语音检测方法及装置与流程
本发明涉及语音处理技术领域,特别涉及一种语音检测方法及装置。
背景技术:
环境声音可看出是人声和环境噪音的叠加。当前有很多电子设备(比如蓝牙耳机/蓝牙头盔),利用麦克风(microphone,简称mic)接收设备附近的环境声音,然后识别这些采集到的环境声音是使用者发音还是环境噪音,这种识别可以指导设备或者是该设备连接的设备(比如蓝牙耳机连接的手机)做出各种设备使用者想要的操作。也就是所说的设备具有语音识别技术,这种语音识别可能会在各种环境下进行,比如吵闹的商城,各种人声的会议室,办公室等。在这些语音信号复杂的环境中,电子设备的mic会采集到各种各样的噪音,导致该电子设备使用者的语音识别率很低,甚至完全不能识别该使用者的语音。
另外还有一些特殊情况,比如在有风的时候,特别是大风,会破坏使用者的发音,使设别接收到的语音信号使被破坏的,功率谱和正常说话时候的功率谱大不一样,极大地降低设备的识别率。
现有技术中可以采用浊音检测来区分mic收集语音信号中的人声和环境噪音。虽然一般情况下环境噪音是无规律、无周期的,和人声的浊音周期性谐波特性有比较明显的区别,但是也不排除一些环境中有一些稳定周期的以及谐波的噪音,因此浊音检测也不能有效地区分使用者发音和周围人声的发音。
技术实现要素:
本发明的目的在于,针对上述现有技术中的不足,提供一种语音检测方法,通过对环境声音信息的采集,分帧加窗的处理,再将分帧加窗后的声音信息进行特真信息统计,并将特真信息统计的语音信息用语音分类模块进行分类,根据分类来判断是否有使用者是否发音。
为实现上述目的,本发明实施例采用的技术方案如下:
第一方面,本发明实施例提供了一种语音检测方法,包括:获取采集到的声音信号;将所述声音信号进行分帧加窗处理,获取分段后的多段声音信号;测量获取所述多段声音信号中待处理分段声音信号的特真信号,其中,所述特真信号指示所述待处理分段声音信号的相关性;采用语音分类模块对所述特真信号进行分类,确定所述特真信号的分类,所述特真信号的分类用于指示所述待处理分段声音信号中是否包含预设使用者的语音信号;若所述特真信号中包含预设使用者的语音信号,则输出所述待处理分段声音信号含有使用者语音信号的触发信号。
进一步地,获取采集到的声音信号,包括:获取第一麦克风采集的第一声音信号、以及第二麦克风采集的第二声音信号;其中,所述第一声音信号包括:模拟信号、和/或数字信号;所述第二声音信号包括:模拟信号、和/或数字信号。
进一步地,所述第一声音信号包括模拟信号时,所述采集到第一声音信号之后,还包括:将所述第一声音信号中的模拟信号转换为数字信号;所述第二声音信号包括模拟信号时,所述采集到第二声音信号之后,还包括:将所述第二声音信号中的模拟信号转换为数字信号。
进一步地,所述获取第一麦克风采集的第一声音信号、以及第二麦克风采集的第二声音信号之后,还包括:对所述第一声音信号进行滤波处理,得到滤波后的第一声音信号;对所述第二声音信号进行滤波处理,得到滤波后的第二声音信号。
进一步地,对所述第二声音信号进行滤波处理,得到滤波后的第二声音信号之后,还包括:对所述滤波后的第二声音信号进行延时。
第二方面,本发明实施例还提供一种语音检测装置,包括:采集模块,用于获取采集到的声音信号;分帧加窗模块,将所述声音信号进行分帧加窗处理,获取分段后的多段声音信号;特真统计模块,用于测量统计所述多段声音信号中待处理分段声音信号的特真信号;分类模块,用于对所述特真信号进行分类,确定所述特真信号的分类;输出模块,用于当所述特真信号中包含预设使用者的语音信号时,则输出所述待处理分段声音信号含有预设语音信号。
进一步地,所述采集模块,具体用于获取第一麦克风采集的第一声音信号、以及第二麦克风采集的第二声音信号;其中,所述第一声音信号包括:模拟信号、和/或数字信号;所述第二声音信号包括:模拟信号、和/或数字信号。
进一步地,所述装置还包括:第一模/数转换模块和第二模/数转换模块;所述第一模/数转换模块,用于当所述第一声音信号包括模拟信号时,将所述第一声音信号中的模拟信号转换为数字信号;所述第二模/数转换模块,用于当所述第二声音信号包括模拟信号时,将所述第二声音信号中的模拟信号转换为数字信号。
进一步地,所述装置还包括:第一滤波模块和第二滤波模块;所述第一滤波模块,用于对所述第一声音信号进行滤波处理,得到滤波后的第一声音信号;所述第二滤波模块,用于对所述第二声音信号进行滤波处理,得到滤波后的第二声音信号。
进一步地,所述装置还包括:延时模块;所述延时模块,用于在所述第二滤波模块对所述第二声音信号进行滤波处理后,对所述滤波后的第二声音信号进行延时。
本发明实施例提供的语音检测方法,将采集的声音信号进行分帧加窗处理,获取分段后的多段声音信号,采集多段声音信号的特真信号,并且对特真信号进行分类,从而更精确地判断采集到的声音信号是否包含使用者的声音信号。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
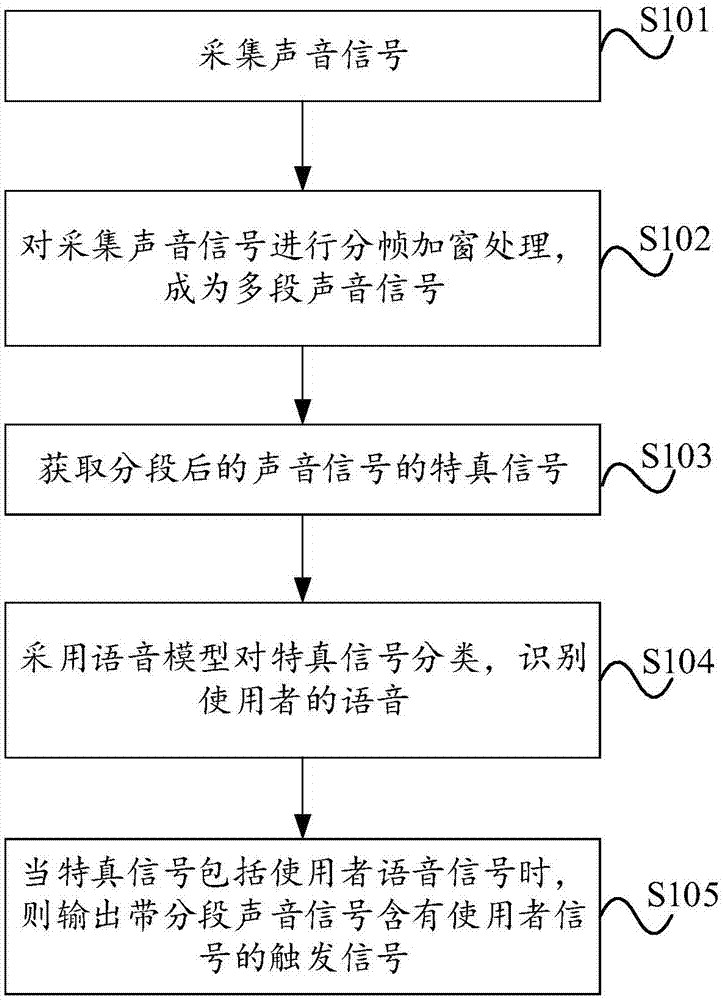
图1为本发明实施例提供的语音检测方法流程示意图一;
图2为本发明实施例提供的语音检测方法流程示意图二;
图3为本发明实施例提供的语音检测装置结构示意图一;
图4为本发明实施例提供的语音检测装置结构示意图二;
图5为本发明实施例提供的语音检测装置结构示意图三;
图6为本发明实施例提供的语音检测装置结构示意图四;
图7为本发明实施例提供的语音检测装置实体结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
此外,术语“第一”、“第二”、“第三”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
图1为本发明一实施例提供的语音检测技术流程示意图。该方法的执行主体可以是终端设备,例如计算机、手机、平板电脑等设备。
如图1所示,该方法包括:
s101、获取采集到的声音信号。
可选地,通过语音输入设备采集环境中的声音信号,为后期的声音信号的处理拾音。
s102、将声音信号进行分帧加窗处理,获取分段后的多段声音信号。
需要说明的是,为了便于处理采集到的声音信号,将采集的声音信号进行分帧加窗处理,将采集的声音信号分为多段声音信号,为后期的特真的提取做预处理准备。
可选地,分帧加窗处理时,可以选用汉明窗作为窗函数。
s103、测量获取多段声音信号中待处理分段声音信号的特真信号。
其中,特真信号指示待处理分段声音信号的相关性。
当只有一个声音采集设备,例如只有一个麦克风采集到的声音信号时,特真信号的相关性为采集到的声音信号的自相关性。当由多个声音采集设备采集到的声音信号时,特真信号的相关性为每个声音采集设备所采集到声音信号的自相关性以及不同声音采集设备采集到声音信号之间的互相关性。
s104、采用语音分类模块对特真信号进行分类,确定特真信号的分类,特真信号的分类用于指示待处理分段声音信号中是否包含预设使用者的语音信号。
其中,通过采集大量的语音场景对语音分类模块进行训练,使得语音分类模块具有多样的训练向量可以适用于多种语音场景,训练的场景越多,对特真信号的分类越精确。
s105、若特真信号中包含预设使用者的语音信号,则输出待处理分段声音信号含有使用者语音信号的触发信号。
其中,触发信号可以为电平的形式输出。当输出电平为低电平时,无触发信号产生,表示采集到的声音信号中无使用者的声音信号;当输出电平为高电平时,有触发信号产生,表示采集到的声音信号中有使用者的声音信号。
在本实施例中,通过对环境声音信息的采集,分帧加窗的处理,再将分帧加窗后的声音信息进行特真信息统计,并将特真信息统计的语音信息用语音分类模块进行分类,根据语音分类的结果来判断是否有使用者是否发音,实现了对采集到的声音信号更精确的识别是否包含有使用者的声音。
上述获取采集到的声音信号,可以是由多个麦克风分别采集的声音信号,例如获取第一麦克风采集的第一声音信号、以及第二麦克风采集的第二声音信号。
其中,第一声音信号包括:模拟信号、和/或数字信号;第二声音信号包括:模拟信号、和/或数字信号。
可选地,第一声音信号包括:模拟信号时,还可以将第一声音信号中的模拟信号转换为数字信号。类似地,第二声音信号包括模拟信号时,还可以将第二声音信号中的模拟信号转换为数字信号。
具体实现时,为了更好地识别语音,还可以对第一声音信号进行滤波处理,得到滤波后的第一声音信号;对第二声音信号进行滤波处理,得到滤波后的第二声音信号。
需要说明的是,不同麦克风采集的声音信号在传输时可能不同步,可以通过延时来进行同步。
可选地,假设第二麦克风采集的第二声音信号传输较慢,可以对滤波后的第二声音信号进行延时。以保证两个麦克风采集的声音信号同步。
当然,本发明实施例中不作限制,若第一麦克风采集的第一声音信号传输较慢,也可以对滤波后的第一声音信号进行延时。
图2为本发明另一实施例提供的语音检测方法流程示意图,以图2为例,示出一个声音识别的过程为:
s201、获取第一麦克风1采集的第一声音信号、以及第二麦克风采集的第二声音信号。
其中,第一麦克风置于环境中,用于采集环境中的声音信号,第一麦克风采集的第一声音信号包括:模拟信号、和/或数字信号。类似地,第二麦克风置于环境中,用于采集环境中的声音信号,第二麦克风采集的第二声音信号包括:模拟信号、和/或数字信号。
可选的,第一麦克风为mic,第二麦克风为语音拾取传感器(voicepickupsensor,简称vpu),可以为重力传感器(gravity-sensor,简称g-sensor),本说明书第二麦克风以vpu为例进行说明。
上述两种麦克风的拾音特性不同,mic主要是采集空气中传播的声音信号,并且将采集的信号转化为电信号。vpu主要采集的是使用者说话时,骨头或者皮肤震动的信号,并且将采集的信号转化为电信号。两种传感器采集的是不同传输特性的声音信号,利用这种特性差异来区分使用者是否在发声。
其中,两种不同拾音特性的麦克风mic和vpu的使用,可以采集不同特性的声音信号,特真统计模块统计mic的自相关性,vpu的自相关性以及mic和vpu的互相关性。利用混合高斯模型对统计的特真信号进行分类,分辨出环境声音信号下使用者的声音信号,使得语音检测装置发出有使用者声音信号的触发信号。
采集到的第一声音信号包括模拟信号时,采集到第一声音信号之后,还可以执行s211。
s211、将第一声音信号中的模拟信号转换为数字信号。
需要说明的是,第一麦克风采集到的声音信号可能为模拟信号,可能为数字信号。
当第一麦克风采集到的声音信号包括模拟信号时,由于采集到的模拟信号不能被设备直接处理,故可以由第一模/数转换模块,用于当第一声音信号包括模拟信号时,将模拟信号转换为数字信号,将转换为数字信号之后的第一声音信号输入检测装置。
当第一麦克风采集到的声音信号包括数字信号时,由于数字信号可以被直接处理,故第一模/数转换模块将数字信号直接输入检测装置。
类似地,采集到的第二声音信号包括模拟信号时,采集到第二声音信号之后,还可以执行s212。
s212、将第二声音信号中的模拟信号转换为数字信号。
同样的,第二麦克风采集到的声音信号可能为模拟信号,可能为数字信号。
当第二麦克风采集到的声音信号包括模拟信号时,由于第二麦克风采集到的模拟信号不能被设备直接处理,故第二模/数转换模块,用于当第二声音信号包括模拟信号时,将模拟信号转换为数字信号,将转换为数字信号之后的第二声音信号输入检测装置。
当第二麦克风采集到的声音信号包括数字信号时,由于数字信号可以被直接处理,故第二模/数转换模块将数字信号直接输入检测装置。
s211、s212的执行不分先后顺序,可以交换。
s221、对第一声音信号进行滤波处理,得到滤波后的第一声音信号。
其中,第一麦克风采集到的声音信号包含一种或多种干扰波,可以使用第一滤波模块对第一麦克风采集到的声音信号进行滤波,第一滤波模块让第一麦克风采集到的声音信号中有用的声音信号尽可能无衰减的通过;让第一麦克风采集到的声音信号中无用的声音信号尽可能最大的衰减。通过第一滤波模块5对第一麦克风采集到的声音信号进行滤波后,尽可能得到较为纯净的音频信号。
可选地,第一滤波模块可以为带通滤波器或者低通滤波器对语音信号进行滤波处理。
s222、对第二声音信号进行滤波处理,得到滤波后的第二声音信号。
其中,第二麦克风采集到的声音信号包含一种或多种干扰波,可以使用第二滤波模块对第二麦克风采集到的声音信号进行滤波,第二滤波模块让第二麦克风采集到的声音信号中有用的声音信号尽可能无衰减的通过;让第二麦克风采集到的声音信号中无用的声音信号尽可能最大的衰减。通过第二滤波模块对第二麦克风采集到的声音信号进行滤波后,尽可能得到较为纯净的音频信号。
可选地,第二滤波模块可以为带通滤波器或者低通滤波器对语音信号进行滤波处理。
s221、s222的执行不分先后顺序,可以交换。
s230、对滤波后的第二声音信号进行延时。
其中,第一麦克风为mic,主要是采集空气中传播的声音信号,并且将采集的信号转化为电信号。第二麦克风为vpu,主要采集的是使用者说话时,骨头或者皮肤震动的信号,并且将采集的信号转化为电信号。两种麦克风声电转化特性不同,使得两麦克风之间的物理特性不同,故vpu采集的信号要进行延时。延时后,使得vpu和mic采集的信号同时到达下一个处理步骤。
s241、对滤波后的第一声音信号进行分帧加窗处理,获取分段后的多段声音信号。
其中,分帧加窗模块包括:第一分帧加窗模块。
第一分帧加窗模块,用于对第一滤波模块滤波后的第一声音信号进行分帧加窗处理,分帧加窗处理后,滤波后的第一声音信号被分为多段声音信号,并获取分段后的多段声音信号。
s242、对滤波后的第二声音信号进行分帧加窗处理,获取分段后的多段声音信号。
其中,分帧加窗模块还包括:第二分帧加窗模块。
第二分帧加窗模块,用于对第二滤波模块滤波后的第二声音信号进行分帧加窗处理,分帧加窗处理后,滤波后的第二声音信号被分为多段声音信号,并获取分段后的多段声音信号。
s241、s242的执行不分先后,可以交换。
s250、测量获取第一声音信号分帧处理后获取的多段声音信号中待处理的分段声音信号和测量获取第二声音信号分帧处理后获取的多段声音信号中待处理的分段声音信号的特真信号。
可选地,特真信号包括mic的自相关性、vpu的自相关性和mic与vpu的互相关性,具体而言,对特真信号统计的函数包括:
mic的自相关函数:
m(n,k)=e(e(n)*e(k));
vpu的自相关函数:
v(n,k)=e(e(n)*e(k));
mic与vip的互相关函数:
c(m,v)=e(e(m)*e(v));
采集到的特真信号的场景如表1所示可以为:
表1
s260、采用语音分类模块对采集到的特真信号进行分类,识别采集到的语音信号中使用者的语音信号。
可选地,语音分类模块可以采用混合高斯模型(gaussianmixedmodel,gmm)。通过在大量的语音场景采集训练向量对混合高斯模型做训练。其中,采集的训练向量越多,gmm模型参数估计越准确,则对特真信号的分类越精确。
其中,gmm模型可以表示为:
式中,i为此gmm模型的个数;ai为为第i个高斯的权重;p(x|i)为第i个高斯概率密度。
对应以上采集的特真信号,gmm模型的输出为:
p(x|h0)、在第一个高斯模型上概率最大,即使用者没发音/轻音,不产生触发信号。
p(x|h1)、在第二个高斯模型上概率最大,即使用者没发音/轻音+吵闹环境,不产生触发信号。
p(x|h2)、在第三个高斯模型上概率最大,即使用者发音/浊音+安静环境,产生触发信号。
p(x|h3)、在第四个高斯模型上概率最大,即使用者发音/浊音+一般吵闹环境,产生触发信号。
p(x|h4)、在第五个高斯模型上概率最大,即使用者发音/浊音+吵闹环境,产生触发信号。
s270、若特真信号中包含预设使用者的语音信号,则输出待处理分段声音信号含有使用者语音信号的触发信号。
其中,未产生触发信号时,即采集到的声音信号中无使用者的语音信号。产生触发信号是,即采集的声音信号包括使用者的语音信号。
图3为本发明一实施例提供的语音检测装置结构示意图。如图3所示,该装置包括:采集模块301、分帧加窗模块302、特真统计模块303、分类模块304和输出模块305。
采集模块301,用于获取采集到的声音信号。
分帧加窗模块302,用于将声音信号进行分帧加窗处理,获取分段后的多段声音信号。
特真统计模块303,用于测量统计多段声音信号中待处理分段声音信号的特真信号。
语音分类模块304,用于对统计所得的特真信号进行分类,确定特真信号的分类。
输出模块305,用于当特真信号中包含预设使用者的语音信号时,则输出待处理分段声音信号含有使用者语音信号的触发信号。
本实施例中,通过采集模块301对声音信号进行采集,分帧加窗模块302将采集的声音信号进行分段处理,特真统计模块303将分段后的声音信号进行特真统计,采集分段后声音信号的特真信息,语音分类模块304将采集的特真信息进行分类,识别出其中是否包含使用者的语音信号。
采集模块301,具体用于获取第一麦克风采集的第一声音信号、以及第二麦克风采集的第二声音信号。
其中,第一声音信号包括:模拟信号、和/或数字信号;第二声音信号包括:模拟信号、和/或数字信号。
图4为本发明另一实施例提供的语音检测装置结构示意图,如图4所示,在图3的基础上,该装置还可以包括:第一模/数转换模块401和第二模/数转换模块402,其中:
第一模/数转换模块401,用于当第一声音信号包括模拟信号时,将第一声音信号中的模拟信号转换为数字信号。
第二模/数转换模块402,用于当第二声音信号包括模拟信号时,将第二声音信号中的模拟信号转换为数字信号。
图5为本发明另一实施例提供的语音检测装置结构示意图,如图5所示,上述装置还可以包括:第一滤波模块501和第二滤波模块502,其中:
第一滤波模块501,用于对第一声音信号进行滤波处理,得到滤波后的第一声音信号;
第二滤波模块502,用于对第二声音信号进行滤波处理,得到滤波后的第二声音信号。
图6为本发明另一实施例提供的语音检测装置结构示意图,如图6所示,上述装置还可以包括:延时模块601。
延时模块601,用于在第二滤波模块501对第二声音信号进行滤波处理后,对滤波后的第二声音信号进行延时。
图7为本发明另一实施例提供的语音检测装置实体结构示意图。
如图7所示,该装置包括:第一麦克风311、第二麦克风321、第一模/数转换器711、第二模/数转换器712、第一滤波器721、第二滤波器722、延时器730、第一分帧加窗器741、第二分帧加窗器742、特真统计器750、语音分类器760、输出接口770和处理器780。
举例说明,第一麦克风311是mic,第二麦克风321是vpu。mic和vpu用于采集外界声音信号。
其中,第一麦克风311、第二麦克风321用于语音信号的采集。
可选地,当第一麦克风311采集到的语音信号包括模拟信号时,第一模/数转换器711用于对第一麦克风311采集的模拟信号进行模/数转换,转换成数字信号。
类似的,当第二麦克风321采集到的语音信号包括模拟信号时,第二模/数转换器712对第二麦克风321采集的模拟信号进行模/数转换,转换成数字信号。
第一滤波器721和第二滤波器722分别用于对第一模/数转换器711、第二模/数转换器712模/数转换后所得的数字信号进行滤波处理。
延时器730用于对集到的两路信号中较快一路信号进行延时,这一路信号可以是第一麦克风311采集的声音信号。
第一分帧加窗器742用于对第一滤波器721滤波后的声音信号进行分帧加窗处理,第二分帧加窗器742用于对第二滤波器722滤波后的声音信号进行分帧加窗处理。
用于特真统计器750用于第一分帧加窗器741和第二分帧加窗器742处理后的信号对声音信号进行特真统计。
语音分类器760用于对特真统计器750统计的特真信号进行分类。
输出接口770用于将语音分类器760的分类结果进行输出。输出接口770输出的触发信号用于指导处理器780的工作。
上述装置用于执行前述实施例提供的方法,其实现原理和技术效果类似,在此不再赘述。
本发明提供的语音检测方法及装置,通过第一麦克风311和第二麦克风321采集环境声音信号,并将采集的声音信号分别通过对应的第一模/数转换模块401和第二模/数转换模块402输入,第一模/数转换模块401,输入的声音信号通过第一滤波模块501进行滤波处理后,进入第一分帧加窗模块312进行分帧加窗处理。第二语音采集模块321采集到的声音信号滤波处理后进行延时模块601进行延时处理后,再通过第二分帧加窗模块322进行分帧加窗处理,将分帧加窗后的声音信号通过特征统计模块303和语音分类模块304进行分类处理,使得采集到的声音信号得到识别,从而判断采集到的声音信号是否包含使用者的声音信号。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!