一种基于抽象凸估计的k-近邻蛋白质结构预测方法与流程
本发明涉及一种智能优化、计算机应用领域,尤其涉及的是一种基于抽象凸估计的k-近邻蛋白质结构预测方法。
背景技术:
蛋白质结构实验测定方法是结构基因组学研究的主要内容。x射线晶体学是测定蛋白质结构最有效的方法,所能达到的精度是其它方法所不能比拟的,缺点主要是蛋白质晶体难以培养且晶体结构测定的周期较长;多维核磁共振(nmr)方法可以直接测定蛋白质在溶液中的构象,但是由于对样品的需要量大、纯度要求高,目前只能测定小分子蛋白质。总体上,结构实验测定方法主要存在两方面问题:一方面,对于现代药物设计的主要靶标膜蛋白而言,通过实验方法极难获得其结构;另一方面,测定过程费时费钱费力。
在理论探索和应用需求的双重推动下,根据anfinsen法则,利用计算机设计适当的算法,以序列为起点,三维结构为目标的蛋白质结构预测自20世纪末蓬勃发展。从头预测方法实质上就是利用计算机的快速处理能力,利用优化算法在蛋白质构象空间搜索全局最低能量构象解。蛋白质能量模型考虑分子体系成键作用以及范德华力、静电、氢键、疏水等非成键作用,致使其形成的能量曲面极其粗糙,构象对应局部极小解数目随序列长度的增加呈指数增长,属于一类非常难解的np-hard问题。
四十多年来,蛋白质从头预测构象空间优化方法一直受到计算生物学领域和进化计算社区的高度关注,成为一个热点研究课题。美国哈佛大学levitt研究小组、佐治亚理工学院skolnick研究小组、华盛顿大学baker研究小组、密歇根大学zhang研究小组;国内上海交通大学沈红斌课题组、中国科技大学刘海燕等研究团队都在该领域进行了深入而广泛的研究,特别是baker研究小组开发的rosetta[15]及zhang研究小组开发的quark[16]从头预测服务器在历届casp赛事中表现突出,已经成为当今国际领先的从头预测服务器。然而,在蛋白质结构预测中,能量函数通常具有上千个自由度,对能量函数评价有时需要调用第三方能量包,对单个构象的能量评价一次需要数分钟,而且,随着序列长度的增长,所需的评价时间更长,从而导致计算代价极高,预测效率较低。
因此,现有的蛋白质结构预测方法计算代价和预测效率方面存在着缺陷,需要改进。
技术实现要素:
为了克服现有蛋白质结构预测方法的计算代价较高和预测效率低的不足,本发明提出一种计算代价较小、预测效率较高的基于抽象凸估计的k-近邻蛋白质结构预测方法。
本发明解决其技术问题所采用的技术方案是:
一种基于抽象凸估计的k-近邻蛋白质结构预测方法,所述方法包括以下步骤:
1)输入待测蛋白质的序列信息,并从robetta服务器(http://www.robetta.org/)上得到片段库;
2)参数设置:设置种群规模np,交叉概率cr,温度因子kt,斜率控制因子m,片段长度为l,近邻个体数量k,最大迭代次数gmax,并初始化迭代次数g=0;
3)根据输入序列,从每个残基位对应的片段库中随机选择片段进行组装生成初始构象种群p={c1,c2,...,cnp},其中,ci,i={1,2,…,np}为种群p中的第i个构象个体;
4)根据rosettasocre3能量函数计算当前种群中每个构象的能量值;
5)根据当前种群中每个构象ci,i∈{1,2,…,np}的碳α原子坐标表示其空间位置坐标
其中,e(ci)为构象ci的能量,
6)将当前种群中所有构象按照能量从低到高进行排序;
7)对种群中的每个构象ci,i∈{1,2,...,np}执行如下操作:
7.1)将构象ci看作目标构象,选出当前种群中能量最低的构象cbest,然后从排名靠前的np/2构象中随机选取一个与ci和cbest均不相同的构象cpbest;
7.2)分别从cbest和cpbest中随机选择一个残基位不同的长度为l的片段替换构象ci中对应位置的片段,生成变异构象
7.3)随机生成一个0和1之间的小数r,如果r<cr,则从构象ci中随机选取一个长度为l的片段替换变异构象
8)如果g=0,则对每个测试构象
8.1)根据rosettascore3能量函数计算
8.2)如果
9.1)计算测试构象
9.2)根据构象的空间位置坐标计算测试构象
9.3)选取与
其中,
9.4)计算构象
9.5)如果
9.6)如果
9.7)如果
9.8)如果
10)g=g+1,如果g>gmax,则输出能量最低的构象作为最终预测结构,否则返回步骤6)。
本发明的技术构思为:在差分进化算法为框架,首先对初始种群中的每个构象计算抽象凸下界估计支撑向量,从而建立能量函数的下界估计模型;然后,选择当前种群中能量最低的构象和局部较优的构象来指导每个构象的变异过程;其次,将初始种群的所有测试构象个体进行能量函数评价,并看作样本构象,基于样本构象中的k个近邻个体来计算测试构象的k-近邻能量值,同时计算测试构象的能量下界估计值,选择两者中较低者为测试构象的能量估计值,从而指导构象选择;最后,根据被接收的构象来更新样本库和下界估计模型。本发明提供一种计算代价较低、预测效率较高、且预测精度也较高的基于抽象凸估计的k-近邻蛋白质结构预测方法。
本发明的有益效果表现在:根据抽象凸下界估计和k-近邻共同指导构象的选择过程,减少不必要的能量函数评价,降低计算代价,从而提高预测效率。
附图说明
图1是基于抽象凸估计的k-近邻蛋白质结构预测方法对蛋白质2mqk进行结构预测时的构象更新示意图。
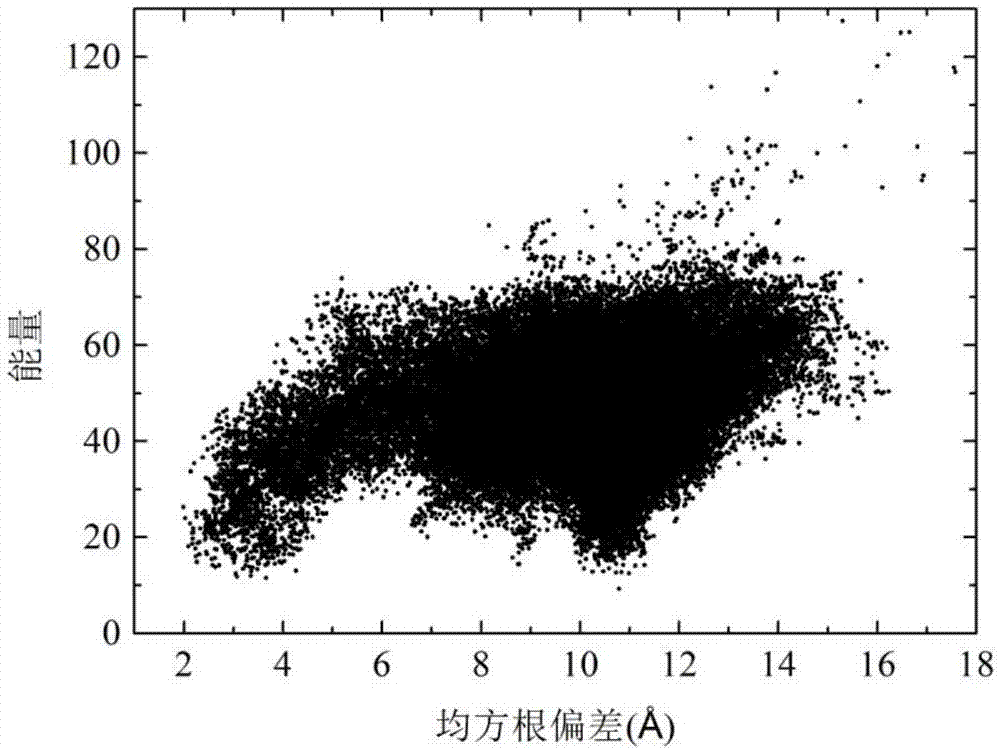
图2是基于抽象凸估计的k-近邻蛋白质结构预测方法对蛋白质2mqk进行结构预测时得到的构象分布图。
图3是基于抽象凸估计的k-近邻蛋白质结构预测方法对蛋白质2mqk进行结构预测得到的三维结构图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1~图3,一种基于抽象凸估计的k-近邻蛋白质结构预测方法,包括以下步骤:
1)输入待测蛋白质的序列信息,并从robetta服务器(http://www.robetta.org/)上得到片段库;
2)参数设置:设置种群规模np,交叉概率cr,温度因子kt,斜率控制因子m,片段长度为l,近邻个体数量k,最大迭代次数gmax,并初始化迭代次数g=0;
3)根据输入序列,从每个残基位对应的片段库中随机选择片段进行组装生成初始构象种群p={c1,c2,...,cnp},其中,ci,i={1,2,…,np}为种群p中的第i个构象个体;
4)根据rosettasocre3能量函数计算当前种群中每个构象的能量值;
5)根据当前种群中每个构象ci,i∈{1,2,…,np}的碳α原子坐标表示其空间位置坐标
其中,e(ci)为构象ci的能量,
6)将当前种群中所有构象按照能量从低到高进行排序;
7)对种群中的每个构象ci,i∈{1,2,...,np}执行如下操作:
7.1)将构象ci看作目标构象,选出当前种群中能量最低的构象cbest,然后从排名靠前的np/2构象中随机选取一个与ci和cbest均不相同的构象cpbest;
7.2)分别从cbest和cpbest中随机选择一个残基位不同的长度为l的片段替换构象ci中对应位置的片段,生成变异构象
7.3)随机生成一个0和1之间的小数r,如果r<cr,则从构象ci中随机选取一个长度为l的片段替换变异构象
8)如果g=0,则对每个测试构象
8.1)根据rosettascore3能量函数计算
8.2)如果
9.1)计算测试构象
9.2)根据构象的空间位置坐标计算测试构象
9.3)选取与
其中,
9.4)计算构象
9.5)如果
9.6)如果
9.7)如果
9.8)如果
10)g=g+1,如果g>gmax,则输出能量最低的构象作为最终预测结构,否则返回步骤6)。
本实施例序列长度为65的α折叠蛋白质2mqk为实施例,一种基于抽象凸估计的k-近邻蛋白质结构预测方法,包括以下步骤:
1)输入待测蛋白质的序列信息,并从robetta服务器(http://www.robetta.org/)上得到片段库;
2)参数设置:设置种群规模np=50,交叉概率cr=0.5,温度因子kt=2,斜率控制因子m=10000,片段长度为l=9,近邻个体数量k=np/5,最大迭代次数gmax=1000,并初始化迭代次数g=0;
3)根据输入序列,从每个残基位对应的片段库中随机选择片段进行组装生成初始构象种群p={c1,c2,...,cnp},其中,ci,i={1,2,…,np}为种群p中的第i个构象个体;
4)根据rosettasocre3能量函数计算当前种群中每个构象的能量值;
5)根据当前种群中每个构象ci,i∈{1,2,…,np}的碳α原子坐标表示其空间位置坐标
其中,e(ci)为构象ci的能量,
6)将当前种群中所有构象按照能量从低到高进行排序;
7)对种群中的每个构象ci,i∈{1,2,...,np}执行如下操作:
7.1)将构象ci看作目标构象,选出当前种群中能量最低的构象cbest,然后从排名靠前的np/2构象中随机选取一个与ci和cbest均不相同的构象cpbest;
7.2)分别从cbest和cpbest中随机选择一个残基位不同的长度为l的片段替换构象ci中对应位置的片段,生成变异构象
7.3)随机生成一个0和1之间的小数r,如果r<cr,则从构象ci中随机选取一个长度为l的片段替换变异构象
8)如果g=0,则对每个测试构象
8.1)根据rosettascore3能量函数计算
8.2)如果
9.1)计算测试构象
9.2)根据构象的空间位置坐标计算测试构象
9.3)选取与
其中,
9.4)计算构象
9.5)如果
9.6)如果
9.7)如果
9.8)如果
10)g=g+1,如果g>gmax,则输出能量最低的构象作为最终预测结构,否则返回步骤6)。
以序列长度为65的α折叠蛋白质2mqk为实施例,运用以上方法得到了该蛋白质的近天然态构象,均方根偏差为
以上阐述的是本发明给出的一个实施例表现出来的优良效果,显然本发明不仅适合上述实施例,在不偏离本发明基本精神及不超出本发明实质内容所涉及内容的前提下可对其做种种变化加以实施。
- 还没有人留言评论。精彩留言会获得点赞!