基于生成对抗网络的语音唤醒方法、装置及存储介质与流程
本技术属于人工智能,尤其涉及一种基于生成对抗网络的语音唤醒方法、装置、存储介质、电子设备及计算机程序产品。
背景技术:
1、随着车载数据娱乐系统((in-vehicle infotainment,ivi)和智能驾驶辅助系统的发展,驾驶员需要一种能够在驾驶过程中与车辆进行交互的方法。
2、车载语音系统是一种新型车内人机交互系统,实现了智能语音技术在车载场景下的应用。基于车载语音系统,驾驶员可以通过说话的方式操作车内的硬件设备和软件系统,实现播放音乐、蓝牙通话、开启导航等一系列人机交互功能。但是车载基于生成对抗网络的语音唤醒方式目前有两种:一种方式为按压方向盘开关上的语音按键,一种为触摸导航主机显示屏上的语音按键,这两种方式均需要驾驶员手动来完成,操作比较繁琐,容易分散驾驶过程中驾驶员的注意力,增加事故风险。
技术实现思路
1、本技术旨在至少解决现有技术中存在的技术问题之一。为此,本技术提出一种基于生成对抗网络的语音唤醒方法、装置、存储介质、电子设备及计算机程序产品,无需用户手动操作即可唤醒车载语音系统,且唤醒准确率高。
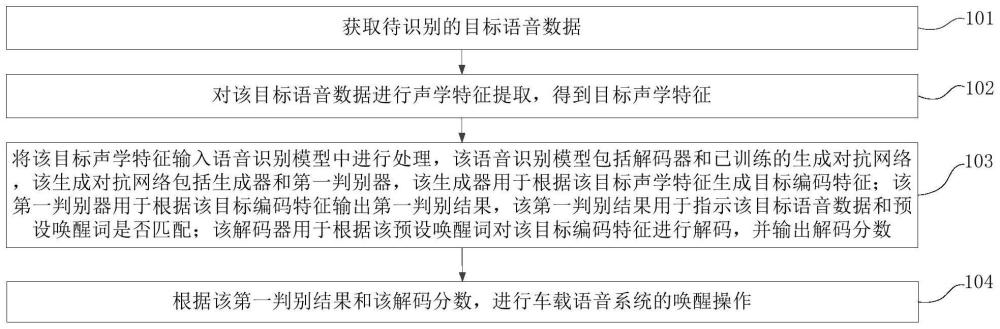
2、第一方面,本技术提供了一种基于生成对抗网络的语音唤醒方法,包括:
3、获取待识别的目标语音数据;
4、对所述目标语音数据进行声学特征提取,得到目标声学特征;
5、将所述目标声学特征输入语音识别模型中进行处理,所述语音识别模型包括解码器和已训练的生成对抗网络,所述生成对抗网络包括生成器和第一判别器,所述生成器用于根据所述目标声学特征生成目标编码特征;所述第一判别器用于根据所述目标编码特征输出第一判别结果,所述第一判别结果用于指示所述目标语音数据和预设唤醒词是否匹配;所述解码器用于根据所述预设唤醒词对所述目标编码特征进行解码,并输出解码分数;
6、根据所述第一判别结果和所述解码分数,进行车载语音系统的唤醒操作。
7、在一些实施例中,所述根据所述第一判别结果和所述解码分数,进行语音系统的唤醒操作,包括:
8、当所述第一判别结果指示所述目标语音数据和预设唤醒词匹配,且所述解码分数大于预设阈值时,唤醒车载语音系统。
9、在一些实施例中,所述生成器包括至少一个特征提取模块,所述特征提取模块包括顺序连接的多头自注意力机制层、第一归一化层、深度分离卷积、第二归一化层和前馈神经网络,所述第一归一化层的输入数据为所述多头自注意力机制层的输出数据和所述多头自注意力机制层的输入数据之和,所述第二归一化层的输入数据为所述深度分离卷积的输出数据和所述多头自注意力机制层的输入数据之和,所述特征提取模块的输出数据为所述前馈神经网络的输出数据和所述多头自注意力机制层的输入数据之和。
10、在一些实施例中,所述生成对抗网络还包括第二判别器,所述方法还包括:
11、获取语音样本集、以及所述语音样本集中每个语音样本的标注标签;
12、对所述语音样本进行声学特征提取,得到相应的声学特征样本;
13、根据预设的损失函数、所述声学特征样本和所述标注标签,对所述生成对抗网络进行训练,所述损失函数包括所述生成器和所述第二判别器对应的对抗损失子函数、所述第一判别器对应的第一分类损失子函数、以及所述第二判别器对应的第二分类损失子函数。
14、在一些实施例中,所述生成器和所述第二判别器采用交替训练方式,所述根据预设的损失函数、所述声学特征样本和所述标注标签,对所述生成对抗网络进行训练,包括:
15、在训练所述生成器的过程中,冻结所述第二判别器的模型参数,且将所述声学特征样本、以及所述生成器根据所述声学特征样本生成的数据一起作为输入数据,输入所述第一判别器和所述第二判别器中;根据所述第一判别器的输出数据、所述第二判别器的输出数据、所述对抗损失子函数、所述第一分类损失子函数和所述第二分类损失子函数对所述生成器的模型参数进行调整;
16、在训练所述第二判别器的过程中,冻结所述生成器的模型参数,且将所述声学特征样本和所述标注标签作为一对真例,以及将所述声学特征样本和所述生成器根据所述声学特征样本生成的数据作一对假例,输入所述第二判别器中;根据所述对抗损失子函数和所述第二判别器的输出数据,对所述第二判别器的模型参数进行调整。
17、在一些实施例中,所述基于生成对抗网络的语音唤醒方法还包括:
18、获取车载环境中采集的至少一个第一语音数据和至少一个第二语音数据,所述第一语音数据是所述预设唤醒词对应的语音数据,所述第二语音数据是非预设唤醒词对应的语音数据;
19、确定所述车载环境中多个采集位置中每个采集位置对应的冲击响应函数;
20、根据所述冲击响应函数、所述第一语音数据和所述第二语音数据生成所述语音样本集。
21、在一些实施例中,所述根据所述冲击响应函数、所述第一语音数据和所述第二语音数据生成所述语音样本集,包括:
22、根据所述第一语音数据和所述冲击响应函数生成每个所述采集位置对应的第一基本语音数据,并根据所述第二语音数据和所述冲击响应函数生成每个所述采集位置对应的第二基本语音数据;
23、分别对所述第一基本语音数据和所述第二基本语音数据进行干扰叠加和扩充处理,得到所述语音样本集。
24、第二方面,本技术提供了一种基于生成对抗网络的语音唤醒装置,包括:
25、获取单元,用于获取待识别的目标语音数据;
26、提取单元,用于对所述目标语音数据进行声学特征提取,得到目标声学特征;
27、处理单元,用于将所述目标声学特征输入语音识别模型中进行处理,所述语音识别模型包括解码器和已训练的生成对抗网络,所述生成对抗网络包括生成器和第一判别器,所述生成器用于根据所述目标声学特征生成目标编码特征;所述第一判别器用于根据所述目标编码特征输出第一判别结果,所述第一判别结果用于指示所述目标语音数据和预设唤醒词是否匹配;所述解码器用于根据所述预设唤醒词对所述目标编码特征进行解码,并输出解码分数;
28、唤醒单元,用于根据所述第一判别结果和所述解码分数,进行车载语音系统的唤醒操作。
29、在一些实施例中,所述唤醒单元具体用于:
30、当所述第一判别结果指示所述目标语音数据和预设唤醒词匹配,且所述解码分数大于预设阈值时,唤醒车载语音系统。
31、在一些实施例中,所述生成器包括至少一个特征提取模块,所述特征提取模块包括顺序连接的多头自注意力机制层、第一归一化层、深度分离卷积、第二归一化层和前馈神经网络,所述第一归一化层的输入数据为所述多头自注意力机制层的输出数据和所述多头自注意力机制层的输入数据之和,所述第二归一化层的输入数据为所述深度分离卷积的输出数据和所述多头自注意力机制层的输入数据之和,所述特征提取模块的输出数据为所述前馈神经网络的输出数据和所述多头自注意力机制层的输入数据之和。
32、在一些实施例中,所述生成对抗网络还包括第二判别器,所述装置还包括训练单元,用于:
33、获取语音样本集、以及所述语音样本集中每个语音样本的标注标签;
34、对所述语音样本进行声学特征提取,得到相应的声学特征样本;
35、根据预设的损失函数、所述声学特征样本和所述标注标签,对所述生成对抗网络进行训练,所述损失函数包括所述生成器和所述第二判别器对应的对抗损失子函数、所述第一判别器对应的第一分类损失子函数、以及所述第二判别器对应的第二分类损失子函数。
36、在一些实施例中,所述生成器和所述第二判别器采用交替训练方式,所述训练单元具体用于:
37、在训练所述生成器的过程中,冻结所述第二判别器的模型参数,且将所述声学特征样本、以及所述生成器根据所述声学特征样本生成的数据一起作为输入数据,输入所述第一判别器和所述第二判别器中;根据所述第一判别器的输出数据、所述第二判别器的输出数据、所述对抗损失子函数、所述第一分类损失子函数和所述第二分类损失子函数对所述生成器的模型参数进行调整;
38、在训练所述第二判别器的过程中,冻结所述生成器的模型参数,且将所述声学特征样本和所述标注标签作为一对真例,以及将所述声学特征样本和所述生成器根据所述声学特征样本生成的数据作一对假例,输入所述第二判别器中;根据所述对抗损失子函数和所述第二判别器的输出数据,对所述第二判别器的模型参数进行调整。
39、在一些实施例中,所述训练单元还用于:
40、获取车载环境中采集的至少一个第一语音数据和至少一个第二语音数据,所述第一语音数据是所述预设唤醒词对应的语音数据,所述第二语音数据是非预设唤醒词对应的语音数据;
41、确定所述车载环境中多个采集位置中每个采集位置对应的冲击响应函数;
42、根据所述冲击响应函数、所述第一语音数据和所述第二语音数据生成所述语音样本集。
43、在一些实施例中,所述训练单元具体用于:
44、根据所述第一语音数据和所述冲击响应函数生成每个所述采集位置对应的第一基本语音数据,并根据所述第二语音数据和所述冲击响应函数生成每个所述采集位置对应的第二基本语音数据;
45、分别对所述第一基本语音数据和所述第二基本语音数据进行干扰叠加和扩充处理,得到所述语音样本集。
46、第三方面,本技术提供了一种非暂态计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一项所述的基于生成对抗网络的语音唤醒方法。
47、第四方面,本技术提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述任一项所述的基于生成对抗网络的语音唤醒方法。
48、第五方面,本技术提供了一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现上述任一项所述的基于生成对抗网络的语音唤醒方法。
49、本技术实施例提供的基于生成对抗网络的语音唤醒方法、装置、存储介质、电子设备及计算机程序产品,通过获取待识别的目标语音数据;对目标语音数据进行声学特征提取,得到目标声学特征;将目标声学特征输入语音识别模型中进行处理,语音识别模型包括解码器和已训练的生成对抗网络,生成对抗网络包括生成器和第一判别器,生成器用于根据目标声学特征生成目标编码特征;第一判别器用于根据目标编码特征输出第一判别结果,第一判别结果用于指示目标语音数据和预设唤醒词是否匹配;解码器用于根据预设唤醒词对目标编码特征进行解码,并输出解码分数;根据第一判别结果和解码分数,进行车载语音系统的唤醒操作,从而无需用户手动操作即可唤醒车载语音系统,简化了唤醒流程,用户体验感好,且通过将对抗式训练得到的生成器和二值分类器相结合,可以在保证较高的唤醒率的基础上,保持较低的误唤醒率,唤醒效果好。
- 还没有人留言评论。精彩留言会获得点赞!