语音识别方法、程序、语音识别装置和机器人与流程
本公开涉及语音识别的技术。
背景技术:
近年来,提出了根据说出的语音数据来推定表示说话内容的单词串的各种语音识别方法。
例如,在专利文献1中,公开了下述语音识别方法。即,将说出的语音数据划分为多个音素区间x,对各音素区间x分配音素模型,求出对第n个音素区间x分配的音素模型p的似然度(likelihood)psn以及似然度psn与除音素模型p之外的音素模型的音素区间x的似然度的最高值pmaxn之间的差分似然度pdn。进而,分别将似然度psn和差分似然度pdn输入到正解音素区间似然度模型和非正解音素似然度模型,求出正解音素区间似然度模型的似然度lnc和非正解音素似然度模型的似然度lni。进而,求出似然度lnc与似然度lni的差分似然度cn,求出差分似然度cn的全部音素区间的相加值作为单词可信度wc,如果单词可信度wc为阈值以上,则输出对该语音数据分配的音素串,如果单词可信度wc小于阈值,则放弃该音素串。
但是,在专利文献1中,仅考虑了音素似然度,没有考虑语言似然度,因此存在不能再现作为语言而具有自然感的音素串这样的问题。
因此,在非专利文献1中,公开了如下方法:使用音响(声学)似然度和语言似然度,对话语进行语音识别,推定单词串。具体而言,在非专利文献1中,选择使式(1)的右边所示的概率之积最大的单词串w来作为识别结果。此处,w是任意单词串,p(o|w)是单词串w的音素串为o的概率(音响似然度),通过音响模型来计算。p(w)是表示作为w的语言的最大可能性的概率(语言似然度),基于n-gram(n元语法)等连续单词的出现频度信息,通过语言模型来计算。
另外,在该方法中,将该音响似然度和语言似然度之积作为识别结果的可信度(文章的可信度),与识别结果一同输出。
现有技术文献
专利文献1:日本特开平11-249688号公报
非专利文献1:堀貴明·塚田元著、情報処理学会誌45巻10号pp.1020-1026、音声情報処理技術の最先端:3.重み付き有限状態トランスデューサによる音声認識、2004年10月
技术实现要素:
发明要解决的问题
但是,在非专利文献1中,在输入话语模糊或输入话语受噪声等影响较大的情况下,文章的可信度会成为低值。进而,在文章的可信度低的情况下,存在识别结果中包含错误的可能性升高这样的问题。
本公开是为了解决这样的问题而完成的。
用于解决问题的手段
本公开的一个方式的语音识别方法,包括:经由麦克风接收由说话人意图说一单词而说出的第1话语,所述第1话语由n个音素构成,所述n为2以上的自然数,按构成所述第1话语的所述n个音素,计算全部种类的音素的出现概率,将在构成所述第1话语的第1音素到第n音素依次排列具有与各所述n个音素对应的最大出现概率的音素而得到的音素串识别为与所述第1话语对应的第1音素串,使构成所述第1音素串的n个音素所具有的出现概率彼此相乘,由此计算第1值,在所述第1值小于第1阈值的情况下,通过扬声器输出促使所述说话人再次说出所述一单词的语音,经由所述麦克风接收由所述说话人意图说所述一单词而再次说出的第2话语,所述第2话语由m个音素构成,所述m为2以上的自然数,按构成所述第2话语的所述m个音素,对全部种类的音素计算出现概率,将在构成所述第2话语的第1音素到第m音素依次排列具有与各所述m个音素对应的最大出现概率的音素而得到的音素串识别为与所述第2话语对应的第2音素串,使构成所述第2音素串的m个音素所具有的出现概率彼此相乘,由此计算第2值,在所述第2值小于所述第1阈值的情况下,提取在所述第1音素串中具有第2阈值以上的出现概率的音素和在所述第2音素串中具有所述第2阈值以上的出现概率的音素,从存储器所存储的词典中提取包含所述提取出的音素的单词,所述词典将各单词与和所述各单词对应的音素串进行关联,在所述提取出的单词为一个的情况下,将所述提取出的单词识别为与所述一单词对应。
发明效果
本公开在说话人是幼儿的情况下或在输入话语受噪声影响较大的环境下,也能够提高识别精度。
附图说明
图1是示出实施方式1中的语音对话系统的整体结构的一例的图。
图2是示出在由二音素构成的说话中对每个音素计算出的出现概率的一例的图。
图3是汇总了在图2中针对第一音素的音素和第二音素的音素的组合的出现概率之积的图。
图4是示出实施方式1中的识别处理的一例的流程图。
图5是示出实施方式1中的对话的一例的图。
图6是示出针对图5的对话例的第一识别结果和第二识别结果的一例的图。
图7是示出单词词典的数据结构的一例的图。
图8是示出从第一识别结果中提取出的识别候选单词的一例的图。
图9是示出在实施方式1中,根据第一识别结果和第二识别结果来筛选识别候选单词的处理的另一例的图。
图10是示出实施方式2中的语音对话系统的整体结构的一例的图。
图11是示出划分为多个帧的语音信号的一例的图。
图12是示出实施方式2中的识别处理的一例的流程图。
图13是示出在实施方式2的具体例中采用1-gram语言模型的情况下的搜索空间的一例的图。
图14是示出在实施方式2的具体例中采用2-gram语言模型的情况下的单词词典的一例的图。
图15是示出在实施方式2的具体例中采用2-gram语言模型的情况下的搜索空间的一例的图。
图16是示出将实施方式2的具体例中的第一识别结果的各音素和第二识别结果的各音素的出现概率进行了合成的情况下的搜索空间的图。
图17是示出实施方式3中的语音对话系统的整体结构的一例的图。
图18是说明实施方式3中的识别处理的一例的流程图。
图19是示出实施方式3中的第一识别结果的5-best的一例的图。
图20是示出实施方式3中的第二识别结果的5-best的一例的图。
图21是安装有实施方式1~3的语音识别装置的机器人的外观图。
标号说明
20cpu
30存储器
100语音识别装置
200语音识别部
201音素推定部
202单词推定部
203音素出现概率判定部
210单词可信度判定部
220意图解释部
230行动选择部
240应答生成部
250语音合成部
260话语提取部
270共同候选提取部
301单词词典
302识别结果存储部
400麦克风
410扬声器
500机器人
1202文章推定部
1203音素出现概率合成部
1210文章可信度判定部
具体实施方式
(成为本公开的基础的见解)
提供了与如下语音对话系统相关的技术:根据用户说出的语音,解析说话内容,基于解析结果返回自然的应答,由此,实现与用户的自然对话,或提供设备控制或信息提供等服务。
在以成人为对象的一般的语音识别系统中,识别精度超过90%,即使未能识别,但通过放弃可信度低的识别结果,利用反问来慢慢说话或清楚地说话,也能够充分取得具有高可信度的识别结果。
但是,在一般的语音识别系统中,在处于语言学习阶段的幼儿的话语或者输入话语受噪声影响较大的环境下,识别精度变低,故而存在即使进行了反问也得不到可信度高的识别结果这样的问题。
在非专利文献1中,没有在虽然能够输出像是语言的单词串但得到了可信度较低的识别结果的情况下关于反问的公开,因此,未能解决上述问题。
在专利文献1中,只是公开了在得到了可信度较低的识别结果的情况下放弃该识别结果,没有关于进行反问的公开,因此与非专利文献1同样,不能解决上述问题。
因此,本发明人获得了如下见解而想到了本公开:如果不是直接放弃可信度低的识别结果而考虑该识别结果和通过反问得到的识别结果,则在说话人是幼儿的情况下或在输入话语受噪声影响较大的环境下,也能够提高识别精度。
本公开的一个方式的语音识别方法,包括:经由麦克风接收由说话人意图说一单词而说出的第1话语,所述第1话语由n个音素构成,所述n为2以上的自然数,按构成所述第1话语的所述n个音素,计算全部种类的音素的出现概率,将在构成所述第1话语的第1音素到第n音素依次排列具有与各所述n个音素对应的最大出现概率的音素而得到的音素串识别为与所述第1话语对应的第1音素串,使构成所述第1音素串的n个音素所具有的出现概率彼此相乘,由此计算第1值,在所述第1值小于第1阈值的情况下,通过扬声器输出促使所述说话人再次说出所述一单词的语音,经由所述麦克风接收由所述说话人意图说所述一单词而再次说出的第2话语,所述第2话语由m个音素构成,所述m为2以上的自然数,按构成所述第2话语的所述m个音素,对全部种类的音素计算出现概率,将在构成所述第2话语的第1音素到第m音素依次排列具有与各所述m个音素对应的最大出现概率的音素而得到的音素串识别为与所述第2话语对应的第2音素串,使构成所述第2音素串的m个音素所具有的出现概率彼此相乘,由此计算第2值,在所述第2值小于所述第1阈值的情况下,提取在所述第1音素串中具有第2阈值以上的出现概率的音素和在所述第2音素串中具有所述第2阈值以上的出现概率的音素,从存储器所存储的词典中提取包含所述提取出的音素的单词,所述词典将各单词与和所述各单词对应的音素串进行关联,在所述提取出的单词为一个的情况下,将所述提取出的单词识别为与所述一单词对应。
根据该结构,即使在通过识别意图说一单词的第1话语而得到的第1音素串的第1值低于第1阈值而第1音素串的可信度较低的情况下,也不放弃第1音素串。进而,在通过反问得到的、意图说一单词的第2话语的第2值低于第1阈值且第2音素串的可信度也较低的情况下,从第1音素串和第2音素串中分别提取可信度高的音素,与词典进行比较,由此提取与一单词对应的单词。
这样,在本结构中,即使对第1话语得到了可信度较低的识别结果,也不放弃该识别结果,而将该识别结果应用于对第2话语得到了可信度较低的识别结果的情况。因此,即使通过反问未得到可信度高的识别结果,也能够使用作为两个识别结果的第1音素串和第2音素串中的可信度高的音素来识别一单词,因此,能够提高一单词的识别精度。
此外,在本结构中,从词典中提取包含第1音素串和第2音素串中的可信度高的音素的单词,因此,能够防止得到语言上不自然的识别结果。
通过以上方式,本结构即使在说话人是幼儿的情况下或在输入话语受噪声影响较大的环境下,也能够提高识别精度。
在上述结构中,可以是,在所述提取出的单词为多个的情况下,通过所述扬声器输出询问说话人是否说出了所述提取出的各单词的语音,经由所述麦克风从所述说话人接收肯定或否定的回答,将与所述肯定的回答对应的单词识别为与所述一单词对应。
根据本结构,在从词典中提取出包含第1音素串和第2音素串中的可信度高的音素的多个单词的情况下,向说话人直接确认说出了哪个单词,因此,能够提高识别精度。
本公开的另一方式的声识别方法,包括:经由麦克风接收由说话人意图说一单词串而说出的第1话语,所述第1话语由n个音素构成,所述n为2以上的自然数,计算对所述第1话语推定的单词串的可信度x1,
t表示指定构成所述第1话语的帧的编号,t表示构成所述第1话语的帧的总数,pa1(ot,st|st-1)表示在与所述第1话语的第1帧至第t-1帧的状态st-1对应的音素串之后在第t帧出现任意音素而转变到与状态st对应的音素串的概率,ot表示根据所述第1话语得到的、用于推定所述任意音素的物理量,所述任意音素表示全部种类的音素,pl1(st,st-1)表示在所述第1话语中在与所述状态st-1对应的单词串之后在第t帧出现任意单词而转变到与所述状态st对应的单词串的概率,判定所述可信度x1是否为阈值以上,在所述可信度x1小于所述阈值的情况下,通过扬声器输出促使所述说话人再次说出所述一单词串的语音,经由所述麦克风接收由所述说话人意图说所述一单词串而再次说出的第2话语,在所述第2话语的可信度x1小于所述阈值的情况下,对根据所述第1话语和所述第2话语推定的全部单词串计算合成可信度,
t表示指定构成所述第1话语和所述第2话语的帧的编号,t表示构成所述第1话语和所述第2话语的帧的总数,pa1(ot,st|st-1)表示在与所述第1话语的第1帧至第t-1帧的状态st-1对应的音素串之后在第t帧出现任意音素而转变到与状态st对应的音素串的概率,ot表示根据所述第1话语得到的、用于推定所述任意音素的物理量,所述任意音素表示全部种类的音素,pa2(qt,st|st-1)表示在与所述第2话语的第1帧至第t-1帧的状态st-1对应的音素串之后在第t帧出现任意音素而转变到与状态st对应的音素串的概率,qt表示根据所述第2话语得到的、用于推定所述任意音素的物理量,pl(st,st-1)表示在所述第1话语中在与所述状态st-1对应的单词串之后在第t帧出现任意单词而转变到与所述状态st对应的单词串的概率,将与给予所述合成可信度x中的最大值的所述状态st对应的单词串识别为所述一单词串。
根据本结构,意图说一单词串的第1话语分为t个帧,将使从截止到第t-1帧的状态st-1转变到截止到第t帧的状态st时的音素串的概率pa1(ot,st|st-1)与单词串的概率pl1(st,st-1)之积最大化的单词串识别为一单词串。
进而,即使在第1话语的单词串的可信度x1低于阈值而第1话语的单词串的可信度低的情况下,也不放弃第1话语的单词串。进而,在通过反问得到的意图说一单词串的第2话语的单词串的可信度x1低于阈值而第2话语的单词串的可信度也低的情况下,计算出状态st下的第1话语的音素串的概率pa1(ot,st|st-1)与第2话语的音素串的概率pa2(qt,st|st-1)的相加值和状态st下的单词串的概率pl(st,st-1)之积来作为合成可信度x,将使合成可信度x最大化的单词串识别为一单词。
这样,在本结构中,即使对第1话语得到了可信度低的识别结果,也不放弃该识别结果,而将该识别结果应用于对第2话语得到了可信度低的识别结果的情况。因此,即使通过反问未得到可信度高的识别结果,也通过合成两个识别结果来识别一单词串,故而能够提高一单词串的识别精度。
此外,在本结构中,不仅考虑音素串的概率还考虑单词串的概率,因此,能够防止得到语言上不自然的识别结果。
通过以上方式,本结构即使在说话人是幼儿的情况下或在输入话语受噪声影响较大的环境下,也能够提高识别精度。
本公开的另一方式的语音识别方法,包括:经由麦克风接收由说话人意图说一单词串而说出的第1话语,所述第1话语由n个音素构成,所述n为2以上的自然数,计算对所述第1话语推定的全部单词串的可信度x1,
t1表示指定构成所述第1话语的帧的编号,t1表示构成所述第1话语的帧的总数,pa1(ot1,st1|st1-1)表示在与所述第1话语的第1帧至第t1-1帧的状态st1-1对应的音素串之后在第t1帧出现任意音素而转变到与状态st1对应的音素串的概率,ot1表示根据所述第1话语得到的、用于推定所述任意音素的物理量,所述任意音素表示全部种类的音素,pl1(st1,st1-1)表示在所述第1话语中在与所述状态st1-1对应的单词串之后在第t1帧出现任意单词而转变到与所述状态st1对应的单词串的概率,判定所述可信度x1的最大值maxx1是否为阈值以上,在所述最大值maxx1小于所述阈值的情况下,提取给予所述可信度x1的前m个可信度的对所述第1话语推定的第1单词串,所述m为2以上的自然数,通过扬声器输出促使所述说话人再次说出所述一单词串的语音,经由麦克风接收由所述说话人意图说所述一单词串而再次说出的第2话语,计算对所述第2话语推定的全部单词串的可信度x2,
t2表示指定构成所述第2话语的帧的编号,t2表示构成所述第2话语的帧的总数,pa2(ot2,st2|st2-1)表示在与所述第2话语的第1帧至第t2-1帧的状态st2-1对应的音素串之后在第t2帧出现任意音素而转变到与状态st2对应的音素串的概率,ot2表示根据所述第2话语得到的、用于推定所述任意音素的物理量,pl2(st2,st2-1)表示在所述第2话语中在与所述状态st2-1对应的单词串之后在第t2帧出现任意单词而转变到与所述状态st2对应的单词串的概率,判定所述可信度x2的最大值maxx2是否为阈值以上,在所述最大值maxx2小于所述阈值的情况下,提取给予所述可信度x2的所述前m个可信度的对所述第2话语推定的第2单词串,在所述第1单词串和所述第2单词串具有共同的单词串的情况下,将所述共同的单词串识别为所述一单词串。
根据本结构,意图说一单词串的第1话语分为t个帧,计算从截止到第t-1帧的状态st-1转变到截止到第t帧的状态st时的、音素串的概率pa1(ot,st|st-1)与单词串的概率pl1(st,st-1)之积来作为可信度x1。
进而,在可信度x1的最大值maxx1低于阈值而根据第1话语识别出的单词串的可信度低的情况下,提取具有前m个可信度x1的第1单词串,通过反问得到第2话语。
进而,在第2话语的单词串的可信度x2的最大值maxx2低于阈值而第2话语的单词串的可信度也低的情况下,提取具有前m个可信度x2的第2单词串,在第1单词串和第2单词串中具有共同的单词串的情况下,将共同的单词串识别为一单词串。
这样,在本结构中,即使对第1话语得到了可信度较低的识别结果,也不放弃该识别结果,而将该识别结果应用于对第2话语得到了可信度较低的识别结果的情况。因此,即使通过反问未得到可信度高的识别结果,也将通过第1话语和第2话语这两者识别出的单词串识别为一单词串,因此,能够提高一单词串的识别精度。
此外,在本结构中,不仅考虑音素串的概率还考虑单词串的概率,因此,能够防止得到语言上不自然的识别结果。
通过以上方式,本结构即使在说话人是幼儿的情况下或在输入话语受噪声影响较大的环境下,也能够提高识别精度。
上述语音识别方法也可以应用于机器人。
另外,本公开不仅可以作为执行以上那样的特征性处理的语音识别方法来实现,也可以作为具有用于执行语音识别方法中包含的特征性步骤的处理部的语音识别装置等来实现。另外,也可以作为使计算机执行这样的语音识别方法中包含的特征性的各步骤的计算机程序来实现。进而,不言而喻,可以经由cd-rom等计算机可读取的非瞬时性记录介质或互联网等通信网络来使那样的计算机程序流通。
以下,参照附图,对本公开的实施方式进行说明。此外,以下说明的实施方式均表示本公开的一具体例。以下的实施方式所示的数值、形状、构成要素、步骤和步骤的顺序等只是一例,不限定本公开的主旨。另外,关于以下的实施方式中的构成要素中的、表示顶部概念的独立权利要求中未记载的构成要素,作为任意构成要素来说明。另外,在全部实施方式中,可以组合各内容。
(实施方式1)
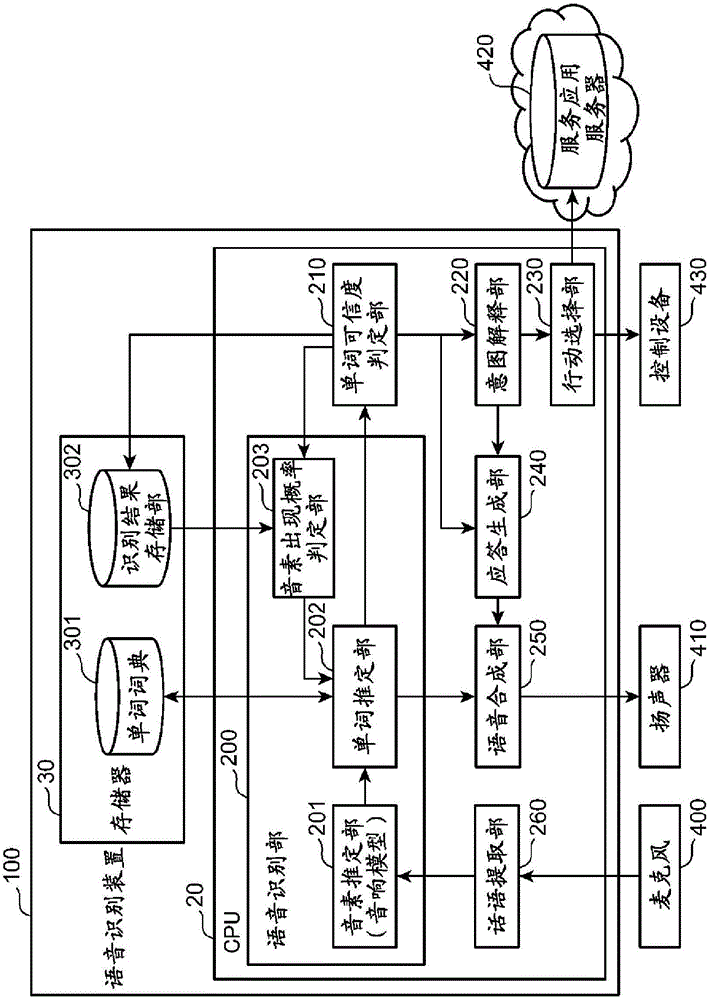
图1是示出实施方式1中的语音对话系统的整体结构的一例的图。图1所示的语音对话系统具有语音识别装置100、麦克风(传声器)400、扬声器410、服务应用服务器420和控制设备430。
语音识别装置100具有作为处理器的cpu(中央运算处理装置)20和存储器30。cpu20具有语音识别部200、单词可信度判定部210、意图解释部220、行动选择部230、应答生成部240、语音合成部250和话语提取部260。存储器30具有单词词典301和识别结果存储部302。语音识别部200具有音素推定部201、单词推定部202和音素出现概率判定部203。
单词词典301存储语音识别装置100能够识别的单词和音素串的组合。图7是示出单词词典的数据结构的一例的图。单词词典中关联地存储有“マンゴー(芒果)”和“レンガ”这样的单词与“mango:”和“renga”这样的各单词的音素串。
回过来参照图1。在安装有语音识别装置100的机器人或终端中组装的存储器30中保存有使计算机作为语音识别装置100发挥功能的程序,并由cpu20等处理器执行。另外,构成语音识别装置100的全部要素可以安装于同一终端,也可以个别地安装在经由光纤、无线或公共电话线路等任意网络连接的其他终端或服务器上,语音识别装置100与其他终端或服务器彼此进行通信,由此实现语音对话处理。
麦克风400例如由指向性麦克风构成,组装在安装有语音识别装置100的终端或机器人中。另外,麦克风400例如可以由手持麦克风、针式麦克风或桌上麦克风等任意收音设备构成。在该情况下,麦克风400经由有线或无线与安装有语音识别装置100的终端连接。另外,麦克风400可以由智能手机或平板终端等具有收音和通信功能的设备中搭载的麦克风构成。
扬声器410可以组装在安装有语音识别装置100的终端或机器人中,也可以经由有线或无线与安装有语音识别装置100的终端或机器人连接。另外,扬声器410可以由智能手机或平板终端等具有拾音和通信功能的设备中搭载的扬声器构成。
服务应用服务器420是经由网络向用户提供天气、语音播放、新闻和游戏等多种服务的云服务器。例如,服务应用服务器420取得语音识别装置100对语音的识别结果,并根据识别结果决定要执行的服务。由服务应用服务器420提供的服务,可以由具有经由网络取得服务应用服务器420中的执行结果的功能的程序来实现,也可以由服务应用服务器420和安装有语音识别装置100的机器人或终端上的存储器中存储的程序来实现。
控制设备430是如下设备:由通过有线或无线与语音识别装置100连接的电视或空调器等设备构成,从语音识别装置100接收语音识别结果来进行控制。
话语提取部260提取从麦克风400输出的语音信号中的说话中的语音信号,并输出到音素推定部201。此处,话语提取部260例如在预定音量以上的语音持续了一定期间以上的情况下,检测到开始了话语这一情况,开始向音素推定部201输出从麦克风400输入的语音信号。另外,话语提取部260在检测到小于预定音量语音持续了预定期间以上的情况下,停止向音素推定部201输出语音信号。在本实施方式中,假设话语提取部260提取说话人意图说一单词而说出的语音的语音信号。另外,假设说话人是处于语言学习阶段的幼儿。
音素推定部201将由话语提取部260输入的语音信号划分为以预定的时间单位构成的多个语音区间,计算在各音素区间中全部种类的音素各自的出现概率。音素是指语言中语音的最小单位,例如由“a”和“i”等记号表示。全部种类的音素是指在说话中使用的全部音素。该全部种类的音素通过音响模型而模型化。作为音响模型,例如,可举出hmm(hiddenmarkovmodel:隐马尔可夫模型)。
音素的种类数根据语言而不同,例如,如果是日语,则为40个左右。此处,音素推定部201可以使用hmm,将连续的共同的音素区间汇总为1个音素区间来推定音素串。进而,音素推定部201将使全音素区间中的出现概率之积最大的音素的组合推定为说话人说出的音素串。
单词推定部202从单词词典301中提取与由音素推定部201推定出的音素串最匹配的单词,将提取出的单词推定为说话人说出的单词。
图2是示出在由二音素构成的说话中对每个音素计算出的出现概率的一例的图。图3是汇总了在图2中针对第一音素的音素和第二音素的音素的组合的出现概率之积的图。
例如,假设说出由二音素构成的单词,得到了图2所示的音素的出现概率。在图2中,针对第一音素,计算出音素“a”和“u”的出现概率分别为“0.4”和“0.5”,针对第二音素,计算出音素“i”和“e”的出现概率分别为“0.3”和“0.6”。
在该情况下,作为第一音素与第二音素的音素的组合,得到“ai”、“ae”、“ui”和“ue”这4个,各组合的出现概率之积为“0.12”、“0.24”、“0.15”和“0.30”。
因此,第一音素与第二音素的音素的出现概率之积最大的组合的出现概率为“0.30”的“ue”。此时,根据音素串“ue”检索单词词典301,输出与音素串“ue”匹配的单词作为识别结果。此时的各音素的出现概率之积、即“ue”=“0.30”是识别出的单词的可信度。
单词可信度判定部210对由单词推定部202识别出的单词的可信度(第1值、第2值的一例)与预定的阈值th1(第1阈值的一例)进行比较,在单词的可信度小于阈值th1的情况下,将包含由单词推定部202识别出的单词的音素串和各音素的出现概率的识别结果作为针对第一话语的第一识别结果而存储在识别结果存储部302中。在该情况下,单词可信度判定部210为了使说话人再次说出一单词,向应答生成部240输出促使再次说话的语音的生成指示。
单词可信度判定部210使说话人通过再次说话而说出意图说一单词的第二话语,在通过单词推定部202得到第二识别结果的情况下,判定第二识别结果的可信度是否小于阈值th1。
音素出现概率判定部203在由单词可信度判定部210判定为第二识别结果的可信度小于阈值th1的情况下,在通过第一识别结果识别出的单词和通过第二识别结果识别出的单词中,分别提取音素的出现概率为阈值th2以上的音素。
单词推定部202从单词词典301中提取包含由音素出现概率判定部203提取出的音素串的单词,并基于提取结果,决定作为最终识别结果的单词。
另外,单词可信度判定部210在单词的可信度为阈值th1以上的情况下,将识别结果输出到意图解释部220。
意图解释部220根据识别结果,推定应答的类别(例如附和或提问回答等)和行动的类别(文字接龙、捉迷藏或电视控制等)。进而,意图解释部220向应答生成部240输出应答类别的推定结果,并且,向行动选择部230输出行动类别的推定结果。
行动选择部230根据意图解释部220的推定结果,判断要执行的服务或成为控制对象的控制设备430。进而,行动选择部230在判断为执行服务的情况下,向服务应用服务器420发送要执行的服务的提供请求。另外,行动选择部230在判断为要对控制设备430进行控制的情况下,向成为控制对象的控制设备430输出控制指示。
应答生成部240在从意图解释部220取得了应答类别的推定结果的情况下,生成与推定结果对应的应答文。另一方面,应答生成部240在从单词可信度判定部210取得了促使再次说话的语音的生成指示的情况下,生成向说话人反问一单词的应答文。
语音合成部250将由应答生成部240生成的应答文转换为语音信号,并输出到扬声器410。扬声器410将从语音合成部250输出的语音信号转换为语音,并输出到外部。
图4是示出实施方式1中的识别处理的一例的流程图。首先,话语提取部260判断麦克风400中有无语音输入(步骤s100)。在判断为没有语音输入的情况下(步骤s100:否),反复进行步骤s100的处理,直至有语音输入。
另一方面,在判断为有语音输入的情况下(步骤s100:是),话语提取部260从自麦克风400输出的语音信号中提取说话中的语音信号(步骤s101)。
接下来,语音识别部200实施语音识别处理(步骤s102)。具体而言,音素推定部201将由话语提取部260提取出的语音信号划分为多个语音区间,生成各语音区间的语音信号的特征量,并将所生成的特征量与音响模型对照,由此推定各语音区间的音素。此时,音素推定部201对每一语音区间计算音素的出现概率,并通过使用hmm将连续的同一音素的语音区间总结为一个。例如,若由构成说话语音的第一音素、第二音素和第三音素构成,则音素推定部201对第一音素、第二音素和第三音素分别计算全部种类的音素的出现概率。
例如,关于第一音素,如音素“a”的概率为“0.4”、音素“i”的概率为“0.1”、音素“u”的概率为“0.2”这样,针对全部种类的音素,分别计算第一音素的出现概率。关于第二音素和第三音素,也与第一音素同样地,计算全部种类的音素各自的出现概率。
进而,音素推定部201将使第一音素的出现概率、第二音素的出现概率和第三音素的出现概率之积最大化的3个音素的组合推定为说话语音的音素串。
接下来,单词推定部202参照存储器30中保存的单词词典301,选择与由音素推定部201推定出的音素串匹配的单词。在单词词典301中没有匹配的单词的情况下,单词推定部202使音素推定部201推定各音素的出现概率之积第二大的单词的音素串。进而,单词推定部202从单词词典301中检索与推定出的音素串匹配的单词。这样,在从单词词典301得到匹配的单词时,单词推定部202采用匹配的单词的音素串的出现概率之积作为该单词的可信度,并且,将匹配的单词的音素串和构成该音素串的各音素的出现概率作为识别结果,输出到单词可信度判定部210。
接下来,单词可信度判定部210判断所识别出的单词的可信度是否为阈值th1以上(步骤s103)。在单词的可信度为阈值th1以上的情况下(步骤s103:是),单词可信度判定部210判断识别结果存储部302中是否存储有第一识别结果(步骤s104)。此处,第一识别结果是指在步骤s101得到的语音之前说话的语音的识别结果,是识别结果存储部302中存储的识别结果。
即,在通过上次的说话而识别出的单词的可信度小于阈值th1且该话语的识别结果存储在识别结果存储部302中的情况下,该识别结果成为第一识别结果。
在存储有第一识别结果的情况下(步骤s104:是),单词可信度判定部210删除识别结果存储部302中存储的第一识别结果(步骤s105),并将识别结果输出到意图解释部220。接下来,意图解释部220基于识别结果,实施意图理解处理(步骤s106)。
另一方面,在识别结果存储部302中没有存储第一识别结果的情况下(步骤s104:否),处理转变到步骤s106。在步骤s106中,意图解释部220根据识别结果,推定应答的类别和行动的类别。在步骤s107中,应答生成部240生成与推定出的应答的类别对应的应答文。另外,在步骤s107中,行动选择部230根据所推定出的行动类别,决定要执行的服务或成为控制对象的控制设备430,在决定了服务的情况下,将服务的提供请求发送给服务应用服务器420,在决定了控制设备430的情况下,向成为控制对象的控制设备430输出控制指示。
另一方面,在识别出的单词的可信度小于阈值th1的情况下(步骤s103:否),单词可信度判定部210参照识别结果存储部302,判断是否存储有第一识别结果(步骤s110)。在没有存储第一识别结果的情况下(步骤s110:否),单词可信度判定部210将由单词推定部202推定出的单词的音素串和各音素的出现概率作为第一话语的识别结果(第一识别结果)存储在识别结果存储部302中(步骤s109),并向应答生成部240输出促使再次说话的语音的生成指示。
接下来,应答生成部240生成“慢慢地再讲一次?”这样的反问应答文,使语音识别部200生成所生成的应答文的语音信号,并从扬声器410输出所生成的语音信号的语音(步骤s108)。在通过步骤s108输出反问应答文的语音后,语音识别装置100成为由说话人意图说一单词的再次说话的待机状态,处理返回到s100。
通过该反问,由说话人说出第二话语,通过步骤s100~步骤s102的处理,与第一话语同样地,得到针对第二话语的第二识别结果。进而,如果第二识别结果的可信度小于阈值th1,则在步骤s103中判定为否,处理进入s110。
另一方面,如果第二识别结果的可信度为阈值th1以上(步骤s103:是),则将第二识别结果决定为说话人所意图说的一单词,执行步骤s105~步骤s107的处理。
在步骤s110中,在识别结果存储部302中存储有第一识别结果的情况下(步骤s110:是),音素出现概率判定部203从识别结果存储部302中存储的第一识别结果和通过步骤s102得到的针对说话人的再次说话的第二识别结果中,分别提取预定的阈值th2(第2阈值的一例)以上的音素(步骤s111)。
接下来,单词推定部202参照单词词典301,提取在第一识别结果的音素串中包含阈值th2以上的音素的单词作为识别候选单词(步骤s112)。接下来,单词推定部202从通过步骤s112提取出的识别候选单词的列表中,以在第二识别结果的音素串中包含阈值th2以上的音素的单词来筛选识别候选单词(步骤s113)。
图5是示出实施方式1中的对话的一例的图。在图5中,机器人是指安装有语音识别装置100的机器人,机器人后面附加的数字表示机器人的说话顺序。另外,幼儿是指与机器人对话的幼儿,幼儿后面附加的数字表示说话顺序。
首先,机器人对幼儿说出“どんな果物が好き?(喜欢什么水果?)”(机器人1),针对于此,幼儿说出“リンゴ(苹果)”(幼儿1)。但是,此处,对“リンゴ(苹果)”(幼儿1)的话语而识别出的单词的可信度低,故而机器人通过步骤s108,实施反问。
通过该反问,幼儿再次说出“リンゴ(苹果)”(幼儿2),该再次说话的可信度也较低。以下,使用图6、图7和图8,说明该情况下的语音识别装置100的处理。
图6是示出针对图5的对话例的第一识别结果和第二识别结果的一例的图。如图6所示,在第一识别结果中,针对幼儿的“リンゴ(苹果)”这样的话语,识别出单词“マンゴー(芒果)”,该单词的可信度小于阈值th1。因此,识别结果存储部302中存储有第一识别结果。关于第一识别结果的内容,如图6所示,识别单词是“マンゴー(芒果)”,识别音素串是“m”、……、“o:”,音素的出现概率是“0.4”、……、“0.6”。
由于第一识别结果的可信度低,因此,通过“慢慢地再讲一次?”这样的机器人的反问,幼儿再次说出“リンゴ(苹果)”,得到识别出“リンドウ(龙胆)”的第二识别结果,在第二识别结果中,可信度也是阈值th1以下。关于第二识别结果的内容,如图6所示,识别单词为“リンドウ(龙胆)”,识别音素串为“r”、……、“o:”,音素的出现概率为“0.9”、……、“0.5”。
此处,设音素的出现概率的阈值th2为0.7。在该情况下,音素出现概率判定部203从第一识别结果中,提取音素的出现概率为0.7以上的音素“n”和音素“g”。另外,音素出现概率判定部203从第二识别结果中,提取音素的出现概率为0.7以上的音素“r”、音素“i”和音素“n”。
接下来,单词推定部202参照单词词典301,提取包含从第一识别结果中提取出的连续的“n”和“g”的音素串的单词来作为识别候选单词。图7例示的单词中的、包含连续的音素串“ng”的单词为“マンゴー(芒果)”、“レンガ”、“リンゴ(苹果)”和“リンゴジュース(苹果汁)”。
因此,如图8所示,单词推定部202提取“マンゴー(芒果)”、“レンガ”、“リンゴ(苹果)”和“リンゴジュース(苹果汁)”来作为识别候选单词。图8是示出从第一识别结果中提取出的识别候选单词的一例的图。
此外,单词推定部202通过在所提取出的识别候选单词中提取包含从第二识别结果中提取出的连续的音素串“rin”的单词,由此筛选识别候选单词。图8例示的识别候选单词中的、包含连续的音素串“rin”的单词是“リンゴ(苹果)”和“リンゴジュース(苹果汁)”。
因此,单词推定部202在步骤s113中,最终将“リンゴ(苹果)”和“リンゴジュース(苹果汁)”筛选为识别候选单词。
在图4的步骤s115中,在阈值th3为3时,最终筛选得到的识别候选单词为两个,故而单词推定部202在步骤s115中判定为“是”。在步骤s116中,单词推定部202使语音合成部250生成“リンゴですか?(是苹果?)”、“リンゴジュースですか?(是苹果汁?)”这样的、用于逐一确认识别候选单词的确认话语的语音信号,并从扬声器410输出。
说话人例如对该确认话语作出肯定的说话(例如“はい(是的)”)或否定的说话(例如“いいえ(不是)”)。单词推定部202在识别出对确认话语作出肯定的说话的情况下,将与该确认话语对应的单词识别为意图说一单词的说话。另一方面,单词推定部202在识别出对确认话语作出否定的说话的情况下,发出下一个识别候选单词的确认话语。
图9是示出在实施方式1中,根据第一识别结果和第二识别结果来筛选识别候选单词的处理的另一例的图。在图9的例子中,示出了在第一识别结果和第二识别结果中,阈值th2以上的音素不连续的情况下的筛选方法。
在图9中,对话例与图5相同。在图9的例子中,得到了针对“リンゴ(苹果)”这样的说话而识别出单词“ルンバ(伦巴)”的第一识别结果、和针对“リンゴ(苹果)”这样的再次说话而识别出单词“黄粉”的第二识别结果。进而,在图9的例子中,第一识别结果和第二识别结果的可信度均小于阈值th1=0.7,故而使用单词“ルンバ(伦巴)”和单词“黄粉”,来进行筛选识别候选单词的处理。
如图9所示,在第一识别结果中,阈值th2=0.7以上的音素为“r”、“n”,两音素的顺序是“r”比“n”靠前。在第二识别结果中,阈值th2=0.7以上的音素为“i”、“o”,两音素的顺序是“i”比“o”靠前。
因此,在图9的例子中,单词推定部202根据单词词典301,无论在“r”和“n”之间是否存在音素,提取音素按“r”→“n”排列的单词来作为识别候选单词。接下来,音素出现概率判定部203从提取出的识别候选单词中,无论在“i”和“o”之间是否存在音素,提取按“i”→“o”的顺序排列的单词,进行识别候选单词的进一步筛选。
回过来参照图4。在步骤s114中,在将识别候选单词筛选到1个的情况下(步骤s114:是),单词推定部202将筛选出的单词决定为识别结果,使处理转变到步骤s105,执行步骤s105以后的处理。
另一方面,在识别候选单词未筛选到1个的情况下(步骤s114:否),音素出现概率判定部203判断识别候选单词是否筛选到两个以上且阈值th3以下(步骤s115)。在筛选出的识别候选单词的数量为两个以上且阈值th3以下的情况下(步骤s115:是),单词推定部202指示语音合成部250,发出向说话人逐一确认所筛选出的识别候选单词的确认话语(步骤s116)。作为确认话语,例如,举例:在筛选出的识别候选单词之一中包含リンゴ(苹果)时,进行“あなたはリンゴといいましたか?(您是否说了苹果?)”这样的说话。
针对确认话语,在从说话人作出了“はい(是的)”或“そうです(对)”等表示肯定的说话的情况下,单词推定部202将该被肯定的识别候选单词确定为识别结果。在步骤s117中确定了识别结果的情况下(步骤s117:是),处理转变到s105,执行s105以后的处理。
另一方面,在识别候选单词未被筛选到两个以上且阈值th3以下的情况下(步骤s115:否),处理转变到步骤s109,单词推定部202将第二识别结果存储到存储器30的识别结果存储部302中。此时,如果过去存在相同的识别结果,则该识别结果会覆写过去的识别结果。另外,此时,单词推定部202使筛选出的全部识别候选单词包含在第二识别结果中并存储到识别结果存储部302即可。
另一方面,在步骤s116中,如果未对全部识别候选单词实施肯定的说话、识别结果未被确定的情况下(s117:否),音素出现概率判定部203停止识别,结束处理。
这样,根据实施方式1的语音识别装置100,即使对第一话语得到了可信度较低的识别结果,也不放弃该识别结果,而将该识别结果应用于对第二话语得到了可信度较低的识别结果的情况。因此,即使通过反问未得到可信度高的识别结果,也可使用第一识别结果中包含的音素串和第二识别结果中包含的音素串中的可信度高的音素来识别一个单词。其结果是,能够提高一单词的识别精度。
此外,在通过第一识别结果和第二识别结果没有将识别结果筛选到唯一的情况下,即在步骤s115中判定为否且识别结果存储部302中存储有第二识别结果的情况下(步骤s109),语音识别装置100通过进一步反问来取得第三识别结果即可。进而,在第三识别结果中可信度小于阈值th1的情况下,音素出现概率判定部203执行使用了第一识别结果、第二识别结果和第三识别结果的筛选即可。在该情况下,音素出现概率判定部203根据包含通过第三识别结果识别出的音素串中的出现概率为阈值th2以上的音素的单词来筛选通过第一识别结果和第二识别结果筛选出的识别候选单词即可。由此,如果识别候选单词的数量成为阈值th3以下,则音素出现概率判定部203进行进一步的反问,并反复进行反问,直至识别候选单词的数量成为阈值th3以下为止即可。
(实施方式2)
图10是示出实施方式2中的语音对话系统的整体结构的一例的图。在图10中,与图1的不同点在于将单词推定部202、音素出现概率判定部203和单词可信度判定部210分别替换为文章推定部1202、音素出现概率合成部1203和文章可信度判定部1210。
实施方式1的语音识别部200是作为语音而仅能够识别一个单词的结构,与此相对,实施方式2的语音识别部200的结构采用能够识别由任意单词构成的文章(单词串)的结构。
音素推定部201使用隐马尔可夫模型(hiddenmarkovmodel:hmm)来推定音素串,文章推定部1202使用有限状态语法或n-gram,来推定文章(单词串)。
通过组合hmm和有限状态语法或n-gram,构成了多个音素汇总为网络状的由有向曲线图构成的搜索空间。因此,语音识别处理归结为网络路径搜索问题。即,语音识别处理成为如下处理:寻找对输入的语音信号最合适的网络路径,将与该路径对应的单词串作为识别结果。具体而言,语音识别处理是求出在下式(2)中使音素和单词的出现概率之积最大化的单词串w(s)的处理。
图11是示出划分为多个帧的语音信号的一例的图。如图11所示,帧是指将所输入的语音信号划分为例如25毫秒(msec)这样的一定的时间间隔而得到的结果。ot表示第t帧中的特征向量。特征向量是用于推定音素的物理量的一例,是根据语音信号的音量得到的。t以帧数表示所输入的语音信号的长度。作为特征向量,例如可采用梅尔频率倒谱系数(mel-frequencycepstrumcoefficients)。st表示处理到达第t帧时的状态。
在图11中,右向箭头1101表示状态st。关于音素串,在状态st中,推定出“kykyo:o:nno”或“kyo:no”的音素串。此外,“kykyo:o:nno”和“kyo:no”依存于音响模型的差异。在音素推定部201利用了连续相同音素发生耦合这样的音响模型的情况下,状态st的推定结果成为后者。为了简单,以后使用1帧1音素这样的音响模型进行说明。
另外,关于单词串,在状态st中,推定出“きょうの(今日的)”这样的单词串。因此,pa(ot,st|st-1)表示从与状态st-1对应的音素串转变到与状态st对应的音素串的概率(音素串的出现概率)。另外,pl(st,st-1)表示从与状态st-1对应的单词串转变到与状态st对应的单词串的语言模型的概率(单词串的出现概率)。此外,单词串的出现概率pl(st,st-1)适用于状态st-1与状态st为单词边界的情况,单词边界以外为1。w(s)表示与状态转变过程s即与状态st对应的单词串。
对输入话语的语音信号最终推定出的单词串,对应于第1帧至第t帧的音素串。如第1帧→第2帧→……→第t帧这样,从前面起,依次推定音素串。在存在某些话语的情况下,首先,音素推定部201对话语的语音信号仅推定可推定音素串的数量。可推定的音素串除了针对话语整体的音素串以外,也包含第1帧、第1帧至第2帧和第1帧至第3帧……这样的、从开始话语起到连续说话的中途的音素串。
接下来,文章推定部1202对推定出的音素串尽可能地分配能够分配的单词。进而,文章推定部1202使推定出的音素串的出现概率乘以所分配的单词的出现概率,最终将得到该最大值的音素串和单词的组合推定为单词串。此处,推定出的音素串的出现概率与所分配的单词的出现概率之积表示由推定出的音素串和对其分配的单词构成的单词串的可信度。以下,进行具体说明。
在说出“今日の天気(今日的天气)”的情况下,音素推定部201从状态s1、即第1帧的音素串(在该情况下为音素)起,依次推定整个话语(此处为第1帧至第t=9帧)的状态s9的音素串,对推定出的每个音素串计算其出现概率。
在状态s1的音素串推定为“ky”的情况下,状态s2、即截止到第2帧的音素串例如被推定“kyo:”。进而,该情况下截止到第2帧的音素串的出现概率pa(o2,s2|s1)表示音素“ky”之后出现音素“o:”的概率。
状态s2的音素串的候选不仅有“kyo:”,而存在全部种类的音素数,但根据实际说话时的语音特征,音素串的出现概率发生变化。此处,说出了“今日の天気(今日的天气)”,因此,在状态s2的音素串中,音素串“kyo:”的出现概率pa比音素串“kyu:”的出现概率pa高。同样,在状态s9的音素串中,音素串“kyo:notenki”的出现概率pa比音素串“kyo:nodenchi”的出现概率pa高。
文章推定部1202首先对由音素推定部201推定出的音素串分配单词。例如,在状态s9的音素串推定为“kyo:notenki”的情况下,分配“今日の天気(今日的天气)”或“京の天気(京的天气)”等单词。接下来,文章推定部1202对所分配的单词,分别使用基于n-gram等语言模型的单词的出现概率,来计算单词串的出现概率pl(st,st-1)。例如,在文章推定部1202利用2-gram的语言模型的情况下,关于“今日の(今日的)”的单词的出现概率pl(st,st-1)表示在“今日”之后出现“の(的)”的概率,关于“京の(京的)”的单词的出现概率pl(st,st-1)表示在“京”之后出现“の(的)”的概率。
这些单词的出现概率存储在单词词典301中。关于状态s9的音素串“kyo:notenki”的单词的出现概率,在“今日の”的单词的出现概率大于“京の”的单词的出现概率的情况下,关于“今日の天気(今日的天气)”的单词的出现概率pl(st,st-1)比关于“京の天気(京的天气)”的单词的出现概率pl(st,st-1)大。此处,对2-gram的例子进行了说明,但利用n-gram(n,自然数)中的任一个来计算单词的出现概率是同样的。
文章可信度判定部1210使在音素推定部201中推定出的音素串的出现概率pa(ot,st|st-1)乘以对在文章推定部1202中推定出的全部音素串分别分配的多个单词串的出现概率pl(st,st-1),来计算多个单词串的可信度。进而,文章可信度判定部1210将具有多个可信度中的最大可信度的单词串识别为最终的单词串。即,文章推定部1202将式(2)中的w(s)识别为最终的单词串。
音素出现概率合成部1203通过取第一说话中的各音素的出现概率与第二说话中的各音素的出现概率之和,来合成各音素的出现概率。此外,在合成了各音素的出现概率的情况下,文章推定部1202使用与使用合成的各音素的出现概率对第一话语进行求解的方法同样的方法,来计算多个单词串的可信度,将具有最大的可信度的单词串作为最终的识别结果。即,文章推定部1202将式(3)中的单词串w(s)作为最终的识别结果。
此处,第一话语不是对反问的应答话语,而是对来自语音识别装置100的询问的应答、或从用户对语音识别装置100说话的话语。另外,第二话语是指对反问的应答话语,是意图说第一话语的说话人的话语。
在式(3)中,pa1表示第一话语的音素串的出现概率,pa2表示第二话语的音素串的出现概率。此时,第一话语和第二话语的各音素的出现概率之和,可以采用与第一话语的可信度和第二话语的可信度对应的加权相加后的值。例如,在设第一话语的可信度为α、第二话语的可信度为β时,出现概率之和可以采用第一话语的各音素的出现概率乘以加权值α/α+β而得到的值和第二话语的各音素的出现概率乘以加权值β/α+β而得到的值的相加值。
文章可信度判定部1210判定由文章推定部1202推定出的关于第一话语的识别结果的可信度(音素串的出现概率和单词串的出现概率之积)是否为阈值th1以上。进而,文章可信度判定部1210在可信度小于阈值th1的情况下,将对第一话语的识别结果作为第一识别结果而存储在识别结果存储部302中,并实施反问。此处,第一识别结果中包含用于推定单词串所需的信息,例如识别出的单词串、与该单词串对应的音素串和构成该音素串的各音素的出现概率。
图12是示出实施方式2中的识别处理的一例的流程图。步骤s200和步骤s201的处理与图4所示步骤s100和步骤s101的处理相同。
语音识别部200实施语音识别处理(步骤s202)。具体而言,音素推定部201与实施方式1同样地,使用音响模型来推定各语音区间的音素。文章推定部1202对由音素推定部201推定出的音素串分配单词词典301中登记的单词串。此时,文章推定部1202对由音素推定部201推定出的全部音素串分别分配能够分配的单词串,对推定出的各音素串得到1个以上的单词串的分配结果。进而,文章推定部1202将音素串的出现概率与所分配的单词串的出现概率之积最大的单词串作为识别结果输出,并且,将积的最大值视为作为识别结果而得到的单词串的可信度,输出到文章可信度判定部1210。
接下来,文章可信度判定部1210判断由文章推定部1202识别出的单词串的可信度是否为阈值th1以上(步骤s203)。在文章的可信度为阈值th1以上的情况下(步骤s203:是),处理进入步骤s204。步骤s204~步骤s207与图4所示的步骤s104~步骤s107相同。
另一方面,在由文章推定部1202识别出的单词串的可信度小于阈值th1的情况下(步骤s203:否),文章可信度判定部1210参照识别结果存储部302,判断是否存储有第一识别结果是否(步骤s210)。在没有存储第一识别结果的情况下(步骤s210:否),文章可信度判定部1210将由文章推定部1202识别出的单词串、与该单词串对应的音素串和根据式(2)的pa(ot,st|st-1)求出的各音素的出现概率作为第一话语的识别结果(第一识别结果)存储在识别结果存储部302中(步骤s209)。在步骤s208中,与图4所示的步骤s108同样地,通过语音识别装置100进行反问。通过该反问,由说话人说出第二话语,通过步骤s200~步骤s202的处理,与第一话语同样地,得到针对第二话语的第二识别结果。进而,如果第二识别结果的可信度小于阈值th1,则在步骤s203中判定为“否”,使处理进入s210。
另一方面,如果第二识别结果的可信度为阈值th1以上(步骤s203:是),则将第二识别结果决定为说话人所意图说的一单词串,执行步骤s205~步骤s207的处理。
另一方面,在识别结果存储部302中存储有第一识别结果的情况下(步骤s210:是),音素出现概率合成部1203取得识别结果存储部302中存储的第一识别结果中包含的音素串的各音素的出现概率与通过步骤s202得到的第二话语的音素串的各音素的出现概率之和(步骤s211)。
接下来,文章推定部1202通过使第一话语与第二话语的各音素的出现概率之和相乘来计算后述的合成出现概率,使该合成出现概率乘以单词的出现概率,由此计算各单词串的可信度,并将给予最大可信度的单词串识别为说话人说出的一单词串(步骤s212)。在步骤s212的处理结束时,处理转变到步骤s203。
(实施方式2的具体例)
接下来,对实施方式2的具体例进行说明。在该具体例子中,为了简单而说明如下语音识别装置100:使用仅能够推定“リンゴです(是苹果)”和“マンゴーです(是芒果)”这两个单词串(文章)的模型来识别文章。
作为针对话语的音素串,音素推定部201推定出“ringodesu”和“mango:desu”。在该情况下,各音素串的出现概率作为构成各音素串的音素的出现概率彼此之积来计算。
图13是示出在实施方式2的具体例中采用1-gram的语言模型的情况下的搜索空间的一例的图。
在图13的搜索空间中,第1个音素“sil”是将“silent”缩略的结果,表示无音区间。另外,在图13中,各字母表示音素,各字母下标注的数值是各音素的出现概率。在该搜索空间中,在起始和最终分别配置要素“sil”,且包含有音素串“ringodesu”和音素串“mango:desu”。具体而言,该搜索空间从起始的要素“sil”分支为“ringo”和“mango:”这两个音素串,并再次在音素串“desu”合流,而达到最终的要素“sil”。
在该情况下,计算出音素串“ringodesu”的出现概率为0.7×0.5×0.5×……×0.9×0.9,计算出音素串“mango:desu”的出现概率为0.2×0.3×0.4×……×0.9×0.9。
此处,单词词典301中登记有“リンゴ(苹果)”、“マンゴー(芒果)”和“です(是)”这3个单词以及各单词的出现概率。在该情况下,文章推定部1202对各音素串分配这3个单词,由此得到图13所示的搜索空间。各单词右侧所示的数值表示单词的出现概率。
通常,单词的出现概率使用n-gram。在n-gram中,假定单词的出现概率依存于紧接之前的单词。在图13的例子中,使用了1-gram。1-gram不依存于紧接之前的单词,故而利用单个单词的出现概率。此时,第一单词发音为“リンゴ(苹果)”的概率为0.6,第一单词发音为“マンゴー(芒果)”的概率为0.4。另外,接着“マンゴー(芒果)”和“リンゴ(苹果)”说出“です(是)”的概率为1。
文章推定部1202将总结从起始的要素“sil”至最终的“sil”而得到的全部路径分别提取为音素串,对各音素串分配单词词典301中登记的单词中的能够分配的单词,得到多个单词串。在图13的例子中,对音素串“ringo”分配单词“リンゴ(苹果)”,对音素串“mango:”分配单词“マンゴー(芒果)”,对音素串“desu”分配单词“です(是)”。因此,在图13的例子中,得到单词串“リンゴ(苹果)”和“マンゴー(芒果)”。
进而,单词串“リンゴです(是苹果)”的音素串“rigodesu”+“sil”的各音素的出现概率的乘法值“0.7×0.5×……0.9”乘以单词“リンゴ(苹果)”的出现概率“0.6和“です(是)”的出现概率“1”,得到单词串“リンゴです(是苹果)”的可信度。同样地得到单词串“マンゴーです(是芒果)”的可信度。
进而,将单词串“リンゴです(是苹果)”和“マンゴーです(是芒果)”中的、具有最大可信度的单词串推定为识别结果。在图13的例子中,单词串“リンゴです(是苹果)”的可信度比单词串“マンゴーです(是芒果)”的可信度大,故而单词串“リンゴです(是苹果)”成为识别结果。
在2-gram的情况下,假定单词的出现概率仅依存于紧接之前的单词。即,图14示出由“リンゴ(苹果)”、“マンゴー(芒果)”和“です(是)”这三个单词构成的2-gram的词典。图14是示出在实施方式2的具体例中采用2-gram的语言模型的情况下的单词词典301的一例的图。也包含“sil”,且根据“リンゴ(苹果)”、“マンゴー(芒果)”和“です(是)”这三个单词而得到的2-gram的组合如下述这样。即,关于2-gram的组合,针对“sil”,考虑“リンゴ(苹果)”、“マンゴー(芒果)”和“です(是)”这3组,针对“リンゴ(苹果)”考虑“です(是)”、“マンゴー(芒果)”和“sil”这3组,针对“マンゴー(芒果)”考虑“です(是)”、“リンゴ(苹果)”和“sil”这3组,针对“です(是)”,考虑“リンゴ(苹果)”、“マンゴー(芒果)”和“sil”这3组,合计3×4=12组的组合。因此,在图14所示的单词词典301中,登记有这12组2-gram的单词串。
使用图14所示的单词词典301的2-gram的搜索空间如图15所示这样。图15是示出在实施方式2的具体例中采用2-gram的语言模型的情况下的搜索空间的一例的图。此外,在图15中,音素串和各音素的出现概率与图13相同。
此时,在存储有图14那样的单词词典301的情况下,第一单词中出现“リンゴ(苹果)”的概率、即在要素“sil”之后出现“リンゴ(苹果)”的概率为0.3。另外,第一单词中出现“マンゴー(芒果)”的概率、即在要素“sil”之后出现“マンゴー(芒果)”的概率为0.2。
另外,“リンゴ(苹果)”之后出现“です(是)”的概率为0.5,“マンゴー(芒果)”之后出现“です(是)”的概率为0.4。此外,“です(是)”之后出现要素“sil”的概率为0.6。在该情况下,图15的曲线图所示的各路径的音素串的出现概率与2-gram的单词串的出现概率之积最大的单词串被采用为识别结果。即,计算出音素串“ringodesu”的各音素的出现概率与“sil-リンゴ”、“リンゴです”和“です-sil”各自的出现概率(=0.3、0.5和0.6)之积作为单词串“リンゴです(是苹果)”的可信度。同样地,也计算出单词串“マンゴーです(是芒果)”的可信度。进而,在该例子中,单词串“リンゴです(是苹果)”的可信度比单词串“マンゴーです(是芒果)”的可信度高,故而最终单词串“リンゴです(是苹果)”成为识别结果。这在n-gram为三元语法以上的情况下,也是同样的处理。
文章可信度判定部1210判定在文章推定部1202中推定出的单词串的可信度是否为阈值th1以上。音素出现概率合成部1203在针对第一话语的第一识别结果的可信度和针对第二话语的第二识别结果的可信度均小于阈值th1的情况下,通过使第一说话中的各音素的出现概率和第二说话中的各音素的出现概率之和相乘,来计算合成出现概率。
文章推定部1202使用由音素出现概率合成部1203计算出的合成出现概率,来识别单词串(文章)。
图16是示出对实施方式2的具体例中的第一识别结果的各音素和第二识别结果的各音素的出现概率进行了合成的情况下的搜索空间的图。在图16中,与图15同样地,示出音素串“ringodesu”和音素串“mango:desu”的有向曲线图,关于各音素,示出了第一话语的出现概率和第二话语的出现概率。另外,在图16的例子中,分配了1-gram的单词。在图16中,各音素正下方所记载的数值表示第一话语的出现概率,第一话语的正下方所记载的数值表示第二话语的出现概率。
例如,音素串“ringodesu”的第一说话中的音素“r”的出现概率为0.7,第二说话中的音素“r”的出现概率为0.3。
此处,音素串“ringodesu”的合成出现概率为(0.7+0.3)×(0.5+0.4)×……×(0.9+0.9)。另外,音素串“mango:desu”的合成出现概率为(0.2+0.4)×(0.3+0.5)×……×(0.9+0.9)。
在该情况下,文章推定部1202对音素串“ringodesu”和音素串“mango:desu”分别分配了单词词典301中登记的1-gram的单词串。
进而,文章推定部1202使由音素出现概率合成部1203计算出的合成出现概率乘以单词的出现概率,由此计算各单词串的可信度。进而,文章推定部1202识别具有最大可信度的音素串来作为说话人所意图说的一单词串。
在图16中,第一单词中出现“リンゴ(苹果)”的概率为0.6,“リンゴ(苹果)”之后出现“です(是)”的概率为1,故而计算出单词串“リンゴです(是苹果)”的可信度为(0.7+0.3)×(0.5+0.4)×……×(0.9+0.9)×0.6×1。同样,第一单词中出现“マンゴー(芒果)”的概率为0.4,“マンゴー(芒果)”之后出现“です(是)”的概率为1,故而计算出单词串“マンゴーです(是芒果)”的可信度为(0.2+0.4)×(0.3+0.5)×……×(0.9+0.9)×0.4×1。
进而,此处,单词串“リンゴです(是苹果)”的可信度比单词串“マンゴーです(是芒果)”的可信度高,故而识别为说出单词串“リンゴです(是苹果)”。
这样,根据实施方式2的语音识别装置100,即使对第一话语得到了可信度较低的识别结果,也不放弃该识别结果,而将该识别结果应用于对第二话语得到了可信度较低的识别结果的情况。因此,即使通过反问未得到可信度高的识别结果,也可通过合成两识别结果来识别一个单词串,故而能够提高一单词串的识别精度。
此外,在步骤s209中,识别结果存储部302存储的识别结果不仅可以是紧接之前的识别结果,也可以是通过反问得到的过去多次的识别结果。在该情况下,音素出现概率合成部1203在步骤s211中,对作为过去多次的识别结果而得到的多个音素串的各音素的出现概率和作为最新的识别结果而得到的音素串的各音素的出现概率进行合成即可。
(实施方式3)
图17是示出实施方式3中的语音对话系统的整体结构的一例的图。在图17中,与图10的不同点在于省略了音素出现概率合成部1203,而追加了共同候选提取部270。
在实施方式3中,文章推定部1202与实施方式2同样地推定单词串,但不是提取可信度最大的单词串作为识别结果,而是提取可信度从高到低前n个单词串分别作为识别候选,并将前n个识别候选(n-best)作为识别结果。n-best是指识别结果中包含的多个识别候选中的可信度从高到低的前n个识别候选。
共同候选提取部270在由文章可信度判定部1210判定为第一识别结果中的可信度的最大值小于阈值th1且第二识别结果中的可信度的最大值小于阈值th1的情况下,对第一话语的识别候选(n-best)和第二话语的识别候选(n-best)进行比较,提取共同的识别候选,基于提取结果来决定最终识别的单词串。
图18是说明实施方式3中的识别处理的一例的流程图。步骤s300~步骤s307的处理与图12所示的步骤s200~步骤s207的处理基本相同。不过,在步骤s303中,文章可信度判定部1210判定由文章推定部1202推定出的第一识别结果的可信度的最大值是否为阈值th1以上。
在步骤s303中第一识别结果的可信度的最大值为阈值th1以上的情况下(步骤s303:是),将具有该最大值的识别候选决定为说话人所意图说的一单词串,执行步骤s305~步骤s307的处理。
另一方面,在步骤s303中第一识别结果中的可信度的最大值小于阈值th1的情况下(步骤s303:否),文章可信度判定部1210参照识别结果存储部302,判断是否存储有第一识别结果(步骤s310)。在没有存储第一识别结果的情况下(步骤s310:否),如图19所示,文章可信度判定部1210从文章推定部1202取得第一话语的识别结果中包含的识别候选中的、可信度(每个音素的出现概率之积和每一单词的出现概率之积)从高到低的前n个识别候选作为n-best,并存储在识别结果存储部302中。在步骤s308中,与图10所示的步骤s208同样地,由语音识别装置100进行反问。通过该反问,由说话人说出第二话语,通过步骤s300~步骤s302的处理,与第一话语同样地,得到对第二话语的第二识别结果。进而,如果第二识别结果的可信度的最大值小于阈值th1,则在步骤s303中判定为否,使处理进入s310。
另一方面,如果第二识别结果的可信度的最大值为阈值th1以上(步骤s303:是),则将具有该最大值的识别候选决定为说话人所意图说的一单词串,执行步骤s305~步骤s307的处理。
另一方面,在识别结果存储部302中存储有第一识别结果的情况下(步骤s310:是),共同候选提取部270对第一识别结果的n-best和第二识别结果的n-best进行比较(步骤s311)。
接下来,共同候选提取部270判断比较结果是否存在共同的识别候选(步骤s312)。在存在共同的识别候选的情况下(步骤s312:是),共同候选提取部270判定是否存在多个共同候选(步骤s313)。在存在多个共同的识别候选的情况下(步骤s313:是),共同候选提取部270对共同的多个识别候选分别计算第一识别结果的可信度和第二识别结果的可信度之和。进而,共同候选提取部270可以将可信度之和最大的识别候选决定为最终的识别结果,也可以按可信度之和从高到低的顺序将多个识别候选决定为最终的识别结果。在步骤s313的处理结束时,处理转变到步骤s304。另外,共同候选提取部270也可以针对按可信度之和从高到低的顺序得到的多个识别候选,进行在图4的步骤s116中说明的话语确认,将得到说话人同意的识别候选决定为最终的识别结果。
图19是示出实施方式3中的第一识别结果的5-best的一例的图。图20是示出实施方式3中的第二识别结果的5-best的一例的图。在图19和图20中,共同的识别候选是“リンゴ食べたい”和“インコ飛べた”。此时,第一识别结果和第二识别结果的可信度之和是:“リンゴ食べたい”为0.96(=0.54+0.42),“インコ飛べた”为0.47(=0.20+0.27)。在该情况下,将可信度之和最大的“リンゴ食べたい”决定为最终的识别结果。或者,将这两个识别候选决定为最终的可信度。
另一方面,在不存在共同的识别候选的情况下(步骤s312:否),处理转变到步骤s309。在步骤s309中,共同候选提取部270在识别结果存储部302中除了存储第一识别结果,还存储第二识别结果,并将反问的应答文生成指示输出到应答生成部240,由此对说话人实施进一步反问(步骤s308)。由此,取得第三识别结果。进而,如果第三识别结果的可信度的最大值小于阈值th1,则比较第一识别结果、第二识别结果和第三识别结果,提取出共同的识别候选。在该情况下,如果在第一识别结果、第二识别结果和第三识别结果中存在至少两个共同的识别候选,则提取该识别候选作为共同的识别结果。
这样,根据实施方式3的语音识别装置100,即使对第一话语得到了可信度较低的识别结果,也不放弃该识别结果,而将该识别结果应用于对第二话语得到了可信度较低的识别结果的情况。因此,即使通过反问未得到可信度高的识别结果,也可将通过第一话语和第二话语这两者识别出的单词串识别为一单词串,因此,能够提高一单词串的识别精度。
(机器人)
语音识别装置100可以安装于图21所示的机器人500。图21是安装有实施方式1~3的语音识别装置100的机器人500的外观图。机器人500具有球带状的主壳体501、第1球冠部502和第2球冠部503。主壳体501、第1球冠部502和第2球冠部503整体地构成球体。即,机器人500具有球体形状。另外,机器人500在第2球冠部503具有摄像头504,在第1球冠部502具有距离传感器505、扬声器410和麦克风400。
摄像头504取得机器人500的周边环境的影像。另外,距离传感器505取得距机器人500的周边环境为止的距离信息。此外,在本方式中,机器人500在第2球冠部503具有摄像头504,在第1球冠部502具有距离传感器505、扬声器410和麦克风400,但不限于此,在第1球冠部502和第2球冠部503的至少一方具有摄像头504、距离传感器505、扬声器410和麦克风400即可。
第1球冠部502的中心和第2球冠部503的中心由设置在主壳体501的内部的轴(图略)固定连接。主壳体501以相对于轴旋转自如的方式安装。另外,轴上安装有框架(图略)和显示部(图略)。框架上安装有使主壳体501旋转的第1马达(图略)。该第1马达(图略)进行旋转,由此主壳体501相对于第1球冠部502和第2球冠部503旋转,机器人500前进或后退。第1马达和主壳体501是移动机构的一例。此外,在机器人500前进或后退的情况下,第1球冠部502和第2球冠部503处于停止状态,因此,摄像头504、距离传感器505、麦克风400和扬声器410维持朝向机器人1的正面的状态。另外,在显示部显示表示机器人1的眼睛和口的图像。该显示部以借助第2马达(图略)的动力而相对于轴自由调整角度的方式进行安装。因此,通过调整显示部相对于轴的角度,调整机器人的眼睛和口的方向。此外,显示部与主壳体501独立地安装于轴,因此,即使主壳体501旋转,相对于轴的角度也不变化。因此,机器人500能够在眼睛和口的方向固定的状态下前进或后退。
- 还没有人留言评论。精彩留言会获得点赞!