使用从2.5D视觉数据预测的域不变3D表示的机器人操纵的制作方法
背景技术:
已经提出了机器人控制的各种基于机器学习的方法。这些方法中的一些训练可以用于生成在控制机器人中利用的一个或多个预测的机器学习模型(例如,深度神经网络模型),并且使用仅基于来自真实世界物理机器人的数据的训练数据来训练机器学习模型。然而,这些和/或其他方法可能具有一个或多个缺点。例如,生成基于来自真实世界物理机器人的数据的训练数据需要在生成用于训练数据的数据时大量使用一个或多个物理机器人。这可能很耗时(例如,实际上导航大量路径需要大量时间),可能消耗大量资源(例如,操作机器人所需的电力),可能导致正被利用的机器人的磨损,和/或可能需要非常多的人工干预。
鉴于这些和/或其他考虑,已经提出了使用机器人模拟器来生成模拟机器人数据,其中该模拟机器人数据可以在生成可以在机器学习模型的训练中利用的模拟训练数据中被利用。然而,通常有在真实机器人和真实环境与由机器人模拟器模拟的模拟机器人和/或模拟环境之间存在的有意义的“现实差距”。这可能导致生成没有准确反映真实环境中会发生的情况的模拟训练数据。这可能影响在这样的模拟训练数据上训练的机器学习模型的性能,和/或可能需要在训练中也利用大量的真实世界训练数据以帮助缓解现实差距。
技术实现要素:
本文公开的实施方式涉及训练可以用于处理对象的单视图二维半(2.5d)观察的点云预测模型(诸如神经网络模型的机器学习模型)以生成对象的域不变三维(3d)表示(例如,对象的3d点云)。各种实施方式还涉及利用域不变3d表示来(例如,至少部分在模拟中)训练使用要被操纵的模拟对象的域不变3d表示作为训练期间机器人操纵策略模型的输入的至少一部分的机器人操纵策略模型(例如,评价网络或其他策略模型)。各种实施方式附加地或可替代地涉及基于通过利用机器人操纵策略模型处理所生成的域不变3d表示而生成的输出来在控制机器人中利用经训练的机器人操纵策略模型。
基于使用经训练的形状预测网络(例如,点云预测网络或其他3d形状预测网络)处理由机器人的相机捕捉的2.5d观察来生成域不变3d表示。2.5d观察可以是包括一个或多个颜色通道(例如,红色、绿色和蓝色通道)和深度通道的图像。换句话说,图像的每个像素可以具有深度通道以及一个或多个颜色通道。相机可以是例如包括捕捉视觉数据的一个或多个传感器的rgb-d相机,其中该视觉数据共同地(并且可选地在处理之后)定义具有多个像素的图像,并且对于像素中的每一个共同地定义深度通道以及一个或多个附加通道(例如,红色、绿色和蓝色通道)。可以利用各种类型的rgb-d相机,包括无源rgb-d相机和有源rgb-d相机(例如,包括散斑投影仪或利用光源和飞行时间的相机)。如本文所述,在生成域不变3d表示中利用的每个2.5d图像可以是单视图2.5d图像。
可以通过利用模拟数据训练形状预测模型和/或机器人操纵策略来实现各种效率。例如,可以从模拟有效地获得在训练一个或两个模型中利用的地面真值数据。此外,利用域不变3d表示作为机器人操纵策略模型的输入可以使得网络能够主要(或完全)基于模拟训练数据进行训练,同时当在真实世界机器人上利用机器人操纵策略模型时缓解现实差距。例如,作为对象的3d点云的域不变3d表示描述了当模拟时可以具有最小现实差距/没有现实差距的对象的3d形状。这样的3d点云对于纹理或环境改变是不变的,这在模拟时可能具有显著的现实差距。此外,域不变3d表示可以是紧凑的(在数据方面),同时在语义上可解释并且可直接应用于对象操纵。这可以使得能够使用机器人操纵策略模型来有效处理这样的表示,同时实现高精度和/或鲁棒性。
此外,可以在框架(诸如捕捉2.5d观察(用于生成3d表示)的相机的框架至机器人末端效应器的框架)之间有效地变换域不变3d表示。如本文所述,可以可选地训练机器人操纵策略以在生成引起成功操纵(例如,抓取)的对应的机器人末端效应器姿势(在生成经变换的域不变3d表示中使用)的概率(或其他值)中处理经变换的域不变3d表示(并且可选地仅经变换的表示)。由于域不变3d表示是紧凑的(在数据方面),因此这样的处理在计算上可以是有效的和/或表示策略的(多个)模型(例如,(多个)神经网络模型)可以是紧凑的(在数据方面)。例如,处理域不变3d表示可以比处理(多个)完整的rgb图像更有效。此外,例如,处理经变换的域不变3d表示而不处理用于生成经变换的域不变3d表示的末端效应器姿势可以比处理域不变3d表示和末端效应器姿势两者更有效。此外,域不变3d表示的纹理和环境不变性使得其能够被有效地应用于各种纹理对象和/或各种环境的机器人操纵策略模型。
对象的域不变3d表示可以是对象的完整3d点云。可以利用大量的模拟训练数据和少量(或没有)真实世界训练数据来训练形状预测模型。例如,可以利用模拟中的50,000或更多(例如,60,000、70,000)个事件,而可以利用真实世界中的少于一千(例如,少于600,少于500)个事件。被处理以生成域不变3d表示的对象的2.5d观察可以是rgb-d(其中d是深度)图像。在各种实施方式中,附加的对象遮罩(mask)通道(除了rgb-d通道之外)也可以用作形状预测模型的输入以例如使得能够处理多个对象存在于对象的2.5d观察中的情况。可以基于利用诸如mask-rcnn网络的对象检测网络处理对象的2.5d观察(例如,至少其2d部分)来生成遮罩。例如,假设目标对象是苹果,并且2.5d图像包括苹果和香蕉。对象检测网络可以用于确定与苹果相对应的2.5d图像的像素,以及被生成作为通道中的那些像素具有指示目标对象的值的附加通道的附加遮罩存在于对应像素中。
在一些实施方式中,机器人操纵策略模型是评价预测网络,其中该评价预测网络可以用于基于域不变3d表示和候选末端效应器姿势来生成候选末端效应器姿势的操纵结果预测。例如,在操纵是抓取的地方,评价抓取预测网络可以用于基于(末端效应器的)候选抓取姿势和对象的域不变3d表示来预测候选抓取姿势将成功的概率。例如,可以将作为3d点云的域不变3d表示变换为相对于候选抓取姿势的框架。然后可以使用评价抓取预测网络来处理经变换的3d点云,以生成候选抓取姿势将成功的概率。可以利用评价抓取预测网络来考虑各种候选抓取姿势,并且选择最高概率的候选抓取姿势用于尝试抓取。在其他实施方式中,机器人操纵策略模型可以用于其他机器人任务,诸如例如推动对象、拉动对象等。在一些实施方式中,可以使用机器人操纵策略来处理非变换的域不变3d表示和候选末端效应器姿势,以生成操纵结果预测。换句话说,在那些实施方式中,非变换的域不变3d表示和候选末端效应器姿势两者都可以被应用作为输入,而不是经变换的域不变3d表示。此外,在一些实施方式中,代替评价预测网络或除了评价预测网络之外,机器人操纵策略可以包括动作预测网络。例如,动作预测网络可以用于处理非变换的域不变3d表示以生成指示机器人任务的动作预测的输出。例如,输出可以指示(直接地或间接地)末端效应器姿势。
如上所述,在各种实施方式中,可以可选地将域不变3d表示变换为被考虑的末端效应器姿势的框架。例如,可以通过使用经训练的形状预测模型处理2.5d图像(并且可选地,遮罩)来生成初始的域不变3d表示。然后可以将初始的域不变3d表示变换为候选末端效应器姿势的框架。然后可以使用机器人操纵策略模型来处理经变换的域不变3d表示,以例如利用候选末端效应器姿势来生成操纵成功的预测。因此,在那些各种实施方式中,可以使用机器人操纵策略来处理经变换的域不变3d表示,而不使用机器人操纵策略来直接处理候选末端效应器姿势。更确切地说,候选末端效应器姿势由被变换为候选末端效应器姿势的框架的经变换的域不变3d表示反映。使用经变换的域不变3d表示而不是非变换的初始的域不变3d表示和候选末端效应器姿势的单独表示的实施方式在推断期间可以更有效地训练和/或可以更鲁棒和/或精确。
提供以上描述作为本公开的一些实施方式的概述。那些实施方式的进一步描述和其他实施方式在下面更详细地描述。
附图说明
图1示出了可以实施本文公开的实施方式的示例环境。
图2示出了使用经训练的点云预测网络并基于由机器人捕捉的rgb-d图像来生成预测3d点云的示例。图2还示出了在控制机器人中使用预测3d点云的示例。
图3a和图3b示出了使用模拟数据和真实世界数据来训练点云预测网络的示例方法的流程图。
图4示出了使用预测3d点云来训练评价网络的示例方法的流程图。
图5示出了在控制机器人中使用经训练的评价网络和预测3d点云的示例方法的流程图。
图6示意性地描绘了机器人的示例架构。
图7示意性地描绘了计算机系统的示例架构。
具体实施方式
本文公开的一些实施方式涉及训练可以用于处理对象的单视图二维半(2.5d)观察的点云预测网络(诸如神经网络模型的机器学习模型)以生成对象的域不变三维(3d)表示(例如,对象的3d点云)。在那些实施方式中的一些实施方式中,在训练点云预测网络中利用自我监督。一些实施方式可附加地或可替代地涉及利用域不变3d表示来使用作为训练期间机器人操纵策略模型的输入的至少一部分的要被操纵的对象的域不变3d表示训练机器人操纵策略模型(例如,评价网络)。各种实施方式可附加地或可替代地涉及基于通过利用经训练的机器人操纵策略模型处理生成的域不变3d表示而生成的输出来在控制机器人中利用经训练的机器人操纵策略模型。
通过利用点云预测网络处理对象的2.5d观察而生成的对象的3d点云可以是域不变的、在语义上可解释的、以及可直接应用于对象操纵(例如,抓取、推动、放置和/或(多个)其他操纵)。与其他3d表示(诸如体素栅格和三角形网格)相比,所生成的3d点云可以轻巧灵活。当在控制机器人中使用经训练的机器人操纵策略处理3d点云时,这可以导致利用更少的资源(例如,内存资源)。此外,所生成的3d点云可以描述对象的完整3d形状,其中该完整3d形状对于表面纹理或环境条件是不变的。当在训练评价网络中使用所生成的3d点云,并且所生成的3d点云和在训练策略网络中使用的监督信号至少部分基于模拟数据时,这可以缓解现实差距。如本文所使用的,“现实差距”是在真实机器人和/或真实环境与由机器人模拟器模拟的模拟机器人和/或模拟环境之间存在的差异。此外,所生成的3d点云可以直接用于定位对场景中的对象,从而在训练评价网络或其他策略网络时简化(多个)任务。
在转向附图之前,提供了训练点云预测网络和训练作为抓取评价网络的策略网络的一些特定的非限制性示例。作为训练点云预测网络的一个特定示例,假设rgb-d观察集合
继续该特定示例,对观察的自我监督标记可能出现。虽然可以在模拟中容易地获得用于深度网络的监督学习的目标点云,该任务对于真实世界数据变得非常昂贵(例如,在计算机资源方面)和耗时。此外,真实世界深度传感器中噪声和未建模的非线性特性的存在使得学习更困难,尤其是在迁移学习的上下文中。为了解决该挑战,本文公开的实施方式使用具有差分重新投影算子的基于视图的监督来生成自我监督标签。
作为示例,对象
对于本地化,可以从2d投影得到对应的紧密边界框:
点云预测网络可以用于生成预测点云
其中λb,λm,λθ是加权系数,
在一些实施方式中,点云预测网络可以包括若干编码器-解码器模块和全连接层以预测点云。在一些实施方式中,点云预测网络的输入通道可以包括(多个)颜色通道(例如,r、g和b)、深度通道和对象遮罩通道。此外,输入通道可以可选地是基础图像的动态裁剪(例如,基于对象检测),该动态裁剪聚焦在目标对象上。此外,为了考虑动态裁剪,可以可选地在初始输入的下游提供附加输入作为侧输入。例如,可以在初始编码器之后立即提供附加输入,以为点云预测网络提供从裁剪产生的自适应相机内在特性。附加输入可以是一个或多个相机内参(intrinsics),该一个或多个相机内参定义了考虑图像的裁剪的相机的一个或多个内在参数。
现在提供在训练作为抓取策略网络的策略网络中利用预测3d点云的特定示例。抓取策略网络可以是由
可以将预测点云
在各种实施方式中,可以在模拟中生成用于训练抓取策略的训练数据中的多数、绝大多数(例如,90%或更多)或全部。作为一个示例,用于模拟中的数据收集的启发式抓取策略可以包括:(1)基于预测点云来计算目标对象的体积中心
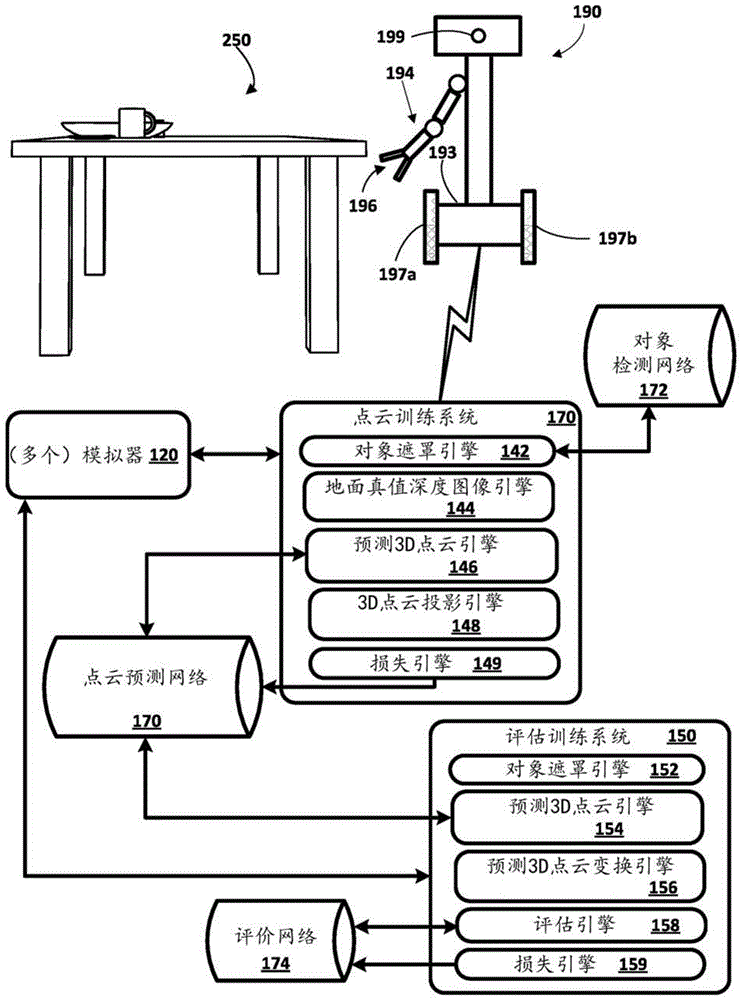
现在转到附图,图1示出了可以实施本文公开的实施方式的示例环境。图1包括点云训练系统140,其由一个或多个计算机系统实施。点云训练系统140在获得具有各种对象的各种环境的rgb-d图像中与一个或多个模拟器120、一个或多个机器人(例如,机器人190)和/或一个或多个人持相机进行接口。例如,机器人190可以在将其视觉组件199(例如,rgb-d相机)引向桌子250的同时部分或一直围绕桌子250行进,以从视觉组件199生成rgb-d图像。同样可以以不同的环境、不同的对象和/或对象布置并且可选地使用不同的视觉组件来捕捉其他相机轨迹。rgb-d图像可以额外地或可替代地使用具有模拟环境和对象的模拟器120来生成。此外,可以额外地或可替代地利用来自人持视觉组件的rgb-d图像。
点云训练系统140利用rgb-d图像来生成自我监督训练数据,并且基于这样的训练数据来训练点云预测网络170。在各种实施方式中,点云训练系统140可以执行图3a和图3b的方法300的一个或多个(例如,全部)方面。
点云训练系统140在图1中示出为包括对象遮罩引擎142、地面真值深度引擎144、预测3d点云引擎146、3d点云投影引擎148和损失引擎149。在其他实施方式中,可以提供更少或更多的引擎,和/或可以组合一个或多个引擎的一个或多个方面。现在参考生成训练数据的实例以及基于这样的实例的训练来描述示出的引擎的实施方式。然而,请注意,点云预测网络的训练将基于训练数据的数千个实例,并且可以可选地利用批量训练技术。
在基于rgb-d图像(例如,来自模拟的渲染图像、或真实世界图像)生成自我监督训练数据的实例时,对象遮罩引擎142生成在rgb-d图像中捕捉的对象的对象遮罩。例如,在rgb-d图像是真实世界图像的情况下,对象遮罩引擎142可以使用对象检测网络172来检测rgb-d图像中的(多个)对象的(多个)对象边界框以及(多个)对象中的每一个的相关联的遮罩。例如,对象检测网络172可以是mask-rcnn网络或其他训练网络。同样,例如,在rgb-d图像是模拟图像的情况下,可以直接从模拟数据获得(多个)边界框以及(多个)相关联的遮罩。在rgb-d图像中捕捉了多个对象的情况下,可以选择对象中的一个以用于在生成自我监督训练数据的实例中使用。可选地,rgb-d图像中的多个对象中的其他对象可以各自在生成自我监督训练数据的对应附加实例中使用。换句话说,可以基于包括多个对象的rgb-d图像来生成多个训练实例,这些实例中的每一个用于对象中的对应单个对象。
在基于rgb-d图像来生成自我监督训练数据的实例中,地面真值深度引擎144可以基于rgb-d图像的对象遮罩和深度通道来生成地面真值深度图像。例如,地面真值深度引擎144可以生成深度图像,以针对表示对象的对象遮罩(由对象遮罩引擎142生成)中的那些像素包括来自深度通道的对应于那些像素的深度值。地面真值深度图像的其他像素可以为零或其他空值。可选地,地面真值深度图像可以被限制为被包括在由对象遮罩引擎142确定的边界框中的那些像素和/或可以包括(例如,在额外通道中)由对象遮罩引擎142确定的边界框。
自我监督训练数据的实例可以包括rgb-d图像(或至少包括被包括在所生成的边界框中的那些像素的裁剪)、对象遮罩、以及可选地考虑了rgb-d图像的裁剪的相机内参的训练实例输入。自我监督训练数据的实例可以包括地面真值深度图像的训练实例输出。
预测3d点云引擎146可以使用点云预测网络170来处理训练实例输入,以生成对象的预测3d点云。例如,预测3d点云引擎146可以将rgb-d图像(或至少裁剪)和对象遮罩应用于点云预测网络170的(多个)初始层,并在(多个)初始层(例如,跟随(多个)初始编码层之后)的下游应用相机内参作为侧输入。预测3d点云引擎146可以基于所应用的输入并使用点云预测网络170的当前权重,使用点云预测网络170来生成预测3d点云。
3d点云投影引擎148生成由预测3d点云引擎146生成的预测3d点云的投影。所生成的投影可以是模拟对象的预测深度图像,并且可以基于预测3d点云来生成。例如,3d点云投影引擎148可以使用相机内参来生成投影,以从点云获得图像空间中的2d投影。例如,可以利用等式(1a)和(1b)(如上所述)。3d点云投影引擎148还可以可选地生成可以从2d投影得到的边界框。
损失引擎149至少部分基于预测3d点云的投影(由引擎148生成)和地面真值深度图像(由引擎144生成)的比较来生成损失。损失引擎149可以基于由引擎144可选地生成的地面真值边界框和由引擎148可选地生成的预测边界框的比较来进一步生成损失。作为一个示例,损失引擎149可以基于等式(2)(如上所述)来生成损失。注意,在各种实施方式中,损失引擎149可以基于一批中的训练数据的多个实例来生成批量损失。损失引擎149然后基于所生成的损失来更新点云预测网络170的一个或多个权重。例如,损失引擎149可以反向传播损失以更新点云预测网络170的权重。
一旦训练了点云预测网络170,真实世界机器人(例如,机器人190)就可以在基于由机器人捕捉的rgb-d图像来生成预测3d点云中利用它。此外,可以由机器人在控制其致动器中的一个或多个中利用预测3d点云。在一些实施方式中,在训练评价网络或其他机器人策略网络中利用经训练的点云预测网络170来处理预测3d点云(使用经训练的点云预测网络170生成的)以生成在控制机器人中利用的对应输出。现在关于图1的评估训练系统150描述这样的训练的一个非限制性示例,其由一个或多个计算机系统实施。
评估训练系统150在训练评价网络174中与经训练的点云预测网络170、一个或多个模拟器120以及可选地一个或多个机器人(例如,机器人190)进行接口。在各种实施方式中,评估训练系统150可以执行图4的方法400的一个或多个(例如,全部)方面。
评估训练系统150在图1中示出为包括对象遮罩引擎152、预测3d点云引擎154、预测3d点云变换引擎156和损失引擎159。在其他实施方式中,可以提供更少或更多的引擎,和/或可以组合一个或多个引擎的一个或多个方面。现在参考生成训练数据的实例以及基于这样的实例的训练来描述示出的引擎的实施方式。然而,应注意的是,评价网络174网络的训练将基于训练数据的数千个实例,并且可以可选地利用批量训练技术。
在生成训练数据的实例中,可以使用模拟环境、(多个)对象和机器人的模拟器120来渲染模拟rgb-d图像。rgb-d图像可以捕捉模拟环境中的(多个)对象中的至少一个。对象遮罩引擎152可以使用诸如针对(点云训练系统140的)对象遮罩引擎142描述的那些技术来生成目标对象的遮罩。当rgb-d图像是渲染的模拟图像时,可以使用来自模拟器120的数据或者可选地利用对象检测网络172来生成遮罩。当它是真实世界图像时,对象遮罩引擎152可以可选地在生成对象遮罩中利用对象检测网络172。对象遮罩引擎152还可以可选地生成对象的边界框。
在生成训练数据的实例中,预测3d点云引擎154可以将rgb-d图像(或至少基于由对象遮罩引擎152生成的边界框的裁剪)和对象遮罩处理到点云预测网络170的(多个)初始层,并且可以可选地在(多个)初始层(例如,跟随(多个)初始编码层之后)的下游应用(捕捉rgb-d图像的相机的)相机内参作为侧输入。预测3d点云引擎146可以基于所应用的输入并使用点云预测网络170的经训练的权重,使用点云预测网络170来生成预测3d点云。
预测3d点云变换引擎156可以使用要用于训练实例的操纵尝试的末端效应器姿势来生成预测3d点云的变换。换句话说,预测3d点云变换引擎156可以将3d点云变换为相对于要用于操纵尝试的末端效应器vk势的末端效应器框架。例如,3d点云变换引擎156可以使用等式(3)(如上所述)和末端效应器姿势来生成变换。
评估引擎158可以使用评价网络来处理预测3d点云的变换,以生成对成功操纵的预测。然后可以例如由模拟器120的模拟机器人使用末端效应器姿势来尝试该操纵。然后可以使用来自模拟器120的数据来确定操纵是否成功,以及基于该确定(例如,如果成功则为“1”,如果不成功则为“0”)而确定的成功操纵的地面真值度量。损失引擎159然后可以基于将成功操纵的预测与成功操纵的地面真值度量进行比较来生成损失。损失引擎159然后基于所生成的损失来更新评价网络174的一个或多个权重。例如,损失引擎159可以反向传播损失以更新评价网络174的权重。
示例机器人190在图1中示出为当训练时可以在执行各种机器人任务中利用点云预测网络170和/或评价网络174的机器人的一个示例。机器人190也是可以用于生成用于训练点云预测网络170和/或评价网络174的数据的机器人的一个示例。
机器人190包括具有抓取末端效应器196的机器人臂194,其中该抓取末端效应器196采取具有两个相对的可致动构件的抓取器的形式。机器人190还包括具有在其相对侧上提供以用于机器人190的运动的轮子197a和197b的基座193。基座193可以包括例如一个或多个电动机,其中该一个或多个电动机用于驱动对应的轮子197a和197b以实现机器人190的移动的期望方向、速度和/或加速度。
机器人190还包括视觉组件199。视觉组件199生成与在其(多个)传感器的视线内的(多个)对象的形状、颜色、深度和/或其他特征有关的图像。视觉组件199可以是例如生成本文描述的rgb-d图像的无源或有源立体相机。尽管在图1中示出了特定的机器人190,但是可以利用额外的和/或可替代的机器人,包括与机器人190类似的附加的机器人手臂、具有机器人手臂形式的机器人、具有人形的机器人、具有动物形态的机器人、经由一个或多个轮子移动的其他机器人、无人飞行器(“unmannedaerialvehicle,uav”)等。此外,尽管在图1中示出了特定的末端效应器,但是可以利用额外的和/或可替代的末端效应器来与对象交互。
(多个)模拟器120由一个或多个计算机系统实施,并且可以用于模拟包括对应的环境对象和(多个)对应的放置位置的各种环境。可以利用各种模拟器,诸如模拟碰撞检测、软体和刚体动力学等的物理引擎。这样的模拟器的一个非限制性示例是bullet物理引擎。
现在参考2,示出了使用经训练的点云预测网络170并基于由机器人(例如,图1的机器人190)捕捉的rgb-d图像201来生成预测3d点云201的示例。图2进一步示出了在控制机器人中使用预测3d点云201的示例。图2可以涉及执行图5的方法500的框中的一个或多个(例如,全部)。
在图2中,由遮罩引擎142使用对象检测网络172来处理rgb-d图像201,以生成由rgb-d图像201捕捉的对象202的遮罩。对象202的遮罩与rgb-d图像的颜色通道203和深度通道204(例如,与对象的边界框相对应的至少那些部分,可选地由对象遮罩引擎142确定)一起被应用作为点云预测网络170的初始输入。点云预测网络的示出的示例包括两对一个编码器-解码器(170a1和170a2;以及170b1和170b2)。它还可以可选地包括额外的或可替代的未示出的层。相机内参205还可以可选地被应用作为如图所示(例如,在编码器170a1之后)的侧输入205。基于使用点云预测网络170处理输入来生成预测3d点云206。
预测3d点云变换引擎148生成3d点云的变换208,该3d点云的变换208是基于考虑候选末端效应器姿势207的预测3d点云206的变换。评估引擎148可以基于使用评价网络174处理3d点云的变换208来生成对成功操纵的预测。如果在尝试操纵中利用用于生成3d点云的变换208的候选末端效应器姿势207,则对成功操纵的预测指示成功操纵的度量。基于处理对应的3d点云的变换,评估引擎148可以生成针对多个候选末端效应器姿势中的每一个的对成功操纵的预测。例如,评估引擎148可以在采样多个候选末端效应器姿势207中利用交叉熵方法(cross-entropymethod,cem)或其他技术,并且可以选择具有对成功操纵的最佳预测的一个作为所选末端效应器姿势209。所选末端效应器姿势209然后可以用于控制机器人的致动器,以使得机器人的末端效应器移动到所选末端效应器姿势209,然后尝试对对象的操纵。
现在参考图3a和图3b,描述了使用模拟数据和真实数据来训练点云预测网络的示例方法300。为了方便起见,参考执行操作的系统来描述流程图的操作。该系统可以包括一个或多个计算设备(诸如点云训练系统140)的各种组件。此外,虽然以特定顺序示出了方法300的操作,但这并不意味着是限制性的。一个或多个操作可以被重新排序、省略或添加。
在框352处,系统渲染包括(多个)颜色通道和深度通道并且捕捉模拟器的模拟环境的(多个)模拟对象的模拟图像。
在框354处,系统生成由模拟图像捕捉的(多个)模拟对象中的模拟对象的对象遮罩。系统还可以可选地生成模拟图像中的模拟对象的边界框。
在框356处,系统基于对象遮罩和深度通道来生成模拟对象的地面真值深度图像。
在框358处,系统基于使用点云预测网络处理模拟图像的至少一部分的对象遮罩和(多个)通道(例如,包括(多个)颜色通道和深度通道)来生成模拟对象的预测3d点云。例如,可以处理捕捉模拟对象的模拟图像的至少一部分。例如,可以处理裁剪的部分,其中裁剪对应于模拟对象的边界框。在一些实施方式中,在生成预测3d点云中,系统还使用点云预测网络来处理相机内参。
在框360处,系统生成框358的预测3d点云的投影。
在框362处,系统基于预测3d点云的投影(框360)和模拟对象的地面真值深度图像(框356)的比较来生成损失。如本文所述,在各种实施方式中,可以基于一批训练实例(例如,基于多个投影和地面真值深度图像的比较)来生成损失。
在框364处,系统基于所生成的损失来更新点云预测网络的(多个)权重。
在框366处,系统确定是否执行对点云预测网络的进一步训练。在一些实施方式中,系统可以基于是否存在任何未处理的训练实例和/或是否尚未满足其他训练标准来确定是否执行进一步训练。其他训练标准可以包括训练时期的阈值数量、训练时间的阈值持续时间和/或其他准则/标准。
如果系统在框366的迭代处确定点云预测网络不需要进一步训练,则系统可以认为点云预测网络完成了训练,并且可以可选地继续到框368。
在框368处,系统可以利用使用经训练的点云预测网络预测的点云来训练机器人操纵策略网络。例如,系统可以执行图4的方法400,以利用使用经训练的点云预测网络预测的点云来训练评价网络。
如果系统在框366的迭代处确定需要进一步训练,则系统可以返回到框352或者继续到图3b的框372。图3b基于真实世界数据来执行对点云预测网络的训练,而图3a的框基于模拟数据来执行对点云预测网络的训练。在一些实施方式中,系统可以仅基于模拟数据来训练点云预测网络(不执行图3b的任何框)。在一些实施方式中,系统可以主要基于模拟数据来训练点云预测网络,但是也可以在一些模拟数据上进行训练。在那些实施方式中,系统可以响应于框366处的是确定中的至少一些而继续到框372。例如,系统可以至少间歇地继续到框372。
现在参考图3b,在框372处,系统捕捉包括(多个)颜色通道和深度通道并且捕捉真实环境的(多个)真实对象的真实图像。系统还可以可选地生成模拟对象的边界框。
在框374处,系统使用对象检测网络来生成(多个)真实对象中的真实对象的对象遮罩。系统还可以可选地生成真实图像中的真实对象的边界框。
在框376处,系统基于对象遮罩和深度通道来生成真实对象的地面真值深度图像。
在框378处,系统基于使用点云预测网络处理真实图像的至少一部分的对象遮罩和(多个)通道(例如,包括(多个)颜色通道和/或深度通道)来生成真实对象的预测3d点云。例如,可以处理捕捉真实对象的真实图像的至少一部分。例如,可以处理裁剪的部分,其中裁剪对应于真实对象的边界框。在一些实施方式中,在生成预测3d点云中,系统还使用点云预测网络来处理相机内参。
在框380处,系统生成框378的预测3d点云的投影。
在框382处,系统基于预测3d点云的投影(380)和真实对象的地面真值深度图像(376)的比较来生成损失。
在框384处,系统基于所生成的损失来更新点云预测网络的(多个)权重,并且系统返回到图3a的框366来确定点云预测网络是否需要任何进一步训练。如本文所述,在各种实施方式中,可以基于一批训练实例(例如,基于多个投影和地面真值深度图像的比较)来生成损失。
现在参考图4,描述了使用预测3d点云来训练评价网络的示例方法400。为了方便起见,参考执行操作的系统来描述流程图的操作。该系统可以包括一个或多个计算设备(诸如评估训练系统150)的各种组件。此外,虽然以特定顺序示出了方法400的操作,但这并不意味着是限制性的。一个或多个操作可以被重新排序、省略或添加。
在框452处,系统识别包括(多个)颜色通道和深度通道并且捕捉环境的(多个)对象的图像。图像可以是真实图像,并且环境可以是真实环境,或者图像可以是渲染的模拟图像,并且环境可以是模拟环境。
在框454处,系统生成(多个)对象中的对象的对象遮罩。系统还可以可选地生成图像中的对象的边界框。
在框456处,系统基于使用经训练的点云预测网络处理图像的至少一部分的对象遮罩和(多个)通道(例如,包括(多个)颜色通道和/或深度通道)来生成对象的预测3d点云。例如,可以处理捕捉对象的图像的至少一部分。例如,可以处理裁剪的部分,其中裁剪对应于对象的边界框。在一些实施方式中,在生成预测3d点云中,系统还使用点云预测网络来处理相机内参。
在框458处,系统识别在对对象的操纵尝试中使用的末端效应器姿势。当图像是真实图像时,操纵尝试可以是真实世界操纵尝试,或者当图像是模拟图像时,操纵尝试可以是模拟操纵尝试。
在框460处,系统基于末端效应器姿势来生成预测3d点云的变换。
在框462处,系统基于使用评价网络处理预测3d点云的变换来生成对对象的成功操纵的预测。
在框464处,系统基于对成功操纵的预测和成功操纵的地面真值度量的比较来生成损失。成功操纵的地面真值度量基于操纵尝试是否成功。例如,跟随操纵尝试之后,可以基于来自模拟器的数据来确定模拟操纵尝试的成功。
在框466处,系统基于所生成的损失来更新评价网络的(多个)权重。如本文所述,在各种实施方式中,可以基于一批训练实例(例如,基于多个成功操纵的预测和成功操纵的地面真值度量的比较)来生成损失。
在框468处,系统确定是否执行对评价网络的进一步训练。在一些实施方式中,系统可以基于是否存在任何未处理的训练实例和/或是否尚未满足其他训练标准来确定是否执行进一步训练。其他训练标准可以包括训练时期的阈值数量、训练时间的阈值持续时间和/或其他准则/标准。
系统如果在框468的迭代处确定执行对评价网络的进一步训练,则系统可以返回到框454。
系统如果在框468的迭代处确定评价网络不需要进一步训练,则系统可以继续到框470。
在框470处,系统在机器人控制中使用评价网络。例如,基于图5的方法500,系统可以在控制机器人中使用评价网络。
现在参考图5,描述了在控制机器人中使用经训练的评价网络和预测3d点云的示例方法500。为了方便起见,参考执行操作的系统来描述流程图的操作。该系统可以包括机器人(例如,图1的机器人190、图6的机器人600和/或(多个)其他机器人)和/或与该机器人通信的一个或多个计算设备(例如,图7的计算设备710)的各种组件。此外,虽然以特定顺序示出了方法500的操作,但这并不意味着是限制性的。一个或多个操作可以被重新排序、省略或添加。
在框552处,系统识别包括(多个)颜色通道和深度通道并且捕捉环境的(多个)对象的图像。图像可以由例如机器人的rgb-d相机捕捉。
在框554处,系统生成(多个)对象中的对象的对象遮罩。系统还可以可选地生成图像中的对象的边界框。
在框556处,系统基于使用点云预测网络处理图像的至少一部分的对象遮罩和(多个)通道(例如,包括(多个)颜色通道和/或深度通道)来生成对象的预测3d点云。例如,可以处理捕捉对象的图像的至少一部分。例如,可以处理裁剪的部分,其中裁剪对应于对象的边界框。在一些实施方式中,在生成预测3d点云中,系统还使用点云预测网络来处理相机内参。
在框558处,系统识别候选末端效应器姿势。
在框560处,系统基于候选末端效应器姿势来生成预测3d点云的变换。
在框562处,系统基于使用评价网络处理预测3d点云的变换来生成对对象的成功操纵的预测。
在框564处,系统确定是否应该考虑更多的(多个)候选末端效应器姿势。例如,系统可以利用cem或其他技术来考虑多个末端效应器姿势。例如,在cem的第一次迭代中,可以随机采样和考虑n个候选末端效应器姿势,然后,在cem的下一次迭代中,可以从具有对成功抓取的最佳预测的第一次迭代的候选末端效应器姿势附近采样附加的候选末端效应器姿势。可以可选地执行cem的附加迭代。
系统如果在框564的迭代处确定存在更多的(多个)候选末端效应器姿势,则系统可以返回到框558来识别附加的候选末端效应器姿势。
系统如果在框564的迭代处确定没有更多的(多个)候选末端效应器姿势,则系统可以继续到框566。
在框566处,系统基于对成功操纵的(多个)预测来选择给定的候选末端效应器姿势,并且控制机器人的(多个)致动器来实现给定的候选末端效应器姿势(即,将末端效应器移动到该姿势)并然后尝试对对象的操纵。当评价网络被训练用于抓取尝试时,操纵可以是例如抓取尝试。
图6示意性地描绘了机器人600的示例架构。图1的机器人190可以实施图6的示例架构的一个或多个组件。机器人600包括机器人控制系统660、一个或多个操作组件604a-604n、以及一个或多个传感器608a-608m。传感器608a-608m可以包括例如视觉传感器(例如,(多个)相机、3d扫描仪)、光传感器、压力传感器、压力波传感器(例如,麦克风)、接近传感器、加速计、陀螺仪、温度计、气压计等等。虽然将传感器608a-608m描绘为与机器人600集成,但这并不意味着是限制性的。在一些实施方式中,传感器608a-608m可以例如作为独立单元位于机器人600的外部。
操作组件604a-604n可以包括例如一个或多个末端效应器(例如,抓取末端效应器)和/或一个或多个伺服电动机或其他致动器,以完成机器人的一个或多个组件的移动。例如,机器人600可以具有多个自由度,并且致动器中的每一个可以响应于控制命令在自由度中的一个或多个内控制机器人600的致动。如本文所使用的,除了可以与致动器相关联并且将所接收的控制命令转换为用于驱动致动器的一个或多个信号的任何(多个)驱动器之外,术语致动器包括产生运动的机械设备或电气设备(例如,电动机)。因此,向致动器提供控制命令可以包括向驱动器提供控制命令,其中该驱动器将控制命令转换为用于驱动电气设备或机械设备产生期望的运动的适当信号。
控制系统602可以在机器人600的一个或多个处理器(诸如cpu、gpu)和/或(多个)其他控制器中被实施。在一些实施方式中,机器人600可以包括“脑箱(brainbox)”,其可以包括控制系统602的全部或方面。例如,脑箱可以向操作组件604a-n提供数据的实时突发,其中实时突发中的每一个包括一个或多个控制命令的集合,其中该一个或多个控制命令尤其指示一个或多个操作组件604a-n中的每一个的运动(如果有的话)的参数。
尽管控制系统602在图6中被示出为机器人600的集成部分,但是在一些实施方式中,控制系统602的全部或方面可以在与机器人600分离但与之通信的组件中被实施。例如,控制系统602的全部或方面可以在与机器人600进行有线和/或无线通信的一个或多个计算设备(诸如计算设备710)上被实施。在一些实施方式中,由控制系统在执行机器人任务中生成的控制命令的全部或方面可以是基于动作的,该动作基于对如本文所述的经训练的机器人操纵策略模型的利用而选择。例如,在选择动作中,可以利用形状预测网络将来自机器人的相机的2.5d视觉数据变换为域不变3d表示,并且利用经训练的机器人操纵策略模型处理域不变3d表示。
图7是可以可选地用于执行本文描述的技术的一个或多个方面的示例计算设备710的框图。计算设备710通常包括至少一个处理器714,其经由总线子系统712与多个外围设备通信。这些外围设备可以包括存储子系统724,其包括例如存储器子系统725和文件存储子系统726、用户界面输出设备720、用户界面输入设备722和网络接口子系统716。输入和输出设备允许与计算设备710的用户交互。网络接口子系统716提供到外部网络的接口,并且耦合到其他计算设备中的对应接口设备。
用户界面输入设备722可以包括键盘、指向设备(诸如鼠标、轨迹球、触摸板或图形输入板)、扫描仪、结合到显示器中的触摸屏、诸如语音识别系统的音频输入设备、麦克风和/或其他类型的输入设备。通常,术语“输入设备”的使用旨在包括将信息输入到计算设备710中或通信网络上的所有可能类型的设备和方式。
用户界面输出设备720可以包括显示子系统、打印机、传真机或诸如音频输出设备的非视觉显示器。显示子系统可以包括阴极射线管(cathoderaytube,crt)、诸如液晶显示器(liquidcrystaldisplay,lcd)的平板设备、投影设备或用于创建可视图像的一些其他机制。显示子系统还可以诸如经由音频输出设备提供非视觉显示。通常,术语“输出设备”的使用旨在包括从计算设备710向用户或者向另一机器或计算设备输出信息的所有可能类型的设备和方式。
存储子系统724存储提供本文描述的模块中的一些或所有模块的功能的编程和数据构造。例如,存储子系统724可以包括执行本文描述的方法的所选方面的逻辑。
这些软件模块一般由处理器714单独或与其他处理器组合执行。在存储子系统724中使用的存储器725可以包括多个存储器,其中该多个存储器包括用于在程序执行期间存储指令和数据的主随机存取存储器(randomaccessmemory,ram)730和存储固定指令的只读存储器(readonlymemory,rom)732。文件存储子系统726可以为程序和数据文件提供永久存储,并且可以包括硬盘驱动器、软盘驱动器以及相关联的可移除介质、cd-rom驱动器、光盘驱动器或可移除介质盒。实施某些实施方式的功能的模块可以由文件存储子系统726存储在存储子系统724中、或者存储在(多个)处理器714可访问的其他机器中。
总线子系统712提供了一种用于使计算设备710的各种组件和子系统按预期彼此通信的机制。尽管总线子系统712被示意性地示出为单个总线,但是总线子系统的替代实施方式可以使用多个总线。
计算设备710可以是各种类型的,包括工作站、服务器、计算集群、刀片服务器、服务器场或者任何其他数据处理系统或计算设备。由于计算机和网络的不断改变的性质,出于说明一些实施方式的目的,图7中描绘的计算设备710的描述仅旨在作为特定示例。计算设备710的许多其他配置可能具有比图7中描绘的计算设备更多或更少的组件。
虽然本文已经描述和说明了若干实施方式,但是可以利用用于执行本文描述的功能和/或获得本文描述的结果和/或优点中的一个或多个的各种其他手段和/或结构,并且这样的变化和/或修改中的每一个被认为在本文描述的实施方式的范围内。更一般地,本文描述的所有参数、尺寸、材料和配置都意味着是示例性的,并且实际参数、尺寸、材料和/或配置将取决于教导被用于的特定应用或多个特定应用。仅使用常规实验,本领域技术人员将认识到或能够确定本文描述的特定实施方式的许多等同物。因此,应当理解,前述实施方式仅以示例的方式呈现,并且在所附权利要求及其等同物的范围内,可以以不同于具体描述和要求保护的方式来实践实施方式。本公开的实施方式针对本文描述的每个单独的特征、系统、物品、材料、套件和/或方法。此外,如果这样的特征、系统、物品、材料、套件和/或方法不是相互矛盾的,则两个或更多个这样的特征、系统、物品、材料、套件和/或方法的任何组合被包括在本公开的范围内。
在一些实施方式中,提供了一种由机器人的一个或多个处理器实施的方法,该方法包括识别由机器人的相机捕捉并且捕捉机器人的环境中的对象的2.5d图像。该方法还包括使用形状预测网络来处理至少2.5d图像,以生成对象的域不变3d表示。该方法还包括利用机器人操纵策略网络确定要应用于机器人的动作,来处理对象的域不变3d表示或域不变3d表示的变换。该方法还包括将控制命令提供给机器人的一个或多个致动器,以使得由机器人执行动作。
该技术的这些和其他实施方式可以包括以下特征中的一个或多个。
在一些实施方式中,对象的域不变3d表示是对象的3d点云。
在一些实施方式中,该方法还包括处理2.5d图像以生成指示2.5d图像的哪些像素包括对象的遮罩。这些实施方式还包括在利用形状预测网络生成对象的域不变3d表示中处理遮罩以及2.5d图像。
在一些实施方式中,该方法包括在利用机器人操纵策略网络确定动作中,处理对象的域不变3d表示的变换。在那些实施方式的一些版本中,该变换是通过使用机器人末端效应器姿势将域不变3d表示变换为机器人末端效应器的框架来生成的。在一些额外的或可替代的版本中,利用机器人操纵策略网络的处理生成机器人末端效应器姿势将引起对对象的成功操纵的度量(例如,概率)。在那些额外的或可替代的版本中的一些中,确定动作包括基于满足阈值的度量来确定尝试以机器人末端效应器姿势的操纵。对对象的操纵可以是例如对象的抓取。
在一些实施方式中,提供了一种由机器人的一个或多个处理器实施的方法,该方法包括识别由机器人的相机捕捉的图像。图像捕捉要由机器人操纵的对象,并且图像包括多个通道,其中该多个通道包括一个或多个颜色通道以及深度通道。该方法还包括生成要由机器人操纵的对象的对象遮罩。生成对象遮罩可以包括使用对象检测网络来处理图像的通道中的一个或多个。该方法还包括生成对象的三维(3d)点云。生成对象的3d点云可以包括使用点云预测网络来处理:图像的至少一部分的所有通道、以及所生成的对象的对象遮罩。该方法还包括在控制机器人的一个或多个致动器中使用所生成的3d点云。
该技术的这些和其他实施方式可以包括以下特征中的一个或多个。
在一些实施方式中,对象检测网络被训练用于处理图像,以在图像中生成对象的边界框和遮罩。在那些实施方式中的一些中,该方法还包括生成要由机器人操纵的对象的边界框。生成边界框可以包括使用对象检测网络来处理图像的通道中的一个或多个。在那些实施方式的一些版本中,使用点云预测网络处理的图像的至少一部分是基于边界框选择的图像的裁剪。例如,该方法还可以包括基于图像的被包括在裁剪中的像素由边界框包围来选择图像的裁剪。在该至少一部分是裁剪的一些版本中,生成对象的3d点云还可以包括使用点云预测网络来处理一个或多个相机内参,一个或多个相机内参定义了考虑图像的裁剪的相机的一个或多个内在参数。在那些版本中的一些中,在使用点云预测网络来处理一个或多个相机内参中,一个或多个相机内参在图像的至少一部分的所有通道和所生成的对象的对象遮罩被应用作为初始输入的初始输入的下游被应用作为点云预测网络的侧输入。例如,图像的至少一部分的所有通道和所生成的对象的对象遮罩可以使用点云预测网络的初始编码器进行初始处理,并且相机内参可以在初始编码器之后并在使用点云预测网络的初始解码器进行处理之前被应用作为侧输入。
在一些实施方式中,在控制机器人的一个或多个致动器中使用所生成的3d点云包括基于对象的3d点云或3d点云的变换来生成对对象的成功操纵的预测,并且基于对成功操纵的预测来控制机器人的一个或多个致动器。在那些实施方式的一些版本中,生成对对象的成功操纵的预测包括通过使用评价网络处理所生成的对象的3d点云或3d点云的变换来生成对成功操纵的预测。在那些版本中的一些中,生成对成功操纵的预测包括:识别机器人的末端效应器的候选末端效应器姿势;通过将3d点云变换为相对于末端效应器姿势的末端效应器框架来生成3d点云的变换;以及通过使用评价网络处理3d点云的变换来生成对成功操纵的预测。此外,在那些版本中的一些中,基于对成功操纵的预测来控制机器人的一个或多个致动器可以包括:基于对成功操纵的预测满足至少一个准则来选择候选末端效应器姿势;以及响应于选择候选末端效应器姿势:控制机器人的一个或多个致动器以使得末端效应器移动到候选末端效应器姿势。可选地,操纵是在抓取,并且基于对成功操纵的预测来控制机器人的一个或多个致动器还包括:在末端效应器处于候选末端效应器姿势之后,使得末端效应器尝试抓取对象。此外,在一些版本中,该方法还包括:识别末端效应器的附加的候选末端效应器姿势;通过将3d点云变换为相对于附加末端效应器姿势的附加末端效应器框架来生成3d点云的附加变换;以及通过使用评价网络处理3d点云的附加变换来生成对成功操纵的附加预测。在基于对成功操纵的预测来选择候选末端效应器姿势中利用的至少一个准则可以包括对成功操纵的预测比对成功操纵的附加预测更能指示成功。
在一些实施方式中,点云预测网络包括多个编码器-解码器模块、以及至少一个全连接层。
在一些实施方式中,提供了一种训练点云预测网络的方法,该方法由一个或多个处理器实施。该方法包括渲染模拟器的模拟环境的模拟图像。模拟图像捕捉模拟环境的至少一个模拟对象,并且模拟图像包括多个通道,其中该多个通道包括一个或多个颜色通道以及深度通道。该方法还包括:生成模拟对象的对象遮罩;以及基于模拟图像的对象遮罩和深度通道来生成对象的地面真值深度图像。该方法还包括生成模拟对象的预测三维(3d)点云。生成模拟对象的预测3d点云包括使用点云预测网络来处理:图像的至少一部分的所有通道、以及所生成的模拟对象的对象遮罩。该方法还包括生成预测3d点云的投影。投影是基于预测3d点云的模拟对象的预测深度图像。该方法还包括至少部分基于以下各项的比较来生成损失:预测3d点云的投影、以及模拟对象的地面真值深度图像。该方法还包括至少部分基于所生成的损失来更新点云预测网络的一个或多个权重。
该技术的这些和其他实施方式可以包括以下特征中的一个或多个。
在各种实施方式中,在确定损失中使用投影和地面真值深度图像的比较提供了一个或多个优点。例如,在模拟中在这样的损失上进行训练,相对于,例如,替代地利用预测3d点云本身与地面真值3d点云(直接从模拟获得)的比较,可以缓解点云预测网络的现实差距。同样,例如,这样的损失也可以在基于真实世界数据训练点云预测网络中被有效地利用。例如,真实世界地面真值深度图像可以被有效地生成。另一方面,获得真实世界中的地面真值3d点云数据可能是耗时和/或在计算上昂贵的。
在一些实施方式中,生成3d点云的投影包括使用用于渲染模拟图像的模拟相机的内在参数来生成预测3d点云的投影。
在一些实施方式中,该方法还包括确定模拟对象的边界框。在那些实施方式中的一些中,使用点云预测网络处理的图像的至少一部分是基于边界框选择的图像的裁剪。例如,图像的裁剪可以基于图像的被包括在裁剪中的像素由边界框包围来选择。
在一些实施方式中,该方法还包括捕捉真实环境的真实图像。真实图像捕捉至少一个真实对象,并且真实图像包括多个通道,其中该多个通道包括一个或多个颜色通道以及深度通道。在那些实施方式中,该方法还包括生成真实对象的附加对象遮罩。生成附加对象遮罩包括使用对象检测网络来处理真实图像的一个或多个通道。在那些实施方式中,该方法还包括:基于真实图像的附加对象遮罩和深度通道来生成真实对象的附加地面真值深度图像;以及生成真实对象的附加的预测三维(3d)点云。生成真实对象的附加的预测3d点云包括使用点云预测网络来处理:真实图像的至少一部分的所有通道、以及所生成的真实对象的对象遮罩。在那些实施方式中,该方法还包括:生成附加的预测3d点云的附加投影;至少部分基于以下各项的比较来生成附加损失:附加的预测3d点云的投影、以及真实对象的附加地面真值深度图像;以及至少部分基于所生成的经更新的损失来更新点云预测网络的一个或多个权重。
在一些实施方式中,该方法还包括确定对点云预测网络的训练满足一个或多个标准。一个或多个标准可以包括例如训练时期的阈值量、训练的阈值持续时间、训练的收敛、指示至少精度和/或鲁棒性的阈值水平的评估、和/或其他标准中的一个或多个。该方法还可以包括:响应于确定对点云预测网络的训练满足一个或多个标准:利用使用经训练的点云预测网络预测的附加点云来训练评价网络。
本文公开的各种实施方式可以包括一种存储指令的非瞬时性计算机可读存储介质,该指令可由一个或多个(多个)处理器(例如,(多个)中央处理单元(centralprocessingunit,cpu)、(多个)图形处理单元(graphicsprocessingunit,gpu)和/或(多个)张量处理单元(tensorprocessingunit,tpu))执行以执行方法(诸如本文描述的方法中的一种或多种)。另一实施方式可以包括一种包括一个或多个处理器的一个或多个计算机和/或一个或多个机器人的系统,该一个或多个处理器可操作来执行存储的指令以执行方法(诸如本文描述的方法中的一种或多种)。
- 还没有人留言评论。精彩留言会获得点赞!