信息处理装置和信息处理方法与流程
本技术涉及信息处理装置和信息处理方法。更具体地,本技术涉及适用于将文本转换成语音以进行输出的信息处理装置和信息处理方法。
背景技术:
在通过tts(文本到语音)技术将文本转换成语音以进行输出的情况下,单调的声调或平的语调会分散用户的注意力。结果,用户可能无法理解文本的内容。
为了防止用户对这样的合成语音感到厌倦,已经提出了措施,其包括根据经过的时间逐渐增加讲话速率并且随机改变除讲话速率之外的各种参数,例如音调、音量和声音质量(例如,参见ptl1)。
引用列表
专利文献
[ptl1]
jp1999-161298a
技术实现要素:
本技术问题
然而,根据ptl1中描述的技术,合成语音的参数仅仅根据经过的时间而改变。这意味着参数的变化并不总是有效的并且可能会或可能不会吸引用户对合成语音的注意力。
在这些情况下,本技术旨在增加用户注意力被引导到合成语音的可能性。
问题的解决方案
根据本技术的一个方面,提供了一种信息处理装置,包括:语音输出控制部,其被配置成基于通过将文本转换成语音而获得的合成语音被输出时的情境(context)来控制合成语音的输出形式。
优选地,在情境满足预定条件的情况下,语音输出控制部可以改变合成语音的输出形式。
优选地,合成语音的输出形式的改变可以包括改变以下中至少之一:合成语音的特性、针对合成语音的效果、合成语音的背景中的bgm(背景音乐)、合成语音中输出的文本或者用于输出合成语音的装置的操作。
优选地,合成语音的特性可以包括以下中至少之一:速度、音调、音量或语调。针对合成语音的效果可以包括以下中至少之一:在文本中重复特定词句或将停顿插入到合成语音中。
优选地,在检测到用户的注意力未被引导至合成语音的状态时,语音输出控制部可以改变合成语音的输出形式。
优选地,在改变合成语音的输出形式之后检测到用户的注意力被引导至合成语音的状态时,语音输出控制部可以将合成语音的输出形式返回至初始形式。
优选地,在合成语音的特性的变化量在预定范围内的状态持续至少预定时间段的情况下,语音输出控制部可以改变合成语音的输出形式。
优选地,语音输出控制部可以基于情境来选择改变合成语音的输出形式的方法。
优选地,信息处理装置还可以包括学习部,其被配置成学习用户对改变合成语音的输出形式的方法的反应。语音输出控制部可以基于对用户的反应的学习结果来选择改变合成语音的输出形式的方法。
优选地,语音输出控制部还可以基于文本的特性来控制合成语音的输出形式。
优选地,语音输出控制部可以在文本的特征量等于或大于第一阈值的情况下或者在文本的特征量小于第二阈值的情况下改变合成语音的输出形式。
优选地,语音输出控制部可以向其他信息处理装置提供用于生成合成语音的语音控制数据,由此控制来自其他信息处理装置的合成语音的输出形式。
优选地,语音输出控制部可以基于从其他信息处理装置获取的与情境有关的情境数据来生成语音控制数据。
优选地,情境数据可以包括以下中至少之一:基于捕获的用户周围的图像的数据、基于来自用户周围的语音的数据或基于与用户有关的生物信息的数据。
优选地,信息处理装置还可以包括情境分析部,其被配置成基于情境数据分析情境。
优选地,情境可以包括以下中至少之一:用户的状况、用户的特性、输出合成语音的环境或合成语音的特性。
优选地,输出合成语音的环境可以包括以下中至少之一:用户的周围环境、用于输出合成语音的装置或用于输出合成语音的应用程序。
此外,根据本技术的第一方面,提供了一种信息处理方法,包括:语音输出控制步骤,用于基于通过将文本转换成语音而获得的合成语音被输出时的情境来控制合成语音的输出形式。
根据本技术的第二方面,提供了一种信息处理装置,包括:通信部,其被配置成向其他信息处理装置传送与通过将文本转换成语音而获得的合成语音被输出时的情境有关的情境数据,通信部还从其他信息处理装置接收用于生成合成语音的语音控制数据,该合成语音的输出形式是基于情境数据来控制的,以及语音合成部,其被配置成基于语音控制数据生成合成语音。
此外根据本技术的第二方面,提供了一种信息处理方法,包括:通信步骤,用于向其他信息处理装置传送与通过将文本转换成语音而获得的合成语音被输出时的情境有关的情境数据,通信步骤还从其他信息处理装置接收用于生成合成语音的语音控制数据,该合成语音的输出形式是基于情境数据来控制的,以及语音合成步骤,用于基于语音控制数据生成合成语音。
因此根据本技术的第一方面,基于通过将文本转换成语音而获得的合成语音被输出时的情境来控制合成语音的输出形式。
根据本技术的第二方面,向其他信息处理装置传送与通过将文本转换成语音而获得的合成语音被输出时的情境有关的情境数据。从其他信息处理装置接收用于生成合成语音的语音控制数据,该合成数据的输出形式是基于情境数据来控制的。然后根据语音控制数据生成合成语音。
发明的有益效果
根据本技术的第一方面或第二方面,用户的注意力被吸引至合成语音。特别地,本技术的第一方面或第二方面增加将用户的注意力吸引至合成语音的可能性。
注意,以上概述的有益效果并非对本公开的限制。本公开的其他优点根据随后的描述将变得明显。
附图说明
[图1]图1是描绘应用本技术的信息处理系统的实施方式的框图。
[图2]图2是描绘由客户端的处理器实现的功能的典型部分配置的框图。
[图3]图3是描绘要在合成语音中输出的典型文本的视图。
[图4]图4是说明合成语音输出处理的流程图。
[图5]图5是说明合成语音输出控制处理的流程图。
[图6]图6是说明tts数据生成处理的细节的流程图。
[图7]图7是描绘正常模式下和注意模式下的tts数据的具体示例的示意图。
[图8]图8是描绘注意模式的具体示例的示意图。
[图9]图9是描绘注意模式的另一具体示例的示意图。
[图10]图10是描绘注意模式的另一具体示例的示意图。
[图11]图11是描绘注意模式的另一具体示例的示意图。
[图12]图12是描绘注意模式的另一具体示例的示意图。
[图13]图13是描绘注意模式的另一具体示例的示意图。
[图14]图14是描绘注意模式的另一具体示例的示意图。
[图15]图15是描绘计算机的典型配置的框图。
具体实施方式
以下描述用于实现本技术的优选模式(称为实施方式)。注意,描述是按照以下标题给出的:
1.实施方式
2.变型例
1.实施方式
1-1.信息处理系统的典型配置
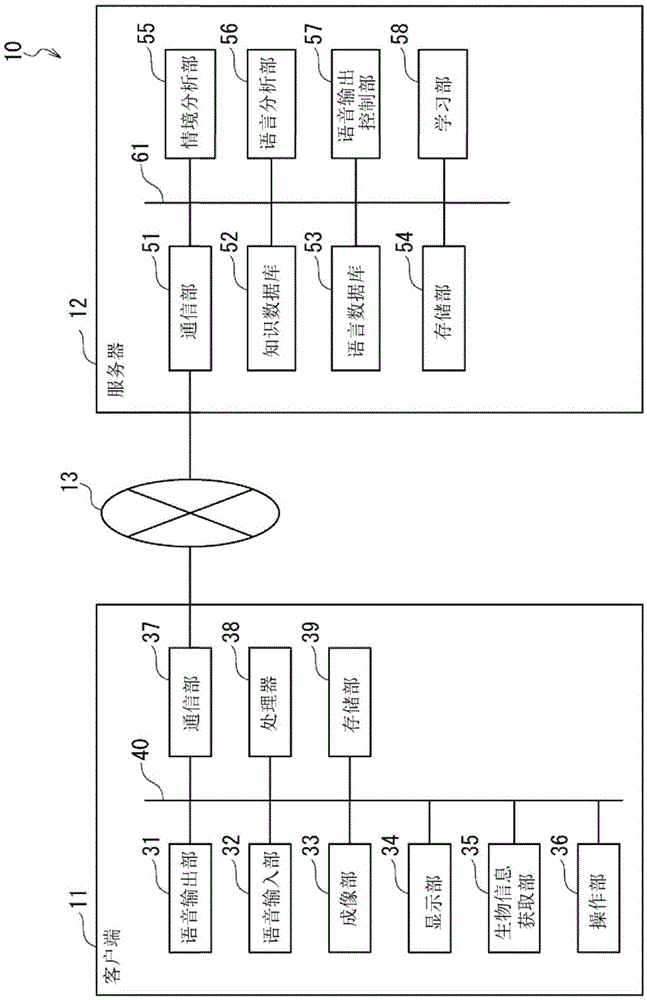
下面首先参照图1说明应用本技术的信息处理系统10的典型配置。
信息处理系统10是通过tts技术将文本转换成语音以进行输出的系统。信息处理系统10配置有客户端11、服务器12和网络13。经由网络13将客户端11与服务器12相互连接。
注意,尽管图1仅描绘了一个客户端11,但是实际上多个客户端11与网络13连接。多个用户经由客户端11使用信息处理系统10。
基于由服务器12提供的tts数据,客户端11将文本转换成语音以进行输出。此外,tts数据是指用于生成合成语音的语音控制数据。
例如,客户端11被配置有例如诸如智能电话、平板电脑、蜂窝电话或膝上型个人计算机的便携式信息终端、可穿戴设备、台式个人计算机、游戏机、视频再现装置或音乐再现装置。可穿戴设备可以具有各种类型,包括例如眼镜类型、手表类型、手镯类型、项链类型、颈带类型、耳机类型、头戴式耳机类型和头戴式类型。
客户端11包括语音输出部31、语音输入部32、成像部33、显示部34、生物信息获取部35、操作部36、通信部37、处理器38和存储部39。经由总线40将语音输出部31、语音输入部32、成像部33、显示部34、生物信息获取部35、操作部36、通信部37、处理器38和存储部39互连。
语音输出部31配置有例如扬声器。可以根据需要确定扬声器的数目。语音输出部31基于从处理器38提供的语音数据输出语音。
语音输出部32配置有例如麦克风。可以根据需要确定麦克风的数目。语音输入部32收集来自用户周围的语音(包括用户的语音)。语音输入部32将表示所收集的语音的语音数据提供给处理器38或将语音数据存储到存储部39中。
成像部33被配置有例如摄像装置。可以根据需要确定摄像装置的数目。成像部33捕获用户周围的图像(包括用户),并且将表示所捕获的图像的图像数据提供给处理器38或将图像数据存储到存储部39中。
显示部34配置有例如显示器。可以根据需要确定显示器的数目。显示部34基于从处理器38提供的图像数据显示图像。
生物信息获取部35被配置有用于获取各种类型的人类生物信息的设备和传感器。由生物信息获取部35获取的生物信息包括例如用于检测用户的身体状况、专注程度和紧张程度的数据(例如,心跳、脉搏率、出汗量和体温)。生物信息获取部35将获取的生物信息提供给处理器38或将信息存储到存储部39中。
操作部36被配置有各种类型的操作构件。使用操作部36来操作客户端11。
通信部37被配置有各种类型的通信设备。通信部37的通信系统不限于任何特定系统;通信部37可以以有线或无线方式进行通信。通信部37可以替选地支持多个通信系统。通信部37经由网络13与服务器12进行通信。通信部37将从服务器12接收到的数据提供给处理器38或将数据存储到存储部39中。
处理器38控制客户端11的组件,并且经由通信部37和网络13与服务器12交换数据。此外,处理器38基于从服务器12获取的tts数据执行语音合成(即,执行再现tts数据的处理),生成表示所获取的合成语音的语音数据,并且将语音数据提供给语音输出部31。
存储部39存储客户端11执行其处理所需的程序和数据。
服务器12根据来自客户端11的请求生成tts数据,并且经由网络13将所生成的tts数据传送至客户端11。服务器12包括通信部51、知识数据库52、语言数据库53、存储部54、情境分析部55、语言分析部56、语音输出控制部57和学习部58。
通信部51被配置有各种类型的通信设备。通信部51的通信系统不限于任何特定系统;通信部51可以以有线或无线方式进行通信。通信部51可以替选地支持多个通信系统。通信部51经由网络13与客户端11进行通信。通信部51将从客户端11接收到的数据提供给服务器12内的组件或将接收到的数据存储到存储部54中。
知识数据库52存储与各种类型的知识有关的数据。例如,知识数据库52存储与可以在基于tts数据的合成语音的背景中播放的bgm音乐有关的数据。
语言数据库53存储与各种语言有关的数据。例如,语言数据库53存储与表达和措辞有关的数据。
存储部54存储服务器12执行其处理所需的程序和数据。例如,存储部54存储针对使用提供给客户端11的tts数据的再现的文本。
情境分析部55例如基于从客户端11获取的数据执行视线识别处理、图像识别处理和语音识别处理。通过这样做,情境分析部55分析客户端11输出合成语音时的情境。情境分析部55将分析结果提供给语音输出控制部57和学习部58并且将分析结果存储到存储部54中。
顺便提及,合成语音被输出时的情境包括例如作为合成语音的输出目标的用户的状况和特性、合成语音被输出的环境以及合成语音的特性。
例如,语言分析部56分析要在合成语音中输出的文本的语言并且由此检测文本的特性。语言分析部56将分析结果提供给语音输出控制部57和学习部58并且将分析结果存储到存储部54中。
语音输出控制部57基于存储在知识数据库52中和语言数据库53中的数据、情境分析部55的分析结果、语言分析部56的分析结果以及学习部58学习的结果,生成用于供客户端11使用的tts数据。语音输出控制部57经由通信部51将所生成的tts数据传送至客户端11。
此外,根据情境和文本的特性,语音输出控制部57将合成语音的输出模式设置成正常模式或注意模式。正常模式是以标准输出形式输出合成语音的模式。注意模式是以不同于正常模式的输出形式的输出形式输出合成语音以便将用户的注意力吸引至合成语音的模式。语音输出控制部57生成符合不同输出模式中的每一个的tts数据,并且以控制客户端11以在每个输出模式下输出合成语音的方式将生成的tts数据提供给客户端11。
学习部58例如基于情境分析部55的分析结果和语言分析部56的分析结果来学习每个用户的特性。学习部58将学习的结果存储到存储部54中。
注意,在下面的描述中,每当客户端11(通信部37)和服务器12(通信部51)被描述为经由网络13彼此通信时将省略措辞“经由网络13”。
1-2.由客户端的处理器实现的部分功能的示例
图2描绘了由客户端11的处理器38实现的部分功能的示例。例如,处理器38通过执行预定的控制程序来实现包括语音合成部101和情境数据获取部102的功能。
语音合成部101基于从服务器12获取的tts数据执行语音合成。语音合成部101将表示所获取的合成语音的语音数据提供给语音输出部31。
情境数据获取部102获取与在输出合成语音时可应用的情境有关的数据,并且基于所获取的数据生成情境数据。情境数据包括例如基于由语音输入部32收集到的语音的数据、基于由成像部33捕获的图像的数据以及基于由生物信息获取部35获取的生物信息的数据。
此处,基于语音的数据包括例如语音数据本身、表示从语音数据提取的特征量的数据以及指示语音数据的分析结果的一些数据。基于图像的数据包括例如图像数据本身、表示从图像数据提取的特征量的数据以及指示图像数据的分析结果的一些数据。基于生物信息的数据包括例如生物信息本身、表示从生物信息提取的特征量的数据以及指示生物信息的分析结果的一些数据。
情境数据获取部102经由通信部37将生成的情境数据传送至服务器12。
1-3.由信息处理系统10执行的处理
下面参照图3至图14说明由信息处理系统10执行的处理。注意,下面的描述将参考例如图3中描绘的文本被转换成语音以进行输出的情况。文本摘自奥巴马总统于2008年11月4日在美国伊利诺伊州芝加哥发表的演讲。
合成语音输出处理
首先参考图4的流程图说明由客户端11执行的合成语音输出处理。例如,当用户操作客户端11的操作部36以开始合成语音的输出时,该处理开始。
在步骤s1中,语音合成部101请求传送tts数据。具体地,语音合成部101生成作为用以请求传送tts数据的命令的tts数据传送请求,并且经由通信部37将请求传送至服务器12。
tts数据传送请求包括例如用于再现tts数据的客户端11的类型和应用程序(以下称为app)的类型以及用户属性信息。用户属性信息包括例如用户的年龄、性别、住所、职业和国籍。可替选地,用户属性信息可以包括例如唯一地标识用户并且与服务器12中保存的用户的属性信息关联的用户id。
服务器12在稍后讨论的图5的步骤s51中接收tts数据传送请求。服务器12在图5的步骤s59中传送tts数据。
在步骤s2中,客户端11开始获取与情境有关的数据。具体地,语音输入部32开始从用户周围收集语音并且将所收集的语音数据提供给情境数据获取部102的处理。成像部33开始获取用户周围的图像并且将所获取的图像数据提供给情境数据获取部102的处理。生物信息获取部35开始获取用户的生物信息并且将所获取的信息提供给情境数据获取部102的处理。
情境数据获取部102开始基于所获取的语音数据、图像数据和生物信息生成情境数据并且经由通信部37将所生成的情境数据传送至服务器12的处理。
服务器12在稍后讨论的图5的步骤s52中接收情境数据。
在步骤s3中,语音合成部101判别是否接收到tts数据。在经由通信部37接收到从服务器12传送的tts数据的情况下,语音合成部101确定接收到tts数据。然后控制转移至步骤s4。
在步骤s4中,客户端11基于tts数据输出合成语音。具体地,语音合成部101基于tts数据执行语音合成,并且将表示获取的合成语音的语音数据提供给语音输出部31。语音输出部31基于语音数据输出合成语音。
在步骤s5中,语音合成部101判别是否指定要停止合成语音的输出。在确定未指定合成语音输出的停止的情况下,控制返回至步骤s3。
此后,重复步骤s3至s5,直到在步骤s3中确定未接收到tts数据或直到在步骤s5中确定指定合成语音输出的停止。
此外,在步骤s5中,如果例如用户操作客户端11的操作部36以停止合成语音输出,则语音合成部101确定指定合成语音输出的停止。然后控制转移至步骤s6。
在步骤s6中,语音合成部101请求停止传送tts数据。具体地,语音合成部101生成作为用以请求停止tts数据传送的命令的tts数据传送停止请求,并且经由通信部37将所生成的请求传送至服务器12。
服务器12在稍后讨论的图5的步骤s62中从客户端11接收tts数据传送停止请求。
此后,使合成语音输出处理结束。
在另一方面,在步骤s3中确定未接收到tts数据的情况下,终止合成语音输出处理。
合成语音输出控制处理
接下来参考图5的流程图、结合图4中的合成语音输出处理说明由服务器12执行的合成语音输出控制处理。
在步骤s51中,通信部51接收tts数据传送请求。也就是说,通信部51接收从客户端11传送的tts数据传送请求。通信部51将tts数据传送请求提供给情境分析部55和语音输出控制部57。
在步骤s52中,服务器12开始分析情境。具体地,通信部51开始从客户端11接收情境数据并且将所接收到的数据提供给情境分析部55的处理。
情境分析部55开始基于tts数据传送请求和情境数据分析情境。
例如,情境分析部55开始基于包括在tts数据传送请求中的用户属性信息以及包括在情境数据中的语音数据和图像数据来分析用户的特性。用户的特性包括例如用户的属性、偏好、能力和专注能力。用户的属性包括例如性别、年龄、住所、职业和国籍。
此外,情境分析部55开始基于包括在情境数据中的语音数据、图像数据和生物信息来分析用户的状况。用户的状况包括例如视线方向、行为、面部表情、紧张程度、专注程度、话语内容和身体状况。
此外,情境分析部55开始基于tts数据传送请求中包括的与客户端11的类型和app的类型有关的信息以及包括在情境数据中的语音数据和图像数据来分析输出合成语音的环境。输出合成语音的环境包括例如用户的周围环境、输出合成语音的客户端11以及用于输出合成语音的app。用户的周围环境包括例如用户的当前位置、用户周围的人和物体的状况、用户周围的亮度以及来自用户周围的语音。
此外,情境分析部55开始将分析结果提供给语音输出控制部57和学习部58并且将分析结果存储到存储部54中的处理。
在步骤s53中,语音输出控制部57设置正常模式。
在步骤s54中,服务器12设置向注意模式转换的条件。具体地,情境分析部55估计例如用户的专注能力和所需的专注能力。
例如,在关于用户过去的专注能力的学习的结果存储在存储部54中的情况下,情境分析部55基于学习结果来估计用户当前的专注能力。
另一方面,在关于用户过去的专注能力的学习的结果未存储在存储部54中的情况下,情境分析部55典型地基于用户属性估计用户当前的专注能力。例如,情境分析部55根据用户的年龄估计用户的专注能力。在用户是例如儿童的情况下,将用户的专注能力估计为低。作为另一示例,情境分析部55基于用户的职业估计用户的专注能力。在用户从事需要高专注能力的职业的情况下,将用户的专注能力估计为高。
此外,情境分析部55通常基于情境的分析结果来修改对专注能力估计的结果。例如,在用户的身体状况良好的情况下,情境分析部55将用户的专注能力修改为更高;在用户的身体状况差的情况下,情境分析部55将用户的专注能力修改为更低。作为另一示例,在用户周围构成引起用户专注的环境(即,安静的地方,或者附近没有人的地方)的情况下,情境分析部55将用户的专注能力修改为更高。另一方面,在用户周围构成倾向于妨碍用户专注的环境(即,嘈杂的地方或者附近有人的地方)的情况下,情境分析部55将用户的专注能力修改为更低。作为另外的示例,在用户使用的app处理与用户的高偏好度关联的内容(例如,处理表示用户的爱好的内容的app)的情况下,情境分析部55将用户的专注能力修改为更高。另一方面,在用户使用的app处理与用户的低偏好度关联的内容(例如,用于为资格而进行研究或用于学习学术科目的app)的情况下,情境分析部55将用户的专注能力修改为更低。
此外,情境分析部55例如基于用户使用的app估计所需的专注能力。在用户使用例如天气预报app的情况下,将所需的专注能力估计为低。这是因为:理解天气预报的内容不需要高专注能力,并且即使错过了一些细节,其也不会过多地降低对预报的整体理解。另一方面,在用户使用用于为资格而进行研究或学习学术科目的app情况下,将所需的专注能力估计为高。原因是研究和学习需要专注并且错过一些语音的细节可能增加用户不理解内容的可能性。
情境分析部55向语音输出控制部57提供对用户的专注能力估计的结果和所需的专注能力。
语音输出控制部57基于对用户的专注能力估计的结果和所需的专注能力来设置向注意模式转换的条件。例如,用户的专注能力越高或者所需的专注能力越低,由语音输出控制部57针对向注意模式的转换所设置的条件越严格。这使得更加难于转换至注意模式。另一方面,用户的专注能力越低或者所需的专注能力越高,由语音输出控制部57针对向注意模式的转换所设置的条件越低。这使得更易于转换至注意模式。
可替选地,在步骤s54中,语音输出控制部57可以始终设置标准转换条件而不管用户或情境。
在步骤s55中,语音输出控制部57判别是否存在要输出的文本。例如,在第一轮的步骤s55中,语音输出控制部57在存储部54中的文本中搜索要在合成语音中输出的文本(以下称为输出目标文本)。在发现输出目标文本的情况下,语音输出控制部57确定存在要输出的文本。然后控制转移到步骤s56。
例如,在第二轮或随后轮中在步骤s55中仍然存在要输出的目标输出文本的任何部分的情况下,语音输出控制部57确定仍然存在要输出的文本。然后控制转移到步骤s56。
在步骤s56中,语音输出控制部57设置要再输出的部分。具体地,语音输出控制部57将从输出目标文本的未输出部分的起始至预定位置的范围的部分设置为要再输出的部分(在下面将该部分称为新输出部分)。注意,以句子、短语或单词为单位设置新输出部分。
在步骤s57中,语言分析部56分析文本。具体地,语音输出控制部57将输出目标文本的新输出部分提供给语言分析部56。语言分析部56对新输出部分进行语言分析。例如,语言分析部56执行语形分析、独立单词分析、复合词分析、短语分析、依赖性分析和语义分析。此时,语言分析部56可以根据需要参考输出目标文本的已输出部分或新输出部分随后的部分。这允许语言分析部56理解输出目标文本的内容和特征量。
此外,语言分析部56基于分析的结果分析输出目标文本的难度。输出目标文本的难度包括内容的难度和基于所使用的单词以及句子的长度的句子的难度。
可替选地,语言分析部56可以例如根据用户的能力执行输出目标文本的难度的相对评估。作为另一替选,语言分析部56可以执行输出目标文本的难度的绝对评估而不管用户的能力。
在上述相对评估的情况下,与用户专业或用户的偏好领域关联的文本的难度为低的;与不同于用户专业的领域或用户不喜欢的领域关联的文本的难度为高的。此外,文本的难度例如根据用户的年龄和学术背景而变化。此外,例如,以用户的母语书写的文本的难度为低的,并且与用户的母语不同的语言的文本的难度为高的。
语言分析部56将分析的结果提供给语音输出控制部57和学习部58。
在步骤s58中,语音输出控制部57执行tts数据生成处理。下面参考图6中的流程图说明tts数据生成处理的细节。
在步骤s101中,语音输出控制部57判别是否设置了注意模式。在未确定设置注意模式的情况下,控制转移到步骤s102。
在步骤s102中,语音输出控制部57判别是否转换至注意模式。在满足向注意模式转换的条件的情况下,语音输出控制部57确定要转换至注意模式。然后控制转移到步骤s103。
注意,例如,至少基于情境或文本特性来设置向注意模式转换的条件。下面是向注意模式转换的典型条件:
-用户的注意力没有被引导至合成语音。
-合成语音几乎没有变化。这构成了条件,因为用户在合成语音几乎没有变化并且保持单调的情况下很可能分心。
-文本的特征量大。这构成了条件,因为具有大特征量的文本很可能包含大量信息或具有高重要度,使得用户更需要注意合成语音。
-文本连续地具有低特征量。这构成了条件,因为具有低特征量的文本部分很可能包含少量信息或具有低重要度,使得用户更可能分心。
例如,在用户的专注程度或紧张程度持续低于预定阈值达至少预定时间段的情况下,语音输出控制部57确定用户的注意力没有被引导至合成语音。可替选地,在用户的注意力持续没有被引导至客户端11达至少预定时间段的情况下,语音输出控制部57确定用户的注意力未被引导至合成语音。作为另一替选,在发现用户打瞌睡的情况下,语音输出控制部57确定用户的注意力未被引导至合成语音。
作为另一示例,表示利用tts数据生成的合成语音的特性(例如,速度、音调、语调和音量)的参数(下面称为特性参数)中的每一个的变化量持续落入预定范围内达至少预定时间段的情况下,语音输出控制部57确定合成语音几乎没有变化。可替选地,在正常模式简单地持续至少预定时间段的情况下,语音输出控制部57确定合成语音几乎没有变化。
作为另一示例,在输出目标文本的新输出部分具有大于预定第一阈值的特征量的情况下,语音输出控制部57确定文本具有大的特征量。
顺便提及,在下面情况下文本的特征量增加:
-在诸如“theglisteningsnow(晶莹的雪)”的名词短语包括在诸如“theglisteningsnowcoveredthefield(晶莹的雪覆盖原野)”的句子中的情况下
-在句子是例如“whatarethosebirds?(那些鸟是什么?)”的包括表示5w1h的单词的疑问句的情况下
-在存在依赖性的情况下,如在句子“thethamesistheriverwhichflowsthroughlondon(泰晤士河是流经伦敦的河)”中在“river(河)”与“whichflowsthroughlondon(流经伦敦)”之间
-在语音包括指示讲话者对话语的内容的判断或感受如何的语言表征(形态(modality))的情况下
作为另一示例,在输出目标文本的新输出部分具有小于预定第二阈值的特征量的情况下,语音输出控制部57确定文本具有小的特征量。第二阈值被设置为小于上述第一阈值。可替选地,在输出目标文本的新输出部分持续具有小于预定第二阈值的特征量达至少预定时间段的情况下,语音输出控制部57可以确定文本具有小的特征量。
注意,例如,在上面讨论的步骤s54和要在下面描述的步骤s61中,调整以上提到的针对上述确定条件的阈值、预定时间段和变化范围。
向注意模式转换的上述条件仅是示例。这些条件可以补充有其他条件或者可以消除其中一些条件。在使用多个转换条件的情况下,可以在满足一些条件时转换至注意模式。可替选地,在满足至少一个转换条件的情况下,可以转换至注意模式。
在步骤s103中,语音输出控制部57设置注意模式。
此后,控制转移到步骤s106。
另一方面,在步骤s102中不满足向注意模式转换的条件的情况下,语音输出控制部57确定不转换至注意模式。然后跳过步骤s103,并且在正常模式保持不变的情况下,控制转移到步骤s106。
在步骤s101中确定注意模式被设置的情况下,控制转移到步骤s104。
在步骤s104中,语音输出控制部57判别是否要取消注意模式。例如,在基于情境分析部55的分析结果检测到用户的注意力被引导至合成语音的情况下,语音输出控制部57确定要取消注意模式。然后控制转移到步骤s105。
通常在下面的情况下用户的注意力被引导至合成语音:
-在用户说出例如“ん?(嗯?)”或“何だ?(什么?)”的表达对注意模式的反应的声音的情况下
-在用户的视线指向客户端11的方向(例如,朝向语音输出部31或显示部34)的情况下
注意,在没有检测到用户的注意力转向合成语音而注意模式持续至少预定时间段的情况下,语音输出控制部57确定要取消注意模式。然后控制转移到步骤s105。
在步骤s105中,语音输出控制部57设置正常模式。设置取消注意模式。
此后,控制转移到步骤s106。
另一方面,在步骤s104中,在没有检测到用户的注意力转向合成语音并且注意模式尚未持续达至少预定时间段的情况下,语音输出控制部57确定不要取消注意模式。然后跳过步骤s105,并且在注意模式保持不变的情况下,控制转移到步骤s106。
在步骤s106中,语音输出控制部57判别注意模式是否被设置。如果确定没有设置注意模式,则控制转移到步骤s107。
在步骤s107中,语音输出控制部57根据正常模式生成tts数据。具体地,语音输出控制部57生成用于生成输出目标文本的新输出部分的合成语音的tts数据。此时,语音输出控制部57将诸如速度、音调、语调和音量的特性参数设置为预定的默认值。
此后,控制转移到步骤s109。
另一方面,在步骤s106中确定注意模式被设置的情况下,控制转移到步骤s108。
在步骤s108中,语音输出控制部57根据注意模式生成tts数据。具体地,语音输出控制部57生成用于生成输出目标文本的新输出部分的合成语音的tts数据。此时,语音输出控制部57以不同于正常模式的输出形式的输出形式输出合成语音的方式生成tts数据。这产生了在从正常模式转换到注意模式之后输出合成语音的形式的变化,从而吸引用户的注意力。
这里是改变合成语音的输出形式的方法的一些示例。示例性方法涉及改变合成语音的特性;另一示例性方法涉及改变针对合成语音的效果;另一示例性方法涉及改变针对输出合成语音的bgm;又一示例性方法涉及改变要在合成语音中输出的文本;以及再一示例性方法涉及改变输出合成语音的客户端的操作。
以下是改变合成语音的特性的方法的示例。
-改变合成语音的特性,例如速度、音调、音量和语调。
以下是改变针对合成语音的效果的方法的示例。
-给予合成语音回声效果。
-以不和谐的音输出合成语音。
-改变合成语音的讲话者的设置(例如,性别、年龄和声音质量)。
-将停顿插入到合成语音中。例如,中途将预定时间段的停顿插入到名词短语中或者连词之后。
-重复在合成语音中输出的文本中的特定词句。
注意,在重复特定词句的情况下,进行以下设置:在输出目标文本的新输出部分中要重复的最大词句数(在下面称为最大重复目标计数);要重复的词句(在下面称为重复目标);重复目标被重复的次数(在下面称为重复计数);以及对重复目标进行重复的方法(在下面称为重复方法)。
通常基于用户、输出目标文本的语言分析的结果和合成语音的输出时间来设置最大重复目标计数。例如,根据输出目标文本的新输出部分中的主要词性的数目,将最大重复目标计数设置为最高3。可替选地,在输出目标文本的新输出部分的合成语音中的输出时间是至少30秒的情况下,最大重复目标计数被设置为3。作为另外的替选,针对输出目标文本的新输出部分将最大重复目标计数设置为每10秒1个。
作为另一示例,在用户是预定年龄以下的儿童的情况下,最大重复目标计数被设置为无限。输出目标文本的新输出部分中的所有名词被设置为重复目标。在用户是超过预定年龄的老年人的情况下,最大重复目标计数被设置为1。在用户不是儿童或老年人的情况下,最大重复目标计数被设置为3。
例如,从名词、专有名词、动词和独立单词中设置重复目标。可替选地,在将停顿插入合成语音中的情况下,将紧接停顿之后的词句设置为重复目标。
例如,基于重复目标的词性设置重复计数。例如,在重复目标包括名词短语或专有名词的情况下,重复计数被设置为3。可替选地,在用户是儿童的情况下,重复计数被设置为2,并且在用户是老年人的情况下,重复计数被设置为3。在用户不是儿童或老年人的情况下,重复计数被设置为1。
例如,如下设置重复方法:
-在重复目标之前插入停顿。
-在重复目标之后添加词句。例如,在“山田さん(山田先生)”是重复目标的情况下,在“山田さん(山田先生)”之后添加后置助词、助动词或者感叹词,例如“山田さんだよ(山田先生哟)”或“山田さんね(山田先生呐)”。
-以与前后词句的特性不同的特性输出重复目标。例如,增加重复目标的音量,增加其音调或降低其速度。
以下是改变bgm的方法的示例。
–开始或停止bgm。
-改变bgm。
注意,在开始或改变bgm的情况下,例如,根据用户的偏好和属性选择合适的bgm。可以将例如用户喜欢的艺术家发布的歌曲或者用户经常收听的歌曲选择为bgm。可替选地,可以将与用户的年代对应的歌曲选择为bgm。作为另一替选,将在用户较年轻时期流行的歌曲选择为bgm。作为另一替选,在用户是儿童的情况下,可以将流行的面向儿童的电视节目的主题曲选择为bgm。
以下是改变要在合成语音中输出的文本的方法的示例。
-添加了特定于用户的词句的选择。例如,如果用户是儿童,则将拟声词或拟态词添加到名词。例如,在诸如“かわいい犬がいます(这是只可爱的小狗)”的文本的情况下,添加拟态词“ぷよぷよの(毛茸茸的)”,使得文本将会出现“かわいいぷよぷよの犬がいます(这是只毛茸茸的可爱的小狗)”。作为另一示例,增加所添加的拟声词或拟态词的音量。
以下是改变输出合成语音的客户端11的操作的方法的示例。
-振动输出合成语音的客户端11的主体或附件(例如,控制器)。
注意,上述改变合成语音的输出形式的方法可以单独实施或组合实施。而且,在单轮注意模式中,输出形式改变方法可以从一个切换到另一个,或者可以使针对每种改变方法的参数(例如,特性参数)变化。
此外,例如,基于情境来选择要实施的改变输出形式的方法。
例如,在用户周围是嘈杂的情况下,选择增加合成语音音量的方法。例如,在用户周围是嘈杂的并且用户在与其他人交谈的情况下,选择振动客户端11的方法。作为另一示例,在用户周围是安静的但是用户没有面向客户端11的方向的情况下,所选择的是如下方法:在输出目标文本的新输出部分中途通过名词短语输出时插入预定时间段的停顿。例如,在用户是小学生的情况下,所选择的是如下方法:将输出目标文本的新输出部分中的包括名词的部分设置为重复目标并且降低针对重复目标的讲话速率。
可替选地,基于用户对不同输出形式改变方法的反应的学习结果来选择要实施的改变输出形式的方法。例如,用户对基于过去学习处理的方法的反应越明显,则更加优选地选择该方法。以该方式,针对每个用户选择更加有效的改变方法。
作为另一替选,基于已向注意模式转换的次数以及已执行这样的转换的频率,来选择要实施的改变输出形式的方法。例如,在已向注意模式转换的次数或者已执行转换的频率太高使得难以将用户的注意力引导至合成语音的情况下,选择涉及输出形式的重大变化的方法以更好地吸引用户的注意力。
图7描绘了关于图3中的文本中的“imissthemtonight.iknowthatmydebttothemisbeyondmeasure(今晚我想念他们。我知道我对他们的亏欠是无法衡量的)”的部分的在正常模式和注意模式两者下的sslm(语音合成标记语言)形式的tts数据的具体示例。图的上部呈现正常模式下的tts数据,并且下部描绘了注意模式下的tts数据。
韵律率(prosodyrate)(速度)在正常模式下被设置为1而在注意模式下降低至0.8。音调(pitch)在正常模式下被设置为100而在注意模式下升高至130。(声音的)音量(volume)在正常模式下被设置为48而在注意模式下降低至20。在注意模式下,3000毫秒(3000ms)的中断时间(breaktime)被设置为“imissthem(我想念他们)”与“tonight(今晚)”之间的3秒停顿。此外,音位(phoneme)被设置到“tonight(今晚)”以提供语调。
顺便提及,在注意模式下改变合成语音的输出形式的目的是将用户的注意力吸引至合成语音。因此合成语音是否听起来不自然或用户是否发现难以捕获合成语音是无关紧要的。
此后,控制转移到步骤s109。
在步骤s109中,语音输出控制部57存储tts数据的特性参数。也就是说,语音输出控制部57将包括生成的tts数据的新输出部分的速度、音调、语调和音量的特性参数存储到存储部54中。
此后,使tts数据生成处理结束。
返回图5,在步骤s59中,语音输出控制部57传送tts数据。也就是说,语音输出控制部57经由通信部51向客户端11传送与输出目标文本的新输出部分有关的tts数据。
在步骤s60中,语音输出控制部57判别是否要改变向注意模式转换的条件。
例如,在上述步骤s54中估计的用户的专注能力与用户当前的专注能力之间的误差大于预定阈值的情况下,语音输出控制部57确定要改变向注意模式转换的条件。用户的专注能力的增加误差的一个原因被估计为例如随时间的推移用户的专注能力下降或者由于用户的身体状况而导致用户的专注能力下降。另一典型的原因被估计为用户关于输出目标文本的内容的偏好。例如,用户关于输出目标文本的内容的偏好程度越高,用户的专注能力越高;用户的偏好程度越低,用户的专注能力越低。
作为另一示例,在上述步骤s54中估计的所需的专注能力与实际所需的专注能力之间的误差大于预定阈值的情况下,语音输出控制部57确定要改变向注意模式转换的条件。所需的专注能力的增加误差的一个典型原因被估计为输出目标文本的高难度。例如,输出目标文本的难度越高,所需的专注能力越高;输出目标文本的难度越低,所需的专注能力越低。
作为另一示例,在已向注意模式转换的次数或者已执行这样的转换的频率高于预定阈值的情况下,语音输出控制部57确定要改变向注意模式转换的条件。然后控制转移到步骤s61。也就是说,频繁转换至注意模式可能给用户带来不适感。例如,可以通过限制可以转换至注意模式的最大次数以便不比所确定的更频繁地转换至注意模式,或者通过随时间的推移降低向注意模式转换的条件以便减小转换的频率,来绕过该问题。
在确定要改变向注意模式转换的条件的情况下,控制转移到步骤s61。
在步骤s61中,语音输出控制部57改变向注意模式转换的条件。例如,语音输出控制部57再次估计用户的专注能力和所需的专注能力,并且基于估计的结果,再次设置向注意模式转换的条件。
作为另外的示例,语音输出控制部57基于已向注意模式转换的次数或者已执行转换的频率,改变向注意模式转换的条件。例如,在已向注意模式转换的次数超过预定阈值(例如,每天50次)的情况下,禁止任何后续的向注意模式的转换。
此后,控制转移到步骤s62。
此外,在步骤s60中确定不要改变向注意模式转换的条件的情况下,跳过步骤s61。然后控制转移到步骤s62。
在步骤s62中,语音输出控制部57判别是否请求停止tts数据的传送。在确定未请求停止tts数据传送的情况下,控制返回到步骤s55。
此后,重复步骤s55至s61,直到在步骤s55中确定不再存在要输出的文本或者直到在步骤s61中确定请求停止tts数据传送。
以上面所述的方式,继续生成tts数据并且将所生成的tts数据传送至客户端11的处理。在满足向注意模式转换的条件时,在转换至注意模式的情况下生成tts数据,并且在满足取消注意模式的条件时,在转换至正常模式的情况下生成tts数据。
另一方面,在语音输出控制部57在第一轮中的步骤s55中未能找到输出目标文本的情况下,语音输出控制部57确定不存在要输出的文本。然后控制转移到步骤s63。例如在语音输出控制部57在第二轮或随后轮中的步骤s55中没有找到输出目标文本中的尚未输出的部分的情况下,语音输出控制部57确定不存在要输出的文本。然后控制转移到步骤s63。
在步骤s62中语音输出控制部57经由通信部51接收从客户端11传送的tts数据传送停止请求的情况下,语音输出控制部57确定请求停止tts数据传送。然后控制转移到步骤s63。
在步骤s63中,学习部58执行学习处理。例如,学习部58基于合成语音输出期间用户的视线方向、行为、紧张程度和专注程度的过去历史来学习用户的专注能力。例如,用户的专注能力由专注程度的高度和专注持续时间来表示。
此外,学习部58基于例如输出目标文本的特性以及合成语音输出期间用户的视线方向、面部表情、行为、紧张程度和专注程度的过去历史来学习用户的偏好。例如,在发现用户的专注能力高的情况下,将用户关于此时的输出目标文本的内容的偏好程度估计为高。另一方面,在发现用户的专注能力低的情况下,将用户关于此时的输出目标文本的内容的偏好程度估计为低。
此外,学习部58基于例如在转换至注意模式时用户的反应存在与否以及反应的时间来学习用户对改变合成语音的输出形式的各种方法中的每一种的反应。例如,这里学到的是用户对输出形式改变方法中的每一种的反应的可能性以及对每种方法做出反应的时间。
学习部58将学习的结果存储到存储部54中。
此后,使提供tts数据的处理结束。
以下出于说明的目的而参照图8至图14说明注意模式的特定图像。
首先,如图8所示,语音输出部31输出从图3中的文本的开端起开始的合成语音。
接下来如图9所示,假设当合成语音输出到达部分“whoiam”时,用户201将他的或她的注意力转移到在电视202上示出的电视节目并且面向电视201的方向。此时,服务器12的情境分析部55基于来自成像部33的图像数据检测到用户201的视线在电视201的方向上。这使得语音输出控制部57将输出模式从正常模式改变成注意模式。
然后如图10所示,降低从语音输出部31输出的句子“imissthemtonight”中的部分“imissthem”的合成语音的音量。此外,在名词短语“them”与下一要输出的单词“tonight”之间插入预定的停顿。当以该方式改变合成语音的输出形式时,用户201感到不舒服。
假设当继续以低音量输出下一单词“tonight”时,用户201说出“what?(什么?)”。此时,服务器12的情境分析部55基于来自语音输入部32的语音数据检测到用户201已对注意模式做出反应。结果,语音输出控制部57将输出模式从注意模式改变回到正常模式。
接下来,假设当在正常模式下在合成语音中输出直到“iknowthatmydebttothemisbeyondmeasure”的部分时,用户201的注意力再次转移到电视节目并且用户面向电视202的方向。结果,输出模式再次从正常模式改变至注意模式。
然后如图11所示,改变要输出的文本,并且重复文本中的特定词句。具体地,在“maya”之前添加“mrs”并且在“alma”之前添加“miss”。此外,重复两次“mrsmaya”和“missalma”的部分。此外,增加重复部分的音量。此外,如图12所示,在第一时间输出的“mrsmaya”与要在第二时间输出的“mrsmaya”之间插入预定的停顿。同样地,如图13所示,在第一时间输出的“missalma”与要在第二时间输出的“missalma”之间插入预定的停顿。当以该方式改变合成语音的输出形式时,用户201再次感觉不舒服。
然后如图14所示,假设当输出“allmyotherbrothersandsisters(我所有的兄弟姐妹)”部分时,用户201的视线从电视201改变朝向客户端11(语音输出部31)。此时,服务器12的情境分析部55基于来自成像部33的图像数据检测到用户201的视线在客户端11的方向上。这使得语音输出控制部57将输出模式从注意模式改变回到正常模式。
然后在正常模式下输出下一文本的合成语音。
如上所述,当基于例如情境和文本的特性转换至注意模式以便以不同于正常模式的输出形式的输出形式输出合成语音时,引起用户的注意力并且增加将用户的注意力吸引至合成语音的可能性。
2.变型例
下面说明上面讨论的实施方式的变型例。
2-1.典型系统配置的变型例
图1中的信息处理系统10的典型配置仅是示例。可以根据需要改变该配置。
例如,客户端11的部分功能可以包括在服务器12中,并且服务器12的部分功能可以并入在客户端11中。
作为另一示例,客户端11和服务器12可以集成到执行上述处理的单个装置中。
2-2.其他变型例
例如,在正常模式下,语音输出控制部57可以从存储部54或从外部获取ttl数据并且将所获取的未修改的ttl数据传送至客户端12。在注意模式下,语音输出控制部57可以修改所获取的ttl数据并且将经修改的ttl数据传送至客户端12以便改变合成语音的输出形式。
2-3.计算机的配置示例
以上所描述的一系列处理可以通过硬件或通过软件来执行。在一系列处理要通过软件执行的情况下,构成软件的程序被安装到合适的计算机中。计算机的变型包括具有预先安装在其专用硬件中的软件的计算机以及能够基于其中安装的程序执行各种功能的通用个人计算机等设备。
图15是描绘使用程序执行上述一系列处理的计算机的典型硬件配置的框图。
在计算机中,经由总线404将cpu(中央处理单元)401、rom(只读存储器)402和ram(随机存取存储器)403互连。
总线404还与输入/输出接口405连接。输入/输出接口405与输入部406、输出部407、存储部408、通信部409和驱动器410连接。
输入部406例如包括键盘、鼠标和麦克风。输出部407例如包括显示单元和扬声器。存储部408通常由硬盘或非易失性存储器形成。通信部409通常由网络接口构成。驱动器410驱动可移除介质411,例如磁盘、光盘、磁光盘或半导体存储器。
在如上所述的那样配置的计算机中,cpu401通过经由输入/输出接口405和总线404将适当的程序从存储部408加载到ram403中并且通过执行所加载的程序来执行上述一系列处理。
在提供有例如封装式介质的可移除介质411的情况下,要由计算机(cpu401)执行的程序可以被记录在可移除介质411上。还可以经由诸如局域网、互联网和数字卫星广播的有线或无线传输介质来提供程序。
在计算机中,可以经由输入/输出接口405将程序从附接至驱动器410的可移除介质411安装到存储部408中。也可以在通过通信部409经由有线或无线传输介质接收到程序之后将程序安装到存储部408中。可替选地,可以将程序预先安装在rom402中或存储部408中。
此外,要由计算机执行的每个程序可以按时间顺序、即以本说明书中描绘的序列进行处理,与其他程序并行地进行处理,或者以另外适当定时的方式、例如当根据需要被调用时进行处理。
此外,多个计算机可以彼此协调以执行上述处理。执行上述处理的单个或多个计算机构成计算机系统。
在本说明书中,术语“系统”指代多个组件(例如,装置或模块(部件))的集合。所有组件是否均被容置在同一壳体中并不重要。因此系统可以被配置有容置在单独的壳体中并且经由网络互连的多个装置或者被配置有将多个模块容置在单个壳体中的单个装置。
此外,本技术不限于上面讨论的实施方式并且可以以各种变型实现,只要它们在所附权利要求书或其等同物的范围内即可。
例如,本技术可以被实现为云计算设置,其中在共享的基础上由多个联网装置协作地处理单个功能。
此外,参考上述流程图讨论的步骤中的每个步骤可以由单个装置执行或者在共享的基础上由多个装置执行。
此外,如果单个步骤包括多个处理,则这些处理可以由单个装置执行或者在共享的基础上由多个装置执行。
本说明书中陈述的有益效果仅是示例,而非对本技术的限制。可以存在从本技术得到的其他有益效果。
在以上描述中公开的本技术可以被优选地配置为如下:
(1)一种信息处理装置,包括:
语音输出控制部,其被配置成基于通过将文本转换成语音而获得的合成语音被输出时的情境来控制所述合成语音的输出形式。
(2)根据上述(1)所述的信息处理装置,其中,在所述情境满足预定条件的情况下,所述语音输出控制部改变所述合成语音的输出形式。
(3)根据上述(2)所述的信息处理装置,其中,所述合成语音的输出形式的改变包括改变以下中至少之一:所述合成语音的特性、针对所述合成语音的效果、所述合成语音的背景中的bgm(背景音乐)、所述合成语音中输出的文本或者用于输出所述合成语音的装置的操作。
(4)根据上述(3)所述的信息处理装置,
其中,所述合成语音的特性包括以下中至少之一:速度、音调、音量或语调,并且
针对所述合成语音的效果包括以下中至少之一:重复所述文本中的特定词句或将停顿插入到所述合成语音中。
(5)根据上述(2)至(4)中任一项所述的信息处理装置,其中,在检测到用户的注意力未被引导至所述合成语音的状态时,所述语音输出控制部改变所述合成语音的输出形式。
(6)根据上述(2)至(5)中任一项所述的信息处理装置,其中,在所述合成语音的输出形式改变之后检测到用户的注意力被引导至所述合成语音的状态时,所述语音输出控制部将所述合成语音的输出形式返回至初始形式。
(7)根据上述(2)至(6)中任一项所述的信息处理装置,其中,在所述合成语音的特性的变化量在预定范围内的状态持续至少预定时间段的情况下,所述语音输出控制部改变所述合成语音的输出形式。
(8)根据上述(2)至(7)中任一项所述的信息处理装置,其中,所述语音输出控制部基于所述情境来选择改变所述合成语音的输出形式的方法。
(9)根据上述(2)至(8)中任一项所述的信息处理装置,还包括:
学习部,其被配置成学习用户对改变所述合成语音的输出形式的方法的反应,
其中所述语音输出控制部基于对所述用户的反应的学习结果来选择改变所述合成语音的输出形式的方法。
(10)根据上述(1)至(9)中任一项所述的信息处理装置,其中,所述语音输出控制部还基于所述文本的特性控制所述合成语音的输出形式。
(11)根据上述(10)所述的信息处理装置,其中,所述语音输出控制部在所述文本的特征量等于或大于第一阈值的情况下或者在所述文本的特征量小于第二阈值的情况下,改变所述合成语音的输出形式。
(12)根据上述(1)至(11)中任一项所述的信息处理装置,其中,所述语音输出控制部向其他信息处理装置提供用于生成所述合成语音时的语音控制数据,由此控制来自所述其他信息处理装置的合成语音的输出形式。
(13)根据上述(12)所述的信息处理装置,其中,所述语音输出控制部基于从所述其他信息处理装置获取的与情境有关的情境数据来生成所述语音控制数据。
(14)根据上述(13)所述的信息处理装置,其中,所述情境数据包括以下中至少之一:基于捕获的用户周围的图像的数据、基于来自所述用户周围的语音的数据或基于与所述用户有关的生物信息的数据。
(15)根据上述(13)或(14)所述的信息处理装置,还包括:
情境分析部,其被配置成基于所述情境数据分析所述情境。
(16)根据上述(1)至(15)中任一项所述的信息处理装置,其中,所述情境包括以下中至少之一:用户的状况、所述用户的特性、输出所述合成语音的环境或所述合成语音的特性。
(17)根据上述(16)所述的信息处理装置,其中,输出所述合成语音的环境包括以下中至少之一:所述用户的周围环境、用于输出所述合成语音的装置或用于输出所述合成语音的应用程序。
(18)一种信息处理方法,包括:
语音输出控制步骤,用于基于通过将文本转换成语音而获得的合成语音被输出时的情境来控制所述合成语音的输出形式。
(19)一种信息处理装置,包括:
通信部,其被配置成向其他信息处理装置传送与通过将文本转换成语音而获得的合成语音被输出时的情境有关的情境数据,所述通信部还从所述其他信息处理装置接收用于生成所述合成语音的语音控制数据,所述合成语音的输出形式是基于所述情境数据来控制的;以及
语音合成部,其被配置成基于所述语音控制数据生成所述合成语音。
(20)一种信息处理方法,包括:
通信步骤,用于向其他信息处理装置传送与通过将文本转换成语音而获得的合成语音被输出时的情境有关的情境数据,所述通信步骤还从所述其他信息处理装置接收用于生成所述合成语音的语音控制数据,所述合成语音的输出形式是基于所述情境数据来控制的;以及
语音合成步骤,用于基于所述语音控制数据生成所述合成语音。
附图标记列表
10信息处理系统、11客户端、12服务器、31语音输出部、32语音输入部、33成像部、34显示部、35生物信息获取部、38处理器、55情境分析部、56语言分析部、57语音输出控制部、58学习部、101语音合成部、102情境数据获取部。
- 还没有人留言评论。精彩留言会获得点赞!