英语听力的训练方法及系统与流程
本发明涉及语言学习领域,特别涉及一种英语听力的训练方法及系统。
背景技术:
大多数人英语学不好,病根在于认字太早。语言首先是语音的集合,文字只是语音的记录。不管是英语还是汉语,母语儿童都是先花几年时间、积累大量语音词汇、贯通思维之后,才开始学习认字及阅读。而非母语的英语学习者在学习英语时基本上均是从一开始就伴随着阅读(认字也是一种阅读)。英语学习过程中,大量词汇积累和语法分析都是以阅读为基础,实际上也仅停留在阅读层面。而英语口语中句子的语音包含大量的连音、略音、弱化、浊化等现象,并不是单词标准读音的简单叠加;而是语音体系里的词汇和语法,其有着与书面文字体系所不同的呈现方式。再加上场景、情感等复杂因素,使得语音的表达更为丰富多变,但对于英语为非母语的英语学习者来说,辨识英语语音的难度却成倍增加。
缺乏语音专项训练的结果就是,很多看到能理解其含义的单词在真实语境中却听不清、听不懂。这里的语音训练,不是指单词发音对应拼写的训练,而是在语言环境下,对特定语音现象的敏感度以及语音组合和语义之间的联系。不幸的是,一直以来,这个问题没有得到足够的重视,也一直没有合适的方法和训练工具帮助实现从阅读认知到语音认知的转化。
技术实现要素:
本发明要解决的技术问题是为了克服现有技术中对于看到能理解其含义的英文语句在真实语境中却听不清、听不懂的缺陷,提供一种能够提高英语学习者的语音认知能力的英语听力的训练方法及系统。
本发明是通过下述技术方案来解决上述技术问题:
本发明提供了一种英语听力的训练方法,其特点在于,包括以下步骤:
S1、获取分级词库,所述分级词库中的单词分为隐藏词级别和显示词级别;获取视听资料的音视频数据以及对应的字幕数据;
S2、将所述字幕数据中所包括的每个单词与所述分级词库进行比对,以确定所述每个单词属于所述隐藏词级别或所述显示词级别,属于所述隐藏词级别的单词为第一类单词,属于所述显示词级别的单词为第二类单词;
S3、以字幕为单位播放所述音视频数据对应的片段,同步显示的字幕为待训练字幕,隐藏所述待训练字幕中的所述第一类单词,显示所述待训练字幕中的所述第二类单词;
S4、播放完所述待训练字幕后等待外部输入相应的待识别字幕;
S5、接收输入的所述待识别字幕,根据所述待训练字幕判断所述待识别字幕中的每个单词是否正确,若否提示输入出错。
本方案中,以每条字幕为最小单位播放音视频数据,每播放完一次后暂停等待外部输入,每次可以播放若干条字幕,英语学习者在看完一次播放对应的片段后根据其听到的内容输入所述待识别字幕,本方案中通过比对所述待训练字幕和待识别字幕,能够确定英语学习者是否听对隐藏的单词,若不对能够提示出错,以便英语学习者进一步训练,从而提高英语学习者的听力水平。
本方案中,通过区分隐藏和显示的字幕,目的是屏蔽文字干扰。只有在文字零干扰的状态下,大脑才有可能真正识别一些语音上细小的差别,并把听到的声音按其本源的状态真实记录下来,储存在大脑里,结合场景,作为以后语言理解之用。
本方案中,在音视频播放的过程中,对同步显示的文字资料即字幕中的已知单词进行隐藏,该已知单词通常为隐藏词级别的单词。通过在真实语境中对隐藏词级别的单词进行隐藏,然后再进行语音认知训练以及语音认知的结果的核对。本方案中,生词全部有文字提示,隐藏部分为已知单词,因此训练内容全部变成是英语学习者没有任何理解性思维难度的语音资料。本方案能够帮助英语学习者突破单词量的束缚,根据已知的核心单词,专项强化训练对于已知单词由阅读识别到语音识别的转化,建立新的语音认知模式,从而搭建英语思维体系,实现英语交流能力的提升。
较佳地,步骤S5中,若是则执行步骤S6;
S6、执行步骤S3,直至所述音视频数据播放完毕。
本方案中,针对一个音视频数据,语音认知训练过程中在听对一组字幕后能够继续播放下一组字幕,也就是下一个音视频片段,继续进行语音认知训练。本方案使得英语学习者能够在具有丰富内容和上下文语境的场景中,强化训练和提升英语的语音认知能力。
较佳地,步骤S5中,若否还包括以下步骤:
将所述待识别字幕中正确的单词作为第三类单词,错误的单词作为第四类单词,再次播放所述待训练字幕对应的所述片段,对同步显示的所述待训练字幕隐藏所述第四类单词,显示所述第二类单词和所述第三类单词,执行步骤S4。
本方案中,对于英语学习者听错的单词进行二次隐藏并继续进行语音认知训练,对于二次隐藏后再次听错的单词可以在再次播放时直接显示正确的答案,即显示之前不显示的单词。
本方案中,二次隐藏的设计使得英语学习者在进行语音识别训练的时候,将自己的问题细化到一句话中的某一个点或者某个音节。帮助英语学习者更细化、更聚焦的发现和突破语音识别的难点和瓶颈,提高英语能力。
较佳地,所述训练方法还包括以下步骤:
生成所述分级词库。
较佳地,
所述训练方法还包括以下步骤:
设置训练级别为M,M为大于等于1的自然数;
生成所述分级词库,包括以下步骤:
获取语料库;
计算所述语料库中每个单词的词频;
按照所述词频从高至低的顺序将所述语料库中的单词依次分成N组,N为大于等于2的自然数,所述词频最高的一组为第1组,前N-1组中每组所包括的单词的数量为一预设数量;
设置所述语料库中前M组所包括的单词的级别为所述隐藏词级别,设置所述语料库中组别大于M的组所包括的单词的级别为所述显示词级别。
本方案中,第N组包括所述语料库中的剩余的其它单词。
本方案中,通过选取合适的语料库,并根据语料库中每个词频的高低将语料库分成若干组,第一组为语料库中词频最高的前预设数量的单词,第二组为除了第一组所包括的单词之外词频最高的前预设数量的单词,其它组以此类推,最后一组则包括所述语料库中剩余的没有被分组的单词。本方案中,英语学习者能够根据自身的英语水平自定义合适的训练级别M,从而完成哪些单词隐藏,哪些单词显示的设置,使得本训练方法能够适合不同水平的英语学习者。
本方案中,统计单词在语料库中出现的频数,并且引入标准化频率的概念(简称词频)加以统计分析。词频(标准化频率/每千字)=(观察频数)/(总体频数)*1000,其中,观察频数即某特定单词实际出现的次数;总体频数即语料库的大小或总单词数量。将单词按照词频从高到低排序,词频越高的单词,在应用中越容易碰到,理论上也是英语学习者学习英语越应该先掌握的单词。
较佳地,所述语料库包括NGSL-S(New General Service List-Spoken,一种口语词频表)词频表。
本方案中,NGSL是基于CEC(Cambridge English Corpus,剑桥英语语料库)子库的2.7亿单词中精选的最常用2800单词,在语料中有超过92%的覆盖度。NGSL-S词频表是专门分析了NGSL语料库中的口语部分给出的词频统计词表,其同音视频数据匹配度更高。最近一次于2017年10月份更新。
较佳地,所述语料库还包括COCA语料库词表和王乐平所著的《1368个单词就够了》中的单词。
本方案中,COCA(Corpus of Contemporary American English,美国当代英语语料库)由美国杨伯翰大学开发,是当今世界上最大的可公开使用的美国英语的大型平衡语料库。库容为4.5亿词,每年更新,具有多种检索功能,可免费在线使用,也提供单词词频及相关数据。《1368个单词就够了》为北京联合出版社出版的一本书,作者王乐平。
较佳地,所述训练方法还包括以下步骤:
根据接收到的指令修改所述隐藏词级别的单词为所述显示词级别和/或修改所述显示词级别的单词为所述隐藏词级别。
本方案中,可以根据英语学习者输入的指令修改英语学习者指定的单词所属的级别,将其由隐藏词级别改为显示词级别,或者由显示词级别改为隐藏词级别,即实现了英语学习者自定义已知单词,使得已知单词即隐藏单词的设定变得可拆分、可细化、可定制,适用于任意英语学习者。
本发明还提供了一种英语听力的训练系统,其特点在于,包括第一获取模块、字幕比对模块、第一播放模块、等待模块以及识别模块;
所述第一获取模块,用于获取分级词库,所述分级词库中的单词分为隐藏词级别和显示词级别;所述第一获取模块还用于获取视听资料的音视频数据以及对应的字幕数据,调用所述字幕比对模块;
所述字幕比对模块,用于将所述字幕数据中所包括的每个单词与所述分级词库进行比对,以确定所述每个单词属于所述隐藏词级别或所述显示词级别,属于所述隐藏词级别的单词为第一类单词,属于所述显示词级别的单词为第二类单词,调用所述第一播放模块;
所述第一播放模块,用于以字幕为单位播放所述音视频数据对应的片段,同步显示的字幕为待训练字幕,隐藏所述待训练字幕中的所述第一类单词,显示所述待训练字幕中的所述第二类单词,调用所述等待模块;
所述等待模块,用于播放完所述待训练字幕后等待外部输入相应的待识别字幕调用所述识别模块;
所述识别模块,用于接收输入的所述待识别字幕,根据所述待训练字幕判断所述待识别字幕中的每个单词是否正确,若否提示输入出错。
较佳地,所述训练系统还包括第二播放模块,所述识别模块中若是则调用所述第二播放模块;
所述第二播放模块用于调用所述第一播放模块,直至所述音视频数据播放完毕。
较佳地,所述识别模块还用于在若否时将所述待识别字幕中正确的单词作为第三类单词,错误的单词作为第四类单词,再次播放所述待训练字幕对应的所述片段,对同步显示的所述待训练字幕隐藏所述第四类单词,显示所述第二类单词和所述第三类单词,调用所述等待模块。
较佳地,所述训练系统还包括词库生成模块;
所述词库生成模块,用于生成所述分级词库。
较佳地,
所述训练系统还包括第一设置模块;
所述第一设置模块,用于设置训练级别为M,M为大于等于1的自然数;
所述词库生成模块包括第二获取模块、词频计算模块、分组模块以及第二设置模块;
所述第二获取模块,用于获取语料库;
所述词频计算模块,用于计算所述语料库中每个单词的词频;
所述分组模块,用于按照所述词频从高至低的顺序将所述语料库中的单词依次分成N组,N为大于等于2的自然数,所述词频最高的一组为第1组,前N-1组中每组所包括的单词的数量为一预设数量;
所述第二设置模块,用于设置所述语料库中前M组所包括的单词的级别为所述隐藏词级别,设置所述语料库中组别大于M的组所包括的单词的级别为所述显示词级别。
较佳地,所述语料库包括NGSL-S词频表。
较佳地,所述语料库还包括COCA语料库词表和王乐平所著的《1368个单词就够了》中的单词。
较佳地,所述训练系统还包括第三设置模块;
所述第三设置模块,用于根据接收到的指令修改所述隐藏词级别的单词为所述显示词级别和/或修改所述显示词级别的单词为所述隐藏词级别。
本发明的积极进步效果在于:本发明提供的英语听力的训练方法及系统实现了在音视频播放过程中,对同步显示的字幕中的已知单词进行隐藏,即通过在真实语境中对隐藏词级别的单词进行隐藏,然后再进行语音认知训练以及语音认知的结果的核对。本发明中生词全部有文字提示,隐藏部分为已知单词,因此训练内容全部变成是英语学习者没有任何理解性思维难度的语音资料。本发明能够帮助英语学习者突破单词量的束缚,根据已知的核心单词,专项强化训练对于已知单词由阅读识别到语音识别的转化,建立新的语音认知模式,从而搭建英语思维体系,实现英语交流能力的提升。
附图说明
图1为本发明实施例1的英语听力的训练方法的流程图。
图2为图1中步骤S100的流程图。
图3为本发明实施例2的英语听力的训练系统的模块示意图。
具体实施方式
下面通过实施例的方式进一步说明本发明,但并不因此将本发明限制在所述的实施例范围之中。
实施例1
如图1所示,本实施例提供了一种英语听力的训练方法,包括以下步骤:
步骤S100、生成分级词库。
步骤S101、获取所述分级词库,所述分级词库中的单词分为隐藏词级别和显示词级别;获取视听资料的音视频数据以及对应的字幕数据;
步骤S102、将所述字幕数据中所包括的每个单词与所述分级词库进行比对,以确定所述每个单词属于所述隐藏词级别或所述显示词级别,属于所述隐藏词级别的单词为第一类单词,属于所述显示词级别的单词为第二类单词;
步骤S103、以字幕为单位播放所述音视频数据对应的片段,同步显示的字幕为待训练字幕,隐藏所述待训练字幕中的所述第一类单词,显示所述待训练字幕中的所述第二类单词;
步骤S104、播放完所述待训练字幕后等待外部输入相应的待识别字幕;
步骤S105、接收输入的所述待识别字幕,根据所述待训练字幕判断所述待识别字幕中的每个单词是否正确,若是执行步骤S106,若否执行步骤S107;
步骤S106、判断所述音视频数据是否播放完毕,若是则流程结束,若否则执行步骤S103;
步骤S107、提示输入出错,将所述待识别字幕中正确的单词作为第三类单词,错误的单词作为第四类单词,再次播放所述待训练字幕对应的所述片段,对同步显示的所述待训练字幕隐藏所述第四类单词,显示所述第二类单词和所述第三类单词,执行步骤S104。
本实施例中,所述训练方法还包括设置训练级别为M,M为大于等于1的自然数;
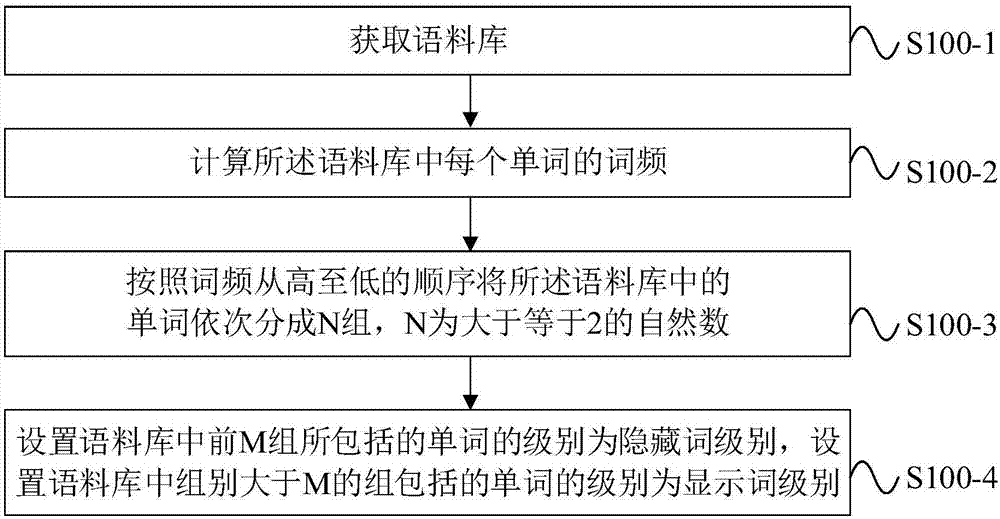
步骤S100包括如图2所示的步骤:
步骤S100-1、获取语料库,所述语料库包括NGSL-S词频表、COCA语料库词表和王乐平所著的《1368个单词就够了》中的单词;
步骤S100-2、计算所述语料库中每个单词的词频;
步骤S100-3、按照所述词频从高至低的顺序将所述语料库中的单词依次分成N组,N为大于等于2的自然数,所述词频最高的一组为第1组,前N-1组中每组所包括的单词的数量为一预设数量,第N组包括所述语料库中的剩余的其它单词;
步骤S100-4、设置所述语料库中前M组所包括的单词的级别为所述隐藏词级别,设置所述语料库中组别大于M的组所包括的单词的级别为所述显示词级别。
本实施例中,通过选取合适的语料库,并根据语料库中每个词频的高低将语料库分成若干组,第1组为语料库中词频最高的前预设数量的单词,第2组为除了第1组所包括的单词之外词频最高的前预设数量的单词,其它组以此类推,最后一组则包括所述语料库中剩余的没有被分组的单词。本实施例中,英语学习者能够根据自身的英语水平自定义合适的训练级别M,从而完成哪些单词隐藏,哪些单词显示的设置,使得本训练方法能够适合不同水平的英语学习者。
本实施例中,统计单词在语料库中出现的频数,并且引入标准化频率的概念加以统计分析。将单词按照词频从高到低排序,词频越高的单词,在应用中越容易碰到,理论上也是英语学习者学习英语越应该先掌握的单词。
本实施例中,所述训练方法还包括根据接收到的指令修改所述隐藏词级别的单词为所述显示词级别和/或修改所述显示词级别的单词为所述隐藏词级别。本实施例中,可以根据英语学习者输入的指令修改英语学习者指定的单词所属的级别,将其由隐藏词级别改为显示词级别,或者由显示词级别改为隐藏词级别,即实现了英语学习者自定义已知单词,使得已知单词即隐藏单词的设定变得可拆分、可细化、可定制,适用于任意英语学习者。本实施例中,英语学习者可以简单选定某一组单词为已知单词;还可以在某一组别内部选出部分单词标注为生词,进行更进一步定制化的已知单词的词表设定。
本实施例中,NGSL-S词频表基于专门的口语语料库,同音视频数据匹配度更高,本实施例中实际应用时选择了NGSL-S词频表的前一万个单词,具体数量可以根据训练情况调整。COCA语料库词表中的单词不是原形词,其中所包括的单词含单词变化形式。COCA的库容为4.5亿词的大型平衡语料库,含有多个字库,具有多种检索功能,可免费在线使用,本实施例中仅选择了COCA语料库词表的前六万个单词。《1368个单词就够了》为王乐平著,北京联合出版社的书籍。
基于本实施例提供的训练方法,生成分级词库并制作词表过程可以参考如下设置:
以口语语料为主,组织整理音视频、文字资料,自建语料库。将语料库内所有单词复原(将单词转换为其原形形式),然后所有原形词汇总,统计出现次数计算词频。按词频由高到低排序,每1千单词为一个级别,级别设定由低到高排序,即词频最高的1千单词组成1级单词,剩余单词中词频最高的1千词为2级单词,以此类推。同时参考权威词库对词频排序做调整,使得最终的词表的词频分布和对语料的覆盖度不仅仅适用于本自建的语料库,还具有普适性。比如,词表1级单词包含NGSL-S词频表的前822个单词(覆盖NGSL-S口语子库90%)。词表前3级单词包含NGSL-S前1850词(覆盖NGSL-S口语子库的95%)和《1368个单词就够了》书中列举的1368单词。经过统计、分析、归纳出的词表,1-3级单词共3千单词,可以满足中国人绝大多数情况下进行连续性英语思维的需要,也是英语学习者为掌握英语必须建立语音认知的单词。在按照词频分级建立词表的过程中,第5级单词是个例外。5级单词为自建语料库中,因为材料的自身属性而多次出现的专有单词,包括人名、地名、首字母缩写等等。随着自建语料库的更新或扩建,5级单词会相应调整。
本实施例中,针对一个音视频数据,语音认知训练过程中在听对一组字幕后能够继续播放下一组字幕,也就是下一个音视频片段,继续进行语音认知训练。
本实施例中,通过区分隐藏和显示的字幕,目的是屏蔽文字干扰。只有在文字零干扰的状态下,大脑才有可能真正识别一些语音上细小的差别,并把听到的声音按其本源的状态真实记录下来,储存在大脑里,结合场景,作为以后语言理解之用。
本实施例中,对于英语学习者听错的单词进行二次隐藏并继续进行语音认知训练,对于二次隐藏后再次听错的单词可以在再次播放时直接显示正确的答案,即显示之前不显示的单词。本实施例中,二次隐藏的设计,使得英语学习者在进行语音识别训练的时候,将自己的问题细化到一句话中的某一个点,或者某个音节。帮助英语学习者更细化、更聚焦的发现和突破语音识别的难点和瓶颈,提高英语能力。
本实施例中,以每条字幕为最小单位播放音视频数据,每播放完一次后暂停等待外部输入,每次可以播放若干条字幕,英语学习者在看完一次播放对应的片段后根据其听到的内容输入所述待识别字幕,本实施例中通过比对所述待训练字幕和待识别字幕,能够确定英语学习者是否听对隐藏的单词,若不对能够提示英语学习者出错,以便英语学习者进一步训练,从而提高英语学习者的听力水平。
本实施例中,在音视频播放的过程中,对同步显示的文字资料即字幕中的已知单词进行隐藏,该已知单词通常为隐藏词级别的单词。通过在真实语境中对隐藏词级别的单词进行隐藏,然后再进行语音认知训练以及语音认知的结果的核对。本实施例中,生词全部有文字提示,隐藏部分为已知单词,因此训练内容全部变成是英语学习者没有任何理解性思维难度的语音资料。本方案能够帮助英语学习者突破单词量的束缚,根据已知的核心单词,专项强化训练对于已知单词由阅读识别到语音识别的转化,建立新的语音认知模式,从而搭建英语思维体系,实现英语交流能力的提升。
采用本实施例提供的训练方法,结合训练资料即所述音视频数据的图像、上下文、情感、语言环境等等,通过强化训练,可以有效地帮助英语学习者建立语音、语义(场景)和思维的连接,把依赖于文字的阅读识别模式转化为语音认知模式,从而实现语音和思维的直接对接,真正掌握英语的语言交流能力。
实施例2
如图3所示,本实施例提供了一种英语听力的训练系统,包括词库生成模块1、第一设置模块2、第一获取模块3、字幕比对模块4、第一播放模块5、等待模块6、识别模块7、第二播放模块8以及第三设置模块9;
所述词库生成模块1,用于生成所述分级词库。所述词库生成模块1包括第二获取模块101、词频计算模块102、分组模块103以及第二设置模块104;所述第二获取模块101用于获取语料库;所述词频计算模块102用于计算所述语料库中每个单词的词频;所述分组模块103用于按照所述词频从高至低的顺序将所述语料库中的单词依次分成N组,N为大于等于2的自然数,所述词频最高的一组为第1组,前N-1组中每组所包括的单词的数量为一预设数量;所述第二设置模块104用于设置所述语料库中前M组所包括的单词的级别为所述隐藏词级别,设置所述语料库中组别大于M的组所包括的单词的级别为所述显示词级别。
所述第一设置模块2,用于设置训练级别为M,M为大于等于1的自然数。
所述第一获取模块3用于获取分级词库,所述分级词库中的单词分为隐藏词级别和显示词级别;所述第一获取模块3还用于获取视听资料的音视频数据以及对应的字幕数据,调用所述字幕比对模块4。
所述字幕比对模块4用于将所述字幕数据中所包括的每个单词与所述分级词库进行比对,以确定所述每个单词属于所述隐藏词级别或所述显示词级别,属于所述隐藏词级别的单词为第一类单词,属于所述显示词级别的单词为第二类单词,调用所述第一播放模块5。
所述第一播放模块5用于以字幕为单位播放所述音视频数据对应的片段,同步显示的字幕为待训练字幕,隐藏所述待训练字幕中的所述第一类单词,显示所述待训练字幕中的所述第二类单词,调用所述等待模块6。
所述等待模块6用于播放完所述待训练字幕后等待外部输入相应的待识别字幕调用所述识别模块7。
所述识别模块7用于接收输入的所述待识别字幕,根据所述待训练字幕判断所述待识别字幕中的每个单词是否正确,若是则调用所述第二播放模块8,若否提示输入出错,并将所述待识别字幕中正确的单词作为第三类单词,错误的单词作为第四类单词,再次播放所述待训练字幕对应的所述片段,对同步显示的所述待训练字幕隐藏所述第四类单词,显示所述第二类单词和所述第三类单词,调用所述等待模块6。
所述第二播放模块8用于调用所述第一播放模块5,直至所述音视频数据播放完毕。
所述第三设置模块9用于根据接收到的指令修改所述隐藏词级别的单词为所述显示词级别和/或修改所述显示词级别的单词为所述隐藏词级别。
本实施例中,所述语料库包括NGSL-S词频表、COCA语料库词表和王乐平所著的《1368个单词就够了》中的单词。
本实施例提出了一种英语学习的训练系统,本发明充分利用高频单词和英语学习者已知单词,训练从阅读认知到语音认知的转化。本训练系统包括单词的分级、阅读熟词(熟词即看到单词知晓其中文含义的单词或叫已知单词)的确定、真实语境中对已知单词的隐藏(或屏蔽)、语音认知训练、语音认知的结果的核对、已知单词的二次隐藏和语音认知训练的继续、语音认知训练内容(正确答案)的展示等步骤。
英语学习者通过本训练系统,对一句或者一段学习资料听了一遍或多次之后,需要输出听到的内容,可以采用复述(即语音输入)或者键盘打字的方式重复听到的内容。本训练系统对比英语学习者的输出内容,正确的部分给于显示,不正确的部分继续隐藏(即二次隐藏)。经过二次隐藏的内容,英语学习者可以选择手动查看正确答案。本实施例中二次隐藏的设计,一是方便英语学习者针对判断错误的部分深入练习,二是便于英语学习者发现自己不熟悉的语音细节,细化到句子中的一个词或一个音节,并相应强化训练,以加深印象和加速该语音现象的思维内化。
本训练系统能够帮助英语学习者突破单词量的束缚,根据已知的核心单词,建立新的语音认知模式,从而搭建英语思维体系,实现英语交流能力的提升。
虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理解,这仅是举例说明,本发明的保护范围是由所附权利要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改,但这些变更和修改均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!