一种芳烃歧化生产环节的产物预测方法和系统与流程
本发明涉及芳烃歧化生产环节中实现关键产物浓度信息的预测技术,具体涉及基于交叉验证与稀疏度的代理模型完整描述原有工业过程,对芳烃歧化生产环节通过代理模型进行建模,从而对芳烃歧化生产环节的关键产物的浓度信息进行预测的技术。
背景技术:
二甲苯是基本的有机化工原料,它广泛地应用于工业生产,对现代化工业的发展有着极其重要的影响。甲苯歧化是生产对二甲苯的重要环节,甲苯歧化反应将甲苯转化成苯和二甲苯。甲苯歧化装置与芳烃装置结合起来,可以最大限度的提高高品质的苯和对二甲苯产量,同时也将低品质的甲苯和重质芳烃等副产品降到最低。
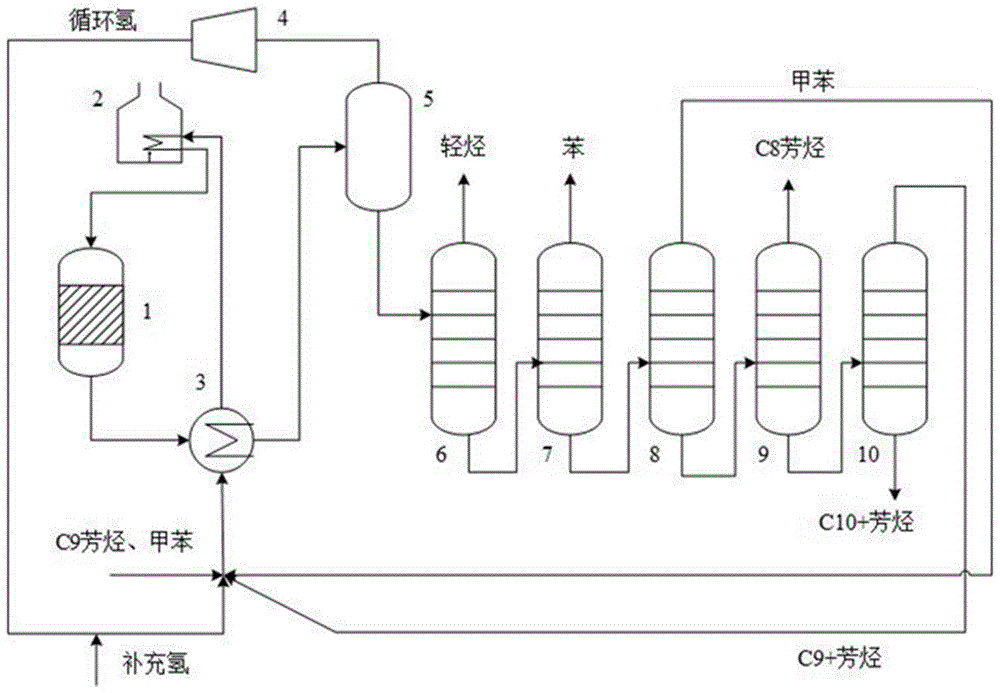
甲苯歧化工艺简流程图如图1所示。新鲜进料先与富含氢气的循环气混合,与热反应器1的排出物换热后进入加热炉2,在加热炉2内汽化,达到反应温度时,热的蒸汽进料送至反应器1,然后向下流过固定床催化剂。反应器1的产物通过与混合进料换热器3换热,进行冷却。然后送至一个气液分离罐5。氢气从分离罐5顶部抽出通过压缩机4进入换热器3,再返回反应器1,小部分循环气用来吹扫,清除循环线路中积累的轻质轻。分离器5底部的液体送至汽提塔6,汽提塔6塔顶的轻质烃类冷却后分离出气、液相产品,反应产物中的苯和二甲苯产品,伴随未反应的甲苯和c9芳烃,从汽提塔6底部抽出,再通过后续精馏装置(包括苯塔7、甲苯塔8、二甲苯塔9、c9芳烃塔10)对其中的纯苯、循环甲苯、c8芳烃以及重芳烃进行分离,部分循环利用。
实际生产过程中,歧化过程的温度、压力、进料流量、进料组分浓度等参数都会由于操作条件的改变发生间歇或者周期性的波动,某些参数对最终的关键产物产率影响较大,操作不当很容易对整个生产过程造成较大的影响。但是直接将歧化过程的机理模型用于仿真和优化会导致计算耗时过长和计算费用过高等问题。因此,建立一个与实际工艺相符,能准确反映产物浓度等关键性能指标的代理模型,对指导实际工业生产具有重要意义。
技术实现要素:
以下给出一个或多个方面的简要概述以提供对这些方面的基本理解。此概述不是所有构想到的方面的详尽综览,并且既非旨在指认出所有方面的关键性或决定性要素亦非试图界定任何或所有方面的范围。其唯一的目的是要以简化形式给出一个或多个方面的一些概念以为稍后给出的更加详细的描述之序。
本发明的目的在于解决上述问题,提供了一种芳烃歧化生产环节的产物预测方法和系统,通过对整体歧化环节的完整描述建立代理模型,基于代理模型正确预测产物浓度随进料以及操作参数改变的变化情况,从而保证产品质量和生产过程的稳定运行。
本发明的技术方案为:本发明揭示了一种芳烃歧化生产环节的产物预测方法,方法包括:
步骤1:接收选定的芳烃歧化生产环节的操作条件作为代理模型的输入变量,接收选定的芳烃歧化生产环节的产物产率作为代理模型的输出变量,设定输入变量的上下限范围,生成若干个初始样本点,利用机理模型获得所有初始样本点的实际输出响应值,同时生成测试样本集用于代理模型的精度验证;
步骤2:根据初始样本点以及初始样本点的实际输出响应值,建立多个子kriging代理模型;
步骤3:在样本空间内随机生成多个候选采样点,分别计算该多个候选采样点在该多个子kriging代理模型上的输出响应值,并得到每个候选采样点在该多个子kriging代理模型上的输出响应值的交叉验证方差;
步骤4:分别计算该多个候选采样点的稀疏度,将每个候选采样点的稀疏度与交叉验证方差分别归一化后相加,得到每个候选采样点的不确定性权重;
步骤5:选择不确定性权重最大的候选采样点作为新增采样点,反归一化后利用机理模型计算出实际输出响应值,将新增采样点加入到代理模型的训练样本集中以重新训练代理模型,通过多次迭代后得到最终的代理模型;
步骤6:通过建立的代理模型实现对芳烃歧化生产过程的模拟,对芳烃歧化产物产率进行预测。
根据本发明的芳烃歧化生产环节的产物预测方法的一实施例,作为代理模型的输入变量的芳烃歧化生产环节的操作条件包括:歧化进料总量、进料甲苯流量、进料c9流量、循环氢流量、补充氢流量、反应温度、反应压力、进料甲苯含量、进料甲乙苯含量、进料三甲苯含量;输出变量选择歧化环节的产物产率包括:歧化氢气收率、干气收率、轻烃收率、苯收率、c8+收率。
根据本发明的芳烃歧化生产环节的产物预测方法的一实施例,步骤1中的初始样本点是在各输入变量上下限范围内利用拉丁超立方采样生成,用于测试的样本集也是在搜索空间中利用拉丁超立方采样生成。
根据本发明的芳烃歧化生产环节的产物预测方法的一实施例,步骤2中的初始样本点在建立多个子kriging代理模型之前先进行归一化操作。
根据本发明的芳烃歧化生产环节的产物预测方法的一实施例,步骤4中的每个候选采样点的不确定性权重为:
weight=δ2(x)/max(δ2(x))+sparsity(x)/max(sparsity(x)),其中sparsity(x)是每个候选点的稀疏度,δ2(x)是步骤3中得到的每个候选采样点在该多个子kriging代理模型上的输出响应值的交叉验证方差。
本发明还揭示了一种芳烃歧化生产环节的产物预测系统,包括:
样本生成模块,接收选定的芳烃歧化生产环节的操作条件作为代理模型的输入变量,接收选定的芳烃歧化生产环节的产物的产率作为代理模型的输出变量,设定输入变量的上下限范围,生成若干个初始样本点,利用机理模型获得所有初始样本点的实际输出响应值,同时生成测试样本集用于代理模型的精度验证;
子kriging代理模型建立模块,根据初始样本点以及初始样本点的实际输出响应值,建立多个子kriging代理模型;
交叉验证方差计算模块,在样本空间内随机生成多个候选采样点,分别计算该多个候选采样点在该多个子kriging代理模型上的输出响应值,并得到每个候选采样点在该多个子kriging代理模型上的输出响应值的交叉验证方差;
不确定性权重获取模块,分别计算该多个候选采样点的稀疏度,将每个候选采样点的稀疏度与交叉验证方差分别归一化后相加,得到每个候选采样点的不确定性权重;
代理模型建立模块,选择不确定性权重最大的候选采样点作为新增采样点,反归一化后利用机理模型计算出实际输出响应值,将新增采样点加入到代理模型的训练样本集中以重新训练代理模型,通过多次迭代后得到最终的代理模型;
模型预测模块,通过建立的代理模型实现对芳烃歧化生产过程的模拟,对芳烃歧化产物产率进行预测。
根据本发明的芳烃歧化生产环节的产物预测系统的一实施例,作为代理模型的输入变量的芳烃歧化生产环节的操作条件包括:歧化进料总量、进料甲苯流量、进料c9流量、循环氢流量、补充氢流量、反应温度、反应压力、进料甲苯含量、进料甲乙苯含量、进料三甲苯含量;输出变量选择歧化环节的产物产率包括:歧化氢气收率、干气收率、轻烃收率、苯收率、c8+收率。
根据本发明的芳烃歧化生产环节的产物预测系统的一实施例,样本生成模块中的初始样本点是在各输入变量上下限范围内利用拉丁超立方采样生成,用于测试的样本集也是在搜索空间中利用拉丁超立方采样生成。
根据本发明的芳烃歧化生产环节的产物预测系统的一实施例,子kriging代理模型建立模块中的初始样本点在建立多个子kriging代理模型之前先进行归一化操作。
根据本发明的芳烃歧化生产环节的产物预测系统的一实施例,不确定性权重获取模块中的每个候选采样点的不确定性权重为:
weight=δ2(x)/max(δ2(x))+sparsity(x)/max(sparsity(x)),其中sparsity(x)是每个候选点的稀疏度,δ2(x)是交叉验证方差计算模块中得到的每个候选采样点在该多个子kriging代理模型上的输出响应值的交叉验证方差。
本发明对比现有技术的有益效果如下:
1.利用代理模型构建芳烃歧化模型,同样的输入变量,对比机理模型,可以在极短时间内得到对应的各关键性能指标的输出,效率更高。
2.由于不使用进化算法,只是在随机生成的点中寻找不确定度最大的点加入训练样本集中,所以计算时间得以缩短。
3.通过交叉验证误差寻找变化最大即最复杂的区域,通过稀疏度确定缺少采样点的区域,两者结合可以在稀疏区域和复杂区域中自适应选择新采样点,这样代理模型的精度随着采样点的增加而不断提高,使得最终模型可以替代原始的机理模型,用于实时预测和优化。
附图说明
在结合以下附图阅读本公开的实施例的详细描述之后,能够更好地理解本发明的上述特征和优点。在附图中,各组件不一定是按比例绘制,并且具有类似的相关特性或特征的组件可能具有相同或相近的附图标记。
图1示出了芳烃歧化生产环节的流程示意图。
图2示出了本发明的芳烃歧化生产环节的产物预测方法的一实施例的流程图。
图3示出了本发明的芳烃歧化生产环节的产物预测系统的一实施例的原理图。
图4a至4e示出了芳烃歧化代理模型rmse变化曲线的示意图。
图5a至5e示出了芳烃歧化代理模型各收率预测结果的示意图。
具体实施方式
以下结合附图和具体实施例对本发明作详细描述。注意,以下结合附图和具体实施例描述的诸方面仅是示例性的,而不应被理解为对本发明的保护范围进行任何限制。
本发明的原理是:通过对芳烃歧化环节的机理模型建立代理模型,利用交叉验证误差以及稀疏度进行自适应采样,使得所构建的代理模型的精确度不断提高,最终用于产物产率的实时预测。
芳烃歧化工艺流程见图1,原料甲苯和c9芳烃先与循环氢混合,再与反应器1出来的物料换热后,经过原料加热炉2预热到反应要求的温度,自上而下通过歧化反应器1,与催化剂接触发生歧化反应。反应产物离开反应器1经换热器3与原料换热。再经冷凝、冷却进入分离器5进行气液分离,再经过汽提塔6、苯塔7、甲苯塔8、二甲苯塔9、c9芳烃塔10分离出各产品。
图2示出了本发明的芳烃歧化生产环节的产物预测方法的一实施例的流程。请参见图2,下面是对本实施例的实施步骤的详细描述。
步骤1:接收选定的芳烃歧化生产环节的操作条件作为代理模型的输入变量,接收选定的芳烃歧化生产环节的产物的产率作为代理模型的输出变量,设定输入变量的上下限范围,利用拉丁超立方采样生成若干个(例如20个)初始样本点构成初始样本集,利用芳烃歧化的hysys机理模型获得所有初始样本点的实际输出响应值(主要包括:歧化氢气收率、干气收率、轻烃收率、苯收率、c8+收率),同时随机生成测试样本集用于代理模型的精度验证。
在此步骤中,通常是选取芳烃歧化生产环节中有较大影响的操作条件作为代理模型的输入变量,包括:歧化进料总量、进料甲苯流量、进料c9流量、循环氢流量、补充氢流量、反应温度、反应压力、进料甲苯含量、进料甲乙苯含量、进料三甲苯含量。选取芳烃歧化生产环节的产物产率作为代理模型的输出变量,主要包括歧化氢气收率、干气收率、轻烃收率、苯收率、c8+收率。
在一个示例中,选取芳烃歧化生产环节的包括歧化进料总量、进料甲苯流量、进料c9流量、循环氢流量、补充氢流量、反应温度、反应压力、进料甲苯含量、进料甲乙苯含量、进料三甲苯含量在内的10个操作条件作为输入变量,再设置这10个输入变量的上下限
其中,在利用hysys机理模型获得这20个初始样本的初始响应值的处理中,先将这20个初始样本逐个归一化,以消除样本维度对计算的影响:
(1)式中,
步骤2:根据初始样本点以及初始样本点的产物产率的实际输出响应值,获得多个子kriging代理模型(子kriging代理模型包括子kriging模型)。
继续上述的示例,将20个初始样本随机分成10份,[date1,date2,...,daten],n=10。
再建立kriging代理模型(kriging是一种基于统计学的插值技术)。公式如下:
z(x)期望为0,方差为σ2,协方差为σ2r(θ,xi,xj),其中,r(θ,xi,xj)表示两个样本点xi和xj之间的相关函数;θ={θ1,θ2,......θd}是决定r(θ,xi,xj)梯度的一组参数。本实施例采用的是高斯相关函数,其定义如下:
r(θk,xi,xj)=exp(-θk|xi-xj|2)(4)
对于给定的θ值,在x处的预测值
其中r是n×1的列向量,表示预测点x与样本点之间的相关矩阵,其第i个元素为r(x,xi),其中i=1,2,3,...,n;r是n×n阶对称的相关矩阵,其第(i,j)个元素为r(xi,xj),其中i,j=1,2,3,...,n;y为n×1的列向量,其第i个元素为点xi的目标函数值y(xi);1是n×1的单位列向量。
通常,超参数θ可由极大似然法求得,求解过程如下:
对上式求导并令其导数为零,可得u和σ2的极大似然估计
其中,
建立10个子kriging代理模型,每次构建时,选择datei中的9个作为训练样本,及每次舍弃一个样本集,最终得到10个子kriging代理模型fk(x),k=1,2,...,10,用于后续计算交叉验证方差。
步骤3:在样本空间内随机生成多个候选采样点,分别计算该多个候选采样点在步骤2的该多个子kriging代理模型上的输出响应值,并得到每个候选采样点在该多个子kriging代理模型上的输出响应值的交叉验证方差。交叉验证方差δ2(x)公式如下:
其中n表示样本点个数,x表示样本平均数。
继续上述的示例,利用拉丁超立方采样在样本空间内随机生成2000个候选采样点xcandidate,分别计算这个1000个样本点在样本响应值fk(x)上的结果,再计算10个子kriging代理模型响应值的方差δ2(x)。
步骤4:分别计算这些候选采样点的稀疏度,将稀疏度与交叉验证方差分别归一化后相加,得到每个候选采样点的不确定性权重。
继续上述的示例,计算每个候选采样点的稀疏度,稀疏度定义如下:
已有采样点x=[x1,x2,...,xn]t,搜索上下限为up={up1,up2,...,upd}和down={down1,down2,...,downd}。在搜索空间内的任意一点xnew的稀疏度定义如下:
step1计算新采样点xnew与已有采样点x=[x1,x2,...,xn]t的欧式距离diatance,并进行排序得到diatancesort。
step2x2=[x1,x2,...,xn,xnew]t
step3forj=1:d(for表示循环处理,以下是循环体的处理内容)
对
ifpos=1
第i维稀疏度下限为采样空间下限
elseifpos=n+1
第i维稀疏度上限为采样空间上限
else
第i维稀疏度上限为第i维中,比xnew,i大的点中,距离xnew最近的点的第i维值
end(循环体结束)
step4最终得到稀疏度sparsity:
再计算每个候选采样点的不确定性权重:
weight(x)=δ2(x)/max(δ2(x))+sparsity(x)/max(sparsity(x))(10)
步骤5:选择不确定性权重最大的候选采样点作为新增采样点加入到训练样本集中,利用机理模型计算出产物产率的实际输出响应值,重新训练代理模型,这样不断迭代直到达到机理模型评估次数上限,得到最终的kriging代理模型。
继续上述的示例,选择其中不确定性权重最大的候选采样点作为新采样点
反归一化后得到实际值:
利用hysys机理模型得到实际的输出响应值,加入训练样本集中,重新训练kriging代理模型。
重复上述添加新样本点的过程,直到机理模型评估次数达到上限,最终得到歧化过程的代理模型。
本示例中选择初始样本集为20个样本点,机理模型评估总次数为200,即新增采样点数为180。分别对五个收率重复上述构建代理模型的过程,每次得到的代理模型计算均方根误差(rmse):
式(14)中,yi和
步骤6:通过建立的代理模型实现对芳烃歧化生产过程的模拟,对芳烃歧化产物产率进行预测。
图3示出了本发明的芳烃歧化生产环节的产物预测系统的一实施例的原理。请参见图3,本实施例的系统包括:样本生成模块、子kriging代理模型建立模块、交叉验证方差计算模块、不确定性权重获取模块、代理模型建立模块、模型预测模块。
样本生成模块,接收选定的芳烃歧化生产环节的操作条件作为代理模型的输入变量,接收选定的芳烃歧化生产环节的产物的产率作为代理模型的输出变量,设定输入变量的上下限范围,生成若干个初始样本点,利用hysys机理模型获得所有初始样本点的产物产率的实际输出响应值,同时生成测试样本集用于代理模型的精度验证。
作为代理模型的输入变量的芳烃歧化生产环节的操作条件包括:歧化进料总量、进料甲苯流量、进料c9流量、循环氢流量、补充氢流量、反应温度、反应压力、进料甲苯含量、进料甲乙苯含量、进料三甲苯含量;产物产率包括:歧化氢气收率、干气收率、轻烃收率、苯收率、c8+收率。
样本生成模块中的初始样本点是在各输入变量上下限范围内利用拉丁超立方采样生成,用于测试的样本集也是在搜索空间中利用拉丁超立方采样生成。
子kriging代理模型建立模块,根据初始样本点以及初始样本点的实际输出响应值,首先进行归一化操作,再建立多个子kriging代理模型。
交叉验证方差计算模块,在样本空间内随机生成多个候选采样点,分别计算该多个候选采样点在不同子kriging代理模型上的输出响应值,并得到每个候选采样点在该多个子kriging代理模型上的输出响应值的交叉验证方差。
不确定性权重获取模块,分别计算该多个候选采样点的稀疏度,将每个候选采样点的稀疏度与交叉验证方差分别归一化后相加,得到每个候选采样点的不确定性权重。
不确定性权重获取模块中的每个候选采样点的不确定性权重为:weight=δ2(x)/max(δ2(x))+sparsity(x)/max(sparsity(x)),其中sparsity(x)是每个候选点的稀疏度,δ2(x)是交叉验证方差计算模块中得到的每个候选采样点在该多个子kriging代理模型上的输出响应值的交叉验证方差。
代理模型建立模块,选择不确定性权重最大的候选采样点作为新增采样点,反归一化后利用机理模型计算出产物产率的实际输出响应值,将新增采样点加入到代理模型的训练样本集中以重新训练代理模型,通过多次迭代后得到最终的代理模型。
模型预测模块,通过建立的代理模型实现对芳烃歧化生产过程的模拟,对芳烃歧化产物产率进行预测。
提供对本公开的先前描述是为使得本领域任何技术人员皆能够制作或使用本公开。对本公开的各种修改对本领域技术人员来说都将是显而易见的,且本文中所定义的普适原理可被应用到其他变体而不会脱离本公开的精神或范围。由此,本公开并非旨在被限定于本文中所描述的示例和设计,而是应被授予与本文中所公开的原理和新颖性特征相一致的最广范围。
- 还没有人留言评论。精彩留言会获得点赞!