一种基于Loop区域高斯扰动的群体蛋白质结构预测方法与流程
本发明涉及一种生物信息学、智能优化、计算机应用领域、尤其涉及的是,一种基于loop区域高斯扰动的群体蛋白质结构预测方法。
背景技术:
蛋白质是生物的物质基础,是有机大分子,是构成细胞的基本有机物,是生命活动的主要承担者。没有蛋白质就没有生命,氨基酸是蛋白质的基本组成单位,它是与生命及与各种形式的生命活动紧密联系在一起的物质。因为蛋白质特定的三维结构决定了蛋白质的功能,所以了解蛋白质的结构对于认识蛋白质的功能有十分重要的意义。了解蛋白质结构和功能之间的关系可以帮助我们设计具有特定功能的新型蛋白质、设计药物和疫苗解决人类的许多疾病,通过了解蛋白质折叠类疾病的病理,从而找出解决这类疾病的治疗方法。目前,实验室测定蛋白质结构的方法主要有x-射线衍射法和核磁共振法(nmr),但是这两种方法所需时间长且耗资巨大,通常需要半年至一年时间,耗资几十万美元,而且有局限性,不能大规模地测定蛋白质三级结构,而使用计算机模拟的蛋白质结构预测是现在最有前景的蛋白质结构预测方法。
使用计算机模拟的蛋白质结构预测方法主要有同源建模法和从头预测法。同源建模法的出发点是认为序列相似的蛋白质结构也相似。基于这种认识,同源建模法计算目标蛋白质序列与模板之间的相似性,并以序列联配的形式呈现序列相似性计算结果,最后从联配出发构建目标蛋白质的空间结构。同源建模法适用于在模板库中存在同源序列的目标蛋白质,当目标蛋白质与结构模板之间的相似度>30%时,同源建模法一般可以预测到较高精度的蛋白质三级结构。当序列相似度较低时,蛋白质结构预测精度较差。从头建模法也叫无模板建模方法,不依赖于已知结构数据库,因此即使在模板数据库中不存在与目标蛋白相似的结构时,从头预测法也能对目标蛋白质预测。
目前在从头蛋白质结构预测方面主要有两个挑战:一方面是巨大的构象搜索空间,另一方面是缺少一个精确的能量函数去确定接近天然态的蛋白质模型。伴随着能量函数的发展,已经有一些方法被提出解决构象采样的问题。片段组装方法的是一个非常有效地方法来减少巨大的搜索空间,片段组装仅使用蛋白质骨架原子的扭转角来简化的表示蛋白质的三维结构,首先将整条序列分割成多个9-mer或者3-mer片段,片段之间允许相互重叠,对每个片段,从psi-blast计算出的相似序列对应的结构中,截取出相应位置的局部结构作为候选结构,然后使用montecarlo算法从每个片段的候选结构集中挑选出一个进行组合,使得组合成的全长结构能量最小。因此,在片段组装方法中,片段的质量是十分重要的。
在蛋白质结构从头预测方法中,由于能量函数的不精确以及采样能力的不足会导致构象空间的搜索效率低、收敛速度慢,局部搜索能力弱的问题,从而影响预测精度。比如蛋白质结构的loop区域灵活多变,使用常规的片段组装方法不能对此部分进行充分的采样,因此,如何加强对蛋白质结构的loop区域的局部搜索是我们需要解决的问题。
技术实现要素:
为了解决现有能量函数的不精确和构象空间搜索不充分导致的蛋白质结构预测精度较低的问题,本发明提出了一种预测精度较高的基于loop区域高斯扰动的群体蛋白质结构预测方法。
本发明解决其技术问题所采用的技术方案是:
一种基于loop区域高斯扰动的群体蛋白质结构预测方法,所述方法包括以下步骤:
1)参数设置:设置初始种群大小np,交叉概率cr,种群交叉代数g,最大迭代次数gmax,温度参数kt,扰动参数a,设置能量函数;
2)使用psipred服务器(http://bioinf.cs.ucl.ac.uk/psipred/)预测目标序列的二级结构,得到每个残基的二级结构,标记二级结构为loop类型的残基;
3)设置蛋白质构象的初始种群为{x1,x2,...,xnp},其中xi,i∈[1,np]表示种群的第i个个体,对种群所有个体进行片段组装,直到个体中所有位置的残基都被替换一次,则完成初始化操作,初始化操作后得到种群p;
4)种群交叉操作,过程如下:
4.1)对种群p中的np个个体两两配对,组成np/2对,并对其编号a1,a2,...,anp/2,,其中aj,j∈[1,np/2]表示第j组;
4.2)随机选择其中的一组aj,根据交叉概率cr判断是否对这两个个体进行交叉,若random(0,1)<cr,则随机选取这一组个体的对应的loop区域交换它,形成两个新的子代,否则,保留aj中个体不变,遍历所有组后得到交叉后的种群p′;
5)把交叉后的种群p′和初始种群p合并,使用能量函数计算种群p′∪p中每个个体的能量,根据能量的高低对种群的个体排序,挑选出能量较低的前np个个体组成新的种群;
6)对loop区域二面角高斯扰动,过程如下:
6.1)选择种群中的一个个体xi,随机选择xi的一个loop区域,通过(1)式产生独立的高斯随机数ψ,通过(2)得到扰动后的角度
ψ=(-lnr1)1/2cos2πr2(1)
其中r1和r2是在(0,1)之间均匀分布的随机数字,ψ表示独立的高斯随机数,
6.2)使用新得到的角度
7)对种群所有个体执行步骤4)-6)操作后,设置g=g+1,判断g是否达到最大迭代次数,若g≤gmax,则返回步骤4),否则,进行步骤8);
8)输出最后一代的种群,使用k均值聚类方法挑出最大类的类心构象作为最终结果。
本发明的技术构思为:首先,通过种群初始化得到全局搜索的构象;然后通过交叉操作,交叉种群中个体loop区域的部分;其次,对交叉后的种群和初始种群合并到一起挑选出能量较小的个体,使用高斯分布的二面角来对构象的loop区域扰动,并使用玻尔兹曼概率判断是否接收;最后使用聚类算法对输出的最后一代种群聚类,得到最终的蛋白质三级结构。
本发明的有益效果表现为:使用群体算法可以有效提高构象空间的搜索效率,种群对loop区域的交叉操作增加了种群的多样性,加大了对loop区域的构象空间搜索,因为loop区域的残基二面角是灵活多变的,所以采用了高斯扰动的二面角来替换构象loop区域的二面角,加强对构象loop区域的进一步搜索。
附图说明
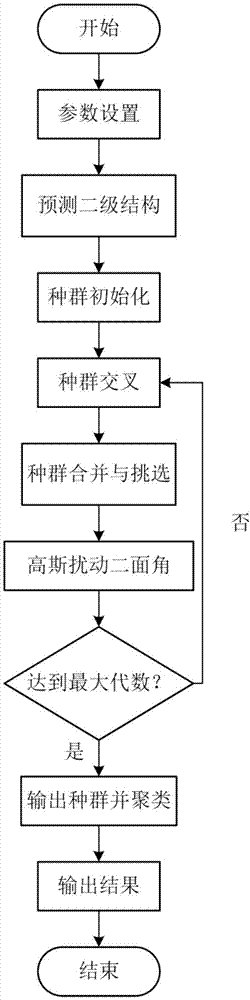
图1是基于loop区域高斯扰动的群体蛋白质结构预测方法的流程图。
图2是基于loop区域高斯扰动的群体蛋白质结构预测方法对蛋白质1ail进行结构预测得到的构象分布图。
图3是基于loop区域高斯扰动的群体蛋白质结构预测方法对蛋白质1ail进行结构预测得到的构象分布图。
具体实施方式
下面结合附图对本发明做进一步描述。
参照图1~图3,一种基于loop区域高斯扰动的群体蛋白质结构预测方法,所述方法包括以下步骤:
1)参数设置:设置初始种群大小np,交叉概率cr,种群交叉代数g,最大迭代次数gmax,温度参数kt,扰动参数a,设置能量函数;
2)使用psipred服务器(http://bioinf.cs.ucl.ac.uk/psipred/)预测目标序列的二级结构,得到每个残基的二级结构,标记二级结构为loop类型的残基;
3)设置蛋白质构象的初始种群为{x1,x2,...,xnp},其中xi,i∈[1,np]表示种群的第i个个体,对种群所有个体进行片段组装,直到个体中所有位置的残基都被替换一次,则完成初始化操作,初始化操作后得到种群p;
4)种群交叉操作,过程如下:
4.1)对种群p中的np个个体两两配对,组成np/2对,并对其编号a1,a2,...,anp/2,,其中aj,j∈[1,np/2]表示第j组;
4.2)随机选择其中的一组aj,根据交叉概率cr判断是否对这两个个体进行交叉,若random(0,1)<cr,则随机选取这一组个体的对应的loop区域交换它,形成两个新的子代,否则,保留aj中个体不变,遍历所有组后得到交叉后的种群p′;
5)把交叉后的种群p′和初始种群p合并,使用能量函数计算种群p′∪p中每个个体的能量,根据能量的高低对种群的个体排序,挑选出能量较低的前np个个体组成新的种群;
6)对loop区域二面角高斯扰动,过程如下:
6.1)选择种群中的一个个体xi,随机选择xi的一个loop区域,通过(1)式产生独立的高斯随机数ψ,通过(2)得到扰动后的角度
ψ=(-lnr1)1/2cos2πr2(1)
其中r1和r2是在(0,1)之间均匀分布的随机数字,ψ表示独立的高斯随机数,
6.2)使用新得到的角度
7)对种群所有个体执行步骤4)-6)操作后,设置g=g+1,判断g是否达到最大迭代次数,若g≤gmax,则返回步骤4),否则,进行步骤8);
8)输出最后一代的种群,使用k均值聚类方法挑出最大类的类心构象作为最终结果。
本实施例以序列长度为73的α折叠蛋白质1ail为实施例,一种基于loop区域高斯扰动的蛋白质结构预测方法,所述方法包括以下步骤:
1)参数设置:设置初始种群大小np=300,交叉概率cr=0.5,种群交叉代数g,最大迭代次数gmax=100,温度参数kt=2,扰动参数a=0.4,设置能量函数rosettascore3;
2)使用psipred服务器(http://bioinf.cs.ucl.ac.uk/psipred/)预测目标序列的二级结构,得到每个残基的二级结构,标记二级结构为loop类型的残基;
3)设置蛋白质构象的初始种群为{x1,x2,...,x300},其中xi,i∈[1,300]表示种群的第i个个体,对种群所有个体进行片段组装,直到个体中所有位置的残基都被替换一次,则完成初始化操作,初始化操作后得到种群p;
4)种群交叉操作,过程如下:
4.1)对种群p中的300个个体两两配对,组成150对,并对其编号a1,a2,...,a150,,其中aj,j∈[1,150]表示第j组;
4.2)随机选择其中的一组aj,根据交叉概率判断是否对这两个个体进行交叉,若random(0,1)<0.5,则随机选取这一组个体的对应的loop区域交换它,形成两个新的子代,否则,保留aj中个体不变,遍历所有组后得到交叉后的种群p′;
5)把交叉后的种群p′和初始种群p合并,使用能量函数rosettascore3计算种群p′∪p中每个个体的能量,根据能量的高低对种群的个体排序,挑选出能量较低的前np个个体组成新的种群;
6)对loop区域二面角高斯扰动,过程如下:
6.1)选择种群中的一个个体xi,随机选择xi的一个loop区域,通过(1)式产生独立的高斯随机数ψ,通过(2)得到扰动后的角度
ψ=(-lnr1)1/2cos2πr2(1)
6.2)使用新得到的角度
7)对种群所有个体执行步骤4)-6)操作后,设置g=g+1,判断g是否达到最大迭代次数,若g≤gmax,则返回步骤4),否则,进行步骤8);
8)输出最后一代的种群,使用k均值聚类方法挑出最大类的类心构象作为最终结果。
以序列长度为73的α折叠蛋白质1ail为实施例,运用以上方法得到了该蛋白质的近天然态构象,最小均方根偏差为
以上说明是本发明以1ail为实施例所得出的预测效果,并非限定本发明的实施范围,在不偏离本发明基本内容所涉及范围的前提下对其做各种变形和改进,不应排除在本发明的保护范围之外。
- 还没有人留言评论。精彩留言会获得点赞!