注释数据库索引结构、快速注释遗传变异的方法及系统与流程
本发明涉及生物信息学技术领域,具体涉及一种基因组功能注释数据库的索引结构和快速注释遗传变异的方法及系统。
背景技术:
基因组功能注释是利用生物信息学方法和工具,对基因组所有基因或非编码调控元件的生物学功能进行注释,是当前功能基因组学研究的一个热点。随着高通量测序技术的普及,目前已经产生并积累了海量的基因组注释数据库,数据库的规模正在以接近指数方式增长,平均不到9个月就增加一倍。另外,个体化医学的发展也推动了基因组遗传位点的功能注释在精准医疗上的应用,数据查询已经逐渐接近全基因组规模,例如对个体基因组数百万遗传变异的解读将成为基因检测常规任务。
一个最简单的基因组注释任务可以抽象成先从数据库中获得所有与查询区间(指特定基因组染色体上的一段或一个位点)相关的信息行(指落在查询染色体位置内或相交的所有信息),再从获得的信息行中提取需要的注释项。现有的基因组注释算法工具及产品主要采用两种不同的策略进行基因组注释数据库的检索,包括采用独立的随机定位访问(例如tabix,vep和giggle),或采用逐行扫描方法扫描注释数据库文件(例如bedtools,bcftools和vcfanno)。然而,这些已有算法在面对大规模查询或注释数据库文件的时候由于计算效率低、对数据库规模的扩展支持较差等原因已经无法满足大规模全基因组水平的应用需求。例如:面对一个目前常用的注释潜在致病性突变的遗传位点注解数据库combinedannotationdependentdepletion(cadd)中90亿条注释信息(压缩后约300gb),如要从cadd数据库中提取信息对个体基因组(大约500万条遗传变异)进行注释,现有的流行算法需要十几到上百个小时才能完成,耗用时间长。同时现有的工具绝大部分都不支持多线程,容易造成系统资源的浪费。
技术实现要素:
针对现有技术中的缺陷,本发明实施例提供一种基因组功能注释数据库的索引结构;所述索引结构包括基于注释数据库的一级索引文件、基于一级索引文件的二级索引文件,两级索引文件的大小合计约为注释数据库的几十分之一到上百分之一,通过扫描两级索引文件来找到结果所在数据行的文件地址,再根据文件地址定位注释数据库提取注释信息对遗传变异进行注释,比直接扫描注释数据库极大地减少了磁盘读操作,提升查询速度。
本发明实施例还提供一种快速注释遗传变异的方法及系统,所述方法基于所述索引结构。所述方法中的逐行扫描过程仅依赖于所述索引结构中的一级索引文件,而不依赖于注释数据库,极大地减少了磁盘读操作和扫描时间;此外,结合所述索引结构中的二级索引文件和随机定位策略避免对无关联的一级索引文件块的扫描,可以再次节省扫描时间,大幅提升查询速度。
第一方面,本发明实施例提供的一种基因组功能注释数据库的索引结构,包括基于注释数据库的一级索引文件、基于一级索引文件的二级索引文件;所述一级索引文件由多个文件块组成,每个文件块由头部和主体组成,主体由多行压缩数据组成,每个文件块对应注释数据库里的一个压缩块;所述二级索引文件由多行数据组成,每行数据存储一级索引文件中一个文件块主体数据的位置区间以及能直接寻址该文件块第一条数据的64位虚拟文件地址。
进一步地,创建所述一级索引文件的方法包括创建文件块的方法,创建一个文件块的方法包括以下步骤:
获取注释数据库的一个压缩块,提取压缩块里全部数据的位置信息和64位虚拟文件地址并拆分成高48位压缩块地址和低16位地址偏移;
创建一级索引文件块的头部,在头部写入高48位压缩块地址、所述压缩块内数据低16位地址偏移的平均值和所述压缩块内第一条数据的染色体编号、起始位置和终止位置;
创建一级索引文件块的主体,计算所述压缩块内全部数据位置区间信息的差值和低16位地址偏移的差值并由位编码技术压缩后写入文件块主体。
进一步地,注释数据库的一个压缩块内所有数据的高48位压缩块地址都是相同的,将数据的64位虚拟文件地址拆分成高48位压缩块地址和低16位地址偏移,然后将高48位压缩块地址写入文件块头部,每条数据只保留低16位地址偏移,可以将每条数据文件地址的存储量从64位缩减到16位。
进一步地,计算所述压缩块内全部数据位置区间信息的差值包括计算第n数据和第n-1条数据起始位置的差值、第n条数据自身终止位置和起始位置的差值,其中n为整数且n大于1;计算所述压缩块内全部数据低16位地址偏移的差值包括计算每一条数据与所述压缩块内数据低16位地址偏移平均值的差值。
进一步地,所述位编码技术采用8位存储信息,其中,第一位表示符号位;第二位到第四位表示存储第n条数据和第n-1条数据起始位置的差值信息;第五位到第六位表示存储第n条数据自身终止位置和起始位置的差值信息;第七位表示第n条数据的低16位地址偏移差值的符号为正号或负号;第八位表示第n条数据的低16位地址偏移的差值的范围;其中,n为整数且n大于1。
进一步地,创建二级索引文件的方法包括创建数据的方法,创建一条数据的方法包括以下步骤:对比一级索引文件块主体中全部数据位置区间的起始位置,得到最小值;对比一级索引文件块主体中全部数据位置区间的终止位置,得到最大值;存储所述最小值、最大值和文件块第一条数据的64位虚拟文件地址。
第二方面,本发明提供的一种遗传变异的注释方法,包括:
s21:获取注释数据库文件;构建注释数据库的索引结构,所述索引结构包括一级索引文件和二级索引文件,所述索引结构的构建方法采用本发明第一方面中描述的方法;
s22:获取查询文件,获取分配的线程数,根据所分配的线程数平均拆分查询文件,所述查询文件包含多条查询数据;
s23:每个线程分别从拆分后的查询文件中读取一条查询数据;
s24:每个线程分别根据查询数据的染色体编号,读取二级索引文件中所述染色体编号对应的二级索引数据到内存;
s25:每个线程分别比对匹配一条二级索引数据与查询数据;若匹配成功,则一级索引文件根据二级索引数据中所存的64位虚拟文件地址定位到相应的文件块,再将查询数据与所述文件块主体中的数据进行逐行比对匹配,若匹配成功,则计算文件块主体中匹配成功数据的64位虚拟文件地址,根据地址去注释数据库提取注释数据,返回所述注释数据对待查询注释数据进行注释,得到注释结果;若匹配失败,则一级索引文件跳过二级索引数据对应的文件块;
s26:每个线程分别重复执行步骤s25,直到二级索引数据的起始位置大于查询数据的终止位置;
s27:重复执行s23-s26,直到查询文件的数据注释完毕或二级索引数据读取完毕。
进一步地,在所述步骤s25中,比对匹配为检查两条数据的位置区间是否有交集,有交集则匹配成功,无交集则匹配失败。
进一步地,在所述步骤s25中,计算文件块主体中匹配成功数据的64位虚拟文件地址的具体方法包括:提取所述文件块主体中匹配成功的数据的低16位地址偏移差值;提取所述文件块头部中存储的块内数据低16位地址偏移的平均值和高48位压缩块地址;根据所述差值、平均值和块地址计算该数据的64位虚拟文件地址。
进一步地,在所述步骤s25中,还将一级索引文件块主体中匹配成功的数据暂存在全局链表中,并在整个查询过程维护全局链表来确保逐行扫描的过程是顺序无返回的。
第三方面,本发明实施例还提供一种遗传变异的注释系统,包括注释数据库索引模块、查询文件拆分模块和查询文件注释模块。
所述注释数据库索引模块用于构建两级索引文件,包括:1)注释数据库录入装置,采用国际标准的bgzip格式储存数据作为输入文件;2)注释数据库索引装置,根据本发明第一方面的索引结构和构建方法,对注释数据库进行索引,并输出一级索引文件、二级索引文件;所述索引结构的构建方法采用本发明第一方面中描述的方法。
所述查询文件拆分模块用于根据线程数拆分查询文件,包括:1)查询文件录入装置,采用国际标准的vcf、bed、tab格式储存待注释的基因组特征或遗传变异数据作为输入文件;2)根据线程数将查询文件分成与线程数相同份数,并给每一个线程分配一份拆分后的查询文件。
所述查询文件注释模块用于从注释数据库提取信息注释查询文件数据,包括:1)查询数据读取装置,从拆分后的查询文件中读取一条查询数据,并提取数据的染色体编号和位置区间;2)二级索引匹配装置,根据查询数据的染色体编号读取部分二级索引数据入内存,并与查询数据逐行匹配;3)一级索引匹配装置,根据二级索引匹配成功的数据定位到相应的一级索引文件块,依次读取文件块主体的数据并与查询数据匹配,对匹配成功的数据计算64位虚拟文件地址并将所述数据暂存在全局链表中;4)注释数据库注释信息提取装置,根据一级索引文件块主体中匹配成功数据的64位虚拟文件地址,去注释数据库提取注释对查询数据进行注释;5)全局链表查询维护装置,扫描全局链表中的数据并与查询数据匹配,若成功则根据64位虚拟文件地址去注释数据库中提取注释对查询数据进行注释,若失败并且数据的终止位置小于查询数据起始位置,则从全局链表中移除该数据。
进一步地,在所述一级索引匹配装置中,计算文件块主体中匹配成功数据的64位虚拟文件地址的具体方法包括:提取所述文件块主体中匹配成功的数据的低16位地址偏移差值;提取所述文件块头部中存储的块内数据低16位地址偏移的平均值和高48位压缩块地址;根据所述差值、平均值和块地址计算该数据的64位虚拟文件地址。
本发明的有益效果:
本发明实施例提供的基因组功能注释数据库的索引结构,包括基于注释数据库的一级索引文件和基于一级索引文件的二级索引文件;两级索引文件的大小合计约为注释数据库的几十分之一到上百分之一,通过扫描两级索引文件来找到结果所在数据行的文件地址,再根据文件地址定位注释数据库提取注释信息对遗传变异进行注释,比直接扫描注释数据库极大地减少了磁盘读操作,提升查询速度。
本发明实施例提供快速注释遗传变异的方法,逐行扫描过程仅依赖于一级索引文件,而不依赖于注释数据库,极大地减少了磁盘读操作和扫描时间,此外,结合二级索引文件和随机定位策略避免对无关联的一级索引文件块的扫描,可以再次节省扫描时间,大幅提升查询速度;同时通过维护一个全局链表来确保逐行扫描的过程是顺序无返回的,避免对注释数据库压缩块重复解压和读取,再进一步结合多线程技术合理利用系统资源来并行操作,使得本发明比国际上现有的注释方法快约十几到上百倍。最后,随着注释数据库或查询文件规模的大幅增长,所述注释方法是可扩展的。
本发明实施例提供的基因组功能注释数据库注释系统,通过各级模块和装置实现了本发明实施例中提供的基因组功能注释数据库索引结构和快速注释遗传变异的方法,并且模块之间相互独立,具备极佳的可扩展性。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍。在所有附图中,类似的元件或部分一般由类似的附图标记标识。附图中,各元件或部分并不一定按照实际的比例绘制。
图1示出了本发明第一实施例所提供的一种基因组功能注释数据库的索引结构图;
图2示出了本发明第一实施例中采用的位编码技术的数据存储结构图;
图3示出了本发明第二实施例所提供的一种快速注释遗传变异方法的流程图;
图4示出了本发明第二实施例所提供的一种快速注释遗传变异方法的工作示意图;
图5示出了本发明第三实施例所提供的一种快速注释遗传变异系统的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
应当理解,当在本说明书和所附权利要求书中使用时,术语“包括”和“包含”指示所描述特征、整体、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其它特征、整体、步骤、操作、元素、组件和/或其集合的存在或添加。
还应当理解,在此本发明说明书中所使用的术语仅仅是出于描述特定实施例的目的而并不意在限制本发明。如在本发明说明书和所附权利要求书中所使用的那样,除非上下文清楚地指明其它情况,否则单数形式的“一”、“一个”及“该”意在包括复数形式。
还应当进一步理解,本发明说明书和所附权利要求书中使用的术语“和/或”是指相关联列出的项中的一个或多个的任何组合以及所有可能组合,并且包括这些组合。
如在本说明书和所附权利要求书中所使用的那样,术语“如果”可以依据上下文被解释为“当...时”或“一旦”或“响应于确定”或“响应于检测到”。类似地,短语“如果确定”或“如果检测到[所描述条件或事件]”可以依据上下文被解释为意指“一旦确定”或“响应于确定”或“一旦检测到[所描述条件或事件]”或“响应于检测到[所描述条件或事件]”。
需要注意的是,除非另有说明,本申请使用的技术术语或者科学术语应当为本发明所属领域技术人员所理解的通常意义。
发明人总结了国际上现有的遗传变异注释方法,大致可以归为两类:对注释数据库逐行扫描的方法和依赖索引文件随机定位注释数据库的方法。
逐行扫描方法不适用于注释数据库庞大而查询数据很小的情景,例如从一个含几十亿条注释信息的注释数据库按需提取几条注释,逐行扫描方法仍然需要遍历这几十亿条注释信息,性能较好的计算机设备仍需耗时十几小时以上。
依赖索引文件随机定位注释数据库的方法不适用于查询数据庞大的情景。通过索引文件定位到注释数据库里结果相关的文件块再进行逐行扫描,使得随机定位方法的每一次查询都是毫秒级别。但随机定位方法的每一次查询都是独立操作,若查询文件有几百万行数据,则随机定位方法耗时能达几十小时以上。
另外,现有的注释方法绝大部分不支持多线程,造成系统资源的浪费。
综上,针对现有的注释方法无法适用于不同规模和分布的查询和注释数据库,且面对注释数据库的爆发式增长,现有的方法效率越来越低下的技术问题,本发明实施例提供了下列技术方案解决现有技术存在的问题。
为了更好地理解本发明各个实施例,在此对各个名称做简要解释。
基因注释:简称注释,也有的文献称注解,基因组测序只能测出整个dna的碱基对排列顺序,不能直接测出dna上的基因及其功能,必须通过生物信息学方法,结合蛋白组学、转录组学,对测出来的序列进行分析,将基因及其功能加以挖掘、注释,这个过程即称作基因注释。
基因组功能注释数据库:并非软件领域中的数据库,而是指人类基因组上存在大量的遗传变异,这些变异位点有可能是影响人类健康,或导致人类患病的致病位点。基于下代测序技术,测序得到的序列和基因组进行比对,从比对的结果中找出不同位置上测序序列和基因组序列的差异碱基,这就是变异位点。一个人的基因组中可能发现百万个单核苷酸多态性、插入和缺失变异,这些变异以atcg四种碱基的各种组合形式出现。人类疾病就和这些变异有关,虽然可以发现百万个变异,但是真正跟疾病相关的变异数量极少。科研工作者要在大量的变异位点中找到候选致病的基因和变异位点,这需要借助基因组注释数据库进行注释分析,从注释的结果中挖掘出和疾病、药物等相关的变异位点。
基因组功能注释数据库数据格式:采用国际标准的vcf、bed或tab格式储存变异数据并经过bgzip压缩而成。数据库里的数据有多行,每一行有多列,列之间以tab键来分隔。有几列数据是必须存在的,包括:染色体编号、变异位点相对于参考基因组所在的位置,这个位置是一个区间,包含起始位置和终止位置;数据按染色体编号和起始位置升序排列,对于每一行数据要求终止位置须大于起始位置。
查询文件(待注释文件):采用国际标准的vcf、bed、tab格式储存待注释的基因组特征或遗传变异数据作为输入文件。
bgzip压缩格式:基因组功能注释数据库的数据文件都采用bgzip无损压缩,bgzip是一种兼容gzip的压缩格式,由多个压缩块组成,每一块数据在压缩前不超过216字节。
64位虚拟文件地址:bgzip压缩的文件,每一条数据都能通过一个唯一的64位虚拟文件地址来直接寻址。这个64位虚拟文件地址由高48位压缩块地址和低16位块内地址偏移组成。
高48位压缩块地址:指一个压缩块在整个压缩文件中的地址(文中简称块高48位地址)。
低16位块内地址偏移:指一条数据在当前压缩块内的地址(文中简称低16位地址偏移)。
一级索引文件块:一个一级索引文件块的数据对应一个全基因组功能注释数据库压缩块里的数据,并由压缩块的数据提取查询依赖的位置信息及每条数据的64位虚拟文件地址后用位编码技术压缩而成。
位置信息:本文中提到的数据位置信息由三个数据组成,包括:染色体编号、起始位置和终止位置;染色体编号取值范围是[1-22,x,y],起始位置和终止位置的取值范围是[1到229-1],终止位置大于起始位置。
位置区间:本文中提到的位置区间指代位置信息里的起始位置和终止位置。
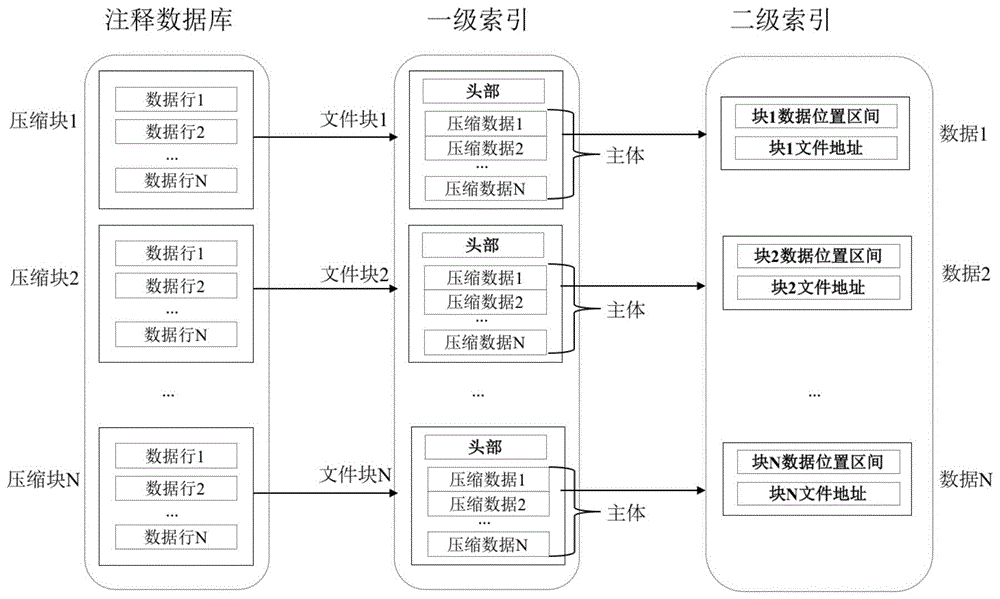
如图1所示,示出了本发明实施例提供的一种基因组功能注释数据库索引结构,所述索引结构包括基于注释数据库的一级索引文件、基于一级索引文件的二级索引文件。
所述一级索引文件格式为bgzip,由文件块组成,每个文件块由头部和主体组成,主体由多行压缩数据组成,每个文件块对应注释数据库里的一个压缩块;所述二级索引文件由多行数据组成,每行数据存储一级索引文件中一个文件块主体数据的位置区间以及能直接寻址该文件块第一条数据的64位虚拟文件地址。
具体地,创建注释数据库的一级索引文件的方法包括创建文件块的方法,创建文件块的方法包括以下步骤:
获取注释数据库的一个压缩块,提取压缩块里全部数据的位置信息和64位虚拟文件地址并拆分成高48位压缩块地址和低16位地址偏移;
创建一级索引文件块的头部,在头部写入高48位压缩块地址、所述压缩块内数据低16位地址偏移的平均值和所述压缩块内第一条数据的染色体编号、起始位置和终止位置;
创建一级索引文件块的主体,计算所述压缩块内全部数据位置区间信息的差值和低16位地址偏移的差值并由位编码技术压缩后写入文件块主体。
上述步骤中,注释数据库为基因组功能注释数据库。注释数据库的格式为bgzip,由多个压缩块组成。一级索引文件里的每一个文件块对应注释数据库里的一个压缩块。
上述步骤中,注释数据库的一个压缩块内所有数据的高48位压缩块地址都是相同的,将数据的64位虚拟文件地址拆分成高48位压缩块地址和低16位地址偏移,然后将高48位压缩块地址写入文件块头部,每条数据只保留低16位地址偏移,可以将每条数据文件地址的存储量从64位缩减到16位。
上述步骤中,计算所述压缩块内全部数据位置区间信息的差值包括计算第n数据和第n-1条数据起始位置的差值、第n条数据自身终止位置和起始位置的差值,其中n为整数且n大于1;计算所述压缩块内全部数据低16位地址偏移的差值包括计算每一条数据与所述压缩块内数据低16位地址偏移平均值的差值。
上述步骤中,所述差值由本发明第一实施例中的位编码技术进一步压缩。如图2所示,示出了本发明第一实施例中的位编码技术的数据存储结构图。原本三个差值(起始位置差值、终止位置差值、地址偏移差值)需要三个整型(12字节)来存储,采用位编码技术压缩之后,大部分差值只需要2个字节来存储。位编码技术采用1个字节(8位)来存储大部分差值信息,包括以下部分:1)第一位为符号位;2)用第二位到第四位存储第n条数据和第n-1条数据起始位置的差值信息;第二到第四位可以表示8种不同的状态,分别是000、001、010、011、100、101、110、111;若差值范围为0到4,则用前五种状态记录;若差值范围为5到27-1,则用101加一个字节记录;若差值范围为27到215-1,则用第110加两个字节记录;若差值范围为215到229-1,则用第111加四个字节记录;3)用第五位和第六位存储第n条数据自身终止位置和起始位置的差值信息;五到六位可以表示4种不同的状态,分别是00、01、10、11;若差值为1,则用00记录;若差值范围为2到27-1,则用01加一个字节记录;若差值范围为27到215-1,则用第10加两个字节记录;若差值范围为215到229-1,则用第11加四个字节记录;4)用第七位记录第n条数据的低16位地址偏移差值的符号为正号或负号;5)用第八位记录第n条数据的低16位地址偏移差值的范围;其中,n为整数且n大于1。由于大型注释数据库里的绝大部分数据的起始位置和上一条数据的差值不会超过4,因此绝大部份数据无需多加字节来记录起始位置差值。同时,大部分注释数据库里99%以上的数据都是单核苷酸多态性,即终止位置和起始位置的差值是1,因此99%以上的数据无需多加字节来记录终止位置差值。
具体地,创建所述二级索引文件的方法包括创建一条数据的方法,创建一条数据的方法包括以下步骤:对比一级索引文件块主体中全部数据位置区间的起始位置,得到最小值;对比一级索引文件块主体中全部数据位置区间的终止位置,得到最大值;存储所述最小值、最大值和文件块第一条数据的64位虚拟文件地址。
本发明第二实施例提供了一种快速注释遗传变异的方法,该方法结合随机定位和逐行扫描两个方法的优点并使用多线程来快速提升注释的速度,所述方法基于本发明第一实施例的索引结构,如图3所示,该方法包括以下步骤:
s21:获取注释数据库文件;构建注释数据库的索引结构,所述索引结构包括一级索引文件和二级索引文件,所述索引结构的构建方法采用第一实施例中描述的方法;
s22:获取查询文件,获取分配的线程数,根据所分配的线程数平均拆分查询文件,所述查询文件包含多条查询数据;
s23:每个线程分别从拆分后的查询文件中读取一条查询数据;
s24:每个线程分别根据查询数据的染色体编号,读取二级索引文件中所述染色体编号对应的二级索引数据到内存;
s25:每个线程分别比对匹配一条二级索引数据与查询数据;若匹配成功,则一级索引文件根据二级索引数据中所存的64位虚拟文件地址定位到相应的文件块,再将查询数据与所述文件块主体中的数据进行逐行比对匹配,若匹配成功,则计算文件块主体中匹配成功数据的64位虚拟文件地址,根据地址去注释数据库提取注释数据,返回所述注释数据对待查询注释数据进行注释,得到注释结果;若匹配失败,则一级索引文件跳过二级索引数据对应的文件块;
s26:每个线程分别重复执行步骤s25,直到二级索引数据的起始位置大于查询数据的终止位置;
s27:重复执行s23-s26,直到查询文件的数据注释完毕或二级索引数据读取完毕。
在上述步骤s25中,比对为检查两条数据的位置区间是否有交集,有交集则匹配成功,无交集则匹配失败。
在上述步骤s25中,计算文件块主体中匹配成功数据的64位虚拟文件地址的具体方法包括:提取所述文件块主体中匹配成功的数据的低16位地址偏移差值;提取所述文件块头部中存储的块内数据低16位地址偏移的平均值和高48位压缩块地址;根据所述差值、平均值和块地址计算该数据的64位虚拟文件地址。
在上述步骤s25中,还将一级索引文件块主体中匹配成功的数据暂存在全局链表中,并在整个查询过程维护全局链表来确保逐行扫描的过程是顺序无返回的。全局链表的维护方法包括:
1)所述方法步骤中的s25执行之前,先逐行扫描全局链表中的数据并与查询数据匹配;若成功,则根据全局链表中数据所存的文件地址去注释数据库提取注释数据,返回数据对查询数据进行注释;若失败并且数据的终止位置小于查询数据起始位置,则从全局链表中移除该数据(即这些数据与之后的查询数据位置区间无交集,无法匹配成功)。
2)所述方法步骤中的s26执行完毕后,将一级索引文件块主体中匹配成功的数据暂时存储在全局链表中。
具体地,查询数据是按染色体编号和起始位置升序排列的,而注释数据库、一级索引文件、二级索引文件也是按染色体编号和起始位置升序排列的;若一级索引文件块与一条查询数据不匹配,则该文件块与下一条查询数据也无法匹配(匹配不成功是因为该文件块所有数据的终止位置都小于查询数据的起始位置,按起始位置升序的原则,这些数据会更加小于下一条查询数据的起始位置从而无法匹配);全局链表的使用能确保查询数据可以直接从链表中获得之前遍历过的已匹配成功的数据,而无需返回重头开始再次扫描一级索引文件块。无返回操作确保与结果相关的一级索引文件块、注释数据库压缩块在整个查询过程中仅被解压和读取一次;相比国际上现有流行方法对注释数据库压缩快重复解压和读取的技术缺陷,本发明极大的节省了内存消耗和查询时间,同时提升查询性能。
如图4所示,示出了本发明第二实施例提供的快速注释遗传变异方法的工作示意图。如图所示,查询数据的位置区间是[9-11],而二级索引第一条数据位置区间是[0-3](表示一级索引第一个文件块主体数据的位置区间是[0-3]);查询数据匹配二级索引第一条失败,则一级索引文件跳过第一个文件块。查询数据匹配二级索引第二条成功,则一级索引定位至第二个文件块进行逐行扫描,扫描匹配到结果,则去注释数据库定位提取注释信息返回。示意图中一级索引的第一个文件块只示出了3条数据,实际一个一级索引文件块数据有约29-210字节,通过该方法随机定位能避免对无关联的一级索引文件块的扫描,提升速度。另外,实际基因组功能注释数据库中一个压缩块数据有216字节,逐行扫描一级索引文件相对逐行扫描注释数据库又能极大的缩减磁盘读操作,将速度提升至原来的十几到上百倍。
此外,本发明实施例还采用多线程技术,通过合理利用系统资源来再次提升查询速度。
本发明第三实施例提供了一种快速注释遗传变异的系统,如图5所示,包括注释数据库索引模块、查询文件拆分模块和查询文件注释模块,所述系统基于本发明第一实施例的索引结构和本发明第二实施例的注释方法。
所述注释数据库索引模块用于构建两级索引文件,包括:1)注释数据库录入装置,采用国际标准的bgzip格式储存数据作为输入文件;2)注释数据库索引装置,根据本发明第一实施例的索引结构和构建方法,对注释数据库进行索引,并输出一级索引文件、二级索引文件;所述索引结构的构建方法采用第一实施例中描述的方法。
所述查询文件拆分模块用于根据线程数拆分查询文件,包括:1)查询文件录入装置,采用国际标准的vcf、bed、tab格式储存待注释的基因组特征或遗传变异数据作为输入文件;2)根据线程数将查询文件分成与线程数相同份数,并给每一个线程分配一份拆分后的查询文件。
所述查询文件注释模块用于从注释数据库提取信息注释查询文件数据,包括:1)查询数据读取装置,从拆分后的查询文件中读取一条查询数据,并提取数据的染色体编号和位置区间;2)二级索引匹配装置,根据查询数据的染色体编号读取部分二级索引数据入内存,并与查询数据逐行匹配;3)一级索引匹配装置,根据二级索引匹配成功的数据定位到相应的一级索引文件块,依次读取文件块主体的数据并与查询数据匹配,对匹配成功的数据计算64位虚拟文件地址并将所述数据暂存在全局链表中;4)注释数据库注释信息提取装置,根据一级索引文件块主体中匹配成功数据的64位虚拟文件地址,去注释数据库提取注释对查询数据进行注释;5)全局链表查询维护装置,扫描全局链表中的数据并与查询数据匹配,若成功则根据64位虚拟文件地址去注释数据库中提取注释对查询数据进行注释,若失败并且数据的终止位置小于查询数据起始位置,则从全局链表中移除该数据。
在上述一级索引匹配装置中,计算文件块主体中匹配成功数据的64位虚拟文件地址的方法采用第二实施例中描述的方法。
在上述全局链表查询维护装置中,全局链表的维护方法采用第二实施例中描述的方法。
应用本发明的技术方案具有至少以下技术效果:
1)注释数据库中一条数据包括:位置信息、注释信息及其他信息,大约占26-210个字节(具体大小取决于注释信息的长度)。经过信息提取及采用本发明第一实施例子中的位编码技术再压缩之后,存储在本发明第一实施例中一级索引文件的一条数据只有2-13个字节,大约是注释数据的几十分之一到上百分之一。因此相对于逐行比对注释数据库,逐行比对索引文件可以极大地减少磁盘读操作,提升查询速度。
2)通过二级索引文件随机定位一级索引文件结果相关的文件块,避免对无关联文件块数据的逐行比对,缩小查询范围,极大减少了查询所需比对的行数据,提升查询速度。
3)通过二级索引文件随机定位一级索引文件块之后,逐行比对所述文件块主体里的数据来定位结果所在的数据行,再依据数据里存的64位虚拟文件地址去注释数据库定位提取注释数据来对查询数据进行注释,比国际上现有的直接对注释数据库进行逐行比对的方法快约十几到上百倍。
4)通过维护一个全局链表来存储一级索引文件块主体中匹配成功的数据,来确保逐行扫描的过程是顺序无返回的。无返回操作确保与结果相关的一级索引文件块、注释数据库压缩块在整个查询过程中仅被解压和读取一次,相比国际上现有流行方法对注释数据库压缩快重复解压和读取的技术缺陷能极大的节省内存消耗和查询时间,同时提升查询性能。
5)通过多线程操作使得本发明可以合理利用系统资源再次提升查询速度。
本发明还提供一种计算机可读存储介质的实施例,所述计算机存储介质存储有计算机程序,所述计算机程序包括程序指令,所述程序指令当被处理器执行时使所述处理器执上述实施例描述的方法。
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,上述描述的终端和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
在本申请所提供的几个实施例中,应该理解到,所揭露终端和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另外,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口、装置或单元的间接耦合或通信连接,也可以是电的,机械的或其它的形式连接。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。
- 还没有人留言评论。精彩留言会获得点赞!