细胞选择的多变量方法与流程
细胞选择的多变量方法
1.描述
2.本申请涉及细胞、培养基和过程条件选择。更具体地,本申请涉及从多组候选细胞中选择至少一组目标细胞。细胞可以是生物的或微生物的。细胞可以是克隆。
3.候选细胞可以来自异质细胞群组的池。细胞可以被转染或转化。可能可取的是从第一尺度(微尺度)放大到比第一尺度大一个或多个数量级并且使目标细胞在整个制造生命周期(例如药物制造生命周期)内稳定的第二尺度(宏观尺度)。目标细胞可能需要满足对应于预定产物质量属性或预定关键性能指标的目标。
4.通常,在处理过程期间可以针对每组候选细胞生成大量数据。细胞可以用作(或者用于容纳(host))化学品、药物、生物药物和/或生物产品的一部分。在一些情况下,可能可取的是鉴定候选细胞或亲本细胞中有问题的异质性。
5.过程(例如,在容器或生物反应器中进行的)可以产生大量数据,特别是关于过程参数和/或冲突的(例如,负相关的)产物质量属性。在能够至少部分地并行控制多个容器中的过程的过程控制装置的情况下,关于处理大量数据的问题可能特别严重。例如,过程控制装置可能能够管理12个容器、24个容器或48个容器中的过程。每个容器可以是生物反应器。容器可以是微尺度容器。特别地,容器可以具有小于5l、小于1l、或小于500ml的体积。更具体地,容器可以具有1ml至500ml的体积。
6.来自涉及过程控制装置的实验的数据分析可能涉及多名技术人员可能使用诸如microsoft excel的电子表格程序花费数小时或数天来分析不同数据格式的数据。分析的结果可能是不一致的和/或主观的。特别地,可能难以评估过程参数的时间序列数据。此外,产物质量属性可能是冲突的(例如,负相关的),使得不可能针对同一过程优化两种产物质量属性。
7.此外,通常根据常规方法来设置产物质量属性的硬限制。可能难以确定为哪些产物质量属性设置硬限制以及那些硬限制应该是什么。不正确地设置硬限制(即,导致排除一组候选细胞的限制值)可能导致最佳执行的候选细胞组被忽略或不必要地排除。不正确的细胞选择(即,选择错误的目标细胞组)可能导致在较大的规模下的差的性能或下游的复杂化(即,在制造过程后期的复杂化)。因此,目标细胞的不正确选择可能导致时间、金钱和资源的浪费。特别地,使用低效的目标细胞或者为选择目标细胞而进行的过程的迭代次数过多,资源可能被不良地分配给过程。
8.另一个问题是,从多个过程收集的数据,特别是当在过程控制装置处接收数据时(例如,一些数据由装置本身生成,其它数据由外部分析装置生成),存在丢失的或不可靠的数据点。这样的丢失的或不可靠的数据可能导致候选细胞被不正确地评估和/或选择低效的目标细胞组。
9.通常,从多个过程收集的数据可以存储在多个或许多数据文件中。数据文件可以是电子表格文件,例如microsoft excel文件。有时,使用宏命令来帮助对数据进行排序和绘图。确定如何使用所有数据,特别是时间序列数据可能是有挑战性的。确定要考虑哪些过程输出,或者过程输出应具有哪些特性可能是有挑战性的。此外,当任何候选细胞组不能满
足最初选择的特性时,确定一组新的特性以便达到目标细胞的选择可能是有挑战性的。另外,优先处理过程输出而不丢弃一个输出以利于另一个输出可能是一个问题。最小化选择目标细胞组的过程的迭代次数也可能是一个问题。
10.根据一个方面,提供了用于从多组候选细胞中选择至少一组目标细胞的计算机实现的方法。所述方法包括接收从多个过程收集的数据,其中每个所述过程产生一组独特的候选细胞。接收的数据包括所述过程的过程参数值和过程输出,每个所述过程输出是用于选择目标细胞的产物质量属性或关键性能指标。所述方法还包括使接收的数据相关联,以及接收对过程参数的选择和对过程输出的选择。所述方法还包括接收针对所选择的过程参数和/或选择的过程输出的多变量评估标准,所述多变量评估标准包括以下中的一个或多个:
11.‑
用于优先化的权重,
12.‑
优先化范围和/或(优先化)目标。
13.每个优先化范围可以指定值的可允许跨度,例如3到10。优先化范围还可以包括极值,例如,以指示该范围内的较高值还是较低值是优选的。
14.每个优先化目标是极值(最大值或最小值)和/或目标值。例如,优先化目标可以包括极值(例如,最大值)和目标值(例如,4.5)。可选地,优先化目标可以包括没有目标值的极值或没有极值的目标值。
[0015]“每个所述过程产生一组独特的候选细胞”可以被理解为意指每个过程产生一组不同的候选细胞。例如,如果有18个过程,则产生18个不同的候选细胞组。每组候选细胞可以相对于其它组的候选细胞是唯一的。
[0016]
术语“过程输出”可以被认为是覆盖产物质量属性和关键性能指标的总体表述。在一些情况下,术语“变量”可以用于指过程输出或过程参数。
[0017]
一组细胞可以是一组具有相同类型的细胞或具有相同类型的细胞的集合(例如,一组cs1_1克隆可以是一组细胞)。
[0018]
可以通过过程控制装置中的名称(例如,唯一标识符)或位置(例如,培养站(culture station)和/或容器编号)来鉴定一组细胞。例如,“cs1”可以用于指位于过程控制装置的培养站1中的容器中的细胞。在“_”之后的数字可以鉴定各个容器。例如,“cs1_1”可以指培养站1中的第一容器,cs2_3可以指培养站2中的第三容器。
[0019]
所述方法还包括根据多变量评估标准,经由多变量选择函数,从相关联数据计算候选细胞组中的每一个的得分。所述方法还包括根据得分对候选细胞组进行排名,以及使用排名选择候选细胞组中的至少一个作为目标细胞。
[0020]
目标细胞可以用于(或用于容纳)化学品、药物、生物药物和/或生物产品。更具体地,目标细胞可以容纳产物,或者目标细胞可以是产物。每个过程可以由过程控制装置执行。所述过程可以由单一过程控制装置控制,使得所述过程至少部分或全部地并行执行,或者所述过程可以由额外的过程控制装置执行。所述过程可以在微尺度上执行。可选地,所述过程的一部分可以在微尺度上执行,所述过程的一部分可以在宏观尺度上执行。作为另一种替代,所有过程可以在宏观尺度上执行。在该上下文中,微尺度可以是指具有如上所论述的体积(即,工作体积)的容器。宏观尺度可以是指体积(即工作体积)大于1l的容器。更具体地,微尺度可以小于250ml,宏观尺度可以大于3l。
[0021]
过程参数可以包括设定点、流速、进料特性、初始条件、在线测量和离线测量。设定点的实例包括温度、ph、溶解氧、搅拌速度。流速可以包括空气流量、二氧化碳、氧气和酸/碱。营养特性可以包括初始营养进料日、营养进料量和进料添加。初始条件可以包括接种密度和渗透压。在线测量可以包括温度、ph、溶解氧、执行该过程的容器中流体的体积。离线测量可以包括葡萄糖、乳酸、活细胞密度(vcd)、氨基酸水平、单克隆抗体浓度。
[0022]
可以在相应过程结束时确定过程输出。例如,过程参数可以是细胞活力(例如,在过程期间测量的),过程输出可以是最终细胞活力(在过程结束时)。
[0023]
过程输出可以包括以下中的一个或多个:细胞的总量,每单位体积的输入流体的细胞的量,细胞的化学组成,纯度,细胞碎片的量,剪切损伤或化学损伤的量,起始材料成本,用于过程的能量成本,产物浓度,比生产率,描述相应的候选细胞组的图谱(例如,聚糖图谱、光谱图谱),细胞活力。
[0024]
在一个实例中,选定的过程输出和相应的优先化目标可以指定如下:
[0025]
‑
最终产物浓度,其具有相应的优先化目标以使其最大化,所述目标包括目标值;
[0026]
‑
最终比生产率,其具有相应的优先化目标以使其最大化,所述目标具有目标值;
[0027]
‑
从相应的候选细胞组的图谱到具有最小距离的相应目标的指定的聚糖图谱或指定的光谱图谱的图谱距离;
[0028]
‑
最终细胞活力,其具有相应的优先化目标以使其最大化,所述目标具有目标值。
[0029]
在图谱距离的情况下,过程输出是候选细胞组的图谱,并且所述距离是针对过程输出接收的评估标准。
[0030]
细胞(即,目标细胞或候选细胞)可以是以下中的至少一种:细胞系、细胞株、克隆。多组候选细胞可以形成异质细胞池。更具体地,多组候选细胞可以形成异质转染池。
[0031]
过程参数的值可以包括时间序列值。可以在每个过程期间控制(受控过程参数)和/或测量(测量过程参数)过程参数。可以在线(online)、旁线(at line)或离线执行测量。
[0032]
术语“离线”、“旁线”和“在线”可以指例如通过进行监测步骤(如对流体取样)来监测容器(例如生物反应器)中的流体的频率。流体可以包含一组候选细胞。术语“离线”还可以指示在实验室中至少部分地进行监测结果的分析。例如,可以将经由离线监测获得的样品转移到实验室进行时间延迟的实验室分析。离线测量可以每小时进行少于一次,例如每天两次。
[0033]
可以以与离线测量相似的频率进行旁线测量。旁线测量可以涉及分析与离线测量相比更接近血管的提取样品。
[0034]
在线测量可以以比旁线测量或离线测量更高的频率执行。例如,在线测量可以每小时进行一次以上、每小时进行三次以上、或每小时进行约六十次。在线测量可以原位或非原位执行。原位测量可能不涉及从容器中取出样品。相反,传感器(例如,温度或ph传感器点)可以直接插入容器中或通过壁与容器分离。另一种可能的原位配置涉及具有一个在线传感器或非破坏性在线分析器,并且在分析之后将样品返回到容器的取样环路。在在线非原位测量中,样品可以被运送到在线分析器,并且在分析之后不返回到容器中。
[0035]
除了从多组候选细胞中选择至少一组目标细胞之外,所述方法还可以用于选择细胞培养的培养基或用于设定所述过程的条件。
[0036]
接收的数据可以包括来自每个过程的基本上所有的数据。特别地,接收的数据可
以包括每个受控过程参数的值和每个测量的过程参数的值。例如,如果在整个过程中测量容器内的温度,则接收的数据可以包括在过程期间收集的所有温度测量值。
[0037]
所述方法还可以包括鉴定针对所述过程中的任一个接收的数据是否不完整,其中,当在过程的一部分期间没有收集数据时,将所述过程中的一个鉴定为具有不完整数据。当所述过程中的任一个具有不完整数据时,所述方法还可以包括使用至少一种多变量技术预测不完整数据的值。多变量技术可以包括偏最小二乘回归或内插。另外,还可以使用机理建模。
[0038]
在一些情况下,相关联可以包括验证和校正数据的值。校正可以包括修改或排除违反一个或多个已知代谢依赖性的值。所述依赖性可以是比率。
[0039]
所述方法还可以包括将机理建模应用于接收的数据以获得过程参数的额外值和/或额外的过程输出。所述方法还可以包括用过程参数的额外值和/或额外的过程输出来补充接收的数据。
[0040]
更具体地,至少一个机理模型(即,动力学模型)可以用于将过程参数值和过程输出(可能以过程轨迹或细胞生长曲线的形式)拟合为莫诺生长动力学。机制模型可以用于数据平滑和/或填充丢失的数据,以及其它有益的应用。例如,给定示例性动力学生长模型,可以从形成过程轨迹或细胞生长曲线的选定过程输出中确定最大生长速率、死亡率和对生长的其它影响。机理模型和来自机理模型的估计值可以用于平滑过程参数值和过程输出。平滑可能涉及鉴定和排除测量噪声(即,不准确的测量)。例如,活细胞密度测量可能具有+/
‑
10%的误差。平滑可能涉及排除错误的测量,例如,过程参数值或过程输出。
[0041]
除了平滑和填充丢失的数据之外,该方法提供了明确鉴定生长、抑制和死亡率的有意义的信息,并且可以用于计算过程输出,如最大活细胞密度或代谢物浓度(例如,蛋白质滴度)。
[0042]
所述方法还可以包括根据排除标准从关联数据中排除从所述过程中的一些接收的数据。如果至少一个选择的过程输出具有相应的可接受性范围,则排除标准可以包括至少一个选择的过程输出的相应的可接受性范围。
[0043]
评估标准还可以包括:
[0044]
‑
一个或多个过程参数的基于时间的图谱,
[0045]
‑
描述一个或多个过程输出的图谱,
[0046]
‑
描述一个或多个过程参数的基于时间的发展的轨迹。
[0047]
描述过程输出的图谱可以是聚糖图谱或光谱图谱。光谱图谱可以是光谱线。
[0048]
评估标准可以包括指定的图谱(例如,指定的聚糖图谱和/或指定的光谱图谱)。指定的图谱可以对应于(即,描述)一组参照细胞,并且可以用于与候选细胞组进行比较。
[0049]
评估标准可以是特定于一组细胞或不同细胞的群组。
[0050]
所述方法还可以包括显示针对所选择的过程参数和/或选择的过程输出的关联数据,包括显示候选细胞组的聚糖图谱的关联模式。显示聚糖图谱的关联模式可以涉及显示一组候选细胞的一些或所有最终聚糖测量值和/或组合(例如,经由主成分分析)多组候选细胞的聚糖图谱。
[0051]
选择函数可以包括目的函数,特别是成本函数。目的函数可以用于计算不同组的细胞之间的距离(例如,欧几里得距离)。可以基于从所选择的过程参数和所选择的过程变
量得到的正交分量来计算距离。例如,目的函数可以提供候选细胞组之一与例如来自一组参照细胞的一组目标值之间的距离。换句话说,目的函数的输出可以反映候选细胞组之一与一组目标值之间的差异。目的函数的输出可以反映根据针对候选细胞组之一和一组目标值(例如,参照细胞)的所选择的过程参数值和选择的过程输出的距离的组合。
[0052]
选择函数可以包括(可能除了目的函数之外)至少一个放大函数(也称为罚函数)。放大函数可以放大值(例如,与候选细胞组之一相关的值与目标值之间的距离)之间的距离。每个优先化范围和/或目标可以具有相关的放大函数。放大函数可以是非线性多项式函数,例如指数函数或二次函数。在一些情况下,可以使用对数函数(例如,自然对数或欧拉数的函数)。对于所有的优先化目标或范围,放大函数可以是相同的。这可以具有使按权重优先化目标或范围更容易的优点。
[0053]
可选地,放大函数可以根据优先化目标或范围而不同。特别地,根据相应目标的重要性,可以使用不同的放大函数。
[0054]
因此,可以使用目的函数计算初始距离,然后使用放大函数放大。在放大之后,可以经由权重改变该距离。特别地,该距离可以乘以该权重。
[0055]
放大函数和权重的使用提供了额外的灵活性,然而,对于特定的优先化范围/目标,可以省略一个或两个,或者从评估中完全省略。特别地,可以在不使用放大函数和/或权重的情况下提供最佳或至少适当的细胞选择。
[0056]
可以组合(例如,求和)用于每个所选择的过程参数和/或选择的过程输出的选择函数的输出,以计算候选细胞组的得分。
[0057]
在一些情况下,存在至少5组候选细胞、至少10组候选细胞、至少20组候选细胞、至少30组候选细胞、或至少50组候选细胞。因此,可以存在约5组至约500组,优选约5组至约200组候选细胞。
[0058]
根据一个方面,提供了包括计算机可读指令的计算机程序。当在计算机系统上加载和执行时,指令使计算机系统执行根据上述方法的操作。计算机程序可以以计算机程序产品的形式实现,可能(有形地)体现在计算机可读介质中。
[0059]
根据另一方面,提供了用于从多组候选细胞中选择至少一组目标细胞的过程控制装置。所述装置包括多个容器,每个容器被配置成容纳包括候选细胞组中的一个的流体。所述装置还包括机器人,其能够寻址每个容器,将流体分配到每个容器中,并从每个容器中提取流体样品。所述装置还包括控制器,其是可操作的以至少部分地并行控制每个容器中的条件。所述控制器还是可操作的以接收从多个过程收集的数据,其中每个所述过程产生一组独特的候选细胞。接收的数据包括所述过程的过程参数值和过程输出,每个过程输出是用于选择目标细胞的产物质量属性或关键性能指标。所述控制器还是可操作的以关联接收的数据,以及接收对过程参数的选择和对过程输出的选择。控制器还是可操作的以接收针对所选择的过程参数和/或选择的过程输出的多变量评估标准。多变量评估标准包括以下中的一个或多个:
[0060]
‑
用于优先化的权重,
[0061]
‑
优先化范围和/或目标,其中每个目标是极值(最大值或最小值)和/或目标值。
[0062]
控制器还是可操作的以根据多变量评估标准,经由多变量选择函数,从相关联数据计算候选细胞组中的每一个的得分。控制器还是可操作的以根据得分对候选细胞组进行
排名,以及使用排名选择候选细胞组中的至少一个作为目标细胞。
[0063]
例如,可以仅选择一组候选细胞作为目标细胞。可选地,可以使用排名来选择多组候选细胞(例如,2
‑
5组)作为目标细胞。
[0064]
每个容器可以具有以下特性中的至少一种:
[0065]
‑
它是生物反应器或微型生物反应器,
[0066]
‑
它包括用于搅拌其内容物的搅拌装置,其中所述搅拌装置可以是叶轮(即,搅拌器),
[0067]
‑
它包括用于气体输送的输送装置,其中所述输送装置可以是喷射管,
[0068]
‑
它包括用于测量以下中的至少一种的传感装置(例如,一个或多个传感器):ph、溶解氧、温度;
[0069]
‑
它的体积为:至少1ml、至少10ml、至少15ml、小于2000l、小于1000l、小于100l、小于50l、小于5l、小于1l;
[0070]
‑
它是一次性的。
[0071]
本申请中描述的主题排除了通过手术或治疗对人或动物体的治疗以及在人或动物体上实施的诊断方法。
[0072]
本申请中描述的主题可以可能以一个或多个计算机程序(例如,计算机程序产品)的形式作为方法或在装置上实现。这样的计算机程序可以使数据处理设备执行本申请中描述的一个或多个操作。
[0073]
本申请中描述的主题可以在数据信号中或在机器可读介质上实现,其中所述介质(有形地)体现在一个或多个信息载体中,如cd
‑
rom、dvd
‑
rom、半导体存储器或硬盘。
[0074]
另外,本申请中描述的主题可以实现为包括处理器和耦合到处理器的存储器的系统。存储器可以对一个或多个程序进行编码,以使处理器执行本申请中描述的一个或多个方法。可以使用各种机器来实现本申请中描述的其它主题。
[0075]
附图简述
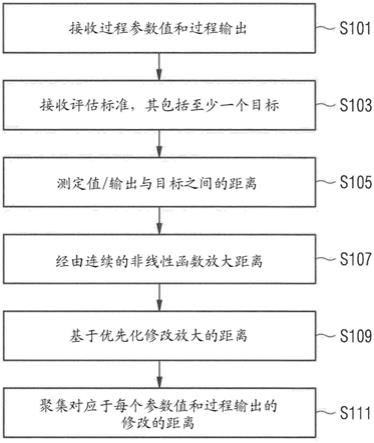
[0076]
图1显示了可以在用于从多组候选细胞中选择至少一组目标细胞的方法中执行的步骤。
[0077]
图2显示了用于从多组候选细胞中选择至少一组目标细胞的方法的输出,其中突出显示目标细胞组。
[0078]
图3显示了根据多变量评估标准的多个过程的评估。
[0079]
图4显示了多组候选细胞的聚糖图谱。
[0080]
图5显示了多组候选细胞的多变量评估。
[0081]
图6还显示了可以作为用于从多组候选细胞中选择至少一组目标细胞的方法的一部分来执行的步骤。
[0082]
图7显示了用于平滑过程输出的机理建模的示例性使用。
[0083]
图8是过程控制装置的一部分的从上方观察的透视图。
[0084]
图9显示了过程控制装置的容器的剖视图。
[0085]
详述
[0086]
在以下的文本中,将参照附图给出实例的详细描述。应理解,可以对实例进行各种修改。特别地,可以组合一个实例的一个或多个元素并且将其用于其它实例中以形成新的
实例。
[0087]
图1显示了可以在用于从多组候选细胞中选择至少一组目标细胞的方法中执行的步骤。在步骤s101,接收从多个过程收集的数据。每个过程产生一组独特的候选细胞。接收的数据包括所述过程的过程参数值和过程输出。每个过程输出是用于选择目标细胞的产物质量属性或关键性能指标。
[0088]
在以下的实例中,候选细胞组是克隆,目标细胞是候选克隆组中的最佳克隆。应理解,尽管在克隆的上下文中描述了以下实施例,但其也可应用于其它类型的细胞。
[0089]
经由过程控制装置并行地执行多个过程(在图8和图9中示出并且在下文中更详细地论述)。更具体地,存在在24个容器中进行的24个过程。每个容器具有约11ml至15ml的工作容积。在过程控制装置处接收来自离线测量的数据(例如,聚糖测量、葡萄糖、乳酸、活细胞密度(vcd)、氨基酸水平、单克隆抗体浓度)。
[0090]
对于24个候选克隆,将接收的数据组织成两个单独的表(未示出)。第一个表是七个过程参数的过程数据表,所述过程参数包括细胞活力、过程浓度和比生产率。在每天进行一次测量的几天的过程中获得过程参数值。第二数据表是质量数据表。质量数据表包括过程输出,具体地,一个聚糖图谱具有针对每个克隆的13个单独的过程输出(即,测量值)和与目标图谱的计算距离。
[0091]
步骤s101还可以包括使接收的数据相关联。步骤s101还可以包括接收对过程参数的选择和对过程输出的选择。在当前情况下,选择可以由存储在过程数据表(即,过程参数的选择)和质量数据表(即,过程输出的选择)中的数据来表示。
[0092]
在步骤s103,接收所选择的过程参数和/或选择的过程输出的多变量评估标准。根据本实例,多变量标准包括以下四个优先化目标:
[0093]
‑
最终产物浓度:最大化,但至少最小的产物浓度值(例如3.5g/l);
[0094]
‑
最终比生产率:最大化,但至少最小的比生产率值(例如,4.5克/细胞/天);
[0095]
‑
质量(从候选细胞的图谱到参照细胞的图谱的距离):最小化,但不超过最大的距离值(例如,15个单位);
[0096]
‑
最终活力:最大化,但至少最小的活力值(例如65%)。
[0097]
为质量优先化目标指定的距离可以是根据在s105的上下文中指定的式计算的欧几里得距离。
[0098]
可以按照优先化的顺序列出优先化目标。优先化可以通过权重来设置,如下文更详细论述的。例如,最终产物浓度可以具有比质量更高的权重。
[0099]
在上述实例中,每个优先化目标包括极值;三个优先化目标包括最大值,一个优先化目标包括最小值。每个优先化目标还包括目标值(特别是最小产物浓度值、最小比生产率值、最大距离值和/或最小活力值,例如分别为3.5g/l、4.5克/细胞/天、65%或15个单位,如上所述)。
[0100]
应注意,尽管上述实例仅包括优先化目标;但优先化范围可以作为添加或替代来提供。
[0101]
在上述过程控制装置中进行该实例。因此,当将四个优先化目标应用至24个候选克隆时,没有一个克隆满足所有标准。然而,将最终活力的限制(即最小活力值)从65%降低到60%导致选择称为cs1_7的克隆作为目标克隆的结果。cs1_7的产物浓度为4.5g/l,比生
产率为4.51g/细胞/天,质量为14,最终活力为60%。根据常规方法,克隆cs1_7将被选择作为目标克隆,特别是因为常规方法通常依赖于至少一个硬限制,其导致排除不满足硬限制的克隆。
[0102]
包括硬限制的常规方法可以使用决策树自动进行。此外,用户可以设置多个硬限制。然而,使用一个或多个硬限制可能导致严格排除不满足那些限制的克隆,并且可能不会导致选择最好的(即,最佳的)目标克隆。
[0103]
如以下步骤中更详细论述的,应用多变量方法导致选择更好地匹配给定标准的克隆,从而增加了所选择的克隆将导致安全且有效的产物的可能性。根据以下步骤选择的克隆将根据传统方法被排除,因为克隆的比生产率刚好落在4.5克/天/细胞的指定限制之外。下文论述的步骤使过程参数值和过程输出能够被组合成一个共同的得分。然后可以对候选克隆的得分进行排序,以提供最终的排名,从而导致选择给定数量的克隆。在排名中使用的多变量选择函数(下文更详细论述的)说明每个优先化目标和/或优先化范围,以及用于优先化的权重。因此,提供了可用克隆的一致排名的列表。排除了主观性,并且对相同数据(甚至由不同用户)执行的每个排名导致可靠且一致的结果。
[0104]
在步骤s105至s111中,根据多变量评估标准,多变量选择函数用于从关联数据计算每个克隆组的得分。
[0105]
在步骤s105,目的函数可以用于确定过程变量值(过程参数值和/或过程输出)与优先化目标之间的距离。更具体地,多个过程参数和/或过程输出可以被组合成分量,并且所述距离可以在分量与优先化目标之间。可以使用主成分分析(pca)得出该分量,然而,也可以使用适于从变量计算正交分量(即,向量)的其它手段。因此,可以计算每个优先化目标的分量。所述分量可以是正交的(即,不相关联的)并且适于欧几里得距离的计算。还可以使用偏最小二乘或正交偏最小二乘投影来进行距离计算。根据一个实例,可以如下计算候选克隆与优先化目标之间的距离:
[0106]
1.计算每个克隆的投影向量t
i
,
[0107]
2.投影向量t
i
是正交的,其长度与所述向量所解释的方差成比例,以及
[0108]
3.特定克隆之间的距离(d),
[0109]
‑
其中c是候选克隆,以及
[0110]
‑
r是优先化目标或参照克隆组。
[0111]
因此,在上面的第3点中提供了示例性目的函数。目的函数可以包括从过程参数和/或过程输出得到的主成分(即,投影向量)。目的函数可以包括涉及主(正交)分量的欧几里德距离计算。欧几里得距离和正交分量的组合可能是特别有利的,因为变量(例如,相关联的聚糖,如图4所示)之间的可能的关联反映在正交分量中,并且不需要变量不相关联的假设。
[0112]
关于上面的第1点和第2点,常规方法可以将过程输出的子集视为评估的基础。在这样的方法中,优先化可以假设在这些过程输出之间没有关联,特别是因为当变量相关联时,很难将一个变量优先于另一个变量。通过比较,第3点中的目的函数不需要变量(即,参数或输出)不相关联的假设,因为反映变量关联的正交投影向量是从变量计算出来的,然后用于确定距离d。
[0113]
有利地,目的函数可以考虑所有的过程参数和过程输出(即,如果全部被选择)或者过程参数和过程输出的子集(例如,适当的子集),如实例中所论述的。此外,不存在硬限制可以防止排除最佳(例如,最有效的)克隆。
[0114]
回到实例,克隆cs2_2可以具有4.8g/l的产物浓度。步骤s105可以包括确定4.8g/l与3.5g/l的目标产物浓度之间的距离。确定距离可以涉及归一化该距离。在这种情况下,由于要使产物浓度最大化,因此可以使用克隆cs2_2的产物浓度与目标产物浓度之间的差的倒数。
[0115]
在经由目的函数确定距离之后,在步骤s107中放大该距离。特别地,选择函数包括放大函数。放大函数可以是连续的非线性函数。
[0116]
使用非线性放大函数(与线性函数相反)可能是有利的,因为与具有较少可接受值的克隆相比,这样的函数将有利于具有更多可接受值(例如,过程输出)的克隆(即,使它们排名更高)。在这种情况下,可接受值可以在优先化范围内(例如,在2
‑
6的范围内的可接受值4.5),或者在目标值与其相应的极值之间(例如,具有目标值3与最大化极值的可接受值4.5)。
[0117]
相比之下,使用线性放大函数(或不使用放大函数)可能导致仅满足所选择的一些目标(例如,在目标值与其相应的极值之间具有相对较少的可接受值)的克隆,如果与其它克隆相比,少数可接受值(例如,过程输出)足够接近极值的话。换句话说,使用线性函数(或不使用函数)可能导致选择相对于相对大量的目标不具有可接受值的克隆。这可能是不希望的。
[0118]
放大函数也可以被称为罚函数,因为放大函数用于增加对应于候选克隆的值(例如,过程输出)与优先化目标之间的距离的影响(即,根据距离强加惩罚)。
[0119]
对于所有优先化目标,放大函数可以是相同的。以此方式,放大函数可以用于影响对应于候选克隆的值(不考虑其它克隆),而权重可以用于将对应于不同优先化目标的值针对彼此优先化(例如,通过将一个优先化目标的权重设置为高于另一个优先化目标的权重)。
[0120]
在步骤s109,可以基于优先化来修改放大的距离。特别地,优先化的权重可以用于修改放大的距离。每个权重可以是0至1的值,并且放大的距离可以通过将它们乘以它们相应的权重来修改。
[0121]
在步骤s111,可以聚集修改的距离以产生对应于克隆的得分。特别地,对于每个克隆,将所有变量(即,过程参数和过程输出)的距离组合为总距离值。更具体地,可以将距离加在一起。
[0122]
应用这种方法导致克隆cs2_2的排名高于克隆cs1_7(即,与优先化目标具有较低的总距离)。特别地,克隆cs2_2具有4.8g/l的产物浓度,4.45克/细胞/天的比生产率,8.0的质量和70%的最终活力。即使没有达到4.5克/细胞/天的比生产率目标,所述方法也导致选择克隆cs2_2作为目标克隆。尽管与其它候选克隆相比,克隆cs2_2在目标中具有较好的值(除了比生产率之外),但根据常规方法仍然会丢弃克隆cs2_2。
[0123]
以上描述的选择函数和多变量方法的使用确保了最佳可能的排名,并且能够在克隆选择中考虑任意数量的过程参数和过程输出。
[0124]
图2显示了从多组候选细胞中选择一组目标细胞。在图2的实例中,目标细胞和候
选细胞是克隆,然而,所描述的方法可应用于其它类型的细胞。
[0125]
在标准过滤器窗格201中,显示了选择的过程输出的多变量评估标准。特别地,所显示的优先化目标包括最终活力(显示为百分比,目标值为65)、最终产物浓度(以g/l显示,目标值为3.5)、最终比生产率(显示为“qp”,目标值为4.5)和质量(显示为“距离”,目标值为15单位)。使最终活力、产物浓度和最终比生产率最大化。使质量(即,距离)最小化。还显示了优先化的权重,其中最终活力的权重是0.4,最终产物浓度的权重是1,最终比生产率的权重是0.8,以及质量的权重是0.8。
[0126]
还显示了排名窗格203。排名窗格203包括针对候选克隆的第一列和针对候选克隆的相应得分的第二列。如所描绘的实例所示,克隆cs2_2(显示为cs2
‑
2)具有0.473的最低得分,因此排名最高。克隆/变量图205显示了克隆cs2_2相对于其它候选克隆的每个标准。因此,克隆cs2_2具有最高的产物浓度,cs2_2的最终活力和最终比生产率值约为平均值,以及cs2_2具有相对较低的质量(即,距离)。然而,特别由于分配给每个标准的优先化的权重,因此cs2_2被给予了最高的排名。
[0127]
原始数据窗格207显示了与其它克隆的处理轨迹相比的cs2_2的过程轨迹。
[0128]
图3显示了如何将过程参数值和过程输出进行组合以进行评估。特别地,多变量统计技术(例如,主成分分析)可以用于组合多个过程参数和/或多个过程输出。例如,可以在质量域中(例如,使用聚糖图谱或光谱指纹)以及在过程域中计算细胞相似性指数,其中可以组合和评估时间序列数据。过程输出可以对应于质量域,而过程参数可以对应于过程数据域。
[0129]
关于主成分分析和其它多变量统计过程控制方法的进一步细节可以见于“process analysis,monitoring and diagnosis using multivariate projection methods”,theodore curti,john f.mcgregor,chemometrics and intelligent laboratory systems 28,1995”,将其通过引用并入本文。
[0130]
除了主成分分析之外,还可以实现偏最小二乘和/或正交偏最小二乘来选择目标细胞。因此,可以呈现概览图(如图3所示),使得可以可视化和解释细胞之间的相似性。
[0131]
在图3所描绘的实例中,显示了cs1克隆组和cs2克隆组。组cs1和cs2可以根据过程控制装置的单独培养站来描绘。尽管提及了克隆,但所公开的技术可应用于其它类型的细胞。
[0132]
在所描绘的实例中,每个点是一个克隆的过程参数和过程输出的多变量表示。如图3所示的过程参数和过程输出的组合可能突出在基础数据中不容易检测到的潜在实验问题。此外,所描绘的多变量分析可以用于选择目标克隆。
[0133]
当使用一组过程输出(例如聚糖图谱)表示克隆时,多变量统计(例如,主成分分析)可能是特别有用的。因此,多变量统计分析可以提供相似性指数(例如,从过程输出得到的主成分),如图3所示,以用于候选克隆组的排名。可以使用目的函数来评估相似性指数,例如,如以上在步骤s105的上下文中所论述的。
[0134]
此外,所描绘的实例还可以提供关于不同过程参数之间的关联的信息。当针对优先化目标评估过程参数和过程输出时,可以应用该信息,从而提高排名。此外,当设置优先化目标或优先化范围的值时,关联信息对于用户可能是有用的。
[0135]
在图3的实例中,从24个过程收集数据。每个过程产生独特的克隆。cs1克隆在第一
培养站中产生,cs2克隆在第二培养站中产生。从执行过程以产生克隆中收集的数据可以相关联和进一步评价,如在图1的上下文中所描述的。图3显示了关于两个主成分t[1]和t[2]的值。为了经由多变量选择函数来计算得分,还可以评估除了如在图1的上下文中所论述的优先化范围、优先化目标和优先化的权重之外的其它主成分。
[0136]
与许多过程参数和过程输出相比,图3中使用的正交分量可以更有效地用于排名过程。如在图4的上下文中更详细地论述的,这特别是由于冲突(例如,负相关)的目标的情况。
[0137]
图4显示了从多个过程收集的过程输出(即聚糖)。更具体地,图4显示了来源于从产生图3所示的24个克隆的成分的过程收集的数据的聚糖图谱。
[0138]
在图4的上下文中,已经为g1'f和g0f两者设置了目标(即,优先化目标)。优先化目标包括极值,即最小值。因此,希望g1'f和g0f都具有尽可能低的值。然而,由于g1'f和g0f是负相关的,因此不可能使g1'f和g0f都最小化。因此,这些优先化目标之一必须优先于另一个。换句话说,使g1'f最小化的优先化目标必须优先于使g0f最小化的优先化目标,或者使g0f最小化的优先化目标必须优先于使g1'f最小化的优先化目标。更一般地,一旦接收针对选择的过程输出的多变量评估标准,就可以提供指示这些选择的过程输出中的至少两个之间的负相关的显示。因此,在经由多变量选择函数计算得分之前,外部输入(如由用户)可以提供进一步的优先化目标。
[0139]
在图4所描绘的实例中,每个克隆的聚糖图谱基于12个过程输出。聚糖图谱提供了关于不同过程输出之间的依赖性的信息。特别地,每种聚糖可以被认为是独特的过程输出,并且聚糖图谱可以显示聚糖之间的关联模式。
[0140]
图5显示了描绘图4中所描绘的12个聚糖图谱变量的主成分转化的投影图。因此,显示了每个克隆的值,并从该克隆的12个聚糖图谱变量值中得到该值。图5中所描绘的主成分是可以用于结合图1所论述的目的函数的上下文中的成分(即,投影向量t
i
)的实例。此外,图5中所描绘的成分可以用于经由多变量选择函数来计算得分。
[0141]
图5中所描绘的x轴代表12个聚糖图谱变量的总变化的98%。因此,12个聚糖图谱过程输出中98%的变化是一维的。尽管将过程输出组合到主成分可以使经由多变量选择函数计算得分更有效,但也可以直接使用过程参数和/或过程输出,而不需要确定主成分的额外步骤。
[0142]
应注意,即使在图3和图5的上下文中论述了主成分分析,也可以使用其它多变量统计分析技术,如偏最小二乘回归和/或正交偏最小二乘回归。
[0143]
在图5的实例中,投影图的起点是对应于参照克隆的得分。参照克隆可由多个目标值表示。
[0144]
图6显示了可以用于实现如上所论述的用于从多组候选细胞中选择至少一组目标细胞的方法的工具的功能。所述工具可以在硬件和/或软件中实现。特别地,所述工具可以在上文提及的且图7和图8中所描绘的过程控制装置中实现。
[0145]
如图6中的箭头所示,在步骤s601到s609之间可能存在一些重叠。例如,在步骤s601中执行的动作可以在步骤s603中执行的动作之后执行。相似地,如箭头所示,步骤s601的一些结果可以在步骤s603之后的步骤中使用,而不需要在步骤s603中执行的处理。相应的考虑可以应用于其它步骤。
[0146]
在步骤s601,导入数据。步骤s601可以包括接收从多个过程收集的数据,其中每个过程产生一组独特的候选细胞。导入的数据可以包括过程数据。过程数据可以被认为与过程参数值同义。过程数据可以包括从过程取样的时间关联数据。过程数据的实例是ph、产物滴度、活细胞密度、葡萄糖、溶解氧和/或耗氧量。
[0147]
另外,在步骤s601中,可以导入质量数据。质量数据可以被理解为过程输出。质量数据可以描述候选细胞的最终质量。更具体地,质量数据可以描述所处理的细胞系、细胞株或克隆。典型的质量数据可以是糖基化模式、电荷变体、聚集体、低分子量物质和/或作为图谱(例如,作为图谱向量)显示的聚糖残基。过程输出还可以包括聚集的过程数据。例如,可以在整个过程中测量活细胞密度,并且可以接收测量值作为过程参数值。可以接收最终的活细胞密度作为过程的过程输出。
[0148]
步骤s601还可以包括处理丢失的数据。该步骤可以在对接收的数据进行相关联的上下文中执行。丢失的数据可以包括没有被足够频繁地收集或取样的数据。例如,葡萄糖和/或乳酸可能每天仅取样一次,然而,可能需要更完整的葡萄糖和/或乳酸水平图像。因此,可能可取的是通过填写丢失样品的数据来模拟葡萄糖或乳酸的每小时测量。
[0149]
可以使用机理建模程序和/或多变量预测(例如,偏最小二乘回归)来填充丢失的数据。机理建模和多变量预测模型也可以用于预测候选细胞的未来行为。因此,机理建模可以在任何给定时间提供关于候选细胞的生物学状态的输入,并且可以实现候选细胞的早期评估。
[0150]
未来行为的预测可以使得可能确定如果过早地终止候选细胞的处理(例如,由于感染)将会发生什么。例如,如果过早地终止候选细胞的处理,则对候选细胞的未来行为的预测仍然可以能够将那些候选细胞的过程数据合并到经由多变量选择函数进行的计算中,以便获得可用于以上论述的排名中的候选细胞的得分。
[0151]
机理建模还可以用于通过验证和校正违反已知代谢比率的值来改善测量数据的质量,从而确保在排名中使用更高质量的数据。机理建模还可以用于估计难以或不可能直接测量的过程参数值(例如,细胞死亡率),并由此添加在计算每个候选细胞的得分时可以使用的进一步可行的信息。
[0152]
例如,活细胞密度测量可能具有+/
‑
10%的误差。可以执行测量的平滑以便排除错误的测量,例如,过程参数值或过程输出。
[0153]
在图7的上下文中描述了可以用于填充丢失数据或改善测量数据的质量(例如,经由数据平滑)的机制模型的特定实例。
[0154]
步骤s601还可以包括视觉质量控制。因此,可以以图形方式呈现接收的数据,使得可以容易地鉴定和排除异常值。此外,可以根据需要校正数据。
[0155]
步骤s601还可以包括数据排除。更具体地,至少一个过程可能失败。特别地,诸如污染和/或系统故障、无法解释的或不一致的生物因素或者人为误差的事件可能导致过程失败。可以排除来自失败过程的数据。
[0156]
步骤s601还可以包括对接收的数据进行分组。例如,可以将复制物、微库或生物相似细胞(例如克隆)分组用于分析。可以为每个组或为整组细胞设置优先化范围和/或优先化目标。
[0157]
步骤s601还可以包括数据匹配。特别地,可以从各种源接收数据。可以将数据进行
匹配和同步用于分析。源可以包括过程控制装置本身,并且可能包括外部分析装置。外部分析装置可以包括以下中的一个或多个:用于离线光谱测量的装置(光谱仪)、用于内联(inline)(即在线,原位)生物量测量的装置、用于营养物和代谢物测量的装置。
[0158]
光谱仪可以是通过其质量、动量或能量来分离(亚原子)粒子、原子和分子的设备。例如,可以使用acquity iclass uplc and xevo tqs三重四极杆质谱仪(waters,milford,ma)执行光谱测量。也可以使用其它装置。
[0159]
用于营养物和代谢物测量的装置可以在线测量参数。营养物的实例包括葡萄糖和乳酸。代谢物的实例包括甲醇和乙醇。特别地,装置可以对过滤探针进行多达60次分析/小时,并且可以经由透析设置进行多达30次分析/小时。更具体地,可以使用bioprofile flex(nova biomedical corporation,waltham,ma)分析葡萄糖和乳酸。
[0160]
活细胞浓度可以使用细胞活力分析仪,如vi
‑
cell自动细胞活力分析仪(beckman coulter,brea,california)进行分析。也可以使用其它装置。
[0161]
步骤s601还可以包括创建项目。该项目可以提供使用和存储多变量评估标准的框架,如下文更详细论述的。
[0162]
在步骤s603,可以设置用于所选择的过程参数和/或选择的过程输出的标准。特别地,步骤s603可以包括选择过程参数的(适当的)子集和/或过程输出的(适当的)子集。因此,过程参数的选择可以排除一个或多个过程参数。过程输出的选择可以排除一个或多个过程输出。然后可以接收所选择的过程参数和/或过程输出,例如由过程控制装置存储。
[0163]
步骤s603可以包括显示从多个过程收集的接收数据。此外,可以显示过程参数和过程输出。
[0164]
数据可以以表的形式显示。特别地,过程参数值可以在数据表中可视化。该表可以有助于数据中明显错误的校正。
[0165]
在数据表中显示数据可以有助于排除候选细胞或者将一组或多组候选细胞鉴定为参照细胞。例如,如果候选细胞组之一表现出异常图谱,则可以消除该候选细胞组。
[0166]
可以设置过程输出的可接受性范围。可以设置可接受性范围以便排除一个或多个异常值。设置可接受性范围(即,可接受范围)可以是预过滤过程的一部分。为了帮助设置可接受性范围,可以提供接收数据的概览显示。因此,通过设置可接受性范围,可以容易地确定排除多少接收数据。如果可接受性范围被设置得太严格,则通过预过滤过程的候选细胞组的数量可能太有限。例如,如果可接受性范围被设置为滤除具有低滴度的候选细胞组,则在所有候选细胞组中不存在产生高滴度的候选细胞组可能限制通过预过滤过程的候选细胞组的数量。这可能是不期望的。
[0167]
显示针对指定的可接受性范围排除的候选细胞组的显示器可以用于帮助用户设置合适的可接受性范围。步骤s603还可以包括原始数据可视化。原始数据可视化可以有助于理解哪些数据被指定的可接受性范围排除。
[0168]
步骤s605可以包括接收用于所选择的过程参数和/或选择的过程输出的多变量评估标准。多变量评估标准可以包括聚集或进一步处理至少一个选定的过程参数和/或选定的过程输出。
[0169]
多变量评估标准可以包括用于优先化的权重。多变量评估标准可以包括优先化范围和/或目标,其中每个目标是极值和/或目标值。可以为所选择的过程参数和/或过程输出
的(适当的)子集设置优先化目标。极值可以最大化或最小化。优先化目标可以包括目标值或设定点。目标值可以是特定的参照值或限制值。
[0170]
优先化范围可以作为来自用户的输入被接收。然而,当计算候选细胞组中的每一个的得分时,可以修改优先化范围。用于优先化的权重可以用于定义每个优先化目标的重要性。例如,可以将1.0的权重给予最重要的优先化目标。接近0的权重可以被给予相对不重要的优先化目标或优先化范围。
[0171]
步骤s605可以包括根据多变量评估标准经由多变量选择函数从相关联数据计算候选细胞组中的每一个的得分。多变量选择函数可以包括目的函数,更具体地成本函数。目的函数可以被称为期望函数。目的函数可以用于根据候选细胞符合多变量评估标准的程度来对候选细胞进行排名。目的函数可以是非线性的。目的函数可以是指数的,例如,二次的。目的函数可以基于评估标准和优先化的权重来量化与数值目标(例如,优先化目标或范围)的距离和总惩分。数值目标可以是与候选细胞组相比具有生物相似定义的参照细胞组。目的函数可以如以上图1的步骤s105的论述中所指定的。
[0172]
对于候选细胞组中的每一个的得分的计算可以使用不同的评估标准来进行多次(即,迭代地),特别是因为可以确定两个或更多个评估标准是负相关的,如图4所示。
[0173]
多变量选择函数可以产生反映一组候选细胞满足多变量评估标准的程度的得分。得分可以被称为期望指数。候选细胞的所选择的分布可以以图形方式可视化并且能够检查具有彼此接近的得分的细胞分布,如图2所示。例如,如果一组候选细胞例如,在排名203中排名第五,则该组候选细胞和其它组的候选细胞的相应变量图可以有助于确定如何生成排名。这样的比较可以能够重新优先化并且指导进一步的选择迭代。因此,例如,如图2所示的图形数据的显示可以有助于从基础原始数据中不可能进行的分析。而且,与常规方法相比,可以减少选择迭代的次数并且需要更少的用户干预。
[0174]
多变量相关分析工具,例如实现针对多个候选细胞组选择至少一个目标细胞组的方法的工具,可以帮助用户调整选择过程(包括优先化目标、权重和范围),以便确保选择最佳组的目标细胞。此外,以上论述的候选细胞组的选择可以反映过程参数值和过程输出。
[0175]
可以保存评估标准以便稍后与其它组的候选细胞一起使用或者与其它用户共享。对于不同的评估,由多个用户使用相同的多变量评估标准可以确保一致性。特别地,相同的标准可以由不同的用户应用于不同的数据集。这可以消除常规方法中通常存在的主观性。此外,相同的标准可以用于来自同一项目的不同批次的数据。
[0176]
在步骤s607,可以执行分析。如上所述,在步骤s607的上下文中执行的一些动作可以与在步骤s605的上下文中执行的步骤组合执行或者甚至在步骤s605的上下文中执行的步骤之前执行。
[0177]
为了有助于候选细胞组的排名,可以计算至少一个优先化目标。更具体地,可以计算至少一个目标值。例如,可以计算过程参数值、关系和基于过程历史的预测的积分和/或平均值。此外,还可以计算一些过程输出。计算的和/或预测的值可以为候选细胞组的排名和选择候选细胞组中的至少一个作为目标细胞提供更稳定的输入。
[0178]
此外,如上所论述的,机理建模算法可以用于填充丢失的数据并预测过程轨迹和/或最终结果。例如,可以将比预期更早地停止生长的候选细胞与继续产生结果直到相应的过程结束的其它候选细胞进行比较。可以从继续产生结果直到相应的过程结束的其它候选
细胞外推或内插比预期更早地停止生长的候选细胞的过程数据和质量数据。对提早终止的候选细胞的轨迹预测可以提供可以用于改进候选细胞组的排名的更完整的数据集。
[0179]
此外,如上文结合使接收的数据相关联而论述的多变量建模可以用于补偿由于外部分析装置中的取样、处理或固有缺陷而导致的测量误差。多变量建模可以使用基本的生物处理关联来产生更可靠的数据。这可以是在接收数据之后执行的关联的一部分,或者可以在已经产生候选细胞组的初始排名之后在所述方法的进一步迭代中执行。经由多变量选择函数计算的得分可以基于所有选择的过程参数和所有选择的过程输出。此外,还可以使用来自每个过程的过程轨迹的信息。经由多变量选择函数计算的得分可以与优先化目标(例如,生物相似的细胞或群组值)相比较。
[0180]
可以在群组内或与特定参照过程(即,产生参照细胞的过程)进行比较。这些比较可以有助于在上述方法的进一步迭代中设置不同的优先化范围、目标和权重。此外,候选细胞组中每一个的过程轨迹可以用于计算候选细胞组、群组之间的距离,或者根据目标值计算用于候选细胞组的排名的距离。除了过程轨迹之外,在候选细胞的排名中可以使用其它多变量标准,特别是其它质量数据,如聚糖图谱。
[0181]
步骤s607还可以包括关联分析,如结合图4和5所论述的。由于一些所接收的评估标准可能与其它标准(例如,标准可以包括负相关的目标)相矛盾,因此关联分析可以给出关于如何改进候选细胞选择的信息。理解不同变量(即,过程参数和过程输出)之间的关联可以有助于工具的调谐,以便例如以最小次数的迭代达到目标细胞的最佳选择。
[0182]
可以将所选择的候选细胞与所有其它候选细胞进行比较以进行分析。诸如主成分分析(pca)和偏最小二乘(pls)回归的多变量方法可以用于视觉比较和不同候选细胞组之间的距离的计算。结果的图形表示和可视化可以帮助用户确定特定的候选细胞组或群组之间的相似性。描述候选细胞的各个组的分量可以在二维图中显示为具有根据在选择过程中使用的任何变量或偏好来着色或设置大小的可能性的点,如图3和5所示。着色和定尺寸可以是三维图的一部分。
[0183]
在步骤s609,可以可选地产生报告。报告可以包括报告一个或多个选择结果、多变量评估标准、优先化目标、目标值和/或极值、排名、统计关联和/或观察结果的文档。特别地,报告可以提供支持(即,原因)从多个候选细胞组中选择目标细胞组的信息。如果已经执行了方法的多次迭代,则报告可以包括来自每次迭代的结果的总结。
[0184]
图7显示了机理建模如何可以用于平滑过程输出的实例。图7的实例描绘了“e5”细胞,即,特定类型的候选细胞。
[0185]
vcd测量值(以细胞/ml计)用“x”标记表示,细胞活力测量值(表示活(即仍然存活的)细胞的百分比)用实心圆圈表示。vcd测量值包括2.38827的初始vcd测量值。细胞活力测量值包括接近100%的初始细胞活力测量值。以细胞/ml计的vcd和以百分比计的细胞活力显示在垂直轴上,以天计的时间显示在水平轴上。
[0186]
vcd曲线701和细胞活力曲线703由对应于细胞的测量值和细胞特异性常数“k”计算。常数“k”对于所描绘的候选细胞是特定的,并且对于其它(不同的)候选细胞组是不同的。
[0187]
可以根据以下等式从选择的过程输出和细胞特异性常数生成曲线701和703:
[0188]
x
总计
=x
vcd
+x
死亡的
ꢀꢀ
(1)
[0189][0190][0191]
以上的等式是如何能够执行机理建模的实例。可以使用其它等式。
[0192]
关于上述等式(1)至(3),x
总计
(细胞(活细胞和死细胞)的总数)、x
vcd
(活细胞密度)和x
死亡的
(死细胞的数量)反映在过程期间测量或控制的过程参数的值,u
max
、k
死亡的
、k
有毒的
和k
抑制
是细胞特异性常数;等式(1)至(3)可以根据常规的优化方法求解以得到细胞特异性常数。
[0193]
因此,如图7所描绘的,u
max
(细胞的最大生长速率)是0.714950953243,k
有毒的
(死细胞引起的环境毒性导致的死亡率增加)是0.00439812036682,k
死亡的
(细胞死亡率)是0.178336658011以及k
抑制
(表征由于细胞总数导致的生长速率降低的系数)是108.398985599。
[0194]
k
抑制
反映了当细胞总数较多时细胞生长更缓慢的原理。因此,k
抑制
可以随着细胞密度生长(即,随着细胞密度增加可以抑制细胞生长)。等式(1)至(3)反映了细胞密度对细胞生长的影响,但也可以考虑其它影响。
[0195]
机理建模可以在接收数据的关联期间执行,以便填充丢失的测量值,例如,通过基于细胞的现有测量值和已知物理特性绘制一个或多个曲线(如图7所示)。因此,机理建模可以影响所选择的过程参数和选择的过程输出的值。
[0196]
在经由机理建模(如上所述)的过程参数值和过程输出的关联(例如,填充丢失的数据,数据平滑或内插)的上下文中使用细胞特异性常数具有在执行关联时反映细胞的物理特性的效果。这可以导致对候选细胞组的得分的更精确的计算(特别是与完全依赖于多变量统计方法(例如pca或pls)的方法相比),以及相应地从候选细胞组中选择最佳目标细胞。
[0197]
包括容器100(例如,微尺度生物反应器)的阵列的过程控制装置10(也称为生物反应器系统)显示在图8中。过程控制装置10可以安装到较大规模的过程控制装置中的基站的平台上。特别地,过程控制装置10可以是适于安装到宏观尺度过程控制装置的微尺度过程控制装置。宏观尺度过程控制装置可以包括具有与微尺度过程控制装置的容器的尺寸相差至少一个数量级的尺寸的容器。
[0198]
过程控制装置10包括基座12,基板13安装在基座12上,基板13限定了用于可拆卸地接收多个容器100的接收站14。夹板(未示出)可以经由从基板13的上表面突出的一对柱22在覆盖接收站14的位置中可拆卸地连接到基板13。夹板可以有助于搅拌器116的驱动机构之间的驱动连接(下文描述)。
[0199]
在所描绘的实例中,接收站14可以在相应的位置16处以两排六个的方式容纳多达十二个容器100。在图8中,显示了六个容器100在它们各自的容器接收位置16中的位置,而显示了六个容器接收位置16是空的,以更好地示出基板13中的流体端口314a
‑
c。
[0200]
接收站14可以被设计成容纳更多或更少数量的容器100,并且容器100可以被布置成任何合适的构造。
[0201]
一个或多个加热器或冷却器(未示出)可以位于邻近容器接收位置16以控制容器100的温度。
[0202]
参照图8,容器100中的一个包括用于接收在上方具有顶部空间109的流体107(例如,细胞培养液)的室105。容器100包括移液器进入端口106,盖108可拆卸地连接到移液器进入端口106。移除盖108以便流体被吸进或吸出容器100。流体输入端口112可以包括过滤器114。
[0203]
包括叶片118的搅拌器116可以可旋转地安装在容器100内的垂直轴120的底部。垂直轴120的上端包括驱动输入124(例如,用于驱动机构,未示出)。
[0204]
ph传感器点126和溶解氧(do)传感器点128设置在容器100的底部,使得它们能够检测流体107的ph和do水平,并且能够从容器100的外部询问。
[0205]
容器室105的通气经由迷宫路径实现,该迷宫路径经由搅拌器轴驱动输入124将室105连接到大气中。可替代地,可以向容器100的顶部提供单独的通气口。
[0206]
唇缘130可以突出到容器100的侧面。唇缘130包括贯通端口(through port)132b(未示出两个可选的额外端口132a和132c)。通道板134固定在容器100顶部的一部分上方。通道板134包括在至少一个管110b的顶部延伸到流体输入端口112的至少一个凹槽136b。通道板还包括至少一个贯通端口132b。唇缘130和通道板134一起形成向容器的侧面突出的刚性凸缘。
[0207]
夹板(未示出)还可以加强贯通端口132b与流体端口314a
‑
c之间的密封。
[0208]
阀组件300安装在基座12的下侧。当过程控制装置10连接到基站时,在基站的腔中接收阀组件。
[0209]
为了执行过程,过程控制装置10装载有容器100,每个容器放置在接收站14内的相应容器接收位置。当容器100插入接收站14时,唇缘130的底面中的端口132b与基板13的上表面上的相应接收站流体端口314b对齐并形成密封连接。
[0210]
借助于容器接收站的限定位置,各自的端口在插入时自动彼此对准,包括与其相邻的流体端口314a
‑
c和刚性凸缘,其使相应的容器连接端口132a
‑
c与接收站流体端口314a
‑
c对准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1