依据多组学数据建立的食管癌预测免疫治疗评效系统
本技术涉及食管癌的多组学数据预测免疫治疗评效系统和机器。本技术还涉及食管癌的多组学数据预测免疫治疗评效分类器以及训练分类器的方法。
背景技术:
1、食管鳞癌(esophageal squamous cell carcinoma,escc)是目前最常见、致死率最高的肿瘤之一。目前临床上广泛接受的晚期食管癌一线治疗方法是铂类试剂和氟嘧啶的联合治疗,紫杉烷类和伊立替康作为二线治疗药物也被证明有生存获益,一线治疗的患者反应率在2%-50%之间,治疗后总的中位生存期只有9-11个月。
2、由于目前食管癌靶向治疗的结果并不十分令人满意,许多研究把目光投向免疫治疗,特别是针对免疫检查点的阻断治疗(immune checkpoint blockade,icb)。pd-1抑制剂可以结合t细胞上的pd-1,pd-l1抑制剂可以结合肿瘤细胞上的pd-l1,它们都可以抑制pd-1和pd-l1的结合,从而增强肿瘤抗原特异性t细胞的增殖、激活和毒性作用,抑制肿瘤生长。
3、帕博利珠单抗(pembrolizumab)是最早进入临床研发的pd-1抑制剂,也是目前获批适应证最广的pd-1抑制剂。2018年,美国fda批准帕博利珠单抗治疗pd-l1阳性的复发性局部晚期或转移性胃癌/食管胃结合部腺癌;nccn指南(version1.2018)推荐帕博利珠单抗用于三线治疗pd-l1阳性的食管和食管胃结合部腺癌,对于微卫星高度不稳定(msi-h)/错配修复基因缺陷(dmmr)型患者,推荐二线治疗。keynote-028是第一个证明了pd-1抑制剂安全性和抗肿瘤活性的临床试验,试验评价了帕博利珠单抗在现有疗法无疗效的pd-l1阳性的晚期食管癌患者中应用的安全和有效性[1]。随后进行的2期临床试验keynote-180在胃食管连接部癌患者中评价了帕博利珠单抗作为三线治疗的有效性;3期临床试验keynote-181在晚期或转移性食管鳞癌或腺癌/siewert i型食管胃结合部腺癌患者的二线治疗中比较帕博利珠单抗与化疗方案的疗效,这项研究的初步结果在2019年胃肠癌研讨会(ascogi)口头报告中公布,该研究共入组628例患者,其中鳞癌401例,pd-l1阳性(cps≥10)的患者222例,结果显示,在pd-l1表达阳性(cps评分≥10)的患者中(n=222),帕博利珠单抗(keytruda)显著降低患者的死亡风险31%,帕博利珠单抗组患者在12个月时的总生存率也更有优势;对于鳞状细胞癌患者(n=401),keytruda为患者带来了具有临床意义的生存改善,但尚未达到研究预期设定的统计学显著性。在所有患者中,keytruda虽然与化疗相比对os有所改善,但是未能达到统计显著标准。另外有多项帕博利珠单抗作为一线二线治疗食管腺癌的2期3期临床试验也在进行中,目前有结果的keynote-061试验结果显示帕博利珠单抗作为pd-l1 cps≥1的晚期胃癌或胃食管交界癌的二线治疗,与紫杉醇相比并没有显著的生存获益[2]。
4、纳武利尤单抗(nivolumab)也是pd-1抑制剂,fda于2015年批准纳武利尤单抗治疗转移性黑色素瘤,在非小细胞肺癌和肾细胞癌中纳武利尤单抗也显示出治疗活性。日本的一项2期临床试验(clinicaltrials.jp,number ono-4538-07/japiccti-no.142422)初步结果显示,在化疗治疗耐药的晚期食管鳞癌患者中,纳武利尤单抗的安全性和有效性得到了证实,试验没有区分患者的pd-l1阳性状态,进一步生存获益的结果还在研究中。对于食管腺癌,checkmate-032 1/2期临床试验证实了纳武利尤单抗的安全性和有效性[3],在日本患者中进行的3期临床试验证明了纳武利尤单抗的生存获益[4]。
5、度伐单抗(durvalumab)是pd-l1的抑制剂,在韩国进行的一项度伐单抗与放化疗联用治疗晚期食管鳞癌患者的2期临床试验正在研究中(clinicaltrials.gov id:nct03377400)。
6、免疫疗法的联用,如帕博利珠单抗和抗肿瘤疫苗crs207联用于胃食管腺癌的2期临床试验(clinicaltrials.gov id:nct03122548);免疫疗法与靶向治疗的联用,如帕博利珠单抗和曲妥珠单抗联用治疗食管癌等多种癌症的1/2期临床试验均未显示出好的临床治疗效果;不同免疫检查点通路阻断的联用,如纳武利尤单抗和伊普利单抗联用的安全性和有效性在晚期食管腺癌患者中的1/2期临床试验中得到了证实[3]。
7、针对免疫检查点的阻断治疗显示出一定的疗效,但仍旧存在许多悬而未决的问题。一是还不清楚究竟哪些患者能从免疫检查点的阻断治疗中获益,目前还没有确切的预测性生物标志物被发现,二是免疫疗法的联用显示出不确定的疗效。
技术实现思路
1、为了解决本领域存在的技术问题,本技术提供了以下所述的技术方案。
2、1.一种计算机实现的方法,包括:
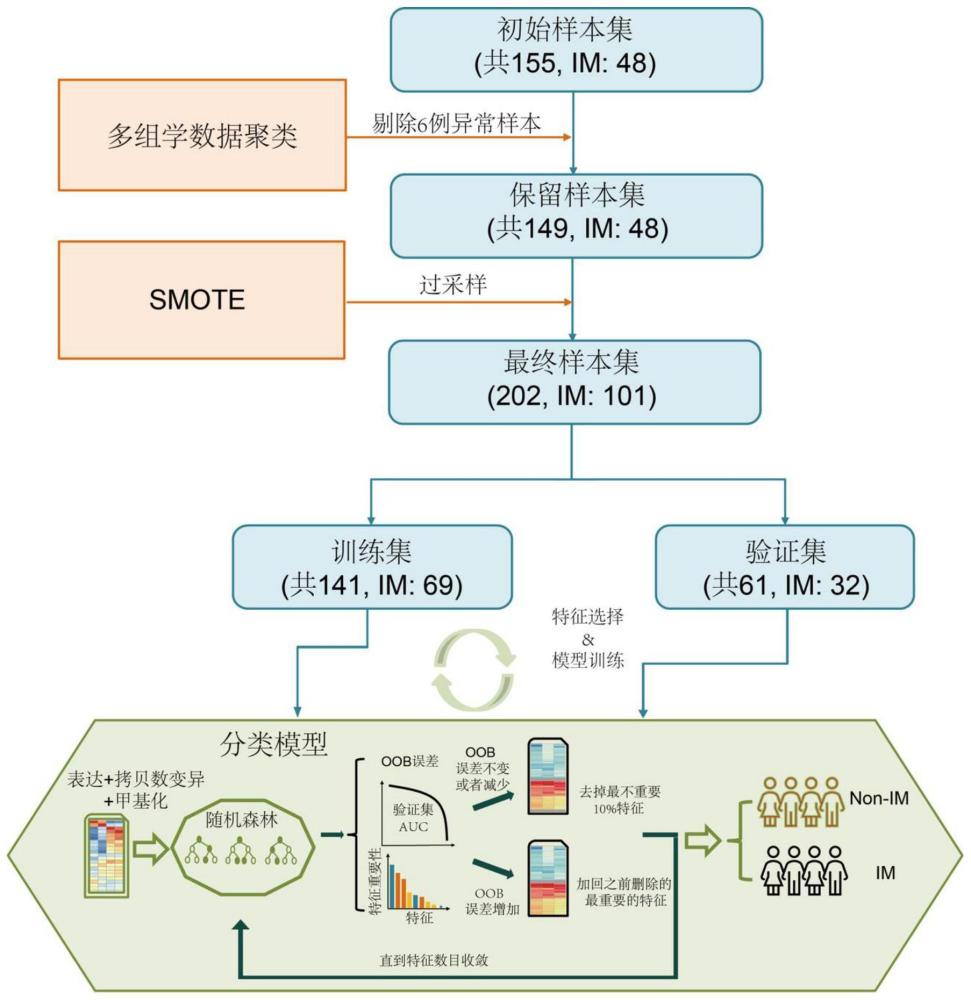
3、对来自接受过免疫检查点的阻断治疗的食管癌患者的初始样本集进行多组学数据的聚类分析,例如层次聚类(hierarchical clustering)分析,进行初始特征选择和样本集过滤,得到初始特征和保留样本集;
4、对保留样本集进行过采样得到最终样本集,
5、将最终样本集分为训练集和验证集,并使用训练集和验证集对随机森林模型进行训练,采用迭代更新进行分类特征选择和分类模型构建,直到特征数目收敛,
6、在所述迭代过程中得到的特征集中,选择在验证集上具有最低袋外误差和最优受试者操作特征曲线下面积(auroc)的特征集作为最终特征集并构建经训练的机器学习分类器;
7、向所述经训练的机器学习分类器输入非训练受试者的多组学数据,
8、使用经训练的机器学习分类器,生成非训练受试者对食管癌的免疫检查点的阻断治疗的反应性分类,其中所述反应性分类预测非训练受试者对所述治疗的反应性;以及
9、使用图形化用户界面,报告非训练受试者对食管癌的免疫检查点的阻断治疗的反应性分类,
10、其中所述多组学数据包括表达谱rna测序、表观组学甲基化测序和基因组学外显子测序数据,
11、优选地,所述免疫检查点的阻断治疗为抗pd-1抗体或抗pd-l1抗体治疗。
12、2.项目1所述的方法,其中使用smote技术进行过采样,使得最终样本集中阳性样本和阴性样本比例为1:1。
13、3.项目1所述的方法,其中所述训练集和验证集中样本的比例为5:5至9:1,优选7:3。
14、4.项目1所述的方法,其中所述随机森林模型的训练包括特征选择和模型建立,其包括如下步骤:
15、a)使用所有初始特征构建随机森林模型;
16、b)计算模型中每个特征的重要性得分,并按降序排列;
17、c)删除最不重要的特征(4或5个特征,约占总特征的10%),得到一个新的特征集;
18、d)使用新的特征集重新构建一个新的随机森林模型;
19、e)比较计算新模型与前一个模型的袋外误差,其中,如果该值增加,则将之前删除的贡献最大的特征添加回来,如袋外误差减少,则将继续删除4-5个特征;
20、f)重复步骤d)和e),直到特征数量收敛,其中记录所有可能的特征集和迭代过程中的相应模型,以及在验证集上的受试者操作特征曲线下面积(auroc)值;
21、g)在上述步骤得到的特征集中,选择在验证集上具有最低袋外误差和最优受试者操作特征曲线下面积(auroc)的特征集作为最终特征集并构建分类器。
22、5.根据项目1-4任一项所述的方法,其中所述初始特征包括12个拷贝数变异特征:11q13.3、3q28、8p23.2、11q22.2、2q31.2、7p11.2、3p14.2、3p11.1、5p15.33、9p21.3、18q23和13q22;26个mrna表达特征:ano1,ccl4,ccnd1,cdkn2a,cdkn2b,cst7,cttn,cul3,cxcl10,cxcl9,havcr2,ifng,keap1,nfe2l2,nkg7,oraov1,pdcd1,sox2,tigit,tp63,i1,i2,c1,c2,e1,和e2;和10个甲基化特征:dmr_rab40a,dmr_c16orf78,dmr_kifap3,dmr_ccr8,dmr_wt1,dmr_vipr2,dmr_shisa9,dmr_foxb2,dmr_fgf3和dmr_sall153。
23、6.一种用于实施食管癌预测免疫治疗评效的计算机系统,其包括:
24、一个或多个微处理器,
25、一个或多个用于存储经训练的机器学习分类器和非训练受试者的多组学数据的存储器,其中所述经训练的机器学习分类器为项目1-5任一项所述的经训练的机器学习分类器,并且所述经训练的机器学习分类器预测所述非训练受试者对食管癌的免疫检查点的阻断治疗的反应性分类;
26、一个或多个存储指令的存储器,所述指令由所述一个或多个微处理器执行时,引起计算机系统使用所述经训练的机器学习分类器,生成非训练受试者的检查点抑制作用反应性分类,并且使用图形化用户界面,报告非训练受试者的免疫检查点的阻断治疗的反应性分类,其中所述免疫检查点的阻断治疗的反应性分类预测非训练受试者对免疫检查点的阻断治疗的反应性;
27、其中所述多组学数据包括表达谱rna测序、表观组学甲基化测序和基因组学外显子测序数据,
28、优选地,所述免疫检查点的阻断治疗为抗pd-1抗体或抗pd-l1抗体治疗。
29、7.一种训练分类器的方法,其包括:
30、对来自接受过免疫检查点的阻断治疗的食管癌患者的初始样本集进行多组学数据的聚类分析,例如层次聚类(hierarchical clustering)分析,进行初始特征选择和样本集过滤,得到初始特征和保留样本集;
31、对保留样本集进行过采样得到最终样本集,
32、将最终样本集分为训练集和验证集,并使用训练集和验证集对随机森林模型进行训练,采用迭代更新进行分类特征选择和分类模型构建,直到特征数目收敛,
33、在所述迭代过程中得到的特征集中,选择在验证集上具有最低袋外误差和最优auroc的特征集作为最终特征集并构建经训练的机器学习分类器。
34、8.项目7所述的方法,其中使用smote技术进行过采样,使得最终样本集中阳性样本和阴性样本比例为1:1。
35、9.项目7所述的方法,其中所述训练集和验证集中样本的比例为5:5至9:1,优选7:3。
36、10.项目7所述的方法,其中所述随机森林模型的训练包括特征选择和模型建立,其包括如下步骤:
37、a)使用所有初始特征构建随机森林模型;
38、b)计算模型中每个特征的重要性得分,并按降序排列;
39、c)删除最不重要的特征(4或5个特征,约占总特征的10%),得到一个新的特征集;
40、d)使用新的特征集重新构建一个新的随机森林模型;
41、e)比较计算新模型与前一个模型的袋外误差,其中,如果该值增加,则将之前删除的贡献最大的特征添加回来,如袋外误差减少,则将继续删除4-5个特征;
42、f)重复步骤d)和e),直到特征数量收敛,其中记录所有可能的特征集和迭代过程中的相应模型,以及在验证集上的受试者操作特征曲线下面积(auroc)值;
43、g)在上述步骤得到的特征集中,选择在验证集上具有最低袋外误差和最优受试者操作特征曲线下面积(auroc)的特征集作为最终特征集并构建分类器。
44、11.根据项目7-10任一项所述的方法,其中所述初始特征包括12个拷贝数变异特征:11q13.3、3q28、8p23.2、11q22.2、2q31.2、7p11.2、3p14.2、3p11.1、5p15.33、9p21.3、18q23和13q22;26个mrna表达特征:ano1,ccl4,ccnd1,cdkn2a,cdkn2b,cst7,cttn,cul3,cxcl10,cxcl9,havcr2,ifng,keap1,nfe2l2,nkg7,oraov1,pdcd1,sox2,tigit,tp63,i1,i2,c1,c2,e1,和e2;和10个甲基化特征:dmr_rab40a,dmr_c16orf78,dmr_kifap3,dmr_ccr8,dmr_wt1,dmr_vipr2,dmr_shisa9,dmr_foxb2,dmr_fgf3和dmr_sall153。
45、与基于单基因组学构建的分类器相比,本技术基于多组学数据构建的分类器对于食管癌预测免疫治疗(如抗pd-1抗体治疗)的效果评价更准确(基于auroc值的高低进行比较)。本技术的实验结果表明,本技术的分类器可用于在临床实践中识别食管癌患者的免疫检查点的阻断治疗(如抗pd-1疗法)的应答者/获益者。
- 还没有人留言评论。精彩留言会获得点赞!