一种针对电子病历描述的查询重构方法与流程
本发明涉及文本检索领域,尤其涉及文本检索中查询的处理。
背景技术:
信息检索是从非结构化的大规模数据中找到用户所需信息的过程,是在海量数据中获取关键信息的有效方法。早在上世纪,医学专家就考虑利用数据、模型辅助临床决策,由此提出了临床决策支持系统。临床决策支持系统是一个医疗信息技术应用系统,包括利用信息检索技术预测诊断,即将病历中的病人描述作为查询查找相关医学文献辅助决策。通过这种方法,临床决策支持系统能有效挖掘医疗中的深层数据,提高医疗服务效率,加快医疗信息化进程。
随着医疗卫生事业的发展和科学技术的进步,医疗行业的科技化水平和信息化程度在不断提高,诊断决策支持系统作为临床决策支持系统中的一个非常活跃应用分支,一直是国内外研究与应用的热点。诊断决策支持系统是指能为医生在诊断决策过程中提供辅助支持的计算机应用系统,其可以为临床医生提供大量的医学支持,从而帮助临床医生做出最合理的诊断、选择最佳治疗措施。大量研究表明诊断决策支持系统可以有效解决临床医生疾病诊断过程中知识的局限性问题,并减少人为疏忽、相对降低医疗费用,为医疗质量提供保障。
为了更好地研究医疗文本检索技术,文本检索会议trec在2014年提出了临床决策支持(cds)任务。该任务给出电子病历的描述作为输入查询,参赛者在已有医疗文献集合中搜索返回与该查询最相关的文档,提供给医生辅助判断患者的真实需求。作为查询的电子病历以自由文本的形式存储,病历数据来源于icu临床数据库mimic-iii,而作为检索库的目标文档集则来自美国生物医学和生命科学全文本数据库pubmedcentral。
从treccds任务目前已有的研究成果来看,文献检索的主要工作集中在对原始查询语句的处理上,主流方法是基于关键词的查询扩展,而针对电子病历长文本的查询处理工作非常稀少。电子病历文本具有高度多义性,文本存在大量冗余且语义不清晰,它的处理方法无疑是医疗文献检索任务的难点。
技术实现要素:
从treccds任务目前已有的研究成果来看,文献检索的主要工作集中在对原始查询语句的处理上,主流方法是基于关键词的查询扩展,而针对电子病历长文本的查询处理工作非常稀少。普通查询长度在几到十几个查询词,而临床决策中任一电子病历描述平均长度在50-200个查询词,大多数商业及学术搜索引擎在处理这种长查询时效果并不理想,这意味着它将原始查询缩减为较短查询的任务留给了用户。另一方面,明确的查询意图可以进行针对性检索以提高检索效率。
针对上述问题,本发明以重构查询语句为目的,采用svm分类器获取查询语句的查询意图,生成电子病历的子查询并对其进行筛选,之后通过训练查询质量预测模型获取子查询中最优子查询,将其与查询意图相结合生成重构的查询语句。
为了实现上述目的,本发明给出的技术方案为:
本发明提供一种针对电子病历描述的查询重构方法,包括:
步骤1、对数据集中的电子病历文本和医疗文献文本进行预处理;
步骤2、训练svm分类器对电子病历文本进行查询意图预测;
步骤3、获取电子病历文本的所有子查询并对其进行初步预筛选;
步骤4、训练查询质量预测模型,从步骤3中预筛选输出的子查询中选取最优子查询;
步骤5、结合步骤2得到的查询意图与步骤4输出的最优子查询得到最终的重构查询。
有益效果
本发明针对具有冗余信息的电子病历描述长文本做查询重构处理,包括查询意图的预测和基于查询质量预测技术的原始查询的缩减。本发明分析原始查询语义,训练了一个分类器实现查询意图的判断。另一方面本发明将分析原始查询的所有子查询集,通过一组查询质量指标表示每个子查询,并首次提出了一个反映查询扩展性能的指标,在此基础上训练查询质量预测模型获取查询质量最高的子查询替代原始查询。
本发明在treccds数据集上进行了查询重构实验,并观察到性能的显著改善,这也证实了查询重构对检索结果的提升。其针对电子病历长文本实现的查询重构方法,对解决临床医生疾病诊断过程中知识的局限性问题,以及对减少人为疏忽、相对降低医疗费用、为医疗质量提供保障都有重大意义。
附图说明
附图是对本发明的进一步说明,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明,但不构成对本发明的限制。在附图中:
图1为查询重构方法的流程示意图;
图2为trec查询主题示例;
图3为利用该查询重构处理电子病历文本的结果。
具体实施方式
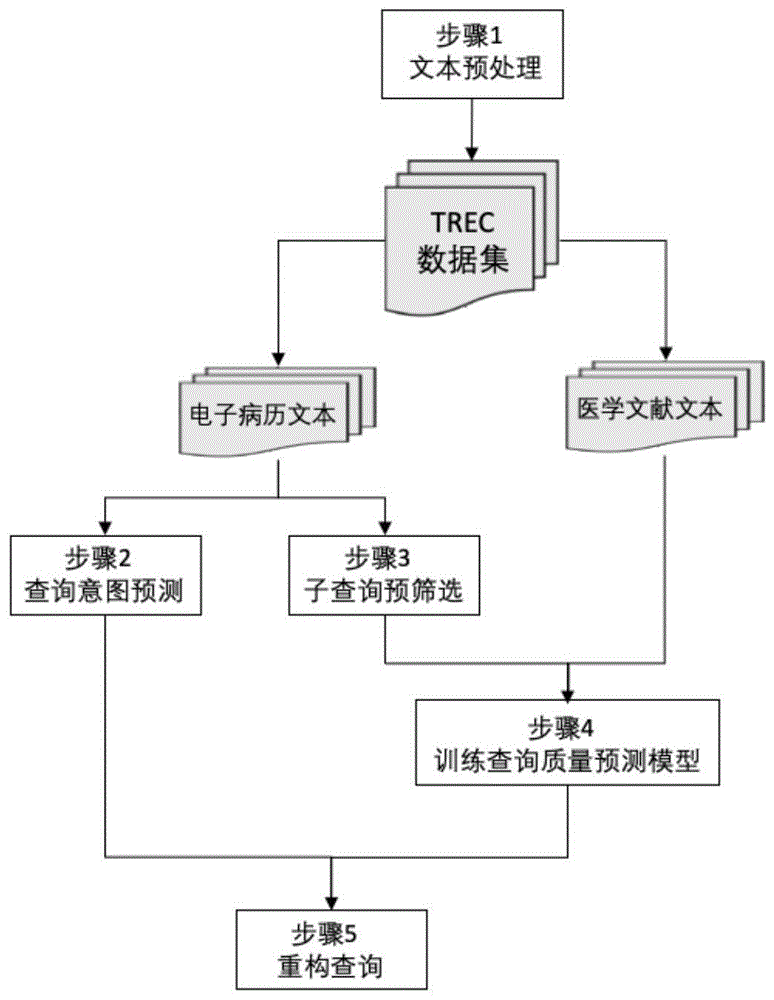
本发明的具体实施过程如图1所示,包括以下5个步骤:
步骤1、对数据集中的电子病历文本和医疗文献文本进行预处理;
步骤2、训练svm分类器对电子病历文本进行查询意图预测;
步骤3、获取电子病历文本的所有子查询并对其进行初步预筛选;
步骤4、训练查询质量预测模型,从步骤3中预筛选输出的子查询中选取最优子查询;
步骤5、结合步骤2得到的查询意图与步骤4输出的最优子查询得到最终的重构查询。
各个步骤详述如下。
步骤1:对数据集中的电子病历文本和医疗文献文本进行预处理
作为实施例,使用到的数据集来自treccdstrack数据集,包括电子病历文本和医疗文献集。其中电子病历文本来自于trec会议2014-2016定义的90个查询主题(topic),病历数据来源于icu临床数据库mimic-iii,我们选取每个主题中的描述域(descriptionfield)作为一个原始查询。图2展示了一个查询主题(topic)的示例。另一方面,医疗文献集为来自美国生物医学和生命科学文本数据库pubmedcentral的73万余份医疗相关文献。
步骤1中需要对电子病历文本和医疗文献文本进行预处理,具体包括以下步骤:
1.4、提取纯文本
因为电子病历文本本身就是纯文本,所以无需此步骤。而医疗文献文本是以xml格式存储的网页文件,需要去除其中无用的css和js代码,并根据xml标签取出需要的纯文本数据,包括文献的标题、摘要、关键词和正文部分,使预处理后的文献文本拥有统一格式。
将电子病历纯文本和医疗文献提取后的纯文本提供给步骤1.2;
1.5、去除停用词
利用预处理词表去除纯文本中的停用词,包括一些不含有语义信息的词汇,以及使用频率过高的词汇。
去除停用词后结果提供给步骤1.3;
1.6、还原词性
将不同的词性整合还原为词根,英文中同一个含义的词会有不同时态的变化,将这些词进行词性还原。
还原词性后即完成了步骤1的文本预处理工作,将预处理后的电子病历文本提供给步骤2和步骤3,而将预处理后的医疗文献文本提供给步骤4。
步骤2:训练svm三分类器对电子病历文本进行查询意图预测
步骤2利用步骤1中得到的预处理后的电子病历文本作为训练集来训练svm分类器进行查询意图的判断,具体包括以下步骤。
2.1、为训练集中的每一个电子病历文本标注三分类标签:若电子病历文本内容属于诊断(diagnosis),标注为1;若电子病历文本内容属于治疗方案(treatment),标注为2;若电子病历文本内容属于诊断检测手段(test),标注为3。标注后的结果提供给步骤2.2。
2.2、训练三分类器。
三分类器的训练使用现有的支持向量机svm算法,训练时需要输入电子病历文本的特征和步骤2.1中标注的三种分类标签。分类器的训练需要用到两个电子病历文本的特征:(1)tf-idf值;(2)语义信息。
(1)tf-idf是一种统计方法,用以评估一字词对于一个语料库中的其中一份文件的重要程度。其中词频(termfrequency,tf)指的是某一个给定的词语在该文件中出现的频率。逆向文件频率(inversedocumentfrequency,idf)是由总文件数目除以包含该词语的文件数目,再将得到的商取以10为底的对数得到。tf-idf值是这两个值的乘积,公式为
其中nω表示文件中词ω出现的次数,n表示文件中的总词数,nd表示语料库中文件总数,nω表示语料库中包含词ω的文件数。
(2)语义信息指三部分信息:是否包含诊断结果(值为0/1)、是否表明已完成检查(值为0/1)、查询文本长度(值为0-200)。
将训练得到的三分类器提供给步骤2.3。
2.3、将电子病历文本输入已训练好的三分类器,并将分类结果(即查询意图)提供给步骤5。
步骤3:获取电子病历文本的所有子查询并对其进行初步预筛选
理论上一个包含n个查询词的查询可以得到指数量级个子查询,例如含3个查询词的查询语句“fevercoughheadache”可拆分成的子查询有“fever”、“cough”、“headache”、“fevercough”、“feverheadache”、“coughheadache”、“fevercoughheadache”。穷举所有可能的子查询进行排序是不现实的,所以首先需要对子查询进行预筛选。子查询预筛选包含以下步骤。
3.1、在电子病历文本的所有子查询中选取长度在3-10之间的子查询。子查询长度指的是查询中的单词数目。研究表明使检索效果最佳的查询长度在3-6之间,考虑到本发明针对的电子病历长文本,将长度最大阈值定义在10。结果提供给步骤3.2。
3.2、计算3.1中得到的每个子查询的平均互信息量,选取互信息量最高的30个子查询。子查询的平均互信息量计算公式如下:
其中n(x,y)表示在整个语料库中,单词x和单词y同时出现在窗口大小为25的文档中的频率,n(x)、n(y)分别表示单词x和单词y在语料库中出现的频率。nc表示整个语料库的单词数。计算一个子查询中任意两个单词的互信息量,并将它们的加权平均值作为子查询的平均互信息量。
步骤3最终得到预筛选后的30个子查询,此结果提供给步骤4。
步骤4:训练查询质量预测模型,从预筛选后的子查询中选取最优子查询
4.1、为子查询标注查询质量分数
对步骤3得到的每一个预筛选后的子查询进行一轮检索,检索的目标文献集来自步骤1中预处理后的医疗文献文本集。搜索引擎使用的是lemur开源项目中的indri5.11。将检索结果与trec会议提供的评价标准对比,计算得到检索的平均准确率得分,并将其标注为该子查询的查询质量分数。标注了查询质量分数的子查询作为此步骤的结果提供给步骤4.2。
4.2、训练查询质量预测模型
查询质量预测模型的训练使用现有的svmrank算法,训练时需要输入可以表征子查询质量的指标和步骤4.1中标注的查询质量分数。
模型训练需要用到以下指标,对训练集中的每个子查询计算:(1)逆文档频率相关指标;(2)简化查询清晰度指标;(3)语料/查询相似特征指标;(4)查询可扩展性指标。
在分别介绍这些指标前定义此步骤用到的符号含义。对一个查询q,假设它包含查询词ω1,…ωn,语料库c中n(ωi)表示查询词ωi在语料库中出现的频率,n(ωi,ωj)表示语料库中查询词ωi,ωj(i≠j)同时出现在一个长度为25个单词的窗口中的频率,nc表示语料库包含的词语总数,nω表示出现过查询词ω的文档数,nd表示语料库中所有文件的数目。pc(ω)表示语料库中查询词ω出现的概率,p(ω|q)表示查询语句q中ω出现的概率,sω表示词语ω的同义词集。
(1)逆文档频率相关指标计算公式为:
其中nω为包含单词ω的文档数,nd为语料库中总文档数。对于每个子查询,计算每个查询词idf值的和、最大值、标准偏差、算术平均值、几何平均值和调和平均值共同作为查询质量指标。
(2)简化查询清晰度指标计算公式为:
其中pml(ω|q)为查询q中单词ω的出现的频率,pc(ω)单词ω在语料库中出现的频率。
(3)语料/查询相似特征指标计算公式为:
和逆文档频率相关指标一样,我们计算每个查询词scq值的和、最大值、标准偏差、算术平均值、几何平均值和调和平均值共同作为查询质量指标。
(4)查询可扩展性指标
本发明首次提出了一个反映查询扩展性能的指标——查询可扩展性指标。计算公式为:
其中sω为查询词ω的同义词集,p(α|q)指查询模型中查询词α的出现概率。可以认为查询可扩展性越高的查询,其查询质量越高,因为在对它们进行查询扩展后可以检索到更多的相关文档。
将训练得到的查询质量预测模型提供给步骤4.3。
4.3、对步骤3得到的每一个预筛选后的子查询,计算步骤4.2中表征子查询质量的4个指标,并将其输入到步骤4.2训练得到的查询质量预测模型得到该子查询的查询质量得分。选取30个子查询中查询质量得分最高的子查询作为最优子查询,结果提供给步骤5。
步骤5:结合查询意图和最优子查询得到最终的重构查询
将步骤2得到的查询意图和步骤4得到的最优子查询结合作为最终结果的重构查询。
- 还没有人留言评论。精彩留言会获得点赞!