一种基于强化学习的半自主挖掘系统和方法与流程
本发明涉及液压挖掘机的自动控制领域,具体涉及一种基于强化学习的半自主挖掘控制系统和方法。
背景技术:
挖掘机在建筑、地震抢险救援施工等领域有着重要的地位,被广泛应用于各类机械化施工中。对于人类不便于直接进入或者长时间暴露的工作环境来说,自主挖掘是不可或缺的得力助手,这也促使挖掘机向挖掘智能化、自动化方向发展。液压挖掘机工作时,都是靠操作员不停地调整左右手柄,做好动臂、斗杆和铲斗的配合,需要熟练的挖机操作员才能达到较高的效率。且挖掘工作重复性高,工作量大,操作费时费力,操作员易疲劳。
现有技术中,在201610071322.4号专利申请中,公开了一种基于循迹模式的挖掘机及其自动控制方法,采用主控制器采集整个操作循环中发动机、电控柱塞泵和电控多路阀工作参数,并基于这些工作参数自动复现机手示范性操作。但该方法需重复操作设定好的同一个动作,无法适应挖掘作业面的变化。在201010581065.1号专利申请中,公开了一种挖掘机工作装置的自动控制系统及方法,利用激光定位仪、角度传感器、压力传感器、转速传感器,并创造性地使用了bp神经网络方法,实现了一种挖掘机自动挖掘系统。但该方法采用bp神经网络方法需要重复多次地采集操作员的数据,训练出的模型受操作员挖掘水平的限制,无法达到最优。
技术实现要素:
本发明所要解决的技术问题(发明目的)
(1)解决对熟练操作员的依赖以及操作员工作强度大的问题;
(2)解决传统自动控制方法重复操作设定好的同一个动作,无法适应挖掘作业面的变化的问题;
(3)解决仅采用bp神经网络方法需要重复多次地采集操作员的数据,训练出的模型受操作员挖掘水平的限制,无法达到最优化的问题。
本发明解决上述技术问题的技术方案是:
一种基于强化学习的半自主挖掘系统,其特征是,包括设置在挖掘机上的激光雷达、动臂油缸长度传感器、斗杆油缸长度传感器、铲斗油缸长度传感器、动臂倾角传感器、斗杆倾角传感器、铲斗倾角传感器、铲斗重量传感器、动臂油缸压力传感器、斗杆油缸压力传感器、铲斗油缸压力传感器、动臂油缸电液控制阀、斗杆油缸电液控制阀、铲斗油缸电液控制阀和可编程控制器;
动臂油缸长度传感器、斗杆油缸长度传感器、铲斗油缸长度传感器分别对应地安装在动臂、斗杆和铲斗的油缸上,对应采集动臂、斗杆和铲斗的油缸伸缩长度;
动臂油缸压力传感器、斗杆油缸压力传感器、铲斗油缸压力传感器分别对应地安装在动臂、斗杆和铲斗的油缸上,对应采集动臂、斗杆和铲斗的油缸压力;
动臂倾角传感器、斗杆倾角传感器、铲斗倾角传感器分别对应地安装在动臂、斗杆和铲斗上,对应采集动臂、斗杆和铲斗的倾角;
激光雷达安装在动臂下方,用于获取动臂与挖掘物的距离;
铲斗重量传感器安装在铲斗上,用于采集铲斗中挖掘物料质量;
可编程控制器用于接收上述各个传感器采集的信号,并向各个电液控制阀发送控制信号控制动臂、斗杆和铲斗的动作。
进一步地,可编程控制器内采用强化学习和神经网络结合的方法训练得到挖掘过程训练模型,根据挖掘过程训练模型控制自动执行挖掘任务。
一种基于强化学习的半自主挖掘方法,其特征是,包括以下步骤:
步骤1:强化学习感知:在强化学习决策时间点,获取挖掘机当前状态st,
步骤2:强化学习决策:对每一单步时间,检测当前挖掘机状态st和bp神经网络的输出q(st,ai),根据贪婪策略选择奖赏值最高的决策行为a1执行;
步骤3:q值更新:执行决策行为a1,若过程中没有障碍物,得到立即奖赏值r,同时观测下一状态;若过程中有障碍物,则选取其他决策行为ai重复步骤1至步骤2;
获取挖掘机下一状态st+1,将bp神经网络的输出q(st,a1)值更新为q’(st,a1);
步骤4:判断挖掘动作是否完成,完成后根据物料质量给予奖赏值;若未完成挖掘,则重复步骤3至步骤4直到挖掘动作完成;
步骤5:利用误差信号δ=q’(st,a1)-q(st,a1),更新bp神经网络的权值和阈值,使bp神经网络实际输出逼近或等于理想的输出,直到bp神经网络完全收敛,训练完成,得到最终挖掘过程训练模型。
运行训练好的挖掘过程训练模型,挖机自动执行挖掘操作。
进一步地,步骤1中,挖掘机当前状态st包括:掘机的动臂、斗杆和铲斗与挖掘物的相对位置e’,各长度传感器分别获取动臂、斗杆和铲斗的油缸长度数据l,各倾角传感器分别获取动臂、斗杆和铲斗的相对倾角数据φ,各压力传感器分别获取动臂油缸、斗杆油缸和铲斗油缸的压力数据p,动臂、斗杆和铲斗油缸的伸缩加速度数据a,动臂、斗杆和铲斗关节的角加速度数据a’,动臂、斗杆和铲斗油缸的电液控制阀控制信号u。
进一步地,动臂、斗杆和铲斗油缸的伸缩加速度数据a通过各油缸长度数据二次差分计算而得。
进一步地,以动臂关节点为坐标原点o,根据动臂与挖掘物距离e、角度信息φ、激光雷达与原点的距离、动臂与斗杆的长度计算出动臂、斗杆和铲斗与挖掘物的相对位置e’。
进一步地,步骤2中,为每种决策行为初始化q(st,ai)值为全0的矩阵。
进一步地,奖赏值设置的过程为:
在挖掘过程中,单步时间内,根据挖掘机状态采取决策行为后,奖赏值为r1=-1,训练目标是使挖掘机以最短时间完成一次挖掘;
在完成一次挖掘后,根据铲斗中挖掘物料质量产生奖赏值r2;
若执行决策行为后发生碰撞,则给与奖赏值r3=-100,同时终止本次训练,自动将挖掘机复位到挖掘起始位置。
进一步地,更新的q’(st,a1)值为:q’(st,a1)=(1-α)*q(st,a1)+α[r+γ*maxq(st+1,ai)],其中α为学习率,γ为折扣系数,q(st+1,ai)为bp神经网络的输出q值矩阵在状态st+1下、决策行为ai时的矩阵元素。
进一步地,步骤4中,通过铲斗内物料质量判断挖掘动作是否完成。
采用本发明所涉及的技术方案具有以下有益效果:
为了减少对熟练挖机操作员的依赖以及减轻操作员的劳动强度,本发明提供一种基于强化学习的半自主挖掘系统和方法,使用了强化学习和神经网络相结合的方法,通过训练好的可编程控制器,实现对液压挖掘机动臂、斗杆和铲斗的自动控制,操作员可以只将挖掘机定位到挖掘地点,由挖掘机自主完成挖掘过程。从而能够降低操作员的工作量,提高挖掘作业的工作效率。
附图说明
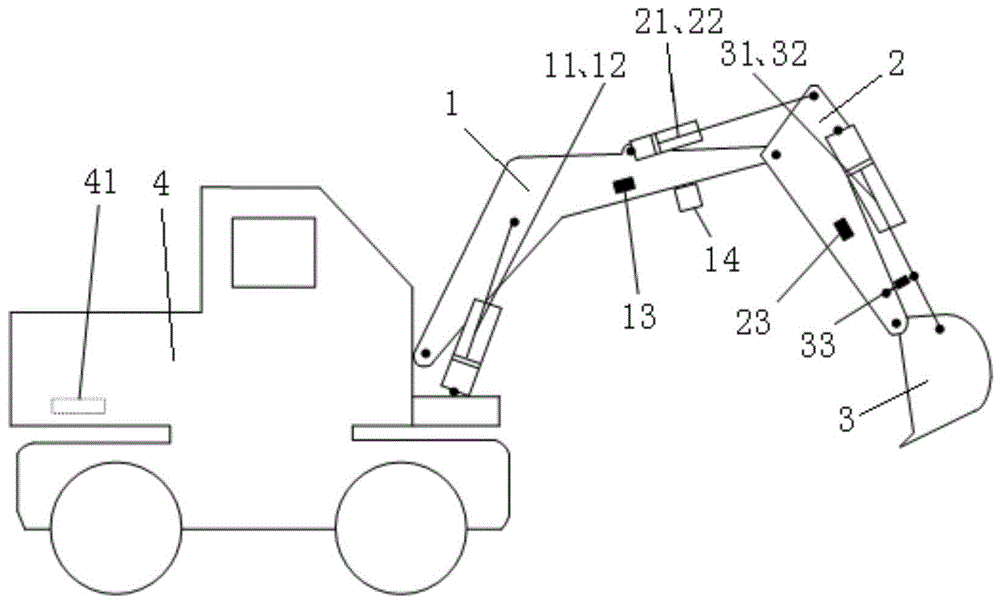
图1为本发明各器件的安装示意图;
图2为本发明工作流程图。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
结合图1,本发明的系统包括激光雷达14、动臂油缸长度传感器11、斗杆油缸长度传感器21、铲斗油缸长度传感器31、动臂倾角传感器13、斗杆倾角传感器23、铲斗倾角传感器33、铲斗重量传感器34、动臂油缸压力传感器12、斗杆油缸压力传感器22、铲斗油缸压力传感器32、动臂油缸电液控制阀、斗杆油缸电液控制阀、铲斗油缸电液控制阀、can总线和可编程控制器41。
动臂油缸长度传感器11、斗杆油缸长度传感器21、铲斗油缸长度传感器31分别对应地安装在动臂1、斗杆2和铲斗3的油缸上。动臂油缸压力传感器12、斗杆油缸压力传感器22、铲斗油缸压力传感器32分别对应地安装在动臂1、斗杆2和铲斗3的油缸上,动臂倾角传感器13、斗杆倾角传感器23、铲斗倾角传感器33分别对应地安装在动臂1、斗杆2和铲斗3上;激光雷达14安装在动臂1下方,铲斗重量传感器34安装在铲斗3上。可编程控制器41安装在车身4后侧,用于接收各个传感器信号和向各个电液控制阀发送控制信号。可编程控制器中的软件程序包括分别控制动臂、斗杆和铲斗的控制模块,以及分别控制各个电液控制阀的电液控制模块。
系统采用q学习方法实现强化学习的半自主挖掘。在训练过程中,系统感知环境状态,按照一定的原则选择行为,系统执行该动作;环境由于执行该动作而使状态发生变化,并计算得到执行该行为后的奖赏值;系统根据奖励函数和系统当前状态选择下一动作,选择的原则是使受到奖励的概率增加。所选动作不仅影响下一状态得到的立即奖赏值,同时影响累积奖赏。
结合图2,本发明基于强化学习方法的半自主挖掘详细步骤如下:
步骤1:强化学习感知:在决策时间点,获取当前的挖掘机环境状态s0;
挖掘机状态具体的获取方法为:操作员将挖掘机停放在指定挖掘区域,利用激光雷达获取动臂与挖掘物的距离e,各长度传感器分别获取动臂、斗杆和铲斗的油缸长度数据l,各倾角传感器分别获取动臂、斗杆和铲斗的相对倾角数据φ,各压力传感器分别获取动臂油缸、斗杆油缸和铲斗油缸的压力数据p,can总线传输动臂、斗杆和铲斗油缸的电液控制阀控制信号u;
对传感器及其他元件设备获取的数据在可编程控制器上进行处理。对各油缸长度数据l进行二次差分计算,可得到动臂、斗杆和铲斗油缸的伸缩加速度数据a,再通过余弦定理计算出动臂、斗杆和铲斗关节的角加速度数据a’。以动臂关节点为坐标原点o,根据动臂与挖掘物距离e、角度信息φ、激光雷达与原点的距离、动臂与斗杆的长度可以计算出动臂、斗杆和铲斗与挖掘物的相对位置e’;
步骤2:强化学习决策:
在强化学习决策时间点,采样记录挖掘机动臂、斗杆和铲斗与挖掘物的相对位置e’、油缸压力信息p、油缸长度信息l、相对倾角信息φ、伸缩加速度a、角加速度a’、电液控制阀控制信号u;
对每一单步时间,决策行为ai时的神经网络的输出q(st,ai),选择奖赏值最高的行为(例如为a1),并分别交由动臂、斗杆和铲斗液压缸电液控制阀执行;
挖掘机实现挖掘动作是依靠动臂、斗杆和铲斗油缸的伸缩动作的随机组合,设定动臂、斗杆和铲斗油缸每次伸缩距离为固定值,分别为l,m,n。例如:动作a1为动臂伸长l、斗杆伸长m、铲斗伸长n;a2为动臂伸长l、斗杆缩短m、铲斗缩短n;a3为动臂不动、铲斗伸长m和斗杆伸长n。因此,挖掘机在挖掘过程中单步时间内运动所产生的行为可分类为33种。
强化学习强调,在不同的状态下,不同的行为对应着不同的回报值。首先为每种行为初始化q值为全0的矩阵。对每一单步时间,检测当前环境状态st和决策行为ai时的神经网络的输出q(st,ai),根据贪婪策略选择对应q值最大的决策行为例如为a1,并分别交由动臂、斗杆和铲斗液压缸电液控制阀执行,控制信号记为u。
步骤3:q值更新:
执行该决策行为a1,若过程中没有障碍物,则观测下一状态st+1,同时得到立即奖赏值r;若过程中有障碍物,则选取其他决策行为ai执行重复步骤1至步骤2;
观察挖掘机下一状态s1,更新q(st,a1)值,更新结果为q’(st,a1)。
步骤4:判断挖掘动作是否完成,完成后根据物料质量给予奖赏值;若未完成挖掘,则重复步骤3至步骤4;
步骤5:利用误差信号δ=q’(st,a1)-q(st,a1),更新bp神经网络的权值和阈值,使bp神经网络实际输出逼近或等于理想的输出;
步骤6:重复步骤1到步骤5实现重复挖掘,直到神经网络完全收敛,训练完成,得到最终挖掘过程训练模型,可用于半自主挖掘作业;
操作员将挖掘机定位到挖掘地点,运行训练好的可编程控制器,挖机自动执行挖掘操作。
奖赏值设置:在挖掘过程中,单步时间内,根据环境状态采取动作ai后,奖赏值为r1=-1,训练目标是使挖机臂以最短时间完成一次挖掘;在完成一次挖掘后,根据铲斗中挖掘物料质量产生回报r2;若执行动作后发生碰撞,则给与奖励值r3=-100,同时终止本次训练,自动将机械臂复位到挖掘起始位置。
具体地,q’(st,a1)=(1-α)*q(st,a1)+α[r+γ*maxq(st+1,ai)],其中α为学习率,γ为折扣系数,q(st+1,ai)为bp神经网络的输出q值矩阵在状态st+1下、决策行为ai时的矩阵元素。
具体地,可通过铲斗内物料质量判断挖掘动作是否完成。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!