一种便携式心电在线智能监测诊断系统设计方法与流程
本发明涉及一种便携式心电在线智能监测诊断系统设计方法,属于智能医疗技术领域。
背景技术:
心血管病是影响健康的重要杀手,2017年6月《中国心血管病报告2016》发布。报告指出:目前,心血管病死亡占城乡居民总死亡原因的首位,且今后10年心血管病患病人数仍将快速增长。此外,根据世界卫生组织的报告,到2030年大约要有2330万人死于心血管病。面对这种趋势,对心血管病的早期诊断与预防显得尤为重要。
传统的诊断方法是患者到医院,医师对其进行心电图检查,进而给出诊断结果,任务繁重且需要医师有丰富的临床经验和专业知识;而稀缺的医疗资源,很难满足数量庞大患者群体的要求。为了提高就诊效率,方便性和快捷性,出现了自动化诊断技术,辅助医师进行诊断。
心率变异是指心动间期之间的时间变异数,其研究对象是心动间期而不是心率。人的心率不是一成不变的,两次心搏之间存在着微小的时间差异,计算心动间期的差异,即可了解心率变异性(heartratevariability,hrv)。
心率变异性可以评估心脏交感神经与副交感神经对心血管活动的影响,蕴含着心血管方面的大量信息。临床研究表明,心率变异性的降低是心肌梗死、高血压、心绞痛等心血管疾病发病的症状。因此,心率变异性的研究,在评价心血管系统功能、预测心血管疾病的发作,以及为心血管疾病的早期诊断具有重要的意义。
poincare散点图是心率变异性一种重要的研究方法:通过使用连续的心搏间期在直角坐标系中绘制图形,反映相邻心搏间期的变化,能显示心搏间期的特征;poincare散点图有多种形态,包括彗星状、扇形等,不同的形状反映不同的心脏状态。
虽然poincare散点图是一种有效的心率变异性分析方法,但是并不能体现其随时间变化的趋势,对于某些心血管疾病、身体健康状况等不能很好的体现其心率变异性性质。于是,一些学者提出了改进策略,即一阶差分散点图,通过相邻心搏间期的差值来绘制散点图。然而,这种方法又丢失了原有的心搏间期绝对值信息;因此,又有学者将二者结合起来,提出了一种rdr散点图,以此来同时反映心搏间期及其变化。
目前,对于不同心血管疾病的心率变异性分析很多;但是,并没有根据散点图来自动识别、区分不同的心血管疾病,实现心电自动化诊断。
技术实现要素:
针对上述现有技术存在的问题,本发明提供一种便携式心电在线智能监测诊断系统设计方法,通过集成稀疏核主分量分析方法能够自动识别分类散点图,对心率变异性作分析,为实现自动化诊断、缓解紧缺的医疗资源、减少医疗资源的浪费、提高就诊效率提供基础。
为了实现上述目的,本发明提供一种便携式心电在线智能监测诊断系统设计方法,具体步骤为:
步骤1)采集心电信号,对心电信号进行滤波去噪处理,提取r波峰值位置;
步骤2)使用心搏间期绘制心电rdr散点图;
步骤3)对心电rdr散点图进行缩放,缩放到同一规格,转成灰度图,并对图像数据进行归一化处理,以减少计算量;
步骤4)对获得的散点图样本进行标记;
步骤5)对样本进行采样,随机抽取85%的数据作为训练样本;
步骤6)设置参数,参数包括近似基的误差参数、高斯核函数参数以及控制限的值;
步骤7)分别对每类样本求解近似基、特征值、特征向量;
步骤8)分别计算每个测试样本的spe,其值与某类样本的spe差值最小者为测试样本的预测类别,与实际类别比较,计算准确率,若满足要求则步骤9),否则返回步骤6)重新设置参数训练;
步骤9)获得分类模型参数,并将获得的分类模型用于心电诊断系统当中。
进一步,采用集成稀疏核主分量分析方法用于对所述心电rdr散点图的分类识别。rdr散点图是一种心率变异性分析方法,可以体现其随时间变化的趋势。
进一步,将集成稀疏核主分量分析方法用于对所述心电rdr散点图的分类识别,先建立集成稀疏核主分量分析模型,然后通过平方预测误差法选择控制指标。
集成稀疏核主分量分析是一种无监督机器学习算法,集成稀疏核主分量分析的基本方法如下:
主分量分析是一种典型的无监督算法,常用于解决原始空间的线性问题,而为了在特征空间中用线性方法解决原始空间的非线性问题,b.scholkopf等人提出了核主分量分析(kernelprincipalcomponentanalysis,kpca)。定义从原始空间rn到特征空间f的非线性映射:
如果该组向量
其中,
k=φtφ;
其中,矩阵k是nxn的矩阵,也称核矩阵。则问题转换为:
kɑ=nλɑ;
其中,ɑ=[ɑ1,…,ɑn]。当
其中,
本发明选择一种常用的核函数,径向基核函数来进行计算。当选择径向基核函数时,会有明显的过学习问题,主要是由于径向基核函数对应的特征空间是无线维的,通过该方法得出的主分量的次数与给定样本的维数无关,而与样本数量有关。为解决这个问题,引入了稀疏化方法,即为稀疏核主分量分析(sparsekernelprincipalcomponentanalysis,skpca)。
在核主分量分析中,特征向量能用样本
近似基求解的具体步骤是:
a.建立集合
b.对于k=2,...,n的
c.如果得到极小值value≤ε,则把对应的元素加到xa当中,否则为xl。ε是线性相关截尾误差,在有限的样本中求无限维空间的基几乎没有稀疏性,因此选择近似计算。
d.返回步骤b,直至完成所有的计算,计算结束。
其中,步骤b中的求解过程如下:
由lagrange条件
假设求得的一组近似基为
两边同乘
可知是特征值与特征向量的问题,即
推导得:
其中,k(m,:)表示核矩阵k的第m行,k(:,n)表示第n列,1n=[1,...,1]表示1行n列的行向量。问题也就转换成了(ki)-1ksα=λα,为典型的特征值与特征向量问题。
虽然稀疏化可以控制学习机的学习能力,防止过学习,但是稀疏化方法仍然可能会丢失数据集的某些重要特性,即欠学习问题。因此,有必要引入集成方法,称为集成稀疏核主分量分析(integrationsparsekernelprincipalcomponentanalysis,iskpca)。
由于核主分量分析是一种无监督学习,不能从外部获得指导,即不能对某次学习结果进行奖赏或惩罚,所以,本文选择简单平均的方法。skpca的集成方法具体步骤流程如下:
a.设置重复的次数re;
b.计算核矩阵k=φtφ;
c.计算样本集
d.根据上述的skpca方法,对各个组的近似基φik求特征值λk,特征向量ɑk,共获得re组特征值λ1,…,λre和特征向量ɑ1,…,ɑre;
e.对前n个特征值λ1≥…≥λn和对应的特征向量,分别求集成特征值
f.对集成特征值
将集成稀疏核主分量分析方法用于心电rdr散点图的分类识别,需要先建立集成稀疏核主分量分析模型,然后选择控制指标。本发明选择一种常用的控制指标,即平方预测误差(squaredpredictionerror,spe)。
平方预测误差的具体方法:
对于第i个样本xi,假设经过skpca求得其前n个主分量为t1,…,tn,对应的特征值为λ1,…,λn。用
其中,
与现有技术相比,本发明的有益效果如下:
本发明利用集成稀疏核主分量分析方法,通过计算样本数据与使用核主分量分析映射数据之间的差值来研究数据之间的最大相关性,并以此来判断心电数据类别,研究自动识别分类rdr散点图。使用本发明方法来对心率变异性作分析,可以为实现自动化诊断、缓解紧缺的医疗资源、减少医疗资源的浪费、提高就诊效率提供一些基础。
附图说明
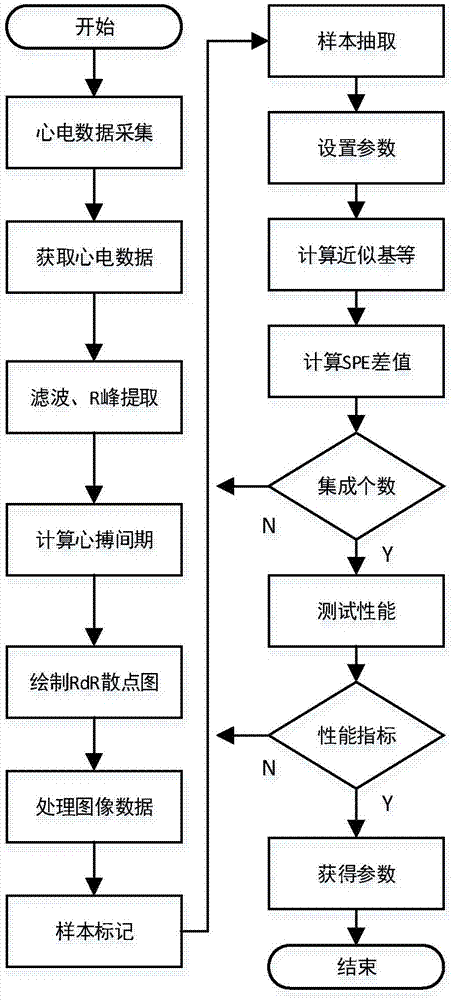
图1为本发明具体方法流程图;
图2为系统结构框图;
图3为rdr散点图。
图4为随机选择测试样本与各类的spe差值;
图5为用测试数据测试分类器性能的部分测试结果图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明提供的一种便携式心电在线智能监测诊断系统设计方法,具体步骤为:
步骤1)采集心电信号,对心电信号进行滤波去噪处理,提取r波峰值位置;
步骤2)使用心搏间期绘制心电rdr散点图;
步骤3)对心电rdr散点图进行缩放,缩放到同一规格,转成灰度图,并对图像数据进行归一化处理,以减少计算量;
步骤4)对获得的散点图样本进行标记;
步骤5)对样本进行采样,随机抽取85%的数据作为训练样本;
步骤6)设置参数,参数包括近似基的误差参数、高斯核函数参数以及控制限的值;
步骤7)分别对每类样本求解近似基、特征值、特征向量;
步骤8)分别计算每个测试样本的spe,其值与某类样本的spe差值最小者为测试样本的预测类别,与实际类别比较,计算准确率,若满足要求则步骤9),否则返回步骤6)重新设置参数训练;
步骤9)获得分类模型参数,并将获得的分类模型用于心电诊断系统当中。
进一步,采用集成稀疏核主分量分析方法用于对所述心电rdr散点图的分类识别。rdr散点图是一种心率变异性分析方法,可以体现其随时间变化的趋势。
进一步,将集成稀疏核主分量分析方法用于对所述心电rdr散点图的分类识别,先建立集成稀疏核主分量分析模型,然后通过平方预测误差法选择控制指标。
集成稀疏核主分量分析是一种无监督机器学习算法,集成稀疏核主分量分析的基本方法如下:
主分量分析是一种典型的无监督算法,常用于解决原始空间的线性问题,而为了在特征空间中用线性方法解决原始空间的非线性问题,b.scholkopf等人提出了核主分量分析(kernelprincipalcomponentanalysis,kpca)。定义从原始空间rn到特征空间f的非线性映射:
如果该组向量
其中,
k=φtφ;
其中,矩阵k是nxn的矩阵,也称核矩阵。则问题转换为:
kɑ=nλɑ;
其中,ɑ=[ɑ1,…,ɑn]。当
其中,
本发明选择一种常用的核函数,径向基核函数来进行计算。当选择径向基核函数时,会有明显的过学习问题,主要是由于径向基核函数对应的特征空间是无线维的,通过该方法得出的主分量的次数与给定样本的维数无关,而与样本数量有关。为解决这个问题,引入了稀疏化方法,即为稀疏核主分量分析(sparsekernelprincipalcomponentanalysis,skpca)。
在核主分量分析中,特征向量能用样本
近似基求解的具体步骤是:
a.建立集合
b.对于k=2,...,n的
其中,
c.如果得到极小值value≤ε,则把对应的元素加到xa当中,否则为xl。ε是线性相关截尾误差,在有限的样本中求无限维空间的基几乎没有稀疏性,因此选择近似计算。
d.返回步骤b,直至完成所有的计算,计算结束。
其中,步骤b中的求解过程如下:
令
由lagrange条件
假设求得的一组近似基为
两边同乘
可知是特征值与特征向量的问题,即
推导得:
其中,k(m,:)表示核矩阵k的第m行,k(:,n)表示第n列,1n=[1,...,1]表示1行n列的行向量。问题也就转换成了(ki)-1ksα=λα,为典型的特征值与特征向量问题。
虽然稀疏化可以控制学习机的学习能力,防止过学习,但是稀疏化方法仍然可能会丢失数据集的某些重要特性,即欠学习问题。因此,有必要引入集成方法,称为集成稀疏核主分量分析(integrationsparsekernelprincipalcomponentanalysis,iskpca)。
由于核主分量分析是一种无监督学习,不能从外部获得指导,即不能对某次学习结果进行奖赏或惩罚,所以,本文选择简单平均的方法。skpca的集成方法具体步骤流程如下:
a.设置重复的次数re;
b.计算核矩阵k=φtφ;
c.计算样本集
d.根据上述的skpca方法,对各个组的近似基φik求特征值λk,特征向量ɑk,共获得re组特征值λ1,…,λre和特征向量ɑ1,…,ɑre;
e.对前n个特征值λ1≥…≥λn和对应的特征向量,分别求集成特征值
f.对集成特征值
将集成稀疏核主分量分析方法用于心电rdr散点图的分类识别,需要先建立集成稀疏核主分量分析模型,然后选择控制指标。本发明选择一种常用的控制指标,即平方预测误差(squaredpredictionerror,spe)。
平方预测误差的具体方法:
对于第i个样本xi,假设经过skpca求得其前n个主分量为t1,…,tn,对应的特征值为λ1,…,λn。用
其中,
为便于叙述,使用mit-bih数据库中的心电数据,以此数据库的数据作示意性分析介绍。
图2是系统结构框图,该系统的硬件主要由采集电路、微控制器电路、存储电路、ram电路、jtag电路、通信电路、警报电路、led运行指示电路、电源管理电路和云服务器等组成。为了降低系统的复杂度,本系统在远程监测终端部分选择b/s(浏览器/服务器)模式来开发。本系统通过互联网连接成一个整体,且为符合便携式特点,采用单导联设计。采集电路负责采集心电信号,在微处理器上进行数据滤波,然后lcd显示波形、心率等信息,可以利用通信电路将数据上传至云服务器,服务器端接收到数据,对数据进行处理,并得出诊断分析报告,根据诊断分析结果,判断是否需要发送警报信息等操作。医生也可以通过浏览器查看用户心电数据,并给出诊断意见。
图3是通过matlab来绘制mit-bih心电数据的rdr散点图示意图。rdr散点图可以有效反映心搏间期随时间的变化趋势,蕴含大量的临床信息,能显示不同的心搏特征。实验显示,使用本发明方法来对其进行识别分类,效果较好。
图4是从测试样本中随机选择某一类的心电数据样本,如图是选择到实际类别为“3”的一些测试样本集,将其分别与各个类别计算其spe的差值,结果如图(4),可以看到其与类别为“3”的spe差值最小,分类全部正确;
图5是依据本发明方法,部分分类的结果展示图,实验显示,准确率较高,图中,参数true是实际的样本类别,predicted是分类器预测的类别,图中显示的图像是rdr散点图,可以看到分类结果全部正确。
综上所述,本发明利用集成稀疏核主分量分析方法,通过计算样本数据与使用核主分量分析映射数据之间的差值来研究数据之间的最大相关性,并以此来判断心电数据类别,研究自动识别分类rdr散点图。使用本发明方法来对心率变异性作分析,可以为实现自动化诊断、缓解紧缺的医疗资源、减少医疗资源的浪费、提高就诊效率提供一些基础。
以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!