语音识别装置和语音识别方法与流程
本发明涉及提高噪声下的语音识别的识别性能的技术。
背景技术:
通过从输入信号中剪切讲话的语音区间并与预先准备好的标准模式对照来进行语音识别。在讲话开头为无声辅音的情况或发声较弱的情况下,很难准确地剪切语音区间,因此,通常是对讲话的前后附加少许的裕量(例如200msec)区间而进行语音区间的剪切。有可能裕量区间仅包含不包含语音的区间即周围的环境噪声(以下记作噪声)。因此,作为用于语音识别的标准模式,一般不仅生成语音的标准模式,还预先生成噪声的标准模式,在语音识别时包含裕量区间在内进行模式匹配。
但是,噪声的种类是多种多样的,因此,很难预先生成针对全部噪声的标准模式。存在如下问题:在识别时的噪声区间与噪声的标准模式较大不同的情况下,语音的标准模式的相对于噪声区间的相似度即似然度高于噪声的标准模式,成为将噪声误识别为语音的原因。
作为解决该问题的技术,专利文献1中公开有根据输入数据的特征量来校正作为噪声的标准模式的垃圾模型(garbagemodel)的似然度的语音识别装置。在专利文献1的语音识别装置中,使用输入数据的各种特征量,判定作为似然度计算对象的区间像噪声还是像语音,在作为似然度计算对象的区间像噪声的情况下,对垃圾模型的似然度加上正值。由此,可减少如下现象:在噪声区间内,语音的标准模式的似然度高于噪声的标准模式,成为误识别为语音的原因。
现有技术文献
专利文献
专利文献1:日本特开2007-17736号公报
技术实现要素:
发明要解决的课题
在上述专利文献1记载的语音识别装置中,存在无法克服如下现象的课题:由于是校正垃圾模型的似然度的方式,因此,当在生成垃圾模型时使用的噪声数据与语音识别时的噪声数据的特征量较大不同时,例如,在校正前的垃圾模型的似然度的下降较大的情况下,即使校正似然度,语音的标准模式的似然度也更高。
本发明正是为了解决上述课题而完成的,其目的在于,即使在生成噪声的标准模式时使用的噪声数据与语音识别时的噪声数据的特征量较大不同的情况下,也抑制语音识别的性能下降。
用于解决课题的手段
本发明的语音识别装置具有:第1特征向量计算部,其根据输入的语音数据计算第1特征向量;声学似然度计算部,其使用用于计算特征向量的声学似然度的声学模型,计算第1特征向量计算部计算出的第1特征向量的声学似然度;第2特征向量计算部,其根据语音数据计算第2特征向量;噪声度计算部,其使用用于计算表示特征向量是噪声还是语音的噪声度的判别模型,计算第2特征向量计算部计算出的第2特征向量的噪声度;噪声似然度重新计算部,其根据声学似然度计算部计算出的第1特征向量的声学似然度和噪声度计算部计算出的第2特征向量的噪声度,重新计算噪声的声学似然度;以及对照部,其使用声学似然度计算部计算出的声学似然度和噪声似然度重新计算部重新计算出的噪声的声学似然度,进行与作为识别对象的词汇模式之间的对照,输出语音数据的识别结果。
发明效果
根据本发明,即使在生成噪声的标准模式时使用的噪声数据与语音识别时的噪声数据的特征量较大不同的情况下,也能够抑制语音识别的性能下降。
附图说明
图1是示出实施方式1的语音识别装置的结构的框图。
图2是示出实施方式1的语音识别装置的声学模型的一例的图。
图3a、图3b是示出实施方式1的语音识别装置的硬件结构例的图。
图4是示出实施方式1的语音识别装置的动作的流程图。
图5是示出实施方式2的语音识别装置的判别模型的一例的结构的图。
图6是示出实施方式3的语音识别装置的判别模型的一例的结构的图。
具体实施方式
以下,为了更详细地说明本发明,按照附图说明用于实施本发明的方式。
实施方式1
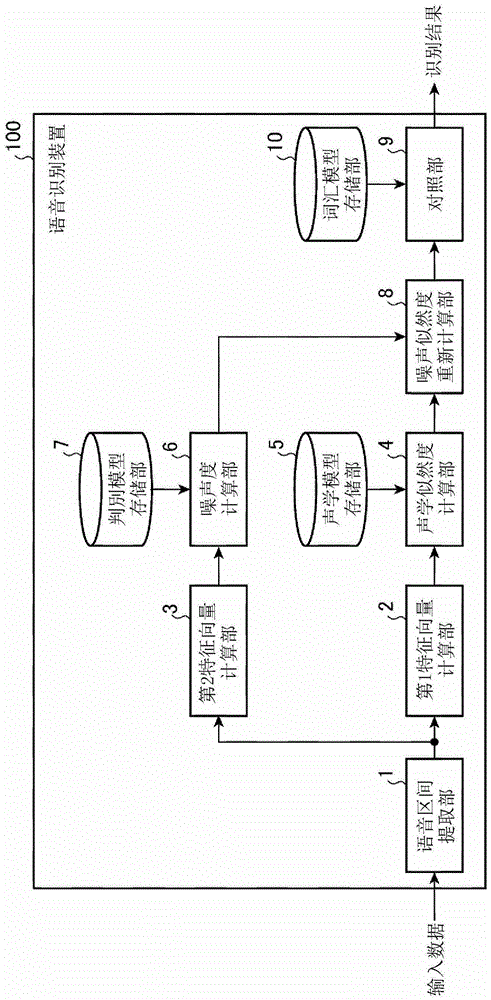
图1是示出实施方式1的语音识别装置100的结构的框图。
语音识别装置100具有语音区间提取部1、第1特征向量计算部2、第2特征向量计算部3、声学似然度计算部4、声学模型存储部5、噪声度计算部6、判别模型存储部7、噪声似然度重新计算部8、对照部9和词汇模型存储部10。
语音区间提取部1从输入数据提取包含语音的区间。语音区间提取部1将包含提取出的语音的区间的语音数据输出到第1特征向量计算部2和第2特征向量计算部3。语音区间提取部1例如计算输入数据的功率,提取对功率为预先设定的阈值以上的区间的前后加上预先设定的裕量(例如200msec)而得到的区间。在讲话开头为无声辅音的情况或发声较弱的情况下,区间的功率小于预先设定的阈值,语音区间有时欠缺。语音区间提取部1通过提取对功率为预先设定的阈值以上的区间的前后加上预先设定的裕量而得到的区间,能够抑制上述的语音区间的欠缺。另外,作为裕量而加上的区间有可能包含语音和噪声双方。
第1特征向量计算部2将语音区间提取部1提取出的语音数据分割成称作帧的较短的时间区间。第1特征向量计算部2对分割出的各帧进行语音识别用的声学分析,计算语音识别用的特征向量(以下,记作第1特征向量)。第1特征向量为mfcc(mel-frequencycepstrumcoefficients:mel频率倒谱系数1)的1阶至12阶的十二维的向量。第1特征向量计算部2将计算出的第1特征向量输出到声学似然度计算部4。
第2特征向量计算部3将语音区间提取部1提取出的语音数据分割成与第1特征向量计算部2相同的帧。第2特征向量计算部3对各帧进行用于判别语音和噪声的声学分析,计算用于判别语音和噪声的特征向量(以下,记作第2特征向量)。第2特征向量计算部3将计算出的第2特征向量输出到噪声度计算部6。
这里,第2特征向量为对作为第1特征向量的mfcc的十二维数据加上自相关系数的高阶峰值而得到的十三维的向量。自相关系数的高阶为相当于语音的基本频率即80hz至350hz的阶数。自相关系数的高阶峰值是对元音和噪声的判别有效的特征量,因此,用作语音和噪声的第2特征向量的1个要素。
声学似然度计算部4按照每个帧对第1特征向量计算部2计算出的第1特征向量与声学模型存储部5中存储的声学模型进行对照,计算各音素和噪声的声学似然度的时间序列。声学似然度计算部4将计算出的各音素和噪声的声学似然度的时间序列输出到噪声似然度重新计算部8。
这里,音素是指元音和辅音。此外,似然度是与相似等同的指标,例如,元音a的似然度较高的帧表示该帧为元音a的数据的概率较高。
声学模型存储部5存储声学模型。声学模型例如由dnn(deepneuralnetwork:深层神经网络)构成。图2示出作为声学模型的dnn的例子。
图2是示出实施方式1的语音识别装置100的声学模型的一例的图。
如图2所示,使dnn的输出单元与各音素(图2中的“あ”、“い”、……、“ん”等)和噪声区间对应。而且,预先进行学习以输出各音素和噪声的似然度。在学习中使用对大量讲话者的语音数据进行分析而得到的语音识别用特征向量。此外,对于用于学习的语音数据,通过使用在讲话的前后存在背景噪声的区间的数据,还学习针对噪声的输出单元。
噪声度计算部6将第2特征向量计算部3的输出即各帧的第2特征向量与判别模型存储部7中存储的判别模型即语音gmm(gaussianmixturemodel:高斯混合模型)和噪声gmm进行对照。噪声度计算部6求出语音gmm的似然度gs和噪声gmm的似然度gn,根据以下的式(1)计算噪声度pn。
pn=gn-gs(1)
如式(1)所示,由于噪声度pn为噪声gmm与语音gmm的似然度差,因此,如果用于后述的对照的帧的数据像噪声则取正值,如果像语音则取负值。
判别模型存储部7存储用于判别输入到噪声度计算部6的各帧的数据是语音还是噪声的判别模型。在本实施方式1中,示出使用gmm(gaussianmixturemodel:高斯混合模型)作为判别模型的情况。判别模型存储部7存储由语音gmm和噪声gmm构成的gmm。语音gmm是使用用于判别大量讲话者的多种多样的讲话数据的语音和噪声的特征向量而学习到的。此外,噪声gmm是使用用于判别在假设使用语音识别装置100的环境下多种多样的噪声数据中的语音和噪声的特征向量而学习到的。
判别模型是以判别各帧的数据的语音和噪声为目标的模型,不是以判别语音是什么音素为目标的模型。语音gmm是通过使用比用于学习声学模型存储部5中存储的声学模型的语音数据少的数据的学习而得到的。另一方面,噪声gmm通过使用比声学模型存储部5中存储的声学模型的学习数据更多种多样的噪声进行学习,能够高精度地对多种多样的噪声进行语音和噪声的判别。
噪声似然度重新计算部8将声学似然度计算部4的输出即各音素与噪声的声学似然度、以及噪声度计算部6的输出即噪声度pn作为输入,根据以下的式(2)计算重新计算噪声似然度ln。
ln=max(ln0,ln1)(2)
上述的式(2)中的ln0是从声学似然度计算部4输入的噪声的声学似然度,ln1是根据噪声度pn使用以下的式(3)计算出的似然度。
ln1=lmax+α*pn(3)
上述的式(3)中的lmax是从声学似然度计算部4输出的各音素的声学似然度的最大值,α是通过实验确定正的常数。
如式(3)所示,在噪声度pn为正值的情况下,ln1成为lmax以上的值。因此,利用式(2)计算的重新计算噪声似然度ln也成为lmax以上的值。如上所述,由于lmax为各音素的声学似然度的最大值,因此,可保障重新计算噪声似然度ln成为各音素的声学似然度以上的值。因此,能够防止在噪声区间内音素的声学似然度高于噪声的声学似然度。由此,在语音识别装置100中,能够抑制将像噪声的区间误识别为像语音的区间。此外,如式(3)所示,在噪声度pn为负值的情况下,ln1成为小于lmax的值,能够防止在不像噪声的区间内重新计算噪声似然度ln成为不适当地高的值。
噪声似然度重新计算部8将计算出的重新计算噪声似然度ln和声学似然度计算部4计算出的各音素的声学似然度输出到对照部9。
对照部9将从噪声似然度重新计算部8输出的重新计算噪声似然度ln和各音素的声学似然度作为输入,使用词汇模型存储部10中存储的识别对象词汇的词汇模型的各词汇的标准模式和维特比算法进行对照,计算各词汇的似然度。对照部9将计算出的似然度最高的词汇作为识别结果输出。
词汇模型存储部10存储作为识别对象的词汇的标准模式。词汇的标准模式例如是将以音素为单位的hmm(hiddenmarkovmodel:隐马尔科夫模型)连接而生成的。
以识别对象为日本的都道府县名称的情况为例,说明词汇模型存储部10中存储的标准模式。例如,在“东京(とーきょー)”这样的词汇的情况下,音素系列为“t、o、o、k、j、o、o”,因此,连接该音素的hmm而生成标准模式。但是,作为对照对象的输入数据在语音区间的前后附加有裕量区间,因此,标准模式是在识别词汇的音素系列的前后附加噪声的hmm而构成的。因此,在词汇“东京(とーきょー)”的情况下,标准模式成为“#、t、o、o、k、j、o、o、#”。这里,#表示噪声的hmm。
另外,在使用hmm的通常的语音识别中,使用hmm计算声学似然度。另一方面,在语音识别装置100中,由声学似然度计算部4和噪声似然度重新计算部8计算各音素与噪声的声学似然度,因此,替代使用hmm计算声学似然度的处理,使用各音素与噪声的声学似然度。例如,作为音素a的hmm的声学似然度,使用声学似然度计算部4计算出的音素a的声学似然度。
接着,说明语音识别装置100的硬件结构例。
图3a和图3b是示出语音识别装置100的硬件结构例的图。
语音识别装置100中的语音区间提取部1、第1特征向量计算部2、第2特征向量计算部3、声学似然度计算部4、噪声度计算部6、噪声似然度重新计算部8和对照部9的各功能通过处理电路来实现。即,语音识别装置100具有用于实现上述各功能的处理电路。该处理电路可以如图3a所示是作为专用硬件的处理电路100a,也可以如图3b所示是执行存储器100c中存储的程序的处理器100b。
如图3a所示,在语音区间提取部1、第1特征向量计算部2、第2特征向量计算部3、声学似然度计算部4、噪声度计算部6、噪声似然度重新计算部8和对照部9是专用硬件的情况下,处理电路100a例如是单一电路、复合电路、程序化的处理器、并列程序化的处理器、asic(applicationspecificintegratedcircuit:面向特定用途的集成电路)、fpga(field-programmablegatearray:现场可编程门阵列)或者将它们组合而成的部件。可以由处理电路分别实现语音区间提取部1、第1特征向量计算部2、第2特征向量计算部3、声学似然度计算部4、噪声度计算部6、噪声似然度重新计算部8和对照部9的各部的功能,也可以汇总各部的功能而由1个处理电路实现。
如图3b所示,在语音区间提取部1、第1特征向量计算部2、第2特征向量计算部3、声学似然度计算部4、噪声度计算部6、噪声似然度重新计算部8和对照部9是处理器100b的情况下,各部的功能通过软件、固件或软件与固件的组合来实现。软件或固件记作程序而存储在存储器100c中。处理器100b通过读出并执行存储器100c中存储的程序,实现语音区间提取部1、第1特征向量计算部2、第2特征向量计算部3、声学似然度计算部4、噪声度计算部6、噪声似然度重新计算部8和对照部9的各功能。即,在由处理器100b执行语音区间提取部1、第1特征向量计算部2、第2特征向量计算部3、声学似然度计算部4、噪声度计算部6、噪声似然度重新计算部8和对照部9时,具有用于存储结果是执行后述的图4所示的各步骤的程序的存储器100c。此外,这些程序也可以说是使计算机执行语音区间提取部1、第1特征向量计算部2、第2特征向量计算部3、声学似然度计算部4、噪声度计算部6、噪声似然度重新计算部8和对照部9的过程或方法的程序。
这里,处理器100b例如是cpu(centralprocessingunit:中央处理器)、处理装置、运算装置、处理器、微型处理器、微型计算机或dsp(digitalsignalprocessor:数字信号处理器)等。
存储器100c例如可以是ram(randomaccessmemory:随机存取存储器)、rom(readonlymemory:只读存储器)、闪存、eprom(erasableprogrammablerom:可除擦可编程rom)、eeprom(electricallyeprom)等非易失性或者易失性的半导体存储器,也可以是硬盘、软盘等磁盘,还可以是迷你盘、cd(compactdisc:光盘)、dvd(digitalversatiledisc:数字多功能盘)等光盘。
另外,关于语音区间提取部1、第1特征向量计算部2、第2特征向量计算部3、声学似然度计算部4、噪声度计算部6、噪声似然度重新计算部8和对照部9的各功能,也可以通过专用硬件实现一部分,通过软件或固件实现一部分。这样,语音识别装置100中的处理电路100a可以通过硬件、软件、固件或者它们的组合实现上述各功能。
接着,对语音识别装置100的动作进行说明。
图4是示出实施方式1的语音识别装置100的动作的流程图。
当对语音识别装置100输入数据时(步骤st1),语音区间提取部1从该输入数据提取对功率为阈值以上的区间的前后加上预先设定的裕量而得到的区间,作为语音区间(步骤st2)。语音区间提取部1将提取出的语音区间的语音数据输出到第1特征向量计算部2和第2特征向量计算部3。第1特征向量计算部2将在步骤st2中提取出的语音区间的语音数据分割成帧,对各帧进行语音识别用的声学分析,计算第1特征向量(步骤st3)。第1特征向量计算部2将计算出的第1特征向量输出到声学似然度计算部4。
声学似然度计算部4对在步骤st3中计算出的各帧的第1特征向量与声学模型存储部5中存储的声学模型进行对照,计算各音素与噪声的声学似然度(步骤st4)。声学似然度计算部4将计算出的声学似然度输出到噪声似然度重新计算部8。第2特征向量计算部3与第1特征向量计算部2并行地进行动作,将在步骤st2中提取出的语音区间的语音数据分割成帧,对各帧进行用于判别语音和噪声的声学分析,计算第2特征向量(步骤st5)。第2特征向量计算部3将计算出的第2特征向量输出到噪声度计算部6。
噪声度计算部6对在步骤st5中计算出的第2特征向量与判别模型存储部7中存储的判别模型即语音gmm和噪声gmm进行对照,计算语音gmm的似然度gs和噪声gmm的似然度gn(步骤st6)。噪声度计算部6使用在步骤st6中计算出的语音gmm的似然度gs和噪声gmm的似然度gn,根据上述的式(1)计算噪声度pn(步骤st7)。噪声度计算部6将计算出的噪声度pn输出到噪声似然度重新计算部8。
噪声似然度重新计算部8使用在步骤st4中计算出的各音素与噪声的声学似然度以及在步骤st7中计算出的噪声度pn,根据上述的式(2)计算再次计算出的重新计算噪声似然度ln(步骤st8)。噪声似然度重新计算部8将计算出的重新计算噪声似然度ln和各音素的声学似然度输出到对照部9(步骤st9)。
对照部9将在步骤st9中从噪声似然度重新计算部8输出的重新计算噪声似然度ln和各音素的声学似然度作为输入,使用词汇模型存储部10中存储的词汇模型的各词汇的标准模式和维特比算法进行对照,计算各词汇的似然度(步骤st10)。对照部9设在步骤st10中计算出的各词汇的似然度中的最高似然度的词汇为识别结果(步骤st11)。对照部9将在步骤st11中取得的识别结果输出到外部(步骤st12),结束处理。
如上所述,根据实施方式1,构成为具有:第1特征向量计算部2,其根据输入的语音数据计算第1特征向量;声学似然度计算部4,其使用用于计算特征向量的声学似然度的声学模型,计算第1特征向量的声学似然度;第2特征向量计算部3,其根据语音数据计算第2特征向量;噪声度计算部6,其使用用于计算表示特征向量是噪声还是语音的噪声度的判别模型,计算第2特征向量的噪声度;噪声似然度重新计算部8,其根据第1特征向量的声学似然度和第2特征向量的噪声度,重新计算噪声的声学似然度;以及对照部9,其使用计算出的声学似然度和重新计算出的噪声的声学似然度进行与作为识别对象的词汇模式之间的对照,输出语音数据的识别结果。因此,能够抑制在噪声区间中音素的似然度超过噪声的似然度,在噪声区间中对噪声的标准模式标注适当的似然度。由此,能够提高语音识别装置的识别性能。
实施方式2
在本实施方式2中,示出使用神经网络作为判别模型的结构。
实施方式2的语音识别装置100的结构与图1所示的实施方式1的语音识别装置100的结构相同,因此,省略框图的记载。此外,实施方式2的语音识别装置100的各结构标注与在实施方式1中使用的标记相同的标记进行说明。
第1特征向量计算部2与第2特征向量计算部3的结构相同。因此,第1特征向量计算部2计算出的第1特征向量与第2特征向量计算部3计算出的第2特征向量是相同的特征向量。
声学模型存储部5中存储的声学模型是具有一层以上的中间层的神经网络。
判别模型存储部7中存储的判别模型是对声学模型存储部5中存储的声学模型的神经网的中间层或输出层追加0层以上的中间层和一层的输出层而得到的神经网络。
图5是示出实施方式2的语音识别装置100的判别模型的一例的图。
图5所示的判别模型是对声学模型的神经网追加一层的中间层和一层的输出层而构成的。向判别模型的神经网络的输入是语音识别用的第2特征向量a。判别模型的神经网络的输出单元存在2个,一个输出单元b对应于语音的似然度,另一个输出单元c对应于噪声的似然度。通过将输出单元b的输出置换成实施方式1所示的语音gmm的似然度gs,将输出单元c的输出置换成噪声gmm的似然度gn并应用于式(1),与实施方式1同样,根据式(1)计算噪声度。
判别模型仅对追加层的参数另行进行学习,其他参数为与声学模型存储部5中存储的声学模型相同的参数。在判别模型中需要学习的仅是追加层的参数,因此,与声学模型存储部5中存储的声学模型的学习相比,应该学习的参数变少,可实现学习的高速化。
噪声度计算部6将第2特征向量计算部3计算出的语音识别用的第2特征向量输入到判别模型存储部7中存储的判别模型的神经网络。噪声度计算部6将输出单元的一个输出应用于式(1)的语音似然度gs,将输出单元的另一个输出应用于式(1)的噪声似然度gn。噪声度计算部6根据式(1)计算噪声度pn。
如上所述,根据本实施方式2,第2特征向量计算部3构成为计算与第1特征向量计算部2计算出的第1特征向量相同的特征向量,作为第2特征向量,声学模型是具有一层以上的中间层的神经网络,判别模型是对声学模型的神经网的中间层或输出层追加0层以上的中间层和一层的输出层而得到的神经网络,仅学习追加的中间层和输出层的参数。因此,判别模型中所需的学习能够仅为对声学模型追加的层的参数,能够高速地进行判别模型的学习。由此,能够使用比声学模型的学习数据更多种多样的噪声进行判别模型的学习,能够高精度地将多种多样的噪声与语音进行区分。
实施方式3
在本实施方式3中,作为输入到神经网络的中间层或输出层的输入数据,示出加上第2特征向量计算部3计算出的特征向量的结构。
实施方式3的语音识别装置100的结构与图1所示的实施方式1的语音识别装置100的结构相同,因此,省略框图的记载。此外,实施方式3的语音识别装置100的各结构标注与在实施方式1中所使用的标记相同的标记进行说明。
第2特征向量计算部3计算与第1特征向量计算部2计算的第1特征向量不同的一维以上的第2特征向量。第2特征向量计算部3例如计算自相关系数的高阶的峰值。自相关系数的高阶为相当于语音的基本频率即80至350hz的阶数。自相关系数的高阶的峰值是对元音和噪声的判别有效的特征量,因此,用作用于判别语音和噪声的特征向量的1个要素。
声学模型存储部5中存储的声学模型是具有一层以上的中间层的神经网络。
判别模型存储部7中存储的判别模型是对声学模型存储部5中存储的声学模型的神经网的中间层或输出层追加0层以上的中间层和一层的输出层而得到的神经网络。并且,判别模型新追加第2特征向量计算部3计算出的参数学习用的第2特征向量的特征量,作为输入到追加的最初的中间层或输出层的输入数据。如上所述,第3特征向量是自相关函数的高阶的峰值,且是一维的向量。
图6是示出实施方式3的语音识别装置100的判别模型的一例的图。
如图6所示,判别模型是对声学模型的神经网追加一层的中间层和一层的输出层而构成的。此外,判别模型构成为对追加的一层的中间层新追加参数学习用的第2特征向量的特征量d。
向判别模型的神经网络的输入是语音识别用的第2特征向量a。判别模型的神经网络的输出单元存在2个,一个输出单元b对应于语音的似然度,另一个输出单元c对应于噪声的似然度。通过将输出单元b的输出置换成实施方式1所示的语音gmm的似然度gs,将输出单元c的输出置换成噪声gmm的似然度gn,与实施方式1同样,根据式(1)计算噪声度。
判别模型仅对追加层的参数另行进行学习,其他参数为与声学模型存储部5中存储的声学模型相同的参数。在判别模型中需要学习的仅是追加层的参数,因此,与声学模型存储部5中存储的声学模型的学习相比,应该学习的参数变少,可实现学习的高速化。
噪声度计算部6将第2特征向量计算部3计算出的语音识别用的第2特征向量输入到判别模型存储部7中存储的判别模型的神经网络。噪声度计算部6将输出单元的一个输出应用于式(1)的语音似然度gs,将输出单元的另一个输出应用于式(1)的噪声似然度gn。噪声度计算部6根据式(1)计算噪声度pn。
如上所述,根据本实施方式3,第2特征向量计算部3构成为计算与第1特征向量计算部2计算出的第1特征向量不同的一维以上的特征向量,作为第2特征向量,声学模型是具有一层以上的中间层的神经网络,判别模型是对声学模型的神经网的中间层或输出层追加0层以上的中间层和一层的输出层而得到的神经网络,追加第2特征向量计算部3计算出的第2特征向量的特征量作为输入到追加的最初的中间层或输出层的输入数据,仅学习追加的中间层和输出层的参数。因此,能够提高语音和噪声的判别精度。此外,判别模型中所需的学习能够仅为对声学模型追加的层的参数,能够高速地进行判别模型的学习。由此,能够使用比声学模型的学习数据更多种多样的噪声进行判别模型的学习,能够高精度地将多种多样的噪声与语音进行区分。
此外,根据本实施方式3,构成为新增加第2特征向量计算部3计算出的特征向量作为输入到追加于神经网络的最初的中间层或输出层的输入数据。因此,能够提高语音和噪声的判别精度。
除了上述以外,本发明能够在其发明范围内进行各实施方式的自由组合、或各实施方式的任意结构要素的变形、或各实施方式的任意结构要素的省略。
产业上的可利用性
本发明的语音识别装置适用于在要求提高判定精度的噪声环境下使用的设备等,适合于实现准确地区分出语音和噪声的语音识别处理。
标号说明
1:语音区间提取部;2:第1特征向量计算部;3:第2特征向量计算部;4:声学似然度计算部;5:声学模型存储部;6:噪声度计算部;7:判别模型存储部;8:噪声似然度重新计算部;9:对照部;10:词汇模型存储部;100:语音识别装置。
- 还没有人留言评论。精彩留言会获得点赞!