一种基于成功经验衍生回放机制的多机械臂运动规划方法
本发明属于机械臂运动智能规划,涉及一种基于成功经验衍生回放机制的多机械臂运动规划方法。
背景技术:
1、在工业自动化和机器人领域,多机械臂系统被广泛应用于各种任务,如装配、搬运和协作操作等,而多机械臂系统的运动规划是实现这些任务的关键问题之一。传统的运动规划方法往往面临着高维状态空间、复杂约束和协作问题等挑战,因此在多机器臂系统的应用场景中表现出较低的效率和性能。特别是当面对具有较多机械臂数量的高维度问题时,这些方法往往难以生成有效路径。为了解决这些问题,多智能体深度强化学习成为一种有潜力的方法。
2、多智能体深度强化学习是深度强化学习在多智能体系统中的应用扩展。深度强化学习是一种结合深度学习和强化学习的方法,用于让智能体从与环境的交互中学习到决策策略。它通过智能体与环境的交互,通过试错学习和奖励信号来优化决策策略,从而使智能体能够在复杂环境中自主地进行决策和行动。在多智能体系统中,存在多个智能体相互作用和协调的情况。每个智能体都需要同时考虑个体的目标和整体系统的目标,并与其他智能体进行合作和竞争。多智能体深度强化学习旨在通过深度强化学习的方法,让智能体能够在多智能体系统中学习到合适的决策策略,实现整体系统的优化和协调。其中,经验回放是一种用于训练深度强化学习模型的重要技术。在强化学习中,智能体通过与环境的交互收集经验,然后使用这些经验进行学习。传统的经验回放方法将智能体的经验存储在一个缓冲区中,并随机抽样一批经验用于训练模型。这种方法可以解决数据相关性和样本效率的问题,并提高模型的学习效率和稳定性。因此经验回放方法在深度强化学习中被广泛应用,如深度q网络(dqn)和确定性策略梯度(ddpg)等算法。
3、然而,将多智能体深度强化学习应用于多机械臂运动规划问题时,仍然存在一些挑战。首先,多机械臂系统通常涉及高维的状态空间和大量的动作空间。这导致深度强化学习方法在多机械臂系统中的训练效率较低,需要大量的样本数据和训练时间。其次,大多数多机械臂深度强化学习的研究只针对于数量和位置关系固定的多机械臂系统,不具有扩展性和灵活性,若要改变多机械臂系统中的数量或位置关系,则需重新训练运动策略,成本极高。而对于更加灵活可扩展的分散式多机械臂系统来说,各机械臂之间的距离与任务复杂度有着密切的联系,距离越近,工作空间的重叠越大,机械臂各连杆之间发生碰撞的概率越大,需要机械臂之间存在更复杂的相互作用和协调策略,才能避免在工作过程中发生碰撞。因此,如何提高深度强化学习在多机械臂系统中样本训练的效率,如何使机械臂更有效地学习到工作空间高耦合环境下完成复杂任务的运动策略是本领域内重要技术课题。
技术实现思路
1、为了解决上述问题,本发明提出了一种适用于分散式多机械臂系统的成功经验衍生回放机制,旨在提高多机械臂系统的运动规划的效率和性能。
2、本发明针对分散式多机械臂系统中,各机械臂如何控制末端执行器到达各自目标点且互不相碰的运动规划问题,提出一种事后成功经验衍生回放机制,在获得一次成功经验后,对某一机械臂初始状态和目标状态进行重新采样,在合理范围内改变各机械臂之间的位置关系,模拟多机械臂系统在更紧密的队形中做出相同的动作并且无碰撞地到达各自目标点,从较简单任务的成功经验衍生出较困难任务的成功经验,并放入经验缓冲池中,从而为经验回放机制提供更多的可用经验,改善机械臂的学习效果。在所述分散式多机械臂系统中,多机械臂的系统规模可扩展,且各机械臂之间无位置约束关系,机械臂经过训练学习到运动策略后,在不同规模、不同队形的多机械臂系统中皆能完成任务。
3、为了达到上述目的,本发明的技术方案如下:
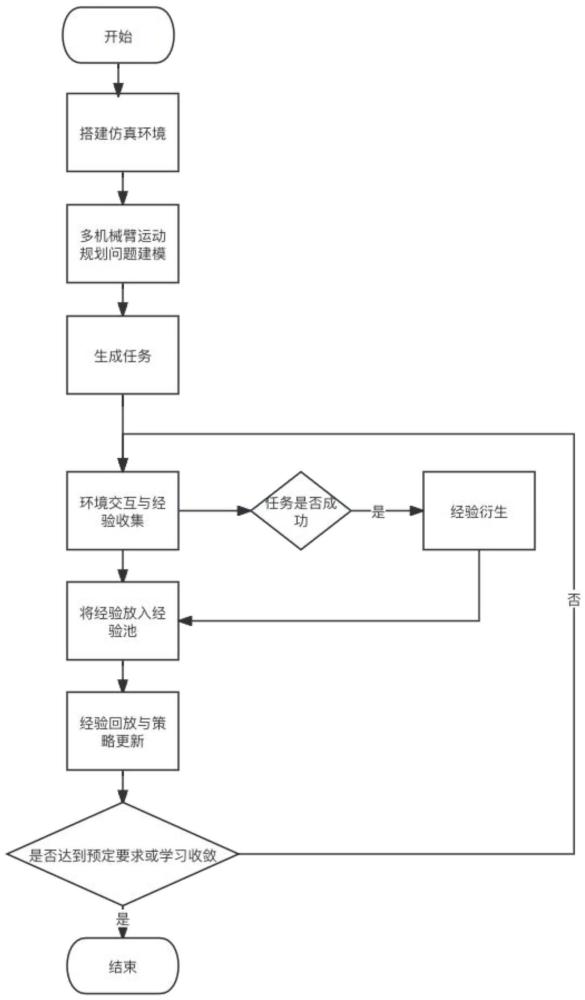
4、一种基于成功经验衍生回放机制的多机械臂运动规划方法,步骤如下:
5、步骤1:搭建仿真环境
6、选择一个仿真平台,导入多个机械臂的模型,并配置物理引擎,以模拟机械臂和环境之间的物理交互。物理引擎可以处理碰撞检测、物体运动等物理效应,确保仿真环境的真实性。
7、步骤2:多机械臂运动规划问题建模
8、将多机械臂系统看作是一个多智能体系统,其中一个机械臂看作是一个智能体,从而将多机械臂运动规划问题建模为多智能体部分可观测马尔可夫决策过程,用元组m=<n,s,a,o,p,r,>表示;
9、其中:n是智能体数量;
10、s是状态空间,表示环境的可能状态集合;
11、a是动作空间,表示智能体可以采取的行动集合,每个智能体在每个时间步都需要选择一个动作;
12、o是观测空间,表示智能体可以观测到的信息的集合,观测是智能体对环境状态的一种推断;
13、p是状态转移函数,描述在给定状态和动作下,环境状态如何转移的概率分布;
14、r是奖励函数,定义在每个时间步上,智能体获得的即时奖励。
15、多智能体部分可观测马尔可夫决策的求解是一个动态规划问题,目标是找到最优策略,使得智能体在部分可观测环境中获得最大累积奖励。
16、步骤3:生成任务
17、随机生成若干任务供后续多机械臂在不同的任务场景中与环境进行交互学习。根据分散式多机械臂系统运动规划问题,设定任务参数包含机械臂数量、机械臂初始姿态、目标末端执行器位姿。多机械臂系统中的所有机械臂在一定时间步长内都到达目标视为执行任务成功,若发生碰撞或存在未达到目标的机械臂则视为任务失败。
18、步骤4:环境交互
19、机械臂i根据读取到的任务,使用当前的策略与环境进行交互,并通过执行一系列动作来收集经验。每次机械臂与环境交互时,记录下当前状态、执行的动作、获得的奖励、下一个状态。其中,当前状态和下一个状态可以生成当前观测值、下一个观测值、动作值和奖励值共同形成一条完整的经验。与机械臂i的基座位置相邻且工作空间与自身有交集的所有机械臂为机械臂i的相邻机械臂组,机械臂i只观察相邻机械臂组的机械臂状态构成观测值。执行完一次任务通常对应于多个动作的序列,这些动作的经验会被逐步积累。当任务完成时,可以将整个任务的经验作为一个经验序列保存起来,以便后续的经验回放和训练。除此之外,在交互过程中还要额外维护一个机械臂i与相邻机械臂组之间的最小安全位移di,用于后续的经验衍生。其中,最小安全位移di的含义是:pi为任务中机械臂i的原始基座位置,将机械臂i的基座位置由pi移动到qi,保持交互过程中的动作序列不变,在整个交互过程中仍不会与相邻机械臂组发生碰撞。具体而言,qi的计算方式为qi=pi+di。
20、步骤5:经验衍生
21、根据任务成功与否来决定是否进行经验衍生。若任务成功,则在各机械臂与相邻机械臂组的最小安全位移中选择距离最大的一个机械臂i,记其最小安全位移为向量di,其方向为αi,距离为di。将机械臂i的基座位置与末端执行器目标位置同时在αi方向上增加一个小于di的随机值,使其与相邻机械臂组的距离更近,但执行相同动作仍能够无碰撞地达到目标点。通过这种变换,改变了当前观测值和下一个观测值,而保持经验序列中的动作值、奖励值和完成标志不变,从而衍生出一个更复杂的任务经验序列。最后,将两个经验序列都存储在经验回放缓冲区中。
22、步骤6:经验收集与策略更新
23、将环境交互过程中获得的原始经验和经验衍生步骤中获得的衍生经验存入经验回放缓冲区中,当缓冲区满时,从中随机选择一批经验用作训练数据,并将其用于优化神经网络或价值函数等模型参数。通过将这些经验与当前策略的预测结果进行比较,可以计算出更新的方向和幅度,从而更新机械臂的策略,以改进智能体的决策能力,使其能够更好地适应任务的要求。策略更新可以使用各种强化学习算法,如深度q网络(dqn)、确定性策略梯度(ddpg)等。
24、步骤7:重复步骤4至6
25、重复执行步骤4至6,直到机械臂运动规划策略的性能达到预定的要求或学习过程收敛。通过不断地与环境进行来生成经验、通过计算来衍生经验、回放经验来更新策略,机械臂可以逐步改进其学习能力和性能。
26、本发明的有益效果:
27、在机械臂基座位置不固定或可移动的分散式多机械臂系统中,任务的复杂度与各机械臂的距离有着密切关系。机械臂在与环境的交互中,首先在较简单的任务中学会怎样接近目标点,然后缓慢地在更复杂的任务中学习怎样与其他机械臂进行合作,互不干涉地到达各自目标点。本发明提出的成功经验衍生回放机制,可以帮助机械臂直接从较简单任务的成功经验中直接学习到更复杂任务的成功经验,在尽可能少的交互样本下,更快速地学习到一个良好的策略。同时,更大程度上地探索碰撞边界,提高样本多样性和覆盖率,有效帮助机械臂学习到工作空间高耦合环境下完成复杂任务的运动策略。
- 还没有人留言评论。精彩留言会获得点赞!