通过基于可配置机器学习的算术编码进行的基因组信息压缩的制作方法
本文公开的各种示例性实施例总体上涉及用于mpeg-g的上下文选择、模型训练和基于机器学习的算术编码的可扩展框架的系统和方法。背景领域高通量测序已经使得以不断降低的成本扫描遗传物质成为可能,从而使得遗传数据量不断增加,并且需要有效地压缩这些数据,但是优选地以与设想的用途相兼容的方式来有效地压缩这些数据。应用发生在例如医学(疾病检测)和人口监测(例如,sars-cov-2检测)、法医学等领域中。由于dna(脱氧核糖核酸)和rna(核糖核酸)仅由4种不同的核酸碱基组成(针对dna分别为胞嘧啶[c]、鸟嘌呤[g]、腺嘌呤[a]和胸腺嘧啶[t],而针对rna分别为腺嘌呤、胞嘧啶、鸟嘌呤和尿嘧啶[u]),人们可能天真地认为编码会很容易。然而,遗传信息以新的不同形式出现。例如,原始数据可能来自不同的测序技术(例如,第二代测序vs长读段测序),这引起不同长度的阅读,但也具有不同的碱基调用确定性,碱基调用确定性作为质量信息(如质量分数)被添加到一个或多个碱基序列中,质量信息也必须被编码。此外,在dna的下游分析中,可以生成关于dna的性质的信息,例如,与参考序列相比的差异。然后,人们能够注释,例如,与参照相比,一个或多个碱基缺失。已知单核苷酸变体可能导致疾病或某种其他遗传决定的性质,并且能够以某种方式注释这种情况,使得编码数据的另一用户能够容易地找到该信息。表观遗传学(其研究对dna序列的外部修饰)同样产生大量的额外数据,如甲基化、揭示细胞中的染色质的空间组织形式的染色体接触矩阵等。所有这些应用在未来都将创建丰富的数据集,这些数据集需要强大的编码技术。mpeg-g是移动图像专家组最近的一项倡议,其旨在基于对用户的各种需求的彻底辩论来实现对遗传信息的通用表示。当前使用上下文自适应二进制算术编码(cabac)作为用于mpeg-g中的描述符压缩的熵编码机制。然而,在大多数案例中,当前标准仅允许先前的符号作为上下文。
背景技术:
技术实现思路
1、下文呈现了对各种示例性实施例的概述。在下面的概述中可以进行一些简化和省略,这旨在突出和介绍各种示例性实施例的一些方面,而并不旨在限制本发明的范围。在后面的章节中将详细描述足以允许本领域普通技术人员实践和使用本发明构思的示例性实施例。
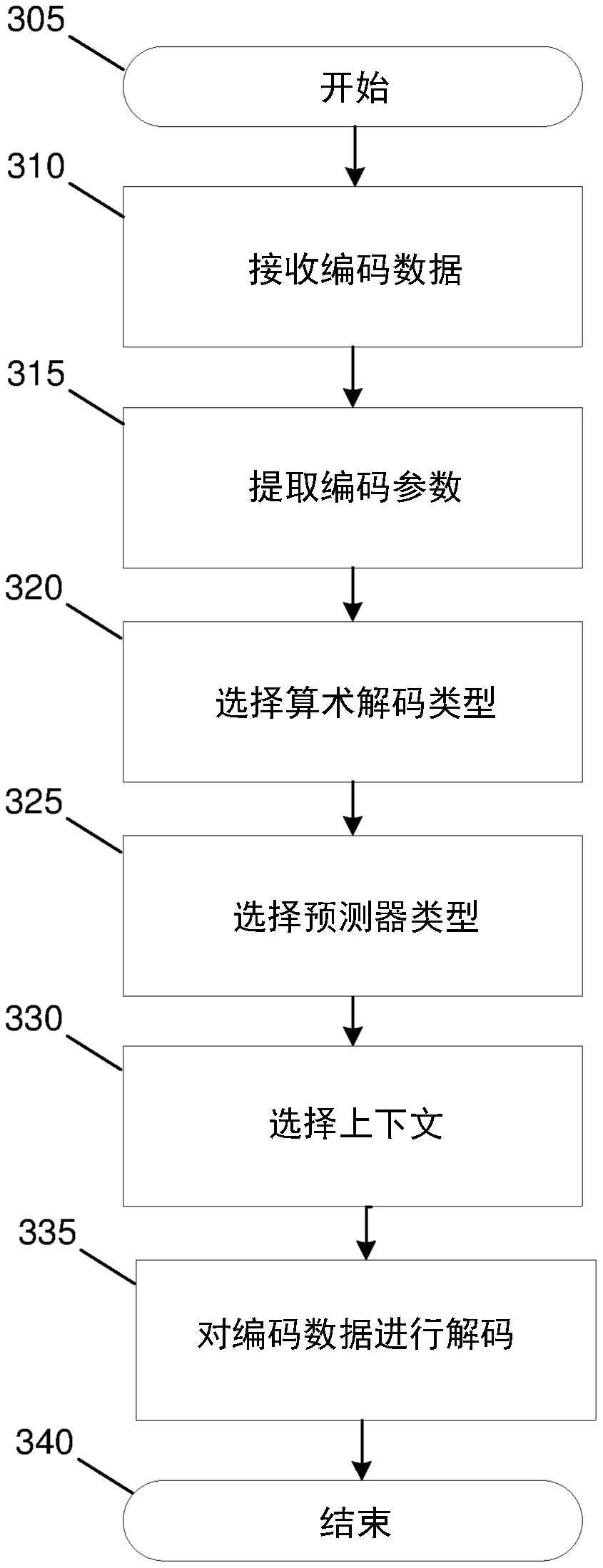
2、各种实施例涉及一种用于对mpeg-g编码数据进行解码的方法,包括:接收mpeg-g编码数据;从所述编码数据中提取编码参数;基于所提取的编码参数来选择算术编码类型;基于所提取的编码参数来选择预测器类型;基于所提取的编码参数来选择上下文;并且使用所选择的预测器和所选择的上下文对所述编码数据进行解码。编码参数的技术元素包括接收解码器以确定其解码过程所需的参数,并且特别地可以包括控制对各种替代解码算法的选择或配置的参数。编码数据可以特指算术编码数据。算术编码基于符号(例如,a、t、c、g)的出现概率将这些符号的序列映射到范围[0.0-1.0]内的区间。基于概率的编码的一个性质是:能够通过在编码的比特串中给不太可能出现的符号较多的比特并且给更可能出现的符号较少的比特来优化所需的比特量,即,使用概率估计来指导这个原理。概率能够随时间(即,在运行解码过程期间)变化。上下文自适应算术编码能够基于对不同情况(即,不同上下文)的识别来进一步优化概率(当使用词语上下文时,我们在算术编码的意义上表示它,即,算术编码上下文)。常规地,上下文由先前解码的符号的结果形成。例如,如果对于先前的碱基发现了一组低质量分数,则可以合理地假定:对于当前的阅读碱基,阅读仍然不是非常确定的,即,在基因组信息中它也将具有低质量分数。因此,可以将低分数值的概率设置为高,其中,高分数值指示关于当前碱基的高确定性。然而,根据本发明人,可以定义更多不同的上下文,这些上下文也能够考虑其他数据,例如,除了质量分数之外的其他量的解码值,如当前正被解码的染色体的基因组位置。
3、算术编码类型向解码器指定(如在传送的编码mpeg-g数据信号中存在的编码参数中传送的)生成编码数据的编码器使用了数据的各种可能的算术编码方式的类型。描述了各种实施例,其中,算术编码类型是二进制编码和多符号编码中的一项。在多符号编码中,定义了在未编码信号中会遇到的符号的字母表。例如,对于dna核酸碱基,这些符号可以包含针对肯定的阅读碱基的符号(例如,针对胸腺嘧啶的t)或者针对不肯定的阅读碱基的符号,并且对于质量分数,能够定义一组针对分数的量化值。在二进制算术编码中,作为预处理步骤,通过选择的二进制化方案将这n个字母符号变换成二进制数,例如,n个符号能够由一组递增的二进制一后跟一个零来表示,例如,t=0,c=10,g=110,a=1110。
4、本发明人还发现,在与更好的上下文的选择和传送一起或分开的情况下,还可以通过选择若干不同预测器类型中的一种预测器类型来进行优化,例如通过modeltype参数来进行优化,该modeltype参数指示正在使用的预测器是基于计数的类型还是机器学习模型类型中的一项(例如,特定的神经网络(正被传送的拓扑和/或优化权重)),以基于正在使用的任何上下文来预测各种符号的固定或不断变化的概率。这些内容能够用作针对神经网络的输入,或者选择若干替代神经网络中的一个神经网络,或者影响神经网络的性质。替代地,可以使用其他机器学习技术来预测概率,即,形成预测器模型或类型。因此,预测器类型能够指示主要类型(神经网络vs常规的基于计数的概率重新估计)以及具有更多细节的子类型(特别是对于神经网络)。
5、描述了各种实施例,其中,当所述预测器类型识别机器学习模型时,所述编码参数还包括所述机器学习模型的定义。通过传送定义机器学习模型的参数(例如,指定拓扑(如具有隐藏层的连接、针对连接的固定或初始权重等)的参数,编码器能够选择一个非常好的模型并将其传送给解码器,解码器然后能够在开始对传入的编码数据进行解码前配置该模型。编码数据信号中的参数也可以重复重置或重新配置该模型。
6、描述了各种实施例,其中,所提取的编码参数包括训练模式数据。训练模式是指模型将如何动态地调整自身以适应变化的数据(即,训练自身以适应如在编码数据中所使用的原始未编码数据的变化的概率),或者保持相对固定(例如,具有权重的神经网络,该权重由编码器针对整个数据集优化一次并且被传送到解码器以在整个解码期间使用)。例如,可以在前2000个符号上在外部处理环中训练神经网络,然后在对第2001个编码比特进行解码前替换新的最优权重。
7、描述了各种实施例,其中,所述训练模式数据包括初始化类型,所述初始化类型包括静态训练模式、半自适应训练模式和自适应训练模式中的一项。静态模式的典型示例可以是存在标准预定义模型的情况,该标准预定义模型潜在地能从一组标准模型中选择,由编码器和解码器使用,并且所选择的模型可以通过例如指定所选择的模型的模型号被传送到解码器。半自适应模型的示例可以是使用正被压缩的数据来训练模型的情况。在这种情况下,针对该特定数据集来优化权重。
8、描述了各种实施例,其中,所述训练模式数据包括训练算法定义、训练算法参数、训练频率和训练时期中的一项。训练频率是模型(在解码侧)应当更新的频率,例如,在每1000个符号之后应当更新。训练时期是机器学习的一个概念,它指定了机器学习算法处理整个训练数据集以更新模型的次数。
9、描述了各种实施例,其中,所提取的编码参数包括上下文数据。
10、描述了各种实施例,其中,所述上下文数据包括编码顺序、使用的额外上下文的数量、上下文类型和范围中的一项。
11、描述了各种实施例,其中,所述上下文数据包括范围标志。
12、描述了各种实施例,其中,所述上下文数据包括上下文描述符、上下文输出变量、上下文内部变量、上下文计算变量和上下文计算函数中的一项。
13、另外,各种实施例涉及一种用于对mpeg-g编码数据进行编码的方法,包括:接收要用于对数据进行编码的编码参数;基于所接收的编码参数来选择算术编码类型;基于所接收的编码参数来选择预测器类型;基于所接收的编码参数来选择训练模式;基于所接收的编码参数来选择上下文;基于所接收的编码参数来训练编码器;并且使用经训练的编码器对所述数据进行编码。
14、描述了各种实施例,其中,所述算术编码类型是二进制编码和多符号编码中的一项。
15、描述了各种实施例,其中,所述预测器类型是基于计数的类型或机器学习模型类型中的一项。
16、描述了各种实施例,其中,当所述预测器类型识别机器学习模型时,所述编码参数还包括所述机器学习模型的定义。
17、描述了各种实施例,其中,所提取的编码参数包括训练模式数据。
18、描述了各种实施例,其中,所述训练模式数据包括初始化类型,所述初始化类型包括静态训练模式、半自适应训练模式和自适应训练模式中的一项。
19、描述了各种实施例,其中,所述训练模式数据包括训练算法定义、训练算法参数、训练频率和训练时期中的一项。
20、描述了各种实施例,其中,所提取的编码参数包括上下文数据。
21、描述了各种实施例,其中,所述上下文数据包括编码顺序、使用的额外上下文的数量、上下文类型和范围中的一项。
22、描述了各种实施例,其中,所述上下文数据包括范围标志。
23、描述了各种实施例,其中,所述上下文数据包括上下文描述符、上下文输出变量、上下文内部变量、上下文计算变量和上下文计算函数中的一项。
24、另外,各种实施例涉及一种用于对mpeg-g编码数据进行解码的系统,包括:存储器;被耦合到所述存储器的处理器,其中,所述处理器还被配置为:接收mpeg-g编码数据;从所述编码数据中提取编码参数;基于所提取的编码参数来选择算术解码类型;基于所提取的编码参数来选择预测器类型;基于所提取的编码参数来选择上下文;并且使用所选择的预测器类型和所选择的上下文对所述编码数据进行解码。
25、描述了各种实施例,其中,所述算术编码类型是二进制编码和多符号编码中的一项。
26、描述了各种实施例,其中,所述预测器类型是基于计数的类型或机器学习模型类型中的一项。
27、描述了各种实施例,其中,当所述预测器类型识别机器学习模型时,所述编码参数还包括所述机器学习模型的定义。
28、描述了各种实施例,其中,所提取的编码参数包括训练模式数据。
29、描述了各种实施例,其中,所述训练模式数据包括初始化类型,所述初始化类型包括静态训练模式、半自适应训练模式和自适应训练模式中的一项。
30、描述了各种实施例,其中,所述训练模式数据包括训练算法定义、训练算法参数、训练频率和训练时期中的一项。
31、描述了各种实施例,其中,所提取的编码参数包括上下文数据。
32、描述了各种实施例,其中,所述上下文数据包括编码顺序、使用的额外上下文的数量、上下文类型和范围中的一项。
33、描述了各种实施例,其中,所述上下文数据包括范围标志。
34、描述了各种实施例,其中,所述上下文数据包括上下文描述符、上下文输出变量、上下文内部变量、上下文计算变量和上下文计算函数中的一项。
35、另外,各种实施例涉及一种用于对mpeg-g编码数据进行编码的系统,包括:存储器;被耦合到所述存储器的处理器,其中,所述处理器还被配置为:接收要用于对数据进行编码的编码参数;基于所接收的编码参数来选择算术编码类型;基于所接收的编码参数来选择预测器类型;基于所接收的编码参数来选择训练模式;基于所接收的编码参数来选择上下文;基于所接收的编码参数来训练编码器;并且使用经训练的编码器对所述数据进行编码。
36、描述了各种实施例,其中,所述算术编码类型是二进制编码和多符号编码中的一项。
37、描述了各种实施例,其中,所述预测器类型是基于计数的类型或机器学习模型类型中的一项。
38、描述了各种实施例,其中,当所述预测器类型识别机器学习模型时,所述编码参数还包括所述机器学习模型的定义。
39、描述了各种实施例,其中,所提取的编码参数包括训练模式数据。
40、描述了各种实施例,其中,所述训练模式数据包括初始化类型,所述初始化类型包括静态训练模式、半自适应训练模式和自适应训练模式中的一项。
41、描述了各种实施例,其中,所述训练模式数据包括训练算法定义、训练算法参数、训练频率和训练时期中的一项。
42、描述了各种实施例,其中,所提取的编码参数包括上下文数据。
43、描述了各种实施例,其中,所述上下文数据包括编码顺序、使用的额外上下文的数量、上下文类型和范围中的一项。
44、描述了各种实施例,其中,所述上下文数据包括范围标志。
45、描述了各种实施例,其中,所述上下文数据包括上下文描述符、上下文输出变量、上下文内部变量、上下文计算变量和上下文计算函数中的一项。
- 还没有人留言评论。精彩留言会获得点赞!