用于治疗花生过敏的核酸的制作方法
本申请要求2014年6月23日提交的美国申请号62/015,981的利益,所述申请整体通过参考并入本文。
技术领域
本公开的主题内容涉及分子生物学和医学领域。更具体来说,本公开的主题内容涉及用作DNA疫苗的核酸和使用它们治疗患有花生过敏反应或对花生过敏反应易感的受试者的方法。
背景技术:
当免疫系统对被称为过敏原的无害外来物质做出反应时,发生过敏反应。由于过敏性反应这种潜在致死的系统性休克的高风险,食物过敏是重要的公共健康问题(Sampson等,(1992)N.Engl.J.Med.327:380-384;Bock等,(2001)J.Allergy Clin.Immunol.107:191-193)。幼儿具有比公众更高的发生食物过敏的风险(Lack等,(2003)N.Engl.J.Med 348:977-985;Zimmerman等,(1989)J.Allergy Clin.Immunol.83:764-770;Green等,(2007)Pediatrics 120:1304-1310)。在生命的前三年中,6-8%的儿童经历由食物引起的过敏反应(Bock(1987)Allergy 45:587-596;Burks和Sampson(1993)Curr.Prob.Pediatr.23:230-252;Jansen等,(1994)J.Allergy Clin.Immunol.93;2:446-456;Sampson(1999)J.Allergy Clin.Immunol.103;5:717-728)。奶、蛋和花生是三种最常见的食物过敏原(Sampson(1988)J.Allergy Clin.Immunol.81:635-645),并且到5岁为止,80-85%的具有奶或蛋过敏的儿童将长大而不再发生过敏(Host等,(1997)J.Allergy Clin.Immunol.99:S490)。相反,只有20%的婴儿发展出对花生的耐受(Skolnick等,(2001)J.Allergy Clin.Immunol.107;2:367-374)。
由暴露于食物过敏原、特别是花生而引起的过敏性反应,引起以组胺的过量生产为特征的严重免疫反应,并造成每年美国过敏性反应急诊的一半。在美国,这些对花生的极端反应每年引起超过30,000例过敏性反应事件和100–200例死亡。痕量的花生通常存在于数千种各种品牌但未标注的包装食品类别中。超过150万美国人苦于花生过敏的症状,并且症状通常持续终生。许多人在痕量暴露后经历危险的反应。
没有用于缓解花生过敏症状的治疗方法;患有花生过敏的个人和诸如小学的机构必须采取严格措施来避免暴露或摄入和潜在致命的过敏性反应发作的风险。花生过敏的诊断要求维持恒定的饮食警觉以避免过敏性反应的风险(Yunginger等,(1988)JAMA 260:1450-1452)。在儿童的情况下,这种警觉也必须由父母亲、学校和看护者实行。在过去的十年中,花生过敏的患病率已经加倍,影响2%的成年美国人(Sampson(1999)J.Allergy Clin.Immunol.103;5:717-728;Sicherer等,(2003)J.Allergy Clin.Immunol.112:1203-1207)。尽管许多其他过敏症如枯草热和短豚草花粉的症状不危及生命,但对于花生过敏的个体来说,摄入少至1/1000的花生可以引起过敏性休克和死亡(Taylor等,(2002)J.Allergy Clin.Immunol.109(1):24-30;Wensing等,(2002)J.Allergy Clin.Immunol.110(6):915-920)。所有食物诱导的过敏性休克中的三分之二已与花生的意外摄入相关联(Bock等,(2001)J.Allergy Clin.Immunol.107:191-193)。在意外摄入引发过敏性反应的情形中,使用肾上腺素注射来打开气道通道(Stark和Sullivan(1986)J.Allergy Clin.Immunol.78:76-83;Sampson(2003)Pediatrics 111(6):1601-1608)。
当个体未能发展出口腔耐受而是相反变得对随后的过敏原暴露敏感时,则发生食物过敏(Till等,(2004)J.Allergy Clin.Immunol.113(6):1025-1034)。在过敏患者中,过敏原倾向性地激活2型辅助性CD4+T淋巴细胞(Th2),所述细胞产生促过敏细胞因子白介素IL-4、IL-5和IL-13,其帮助协调地产生作为大多数过敏症状的基础的炎症(Woodfolk(2007)J.Allergy Clin.Immunol.118(2):260-294)。IL-4指导产生抗体的B细胞分泌过敏原特异性免疫球蛋白(Ig)E(Del Prete等,(1988)J.Immunol.140:4193-4198;Swain等,(1990)J.Immunol.145:3796-3806)。与中和性IgG不同,IgE结合于其被肥大细胞和嗜曙红细胞表达的高亲和性受体Fc--εRI(Blank等,(1989)Nature 337:187-190;Benhamou等,(1990)J.Immunol.144:3071-3077),由此使这些细胞敏感。在随后的暴露后,IgE结合引起麻烦的过敏原,交联,并转导信号以指导肥大细胞脱粒并释放出引发过敏反应的挥发性化学物质。
免疫疗法,即给药逐渐增加剂量的过敏原以引起耐受,是过敏性疾病的标准治疗,但由于频繁的过敏性反应,尚未被批准用于治疗花生过敏(Nelson等,(1997)J.Allergy Clin.Immunol 99;6:744-751;Oppenheimer等,(1992)J.Allergy Clin.Immunol 90:256-262)。此外,免疫疗法的应用受到治疗长度的限制,其需要长达36个月的每周或两周一次的注射,并且成功和依从的程度变化不定(Bousquet等,(1998)J.Allergy Clin.Immunol 102:558-562;Rank和Li(2007)Mayo Clin.Proc.82(9):1119-1123;Ciprandi等,(2007)Allergy Asthma Proc.28:40-43)。
技术实现要素:
一方面,本文提供了一种分离或纯化的核酸,其按顺序排列包含:编码信号序列的序列;编码细胞器内稳定化/运输结构域的序列;编码花生过敏原结构域的序列,其中所述花生过敏原结构域包含至少一种花生过敏原,所述至少一种花生过敏原不包括所述花生过敏原的天然存在的信号序列;编码跨膜结构域的序列;和编码内吞体/溶酶体靶向结构域的序列。在某些实施方式中,所述至少一种花生过敏原是Ara H1,Ara H2,Ara H3,AraH3del,Ara H1、Ara H2或Ara H3的具有至少一个花生过敏表位的部分,或其任何组合。
另一方面提供了一种药物组合物,其包含一种或多种分离或纯化的核酸,所述核酸按顺序排列包含:编码信号序列的序列;编码细胞器内稳定化/运输结构域的序列;编码花生过敏原结构域的序列,其中所述花生过敏原结构域包含至少一种花生过敏原,所述至少一种花生过敏原不包括所述花生过敏原的天然存在的信号序列;编码跨膜结构域的序列;和编码内吞体/溶酶体靶向结构域的序列。在某些实施方式中,所述至少一种花生过敏原是Ara H1,Ara H2,Ara H3,AraH3del,Ara H1、Ara H2或Ara H3的具有至少一个花生过敏表位的部分,或其任何组合。
另一方面,提供了在受试者中减轻、消除或阻止过敏反应的方法,所述方法包括以足以减少或消除过敏原特异性IgE应答的产生的量向所述受试者给药本文公开的DNA疫苗。
本公开的主题内容的某些方面已在上文中陈述,其完全或部分由本公开的主题内容应对,当结合随附的实施例和图进行描述时,其他方面将变得明显,正如在下文中最好地描述的。
附图说明
图1是过敏原-LAMP1蛋白的示意图。
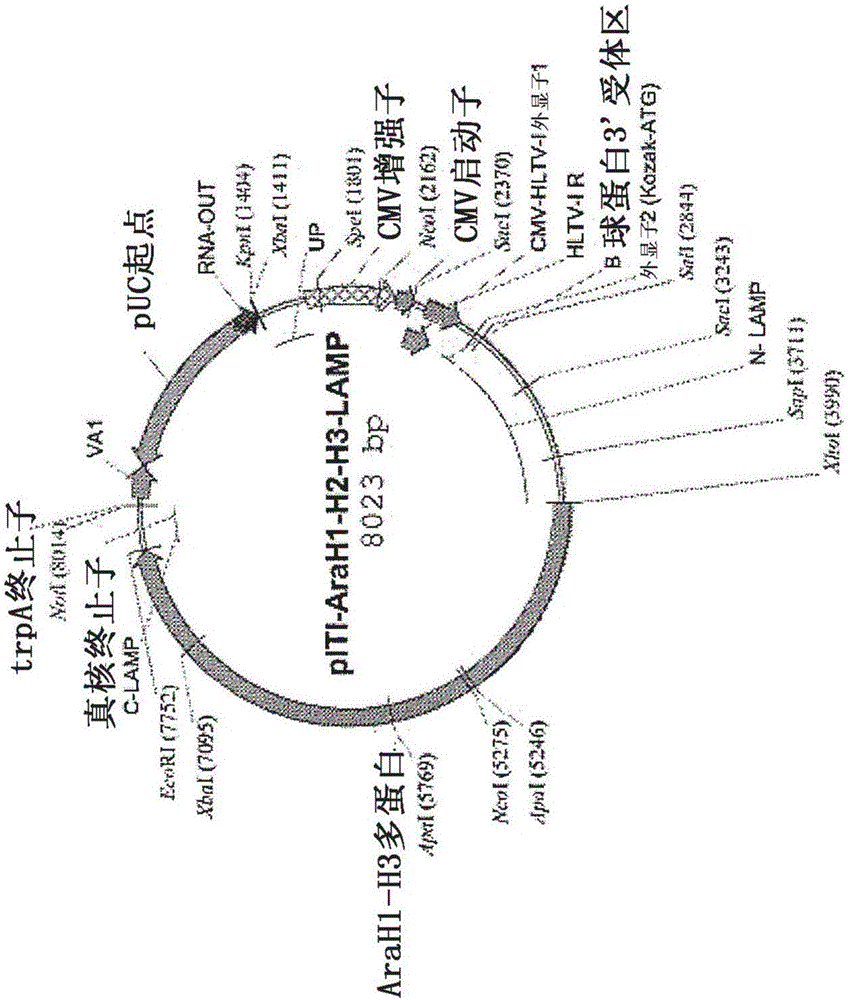
图2示出了在过敏原结构域中包括三种花生过敏原(AraHl、AraH2和AraH3,全都缺少它们本源或天然存在的信号序列)的核酸的载体图谱。
图3示出了由图2的核酸编码的蛋白质的示意图。
图4示出了Western印迹,其显示了花生过敏原Ara H1、H2和H3从本公开的构建物的共表达。
图5示出了在通过真皮内(ID)或肌内(IM)注射用Ara H1-LAMP、Ara H2-LAMP和Ara-H3del-LAMP质粒的组合或单个多价-Ara H1/H2/H3-LAMP质粒(H1-3多价质粒)免疫接种后,小鼠中的IgG1抗体水平;每组三个条代表如下:左边的条,免疫接种后第49天;中间的条,第70天;右边的条,第84天。
图 6A-6B示出了在用Ara H1-LAMP、Ara H2-LAMP和Ara-H3del-LAMP质粒的组合或单个多价Ara H1/H2/H3-LAMP质粒免疫接种中,小鼠中的IgG2a抗体水平:A)真皮内(ID)注射;每组三个条代表如下:左边的条,免疫接种后第21天;中间的条,第35天;右边的条,第49天;以及B)真皮内(ID)或肌内(IM)注射;蓝色的条,免疫接种后第49天;红色的条第70天,绿色的条,第84天。
图7示出了用于本文中示出的预防性研究的方案的代表性实施方式。
图8示出了在用ARA-LAMP-vax(被定义为Ara H1、Ara H2和Ara H3del质粒的组合)免疫接种后,小鼠中的IgG1和IgG2a抗体水平。免疫接种方案:将5周龄雌性C3H/HeJ小鼠(N=10只小鼠/组)在第0、7和14天用Ara-LAMP DNA疫苗免疫接种(周-3、-2、-1)。对照组接受仅含LAMP的载体。CPE被定义为花生粗提物。
图9示出了在用ARA-LAMP-vax免疫接种并致敏后第58天,小鼠中的IgG1和IgG2a抗体水平。致敏方案:首先在第0周(W)三次然后每周一次直至W5将小鼠用10mg花生酱(PN)+20ug霍乱毒素(CT)胃内(i.g.)致敏,随后在W6和W8用50mg PN+20ug CT两次加强。
图10示出了在用ARA-LAMP-vax免疫接种并致敏后第92天,小鼠中的IgG1和IgG2a抗体水平。在5轮PN-CT致敏之后PN激惹之前——第92天的抗体滴度。致敏方案继续。
图11示出了在用ARA-LAMP-vax免疫接种、致敏和过敏性反应激惹后,小鼠中的IgG1和IgG2a抗体水平。过敏性反应激惹:然后在W12将小鼠用200mg花生酱(PN)i.g.激惹。
图12示出了在免疫接种、致敏和过敏性反应激惹后小鼠中的IgE抗体水平,支持了ARA-LAMP-vax的预防机制;每组两个条代表如下:左边的条,对照载体;右边的条,Ara H-LAMP疫苗;最左边的与其他组的条分开单独设置的条代表取血前。
图13示出了图9至12中示出的数据的概述。
图14示出了图9至12中示出的数据的另一个概述;下图示出了两条表示数据点的线,顶部的线表示对照载体,底部的线表示ARA-LAMP vax。
图15示出了用于本文中示出的预防研究的代表性方案。
图16示出了当经Bioject B2000无针装置通过真皮内注射(ID)递送时,对ARA-LAMP-vax或单个多价Ara H1/H2/H3-LAMP质粒的IgG1(图A)、IgG2a(图B)和IgE(图C)应答。在x-轴上描绘了第28、57、92、108、140和171天时间点,每个时间点示出了3个条,其代表如下:对照载体(左边的条),3个质粒的组合(中间的条)和单个多过敏原质粒(右边的条)。
图17示出了用于本文中示出的治疗研究的方案的代表性实施方式。
图18示出了在用ARA-LAMP-vax疫苗治疗之前,小鼠中的血清花生特异性IgE抗体水平。
图19示出了在用ARA-LAMP-vax疫苗治疗之前和之后小鼠中的血清花生特异性IgE抗体水平。
图20示出了在使用ARA-LAMP-vax和治疗方案的第15周,小鼠中的过敏性反应激惹结果(症状分值,图A;体温,图B)。
图21示出了在使用ARA-LAMP-vax和治疗方案的第15周,口服激惹后小鼠中的血浆组胺水平。
图22示出了在使用ARA-LAMP-vax和治疗方案的第15周,小鼠中的IL-4细胞因子水平。
图23示出了在使用ARA-LAMP-vax和治疗方案的第15周,小鼠中的IFN-γ水平。
示例性实施方式的详细描述
现在将详细参考本公开的各个示例性实施方式。应该理解,下面示例性实施方式的讨论不打算作为对本发明的限制,正如在本文中广泛公开的。相反,提供下面的讨论是为了给读者提供本发明的某些方面和特点的更详细的理解。除非另有指明,否则本发明的实践利用在本领域技术人员的技巧范围之内的常规分子生物学、微生物学和重组DNA技术。这些技术在文献中充分解释,对于这些领域的普通技术人员来说是公知的,因此不需在本文中详述。同样地,本发明的用于医学治疗的实践遵照本领域中已知的标准流程,并且那些流程不需在本文中详述。
在详细描述本发明的实施方式之前,应该理解,本文中使用的术语仅仅用于描述特定实施方式的目的,不打算是限制性的。此外,当提供值的范围时,应该理解,除非上下文另有明确陈述,否则在该范围的上限与下限之间的精确到所述下限的单位的十分之一的每个中间值,也被具体地公开。在陈述的范围内任何陈述的值或中间值之间的每个较小范围以及该陈述的范围内的任何其他陈述的值或中间值,均被涵盖在本发明之内。这些较小范围的上限和下限可以被独立地包含或不包含在所述范围内,并且所述较小范围中的包括了任一、两个或不包括任一限度的每个范围,也被涵盖在本发明之内,除了在所述陈述的范围中任何被具体排除的限度之外。当所述陈述的范围包括一个或两个所述限度时,排除了任一或两个这些被包括的限度的范围,也被包括在本发明之中。因此应该理解,当陈述值的范围时,该范围内的每个值以及落于该范围之内的每个范围也被固有地叙述,并且避免每一个值和每一个可能的值的范围的具体叙述,不是省略了这些值和范围,而是为了方便读者和本公开的简洁。
除非另有定义,否则在本文中使用的所有技术和科学术语都具有与该术语所属领域的普通技术人员通常理解的相同的意义。尽管与本文中所描述的相似或等同的任何方法和材料可用于本发明的实践或试验,但现在描述优选的方法和材料。本文中提到的所有出版物通过参考并入本文,以与所述出版物被引用的内容相结合公开并描述所述方法和/或材料。当本公开与任何并入的出版物冲突时,以本公开为准。
当在本文和随附的权利要求书中使用时,除非上下文另有明确叙述,否则单数形式包括复数指称物。因此,例如,对“过敏原”的指称包括多个这种过敏原,并且对“样品”的指称包括对一个或多个样品及其本领域技术人员已知的等同物的指称,等等。此外,可以使用等同术语来描述的术语的使用,包括那些等同的术语的使用。因此,例如,术语“受试者”的使用应该被理解为包括术语“动物”、“人”和在本领域中用于指示经历医学治疗的个体的其他术语。
当在本文中使用时,术语“包含”打算意味着所述构建物、组合物和方法包括所叙述的要素和/或步骤,但是不排除其他要素和/或步骤。当用于定义构建物、组合物和方法时,“基本上由……构成”意味着排除了对于所叙述的构建物、组合物和方法来说具有本质上的重要性的其他要素和步骤。因此,基本上由本文中所定义的要素构成的组合物将不排除来自于分离和纯化方法的痕量污染物和可药用载体,例如磷酸盐缓冲盐水、防腐剂等。“由……构成”意味着排除了其他成分的超过痕量的要素和用于给药本发明的组合物的实质性方法步骤。由每个这些过渡性术语定义的实施方式都在本发明的范围之内。
“嵌合DNA”是较大DNA分子内可辨别的DNA区段,其在自然界中不与所述较大分子相关联出现。因此,当嵌合DNA编码蛋白质区段时,所述区段编码序列将在侧翼带有不在任何天然存在的基因组中位于所述编码序列侧翼的DNA。在侧翼DNA编码多肽序列的情形中,所述被编码的蛋白质被称为“嵌合蛋白”(即具有融合在一起的非天然存在的氨基酸序列的蛋白)。基因等位变异或天然存在的突变事件不产生本文中所定义的嵌合DNA或嵌合蛋白。
当在本文中使用时,术语“多核苷酸”和“核酸分子”可互换使用,是指任何长度的核苷酸的聚合形式。多核苷酸可以含有脱氧核糖核苷酸、核糖核苷酸和/或它们的类似物。核苷酸可以具有任何三维结构,并且可以执行任何已知或未知的功能。术语“多核苷酸”包括例如单链、双链和三螺旋分子、基因或基因片段、外显子、内含子、mRNA、tRNA、rRNA、核酶、反义分子、cDNA、重组多核苷酸、支链多核苷酸、适体、质粒、载体、任何序列的分离的DNA、任何序列的分离的RNA、核酸探针和引物。核酸分子也可以包含修饰的核酸分子(例如包含修饰的碱基、糖和/或核苷酸间连接物)。
当在本文中使用时,术语“肽”是指两个或更多个子单元氨基酸、氨基酸类似物或肽模拟物的化合物。所述子单元可以通过肽键或通过其他键(例如酯、醚等)相连。术语“肽”在本文中被用于一般性地指称肽(即2至约20个残基的聚氨基酸)、多肽(即约20个残基至约100个残基的肽)和蛋白质(即具有约100或更多个残基的肽)。
当在本文中使用时,术语“氨基酸”是指天然和/或非天然或合成的氨基酸,包括甘氨酸和D或L两种光学异构体以及氨基酸类似物和肽模拟物。3或更多个氨基酸的肽通常被称为寡肽,如果所述肽链短的话。尽管术语“蛋白质”涵盖了术语“多肽”,但“多肽”可以是少于全长的蛋白质。
术语“过敏原”是指已被报道在重复地暴露于个体后诱导过敏性、即IgE介导的反应的任何天然存在的蛋白质或蛋白质混合物。过敏原是能够唤起过敏反应的任何化合物、物质或材料。过敏原通常被理解为是抗原的亚类,抗原是能够唤起免疫应答的化合物、物质或材料。为了执行本发明,过敏原可以选自天然或本源过敏原、修饰的天然过敏原、合成的过敏原、重组的过敏原、类过敏原及其混合物或组合等。特别感兴趣的是花生过敏原,尤其是能够引起IgE介导的速发型超敏反应的花生过敏原。根据它们的化学或生物化学本质,过敏原可以表示本源或重组的蛋白质或肽、本源或重组的蛋白质或肽的片段或截短的版本、融合蛋白、合成的化合物(化学过敏原)、模拟过敏原的合成的化合物或化学或物理改变的过敏原,例如通过热变性改性的过敏原。
“表位”是被免疫系统的组分特异性识别或特异性结合的结构,通常由短的肽序列或寡糖构成。T细胞表位通常被显示是线性寡肽。两个表位如果可以被同一抗体特异性结合,则它们彼此对应。两个表位如果都能结合于同一B细胞受体或同一T细胞受体,并且一个抗体与其表位的结合显著阻止了被另一个表位结合(例如少于约30%,优选地少于约20%,更优选地少于约10%、5%、1%或约0.1%的另一个表位结合),则它们彼此对应。
当在本文中使用时,如果两个核酸编码序列或它们的互补序列编码相同氨基酸序列,则这两个序列彼此“对应”。
当在本文中使用时,与另一个序列具有一定百分率(例如至少约50%、至少约60%、至少约70%、至少约80%、至少约85%、至少约90%、至少约95%、至少约99%)的“序列同一性”的多核苷酸或多核苷酸区域(或多肽或多肽区域),意味着当手动或使用本领域中常规的软件程序进行最大比对时,在所述两个序列中该百分率的碱基(或氨基酸)是相同的。
两个核苷酸序列,当在DNA序列的确定长度内至少约50%、至少约60%、至少约70%、至少约75%、优选地至少约80%、最优选地至少约90或95%的核苷酸匹配时,是“基本上同源的”或“基本上相似的”。同样地,两个多肽序列,当在多肽序列的确定长度内多肽的至少约40%、至少约50%、至少约60%、至少约66%、至少约70%、至少约75%、优选地至少约80%、最优选地至少约90或95%或98%的氨基酸残基匹配时,是“基本上同源的”或“基本上相似的”。基本上同源的序列可以通过使用在序列数据库中可用的标准软件对所述序列进行比较来鉴定。基本上同源的核酸序列也可以在Southern杂交实验中,在例如为该特定系统所确定的严紧条件下鉴定。适合的杂交条件的确定在本领域技术的范围之内。例如,严紧条件可以是:在5xSSC和50%>甲酰胺下在42℃杂交,并在0.l x SSC和0.1%十二烷基硫酸钠下在60℃清洗。
也可以提供结构域序列的“保守修饰的变体”。对于特定核酸序列来说,术语保守修饰的变体是指那些编码一致或基本上一致的氨基酸序列的核酸,或者在所述核酸不编码氨基酸序列的情况下,是指基本上一致的序列。具体来说,可以通过产生其中一个或多个所选(或所有)密码子的第三位被混合碱基和/或脱氧次黄苷残基替换的序列,来实现简并密码子替换(Batzer等,(1991)Nucleic Acid Res.19:508;Ohtsuka等,(1985)J.Biol.Chem.260:2605-2608;Rossolini等,(1994)Mol.Cell.Probes 8:91-98)。
术语野生型蛋白质的“生物活性片段”、“生物活性形式”、“生物活性等同物”和“功能衍生物”,是指当使用适合于检测野生型蛋白质的生物活性的测定法测量时,具有的生物活性至少基本上等于(例如不显著不同于)所述野生型蛋白质的生物活性的物质。例如,包含运输结构域的生物活性片段是可以与包含所述运输结构域的全长多肽共定位到同一区室的片段。
当外源或异源核酸被导入到细胞内时,所述细胞已被这些核酸“转化”、“转导”或“转染”。
转化的DNA可以与构成细胞基因组的染色体DNA整合(共价连接),或者可以不与其整合。例如,在原核生物、酵母和哺乳动物细胞中,转化的DNA可以维持在游离元件例如质粒上。在真核细胞中,稳定转化的细胞是其中转化的DNA已变得整合在染色体中,使得它通过染色体复制被子代细胞继承的细胞。这种稳定性通过所述真核细胞建立细胞系或包含大量含有所述转化的DNA的子代细胞的克隆的能力来证实。“克隆”是从单一细胞或共同祖先通过有丝分裂产生的一群细胞。“细胞系”是能够在体外稳定生长许多代(例如至少约10代)的原代细胞的克隆。
“复制子”是在体内起到DNA复制的自主单元作用的任何遗传元件(例如质粒、染色体、病毒)。
当在本文中使用时,“病毒载体”是指包含待递送到宿主细胞中的多核苷酸的病毒或病毒粒子,不论是在体内、离体还是体外。病毒载体的实例包括但不限于腺病毒载体、腺相关病毒载体、反转录病毒载体等。在基因转移由腺病毒载体介导的情况下,载体构建物是指与腺病毒衣壳蛋白一起还包含腺病毒基因组或其部分和所选的非腺病毒基因的多核苷酸。
当在本文中使用时,“核酸递送载体”是可以将目标多核苷酸运输到细胞内的核酸分子。优选地,这种载体包含可操作地连接到表达控制序列的编码序列。然而,目标多核苷酸序列不必定包含编码序列。例如,目标多核苷酸序列可以是结合到靶分子的适体。在另一个实例中,目标序列可以是调控序列的互补序列,其结合到调控序列以抑制所述调控序列的调控。在另一个实例中,目标序列本身是调控序列(例如,用于找出细胞中的调控因子)。
当在本文中使用时,“核酸递送介质”被定义为能够将插入的多核苷酸携带到宿主细胞中的任何分子或一组分子或大分子(例如基因或基因片段、反义分子、核酶、适体等),并且所述递送与如上所述的核酸递送载体相结合发生。
当在本文中使用时,“核酸递送”或“核酸转移”是指将外源多核苷酸(例如转基因)导入到宿主细胞中,不论所述导入使用何种方法。导入的多核苷酸可以稳定地或暂时地维持在所述宿主细胞中。稳定的维持通常要求导入的多核苷酸含有与所述宿主细胞相容的复制原点,或者整合到宿主细胞的复制子例如染色体外复制子(例如质粒)或核或线粒体染色体中。
当在本文中使用时,“表达”是指将多核苷酸转录成mRNA和/或翻译成肽、多肽或蛋白质的过程。如果所述多核苷酸源自于基因组DNA,表达可以包括从基因组DNA转录的mRNA的拼接。
当在本文中使用时,“在转录控制下”或“可操作地连接”是指多核苷酸序列的表达(例如转录或翻译)通过表达控制元件和编码序列的适合的并置来控制。在一种情况下,当表达控制序列控制并调节DNA序列的转录时,该DNA序列“可操作地连接”到所述表达控制序列。
当在本文中使用时,“编码序列”是当置于适合的表达控制序列的控制之下时被转录并翻译成多肽的序列。编码序列的边界由5’(氨基)端的起始密码子和3’(羧基)端的翻译终止密码子确定。编码序列可以包括但不限于原核序列、来自于真核mRNA的cDNA、来自于真核(例如哺乳动物)DNA的基因组DNA序列和甚至合成的DNA序列。例如,这些合成的DNA序列可以包括为打算在其中表达所述序列的生物体进行过密码子优化的序列。多腺苷化信号和转录终止序列通常位于编码序列的3’。
当在本文中使用时,“遗传修饰”是指细胞的正常核苷酸序列的任何添加或缺失或破坏。本领域公认的方法包括病毒介导的基因转移、脂质体介导的转移、转化、转染和转导,例如病毒介导的基因转移,例如使用基于DNA病毒如腺病毒、腺相关病毒和疱疹病毒的载体以及基于反转录病毒的载体。
当在本文中使用时,“溶酶体/内吞体区室”是指膜结合性酸性液泡,其含有膜中的LAMP分子、在抗原加工中起作用的水解酶类和用于抗原识别和呈递的II类MHC分子。该区室起到通过各种不同机制包括胞吞作用、吞噬作用和胞饮作用从细胞表面内化的外来材料和通过专门的自溶现象递送到该区室的细胞内材料的降解位点的作用(参见例如de Duve(1983)Eur.J.Biochem.137:391)。当在本文中使用时,术语“内吞体”涵盖了溶酶体。
当在本文中使用时,“溶酶体相关的细胞器”是指包含溶菌酶的任何细胞器,并包括但不限于MIIC、CUV、黑素体、分泌颗粒、裂解性颗粒、血小板致密颗粒、嗜碱颗粒、伯贝克颗粒、吞噬溶酶体、分泌溶酶体等。优选地,这种细胞器缺少甘露糖6-磷酸受体并包含LAMP,但可以包含或可以不包含II类MHC分子。对于综述来说,参见例如Blott和Griffiths(2002)Nature Reviews,Molecular Cell Biology;DellAngelica等,(2000)The FASEB Journal 14:1265-1278。
当在本文中使用时,“溶酶体相关膜蛋白”或“LAMP”是指包含存在于内吞体/溶酶体区室或溶酶体相关的细胞器的膜中的结构域并且还包含腔内结构域(luminal domain)的任何蛋白质。示例性的LAMP包括但不限于LAMP-1、LAMP-2、CD63/LAMP-3(DC-LAMP)或其同源物、直向同源物、变体(例如等位基因变体)和修饰的形式(例如包含一个或多个天然存在的或工程化的突变)。在某些实施方式中,LAMP是哺乳动物的溶酶体相关膜蛋白,例如人类或小鼠的溶酶体相关膜蛋白。示例性的LAMP包括包含与SEQ ID NO:22、23、24、25或30具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的氨基酸序列的肽。可用于本公开的核酸分子的编码LAMP肽的示例性核苷酸序列包括但不限于与SEQ ID NO:10、11、12、13或29具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的任何序列。
当在本文中使用时,术语“稳定化结构域”打算是指有助于保持蛋白质有活性和/或处于其天然构象下的结构域。
当在本文中使用时,术语“运输结构域”打算是指有助于将蛋白质靶向细胞的特定部位的结构域。
当在本文中使用时,“靶向结构域”是指将本发明的嵌合蛋白导向优选位点例如细胞的细胞器或发生抗原加工和与MHC II结合的区室的多肽序列。因此,“靶向结构域”是指向细胞区室/细胞器递送所需的一系列氨基酸。优选地,靶向结构域是结合到接头或AP蛋白(例如AP1、AP2或AP3蛋白)的序列。示例性的靶向结构域序列描述在例如DellAngelica,2000中。
当在本文中使用时,“内吞体/溶酶体靶向结构域”是指向内吞体/溶酶体区室或溶酶体相关的细胞器递送所需的一系列氨基酸。例如,LAMP向溶酶体外膜的运输,由接头蛋白与内吞体/溶酶体靶向结构域的结合所介导,所述靶向结构域是羧基端细胞质尾部中的酪氨酸识别序列(其中Y是酪氨酸残基,X可以是任何氨基酸,并且是大的疏水残基)。示例性的酪氨酸识别序列包括氨基酸序列YQTI、YQRI、YEQF和YHTL。
当在本文中使用时,体内核酸递送、核酸转移、核酸疗法等,是指将包含外源多核苷酸的载体直接导入到生物体例如人类或非人类哺乳动物的体内,由此将所述外源多核苷酸体内导入到该生物体的细胞中。
当在本文中使用时,术语“原位”是指一种类型的体内核酸递送,在其中将所述核酸带到靶细胞附近(例如,所述核酸未被系统性给药)。例如,原位递送方法包括但不限于将核酸直接注射在位点处(例如注射到组织如肿瘤或心肌中),将所述核酸通过开放的手术野与细胞或组织相接触,或使用医学接入装置例如导管将所述核酸递送到位点。
当在本文中使用时,术语“分离的”和“纯化的”有时可互换使用,意味着与在天然情况下通常伴随着所述多核苷酸、肽、多肽、蛋白质、抗体或其片段的细胞或其他方面的组成成分分离开。例如,对于多核苷酸而言,分离的多核苷酸是与在染色体中通常与其相伴的5’和3’序列分离开的多核苷酸。对于本领域技术人员来说,显然非天然存在的多核苷酸、肽、多肽、蛋白质、抗体或其片段不需“分离”以将其与其天然存在的对应物区分开。此外,术语“分离的”和“纯化的”不暗示彻底分离和彻底纯化。这些术语被用于指称从天然与所述多核苷酸等相伴存在的一些或所有其他物质中部分和彻底纯化两者。因此,这些术语可以意味着与一种天然相伴的物质分离或纯化(例如从RNA分离或纯化DNA),从同一分子总类的其他物质中分离或纯化(例如与样品中的所有蛋白质相比显示出20%纯度的特定蛋白质),或任何组合。分离和纯化可以意味着从约1%至约100%的任何水平,包括100%。因此,“分离的”或“纯化的”细胞群体基本上不含在天然条件下与其相伴的细胞和材料。当然,本领域技术人员将会认识到,所有特定值、包括值的分数,被涵盖在这些范围之内,而不需将每个特定值在本文中列出。出于简洁的目的没有具体公开每个值;然而,读者应该理解,每个和所有的特定值都固有地被本发明公开并涵盖。
当在本文中使用时,“靶细胞”或“受体细胞”是指个体细胞或希望成为或已经成为外源核酸分子、多核苷酸和/或蛋白质的接受者的细胞。所述术语还打算包括单个细胞的后代,并且由于天然、偶然或故意的突变,所述后代可以不必与原始亲代细胞完全一致(在形态或基因组或全套总DNA方面)。靶细胞可能与其他细胞相接触(例如当在组织中时),或者可能在生物体的身体内循环存在。
当在本文中使用时,术语“抗原呈递细胞”或“APC”是指在表面上呈递与主要组织相容性复合物分子或其一部分或者一个或多个非经典MHC分子或其一部分相结合的抗原的任何细胞。适合的APC的实例在下面详细讨论,并且包括但不限于完整细胞例如巨噬细胞、树突状细胞、B细胞、杂合APC和foster抗原呈递细胞。
当在本文中使用时,“工程化的抗原呈递细胞”是指在表面上具有非天然分子组成部分的抗原呈递细胞。例如,这种细胞在其表面上可能不天然具有辅助刺激因子,或者除了天然的辅助刺激因子之外在其表面上可能具有其他人造的辅助刺激因子,或者可以在其表面上表达非天然的II类分子。
当在本文中使用时,术语“免疫效应细胞”是指能够结合抗原并介导免疫应答的细胞。这些细胞包括但不限于T细胞、B细胞、单核细胞、巨噬细胞、NK细胞和细胞毒性T淋巴细胞(CTL)例如CTL株系、CTL克隆和来自于肿瘤、炎性或其他浸润液的CTL。
当在本文中使用时,术语“受试者”和“患者”可互换使用,以指示本发明所针对的动物。术语动物应该被理解为包括人类和非人类动物;在希望区分这两者的情况下,使用术语人类和/或非人类动物。在某些实施方式中,受试者或患者是脊椎动物,优选为哺乳动物,更优选为人。哺乳动物包括但不限于鼠类、猿类、人类、耕畜(例如牛、绵羊、猪)、运动动物(例如马)和宠物(例如犬和猫)。
临床过敏症状对于本领域技术人员来说是已知的,并且不需在本文中详尽列出。非限制性实例包括鼻炎、结膜炎、哮喘、荨麻疹、湿疹,其包括在皮肤、眼、鼻、上下气道中的反应,并伴有常见症状例如眼和鼻的发红发痒、鼻痒和流涕、咳嗽、气喘、呼吸短促、瘙痒和组织肿胀。
“体内免疫试验”的实例包括皮肤点刺试验(SPT)、结膜激发试验(CPT)、使用过敏原的支气管激惹(BCA)以及各种不同的在其中监测一种或多种过敏症状的临床试验。参见例如Haugaard等,J Allergy Clin Immunol,Vol.91,No.3,pp 709-722,March 1993。
当在本文中使用时,术语“可药用载体”涵盖了本领域中已知的任何标准的制药载体,例如磷酸盐缓冲盐水溶液、水和乳液,例如油/水或水/油乳液,以及各种不同类型的润湿剂。组合物还可以包括稳定剂和防腐剂。对于载体、稳定剂和佐剂的实例,参见Martin Remington's Pharm.Sci.,15th Ed.(Mack Publ.Co.,Easton(1975))。
当在本文中使用时,“治疗有效量”在本文中用于指称足以阻止、校正异常生理反应和/或使其正常化的量。在一种情况下,“治疗有效量”是足以使疾病的临床显著特点例如临床过敏症状、抗体生产、细胞因子生产、发热或白细胞计数或组胺水平降低至少约30%、更优选地至少50%、最优选地至少90%的量。
“抗体”是任何免疫球蛋白,包括抗体及其结合特定表位的片段。所述术语涵盖了多克隆、单克隆和嵌合抗体(例如双特异性抗体)。“抗体结合部位”是抗体分子的由重链和轻链可变和超变区构成的特异性结合抗原的结构部分。示例性的抗体分子是完整的免疫球蛋白分子、基本上完整的免疫球蛋白分子和免疫球蛋白分子的含有补位的部分,包括Fab、Fab'、F(ab')2和F(v)部分,在本文描述的治疗方法中优选使用所述部分。
术语“口腔粘膜给药”是指将剂型置于舌下或口腔中的其他地方以允许活性成分与患者的口腔或咽喉的粘膜发生接触,以便获得所述活性成分的局部或系统效应的给药途径。口腔粘膜给药途径的实例是舌下给药。术语“舌下给药”是指将剂型置于舌下以便获得活性成分的局部或系统效应的给药途径。当在本文中使用时,术语“真皮内递送”意味着将疫苗递送到皮肤中的真皮。然而,疫苗将不一定仅仅位于真皮中。真皮是皮肤中的一层,在人类皮肤中位于距表面约1.0至约2.0mm之间,但是在个体之间以及身体的不同部分中存在一定量的可变性。一般来说,通过进入皮肤表面下方1.5mm,预期可以到达真皮。真皮位于表面处的角质层和表皮与下方的皮下层之间,取决于递送方式,疫苗最终可以仅仅或主要位于真皮内,或者它最终可以分布在表皮和真皮内。
当在本文中使用时,在过敏免疫疗法、过敏治疗或描述被设计用于过敏患者的干预的其他术语的背景中,术语“预防”或“预防性的”意味着在所有患者中的至少20%的患者中阻止IgE应答。术语“预防”不要求在所有患者中完全阻止IgE介导的疾病的发生,并且对于通过减轻过敏症状的机制治疗过敏来说,这种定义在本发明的范围之外,并且与该术语在本领域中的使用不一致。对于过敏免疫治疗领域的技术人员来说,众所周知,过敏治疗不是在100%的患者中100%有效的,因此在本发明的背景中,不使用“预防”的绝对定义。本发明考虑到了本领域公认的预防概念。
广义来说,本公开提供了多核酸、多氨基酸和治疗需要所述多核酸和多氨基酸的受试者的方法。所述多核酸及其组合物可以被认为是用于在细胞内产生花生过敏原序列(多氨基酸),在给药所述多核酸的受试者体内引发保护性免疫应答的核酸(例如DNA、RNA)疫苗。所述多核酸在给药时,倾向性地通过MHC-II途径唤起细胞介导的免疫应答,并通过激活花生过敏原特异性1型辅助性T细胞(Thl)细胞应答来唤起IgG抗体的生产,并由APC、NK细胞和T细胞生产干扰素,而不是激活Th2类型的应答,其涉及IgE抗体、粒细胞(例如嗜曙红细胞)和其他物质的产生。在某种程度上,MHC-II和MHC-I应答两者都可以产生;然而,本发明提供了主要或基本上是MHC-II应答的应答。在某些实施方式中,免疫系统被重新平衡以有利于IgG/Th1应答而不是过敏性IgE/Th2应答。优选地,所述核酸不编码抗生素抗性基因。
具体来说,本文提供了新的花生过敏DNA疫苗,其利用溶酶体相关膜蛋白(“LAMP”)嵌合构建物将花生过敏原引入MHC II/内吞体途径中。本公开的疫苗,包括本文中描述的核酸分子、载体和药物组合物,为花生过敏患者提供了安全、低过敏原性且成本效益高的疗法,显著降低或消除对花生的敏感性。
本公开的核酸当给药到受试者时,将抗原隔离在抗原呈递细胞的溶酶体区室中,并在过敏患者中实施Th2到Th1应答的调节。另一个优点在于本公开的构建物被设计用于防止意外的过敏原暴露。过敏原作为核酸被编码,因此在给药后没有显著量的过敏原被系统性暴露。它被编码在LAMP内,以备高保真度的溶酶体运输。在溶酶体中,所述过敏原经历蛋白水解,将过敏原性表位暴露于MHC-II并呈递给辅助性T细胞。因此,接受本公开的疗法的受试者在不暴露于游离过敏原的情况下显示出临床反应。
因此,在某些实施方式中提供了一种分离或纯化的核酸分子,其按顺序排列包含:编码信号序列的核酸序列;编码细胞器内稳定化/运输结构域的核酸序列;编码花生过敏原结构域的核酸序列,所述花生过敏原结构域可以包含单一花生过敏原或两种或更多种花生过敏原,每种过敏原包含一个或多个花生过敏原性表位,并且其中所述至少一种花生过敏原不包括所述花生过敏原本源的信号序列;编码跨膜结构域的核酸序列;和编码内吞体/溶酶体靶向结构域的核酸序列。
本文中提供的分离或纯化的核酸分子包含信号序列。在某些实施方式中,所述信号序列包含LAMP的信号序列。在某些实施方式中,所述信号序列是内质网易位序列。示例性的LAMP信号序列包括但不限于LAMP-1、LAMP2、LAMP-3(DC-LAMP)、LIMP II或ENDOLYN的信号序列。示例性的LAMP信号序列包括的肽包含与SEQ ID NO:1的第1-27位氨基酸、SEQ ID NO:22的第1-27位氨基酸、SEQ ID NO:23的第1-28位氨基酸、SEQ ID NO:24的第5-27位氨基酸和SEQ ID NO:25的第1-24位氨基酸具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的氨基酸序列。可用于本公开的核酸分子的编码LAMP信号序列的示例性核苷酸序列包括但不限于与SEQ ID NO:18的第1-86位核苷酸、SEQ ID NO:19的第1-86位核苷酸、SEQ ID NO:20的第1-86位核苷酸、SEQ ID NO:21的第1-86位核苷酸、SEQ ID NO:10的第1-84位核苷酸、SEQ ID NO:11的第1-81位核苷酸、SEQ ID NO:12的第1-72位核苷酸和SEQ ID NO:13的第13-81位核苷酸具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的任何序列。
本文中描述的分离或纯化的核酸分子还包含编码细胞器内稳定化/运输结构域的序列,所述结构域包含编码溶酶体相关膜蛋白(LAMP)的序列。例如,所述细胞器内稳定化/运输结构域可以包含LAMP的腔内结构域。在另一个实施方式中,所述细胞器内稳定化/运输结构域包含LAMP1、LAMP2、LAMP-3(DC-LAMP)、LIMP II或ENDOLYN的腔内结构域。示例性的细胞器内稳定化/运输结构域包括但不限于与SEQ ID NO:1的第28至380位氨基酸、SEQ ID NO:22的第28-381位氨基酸、SEQ ID NO:23的第29-375位氨基酸、SEQ ID NO:24的第28-433位氨基酸或SEQ ID NO:25的第25-162位氨基酸具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的氨基酸序列。示例性的细胞器内稳定化/运输结构域可以由与SEQ ID NO:18的第87-1146位核苷酸、SEQ ID NO:19的第87-1146位核苷酸、SEQ ID NO:20的第87-1146位核苷酸、SEQ ID NO:21的第87-1146位核苷酸、SEQ ID NO:10的第85-1125位核苷酸、SEQ ID NO:11的第82-1143位核苷酸、SEQ ID NO:12的第73-486位核苷酸或SEQ ID NO:13的第82-1299位核苷酸具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的核苷酸序列编码。
本文中描述的核酸分子还包含编码花生过敏原结构域的序列。所述编码花生过敏原结构域的序列包含编码一种或多种花生过敏原蛋白、多肽或肽的核酸序列,所述蛋白、多肽或肽包含一个或多个过敏原性表位。所述花生过敏原结构域优选地不包括来自于所述花生过敏原的天然存在的信号序列。当使用小于全长的花生过敏原性序列时,优选地将所述全长花生过敏原蛋白的一个或多个表位提供在所述过敏原性蛋白内它们的天然位置的背景中。所述花生过敏原结构域可以包括两种或更多种过敏原,其各自含有一个或多个过敏原性表位。在其他实施方式中,所述编码花生过敏原结构域的序列包含编码三种花生过敏原的序列。已知某些过敏原性蛋白含有两个或更多个表位。在某些实施方式中,所述编码花生过敏原结构域的序列包含花生过敏原性蛋白的整个过敏原性编码区(即缺少信号序列的编码区)或其显著部分。一些花生过敏原结构域包括处于其天然存在的关系的两个或更多个表位。或者,可以将两个或更多个已知的花生过敏原性表位融合在一个编码区中。同样地,在示例性实施方式中,在所述花生过敏原结构域中存在两种或更多种花生过敏原性蛋白或其过敏原性区域。在将两个或更多个表位工程化以存在于单一表位结构域中的情况下,所述表位可以来自于同一抗原性蛋白。在某些实施方式中,所述分离或纯化的核酸分子包含的核酸序列包含编码两个或更多个花生过敏原性表位的核酸序列。在又一个实施方式中,所述编码花生过敏原结构域的核酸序列包含编码两种或更多种花生过敏原的核酸序列。在又一个实施方式中,所述编码花生过敏原结构域的核酸序列包含编码三种花生过敏原的核酸序列。在某些实施方式中,所述至少一种花生过敏原是Ara H1、Ara H2、Ara H3、AraH3del、其具有至少一个花生过敏原性表位的部分,或其任何组合。
在某些实施方式中,编码所述至少一个花生过敏原结构域的核酸序列包含与SEQ ID NO:14、SEQ ID NO:15、SEQ ID NO:16、SEQ ID NO:17、SEQ ID NO:26、SEQ ID NO:18的第1147-2943位核苷酸、SEQ ID NO 19的第1147-1600位核苷酸、SEQ ID NO:20的第1147-2623位核苷酸、SEQ ID NO:21的第1147-2949位核苷酸、SEQ ID NO:21的第2962-3414位核苷酸和/或SEQ ID NO:21的第3427-4902位核苷酸具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的核苷酸序列。在某些实施方式中,所述Ara H花生过敏原结构域包含与SEQ ID NO:2、SEQ ID NO:3、SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:1的第383至983位氨基酸、SEQ ID NO:1的第988至1138位氨基酸、SEQ ID NO:1的第1143至1634位氨基酸和/或SEQ ID NO:1的第383至1634位氨基酸具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的氨基酸序列。
在某些实施方式中,所述花生过敏原性表位或花生过敏原被连接序列分隔开。例如,所述连接序列可以包含氨基酸序列GGGG或GGGGS。
本文中提供的分离或纯化的核酸分子还包含跨膜结构域。跨膜结构域是部分存在于生物膜两侧上的已被良好表征的蛋白质的物理和功能元件。一般来说,跨膜结构域是线性氨基酸序列,其在本质上是疏水或亲脂的,并且起到将蛋白质锚定在生物膜处的作用。这些序列的长度通常为20-25个残基。本领域技术人员清楚地知道这些序列,并且可以容易地获得或工程化适合用于本发明的跨膜序列。在某些实施方式中,所述跨膜结构域包含LAMP例如但不限于LAMP-1、LAMP2、LAMP-3(DC-LAMP)、LIMP II或ENDOLYN的跨膜结构域。可用于本公开的核酸分子的编码跨膜结构域的示例性核苷酸序列包括但不限于与SEQ ID NO:10的第1126-1188位核苷酸、SEQ ID NO:11的第1144-1212位核苷酸、SEQ ID NO:12的第487-555位核苷酸、SEQ ID NO:13的第1300-1395位核苷酸或SEQ ID NO:29的第1141-1212位核苷酸具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的任何序列。示例性的LAMP跨膜结构域包括与SEQ ID NO:23的第376-396位氨基酸、SEQ ID NO:22的第382-404位氨基酸、SEQ ID NO:24的第434-466位氨基酸、SEQ ID NO:25的第163-185位氨基酸或SEQ ID NO:30的第381-404位氨基酸具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的氨基酸序列。
所述核酸分子还包含编码内吞体/溶酶体靶向结构域的核酸序列。在某些实施方式中,所述内吞体/溶酶体靶向结构域可以是羧基端细胞质尾部中的酪氨酸识别序列(信号)(其中Y是酪氨酸残基,X可以是任何氨基酸,并且是大的疏水性残基)。在某些实施方式中,所述酪氨酸识别序列(信号)包含氨基酸序列YQTI、YQRI、YEQF或YHTL。所述编码内吞体/溶酶体靶向结构域的核酸序列可以包含SEQ ID NO:21的第5005-5016位核苷酸、SEQ ID NO:10的第1213-1224位核苷酸、SEQ ID NO:11的第1237-1248位核苷酸或SEQ ID NO:12的第580-591位核苷酸。在某些实施方式中,所述编码内吞体/溶酶体靶向结构域的核酸序列可以包含SEQ ID NO:13的第1420-1431位核苷酸。
在某些实施方式中,本公开的核酸分子包含与SEQ ID NO:18、SEQ ID NO:19、SEQ ID NO:20、SEQ ID NO:21或SEQ ID NO:27具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的核苷酸序列。本文中提供的本公开的核酸分子可以包含与SEQ ID NO:1、SEQ ID NO:6、SEQ ID NO:7、SEQ ID NO:8或SEQ ID NO:28具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的氨基酸序列的编码核酸序列。
本公开的核酸分子可以包含脱氧核糖核酸(DNA)。
在某些实施方式中,所述分离或纯化的核酸出现在单个嵌合或工程化的核酸上,所述分离或纯化的核酸按顺序排列包含:编码信号序列的序列;编码细胞器内稳定化/运输结构域的序列;编码花生过敏原结构域的序列,所述花生过敏原结构域可以包含单一花生过敏原或两种或更多种花生过敏原,每种过敏原包含一个或多个花生过敏原性表位,并且其中所述至少一种花生过敏原不包括所述花生过敏原的天然存在的信号序列;编码跨膜结构域的序列;和编码内吞体/溶酶体靶向结构域的序列。编码本公开的分离或纯化的核酸的相应结构域的序列,可以使用本领域中已知并广泛使用的技术以任何顺序组合。在某些实施方式中,将所述结构域组合并排列以使它们包含编码嵌合蛋白的单一开放阅读框,所述开放阅读框可操作地连接到足以用于所述嵌合蛋白表达的转录元件。因此,所述核酸可以包括表达载体例如质粒、噬粒、病毒载体等。优选地,所述核酸包含适用于在哺乳动物细胞例如人类细胞中表达的转录元件。
在某些实施方式中,本公开将花生过敏原例如Ara H1、Ara H2、Ara H3和/或AraH3del提供在一个质粒内。作为代表性实例,本文公开的单个多价Ara H1/H2/H3LAMP质粒将主要的花生过敏原Ara H1、Ara H2和Ara H3包含在单个质粒中。本文中还提供了单个多价AraH1/H2/H3del LAMP质粒。质粒也可以在单个质粒中包含两种花生过敏原例如Ara H1与Ara H2、Ara H2与Ara H3、或Ara H1与Ara H3的组合。
在某些实施方式中,本公开提供了花生过敏原例如Ara H1、Ara H2、AraH3和/或Ara H3del,其各自在自身的质粒上。作为代表性实例,ARA-LAMP vax组合物包含由分开的质粒编码的主要花生过敏原Ara H1、Ara H2和Ara H3del。本文中还提供了包含由分开的质粒编码的Ara H1、Ara H2和Ara H3的组合物。在这些情况下,组合物包含至少两种DNA疫苗的混合物,其中每种疫苗包含一种花生过敏原的序列。所述疫苗构建物可以以1:1、1:2、1:3、1:4、依次直至1:10(例如1:5、1:6、1:7、1:8和1:9)的比率混合在一起。优选的比率是1:1。
在某些实施方式中,本公开的核酸是在宿主中诱导免疫应答的DNA疫苗。在某些实施方式中,所述DNA疫苗包含前面描述的分离或纯化的核酸,所述核酸按顺序排列包含:编码信号序列的序列;编码细胞器内稳定化/运输结构域的序列;编码花生过敏原结构域的序列,所述花生过敏原结构域可以包含单一花生过敏原或两种或更多种花生过敏原,每种过敏原包含一个或多个花生过敏原性表位,并且其中所述至少一种花生过敏原不包括所述花生过敏原的天然存在的信号序列;编码跨膜结构域的序列;和编码内吞体/溶酶体靶向结构域的序列。在某些实施方式中,所述DNA疫苗包含至少两种分离或纯化的核酸,所述核酸按顺序排列包含:编码信号序列的序列;编码细胞器内稳定化/运输结构域的序列;编码花生过敏原结构域的序列,所述花生过敏原结构域可以包含单一花生过敏原或两种或更多种花生过敏原,每种过敏原包含一个或多个花生过敏原性表位,并且其中所述至少一种花生过敏原不包括所述花生过敏原的天然存在的信号序列;编码跨膜结构域的序列;和编码内吞体/溶酶体靶向结构域的序列。在某些实施方式中,所述DNA疫苗包含至少三种分离或纯化的核酸,所述核酸按顺序排列包含:编码信号序列的序列;编码细胞器内稳定化/运输结构域的序列;编码花生过敏原结构域的序列,所述花生过敏原结构域可以包含单一花生过敏原或两种或更多种花生过敏原,每种过敏原包含一个或多个花生过敏原性表位,并且其中所述至少一种花生过敏原不包括所述花生过敏原的天然存在的信号序列;编码跨膜结构域的序列;和编码内吞体/溶酶体靶向结构域的序列。
还提供了表达本文中提供的核酸或载体的宿主细胞。在某些实施方式中,所述宿主细胞是哺乳动物宿主细胞,优选为人类细胞。
本文中还提供了多肽,所述多肽包含:信号序列;细胞器内稳定化/运输结构域;花生过敏原结构域,其可以包含单一花生过敏原或两种或更多种花生过敏原,每种过敏原包含一个或多个花生过敏原性表位,并且其中所述至少一种花生过敏原不包括所述花生过敏原的天然存在的信号序列;跨膜结构域;和内吞体/溶酶体靶向结构域。
在本文提供的多肽的某些实施方式中,所述信号序列包含LAMP的信号序列。在某些实施方式中,所述信号序列是内质网易位序列。示例性的LAMP信号序列包括但不限于LAMP-1、LAMP2、LAMP-3(DC-LAMP)、LIMP II或ENDOLYN的信号序列。示例性的LAMP信号序列包括的肽包含与SEQ ID NO:1的第1-27位氨基酸、SEQ ID NO:22的第1-27位氨基酸、SEQ ID NO:23的第1-28位氨基酸、SEQ ID NO:24的第5-27位氨基酸和SEQ ID NO:25的第1-24位氨基酸具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的氨基酸序列。
所述多肽还包含细胞器内稳定化/运输结构域。例如,所述细胞器内稳定化/运输结构域可以包含LAMP的腔内结构域。在另一个实施方式中,所述细胞器内稳定化/运输结构域包含LAMP1、LAMP2、LAMP-3(DC-LAMP)、LIMP II或ENDOLYN的腔内结构域。示例性的细胞器内稳定化/运输结构域包括但不限于与SEQ ID NO:1的第28至380位氨基酸、SEQ ID NO:22的第28-381位氨基酸、SEQ ID NO:23的第29-375位氨基酸、SEQ ID NO:24的第28-433位氨基酸或SEQ ID NO:25的第25-162位氨基酸具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的氨基酸序列。
本文中描述的多肽还包含花生过敏原结构域。所述花生过敏原结构域包含一种或多种花生过敏原蛋白、多肽或肽,其包含一个或多个过敏原性表位。所述花生过敏原结构域优选地不包括来自于所述花生过敏原的天然存在的信号序列。当使用小于全长的花生过敏原性序列时,优选地将所述全长花生过敏原蛋白的一个或多个表位提供在所述过敏原性蛋白内它们的天然位置的背景中。所述花生过敏原结构域可以包括两种或更多种过敏原,其各自含有一个或多个过敏原性表位。在其他实施方式中,所述花生过敏原结构域包含三种花生过敏原。已知某些过敏原性蛋白含有两个或更多个表位。一些花生过敏原结构域包括处于其天然存在的关系的两个或更多个表位。在将两个或更多个表位工程化以存在于单一表位结构域中的情况下,所述表位可以来自于同一抗原性蛋白。在某些实施方式中,所述至少一种花生过敏原是Ara H1、Ara H2、Ara H3、AraH3del、其具有至少一个花生过敏原性表位的部分,或其任何组合。
在某些实施方式中,所述Ara H花生过敏原结构域包含与SEQ ID NO:2、SEQ ID NO:3、SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:1的第383至983位氨基酸、SEQ ID NO:1的第988至1138位氨基酸、SEQ ID NO:1的第1143至1634位氨基酸和/或SEQ ID NO:1的第383至1634位氨基酸具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的氨基酸序列。
在某些实施方式中,所述花生过敏原性表位或花生过敏原被连接序列分隔开。例如,所述连接序列可以包含氨基酸序列GGGG或GGGGS。
本文中提供的多肽还包含跨膜结构域。在某些实施方式中,所述跨膜结构域包含LAMP例如但不限于LAMP-1、LAMP2、LAMP-3(DC-LAMP)、LIMP II或ENDOLYN的跨膜结构域。示例性的LAMP跨膜结构域包括与SEQ ID NO:1的第1637至1660位氨基酸、SEQ ID NO:23的第376-396位氨基酸、SEQ ID NO:22的第382-404位氨基酸、SEQ ID NO:24的第434-466位氨基酸、SEQ ID NO:25的第163-185位氨基酸或SEQ ID NO:30的第381-404位氨基酸具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的氨基酸序列。
所描述的多肽还包含内吞体/溶酶体靶向结构域。在某些实施方式中,所述内吞体/溶酶体靶向结构域可以在羧基端细胞质尾部中包含酪氨酸识别序列(信号)(其中Y是酪氨酸残基,X可以是任何氨基酸,并且是大的疏水残基)。在某些实施方式中,所述酪氨酸识别序列(信号)包含氨基酸序列YQTI、YQRI、YEQF或YHTL。在某些实施方式中,所述内吞体/溶酶体靶向结构域包含氨基酸序列LIRT。
在某些实施方式中,所描述的多肽包含与SEQ ID NO:1、SEQ ID NO:6、SEQ ID NO:7、SEQ ID NO:8或SEQ ID NO:28具有至少约80%同一性、至少约81%同一性、至少约82%同一性、至少约83%同一性、至少约84%同一性、至少约85%同一性、至少约86%同一性、至少约87%同一性、至少约88%同一性、至少约89%同一性、至少约90%同一性、至少约91%同一性、至少约92%同一性、至少约93%同一性、至少约94%同一性、至少约95%同一性、至少约96%同一性、至少约97%同一性、至少约98%同一性、至少约99%同一性或100%同一性的氨基酸序列。
在某些实施方式中提供了包含至少一种本公开的核酸分子的药物组合物。还提供了包含至少一种本公开的载体的药物组合物。在某些实施方式中,所述药物组合物可以包含含有编码SEQ ID NO:1、SEQ ID NO:6、SEQ ID NO:7、SEQ ID NO:8或SEQ ID NO:28的核酸的载体。例如,所述核酸可以由SEQ ID NO:20、SEQ ID NO:21、SEQ ID NO:27、SEQ ID NO:19或SEQ ID NO:18编码。在某些实施方式中提供了包含至少两种本公开的核酸分子或载体的药物组合物。在其他实施方式中提供了包含至少三种本公开的核酸分子或载体的药物组合物。例如,所述至少三种本公开的核酸分子可以包含编码SEQ ID NO:6的核酸分子、编码SEQ ID NO:7的核酸分子和编码SEQ ID NO:8的核酸分子。示例性的核酸序列包括SEQ ID NO:27、SEQ ID NO:19和SEQ ID NO:18。在另一个实施方式中,所述药物组合物包含至少两种载体,其各自包含本公开的核酸分子。本文中还提供了包含第一、第二和第三载体的药物组合物,其中所述第一载体包含编码SEQ ID NO:6的核酸分子,第二载体包含编码SEQ ID NO:7的核酸分子,第三载体包含编码SEQ ID NO:8的核酸分子。示例性的核酸序列包括SEQ ID NO:20、SEQ ID NO:27、SEQ ID NO:19和SEQ ID NO:18。
在某些实施方式中,本公开的药物组合物还包含可药用载体。本公开的核酸或载体可以作为纯化或分离的分子提供。所述核酸或载体也可以被提供为组合物的一部分。所述组合物可以基本上由所述核酸或载体构成,意味着所述核酸或载体是所述组合物中适合于编码序列表达的仅有的核酸或载体。或者,所述组合物可以包含本文中所公开的核酸或载体。在示例性实施方式中,所述组合物是药物组合物,其包含本文中所公开的核酸或载体以及一种或多种可药用物质或载体例如盐水。在某些实施方式中,所述组合物包含促进核酸被细胞摄入的物质。在某些实施方式中,所述组合物包含有助于将核酸递送到特定细胞类型例如免疫细胞(例如APC或抗原呈递细胞)的靶向分子。在其他实施方式中,所述核酸是用于将核酸递送到细胞或组织的递送介质或递送载体的一部分。在优选实施方式中,本公开的配方包含在例如盐水中的裸露DNA。在其他优选实施方式中,所述DNA疫苗通过肌内(IM)或真皮内(ID)注射来递送。
本公开还提供了使用本公开的核酸分子、载体和药物组合物的方法。在某些实施方式中,本公开提供了在需要的受试者中预防或治疗花生过敏反应的方法,所述方法包括向所述受试者给药治疗有效量的本公开的核酸分子、载体或药物组合物。在某些实施方式中,所述核酸分子、载体或药物组合物以足以减少IgE应答的产生的量给药。在某些实施方式中,所述核酸分子、载体或药物组合物以足以降低血浆组氨酸水平的量给药。在某些实施方式中,所述核酸分子、载体或药物组合物以足以减少IL-4的生产的量给药。在某些实施方式中,所述核酸分子、载体或药物组合物以足以提高IFN-γ水平的量给药。在某些实施方式中,所述方法减轻、消除或阻止至少一种临床过敏症状。在某些实施方式中,所述核酸分子、载体或药物组合物通过肌内(IM)注射给药到所述受试者。在某些实施方式中,所述核酸分子、载体或药物组合物通过真皮内(ID)注射给药到所述受试者。在某些实施方式中,所述核酸分子、载体或药物组合物以足以诱导或增加过敏原特异性IgG应答的产生的量给药。在某些实施方式中,所述核酸分子、载体或药物组合物以足以减弱IgE应答的量给药。在某些实施方式中,所述受试者是人类。
在某些实施方式中,本公开提供了一种在需要的受试者中预防或治疗花生过敏反应的方法,所述方法包括向所述受试者给药治疗有效量的本公开的核酸分子、载体或药物组合物,其中所述受试者在所述给药之前暴露于花生过敏原。在某些实施方式中,所述核酸分子、载体或药物组合物以足以减少IgE应答的产生的量给药。在某些实施方式中,所述核酸分子、载体或药物组合物以足以降低血浆组氨酸水平的量给药。在某些实施方式中,所述核酸分子、载体或药物组合物以足以减少IL-4的生产的量给药。在某些实施方式中,所述核酸分子、载体或药物组合物以足以提高IFN-γ水平的量给药。在某些实施方式中,所述方法减轻、消除或阻止至少一种临床过敏症状。在某些实施方式中,所述核酸分子、载体或药物组合物通过肌内(IM)注射给药到所述受试者。在某些实施方式中,所述核酸分子、载体或药物组合物通过真皮内(ID)注射给药到所述受试者。在某些实施方式中,所述核酸分子、载体或药物组合物以足以诱导或增加过敏原特异性IgG应答的产生的量给药。在某些实施方式中,所述核酸分子、载体或药物组合物以足以减弱IgE应答的量给药。在某些实施方式中,所述受试者是人类。
在某些实施方式中,本公开提供了一种在需要的受试者中预防或治疗花生过敏反应的方法,所述方法包括向所述受试者给药治疗有效量的本公开的核酸分子、载体或药物组合物,其中所述受试者是人类。在某些实施方式中,所述核酸分子、载体或药物组合物以足以减少IgE应答的产生的量给药。在其他实施方式中,所述核酸分子、载体或药物组合物以足以降低血浆组氨酸水平的量给药。在某些实施方式中,所述核酸分子、载体或药物组合物以足以减少IL-4的生产的量给药。在某些实施方式中,所述核酸分子、载体或药物组合物以足以提高IFN-γ水平的量给药。在某些实施方式中,所述方法减轻、消除或阻止至少一种临床过敏症状。在某些实施方式中,所述核酸分子、载体或药物组合物通过肌内(IM)注射给药到所述受试者。在某些实施方式中,所述核酸分子、载体或药物组合物通过真皮内(ID)注射给药到所述受试者。在某些实施方式中,所述核酸分子、载体或药物组合物以足以诱导或提高过敏原特异性IgG应答的生产的量给药。在某些实施方式中,所述核酸分子、载体或药物组合物以足以减弱IgE应答的量给药。在某些实施方式中,所述受试者是人类。
在某些实施方式中,本公开提供了一种在需要的受试者中预防或治疗花生过敏反应的方法,所述方法包括向所述受试者给药治疗有效量的本公开的核酸分子、载体或药物组合物,其中所述受试者在所述给药之前暴露于花生过敏原,其中所述受试者是人类。在某些实施方式中,所述核酸分子、载体或药物组合物以足以减少IgE应答的产生的量给药。在某些实施方式中,所述核酸分子、载体或药物组合物以足以降低血浆组氨酸水平的量给药。在某些实施方式中,所述核酸分子、载体或药物组合物以足以减少IL-4的生产的量给药。在某些实施方式中,所述核酸分子、载体或药物组合物以足以提高IFN-γ水平的量给药。在某些实施方式中,所述方法减轻、消除或阻止至少一种临床过敏症状。在某些实施方式中,所述核酸分子、载体或药物组合物通过肌内(IM)注射给药到所述受试者。在某些实施方式中,所述核酸分子、载体或药物组合物通过真皮内(ID)注射给药到所述受试者。在某些实施方式中,所述核酸分子、载体或药物组合物以足以诱导或提高过敏原特异性IgG应答的生产的量给药。在某些实施方式中,所述核酸分子、载体或药物组合物以足以减弱IgE应答的量给药。在某些实施方式中,所述受试者是人类。
在其他实施方式中,所述方法包括以足以诱导或提高过敏原特异性IgG应答的生产的量向所述受试者给药本公开的核酸、载体、药物组合物或DNA疫苗。在其他实施方式中,所述方法预防花生过敏反应。在其他实施方式中,所述方法减轻、消除或阻止至少一种临床过敏症状。在其他实施方式中,将所述DNA疫苗预防性给药到所述受试者以防止花生过敏反应。在其他实施方式中,将所述DNA疫苗治疗性给药到所述受试者以治疗花生过敏反应。
本公开还提供了使用本公开的疫苗治疗需要的受试者的方法。在某些实施方式中,所述方法是预防性治疗或治疗性治疗具有发生对一种或多种花生过敏原的过敏反应的风险的受试者或患有所述过敏反应的受试者的方法。在其他实施方式中,所述方法包括以足以引起符合本发明的DNA疫苗被APC摄入和表达的量向所述受试者给药所述DNA疫苗。不将本发明限制到特定作用机制,所述DNA疫苗的表达引起编码的过敏原性表位在APC上的呈递和IgG免疫应答的发生。
在本发明的特定情况下,将编码SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3、SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:6、SEQ ID NO:7、SEQ ID NO:8或SEQ ID NO:28的核酸序列、这些序列中的至少一者的一部分和/或另一种花生过敏原编码序列给药到细胞。在本发明的另一种特定情况下,将存在于分开的DNA构建物上的至少两种花生过敏原组合给药到细胞。在优选实施方式中,所述细胞是抗原呈递细胞例如树突状细胞。优选地,所述树突状细胞是人类树突状细胞。本发明可以通过本领域中已知是用于核酸疫苗的有效递送方法的方法,包括肌内注射、真皮内注射、皮下注射、电穿孔、基因枪疫苗接种或脂质体介导的转移来给药。
本发明提供了当给药到细胞时引起特定抗体应答提高的配方。对花生过敏原的抗体应答的提高对治疗IgE介导的过敏疾病有用。IgE具有与其细胞限制和结合同源过敏原后得到的细胞内信号传导相关的某些性质。当B细胞接受由Th2细胞分泌的IL-4时,产生针对花生过敏原的IgE。这帮助指导B细胞产生IgE类抗体。在被B细胞分泌后,IgE结合到它的由肥大细胞和嗜曙红细胞表达的高亲和性受体Fc-eRI,导致这些细胞和所述动物变得对将来的过敏原暴露敏感。因此,在摄入、吸入花生过敏原或与花生过敏原粘膜接触后,可以引发过敏的症状。由于抗体的结合性质,已提出减轻花生过敏症状的一种方式是通过与其他抗体类别的竞争来螯合可用于被IgE结合的游离过敏原。具体来说,已提出增加IgG的过敏配方是减轻过敏疾病的途径。本文描述的发明引起IgG生产增加,由此以临床上显著的方式造成IgE与IgG比率的降低。
实施例
现在将参考本发明的示例性实施方式对本发明进行描述。下面的实施例旨在给读者提供对本发明构建物的构建和活性的更好的理解,并且不应被解释为对本发明范围的限制。
实施例1:通用材料和方法
将编码花生过敏原Ara H1、Ara H2和Ara H3的遗传序列作为本源序列(对照质粒)和作为与人类LAMP-1的嵌合体(实验质粒)制备,其中所述每个序列被插入在LAMP的腔内结构域与跨膜结构域之间。以前的研究显示,抗原性序列必须被优化成用于人类使用,因此将所有非必需或有害的元件(隐蔽剪接位点、二级RNA/DNA结构、二级ORF)去除,以便最大化RNA稳定性和蛋白表达。AraH1-LAMP包含SEQ ID NO:15。AraH2-LAMP包含SEQ ID NO:12。最终优化的序列被化学合成并插入到无抗生素的pDNA-VACC-ultra载体(Nature Pharmaceuticals,Lincoln,NE)的LAMP开放阅读框(ORF)中。通过转染NIH3T3细胞并随后进行Western印迹分析,确定每个质粒的嵌合蛋白表达。向溶酶体的细胞运输通过共聚焦显微术并通过对细胞裂解物进行免疫印迹分析来确认。
使用GeneArt/Invitrogen在线基因设计软件,对AraH3del基因进行用于人类使用的密码子优化。合成的基因由GeneArt/Invitrogen(Life Technologies,Grand Island,NY)制造。将所述合成的基因插入到N LAMP-C LAMP基因中,以产生N LAMP-AraH3del-C LAMP(SEQ ID NO:27),然后将其插入到表达载体中。在本源AraH3蛋白被蛋白水解加工成酸性和碱性亚基的基础上产生所述缺失。所述酸性亚基作为单一质粒被产生并使用。
通过合成插入到LAMP-vax免疫接种载体中的编码每种显性花生过敏原(Ara H1、Ara H2、Ara H3)的DNA来制备单一多价构建物(包含SEQ ID NO:21的AraH1/H2/H3-LAMP)(图2和3)。在该单一多价花生构建物中,将5个氨基酸的连接序列(GGGGS)插入到Ara H1与Ara H2之间和Ara H2与Ara H3之间。Western印迹分析显示出花生过敏原Ara H1、H2和H3从Ara-LAMP-vax单一多价构建物共表达(图4)。ARA-LAMP vax组合物包含三个质粒,其各自在pDNAVACC-ultra载体(Nature Technology Corp.,Lincoln,NE)中的LAMP的腔内结构域和跨膜结构域内包含插入到LAMP-vax免疫接种载体中的编码单一花生过敏原(Ara H1、H2或H3del)的DNA(即SEQ ID NO:18、19和20)。Ara-LAMP-vax在本文中也被称为Ara-H-LAMP。已确定,每个质粒在转染的细胞培养物中表达嵌合的Ara/LAMP蛋白,并且小鼠作为治疗的结果产生过敏原特异性抗体。每个载体的表达在单个和组合转染的细胞中进行评估。
所有动物实验按照实验室动物福利办公室动物伦理学委员会(animal ethics committee of the Office of Laboratory Animal Welfare(OLAW))批准的设施来进行。将BALB/c小鼠用Ara-LAMP-vax单一多价构建物或Ara-LAMP-vax三质粒组合物,通过肌内(IM)或真皮内(ID)注射进行免疫接种,并对免疫应答进行表征。对照小鼠用相同浓度下的空白载体(即不含Ara-LAMP构建物的pDNAVACC-ultra载体;“对照载体”)进行免疫接种。在抗原激惹的前一天,按照以前的描述准备用于被动皮肤过敏性反应(PCA)试验的小鼠(Saloga等,(1993)J.Clin.Invest.91(1):133-40;Li等,(1999)J.Immunol.162:5624-5630)。
为了确定治疗效能,使未接触过抗原的小鼠对花生致敏,然后在两周后用Ara-LAMP-vax配方(每只动物50μg单一多价Ara-LAMP-vax质粒/200μL PBS或每只动物AraH1-LAMP-vax质粒、AraH2-LAMP-vax质粒和AraH3-LAMP-vax质粒各50μg/200μL PBS)以两周的间隔免疫接种三次。在免疫接种后,通过使用球形末端小鼠进样针每周一次共8周给药10mg花生酱(PN)和20μg霍乱毒素(CT)来实验性诱导食物过敏,对小鼠进行激惹,并对过敏症状进行评分。
为了确定预防效率,在第0天、第14天和第28天将未接触过花生的BALB/c小鼠用Ara-LAMP-vax(每只动物50μg单一多价Ara-LAMP-vax质粒/200μL PBS或每只动物AraH1-LAMP-vax质粒、AraH2-LAMP-vax质粒和AraH3-LAMP-vax质粒各50μg/200μL PBS的配方)免疫接种三次,然后用花生提取物和霍乱毒素致敏(图7)。在每个疫苗接种日期并随后每周一次收集血清样品,直至第42天。
在抗原激惹后,由不知情的独立调查人员按照0-5的量表对过敏症状进行评分,其中0表示没有症状,5表示死亡(Li等,(2001)J.Allergy Clin.Immunol.108:639-646)。为了确定组胺水平,在激惹后30-40分钟收集血清并进行测定。使用光学显微镜对耳样品进行组织学研究,以确定作为系统性过敏性反应结果的肥大细胞脱粒的程度。
将小鼠每周取血并将血清储存在-80℃。将小鼠处死,测定由每种疫苗配方产生的免疫应答,并测量IgG亚型、IgE的抗体水平和细胞因子。T细胞和B-细胞的免疫学应答利用ELISPOT、ELISA、细胞增殖测定法和细胞因子测定法来评估。为了确定任何疫苗配方是否引起过敏原泄漏,通过夹心ELISA测定血清样品的花生过敏原。
对于细胞因子测定法来说,通过ELISA测定上清液中IFN-γ和IL-4的存在。将匹配的抗体对用于IFN-γ和IL-4,并按照制造商的说明书进行。使用小鼠重组IFN-γ和IL-4产生标准曲线。所有抗体和细胞因子购自Invitrogen,Carlsbad,CA。IFN-γ和IL-4测定法的检测极限分别为20和10pg/ml。
实施例2:ARA-LAMP预防研究
在小鼠模型中试验包含花生过敏原Ara H1、Ara H2和/或Ara H3的DNA构建物的预防有效性。将编码花生过敏原Ara H1、Ara H2和Ara H3的多价LAMP质粒(按照实施例1产生的AraH1/H2/H3-LAMP)与每个质粒编码单一花生过敏原的三质粒混合物(按照实施例1制备的AraH1-LAMP、AraH2-LAMP和ARAH3del-LAMP)进行比较。将BALB/c小鼠每周一次共三周用50μg单一多价花生质粒或50μg每种单独质粒通过真皮内(ID)或肌内(IM)注射进行免疫接种。在最后一次免疫接种后5周,通过ELISA测定IgG1和IgG2a抗体滴度。发现多价质粒具有过敏原性,但抗体应答的量级低于在多个质粒中的单次过敏原递送(图5和6)。不希望受到任一特定理论限制,据信抗原竞争例如表位通往MHC-II呈递的途径,可能限制对所有抗原的免疫应答。免疫接种后最强的应答是使用通过真皮内(ID)注射递送的多个质粒的情况。
将图7中示出的代表性方案用于进一步的预防研究。将小鼠在第0、7和14天用单一多价Ara H-LAMP DNA疫苗免疫接种(第-3、-2、-1周)。在免疫接种后测量IgG1和IgG2a抗体水平,并且发现与对照载体相比,使用单一多价疫苗时IgG2a水平明显更高(图8)。然后将小鼠首先在第0周用花生酱(PN)和霍乱毒素(CT)致敏三次,随后每周一次直至第5周,然后在第6和8周进行两次加强。与对照载体相比,使用多价疫苗时第58天(第5周)的IgG2a抗体水平明显更高(图9)。在两次加强后,与对照载体相比,使用单一多价疫苗时第92天的IgG2a抗体水平也明显更高(图10)。在第12周用花生酱激惹后,这种IgG2a抗体水平的显著差异继续存在(图11)。在使用单一多价疫苗时,始终观察到IgE应答的减弱(图12),这支持了所述多价疫苗的预防机制。图13和14示出了所述预防研究的概述。
有趣的是,使用单一多价质粒的细胞转染显示,所有Ara h过敏原都以与编码单一过敏原的质粒相近的量产生融合蛋白。因此,修改连接序列的同一性长度可能提高对所有过敏原的免疫原性。这些结果说明可以成功地设计具有出色的体外表达和广泛的免疫原性的多价过敏质粒。这些结果进一步显示,本公开的DNA疫苗可用于预防性治疗花生过敏受试者。
按照图15中示出的代表性方案进行了进一步的预防研究,以对使用Bioject ID递送的AraH1-LAMP、AraH2-LAMP和AraH3del-LAMP质粒的组合与单一多价AraH1/H2/H3-LAMP质粒进行比较。在第0、7和14天(wk-3、-2、-1),将5周龄雌性C3H/HeJ小鼠(N=10只小鼠/组)用Ara H1-LAMP、Ara H2-LAMP和Ara H3del-LAMP质粒的组合(各50ug)或单一多价AraH1/H2/H3 LAMP DNA质粒(50ug)免疫接种。然后将小鼠首先在第0周用10mg花生酱(PN)+20ug CT胃内(i.g.)致敏三次,然后每周一次直至W5,随后在W6和W8用50mg PN+20ug CT进行两次i.g.加强。包含接受对照载体(50ug)的小鼠作为对照。然后在W12、W16和W20用200mg PN i.g.激惹小鼠。测定免疫学应答。
图16中的结果显示,AraH1-LAMP-vax、AraH2-LAMP-vax和Ara-H3del-LAMP-vax质粒的组合和单一多价Ara H1/H2/H3-LAMP质粒两者,当经Bioject B2000无针装置通过真皮内注射(ID)递送时,都诱导强烈的IgG2a应答。然而,所述单一多价Ara H1/H2/H3 LAMP质粒总的来说诱导更强的抗体应答,并且也抑制花生特异性IgE。
实施例3:ARA-LAMP治疗性研究
还进行了实验以确定本公开的DNA疫苗提供治疗性治疗的能力。代表性的方案示出在图17中,其中将小鼠首先用花生酱和霍乱毒素致敏,然后用本公开的ARA-LAMP-vax三质粒(按照实施例1制备的AraH1-LAMP、AraH2-LAMP和Ara-H3del-LAMP)组合物治疗。图18示出了在使用每种质粒编码单一花生过敏原的三质粒混合物ARA-LAMP-vax的疫苗治疗之前的数周中的IgE抗体水平。
当使用多价DNA疫苗时,在疫苗治疗后,第15周的IgE抗体水平降低(图19)。第15周的过敏性反应激惹结果(症状分值,图20,图A;体温,图20,图B;图21)显示,与对照载体相比,ARA-LAMP-vax三质粒组合物的给药引起严重性较低的症状和较低的血浆组胺水平。此外发现,相对于对照载体,使用ARA-LAMP-vax三质粒组合物给药时促过敏细胞因子IL-4更少(图22),而IFN-γ的水平升高(图23)。这些结果显示本公开的DNA疫苗可用于治疗性治疗。
参考文献
在本说明书中提到的所有出版物、专利申请、专利和其他参考文献指示了本公开的主题内容所属领域的专业技术人员的水平。所有出版物、专利申请、专利和其他参考文献通过参考并入本文,其程度等同于每个单独的出版物、专利申请、专利和其他参考文献被具体且单独地指明通过参考并入。应该理解,尽管在本文中参考了大量专利申请、专利和其他参考文献,但这种参考并不构成对这些文献中的任一者形成了本领域常识的一部分的承认。
尽管出于清晰理解的目的已通过图示和实例对上述主题内容进行了一定细节的描述,但本领域技术人员应该理解,可以在随附的权利要求书的范围之内实施某些改变和修改。
序列表
SEQ ID NO:1-AraH-LAMP(或AraH1-H2-H3-LAMP)
Ara HI/H2/H3多蛋白嵌合构建物的编码区的氨基酸序列如下:
信号:(1)..(27)
N-LAMP:(28)..(380)
AraH1:(383)..(983)
AraH2:(988)..(1138)
AraH3:(1143)..(1634)
TM/CYTO:(1637)..(1672)
SEQ ID NO:2-Ara H1
不带信号序列的Ara H1蛋白的编码区的氨基酸序列(在Ara H1/H2/H3多蛋白嵌合构建物AraH-LAMP中,以及在单独的Ara H1构建物AraH1-LAMP中)如下:
KSSPYQKKTENPCAQRCLQSCQQEPDDLKQKACESRCTKLEYDPRCVYDPRGHTGTTNQRSPPGERTRGRQPGDYDDDRRQPRREEGGRWGPAGPREREREEDWRQPREDWRRPSHQQPRKIRPEGREGEQEWGTPGSHVREETSRNNPFYFPSRRFSTRYGNQNGRIRVLQRFDQRSRQFQNLQNHRIVQIEAKPNTLVLPKHADADNILVIQQGQATVTVANGNNRKSFNLDEGHALRIPSGFISYILNRHDNQNLRVAKISMPVNTPGQFEDFFPASSRDQSSYLQGFSRNTLEAAFNAEFNEIRRVLLEENAGGEQEERGQRRWSTRSSENNEGVIVKVSKEHVEELTKHAKSVSKKGSEEEGDITNPINLREGEPDLSNNFGKLFEVKPDKKNPQLQDLDMMLTCVEIKEGALMLPHFNSKAMVIVVVNKGTGNLELVAVRKEQQQRGRREEEEDEDEEEEGSNREVRRYTARLKEGDVFIMPAAHPVAINASSELHLLGFGINAENNHRIFLAGDKDNVIDQIEKQAKDLAFPGSGEQVEKLIKNQKESHFVSARPQSQSQSPSSPEKESPEKEDQEEENQGGKGPLLSILKAFN
SEQ ID NO:3-Ara H2
不带本源信号序列的Ara H2蛋白的编码区的氨基酸序列(在Ara H1/H2/H3多蛋白嵌合构建物AraH-LAMP中,以及在单独的Ara H2构建物AraH2-LAMP中)如下:
RQQWELQGDRRCQSQLERANLRPCEQHLMQKIQRDEDSYGRDPYSPSQDPYSPSQDPDRRDPYSPSPYDRRGAGSSQHQERCCNELNEFENNQRCMCEALQQIMENQSDRLQGRQQEQQFKRELRNLPQQCGLRAPQRCDLEVESGGRDRY
SEQ ID NO:4-多蛋白嵌合构建物AraH-LAMP(或AraH1-H2-H3-LAMP)中的Ara H3
Ara H1/H2/H3多蛋白嵌合构建物中不带本源信号序列的Ara H3蛋白的编码区的氨基酸序列如下:
VTFRQGGEENECQFQRLNAQRPDNRIESEGGYIETWNPNNQEFQCAGVALSRTVLRRNALRRPFYSNAPLEIYVQQGSGYFGLIFPGCPSTYEEPAQEGRRYQSQKPSRRFQVGQDDPSQQQQDSHQKVHRFDEGDLIAVPTGVAFWMYNDEDTDVVTVTLSDTSSIHNQLDQFPRRFYLAGNQEQEFLRYQQQQGSRPHYRQISPRVRGDEQENEGSNIFSGFAQEFLQHAFQVDRQTVENLRGENEREEQGAIVTVKGGLRILSPDEEDESSRSPPNRREEFDEDRSRPQQRGKYDENRRGYKNGIEETICSASVKKNLGRSSNPDIYNPQAGSLRSVNELDLPILGWLGLSAQHGTIYRNAMFVPHYTLNAHTIVVALNGRAHVQVVDSNGNRVYDEELQEGHVLVVPQNFAVAAKAQSENYEYLAFKTDSRPSIANQAGENSIIDNLPEEVVANSYRLPREQARQLKNNNPFKFFVPPFDHQSMREVA
SEQ ID NO:5-单独的Ara H3del构建物AraH3del LAMP中的Ara H3del
Ara H3del单独构建物中Ara H3del蛋白(被设计用于避开剪接位点的截短的版本;le=Xho,ef=EcoRI)的编码区的氨基酸序列如下:
VTFRQGGEENECQFQRLNAQRPDNRIESEGGYIETWNPNNQEFQCAGVALSRTVLRRNALRRPFYSNAPLEIYVQQGSGYFGLIFPGCPSTYEEPAQEGRRYQSQKPSRRFQVGQDDPSQQQQDSHQKVHRFDEGDLIAVPTGVAFWMYNDEDTDVVTVTLSDTSSIHNQLDQFPRRFYLAGNQEQEFLRYQQQQGSRPHYRQISPRVRGDEQENEGSNIFSGFAQEFLQHAFQVDRQTVENLRGENEREEQGAIVTVKGGLRILSPDEEDESSRSPPNRREEFDEDRSRPQQRGKYDENRRGYKN
SEQ ID NO:6-AraH3del LAMP
Ara H3 LAMP融合蛋白的编码区的氨基酸序列(LAMP为粗体;侧翼XhoI(LE)和EcoRI(EF)位点为大写字母并下划线)如下:
SEQ ID NO:7–AraH2LAMP
Ara H2 LAMP融合蛋白的编码区的氨基酸序列(LAMP为粗体;侧翼XhoI(LE)和EcoRI(EF)位点为大写字母并下划线)如下:
SEQ ID NO:8–AraH1LAMP
Ara H1 LAMP融合蛋白的编码区的氨基酸序列(LAMP为粗体;侧翼XhoI(LE)和EcoRI(EF)位点为大写字母并下划线)如下:
SEQ ID NO:9–缺失的Ara H3区域
未包含在单独Ara H3del构建物中的Ara H3的氨基酸序列如下:
GIEETICSASVKKNLGRSSNPDIYNPQAGSLRSVNELDLPILGWLGLSAQHGTIYRNAMFVPHYTLNAHTIVVALNGRAHVQVVDSNGNRVYDEELQEGHVLVVPQNFAVAAKAQSENYEYLAFKTDSRPSIANQAGENSIIDNLPEEVVANSYRLPREQARQLKNNNPFKFFVPPFDHQSMREVA
SEQ ID NO:10-LAMP2核苷酸序列
信号:(1)..(84)
稳定化:(85)..(1125)
TM/CYTO:(1126)..(1227)
atggtgtgcttccgcctcttcccggttccgggctcagggctcgttctggtctgcctagtcctgggagctgtgcggtcttatgcattggaacttaatttgacagattcagaaaatgccacttgcctttatgcaaaatggcagatgaatttcacagttcgctatgaaactacaaataaaacttataaaactgtaaccatttcagaccatggcactgtgacatataatggaagcatttgtggggatgatcagaatggtcccaaaatagcagtgcagttcggacctggcttttcctggattgcgaattttaccaaggcagcatctacttattcaattgacagcgtctcattttcctacaacactggtgataacacaacatttcctgatgctgaagataaaggaattcttactgttgatgaacttttggccatcagaattccattgaatgacctttttagatgcaatagtttatcaactttggaaaagaatgatgttgtccaacactactgggatgttcttgtacaagcttttgtccaaaatggcacagtgagcacaaatgagttcctgtgtgataaagacaaaacttcaacagtggcacccaccatacacaccactgtgccatctcctactacaacacctactccaaaggaaaaaccagaagctggaacctattcagttaataatggcaatgatacttgtctgctggctaccatggggctgcagctgaacatcactcaggataaggttgcttcagttattaacatcaaccccaatacaactcactccacaggcagctgccgttctcacactgctctacttagactcaatagcagcaccattaagtatctagactttgtctttgctgtgaaaaatgaaaaccgattttatctgaaggaagtgaacatcagcatgtatttggttaatggctccgttttcagcattgcaaataacaatctcagctactggatgcccccaagttcttatatgtgcaacaaagagcagactgtttcagtgtctggagcatttcagataaatacctttgatctaagggttcagcctttcaatgtgacacaaggaaagtattctacagctcaagactgcagtgcagatgacgacaacttccttgtgcccatagcggtgggagctgccttggcaggagtacttattctagtgttgctggcttattttattggtctcaagcaccatcatgctggatatgagcaattttag
SEQ ID NO:11–LAMP-3(DC-LAMP)核苷酸序列
信号:(1)..(81)
稳定化:(82)..(1143)
TM/CYTO:(1144)..(1248)
atgccccggcagctcagcgcggcggccgcgctcttcgcgtccctggccgtaattttgcacgatggcagtcaaatgagagcaaaagcatttccagaaaccagagattattctcaacctactgcagcagcaacagtacaggacataaaaaaacctgtccagcaaccagctaagcaagcacctcaccaaactttagcagcaagattcatggatggtcatatcacctttcaaacagcggccacagtaaaaattccaacaactaccccagcgactacaaaaaacactgcaaccaccagcccaattacctacaccctggtcacaacccaggccacacccaacaactcacacacagctcctccagttactgaagttacagtcggccctagcttagccccttattcactgccacccaccatcaccccaccagctcatacaactggaaccagttcatcaaccgtcagccacacaactgggaacaccactcaacccagtaaccagaccacccttccagcaactttatcgatagcactgcacaaaagcacaaccggtcagaagcctgttcaacccacccatgccccaggaacaacggcagctgcccacaataccacccgcacagctgcacctgcctccacggttcctgggcccacccttgcacctcagccatcgtcagtcaagactggaatttatcaggttctaaacggaagcagactctgtataaaagcagagatggggatacagctgattgttcaagacaaggagtcggttttttcacctcggagatacttcaacatcgaccccaacgcaacgcaagcctctgggaactgtggcacccgaaaatccaaccttctgttgaattttcagggcggatttgtgaatctcacatttaccaaggatgaagaatcatattatatcagtgaagtgggagcctatttgaccgtctcagatccagagacaatttaccaaggaatcaaacatgcggtggtgatgttccagacagcagtcgggcattccttcaagtgcgtgagtgaacagagcctccagttgtcagcccacctgcaggtgaaaacaaccgatgtccaacttcaagcctttgattttgaagatgaccactttggaaatgtggatgagtgctcgtctgactacacaattgtgcttcctgtgattggggccatcgtggttggtctctgccttatgggtatgggtgtctataaaatccgcctaaggtgtcaatcatctggataccagagaatc
SEQ ID NO:12-ENDOLYN核苷酸序列
信号:(1)..(72)
稳定化:(73)..(486)
TM/CYTO:(487)..(594)
atgtcgcggctctcccgctcactgctttgggccgccacctgcctgggcgtgctctgcgtgctgtccgcggacaagaacacgacccagcacccgaacgtgacgactttagcgcccatctccaacgtaacctcggcgccggtgacgtccctcccgctggtcaccactccggcaccagaaacctgtgaaggtcgaaacagctgcgtttcctgttttaatgttagcgttgttaatactacctgcttttggatagaatgtaaagatgagagctattgttcacataactcaacagttagtgattgtcaagtggggaacacgacagacttctgttccgtttccacggccactccagtgccaacagccaattctacagctaaacccacagttcagccctccccttctacaacttccaagacagttactacatcaggtacaacaaataacactgtgactccaacctcacaacctgtgcgaaagtctacctttgatgcagccagtttcattggaggaattgtcctggtcttgggtgtgcaggctgtaattttctttctttataaattctgcaaatctaaagaacgaaattaccacactctgtaa
SEQ ID NO:13-LIMP II核苷酸序列
信号:(13)..(81)
稳定化:(82)..(1299)
TM/CYTO:(1300)..(1434)
atgggccgatgctgcttctacacggcggggacgttgtccctgctcctgctggtgaccagcgtcacgctgctggtggcccgggtcttccagaaggctgtagaccagagtatcgagaagaaaattgtgttaaggaatggtactgaggcatttgactcctgggagaagccccctctgcctgtgtatactcagttctatttcttcaatgtcaccaatccagaggagatcctcagaggggagacccctcgggtggaagaagtggggccatacacctacagggaactcagaaacaaagcaaatattcaatttggagataatggaacaacaatatctgctgttagcaacaaggcctatgtttttgaacgagaccaatctgttggagaccctaaaattgacttaattagaacattaaatattcctgtattgactgtcatagagtggtcccaggtgcacttcctcagggagatcatcgaggccatgttgaaagcctatcagcagaagctctttgtgactcacacagttgacgaattgctctggggctacaaagatgaaatcttgtcccttatccatgttttcaggcccgatatctctccctattttggcctattctatgagaaaaatgggactaatgatggagactatgtttttctaactggagaagacagttaccttaactttacaaaaattgtggaatggaatgggaaaacgtcacttgactggtggataacagacaagtgcaatatgattaatggaacagatggagattcttttcacccactaataaccaaagatgaggtcctttatgtcttcccatctgacttttgcaggtcagtgtatattactttcagtgactatgagagtgtacagggactgcctgcctttcggtataaagttcctgcagaaatattagccaatacgtcagacaatgccggcttctgtatacctgagggaaactgcctgggctcaggagttctgaatgtcagcatctgcaagaatggtgcacccatcattatgtctttcccacacttttaccaagcagatgagaggtttgtttctgccatagaaggcatgcacccaaatcaggaagaccatgagacatttgtggacattaatcctttgactggaataatcctaaaagcagccaagaggttccaaatcaacatttatgtcaaaaaattagatgactttgttgaaacgggagacattagaaccatggttttcccagtgatgtacctcaatgagagtgttcacattgataaagagacggcgagtcgactgaagtctatgattaacactactttgatcatcaccaacataccctacatcatcatggcgctgggtgtgttctttggtttggtttttacctggcttgcatgcaaaggacagggatccatggatgagggaacagcggatgaaagagcacccctcattcgaacctag
SEQ ID NO:14-AraH1-AraH2-AraH3核苷酸序列
AraH1:(1)..(1803)
连接序列:(1804)..(1815)
AraH2:(1816)..(2268)
连接序列:(2269)..(2280)
AraH3:(2281)..(3756)
aagtccagcccctaccagaagaaaaccgagaacccctgcgcccagcggtgcctgcagtcttgtcagcaggaacccgacgacctgaagcagaaggcctgcgagagccggtgcaccaagctggaatacgaccccagatgcgtgtacgaccctagaggccacaccggcaccaccaaccagagaagccctccaggcgagcggaccagaggcagacagcctggcgactacgacgacgacagacggcagcccagaagagaagagggcggcagatggggacctgccggccctagagagagagaacgcgaggaagattggagacagcccagagaggactggcggaggccttctcaccagcagccccggaagatcagacccgagggcagagaaggcgagcaggaatggggcacacctggctctcacgtgcgcgaggaaaccagccggaacaaccccttctacttcccctcccggcggttcagcaccagatacggcaaccagaacggccggatcagagtgctgcagagattcgaccagcggagccggcagttccagaacctgcagaaccaccggatcgtgcagatcgaggccaagcccaacaccctggtgctgcccaaacacgccgacgccgacaacatcctcgtgatccagcagggccaggccaccgtgacagtggccaacggcaacaacagaaagagcttcaacctggacgagggccacgccctgagaatccccagcggcttcatcagctacatcctgaacagacacgacaatcagaacctgagggtggccaagatcagcatgcccgtgaacacccctggccagttcgaggacttcttccccgcatcctcccgggaccagagcagctacctgcagggcttcagccggaataccctggaagccgccttcaacgccgagttcaacgagatcagacgggtgctgctggaagagaacgctggcggagagcaggaagaacggggccagagaagatggtccaccagaagcagcgagaacaacgagggcgtgatcgtgaaggtgtccaaagaacacgtggaagaactgaccaagcacgccaagagcgtgtccaagaagggctccgaggaagagggggacatcaccaaccccatcaatctgagagagggcgagcccgacctgagcaacaacttcggcaagctgttcgaagtgaagcccgacaagaagaacccccagctgcaggacctggacatgatgctgacctgcgtggaaatcaaagagggggccctgatgctgccacacttcaactccaaagccatggtcatcgtggtcgtgaacaagggcaccggcaacctggaactggtggccgtgcggaaagagcagcagcagagaggccgcagagaggaagaagaggacgaggacgaagaagaagagggatccaaccgggaagtgcggcggtacaccgccagactgaaagaaggcgacgtgttcatcatgcctgccgcccaccccgtggccatcaatgcctctagcgagctgcatctgctgggcttcggcattaacgccgagaacaatcaccggatctttctggccggcgacaaagacaacgtgatcgaccagatcgagaagcaggccaaggacctggcctttcccggctctggcgaacaagtggaaaagctgatcaagaaccagaaagaaagccacttcgtgtccgccagaccccagagccagtctcagagccctagctcccccgagaaagagtctcctgagaaagaggaccaggaagaggaaaaccagggcggcaagggccctctgctgagcatcctgaaggccttcaatggcggcggaggcaggcagcagtgggaactgcagggcgacagaagatgccagtcccagctggaacgggccaacctgaggccttgcgagcagcacctgatgcagaaaatccagcgcgacgaggacagctacggccgggatccttacagccccagccaggacccttactcccctagccaggatcccgacagaagggacccctacagccctagcccctacgatagaagaggcgccggaagcagccagcaccaggaaagatgctgcaacgagctgaacgagtttgagaacaaccagcgctgcatgtgcgaggccctgcagcagatcatggaaaatcagagcgaccggctgcagggacggcagcaggaacagcagttcaagagagagctgcggaacctgccccagcagtgtggactgagagccccccagagatgcgacctggaagtggaaagcggcggcagagataggtacggcggagggggcgtgaccttcagacagggcggagaagagaatgagtgccagtttcagcggctgaacgcccagaggcccgacaacagaatcgagagcgagggcggctacatcgagacatggaaccccaacaaccaggaatttcagtgcgctggggtggccctgagcaggaccgtgctgagaagaaatgccctgaggcggcccttctacagcaacgcccccctggaaatctacgtgcagcagggcagcggctacttcggcctgatctttcccggatgcccctccacctatgaggaacccgctcaggaaggcagacggtatcagagccagaagcctagcagacggttccaagtgggccaggacgatcccagccaacagcagcaggactctcaccagaaggtgcaccgcttcgacgagggcgacctgatcgctgtgccaaccggcgtggccttctggatgtacaacgacgaggataccgacgtcgtgaccgtgaccctgagcgacaccagctccatccacaaccagctggaccagttccccaggcggttttacctggccggcaatcaggaacaggaatttctgagataccagcagcagcagggctccagaccccactacagacagatcagccctagagtgcggggcgacgaacaggaaaatgagggcagcaacatcttctccggctttgcccaggaatttctgcagcacgccttccaggtggaccggcagaccgtggaaaacctgagaggcgagaacgagagagaggaacagggcgccatcgtgactgtgaagggcggcctgaggatcctgagccccgacgaagaggatgagtcctctagaagcccccccaaccgccgggaagagttcgatgaggaccgcagcagacctcagcagcgggggaagtacgacgagaacaggcggggctacaagaacggcatcgaggaaacaatctgcagcgccagcgtgaagaagaatctgggccggtccagcaaccccgacatctacaatccacaggccggcagcctgcggagcgtgaacgaactggatctgcccatcctgggatggctgggcctgtctgcccagcacggcaccatctaccggaacgccatgttcgtgcctcactacaccctgaatgcccacaccatcgtggtggctctgaacggccgcgcccacgtccaagtggtggacagcaacggcaatcgggtgtacgatgaagaactgcaggaaggacacgtcctggtggtgccccagaattttgccgtggccgccaaggcccagtccgagaactatgagtatctggccttcaagaccgacagccggccctctatcgccaatcaagccggcgagaacagcatcatcgacaacctgcccgaggaagtggtggccaacagctaccggctgcctagagagcaggcccggcagctgaagaacaacaaccctttcaagttcttcgtgcccccattcgaccaccagagcatgagagaggtggcc
SEQ ID NO:15-AraH1核苷酸序列
aagtccagcccctaccagaagaaaaccgagaacccctgcgcccagcggtgcctgcagtcttgtcagcaggaacccgacgacctgaagcagaaggcctgcgagagccggtgcaccaagctggaatacgaccccagatgcgtgtacgaccctagaggccacaccggcaccaccaaccagagaagccctccaggcgagcggaccagaggcagacagcctggcgactacgacgacgacagacggcagcccagaagagaagagggcggcagatggggacctgccggccctagagagagagaacgcgaggaagattggagacagcccagagaggactggcggaggccttctcaccagcagccccggaagatcagacccgagggcagagaaggcgagcaggaatggggcacacctggctctcacgtgcgcgaggaaaccagccggaacaaccccttctacttcccctcccggcggttcagcaccagatacggcaaccagaacggccggatcagagtgctgcagagattcgaccagcggagccggcagttccagaacctgcagaaccaccggatcgtgcagatcgaggccaagcccaacaccctggtgctgcccaaacacgccgacgccgacaacatcctcgtgatccagcagggccaggccaccgtgacagtggccaacggcaacaacagaaagagcttcaacctggacgagggccacgccctgagaatccccagcggcttcatcagctacatcctgaacagacacgacaatcagaacctgagggtggccaagatcagcatgcccgtgaacacccctggccagttcgaggacttcttccccgcatcctcccgggaccagagcagctacctgcagggcttcagccggaataccctggaagccgccttcaacgccgagttcaacgagatcagacgggtgctgctggaagagaacgctggcggagagcaggaagaacggggccagagaagatggtccaccagaagcagcgagaacaacgagggcgtgatcgtgaaggtgtccaaagaacacgtggaagaactgaccaagcacgccaagagcgtgtccaagaagggctccgaggaagagggggacatcaccaaccccatcaatctgagagagggcgagcccgacctgagcaacaacttcggcaagctgttcgaagtgaagcccgacaagaagaacccccagctgcaggacctggacatgatgctgacctgcgtggaaatcaaagagggggccctgatgctgccacacttcaactccaaagccatggtcatcgtggtcgtgaacaagggcaccggcaacctggaactggtggccgtgcggaaagagcagcagcagagaggccgcagagaggaagaagaggacgaggacgaagaagaagagggatccaaccgggaagtgcggcggtacaccgccagactgaaagaaggcgacgtgttcatcatgcctgccgcccaccccgtggccatcaatgcctctagcgagctgcatctgctgggcttcggcattaacgccgagaacaatcaccggatctttctggccggcgacaaagacaacgtgatcgaccagatcgagaagcaggccaaggacctggcctttcccggctctggcgaacaagtggaaaagctgatcaagaaccagaaagaaagccacttcgtgtccgccagaccccagagccagtctcagagccctagctcccccgagaaagagtctcctgagaaagaggaccaggaagaggaaaaccagggcggcaagggccctctgctgagcatcctgaaggccttcaat
SEQ ID NO:16-AraH2核苷酸序列
aggcagcagtgggaactgcagggcgacagaagatgccagtcccagctggaacgggccaacctgaggccttgcgagcagcacctgatgcagaaaatccagcgcgacgaggacagctacggccgggatccttacagccccagccaggacccttactcccctagccaggatcccgacagaagggacccctacagccctagcccctacgatagaagaggcgccggaagcagccagcaccaggaaagatgctgcaacgagctgaacgagtttgagaacaaccagcgctgcatgtgcgaggccctgcagcagatcatggaaaatcagagcgaccggctgcagggacggcagcaggaacagcagttcaagagagagctgcggaacctgccccagcagtgtggactgagagccccccagagatgcgacctggaagtggaaagcggcggcagagataggtac
SEQ ID NO:17-AraH3核苷酸序列
gtgaccttcagacagggcggagaagagaatgagtgccagtttcagcggctgaacgcccagaggcccgacaacagaatcgagagcgagggcggctacatcgagacatggaaccccaacaaccaggaatttcagtgcgctggggtggccctgagcaggaccgtgctgagaagaaatgccctgaggcggcccttctacagcaacgcccccctggaaatctacgtgcagcagggcagcggctacttcggcctgatctttcccggatgcccctccacctatgaggaacccgctcaggaaggcagacggtatcagagccagaagcctagcagacggttccaagtgggccaggacgatcccagccaacagcagcaggactctcaccagaaggtgcaccgcttcgacgagggcgacctgatcgctgtgccaaccggcgtggccttctggatgtacaacgacgaggataccgacgtcgtgaccgtgaccctgagcgacaccagctccatccacaaccagctggaccagttccccaggcggttttacctggccggcaatcaggaacaggaatttctgagataccagcagcagcagggctccagaccccactacagacagatcagccctagagtgcggggcgacgaacaggaaaatgagggcagcaacatcttctccggctttgcccaggaatttctgcagcacgccttccaggtggaccggcagaccgtggaaaacctgagaggcgagaacgagagagaggaacagggcgccatcgtgactgtgaagggcggcctgaggatcctgagccccgacgaagaggatgagtcctctagaagcccccccaaccgccgggaagagttcgatgaggaccgcagcagacctcagcagcgggggaagtacgacgagaacaggcggggctacaagaacggcatcgaggaaacaatctgcagcgccagcgtgaagaagaatctgggccggtccagcaaccccgacatctacaatccacaggccggcagcctgcggagcgtgaacgaactggatctgcccatcctgggatggctgggcctgtctgcccagcacggcaccatctaccggaacgccatgttcgtgcctcactacaccctgaatgcccacaccatcgtggtggctctgaacggccgcgcccacgtccaagtggtggacagcaacggcaatcgggtgtacgatgaagaactgcaggaaggacacgtcctggtggtgccccagaattttgccgtggccgccaaggcccagtccgagaactatgagtatctggccttcaagaccgacagccggccctctatcgccaatcaagccggcgagaacagcatcatcgacaacctgcccgaggaagtggtggccaacagctaccggctgcctagagagcaggcccggcagctgaagaacaacaaccctttcaagttcttcgtgcccccattcgaccaccagagcatgagagaggtggcc
SEQ ID NO:18-AraH1-LAMP核苷酸序列
信号:(1)..(86)
稳定化:(87)..(1146)
AraH1:(1147)..(2943)
TM/CYTO:(2943)..(3066)
atggcgccccgcagcgcccggcgacccctgctgctgctactgctgttgctgctgctcggcctcatgcattgtgcgtcagcagcaatgtttatggtgaaaaatggcaacgggaccgcgtgcataatggccaacttctctgctgccttctcagtgaactacgacaccaagagtggccctaagaacatgacccttgacctgccatcagatgccacagtggtgctcaaccgcagctcctgtggaaaagagaacacttctgaccccagtctcgtgattgcttttggaagaggacatacactcactctcaatttcacgagaaatgcaacacgttacagcgttcagctcatgagttttgtttataacttgtcagacacacaccttttccccaatgcgagctccaaagaaatcaagactgtggaatctataactgacatcagggcagatatagataaaaaatacagatgtgttagtggcacccaggtccacatgaacaacgtgaccgtaacgctccatgatgccaccatccaggcgtacctttccaacagcagcttcagcaggggagagacacgctgtgaacaagacaggccttccccaaccacagcgccccctgcgccacccagcccctcgccctcacccgtgcccaagagcccctctgtggacaagtacaacgtgagcggcaccaacgggacctgcctgctggccagcatggggctgcagctgaacctcacctatgagaggaaggacaacacgacggtgacaaggcttctcaacatcaaccccaacaagacctcggccagcgggagctgcggcgcccacctggtgactctggagctgcacagcgagggcaccaccgtcctgctcttccagttcgggatgaatgcaagttctagccggtttttcctacaaggaatccagttgaatacaattcttcctgacgccagagaccctgcctttaaagctgccaacggctccctgcgagcgctgcaggccacagtcggcaattcctacaagtgcaacgcggaggagcacgtccgtgtcacgaaggcgttttcagtcaatatattcaaagtgtgggtccaggctttcaaggtggaaggtggccagtttggctctgtggaggagtgtctgctggacgagaacagcctcgagaagtccagcccctaccagaagaaaaccgagaacccctgcgcccagcggtgcctgcagtcttgtcagcaggaacccgacgacctgaagcagaaggcctgcgagagccggtgcaccaagctggaatacgaccccagatgcgtgtacgaccctagaggccacaccggcaccaccaaccagagaagccctccaggcgagcggaccagaggcagacagcctggcgactacgacgacgacagacggcagcccagaagagaagagggcggcagatggggacctgccggccctagagagagagaacgcgaggaagattggagacagcccagagaggactggcggaggccttctcaccagcagccccggaagatcagacccgagggcagagaaggcgagcaggaatggggcacacctggctctcacgtgcgcgaggaaaccagccggaacaaccccttctacttcccctcccggcggttcagcaccagatacggcaaccagaacggccggatcagagtgctgcagagattcgaccagcggagccggcagttccagaacctgcagaaccaccggatcgtgcagatcgaggccaagcccaacaccctggtgctgcccaaacacgccgacgccgacaacatcctcgtgatccagcagggccaggccaccgtgacagtggccaacggcaacaacagaaagagcttcaacctggacgagggccacgccctgagaatccccagcggcttcatcagctacatcctgaacagacacgacaatcagaacctgagggtggccaagatcagcatgcccgtgaacacccctggccagttcgaggacttcttccccgcatcctcccgggaccagagcagctacctgcagggcttcagccggaataccctggaagccgccttcaacgccgagttcaacgagatcagacgggtgctgctggaagagaacgctggcggagagcaggaagaacggggccagagaagatggtccaccagaagcagcgagaacaacgagggcgtgatcgtgaaggtgtccaaagaacacgtggaagaactgaccaagcacgccaagagcgtgtccaagaagggctccgaggaagagggggacatcaccaaccccatcaatctgagagagggcgagcccgacctgagcaacaacttcggcaagctgttcgaagtgaagcccgacaagaagaacccccagctgcaggacctggacatgatgctgacctgcgtggaaatcaaagagggggccctgatgctgccacacttcaactccaaagccatggtcatcgtggtcgtgaacaagggcaccggcaacctggaactggtggccgtgcggaaagagcagcagcagagaggccgcagagaggaagaagaggacgaggacgaagaagaagagggatccaaccgggaagtgcggcggtacaccgccagactgaaagaaggcgacgtgttcatcatgcctgccgcccaccccgtggccatcaatgcctctagcgagctgcatctgctgggcttcggcattaacgccgagaacaatcaccggatctttctggccggcgacaaagacaacgtgatcgaccagatcgagaagcaggccaaggacctggcctttcccggctctggcgaacaagtggaaaagctgatcaagaaccagaaagaaagccacttcgtgtccgccagaccccagagccagtctcagagccctagctcccccgagaaagagtctcctgagaaagaggaccaggaagaggaaaaccagggcggcaagggccctctgctgagcatcctgaaggccttcaatgaattcacgctgatccccatcgctgtgggtggtgccctggcggggctggtcctcatcgtcctcatcgcctacctcgtcggcaggaagaggagtcacgcaggctaccagactatctag
SEQ ID NO:19-AraH2-LAMP核苷酸序列
信号:(1)..(86)
稳定化:(87)..(1146)
ARA H2:(1147)-(1600)
TM/CYTO:(1601)..(1716)
atggcgccccgcagcgcccggcgacccctgctgctgctactgctgttgctgctgctcggcctcatgcattgtgcgtcagcagcaatgtttatggtgaaaaatggcaacgggaccgcgtgcataatggccaacttctctgctgccttctcagtgaactacgacaccaagagtggccctaagaacatgacccttgacctgccatcagatgccacagtggtgctcaaccgcagctcctgtggaaaagagaacacttctgaccccagtctcgtgattgcttttggaagaggacatacactcactctcaatttcacgagaaatgcaacacgttacagcgttcagctcatgagttttgtttataacttgtcagacacacaccttttccccaatgcgagctccaaagaaatcaagactgtggaatctataactgacatcagggcagatatagataaaaaatacagatgtgttagtggcacccaggtccacatgaacaacgtgaccgtaacgctccatgatgccaccatccaggcgtacctttccaacagcagcttcagcaggggagagacacgctgtgaacaagacaggccttccccaaccacagcgccccctgcgccacccagcccctcgccctcacccgtgcccaagagcccctctgtggacaagtacaacgtgagcggcaccaacgggacctgcctgctggccagcatggggctgcagctgaacctcacctatgagaggaaggacaacacgacggtgacaaggcttctcaacatcaaccccaacaagacctcggccagcgggagctgcggcgcccacctggtgactctggagctgcacagcgagggcaccaccgtcctgctcttccagttcgggatgaatgcaagttctagccggtttttcctacaaggaatccagttgaatacaattcttcctgacgccagagaccctgcctttaaagctgccaacggctccctgcgagcgctgcaggccacagtcggcaattcctacaagtgcaacgcggaggagcacgtccgtgtcacgaaggcgttttcagtcaatatattcaaagtgtgggtccaggctttcaaggtggaaggtggccagtttggctctgtggaggagtgtctgctggacgagaacagcctcgagaggcagcagtgggaactgcagggcgacagaagatgccagtcccagctggaacgggccaacctgaggccttgcgagcagcacctgatgcagaaaatccagcgcgacgaggacagctacggccgggatccttacagccccagccaggacccttactcccctagccaggatcccgacagaagggacccctacagccctagcccctacgatagaagaggcgccggaagcagccagcaccaggaaagatgctgcaacgagctgaacgagtttgagaacaaccagcgctgcatgtgcgaggccctgcagcagatcatggaaaatcagagcgaccggctgcagggacggcagcaggaacagcagttcaagagagagctgcggaacctgccccagcagtgtggactgagagccccccagagatgcgacctggaagtggaaagcggcggcagagataggtacgaattcacgctgatccccatcgctgtgggtggtgccctggcggggctggtcctcatcgtcctcatcgcctacctcgtcggcaggaagaggagtcacgcaggctaccagactatctag
SEQ ID NO:20-AraH3-LAMP核苷酸序列
信号:(1)..(86)
稳定化:(87)..(1146)
AraH3:(1147)..(2623)
TM/CYTO:(2624)..(2739)
atggcgccccgcagcgcccggcgacccctgctgctgctactgctgttgctgctgctcggcctcatgcattgtgcgtcagcagcaatgtttatggtgaaaaatggcaacgggaccgcgtgcataatggccaacttctctgctgccttctcagtgaactacgacaccaagagtggccctaagaacatgacccttgacctgccatcagatgccacagtggtgctcaaccgcagctcctgtggaaaagagaacacttctgaccccagtctcgtgattgcttttggaagaggacatacactcactctcaatttcacgagaaatgcaacacgttacagcgttcagctcatgagttttgtttataacttgtcagacacacaccttttccccaatgcgagctccaaagaaatcaagactgtggaatctataactgacatcagggcagatatagataaaaaatacagatgtgttagtggcacccaggtccacatgaacaacgtgaccgtaacgctccatgatgccaccatccaggcgtacctttccaacagcagcttcagcaggggagagacacgctgtgaacaagacaggccttccccaaccacagcgccccctgcgccacccagcccctcgccctcacccgtgcccaagagcccctctgtggacaagtacaacgtgagcggcaccaacgggacctgcctgctggccagcatggggctgcagctgaacctcacctatgagaggaaggacaacacgacggtgacaaggcttctcaacatcaaccccaacaagacctcggccagcgggagctgcggcgcccacctggtgactctggagctgcacagcgagggcaccaccgtcctgctcttccagttcgggatgaatgcaagttctagccggtttttcctacaaggaatccagttgaatacaattcttcctgacgccagagaccctgcctttaaagctgccaacggctccctgcgagcgctgcaggccacagtcggcaattcctacaagtgcaacgcggaggagcacgtccgtgtcacgaaggcgttttcagtcaatatattcaaagtgtgggtccaggctttcaaggtggaaggtggccagtttggctctgtggaggagtgtctgctggacgagaacagcctcgaggtgaccttcagacagggcggagaagagaatgagtgccagtttcagcggctgaacgcccagaggcccgacaacagaatcgagagcgagggcggctacatcgagacatggaaccccaacaaccaggaatttcagtgcgctggggtggccctgagcaggaccgtgctgagaagaaatgccctgaggcggcccttctacagcaacgcccccctggaaatctacgtgcagcagggcagcggctacttcggcctgatctttcccggatgcccctccacctatgaggaacccgctcaggaaggcagacggtatcagagccagaagcctagcagacggttccaagtgggccaggacgatcccagccaacagcagcaggactctcaccagaaggtgcaccgcttcgacgagggcgacctgatcgctgtgccaaccggcgtggccttctggatgtacaacgacgaggataccgacgtcgtgaccgtgaccctgagcgacaccagctccatccacaaccagctggaccagttccccaggcggttttacctggccggcaatcaggaacaggaatttctgagataccagcagcagcagggctccagaccccactacagacagatcagccctagagtgcggggcgacgaacaggaaaatgagggcagcaacatcttctccggctttgcccaggaatttctgcagcacgccttccaggtggaccggcagaccgtggaaaacctgagaggcgagaacgagagagaggaacagggcgccatcgtgactgtgaagggcggcctgaggatcctgagccccgacgaagaggatgagtcctctagaagcccccccaaccgccgggaagagttcgatgaggaccgcagcagacctcagcagcgggggaagtacgacgagaacaggcggggctacaagaacggcatcgaggaaacaatctgcagcgccagcgtgaagaagaatctgggccggtccagcaaccccgacatctacaatccacaggccggcagcctgcggagcgtgaacgaactggatctgcccatcctgggatggctgggcctgtctgcccagcacggcaccatctaccggaacgccatgttcgtgcctcactacaccctgaatgcccacaccatcgtggtggctctgaacggccgcgcccacgtccaagtggtggacagcaacggcaatcgggtgtacgatgaagaactgcaggaaggacacgtcctggtggtgccccagaattttgccgtggccgccaaggcccagtccgagaactatgagtatctggccttcaagaccgacagccggccctctatcgccaatcaagccggcgagaacagcatcatcgacaacctgcccgaggaagtggtggccaacagctaccggctgcctagagagcaggcccggcagctgaagaacaacaaccctttcaagttcttcgtgcccccattcgaccaccagagcatgagagaggtggccgaattcacgctgatccccatcgctgtgggtggtgccctggcggggctggtcctcatcgtcctcatcgcctacctcgtcggcaggaagaggagtcacgcaggctaccagactatctag
SEQ ID NO:21-AraH1-AraH2-AraH3-LAMP(AraH-LAMP,AraH1-H2-H3-LAMP)核苷酸序列
信号:(1)..(86)
稳定化:(87)..(1146)
AraH1:(1147)..(2949)
连接序列:(2950)..(2961)
AraH2:(2962)..(3414)
连接序列:(3415)..(3426)
AraH3:(3427)..(4902)
TM/CYTO:(4903)..(5019)
atggcgccccgcagcgcccggcgacccctgctgctgctactgctgttgctgctgctcggcctcatgcattgtgcgtcagcagcaatgtttatggtgaaaaatggcaacgggaccgcgtgcataatggccaacttctctgctgccttctcagtgaactacgacaccaagagtggccctaagaacatgacccttgacctgccatcagatgccacagtggtgctcaaccgcagctcctgtggaaaagagaacacttctgaccccagtctcgtgattgcttttggaagaggacatacactcactctcaatttcacgagaaatgcaacacgttacagcgttcagctcatgagttttgtttataacttgtcagacacacaccttttccccaatgcgagctccaaagaaatcaagactgtggaatctataactgacatcagggcagatatagataaaaaatacagatgtgttagtggcacccaggtccacatgaacaacgtgaccgtaacgctccatgatgccaccatccaggcgtacctttccaacagcagcttcagcaggggagagacacgctgtgaacaagacaggccttccccaaccacagcgccccctgcgccacccagcccctcgccctcacccgtgcccaagagcccctctgtggacaagtacaacgtgagcggcaccaacgggacctgcctgctggccagcatggggctgcagctgaacctcacctatgagaggaaggacaacacgacggtgacaaggcttctcaacatcaaccccaacaagacctcggccagcgggagctgcggcgcccacctggtgactctggagctgcacagcgagggcaccaccgtcctgctcttccagttcgggatgaatgcaagttctagccggtttttcctacaaggaatccagttgaatacaattcttcctgacgccagagaccctgcctttaaagctgccaacggctccctgcgagcgctgcaggccacagtcggcaattcctacaagtgcaacgcggaggagcacgtccgtgtcacgaaggcgttttcagtcaatatattcaaagtgtgggtccaggctttcaaggtggaaggtggccagtttggctctgtggaggagtgtctgctggacgagaacagcctcgagaagtccagcccctaccagaagaaaaccgagaacccctgcgcccagcggtgcctgcagtcttgtcagcaggaacccgacgacctgaagcagaaggcctgcgagagccggtgcaccaagctggaatacgaccccagatgcgtgtacgaccctagaggccacaccggcaccaccaaccagagaagccctccaggcgagcggaccagaggcagacagcctggcgactacgacgacgacagacggcagcccagaagagaagagggcggcagatggggacctgccggccctagagagagagaacgcgaggaagattggagacagcccagagaggactggcggaggccttctcaccagcagccccggaagatcagacccgagggcagagaaggcgagcaggaatggggcacacctggctctcacgtgcgcgaggaaaccagccggaacaaccccttctacttcccctcccggcggttcagcaccagatacggcaaccagaacggccggatcagagtgctgcagagattcgaccagcggagccggcagttccagaacctgcagaaccaccggatcgtgcagatcgaggccaagcccaacaccctggtgctgcccaaacacgccgacgccgacaacatcctcgtgatccagcagggccaggccaccgtgacagtggccaacggcaacaacagaaagagcttcaacctggacgagggccacgccctgagaatccccagcggcttcatcagctacatcctgaacagacacgacaatcagaacctgagggtggccaagatcagcatgcccgtgaacacccctggccagttcgaggacttcttccccgcatcctcccgggaccagagcagctacctgcagggcttcagccggaataccctggaagccgccttcaacgccgagttcaacgagatcagacgggtgctgctggaagagaacgctggcggagagcaggaagaacggggccagagaagatggtccaccagaagcagcgagaacaacgagggcgtgatcgtgaaggtgtccaaagaacacgtggaagaactgaccaagcacgccaagagcgtgtccaagaagggctccgaggaagagggggacatcaccaaccccatcaatctgagagagggcgagcccgacctgagcaacaacttcggcaagctgttcgaagtgaagcccgacaagaagaacccccagctgcaggacctggacatgatgctgacctgcgtggaaatcaaagagggggccctgatgctgccacacttcaactccaaagccatggtcatcgtggtcgtgaacaagggcaccggcaacctggaactggtggccgtgcggaaagagcagcagcagagaggccgcagagaggaagaagaggacgaggacgaagaagaagagggatccaaccgggaagtgcggcggtacaccgccagactgaaagaaggcgacgtgttcatcatgcctgccgcccaccccgtggccatcaatgcctctagcgagctgcatctgctgggcttcggcattaacgccgagaacaatcaccggatctttctggccggcgacaaagacaacgtgatcgaccagatcgagaagcaggccaaggacctggcctttcccggctctggcgaacaagtggaaaagctgatcaagaaccagaaagaaagccacttcgtgtccgccagaccccagagccagtctcagagccctagctcccccgagaaagagtctcctgagaaagaggaccaggaagaggaaaaccagggcggcaagggccctctgctgagcatcctgaaggccttcaatggcggcggaggcaggcagcagtgggaactgcagggcgacagaagatgccagtcccagctggaacgggccaacctgaggccttgcgagcagcacctgatgcagaaaatccagcgcgacgaggacagctacggccgggatccttacagccccagccaggacccttactcccctagccaggatcccgacagaagggacccctacagccctagcccctacgatagaagaggcgccggaagcagccagcaccaggaaagatgctgcaacgagctgaacgagtttgagaacaaccagcgctgcatgtgcgaggccctgcagcagatcatggaaaatcagagcgaccggctgcagggacggcagcaggaacagcagttcaagagagagctgcggaacctgccccagcagtgtggactgagagccccccagagatgcgacctggaagtggaaagcggcggcagagatcggtacggcggagggggcgtgaccttcagacagggcggagaagagaatgagtgccagtttcagcggctgaacgcccagaggcccgacaacagaatcgagagcgagggcggctacatcgagacatggaaccccaacaaccaggaatttcagtgcgctggggtggccctgagcaggaccgtgctgagaagaaatgccctgaggcggcccttctacagcaacgcccccctggaaatctacgtgcagcagggcagcggctacttcggcctgatctttcccggatgcccctccacctatgaggaacccgctcaggaaggcagacggtatcagagccagaagcctagcagacggttccaagtgggccaggacgatcccagccaacagcagcaggactctcaccagaaggtgcaccgcttcgacgagggcgacctgatcgctgtgccaaccggcgtggccttctggatgtacaacgacgaggataccgacgtcgtgaccgtgaccctgagcgacaccagctccatccacaaccagctggaccagttccccaggcggttttacctggccggcaatcaggaacaggaatttctgagataccagcagcagcagggctccagaccccactacagacagatcagccctagagtgcggggcgacgaacaggaaaatgagggcagcaacatcttctccggctttgcccaggaatttctgcagcacgccttccaggtggaccggcagaccgtggaaaacctgagaggcgagaacgagagagaggaacagggcgccatcgtgactgtgaagggcggcctgaggatcctgagccccgacgaagaggatgagtcctctagaagcccccccaaccgccgggaagagttcgatgaggaccgcagcagacctcagcagcgggggaagtacgacgagaacaggcggggctacaagaacggcatcgaggaaacaatctgcagcgccagcgtgaagaagaatctgggccggtccagcaaccccgacatctacaatccacaggccggcagcctgcggagcgtgaacgaactggatctgcccatcctgggatggctgggcctgtctgcccagcacggcaccatctaccggaacgccatgttcgtgcctcactacaccctgaatgcccacaccatcgtggtggctctgaacggccgcgcccacgtccaagtggtggacagcaacggcaatcgggtgtacgatgaagaactgcaggaaggacacgtcctggtggtgccccagaattttgccgtggccgccaaggcccagtccgagaactatgagtatctggccttcaagaccgacagccggccctctatcgccaatcaagccggcgagaacagcatcatcgacaacctgcccgaggaagtggtggccaacagctaccggctgcctagagagcaggcccggcagctgaagaacaacaaccctttcaagttcttcgtgcccccattcgaccaccagagcatgagagaggtggccgaattcacgctgatccccatcgctgtgggtggtgccctggcggggctggtcctcatcgtcctcatcgcctacctcgtcggcaggaagaggagtcacgcaggctaccagactatctag
SEQ ID NO:22–LAMP-3(DC-LAMP)氨基酸序列
信号:(1)..(27)
稳定化:(28)..(381)
TM/CYTO:(382)..(416)
MPRQLSAAAALFASLAVILHDGSQMRAKAFPETRDYSQPTAAATVQDIKKPVQQPAKQAPHQTLAARFMDGHITFQTAATVKIPTTTPATTKNTATTSPITYTLVTTQATPNNSHTAPPVTEVTVGPSLAPYSLPPTITPPAHTTGTSSSTVSHTTGNTTQPSNQTTLPATLSIALHKSTTGQKPVQPTHAPGTTAAAHNTTRTAAPASTVPGPTLAPQPSSVKTGIYQVLNGSRLCIKAEMGIQLIVQDKESVFSPRRYFNIDPNATQASGNCGTRKSNLLLNFQGGFVNLTFTKDEESYYISEVGAYLTVSDPETIYQGIKHAVVMFQTAVGHSFKCVSEQSLQLSAHLQVKTTDVQLQAFDFEDDHFGNVDECSSDYTIVLPVIGAIVVGLCLMGMGVYKIRLRCQSSGYQRI
SEQ ID NO:23-LAMP2氨基酸序列
信号:(1)..(28)
稳定化:(29)..(375)
TM/CYTO:(376)..(408)
MVCFRLFPVPGSGLVLVCLVLGAVRSYALELNLTDSENATCLYAKWQMNFTVRYETTNKTYKTVTISDHGTVTYNGSICGDDQNGPKIAVQFGPGFSWIANFTKAASTYSIDSVSFSYNTGDNTTFPDAEDKGILTVDELLAIRIPLNDLFRCNSLSTLEKNDVVQHYWDVLVQAFVQNGTVSTNEFLCDKDKTSTVAPTIHTTVPSPTTTPTPKEKPEAGTYSVNNGNDTCLLATMGLQLNITQDKVASVININPNTTHSTGSCRSHTALLRLNSSTIKYLDFVFAVKNENRFYLKEVNISMYLVNGSVFSIANNNLSYWMPPSSYMCNKEQTVSVSGAFQINTFDLRVQPFNVTQGKYSTAQDCSADDDNFLVPIAVGAALAGVLILVLLAYFIGLKHHHAGYEQF
SEQ ID NO:24-LIMP II氨基酸序列
信号:(5)..(27)
稳定化:(28)..(433)
TM/CYTO:(434)..(478)
MGRCCFYTAGTLSLLLLVTSVTLLVARVFQKAVDQSIEKKIVLRNGTEAFDSWEKPPLPVYTQFYFFNVTNPEEILRGETPRVEEVGPYTYRELRNKANIQFGDNGTTISAVSNKAYVFERDQSVGDPKIDLIRTLNIPVLTVIEWSQVHFLREIIEAMLKAYQQKLFVTHTVDELLWGYKDEILSLIHVFRPDISPYFGLFYEKNGTNDGDYVFLTGEDSYLNFTKIVEWNGKTSLDWWITDKCNMINGTDGDSFHPLITKDEVLYVFPSDFCRSVYITFSDYESVQGLPAFRYKVPAEILANTSDNAGFCIPEGNCLGSGVLNVSICKNGAPIIMSFPHFYQADERFVSAIEGMHPNQEDHETFVDINPLTGIILKAAKRFQINIYVKKLDDFVETGDIRTMVFPVMYLNESVHIDKETASRLKSMINTTLIITNIPYIIMALGVFFGLVFTWLACKGQGSMDEGTADERAPLIRT
SEQ ID NO:25-ENDOLYN氨基酸序列
信号:(1)..(24)
稳定化:(25)..(162)
TM/CYTO:(163)..(197)
MSRLSRSLLWAATCLGVLCVLSADKNTTQHPNVTTLAPISNVTSAPVTSLPLVTTPAPETCEGRNSCVSCFNVSVVNTTCFWIECKDESYCSHNSTVSDCQVGNTTDFCSVSTATPVPTANSTAKPTVQPSPSTTSKTVTTSGTTNNTVTPTSQPVRKSTFDAASFIGGIVLVLGVQAVIFFLYKFCKSKERNYHTL
SEQ ID NO:26–AraH3del核苷酸序列
gtgaccttcagacagggcggagaagagaatgagtgccagtttcagcggctgaacgcccagaggcccgacaacagaatcgagagcgagggcggctacatcgagacatggaaccccaacaaccaggaatttcagtgcgctggggtggccctgagcaggaccgtgctgagaagaaatgccctgaggcggcccttctacagcaacgcccccctggaaatctacgtgcagcagggcagcggctacttcggcctgatctttcccggatgcccctccacctatgaggaacccgctcaggaaggcagacggtatcagagccagaagcctagcagacggttccaagtgggccaggacgatcccagccaacagcagcaggactctcaccagaaggtgcaccgcttcgacgagggcgacctgatcgctgtgccaaccggcgtggccttctggatgtacaacgacgaggataccgacgtcgtgaccgtgaccctgagcgacaccagctccatccacaaccagctggaccagttccccaggcggttttacctggccggcaatcaggaacaggaatttctgagataccagcagcagcagggctccagaccccactacagacagatcagccctagagtgcggggcgacgaacaggaaaatgagggcagcaacatcttctccggctttgcccaggaatttctgcagcacgccttccaggtggaccggcagaccgtggaaaacctgagaggcgagaacgagagagaggaacagggcgccatcgtgactgtgaagggcggcctgaggatcctgagccccgacgaagaggatgagtcctctagaagcccccccaaccgccgggaagagttcgatgaggaccgcagcagacctcagcagcgggggaagtacgacgagaacaggcggggctacaagaac
SEQ ID NO:27–AraH3del-LAMP核苷酸序列
信号:(1)..(86)
稳定化:(87)..(1146)
ARAH3del:(1147)..(2064)
TM/CYTO:(2065)..(2181)
atggcgccccgcagcgcccggcgacccctgctgctgctactgctgttgctgctgctcggcctcatgcattgtgcgtcagcagcaatgtttatggtgaaaaatggcaacgggaccgcgtgcataatggccaacttctctgctgccttctcagtgaactacgacaccaagagtggccctaagaacatgacccttgacctgccatcagatgccacagtggtgctcaaccgcagctcctgtggaaaagagaacacttctgaccccagtctcgtgattgcttttggaagaggacatacactcactctcaatttcacgagaaatgcaacacgttacagcgtccagctcatgagttttgtttataacttgtcagacacacaccttttccccaatgcgagctccaaagaaatcaagactgtggaatctataactgacatcagggcagatatagataaaaaatacagatgtgttagtggcacccaggtccacatgaacaacgtgaccgtaacgctccatgatgccaccatccaggcgtacctttccaacagcagcttcagccggggagagacacgctgtgaacaagacaggccttccccaaccacagcgccccctgcgccacccagcccctcgccctcacccgtgcccaagagcccctctgtggacaagtacaacgtgagcggcaccaacgggacctgcctgctggccagcatggggctgcagctgaacctcacctatgagaggaaggacaacacgacggtgacaaggcttctcaacatcaaccccaacaagacctcggccagcgggagctgcggcgcccacctggtgactctggagctgcacagcgagggcaccaccgtcctgctcttccagttcgggatgaatgcaagttctagccggtttttcctacaaggaatccagttgaatacaattcttcctgacgccagagaccctgcctttaaagctgccaacggctccctgcgagcgctgcaggccacagtcggcaattcctacaagtgcaacgcggaggagcacgtccgtgtcacgaaggcgttttcagtcaatatattcaaagtgtgggtccaggctttcaaggtggaaggtggccagtttggctctgtggaggagtgtctgctggacgagaacagcctcgaggtgaccttcagacagggcggagaagagaatgagtgccagtttcagcggctgaacgcccagaggcccgacaacagaatcgagagcgagggcggctacatcgagacatggaaccccaacaaccaggaatttcagtgcgctggggtggccctgagcaggaccgtgctgagaagaaatgccctgaggcggcccttctacagcaacgcccccctggaaatctacgtgcagcagggcagcggctacttcggcctgatctttcccggatgcccctccacctatgaggaacccgctcaggaaggcagacggtatcagagccagaagcctagcagacggttccaagtgggccaggacgatcccagccaacagcagcaggactctcaccagaaggtgcaccgcttcgacgagggcgacctgatcgctgtgccaaccggcgtggccttctggatgtacaacgacgaggataccgacgtcgtgaccgtgaccctgagcgacaccagctccatccacaaccagctggaccagttccccaggcggttttacctggccggcaatcaggaacaggaatttctgagataccagcagcagcagggctccagaccccactacagacagatcagccctagagtgcggggcgacgaacaggaaaatgagggcagcaacatcttctccggctttgcccaggaatttctgcagcacgccttccaggtggaccggcagaccgtggaaaacctgagaggcgagaacgagagagaggaacagggcgccatcgtgactgtgaagggcggcctgaggatcctgagccccgacgaagaggatgagtcctctagaagcccccccaaccgccgggaagagttcgatgaggaccgcagcagacctcagcagcgggggaagtacgacgagaacaggcggggctacaagaacgaattcacgctgatccccatcgctgtgggtggtgccctggcggggctggtcctcatcgtcctcatcgcctacctcgtcggcaggaagaggagtcacgcaggctaccagactatctag
SEQ ID NO:28–AraH3-LAMP氨基酸序列
信号:(1)..(27)
稳定化:(28)..(380)
ARAH3:(381)..(884)
TM/CYTO:(885)..(912)
MAPRSARRPLLLLLLLLLLGLMHCASAAMFMVKNGNGTACIMANFSAAFSVNYDTKSGPKNMTLDLPSDATVVLNRSSCGKENTSDPSLVIAFGRGHTLTLNFTRNATRYSVQLMSFVYNLSDTHLFPNASSKEIKTVESITDIRADIDKKYRCVSGTQVHMNNVTVTLHDATIQAYLSNSSFSRGETRCEQDRPSPTTAPPAPPSPSPSPVPKSPSVDKYNVSGTNGTCLLASMGLQLNLTYERKDNTTVTRLLNINPNKTSASGSCGAHLVTLELHSEGTTVLLFQFGMNASSSRFFLQGIQLNTILPDARDPAFKAANGSLRALQATVGNSYKCNAEEHVRVTKAFSVNIFKVWVQAFKVEGGQFGSVEECLLDENSLEVTFRQGGEENECQFQRLNAQRPDNRIESEGGYIETWNPNNQEFQCAGVALSRTVLRRNALRRPFYSNAPLEIYVQQGSGYFGLIFPGCPSTYEEPAQEGRRYQSQKPSRRFQVGQDDPSQQQQDSHQKVHRFDEGDLIAVPTGVAFWMYNDEDTDVVTVTLSDTSSIHNQLDQFPRRFYLAGNQEQEFLRYQQQQGSRPHYRQISPRVRGDEQENEGSNIFSGFAQEFLQHAFQVDRQTVENLRGENEREEQGAIVTVKGGLRILSPDEEDESSRSPPNRREEFDEDRSRPQQRGKYDENRRGYKNGIEETICSASVKKNLGRSSNPDIYNPQAGSLRSVNELDLPILGWLGLSAQHGTIYRNAMFVPHYTLNAHTIVVALNGRAHVQVVDSNGNRVYDEELQEGHVLVVPQNFAVAAKAQSENYEYLAFKTDSRPSIANQAGENSIIDNLPEEVVANSYRLPREQARQLKNNNPFKFFVPPFDHQSMREVAEFTLIPIAVGGALAGLVLIVLIAYLVGRKRSHAGYQTI
SEQ ID NO:29–LAMP1核苷酸序列
信号:(1)..(81)
稳定化:(82)..(1140)
TM/CYTO:(1141)..(1251)
atggcgccccgcagcgcccggcgacccctgctgctgctactgctgttgctgctgctcggcctcatgcattgtgcgtcagcagcaatgtttatggtgaaaaatggcaacgggaccgcgtgcataatggccaacttctctgctgccttctcagtgaactacgacaccaagagtggccctaagaacatgacccttgacctgccatcagatgccacagtggtgctcaaccgcagctcctgtggaaaagagaacacttctgaccccagtctcgtgattgcttttggaagaggacatacactcactctcaatttcacgagaaatgcaacacgttacagcgtccagctcatgagttttgtttataacttgtcagacacacaccttttccccaatgcgagctccaaagaaatcaagactgtggaatctataactgacatcagggcagatatagataaaaaatacagatgtgttagtggcacccaggtccacatgaacaacgtgaccgtaacgctccatgatgccaccatccaggcgtacctttccaacagcagcttcagccggggagagacacgctgtgaacaagacaggccttccccaaccacagcgccccctgcgccacccagcccctcgccctcacccgtgcccaagagcccctctgtggacaagtacaacgtgagcggcaccaacgggacctgcctgctggccagcatggggctgcagctgaacctcacctatgagaggaaggacaacacgacggtgacaaggcttctcaacatcaaccccaacaagacctcggccagcgggagctgcggcgcccacctggtgactctggagctgcacagcgagggcaccaccgtcctgctcttccagttcgggatgaatgcaagttctagccggtttttcctacaaggaatccagttgaatacaattcttcctgacgccagagaccctgcctttaaagctgccaacggctccctgcgagcgctgcaggccacagtcggcaattcctacaagtgcaacgcggaggagcacgtccgtgtcacgaaggcgttttcagtcaatatattcaaagtgtgggtccaggctttcaaggtggaaggtggccagtttggctctgtggaggagtgtctgctggacgagaacagcacgctgatccccatcgctgtgggtggtgccctggcggggctggtcctcatcgtcctcatcgcctacctcgtcggcaggaagaggagtcacgcaggctaccagactatctag
SEQ ID NO:30–LAMP1氨基酸序列
信号:(1)..(27)
稳定化:(28)..(380)
TM/CYTO:(381)..(416)
MAPRSARRPLLLLLLLLLLGLMHCASAAMFMVKNGNGTACIMANFSAAFSVNYDTKSGPKNMTLDLPSDATVVLNRSSCGKENTSDPSLVIAFGRGHTLTLNFTRNATRYSVQLMSFVYNLSDTHLFPNASSKEIKTVESITDIRADIDKKYRCVSGTQVHMNNVTVTLHDATIQAYLSNSSFSRGETRCEQDRPSPTTAPPAPPSPSPSPVPKSPSVDKYNVSGTNGTCLLASMGLQLNLTYERKDNTTVTRLLNINPNKTSASGSCGAHLVTLELHSEGTTVLLFQFGMNASSSRFFLQGIQLNTILPDARDPAFKAANGSLRALQATVGNSYKCNAEEHVRVTKAFSVNIFKVWVQAFKVEGGQFGSVEECLLDENSTLIPIAVGGALAGLVLIVLIAYLVGRKRSHAGYQTI
- 还没有人留言评论。精彩留言会获得点赞!