGPGAVGGTSGKPALEDLYWMSGYQHHLNPEALNLTPEDAVEALIGSGHHGAHHGAHHPAAAAAYEAFRGPGFAGGGGADDMGAGHHHGAHHAAHHHHAAHHHHHHHHHHGGAGHGGGAGHHVRLEERFSDDQLVSMSVRELNRQLRGFSKEEVIRLKQKRRTLKNRGYAQSCRFKRVQQRHILESEKCQLQSQVEQLKLEVGRLAKERDLYKEKYEKLAGRGGPGSAGGAGFPREPSPPQAGPGGAKGTADFFL(SEQ ID NO:16)
atggccgcggagctggcgatgggcgccgagctgcccagcagcccgctggccatcgagtacgtcaacgacttcgacctgatgaagttcgaggtgaagaaggagcctcccgaggccgagcgcttctgccaccgcctgccgccaggctcgctgtcctcgacgccgctcagcacgccctgctcctccgtgccctcctcgcccagcttctgcgcgcccagcccgggcaccggcggcggcggcggcgcggggggcggcggcggctcgtctcaggccgggggcgcccccgggccgccgagcgggggccccggcgccgtcgggggcacctcggggaagccggcgctggaggatctgtactggatgagcggctaccagcatcacctcaaccccgaggcgctcaacctgacgcccgaggacgcggtggaggcgctcatcggcagcggccaccacggcgcgcaccacggcgcgcaccacccggcggccgccgcagcctacgaggctttccgcggcccgggcttcgcgggcggcggcggagcggacgacatgggcgccggccaccaccacggcgcgcaccacgccgcccaccatcaccacgccgcccaccaccaccaccaccaccaccaccaccatggcggcgcgggacacggcggtggcgcgggccaccacgtgcgcctggaggagcgcttctccgacgaccagctggtgtccatgtcggtgcgcgagctgaaccggcagctccgcggcttcagcaaggaggaggtcatccggctcaagcagaagcggcgcacgctcaagaaccgcggctacgcgcagtcctgccgcttcaagcgggtgcagcagcggcacattctggagagcgagaagtgccaactccagagccaggtggagcagctgaagctggaggtggggcgcctggccaaagagcgggacctgtacaaggagaaatacgagaagctggcgggccggggcggccccgggagcgcgggcggggccggtttcccgcgggagccttcgccgccgcaggccggtcccggcggggccaagggcacggccgacttcttcctgtag(SEQ ID NO:80)
人类神经原分化1(NEUROD1)(NM_002500.4)SEQ ID NO:17(蛋白质)和SEQ ID NO:81(DNA)
MTKSYSESGLMGEPQPQGPPSWTDECLSSQDEEHEADKKEDDLEAMNAEEDSLRNGGEEEDEDEDLEEEEEEEEEDDDQKPKRRGPKKKKMTKARLERFKLRRMKANARERNRMHGLNAALDNLRKVVPCYSKTQKLSKIETLRLAKNYIWALSEILRSGKSPDLVSFVQTLCKGLSQPTTNLVAGCLQLNPRTFLPEQNQDMPPHLPTASASFPVHPYSYQSPGLPSPPYGTMDSSHVFHVKPPPHAYSAALEPFFESPLTDCTSPSFDGPLSPPLSINGNFSFKHEPSAEFEKNYAFTMHYPAATLAGAQSHGSIFSGTAAPRCEIPIDNIMSFDSHSHHERVMSAQLNAIFHD(SEQ ID NO:17)
atgaccaaatcgtacagcgagagtgggctgatgggcgagcctcagccccaaggtcctccaagctggacagacgagtgtctcagttctcaggacgaggagcacgaggcagacaagaaggaggacgacctcgaagccatgaacgcagaggaggactcactgaggaacgggggagaggaggaggacgaagatgaggacctggaagaggaggaagaagaggaagaggaggatgacgatcaaaagcccaagagacgcggccccaaaaagaagaagatgactaaggctcgcctggagcgttttaaattgagacgcatgaaggctaacgcccgggagcggaaccgcatgcacggactgaacgcggcgctagacaacctgcgcaaggtggtgccttgctattctaagacgcagaagctgtccaaaatcgagactctgcgcttggccaagaactacatctgggctctgtcggagatcctgcgctcaggcaaaagcccagacctggtctccttcgttcagacgctttgcaagggcttatcccaacccaccaccaacctggttgcgggctgcctgcaactcaatcctcggacttttctgcctgagcagaaccaggacatgcccccccacctgccgacggccagcgcttccttccctgtacacccctactcctaccagtcgcctgggctgcccagtccgccttacggtaccatggacagctcccatgtcttccacgttaagcctccgccgcacgcctacagcgcagcgctggagcccttctttgaaagccctctgactgattgcaccagcccttcctttgatggacccctcagcccgccgctcagcatcaatggcaacttctctttcaaacacgaaccgtccgccgagtttgagaaaaattatgcctttaccatgcactatcctgcagcgacactggcaggggcccaaagccacggatcaatcttctcaggcaccgctgcccctcgctgcgagatccccatagacaatattatgtccttcgatagccattcacatcatgagcgagtcatgagtgcccagctcaatgccatatttcatgattag(SEQ ID NO:81)
人类生肌因子5(MYF5)(NM_005593.2)SEQ ID NO:18(蛋白质)和SEQ ID NO:82(DNA)
MDVMDGCQFSPSEYFYDGSCIPSPEGEFGDEFVPRVAAFGAHKAELQGSDEDEHVRAPTGHHQAGHCLMWACKACKRKSTTMDRRKAATMRERRRLKKVNQAFETLKRCTTTNPNQRLPKVEILRNAIRYIESLQELLREQVENYYSLPGQSCSEPTSPTSNCSDGMPECNSPVWSRKSSTFDSIYCPDVSNVYATDKNSLSSLDCLSNIVDRITSSEQPGLPLQDLASLSPVASTDSQPATPGASSSRLIYHVL(SEQ ID NO:18)
atggacgtgatggatggctgccagttctcaccttctgagtacttctacgacggctcctgcataccgtcccccgagggtgaatttggggacgagtttgtgccgcgagtggctgccttcggagcgcacaaagcagagctgcagggctcagatgaggacgagcacgtgcgagcgcctaccggccaccaccaggctggtcactgcctcatgtgggcctgcaaagcctgcaagaggaagtccaccaccatggatcggcggaaggcagccactatgcgcgagcggaggcgcctgaagaaggtcaaccaggctttcgaaaccctcaagaggtgtaccacgaccaaccccaaccagaggctgcccaaggtggagatcctcaggaatgccatccgctacatcgagagcctgcaggagttgctgagagagcaggtggagaactactatagcctgccgggacagagctgctcggagcccaccagccccacctccaactgctctgatggcatgcccgaatgtaacagtcctgtctggtccagaaagagcagtacttttgacagcatctactgtcctgatgtatcaaatgtatatgccacagataaaaactccttatccagcttggattgcttatccaacatagtggaccggatcacctcctcagagcaacctgggttgcctctccaggatctggcttctctctctccagttgccagcaccgattcacagcctgcaactccaggggcttctagttccaggcttatctatcatgtgctatga(SEQ ID NO:82)
人类含PR-结构域的蛋白16(PRDM16)(AF294278.1)SEQ ID NO:19(蛋白质)和SEQ ID NO:83(DNA)
MRSKARARKLAKSDGDVVNNMYEPNRDLLASHSAEDEAEDSAMSPIPVGSPPPFPTSEDFTPKEGSPYEAPVYIPEDIPIPADFELRESSIPGAGLGVWAKRKMEAGERLGPCVVVPRAAAKETDFGWEQILTDVEVSPQEGCITKISEDLGSEKFCVDANQAGAGSWLKYIRVACSCDDQNLTMCQISEQVIYYKVIKDIEPGEELLVHVKEGVYPLGTVPPGLDEEPTFRCDECDELFQSKLDLRRHKKYTCGSVGAALYEGLAEELKPEGLGGGSGQAHECKDCERMFPNKYSLEQHMVIHTEEREYKCDQCPKAFNWKSNFIRHQMSHDSGKRFECENCVKVFTDPSNLQRHIRSQHVGARAHACPDCGKTFATSSGLKQHKHIHSTVKPFICEVCHKSYTQFSNLCRHKRMHADCRTQIKCKDCGQMFSTTSSLNKHRRFCEGKNHYTPGGIFAPGLPLTPSPMMDKAKPSPSLNHASLGFNEYFPYRPHPGSLPFSTAPPTFPALTPGFPGIFPPSLYPRPPLLPPTSLLKSPLNHTQDAKLPSPLGNPALPLVSAVSNSSQGTTAAAGPEEKFESRLEDSCVEKLKTRSSDMSDGSDFEDVNTTTGTDLDTTTGTGSDLDSDVDSDPDKDKGKGKSAEGQPKFGGGLAPPGAPNSVAEVPVFYSQHSFFPPPDEQLLTATGAAGDSIKAIASIAEKYFGPGFMGMQEKKLGSLPYHSAFPFQFLPNFPHSLYPFTDRALAHNLLVKAEPKSPRDALKVGGPSAECPFDLTTKPKDVKPILPMPKGPSAPASGEEQPLDLSIGSRARASQNGGGREPRKNHVYGERKLGAGEGLPQVCPARMPQQPPLHYAKPSPFFMDPIYRVEKRKVTDPVGALKEKYLRPSPLLFHPQMSAIETMTEKLESFAAMKADSGSSLQPLPHHPFNFRSPPPTLSDPILRKGKERYTCRYCGKIFPRSANLTRHLRTHTGEQPYRCKYCDRSFSISSNLQRHVRNIHNKEKPFKCHLCNRCFGQQTNLDRHLKKHEHENAPVSQHPGVLTNHLGTSASSPTSESDNHALLDEKEDSYFSEIRNFIANSEMNQASTRTEKRADMQIVDGSAQCPGLASEKQEDVEEEDDDDLEEDDEDSLAGKSQDDTVSPAPEPQAAYEDEEDEEPAASLAVGFDHTRRCAEDHEGGLLALEPMPTFGKGLDLRRAAEEAFEVKDVLNSTLDSEALKHTLCRQAKNQAYAMMLSLSEDTPLHTPSQGSLDAWLKVTGATSESGAFHPINHL(SEQ ID NO:19)
atgcgatccaaggcgagggcgaggaagctagccaaaagtgacggtgacgttgtaaataatatgtatgagcccaaccgggacctgctggccagccacagcgcggaggacgaggccgaggacagtgccatgtcgcccatccccgtggggtcaccgccccccttccccaccagcgaggacttcacccccaaggagggctcgccgtacgaggcccctgtctacattcctgaagacattccgatcccagcagacttcgagctccgagagtcctccatcccaggggctggcctgggggtctgggccaagaggaagatggaagccggggagaggctgggcccctgcgtggtggtgccccgggcggcggcaaaggagacagacttcggatgggagcaaatactgacggacgtggaagtgtcgccccaggaaggctgcatcacaaagatctccgaagacctgggcagtgagaagttctgcgtggatgcaaatcaggcgggggctggcagctggctcaagtacatccgtgtggcgtgctcctgcgatgaccagaacctcaccatgtgtcagatcagtgagcaggtaatttactataaagtcattaaggacattgagccaggtgaggagctgctggtgcacgtgaaggaaggcgtctaccccctgggcacagtgccgcccggcctggacgaggagcccacgttccgctgtgacgagtgtgacgaactcttccagtccaagctggacctgcggcgccataagaagtacacgtgtggctcagtgggggctgcgctctacgagggcctggctgaggagctcaagcccgagggccttggcggtggcagcggccaagcccacgagtgcaaggactgcgagcggatgttccccaacaagtacagcctggagcagcacatggtcatccacacggaggagcgcgagtacaaatgcgaccagtgtcccaaggccttcaactggaagtccaacttcatccgccaccagatgtcccacgacagcggcaaacgcttcgaatgtgaaaactgcgtgaaggtgttcacggaccccagcaaccttcagcggcacatccgctcgcagcacgtgggcgctcgggcccacgcctgccccgactgcgggaagaccttcgccacgtcctccggcctcaagcagcacaagcatatccacagcacggtgaagcctttcatatgtgaggtctgccacaagtcctacacgcagttctccaacctgtgccggcacaagcggatgcacgccgactgccgcacgcagatcaagtgcaaggactgtggccagatgttcagcactacctcctccctcaacaagcaccggcgcttctgcgagggcaagaaccattacacgccgggcggcatctttgccccgggcctgcccttgacccccagccccatgatggacaaggcaaaaccctcccccagcctcaatcacgccagcctgggcttcaacgagtactttccctacaggccgcacccggggagcctgcccttctccacggcgcctcccacgttccccgcactcacccccggcttcccgggcatcttccctccatccttgtacccccggccgcctctgctacctcccacatcgctgctcaagagccccctgaaccacacccaggacgccaagctccccagtcccctggggaacccagccctgcccctggtctccgccgtcagcaacagcagccagggcacgacggcagctgcggggcccgaggagaagttcgagagccgcctggaggactcctgtgtggagaagctgaagaccaggagcagcgacatgtcggacggcagtgactttgaggacgtcaacaccaccacggggaccgacctggacacgaccacggggacgggctcggacctggacagcgacgtggacagcgaccctgacaaggacaagggcaagggcaagtccgccgagggccagcccaagtttgggggcggcttggcgcccccgggggccccgaacagcgtggccgaggtgcctgtcttctattcccagcactcattcttcccgccacccgacgagcagctgctgactgcaacgggcgccgccggggactccatcaaggccatcgcatccattgccgagaagtactttggccccggcttcatggggatgcaggagaagaagctgggctcgctcccctaccactcggcgttccccttccagttcctgcccaacttcccccactccctttaccccttcacggaccgagccctcgcccacaacttgctggtcaaggccgagccaaagtcaccccgggacgccctcaaggtgggcggccccagtgccgagtgcccctttgatctcaccaccaagcccaaagacgtgaagcccatcctgcccatgcccaagggcccctcggcccccgcatccggcgaggagcagccgctggacctgagcatcggcagccgggcccgtgccagccaaaacggcggcgggcgggagccccgcaagaaccacgtctatggggaacgcaagctgggcgccggcgaggggctgccccaggtgtgcccggcgcggatgccccagcagcccccgctccactacgccaagccctcgcccttcttcatggaccccatctacagggtagaaaagcggaaggtcacagaccccgtgggagccctgaaggagaagtacctgcggccgtccccgctgctcttccacccccagatgtcagccatagagaccatgacagagaagctggagagctttgcagccatgaaggcggactcgggcagctccctgcagcccctcccccaccaccccttcaacttccggtccccacccccaacgctctccgaccccatcctcaggaagggcaaggagcgatacacgtgcaggtactgtgggaagatcttccccagatcagccaatctcaccagacacctgaggacgcacactggggagcagccgtacaggtgtaagtactgcgaccgctccttcagcatctcttcgaacctccagcggcacgtccggaacatccacaacaaggagaagcctttcaagtgccacctgtgcaaccgctgcttcgggcagcagaccaacctggaccggcacctcaagaagcacgagcacgagaacgcaccagtgagccagcaccccggggtcctcacgaaccacctggggaccagcgcgtcctctcccacctcagagtcggacaaccacgcacttttagacgagaaagaagactcttatttctcggaaatcagaaactttattgccaatagtgagatgaaccaagcatcaacgcgaacagagaaacgggcggacatgcagatcgtggacggcagtgcccagtgtccaggcctagccagtgagaagcaggaggacgtggaggaggaggacgacgatgacctggaggaggacgatgaggacagcctggccgggaagtcgcaggatgacaccgtgtcccccgcacccgagccccaggccgcctacgaggatgaggaggatgaggagccagccgcctccctggccgtgggctttgaccacacccgaaggtgtgctgaggaccacgaaggcggtctgttagctttggagccgatgccgacttttgggaaggggctggacctccgcagagcagctgaggaagcatttgaagttaaagatgtgcttaattccaccttagattctgaggctttaaaacatacactgtgcaggcaggctaagaaccaggcatatgcaatgatgctgtccctttccgaagacactcctctccacaccccctcccagggttctctggacgcttggttgaaggtcactggagccacgtcggagtctggagcatttcaccccatcaaccacctctga(SEQ ID NO:83)
人类配对盒6(PAX6)(NM_001604.5)SEQ ID NO:20(蛋白质)和SEQ ID NO:84(DNA)
MQNSHSGVNQLGGVFVNGRPLPDSTRQKIVELAHSGARPCDISRILQTHADAKVQVLDNQNVSNGCVSKILGRYYETGSIRPRAIGGSKPRVATPEVVSKIAQYKRECPSIFAWEIRDRLLSEGVCTNDNIPSVSSINRVLRNLASEKQQMGADGMYDKLRMLNGQTGSWGTRPGWYPGTSVPGQPTQDGCQQQEGGGENTNSISSNGEDSDEAQMRLQLKRKLQRNRTSFTQEQIEALEKEFERTHYPDVFARERLAAKIDLPEARIQVWFSNRRAKWRREEKLRNQRRQASNTPSHIPISSSFSTSVYQPIPQPTTPVSSFTSGSMLGRTDTALTNTYSALPPMPSFTMANNLPMQPPVPSQTSSYSCMLPTSPSVNGRSYDTYTPPHMQTHMNSQPMGTSGTTSTGLISPGVSVPVQVPGSEPDMSQYWPRLQ(SEQ ID NO:20)
atgcagaacagtcacagcggagtgaatcagctcggtggtgtctttgtcaacgggcggccactgccggactccacccggcagaagattgtagagctagctcacagcggggcccggccgtgcgacatttcccgaattctgcagacccatgcagatgcaaaagtccaagtgctggacaatcaaaacgtgtccaacggatgtgtgagtaaaattctgggcaggtattacgagactggctccatcagacccagggcaatcggtggtagtaaaccgagagtagcgactccagaagttgtaagcaaaatagcccagtataagcgggagtgcccgtccatctttgcttgggaaatccgagacagattactgtccgagggggtctgtaccaacgataacataccaagcgtgtcatcaataaacagagttcttcgcaacctggctagcgaaaagcaacagatgggcgcagacggcatgtatgataaactaaggatgttgaacgggcagaccggaagctggggcacccgccctggttggtatccggggacttcggtgccagggcaacctacgcaagatggctgccagcaacaggaaggagggggagagaataccaactccatcagttccaacggagaagattcagatgaggctcaaatgcgacttcagctgaagcggaagctgcaaagaaatagaacatcctttacccaagagcaaattgaggccctggagaaagagtttgagagaacccattatccagatgtgtttgcccgagaaagactagcagccaaaatagatctacctgaagcaagaatacaggtatggttttctaatcgaagggccaaatggagaagagaagaaaaactgaggaatcagagaagacaggccagcaacacacctagtcatattcctatcagcagtagtttcagcaccagtgtctaccaaccaattccacaacccaccacaccggtttcctccttcacatctggctccatgttgggccgaacagacacagccctcacaaacacctacagcgctctgccgcctatgcccagcttcaccatggcaaataacctgcctatgcaacccccagtccccagccagacctcctcatactcctgcatgctgcccaccagcccttcggtgaatgggcggagttatgatacctacacccccccacatatgcagacacacatgaacagtcagccaatgggcacctcgggcaccacttcaacaggactcatttcccctggtgtgtcagttccagttcaagttcccggaagtgaacctgatatgtctcaatactggccaagattacagtaa(SEQ ID NO:84)
SEQ ID NO:21:人类HNF1同源异型框A(HNF1A)(NM_000545.5)SEQ ID NO:21(蛋白质)和SEQ ID NO:85(DNA)
MVSKLSQLQTELLAALLESGLSKEALIQALGEPGPYLLAGEGPLDKGESCGGGRGELAELPNGLGETRGSEDETDDDGEDFTPPILKELENLSPEEAAHQKAVVETLLQEDPWRVAKMVKSYLQQHNIPQREVVDTTGLNQSHLSQHLNKGTPMKTQKRAALYTWYVRKQREVAQQFTHAGQGGLIEEPTGDELPTKKGRRNRFKWGPASQQILFQAYERQKNPSKEERETLVEECNRAECIQRGVSPSQAQGLGSNLVTEVRVYNWFANRRKEEAFRHKLAMDTYSGPPPGPGPGPALPAHSSPGLPPPALSPSKVHGVRYGQPATSETAEVPSSSGGPLVTVSTPLHQVSPTGLEPSHSLLSTEAKLVSAAGGPLPPVSTLTALHSLEQTSPGLNQQPQNLIMASLPGVMTIGPGEPASLGPTFTNTGASTLVIGLASTQAQSVPVINSMGSSLTTLQPVQFSQPLHPSYQQPLMPPVQSHVTQSPFMATMAQLQSPHALYSHKPEVAQYTHTGLLPQTMLITDTTNLSALASLTPTKQVFTSDTEASSESGLHTPASQATTLHVPSQDPAGIQHLQPAHRLSASPTVSSSSLVLYQSSDSSNGQSHLLPSNHSVIETFISTQMASSSQ(SEQ ID NO:21)
atggtttctaaactgagccagctgcagacggagctcctggcggccctgctcgagtcagggctgagcaaagaggcactgatccaggcactgggtgagccggggccctacctcctggctggagaaggccccctggacaagggggagtcctgcggcggcggtcgaggggagctggctgagctgcccaatgggctgggggagactcggggctccgaggacgagacggacgacgatggggaagacttcacgccacccatcctcaaagagctggagaacctcagccctgaggaggcggcccaccagaaagccgtggtggagacccttctgcaggaggacccgtggcgtgtggcgaagatggtcaagtcctacctgcagcagcacaacatcccacagcgggaggtggtcgataccactggcctcaaccagtcccacctgtcccaacacctcaacaagggcactcccatgaagacgcagaagcgggccgccctgtacacctggtacgtccgcaagcagcgagaggtggcgcagcagttcacccatgcagggcagggagggctgattgaagagcccacaggtgatgagctaccaaccaagaaggggcggaggaaccgtttcaagtggggcccagcatcccagcagatcctgttccaggcctatgagaggcagaagaaccctagcaaggaggagcgagagacgctagtggaggagtgcaatagggcggaatgcatccagagaggggtgtccccatcacaggcacaggggctgggctccaacctcgtcacggaggtgcgtgtctacaactggtttgccaaccggcgcaaagaagaagccttccggcacaagctggccatggacacgtacagcgggccccccccagggccaggcccgggacctgcgctgcccgctcacagctcccctggcctgcctccacctgccctctcccccagtaaggtccacggtgtgcgctatggacagcctgcgaccagtgagactgcagaagtaccctcaagcagcggcggtcccttagtgacagtgtctacacccctccaccaagtgtcccccacgggcctggagcccagccacagcctgctgagtacagaagccaagctggtctcagcagctgggggccccctcccccctgtcagcaccctgacagcactgcacagcttggagcagacatccccaggcctcaaccagcagccccagaacctcatcatggcctcacttcctggggtcatgaccatcgggcctggtgagcctgcctccctgggtcctacgttcaccaacacaggtgcctccaccctggtcatcggcctggcctccacgcaggcacagagtgtgccggtcatcaacagcatgggcagcagcctgaccaccctgcagcccgtccagttctcccagccgctgcacccctcctaccagcagccgctcatgccacctgtgcagagccatgtgacccagagccccttcatggccaccatggctcagctgcagagcccccacgccctctacagccacaagcccgaggtggcccagtacacccacacgggcctgctcccgcagactatgctcatcaccgacaccaccaacctgagcgccctggccagcctcacgcccaccaagcaggtcttcacctcagacactgaggcctccagtgagtccgggcttcacacgccggcatctcaggccaccaccctccacgtccccagccaggaccctgccggcatccagcacctgcagccggcccaccggctcagcgccagccccacagtgtcctccagcagcctggtgctgtaccagagctcagactccagcaatggccagagccacctgctgccatccaaccacagcgtcatcgagaccttcatctccacccagatggcctcttcctcccagtaa(SEQ ID NO:85)
人类叉头盒A3(FOXA3)(NM_004497.2)SEQ ID NO:22(蛋白质)和SEQ ID NO:86(DNA)
MLGSVKMEAHDLAEWSYYPEAGEVYSPVTPVPTMAPLNSYMTLNPLSSPYPPGGLPASPLPSGPLAPPAPAAPLGPTFPGLGVSGGSSSSGYGAPGPGLVHGKEMPKGYRRPLAHAKPPYSYISLITMAIQQAPGKMLTLSEIYQWIMDLFPYYRENQQRWQNSIRHSLSFNDCFVKVARSPDKPGKGSYWALHPSSGNMFENGCYLRRQKRFKLEEKVKKGGSGAATTTRNGTGSAASTTTPAATVTSPPQPPPPAPEPEAQGGEDVGALDCGSPASSTPYFTGLELPGELKLDAPYNFNHPFSINNLMSEQTPAPPKLDVGFGGYGAEGGEPGVYYQGLYSRSLLNAS(SEQ ID NO:22)
atgctgggctcagtgaagatggaggcccatgacctggccgagtggagctactacccggaggcgggcgaggtctactcgccggtgaccccagtgcccaccatggcccccctcaactcctacatgaccctgaatcctctaagctctccctatccccctggggggctccctgcctccccactgccctcaggacccctggcacccccagcacctgcagcccccctggggcccactttcccaggcctgggtgtcagcggtggcagcagcagctccgggtacggggccccgggtcctgggctggtgcacgggaaggagatgccgaaggggtatcggcggcccctggcacacgccaagccaccgtattcctatatctcactcatcaccatggccatccagcaggcgccgggcaagatgctgaccttgagtgaaatctaccagtggatcatggacctcttcccttactaccgggagaatcagcagcgctggcagaactccattcgccactcgctgtctttcaacgactgcttcgtcaaggtggcgcgttccccagacaagcctggcaagggctcctactgggccctacaccccagctcagggaacatgtttgagaatggctgctacctgcgccgccagaaacgcttcaagctggaggagaaggtgaaaaaagggggcagcggggctgccaccaccaccaggaacgggacagggtctgctgcctcgaccaccacccccgcggccacagtcacctccccgccccagcccccgcctccagcccctgagcctgaggcccagggcggggaagatgtgggggctctggactgtggctcacccgcttcctccacaccctatttcactggcctggagctcccaggggagctgaagctggacgcgccctacaacttcaaccaccctttctccatcaacaacctaatgtcagaacagacaccagcacctcccaaactggacgtggggtttgggggctacggggctgaaggtggggagcctggagtctactaccagggcctctattcccgctctttgcttaatgcatcctag(SEQ ID NO:86)
人类叉头盒A1(FOXA1)(NM_004496.3)SEQ ID NO:23(蛋白质)和SEQ ID NO:87(DNA)
MLGTVKMEGHETSDWNSYYADTQEAYSSVPVSNMNSGLGSMNSMNTYMTMNTMTTSGNMTPASFNMSYANPGLGAGLSPGAVAGMPGGSAGAMNSMTAAGVTAMGTALSPSGMGAMGAQQAASMNGLGPYAAAMNPCMSPMAYAPSNLGRSRAGGGGDAKTFKRSYPHAKPPYSYISLITMAIQQAPSKMLTLSEIYQWIMDLFPYYRQNQQRWQNSIRHSLSFNDCFVKVARSPDKPGKGSYWTLHPDSGNMFENGCYLRRQKRFKCEKQPGAGGGGGSGSGGSGAKGGPESRKDPSGASNPSADSPLHRGVHGKTGQLEGAPAPGPAASPQTLDHSGATATGGASELKTPASSTAPPISSGPGALASVPASHPAHGLAPHESQLHLKGDPHYSFNHPFSINNLMSSSEQQHKLDFKAYEQALQYSPYGSTLPASLPLGSASVTTRSPIEPSALEPAYYQGVYSRPVLNTS(SEQ ID NO:23)
atgctgggctcagtgaagatggaggcccatgacctggccgagtggagctactacccggaggcgggcgaggtctactcgccggtgaccccagtgcccaccatggcccccctcaactcctacatgaccctgaatcctctaagctctccctatccccctggggggctccctgcctccccactgccctcaggacccctggcacccccagcacctgcagcccccctggggcccactttcccaggcctgggtgtcagcggtggcagcagcagctccgggtacggggccccgggtcctgggctggtgcacgggaaggagatgccgaaggggtatcggcggcccctggcacacgccaagccaccgtattcctatatctcactcatcaccatggccatccagcaggcgccgggcaagatgctgaccttgagtgaaatctaccagtggatcatggacctcttcccttactaccgggagaatcagcagcgctggcagaactccattcgccactcgctgtctttcaacgactgcttcgtcaaggtggcgcgttccccagacaagcctggcaagggctcctactgggccctacaccccagctcagggaacatgtttgagaatggctgctacctgcgccgccagaaacgcttcaagctggaggagaaggtgaaaaaagggggcagcggggctgccaccaccaccaggaacgggacagggtctgctgcctcgaccaccacccccgcggccacagtcacctccccgccccagcccccgcctccagcccctgagcctgaggcccagggcggggaagatgtgggggctctggactgtggctcacccgcttcctccacaccctatttcactggcctggagctcccaggggagctgaagctggacgcgccctacaacttcaaccaccctttctccatcaacaacctaatgtcagaacagacaccagcacctcccaaactggacgtggggtttgggggctacggggctgaaggtggggagcctggagtctactaccagggcctctattcccgctctttgcttaatgcatcctag(SEQ ID NO:87)人
人类叉头盒A2(FOXA2)(NM_021784.4)SEQ ID NO:24(蛋白质)和SEQ ID NO:88(DNA)
MHSASSMLGAVKMEGHEPSDWSSYYAEPEGYSSVSNMNAGLGMNGMNTYMSMSAAAMGSGSGNMSAGSMNMSSYVGAGMSPSLAGMSPGAGAMAGMGGSAGAAGVAGMGPHLSPSLSPLGGQAAGAMGGLAPYANMNSMSPMYGQAGLSRARDPKTYRRSYTHAKPPYSYISLITMAIQQSPNKMLTLSEIYQWIMDLFPFYRQNQQRWQNSIRHSLSFNDCFLKVPRSPDKPGKGSFWTLHPDSGNMFENGCYLRRQKRFKCEKQLALKEAAGAAGSGKKAAAGAQASQAQLGEAAGPASETPAGTESPHSSASPCQEHKRGGLGELKGTPAAALSPPEPAPSPGQQQQAAAHLLGPPHHPGLPPEAHLKPEHHYAFNHPFSINNLMSSEQQHHHSHHHHQPHKMDLKAYEQVMHYPGYGSPMPGSLAMGPVTNKTGLDASPLAADTSYYQGVYSRPIMNSS(SEQ ID NO:24)
atgcactcggcttccagtatgctgggagcggtgaagatggaagggcacgagccgtccgactggagcagctactatgcagagcccgagggctactcctccgtgagcaacatgaacgccggcctggggatgaacggcatgaacacgtacatgagcatgtcggcggccgccatgggcagcggctcgggcaacatgagcgcgggctccatgaacatgtcgtcgtacgtgggcgctggcatgagcccgtccctggcggggatgtcccccggcgcgggcgccatggcgggcatgggcggctcggccggggcggccggcgtggcgggcatggggccgcacttgagtcccagcctgagcccgctcggggggcaggcggccggggccatgggcggcctggccccctacgccaacatgaactccatgagccccatgtacgggcaggcgggcctgagccgcgcccgcgaccccaagacctacaggcgcagctacacgcacgcaaagccgccctactcgtacatctcgctcatcaccatggccatccagcagagccccaacaagatgctgacgctgagcgagatctaccagtggatcatggacctcttccccttctaccggcagaaccagcagcgctggcagaactccatccgccactcgctctccttcaacgactgtttcctgaaggtgccccgctcgcccgacaagcccggcaagggctccttctggaccctgcaccctgactcgggcaacatgttcgagaacggctgctacctgcgccgccagaagcgcttcaagtgcgagaagcagctggcgctgaaggaggccgcaggcgccgccggcagcggcaagaaggcggccgccggagcccaggcctcacaggctcaactcggggaggccgccgggccggcctccgagactccggcgggcaccgagtcgcctcactcgagcgcctccccgtgccaggagcacaagcgagggggcctgggagagctgaaggggacgccggctgcggcgctgagccccccagagccggcgccctctcccgggcagcagcagcaggccgcggcccacctgctgggcccgccccaccacccgggcctgccgcctgaggcccacctgaagccggaacaccactacgccttcaaccacccgttctccatcaacaacctcatgtcctcggagcagcagcaccaccacagccaccaccaccaccaaccccacaaaatggacctcaaggcctacgaacaggtgatgcactaccccggctacggttcccccatgcctggcagcttggccatgggcccggtcacgaacaaaacgggcctggacgcctcgcccctggccgcagatacctcctactaccagggggtgtactcccggcccattatgaactcctcttaa(SEQ ID NO:88)
SEQ ID NO:25:人类CCAAT/增强子结合蛋白(C/EBP),α(CEBPA)(NM_001287435.1)SEQ ID NO:25(蛋白质)和SEQ ID NO:89(DNA)
MSSHLQSPPHAPSSAAFGFPRGAGPAQPPAPPAAPEPLGGICEHETSIDISAYIDPAAFNDEFLADLFQHSRQQEKAKAAVGPTGGGGGGDFDYPGAPAGPGGAVMPGGAHGPPPGYGCAAAGYLDGRLEPLYERVGAPALRPLVIKQEPREEDEAKQLALAGLFPYQPPPPPPPSHPHPHPPPAHLAAPHLQFQIAHCGQTTMHLQPGHPTPPPTPVPSPHPAPALGAAGLPGPGSALKGLGAAHPDLRASGGSGAGKAKKSVDKNSNEYRVRRERNNIAVRKSRDKAKQRNVETQQKVLELTSDNDRLRKRVEQLSRELDTLRGIFRQLPESSLVKAMGNCA(SEQ ID NO:25)
atgagcagccacctgcagagccccccgcacgcgcccagcagcgccgccttcggctttccccggggcgcgggccccgcgcagcctcccgccccacctgccgccccggagccgctgggcggcatctgcgagcacgagacgtccatcgacatcagcgcctacatcgacccggccgccttcaacgacgagttcctggccgacctgttccagcacagccggcagcaggagaaggccaaggcggccgtgggccccacgggcggcggcggcggcggcgactttgactacccgggcgcgcccgcgggccccggcggcgccgtcatgcccgggggagcgcacgggcccccgcccggctacggctgcgcggccgccggctacctggacggcaggctggagcccctgtacgagcgcgtcggggcgccggcgctgcggccgctggtgatcaagcaggagccccgcgaggaggatgaagccaagcagctggcgctggccggcctcttcccttaccagccgccgccgccgccgccgccctcgcacccgcacccgcacccgccgcccgcgcacctggccgccccgcacctgcagttccagatcgcgcactgcggccagaccaccatgcacctgcagcccggtcaccccacgccgccgcccacgcccgtgcccagcccgcaccccgcgcccgcgctcggtgccgccggcctgccgggccctggcagcgcgctcaaggggctgggcgccgcgcaccccgacctccgcgcgagtggcggcagcggcgcgggcaaggccaagaagtcggtggacaagaacagcaacgagtaccgggtgcggcgcgagcgcaacaacatcgcggtgcgcaagagccgcgacaaggccaagcagcgcaacgtggagacgcagcagaaggtgctggagctgaccagtgacaatgaccgcctgcgcaagcgggtggaacagctgagccgcgaactggacacgctgcggggcatcttccgccagctgccagagagctccttggtcaaggccatgggcaactgcgcgtga(SEQ ID NO:89)
人类Spi-1原致癌基因(SPI1)(PU.1)(NM_001080547.1)SEQ ID NO:26(蛋白质)和SEQ ID NO:90(DNA)
MLQACKMEGFPLVPPQPSEDLVPYDTDLYQRQTHEYYPYLSSDGESHSDHYWDFHPHHVHSEFESFAENNFTELQSVQPPQLQQLYRHMELEQMHVLDTPMVPPHPSLGHQVSYLPRMCLQYPSLSPAQPSSDEEEGERQSPPLEVSDGEADGLEPGPGLLPGETGSKKKIRLYQFLLDLLRSGDMKDSIWWVDKDKGTFQFSSKHKEALAHRWGIQKGNRKKMTYQKMARALRNYGKTGEVKKVKKKLTYQFSGEVLGRGGLAERRHPPH(SEQ ID NO:26)
atgttacaggcgtgcaaaatggaagggtttcccctcgtcccccctcagccatcagaagacctggtgccctatgacacggatctataccaacgccaaacgcacgagtattacccctatctcagcagtgatggggagagccatagcgaccattactgggacttccacccccaccacgtgcacagcgagttcgagagcttcgccgagaacaacttcacggagctccagagcgtgcagcccccgcagctgcagcagctctaccgccacatggagctggagcagatgcacgtcctcgatacccccatggtgccaccccatcccagtcttggccaccaggtctcctacctgccccggatgtgcctccagtacccatccctgtccccagcccagcccagctcagatgaggaggagggcgagcggcagagccccccactggaggtgtctgacggcgaggcggatggcctggagcccgggcctgggctcctgcctggggagacaggcagcaagaagaagatccgcctgtaccagttcctgttggacctgctccgcagcggcgacatgaaggacagcatctggtgggtggacaaggacaagggcaccttccagttctcgtccaagcacaaggaggcgctggcgcaccgctggggcatccagaagggcaaccgcaagaagatgacctaccagaagatggcgcgcgcgctgcgcaactacggcaagacgggcgaggtcaagaaggtgaagaagaagctcacctaccagttcagcggcgaagtgctgggccgcgggggcctggccgagcggcgccacccgccccactga(SEQ ID NO:90)
人类POU 3类同源异型框2(POU3F2)(Brn2)(NM_005604.3)SEQ ID NO:27(蛋白质)和SEQ ID NO:91(DNA)
MATAASNHYSLLTSSASIVHAEPPGGMQQGAGGYREAQSLVQGDYGALQSNGHPLSHAHQWITALSHGGGGGGGGGGGGGGGGGGGGGDGSPWSTSPLGQPDIKPSVVVQQGGRGDELHGPGALQQQHQQQQQQQQQQQQQQQQQQQQQRPPHLVHHAANHHPGPGAWRSAAAAAHLPPSMGASNGGLLYSQPSFTVNGMLGAGGQPAGLHHHGLRDAHDEPHHADHHPHPHSHPHQQPPPPPPPQGPPGHPGAHHDPHSDEDTPTSDDLEQFAKQFKQRRIKLGFTQADVGLALGTLYGNVFSQTTICRFEALQLSFKNMCKLKPLLNKWLEEADSSSGSPTSIDKIAAQGRKRKKRTSIEVSVKGALESHFLKCPKPSAQEITSLADSLQLEKEVVRVWFCNRRQKEKRMTPPGGTLPGAEDVYGGSRDTPPHHGVQTPVQ(SEQ ID NO:27)
atggcgaccgcagcgtctaaccactacagcctgctcacctccagcgcctccatcgtgcacgccgagccgcccggcggcatgcagcagggcgcggggggctaccgcgaagcgcagagcctggtgcagggcgactacggcgctctgcagagcaacggacacccgctcagccacgctcaccagtggatcaccgcgctgtcccacggcggcggcggcgggggcggtggcggcggcggggggggcgggggcggcggcgggggcggcggcgacggctccccgtggtccaccagccccctgggccagccggacatcaagccctcggtggtggtgcagcagggcggccgcggagacgagctgcacgggccaggcgccctgcagcagcagcatcagcagcagcaacagcaacagcagcagcaacagcagcaacagcagcagcagcagcagcaacagcggccgccgcatctggtgcaccacgccgctaaccaccacccgggacccggggcatggcggagcgcggcggctgcagcgcacctcccaccctccatgggagcgtccaacggcggcttgctctactcgcagcccagcttcacggtgaacggcatgctgggcgccggcgggcagccggccggtctgcaccaccacggcctgcgggacgcgcacgacgagccacaccatgccgaccaccacccgcacccgcactcgcacccacaccagcagccgccgcccccgccgcccccgcagggtccgcctggccacccaggcgcgcaccacgacccgcactcggacgaggacacgccgacctcggacgacctggagcagttcgccaagcagttcaagcagcggcggatcaaactgggatttacccaagcggacgtggggctggctctgggcaccctgtatggcaacgtgttctcgcagaccaccatctgcaggtttgaggccctgcagctgagcttcaagaacatgtgcaagctgaagcctttgttgaacaagtggttggaggaggcggactcgtcctcgggcagccccacgagcatagacaagatcgcagcgcaagggcgcaagcggaaaaagcggacctccatcgaggtgagcgtcaagggggctctggagagccatttcctcaaatgccccaagccctcggcccaggagatcacctccctcgcggacagcttacagctggagaaggaggtggtgagagtttggttttgtaacaggagacagaaagagaaaaggatgacccctcccggagggactctgccgggcgccgaggatgtgtacggggggagtagggacactccaccacaccacggggtgcagacgcccgtccagtga(SEQ ID NO:91)人
人类叉头盒G1(FOXG1)(NM_005249.4)SEQ ID NO:28(蛋白质)和SEQ ID NO:92(DNA)
MLDMGDRKEVKMIPKSSFSINSLVPEAVQNDNHHASHGHHNSHHPQHHHHHHHHHHHPPPPAPQPPPPPQQQQPPPPPPPAPQPPQTRGAPAADDDKGPQQLLLPPPPPPPPAAALDGAKADGLGGKGEPGGGPGELAPVGPDEKEKGAGAGGEEKKGAGEGGKDGEGGKEGEKKNGKYEKPPFSYNALIMMAIRQSPEKRLTLNGIYEFIMKNFPYYRENKQGWQNSIRHNLSLNKCFVKVPRHYDDPGKGNYWMLDPSSDDVFIGGTTGKLRRRSTTSRAKLAFKRGARLTSTGLTFMDRAGSLYWPMSPFLSLHHPRASSTLSYNGTTSAYPSHPMPYSSVLTQNSLGNNHSFSTANGLSVDRLVNGEIPYATHHLTAAALAASVPCGLSVPCSGTYSLNPCSVNLLAGQTSYFFPHVPHPSMTSQSSTSMSARAASSSTSPQAPSTLPCESLRPSLPSFTTGLSGGLSDYFTHQNQGSSSNPLIH(SEQ ID NO:28)
atgctggacatgggagataggaaagaggtgaaaatgatccccaagtcctcgttcagcatcaacagcctggtgcccgaggcggtccagaacgacaaccaccacgcgagccacggccaccacaacagccaccacccccagcaccaccaccaccaccaccaccatcaccaccacccgccgccgcccgccccgcaaccgccgccgccgccgcagcagcagcagccgccgccgccgccgcccccggcaccgcagcccccccagacgcggggcgccccggccgccgacgacgacaagggcccccagcagctgctgctcccgccgccgccaccgccaccaccggccgccgccctggacggggctaaagcggacgggctgggcggcaagggcgagccgggcggcgggccgggggagctggcgcccgtcgggccggacgagaaggagaagggcgccggcgccgggggggaggagaagaagggggcgggcgagggcggcaaggacggggaggggggcaaggagggcgagaagaagaacggcaagtacgagaagccgccgttcagctacaacgcgctcatcatgatggccatccggcagagccccgagaagcggctcacgctcaacggcatctacgagttcatcatgaagaacttcccttactaccgcgagaacaagcagggctggcagaactccatccgccacaatctgtccctcaacaagtgcttcgtgaaggtgccgcgccactacgacgacccgggcaagggcaactactggatgctggacccgtcgagcgacgacgtgttcatcggcggcaccacgggcaagctgcggcgccgctccaccacctcgcgggccaagctggccttcaagcgcggtgcgcgcctcacctccaccggcctcaccttcatggaccgcgccggctccctctactggcccatgtcgcccttcctgtccctgcaccacccccgcgccagcagcactttgagttacaacggcaccacgtcggcctaccccagccaccccatgccctacagctccgtgttgactcagaactcgctgggcaacaaccactccttctccaccgccaacggcctgagcgtggaccggctggtcaacggggagatcccgtacgccacgcaccacctcacggccgccgcgctagccgcctcggtgccctgcggcctgtcggtgccctgctctgggacctactccctcaacccctgctccgtcaacctgctcgcgggccagaccagttactttttcccccacgtcccgcacccgtcaatgacttcgcagagcagcacgtccatgagcgccagggccgcgtcctcctccacgtcgccgcaggccccctcgaccctgccctgtgagtctttaagaccctctttgccaagttttacgacgggactgtctgggggactgtctgattatttcacacatcaaaatcaggggtcttcttccaaccctttaatacattaa(SEQ ID NO:92)
人类ASC1蛋白的mRNA(SLC7A10基因)(AJ277731.1)SEQ ID NO:29(蛋白质)和SEQ ID NO:93(DNA)
MAGHTQQPSGRGNPRPAPSPSPVPGTVPGASERVALKKEIGLLSACTIIIGNIIGSGIFISPKGVLEHSGSVGLALFVWVLGGGVTALGSLCYAELGVAIPKSGGDYAYVTEIFGGLAGFLLLWSAVLIMYPTSLAVISMTFSNYVLQPVFPNCIPPTTASRVLSMACLMLLTWVNSSSVRWATRIQDMFTGGKLLALSLIIGVGLLQIFQGHFEELRPSNAFAFWMTPSVGHLALAFLQGSFAFSGWNFLNYVTEEMVDARKNLPRAIFISIPLVTFVYTFTNIAYFTAMSPQELLSSNAVAVTFGEKLLGYFSWVMPVSVALSTFGGINGYLFTYSRLCFSGAREGHLPSLLAMIHVRHCTPIPALLVCCGATAVIMLVGDTYTLINYVSFINYLCYGVTILGLLLLRWRRPALHRPIKVNLLIPVAYLVFWAFLLVFSFISEPMVCGVGVIIILTGVPIFFLGVFWRSKPKCVHRLTESMTHWGQELCFVVYPQDAPEEEENGPCPPSLLPATDKPSKPQ(SEQ ID NO:29)
atggccggccacacgcagcagccgagcgggcgcgggaaccccaggcctgcgccctcgccctccccagtcccagggaccgtccccggcgcctcggagcgggtggcgctcaagaaggagatcgggctgctgagcgcctgcaccatcatcatcgggaacatcatcggctcgggcatcttcatctcgcccaagggggtcctggagcactcaggctccgtgggtctggccctgttcgtctgggtcctgggtgggggcgtgacggctctgggctccctctgctatgcagagctgggagtcgccatccccaagtctggcggggactacgcctacgtcacagagatcttcgggggcctggctggctttctgctgctctggagcgccgtcctcatcatgtaccccaccagccttgctgtcatctccatgaccttctccaactacgtgctgcagcccgtgttccccaactgcatcccccccaccacagcctcccgggtgctgtccatggcctgcctgatgctcctgacatgggtgaacagctccagtgtgcgctgggccacgcgcatccaggacatgttcacaggcgggaagctgctggccttgtccctcatcatcggcgtgggccttctccagatcttccaaggacacttcgaggagctgaggcccagcaatgcctttgctttctggatgacgccctccgtgggacacctggccctggccttcctccagggctccttcgccttcagtggctggaacttcctcaactatgtcaccgaggagatggttgacgcccgaaagaacctacctcgcgccatcttcatctccatcccactggtgaccttcgtgtacacgttcaccaacattgcctacttcacggccatgtccccccaggagctgctctcctccaatgcggtggctgtgaccttcggggagaagctgctgggctacttttcttgggtcatgcctgtctccgtggctctgtcaaccttcggagggatcaatggttacctgttcacctactccaggctgtgcttctctggagcccgcgaggggcacctgcccagcctgctggccatgatccacgtcagacactgcacccccatccccgccctcctcgtctgttgcggggccacagccgtcatcatgctcgtgggcgacacgtacacgctcatcaactatgtgtccttcatcaactacctctgctacggcgtcaccatcctgggcctgctgctgctgcgctggaggcggcctgcactccacaggcccatcaaggtgaaccttctcatccccgtggcgtacttggtcttctgggccttcctgctggtcttcagcttcatctcagagcctatggtctgtggggtcggcgtcatcatcatccttacgggggtgcccattttctttctgggagtgttctggagaagcaaaccaaagtgtgtgcacagactcacagagtccatgacacactggggccaggagctgtgtttcgtggtctacccccaggacgcccccgaagaggaggagaatggcccctgcccaccctccctgctgcctgccacagacaagccctcgaagccacaatga(SEQ ID NO:93)
人类achaete-scuteb家族bHLH转录因子1(ASCL1)(NM_004316.3)SEQ ID NO:30(蛋白质)和SEQ ID NO:94(DNA)
MESSAKMESGGAGQQPQPQPQQPFLPPAACFFATAAAAAAAAAAAAAQSAQQQQQQQQQQQQAPQLRPAADGQPSGGGHKSAPKQVKRQRSSSPELMRCKRRLNFSGFGYSLPQQQPAAVARRNERERNRVKLVNLGFATLREHVPNGAANKKMSKVETLRSAVEYIRALQQLLDEHDAVSAAFQAGVLSPTISPNYSNDLNSMAGSPVSSYSSDEGSYDPLSPEEQELLDFTNWF(SEQ ID NO:30)
atggaaagctctgccaagatggagagcggcggcgccggccagcagccccagccgcagccccagcagcccttcctgccgcccgcagcctgtttctttgccacggccgcagccgcggcggccgcagccgccgcagcggcagcgcagagcgcgcagcagcagcagcagcagcagcagcagcagcagcaggcgccgcagctgagaccggcggccgacggccagccctcagggggcggtcacaagtcagcgcccaagcaagtcaagcgacagcgctcgtcttcgcccgaactgatgcgctgcaaacgccggctcaacttcagcggctttggctacagcctgccgcagcagcagccggccgccgtggcgcgccgcaacgagcgcgagcgcaaccgcgtcaagttggtcaacctgggctttgccacccttcgggagcacgtccccaacggcgcggccaacaagaagatgagtaaggtggagacactgcgctcggcggtcgagtacatccgcgcgctgcagcagctgctggacgagcatgacgcggtgagcgccgccttccaggcaggcgtcctgtcgcccaccatctcccccaactactccaacgacttgaactccatggccggctcgccggtctcatcctactcgtcggacgagggctcttacgacccgctcagccccgaggagcaggagcttctcgacttcaccaactggttctga(SEQ ID NO:94)
人类Nurr1基因(AB017586)SEQ ID NO:31(蛋白质)和SEQ ID NO:95(DNA)
MPCVQAQYGSSPQGASPASQSYSYHSSGEYSSDFLTPEFVKFSMDLTNTEITATTSLPSFSTFMDNYSTGYDVKPPCLYQMPLSGQQSSIKVEDIQMHNYQQHSHLPPQSEEMMPHSGSVYYKPSSPPTPTTPGFQVQHSPMWDDPGSLHNFHQNYVATTHMIEQRKTPVSRLSLFSFKQSPPGTPVSSCQMRFDGPLHVPMNPEPAGSHHVVDGQTFAVPNPIRKPASMGFPGLQIGHASQLLDTQVPSPPSRGSPSNEGLCAVCGDNAACQHYGVRTCEGCKGFFKRTVQKNAKYVCLANKNCPVDKRRRNRCQYCRFQKCLAVGMVKEVVRTDSLKGRRGRLPSKPKSPQEPSPPSPPVSLISALVRAHVDSNPAMTSLDYSRFQANPDYQMSGDDTQHIQQFYDLLTGSMEIIRGWAEKIPGFADLPKADQDLLFESAFLELFVLRLAYRSNPVEGKLIFCNGVVLHRLQCVRGFGEWIDSIVEFSSNLQNMNIDISAFSCIAALAMVTERHGLKEPKRVEELQNKIVNCLKDHVTFNNGGLNRPNYLSKLLGKLPELRTLCTQGLQRIFYLKLEDLVPPPAIIDKLFLDTLPF(SEQ ID NO:31)
atgccttgtgttcaggcgcagtatgggtcctcgcctcaaggagccagccccgcttctcagagctacagttaccactcttcgggagaatacagctccgatttcttaactccagagtttgtcaagtttagcatggacctcaccaacactgaaatcactgccaccacttctctccccagcttcagtacctttatggacaactacagcacaggctacgacgtcaagccaccttgcttgtaccaaatgcccctgtccggacagcagtcctccattaaggtagaagacattcagatgcacaactaccagcaacacagccacctgcccccccagtctgaggagatgatgccgcactccgggtcggtttactacaagccctcctcgcccccgacgcccaccaccccgggcttccaggtgcagcacagccccatgtgggacgacccgggatctctccacaacttccaccagaactacgtggccactacgcacatgatcgagcagaggaaaacgccagtctcccgcctctccctcttctcctttaagcaatcgccccctggcaccccggtgtctagttgccagatgcgcttcgacgggcccctgcacgtccccatgaacccggagcccgccggcagccaccacgtggtggacgggcagaccttcgctgtgcccaaccccattcgcaagcccgcgtccatgggcttcccgggcctgcagatcggccacgcgtctcagctgctcgacacgcaggtgccctcaccgccgtcgcggggctccccctccaacgaggggctgtgcgctgtgtgtggggacaacgcggcctgccaacactacggcgtgcgcacctgtgagggctgcaaaggcttctttaagcgcacagtgcaaaaaaatgcaaaatacgtgtgtttagcaaataaaaactgcccagtggacaagcgtcgccggaatcgctgtcagtactgccgatttcagaagtgcctggctgttgggatggtcaaagaagtggttcgcacagacagtttaaaaggccggagaggtcgtttgccctcgaaaccgaagagcccacaggagccctctcccccttcgcccccggtgagtctgatcagtgccctcgtcagggcccatgtcgactccaacccggctatgaccagcctggactattccaggttccaggcgaaccctgactatcaaatgagtggagatgacacccagcatatccagcaattctatgatctcctgactggctccatggagatcatccggggctgggcagagaagatccctggcttcgcagacctgcccaaagccgaccaagacctgctttttgaatcagctttcttagaactgtttgtccttcgattagcatacaggtccaacccagtggagggtaaactcatcttttgcaatggggtggtcttgcacaggttgcaatgcgttcgtggctttggggaatggattgattccattgttgaattctcctccaacttgcagaatatgaacatcgacatttctgccttctcctgcattgctgccctggctatggtcacagagagacacgggctcaaggaacccaagagagtggaagaactgcaaaacaagattgtaaattgtctcaaagaccacgtgactttcaacaatggggggttgaaccgccccaattatttgtccaaactgttggggaagctcccagaacttcgtaccctttgcacacaggggctacagcgcattttctacctgaaattggaagacttggtgccaccgccagcaataattgacaaacttttcctggacactttacctttctaa(SEQ ID NO:95)
SEQ ID NO:32:人类神经原素2(NEUROG2)(NM_024019)SEQ ID NO:32(蛋白质)和SEQ ID NO:96(DNA)
MFVKSETLELKEEEDVLVLLGSASPALAALTPLSSSADEEEEEEPGASGGARRQRGAEAGQGARGGVAAGAEGCRPARLLGLVHDCKRRPSRARAVSRGAKTAETVQRIKKTRRLKANNRERNRMHNLNAALDALREVLPTFPEDAKLTKIETLRFAHNYIWALTETLRLADHCGGGGGGLPGALFSEAVLLSPGGASAALSSSGDSPSPASTWSCTNSPAPSSSVSSNSTSPYSCTLSPASPAGSDMDYWQPPPPDKHRYAPHLPIARDCI(SEQ ID NO:32)
atgttcgtcaaatccgagaccttggagttgaaggaggaagaggacgtgttagtgctgctcggatcggcctcccccgccttggcggccctgaccccgctgtcatccagcgccgacgaagaagaggaggaggagccgggcgcgtcaggcggggcgcgtcggcagcgcggggctgaggccgggcagggggcgcggggcggcgtggctgcgggtgcggagggctgccggcccgcacggctgctgggtctggtacacgattgcaaacggcgcccttcccgggcgcgggccgtctcccgaggcgccaagacggccgagacggtgcagcgcatcaagaagacccgtagactgaaggccaacaaccgcgagcgaaaccgcatgcacaacctcaacgcggcactggacgcgctgcgcgaggtgctccccacgttccccgaggacgccaagctcaccaagatcgagaccctgcgcttcgcccacaactacatctgggcactcaccgagaccctgcgcctggcggatcactgcgggggcggcggcgggggcctgccgggggcgctcttctccgaggcagtgttgctgagcccgggaggagccagcgccgccctgagcagcagcggagacagcccctcgcccgcctccacgtggagttgcaccaacagccccgcgccgtcctcctccgtgtcctccaattccacctccccctacagctgcactttatcgcccgccagcccggccgggtcagacatggactattggcagcccccacctcccgacaagcaccgctatgcacctcacctccccatagccagggattgtatctag(SEQ ID NO:96)
人类LIM同源异型框转录因子1,α(LMX1A)(NM_177398)SEQ ID NO:33(蛋白质)和SEQ ID NO:97(DNA)
MLDGLKMEENFQSAIDTSASFSSLLGRAVSPKSVCEGCQRVILDRFLLRLNDSFWHEQCVQCASCKEPLETTCFYRDKKLYCKYDYEKLFAVKCGGCFEAIAPNEFVMRAQKSVYHLSCFCCCVCERQLQKGDEFVLKEGQLLCKGDYEKERELLSLVSPAASDSGKSDDEESLCKSAHGAGKGTAEEGKDHKRPKRPRTILTTQQRRAFKASFEVSSKPCRKVRETLAAETGLSVRVVQVWFQNQRAKMKKLARRQQQQQQDQQNTQRLSSAQTNGGGSAGMEGIMNPYTALPTPQQLLAIEQSVYSSDPFRQGLTPPQMPGDHMHPYGAEPLFHDLDSDDTSLSNLGDCFLATSEAGPLQSRVGNPIDHLYSMQNSYFTS(SEQ ID NO:33)
atgctggacggcctaaagatggaggagaacttccaaagcgcgatcgacacctcggcctccttctcctcgctgctgggcagagcggtgagccccaagtctgtctgcgagggctgtcagcgggtcatcttggacaggtttctgctgcggctcaacgacagcttctggcatgagcagtgcgtgcagtgcgcctcctgcaaagagcccctggagaccacctgcttctaccgggacaagaagctgtactgcaagtatgactacgagaagctgtttgctgttaaatgtgggggctgcttcgaggccatcgctcccaatgagtttgttatgcgggcccagaagagtgtataccacctgagctgcttctgctgctgtgtctgcgagcgacagcttcagaagggtgatgagtttgtcctgaaggaggggcagctgctctgcaaaggggactatgagaaggagcgggagctgctcagcctggtgagcccagcagcctcagactcaggtaaaagtgatgatgaagaaagtctctgcaagtcagcccatggggcagggaaaggaactgctgaggaaggcaaggaccataagcgccccaaacgtccgagaaccatcttgacaactcaacagaggcgagcattcaaggcctcatttgaagtatcctccaagccctgcaggaaggtgagagagactctggctgcagagacagggctgagtgtccgtgtcgtccaggtgtggttccaaaaccagagagcgaagatgaagaagctggccaggcgacagcagcagcagcagcaagatcagcagaacacccagaggctgagctctgctcagacaaacggtggtgggagtgctgggatggaaggaatcatgaacccctacacggctctgcccaccccacagcagctcctggccatcgagcagagtgtctacagctcagatcccttccgacagggtctcaccccaccccagatgcctggagaccacatgcacccttatggtgccgagccccttttccatgacctggatagcgacgacacctccctcagtaacctgggtgattgtttcctagcaacctcagaagctgggcctctgcagtccagagtgggaaaccccattgaccatctgtactccatgcagaattcttacttcacatcttga(SEQ ID NO:97)
人类HB9同源异型框基因,(U07663)SEQ ID NO:34(蛋白质)和SEQ ID NO:98(DNA)
MEKSKNFRIEPCWRWTPHEPPLAERALAKVTSPPVPASGTGGGGGGGGASGGTSGSCSPASSEPPAAPADRLRAESPSPPRLLAAHCALLPKPGFLGAGGGGGGTGGGHGGPHHHAHPGAAAAAAAAAAAAAAAAGGLALGLHPGGAQGGAGLPAQAALYGHPVYGYSAAAAAAALAGQHPALSYSYPQVQGAHPAHPADPIKLGAGTFQLDQWLRATAGMILPKMPDFNSQAQSNLLGKCRRPRTAFTSQQLLELEHQFKFNKYLSRPKRFEVATSLMLTETQVKIWFQNRRMKWKRSKKAKEQAAQEAEKQKGGGGGAGKGGAEEPGAEELLGPPAPRDKGSGPPADLRDSDPEEDEDEDDEDHFPYSNGASVHAASSDCSSEDDSPPPRPSHQPAPQ(SEQ ID NO:34)
atggaaaaatccaaaaatttccgcatcgagccctgctggcggtggaccccccacgagccgcctctcgcagagcgcgcgctggccaaggtcacgtcgccgcccgtgcccgcatctggcaccggaggtggcggcggcggcggcggggcgagcggcgggactagcggcagctgcagccccgcgtcctcggagccgccggctgcgcccgccgaccgcctgcgcgccgagagcccgtcgccgccgcgcctgctggccgcgcactgcgcgctgctgcccaagccgggcttcctgggcgcgggcggcggcggcggcggcacgggcggcgggcacggggggccccaccaccacgcgcatccgggcgcagcggccgctgccgccgccgccgccgccgccgccgccgccgccgctgggggcctggcgctggggctgcaccctgggggcgcgcagggcggcgcgggcctcccggcgcaggcggcgctctacggccacccggtctacggctactccgcggcggcggcggcggctgcgctggcgggccagcacccggcgctctcctactcgtacccgcaggtgcaaggcgcgcaccccgcgcaccccgccgaccccatcaagctgggcgccggcaccttccagctggaccagtggctgcgcgcgtccaccgcgggcatgatcctgcctaagatgcccgacttcaact(SEQ ID NO:98)
人类LIM同源异型框3(LHX3)(NM_178138)SEQ ID NO:35(蛋白质)和SEQ ID NO:99(DNA)
MLLETGLERDRARPGAAAVCTLGGTREIPLCAGCDQHILDRFILKALDRHWHSKCLKCSDCHTPLAERCFSRGESVYCKDDFFKRFGTKCAACQLGIPPTQVVRRAQDFVYHLHCFACVVCKRQLATGDEFYLMEDSRLVCKADYETAKQREAEATAKRPRTTITAKQLETLKSAYNTSPKPARHVREQLSSETGLDMRVVQVWFQNRRAKEKRLKKDAGRQRWGQYFRNMKRSRGGSKSDKDSVQEGQDSDAEVSFPDEPSLAEMGPANGLYGSLGEPTQALGRPSGALGNFSLEHGGLAGPEQYRELRPGSPYGVPPSPAAPQSLPGPQPLLSSLVYPDTSLGLVPSGAPGGPPPMRVLAGNGPSSDLSTGSSGGYPDFPASPASWLDEVDHAQF(SEQ ID NO:35)
atgctgctggaaacggggctcgagcgcgaccgagcgaggcccggggccgccgccgtctgcaccttgggcgggactcgggagatcccgctgtgcgctggctgtgaccagcacatcctggaccgcttcatcctcaaggctctggaccgccactggcacagcaagtgtctcaagtgcagcgactgccacacgccactggccgagcgctgcttcagccgaggggagagcgtttactgcaaggacgactttttcaagcgcttcgggaccaagtgcgccgcgtgccagctgggcatcccgcccacgcaggtggtgcgccgcgcccaggacttcgtgtaccacctgcactgctttgcctgcgtcgtgtgcaagcggcagctggccacgggcgacgagttctacctcatggaggacagccggctcgtgtgcaaggcggactacgaaaccgccaagcagcgagaggccgaggccacggccaagcggccgcgcacgaccatcaccgccaagcagctggagacgctgaagagcgcttacaacacctcgcccaagccggcgcgccacgtgcgcgagcagctctcgtccgagacgggcctggacatgcgcgtggtgcaggtttggttccagaaccgccgggccaaggagaagaggctgaagaaggacgccggccggcagcgctgggggcagtatttccgcaacatgaagcgctcccgcggcggctccaagtcggacaaggacagcgttcaggaggggcaggacagcgacgctgaggtctccttccccgatgagccttccttggcggaaatgggcccggccaatggcctctacgggagcttgggggaacccacccaggccttgggccggccctcgggagccctgggcaacttctccctggagcatggaggcctggcaggcccagagcagtaccgagagctgcgtcccggcagcccctacggtgtccccccatcccccgccgccccgcagagcctccctggcccccagcccctcctctccagcctggtgtacccagacaccagcttgggccttgtgccctcgggagcccccggcgggcccccacccatgagggtgctggcagggaacggacccagttctgacctatccacggggagcagcgggggttaccccgacttccctgccagccccgcctcctggctggatgaggtagaccacgctcagttctga(SEQ ID NO:99)
人类远端缺失同源异型框2(DLX2)(NM_004405)SEQ ID NO:36(蛋白质)和SEQ ID NO:100(DNA)
MTGVFDSLVADMHSTQIAASSTYHQHQQPPSGGGAGPGGNSSSSSSLHKPQESPTLPVSTATDSSYYTNQQHPAGGGGGGGSPYAHMGSYQYQASGLNNVPYSAKSSYDLGYTAAYTSYAPYGTSSSPANNEPEKEDLEPEIRIVNGKPKKVRKPRTIYSSFQLAALQRRFQKTQYLALPERAELAASLGLTQTQVKIWFQNRRSKFKKMWKSGEIPSEQHPGASASPPCASPPVSAPASWDFGVPQRMAGGGGPGSGGSGAGSSGSSPSSAASAFLGNYPWYHQTSGSASHLQATAPLLHPTQTPQPHHHHHHHGGGGAPVSAGTIF(SEQ ID NO:36)
atgactggagtctttgacagtctagtggctgatatgcactcgacccagatcgccgcctccagcacgtaccaccagcaccagcagcccccgagcggcggcggcgccggcccgggtggcaacagcagcagcagcagcagcctccacaagccccaggagtcgcccacccttccggtgtccaccgccaccgacagcagctactacaccaaccagcagcacccggcgggcggcggcggcggcgggggctcgccctacgcgcacatgggttcctaccagtaccaagccagcggcctcaacaacgtcccttactccgccaagagcagctatgacctgggctacaccgccgcctacacctcctacgctccctatggaaccagttcgtccccagccaacaacgagcctgagaaggaggaccttgagcctgaaattcggatagtgaacgggaagccaaagaaagtccggaaaccccgcaccatctactccagtttccagctggcggctcttcagcggcgtttccaaaagactcaatacttggccttgccggagcgagccgagctggcggcctctctgggcctcacccagactcaggtcaaaatctggttccagaaccgccggtccaagttcaagaagatgtggaaaagtggtgagatcccctcggagcagcaccctggggccagcgcttctccaccttgtgcttcgccgccagtctcagcgccggcctcctgggactttggtgtgccgcagcggatggcgggcggcggtggtccgggcagtggcggcagcggcgccggcagctcgggctccagcccgagcagcgcggcctcggcttttctgggcaactacccctggtaccaccagacctcgggatccgcctcacacctgcaggccacggcgccgctgctgcaccccactcagaccccgcagccgcatcaccaccaccaccatcacggcggcgggggcgccccggtgagcgcggggacgattttctaa(SEQ ID NO:100)
人类runt相关的转录因子2(RUNX2)(NM_001024630)SEQ ID NO:37(蛋白质)和SEQ ID NO:101(DNA)
MASNSLFSTVTPCQQNFFWDPSTSRRFSPPSSSLQPGKMSDVSPVVAAQQQQQQQQQQQQQQQQQQQQQQQEAAAAAAAAAAAAAAAAAVPRLRPPHDNRTMVEIIADHPAELVRTDSPNFLCSVLPSHWRCNKTLPVAFKVVALGEVPDGTVVTVMAGNDENYSAELRNASAVMKNQVARFNDLRFVGRSGRGKSFTLTITVFTNPPQVATYHRAIKVTVDGPREPRRHRQKLDDSKPSLFSDRLSDLGRIPHPSMRVGVPPQNPRPSLNSAPSPFNPQGQSQITDPRQAQSSPPWSYDQSYPSYLSQMTSPSIHSTTPLSSTRGTGLPAITDVPRRISDDDTATSDFCLWPSTLSKKSQAGASELGPFSDPRQFPSISSLTESRFSNPRMHYPATFTYTPPVTSGMSLGMSATTHYHTYLPPPYPGSSQSQSGPFQTSSTPYLYYGTSSGSYQFPMVPGGDRSPSRMLPPCTTTSNGSTLLNPNLPNQNDGVDADGSHSSSPTVLNSSGRMDESVWRPY(SEQ ID NO:37)
atggcatcaaacagcctcttcagcacagtgacaccatgtcagcaaaacttcttttgggatccgagcaccagccggcgcttcagccccccctccagcagcctgcagcccggcaaaatgagcgacgtgagcccggtggtggctgcgcaacagcagcagcaacagcagcagcagcaacagcagcagcagcagcagcaacagcagcagcagcagcaggaggcggcggcggcggctgcggcggcggcggcggctgcggcggcggcagctgcagtgccccggttgcggccgccccacgacaaccgcaccatggtggagatcatcgccgaccacccggccgaactcgtccgcaccgacagccccaacttcctgtgctcggtgctgccctcgcactggcgctgcaacaagaccctgcccgtggccttcaaggtggtagccctcggagaggtaccagatgggactgtggttactgtcatggcgggtaacgatgaaaattattctgctgagctccggaatgcctctgctgttatgaaaaaccaagtagcaaggttcaacgatctgagatttgtgggccggagtggacgaggcaagagtttcaccttgaccataaccgtcttcacaaatcctccccaagtagctacctatcacagagcaattaaagttacagtagatggacctcgggaacccagaaggcacagacagaagcttgatgactctaaacctagtttgttctctgaccgcctcagtgatttagggcgcattcctcatcccagtatgagagtaggtgtcccgcctcagaacccacggccctccctgaactctgcaccaagtccttttaatccacaaggacagagtcagattacagaccccaggcaggcacagtcttccccgccgtggtcctatgaccagtcttacccctcctacctgagccagatgacgtccccgtccatccactctaccaccccgctgtcttccacacggggcactgggcttcctgccatcaccgatgtgcctaggcgcatttcagatgatgacactgccacctctgacttctgcctctggccttccactctcagtaagaagagccaggcaggtgcttcagaactgggccctttttcagaccccaggcagttcccaagcatttcatccctcactgagagccgcttctccaacccacgaatgcactatccagccacctttacttacaccccgccagtcacctcaggcatgtccctcggtatgtccgccaccactcactaccacacctacctgccaccaccctaccccggctcttcccaaagccagagtggacccttccagaccagcagcactccatatctctactatggcacttcgtcaggatcctatcagtttcccatggtgccggggggagaccggtctccttccagaatgcttccgccatgcaccaccacctcgaatggcagcacgctattaaatccaaatttgcctaaccagaatgatggtgttgacgctgatggaagccacagcagttccccaactgttttgaattctagtggcagaatggatgaatctgtttggcgaccatattga(SEQ ID NO:101)
人类SRY(性别决定区Y)-盒5(SOX5)(NM_006940)SEQ ID NO:38(蛋白质)和SEQ ID NO:102(DNA)
MLTDPDLPQEFERMSSKRPASPYGEADGEVAMVTSRQKVEEEESDGLPAFHLPLHVSFPNKPHSEEFQPVSLLTQETCGHRTPTSQHNTMEVDGNKVMSSFAPHNSSTSPQKAEEGGRQSGESLSSTALGTPERRKGSLADVVDTLKQRKMEELIKNEPEETPSIEKLLSKDWKDKLLAMGSGNFGEIKGTPESLAEKERQLMGMINQLTSLREQLLAAHDEQKKLAASQIEKQRQQMELAKQQQEQIARQQQQLLQQQHKINLLQQQIQVQGQLPPLMIPVFPPDQRTLAAAAQQGFLLPPGFSYKAGCSDPYPVQLIPTTMAAAAAATPGLGPLQLQQLYAAQLAAMQVSPGGKLPGIPQGNLGAAVSPTSIHTDKSTNSPPPKSKDEVAQPLNLSAKPKTSDGKSPTSPTSPHMPALRINSGAGPLKASVPAALASPSARVSTIGYLNDHDAVTKAIQEARQMKEQLRREQQVLDGKVAVVNSLGLNNCRTEKEKTTLESLTQQLAVKQNEEGKFSHAMMDFNLSGDSDGSAGVSESRIYRESRGRGSNEPHIKRPMNAFMVWAKDERRKILQAFPDMHNSNISKILGSRWKAMTNLEKQPYYEEQARLSKQHLEKYPDYKYKPRPKRTCLVDGKKLRIGEYKAIMRNRRQEMRQYFNVGQQAQIPIATAGVVYPGAIAMAGMPSPHLPSEHSSVSSSPEPGMPVIQSTYGVKGEEPHIKEEIQAEDINGEIYDEYDEEEDDPDVDYGSDSENHIAGQAN(SEQ ID NO:38)
atgcttactgaccctgatttacctcaggagtttgaaaggatgtcttccaagcgaccagcctctccgtatggggaagcagatggagaggtagccatggtgacaagcagacagaaagtggaagaagaggagagtgacgggctcccagcctttcaccttcccttgcatgtgagttttcccaacaagcctcactctgaggaatttcagccagtttctctgctgacgcaagagacttgtggccataggactcccacttctcagcacaatacaatggaagttgatggcaataaagttatgtcttcatttgccccacacaactcatctacctcacctcagaaggcagaagaaggtgggcgacagagtggcgagtccttgtctagtacagccctgggaactcctgaacggcgcaagggcagtttagctgatgttgttgacaccttgaagcagaggaaaatggaagagctcatcaaaaacgagccggaagaaacccccagtattgaaaaactactctcaaaggactggaaagacaagcttcttgcaatgggatcggggaactttggcgaaataaaagggactcccgagagcttagctgagaaagaaaggcaactcatgggtatgatcaaccagctgaccagcctccgagagcagctgttggctgcccacgatgagcagaagaaactagctgcctctcagattgagaaacagcgtcagcaaatggagctggccaagcagcaacaagaacaaattgcaagacagcagcagcagcttctacagcaacaacacaaaatcaatttgctccagcaacagatccaggttcaaggtcagctgccgccattaatgattcccgtattccctcctgatcaacggacactggctgcagctgcccagcaaggattcctcctccctccaggcttcagctataaggctggatgtagtgacccttaccctgttcagctgatcccaactaccatggcagctgctgccgcagcaacaccaggcttaggcccactccaactgcagcagttatatgctgcccagctagctgcaatgcaggtatctccaggagggaagctgccaggcataccccaaggcaaccttggtgctgctgtatctcctaccagcattcacacagacaagagcacaaacagcccaccacccaaaagcaaggatgaagtggcacagccactgaacctatcagctaaacccaagacctctgatggcaaatcacccacatcacccacctctccccatatgccagctctgagaataaacagtggggcaggccccctcaaagcctctgtcccagcagcgttagctagtccttcagccagagttagcacaataggttacttaaatgaccatgatgctgtcaccaaggcaatccaagaagctcggcaaatgaaggagcaactccgacgggaacaacaggtgcttgatgggaaggtggctgttgtgaatagtctgggtctcaataactgccgaacagaaaaggaaaaaacaacactggagagtctgactcagcaactggcagttaaacagaatgaagaaggaaaatttagccatgcaatgatggatttcaatctgagtggagattctgatggaagtgctggagtctcagagtcaagaatttatagggaatcccgagggcgtggtagcaatgaaccccacataaagcgtccaatgaatgccttcatggtgtgggctaaagatgaacggagaaagatccttcaagcctttcctgacatgcacaactccaacatcagcaagatattgggatctcgctggaaagctatgacaaacctagagaaacagccatattatgaggagcaagcccgtctcagcaagcagcacctggagaagtaccctgactataagtacaagcccaggccaaagcgcacctgcctggtggatggcaaaaagctgcgcattggtgaatacaaggcaatcatgcgcaacaggcggcaggaaatgcggcagtacttcaatgttgggcaacaagcacagatccccattgccactgctggtgttgtgtaccctggagccatcgccatggctgggatgccctcccctcacctgccctcggagcactcaagcgtgtctagcagcccagagcctgggatgcctgttatccagagcacttacggtgtgaaaggagaggagccacatatcaaagaagagatacaggccgaggacatcaatggagaaatttatgatgagtacgacgaggaagaggatgatccagatgtagattatgggagtgacagtgaaaaccatattgcaggacaagccaactga(SEO ID NO:102)
人类SOX6 mRNA(AF309034)SEQ ID NO:39(蛋白质)和SEQ ID NO:103(DNA)
MSSKQATSPFACAADGEDAMTQDLTSREKEEGSDQHVASHLPLHPIMHNKPHSEELPTLVSTIQQDADWDSVLSSQQRMESENNKLCSLYSFRNTSTSPHKPDEGSRDREIMTSVTFGTPERRKGSLADVVDTLKQKKLEEMTRTEQEDSSCMEKLLSKDWKEKMERLNTSELLGEIKGTPESLAEKERQLSTMITQLISLREQLLAAHDEQKKLAASQIEKQRQQMDLARQQQEQIARQQQQLLQQQHKINLLQQQIQVQGHMPPLMIPIFPHDQRTLAAAAAAQQGFLFPPGITYKPGDNYPVQFIPSTMAAAAASGLSPLQLQKGHASHPQINQRLKGLSDRFGRNLDTFEHGGGHSYNHKQIEQLYAAQLASMQVSPGAKMPSTPQPPNTAGTVSPTGIKNEKRGTSPVTQVKDEAAAQPLNLSSRPKTAEPVKSPTSPTQNLFPASKTSPVNLPNKSSIPSPIGGSLGRGSSLDILSSLNSPALFGDQDTVMKAIQEARKMREQIQREQQQQQPHGVDGKLSSINNMGLNSCRNEKERTRFENLGPQLTGKSNEDGKLGPGVIDLTRPEDAEGGATVAEARVYRDARGRASSEPHIKRPMNAFMVWAKDERRKILQAFPDMHNSNISKILGSRWKSMSNQEKQPYYEEQARLSKIHLEKYPNYKYKPRPKRTCIVDGKKLRIGEYKQLMRSRRQEMRQFFTVGQQPQIPITTGTGVVYPGAITMATTTPSPQMTSDCSSTSASPEPSLPVIQSTYGMKTDGGSLAGNEMINGEDEMEMYDDYEDDPKSDYSSENEAPEAVSAN(SEQ ID NO:39)
atgtcttccaagcaagccacctctccatttgcctgtgcagctgatggagaggatgcaatgacccaggatttaacctcaagggaaaaggaagagggcagtgatcaacatgtggcctcccatctgcctctgcaccccataatgcacaacaaacctcactctgaggagctaccaacacttgtcagtaccattcaacaagatgctgactgggacagcgttctgtcatctcagcaaagaatggaatcagagaataataagttatgttccctatattccttccgaaatacctctacctcaccacataagcctgacgaagggagtcgggaccgtgagataatgaccagtgttacttttggaaccccagagcgccgcaaagggagtcttgccgatgtggtggacacactgaaacagaagaagcttgaggaaatgactcggactgaacaagaggattcctcctgcatggaaaaactactttcaaaagattggaaggaaaaaatggaaagactaaataccagtgaacttcttggagaaattaaaggtacacctgagagcctggcagaaaaagaacggcagctctccaccatgattacccagctgatcagtttacgggagcagctactggcagcgcatgatgaacagaaaaaactggcagcgtcacaaattgagaaacaacggcagcaaatggaccttgctcgccaacagcaagaacagattgcgagacaacagcagcaacttctgcaacagcagcacaaaattaatctcctgcagcaacagatccaggttcagggtcacatgcctccgctcatgatcccaatttttccacatgaccagcggactctggcagcagctgctgctgcccaacagggattcctcttcccccctggaataacatacaaaccaggtgataactaccccgtacagttcattccatcaacaatggcagctgctgctgcttctggactcagccctttacagctccagaagggtcatgcctcccacccacaaattaaccaaaggctaaagggcctaagtgaccgttttggcaggaatttggacacctttgaacatggtggtggccactcttacaaccacaaacagattgagcagctctatgccgctcagctggccagcatgcaggtgtcacctggagcaaagatgccatcaactccacagccaccaaacacagcagggacggtctcacctactgggataaaaaatgaaaagagagggaccagccctgtaactcaagttaaggatgaagcagcagcacagcctctgaatctctcatcccgacccaagacagcagagcctgtaaagtccccaacgtctcccacccagaacctcttcccagccagcaaaaccagccctgtcaatctgccaaacaaaagcagcatccctagccccattggaggaagcctgggaagaggatcctctttagatatcctatctagtctcaactcccctgccctttttggggatcaggatacagtgatgaaagccattcaggaggcgcggaagatgcgagagcagatccagcgggagcaacagcagcaacagccacatggtgttgacgggaaactgtcctccataaataatatggggctgaacagctgcaggaatgaaaaggaaagaacgcgctttgagaatttggggccccagttaacgggaaagtcaaatgaagatggaaaactgggcccaggtgtcatcgaccttactcggccagaagatgcagagggaggtgccactgtggctgaagcacgagtctacagggacgcccgcggccgtgccagcagcgagccacacattaagcgaccaatgaatgcattcatggtttgggcaaaggatgagaggagaaaaatccttcaggccttccccgacatgcataactccaacattagcaaaatcttaggatctcgctggaaatcaatgtccaaccaggagaagcaaccttattatgaagagcaggcccggctaagcaagatccacttagagaagtacccaaactataaatacaaaccccgaccgaaacgcacctgcattgttgatggcaaaaagcttcggattggggagtataagcaactgatgaggtctcggagacaggagatgaggcagttctttactgtggggcaacagcctcagattccaatcaccacaggaacaggtgttgtgtatcctggtgctatcactatggcaactaccacaccatcgcctcagatgacatctgactgctctagcacctcggccagcccggagcccagcctcccggtcatccagagcacttatggtatgaagacagatggcggaagcctagctggaaatgaaatgatcaatggagaggatgaaatggaaatgtatgatgactatgaagatgaccccaaatcagactatagcagtgaaaatgaagccccggaggctgtcagtgccaactga(SEQ ID NO:103)
人类GATA结合蛋白6(GATA6)(NM_005257)SEQ ID NO:40(蛋白质)和SEQ ID NO:104(DNA)
MALTDGGWCLPKRFGAAGADASDSRAFPAREPSTPPSPISSSSSSCSRGGERGPGGASNCGTPQLDTEAAAGPPARSLLLSSYASHPFGAPHGPSAPGVAGPGGNLSSWEDLLLFTDLDQAATASKLLWSSRGAKLSPFAPEQPEEMYQTLAALSSQGPAAYDGAPGGFVHSAAAAAAAAAAASSPVYVPTTRVGSMLPGLPYHLQGSGSGPANHAGGAGAHPGWPQASADSPPYGSGGGAAGGGAAGPGGAGSAAAHVSARFPYSPSPPMANGAAREPGGYAAAGSGGAGGVSGGGSSLAAMGGREPQYSSLSAARPLNGTYHHHHHHHHHHPSPYSPYVGAPLTPAWPAGPFETPVLHSLQSRAGAPLPVPRGPSADLLEDLSESRECVNCGSIQTPLWRRDGTGHYLCNACGLYSKMNGLSRPLIKPQKRVPSSRRLGLSCANCHTTTTTLWRRNAEGEPVCNACGLYMKLHGVPRPLAMKKEGIQTRKRKPKNINKSKTCSGNSNNSIPMTPTSTSSNSDDCSKNTSPTTQPTASGAGAPVMTGAGESTNPENSELKYSGQDGLYIGVSLASPAEVTSSVRPDSWCALALA(SEQ ID NO:40)
atggccttgactgacggcggctggtgcttgccgaagcgcttcggggccgcgggtgcggacgccagcgactccagagcctttccagcgcgggagccctccacgccgccttcccccatctcttcctcgtcctcctcctgctcccggggcggagagcggggccccggcggcgccagcaactgcgggacgcctcagctcgacacggaggcggcggccggacccccggcccgctcgctgctgctcagttcctacgcttcgcatcccttcggggctccccacggaccttcggcgcctggggtcgcgggccccgggggcaacctgtcgagctgggaggacttgctgctgttcactgacctcgaccaagccgcgaccgccagcaagctgctgtggtccagccgcggcgccaagctgagccccttcgcacccgagcagccggaggagatgtaccagaccctcgccgctctctccagccagggtccggccgcctacgacggcgcgcccggcggcttcgtgcactctgcggccgcggcggcagcagccgcggcggcggccagctccccggtctacgtgcccaccacccgcgtgggttccatgctgcccggcctaccgtaccacctgcaggggtcgggcagtgggccagccaaccacgcgggcggcgcgggcgcgcaccccggctggcctcaggcctcggccgacagccctccatacggcagcggaggcggcgcggctggcggcggggccgcggggcctggcggcgctggctcagccgcggcgcacgtctcggcgcgcttcccctactctcccagcccgcccatggccaacggcgccgcgcgggagccgggaggctacgcggcggcgggcagtgggggcgcgggaggcgtgagcggcggcggcagtagcctggcggccatgggcggccgcgagccccagtacagctcgctgtcggccgcgcggccgctgaacgggacgtaccaccaccaccaccaccaccaccaccaccatccgagcccctactcgccctacgtgggggcgccactgacgcctgcctggcccgccggacccttcgagaccccggtgctgcacagcctgcagagccgcgccggagccccgctcccggtgccccggggtcccagtgcagacctgctggaggacctgtccgagagccgcgagtgcgtgaactgcggctccatccagacgccgctgtggcggcgggacggcaccggccactacctgtgcaacgcctgcgggctctacagcaagatgaacggcctcagccggcccctcatcaagccgcagaagcgcgtgccttcatcacggcggcttggattgtcctgtgccaactgtcacaccacaactaccaccttatggcgcagaaacgccgagggtgaacccgtgtgcaatgcttgtggactctacatgaaactccatggggtgcccagaccacttgctatgaaaaaagagggaattcaaaccaggaaacgaaaacctaagaacataaataaatcaaagacttgctctggtaatagcaataattccattcccatgactccaacttccacctcttctaactcagatgattgcagcaaaaatacttcccccacaacacaacctacagcctcaggggcgggtgccccggtgatgactggtgcgggagagagcaccaatcccgagaacagcgagctcaagtattcgggtcaagatgggctctacataggcgtcagtctcgcctcgccggccgaagtcacgtcctccgtgcgaccggattcctggtgcgccctggccctggcctga(SEQ ID NO:104)
人类GATA结合蛋白1(GATA1)(NM_002049)SEQ ID NO:41(蛋白质)和SEQ ID NO:105(DNA)
MEFPGLGSLGTSEPLPQFVDPALVSSTPESGVFFPSGPEGLDAAASSTAPSTATAAAAALAYYRDAEAYRHSPVFQVYPLLNCMEGIPGGSPYAGWAYGKTGLYPASTVCPTREDSPPQAVEDLDGKGSTSFLETLKTERLSPDLLTLGPALPSSLPVPNSAYGGPDFSSTFFSPTGSPLNSAAYSSPKLRGTLPLPPCEARECVNCGATATPLWRRDRTGHYLCNACGLYHKMNGQNRPLIRPKKRLIVSKRAGTQCTNCQTTTTTLWRRNASGDPVCNACGLYYKLHQVNRPLTMRKDGIQTRNRKASGKGKKKRGSSLGGTGAAEGPAGGFMVVAGGSGSGNCGEVASGLTLGPPGTAHLYQGLGPVVLSGPVSHLMPFPGPLLGSPTGSFPTGPMPPTTSTTVVAPLSS(SEQ ID NO:41)
atggagttccctggcctggggtccctggggacctcagagcccctcccccagtttgtggatcctgctctggtgtcctccacaccagaatcaggggttttcttcccctctgggcctgagggcttggatgcagcagcttcctccactgccccgagcacagccaccgctgcagctgcggcactggcctactacagggacgctgaggcctacagacactccccagtctttcaggtgtacccattgctcaactgtatggaggggatcccagggggctcaccatatgccggctgggcctacggcaagacggggctctaccctgcctcaactgtgtgtcccacccgcgaggactctcctccccaggccgtggaagatctggatggaaaaggcagcaccagcttcctggagactttgaagacagagcggctgagcccagacctcctgaccctgggacctgcactgccttcatcactccctgtccccaatagtgcttatgggggccctgacttttccagtaccttcttttctcccaccgggagccccctcaattcagcagcctattcctctcccaagcttcgtggaactctccccctgcctccctgtgaggccagggagtgtgtgaactgcggagcaacagccactccactgtggcggagggacaggacaggccactacctatgcaacgcctgcggcctctatcacaagatgaatgggcagaacaggcccctcatccggcccaagaagcgcctgattgtcagtaaacgggcaggtactcagtgcaccaactgccagacgaccaccacgacactgtggcggagaaatgccagtggggatcccgtgtgcaatgcctgcggcctctactacaagctacaccaggtgaaccggccactgaccatgcggaaggatggtattcagactcgaaaccgcaaggcatctggaaaagggaaaaagaaacggggctccagtctgggaggcacaggagcagccgaaggaccagctggtggctttatggtggtggctgggggcagcggtagcgggaattgtggggaggtggcttcaggcctgacactgggccccccaggtactgcccatctctaccaaggcctgggccctgtggtgctgtcagggcctgttagccacctcatgcctttccctggacccctactgggctcacccacgggctccttccccacaggccccatgccccccaccaccagcactactgtggtggctccgctcagctcatga(SEQ ID NO:105)
人类Fli-1原致癌基因,ETS转录因子(FLI1)(NM_002017)SEQ ID NO:42(蛋白质)和SEQ ID NO:106(DNA)
MDGTIKEALSVVSDDQSLFDSAYGAAAHLPKADMTASGSPDYGQPHKINPLPPQQEWINQPVRVNVKREYDHMNGSRESPVDCSVSKCSKLVGGGESNPMNYNSYMDEKNGPPPPNMTTNERRVIVPADPTLWTQEHVRQWLEWAIKEYSLMEIDTSFFQNMDGKELCKMNKEDFLRATTLYNTEVLLSHLSYLRESSLLAYNTTSHTDQSSRLSVKEDPSYDSVRRGAWGNNMNSGLNKSPPLGGAQTISKNTEQRPQPDPYQILGPTSSRLANPGSGQIQLWQFLLELLSDSANASCITWEGTNGEFKMTDPDEVARRWGERKSKPNMNYDKLSRALRYYYDKNIMTKVHGKRYAYKFDFHGIAQALQPHPTESSMYKYPSDISYMPSYHAHQQKVNFVPPHPSSMPVTSSSFFGAASQYWTSPTGGIYPNPNVPRHPNTHVPSHLGSYY(SEQ ID NO:42)
atggacgggactattaaggaggctctgtcggtggtgagcgacgaccagtccctctttgactcagcgtacggagcggcagcccatctccccaaggccgacatgactgcctcggggagtcctgactacgggcagccccacaagatcaaccccctcccaccacagcaggagtggatcaatcagccagtgagggtcaacgtcaagcgggagtatgaccacatgaatggatccagggagtctccggtggactgcagcgttagcaaatgcagcaagctggtgggcggaggcgagtccaaccccatgaactacaacagctatatggacgagaagaatggcccccctcctcccaacatgaccaccaacgagaggagagtcatcgtccccgcagaccccacactgtggacacaggagcatgtgaggcaatggctggagtgggccataaaggagtacagcttgatggagatcgacacatcctttttccagaacatggatggcaaggaactgtgtaaaatgaacaaggaggacttcctccgcgccaccaccctctacaacacggaagtgctgttgtcacacctcagttacctcagggaaagttcactgctggcctataatacaacctcccacaccgaccaatcctcacgattgagtgtcaaagaagacccttcttatgactcagtcagaagaggagcttggggcaataacatgaattctggcctcaacaaaagtcctccccttggaggggcacaaacgatcagtaagaatacagagcaacggccccagccagatccgtatcagatcctgggcccgaccagcagtcgcctagccaaccctggaagcgggcagatccagctgtggcaattcctcctggagctgctctccgacagcgccaacgccagctgtatcacctgggaggggaccaacggggagttcaaaatgacggaccccgatgaggtggccaggcgctggggcgagcggaaaagcaagcccaacatgaattacgacaagctgagccgggccctccgttattactatgataaaaacattatgaccaaagtgcacggcaaaagatatgcttacaaatttgacttccacggcattgcccaggctctgcagccacatccgaccgagtcgtccatgtacaagtacccttctgacatctcctacatgccttcctaccatgcccaccagcagaaggtgaactttgtccctccccatccatcctccatgcctgtcacttcctccagcttctttggagccgcatcacaatactggacctcccccacggggggaatctaccccaaccccaacgtcccccgccatcctaacacccacgtgccttcacacttaggcagctactactag(SEQ ID NO:106)
人类红系Kruppel样因子EKLF基因(U37106)SEQ ID NO:43(蛋白质)和SEQ ID NO:107(DNA)
MATAETALPSISTLTALGPFPDTQDDFLKWWRSEEAQDMGPGPPDPTEPPLHVKSEDQPGEEEDDERGADATWDLDLLLTNFSGPEPGGAPQTCALAPSEASGAQYPPPPETLGAYAGGPGLVAGLLGSEDHSGWVRPALRARAPDAFVGPALAPAPAPEPKALALQPVYPGPGAGSSGGYFPRTGLSVPAASGAPYGLLSGYPAMYPAPQYQGHFQLFRGLQGPAPGPATSPSFLSCLGPGTVGTGLGGTAEDPGVIAETAPSKRGRRSWARKRQAAHTCAHPGCGKSYTKSSHLKAHLRTHTGEKPYACTWEGCGWRFARSDELTRHYRKHTGQRPFRCQLCPRAFSRSDHLALHMKRHL(SEQ ID NO:43)
atggccacagccgagaccgccttgccctccatcagcacactgaccgccctgggccccttcccggacacacaggatgacttcctcaagtggtggcgctccgaagaggcgcaggacatgggcccgggtcctcctgaccccacggagccgcccctccacgtgaagtctgaggaccagcccggggaggaagaggacgatgagaggggcgcggacgccacctgggacctggatctcctcctcaccaacttctcgggcccggagcccggtggcgcgccccagacctgcgctctggcgcccagcgaggcctccggggcgcaatatccgccgccgcccgagactctgggcgcatatgctggcggcccggggctggtggctgggcttttgggttcggaggatcactcgggttgggtgcgccctgccctgcgagcccgggctcccgacgccttcgtgggcccagccctggctccagccccggcccccgagcccaaggcgctggcgctgcaaccggtgtacccggggcccggcgccggctcctcgggtggctacttcccgcggaccgggctttcagtgcctgcggcgtcgggcgccccctacgggctactgtccgggtaccccgcgatgtacccggcgcctcagtaccaagggcacttccagctcttccgcgggctccagggacccgcgcccggtcccgccacgtccccctccttcctgagttgtttgggacccgggacggtgggcactggactcggggggactgcagaggatccaggtgtgatagccgagaccgcgccatccaagcgaggccgacgttcgtgggcgcgcaagaggcaggcagcgcacacgtgcgcgcacccgggttgcggcaagagctacaccaagagctcccacctgaaggcgcatctgcgcacgcacacaggggagaagccatacgcctgcacgtgggaaggctgcggctggagattcgcgcgctcggacgagctgacccgccactaccggaaacacacggggcagcgccccttccgctgccagctctgcccacgtgctttttcgcgctctgaccacctggccttgcacatgaagcgccacctttga(SEQ ID NO:107)
人类MyoD(X56677)SEQ ID NO:44(蛋白质)和SEQ ID NO:108(DNA)
MELLSPPLRDVDLTAPDGSLCSFATTDDFYDDPCFDSPDLRFFEDLDPRLMHVGALLKPEEHSHFPAAVHPAPGAREDEHVRAPSGHHQAGRCLLWACKACKRKTTNADRRKAATMRERRRLSKVNEAFETLKRCTSSNPNQRLPKVEILRNAIRYIEGLQALLRDQDAAPPGAAAFYAPGPLPPGRGGEHYSGDSDASSPRSNCSDGMMDYSGPPSGARRRNCYEGAYYNEAPSEPRPGKSAAVSSLDYLSSIVERISTESPAAPALLLADVPSESPPRRQEAAAPSEGESSGDPTQSPDAAPQCPAGANPNPIYQVL(SEQ ID NO:44)
atggagctactgtcgccaccgctccgcgacgtagacctgacggcccccgacggctctctctgctcctttgccacaacggacgacttctatgacgacccgtgtttcgactccccggacctgcgcttcttcgaagacctggacccgcgcctgatgcacgtgggcgcgctcctgaaacccgaagagcactcgcacttccccgcggcggtgcacccggccccgggcgcacgtgaggacgagcatgtgcgcgcgcccagcgggcaccaccaggcgggccgctgcctactgtgggcctgcaaggcgtgcaagcgcaagaccaccaacgccgaccgccgcaaggccgccaccatgcgcgagcggcgccgcctgagcaaagtaaatgaggcctttgagacactcaagcgctgcacgtcgagcaatccaaaccagcggttgcccaaggtggagatcctgcgcaacgccatccgctatatcgagggcctgcaggctctgctgcgcgaccaggacgccgcgccccctggcgcagccgccttctatgcgccgggcccgctgcccccgggccgcggcggcgagcactacagcggcgactccgacgcgtccagcccgcgctccaactgctccgacggcatgatggactacagcggccccccgagcggcgcccggcggcggaactgctacgaaggcgcctactacaacgaggcgcccagcgaacccaggcccgggaagagtgcggcggtgtcgagcctagactacctgtccagcatcgtggagcgcatctccaccgagagccctgcggcgcccgccctcctgctggcggacgtgccttctgagtcgcctccgcgcaggcaagaggctgccgcccccagcgagggagagagcagcggcgaccccacccagtcaccggacgccgccccgcagtgccctgcgggtgcgaaccccaacccgatataccaggtgctctga(SEQ ID NO:108)
人类NGFI-A结合蛋白2(EGR1结合蛋白2)(NAB2)(NM_005967)SEQ ID NO:45(蛋白质)和SEQ ID NO:109(DNA)
MHRAPSPTAEQPPGGGDSARRTLQPRLKPSARAMALPRTLGELQLYRVLQRANLLSYYETFIQQGGDDVQQLCEAGEEEFLEIMALVGMATKPLHVRRLQKALREWATNPGLFSQPVPAVPVSSIPLFKISETAGTRKGSMSNGHGSPGEKAGSARSFSPKSPLELGEKLSPLPGGPGAGDPRIWPGRSTPESDVGAGGEEEAGSPPFSPPAGGGVPEGTGAGGLAAGGTGGGPDRLEPEMVRMVVESVERIFRSFPRGDAGEVTSLLKLNKKLARSVGHIFEMDDNDSQKEEEIRKYSIIYGRFDSKRREGKQLSLHELTINEAAAQFCMRDNTLLLRRVELFSLSRQVARESTYLSSLKGSRLHPEELGGPPLKKLKQEVGEQSHPEIQQPPPGPESYVPPYRPSLEEDSASLSGESLDGHLQAVGSCPRLTPPPADLPLALPAHGLWSRHILQQTLMDEGLRLARLVSHDRVGRLSPCVPAKPPLAEFEEGLLDRCPAPGPHPALVEGRRSSVKVEAEASRQ(SEQ ID NO:45)
atgcacagagcgccttcccccacagccgagcagccgccgggcggaggggacagcgcccgccggaccctgcagcccagactcaagcccagtgcccgagccatggcactgcctcggacgctgggggagctgcagctgtaccgggtcctgcagcgcgccaacctcctttcctactatgagaccttcatccagcagggaggggacgacgtgcagcagctgtgtgaggcgggtgaggaggagtttctggagatcatggcacttgtgggcatggccaccaagcccctccatgtccggcgcctgcagaaggcactgagagagtgggccaccaatccagggctcttcagtcaaccagtgcctgctgttcccgtctccagcatcccgctcttcaagatctctgagactgcgggtacccggaaagggagcatgagcaatgggcatggcagcccaggggaaaaggcaggcagtgcccgcagttttagccccaagagcccccttgaacttggagagaagctatcaccactgcctgggggacctggggcaggggacccccggatctggccaggccggagcactccagagtcggacgttggggcaggaggagaagaggaggctggctcgccccccttctccccccctgcagggggaggagtccctgaggggactggggctggggggctggcagcaggtgggactgggggtggtccagaccgactggagccagagatggtacgcatggtggtggaaagtgtggagaggatcttccggagcttcccaaggggggatgctggggaggtcacatccctgctaaagctgaataagaagctggcacggagcgttgggcacatctttgagatggatgataatgacagccagaaggaagaggagatccgcaaatacagcatcatctatggccgtttcgactctaagcggcgggagggcaagcagctcagcctgcacgagctcaccatcaacgaggctgctgcccagttctgcatgagggacaacacgctcttattacggagagtggagctcttctctttgtcccgccaagtagcccgagagagcacctacttgtcctccttgaagggctccaggcttcaccctgaagaactgggaggccctccactgaagaagctgaaacaagaggttggagaacagagtcaccctgaaatccagcagcctcccccaggccctgagtcctatgtacccccataccgccccagcctggaggaggacagcgccagcctgtctggggagagtctggatggacatttgcaggctgtggggtcatgtccaaggctgacgccgccccctgctgacctgcctctggcattgccagcccatgggctatggagccgacacatcctgcagcagacactgatggacgaggggctgcggctcgcccgcctcgtctcccacgaccgcgtgggccgcctcagcccctgtgtgcctgcgaagccacctctcgcagagttcgaggaagggctgctggacagatgtcctgccccaggaccccatcccgcgctggtggagggtcgcaggagcagcgtgaaagtggaggctgaggccagccggcagtga(SEQ ID NO:109)
人类早期生长响应1(EGR1)(NM_001964)SEQ ID NO:46(蛋白质)和SEQ ID NO:110(DNA)
MAAAKAEMQLMSPLQISDPFGSFPHSPTMDNYPKLEEMMLLSNGAPQFLGAAGAPEGSGSNSSSSSSGGGGGGGGGSNSSSSSSTFNPQADTGEQPYEHLTAESFPDISLNNEKVLVETSYPSQTTRLPPITYTGRFSLEPAPNSGNTLWPEPLFSLVSGLVSMTNPPASSSSAPSPAASSASASQSPPLSCAVPSNDSSPIYSAAPTFPTPNTDIFPEPQSQAFPGSAGTALQYPPPAYPAAKGGFQVPMIPDYLFPQQQGDLGLGTPDQKPFQGLESRTQQPSLTPLSTIKAFATQSGSQDLKALNTSYQSQLIKPSRMRKYPNRPSKTPPHERPYACPVESCDRRFSRSDELTRHIRIHTGQKPFQCRICMRNFSRSDHLTTHIRTHTGEKPFACDICGRKFARSDERKRHTKIHLRQKDKKADKSVVASSATSSLSSYPSPVATSYPSPVTTSYPSPATTSYPSPVPTSFSSPGSSTYPSPVHSGFPSPSVATTYSSVPPAFPAQVSSFPSSAVTNSFSASTGLSDMTATFSPRTIEIC(SEQ ID NO:46)
atggccgcggccaaggccgagatgcagctgatgtccccgctgcagatctctgacccgttcggatcctttcctcactcgcccaccatggacaactaccctaagctggaggagatgatgctgctgagcaacggggctccccagttcctcggcgccgccggggccccagagggcagcggcagcaacagcagcagcagcagcagcgggggcggtggaggcggcgggggcggcagcaacagcagcagcagcagcagcaccttcaaccctcaggcggacacgggcgagcagccctacgagcacctgaccgcagagtcttttcctgacatctctctgaacaacgagaaggtgctggtggagaccagttaccccagccaaaccactcgactgccccccatcacctatactggccgcttttccctggagcctgcacccaacagtggcaacaccttgtggcccgagcccctcttcagcttggtcagtggcctagtgagcatgaccaacccaccggcctcctcgtcctcagcaccatctccagcggcctcctccgcctccgcctcccagagcccacccctgagctgcgcagtgccatccaacgacagcagtcccatttactcagcggcacccaccttccccacgccgaacactgacattttccctgagccacaaagccaggccttcccgggctcggcagggacagcgctccagtacccgcctcctgcctaccctgccgccaagggtggcttccaggttcccatgatccccgactacctgtttccacagcagcagggggatctgggcctgggcaccccagaccagaagcccttccagggcctggagagccgcacccagcagccttcgctaacccctctgtctactattaaggcctttgccactcagtcgggctcccaggacctgaaggccctcaataccagctaccagtcccagctcatcaaacccagccgcatgcgcaagtaccccaaccggcccagcaagacgcccccccacgaacgcccttacgcttgcccagtggagtcctgtgatcgccgcttctcccgctccgacgagctcacccgccacatccgcatccacacaggccagaagcccttccagtgccgcatctgcatgcgcaacttcagccgcagcgaccacctcaccacccacatccgcacccacacaggcgaaaagcccttcgcctgcgacatctgtggaagaaagtttgccaggagcgatgaacgcaagaggcataccaagatccacttgcggcagaaggacaagaaagcagacaaaagtgttgtggcctcttcggccacctcctctctctcttcctacccgtccccggttgctacctcttacccgtccccggttactacctcttatccatccccggccaccacctcatacccatcccctgtgcccacctccttctcctctcccggctcctcgacctacccatcccctgtgcacagtggcttcccctccccgtcggtggccaccacgtactcctctgttccccctgctttcccggcccaggtcagcagcttcccttcctcagctgtcaccaactccttcagcgcctccacagggctttcggacatgacagcaaccttttctcccaggacaattgaaatttgctaa(SEQ ID NO:110)
人类独立生长因子1转录阻遏物(GFI1)(NM_005263)SEQ ID NO:47(蛋白质)和SEQ ID NO:111(DNA)
MPRSFLVKSKKAHSYHQPRSPGPDYSLRLENVPAPSRADSTSNAGGAKAEPRDRLSPESQLTEAPDRASASPDSCEGSVCERSSEFEDFWRPPSPSASPASEKSMCPSLDEAQPFPLPFKPYSWSGLAGSDLRHLVQSYRPCGALERGAGLGLFCEPAPEPGHPAALYGPKRAAGGAGAGAPGSCSAGAGATAGPGLGLYGDFGSAAAGLYERPTAAAGLLYPERGHGLHADKGAGVKVESELLCTRLLLGGGSYKCIKCSKVFSTPHGLEVHVRRSHSGTRPFACEMCGKTFGHAVSLEQHKAVHSQERSFDCKICGKSFKRSSTLSTHLLIHSDTRPYPCQYCGKRFHQKSDMKKHTFIHTGEKPHKCQVCGKAFSQSSNLITHSRKHTGFKPFGCDLCGKGFQRKVDLRRHRETQHGLK(SEQ ID NO:47)
atgccgcgctcatttctcgtcaaaagcaagaaggctcacagctaccaccagccgcgctccccaggaccagactattccctccgtttagagaatgtaccggcgcctagccgagcagacagcacttcaaatgcaggcggggcgaaggcggagccccgggaccgtttgtcccccgaatcgcagctgaccgaagccccagacagagcctccgcatccccagacagctgcgaaggcagcgtctgcgaacggagctcggagtttgaggacttctggaggcccccgtcaccctccgcgtctccagcctcggagaagtcaatgtgcccatcgctggacgaagcccagcccttccccctgcctttcaaaccgtactcatggagcggcctggcgggttctgacctgcggcacctggtgcagagctaccgaccgtgtggggccctggagcgtggcgctggcctgggcctcttctgcgaacccgccccggagcctggccacccggccgcgctgtacggcccgaagcgggctgccggcggcgcgggggccggggcgccagggagctgcagcgcaggggccggtgccaccgctggccctggcctagggctctacggcgacttcgggtctgcggcagccgggctgtatgagaggcccacggcagcggcgggcttgctgtaccccgagcgtggccacgggctgcacgcagacaagggcgctggcgtcaaggtggagtcggagctgctgtgcacccgcctgctgctgggcggcggctcctacaagtgcatcaagtgcagcaaggtgttctccacgccgcacgggctcgaggtgcacgtgcgcaggtcccacagcggtaccagaccctttgcctgcgagatgtgcggcaagaccttcgggcacgcggtgagcctggagcagcacaaagccgtgcactcgcaggaacggagctttgactgtaagatctgtgggaagagcttcaagaggtcatccacactgtccacacacctgcttatccactcagacactcggccctacccctgtcagtactgtggcaagaggttccaccagaagtcagacatgaagaaacacactttcatccacactggtgagaagcctcacaagtgccaggtgtgcggcaaggcattcagccagagctccaacctcatcacccacagccgcaaacacacaggcttcaagcccttcggctgcgacctctgtgggaagggtttccagaggaaggtggacctccgaaggcaccgggagacgcagcatgggctcaaatga(SEQ ID NO:111)
人类配对盒5(PAX5)(NM_016734)SEQ ID NO:48(蛋白质)和SEQ ID NO:112(DNA)
MDLEKNYPTPRTSRTGHGGVNQLGGVFVNGRPLPDVVRQRIVELAHQGVRPCDISRQLRVSHGCVSKILGRYYETGSIKPGVIGGSKPKVATPKVVEKIAEYKRQNPTMFAWEIRDRLLAERVCDNDTVPSVSSINRIIRTKVQQPPNQPVPASSHSIVSTGSVTQVSSVSTDSAGSSYSISGILGITSPSADTNKRKRDEGIQESPVPNGHSLPGRDFLRKQMRGDLFTQQQLEVLDRVFERQHYSDIFTTTEPIKPEQTTEYSAMASLAGGLDDMKANLASPTPADIGSSVPGPQSYPIVTGRDLASTTLPGYPPHVPPAGQGSYSAPTLTGMVPGSEFSGSPYSHPQYSSYNDSWRFPNPGLLGSPYYYSAAARGAAPPAAATAYDRH(SEQ ID NO:48)
atggatttagagaaaaattatccgactcctcggaccagcaggacaggacatggaggagtgaatcagcttgggggggtttttgtgaatggacggccactcccggatgtagtccgccagaggatagtggaacttgctcatcaaggtgtcaggccctgcgacatctccaggcagcttcgggtcagccatggttgtgtcagcaaaattcttggcaggtattatgagacaggaagcatcaagcctggggtaattggaggatccaaaccaaaggtcgccacacccaaagtggtggaaaaaatcgctgaatataaacgccaaaatcccaccatgtttgcctgggagatcagggaccggctgctggcagagcgggtgtgtgacaatgacaccgtgcctagcgtcagttccatcaacaggatcatccggacaaaagtacagcagccacccaaccaaccagtcccagcttccagtcacagcatagtgtccactggctccgtgacgcaggtgtcctcggtgagcacggattcggccggctcgtcgtactccatcagcggcatcctgggcatcacgtcccccagcgccgacaccaacaagcgcaagagagacgaaggtattcaggagtctccggtgccgaacggccactcgcttccgggcagagacttcctccggaagcagatgcggggagacttgttcacacagcagcagctggaggtgctggaccgcgtgtttgagaggcagcactactcagacatcttcaccaccacagagcccatcaagcccgagcagaccacagagtattcagccatggcctcgctggctggtgggctggacgacatgaaggccaatctggccagccccacccctgctgacatcgggagcagtgtgccaggcccgcagtcctaccccattgtgacaggccgtgacttggcgagcacgaccctccccgggtaccctccacacgtcccccccgctggacagggcagctactcagcaccgacgctgacagggatggtgcctgggagtgagttttccgggagtccctacagccaccctcagtattcctcgtacaacgactcctggaggttccccaacccggggctgcttggctccccctactattatagcgctgccgcccgaggagccgccccacctgcagccgccactgcctatgaccgtcactga(SEQ ID NO:112)
人类T细胞特异性T框转录因子T-bet mRNA(AF241243)SEQ ID NO:49(蛋白质)和SEQ ID NO:113(DNA)
MGIVEPGCGDMLTGTEPMPGSDEGRAPGADPQHRYFYPEPGAQDADERRGGGSLGSPYPGGALVPAPPSRFLGAYAYPPRPQAAGFPGAGESFPPPADAEGYQPGEGYAAPDPRAGLYPGPREDYALPAGLEVSGKLRVALNNHLLWSKFNQHQTEMIITKQGRRMFPFLSFTVAGLEPTSHYRMFVDVVLVDQHHWRYQSGKWVQCGKAEGSMPGNRLYVHPDSPNTGAHWMRQEVSFGKLKLTNNKGASNNVTQMIVLQSLHKYQPRLHIVEVNDGEPEAACNASNTHIFTFQETQFIAVTAYQNAEITQLKIDNNPFAKGFRENFESMYTSVDTSIPSPPGPNCQFLGGDHYSPLLPNQYPVPSRFYPDLPGQAKDVVPQAYWLGAPRDHSYEAEFRAVSMKPAFLPSAPGPTMSYYRGQEVLAPGAGWPVAPQYPPKMGPASWFRPMRTLPMEPGPGGSEGRGPEDQGPPLVWTEIAPIRPESSDSGLGEGDSKRRRVSPYPSSGDSSSPAGAPSPFDKEAEGQFYNYFPN(SEQ ID NO:49)
atgggcatcgtggagccgggttgcggagacatgctgacgggcaccgagccgatgccggggagcgacgagggccgggcgcctggcgccgacccgcagcaccgctacttctacccggagccgggcgcgcaggacgcggacgagcgtcgcgggggcggcagcctggggtctccctacccggggggcgccttggtgcccgccccgccgagccgcttccttggagcctacgcctacccgccgcgaccccaggcggccggcttccccggcgcgggcgagtccttcccgccgcccgcggacgccgagggctaccagccgggcgagggctacgccgccccggacccgcgcgccgggctctacccggggccgcgtgaggactacgcgctacccgcgggactggaggtgtcggggaaactgagggtcgcgctcaacaaccacctgttgtggtccaagtttaatcagcaccagacagagatgatcatcaccaagcagggacggcggatgttcccattcctgtcatttactgtggccgggctggagcccaccagccactacaggatgtttgtggacgtggtcttggtggaccagcaccactggcggtaccagagcggcaagtgggtgcagtgtggaaaggccgagggcagcatgccaggaaaccgcctgtacgtccacccggactcccccaacacaggagcgcactggatgcgccaggaagtttcatttgggaaactaaagctcacaaacaacaagggggcgtccaacaatgtgacccagatgattgtgctccagtccctccataagtaccagccccggctgcatatcgttgaggtgaacgacggagagccagaggcagcctgcaacgcttccaacacgcatatctttactttccaagaaacccagttcattgccgtgactgcctaccagaatgccgagattactcagctgaaaattgataataacccctttgccaaaggattccgggagaactttgagtccatgtacacatctgttgacaccagcatcccctccccgcctggacccaactgtcaattccttgggggagatcactactctcctctcctacccaaccagtatcctgttcccagccgcttctaccccgaccttcctggccaggcgaaggatgtggttccccaggcttactggctgggggccccccgggaccacagctatgaggctgagtttcgagcagtcagcatgaagcctgcattcttgccctctgcccctgggcccaccatgtcctactaccgaggccaggaggtcctggcacctggagctggctggcctgtggcaccccagtaccctcccaagatgggcccggccagctggttccgccctatgcggactctgcccatggaacccggccctggaggctcagagggacggggaccagaggaccagggtccccccttggtgtggactgagattgcccccatccggccggaatccagtgattcaggactgggcgaaggagactctaagaggaggcgcgtgtccccctatccttccagtggtgacagctcctcccctgctggggccccttctccttttgataaggaagctgaaggacagttttataactattttcccaactga(SEQ ID NO:113)
人类GATA结合蛋白3(GATA3)(NM_001002295)SEQ ID NO:50(蛋白质)和SEQ ID NO:114(DNA)
MEVTADQPRWVSHHHPAVLNGQHPDTHHPGLSHSYMDAAQYPLPEEVDVLFNIDGQGNHVPPYYGNSVRATVQRYPPTHHGSQVCRPPLLHGSLPWLDGGKALGSHHTASPWNLSPFSKTSIHHGSPGPLSVYPPASSSSLSGGHASPHLFTFPPTPPKDVSPDPSLSTPGSAGSARQDEKECLKYQVPLPDSMKLESSHSRGSMTALGGASSSTHHPITTYPPYVPEYSSGLFPPSSLLGGSPTGFGCKSRPKARSSTEGRECVNCGATSTPLWRRDGTGHYLCNACGLYHKMNGQNRPLIKPKRRLSAARRAGTSCANCQTTTTTLWRRNANGDPVCNACGLYYKLHNINRPLTMKKEGIQTRNRKMSSKSKKCKKVHDSLEDFPKNSSFNPAALSRHMSSLSHISPFSHSSHMLTTPTPMHPPSSLSFGPHHPSSMVTAMG(SEQ ID NO:50)
atggaggtgacggcggaccagccgcgctgggtgagccaccaccaccccgccgtgctcaacgggcagcacccggacacgcaccacccgggcctcagccactcctacatggacgcggcgcagtacccgctgccggaggaggtggatgtgctttttaacatcgacggtcaaggcaaccacgtcccgccctactacggaaactcggtcagggccacggtgcagaggtaccctccgacccaccacgggagccaggtgtgccgcccgcctctgcttcatggatccctaccctggctggacggcggcaaagccctgggcagccaccacaccgcctccccctggaatctcagccccttctccaagacgtccatccaccacggctccccggggcccctctccgtctaccccccggcctcgtcctcctccttgtcggggggccacgccagcccgcacctcttcaccttcccgcccaccccgccgaaggacgtctccccggacccatcgctgtccaccccaggctcggccggctcggcccggcaggacgagaaagagtgcctcaagtaccaggtgcccctgcccgacagcatgaagctggagtcgtcccactcccgtggcagcatgaccgccctgggtggagcctcctcgtcgacccaccaccccatcaccacctacccgccctacgtgcccgagtacagctccggactcttcccccccagcagcctgctgggcggctcccccaccggcttcggatgcaagtccaggcccaaggcccggtccagcacagaaggcagggagtgtgtgaactgtggggcaacctcgaccccactgtggcggcgagatggcacgggacactacctgtgcaacgcctgcgggctctatcacaaaatgaacggacagaaccggcccctcattaagcccaagcgaaggctgtctgcagccaggagagcagggacgtcctgtgcgaactgtcagaccaccacaaccacactctggaggaggaatgccaatggggaccctgtctgcaatgcctgtgggctctactacaagcttcacaatattaacagacccctgactatgaagaaggaaggcatccagaccagaaaccgaaaaatgtctagcaaatccaaaaagtgcaaaaaagtgcatgactcactggaggacttccccaagaacagctcgtttaacccggccgccctctccagacacatgtcctccctgagccacatctcgcccttcagccactccagccacatgctgaccacgcccacgccgatgcacccgccatccagcctgtcctttggaccacaccacccctccagcatggtcaccgccatgggttag(SEQ ID NO:114)
人类FOXP3(EF534714)SEQ ID NO:51(蛋白质)和SEQ ID NO:115(DNA)
MPNPRPGKPSAPSLALGPSPGASPSWRAAPKASDLLGARGPGGTFQGRDLRGGAHASSSSLNPMPPSQLQLPTLPLVMVAPSGARLGPLPHLQALLQDRPHFMHQLSTVDAHARTPVLQVHPLESPAMISLTPPTTATGVFSLKARPGLPPGINVASLEWVSREPALLCTFPNPSAPRKDSTLSAVPQSSYPLLANGVCKWPGCEKVFEEPEDFLKHCQADHLLDEKGRAQCLLQREMVQSLEQQLVLEKEKLSAMQAHLAGKMALTKASSVASSDKGSCCIVAAGSQGPVVPAWSGPREAPDSLFAVRRHLWGSHGNSTFPEFLHNMDYFKFHNMRPPFTYATLIRWAILEAPEKQRTLNEIYHWFTRMFAFFRNHPATWKNAIRHNLSLHKCFVRVESEKGAVWTVDELEFRKKRSQRPSRCSNPTPGP(SEQ ID NO:51)
atgcccaaccccaggcctggcaagccctcggccccttccttggcccttggcccatccccaggagcctcgcccagctggagggctgcacccaaagcctcagacctgctgggggcccggggcccagggggaaccttccagggccgagatcttcgaggcggggcccatgcctcctcttcttccttgaaccccatgccaccatcgcagctgcagctgcccacactgcccctagtcatggtggcaccctccggggcacggctgggccccttgccccacttacaggcactcctccaggacaggccacatttcatgcaccagctctcaacggtggatgcccacgcccggacccctgtgctgcaggtgcaccccctggagagcccagccatgatcagcctcacaccacccaccaccgccactggggtcttctccctcaaggcccggcctggcctcccacctgggatcaacgtggccagcctggaatgggtgtccagggagccggcactgctctgcaccttcccaaatcccagtgcacccaggaaggacagcaccctttcggctgtgccccagagctcctacccactgctggcaaatggtgtctgcaagtggcccggatgtgagaaggtcttcgaagagccagaggacttcctcaagcactgccaggcggaccatcttctggatgagaagggcagggcacaatgtctcctccagagagagatggtacagtctctggagcagcagctggtgctggagaaggagaagctgagtgccatgcaggcccacctggctgggaaaatggcactgaccaaggcttcatctgtggcatcatccgacaagggctcctgctgcatcgtagctgctggcagccaaggccctgtcgtcccagcctggtctggcccccgggaggcccctgacagcctgtttgctgtccggaggcacctgtggggtagccatggaaacagcacattcccagagttcctccacaacatggactacttcaagttccacaacatgcgaccccctttcacctacgccacgctcatccgctgggccatcctggaggctccagagaagcagcggacactcaatgagatctaccactggttcacacgcatgtttgccttcttcagaaaccatcctgccacctggaagaacgccatccgccacaacctgagtctgcacaagtgctttgtgcgggtggagagcgagaagggggctgtgtggaccgtggatgagctggagttccgcaagaaacggagccagaggcccagcaggtgttccaaccctacacctggcccctga(SEQ ID NO:115)
人类孤独受体RORγ(U16997)SEQ ID NO:52(蛋白质)和SEQ ID NO:116(DNA)
MDRAPQRQHRASRELLAAKKTHTSQIEVIPCKICGDKSSGIHYGVITCEGCKGFFRRSQRCNAAYSCTRQQNCPIDRTSRNRCQHCRLQKCLALGMSRDAVKFGRMSKKQRDSLHAEVQKQLQQRQQQQQEPVVKTPPAGAQGADTLTYTLGLPDGQLPLGSSPDLPEASACPPGLLKASGSGPSYSNNLAKAGLNGASCHLEYSPERGKAEGRESFYSTGSQLTPDRCGLRFEEHRHPGLGELGQGPDSYGSPSFRSTPEAPYASLTEIEHLVQSVCKSYRETCQLRLEDLLRQRSNIFSREEVTGYQRKSMWEMWERCAHHLTEAIQYVVEFAKRLSGFMELCQNDQIVLLKAGAMEVVLVRMCRAYNADNRTVFFEGKYGGMELFRALGCSELISSIFDFSHSLSALHFSEDEIALYTALVLINAHRPGLQEKRKVEQLQYNLELAFHHHLCKTHRQSILAKLPPKGKLRSLCSQHVERLQIFQHLHPIVVQAAFPPLYKELFSTETESPVGCPSDLEEGLLASPYGLLATSLDPVPPSPFSFPMNPGGWSPPALWK(SEQ ID NO:52)
atggacagggccccacagagacagcaccgagcctcacgggagctgctggctgcaaagaagacccacacctcacaaattgaagtgatcccttgcaaaatctgtggggacaagtcgtctgggatccactacggggttatcacctgtgaggggtgcaagggcttcttccgccggagccagcgctgtaacgcggcctactcctgcacccgtcagcagaactgccccatcgaccgcaccagccgaaaccgatgccagcactgccgcctgcagaaatgcctggcgctggggatgtcccgagatgctgtcaagttcggccgcatgtccaagaagcagagggacagcctgcatgcagaagtgcagaaacagctgcagcagcggcaacagcagcaacaggaaccagtggtcaagacccctccagcaggggcccaaggagcagataccctcacctacaccttggggctcccagacgggcagctgcccctgggctcctcgcctgacctgcctgaggcttctgcctgtccccctggcctcctgaaagcctcaggctctgggccctcatattccaacaacttggccaaggcagggctcaatggggcctcatgccaccttgaatacagccctgagcggggcaaggctgagggcagagagagcttctatagcacaggcagccagctgacccctgaccgatgtggacttcgttttgaggaacacaggcatcctgggcttggggaactgggacagggcccagacagctacggcagccccagtttccgcagcacaccggaggcaccctatgcctccctgacagagatagagcacctggtgcagagcgtctgcaagtcctacagggagacatgccagctgcggctggaggacctgctgcggcagcgctccaacatcttctcccgggaggaagtgactggctaccagaggaagtccatgtgggagatgtgggaacggtgtgcccaccacctcaccgaggccattcagtacgtggtggagttcgccaagaggctctcaggctttatggagctctgccagaatgaccagattgtgcttctcaaagcaggagcaatggaagtggtgctggttaggatgtgccgggcctacaatgctgacaaccgcacggtcttttttgaaggcaaatacggtggcatggagctgttccgagccttgggctgcagcgagctcatcagctccatctttgacttctcccactccctaagtgccttgcacttttccgaggatgagattgccctctacacagcccttgttctcatcaatgcccatcggccagggctccaagagaaaaggaaagtagaacagctgcagtacaatctggagctggcctttcatcatcatctctgcaagactcatcgccaaagcatcctggcaaagctgccacccaaggggaagcttcggagcctgtgtagccagcatgtggaaaggctgcagatcttccagcacctccaccccatcgtggtccaagccgctttccctccactctacaaggagctcttcagcactgaaaccgagtcacctgtgggctgtccaagtgacctggaagagggactccttgcctctccctatggcctgctggccacctccctggaccccgttccaccctcacccttttcctttcccatgaaccctggagggtggtccccaccagctctttggaagtga(SEQ ID NO:116)
人类肝细胞核因子4,α(HNF4A),(NM_178849)SEQ ID NO:53(蛋白质)和SEQ ID NO:117(DNA)
MRLSKTLVDMDMADYSAALDPAYTTLEFENVQVLTMGNDTSPSEGTNLNAPNSLGVSALCAICGDRATGKHYGASSCDGCKGFFRRSVRKNHMYSCRFSRQCVVDKDKRNQCRYCRLKKCFRAGMKKEAVQNERDRISTRRSSYEDSSLPSINALLQAEVLSRQITSPVSGINGDIRAKKIASIADVCESMKEQLLVLVEWAKYIPAFCELPLDDQVALLRAHAGEHLLLGATKRSMVFKDVLLLGNDYIVPRHCPELAEMSRVSIRILDELVLPFQELQIDDNEYAYLKAIIFFDPDAKGLSDPGKIKRLRSQVQVSLEDYINDRQYDSRGRFGELLLLLPTLQSITWQMIEQIQFIKLFGMAKIDNLLQEMLLGGSPSDAPHAHHPLHPHLMQEHMGTNVIVANTMPTHLSNGQMSTPETPQPSPPGGSGSEPYKLLPGAVATIVKPLSAIPQPTITKQEVI(SEQ ID NO:53)
atgcgactctccaaaaccctcgtcgacatggacatggccgactacagtgctgcactggacccagcctacaccaccctggaatttgagaatgtgcaggtgttgacgatgggcaatgacacgtccccatcagaaggcaccaacctcaacgcgcccaacagcctgggtgtcagcgccctgtgtgccatctgcggggaccgggccacgggcaaacactacggtgcctcgagctgtgacggctgcaagggcttcttccggaggagcgtgcggaagaaccacatgtactcctgcagatttagccggcagtgcgtggtggacaaagacaagaggaaccagtgccgctactgcaggctcaagaaatgcttccgggctggcatgaagaaggaagccgtccagaatgagcgggaccggatcagcactcgaaggtcaagctatgaggacagcagcctgccctccatcaatgcgctcctgcaggcggaggtcctgtcccgacagatcacctcccccgtctccgggatcaacggcgacattcgggcgaagaagattgccagcatcgcagatgtgtgtgagtccatgaaggagcagctgctggttctcgttgagtgggccaagtacatcccagctttctgcgagctccccctggacgaccaggtggccctgctcagagcccatgctggcgagcacctgctgctcggagccaccaagagatccatggtgttcaaggacgtgctgctcctaggcaatgactacattgtccctcggcactgcccggagctggcggagatgagccgggtgtccatacgcatccttgacgagctggtgctgcccttccaggagctgcagatcgatgacaatgagtatgcctacctcaaagccatcatcttctttgacccagatgccaaggggctgagcgatccagggaagatcaagcggctgcgttcccaggtgcaggtgagcttggaggactacatcaacgaccgccagtatgactcgcgtggccgctttggagagctgctgctgctgctgcccaccttgcagagcatcacctggcagatgatcgagcagatccagttcatcaagctcttcggcatggccaagattgacaacctgttgcaggagatgctgctgggagggtcccccagcgatgcaccccatgcccaccaccccctgcaccctcacctgatgcaggaacatatgggaaccaacgtcatcgttgccaacacaatgcccactcacctcagcaacggacagatgtccacccctgagaccccacagccctcaccgccaggtggctcagggtctgagccctataagctcctgccgggagccgtcgccacaatcgtcaagcccctctctgccatcccccagccgaccatcaccaagcaggaagttatctag(SEQ ID NO:117)
人类信号传导子及转录激活子Stat5A(U43185)SEQ ID NO:54(蛋白质)和SEQ ID NO:118(DNA)
MAGWIQAQQLQGDALRQMQVLYGQHFPIEVRHYLAQWIESQPWDAIDLDNPQDRAQATQLLEGLVQELQKKAEHQVGEDGFLLKIKLRHYATQLQKTYDRCPLELVRCIRHILYNEQRLVREANNCSSPAGILVDAMSQKHLQINQTFEELRLVTQDTENELKKLQQTQEYFIIQYQESLRIQAQFAQLAQLSPQERLSRETALQQKQVSLEAWLQREAQTLQQYRVELAEKHQKTLQLLRKQQTIILDDELIQWKRRQQLAGNGGPPEGSLDVLQSWCEKLAEIIWQNRQQIRRAEHLCQQLPIPGPVEEMLAEVNATITDIISALVTSTFIIEKQPPQVLKTQTKFAATVRLLVGGKLNVHMNPPQVKATIISEQQAKSLLKNENTRNECSGEILNNCCVMEYHQATGTLSAHFRNMSLKRIKRADRRGAESVTEEKFTVLFESQFSVGSNELVFQVKTLSLPVVVIVHGSQDHNATATVLWDNAFAEPGRVPFAVPDKVLWPQLCEALNMKFKAEVQSNRGLTKENLVFLAQKLFNNSSSHLEDYSGLSVSWSQFNRENLPGWNYTFWQWFDGVMEVLKKHHKPHWNDGAILGFVNKQQAHDLLINKPDGTFLLRFSDSEIGGITIAWKFDSPERNLWNLKPFTTRDFSIRSLADRLGDLSYLIYVFPDRPKDEVFSKYYTPVLAKAVDGYVKPQIKQVVPEFVNASADAGGSSATYMDQAPSPAVCPQAPYNMYPQNPDHVLDQDGEFDLDETMDVARHVEELLRRPMDSLDSRLSPPAGLFTSARGSLS(SEQ ID NO:54)
atggcgggctggatccaggcccagcagctgcagggagacgcgctgcgccagatgcaggtgctgtacggccagcacttccccatcgaggtccggcactacttggcccagtggattgagagccagccatgggatgccattgacttggacaatccccaggacagagcccaagccacccagctcctggagggcctggtgcaggagctgcagaagaaggcggagcaccaggtgggggaagatgggtttttactgaagatcaagctgaggcactacgccacgcagctccagaaaacatatgaccgctgccccctggagctggtccgctgcatccggcacattctgtacaatgaacagaggctggtccgagaagccaacaattgcagctctccggctgggatcctggttgacgccatgtcccagaagcaccttcagatcaaccagacatttgaggagctgcgactggtcacgcaggacacagagaatgagctgaagaaactgcagcagactcaggagtacttcatcatccagtaccaggagagcctgaggatccaagctcagtttgcccagctggcccagctgagcccccaggagcgtctgagccgggagacggccctccagcagaagcaggtgtctctggaggcctggttgcagcgtgaggcacagacactgcagcagtaccgcgtggagctggccgagaagcaccagaagaccctgcagctgctgcggaagcagcagaccatcatcctggatgacgagctgatccagtggaagcggcggcagcagctggccgggaacggcgggccccccgagggcagcctggacgtgctacagtcctggtgtgagaagttggccgagatcatctggcagaaccggcagcagatccgcagggctgagcacctctgccagcagctgcccatccccggcccagtggaggagatgctggccgaggtcaacgccaccatcacggacattatctcagccctggtgaccagcacattcatcattgagaagcagcctcctcaggtcctgaagacccagaccaagtttgcagccaccgtacgcctgctggtgggcgggaagctgaacgtgcacatgaatcccccccaggtgaaggccaccatcatcagtgagcagcaggccaagtctctgcttaaaaatgagaacacccgcaacgagtgcagtggtgagatcctgaacaactgctgcgtgatggagtaccaccaagccacgggcaccctcagtgcccacttcaggaacatgtcactgaagaggatcaagcgtgctgaccggcggggtgcagagtccgtgacagaggagaagttcacagtcctgtttgagtctcagttcagtgttggcagcaatgagcttgtgttccaggtgaagactctgtccctacctgtggttgtcatcgtccacggcagccaggaccacaatgccacggctactgtgctgtgggacaatgcctttgctgagccgggcagggtgccatttgccgtgcctgacaaagtgctgtggccgcagctgtgtgaggcgctcaacatgaaattcaaggccgaagtgcagagcaaccggggcctgaccaaggagaacctcgtgttcctggcgcagaaactgttcaacaacagcagcagccacctggaggactacagtggcctgtccgtgtcctggtcccagttcaacagggagaacttgccgggctggaactacaccttctggcagtggtttgacggggtgatggaggtgttgaagaagcaccacaagccccactggaatgatggggccatcctaggttttgtgaataagcaacaggcccacgacctgctcatcaacaagcccgacgggaccttcttgttgcgctttagtgactcagaaatcgggggcatcaccatcgcctggaagtttgattccccggaacgcaacctgtggaacctgaaaccattcaccacgcgggatttctccatcaggtccctggctgaccggctgggggacctgagctatctcatctatgtgtttcctgaccgccccaaggatgaggtcttctccaagtactacactcctgtgctggctaaagctgttgatggatatgtgaaaccacagatcaagcaagtggtccctgagtttgtgaatgcatctgcagatgctgggggcagcagcgccacgtacatggaccaggccccctccccagctgtgtgcccccaggctccctataacatgtacccacagaaccctgaccatgtactcgatcaggatggagaattcgacctggatgagaccatggatgtggccaggcacgtggaggaactcttacgccgaccaatggacagtcttgactcccgcctctcgccccctgccggtcttttcacctctgccagaggctccctctcatga(SEQ ID NO:118)
人类鲨烯环氧酶(ERG1)mRNA,(AF098865)SEQ ID NO:55(蛋白质)和SEQ ID NO:119(DNA)
MWTFLGIATFTYFYKKFGDFITLANREVLLCVLVFLSLGLVLSYRCRHRNGGLLGRQQSGSQFALFSDILSGLPFIGFFWAKSPPESENKEQLEARRRRKGTNISETSLIGTAACTSTSSQNDPEVIIVGAGVLGSALAAVLSRDGRKVTVIERDLKEPDRIVGEFLQPGGYHVLKDLGLGDTVEGLDAQVVNGYMIHDQESKSEVQIPYPLSENNQVQSGRAFHHGRFIMSLRKAAMAEPNAKFIEGVVLQLLEEDDVVMGVQYKDKETGDIKELHAPLTVVADGLFSKFRKSLVSNKVSVSSHFVGFLMKNAPQFKANHAELILANPSPVLIYQISSSETRVLVDIRGEMPRNLREYMVEKIYPQIPDHLKEPFLEATDNSHLRSMPASFLPPSSVKKRGVLLLGDAYNMRHPLTGGGMTVAFKDIKLWRKLLKGIPDLYDDAAIFEAKKSFYWARKTSHSFVVNILAQALYELFSATDDSLHQLRKACFLYFKLGGECVAGPVGLLSVLSPNPLVLIGHFFAVAIYAVYFCFKSEPWITKPRALLSSGAVLYKACSVIFPLIYSEMKYMVH(SEQ ID NO:55)
atgtggacttttctgggcattgccactttcacctatttttataagaagttcggggacttcatcactttggccaacagggaggtcctgttgtgcgtgctggtgttcctctcgctgggcctggtgctctcctaccgctgtcgccaccgaaacgggggtctcctcgggcgccagcagagcggctcccagttcgccctcttctcggatattctctcaggcctgcctttcattggcttcttctgggccaaatccccccctgaatcagaaaataaggagcagctcgaggccaggaggcgcagaaaaggaaccaatatttcagaaacaagcttaataggaacagctgcctgtacatcaacatcttctcagaatgacccagaagttatcatcgtgggagctggcgtgcttggctctgctttggcagctgtgctttccagagatggaagaaaggtgacagtcattgagagagacttaaaagagcctgacagaatagttggagaattcctgcagccgggtggttatcatgttctcaaagaccttggtcttggagatacagtggaaggtcttgatgcccaggttgtaaatggttacatgattcatgatcaggaaagcaaatcagaggttcagattccttaccctctgtcagaaaacaatcaagtgcagagtggaagagctttccatcacggaagattcatcatgagtctccggaaagcagctatggcagagcccaatgcaaagtttattgaaggtgttgtgttacagttattagaggaagatgatgttgtgatgggagttcagtacaaggataaagagactggagatatcaaggaactccatgctccactgactgttgttgcagatgggcttttctccaagttcaggaaaagcctggtctccaataaagtttctgtatcatctcattttgttggctttcttatgaagaatgcaccacagtttaaagcaaatcatgctgaacttattttagctaacccgagtccagttctcatctaccagatttcatccagtgaaactcgagtacttgttgacattagaggagaaatgccaaggaatttaagagaatacatggttgaaaaaatttacccacaaatacctgatcacctgaaagaaccattcttagaagccactgacaattctcatctgaggtccatgccagcaagcttccttcctccttcatcagtgaagaaacgaggtgttcttcttttgggagacgcatataatatgaggcatccacttactggtggaggaatgactgttgcttttaaagatataaaactatggagaaaactgctaaagggtatccctgacctttatgatgatgcagctattttcgaggccaaaaaatcattttactgggcaagaaaaacatctcattcctttgtcgtgaatatccttgctcaggctctttatgaattattttctgccacagatgattccctgcatcaactaagaaaagcctgttttctttatttcaaacttggtggcgaatgtgttgcgggtcctgttgggctgctttctgtattgtctcctaaccctctagttttaattggacacttctttgctgttgcaatctatgccgtgtatttttgctttaagtcagaaccttggattacaaaacctcgagcccttctcagtagtggtgctgtattgtacaaagcgtgttctgtaatatttcctctaatttactcagaaatgaagtatatggttcattaa(SEQ ID NO:119)
人类ets变体2(ETV2/ER71),(NM_014209)SEQ ID NO:56(蛋白质)和SEQ ID NO:120(DNA)
MDLWNWDEASPQEVPPGNKLAGLEGAKLGFCFPDLALQGDTPTATAETCWKGTSSSLASFPQLDWGSALLHPEVPWGAEPDSQALPWSGDWTDMACTAWDSWSGASQTLGPAPLGPGPIPAAGSEGAAGQNCVPVAGEATSWSRAQAAGSNTSWDCSVGPDGDTYWGSGLGGEPRTDCTISWGGPAGPDCTTSWNPGLHAGGTTSLKRYQSSALTVCSEPSPQSDRASLARCPKTNHRGPIQLWQFLLELLHDGARSSCIRWTGNSREFQLCDPKEVARLWGERKRKPGMNYEKLSRGLRYYYRRDIVRKSGGRKYTYRFGGRVPSLAYPDCAGGGRGAETQ(SEQ ID NO:56)
atggacctgtggaactgggatgaggcatccccacaggaagtgcctccagggaacaagctggcagggcttgaaggagccaaattaggcttctgtttccctgatctggcactccaaggggacacgccgacagcgacagcagagacatgctggaaaggtacaagctcatccctggcaagcttcccacagctggactggggctccgcgttactgcacccagaagttccatggggggcggagcccgactctcaggctcttccgtggtccggggactggacagacatggcgtgcacagcctgggactcttggagcggcgcctcgcagaccctgggccccgcccctctcggcccgggccccatccccgccgccggctccgaaggcgccgcgggccagaactgcgtccccgtggcgggagaggccacctcgtggtcgcgcgcccaggccgccgggagcaacaccagctgggactgttctgtggggcccgacggcgatacctactggggcagtggcctgggcggggagccgcgcacggactgtaccatttcgtggggcgggcccgcgggcccggactgtaccacctcctggaacccggggctgcatgcgggtggcaccacctctttgaagcggtaccagagctcagctctcaccgtttgctccgaaccgagcccgcagtcggaccgtgccagtttggctcgatgccccaaaactaaccaccgaggtcccattcagctgtggcagttcctcctggagctgctccacgacggggcgcgtagcagctgcatccgttggactggcaacagccgcgagttccagctgtgcgaccccaaagaggtggctcggctgtggggcgagcgcaagagaaagccgggcatgaattacgagaagctgagccggggccttcgctactactatcgccgcgacatcgtgcgcaagagcggggggcgaaagtacacgtaccgcttcgggggccgcgtgcccagcctagcctatccggactgtgcgggaggcggacggggagcagagacacaataa(SEQ ID NO:120)
人类GATA结合蛋白2(GATA2)(NM_001145661)SEQ ID NO:57(蛋白质)和SEQ ID NO:121(DNA)
MEVAPEQPRWMAHPAVLNAQHPDSHHPGLAHNYMEPAQLLPPDEVDVFFNHLDSQGNPYYANPAHARARVSYSPAHARLTGGQMCRPHLLHSPGLPWLDGGKAALSAAAAHHHNPWTVSPFSKTPLHPSAAGGPGGPLSVYPGAGGGSGGGSGSSVASLTPTAAHSGSHLFGFPPTPPKEVSPDPSTTGAASPASSSAGGSAARGEDKDGVKYQVSLTESMKMESGSPLRPGLATMGTQPATHHPIPTYPSYVPAAAHDYSSGLFHPGGFLGGPASSFTPKQRSKARSCSEGRECVNCGATATPLWRRDGTGHYLCNACGLYHKMNGQNRPLIKPKRRLSAARRAGTCCANCQTTTTTLWRRNANGDPVCNACGLYYKLHNVNRPLTMKKEGIQTRNRKMSNKSKKSKKGAECFEELSKCMQEKSSPFSAAALAGHMAPVGHLPPFSHSGHILPTPTPIHPSSSLSFGHPHPSSMVTAMG(SEQ ID NO:57)
atggaggtggcgcccgagcagccgcgctggatggcgcacccggccgtgctgaatgcgcagcaccccgactcacaccacccgggcctggcgcacaactacatggaacccgcgcagctgctgcctccagacgaggtggacgtcttcttcaatcacctcgactcgcagggcaacccctactatgccaaccccgctcacgcgcgggcgcgcgtctcctacagccccgcgcacgcccgcctgaccggaggccagatgtgccgcccacacttgttgcacagcccgggtttgccctggctggacgggggcaaagcagccctctctgccgctgcggcccaccaccacaacccctggaccgtgagccccttctccaagacgccactgcacccctcagctgctggaggccctggaggcccactctctgtgtacccaggggctgggggtgggagcgggggaggcagcgggagctcagtggcctccctcacccctacagcagcccactctggctcccaccttttcggcttcccacccacgccacccaaagaagtgtctcctgaccctagcaccacgggggctgcgtctccagcctcatcttccgcggggggtagtgcagcccgaggagaggacaaggacggcgtcaagtaccaggtgtcactgacggagagcatgaagatggaaagtggcagtcccctgcgcccaggcctagctactatgggcacccagcctgctacacaccaccccatccccacctacccctcctatgtgccggcggctgcccacgactacagcagcggactcttccaccccggaggcttcctggggggaccggcctccagcttcacccctaagcagcgcagcaaggctcgttcctgttcagaaggccgggagtgtgtcaactgtggggccacagccacccctctctggcggcgggacggcaccggccactacctgtgcaatgcctgtggcctctaccacaagatgaatgggcagaaccgaccactcatcaagcccaagcgaagactgtcggccgccagaagagccggcacctgttgtgcaaattgtcagacgacaaccaccaccttatggcgccgaaacgccaacggggaccctgtctgcaacgcctgtggcctctactacaagctgcacaatgttaacaggccactgaccatgaagaaggaagggatccagactcggaaccggaagatgtccaacaagtccaagaagagcaagaaaggggcggagtgcttcgaggagctgtcaaagtgcatgcaggagaagtcatcccccttcagtgcagctgccctggctggacacatggcacctgtgggccacctcccgcccttcagccactccggacacatcctgcccactccgacgcccatccacccctcctccagcctctccttcggccacccccacccgtccagcatggtgaccgccatgggctag(SEQ ID NO:121)
具有YRPW基序1(HEY1)的人类hes-相关家族bHLH转录因子(NM_012258)SEQ ID NO:58(蛋白质)和SEQ ID NO:122(DNA)
MKRAHPEYSSSDSELDETIEVEKESADENGNLSSALGSMSPTTSSQILARKRRRGIIEKRRRDRINNSLSELRRLVPSAFEKQGSAKLEKAEILQMTVDHLKMLHTAGGKGYFDAHALAMDYRSLGFRECLAEVARYLSIIEGLDASDPLRVRLVSHLNNYASQREAASGAHAGLGHIPWGTVFGHHPHIAHPLLLPQNGHGNAGTTASPTEPHHQGRLGSAHPEAPALRAPPSGSLGPVLPVVTSASKLSPPLLSSVASLSAFPFSFGSFHLLSPNALSPSAPTQAANLGKPYRPWGTEIGAF(SEQ ID NO:58)
atgaagcgagctcaccccgagtacagctcctcggacagcgagctggacgagaccatcgaggtggagaaggagagtgcggacgagaatggaaacttgagttcggctctaggttccatgtccccaactacatcttcccagattttggccagaaaaagacggagaggaataattgagaagcgccgacgagaccggatcaataacagtttgtctgagctgagaaggctggtacccagtgcttttgagaagcagggatctgctaagctagaaaaagccgagatcctgcagatgaccgtggatcacctgaaaatgctgcatacggcaggagggaaaggttactttgacgcgcacgcccttgctatggactatcggagtttgggatttcgggaatgcctggcagaagttgcgcgttatctgagcatcattgaaggactagatgcctctgacccgcttcgagttcgactggtttcgcatctcaacaactacgcttcccagcgggaagccgcgagcggcgcccacgcgggcctcggacacattccctgggggaccgtcttcggacatcacccgcacatcgcgcacccgctgttgctgccccagaacggccacgggaacgcgggcaccacggcctcacccacggaaccgcaccaccagggcaggctgggctcggcacatccggaggcgcctgctttgcgagcgccccctagcggcagcctcggaccggtgctccctgtggtcacctccgcctccaaactgtcgccgcctctgctctcctcagtggcctccctgtcggccttccccttctctttcggctccttccacttactgtctcccaatgcactgagcccttcagcacccacgcaggctgcaaaccttggcaagccctatagaccttgggggacggagatcggagctttttaa(SEQ ID NO:122)
人类Hey2(AB044755)SEQ ID NO:59(蛋白质)和SEQ ID NO:123(DNA)
MKRPCEETTSESDMDETIDVGSENNYSGQSTSSVIRLNSPTTTSQIMARKKRRGIIEKRRRDRINNSLSELRRLVPTAFEKQGSAKLEKAEILQMTVDHLKMLQATGGKGYFDAHALAMDFMSIGFRECLTEVARYLSSVEGLDSSDPLRVRLVSHLSTCATQREAAAMTSSMAHHHHPLHPHHWAAAFHHLPAALLQPNGLHASESTPCRLSTTSEVPPAHGSALLTATFAHADSALRMPSTGSVAPCVPPLSTSLLSLSATVHAAAAAATAAAHSFPLSFAGAFPMLPPNAAAAVAAATAISPPLSVSATSSPQQTSSGTNNKPYRPWGTEVGAF(SEQ ID NO:59)
atgaagcgcccctgcgaggagacgacctccgagagcgacatggacgagaccatcgacgtggggagcgagaacaattactcggggcaaagtactagctctgtgattagattgaattctccaacaacaacatctcagattatggcaagaaagaaaaggagagggattatagagaaaaggcgtcgggatcggataaataacagtttatctgagttgagaagacttgtgccaactgcttttgaaaaacaaggatctgcaaagttagaaaaagctgaaatattgcaaatgacagtggatcatttgaagatgcttcaggcaacagggggtaaaggctactttgacgcacacgctcttgccatggacttcatgagcataggattccgagagtgcctaacagaagttgcgcggtacctgagctccgtggaaggcctggactcctcggatccgctgcgggtgcggcttgtgtctcatctcagcacttgcgccacccagcgggaggcggcggccatgacatcctccatggcccaccaccatcatccgctccacccgcatcactgggccgccgccttccaccacctgcccgcagccctgctccagcccaacggcctccatgcctcagagtcaaccccttgtcgcctctccacaacttcagaagtgcctcctgcccacggctctgctctcctcacggccacgtttgcccatgcggattcagccctccgaatgccatccacgggcagcgtcgccccctgcgtgccacctctctccacctctctcttgtccctctctgccaccgtccacgccgcagccgcagcagccaccgcggctgcacacagcttccctctgtccttcgcgggggcattccccatgcttcccccaaacgcagcagcagcagtggccgcggccacagccatcagcccgcccttgtcagtatcagccacgtccagtcctcagcagaccagcagtggaacaaacaataaaccttaccgaccctgggggacagaagttggagctttttaa(SEQ ID NO:123)
人类叉头盒C1(FOXC1)(NM_001453)SEQ ID NO:60(蛋白质)和SEQ ID NO:124(DNA)
MQARYSVSSPNSLGVVPYLGGEQSYYRAAAAAAGGGYTAMPAPMSVYSHPAHAEQYPGGMARAYGPYTPQPQPKDMVKPPYSYIALITMAIQNAPDKKITLNGIYQFIMDRFPFYRDNKQGWQNSIRHNLSLNECFVKVPRDDKKPGKGSYWTLDPDSYNMFENGSFLRRRRRFKKKDAVKDKEEKDRLHLKEPPPPGRQPPPAPPEQADGNAPGPQPPPVRIQDIKTENGTCPSPPQPLSPAAALGSGSAAAVPKIESPDSSSSSLSSGSSPPGSLPSARPLSLDGADSAPPPPAPSAPPPHHSQGFSVDNIMTSLRGSPQSAAAELSSGLLASAAASSRAGIAPPLALGAYSPGQSSLYSSPCSQTSSAGSSGGGGGGAGAAGGAGGAGTYHCNLQAMSLYAAGERGGHLQGAPGGAGGSAVDDPLPDYSLPPVTSSSSSSLSHGGGGGGGGGGQEAGHHPAAHQGRLTSWYLNQAGGDLGHLASAAAAAAAAGYPGQQQNFHSVREMFESQRIGLNNSPVNGNSSCQMAFPSSQSLYRTSGAFVYDCSKF(SEQ ID NO:60)
atgcaggcgcgctactccgtgtccagccccaactccctgggagtggtgccctacctcggcggcgagcagagctactaccgcgcggcggccgcggcggccgggggcggctacaccgccatgccggcccccatgagcgtgtactcgcaccctgcgcacgccgagcagtacccgggcggcatggcccgcgcctacgggccctacacgccgcagccgcagcccaaggacatggtgaagccgccctatagctacatcgcgctcatcaccatggccatccagaacgccccggacaagaagatcaccctgaacggcatctaccagttcatcatggaccgcttccccttctaccgggacaacaagcagggctggcagaacagcatccgccacaacctctcgctcaacgagtgcttcgtcaaggtgccgcgcgacgacaagaagccgggcaagggcagctactggacgctggacccggactcctacaacatgttcgagaacggcagcttcctgcggcggcggcggcgcttcaagaagaaggacgcggtgaaggacaaggaggagaaggacaggctgcacctcaaggagccgcccccgcccggccgccagcccccgcccgcgccgccggagcaggccgacggcaacgcgcccggtccgcagccgccgcccgtgcgcatccaggacatcaagaccgagaacggtacgtgcccctcgccgccccagcccctgtccccggccgccgccctgggcagcggcagcgccgccgcggtgcccaagatcgagagccccgacagcagcagcagcagcctgtccagcgggagcagccccccgggcagcctgccgtcggcgcggccgctcagcctggacggtgcggattccgcgccgccgccgcccgcgccctccgccccgccgccgcaccatagccagggcttcagcgtggacaacatcatgacgtcgctgcgggggtcgccgcagagcgcggccgcggagctcagctccggccttctggcctcggcggccgcgtcctcgcgcgcggggatcgcacccccgctggcgctcggcgcctactcgcccggccagagctccctctacagctccccctgcagccagacctccagcgcgggcagctcgggcggcggcggcggcggcgcgggggccgcggggggcgcgggcggcgccgggacctaccactgcaacctgcaagccatgagcctgtacgcggccggcgagcgcgggggccacttgcagggcgcgcccgggggcgcgggcggctcggccgtggacgaccccctgcccgactactctctgcctccggtcaccagcagcagctcgtcgtccctgagtcacggcggcggcggcggcggcggcgggggaggccaggaggccggccaccaccctgcggcccaccaaggccgcctcacctcgtggtacctgaaccaggcgggcggagacctgggccacttggcgagcgcggcggcggcggcggcggccgcaggctacccgggccagcagcagaacttccactcggtgcgggagatgttcgagtcacagaggatcggcttgaacaactctccagtgaacgggaatagtagctgtcaaatggccttcccttccagccagtctctgtaccgcacgtccggagctttcgtctacgactgtagcaagttttga(SEQ ID NO:124)
人类叉头盒C2(MFH-1,间质叉头1)(FOXC2)(NM_005251)SEQ ID NO:61(蛋白质)和SEQ ID NO:125(DNA)
MQARYSVSDPNALGVVPYLSEQNYYRAAGSYGGMASPMGVYSGHPEQYSAGMGRSYAPYHHHQPAAPKDLVKPPYSYIALITMAIQNAPEKKITLNGIYQFIMDRFPFYRENKQGWQNSIRHNLSLNECFVKVPRDDKKPGKGSYWTLDPDSYNMFENGSFLRRRRRFKKKDVSKEKEERAHLKEPPPAASKGAPATPHLADAPKEAEKKVVIKSEAASPALPVITKVETLSPESALQGSPRSAASTPAGSPDGSLPEHHAAAPNGLPGFSVENIMTLRTSPPGGELSPGAGRAGLVVPPLALPYAAAPPAAYGQPCAQGLEAGAAGGYQCSMRAMSLYTGAERPAHMCVPPALDEALSDHPSGPTSPLSALNLAAGQEGALAATGHHHQHHGHHHPQAPPPPPAPQPQPTPQPGAAAAQAASWYLNHSGDLNHLPGHTFAAQQQTFPNVREMFNSHRLGIENSTLGESQVSGNASCQLPYRSTPPLYRHAAPYSYDCTKY(SEQ ID NO:61)
atgcaggcgcgctactccgtgtccgaccccaacgccctgggagtggtgccctacctgagcgagcagaattactaccgggctgcgggcagctacggcggcatggccagccccatgggcgtctattccggccacccggagcagtacagcgcggggatgggccgctcctacgcgccctaccaccaccaccagcccgcggcgcctaaggacctggtgaagccgccctacagctacatcgcgctcatcaccatggccatccagaacgcgcccgagaagaagatcaccttgaacggcatctaccagttcatcatggaccgcttccccttctaccgggagaacaagcagggctggcagaacagcatccgccacaacctctcgctcaacgagtgcttcgtcaaggtgccccgcgacgacaagaagcccggcaagggcagttactggaccctggacccggactcctacaacatgttcgagaacggcagcttcctgcggcgccggcggcgcttcaaaaagaaggacgtgtccaaggagaaggaggagcgggcccacctcaaggagccgcccccggcggcgtccaagggcgccccggccaccccccacctagcggacgcccccaaggaggccgagaagaaggtggtgatcaagagcgaggcggcgtccccggcgctgccggtcatcaccaaggtggagacgctgagccccgagagcgcgctgcagggcagcccgcgcagcgcggcctccacgcccgccggctcccccgacggctcgctgccggagcaccacgccgcggcgcccaacgggctgcctggcttcagcgtggagaacatcatgaccctgcgaacgtcgccgccgggcggagagctgagcccgggggccggacgcgcgggcctggtggtgccgccgctggcgctgccctacgccgccgcgccgcccgccgcctacggccagccgtgcgctcagggcctggaggccggggccgccgggggctaccagtgcagcatgcgagcgatgagcctgtacaccggggccgagcggccggcgcacatgtgcgtcccgcccgccctggacgaggccctctcggaccacccgagcggccccacgtcgcccctgagcgctctcaacctcgccgccggccaggagggcgcgctcgccgccacgggccaccaccaccagcaccacggccaccaccacccgcaggcgccgccgcccccgccggctccccagccccagccgacgccgcagcccggggccgccgcggcgcaggcggcctcctggtatctcaaccacagcggggacctgaaccacctccccggccacacgttcgcggcccagcagcaaactttccccaacgtgcgggagatgttcaactcccaccggctggggattgagaactcgaccctcggggagtcccaggtgagtggcaatgccagctgccagctgccctacagatccacgccgcctctctatcgccacgcagccccctactcctacgactgcacgaaatactga(SEQ ID NO:125)
SEQ ID NO:62:人类SRY(性别决定区Y)-盒7(SOX7)NM_031439SEQ ID NO:62(蛋白质)和SEQ ID NO:126(DNA)
MASLLGAYPWPEGLECPALDAELSDGQSPPAVPRPPGDKGSESRIRRPMNAFMVWAKDERKRLAVQNPDLHNAELSKMLGKSWKALTLSQKRPYVDEAERLRLQHMQDYPNYKYRPRRKKQAKRLCKRVDPGFLLSSLSRDQNALPEKRSGSRGALGEKEDRGEYSPGTALPSLRGCYHEGPAGGGGGGTPSSVDTYPYGLPTPPEMSPLDVLEPEQTFFSSPCQEEHGHPRRIPHLPGHPYSPEYAPSPLHCSHPLGSLALGQSPGVSMMSPVPGCPPSPAYYSPATYHPLHSNLQAHLGQLSPPPEHPGFDALDQLSQVELLGDMDRNEFDQYLNTPGHPDSATGAMALSGHVPVSQVTPTGPTETSLISVLADATATYYNSYSVS(SEQ ID NO:62)
atggcttcgctgctgggagcctacccttggcccgagggtctcgagtgcccggccctggacgccgagctgtcggatggacaatcgccgccggccgtcccccggcccccgggggacaagggctccgagagccgtatccggcggcccatgaacgccttcatggtttgggccaaggacgagaggaaacggctggcagtgcagaacccggacctgcacaacgccgagctcagcaagatgctgggaaagtcgtggaaggcgctgacgctgtcccagaagaggccgtacgtggacgaggcggagcggctgcgcctgcagcacatgcaggactaccccaactacaagtaccggccgcgcaggaagaagcaggccaagcggctgtgcaagcgcgtggacccgggcttccttctgagctccctctcccgggaccagaacgccctgccggagaagagaagcggcagccggggggcgctgggggagaaggaggacaggggtgagtactcccccggcactgccctgcccagcctccggggctgctaccacgaggggccggctggtggtggcggcggcggcaccccgagcagtgtggacacgtacccgtacgggctgcccacacctcctgaaatgtctcccctggacgtgctggagccggagcagaccttcttctcctccccctgccaggaggagcatggccatccccgccgcatcccccacctgccagggcacccgtactcaccggagtacgccccaagccctctccactgtagccaccccctgggctccctggcccttggccagtcccccggcgtctccatgatgtcccctgtacccggctgtcccccatctcctgcctattactccccggccacctaccacccactccactccaacctccaagcccacctgggccagctttccccgcctcctgagcaccctggcttcgacgccctggatcaactgagccaggtggaactcctgggggacatggatcgcaatgaattcgaccagtatttgaacactcctggccacccagactccgccacaggggccatggccctcagtgggcatgttccggtctcccaggtgacaccaacgggtcccacagagaccagcctcatctccgtcctggctgatgccacggccacgtactacaacagctacagtgtgtcatag(SEO ID NO:126)
人类SOX18(AB033888)SEQ ID NO:63(蛋白质)和SEQ ID NO:127(DNA)
MQRSPPGYGAQDDPPARRDCAWAPGHGAAADTRGLAAGPAALAAPAAPASPPSPQRSPPRSPEPGRYGLSPAGRGERQAADESRIRRPMNAFMVWAKDERKRLAQQNPDLHNAVLSKMLGKAWKELNAAEKRPFVEEAERLRVQHLRDHPNYKYRPRRKKQARKARRLEPGLLLPGLAPPQPPPEPFPAASGSARAFRELPPLGAEFDGLGLPTPERSPLDGLEPGEAAFFPPPAAPEDCALRPFRAPYAPTELSRDPGGCYGAPLAEALRTAPPAAPLAGLYYGTLGTPGPYPGPLSPPPEAPPLESAEPLGPAADLWADVDLTEFDQYLNCSRTRPDAPGLPYHVALAKLGPRAMSCPEESSLISALSDASSAVYYSACISG(SEQ ID NO:63)
atgcagagatcgccgcccggctacggcgcacaggacgacccgcccgcccgccgcgactgtgcatgggccccgggacacggggccgccgctgacacgcgcggcctcgccgccggccccgccgccctcgccgcgcccgccgcgcccgcctcgccgcccagcccgcagcgcagtcccccgcgcagccccgagccggggcgctatggcctcagcccggccggccgcggggaacgccaggcggcagacgagtcgcgcatccggcggcccatgaacgccttcatggtgtgggcaaaggacgagcgcaagcggctggctcagcagaacccggacctgcacaacgcggtgctcagcaagatgctgggcaaagcgtggaaggagctgaacgcggcggagaagcggcccttcgtggaggaagccgaacggctgcgcgtgcagcacttgcgcgaccaccccaactacaagtaccggccgcgccgcaagaagcaggcgcgcaaggcccggcggctggagcccggcctcctgctcccgggattagcgcccccgcagccaccgcccgagcctttccccgcggcgtctggctcggctcgcgccttccgcgagctgcccccgctgggcgccgagttcgacggcctggggctgcccacgcccgagcgctcgcctctggacggcctggagcccggcgaggctgccttcttcccaccgcccgcggcgcccgaggactgcgcgctgcggcccttccgcgcgccctacgcgcccaccgagttgtcgcgggaccccggcggttgctacggggctcccctggcggaggcgctcaggaccgcgccccccgcggcgccgctcgctggcctgtactacggcaccctgggcacgcccggcccgtaccccggcccgctgtcgccgccgcccgaggccccgccgctggagagcgccgagccgctggggcccgccgccgatctgtgggccgacgtggacctcaccgagttcgaccagtacctcaactgcagccggactcggcccgacgcccccgggctcccgtaccacgtggcactggccaaactgggcccgcgcgccatgtcctgcccagaggagagcagcctgatctccgcgctgtcggacgccagcagcgcggtctattacagcgcgtgcatctccggctag(SEQ ID NO:127)
本说明书提及的任何专利或出版物都以引用的方式纳入本文,其程度如同每一个单独的出版物被具体地并且单独地被指明以引用的方式纳入本文一样。于2013年10月25日提交的序列号为61/895,562的美国临时专利申请以引用的方式纳入本文。
本文所述的组合物和方法目前代表优选的实施方案,其为示例性的且不意欲对本发明的范围进行限制。本领域技术人员会了解其中的改变和其他用途。可在不脱离如权利要求中所述的本发明的范围的情况下进行这类改变和其他用途。
- 还没有人留言评论。精彩留言会获得点赞!