声纹识别垃圾箱开门的方法与流程
本发明涉及一种垃圾箱箱门的开启方法,尤其涉及一种用声纹识别用户身份开启垃圾箱门的方法。
背景技术:
城市中无序丢弃垃圾严重影响市容市貌、污染生活环境,给垃圾回收的工作人员增加负担,给城市和居民带来极大的不便。目前,智能垃圾分类回收箱已经在很多小区广泛的使用,智能垃圾分类回收箱使用时先给用户进行身份登记,对用户投放后的垃圾重量进行称重并积分,当积分累积打一定值,用户可以用积分进行兑换商品。通过对用户进行身份认证的方法开启垃圾箱箱门,目前常规是通过扫二维码的方式,需要用户带着印有二维码的卡片或者有包含用户信息的二维码的手机进行扫码,这就需要用户随身携带着卡片和手机,尤其是当手持垃圾时再扫码使用不方便,给用户带来不便的交互体验。
技术实现要素:
本发明的目的是公开一种使用方便,识别准确率高的声纹识别垃圾箱开门的方法。
本发明通过以下技术方案来实现上述目的:声纹识别垃圾箱开门的方法,依次包括语音注册、语音开门和逻辑决策,语音注册依次包括如下步骤:(1)采集注册语音,通过麦克风阵列技术对注册语音进行采集,并且采用固定波束形成算法通过延时控制来补偿声源延时;(2)特征提取,通过模拟和数字处理,采用mfcc特征提取方式从注册语音中提取表征注册用户特征的语音信息;(3)模型训练,建立注册用户语音模型,模型训练方法选择最小分类错误准则即mce准则进行区分训练;所述语音开门依次包括如下步骤:(1)采集开门语音,通过麦克风阵列技术对开门语音进行采集,并且采用固定波束形成算法通过延时控制来补偿声源延时;(2)特征提取,通过模拟和数字处理技术,采用mfcc特征提取方式从开门语音中选择和提取表征开门用户特征的语音信息;(3)模型训练,建立开门用户语音模型,模型训练方法选择最小分类错误准则即mce准则进行区分训练;所述逻辑决策依次包括模式匹配和进行决策步骤。
作为优选,通过多个麦克风阵列技术对注册语音和开门语音信息进行采集,麦克风阵列有2麦、4麦、6麦,对应麦数越多,降噪和语音增强的效果越好。
作为优选,语音注册中的mfcc特征提取方式是指将采集的注册语音转换为模拟语音信号,对语音信号进行采样量化,量化后进行预加重处理、汉明窗处理,最后输出语音帧序列。
作为优选,语音开门中的mfcc特征提取方式是指将采集的开门语音转换为模拟语音信号,对语音信号进行采样量化,量化后进行预加重处理、加汉明窗处理,最后输出语音帧序列。
作为优选,模式匹配是将注册用户语音模型与开门用户语音模型进行匹配,计算二者的对数似然比,得出对数似然比得分;进行决策是计算匹配得分,达到设定阈值垃圾箱门开启,达不到设定阈值垃圾箱门不打开。
作为优选,固定波束形成算法
作为优选,语音注册中的模型训练是先将注册用户模型分成非重叠和共性重叠部分,利用注册用户语音数据集建立注册用户语音gmm模型;语音开门中的模型训练是先将开门用户模型分成非重叠和共性重叠部分,利用开门语音数据集建立开门用户语音gmm模型。进一步的,对于所有的模型进行svm支持向量机训练,通过计算其在所有说话人模型上的相似度,即对应最大相似度和最小相似度之比小于一个阈值,则归为共性重叠部分,否则归为非重叠部分;注册用户语音gmm模型和开门用户语音gmm模型的训练过程算法是:
p=(maxpr(xj|mi)/minpr(xj|mk)),i=1,...,s,k=1,...,s,,p为向量在说话人模型上的最大相似度与最小相似度之比,s为说话人个数,xj第j个训练输入向量,j=1,...,n,n为训练特征向量个数,p小于阈值t,则该向量xj→q,属于共性重叠部分向量;p大于阈值t,则该向量xj→p,属于说话人非重叠部分向量集。
采用了上述技术方案的声纹识别垃圾箱开门的方法,采集注册语音和采集开门语音时,通过麦克风阵列技术对注册语音进行采集,并且采用固定波束形成算法通过延时控制来补偿声源延时,特征提取时采用mfcc特征提取方式,模型训练方法选择最小分类错误准则即mce准则进行区分训练,该声纹识别垃圾箱开门的方法的优点是用户不用近距离对着声音采集设备发声仍然可以准确采集声音信号,在声音嘈杂的环境下仍然可以准确识别用户,打开垃圾箱门。
附图说明
图1是本发明实施例中麦克风阵列示意图。
图2是本发明实施例中固定波束形成示意图。
图3是本发明实施例中mfcc特征提取流程示意图。
具体实施方式
下面结合图1、图2和图3对本发明作进一步说明。
如图1、图2和图3所示的声纹识别垃圾箱开门的方法,依次包括语音注册、语音开门和逻辑决策步骤。
语音注册依次包括如下步骤:
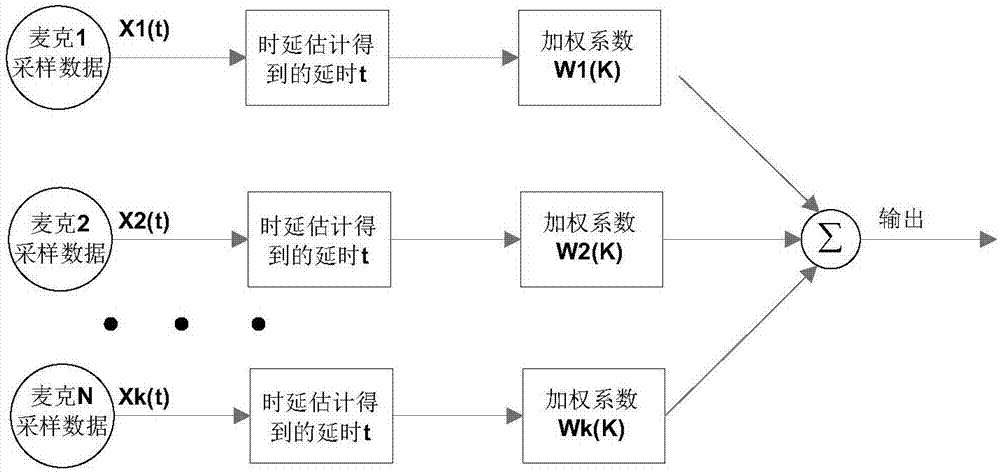
(1)采集语音注册,语音注册时,录入一段一定时长的用户的声音,重复多遍;通过多个麦克风阵列技术对注册用户语音进行采集,并且采用固定波束形成算法通过延时控制来补偿声源延时;用户在一定距离范围内朝双麦阵列录入音,通过声波抵达阵列中每个麦克风之间的微小时差的相互作用,得到更好的指向性,可以有效降低周边的环境噪音的影响。双麦阵列通过时延估计、时延补偿、加权求和。麦克风阵列有2麦、4麦、6麦,对应麦数越多,降噪和语音增强的效果越好,麦克风1接收到的信号为x1(t)、麦克风2接收到的信号为x2(t),由于麦克风阵元空间位置的差异,各阵元接收到的信号存在时延,xi(k)经延时估计得到的麦克风时延为τi,在对信号进行处理之前进行时延补偿,保证各阵元待处理数据的一致性。使阵列指向期望的方向。再乘以加权系数wi(k),进行加权同相相加,使得波束形成器的输出得到最大输出。
(2)特征提取,通过模拟和数字处理,采用mfcc特征提取方式从注册用户语音中提取表征注册用户特征的语音信息;
(3)模型训练,估计特征参数分布,建立注册用户语音模型。模型训练方法选择最小分类错误准则即mce准则进行区分训练。
语音开门依次包括如下步骤:
(1)采集开门语音信息,通过麦克风阵列技术对开门语音进行采集,并且采用固定波束形成算法通过延时控制来补偿声源延时;
(2)特征提取,通过模拟和数字处理技术,采用mfcc特征提取方式从开门语音中选择和提取表征开门用户特征的语音信息;
(3)模型训练,估计特征参数分布,建立开门用户语音模型,模型训练方法选择最小分类错误准则即mce准则进行区分训练;
逻辑决策是比对语音注册和语音开门,判断是否开门,依次包括如下步骤:
(1)模式匹配,将注册用户语音模型与开门用户语音模型进行匹配,计算二者的对数似然比,得出对数似然比得分;
(2)进行决策,对匹配的得分进行判决,确定发出开门语音的人是否为语音注册用户,与语音注册匹配达到设定阈值得分,垃圾箱门开启,否则垃圾箱门不会打开。
给逻辑决策判决设定一个阈值分数,通过得出的对数似然比得分与设定的阈值分数进行比较,达到预设获高于预设分数,则逻辑决策判决开门语音属于注册人,启动电机,开启箱门;否则箱门电机不动作。
上述采集语音注册和语音开门信息,必须有采集语音的硬件设备,因为垃圾箱会有异味,用户不会近距离靠近麦克风进行语音注册和语音开门,所以需要有远距离采集注册语音的硬件设备,因此采用麦克风阵列技术采集语音信息。采样距离变远了,在目标语音的实际拾取过程中,不可避免受到外界环境噪声和其他说话人的干扰,这些干扰共同作用,严重影响了声纹语音的采集,利用麦克风阵列技术尤其是多麦阵列能够充分利用语音信号的空时信息,具有灵活的波束控制,较高的空间分辨率、高的信号增益和较强的抗干扰能力等特点。麦克风阵列如图1所示。用户语音注册和语音开门发声后,固定波束形成算法通过延时控制来补偿从声源到每个麦克风的延时,对每个麦克风接收到的信号进行延时补偿,然后使麦克风阵列波束指向有最大输出功率的方向,以此解决不用靠近麦克风,又能良好采样声音的特定的垃圾箱声纹识别场景需求。延迟求和-波束形成输出,其中,xi(t)为麦克风接收到的信号,权系数为wi(k),k为麦克风的数目,τi为时延估计得到的时延,
上述mfcc特征提取流程如图3所示。首先将注册语音和语音开门的语音进行前端处理,将声音转换为模拟语音信号进行采样,并对其振幅值进行量化编码,从而转化为数字信号,模拟语音信号经采样量化获得语音信号的波形。其次,由于唇端辐射导致语音信号的高频能量损耗,为了去除口唇辐射的影响,将经采样量化后得到的语音信号波形进行预加重处理,增加语音信号的高频分辨率,加强语音高频信号能量,使其适用于统一的分析处理。基于语音的短时平稳特性,即短时段的语音信号对应的声道形状、激励性质基本不会发生改变,将经预加重处理的波形再进行加汉明窗处理,即采用汉明窗对语音进行重叠分帧处理,使语音特征更加明显、清晰,易于观察,最终输出语音帧序列。对加汉明窗分帧后获得的语音帧序列进行时域和频域分析,并采用相应的特征参数描述。mfcc特征参数是一种听觉感知频域倒普参数,该参数依据人耳对声音频率高低的非线性心里感觉构造语音短时幅度谱特征。对输入的语音帧信号作离散傅里叶变换。计算频谱幅度的平方,得到能量谱。将能量谱通过mel三角滤波器组。计算每个滤波器组输出的对数能量。经离散余弦变换得到mfcc参数和特征向量序列。
上述模型训练是区分“目标”和“冒认者”的训练,由于声纹密码的任务是对两类最小错误进行分类,实现短句上说话人确认错误的最小化。因此选择最小分类错误准则即mce准则进行区分训练。通过对训练集合总体平均错误率的平滑近似策略,实现最小化识别(分类)错误率的目的。在描述相同密码文本说话人语音特征分布空间中,相同说话人对应的特征向量分布集中,不同说话人对应的特征向量分布相对分散,距离具有区分“目标”和“冒认”的能力。因此设计一种表征距离度量的新特征用以表示区分性训练中正反例样本。如果直接将测试语音y相对注册语音x的距离d(x,y)设定为y的新特征,则将分别产生目标语音新特征和冒认语音新特征,记作ztar和zim,此时与原始声学特征不同,所有注册者对应的ztar和zim可以被组合成统一的正例集合p和反例集合n。
训练过程首先将用户模型分成非重叠和共性重叠部分,利用用户语音数据集建立gmm模型(高斯混合模型);根据相似度计算和gmm模型确定特征向量的类别,如果两个竞争的说话人模型有公共重叠部分,则其相应特征向量就被归于此部分;对于所有的模型进行svm支持向量机训练,通过计算其在所有说话人模型上的相似度,若对应最大相似度和最小相似度之比小于一个阈值,则归为共性重叠部分,否则归为非重叠部分。基于重新分类过的特征向量,对每个说话人重新建立模型,即产生了一个共性重叠模型和各自说话人的非重叠模型。假设有s个说话人,则训练过程算法实现过程如下:(1)xj第j个训练输入向量,j=1,...,n,n为训练特征向量个数。p=(maxpr(xj|mi)/minpr(xj|mk)),i=1,...,s,k=1,...,s,p为向量在说话人模型上的最大相似度与最小相似度之比。如果p小于一定的阈值t,则该向量xj→q,属于共性重叠部分向量。否则xj→p,属于说话人非重叠部分向量集。
- 还没有人留言评论。精彩留言会获得点赞!