一种基于主题模型的胸部X光片诊断报告异常检测方法与流程
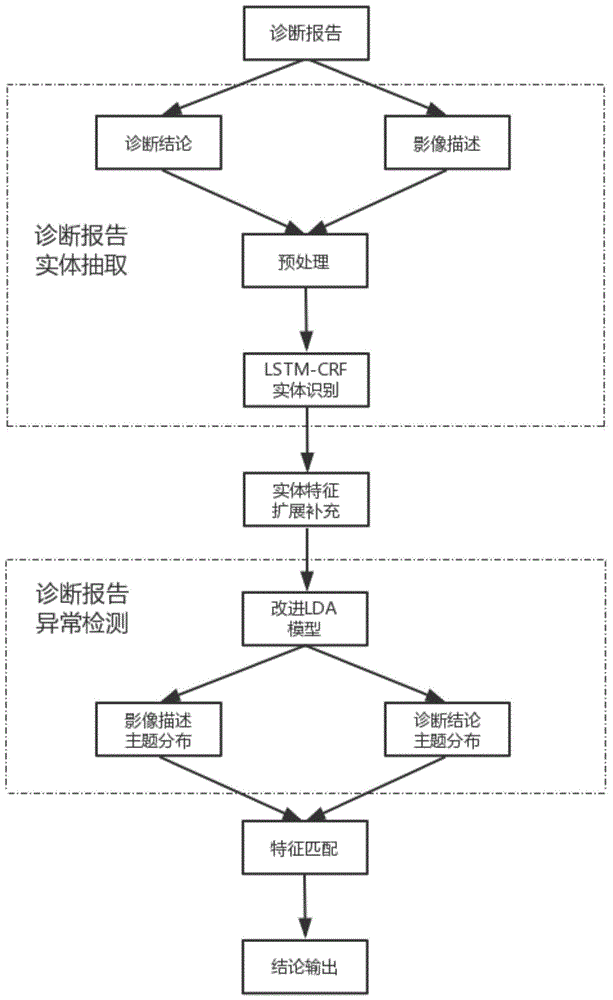
本发明涉及一种基于主题模型的胸部x光片诊断报告异常检测方法,属于计算机自然语言处理
技术领域:
。
背景技术:
:胸部x光片是患者胸部检查的优先选择,对患者的诊断治疗起着重要的作用。医生依据自身的经验和习惯书写胸部x光片诊断报告,诊断报告核心的内容是影像描述和诊断结论,这两部分是辅助医生诊断和患者治疗的重要参考,也是用于诊断报告异常检测的关键信息。医生书写诊断报告具有相当大的主观性,有可能会因为经验不足或疲劳而产生影像描述内容的解读错误,使一些疾病漏诊,误诊。另外诊断报告中影像所见部分描述自由,多为医疗惯例描述语言,复杂的影像描述内容,也可能影响医生的鉴别诊断,得出错误的诊断结论。筛选出这些异常的诊断报告,首先可以减少疾病误诊率,为临床医生的诊断治疗,提供更准确有效的参考。其次,为建立规范化的医疗检查体系和实现高效精准的医疗服务提供了基础。最后,增强医院的管理水平,监督考察医疗工作者的技术素养。所以,对诊断报告进行异常检测方法的研究意义重大。传统的异常检测方法都是为了找出不满足规则和期望的样本。目前在医疗领域出现了大量的异常检测方法用于检测医疗保险记录,医疗处方等医疗数据。有监督的异常检测方法,首先通过大量高质量的人工标注数据,利用传统的分类方法,找出异常类别的数据。传统的有监督检测,异常点检测,上下文异常检测等方法检测异常诊断报告效果不佳。由于缺乏有效的标注数据,诊断报告不适用于有监督的检测方法。诊断报告文本描述自由,一些影像描述的症状或者疾病出现较少,但不能归为异常,所以异常点检测会出现偏差。诊断报告数据高维稀疏,通过传统的映射函数进行上下文的特征匹配,效果不佳。诊断报告中的诊断结论是根据影像描述得到的,影像描述中的症状实体与诊断中的结论实体存在特有的语义信息和对应关系。诊断报告中存在大量的专业术语,如果不进行实体的抽取,直接以字符或者词语特征进行训练,输入特征就会失去原有的语义信息和对应关系。如:影像描述中的“双侧膈肌光滑,双肋膈角锐利”对应结论中的“膈无异常”,分成字符或词语就失去了原有的语义信息和对应关系。通过计算这两类实体之间的对应关系是否成立,就可以判断该诊断报告影像描述与诊断结论是否匹配,既可以检测该诊断报告是否异常。技术实现要素:本发明提供了一种基于主题模型的胸部x光片诊断报告异常检测方法,用于提高实体提取的效果、缓解了特征稀疏的问题、取得很好的检测识别效果。本发明的技术方案是:一种基于主题模型的胸部x光片诊断报告异常检测方法,所述方法的具体步骤如下:step1、诊断报告实体抽取:诊断报告核心的内容是影像描述和诊断结论,根据诊断报告自身特性提出了基于lstm-crf模型进行诊断报告的实体抽取;step2、实体特征扩展补充:将step1中抽取的实体进行特征扩展和补充,并将诊断的性质加入结论部分,并与影像描述中的症状实体进行匹配;step3、诊断报告异常检测:利用改进的lda模型得到影像描述和诊断结论这两种诊断报告的实例主题分布;step4、特征匹配得出结论:通过计算比较影像描述实体和诊断结论实体得到的实例主题分布是否匹配,就能用来检测异常诊断报告。进一步地,所述步骤step1的具体步骤如下:step1.1、以字符基本特征结合诊断报告特有的实体后缀特征,生成表示其类型的字嵌入向量;解决了未登录词过多的问题,减少分词带来的负面影响,并且结合症状实体和疾病实体的字符特级征,对诊断报告中较长实体的识别,取得了很好的效果。step1.2、把step1.1得出的字嵌入向量输入bi-lstm神经网络层,得到序列中字符标签的分布矩阵;step1.3、根据step1.2输出的标签概率分布,利用crf层的序列标注功能预测出最优的序列组合,完成对诊断报告实体进行抽取。进一步地,所述步骤step2的具体步骤如下:step2.1、特征扩展:诊断报告中存在较多并列描述,将这些并列实体分开描述如“双肺纹理增强,紊乱”改为“双肺纹理增强”和“双肺纹理紊乱”;“心脏大小形态无异常”改为“心脏大小无异常”和“心脏形态无异常”;通过特征扩展能大大丰富特征信息;缓解数据稀疏问题;step2.2、特征补充:诊断结论主要突出表征的是影像描述中的异常,主要给出异常结论,很多正常的影像描述没有给出相应的结论,这是造成诊断结论简短的一个主要原因;对于胸部x光片,当地医院和在线医疗网站都有对应的参考模板,诊断报告中的结论都有着与之相对应的规范描述;依据这些模板对诊断报告中的正常结论进行补充;大大缓解了诊断结论特征稀疏,主题提取困难的问题;step2.3、将诊断的性质即阴阳性加入结论部分,并与影像描述中的症状实体进行匹配。进一步地,所述步骤step3的具体步骤如下:step3.1、利用改进的lda模型,对同一个实例分为两个部分进行采样,得到每一份实例(胸片诊断报告)的a类(影像描述)特征和b类(诊断结论)特征;该模型既能够挖掘上下两部分潜在的特征主题,又能够将上下两部分进行关联,得到具有对应关系的主题;step3.2、由step3.1抽取到的影像描述和诊断结论两类特征语义相似,并且两类主题分布能进行关联分析最后得到影像描述和诊断结论之间的对应关系。进一步地,所述改进的lda模型;首先通过以共同的参数α得到每一份诊断报告实例共同的主题分布θ,然后分为两部分进行主题建模和求解,分别以βa和βb为参数得到影像描述部分的特征分布和诊断结论部分的特征分布基于以上参数信息得到每一份实例胸片诊断报告的a类影像描述特征和b类诊断结论特征;改进的lda模型参数包括参数α、βa和βb求解使用吉布斯采样方法,对同一个实例分为两个部分a类影像描述特征和b类诊断结论特征进行采样,两者有着相同的求解过程;以a类影像描述特征为例,计算实例d中a类影像描述特征w属于主题t的概率,即a类影像描述类实体特征在该lda模型上的实例主题分布为:其中,标记为主题t的所有a类影像描述特征中,特征w的比重为:其中,实例d标记为主题t的特征在所有特征中的比重:zw表示当前的特征项的主题标识,z-w表示a类影像描述特征全部特征去除zw后的主题标识,va表示a类影像描述特征的种类数,k表示主题的数目,n代表矩阵,表示全体实例特征w标记为主题t的个数,表示所有标记为主题t的a类影像描述特征的个数,表示d中所有特征标记为主题k的个数,表示d中所有特征的个数;将诊断报告分为影像描述和诊断结论单独出发进行推断,得到两个诊断报告的实例主题分布。所述对胸片诊断报告进行特征的扩展和补充中,为进一步解决实体特征较少稀疏、进行主题提取面临挑战这一问题,提出了特征进行特征扩展和特征补充,对诊断报告中的正常结论进行补充,将诊断的性质即阴阳性加入结论部分,并与影像描述中的症状实体进行匹配。本发明的有益效果是:1、本发明中的模型以字嵌入向量作为模型的输入,解决了未登录词过多的问题,减少分词带来的负面影响,并且结合症状实体和疾病实体的字符特级征,对诊断报告中较长实体的识别,取得了很好的效果。2、改进的lda主题模型,首先通过以共同的参数α得到每一份诊断报告实例共同的主题分布θ,然后分为两部分进行主题建模和求解,分别以βa和βb为参数得到影像描述部分的特征分布和诊断结论部分的特征分布基于以上参数信息可以得到每一份实例(胸片诊断报告)的a类(影像描述)特征和b类(诊断结论)特征。该模型既能够挖掘上下两部分潜在的特征主题,又能够将上下两部分进行关联,得到具有对应关系的主题。3、胸部x光片诊断报告影像描述中的内容较长,实体特征丰富,利用lda模型可以很好的进行主题提取。但是一些诊断结论中的实体特征较少稀疏,进行主题提取面临挑战。针对诊断报告的特点,通过以下方式缓解上述问题:将诊断的性质即阴阳性加入结论部分,并与影像描述中的症状实体进行匹配。综上所述此发明方法的主要改进有(1)针对胸片诊断报告的特点,利用加入后缀特征的双向lstm-crf模型,对描述症状实体和诊断结论实体进行提取,提高了实体提取的效果。(2)利用领域知识和模板,对胸片诊断报告进行特征的扩展和补充,一定程度上缓解了特征稀疏的问题。(3)将胸片诊断报告的异常检测,转换为影像症状实体特征与诊断结论实体特征判断能否匹配的问题,利用lda主题模型来进行异常检测,取得了很好的识别效果。附图说明图1为本发明中的流程图。具体实施方式实施例1:如图1所示,一种基于主题模型的胸部x光片诊断报告异常检测方法,所述方法的具体步骤如下:step1、诊断报告实体抽取:诊断报告核心的内容是影像描述和诊断结论,根据诊断报告自身特性提出了基于lstm-crf模型进行诊断报告的实体抽取;step2、实体特征扩展补充:将step1中抽取的实体进行特征扩展和补充,并将诊断的性质加入结论部分,并与影像描述中的症状实体进行匹配;step3、诊断报告异常检测:利用改进的lda模型得到影像描述和诊断结论这两种诊断报告的实例主题分布;step4、特征匹配得出结论:通过计算比较影像描述实体和诊断结论实体得到的实例主题分布是否匹配,就能用来检测异常诊断报告。进一步地,所述步骤step1的具体步骤如下:step1.1、以字符基本特征结合诊断报告特有的实体后缀特征,生成表示其类型的字嵌入向量;解决了未登录词过多的问题,减少分词带来的负面影响,并且结合症状实体和疾病实体的字符特级征,对诊断报告中较长实体的识别,取得了很好的效果。字符级特征分类如下表1所示:表1为字符级特征分类step1.2、把step1.1得出的字嵌入向量输入bi-lstm神经网络层,得到序列中字符标签的分布矩阵;step1.3、根据step1.2输出的标签概率分布,利用crf层的序列标注功能预测出最优的序列组合,完成对诊断报告实体进行抽取。表2为本发明诊断报告实体抽取结果对比;表2为诊断报告实体抽取结果对比进一步地,所述步骤step2的具体步骤如下:step2.1、特征扩展:诊断报告中存在较多并列描述,将这些并列实体分开描述如“双肺纹理增强,紊乱”改为“双肺纹理增强”和“双肺纹理紊乱”;“心脏大小形态无异常”改为“心脏大小无异常”和“心脏形态无异常”;通过特征扩展能大大丰富特征信息;step2.2、特征补充:诊断结论主要突出表征的是影像描述中的异常,主要给出异常结论,很多正常的影像描述没有给出相应的结论,这是造成诊断结论简短的一个主要原因;对于胸部x光片,当地医院和在线医疗网站都有对应的参考模板,诊断报告中的结论都有着与之相对应的规范描述;依据这些模板对诊断报告中的正常结论进行补充;大大缓解了诊断结论特征稀疏,主题提取困难的问题;诊断报告样本实例特征扩展补充如表3所示:表3为特征扩展补充step2.3、将诊断的性质即阴阳性加入结论部分,并与影像描述中的症状实体进行匹配。进一步地,所述步骤step3的具体步骤如下:step3.1、利用改进的lda模型,对同一个实例分为两个部分进行采样,得到每一份实例(胸片诊断报告)的a类(影像描述)特征和b类(诊断结论)特征;该模型既能够挖掘上下两部分潜在的特征主题,又能够将上下两部分进行关联,得到具有对应关系的主题;step3.2、由step3.1抽取到的影像描述和诊断结论两类特征语义相似,并且两类主题分布能进行关联分析最后得到影像描述和诊断结论之间的对应关系。进一步地,所述改进的lda模型;首先通过以共同的参数α得到每一份诊断报告实例共同的主题分布θ,然后分为两部分进行主题建模和求解,分别以βa和βb为参数得到影像描述部分的特征分布和诊断结论部分的特征分布基于以上参数信息得到每一份实例胸片诊断报告的a类影像描述特征和b类诊断结论特征;改进的lda模型参数包括参数α、βa和βb求解使用吉布斯采样方法,对同一个实例分为两个部分a类影像描述特征和b类诊断结论特征进行采样,两者有着相同的求解过程;以a类影像描述特征为例,计算实例d中a类影像描述特征w属于主题t的概率,即a类影像描述类实体特征在该lda模型上的实例主题分布为:其中,标记为主题t的所有a类影像描述特征中,特征w的比重为:其中,实例d标记为主题t的特征在所有特征中的比重:zw表示当前的特征项的主题标识,z-w表示a类影像描述特征全部特征去除zw后的主题标识,va表示a类影像描述特征的种类数,k表示主题的数目,n代表矩阵,表示全体实例特征w标记为主题t的个数,表示所有标记为主题t的a类影像描述特征的个数,表示d中所有特征标记为主题k的个数,表示d中所有特征的个数;将诊断报告分为影像描述和诊断结论单独出发进行推断,得到两个诊断报告的实例主题分布。为了验证本发明的有效性,本发明依据上述方法步骤做实验,由于根据实例主题分布的相似度无法准确的确定检测异常诊断报告的阈值,所以,本文对每一个诊断结论与影像描述中症状进行关系匹配,根据不匹配的数量来确定检测异常诊断报告的阈值。表4不同阈值的实验效果阈值54321准确率(%)10098.6293.3192.8237.23召回率(%)9.7518.6552.6369.5485.46f值(%)17.7731.3767.3079.5151.87由表4可知,当阈值设定为2以上的时候,虽然准确率有着很高的水平,但是召回率却急剧的下降。当阈值设为2以下的时候虽然召回率有所提高,但是准确率出现了明显的下降。最终将检测诊断报告的阈值设置为2,取得了较好的实验效果。本发明实验发现在阈值为2的情况下,异常检测的准确率为92.82,召回率为69.54,检测性能好。上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1