一种人工蜂群优化贝叶斯网络的上位性位点挖掘方法与流程
本发明涉及生物信息技术领域,具体为一种人工蜂群优化贝叶斯网络的上位性位点挖掘方法。
背景技术:
随着人们生活质量的提高、医疗卫生环境的改善和相关生物技术的迅速发展,人类高发病率的疾病类型发生了巨大的改变。营养不良、传染病等主要受环境影响的疾病得到了有效地控制,而复杂疾病和孟德尔遗传病成为了目前困扰人类的主要疾病,孟德尔遗传病是一种单基因疾病,其遗传过程遵循孟德尔遗传定律,目前研究者利用定位克隆的方法确定了相关遗传基因,基本阐明了其遗传方式。复杂疾病是由多个基因,环境因素共同作用的结果,其病因非常复杂。其中复杂疾病占人类疾病的80%以上,主要包括癌症、2型糖尿病、高血压、心脏病等,因此,探索复杂疾病其中的遗传机制具有重要的研究意义。
从生物遗传学的角度看,决定生物复杂性状的遗传因素主要包括三个方面:基因主效应、基因与基因之间的相互作用和基因与环境之间的相互作用。全基因组关联分析(genome-wideassociationstudies,gwas)是用人类全基因组范围内数以百万计的单核苷酸多态性(singlenucleotidepolymorphism,snp)作为遗传标记,通过病例/对照分析,来进一步探索出复杂疾病的相关遗传机制。但是早期开展的全基因组关联研究,主要侧重于主效基因的检测上,忽略了基因与基因之间的相互作用,即上位性(epistasis)。而对于复杂疾病来说,snp之间的上位性作用的影响往往更为重要,因此在全基因组范围内进行上位性检测对于探寻复杂疾病的致病病因有着重要的意义。
近年来,研究人员提出了多种上位性检测方法,但是这些方法仍然存在计算困难、效率低下、算法复杂度高以及假阳性率高等问题,导致不能准确高效地检测出与疾病相关联的snp位点及其组合。
因此,在全基因组范围内提出更有效、更准确的上位性检测算法具有十分重要的研究意义,也对复杂疾病致病机理的发现、诊断、治疗和预防有着非常重要的作用。
技术实现要素:
本发明的目的在于提供一种人工蜂群优化贝叶斯网络的上位性位点挖掘方法,通过人工蜂群算法优化贝叶斯网络构建包括snp位点和表型性状的网络结构,进而挖掘出上位性位点。
为实现上述目的,本发明实施例提供如下技术方案:一种人工蜂群优化贝叶斯网络的上位性位点挖掘方法,包括如下步骤:
s1,利用扩张、收缩、对称性检测三个阶段,将目标节点分为表型class节点和非class节点两种情况,通过条件互信息计算获取不同节点的马尔可夫毯;
s2,根据得到不同节点的马尔可夫毯,构建包括snp位点和表型class的网络,得到初始蜜源,即初始网络结构;
s3,在不生成环的前提下,基于初始蜜源网络个体,通过随机增加边、删除边、逆转边的操作生成新的网络个体,直到网络个体数量达到最大初始蜜源数目;
s4,在步骤3所得初始蜜源的基础上,通过人工蜂群优化算法的三种蜜蜂行为与贝叶斯网络的bic和mit两种打分函数,对包括snp位点和表型class的贝叶斯网络进行演化,得到较优的贝叶斯网络结构,从而准确快速地获取到影响表型性状的上位性基因位点,其中三种蜜蜂分别为采蜜蜂、观察蜂和侦察蜂。
进一步,在所述s1步骤前,将基因型数据表示为0,1,2形式的数据,对于特定snp基因型数据,例如at,进行如下表示:aa用0表示,tt用2表示,at/ta用1表示,其中0表示纯合子常见基因型,1表示杂合子,2表示纯合子少见基因型,表型class取值为0或1,0表示为未患病,1表示为患病。
进一步,在所述s1步骤中,扩张阶段具体为:在构建非class节点的马尔可夫毯时,假设表型class节点已经加入到目标snp节点的马尔可夫毯中,计算任意一个snp节点与class在目标snp节点条件下的条件互信息,并将所述条件互信息小于阈值的snp位点加入目标节点的马尔可夫毯中;在构建class节点的马尔可夫毯时,假设任意一个snp节点已经加入表型class节点的马尔可夫毯中,计算另外任意一个snp节点与已加入马尔可夫毯的snp节点在class条件下的条件互信息,并将小于阈值的snp位点加入class节点的马尔可夫毯中。
进一步,在所述s1步骤中,收缩阶段具体为:去除多余节点;对于任意目标节点snp1或者class节点,计算在去除snp2的马尔可夫毯的条件下目标节点snp1与snp2的条件互信息,若所述条件互信息大于阈值,则删除snp2并更新节点snp1的马尔可夫毯。
进一步,在所述s1步骤中,对称性检测具体为:由于本发明中的方法是基于条件独立性检测,因此任意目标节点马尔可夫毯中的节点之间应该相互依赖,假设snp1存在于snp2的马尔可夫毯中,snp1与snp2应该相互依赖,与之对应,snp2应该存在于snp1的马尔可夫毯中,假如两个节点的马尔可夫毯并不对称,那么分别在两个节点的马尔可夫毯中删除另外一节点。
进一步,在所述s4步骤中,采蜜蜂阶段具体为:
s40,首先采蜜蜂对初始蜜源的邻域进行搜索,即通过加边、减边、逆转边三种操作对网络结构进行更新;
s41,然后利用bic和mit两种评分函数同时对新的网络结构进行打分,并与初始网络结构的分数进行比较,若新的网络结构优于初始网络结构,则将该网络结构进行保存,并记录该网络结构提高的分数;
s42,最后,根据提高的分数使用轮盘赌的方式随机选择新的网络结构,此时采蜜蜂对其进行采蜜;
以上的网络结构即蜜源。
进一步,在所述采蜜蜂阶段的方法中,使网络分数提高越大的操作被选择的概率越大,这不仅可以保证网络演变的正确性,又不至于陷入局部最优,假如轮盘赌方法选择放弃本次加边、减边或者逆转边操作,则说明该蜜源邻域已无更优网络结构,表示该网络结构已是最优的网络结构,此时采蜜蜂对其进行采蜜。
进一步,在所述s4步骤中,观察蜂阶段具体为:观察蜂阶段和采蜜蜂阶段交替进行,每当采蜜蜂搜索一次邻域得到较优的网络结构之后,观察蜂便对采蜜蜂所在的蜜源进行考察,根据两种打分函数计算对应网络结构的适应度值,然后利用轮盘赌的方式随机选择一个蜜源网络结构,适应度越大的网络结构被认为邻域拥有更优网络结构的可能性越大,被选到的几率也就越大,采蜜蜂对选中网络结构的邻域进行搜索,重复采蜜蜂阶段的操作。
进一步,在所述s4步骤中,侦察蜂阶段具体为:侦察蜂在采蜜蜂和观察蜂阶段中扮演监督员的角色,记录每个蜜源网络结构的采蜜次数以及最优蜜源网络结构,当某一蜜源网络结构达到最大采蜜次数,则放弃该蜜源,并通过步骤1重新生成新的蜜源网络结构,假如每只采蜜蜂均将对应蜜源开采至最大采蜜次数,则找到最优蜜源,即最优网络结构,此时算法结束。
进一步,适应度函数是用于评判网络结构好坏的标准,因此采用bic与mit联合打分的方法对网络的优劣进行判断,同时,由于bic打分函数可以处理的父节点个数有限,因此采用可分解bic打分方法处理较多个数的父节点,进而可以处理规模较大的网络结构。
与现有技术相比,本发明的有益效果是:一种人工蜂群优化贝叶斯网络的上位性位点挖掘方法,首先利用扩张、收缩、对称性检测三个阶段,通过条件互信息计算得到节点的马尔可夫毯,构建初始蜜源网络结构,然后,基于初始蜜源通过随机加边、减边、逆转边3种操作生成新的蜜源,直到达到最大初始蜜源数目,利用人工蜂群算法的三种操作(采蜜蜂、观察蜂和侦察蜂)与贝叶斯网络的bic与mit打分方法,对贝叶斯网络结构进行演化,找到最优的网络结构,快速准确的获取到影响表型性状的上位性基因位点,辅助基因功能挖掘。
附图说明
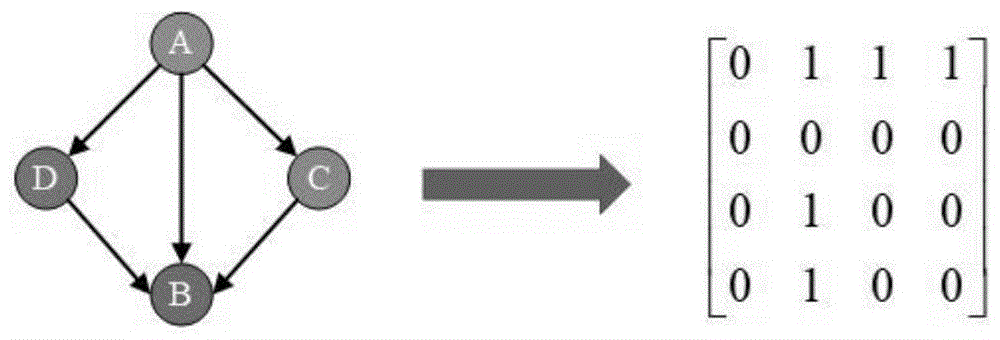
图1为本发明实施例提供的一种人工蜂群优化贝叶斯网络的上位性位点挖掘方法的贝叶斯网络矩阵编码表示图;
图2为本发明实施例提供的一种人工蜂群优化贝叶斯网络的上位性位点挖掘方法的贝叶斯网络三种操作示意图;
图3为本发明实施例提供的一种人工蜂群优化贝叶斯网络的上位性位点挖掘方法的具体实施的流程图;
图4为本发明实施例提供的一种人工蜂群优化贝叶斯网络的上位性位点挖掘方法的不同方法2位点上位性检测的准确率比较;
图5为本发明实施例提供的一种人工蜂群优化贝叶斯网络的上位性位点挖掘方法的不同方法2位点上位性检测的f1-score比较;
图6为本发明实施例提供的一种人工蜂群优化贝叶斯网络的上位性位点挖掘方法的不同方法2位点上位性检测的fpr比较;
图7为本发明实施例提供的一种人工蜂群优化贝叶斯网络的上位性位点挖掘方法的不同方法3位点上位性检测的准确率比较;
图8为本发明实施例提供的一种人工蜂群优化贝叶斯网络的上位性位点挖掘方法的不同方法3位点上位性检测的f1-score比较;
图9为本发明实施例提供的一种人工蜂群优化贝叶斯网络的上位性位点挖掘方法的不同方法3位点上位性检测的fpr比较;
图10为本发明实施例提供的一种人工蜂群优化贝叶斯网络的上位性位点挖掘方法的可分解bic打分方法表示图;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
本发明实施例提供一种人工蜂群优化贝叶斯网络的上位性位点挖掘方法,具体为:
1、用0,1,2形式的数据表示基因型数据,如对snp基因型为at的数据表示如下:aa用0表示,tt用2表示,at/ta用1表示。0表示纯合子常见基因型,1表示杂合子,2表示纯合子少见基因型。图10所示为4个snp(snp1~snp4)对应10个样本的基因型数据,最后一列class表示表型性状,其中class=1表示case(患病),class=0表示control(对照)。
2、将目标节点分为表型class节点和非class节点两种情况,利用扩张、收缩、对称性检测三个阶段,通过条件互信息计算获取不同节点的马尔可夫毯。
(1)扩张阶段:分为目标节点为非class节点与目标节点为class节点两种情况进行处理。构建表型class节点的马尔可夫毯时,在初始阶段假设任意一个节点snp1已经加入class节点的马尔可夫毯中,通过eq.(1)计算另外任意一个节点snp2与已加入马尔可夫毯的snp1节点在class条件下的条件互信息i(snp1,snp2|class)。构建非class节点的马尔可夫毯时,在初始阶段假设表型class节点已经加入到目标snp1节点的马尔可夫毯中,通过eq.(1)计算任意一个节点snp2与class在目标节点snp1条件下的条件互信息i(snp2,class|snp1)。由于g-test服从卡方分布,而g(x,y|z)=i(x,y|z)*2*m,其中m为样本数,通过换算可以将互信息转换成g-test检验,再通过特定阈值筛选节点,从而得到不同节点的马尔可夫毯。
(2)收缩阶段:进行去除多余节点操作。对于任意目标节点snp1(或者class节点),计算在去除节点snp2的马尔可夫毯的条件下目标节点snp1与snp2的条件互信息i(snp1,snp2|mb(snp1))。若条件互信息大于阈值,则删除节点snp2并更新节点snp1的马尔可夫毯。
(3)对称性检测:确保任意目标节点马尔可夫毯中的节点之间相互依赖。假设snp1存在于snp2的马尔可夫毯中,snp1与snp2相互依赖。与之对应,snp2应该存在于snp1的马尔可夫毯中。倘若两个节点的马尔可夫毯并不对称,那么分别在马尔可夫毯中删除另一节点。
3、在贝叶斯网络结构的空间中进行搜索时,本发明采用的人工蜂群优化算法中的每个蜜源对应一个贝叶斯网络结构。用邻接矩阵对贝叶斯网络个体进行表示,设网络中snp位点和表型性状的个数为n,每个个体表示为n×n的邻接矩阵c。采用0/1的编码方案,如果节点i是节点j的父节点,cij=1,否则,cij=0。如图1所示。
人工蜂群算法中的初始蜜源(贝叶斯网络)由snp节点、class节点和节点间的边组成。基于各snp节点以及class节点的马尔可夫毯构建的初始网络(初始蜜源),通过随机增加边、删除边、逆转边操作生成下一个网络个体,直到网络个体数量达到最大初始蜜源数。人工蜂群算法以初始蜜源作为起始点开始迭代。
4、在初始蜜源的基础上,通过人工蜂群优化算法的三种蜜蜂行为(采蜜蜂、观察蜂和侦察蜂)与贝叶斯网络的打分函数,对包括snp位点和表型性状的贝叶斯网络进行演化,得到网络结构的最优解,进而快速准确的获取到影响表型性状的上位性基因位点(图3)。
(1)采蜜蜂阶段
首先采蜜蜂对初始蜜源的邻域进行搜索:通过加边、减边、逆转边3种操作(图2)对网络结构进行更新。然后利用bic和mit两种评分函数同时对新的网络结构(蜜源)进行打分,同时与初始网络结构(蜜源)的分数进行比较。
如果新蜜源网络结构优于初始蜜源,则将该网络结构进行保存,并记录网络结构提高的分数。最后,根据提高的分数使用轮盘赌的方式随机选择新蜜源网络结构。设第i个网络的适应度值为fi,则i被选中的概率pi如eq.(2)所示,其中n表示种群的大小。在该方法中,使网络分数提高越大的操作被选中的概率越大,这不仅可以保证网络演化的正确性,而且可以避免陷入局部最优。假如轮盘赌方法选择放弃本次加边、减边或者逆转边操作,则说明该蜜源邻域已无更优的网络结构。表示该网络结构已是最优的网络结构,采蜜蜂对其进行采蜜。
bic打分函数的计算公式如eq.(3)所示,其中m表示样本的总数量,n表示变量的个数,ri表示第i个变量的取值个数,qi表示第i个变量的父变量的组合个数,mijk表示第i个变量取第k个值,其父变量取第j个组合的样本个数。
mit打分函数的计算公式如eq.(4)所示,其中d表示特定数据集,g表示网络结构,n表示节点数目,n表示样本个数。i(xi,∏xi)表示目标节点xi与其父节点集合∏xi的互信息值,
其中
给定有n个样本的数据集d,假设x和y在给定z的情况下条件独立成立,可得2ni(x,y|z)近似于自由度为l=(rx-1)*(ry-1)*rz的卡方分布x2(l),其中rx,ry和rz分别表示变量x,y和z的取值个数。由此可得2ni(xi,xij|{xi1,…,xi(j-1)})近似于自由度为lij的卡方分布x2(lij)。给定置信区间α,当满足eq.(6)时,可得
(2)观察蜂阶段
观察蜂阶段和采蜜蜂阶段交替进行,每当采蜜蜂搜索一次邻域得到较优的网络结构之后,观察蜂便对采蜜蜂所在的蜜源进行考察(图3中阶段2),根据两种打分函数计算对应网络结构的适应度值。然后利用轮盘赌的方式随机选择一个蜜源网络结构,适应度越大的网络结构被认为邻域拥有更优网络结构的可能性越大,被选到的几率也就越大。采蜜蜂对选中网络结构的邻域进行搜索(图3中阶段2-阶段3),重复采蜜蜂阶段的操作。
(3)侦察蜂阶段
侦察蜂在采蜜蜂和观察蜂阶段中扮演监督员的角色,记录每个蜜源网络结构的采蜜次数以及最优蜜源网络结构。当某一蜜源网络结构达到最大采蜜次数,则放弃该蜜源,并通过步骤2中的方法重新生成新蜜源(图3中阶段4)。
5、可分解bic评分函数
bic评分函数的时间复杂度会随着父节点个数的增长而成指数增长,该方法无法对父节点个数较多的节点进行评分。为了解决此问题,本发明利用可分解bic评分函数进行处理,其计算方式如eq.(7)-eq.(9)所示。
bic*(x,π1,π2)=bic(x,π1)+bic(x,π2)+inter(x,π1,π2)(7)
bic(x,π1∪π2)=bic*(x,π1,π2)+n·(i(π1,π2|x)-i(π1,π2))(9)
在eq.(7)中,将x节点的父节点集合∏分解为∏1和∏2,π1∪π2=π,通过eq.(8)和eq.(9)计算得到近似bic分数。在eq.(9)计算互信息i(∏1,∏2)和条件互信息i(∏1,∏2|x)的过程中,∏1,∏2以及x的组合个数随父节点的增多呈爆炸式增长。计算机内存往往无法存储这么多组合数对应取值个数的频数,因此可分解bic评分方法仍具有局限性,且实验结果表明该方法无法处理18个以上父节点。
考虑到显性上位性数据属于典型的高维少样本型数据,往往没有涵括所有的取值组合,因此本发明采用如下方法进行简化处理:仅仅统计所有样本包括的组合的频数并进行存储,未在样本内出现的组合的频数计为0,从而不对所有组合的频数进行统计。如图10所示,snp的取值有以下三种:0/1/2,理论上两个snp位点的取值组合类型有9种。而实际中,此两个snp位点的取值类型往往少于9种。如图10中所示,snp2和snp3的组合类型数就只有6种。仅仅对这6种组合类型进行频数统计,而不是遍历所有的取值组合,从而大大减少计算的时间和空间复杂度。
6、算法终止
当达到最大迭代次数或者每只采蜜蜂均将对应蜜源开采至最大开采次数,则找到最优蜜源(最优网络结构),算法结束。
7、通过实验说明人工蜂群优化贝叶斯网络的上位性位点挖掘方法的高效性,分别比较二节点和三节点上位性检测的准确率、f1-score、fpr和运行时间。
下面是应用本发明中的方法在gametes软件生成数据集上进行上位性位点挖掘的实例,通过相关的实验来详细说明本发明方法挖掘上位性位点的高效性。gametes软件是一款业界常用的用于生成epistasis模拟数据的软件[9],该软件可以快速准确地生成epistasis模拟数据,通过改变不同的参数生成特定的两位点甚至多位点epistasis模型。可以设置的参数包括:snp位点的个数、遗传率(heritability,h2)、最小等位基因频率(maf)以及患病率(prevalence)等。生成模拟数据的文件中第1行为位点名称,最后1列为class标签,1表示患病,0表示对照。基因型数据用0,1,2表示,0表示纯合子常见基因型,1表示杂合子,2表示纯合子少见基因型。
将本发明中人工蜂群优化贝叶斯网络的上位性位点挖掘方法记为bnbeeepi,实验比较的上位性检测方法包括以下几种:beam,antepiseeker,boost,esmo和未加入人工蜂群算法仅利用马尔可夫毯获取网络的方法omb-fast。通过设置不同的遗传率h2(0.05,0.15,0.25,0.35,0.4)和最小等位基因频率maf(0.1,0.2,0.3,0.4),采用gametes软件生成了不同的数据集,每个参数设置下的数据集包括100个文件。利用了下述几个评价指标对上位性检测的效果进行比较:准确率(eq.(10)),精确率(eq.(11)),召回率(eq.(12)),f-score(eq.(13)),假阳性率(falsepositiverate,fpr)(eq.(14))。其中准确率用于评价输出结果中能否包含所有正确结果。召回率是指输出结果中真阳性的数目和数据中总共真阳性数目的比率。在上位性挖掘研究中,较高的召回率意味着不管snp组合数有多少,该算法也能检测到较全的snp组合。精确率是指输出结果中真阳性的数目占输出总数的多少,较高的精确率意味着该算法的输出结果与标准结果吻合度较高。f1-score综合考虑了精确率与召回率这两个指标。fpr表示输出中假阳性结果的数目占数据中假阳性数目的多少。
实验1.2位点上位性检测的准确率和效率对比
在本实验中,比较了设置不同遗传率h2和最小等位基因频率maf情况下上位性位点挖掘的准确率,f1-score以及fpr。图4,图5和图6分别给出了不同方法2位点上位性挖掘的准确率、f1-score和fpr的比较结果。表1给出了不同方法的2位点上位性挖掘的时间对比。
通过图4可见,beam方法的上位性检测准确率要明显低于其他几种方法,其他方法的准确率基本为100%。由图5可得,boost和bnbeeepi的f1-score相差不大,两者的f1-score明显优于antepiseeker,beam以及esmo。omb-fast的f1-score略低于boost和bnbeeepi方法。由图6可得,bnbeeepi的假阳性率(fpr)明显低于antepiseeker以及esmo方法,稍微高于beam和boost方法。但beam方法的准确性比较低,而boost只能用于两位点的上位性检测,并不能处理多位点上位性检测问题。另外,可见omb-fast的假阳性率(fpr)稍微高于beam,boost与bnbeeepi方法。并且由表1可以看出,omb-fast的运行速度非常快,其速度优于boost。bnbeeepi因为使用了人工蜂群算法进行优化处理增加了迭代次数,减少了假阳性,但牺牲了运行时间。
表1不同方法2-locus上位性检测的时间对比(单位:分)
综上可得,bnbeeepi方法在保证检测准确率的情况下,有较好的f1-score以及较低的假阳性率(fpr),整体上优于其他方法。另外,可见omb-fast和bnbeeepi的检测准确率均为100%,且omb-fast方法的运行效率很高,该方法能快速的学习得到基本正确的网络结构。但bnbeeepi方法的f1-score和fpr明显优于omb-fast,这说明在学习得到基本网络结构的基础上,利用人工蜂群优化方法可以大大的减少上位性检测的假阳性率。但bnbeeepi方法的上位性检测的效率远远低于omb-fast方法,可见利用人工蜂群优化贝叶斯网络花费了一定的时间。
实验2.3位点上位性检测的准确率和效率对比
在本实验中,比较了不同方法在设置不同遗传率h2和最小等位基因频率maf情况下的3位点上位性挖掘的准确率、f1-score以及fpr,如图7-图9所示。表2给出了不同方法的3位点上位性挖掘的时间对比。
由图7可得,beam方法的3-locus上位性检测的准确性最低,esmo,omb-fast与bnbeeepi三种方法的准确性相差不大。由图8,图9以及表2可得,bnbeeepi方法的f1-score和假阳性率(fpr)明显优于其他几种方法。虽然omb-fast方法的准确性略高于bnbeeepi方法,而且速度也非常快,但后者的假阳性率大大减少,可见将人工蜂群用于对贝叶斯网络进行演化,进而用于上位性位点检测方法的有效性。
表2不同方法3-locus上位性检测的时间对比(单位:分)
8、bic可分解打分函数的实验对比
实验3.bic与可分解bic打分函数可处理父节点个数对比
分别在每组参数生成的模拟数据中随机抽取2个数据集进行实验,将原始的bic与可分解bic打分函数进行对比。由表3可得,bic打分函数能够处理的最大父节点数为18个,可分解bic打分函数能够处理的最大父节点数为30个。
表3采用可分解bic打分方法的结果对比
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!