一种低信噪比场景下的ME-MGCRN单通道语音增强算法
本发明涉及一种在低信噪比场景下的me-mgcrn单通道语音增强算法,属于语音增强领域。
背景技术:
1、生活中存在各种各样的噪声,比如在户外打电话时周围的汽车喇叭声、熙攘人群的喧闹声、呼啸而过的风噪声都对语音交流产生负面的影响。为消除或抑制正常语音传递时的背景噪声,提高语音的可懂度并增强语音质量,语音增强方法(speech enhancement,se)应运而生。在涉及到语音交互的系统中,如果存在背景噪声或环境噪声干扰纯净的语音信号将导致交互效果差,因此合适的语音增强算法对于提高语音质量,改善交互效果至关重要。
2、对单个麦克风在低信噪比下捕捉的语音信号进行增强处理,称之为单通道语音增强,而对利用麦克风阵列采集的语音进行增强叫多通道语音增强。单通道语音增强只利用了时域和频域的信息,而麦克风阵列语音增强不仅利用了时域和频域的信息,还利用了空域的信息,因此单声道语音增强的任务更为困难。
3、早些时,学者们提出很多传统方法试图来增强语音,以提升语音的清晰度,例如小波阈值处理方法、谱减法、维纳滤波和最小均方误差(minimum mean squared error,mmse)估计等,这些算法不善于处理非平稳噪声,对于低信噪比下的语音处理效果并不好。
4、随着增强算法不断的发展,huang等人于1998年提出emd算法,自适应地将任何信号分解为固有模态函数(intrinsic mode function,imf)的振荡分量,目前已被广泛用于分析非平稳和非线性信号过程。有研究者对emd方法进行不断改进,提出了一种受小波阈值启发的增强型emd滤波方法,该方法利用浊音和清音段,结合经验模式分解来获得imf,实现递归阈值方法过滤噪声样本。但是干扰噪声是非平稳的,该方法最终导致语音失真和波动的残余背景噪声。随着技术的发展,又出现前后置滤波的emd方法,采用能量阈值法判断出含有残余噪声的imf,对其小波变换后与其余imf重构,获得增强后的语音。综上所述,emd算法与其它方法相比存在一定的优点,它适合于处理非平稳、非均匀和非线性信号,因此本发明考虑将语音信号拆成imf分量,可实现能更好的提取不同频段语音的目的,可以预见,若将emd与神经网络结合起来有较大的发展前景。
5、随着计算机性能的提高和人工智能的发展,越来越多的学者将深度学习算法应用在语音增强上。相比于传统语音增强方法,深度学习的语音增强方法在性能上具有很强的优势。2014年,徐勇等人提出深度神经网络(deep neural networks,dnn),首次建立全连接dnn神经网络学习带噪语音的对数功率谱和干净语音的对数功率谱之间复杂的非线性关系,取得了较好的效果,这也打开了基于深度学习算法的语音增强新篇章。卷积神经网络(convolutional neural network,cnn)由于较强的特征提取能力,且具有局部滤波特性,在语音增强领域应用广泛。park等人提出全卷积神经网络(fully convolutionalnetwork,fcn),建立含噪语音幅度谱和纯净语音幅度谱之间的映射关系,通过编码器对相邻多帧语音信号建模以提取上下文信息,利用解码器挖掘当前待增强语音帧和上下文信息之间的联系,实现语音增强。后来有学者将深度学习模型的卷积层、池化层和全连接层结合起来,提取较全面的语音特征。基不少学者将空洞卷积、残差网络和门控机制引入到语音增强网络中对cnn网络进行改进,以提高网络的感受野和提取语音信息能力,进一步提高语音的增强效果。为了提取语音特征更容易,研究者们往往会采取多层堆叠结构,lee等人利用多层感知器(multi-layer perceptron,mlp)和cnn等提取和训练二维梅尔频谱图图像,提高了语音情感识别准确率。在此基础上e.mishra等人对lee的网络进行改进,采取更多层的cnn网络,利用时间、频率和频谱等声学特征,实现更精确的语音分析。
6、由于cnn的网络结构只关心数据局部信息特征,而忽略了语音信号前后联系的情况,因此出现了考虑时序关系的循环神经网络(recurrent neural network,rnn)。2015年,huang等人采用rnn的方法,利用掩蔽函数和递归神经网络进行联合优化,在递归神经网络与额外屏蔽层联合优化下重建约束,进一步提高了去噪性能。虽然rnn已经被有效地应用于语音增强,但是rnn通常难以训练,通过重复地对同一层执行反向传播,rnn的梯度以指数速率消失或爆炸。后来学者们采用长短时记忆(long short-term memory,lstm)在客观评价和主观评价方面都取得了更好的结果,但lstm序列长度超过一定范围依旧会产生梯度消失的问题,因此在lstm的基础上,tan等人提出了一种cnn和lstm复合的神经网络模型--卷积循环神经网络(convolution recurrent neural network,crn),crn使用了二维卷积,可以更好地提取时域上下文信息,充分发挥了卷积层的特征提取能力,从而获得更高的性能。同时,crn引入了跳跃连接,将神经网络前端和后端的信息相连,减少了训练过程中的特征损失,有效地提升了网络的训练速度和性能。geng等人将离散模型与crn网络相结合,取得了良好的效果,为crn发展提供了新思路。m.strake等人使用卷积长短时记忆网络(conv longshort-term memory,lstm)替换全连接的lstm,用比更少的可训练参数来处理高维输入特征实现语音增强。
7、由于crn网络存在梯度消失问题,会对增强结果产生一定的影响,门控线性单元(gated linear units,glu)作为一种新的门控机制,可以减轻梯度传播,因此学者们研究用门控时间卷积代替递归网络中常用的递归连接,构建新型网络。glu最早是由dauphin等人提出的,通过堆叠层卷积就可以获得上下文信息,解决了rnn梯度消失的问题,仅通过cnn网络产生跟lstm一样的效果,且复杂度低,因此比rnn更具有竞争力。结合clu和crn的优点,tan等人首次将gcrn网络应用于语音增强,把每个编码卷积层或解码卷积层用相应的glu块所取代,实现语音增强,大大提升了增强性能。
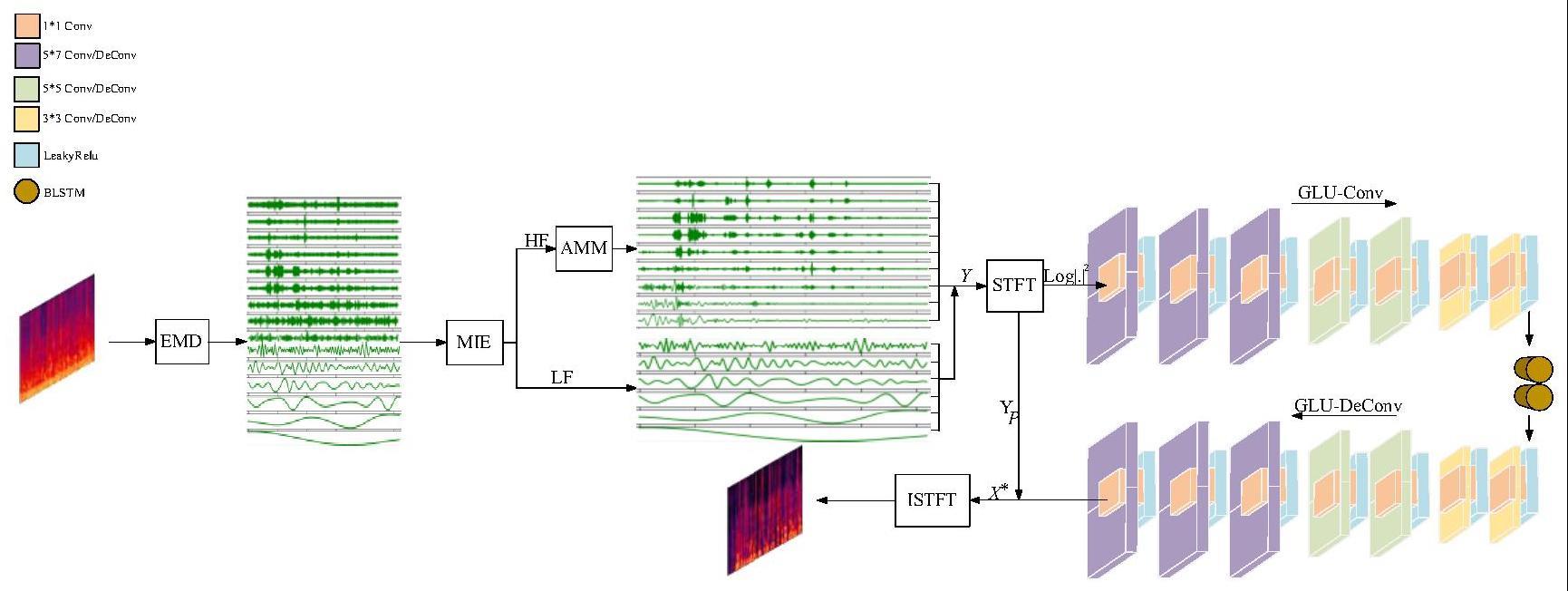
8、根据语音信号的特点,结合上述分析,本发明提出的me-mgcrn网络结构,利用改进的emd算法,对语音信号去噪并提取不同的语音特征分量,送入本发明提出的多层gcrn网络,设置干净语音为标签进行学习,探讨低信噪比下的语音增强效果。
技术实现思路
1、针对单一尺度卷积不能充分提取特征,造成全局特征无法准确的检测和定位重叠部分的声音事件的问题,本发明提供一种多尺度空间通道挤压激励卷积网络和门控循环单元的声音事件检测和定位方法。
2、本发明的一种在低信噪比场景下的me-mgcrn单通道语音增强算法,所述方法包括:
3、s1、采用amm-emd方法对含噪语音进行去噪,得到去除噪声后的语音特征;
4、s2、将提取的语音特征送入mgcrn网络,学习含噪语音到纯净语音的特征映射,实现增强;
5、优选的是,所述s1中包括:
6、s11:为了获得高质量的可听语音信号,去噪过程中阈值点为每个hf分量计算得到的单独阈值点,并估计其阈值。
7、s12:在s11步骤的基础上,利用自适应阈值的方法处理hf组中所有分量,lf组中的分量保持不变,用软阈值函数进行去噪。
8、s13:为实现amm-emd算法,将上述分解后的所有imf分为低频(low frequency,lf)组和高频(high frequency,hf)组,并对低频组和高频组采取不同的处理措施。
9、s14:采用自适应平均中位数(adaptive mean median,amm)的方法,利用阈值过滤噪声,获得增强的语音信号。
10、优选的是,所述s2包括:
11、s21:通过glu模块得到上下文信息;
12、s22:构建多层门控卷积循环神经网络,经mgcrn网络中编、解码器学习带噪语音与干净语音的映射并结合带噪语音的相位实现语音增强。
13、优选的是,所述s22中,在网络中利用多层堆叠glu-conv提取语音特征,后经过blstm对时间依赖性建模,将处理完的数据通过glu-deconv还原到与输入特征相同的维度,并将输出后的增强语音特征通过istft重构,变回一维时域语音信号,完成从带噪语音到干净语音的转换,获得输出的增强语音。
14、本发明提出的简单而有效的me-mgcrn结构,并将mgcrn网络中的损失函数由mse换为huber,用来解决低信噪比下的语音增强问题,对比噪声已知和噪声未知的情况,本发明提出的模型同样比sadnunet模型和gcrn模型均有不同程度的提高,证明本发明模型确实有良好的泛化性,能更好地提高语音的清晰度和可懂度。
- 还没有人留言评论。精彩留言会获得点赞!