声音识别装置及计算机程序的制作方法
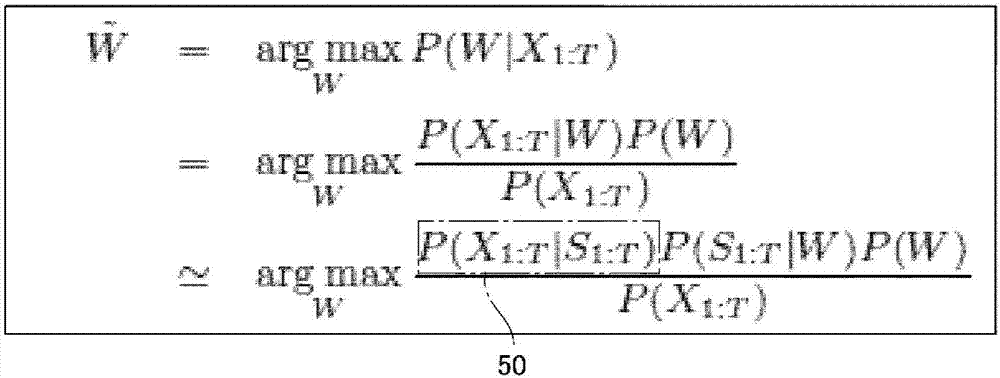
本发明涉及声音识别装置,特别涉及使用神经网络来进行高精度的声音识别的声音识别装置及其计算机程序。
背景技术:
使用基于声音的输入输出来作为人与计算机的接口的装置以及服务不断增加。例如在便携式电话的操作中也利用了基于声音的输入输出。在基于声音的输入输出中,需要尽可能提高构成其基础的声音识别装置的识别精度。
作为声音识别,一般的技术使用通过统计学上的机器学习而得到的模型。例如作为声学模型而使用hmm(隐马尔可夫模型)。另外,还使用:用于算出在声音识别的过程中生成的字符串能以何种程度的概率从hmm的状态串中得到的单词发声辞典;以及用于算出某语言的单词串以何种程度的概率出现的语言模型等。
为了进行这样的处理,现有的声音识别装置包含:帧化处理部,其将声音信号帧化;特征量生成部,其从各帧算出梅尔频率倒谱系数等特征量,生成多维的特征量矢量的序列;和解码器,其使用该特征量矢量的序列,输出用声学模型和语言模型给出该特征量矢量的序列的似然性最高的单词串,作为声音识别结果。在似然性计算中,来自构成声学模型的hmm的各状态的输出概率和状态过渡概率起到重要作用。这些都能通过机器学习而得到。输出概率用通过学习得到的高斯混合模型算出。
参考图1来说明现有的声音识别装置中的声音识别的基本思路。过去,认为单词串30(单词串w)会历经各种噪声的影响而作为观测序列36(观测序列x)被观测到,并输出给出最终的观测序列x的似然性最高那样的单词串作为声音识别的结果。在该过程中,用p(w)表征生成单词串w的概率。将从该单词串w起经过中间生成物即发声串32而生成hmm的状态序列s(状态序列34)的概率设为p(s|w)。进而,将从状态序列s得到观测x的概率用p(x|s)表征。
在声音识别的过程中,如图2的第1式所示那样,在给出开头到时刻t的观测序列x1:t时,将给出这样的观测序列的似然性成为最大那样的单词串作为声音识别的结果输出。即,声音识别的结果的单词串~w通过下式求取。另外,数学表达式中标记在字符的正上方的记号“~”在说明书中记载于紧挨字符之前的地方。
[数学表达式1]
若将该式右边通过贝叶斯式变形,则得到如下数学表达式。
[数学表达式2]
进而,该式的分子的第1项目能通过hmm如下那样求取。
[数学表达式3]
在该式中,状态序列s1:t表示hmm的状态序列s1、...、st。式(3)的右边的第1项表示hmm的输出概率。利用式(1)~式(3),声音识别的结果的单词串~w由下式求取。
[数学表达式4]
在hmm中,时刻t下的观测值xt仅依赖于状态st。因此,式(4)中的hmm的输出概率p(x1:t|s1:t)能通过下式算出。
[数学表达式5]
概率p(xt|st)通过高斯混合模型(gmm)算出。
式(4)的其他项当中的p(s1:t|w)通过hmm的状态过渡概率与单词的发声概率之积算出,p(w)通过语言模型算出。分母的p(x1:t)是对于各假设都共同的值,因此在argmax运算的执行时能够忽视。
最近,研究了不是通过gmm而是通过深度神经网络(dnn)算出hmm中的输出概率这样被称作dnn-hmm混合方式的框架。通过dnn-hmm混合方式达成了比利用gmm的声学模型高的精度,因而受到关注。这时,原本是dnn的输出表征后验概率p(st|xt),因此并不直接适合于利用了使用输出概率p(xt|st)的hmm的现有的机制。为了解决该问题,对dnn输出的后验概率p(st|xt)应用贝叶斯法则,变形成使用输出概率p(xt|st)的形式来使用。
现有技术文献
非专利文献
非专利文献1:c.weng,d.yu,s.watanabe,andb.-h.f.juang,“recurrentdeepneuralnetworksforrobustspeechrecognition,”inacoustics,speechandsignalprocessing(icassp),2014ieeeinternationalconferenceon.ieee,2014,pp.5532-5536.
技术实现要素:
发明要解决的课题
最近,作为应用于声学模型的神经网络,循环神经网络(rnn)受到关注。所谓rnn,是如下结构的神经网络:不仅包含从输入层侧向输出层侧的一个方向的节点间的结合,还包含了从输出侧的层向相邻的输入侧的层的节点间的结合、相同层内的节点间的结合、以及自回归结合等。由于该结构,rnn具备了能表征依赖于时间的信息这样的通常的神经网络中没有的特性。声音是典型的作为依赖于时间的信息。因此,认为rnn适于声学模型。
但是,在现有的研究中,利用rnn的声音识别装置的性能不太高。在非专利文献1中,报告了通过用将误差逆传播法改良后的学习方法进行学习的rnn,使用sigmoid型判别函数,相比过去得到4~7%的精度的提高。但是,非专利文献1公开的rnn的性能提高是与更小规模的dnn之间的比较,在与相同程度规模的dnn的比较中能得到怎样的结果,并不明确。另一方面,若并不限于rnn,对dnn也能用同样的手法来提高精度,则更加优选。
因此,本发明的目的在于,提供一种能有效利用神经网络的特性来提高声音识别精度的声音识别装置。
用于解决课题的手段
本发明的第1局面所涉及的声音识别装置包含:第1后验概率算出单元,其按每个状态序列算出给出由从声音信号得到的给定的声音特征量构成的观测序列时的状态序列的后验概率;第2后验概率算出单元,其针对各单词串算出给出状态序列时的单词串的后验概率;和用于以下处理的单元,即,使用针对输入观测序列由第1后验概率算出单元以及第2后验概率算出单元分别算出的后验概率,基于按与声音信号对应的单词串的每个假设算出的评分来进行针对声音信号的声音识别。
也可以,第2后验概率算出单元包含用于以下处理的单元,即,根据基于语言模型的单词串的发生概率、构成声学模型的hmm的状态过渡概率、和由第1后验概率算出单元算出的状态序列的发生概率,针对与声音信号对应的单词串的各假设算出后验概率。
优选地,构成状态序列的各状态是构成声学模型的hmm的状态。
更优选地,第1后验概率算出单元包含:神经网络,其是将观测序列作为输入并算出产生该观测序列的状态的后验概率那样的学习完毕的神经网络;和第1概率算出单元,其用于通过利用神经网络算出的后验概率的序列算出状态序列所发生的概率。
进一步优选地,神经网络是rnn或dnn。
本发明的第2局面所涉及的计算机程序使计算机作为上述任意的声音识别装置的全部单元起作用。
附图说明
图1是表示现有的声音识别的思路的图。
图2是表示构成现有的声音识别的基础的数学表达式的图。
图3是示意表示通常的dnn的构成的图。
图4是示意表示rnn的构成和不同时刻的rnn的节点间的结合的示例的图。
图5是表示本发明的1个实施方式中的声音识别的思路的图。
图6是表示构成本发明的1个实施方式中的声音识别的基础的数学表达式的图。
图7是表示本发明的1个实施方式所涉及的声音识别装置的构成的框图。
图8是表示实现本发明的1个实施方式所涉及的声音识别装置的计算机的外观的图。
图9是表示图8所示的计算机的硬件构成的框图。
具体实施方式
在以下的说明以及附图中,对同一部件标注同一参考编号。因此,不再重复对它们的详细说明。
最初,说明dnn与rnn的不同。参考图3,dnn70包含输入层72以及输出层78、和设置于输入层72与输出层78之间的多个隐含层74以及76。在该示例中,隐含层仅示出2层,但隐含层的数量并不限定于2。各层具有多个节点。在图3中,各层中的节点数都是5个,是相同的,但它们的数量通常各种各样。相邻的节点间相互结合。但是,数据仅从输入层侧向输出层侧在一个方向上流动。对各结合分配权重以及偏置。这些权重以及偏置通过使用了学习数据的误差逆传播法来学习。
在dnn70中,若在时刻t对输入层72给出时刻t下的声音特征量xt,就从输出层78输出状态预测值st。在声学模型的情况下,输出层78的节点数大多设计成与成为对象的语言的音素的数量一致,在该情况下,各节点表示所输入的声音特征量是该节点所表征的音素的概率。因此,若将输出层78的各节点输出的状态预测值相加,则成为1。
另一方面,图4示出rnn的构成的示例。图4表示时刻t-1下的rnn100(t-1)、时刻t下的rnn100(t)、和时刻t+1下的rnn(t+1)之间的关系。在该示例中,rnn100(t)的隐含层内的各节点不仅接受输入层的各节点的输出,还接受rnn100(t-1)的自己本身的输出。即,rnn100能生成针对所输入的声音特征量的时间序列的输出。
通过dnn求得的是p(st|xt)。即,是在时刻t观测特征量xt时的hmm的状态st的概率。hmm的状态st与音素对应。另一方面,通过rnn求得的是p(st|x1,...,xt)。即,是观测观测序列x1:t时的hmm的状态st的概率。
若将其与式(5)比较,则可知,在dnn的情况下,不能将该输出直接应用到式(5)中。因此,过去如以下所示那样使用贝叶斯法则将dnn的输出变换成p(xt|st)。
[数学表达式6]
在式(6)中,p(xt)在各hmm的状态中是共同的,因此在argmax运算中能够忽视。p(st)能通过在被校准后的学习数据中数出各状态的数量来估计。
结果是,在dnn-hmm混合方式的情况下,通过用dnn的输出p(st|xt)除以概率p(st),从而在现有的利用hmm的机制中使用dnn来计算识别评分。
另一方面,若取代dnn而利用rnn,就能将声音的时间序列的信息有效利用于声音识别中,能期待提高精度。但是,已知,在现有的dnn-hmm混合方式中单纯将dnn置换成rnn的尝试除了一部分以外,其他都只能带来比dnn精度低的结果。虽然也有非专利文献1那样相比利用dnn的情况提高了精度的报告,但是与比rnn规模小的dnn进行比较等,由于使用了rnn,因此不能实现精度变高。如此,在rnn中精度不能变高被认为是出于以下那样的理由。
给出观测序列x1:t的情况下的rnn的输出成为与状态相关的后验概率p(st|x1:t)。若与dnn-hmm混合方式同样地用该输出除以概率p(st),则如下式(7)所示那样,求得的不是本来需要的p(xt|st)(由上述式(6)的左边表征),而是p(x1:t|st)。
[数学表达式7]
p(x1:t|st)由于并不与p(xt|st)成正比,因此不能用在式(5)中。这是因为在时刻t下的状态st与这以前的观测序列x1:t之间存在强的依赖关系。该评分本身包含丰富的信息,但在hmm的机制中无法很好地处理。
出于这样的原因,在rnn的情况下,认为即使要在与dnn-hmm混合方式相同的机制下计算评分,精度也会变低。
因此,为了有效利用rnn的特征来进行精度高的声音识别,需要使用dnn-hmm混合方式以外的机制。图5示出这样的新的机制。本实施方式涉及按照该机制进行声音识别的装置。如前述那样,rnn的输出是后验概率p(st|x1:t)。在本实施方式中,采用有效利用这样的rnn的特性来进行声音识别的思路。
参考图5,在本实施方式中,从观测序列36(观测序列x)中求取状态序列34的概率,进而从各状态串34经过发声串32求取单词串w30的概率,最终输出概率成为最大的单词串w30作为声音识别结果。从观测序列36(观测序列x1:t)得到状态序列s1:t的概率是p(s1:t|x1:t),从状态序列s1:t得到单词串w的概率是p(w|s1:t)。即,通过图6中也示出的以下式子得到针对观测序列x1:t的声音识别结果的单词串~w。
[数学表达式8]
该式子的前半部分意味着通过求取在观测特征量x1:t时成为概率最大的单词串~w来进行声音识别。式子的后半部分意味着单词串w的概率p(w|x1:t)用从特征量x生成状态序列s1:t的概率p(s1:t|x1:t)与从状态序列s1:t生成单词串w的概率p(w|s1:t)之积求得。
在该式中,图6中以参考标号122示出的项目即p(w|s1:t)能通过以下的式(8)计算。
[数学表达式9]
式(8)当中的分子是在现有的手法的式(4)中也出现的式子,能与过去同样计算。分母是状态序列s1:t的语言概率,能通过下式(9)进行近似。若使用该式,p(s1:t)就能使用n元语言模型计算。
[数学表达式10]
另一方面,由图6的参考标号120示出的项目即p(s1:t|x1:t)能如下那样进行近似。
[数学表达式11]
上式的前半部分遵循贝叶斯法则严格成立。后半部分的近似设想了状态st不依赖于未来的观测序列x(t+1):t。虽然通常不能这样进行近似,但若以观测值xt中充分反映了未来的观测序列这点为前提,该近似就成立。因此,在该概率的学习时,利用将包含成为对象的时间点之后的时间点的矢量的连续的特征量矢量(例如对象时间点的矢量和其前后的矢量)衔接在一起而生成的大的特征量矢量,或者将附加在观测序列的标签向后错开。在本实施方式中,使用将对象时间点的矢量与其前后的矢量结合后得到的矢量,进而使用将标签向后错开的矢量。
该最后的式子能进一步如下那样进行近似。
[数学表达式12]
在该变形中,设想了后验概率p(st|s1:t-1,x1:t)能以rnn输出的概率p(st|x1:t)充分近似。这不一定非要以st和s1:t-1是独立的这点为前提。即使在两者之间存在强的依赖关系,rnn只要有足以从观测序列x1:t算出状态st的能力,该近似就成立。实际上,若在理论上考虑,该近似是非常粗略的近似,但如后述那样,在模拟中,能通过该方法提高声音识别的精度。
若将图6所示的式子和式(8)~式(10)综合,则结果是,在现有方法中,如式(6)所示那样,在各时刻进行用各时刻t下的dnn的输出除以概率p(st),来算出识别评分,与此相对,在本实施方式所涉及的手法中,如下式(12)所示那样,通过用关于某假设的rnn的输出(的积)除以概率p(s1:t)来算出假设的识别评分。
[数学表达式13]
即,使用用rnn的输出除以p(s1:t)而得到的值来算出各假设的识别评分。在式(12)中,rnn的输出在各时间点得到,但其他值全都能基于事前的学习算出。在该计算中直接使用rnn的输出,不需要如现有的dnn-hmm混合方式那样强制将dnn的输出变换成hmm的输出形式。将这样的方式在这里称作直接解码方式。
另外,还能取代基于式(9)的近似而采用其他近似。例如还能使用如下那样粗略的近似。
[数学表达式14]
或者还能使用如下那样的近似。
[数学表达式15]
其他还考虑各种近似的方法。
本实施方式所涉及的声音识别装置如上述那样将rnn作为声学模型利用,采用使用了其输出的直接解码方式。
参考图7,本实施方式所涉及的声音识别装置280具备进行针对输入声音282的声音识别并将其输出为声音识别文本284的功能。声音识别装置280包含:a/d变换电路300,其对输入声音282进行模拟/数字(a/d)变换并输出为数字信号;帧化处理部302,其将a/d变换电路300输出的数字化的声音信号帧化,以给定长度以及给定移位量重复一部分地进行帧化;和特征量提取部304,其通过对帧化处理部302输出的各帧进行给定的声学处理来提取该帧的声音特征量,并输出特征量矢量。在各帧以及特征量矢量中附加输入声音282的例如相对于开头的相对时刻等信息。作为特征量而使用mfcc(mel-frequencycepstrumcoefficient:梅尔频率倒谱系数)、其一次微分、二次微分、以及功率等。
声音识别装置280还包含:特征量存储部306,其用于临时存储特征量提取部304输出的特征量矢量;声学模型308,其由rnn构成,将存储于特征量存储部306的特征量矢量作为输入,输出按每个音素表示各时刻下的各帧与某音素对应的后验概率的矢量;和解码器310,其用于使用声学模型308输出的矢量,通过wfst(加权有限状态转换机)输出作为与输入声音282对应的声音识别文本284概率最高的单词串,且基于如后述那样在本说明书中命名为s-1hclg的wfst。采用由rnn构成的声学模型308这一点和作为声音识别解码器而使用遵循直接解码方式预先构成的wfst这一点与以往不同。
声音识别解码器310包含:wfst320,其基于s-1hclg,使用利用声学模型算出的状态序列的后验概率来算出多个假设(单词串)发生的概率,并作为识别评分输出;和假设选择部322,其基于利用wfst320算出的识别评分来输出概率最高的假设作为声音识别文本284。
基于wfst的声音识别如以下那样。作为状态过渡机的模型,已知有限自动机。有限自动机是形成计算理论的基础的概念,作为其一种而有:对所输入的记号串进行基于预先确定的规则的状态过渡,根据状态过渡的结果来决定是否受理所输入的记号串。wfst从这样的自动机派生而来,是受理某记号串来进行状态过渡且同时输出其他记号串的变换机。wfst能表征为由节点和连结节点间的弧构成的图表。节点表征状态,弧表征状态过渡。对各弧赋予输入记号和输出记号。能通过对各弧进一步附加权重来表征概率这样的概念。通过从根节点顺着各弧前进来生成假设,通过与分配给这些弧的权重(概率)相乘,从而能计算该假设的发生概率。
在声音识别中使用各种模型。hmm、单词发声辞典以及语言模型都能以wfst表征。进而,近年来,为了表征音素的上下文关系而利用基于音素单位的三音素hmm,这也能以wfst表征。单词发声辞典是将音素串变换成单词串的wfst,为了求取词汇而使用。语言模型例如是三元的语言模型,是输出输入单词串和同一输出单词串的wfst,表征语言的语法。
在wfst中存在合成这样的运算。通过将2个wfst合成,能用1次合成后wfst进行阶段性应用2个wfst的处理。因此,能将上述的hmm、单词发声辞典、语言模型以及三音素hmm的wfst的组合合成来做出1个wfst。解码器310是使用如此预先进行学习而合成的wfst的解码器。这里使用的wfst是由与语言相关的知识预先构建的图表,使用被称作hclg的知识源。hclg是4个wfst(h,c,l,g)的合成。分别是,h表征hmm,c表征上下文关系,l表征词汇,g表征语法。本实施方式的声音识别解码器的wfst进一步合成嵌入了用于进行上述的基于p(s1:t)的除法计算(p(s1:t)-1)的wfst。该wfst是从hmm的状态序列向hmm的状态序列的wfst,对各弧赋予对p(s1:t)-1进行近似的p(st|s(t-n+1):(t-1))-1。因此,将该wfst在这里简记为“s-1hclg”。
构成本实施方式所涉及的声学模型308的rnn的输入层的节点的数量与特征量矢量的要素的数量一致。rnn的输出层的节点的数量与以声音识别装置280所处理的语言来设想的音素的数量一致。即,各节点表征基于hmm的声学模型的各状态。对输出层的各节点输出在某时刻输入的声音是该节点所表征的音素的概率。因此,声学模型308的输出是以该时刻下的输入声音是各节点所表征的音素的概率为要素的矢量。
基于s-1hclg的解码器310利用基于所述s-1hclg的wfst320针对声学模型308输出的矢量的各要素进行音素串的概率计算,一边适当地进行剪枝一边顺着wfst的图表前进,由此来进行包含假设和概率计算的识别评分的计算。假设选择部322最终输出识别评分最高的(发生概率高的)单词串作为声音识别文本284。这时,wfst320一边直接使用rnn的输出一边计算识别评分。不需要如现有的dnn-hmm框架那样配合hmm的输出形式来对rnn的输出进行变换,能提高识别的效率。
[实验1]
为了确认上述实施方式所涉及的利用rnn的直接解码方式的效果,针对利用dnn的现有方式、利用rnn的现有方式、以及上述实施方式所涉及的利用rnn的直接解码方式使用相同的学习数据进行学习,使用相同的测试数据来调查单词错误率。将其结果在以下的表格1中示出。
[表1]
如从表格1所明确的那样,若使用上述实施方式的直接解码方式,在参数数量7m的rnn中也会发挥参数数量35m的现有手法以上的性能。另外,在利用rnn的直接解码方式中,还可知至少在实验的范围中,通过增加参数数量而提高了识别性能。
[实施方式的效果]
上述实施方式涉及取代dnn-hmm混合方式而利用rnn的直接解码方式的声音识别装置。根据实验结果可知,直接解码方式的声音识别手法以比dnn-hmm混合方式小的构成示出同等以上的性能。
[基于计算机的实现]
本发明的实施方式所涉及的声音识别装置280能通过计算机硬件和在该计算机硬件上执行的计算机程序来实现。图8表示该计算机系统330的外观,图9表示计算机系统330的内部构成。
参考图8,该计算机系统330包括:具有存储器端口352以及dvd(digitalversatiledisc,数字多功能盘)驱动器350的计算机340、键盘346、鼠标348、和监视器342。
参考图9,计算机340除了存储器端口352以及dvd驱动器350以外,还具备:cpu(中央处理装置)356;与cpu356、存储器端口352以及dvd驱动器350连接的总线366;存储引导程序等的读出专用存储器(rom)358;与总线366连接并存储程序命令、系统程序以及作业数据等的随机存取存储器(ram)360;和硬盘354。计算机系统330还包含提供向能与其他终端通信的网络368连接的网络接口(i/f)344。
用于使计算机系统330作为上述的实施方式所涉及的声音识别装置280的各功能部起作用的计算机程序存储在安装于dvd驱动器350或存储器端口352的dvd362或可移动存储器364中,进而被转发给硬盘354。或者,程序也可以经过网络368发送到计算机340,并存储到硬盘354。程序在执行时被载入到ram360。也可以从dvd362、从可移动存储器364或经过网络368直接将程序载入到ram360。
该程序包含由用于使计算机340作为上述实施方式所涉及的声音识别装置280的各功能部起作用的多个命令构成的命令串。使计算机340进行该动作所需的基本的功能中的几个通过在计算机340上动作的操作系统或第三方的程序或安装在计算机340的可动态链接的各种编程工具包或程序库提供。因此,该程序本身不一定非要包含实现本实施方式的系统、装置以及方法所需的全部功能。该程序通过以命令当中的被控制成能得到期望的结果的做法在执行时动态调用合适的功能或编程工具包或程序库内的合适的程序,从而仅包含实现作为上述的系统、装置或方法的功能的命令即可。当然,也可以仅用程序来提供全部所需的功能。
本次公开的实施方式仅是例示,本发明并不仅限制在上述的实施方式。本发明的范围在参酌发明的详细的说明的记载的基础上由权利要求书的各项权利要求示出,包含与其中所记载的语句等同的意义以及范围内的全部变更。
产业上的可利用性
本发明能利用在使用rnn的人工智能的构建以及动作中,特别能利用在高精度地提供声音识别等复杂的功能的装置的制造产业以及提供利用这样的功能的服务的产业中。
标号的说明
30单词串
32发声串
34状态序列
36观测序列
70dnn
72输入层
74、76隐含层
78输出层
100rnn
280声音识别装置
282输入声音
284声音识别文本
300a/d变换电路
302帧化处理部
304特征量提取部
306特征量存储部
308声学模型
310解码器
320基于s-1hclg的wfst
330计算机系统
340计算机
354硬盘
356cpu
358rom
360ram
- 还没有人留言评论。精彩留言会获得点赞!