基于自适应高斯聚类的非平行文本条件下的语音转换方法与流程
本发明涉及一种语音转换技术,尤其是一种非平行文本条件下的语音转换方法,属于语音信号处理技术领域。
背景技术:
语音转换是语音信号处理领域近年来新兴的研究分支,是在语音分析、识别和合成的研究基础上进行的,同时在此基础上发展起来的。
语音转换的目标是改变源说话人的语音个性特征,使之具有目标说话人的语音个性特征,也就是使一个人说的语音经过转换后听起来像是另一个人说的语音,同时保留语义。
大多数的语音转换方法,尤其是基于gmm的语音转换方法,要求用于训练的语料库是平行文本的,即源说话人和目标说话人需要发出语音内容、语音时长相同的句子,并且发音节奏和情绪等尽量一致。然而在语音转换的实际应用中,获取大量的平行语料殊为不易,甚至无法满足,此外训练时语音特征参数矢量对齐的精确度也成为语音转换系统性能的一种制约。无论从语音转换系统的通用性还是实用性来考虑,非平行文本条件下语音转换方法的研究都具有极大的实际意义和应用价值。
目前非平行文本条件下的语音转换方法主要有两种,基于语音聚类的方法和基于参数自适应的方法。基于语音聚类的方法,是通过对语音帧之间距离的度量或者在音素信息的指导下选择相对应的语音单元进行转换,其本质是一定条件下将非平行文本转化为平行文本进行处理。该方法原理简单,但要对语音文本内容进行预提取,预提取的结果会直接影响语音的转换质量。基于参数自适应的方法,是采用语音识别中的说话人归一化或自适应方法对转换模型的参数进行处理,其本质是使得预先建立的模型向基于目标说话人的模型进行转化。该方法能合理地利用预存储的说话人信息,但通常自适应过程会引起频谱的平滑,导致转换语音中的说话人个性信息不强。
技术实现要素:
本发明所要解决的技术问题是:提供一种在非平行文本条件下,能够根据目标说话人的不同,而自适应地确定gmm混合度的语音转换方法,达到增强转换语音中说话人个性特征的同时改善转换语音的质量。
本发明为解决上述技术问题采用以下技术方案:
本发明提出一种基于自适应高斯聚类的非平行文本条件下的语音转换方法,包括训练阶段和转换阶段,其中所述训练阶段包括如下步骤:
步骤1,输入源说话人和目标说话人的非平行训练语料;
步骤2,使用ahocoder语音分析模型分别提取源说话人的非平行训练语料的mfcc特征参数x、目标说话人的非平行训练语料的mfcc特征参数y,以及源语音基频logf0x和目标语音基频logf0y;
步骤3,对步骤2中的mfcc特征参数x、y,进行单元挑选和声道长度归一化相结合的语音特征参数对齐和动态时间规整,从而将非平行语料转变成平行语料;
步骤4,使用期望最大化em算法进行自适应混合高斯模型agmm训练,agmm训练结束,得到后验条件概率矩阵p(x|λ),并保存agmm参数λ;
步骤5,利用步骤3得到的源语音特征参数x和目标语音特征参数y,使用步骤4中的后验条件概率矩阵p(x|λ)进行双线性频率弯折blfw+幅度调节as训练,得到频率弯折因子α(x,λ)和幅度调节因子s(x,λ),从而构建blfw+as转换函数;使用对数基频的均值和方差建立源语音基频logf0x和目标语音基频logf0y之间的基频转换函数;
所述转换阶段包括如下步骤:
步骤6,输入待转换的源说话人语音;
步骤7,使用ahocoder语音分析模型提取源说话人语音的mfcc特征参数x′和对数基频logf0x′;
步骤8,使用步骤4中agmm训练时得到的参数λ,求取后验条件概率矩阵p′(x|λ);
步骤9,使用步骤5中得到的blfw+as转换函数,求得转换后的mfcc特征参数y′;
步骤10,使用步骤5得到的基频转换函数由对数基频logf0x′得到转换后的对数基频logf0y′;
步骤11,使用ahodecoder语音合成模型将转换后的mfcc特征参数y′和对数基频logf0y′合成得到转换后的语音。
进一步的,本发明所提出的语音转换方法,步骤3具体过程如下:
3-1)采用双线性频率弯折方法对源语音mfcc特征参数进行声道长度归一化处理;
3-2)对于给定的n个源语音mfcc特征参数矢量{xk},通过公式(1)来动态地寻找n个目标语音特征参数矢量{yk},使得距离耗费函数值c({yk})最小;
c({yk})=c1({yk})+c2({yk})(1)
其中,c1({yk})和c2({yk})分别由下式表示:
其中,d(xk,yk)函数表示源语音和目标语音特征参数矢量之间的频谱距离,参数γ表示在特征参数帧对齐的准确度和帧间连续性之间的平衡系数,且有0≤γ≤1;c1({yk})表示的是源语音特征参数矢量和目标语音特征参数矢量之间的频谱距离耗费函数,c2({yk})表示的是经单元挑选的目标语音特征参数矢量之间频谱距离耗费函数;
3-3)通过对公式(1)进行多元线性回归分析,得到与源语音特征参数矢量对齐的目标语音特征参数序列集合
通过上述步骤,将非平行的mfcc特征参数x、y转变为平行的语料。
进一步的,本发明所提出的语音转换方法,对于公式(4)的求解,使用维特比搜索方法来优化算法的执行效率。
进一步的,本发明所提出的语音转换方法,步骤4的训练过程如下:
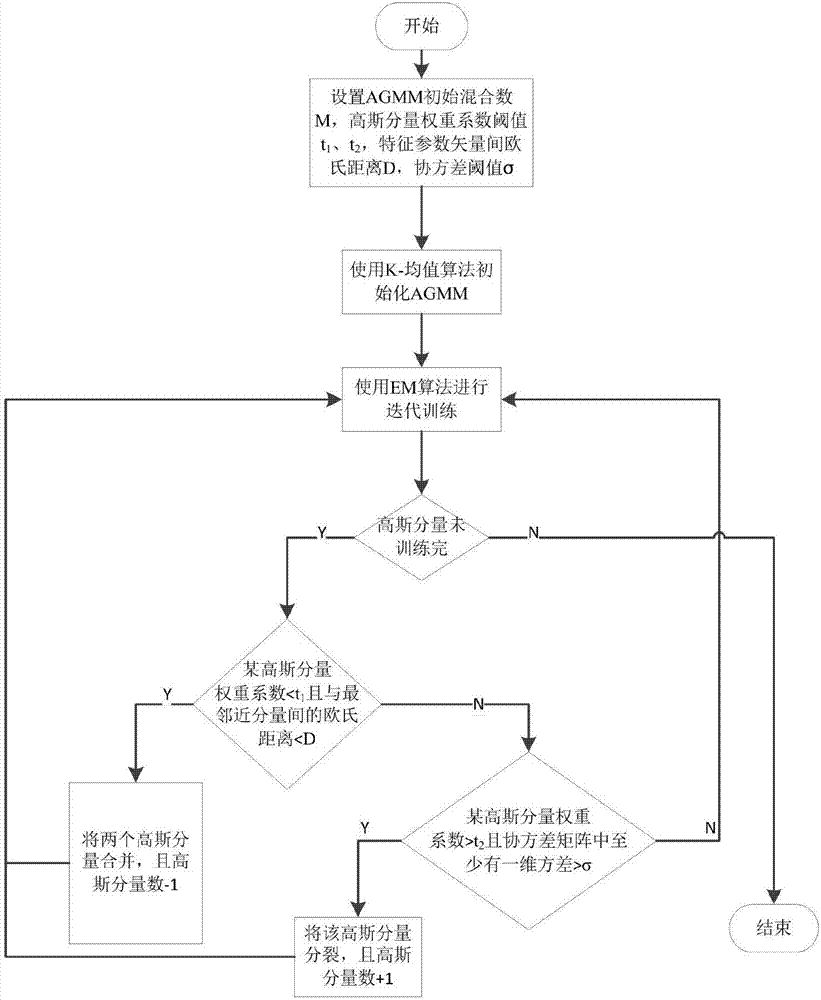
4-1)设定agmm初始混合数m,高斯分量权重系数阈值t1,t2,特征参数矢量之间欧氏距离阈值d和协方差阈值σ;
4-2)使用k-均值迭代算法得到em训练的初始值;
4-3)使用em算法进行迭代训练;将高斯混合模型gmm表示如下:
其中,x为p维的语音特征参数矢量,p=39;p(wi)表示各高斯分量的权重系数,且有
其中μi为均值矢量,∑i为协方差矩阵,λ={p(wi),μi,σi},λ是gmm模型的模型参数,对λ的估算通过最大似然估计法实现,对于语音特征参数矢量集合x={xn,n=1,2,...n}有:
此时:
λ=argλmax(p(x|λ))(8)
使用em算法求解公式(8),随着em计算过程中迭代条件满足p(x|λk)≥p(x|λk-1),
k是迭代的次数,直至模型参数λ,迭代过程中高斯分量权重系数p(wi)、均值向量μi、协方差矩阵σi的迭代公式如下:
4-4)若训练得到的模型中某一高斯分量n(p(wi),μi,∑i)权重系数小于t1,并且与其最邻近分量n(p(wj),μj,σi)之间的欧氏距离小于阈值d,则对其进行合并处理:
此时,高斯分量个数变为m-1,返回步骤4-3)进行下一次训练,若满足合并条件的高斯分量有多个,则选择最小距离的高斯分量进行合并;
4-5)若训练得到的模型中某一高斯分量n(p(wi),μi,∑i)权重系数大于t2,并且协方差矩阵中有至少一维的方差大于σ,则认为该高斯分量包含过量信息,应将其分裂处理:
其中e为全1的列向量,n用于调节高斯分布,经过分裂后高斯分量个数变为m+1,如果满足分裂条件的高斯分量有多个,则选取权重系数最大的分量进行分裂,返回步骤4-3)进行下一次训练;
4-6)agmm训练结束,得到后验条件概率矩阵p(x|λ),保存λ。
进一步的,本发明所提出的语音转换方法,步骤5中构建的blfw+as转换函数,表示如下:
f(x)=wα(x,λ)x+s(x,λ)(15)
其中,m为步骤4中混合高斯模型的高斯分量的个数,α(x,λ)表示频率弯折因子,s(x,λ)表示幅度调节因子。
进一步的,本发明所提出的语音转换方法,步骤5中建立源语音基音频率和目标语音基音频率之间的转换关系:
其中μ,σ2分别表示对数基音频率logf0的均值和方差。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
1、本发明实现了非平行文本条件下的语音转换,解决了平行语料不易获取的问题,提高了语音转换系统的通用性和实用性。
2、本发明使用agmm和blfw+as相结合来实现语音转换系统,该系统能够根据不同说话人的语音特征参数分布,自适应调节gmm的分类数,在增强语音个性相似度的同时改善了语音质量,实现了高质量的语音转换。
附图说明
图1是本发明的非平行文本语音转换的示意图。
图2是自适应高斯混合模型训练流程图。
图3是转换后语音的语谱对比图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
本技术领域技术人员可以理解的是,除非另外定义,这里使用的所有术语(包括技术术语和科学术语)具有与本发明所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样定义,不会用理想化或过于正式的含义来解释。
本发明所述高质量语音转换方法分为两个部分:训练部分用于得到语音转换所需的参数和转换函数,而转换部分用于实现源说话人语音转换为目标说话人语音。
如图1,训练部分实施步骤:
步骤1,输入源说话人和目标说话人的语音非平行语料,非平行语料取自cmu_us_arctic语料库,该语料库是由卡内基梅隆大学语言技术研究所建立的,语料库中的语音由5男2女录制,每个说话人录制了1132段1~6s不等的语音。
步骤2,本发明使用ahocoder语音分析模型分别提取源说话人和目标说话人的梅尔倒谱系数(mfcc,mel-frequencycepstralcoefficient)x、y以及对数基音频率参数logf0x和logf0y。其中ahocoder是西班牙毕尔巴鄂(bilbao)市aholabsignalprocessinglaboratory学者danielerro团队构建的高性能的语音分析合成工具;
步骤3,对步骤2中的源和目标语音的mfcc参数x、y进行单元挑选(unitselection)和声道长度归一化(vtln,vocaltractlengthno6rmalization)相结合的语音特征参数对齐和动态时间规整(dtw,dynamictimewarping)。其中语音特征参数对齐具体过程如下:
3-1)采用双线性频率弯折方法对源语音特征参数进行声道长度归一化处理,使得源语音的共振峰向目标语音靠近,从而增加单元挑选目标语音特征参数的精确性。
3-2)对于给定的n个源语音特征参数矢量{xk},可通过公式(1)来动态地寻找n个目标语音特征参数矢量{yk},使得距离耗费函数值c({yk})最小。在单元挑选的过程中考虑到两个因素:一方面是保证对齐的源语音特征参数矢量和目标语音的特征参数矢量之间的频谱距离最小,以增强音素信息的匹配度;另一方面是保证挑选到的目标语音特征参数矢量具有帧连续性,以使得音素信息更完整。
c({yk})=c1({yk})+c2({yk})(1)
其中,c1({yk})和c2({yk})分别可由下式表示:
其中,d(xk,yk)函数表示源和目标特征参数矢量之间的频谱距离,本发明采用欧氏距离作为距离衡量尺度。参数γ表示在特征参数帧对齐的准确度和帧间连续性之间的平衡系数,且有0≤γ≤1。c1({yk})表示的是源语音特征参数矢量和目标语音的特征参数矢量之间的频谱距离耗费函数,c2({yk})表示的是经单元挑选的目标语音的特征参数矢量之间频谱距离耗费函数。
3-3)通过对公式(1)进行多元线性回归分析,可以得到与源语音特征参数矢量对齐的特征参数序列集合
对于公式(4)的求解,可使用维特比(viterbi)搜索方法来优化算法的执行效率。
通过上述步骤,将非平行的mfcc参数x、y转变为平行的。
步骤4,建立自适应混合高斯模型(adaptiongmm,agmm),采用期望最大化(em,expectation-maximization)算法进行训练,并使用k-均值迭代方法得到em训练的初始值。通过训练得到agmm参数λ,p(x|λ)。
如图2所示,使用自适应聚类算法训练agmm参数,首先需要对各高斯分量的权重系数、均值向量、协方差矩阵和特征参数矢量之间的欧氏距离进行综合分析,动态地调整高斯混合度。其训练过程如下:
4-1)设定agmm初始混合数m,高斯分量权重系数阈值t1,t2,特征参数矢量之间欧氏距离阈值d和协方差阈值σ。
4-2)使用k-均值迭代算法得到em训练的初始值。
4-3)使用em算法进行迭代训练。
传统的高斯混合模型表示如下:
其中,x为p维的语音特征参数矢量,本发明中采用p=39,p(wi)表示各高斯分量的权重系数,且有
其中μi为均值矢量,∑i为协方差矩阵,λ={p(wi),μi,σi},是gmm模型的模型参数,对λ的估算可以通过最大似然估计法(ml,maximumlikelihood)实现,最大似然估计的目的在于使得条件概率p(x|λ)取得最大,对于语音特征参数矢量集合x={xn,n=1,2,...n}有:
此时:
λ=argλmax(p(x|λ))(8)
求解公式(8)可使用em算法,随着em计算过程中迭代条件满足p(x|λk)≥p(x|λk-1),k是迭代的次数,直至模型参数λ。迭代过程中高斯分量权重系数p(wi)、均值向量μi、协方差矩阵σi的迭代公式如下:
4-4)若训练得到的模型中某一高斯分量n(p(wi),μi,σi)权重系数小于t1,并且与其最邻近分量n(p(wj),μj,σi)之间的欧氏距离小于阈值d,则认为这两个分量包含信息较少且成分相似,可对其进行合并处理:
此时,高斯分量个数变为m-1,返回步骤(3)进行下一次训练,若满足合并条件的高斯分量有多个,则选择最小距离的高斯分量进行合并。
4-5)若训练得到的模型中某一高斯分量n(p(wi),μi,∑i)权重系数大于t2,并且协方差矩阵中有至少一维的方差(协方差矩阵对角线上元素即为方差)大于σ,则认为该高斯分量包含过量信息,应将其分裂处理:
其中e为全1的列向量,n用于调节高斯分布,经过分裂后高斯分量个数变为m+1,如果满足分裂条件的高斯分量有多个,则选取权重系数最大的分量进行分裂,返回步骤(3)进行下一次训练。
4-6)agmm训练结束,得到后验条件概率矩阵p(x|λ),保存λ。
步骤5,利用步骤3中得到的源语音特征参数x和目标语音特征参数y以及步骤4中得到的后验条件概率矩阵p(x|λ)进行训练,得到频率弯折因子和幅度调节因子,从而构建双线性频率弯折(blfw,bilinearfrequencywarping)和幅度调节(as,amplitudescaling)语音转换函数,表示如下:
f(x)=wα(x,λ)x+s(x,λ)(15)
建立源语音基音频率和目标语音基音频率之间的转换关系:
其中μ,σ2用于表示对数基音频率logf0的均值和方差。
如图1,转换部分具体实施步骤:
步骤6,输入待转换的源说话人语音;
步骤7,使用ahodecoder语音分析模型提取源说话人的语音39阶mfcc特征参数x′以及源语音对数基音频率参数logf0x′;
步骤8,利用步骤4中agmm训练时得到的λ={p(wi),μi,σi}和步骤7中提取的特征参数x′,代入公式(5),得到后验条件概率矩阵p′(x|λ);
步骤9,利用步骤5中blfw+as训练得到的频率弯折因子α(x,λ)和幅度调节因子s(x,λ)以及步骤8中得到的后验条件概率矩阵p′(x|λ),分别代入公式(15)、(16)、(17)和(18)后,得到转换后语音的mfcc特征参数y′;
步骤10,利用步骤7中得到的源语音对数基音频率参数logf0x′,代入公式(19),得到转换后语音的对数基音频率参数logf0y′;
步骤11,使用ahodecoder语音合成模型将步骤9中的y′和步骤10中的logf0y′作为输入得到转换后的语音。
进一步地,如图3所示,将本发明的方法与inca方法得到的转换语音的语谱图进行了对比,转换方向为f1-m2(女声1-男声2),进一步验证了本发明所采用的方法相对于inca方法的频谱相似度更高的优点。其中,inca方法是文献(errod,morenoa,bonafontea.incaalgorithmfortrainingvoiceconversionsystemsfromnonparallelcorpora[j].ieeetransactionsonaudio,speech,andlanguageprocessing,2010,18(5):944-953.)中提出的。
以上所述仅是本发明的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!