真菌基因组修饰系统及使用方法与流程
相关申请的交叉引用
本申请要求均于2014年12月16日提交的pct专利申请序列号pct/cn2014/093916、pct/cn2014/093914和pct/cn2014/093918的优先权,这些专利通过引用以其全文特此结合。
序列表
将按照37c.f.r.§1.52(e)、经由efs提交的序列表通过引用结合在此。经由efs提交的序列表文本文件包含于2015年12月11日创建的文件“40532-wo-pct-5(2015-831)_st25.txt”,其大小为146千字节。
发明背景
细菌和古细菌已经进化了适应性免疫防御,被称为成簇的规律间隔的短回文重复序列(crispr)/crispr相关(cas)系统,该cas系统能以序列特异性方式在dna中引入双链断裂。cas系统通过包括短rna序列(tracrrna和crrna)和rna依赖性内切核酸酶(cas内切核酸酶)的核糖核蛋白复合物的活性执行它们的功能,该rna依赖性内切核酸酶靶向特定dna序列(通过与crrna的一部分的同源性,被称为可变靶向结构域)并且在靶标中产生双链断裂。crispr基因座首先在大肠杆菌(e.coli)中被识别(ishino等人(1987)j.bacterial.[细菌学杂志]169:5429-5433;nakata等人(1989)j.bacterial.[细菌学杂志]171:3553-3556),其中相似的散置的短序列重复随后在许多细菌物种中被鉴定出,这些细菌物种包括但不限于地中海富盐菌(haloferaxmediterranei)、化脓性链球菌(streptococcuspyogenes)、鱼腥藻(anabaena)和结核分枝杆菌(mycobacteriumtuberculosis)(groenen等人(1993)mol.microbiol.[分子微生物学]10:1057-1065;hoe等人(1999)emerg.infect.dis.[新发传染病]5:254-263;masepohl等人(1996)biochim.biophys.acta[生物化学生物物理学报]1307:26-30;mojica等人(1995)mol.microbiol.[分子微生物学]17:85-93)。
众所周知,在基因组dna中的特定靶位点处诱导剪切可以用于在该位点处或附近引入修饰。例如,当靶向的dna位点含有双链断裂时,已显示用于基因靶向的同源重组被增强(参见,例如rudin等人,genetics[遗传学]122:519-534;smih等人,nucl.acidsres.[核酸研究]23:5012-5019)。鉴于cas系统的位点特异性性质,已经描述了基于这些系统的基因组修饰/工程化技术,包括在哺乳动物细胞中的那些(参见,例如hsu等人;cell[细胞]第157卷,p1262-1278,2014年6月5日,标题为“用于基因组工程的crispr-cas9的开发与应用(developmentandapplicationsofcrispr-cas9forgenomeengineering)”)。基于cas的基因组工程的功能来自于通过设计重组crrna(或等效功能的多核苷酸)(其中crrna的dna靶向区域(可变靶向结构域)与基因组内所希望的靶位点同源)并且将其与cas内切核酸酶(通过任何方便的方法)组合成宿主细胞中的功能性复合物来靶向复杂基因组内几乎任何特定位置的能力。
虽然已经将基于cas的基因组工程技术应用于许多不同的宿主细胞类型,但是在真菌细胞中有效利用这样的系统已被证明是困难的。因此,仍然需要开发有效率且有效的基于cas的基因组工程方法和用于修饰/改变真菌细胞中的基因组靶位点的组合物。
简要概述
提供了组合物和方法,这些组合物和方法涉及使用指导rna/cas内切核酸酶系统用于在真菌细胞(例如丝状真菌细胞)的基因组中的靶位点处插入供体dna。
本披露的方面涉及在真菌细胞的基因组中的靶位点处插入供体dna的方法。在一些实施例中,该方法包括:a)向真菌细胞群体中引入cas内切核酸酶、指导rna和供体dna,其中该cas内切核酸酶和指导rna能够形成一种复合物,该复合物使得cas内切核酸酶能够在真菌细胞的基因组的基因组座位中的靶位点处引入双链断裂;并且b)从该群体中鉴定在基因组座位中的靶位点处已经发生了供体dna的插入的至少一个真菌细胞,其中该cas内切核酸酶、指导rna或两者都被瞬时引入了真菌细胞群体中。
在某些实施例中,其中该插入不是经由该供体dna与所述真菌细胞的基因组之间的同源重组发生的。
在某些实施例中,供体dna不包含与基因组座位中的基因组序列同源的序列。在一些实施例中,供体dna不包含与至少150、200、250、300、350、400、450或500个核苷酸长度的基因组序列同源的序列。在一些实施例中,供体dna不包含与至少200个核苷酸长度上的基因组序列同源的序列。
在某些实施例中,供体dna的插入会中断基因组座位的表达或功能。在某些其他实施例中,插入不会中断基因组座位的表达或功能。
在该方法的一些实施例中,供体dna包含目的基因。在某些实施例中,供体dna包含编码目的基因产物的表达盒。
在一些实施例中,目的基因或表达盒编码目的蛋白质。在某些实施例中,目的蛋白质是酶。在具体实施例中,目的蛋白质是半纤维素酶、过氧化物酶、蛋白酶、纤维素酶、木聚糖酶、脂肪酶、磷脂酶、酯酶、角质酶、果胶酶、角蛋白酶、还原酶、氧化酶、酚氧化酶、脂氧合酶、木质素酶、支链淀粉酶、鞣酸酶、戊聚糖酶、甘露聚糖酶、β-葡聚糖酶、阿拉伯糖苷酶、透明质酸酶、软骨素酶、漆酶、淀粉酶、葡糖淀粉酶、其变体、其功能片段、或其两种或更多种的杂合物或混合物。在又其他具体实施例中,目的蛋白质是肽激素、生长因子、凝血因子、趋化因子、细胞因子、淋巴因子、抗体、受体、粘附分子、微生物抗原、其变体、其功能片段、或其两种或更多种的杂合物或混合物。
在某些实施例中,目的基因或表达盒编码表型标记,例如可检测的标记、可选择标记、显性异源可选择标记、报告基因、营养缺陷型标记、抗生素抗性标记等(参见下面说明书)。可以使用任何方便的表型标记。
在该方法的一些实施例中,供体dna包含或进一步包含(例如,在供体dna包含目的基因或表达盒的实施例中)与基因组座位中的基因组序列同源的序列(有时在本文中被称为“重复序列”),但是该重复序列不用于将供体dna插入基因组座位的靶位点处。在一些实施例中,该重复序列为至少约150、200、300、400或500个核苷酸长。在某些实施例中,该基因组序列(即,与供体dna中的重复序列同源的序列)和该靶位点位于基因组缺失靶标区域的侧翼。该基因组缺失靶标区域是由用户定义的一个区域。在某些实施例中,供体dna的插入导致该基因组序列和与该基因组序列同源的序列(包括在供体dna中)位于包含该基因组缺失靶标区域的环出靶标区域的侧翼。该基因组序列和与该基因组序列同源的序列在本文中有时都被称为“重复序列”。在供体dna包含编码表型标记的表达盒的一些实施例中,该基因组序列和与该基因组序列同源的序列位于包括该基因组缺失靶标区域和该表型标记(例如可选择标记)的环出靶标区域的侧翼。(参见图1,该图1是示出了供体dna和基因组座位结构特征的实例的示意图)。
在某些实施例中,该方法是导致基因组序列(基因组缺失靶标区域)从真菌细胞的基因组中缺失的一种方法。在本披露的这样的方面中,该方法进一步包括:c)在促进或允许环出靶标区域(即,在基因组序列和与该基因组序列同源的在供体dna中的重复序列之间的区域)环出的条件下,培养具有被插入在靶位点处的供体dna的真菌细胞,并且d)在培养物中鉴定出至少一个已经发生了环出靶标区域的环出的真菌细胞。这可以通过在只有已经失去可选择标记的真菌细胞才可以生长的条件下培养真菌细胞来实现,因为该可选择标记是环出靶标区域的一部分。
本披露的另一方面涉及一种用于在真菌细胞基因组中使靶区域缺失的方法,该方法包括:a)向真菌细胞群体中引入cas内切核酸酶、指导rna和供体dna,其中该cas内切核酸酶和指导rna能够形成使得cas内切核酸酶能够在真菌细胞基因组中的靶位点处引入双链断裂的一种复合物,并且允许供体dna被插入在靶位点处,其中该供体dna包含与真菌细胞的基因组序列同源的序列,并且其中该基因组序列和该靶位点位于真菌细胞基因组中靶标区域的侧翼;b)在允许该基因组序列和与该基因组序列同源的序列之间进行同源重组的条件下培养真菌细胞群体;并且c)在培养物中鉴定至少一个已经发生了靶标区域缺失的真菌细胞;其中该cas内切核酸酶、指导rna或两者被瞬时引入真菌细胞群体中。与真菌细胞的基因组序列同源的在供体dna上的序列在本文中有时被称为“重复序列”。在一些实施例中,重复序列不用于将供体dna插入基因组座位的靶位点处。在一些实施例中,该重复序列为至少约150、200、300、400或500个核苷酸长。
在真菌细胞基因组中缺失靶标区域的方法的某些实施例中,该方法进一步包括在步骤a)和b)之间从群体中鉴定出在靶位点处已经发生供体dna的插入的至少一个真菌细胞的步骤。在该方法的一些实施例中,该供体dna不是经由供体dna和真菌细胞基因组之间的同源重组插入靶位点的。
在本文所述方法的某些实施例中,该cas内切核酸酶是ii型cas9内切核酸酶或其变体。在一些实施例中,该cas9内切核酸酶或其变体包含来自选自下组的物种的全长cas9或其功能片段,该组由以下各项组成:链球菌属(streptococcus)物种,化脓性链球菌(s.pyogenes)、变异链球菌(s.mutans)、嗜热链球菌(s.thermophilus);弯曲杆菌属(campylobacter)物种,空肠弯曲杆菌(c.jejuni);奈瑟氏菌属(neisseria)物种,脑膜炎奈瑟球菌(n.meningitides);弗朗西斯氏菌属(francisella)物种,新凶手弗朗西斯菌(f.novicida);巴斯德氏菌属(pasteurella)物种,以及多杀巴斯德菌(p.multocida)。在具体实施例中,可以使用含有与seqidno:1至7中任一项具有至少70%同一性的氨基酸序列的cas9内切核酸酶或其变体,例如与seqidno:1至7中的任一项具有至少80%同一性、至少90%同一性、至少95%同一性、至少96%同一性、至少97%同一性、至少98%同一性、至少99%同一性、并且包括多达100%同一性。在其他实施例中,该cas内切核酸酶或其变体是ii型crispr-cas系统的cpf1内切核酸酶。
在某些实施例中,将cas内切核酸酶和/或指导rna引入真菌细胞中包括将一种或多种dna构建体引入到真菌细胞中,该dna构建体包含用于cas内切核酸酶的表达盒、指导rna或两者。该一种或多种dna构建体一旦在真菌细胞中就表达cas内切核酸酶和/或指导rna。
在某些实施例中,该引入步骤包括将cas内切核酸酶多肽、指导rna或两者直接引入真菌细胞中。可以使用直接引入和使用dna构建体的任何组合(例如,根据需要同时或依次地将具有用于cas内切核酸酶的表达盒的dna构建体引入真菌细胞中并且将指导rna直接引入细胞中)。
在本文所述方法的某些实施例中,在dna构建体中的cas表达盒包括为了在真菌细胞中表达而优化的cas内切核酸酶编码基因。例如,为了在丝状真菌细胞中表达而优化的cas内切核酸酶编码基因包括与seqidno:8具有至少70%序列同一性的序列(编码来自化脓性链球菌的cas9;seqidno:1)。
在一些情况下,cas内切核酸酶有效地连接到一个或多个核靶向信号(也被称为核定位信号/序列;nls)。seqidno:9和seqidno:10分别提供了在n-末端和c-末端具有nls序列的丝状真菌细胞优化的cas9基因和所编码的氨基酸序列的实例。许多不同的nls在真核生物中是已知的。它们包括单分型、双分型和三分型。可以使用任何适合的nls,单分型略微更适合,其中实例包括sv40nls、来自里氏木霉blr2(蓝光调节剂2)基因的nls、或两者的组合。
在某些实施例中,用于指导rna的表达盒包含在真子囊菌纲(euascomycete)或盘菌纲(pezizomycete)中起作用的dna聚合酶iii依赖性启动子,该启动子有效地连接至编码指导rna的dna。在一些情况下,该启动子来源于木霉属(trichoderma)u6snrna基因。在一些实施例中,该启动子包含与seqidno:11或12具有至少60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%同一性的核苷酸序列。在一些实施例中,该启动子包含seqidno:11或12的序列。在某些实施例中,编码指导rna的dna包含来自木霉属u6snrna基因的内含子序列。
可用于本发明方法中的真菌细胞可以是丝状真菌细胞。在一些实施例中,该真菌细胞是真菌亚门或盘菌亚门真菌细胞。在某些实施例中,真菌细胞是选自下组的物种,该组由以下各项组成:木霉属(trichoderma)、青霉属(penicillium)、曲霉属(aspergillus)、腐质霉属(humicola)、金孢子菌属(chrysosporium)、镰孢属(fusarium)、脉孢菌属(neurospora)、毁丝霉属(myceliophthora)、嗜热真菌属(thermomyces)、肉座菌属(hypocrea)、和裸胞壳属(emericella)。在一些实施例中,丝状真菌细胞选自里氏木霉(trichodermareesei)、产黄青霉(p.chrysogenum)、嗜热毁丝霉(m.thermophila)、疏棉状嗜热丝孢菌(thermomyceslanuginosus)、米曲霉(a.oryzae)和黑曲霉(a.niger)。还可以使用其他真菌细胞,包括酵母的物种。
由所披露方法的使用者选择的靶位点可以位于目的基因的选自下组的区域中,该组由以下各项组成:可读框、启动子、调节序列、终止序列、调节元件序列、剪接位点、编码序列、聚泛素化位点、内含子位点和内含子增强基序。目的基因的实例包括编码以下各项的基因:乙酰酯酶、氨肽酶、淀粉酶、阿拉伯糖酶、阿拉伯呋喃糖苷酶、羧肽酶、过氧化氢酶、纤维素酶、几丁质酶、角质酶、脱氧核糖核酸酶、差向异构酶、酯酶、α-半乳糖苷酶、β-半乳糖苷酶、α-葡聚糖酶、葡聚糖裂解酶、内切-β-葡聚糖酶、葡糖淀粉酶、葡萄糖氧化酶、α-葡糖苷酶、β-葡糖苷酶、葡萄糖醛酸酶、半纤维素酶、己糖氧化酶、水解酶、转化酶、异构酶、漆酶、脂肪酶、裂解酶、甘露糖苷酶、氧化酶、氧化还原酶、果胶酸裂解酶、果胶乙酰酯酶、果胶解聚酶、果胶甲酯酶、果胶分解酶、过氧化物酶、酚氧化酶、植酸酶、聚半乳糖醛酸酶、蛋白酶、鼠李糖-半乳糖醛酸酶、核糖核酸酶、转移酶、转运蛋白、转谷氨酰胺酶、木聚糖酶、己糖氧化酶、及其组合。与参与细胞信号传导、形态学、生长速率和蛋白质分泌的基因一样,编码调节蛋白(例如转录因子、抑制子、调节其他蛋白质例如激酶的蛋白质、参与翻译后修饰(例如糖基化)的蛋白质)的靶基因可以经受cas介导的编辑。在这方面不旨在限制。
在这些方法的一些实施例中,鉴定在目的位点处具有基因组修饰的真菌细胞的步骤包括在对靶位点处的修饰进行选择或筛选的条件下培养来自步骤(a)的细胞群体。这些条件包括抗生素选择条件、选择或筛选营养缺陷型细胞的条件等。
本披露的方面涉及通过上文所述方法产生的重组真菌细胞以及在执行这些方法中用作亲本宿主细胞的重组真菌细胞。
在本文中示出了本披露的方法和组合物的另外的实施例。
附图说明
从形成本申请的一部分的以下详细说明和附图中可以更全面地理解本披露。
图1.纯的spycas9介导的dna插入用于在里氏木霉中进行基因缺失的应用的工作流程。
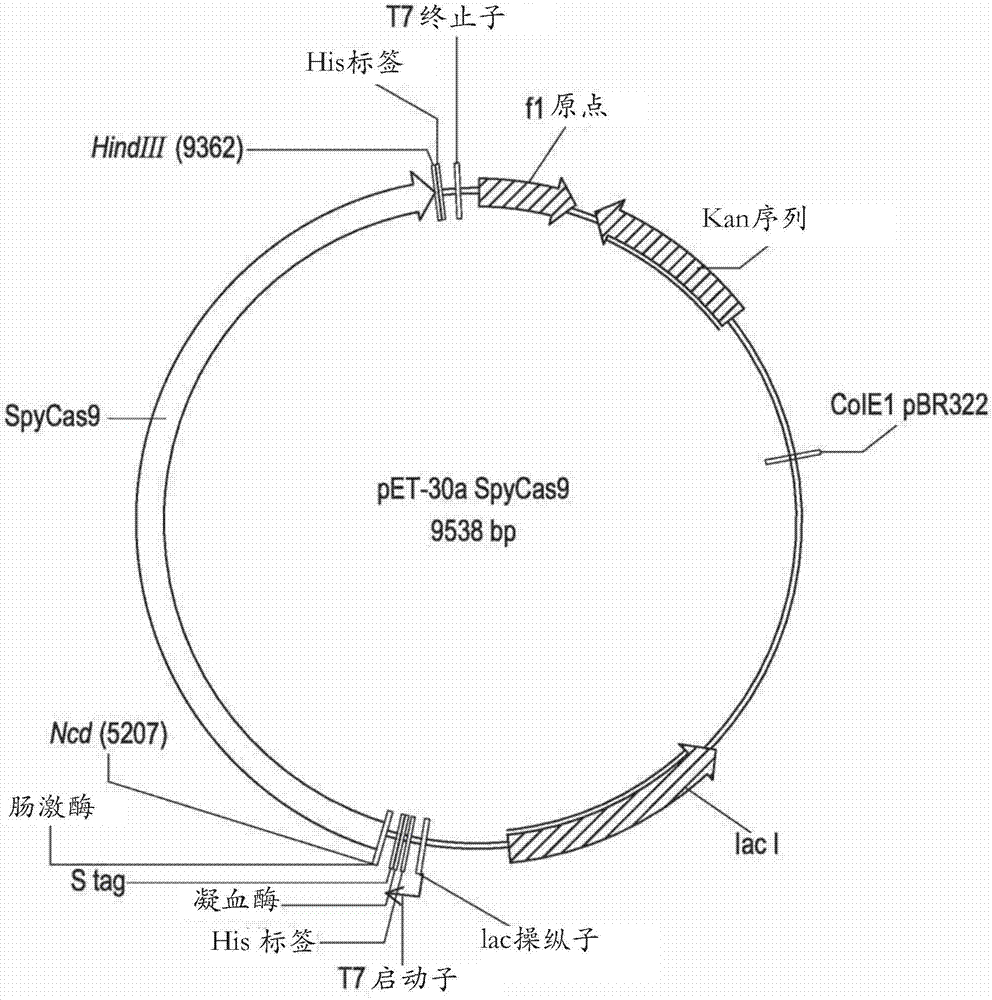
图2.pet30a-spycas9的质粒图。
图3.pmd18t(t7-trga_sth_sgr2)的质粒图。
图4.spycas9核酸酶试验。泳道1,dna梯度;泳道2和泳道3,分别在水和trga_sth_sgr2存在下的spycas9试验。
图5.在vogel淀粉(无葡萄糖)板试验中转化体的形态。从用spycas9/sgrna处理的板上挑取1至14个转化体,同时从对照板中随机选择转化体d1至d5。面板a,常规vogel琼脂板。面板b,vogel淀粉(无葡萄糖)板。
图6a-6c.基于目的基因(goi)中靶位点(或前间区序列,“ps”)的位置的插入方向非依赖性(insertion-orientation-independent)缺失盒设计(供体dna)。基因组序列显示在图6a-6c中每一个的顶部,而供体dna显示在这些图中每一个的底部。针对以下各项显示了供体dna设计:ps在goi的c-末端/3'末端附近(图6a);ps在goi的中间部分处或附近(图6b);ps在goi的n-末端/5'末端附近(图6c)。utr=非翻译区;goi=目的基因;r1=重复序列1;r2=重复序列2;pyr2表达盒=pyr2基因的表达盒。
技术实现要素:
本披露包括可用于在真菌细胞的基因组中的靶位点处插入供体dna的组合物和方法。这些方法使用功能性指导rna/cas内切核酸酶复合物,该复合物识别所希望的靶位点并在该位点处引入双链断裂,从而允许在靶位点处插入供体dna。
在更详细地描述本发明组合物和方法之前,应当理解,本发明组合物和方法不限于所描述的具体实施例,因此当然可以变化。还应当理解,在此使用的术语仅是出于描述具体实施例的目的,并且不旨在进行限制,因为本发明组合物和方法的范围将仅由所附权利要求书限制。
在提供了一系列值的情况下,应理解每个中间值为到下限的十分之一单位(除非上下文清晰地另外指示),该范围的上限与下限之间以及在该陈述范围内的任何其他陈述的或中间值均被涵盖在本发明的组合物和方法之内。这些较小范围的上限和下限可以被独立地包括在所述较小的范围内,并且也被涵盖在本发明的组合物和方法之内,服从所陈述范围中任何特别排除的限值。在所陈述的范围包括一个或者全部两个限值的情况下,排除那些包括的限值的任一个或者全部两个的范围也包括在本发明的组合物和方法中。
本文提供了某些范围,其中数值前面是术语“约”。术语“约”在本文中用于为其后面的确切数字以及与该术语后面的数字接近或近似的数字提供文字支持。在确定数字是否接近或近似于具体叙述的数字时,接近或近似的未列举的数字可以是在呈现其的上下文中提供具体叙述的数字的实质性等值的数字。例如,关于数值,术语“约”是指数值的-10%至+10%的范围,除非术语在上下文中另有具体定义。在另一个实例中,短语“约6的ph值”是指ph值为从5.4至6.6,除非ph值另有具体定义。
本文提供的标题并非对本发明的组合物和方法的各个方面或实施例进行限制,这些方面或实施例可通过将说明书作为一个整体来参考而得到。因此,将说明书作为一个整体参考时,下面即将定义的术语被定义得更全面。
将本文件分为若干部分以便于阅读;然而,读者将理解,在一个部分中进行的陈述可能适用于其他部分。以这种方式,用于本披露的不同部分的标题不应被解释为限制。
除非另有定义,本文使用的所有技术和科学术语具有与本发明组合物和方法所属领域的普通技术人员通常理解的相同含义。虽然类似于或等同于本文描述的那些的任何方法和材料也可以用于本发明组合物和方法的实践或测试中,但现在将对代表性示例方法和材料进行描述。
在本说明书中引用的所有公开物和专利都通过引用结合在此,就好像每个单独的公开物或专利被具体地并单独地指示为通过引用结合,并且通过引用结合在此从而结合引用的公开物来披露和描述这些方法和/或材料。任何公开物的引用内容是针对其在申请日之前的披露,并且不能理解为承认因为先前发明而本发明组合物和方法不能获得比这些公开物更早的申请日。此外,所提供的公开日期可能与实际公开日期不同,实际公开日期可能需要独立地证实。
根据这一详细说明,以下缩写和定义适用。应当注意单数形式“一个/一种(a/an)”和“该(the)”包括复数个指示物,除非上下文中清楚地另外指出。因此,例如提及“酶”包括多个这样的酶,并且提及“剂量”包括提及一个或多个剂量以及本领域技术人员已知的其等效物,等等。
进一步注意的是,权利要求书可以撰写以排除任何可选择的要素。因此,该陈述意在作为使用与权利要求要素的叙述有关的排他性术语例如“单独”、“仅”等或利用“否定型”限定的前提基础。
如将对于本领域技术人员显而易见的是,在阅读本披露时,本文描述和展示的单独实施例中的每一个具有离散的组分和特征,这些组分和特征可以在不偏离本文所述的本发明组合物和方法的范围或精神的情况下容易地与任何其他几个实施例的任何一个的特征分离或组合。可以按照所叙述的事件的顺序或按照逻辑上可行的任何其他顺序来进行任何叙述的方法。
定义
如本文中所使用,被称为“cas内切核酸酶”或具有“cas内切核酸酶活性”的多肽涉及由cas基因编码的crispr相关(cas)多肽,其中当与一种或多种指导多核苷酸功能耦合时,该cas蛋白能够切割靶dna序列(参见,例如名称为“crispr-cas系统和用于改变基因产物的表达的方法(crispr-cassystemsandmethodsforalteringexpressionofgeneproducts)”的美国专利8697359)。保留指导多核苷酸指导的内切核酸酶活性的cas内切核酸酶的变体也包括在该定义中。在本文详述的供体dna插入方法中采用的cas内切核酸酶是在靶位点处向dna中引入双链断裂的内切核酸酶。通过指导多核苷酸指导cas内切核酸酶识别和切割双链dna中的特异性靶位点,例如在细胞基因组中的靶位点。已经描述了若干种不同类型的crispr-cas系统,并且这些crispr-cas系统可以被分类为i型、ii型和iii型crispr-cas系统(参见,例如liu和fan,crispr-cassystem:apowerfultoolforgenomeediting[crispr-cas系统:用于基因组编辑的有力工具],plantmolbiol[植物分子生物学](2014)85:209-218中的描述)。在某些实施例中,该cas内切核酸酶或其变体是ii型crispr-cas系统的cas9内切核酸酶。cas9内切核酸酶可以是任何方便的cas9内切核酸酶,包括但不限于来自以下细菌物种的cas9内切核酸酶及其功能片段:链球菌属物种(例如,化脓性链球菌、变异链球菌和嗜热链球菌);弯曲杆菌属物种(例如,空肠弯曲杆菌);奈瑟氏菌属物种(例如,脑膜炎奈瑟球菌);弗朗西斯氏菌属物种(例如,新凶手弗朗西斯菌);巴斯德氏菌属物种(例如,多杀巴斯德菌)。可以使用许多其他种类的cas9。例如,可以使用含有与seqidno:1至7中任一项具有至少70%同一性的氨基酸序列的功能性cas9内切核酸酶或其变体,例如与seqidno:1至7中的任一项具有至少80%同一性、至少90%同一性、至少95%同一性、至少96%同一性、至少97%同一性、至少98%同一性、至少99%同一性、并且包括多达100%同一性。在其他实施例中,该cas内切核酸酶或其变体是ii型crispr-cas系统的cpf1内切核酸酶。cpf1介导具有与cas9不同的特征的强大的dna干扰。cpf1缺乏tracrrna并且利用富含t的前间区序列邻近基序。它经由交错的dna双链断裂切割dna。参见,例如zetsche等人,cell[细胞](2015)163:759-771。
如本文中所使用,术语“指导多核苷酸”涉及可以与cas内切核酸酶形成复合物的多核苷酸序列,并且使得cas内切核酸酶能够识别并且切割dna靶位点。指导多核苷酸可以是单分子或双分子。指导多核苷酸序列可以是rna序列、dna序列或其组合(rna-dna组合序列)。任选地,指导多核苷酸可以包含至少一种核苷酸、磷酸二酯键或连接修饰,例如但不限于锁核酸(lna)、5-甲基dc、2,6-二氨基嘌呤、2'-氟代a、2’-氟代u、2'-o-甲基rna、硫代磷酸酯键、与胆固醇分子的连接、与聚乙二醇分子的连接、与间隔子18(六乙二醇链)分子的连接、或导致环化的5'至3'共价连接。仅包含核糖核酸的指导多核苷酸也被称为“指导rna”。
指导多核苷酸可以是双分子(也被称为双链体指导多核苷酸),其包含与靶dna中的核苷酸序列互补的第一核苷酸序列结构域(被称为可变靶向结构域或vt结构域)和与cas内切核酸酶多肽相互作用的第二核苷酸序列结构域(被称为cas内切核酸酶识别结构域或cer结构域)。双分子指导多核苷酸的cer结构域包含沿着互补区域杂交的两个单独的分子。两个单独的分子可以是rna、dna和/或rna-dna组合序列。在一些实施例中,包含连接到cer结构域的vt结构域的双链体指导多核苷酸的第一个分子被称为“crdna”(当由dna核苷酸的连续延伸构成时)或“crrna”(当由rna核苷酸的连续延伸构成时)或“crdna-rna”(当由dna和rna核苷酸的组合构成时)。cr核苷酸(crnucleotide)可以包含在细菌和古细菌中天然存在的crrna的片段。在一个实施例中,存在于本文披露的cr核苷酸中、在细菌和古细菌中天然存在的crrna的片段的大小可以在但不限于2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20或更多个核苷酸的范围内。在一些实施例中,包含cer结构域的双链体指导多核苷酸的第二个分子被称为“tracrrna”(当由rna核苷酸的连续延伸构成时)或“tracrdna”(当由dna核苷酸的连续延伸构成时)或“tracrdna-rna”(当由dna和rna核苷酸的组合构成时)。在某些实施例中,指导rna/cas9内切核酸酶复合物的rna是包含双链体crrna-tracrrna的双链体化的rna。
指导多核苷酸还可以是单分子,其包含与靶dna中的核苷酸序列互补的第一核苷酸序列结构域(被称为可变靶向结构域或vt结构域)和与cas内切核酸酶多肽相互作用的第二核苷酸结构域(被称为cas内切核酸酶识别结构域或cer结构域)。“结构域”意指可以为rna、dna和/或rna-dna组合序列的核苷酸的连续延伸。单指导多核苷酸的vt结构域和/或cer结构域可以包含rna序列、dna序列或rna-dna组合序列。在一些实施例中,单指导多核苷酸包含连接到tracr核苷酸(包含cer结构域)的cr核苷酸(包含与cer结构域连接的vt结构域),其中该连接是包含rna序列、dna序列或rna-dna组合序列的核苷酸序列。由来自cr核苷酸和tracr核苷酸的序列构成的单指导多核苷酸可以被称为“单指导rna”(当由rna核苷酸的连续延伸构成时)或“单指导dna”(当由dna核苷酸的连续延伸构成时)或“单指导rna-dna”(当由rna和dna核苷酸的组合构成时)。在本披露的一个实施例中,单指导rna包含可以与ii型cas内切核酸酶形成复合物的、ii型crispr/cas系统的crrna或crrna片段以及tracrrna或tracrrna片段,其中该指导rna/cas内切核酸酶复合物可以将cas内切核酸酶指导到真菌细胞基因组靶位点,使cas内切核酸酶能够在基因组靶位点处引入双链断裂。
使用单指导多核苷酸相对于双链体指导多核苷酸的一个方面是仅需要制备一个表达盒以便在靶细胞中表达单指导多核苷酸。
术语“可变靶向结构域”或“vt结构域”在本文中可互换使用,并且包括与双链dna靶位点的一条链(核苷酸序列)互补的核苷酸序列。在第一个核苷酸序列结构域(vt结构域)与靶序列之间的%互补是至少50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、63%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或是100%互补的。vt结构域可以是至少12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个核苷酸长度。在一些实施例中,vt结构域包含12至30个核苷酸的连续延伸。vt结构域可以由dna序列、rna序列、修饰的dna序列、修饰的rna序列或其任何组合构成。
术语指导多核苷酸的“cas内切核酸酶识别结构域”或“cer结构域”在本文中可互换使用,并且包括与cas内切核酸酶多肽相互作用的核苷酸序列(例如指导多核苷酸的第二核苷酸序列结构域)。cer结构域可以由dna序列、rna序列、修饰的dna序列、修饰的rna序列(参见例如本文所述的修饰)或其任何组合构成。
连接单指导多核苷酸的cr核苷酸和tracr核苷酸的核苷酸序列可以包含rna序列、dna序列或rna-dna组合序列。在一个实施例中,连接单指导多核苷酸的cr核苷酸和tracr核苷酸的核苷酸序列可以是至少3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99或100个核苷酸长度。在另一个实施例中,连接单指导多核苷酸的cr核苷酸和tracr核苷酸的核苷酸序列可以包含四环序列,例如但不限于gaaa四环序列。
指导多核苷酸、vt结构域和/或cer结构域的核苷酸序列修饰可以选自但不限于下组,该组由以下各项组成:5'帽、3'聚腺苷酸化尾巴、核糖开关序列、稳定性控制序列、形成dsrna双链体的序列、将指导多核苷酸靶向亚细胞位置的修饰或序列、提供跟踪的修饰或序列、为蛋白质提供结合位点的修饰或序列、锁核酸(lna)、5-甲基dc核苷酸、2,6-二氨基嘌呤核苷酸、2'-氟代a核苷酸、2'-氟代u核苷酸、2'-o-甲基rna核苷酸、硫代磷酸酯键、与胆固醇分子的键合、与聚乙二醇分子的键合、与间隔区18分子的键合、5'至3'共价键、或其任何组合。这些修饰可以导致至少一个另外的有益特征,其中该另外的有益特征选自以下各项的组:修饰或调节的稳定性、亚细胞靶向、跟踪、荧光标记、蛋白质或蛋白质复合物的结合位点、与互补靶序列的修饰的结合亲和力、对细胞降解的修饰的抗性、以及增加的细胞通透性。
如本文所用,术语“指导多核苷酸/cas内切核酸酶系统”(和等效物)包括能够将双链断裂引入dna靶序列的cas内切核酸酶和指导多核苷酸(单链体或双链体)的复合物。该cas内切核酸酶在基因组靶位点极为贴近处解开dna双链体,并在通过指导rna识别靶序列时切割两条dna链,但只有当正确的前间区序列邻近基序(pam)在靶序列的3'末端适当地定向时才进行上述切割。
术语“功能片段”、“功能等同的片段”、“功能等同片段”等可互换使用,并且是指保留亲本多肽的定性酶活性的亲本多肽的一部分或子序列。例如,cas内切核酸酶的功能片段保留与指导多核苷酸一起产生双链断裂的能力。这里,应当注意到,如与亲本多肽相比,功能片段可能具有改变的定量酶活性。
术语“功能变体”、“功能上等同的变体”、“功能等同变体”等可互换使用,并且是指保留亲本多肽的定性酶活性的亲本多肽的变体。例如,cas内切核酸酶的功能变体保留与指导多核苷酸一起产生双链断裂的能力。这里,应当注意到,如与亲本多肽相比,功能变体可能具有改变的定量酶活性。
可以经由任何方便的方法(包括定点诱变和合成构建)获得这些片段和变体。
当应用于真菌细胞时,术语“基因组”不仅涵盖在细胞核内发现的染色体dna,而且涵盖在细胞的亚细胞组分(例如线粒体)内发现细胞器dna。
“密码子修饰的基因”或“密码子偏好的基因”或“密码子优化的基因”是其密码子使用频率被设计为模拟宿主细胞的偏好的密码子使用频率的基因。进行核酸改变以密码子优化基因是“同义的”,这意味着它们不改变亲本基因的编码多肽的氨基酸序列。然而,天然基因和变体基因二者都可以针对特定宿主细胞进行密码子优化,因此在这方面不意图限制。
“编码序列”是指编码特定氨基酸序列的多核苷酸序列。“调节序列”是指位于编码序列的上游(5'非编码序列)、内部或下游(3'非编码序列)的核苷酸序列,并且其影响相关的编码序列的转录、rna加工或稳定性、或翻译。调节序列可以包括但不限于:启动子、翻译前导序列、5'非翻译序列、3'非翻译序列、内含子、聚腺苷酸化靶序列、rna加工位点、效应子结合位点和茎-环结构。
“启动子”是指能够控制编码序列或功能性rna表达的dna序列。启动子序列由近端和更远端的上游元件组成,后一元件通常被称为增强子。“增强子”是可以促进启动子活性的dna序列,并且可以是启动子的固有元件或被插入以增强启动子的水平或组织特异性的异源元件。启动子可以全部来源于天然基因,或者由来源于在自然界存在的不同启动子的不同元件构成,和/或包含合成的dna区段。本领域技术人员应当理解,不同的启动子可能指导基因在不同组织或细胞类型中、或在不同的发育阶段、或者响应于不同的环境条件中的表达。进一步认识到,由于在大多数情况下调节序列的确切边界尚未完全限定,一些变异的dna片段可能具有相同的启动子活性。如在本领域中熟知的,启动子可以根据其强度和/或它们有活性的条件进行分类,例如组成型启动子、强启动子、弱启动子、诱导型/阻抑型启动子、组织特异性/发育调节性启动子、细胞周期依赖性启动子等。
“rna转录物”是指由rna聚合酶催化的dna序列转录产生的产物。“信使rna”或“mrna”是指不含内含子并且可以被细胞翻译成蛋白质的rna。“cdna”是指使用酶逆转录酶与mrna模板互补并由其合成的dna。“正义”rna是指包含mrna并且可以在细胞内或体外翻译成蛋白质的rna转录物。“反义rna”是指与靶初级转录物或mrna的全部或部分互补、并且在某些条件下阻断靶基因的表达的rna转录物(参见,例如美国专利号5,107,065)。反义rna的互补性可以是与特定基因转录物的任何部分,即在5'非编码序列、3'非编码序列、内含子或编码序列处。“功能性rna”是指反义rna、核酶rna、或不能被翻译成多肽但对细胞加工有影响的其他rna。术语“补体”和“反向互补体”在本文中关于mrna转录物可互换使用,并且意在限定信使的反义rna。
如本文中所使用,“功能附接”或“有效地连接”意指具有已知或期望的活性的多肽或多核苷酸序列的调节区域或功能结构域(例如启动子、增强子区域、终止子、信号序列、表位标签等)按这样一种方式附接于或连接于靶标(例如,基因或多肽):以允许调节区域或功能结构域根据其已知或期望的活性来控制该靶标的表达、分泌或功能的方式。例如,当启动子能够调节编码序列的表达(即,该编码序列在启动子的转录控制下)时,启动子与该编码序列有效地连接。
本文中使用的标准重组dna和分子克隆技术是本领域熟知的。
“pcr”或“聚合酶链式反应”是用于特定dna区段的合成的技术,由一系列重复变性、退火和延伸循环组成,并且是本领域熟知的。
当用于提及生物组分或组合物(例如细胞、核酸、多肽/酶、载体等)时,术语“重组体”表示生物组分或组合物处于自然界中未发现的状态。换句话说,生物组分或组合物已经通过人类干预从其天然状态改变。例如,重组细胞涵盖表达在其天然亲本(即非重组)细胞中未发现的一种或多种基因的细胞、以不同于其天然亲本细胞的量表达一种或多种天然基因的细胞、和/或在不同于其天然亲本细胞的条件下表达一种或多种天然基因的细胞。重组核酸可以通过一个或多个核苷酸与天然序列不同、有效地连接到异源序列(例如异源启动子、编码非天然或变体信号序列的序列等)、缺乏内含子序列、和/或处于分离的形式。重组多肽/酶可以通过一个或多个氨基酸与天然序列不同,可以与异源序列融合,可以被截短或具有氨基酸的内部缺失,能以在天然细胞中未发现的方式表达(例如,来自重组细胞,该重组细胞由于细胞中存在编码多肽的表达载体而过量表达多肽),和/或处于分离的形式。需要强调的是,在一些实施例中,重组多核苷酸或多肽/酶具有与其野生型对应物同一但处于非天然形式(例如,处于分离或富集的形式)的序列。
术语“质粒”、“载体”和“盒”是指携带目的多核苷酸序列的额外的染色体元件,例如将在细胞中表达的目的基因(“表达载体”或“表达盒”)。这样的元件通常处于双链dna的形式,并且可以是来源于任何来源的、单链或双链dna或rna的、处于直链或环状形式的自主复制序列、基因组整合序列、噬菌体、或核苷酸序列,其中许多核苷酸序列已经被连接或重组成能够将目的多核苷酸引入细胞中的独特构造。目的多核苷酸序列可以是编码将在靶细胞中表达的多肽或功能性rna的基因。表达盒/载体通常包含具有有效地连接的元件的基因,这些元件允许该基因在宿主细胞中表达。
如本文中所使用,术语“表达”是指处于前体或成熟形式的功能性终产物(例如,mrna、指导rna或蛋白质)的产生。
在将多核苷酸或多肽插入细胞(例如,重组dna构建体/表达构建体)的背景下,“引入”是指用于执行这样的任务的任何方法,并且包括为了实现所希望的生物分子的引入的“转染”、“转化”、“转导”、物理手段等的任何方法。
“瞬时地引入”、“瞬时引入的”、“瞬时的引入”、“瞬时表达”等意指将生物分子以非永久性方式引入宿主细胞(或宿主细胞的群体)中。关于双链dna,瞬时的引入包括其中引入的dna不整合到宿主细胞的染色体中并因此在生长期间不被传递到所有子代细胞的情况,以及其中在所希望的时间使用任何方便的方法(例如,使用cre-lox系统、通过去除附加型dna构建体的正选择压力、通过使用选择培养基促进整合的多核苷酸的全部或部分从染色体中环出,等等)将可能已经整合到染色体中的引入的dna分子除去的情况。在这方面不旨在限制。通常,将rna(例如,指导rna、信使rna、核糖酶等)或多肽(例如,cas多肽)引入宿主细胞中被认为是瞬时的,因为这些生物分子在细胞生长期间不被复制并且不明确地传递到子代细胞。关于cas/指导rna复合物,瞬时的引入包括当瞬时地引入这两种组分中的任一种时的情况,因为需要两种生物分子都发挥靶向的cas内切核酸酶活性。因此,cas/指导rna复合物的瞬时的引入包括瞬时地引入cas内切核酸酶和指导rna中的任一种或两种的实施例。例如,具有其中瞬时地引入了指导rna的、cas内切核酸酶的基因组整合的表达盒(并且因此不是瞬时地引入)的宿主细胞可以被称为已经瞬时地引入了cas/指导rna复合物(或系统),因为功能性复合物以瞬时的方式存在于宿主细胞中。在某些实施例中,该引入步骤包括:(i)获得稳定表达cas内切核酸酶的亲本真菌细胞群体,和(ii)将指导rna瞬时地引入亲本真菌细胞群体中。相反地,该引入步骤可以包括:(i)获得稳定表达指导rna的亲本真菌细胞群体,和(ii)将cas内切核酸酶瞬时地引入亲本真菌细胞群体中。
“成熟”蛋白质是指翻译后加工的多肽(即,从其中已经除去存在于初级翻译产物中的任何前肽(pre-peptide)或原肽(propeptide)的一种多肽)。“前体”蛋白质是指mrna的翻译的初级产物(即,仍存在前肽或原肽)。前肽或原肽可以是但不限于细胞内定位信号。
“稳定的转化”是指将核酸片段转移到宿主生物体的基因组中,包括细胞核和细胞器基因组二者,导致遗传上稳定的遗传(有时所得的宿主细胞在本文中被称为“稳定的转化体”)。相比之下,“瞬时的转化”是指将核酸片段转移到宿主生物体的细胞核或其他含dna的细胞器中,导致基因表达而没有整合或稳定的遗传(有时在本文中被称为“不稳定的转化”,并且有时所得的宿主细胞在本文中被称为“不稳定的转化体”)。含有转化的核酸片段的宿主生物体被称为“转基因”生物体。
如本文中所使用,“真菌细胞”、“真菌”、“真菌宿主细胞”等包括门子囊菌门(ascomycota)、担子菌门(basidiomycota)、壶菌门(chytridiomycota)和接合菌门(zygomycota)(由hawksworth等人,在:ainsworthandbisby'sdictionaryofthefungi,8thedition,1995,cabinternational,universitypress,cambridge,uk[真菌的安斯沃思和拜斯比词典,第8版,1995年,英国剑桥cab国际集团,大学出版社])以及卵菌门(oomycota)(如在hawksworth等人,同上引用的)和所有有丝分裂孢子真菌(hawksworth等人,同上)。在某些实施例中,真菌宿主细胞是酵母细胞,其中“酵母”意指产子囊酵母(内孢霉目(endomycetales))、产担子酵母、和属于不完全菌纲(fungiimperfecti)(芽孢纲(blastomycetes)))的酵母。因此,酵母宿主细胞包括假丝酵母属(candida)、汉逊酵母属(hansenula)、克鲁维酵母属(kluyveromyces)、毕赤酵母属(pichia)、酵母属(saccharomyces)、裂殖酵母属(schizosaccharomyces)、或耶氏酵母属(yarrowia)细胞。酵母的物种包括但不限于以下各项:卡尔斯伯酵母(saccharomycescarlsbergensis),酿酒酵母(saccharomycescerevisiae)、糖化酵母(saccharomycesdiastaticus)、saccharomycesdouglasii、克鲁弗酵母(saccharomyceskluyveri)、诺地酵母(saccharomycesnorbensis)、卵形酵母(saccharomycesoviformis)、乳酸克鲁维酵母(kluyromomyceslactis)和解脂耶氏酵母(yarrowialipolytica)细胞。
术语“丝状真菌细胞”包括亚门真菌亚门(eumycotina)或盘菌亚门(pezizomycotina)的所有丝状形式。丝状真菌属的合适的细胞包括但不限于:支顶孢属、曲霉属、金孢子菌属、棒囊壳属、毛壳菌属、裸胞壳属、镰孢属、赤霉菌属、腐质霉属、大角间座壳属(magnaporthe)、毁丝霉属、脉孢菌属、拟青霉属、青霉属、scytaldium、踝节菌属(talaromyces)、嗜热子囊菌属(thermoascus)、梭孢壳属、弯颈霉属、肉座菌属和木霉属的细胞。
丝状真菌物种的合适细胞包括但不限于:泡盛曲霉、烟曲霉、臭曲霉、日本曲霉、构巢曲霉、黑曲霉、米曲霉、卢克诺文思金孢子菌(chrysosporiumlucknowense)、杆孢状镰孢菌(fusariumbactridioides)、谷类镰孢菌(fusariumcerealis)、克地镰孢菌(fusariumcrookwellense)、黄色镰孢菌(fusariumculmorum)、禾谷镰孢菌(fusariumgraminearum)、禾赤镰孢菌(fusariumgraminum)、异孢镰孢菌(fusariumheterosporum)、合欢木镰孢菌(fusariumnegundi)、尖孢镰孢菌、多枝镰孢菌、粉红镰孢菌、接骨木镰孢菌、肤色镰孢菌、拟枝孢镰孢菌、硫色镰孢菌、圆镰孢菌、拟丝孢镰孢菌、镶片镰孢菌、特异腐质霉、柔毛腐质霉、红褐肉座菌(hypocreajecorina)、嗜热毁丝霉、粗壮脉纹孢菌、间型脉孢菌、产紫青霉、变灰青霉(penicilliumcanescens)、离生青霉(penicilliumsolitum)、绳状青霉(penicilliumfuniculosum)、黄孢原毛平革菌(phanerochaetechrysosporium)、黄色蠕形霉(talaromycesflavus)、土生梭孢壳、哈茨木霉、康氏木霉、长柄木霉、里氏木霉和绿色木霉的细胞。
术语“靶位点”、“靶序列”、“基因组靶位点”、“基因组靶序列”(和等效物)在本文中可互换使用,并且是指真核细胞的基因组中的多核苷酸序列,其中期望cas内切核酸酶切割会促进基因组修饰,例如,供体dna的插入和随后的目的基因组区域的缺失。然而,使用这个术语的上下文可以稍微改变其含义。例如,cas内切核酸酶的靶位点通常是具有高特异性的,并且通常可以被定义为确切的核苷酸位置,然而在一些情况下,所希望的基因组修饰的靶位点可以比仅dna切割发生的位点更广泛地进行定义,例如有待于从基因组中缺失的基因组座位或区域。因此,在某些情况下,经由cas/指导rna的活性发生的基因组修饰dna切割被描述为发生在靶位点“处或附近”。靶位点可以是真菌细胞基因组中的内源性位点,或者可替代地,靶位点可以与真菌细胞异源,从而不是基因组中天然存在的,或者与其在自然界中存在的地方相比,靶位点可以发现于异源基因组位置中。
如本文中所使用,“核酸”意指多核苷酸,并且包括脱氧核糖核苷酸或核糖核苷酸碱基的单链或双链聚合物。核酸还可以包括片段和修饰的核苷酸。因此,术语“多核苷酸”、“核酸序列”、“核苷酸序列”和“核酸片段”可互换使用以表示单链或双链的rna和/或dna的聚合物,任选地含有合成的、非天然的或改变的核苷酸碱基。核苷酸(通常以其5'-单磷酸酯形式发现)以单字母名称表示如下:“a”表示腺苷或脱氧腺苷(分别用于rna或dna),“c”表示胞苷或脱氧胞苷,“g”表示鸟苷或脱氧鸟苷,“u”表示尿苷,“t”表示脱氧胸苷,“r”表示嘌呤(a或g),“y”表示嘧啶(c或t),“k”表示g或t,“h”表示a或c或t,“i”表示肌苷,并且“n”表示任何核苷酸。
术语“来源于”涵盖术语“起源于”、“获得自”、“可获得自”、“分离自”和“产生自”,并且通常表示一种指定的材料在另一种指定的材料中找到其起源或具有可以参考另一种指定的材料来描述的特征。
如本文中所使用,术语“杂交条件”是指进行杂交反应的条件。这些条件通常根据杂交在其下测量的条件的“严格”度来分类。严格度可以是基于例如结合复合物或探针的核酸的解链温度(tm)。例如,“最大严格”典型地发生在约tm-5℃(低于探针的tm5℃);“高严格”发生在低于tm约5℃-10℃;“中等严格”发生在低于探针的tm约10℃-20℃;并且“低严格”发生在低于tm约20℃-25℃。可替代地,或另外,杂交条件可以基于杂交的盐或离子强度条件,和/或基于一次或多次严格洗涤,例如:6xssc=非常低严格;3xssc=低至中严格;1xssc=中严格;并且0.5xssc=高严格。在功能上,最大严格条件可以用于鉴定与杂交探针具有严格同一性或近乎严格同一性的核酸序列;而高严格条件用于鉴定与探针具有约80%或更多序列同一性的核酸序列。对于需要高选择性的应用,通常希望使用相对严格的条件来形成杂交(例如,使用相对较低的盐和/或高温条件)。
如在此所用,术语“杂交”是指通过碱基配对将核酸链与互补链连接的过程,如本领域已知的。更具体地,“杂交”是指如在印迹杂交技术和pcr技术期间发生的,一条核酸链与互补链形成双链体(即碱基对)的过程。如果两个序列在中至高严格杂交和洗涤条件下彼此特异性杂交,则认为核酸序列可与参考核酸序列“选择性杂交”。杂交条件是基于结合复合物或探针的核酸的解链温度(tm)。例如,“最大严格”典型地发生在约tm-5℃(低于探针的tm5℃);“高严格”发生在低于tm约5℃-10℃;“中等严格”发生在低于探针的tm约10℃-20℃;并且“低严格”发生在低于tm约20℃-25℃。在功能上,最大严格条件可以用于鉴定与杂交探针具有严格同一性或近乎严格同一性的序列;而中等或低严格杂交可用于鉴定或检测多核苷酸序列同系物。
中等和高严格杂交条件是本领域公知的。例如,中等严格杂交可以在包括20%甲酰胺、5×ssc(150mmnacl、15mm柠檬酸三钠)、50mm磷酸钠(ph7.6)、5×登哈特氏溶液(denhardt’ssolution)、10%葡聚糖硫酸酯和20mg/ml变性剪切的鲑鱼精子dna的溶液中在37℃下过夜孵育来进行,随后在约37℃-50℃下在1xssc中洗涤过滤器。高严格杂交条件可以是在65℃和0.1xssc(其中1xssc=0.15mnacl、0.015m柠檬酸钠,ph7.0)下的杂交。可替代地,高严格杂交条件可以在约42℃下在50%甲酰胺、5xssc、5x登哈特溶液、0.5%sds和100μg/ml变性载体dna中进行,随后在室温下在2xssc和0.5%sds中洗涤两次并且在42℃下在0.1xssc和0.5%sds中再洗涤两次。并且非常高的严格杂交条件可能是在68℃和0.1xssc下的杂交。如果需要,本领域技术人员知道如何调节温度、离子强度等以适应因素如探针长度等等。
在至少两种核酸或多肽的背景下,“基本相似”或“基本上同一”意指多核苷酸或多肽包含与亲本或参照序列至少90%,至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、或甚至至少99%同一的序列,或不包括只是为了规避本说明书而不添加功能的氨基酸取代、插入、缺失或修饰。
在核酸或多肽序列的上下文中的“序列同一性”或“同一性”是指在两个序列中的核酸碱基或氨基酸残基当在指定的比较窗口上比对最大对应度时是相同的。
“序列同一性百分比”是指通过在比较窗口上比较两个最佳比对的序列所确定的值,其中与参比序列(其不包含添加或缺失)比较两个序列的最佳比对时,该多核苷酸或多肽序列在比较窗口中的部分可以包含添加或缺失(即空位)。通过以下方式计算该百分比:确定在两个序列中出现相同核酸碱基或氨基酸残基的位置的数目以产生匹配位置的数目,将匹配位置的数目除以比较窗口中的位置的总数目,然后将该结果乘以100以产生序列同一性百分比。百分比序列同一性的有用实例包括但不限于50%、55%、60%、65%、70%、75%、80%、85%、90%或95%,或从50%至100%的任何整数百分比。这些同一性可以使用本文所述的任何程序来确定。
可以使用设计用于检测同源序列的各种比较方法来确定序列比对和百分比同一性或相似性计算,这些比较方法包括但不限于lasergene生物信息学计算套件(威斯康辛州麦迪逊市dnastar公司)的megaligntm程序。在本应用程序的上下文中,应当理解,在将序列分析软件用于分析的情况下,分析结果将基于所引用程序的“默认值”,除非另有规定。如本文中所使用,“默认值”将意味着在初次初始化时最初与软件一起加载的任何一组值或参数。
“clustalv比对方法”对应于标记有clustalv的比对方法(由higgins和sharp,(1989)cabios5:151-153;higgins等人,(1992)computapplbiosci[计算机在生物科学中的应用]8:189-191描述的)并且在lasergene生物信息学计算套件(威斯康辛州麦迪逊市dnastar公司)的megaligntm程序中找到。对于多重比对,默认值对应于空位罚分(gappenalty)=10和空位长度罚分(gaplengthpenalty)=10。使用clustal方法进行逐对比对和蛋白质序列的百分比同一性计算的默认参数是ktuple=1、空位罚分=3、窗口(window)=5、以及存储的对话框(diagonalssaved)=5。对于核酸,这些参数是ktuple=2、空位罚分=5、窗口=4、以及存储的对话框=4。在使用clustalv程序比对序列之后,可以通过查看同一程序中的“序列距离”表来获得“百分比同一性”。
“clustalw比对方法”对应于标记有clustalw的比对方法(由higgins和sharp,(1989)cabios5:151-153;higgins等人,(1992)computapplbiosci[计算机在生物科学中的应用]8:189-191描述的)并且在lasergene生物信息学计算套件(威斯康辛州麦迪逊市dnastar公司)的megaligntmv6.1程序中找到。多重比对的默认参数(空位罚分=10、空位长度罚分=0.2、延迟发散序列(delaydivergenseqs,%)=30、dna转换权重=0.5、蛋白质权矩阵=gonnet系列、dna权矩阵=iub)。在使用clustalw程序比对序列之后,可以通过查看同一程序中的“序列距离”表来获得“百分比同一性”。
除非另有说明,本文中提供的序列同一性/相似性值是指使用gap版本10(gcg,accelrys公司,圣地亚哥,加利福尼亚州)使用以下参数获得的值:核苷酸序列的%同一性和%相似性使用空位创建罚分权重为50、空位长度延伸罚分权重为3、以及nwsgapdna.cmp打分矩阵;氨基酸序列的%同一性和%相似性使用空位创建罚分权重为8、空位长度延伸罚分为2、以及blosum62打分矩阵(henikoff和henikoff,(1989)proc.natl.acad.sci.usa[美国国家科学院院刊]89:10915)。gap使用needleman和wunsch(1970)jmolbiol[分子生物学杂志]48:443-53的算法来找到使匹配数目最大化并且使空位数目最小化的两个完整序列的比对。gap考虑所有可能的比对和空位位置,并且创建具有最大数目的配对碱基和最小空位的比对,使用以配对碱基为单位的空位创建罚分和空位延伸罚分。
本领域技术人员很清楚地理解,许多水平的序列同一性可用于鉴定来自其他物种的多肽或天然或合成修饰的多肽,其中这样的多肽具有相同或相似的功能或活性。百分比同一性的有用实例包括但不限于50%、55%、60%、65%、70%、75%、80%、85%、90%或95%,或从50%至100%的任何整数百分比。实际上,从50%至100%的任何整数氨基酸同一性可以用于描述本披露,例如51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%。
“基因”包括编码并且能够表达功能分子(例如是但不限于特定多肽(例如酶)或功能性rna分子(例如,指导rna、反义rna、核糖酶等))的核酸片段,并且包括在编码序列之前(5'非编码序列)和/或之后(3'非编码序列)的调节序列。“天然基因”是指自然界中发现的具有其自身调节序列的基因。重组基因是指由可以来自不同生物体或相同生物体的不同基因的调节序列调节的基因。
“突变基因”是通过人为干预已经改变的基因。这样的“突变基因”具有通过至少一个核苷酸添加、缺失或取代而与相应的非突变基因的序列不同的序列。在本披露的某些实施例中,突变基因包含由如本文所披露的指导多核苷酸/cas内切核酸酶系统引起的改变。突变的真菌细胞是包含突变基因的真菌细胞。
如本文中所使用,“靶向突变”是通过使用如本文中所披露的或本领域已知的方法来改变天然基因内的靶序列而进行的天然基因中的突变,所述方法涉及能够在靶序列的dna中诱导双链断裂的双链断裂诱导剂。
术语“供体dna”或“供体核酸序列”或“供体多核苷酸”是指包含目的多核苷酸序列的多核苷酸,该目的多核苷酸序列通常结合cas/指导多核苷酸复合物的活性(其中指导多核苷酸限定靶位点,如上所述)将被插入真菌细胞的基因组中的靶位点处。在某些实施例中,供体dna构建体进一步包含与基因组座位中的基因组序列同源的序列(也被称为重复序列)。“同源”意指类似的dna序列。例如,在供体dna上发现的“与基因组序列同源的区域”是与真菌细胞基因组中给定的“基因组序列”具有相似序列的dna区域。总的来说,与基因组座位中的基因组序列同源的序列和基因组序列本身有时在本文中被称为“重复序列”。同源区域可以具有足以经由重复序列和同源基因组序列之间的同源重组(其可以在选择性培养条件下选择)来促进或允许环出靶标区域的环出的任何长度。例如,重复序列可以包含至少50-55、50-60、50-65、50-70、50-75、50-80、50-85、50-90、50-95、50-100、50-200、50-300、50-400、50-500、50-600、50-700、50-800、50-900、50-1000、50-1100、50-1200、50-1300、50-1400、50-1500、50-1600、50-1700、50-1800、50-1900、50-2000、50-2100、50-2200、50-2300、50-2400、50-2500、50-2600、50-2700、50-2800、50-2900、50-3000、50-3100或更多个碱基长度。“足够的同源性”表示两个多核苷酸序列(例如供体dna和真菌细胞基因组中的正向重复序列)具有足够的结构相似性以便例如在适当的选择性培养条件下使在重复序列之间的序列环出。结构相似性包括每个多核苷酸片段的总长度以及多核苷酸的序列相似性。序列相似性可以通过在序列的整个长度上的百分比序列同一性和/或通过包含局部相似性(例如具有100%序列同一性的连续核苷酸)的保守区域以及在序列长度的一部分上的百分比序列同一性来描述。
如本文中所使用,“基因组区域”或“基因组座位”是在真菌细胞的基因组中的染色体的区段,该区段存在于靶位点(例如,包括与供体dna中的重复序列同源的基因组缺失靶标和基因组重复序列)任一侧,或者可替代地也包含靶位点的一部分。基因组区域可以包含至少50-55、50-60、50-65、50-70、50-75、50-80、50-85、50-90、50-95、50-100、50-200、50-300、50-400、50-500、50-600、50-700、50-800、50-900、50-1000、50-1100、50-1200、50-1300、50-1400、50-1500、50-1600、50-1700、50-1800、50-1900、50-2000、50-2100、50-2200、50-2300、50-2400、50-2500、50-2600、50-2700、50-2800、50-2900、50-3000、50-3100或更多个碱基。
“基因组缺失靶标”和等效物是根据本披露的方面(参见图1),使用者想要缺失的真菌基因组中的序列。“环出靶标区域”和等效物是在正向重复序列(例如,基因组重复序列以及在供体dna中与该基因组重复序列同源的重复序列)之间的区域,该区域通过在真菌基因组中正向重复序列之间的同源重组环出。在某些实施例中,环出靶标区域包括基因组缺失靶标和在真菌基因组中的靶位点处插入的供体dna上的可选择标记。表型标记是可筛选或可选择标记,其包括视觉标记和可选择标记,无论其是阳性还是阴性可选择标记。可以使用任何表型标记。具体地,可选择或可筛选的标记包含允许人们通常在特定条件下鉴定、选择或筛选含有它的分子或细胞或对其进行选择的dna区段。这些标记可以编码活性,例如但不限于rna、肽或蛋白质的产生,或可以提供rna、肽、蛋白质、无机和有机化合物或组合物等的结合位点。
可选择标记的实例包括但不限于包含限制酶位点的dna区段;编码对以下各项提供抗性的产物的dna区段:另外的毒性化合物和抗生素,例如氯嘧磺隆乙酯、苯来特、巴斯塔(basta)、和潮霉素磷酸转移酶(hpt);编码另外在受体细胞中缺少的产物的dna区段(例如,trna基因、营养缺陷型标记、显性异源标记-amds);编码可以容易地鉴定的产物的dna区段(例如,表型标记例如β-半乳糖苷酶、gus;荧光蛋白,例如绿色荧光蛋白(gfp)、青色荧光蛋白(cfp)、黄色荧光蛋白(yfp)、红色荧光蛋白(rfp)和细胞表面蛋白);产生用于pcr的新引物位点(例如,以前未并列的两个dna序列的并列),包含通过限制性内切核酸酶或其他dna修饰酶、化学品等不起作用或起作用的dna序列;并且包含允许其鉴定的特异性修饰(例如,甲基化)所需的dna序列。
用于修饰真菌细胞基因组的方法和组合物
提供了使用指导rna/cas内切核酸酶系统用于在真菌细胞(例如丝状真菌细胞)的基因组中的靶位点处插入供体dna的方法。
本披露的方面包括通过将cas内切核酸酶/指导多核苷酸复合物与供体dna一起瞬时引入真菌细胞,在该细胞的基因组中的靶位点处插入供体dna的方法。cas内切核酸酶/指导多核苷酸复合物能够在真菌细胞的基因组中的靶位点引入双链断裂。
能以任何方便的方式进行cas内切核酸酶、指导多核苷酸和供体dna的引入,这些方式包括转染、转导、转化、电穿孔、粒子轰击、细胞融合技术等。这些组件中的每一个可以如用户希望的同时或顺序地引入。例如,可以首先用cas表达dna构建体稳定转染真菌细胞,随后将指导多核苷酸引入稳定的转染子(直接地或使用表达指导多核苷酸的dna构建体)。这种设置甚至可能是有利的,因为使用者可以产生稳定的cas转染子真菌细胞群体,其中可以单独地引入不同的指导多核苷酸(在一些情况下,如果希望的话,可以将多于一个指导多核苷酸引入相同的细胞中)。在一些实施例中,使用者获得表达cas的真菌细胞,因此使用者不需要将能够表达cas内切核酸酶的重组dna构建体引入细胞中,而只需要将指导多核苷酸引入表达cas的细胞中。
在某些实施例中,通过引入包含编码指导多核苷酸的表达盒(或基因)的重组dna构建体,将指导多核苷酸引入真菌细胞中。在一些实施例中,将表达盒有效地连接到真核rnapoliii启动子。这些启动子是特别感兴趣的,因为通过rnapoliii的转录不会导致在rna聚合酶ii从rnapolii依赖性启动子转录时发生的5'帽结构的添加或聚腺苷酸化。在某些实施例中,rnapoliii启动子是丝状真菌细胞u6聚合酶iii启动子(例如,seqidno:11及其功能变体,例如seqidno:12)。
当在宿主细胞的基因组dna中诱导双链断裂(例如,通过在靶位点处的cas内切核酸酶/指导rna复合物的活性,具有双链内切核酸酶活性的复合物)时,细胞的dna修复机制被激活以修复断裂,该断裂由于其易出错的性质,可以在双链断裂位点处产生突变。将断裂的末端合在一起的最常见的修复机制是非同源末端连接(nhej)途径(bleuyard等人,(2006)dnarepair[dna修复]5:1-12)。染色体的结构完整性通常通过修复来保存,但缺失、插入或其他重排是可能的(siebert和puchta,(2002)plantcell[植物细胞]14:1121-31;pacher等人,(2007)genetics[遗传学]175:21-9)。
令人惊讶地,我们已发现在丝状真菌中,在双链断裂处的转化的dna的非同源插入高度优于在双链断裂处染色体dna两个末端之间的简单末端连接。因此,在通过用含有一个或多个dna构建体的表达盒进行转化来提供cas内切核酸酶或指导rna的情况下,那些dna构建体或其片段以很高的频率插入双链断裂处。这种插入发生在cas内切核酸酶或指导rna表达构建体上的dna序列与双链断裂周围的序列之间不存在同源性的情况下。
可以利用这一过程提供将整个供体dna插入靶位点而不需要任何同源区域的有效机制。
通过转化被摄取的dna可以在基因组中以稳定的方式整合,或者其可以瞬时维持。在一些实施例中,供体dna被稳定整合到基因组中是希望的,但是cas内切核酸酶表达盒或指导rna表达盒的整合不是希望的。在这样的实施例中,可以通过瞬时地直接引入cas内切核酸酶和/或指导rna、或瞬时引入cas内切核酸酶表达盒和/或指导rna表达盒来实现这一目标。人们可以针对供体dna的整合选择或筛选稳定的转化体(例如,使用由供体dna编码的基因产物/标记)并且针对cas内切核酸酶表达盒或指导rna表达盒的整合选择或筛选不稳定的转化体(例如,在包含cas内切核酸酶表达盒或指导rna表达盒的dna构建体上编码的不同基因产物/标记的丢失)。在一些其他实施例中,特别是在从宿主基因组中缺失靶序列的方法中,甚至不希望供体dna被稳定整合到基因组中,而是仅需要瞬时地整合,直到发生同源重组以将靶标区域环出。在这样的情况下,人们可以针对供体dna的整合选择或筛选不稳定的转化体(例如,由供体dna编码的基因产物/标记的丢失)。
瞬时维持可以通过不稳定的表型识别。例如,可以通过选择存在于转化的dna上的标记基因来识别dna摄取。在转化和选择之后,转化体可以在非选择性条件下生长数代,然后转移回到选择性条件。稳定的转化体在转移回到选择性条件之后将能够生长,然而不稳定的转化体由于转化的dna的丢失,在转移回到选择性条件之后将不能生长。我们已经证明可以在真菌细胞/不稳定的转化体中瞬时表达cas内切核酸酶和/或指导rna。
在希望不稳定的转化体的实施例中,可以使用具有促进自主复制的端粒序列的质粒。也可以使用被设计成自主复制的其他类型的质粒,例如具有自主复制序列、着丝粒序列或其他序列的质粒。令人惊讶的是,在里氏木霉中,我们已发现可以使用没有已知的复制起点、自主复制序列、着丝粒或端粒序列的质粒。通过筛选关于可选择标记显示不稳定表型的转化体,获得没有载体dna插入的有效靶位点基因修饰(例如,与供体dna中的同源区域的同源重组)。
本披露的某些实施例包括将cas内切核酸酶表达盒和第一可选择标记整合到真菌的基因组中,任选地侧翼是重复序列以允许随后除去(环出)表达盒和第一可选择标记,以产生表达cas内切核酸酶的宿主细胞。能以许多方式将这些细胞用于获得目的遗传修饰,包括在靶位点处插入供体dna。
例如,可以用包含含有第二可选择标记(和任选的单独的供体dna)的指导rna表达盒的dna构建体来转化表达cas内切核酸酶的宿主细胞。使用第二可选择标记选择的宿主细胞将表达来自该dna构建体的指导rna,这使得能够具有cas内切核酸酶活性并靶向基因组中所限定的目的位点。对这些宿主细胞筛选关于第二可选择标记显示不稳定表型的转化体将能够在没有dna构建体插入的情况下获得具有修饰的目的位点(例如与供体dna的同源重组)的宿主细胞。
作为另一个实例,可以诱导表达cas内切核酸酶的宿主细胞以摄取体外合成的指导rna以使得能够具有cas内切核酸酶活性并能靶向到基因组中所限定的位点。在一些情况下,希望诱导指导rna和携带可选择标记基因的单独的dna构建体的摄取,以允许选择已经摄取dna并且以很高的频率期望同时摄取指导rna的那些细胞。如上所述,获得对关于可选择标记显示不稳定表型的那些转化体筛选没有载体dna插入的目的遗传修饰(例如与供体dna的同源重组)。
作为又另一个实例,可以使用表达cas内切核酸酶的宿主细胞来产生可以将cas内切核酸酶(反向)提供给“靶标菌株”的“辅助菌株”。简言之,例如通过来自每个菌株的原生质体的融合或取决于丝状真菌的种类通过菌丝的接合,可以在辅助菌株和靶标菌株之间产生异核体。异核体的维持将取决于合适的营养性或其他标记基因或在每个亲本菌株中的突变,并且在合适的选择性培养基上生长,使得亲本菌株不能生长,而异核体由于互补性而能够生长。在异核体形成时或随后,通过转染引入指导rna和供体dna。指导rna可以直接引入或经由具有cas内切核酸酶表达盒和可选择标记基因的dna构建体引入。cas内切核酸酶从辅助菌株细胞核中的基因表达,并且存在于异核体的细胞质中。cas内切核酸酶与指导rna缔合以产生活性复合物,该复合物靶向供体dna被插入的、基因组中的一个或多个希望的靶位点。随后,从异核体中回收孢子并且对这些孢子进行选择或筛选以回收在靶位点处插入了供体dna的靶标菌株。在使用表达盒引入指导rna的情况下,选择指导rna表达构建体不能稳定维持于其中的异核体。
关于真菌细胞中的dna修复,我们已发现在存在功能性nhej途径的情况下,易错修复高度优于在双链断裂位点的同源重组。换句话说,关于丝状真菌细胞中双链断裂的dna修复,我们已发现在存在功能性nhej途径的情况下,供体dna在断裂处的非同源插入高度优于(1)不具有dna插入的非同源末端连接和(2)在双链断裂位点处与具有希望的同源重组位点的供体dna的同源重组。
在一些情况下,供体dna包括与真菌细胞基因组中相应的第一和第二区域同源的第一区域和第二区域,其中同源区域通常包括或围绕基因组dna被cas内切核酸酶切割的靶位点。这些同源区域促进或允许与其相应的同源基因组区域的同源重组,导致在供体dna和基因组之间的dna交换。因此,所提供的方法导致供体dna的目的多核苷酸在真菌细胞基因组中的靶位点中的切割位点处或附近的整合,从而改变原始靶位点,从而产生改变的基因组靶位点。
在给定的基因组区域和在供体dna上发现的相应的同源区域之间的结构相似性可以是允许同源重组发生的任何程度的序列同一性。例如,由供体dna的“同源区域”和真菌细胞基因组的“基因组区域”享有的同源性或序列同一性的量可以是至少50%、55%、60%、65%、70%、75%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或甚至100%的序列同一性,使得序列进行同源重组。
供体dna上的同源区域可以与靶位点侧翼的任何序列具有同源性。虽然在一些实施例中,同源区域与紧邻靶位点侧翼的基因组序列享有显著的序列同源性,但是应当认识到同源区域可以被设计为与可能进一步使5'或3’靠近靶位点的区域具有足够的同源性。在又其他实施例中,同源区域还可以与靶位点的片段以及下游基因组区域具有同源性。在一个实施例中,第一同源区域进一步包含靶位点的第一片段,并且第二同源区域包含靶位点的第二片段,其中第一片段和第二片段不相似。
与cas内切核酸酶和指导多核苷酸表达构建体一样,供体dna可以通过任何方便的手段引入(如本文别处讨论的)。
在某些实施例中,cas内切核酸酶是cas9内切核酸酶(参见,例如wo2013141680,名称为“通过cas9-crrna复合物的rna指导的dna切割(rna-directeddnacleavagebythecas9-crrnacomplex)”)。cas9内切核酸酶的实例包括来自以下各项中的那些:链球菌属物种(例如,化脓性链球菌、变异链球菌和嗜热链球菌);弯曲杆菌属物种(例如,空肠弯曲杆菌);奈瑟氏菌属物种(例如,脑膜炎奈瑟球菌);弗朗西斯氏菌属物种(例如,新凶手弗朗西斯菌);巴斯德氏菌属物种(例如,多杀巴斯德菌)(参见,例如在如下文献中描述的cas9内切核酸酶:fonfara等人,nucleicacidsres.[核酸研究],2013,第1-14页,通过引用结合在此)。在一些实施例中,cas内切核酸酶由优化的cas9内切核酸酶基因(例如为了在真菌细胞中表达而被优化)编码(例如,cas9编码基因含有seqidno:8,例如seqidno:9,如下所述)。
在某些情况下,cas内切核酸酶基因被有效地连接至编码核定位信号的一种或多种多核苷酸,使得在细胞中表达的cas内切核酸酶/指导多核苷酸复合物被有效地转运到细胞核。可以使用任何方便的核定位信号,例如,编码sv40核定位信号的多核苷酸存在于cas密码子区域的上游并与其同框,并且编码来源于里氏木霉blr2(蓝光调节子2)基因的核定位信号的多核苷酸存在于cas密码子区域的下游并与其同框。可以使用其他核定位信号。
在本披露的某些实施例中,指导多核苷酸是指导rna,该指导rna包括可以与ii型cas内切核酸酶形成复合物的、ii型crispr/cas系统的crrna区域(或crrna片段)和tracrrna区域(或tracrrna片段)。如上所述,指导rna/cas内切核酸酶复合物可以将cas内切核酸酶指导至真菌细胞基因组靶位点,使得cas内切核酸酶能够将双链断裂引入基因组靶位点。在一些情况下,指导rna/cas9内切核酸酶复合物的rna是包含crrna和单独的tracrrna的双链体。在其他情况下,指导rna是包括crrna区域和tracrrna区域二者的单个rna分子(有时被称为融合的指导rna)。使用融合的指导rna相对于双链体crrna-tracrrna的一个优点是仅需要制备一个表达盒来表达融合的指导rna。
在本文披露的方法中使用的宿主细胞可以是来自以下各项的任何真菌宿主细胞:门子囊菌门(ascomycota)、担子菌门(basidiomycota)、壶菌门(chytridiomycota)和接合菌门(zygomycota)(由hawksworth等人,在:ainsworthandbisby'sdictionaryofthefungi,8thedition,1995,cabinternational,universitypress,cambridge,uk[真菌的安斯沃思和拜斯比词典,第8版,1995年,英国剑桥cab国际集团,大学出版社])以及卵菌门(oomycota)(如在hawksworth等人,同上中引用的)和所有有丝分裂孢子真菌(hawksworth等人,同上)。在某些实施例中,真菌宿主细胞是酵母细胞,例如假丝酵母属(candida)、汉逊酵母属(hansenula)、克鲁维酵母属(kluyveromyces)、毕赤酵母属(pichia)、酵母属(saccharomyces)、裂殖酵母属(schizosaccharomyces)、或耶氏酵母属(yarrowia)细胞。酵母的物种包括但不限于以下各项:卡尔斯伯酵母(saccharomycescarlsbergensis),酿酒酵母(saccharomycescerevisiae)、糖化酵母(saccharomycesdiastaticus)、道格拉斯酵母(saccharomycesdouglasii)、克鲁弗酵母(saccharomyceskluyveri)、诺地酵母(saccharomycesnorbensis)、卵形酵母(saccharomycesoviformis)、乳酸克鲁维酵母(kluyromomyceslactis)和解脂耶氏酵母(yarrowialipolytica)细胞。在另外的实施例中,真菌细胞是丝状真菌细胞,包括但不限于木霉属、青霉属、曲霉属、腐质霉属、金孢子菌属、镰孢属、脉孢菌属、毁丝霉属、肉座菌属和裸胞壳属的物种。例如,丝状真菌里氏木霉和黑曲霉可用于所披露的方法的方面。
实际上,可以使用所披露的方法靶向在真菌细胞基因组中的任何位点,只要靶位点包括所需的前间区序列邻近基序或pam。在化脓性链球菌cas9的情况下,pam具有序列ngg(5'至3';其中n为a、g、c或t),因此不对基因组中靶位点的选择施加显著的限制。其他已知的cas9内切核酸酶具有不同的pam位点(参见,例如在fonfara等人,nucleicacidsres.[核酸研究],2013,第1-14页(通过引用结合在此)中描述的cas9内切核酸酶pam位点)。
靶位点的长度可以变化,并且包括例如为至少12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多个核苷酸长度的靶位点。还有可能靶位点可以是回文的,即,一条链上的序列与在互补链上以相反方向的读取相同。切割位点可以在靶序列内,或者切割位点可以在靶序列之外。在另一种变异中,切割可以发生在彼此正好相对的核苷酸位置处,以产生平端切割,或者在其他情况下,切口可以交错以产生单链突出端,也称为“粘性末端”,其可以是5'悬突或3'悬突。
在一些情况下,还可以使用真菌细胞基因组中的活性变体靶序列,这意味着靶位点与指导多核苷酸中的相关序列(在指导多核苷酸的crrna序列内)不是100%同一。这样的活性变体可以包含与给定靶位点至少65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性,其中活性变体靶序列保留生物活性,因此能够被cas内切核酸酶识别和切割。测量由内切核酸酶引起的靶位点的双链断裂的测定是本领域已知的,并且通常测量试剂在含有识别位点的dna底物上的总体活性和特异性。
目的靶位点包括位于目的基因的区域内的靶位点。目的基因内的区域的非限制性实例包括可读框、启动子、转录调节元件、翻译调节元件、转录终止序列、mrna剪接位点、蛋白质编码序列、内含子位点和内含子增强基序。
在某些实施例中,真菌细胞的基因组的修饰导致可以被检测到的表型效应,并且在许多情况下是用户的期望结果。非限制性实例包括获得可选择的细胞生长表型(例如抗生素的抗性或敏感性、营养缺陷特征的获得或丧失、生长速率的增加或降低等)、表达可检测标记(例如,荧光标记、细胞表面分子、显色酶等),以及分泌酶(该酶的活性可以在培养上清液中进行检测)。
当真菌细胞的基因组的修饰导致表型效应时,通常使用包括目的多核苷酸的供体dna,该目的多核苷酸是(或编码)表型标记。可以使用任何方便的表型标记,包括任何可选择或可筛选的标记,其允许人们通常在特定培养条件下鉴定、选择或筛选含有该标记的真菌细胞或对其进行鉴定、选择或筛选。因此,在本发明的一些方面,具有希望的基因组修饰的真菌细胞的鉴定包括在对靶位点处具有修饰的细胞进行选择或筛选的条件下培养已经接受了cas内切核酸酶和指导多核苷酸(和任选地供体dna)的真菌细胞群体。可以使用任何类型的选择系统,包括评估真菌细胞中酶活性的增益或丧失(也称为可选择标记),例如抗生素抗性的获得或营养缺陷型标记的获得/丧失。
在一些情况下,使用任何方便的方法直接检测真菌细胞中的基因组修饰,这些方法包括测序、pcr、dna印迹、限制酶分析等,包括此类方法的组合。
在一些实施例中,使用所披露的方法靶向特定基因用于修饰,包括编码以下酶的基因:例如,乙酰酯酶、氨肽酶、淀粉酶、阿拉伯糖酶、阿拉伯呋喃糖苷酶、羧肽酶、过氧化氢酶、纤维素酶、几丁质酶、角质酶、脱氧核糖核酸酶、差向异构酶、酯酶、α-半乳糖苷酶、β-半乳糖苷酶、α-葡聚糖酶、葡聚糖裂解酶、内切-β-葡聚糖酶、葡糖淀粉酶、葡萄糖氧化酶、α-葡糖苷酶、β-葡糖苷酶、葡萄糖醛酸酶、半纤维素酶、己糖氧化酶、水解酶、转化酶、异构酶、漆酶、脂肪酶、裂解酶、甘露糖苷酶、氧化酶、氧化还原酶、果胶酸裂解酶、果胶乙酰酯酶、果胶解聚酶、果胶甲酯酶、果胶分解酶、过氧化物酶、酚氧化酶、植酸酶、聚半乳糖醛酸酶、蛋白酶、鼠李糖-半乳糖醛酸酶、核糖核酸酶、转移酶、转运蛋白、转谷氨酰胺酶、木聚糖酶、己糖氧化酶、以及其组合。
执行本文所描述的方法存在许多变化。例如,cas表达盒可以被整合到真菌宿主细胞的基因组中,而不是使该表达盒作为外源序列而存在。产生这种亲本细胞系将允许使用者简单地引入希望的指导rna(例如,作为指导rna表达载体),该指导rna然后靶向目的基因组位点,如本文其他地方所详述的。在这些实施例中的一些实施例中,整合的cas基因可以被设计为包括其侧翼的多核苷酸重复序列,用于随后从基因组中的环出/去除(如果需要的话)。
本文披露的组合物和方法的非限制性实例或实施例如下:
1.一种用于在真菌细胞的基因组中的靶位点处插入供体dna的方法,该方法包括:
a)向真菌细胞的群体中引入cas内切核酸酶、指导rna和供体dna,其中该cas内切核酸酶和指导rna能够形成复合物,该复合物使该cas内切核酸酶能够在所述真菌细胞的基因组的基因组座位中的靶位点处引入双链断裂;并且
b)从该群体中鉴定在该基因组座位中的该靶位点处已经发生了该供体dna的插入的至少一个真菌细胞,
其中该cas内切核酸酶、该指导rna或两者都被瞬时地引入该真菌细胞的群体中。
2.如实施例1所述的方法,其中该插入不是经由该供体dna与所述真菌细胞的基因组之间的同源重组发生的。
3.如实施例1或2所述的方法,其中该供体dna不包含与该基因组座位中的基因组序列同源的序列。
4.如前述实施例中任一项所述的方法,其中该供体dna的插入中断该基因组座位的表达或功能。
5.如前述实施例中任一项所述的方法,其中该供体dna包含目的基因。
6.如前述实施例中任一项所述的方法,其中该供体dna包含编码目的基因产物的表达盒。
7.如实施例6所述的方法,其中该目的基因产物是目的蛋白质。
8.如实施例6所述的方法,其中该目的基因产物是表型标记。
9.如实施例8所述的方法,其中该表型标记选自下组,该组由以下各项组成:营养缺陷型标记、抗生素抗性标记、显性异源可选择标记和报告基因。
10.如实施例1、2和4-9中任一项所述的方法,其中该供体dna包含与在基因组座位中的基因组序列同源的序列,其中该基因组序列和该靶位点位于基因组缺失靶标区域侧翼,并且其中该供体dna的插入导致基因组序列以及与该基因组序列同源的序列位于包含该基因组缺失靶标区域的环出靶标区域的侧翼。
11.如实施例10所述的方法,该方法进一步包括:
c)在允许该环出靶标区域环出的条件下培养该至少一个经鉴定的真菌细胞,并且
d)在培养物中鉴定至少一个已经发生了该环出靶标区域的环出的真菌细胞。
12.一种用于在真菌细胞的基因组中使靶标区域缺失的方法,该方法包括:
a)向真菌细胞的群体中引入cas内切核酸酶、指导rna和供体dna,其中该cas内切核酸酶和指导rna能够形成使得cas内切核酸酶能够在真菌细胞的基因组中的靶位点处引入双链断裂的复合物,并且允许供体dna被插入在靶位点处,其中该供体dna包含与真菌细胞的基因组序列同源的序列,并且其中该基因组序列和该靶位点位于真菌细胞基因组中靶标区域的侧翼;
b)在允许该基因组序列以及与该基因组序列同源的序列之间进行同源重组的条件下培养真菌细胞群体;并且
c)在培养物中鉴定至少一个已经发生了靶标区域的缺失的真菌细胞。
其中该cas内切核酸酶、该指导rna或两者都被瞬时地引入该真菌细胞的群体中。
13.如实施例12所述的方法,该方法进一步包括:在步骤a)和b)之间从该群体中鉴定在靶位点处已经发生供体dna的插入的至少一个真菌细胞的步骤。
14.如实施例12或13所述的方法,其中该供体dna不是经由该供体dna和该真菌细胞基因组之间的同源重组插入该靶位点处的。
15.如前述实施例中任一项所述的方法,其中该cas内切核酸酶是ii型cas9内切核酸酶或其变体。
16.如实施例15所述的方法,其中该cas9内切核酸酶或其变体包含来自选自下组的物种的全长cas9或其功能片段,该组由以下各项组成:链球菌属物种(例如,化脓性链球菌、变异链球菌和嗜热链球菌);弯曲杆菌属物种(例如,空肠弯曲杆菌);奈瑟氏菌属物种(例如,脑膜炎奈瑟球菌);弗朗西斯氏菌属物种(例如,新凶手弗朗西斯菌);巴斯德氏菌属物种(例如,多杀巴斯德菌)。
17.如实施例16所述的方法,其中该cas9内切核酸酶或其变体包含与seqidno:1至7中任一项具有至少70%同一性的氨基酸序列。
18.如前述实施例中任一项所述的方法,其中该引入步骤包括将包含cas内切核酸酶的表达盒的dna构建体引入所述真菌细胞中。
19.如前述实施例中任一项所述的方法,其中该引入步骤包括将包含指导rna的表达盒的dna构建体引入所述真菌细胞中。
20.如实施例1至17和19中任一项所述的方法,其中该引入步骤包括将该cas内切核酸酶直接引入所述真菌细胞中。
21.如实施例1至18和20中任一项所述的方法,其中该引入步骤包括将该指导rna直接引入所述真菌细胞中。
22.如实施例18所述的方法,其中该cas核酸内切酶的表达盒包含为了在该真菌细胞中表达而优化的cas编码序列。
23.如实施例22所述的方法,其中该cas编码序列是包含与seqidno:8至少70%同一的多核苷酸序列的cas9编码序列。
24.如前述实施例中任一项所述的方法,其中该cas内切核酸酶被有效地连接至核定位信号。
25.如前述实施例中任一项所述的方法,其中该真菌细胞是丝状真菌细胞。
26.如前述实施例中任一项所述的方法,其中该真菌细胞是真菌亚门或盘菌亚门真菌细胞。
27.如前述实施例中任一项所述的方法,其中该真菌细胞选自下组,该组由以下各项组成:木霉属、青霉属、曲霉属、腐质霉属、金孢子菌属、镰孢属、毁丝霉属、脉孢菌属、肉座菌属和裸胞壳属。
28.如前述实施例中任一项所述的方法,其中该靶位点位于选自下组的目的基因的区域中,该组由以下各项组成:可读框、启动子、调节序列、终止序列、调节元件序列、剪接位点、编码序列、聚泛素化位点、内含子位点和内含子增强基序。
29.一种重组真菌细胞,其通过如前述实施例中任一项所述的方法产生。
实例
在以下实例中,除非另有说明,份数和百分比以重量计,并且度数为摄氏度。应当理解的是,尽管这些实例说明了本披露的实施例,但仅是通过说明的方式给出的。从上述讨论和这些实例,本领域技术人员可以对本披露进行各种改变和修改以使其适应各种用途和条件。这样的修改也旨在落入所附权利要求的范围内。
实例1:crisprspycas9在大肠杆菌中的异源表达
合成大肠杆菌密码子优化的化脓性链球菌cas9(spycas9)基因,并将其通过捷瑞公司(generay)(中国上海)在ncoi和hindiii位点插入表达载体pet30a中,产生质粒pet30a-spycas9(图2)。如图2中的质粒图所示,表达盒的全长编码序列在5'至3’方向上包含编码n-末端his6标签/凝血酶/s·tagtm/肠激酶区域的序列(seqidno:13;包括起始密码子甲硫氨酸)、编码sv40核定位信号的序列(seqidno:14)、编码spycas9的序列(seqidno:15)和编码blr核定位信号的序列(seqidno:16),全部都是有效地连接。该整个编码序列显示于seqidno:17。由seqidno:13编码的n-末端his6标签/凝血酶/s·tagtm/肠激酶区域的氨基酸序列显示于seqidno:18(包括位置1处的甲硫氨酸),由seqidno:14编码的sv40核定位信号的氨基酸序列显示于seqidno:19,由seqidno:15编码的spycas9的氨基酸序列显示于seqidno:1,并且由seqidno:16编码的blr核定位信号的氨基酸序列显示于seqidno:20中。由seqidno:17编码的氨基酸序列显示于seqidno:21。
将pet30a-spycas9质粒转化到rosetta2(de3)plyss大肠杆菌菌株(
实例2:spycas9的纯化
为了纯化spycas9,应用了亲和力、疏水相互作用和尺寸排阻层析步骤的组合。简言之,将表达spycas9的大肠杆菌细胞(rosetta2(de3)plyss,如上所述)在具有25mlmagicmediatm的250ml摇瓶中培养24小时,并通过离心收获。将细胞(约40克)沉淀并重新悬浮于400ml裂解缓冲液(20mmhepes(ph7.5)、500mmnacl、0.1%tritonx-100、1mmdtt和1mmtcep,购自罗氏公司(roche)的蛋白酶抑制剂混合物)中,并且经由超声波发生器(35%功率,20min,2s打开/3s关闭)(scient2-iid,宁波新芝生物技术有限公司(ningboscientzbiotechnologyco.,ltd))裂解。通过在20000g下离心40min来清除裂解物。
使用旋转培养箱(中国海门市麒麟贝尔实验室仪器有限公司(kylin-belllab.instrumentsco.,ltd.haimen,china)),将约400ml的澄清的裂解液与5mlni-nta树脂(ge医疗集团(gehealthcare))一起在4℃下、在30rpm/min振摇下孵育过夜。在离心后,将树脂转移到xk26/20柱(ge医疗集团(gehealthcare))并且连接到aktaexplorer系统(ge医疗集团)上。在用平衡缓冲液(20mmhepes(ph7.5)、300mmnacl、0.1%tritonx-100)、随后用洗涤缓冲液(平衡缓冲液中的25mm咪唑)充分洗涤后,用在平衡缓冲液中的250mm咪唑洗脱靶标蛋白质。
向从亲和步骤收集的活性级分中添加硫酸铵至终浓度为0.8m,并且加载到20ml苯基-琼脂糖hp柱(ge医疗集团(gehealthcare))上。用在50mmhepes缓冲液(ph7.5)中的0.8m至0.0m硫酸铵的梯度洗脱该柱,并且收集流出物。
最后,通过尺寸排阻色谱法在superdex20016/60柱(ge医疗集团(gehealthcare))上在20mmhepesph7.5、150mmkcl和10%甘油中进一步纯化蛋白质。合并具有最高纯度的级分,并且经由amicon30kda膜过滤器(密理博公司(millipore))将其浓缩。在-20℃冷冻器中将最终的蛋白质样品储存在40%甘油中直至使用。
实例3:体外dna切割测定
制备底物dna片段用于体外spycas9dna切割测定
使用来自zymo公司的zf真菌/细菌dna小量制备试剂盒(zffungal/bacterialdnaminiprepkit,目录号d6005),从来源于rl-p37并且具有纤维二糖水解酶1、纤维二糖水解酶2、内切葡聚糖酶1和内切葡聚糖酶2基因缺失(δcbh1,δcbh2,δegl1和δegl2菌株;也被称为“四缺失菌株”;参见wo92/06184和wo05/001036)的里氏木霉菌株提取基因组dna。使用kod-pluspcr试剂盒(日本东洋纺有限公司(toyoboco.,ltd,japan))以及正向引物和反向引物(5’-gactgtctccaccatgtaatttttc-3’(seqidno:23)和5’-ggcagactacaagtctactagtactac-3’(seqidno:24))各0.4μm,使用1ng提取的基因组dna,通过pcr扩增含有里氏木霉葡糖淀粉酶(trga)基因(基因id:18483895)及其部分5'-utr(seqidno:22)的dna片段。将pcr产物纯化并用来自zymo的dnaclean&concentratortm-5试剂盒(目录号d4013(50))浓缩,并且用nanodroptm(赛默飞世尔公司(thermofisher))确定其dna浓度。
seqidno:22(下面)显示了底物dna片段的核苷酸序列。utr序列以小写字母显示,而trga基因以大写字母显示。选择的vt结构域、trga_sth_sgr2以粗体显示(seqidno:25),并且用于进一步环出实验的500bp片段以下划线显示(seqidno:26)。
gactgtctccaccatgtaatttttccctgcgactccatataacgccggatcgtgaaattttcttctttcttttccttccttctcaacaaacaacggatctgtgctttgcggtcccctgcgttcacgcgtcagggtcgactgctctgcagctcgataactccatggagccatcaacttgctatggtgtcaatcatcctatcgacaggtccaagaacaagccggcctccggctgcctcattcgctgtcgcaagacggcttgagtgttgtggctggaggattcgggggccccatattccaacccttttttccaaggccgtcggccggtgaggttgaggaaaaccatgggttgcctacatattatcgatgctggtgtttggtagtagcaatgtttgcggtggcagtttgagccgagcctcgtcttgggcttctgacccaggcaacgccatctgactagctgcgccgaaggaaggatgattcattgtacgacgccagtcaatggaatcttcaagtaaaagcccgacgaaccgaccatgtcagatatcagaattctcctggctggtggggttggttggagactgcttacggagtcgatgcctcgtgactgtcatggccgcgtccagcctcctgggactctgtccgatattatgacacgagtaaagcctgcatgatgtcagtttgctgcgtctcatgtcgagaacaacacacctggtgctacataggcaatactacctcgtagcttcaaagttgactgttttgctttgatgtctttgatcatgcccatccatcccttgtcttgcagtgcatgtggatctctacgtccagacggggagaaagcttgtctgtgataaagtacgatgatgcattgatgcctgtggctacggcccttttatccccatcgtcatgcatctctatattaatccaggagactctcctcctggcatgggtgagtacaagtgacgaggacatgtagaagcagagccacgcaacgtcttgacatctgtacctattttgggccaaaaatcgagacccaccagctcgtcctaccttacatgtgaagatcttagcccacaatcctactgttttactagtattactgcacagctgtcatcacgagtcctcggttgcttgtgaaacccagctcagctcctgagcacatgcagtaacgccgactcggcgtcatttcgccacacccaatttggacctgagggatgctggaagctgctgagcagatcccgttaccgattcatggcactactacatccatacgcagcaaacatgggcttgggcttggcttctcaatgcaaaattgcccgcaaaagtcccggcattgtcgatgcagagatgcagatttcagcgggcgattctagggtagggcgactactactactaataccacctagtcagtatgtatctagcaccggaggctaggcggttagtggacgggaacctggtcattccatcgcaaccaggatcccgcacttcgttgcgcttctgcccccacggggcgggagttggcagaggcagaatgcggagcagccccttgtctgccctggccggggcctgttgaagcaagcagacgagagcagagcggttgagaagcggtggttgacgcttgacggtacgaagacgagcgagaatcccgttaagccgaggctgggctcccccccccgtcatcatcatgcccatcctgctcttccagcccactcgtctccctgcctcgtcgcctcccctccctcccccgattagctgcgcatgttctcctgacagcgtgactaatgacgcgttgccagcccattcgcctgacgcatcccggcatctgagtctagctcgtcacgctggcaatcttggcccaggcagagcagcaagacggcgggcatgattgggccgtgccctggcgggcatcagctggccatccgctgccacccgagaccgcatcaccgacttgtcggatctctccgagcagcaggaggctgatcctggccggcgagacgattgaaaagggctgccgggcccggagcaggacagcggcgagagcgagcgagagagaggaaaagaagaaggtcgactgtcttattttcagccagccccggctcaacagaagcagaggagaaggcgaacgacgtcaacgacgacgacgacgacgacgaagacggtgaagtccgttagttgaagatccttgccgtcacaacaccatctcgtggatattgctttcccctgccgttgcgttgccacctgttccctctttctcttccccccttcttcctcattccgagcgctactggttcctactccgcagccttcggttgtgcctttctctttgtcgaccattgcaccgcccgtcgcggcacttgggccccggagaattcggccctttcgcagcattttggccctcagttccccatggggacggtccacacttcctctcttggccctgcagaccttttgtcgtcggtccgagtcggaagaagctcagtcttgagcgcttgagtagcatctacgcgcgaatcactggacaaagtcggcaagacgaagccgtcgtcgcctgctgctgctgctgttactgcgacaggcgctccgactgggggcatcggcataataaaaagatgcccgccttcgccatggacctggccatgagccactcggcatcggctctctctctcaacgcttcctctcacacatcctccttcattccgcccatcatgcacgtcctgtcgactgcggtgctgctcggctccgttgccgttcaaaaggtcctgggaagaccaggatcaagcggtctgtccgacgtcaccaagaggtctgttgacgacttcatcagcaccgagacgcctattgcactgaacaatcttctttgcaatgttggtcctgatggatgccgtgcattcggcacatcagctggtgcggtgattgcatctcccagcacaattgacccggactgtaagttggccttgatgaaccatatcatatatcgccgagaagtggaccgcgtgctgagactgagacagactattacatgtggacgcgagatagcgctcttgtcttcaagaacctcatcgaccgcttcaccgaaacgtacgatgcgggcctgcagcgccgcatcgagcagtacattactgcccaggtcactctccagggcctctctaacccctcgggctccctcgcggacggctctggtctcggcgagcccaagtttgagttgaccctgaagcctttcaccggcaactggggtcgaccgcagcgggatggcccagctctgcgagccattgccttgattggatactcaaagtggctcatcaacaacaactatcagtcgactgtgtccaacgtcatctggcctattgtgcgcaacgacctcaactatgttgcccagtactggtcagtgcttgcttgctcttgaattacgtctttgcttgtgtgtctaatgcctccaccacaggaaccaaaccggctttgacctctgggaagaagtcaatgggagctcattctttactgttgccaaccagcaccgaggtatgaagcaaatcctcgacattcgctgctactgcacatgagcattgttactgaccagctctacagcacttgtcgagggcgccactcttgctgccactcttggccagtcgggaagcgcttattcatctgttgctccccaggttttgtgctttctccaacgattctgggtgtcgtctggtggatacgtcgactccaacagtatgtcttttcactgtttatatgagattggccaatactgatagctcgcctctagtcaacaccaacgagggcaggactggcaaggatgtcaactccgtcctgacttccatccacaccttcgatcccaaccttggctgtgacgcaggcaccttccagccatgcagtgacaaagcgctctccaacctcaaggttgttgtcgactccttccgctccatctacggcgtgaacaagggcattcctgccggtgctgccgtcgccattggccggtatgcagaggatgtgtactacaacggcaacccttggtatcttgctacatttgctgctgccgagcagctgtacgatgccatctacgtctggaagaagacgggctccatcacggtgaccgccacctccctggccttcttccaggagcttgttcctggcgtgacggccgggacctactccagcagctcttcgacctttaccaacatcatcaacgccgtctcgacatacgccgatggcttcctcagcgaggctgccaagtacgtccccgccgacggttcgctggccgagcagtttgaccgcaacagcggcactccgctgtctgcgcttcacctgacgtggtcgtacgcctcgttcttgacagccacggcccgtcgggctggcatcgtgcccccctcgtgggccaacagcagcgctagcacgatcccctcgacgtgctccggcgcgtccgtggtcggatcctactcgcgtcccaccgccacgtcattccctccgtcgcagacgcccaagcctggcgtgccttccggtactccctacacgcccctgccctgcgcgaccccaacctccgtggccgtcaccttccacgagctcgtgtcgacacagtttggccagacggtcaaggtggcgggcaacgccgcggccctgggcaactggagcacgagcgccgccgtggctctggacgccgtcaactatgccgataaccaccccctgtggattgggacggtcaacctcgaggctggagacgtcgtggagtacaagtacatcaatgtgggccaagatggctccgtgacctgggagagtgatcccaaccacacttacacggttcctgcggtggcttgtgtgacgcaggttgtcaaggaggacacctggcagtcgtaatgaatcggcaaggggtagtactagtagacttgtagtctgcc(seqidno:22)
体外转录和spycas9dna切割测定
鉴定了trga基因中的一个vt结构域,即trga_sth_sgr2(seqidno:25)及其特异性pam,用于下游体外测定和转化实验。通过捷瑞公司(generay)将寡核苷酸插入pmd18t载体中,产生pmd18t(t7-trga_sth_sgr2)(图3)(对于t7启动子、cer结构域和vt结构域trga_sth_sgr2序列,参见下面seqidno:27)。用正向引物和反向引物(5’-ctttttacggttcctggc-3’(seqidno:28)和5’-aaaagcaccgactcgg-3’(seqidno:29))各0.4μm,通过pcr从pmd18t(t7-trga_sth_sgr2)扩增用于体外转录的dna片段。将pcr产物纯化并用来自zymo的dnaclean&concentratortm-5试剂盒(目录号d4013)浓缩,并且确定其dna浓度。
用上述特异性pcr产物作为模板,根据制造商的说明书,使用来自赛默飞世尔科技公司(thermofisherscientificinc.)的megashortscripttmt7转录试剂盒通过体外转录产生用于vt结构域trga_sth_sgr2的rna。使用来自赛默飞世尔科技公司(thermofisherscientificinc.)的megacleartmtranscriptionclean-up试剂盒纯化转录的rna。使用nanodroptm测量rna浓度。
进行spycas9体外dna切割测定以证实合成的单指导rna的活性。为了开始测定,将1μg纯化的spycas9、200ng底物dna片段和200ng单指导rna(或水作为对照)在含有50mmhepesph7.3、150mmkcl、0.5mmdtt和10mmmgcl2的15μl反应缓冲液中混合在一起。测定在37摄氏度下进行20min,随后添加2μg蛋白酶k(西格玛公司(sigma),目录号p6556)。将反应在40℃下继续进行20min,并且通过在80℃下另外孵育20min来终止。使用0.8%琼脂糖凝胶分析反应结果,在140伏特下运行30min。
如图4所示,在特异性单指导rna的存在下,spycas9可以成功地将底物dna片段切割成希望的大小(泳道3),从而证实合成的rna的功能。在指导rna(trga_sth_sgr2)不存在的情况下,没有观察到底物dna的切割(泳道2)。
seqidno:27显示了由t7启动子、cer结构域和vt结构域trga_sth_sgr2组成的用于转录的模板序列。vt结构域以大写字母显示,而t7启动子和cer结构域分别以粗体和小写字母显示。
taatacgactcactatagggtgtggatggaagtcaggagttttagagctagaaatagcaagttaaaataaggctagtccgttatcaacttgaaaaagtggcaccgagtcggtgc(seqidno:27)
实例4:体内spycas9/sgrna摄取实验
原生质体制备
对于原生质体制备,将具有另外的α-淀粉酶缺失的里氏木霉的四缺失菌株(如上所述)的5×108个孢子(在30℃下在pda板上生长5天)接种到在具有4个挡板的250ml摇瓶中的50ml萌发培养基(在美国专利号8,679,815中描述的配方)中,并在27℃、170rpm下孵育17小时。通过将液体体积转移到50ml锥形管中并以3000rpm旋转10分钟来回收菌丝体。轻轻倒出上清液,并且将菌丝沉淀使用1.2mmgso4-10mm磷酸钠缓冲液洗涤两次,并将其重悬于15ml裂解酶缓冲液中。将来自哈茨木霉(西格玛公司(sigma)目录#l1412)的裂解酶溶解于1.2mmgso4-10mm磷酸钠缓冲液(ph5.8,50mg/ml)中。将细胞悬浮液转移到具有4个挡板的250ml摇瓶中,并且在室温下以200rpm振摇至少2小时。通过在玻璃漏斗中折叠的miracloth(卡比化学公司(calbiochem)货号475855)过滤将原生质体收获到greiner管中。在过滤的原生质体上方小心地添加0.6m山梨糖醇-0.1mtris-hcl缓冲液。通过以4000rpm离心15分钟收集原生质体。将含有原生质体的中间相转移到新管中,并且添加至少等体积的1.2m山梨糖醇-10mmtris-hcl缓冲液。通过以4000rpm离心5分钟收集原生质体,并且将其用1.2m山梨糖醇-10mmtris-hcl缓冲液洗涤两次。将沉淀重悬于至少1ml1.2m山梨糖醇-10mmtris-hclph7.5-10mmcacl2缓冲液中,并且在显微镜下计数原生质体的数量。将原生质体悬浮液用4份的1.2m山梨糖醇-10mmtris-hcl-10mmcacl2和1份的25%peg6000-50mmcacl2-10mmtris-hcl稀释,直到5×108/ml用于将来的转化。
缺失盒的制备
trga缺失盒包含含有pyr2启动子、pyr2cds和pyr2终止子的pyr2(乳清酸磷酸-核糖基转移酶)表达盒,接着是用于进一步环出的500bp重复序列。将trga敲除盒的核苷酸序列描绘为seqidno:30。
下面的seqidno:30显示了trga敲除盒的核苷酸序列。pyr2启动子(seqidno:31)、pyr2cds(seqidno:32)、pyr2终止子(seqidno:33)和500bp重复序列(seqidno:34)分别以小写字母、斜体、粗体和下划线显示。
转化
为了开始摄取实验,将20μgspycas9蛋白质与16μgsgrna(实例3中描述的trga_sth_sgr2)和2μl的neb缓冲液#3(新英格兰生物实验室(newenglandbiolabs))混合,并且将最终体积调节至20μl。在室温下孵育30min之后,将spycas9/sgrna预混合液(或溶解于18μl无核酸酶的水中的2μlneb缓冲液#3作为对照)与10μg缺失盒混合以形成最终体积为30μl的预混合溶液。将预混合液添加至200μl原生质体(1×108)中并且在冰上保持30min。在孵育后,将原生质体添加到冷却的熔化的山梨糖醇/vogel琼脂(最小vogel琼脂的1.1m山梨糖醇)中作为最小vogel板的顶层(davis等人,(1970)methodsinenzymology[酶学方法]17a,第79-143页;以及davis、rowland,neurospora,contributionsofamodelorganism[脉胞菌属-模式生物的贡献],oxforduniversitypress[牛津大学出版社](2000))。将板在30℃下孵育一周。详细步骤在美国专利号8,679,815(通过引用结合在此)中有描述。
与具有数百个转化体的对照板(即,没有添加spycas9/sgrna预混合物)相比,从用spycas9/sgrna预混合物处理的原生质体获得仅14个转化体。基于vogel淀粉(无葡萄糖)板测定,在这14个转化体中,13个(>90%)显示出trga敲除表型(图5)(具有trga敲除表型的菌落将在常规vogel琼脂板上生长(面板a;所有克隆均生长),但不在无葡萄糖的vogel淀粉板上生长(面板b;来自spycas9/sgrna预混合物处理的克隆1-4和6-14没有生长,证明它们是trga缺陷的)。
将显示出trga敲除表型的所有13个转化体(1至4、6至14,图5)转移到新的vogel板并且在该新的vogel板上生长用于下游环出实验。在生长7天后,收集所有孢子并且将其稀释至希望的浓度(表1),并且随后涂抹在补充有1.2g/lfoa的vogel琼脂板上以选择pyr2表达盒的环出。类似地处理来自对照板的随机选择的转化体(d1至d5,图4)。在vogel-foa板上生长7天后,对于用spycas9/sgrna处理的转化体观察到菌落,但是对于来自对照(没有用spycas9/sgrna处理;参见表1)的转化体没有观察到菌落。这表明经由存在于基因组和trga敲除盒(seqidno:34)中的重复序列之间的重组事件而不仅仅是pyr2表达盒的自发突变使pyr2表达盒环出。如果自发突变是潜在的原因,则实验样品和对照样品二者都将具有foa抗性菌落。
表1.使用vogel-foa琼脂板的环出实验的结果
环出菌株验证
随机选择来自vogel-foa板的32个菌落,并且用正向引物和反向引物(5’-ggtgtttggtagtagcaatg-3’(seqidno:35)和5’-ggcagactacaagtctactagtactac-3’(seqidno:36))各0.4μm进行pcr确认。在对每个pcr产物进行测序之后,证实了显示出预期环出序列(seqidno:37)的3个菌落,证明使用spycas9、特异性sgrna和缺失盒的组合,成功地使里氏木霉中的靶基因缺失。
seqidno:37显示环出菌株的pcr产物的预期核苷酸序列。上游和下游utr序列以小写字母显示(分别为seqidno:38和39),而部分trgaorf片段以大写字母显示(seqidno:40)。在环出实验后保留的500bp片段被加下划线(seqidno:41),其与存在于基因组中和trga敲除盒中的重复序列(seqidno:34)同一。
ggtgtttggtagtagcaatgtttgcggtggcagtttgagccgagcctcgtcttgggcttctgacccaggcaacgccatctgactagctgcgccgaaggaaggatgattcattgtacgacgccagtcaatggaatcttcaagtaaaagcccgacgaaccgaccatgtcagatatcagaattctcctggctggtggggttggttggagactgcttacggagtcgatgcctcgtgactgtcatggccgcgtccagcctcctgggactctgtccgatattatgacacgagtaaagcctgcatgatgtcagtttgctgcgtctcatgtcgagaacaacacacctggtgctacataggcaatactacctcgtagcttcaaagttgactgttttgctttgatgtctttgatcatgcccatccatcccttgtcttgcagtgcatgtggatctctacgtccagacggggagaaagcttgtctgtgataaagtacgatgatgcattgatgcctgtggctacggcccttttatccccatcgtcatgcatctctatattaatccaggagactctcctcctggcatgggtgagtacaagtgacgaggacatgtagaagcagagccacgcaacgtcttgacatctgtacctattttgggccaaaaatcgagacccaccagctcgtcctaccttacatgtgaagatcttagcccacaatcctactgttttactagtattactgcacagctgtcatcacgagtcctcggttgcttgtgaaacccagctcagctcctgagcacatgcagtaacgccgactcggcgtcatttcgccacacccaatttggacctgagggatgctggaagctgctgagcagatcccgttaccgattcatggcactactacatccatacgcagcaaacatgggcttgggcttggcttctcaatgcaaaattgcccgcaaaagtcccggcattgtcgatgcagagatgcagatttcagcgggcgattctagggtagggcgactactactactaataccacctagtcagtatgtatctagcaccggaggctaggcggttagtggacgggaacctggtcattccatcgcaaccaggatcccgcacttcgttgcgcttctgcccccacggggcgggagttggcagaggcagaatgcggagcagccccttgtctgccctggccggggcctgttgaagcaagcagacgagagcagagcggttgagaagcggtggttgacgcttgacggtacgaagacgagcgagaatcccgttaagccgaggctgggctgacttccatccacaccttcgatcccaaccttggctgtgacgcaggcaccttccagccatgcagtgacaaagcgctctccaacctcaaggttgttgtcgactccttccgctccatctacggcgtgaacaagggcattcctgccggtgctgccgtcgccattggccggtatgcagaggatgtgtactacaacggcaacccttggtatcttgctacatttgctgctgccgagcagctgtacgatgccatctacgtctggaagaagacgggctccatcacggtgaccgccacctccctggccttcttccaggagcttgttcctggcgtgacggccgggacctactccagcagctcttcgacctttaccaacatcatcaacgccgtctcgacatacgccgatggcttcctcagcgaggctgccaagtacgtccccgccgacggttcgctggccgagcagtttgaccgcaacagcggcactccgctgtctgcgcttcacctgacgtggtcgtacgcctcgttcttgacagccacggcccgtcgggctggcatcgtgcccccctcgtgggccaacagcagcgctagcacgatcccctcgacgtgctccggcgcgtccgtggtcggatcctactcgcgtcccaccgccacgtcattccctccgtcgcagacgcccaagcctggcgtgccttccggtactccctacacgcccctgccctgcgcgaccccaacctccgtggccgtcaccttccacgagctcgtgtcgacacagtttggccagacggtcaaggtggcgggcaacgccgcggccctgggcaactggagcacgagcgccgccgtggctctggacgccgtcaactatgccgataaccaccccctgtggattgggacggtcaacctcgaggctggagacgtcgtggagtacaagtacatcaatgtgggccaagatggctccgtgacctgggagagtgatcccaaccacacttacacggttcctgcggtggcttgtgtgacgcaggttgtcaaggaggacacctggcagtcgtaatgaatcggcaaggggtagtactagtagacttgtagtctgcc(seqidno:37)
另外的实施例
这里应注意的是,在上述实例中,将供体dna(seqidno:30)设计为仅在一个方向插入时在环出反应中起作用。考虑到体内dna片段插入可能以任一方向发生的事实,人们可以设计将在两种情况下起作用的供体dna。图6a-6c提供了将在环出反应中起作用的三种替代性供体dna设计,而不管其在靶位点处的插入方向如何(在图6a-6c中的每一个中表示为“ps”)。供体dna构型的这三个实例是基于靶位点(或前间区序列,ps)的位置。
在图6a中,靶位点是在目的基因(goi)的3'末端附近。因此,供体dna包括来源于goi上游(5')的基因组序列的两个不同的重复序列(r1和r2)(箭头的方向表示重复序列的5'至3’方向)。供体dna中的r1和r2重复序列位于pyr2表达盒的侧翼,并且处于头部至头部的构型方向,其中pyr2表达盒位于两者之间。(应注意的是,可以使用任何希望的可检测/可选择标记。而且,虽然图6a-6c中所示的元件的总的方向很重要,这些元件不需要处于相对于goi的精确位置中。例如,这些元件可以存在于非编码区域中,例如增强子元件。)
在图6b中,靶位点是在goi的中心附近。因此,供体dna包括在供体dna的3’末端处于尾部至尾部构型方向的两个不同的重复序列(r1和r2)。基因组r1位点存在于goi的上游,并且基因组r2序列位于goi的下游。
在图6c中,靶位点是在目的基因(goi)的5'末端附近。因此,供体dna包括来源于goi下游(3')的基因组序列的两个不同的重复序列(r1和r2)供体dna中的r1和r2重复序列位于pyr2表达盒的侧翼,并且处于尾部至尾部的构型方向,其中pyr2表达盒位于两者之间。
在图6a-6c中的每个情形中,以任一方向插入供体dna将允许pyr2表达盒和靶向的goi的重要区域的环出。具体地,以任一方向插入供体dna将产生正向重复序列(r1:r1或r2:r2),其将在使希望的区域的环出中起作用。
在本披露中,将在希望的靶位点处spycas9介导的dna片段插入、随后经由重复序列之间的重组事件进行下游环出的应用,成功地使里氏木霉中的trga基因缺失。虽然上述方法使用纯化的spycas9酶和体外合成的sgrna来显著降低其连续功能,但也可以使用在瞬时转化条件下使用重组dna编码的cas和/或指导rna的方法(即,在选择非稳定的转化体的情况下)。本披露的传授内容的应用使得能够进行可以用于广泛的期望结果的高效和序列特异性基因组修饰。
虽然前述组合物和方法已经通过说明和实例的方式出于清楚理解的目的在一些细节方面进行了描述,但是对于本领域的普通技术人员而言根据本文的传授内容显而易见的是可以对其进行某些改变和修改而不偏离所附权利要求的精神或范围。
因此,前面仅仅举例说明了本发明组合物和方法的原理。将了解的是本领域技术人员将能够设计不同的安排,这些不同的安排虽然没有在此明确地描述或显示,但体现本发明组合物和方法的原理并且被包括在其精神和范围之内。此外,本文叙述的所有实例和条件性语言主要旨在帮助读者理解诸位发明人所贡献的本发明的组合物和方法的原理和概念以推动本领域发展,并且将被视为而不限于这些具体叙述的实例和条件。此外,本文中叙述本发明组合物和方法的原理、方面、以及实施例的所有陈述连同其具体实例旨在涵盖其结构和功能等效物两者。另外,预期此类等效物包括当前已知的等效物以及将来开发的等效物两者,即不论结构如何而执行相同功能的任何开发的要素。因此,本发明的组合物和方法的范围不是旨在受限于本文显示和描述的示例性实施例。
序列:
seqidno:1
化脓性链球菌(streptococcuspyogenes)cas9,无nls(由seqidno:8编码)
mdkkysigldigtnsvgwavitdeykvpskkfkvlgntdrhsikknligallfdsgetaeatrlkrtarrrytrrknricylqeifsnemakvddsffhrleesflveedkkherhpifgnivdevayhekyptiyhlrkklvdstdkadlrliylalahmikfrghfliegdlnpdnsdvdklfiqlvqtynqlfeenpinasgvdakailsarlsksrrlenliaqlpgekknglfgnlialslgltpnfksnfdlaedaklqlskdtydddldnllaqigdqyadlflaaknlsdaillsdilrvnteitkaplsasmikrydehhqdltllkalvrqqlpekykeiffdqskngyagyidggasqeefykfikpilekmdgteellvklnredllrkqrtfdngsiphqihlgelhailrrqedfypflkdnrekiekiltfripyyvgplargnsrfawmtrkseetitpwnfeevvdkgasaqsfiermtnfdknlpnekvlpkhsllyeyftvyneltkvkyvtegmrkpaflsgeqkkaivdllfktnrkvtvkqlkedyfkkiecfdsveisgvedrfnaslgtyhdllkiikdkdfldneenediledivltltlfedremieerlktyahlfddkvmkqlkrrrytgwgrlsrklingirdkqsgktildflksdgfanrnfmqlihddsltfkediqkaqvsgqgdslhehianlagspaikkgilqtvkvvdelvkvmgrhkpeniviemarenqttqkgqknsrermkrieegikelgsqilkehpventqlqneklylyylqngrdmyvdqeldinrlsdydvdhivpqsflkddsidnkvltrsdknrgksdnvpseevvkkmknywrqllnaklitqrkfdnltkaergglseldkagfikrqlvetrqitkhvaqildsrmntkydendklirevkvitlksklvsdfrkdfqfykvreinnyhhahdaylnavvgtalikkypklesefvygdykvydvrkmiakseqeigkatakyffysnimnffkteitlangeirkrplietngetgeivwdkgrdfatvrkvlsmpqvnivkktevqtggfskesilpkrnsdkliarkkdwdpkkyggfdsptvaysvlvvakvekgkskklksvkellgitimerssfeknpidfleakgykevkkdliiklpkyslfelengrkrmlasagelqkgnelalpskyvnflylashyeklkgspedneqkqlfveqhkhyldeiieqisefskrviladanldkvlsaynkhrdkpireqaeniihlftltnlgapaafkyfdttidrkrytstkevldatlihqsitglyetridlsqlggd
seqidno:2
嗜热链球菌(streptococcusthermophilus)lmd-9cas9
mtkpysigldigtnsvgwavttdnykvpskkmkvlgntskkyikknllgvllfdsgitaegrrlkrtarrrytrrrnrilylqeifstematlddaffqrlddsflvpddkrdskypifgnlveekayhdefptiyhlrkyladstkkadlrlvylalahmikyrghfliegefnsknndiqknfqdfldtynaifesdlslenskqleeivkdkisklekkdrilklfpgeknsgifseflklivgnqadfrkcfnldekaslhfskesydedletllgyigddysdvflkakklydaillsgfltvtdneteaplssamikrynehkedlallkeyirnislktynevfkddtkngyagyidgktnqedfyvylkkllaefegadyflekidredflrkqrtfdngsipyqihlqemraildkqakfypflaknkeriekiltfripyyvgplargnsdfawsirkrnekitpwnfedvidkessaeafinrmtsfdlylpeekvlpkhsllyetfnvyneltkvrfiaesmrdyqfldskqkkdivrlyfkdkrkvtdkdiieylhaiygydgielkgiekqfnsslstyhdllniindkeflddssneaiieeiihtltifedremikqrlskfenifdksvlkklsrrhytgwgklsaklingirdeksgntildyliddgisnrnfmqlihddalsfkkkiqkaqiigdedkgnikevvkslpgspaikkgilqsikivdelvkvmggrkpesivvemarenqytnqgksnsqqrlkrlekslkelgskilkenipaklskidnnalqndrlylyylqngkdmytgddldidrlsnydidhiipqaflkdnsidnkvlvssasnrgksddvpslevvkkrktfwyqllksklisqrkfdnltkaergglspedkagfiqrqlvetrqitkhvarlldekfnnkkdennravrtvkiitlkstlvsqfrkdfelykvreindfhhahdaylnavvasallkkypklepefvygdypkynsfrerksatekvyfysnimnifkksisladgrvierplievneetgesvwnkesdlatvrrvlsypqvnvvkkveeqnhgldrgkpkglfnanlsskpkpnsnenlvgakeyldpkkyggyagisnsftvlvkgtiekgakkkitnvlefqgisildrinyrkdklnfllekgykdieliielpkyslfelsdgsrrmlasilstnnkrgeihkgnqiflsqkfvkllyhakrisntinenhrkyvenhkkefeelfyyilefnenyvgakkngkllnsafqswqnhsidelcssfigptgserkglfeltsrgsaadfeflgvkipryrdytpssllkdatlihqsvtglyetridlaklgeg
seqidno:3
变异链球菌(streptococcusmutans)ua159cas9
mkkpysigldigtnsvgwavvtddykvpakkmkvlgntdkshieknllgallfdsgntaedrrlkrtarrrytrrrnrilylqeifseemgkvddsffhrledsflvtedkrgerhpifgnleeevkyhenfptiyhlrqyladnpekvdlrlvylalahiikfrghfliegkfdtrnndvqrlfqeflavydntfensslqeqnvqveeiltdkisksakkdrvlklfpneksngrfaeflklivgnqadfkkhfeleekaplqfskdtyeeelevllaqigdnyaelflsakklydsillsgiltvtdvgtkaplsasmiqrynehqmdlaqlkqfirqklsdkynevfsdvskdgyagyidgktnqeafykylkgllnkiegsgyfldkieredflrkqrtfdngsiphqihlqemraiirrqaefypfladnqdrieklltfripyyvgplargksdfawlsrksadkitpwnfdeivdkessaeafinrmtnydlylpnqkvlpkhsllyekftvyneltkvkykteqgktaffdanmkqeifdgvfkvyrkvtkdklmdflekefdefrivdltgldkenkvfnasygtyhdlckildkdfldnsknekiledivltltlfedremirkrlenysdlltkeqvkklerrhytgwgrlsaelihgirnkesrktildyliddgnsnrnfmqlinddalsfkeeiakaqvigetdnlnqvvsdiagspaikkgilqslkivdelvkimghqpenivvemarenqftnqgrrnsqqrlkgltdsikefgsqilkehpvensqlqndrlflyylqngrdmytgeeldidylsqydidhiipqafikdnsidnrvltsskenrgksddvpskdvvrkmksywskllsaklitqrkfdnltkaerggltdddkagfikrqlvetrqitkhvarilderfntetdennkkirqvkivtlksnlvsnfrkefelykvreindyhhahdaylnavigkallgvypqlepefvygdyphfhghkenkatakkffysnimnffkkddvrtdkngeiiwkkdehisnikkvlsypqvnivkkveeqtggfskesilpkgnsdkliprktkkfywdtkkyggfdspivaysilviadiekgkskklktvkalvgvtimekmtferdpvaflerkgyrnvqeeniiklpkyslfklengrkrllasarelqkgneivlpnhlgtllyhaknihkvdepkhldyvdkhkdefkelldvvsnfskkytlaegnlekikelyaqnngedlkelassfinlltftaigapatfkffdknidrkrytstteilnatlihqsitglyetridlnklggd
seqidno:4
空肠弯曲杆菌(campylobacterjejuni)cas9
marilafdigissigwafsendelkdcgvriftkvenpktgeslalprrlarsarkrlarrkarlnhlkhlianefklnyedyqsfdeslakaykgslispyelrfralnellskqdfarvilhiakrrgyddiknsddkekgailkaikqneeklanyqsvgeylykeyfqkfkenskeftnvrnkkesyerciaqsflkdelklifkkqrefgfsfskkfeeevlsvafykralkdfshlvgncsfftdekrapknsplafmfvaltriinllnnlkntegilytkddlnallnevlkngtltykqtkkllglsddyefkgekgtyfiefkkykefikalgehnlsqddlneiakditlikdeiklkkalakydlnqnqidslsklefkdhlnisfkalklvtplmlegkkydeacnelnlkvainedkkdflpafnetyykdevtnpvvlraikeyrkvlnallkkygkvhkinielarevgknhsqrakiekeqnenykakkdaeleceklglkinsknilklrlfkeqkefcaysgekikisdlqdekmleidhiypysrsfddsymnkvlvftkqnqeklnqtpfeafgndsakwqkievlaknlptkkqkrildknykdkeqknfkdrnlndtryiarlvlnytkdyldflplsddentklndtqkgskvhveaksgmltsalrhtwgfsakdrnnhlhhaidaviiayannsivkafsdfkkeqesnsaelyakkiseldyknkrkffepfsgfrqkvldkideifvskperkkpsgalheetfrkeeefyqsyggkegvlkalelgkirkvngkivkngdmfrvdifkhkktnkfyavpiytmdfalkvlpnkavarskkgeikdwilmdenyefcfslykdsliliqtkdmqepefvyynaftsstvslivskhdnkfetlsknqkilfknanekeviaksigiqnlkvfekyivsalgevtkaefrqredfkk
seqidno:5
脑膜炎奈瑟球菌(neisseriameningitides)cas9
maafkpnsinyilgldigiasvgwamveideeenpirlidlgvrvferaevpktgdslamarrlarsvrrltrrrahrllrtrrllkregvlqaanfdenglikslpntpwqlraaaldrkltplewsavllhlikhrgylsqrknegetadkelgallkgvagnahalqtgdfrtpaelalnkfekesghirnqrsdyshtfsrkdlqaelillfekqkefgnphvsgglkegietllmtqrpalsgdavqkmlghctfepaepkaakntytaerfiwltklnnlrileqgserpltdteratlmdepyrkskltyaqarkllgledtaffkglrygkdnaeastlmemkayhaisralekeglkdkksplnlspelqdeigtafslfktdeditgrlkdriqpeileallkhisfdkfvqislkalrrivplmeqgkrydeacaeiygdhygkknteekiylppipadeirnpvvlralsqarkvingvvrrygsparihietarevgksfkdrkeiekrqeenrkdrekaaakfreyfpnfvgepkskdilklrlyeqqhgkclysgkeinlgrlnekgyveidhalpfsrtwddsfnnkvlvlgsenqnkgnqtpyeyfngkdnsrewqefkarvetsrfprskkqrillqkfdedgfkernlndtryvnrflcqfvadrmrltgkgkkrvfasngqitnllrgfwglrkvraendrhhaldavvvacstvamqqkitrfvrykemnafdgktidketgevlhqkthfpqpweffaqevmirvfgkpdgkpefeeadtleklrtllaeklssrpeavheyvtplfvsrapnrkmsgqghmetvksakrldegvsvlrvpltqlklkdlekmvnrerepklyealkarleahkddpakafaepfykydkagnrtqqvkavrveqvqktgvwvrnhngiadnatmvrvdvfekgdkyylvpiyswqvakgilpdravvqgkdeedwqliddsfnfkfslhpndlvevitkkarmfgyfaschrgtgninirihdldhkigkngilegigvktalsfqkyqidelgkeirpcrlkkrppvr
seqidno:6
土拉弗朗西斯菌新凶手亚种(francisellatularensissubsp.novicida)cas9mnfkilpiaidlgvkntgvfsafyqkgtslerldnkngkvyelskdsytllmnnrtarrhqrrgidrkqlvkrlfkliwteqlnlewdkdtqqaisflfnrrgfsfitdgyspeylnivpeqvkailmdifddyngeddldsylklateqeskiseiynklmqkilefklmklctdikddkvstktlkeitsyefelladylanyseslktqkfsytdkqgnlkelsyyhhdkyniqeflkrhatindrildtlltddldiwnfnfekfdfdkneeklqnqedkdhiqahlhhfvfavnkiksemasggrhrsqyfqeitnvldennhqegylknfcenlhnkkysnlsvknlvnlignlsnlelkplrkyfndkihakadhwdeqkftetychwilgewrvgvkdqdkkdgakysykdlcnelkqkvtkaglvdflleldpcrtippyldnnnrkppkcqslilnpkfldnqypnwqqylqelkklqsiqnyldsfetdlkvlksskdqpyfveykssnqqiasgqrdykdldarilqfifdrvkasdelllneiyfqakklkqkasseleklesskkldeviansqlsqilksqhtngifeqgtflhlvckyykqrqrardsrlyimpeyrydkklhkynntgrfdddnqlltycnhkprqkryqllndlagvlqvspnflkdkigsdddlfiskwlvehirgfkkacedslkiqkdnrgllnhkiniarntkgkcekeifnlickiegsedkkgnykhglayelgvllfgepneaskpefdrkikkfnsiysfaqiqqiafaerkgnantcavcsadnahrmqqikitepvednkdkiilsakaqrlpaiptrivdgavkkmatilaknivddnwqnikqvlsakhqlhipiitesnafefepaladvkgkslkdrrkkalerispenifkdknnrikefakgisaysganltdgdfdgakeeldhiiprshkkygtlndeanlicvtrgdnknkgnrifclrdladnyklkqfettddleiekkiadtiwdankkdfkfgnyrsfinltpqeqkafrhalfladenpikqavirainnrnrtfvngtqryfaevlanniylrakkenlntdkisfdyfgiptigngrgiaeirqlyekvdsdiqayakgdkpqasyshlidamlafciaadehrndgsigleidknyslypldkntgevftkdifsqikitdnefsdkklvrkkaiegfnthrqmtrdgiyaenylpilihkelnevrkgytwknseeikifkgkkydiqqlnnlvyclkfvdkpisidiqistleelrnilttnniaataeyyyinlktqklheyyienyntalgykkyskemeflrslayrservkiksiddvkqvldkdsnfiigkitlpfkkewqrlyrewqnttikddyeflksffnvksitklhkkvrkdfslpistnegkflvkrktwdnnfiyqilndsdsradgtkpfipafdiskneiveaiidsftsknifwlpknielqkvdnknifaidtskwfevetpsdlrdigiatiqykidnnsrpkvrvkldyvidddskinyfmnhsllksrypdkvleilkqstiiefessgfnktikemlgmklagiynetsnn
seqidno:7
多杀巴斯德菌cas9
mqttnlsyilgldlgiasvgwavveinenedpiglidvgvriferaevpktgeslalsrrlarstrrlirrrahrlllakrflkregilstidlekglpnqawelrvaglerrlsaiewgavllhlikhrgylskrknesqtnnkelgallsgvaqnhqllqsddyrtpaelalkkfakeeghirnqrgaythtfnrldllaelnllfaqqhqfgnphckehiqqymtellmwqkpalsgeailkmlgkctheknefkaakhtysaerfvwltklnnlriledgaeralneeerqllinhpyekskltyaqvrkllglseqaifkhlryskenaesatfmelkawhairkalenqglkdtwqdlakkpdlldeigtafslyktdediqqyltnkvpnsvinallvslnfdkfielslkslrkilplmeqgkrydqacreiyghhygeanqktsqllpaipaqeirnpvvlrtlsqarkvinaiirqygsparvhietgrelgksfkerreiqkqqednrtkresavqkfkelfsdfssepkskdilkfrlyeqqhgkclysgkeinihrlnekgyveidhalpfsrtwddsfnnkvlvlasenqnkgnqtpyewlqgkinserwknfvalvlgsqcsaakkqrlltqviddnkfidrnlndtryiarflsnyiqenlllvgknkknvftpngqitallrsrwglikarennnrhhaldaivvacatpsmqqkitrfirfkevhpykienryemvdqesgeiisphfpepwayfrqevnirvfdnhpdtvlkemlpdrpqanhqfvqplfvsraptrkmsgqghmetiksakrlaegisvlripltqlkpnllenmvnkerepalyaglkarlaefnqdpakafatpfykqggqqvkairveqvqksgvlvrenngvadnasivrtdvfiknnkfflvpiytwqvakgilpnkaivahknedeweemdegakfkfslfpndlvelktkkeyffgyyigldratgnislkehdgeiskgkdgvyrvgvklalsfekyqvdelgknrqicrpqqrqpvr
seqidno:8
丝状真菌细胞密码子优化的化脓性链球菌cas9编码基因;无nls
atggacaagaagtacagcatcggcctcgacatcggcaccaactcggtgggctgggccgtcatcacggacgaatataaggtcccgtcgaagaagttcaaggtcctcggcaatacagaccgccacagcatcaagaaaaacttgatcggcgccctcctgttcgatagcggcgagaccgcggaggcgaccaggctcaagaggaccgccaggagacggtacactaggcgcaagaacaggatctgctacctgcaggagatcttcagcaacgagatggcgaaggtggacgactccttcttccaccgcctggaggaatcattcctggtggaggaggacaagaagcatgagcggcacccaatcttcggcaacatcgtcgacgaggtggcctaccacgagaagtacccgacaatctaccacctccggaagaaactggtggacagcacagacaaggcggacctccggctcatctaccttgccctcgcgcatatgatcaagttccgcggccacttcctcatcgagggcgacctgaacccggacaactccgacgtggacaagctgttcatccagctcgtgcagacgtacaatcaactgttcgaggagaaccccataaacgctagcggcgtggacgccaaggccatcctctcggccaggctctcgaaatcaagaaggctggagaaccttatcgcgcagttgccaggcgaaaagaagaacggcctcttcggcaaccttattgcgctcagcctcggcctgacgccgaacttcaaatcaaacttcgacctcgcggaggacgccaagctccagctctcaaaggacacctacgacgacgacctcgacaacctcctggcccagataggagaccagtacgcggacctcttcctcgccgccaagaacctctccgacgctatcctgctcagcgacatccttcgggtcaacaccgaaattaccaaggcaccgctgtccgccagcatgattaaacgctacgacgagcaccatcaggacctcacgctgctcaaggcactcgtccgccagcagctccccgagaagtacaaggagatcttcttcgaccaatcaaaaaacggctacgcgggatatatcgacggcggtgccagccaggaagagttctacaagttcatcaaaccaatcctggagaagatggacggcaccgaggagttgctggtcaagctcaacagggaggacctcctcaggaagcagaggaccttcgacaacggctccatcccgcatcagatccacctgggcgaactgcatgccatcctgcggcgccaggaggacttctacccgttcctgaaggataaccgggagaagatcgagaagatcttgacgttccgcatcccatactacgtgggcccgctggctcgcggcaactcccggttcgcctggatgacccggaagtcggaggagaccatcacaccctggaactttgaggaggtggtcgataagggcgctagcgctcagagcttcatcgagcgcatgaccaacttcgataaaaacctgcccaatgaaaaagtcctccccaagcactcgctgctctacgagtacttcaccgtgtacaacgagctcaccaaggtcaaatacgtcaccgagggcatgcggaagccggcgttcctgagcggcgagcagaagaaggcgatagtggacctcctcttcaagaccaacaggaaggtgaccgtgaagcaattaaaagaggactacttcaagaaaatagagtgcttcgactccgtggagatctcgggcgtggaggatcggttcaacgcctcactcggcacgtatcacgacctcctcaagatcattaaagacaaggacttcctcgacaacgaggagaacgaggacatcctcgaggacatcgtcctcaccctgaccctgttcgaggaccgcgaaatgatcgaggagaggctgaagacctacgcgcacctgttcgacgacaaggtcatgaaacagctcaagaggcgccgctacactggttggggaaggctgtcccgcaagctcattaatggcatcagggacaagcagagcggcaagaccatcctggacttcctcaagtccgacgggttcgccaaccgcaacttcatgcagctcattcacgacgactcgctcacgttcaaggaagacatccagaaggcacaggtgagcgggcagggtgactccctccacgaacacatcgccaacctggccggctcgccggccattaaaaagggcatcctgcagacggtcaaggtcgtcgacgagctcgtgaaggtgatgggccggcacaagcccgaaaatatcgtcatagagatggccagggagaaccagaccacccaaaaagggcagaagaactcgcgcgagcggatgaaacggatcgaggagggcattaaagagctcgggtcccagatcctgaaggagcaccccgtggaaaatacccagctccagaatgaaaagctctacctctactacctgcagaacggccgcgacatgtacgtggaccaggagctggacattaatcggctatcggactacgacgtcgaccacatcgtgccgcagtcgttcctcaaggacgatagcatcgacaacaaggtgctcacccggtcggataaaaatcggggcaagagcgacaacgtgcccagcgaggaggtcgtgaagaagatgaaaaactactggcgccagctcctcaacgcgaaactgatcacccagcgcaagttcgacaacctgacgaaggcggaacgcggtggcttgagcgaactcgataaggcgggcttcataaaaaggcagctggtcgagacgcgccagatcacgaagcatgtcgcccagatcctggacagccgcatgaatactaagtacgatgaaaacgacaagctgatccgggaggtgaaggtgatcacgctgaagtccaagctcgtgtcggacttccgcaaggacttccagttctacaaggtccgcgagatcaacaactaccaccacgcccacgacgcctacctgaatgcggtggtcgggaccgccctgatcaagaagtacccgaagctggagtcggagttcgtgtacggcgactacaaggtctacgacgtgcgcaaaatgatcgccaagtccgagcaggagatcggcaaggccacggcaaaatacttcttctactcgaacatcatgaacttcttcaagaccgagatcaccctcgcgaacggcgagatccgcaagcgcccgctcatcgaaaccaacggcgagacgggcgagatcgtctgggataagggccgggatttcgcgacggtccgcaaggtgctctccatgccgcaagtcaatatcgtgaaaaagacggaggtccagacgggcgggttcagcaaggagtccatcctcccgaagcgcaactccgacaagctcatcgcgaggaagaaggattgggacccgaaaaaatatggcggcttcgacagcccgaccgtcgcatacagcgtcctcgtcgtggcgaaggtggagaagggcaagtcaaagaagctcaagtccgtgaaggagctgctcgggatcacgattatggagcggtcctccttcgagaagaacccgatcgacttcctagaggccaagggatataaggaggtcaagaaggacctgattattaaactgccgaagtactcgctcttcgagctggaaaacggccgcaagaggatgctcgcctccgcaggcgagttgcagaagggcaacgagctcgccctcccgagcaaatacgtcaatttcctgtacctcgctagccactatgaaaagctcaagggcagcccggaggacaacgagcagaagcagctcttcgtggagcagcacaagcattacctggacgagatcatcgagcagatcagcgagttctcgaagcgggtgatcctcgccgacgcgaacctggacaaggtgctgtcggcatataacaagcaccgcgacaaaccaatacgcgagcaggccgaaaatatcatccacctcttcaccctcaccaacctcggcgctccggcagccttcaagtacttcgacaccacgattgaccggaagcggtacacgagcacgaaggaggtgctcgatgcgacgctgatccaccagagcatcacagggctctatgaaacacgcatcgacctgagccagctgggcggagac
seqidno:9
丝状真菌细胞密码子优化的化脓性链球菌cas9编码基因;具有n-末端和c-末端nls序列
atggcaccgaagaagaagcgcaaggtgatggacaagaagtacagcatcggcctcgacatcggcaccaactcggtgggctgggccgtcatcacggacgaatataaggtcccgtcgaagaagttcaaggtcctcggcaatacagaccgccacagcatcaagaaaaacttgatcggcgccctcctgttcgatagcggcgagaccgcggaggcgaccaggctcaagaggaccgccaggagacggtacactaggcgcaagaacaggatctgctacctgcaggagatcttcagcaacgagatggcgaaggtggacgactccttcttccaccgcctggaggaatcattcctggtggaggaggacaagaagcatgagcggcacccaatcttcggcaacatcgtcgacgaggtggcctaccacgagaagtacccgacaatctaccacctccggaagaaactggtggacagcacagacaaggcggacctccggctcatctaccttgccctcgcgcatatgatcaagttccgcggccacttcctcatcgagggcgacctgaacccggacaactccgacgtggacaagctgttcatccagctcgtgcagacgtacaatcaactgttcgaggagaaccccataaacgctagcggcgtggacgccaaggccatcctctcggccaggctctcgaaatcaagaaggctggagaaccttatcgcgcagttgccaggcgaaaagaagaacggcctcttcggcaaccttattgcgctcagcctcggcctgacgccgaacttcaaatcaaacttcgacctcgcggaggacgccaagctccagctctcaaaggacacctacgacgacgacctcgacaacctcctggcccagataggagaccagtacgcggacctcttcctcgccgccaagaacctctccgacgctatcctgctcagcgacatccttcgggtcaacaccgaaattaccaaggcaccgctgtccgccagcatgattaaacgctacgacgagcaccatcaggacctcacgctgctcaaggcactcgtccgccagcagctccccgagaagtacaaggagatcttcttcgaccaatcaaaaaacggctacgcgggatatatcgacggcggtgccagccaggaagagttctacaagttcatcaaaccaatcctggagaagatggacggcaccgaggagttgctggtcaagctcaacagggaggacctcctcaggaagcagaggaccttcgacaacggctccatcccgcatcagatccacctgggcgaactgcatgccatcctgcggcgccaggaggacttctacccgttcctgaaggataaccgggagaagatcgagaagatcttgacgttccgcatcccatactacgtgggcccgctggctcgcggcaactcccggttcgcctggatgacccggaagtcggaggagaccatcacaccctggaactttgaggaggtggtcgataagggcgctagcgctcagagcttcatcgagcgcatgaccaacttcgataaaaacctgcccaatgaaaaagtcctccccaagcactcgctgctctacgagtacttcaccgtgtacaacgagctcaccaaggtcaaatacgtcaccgagggcatgcggaagccggcgttcctgagcggcgagcagaagaaggcgatagtggacctcctcttcaagaccaacaggaaggtgaccgtgaagcaattaaaagaggactacttcaagaaaatagagtgcttcgactccgtggagatctcgggcgtggaggatcggttcaacgcctcactcggcacgtatcacgacctcctcaagatcattaaagacaaggacttcctcgacaacgaggagaacgaggacatcctcgaggacatcgtcctcaccctgaccctgttcgaggaccgcgaaatgatcgaggagaggctgaagacctacgcgcacctgttcgacgacaaggtcatgaaacagctcaagaggcgccgctacactggttggggaaggctgtcccgcaagctcattaatggcatcagggacaagcagagcggcaagaccatcctggacttcctcaagtccgacgggttcgccaaccgcaacttcatgcagctcattcacgacgactcgctcacgttcaaggaagacatccagaaggcacaggtgagcgggcagggtgactccctccacgaacacatcgccaacctggccggctcgccggccattaaaaagggcatcctgcagacggtcaaggtcgtcgacgagctcgtgaaggtgatgggccggcacaagcccgaaaatatcgtcatagagatggccagggagaaccagaccacccaaaaagggcagaagaactcgcgcgagcggatgaaacggatcgaggagggcattaaagagctcgggtcccagatcctgaaggagcaccccgtggaaaatacccagctccagaatgaaaagctctacctctactacctgcagaacggccgcgacatgtacgtggaccaggagctggacattaatcggctatcggactacgacgtcgaccacatcgtgccgcagtcgttcctcaaggacgatagcatcgacaacaaggtgctcacccggtcggataaaaatcggggcaagagcgacaacgtgcccagcgaggaggtcgtgaagaagatgaaaaactactggcgccagctcctcaacgcgaaactgatcacccagcgcaagttcgacaacctgacgaaggcggaacgcggtggcttgagcgaactcgataaggcgggcttcataaaaaggcagctggtcgagacgcgccagatcacgaagcatgtcgcccagatcctggacagccgcatgaatactaagtacgatgaaaacgacaagctgatccgggaggtgaaggtgatcacgctgaagtccaagctcgtgtcggacttccgcaaggacttccagttctacaaggtccgcgagatcaacaactaccaccacgcccacgacgcctacctgaatgcggtggtcgggaccgccctgatcaagaagtacccgaagctggagtcggagttcgtgtacggcgactacaaggtctacgacgtgcgcaaaatgatcgccaagtccgagcaggagatcggcaaggccacggcaaaatacttcttctactcgaacatcatgaacttcttcaagaccgagatcaccctcgcgaacggcgagatccgcaagcgcccgctcatcgaaaccaacggcgagacgggcgagatcgtctgggataagggccgggatttcgcgacggtccgcaaggtgctctccatgccgcaagtcaatatcgtgaaaaagacggaggtccagacgggcgggttcagcaaggagtccatcctcccgaagcgcaactccgacaagctcatcgcgaggaagaaggattgggacccgaaaaaatatggcggcttcgacagcccgaccgtcgcatacagcgtcctcgtcgtggcgaaggtggagaagggcaagtcaaagaagctcaagtccgtgaaggagctgctcgggatcacgattatggagcggtcctccttcgagaagaacccgatcgacttcctagaggccaagggatataaggaggtcaagaaggacctgattattaaactgccgaagtactcgctcttcgagctggaaaacggccgcaagaggatgctcgcctccgcaggcgagttgcagaagggcaacgagctcgccctcccgagcaaatacgtcaatttcctgtacctcgctagccactatgaaaagctcaagggcagcccggaggacaacgagcagaagcagctcttcgtggagcagcacaagcattacctggacgagatcatcgagcagatcagcgagttctcgaagcgggtgatcctcgccgacgcgaacctggacaaggtgctgtcggcatataacaagcaccgcgacaaaccaatacgcgagcaggccgaaaatatcatccacctcttcaccctcaccaacctcggcgctccggcagccttcaagtacttcgacaccacgattgaccggaagcggtacacgagcacgaaggaggtgctcgatgcgacgctgatccaccagagcatcacagggctctatgaaacacgcatcgacctgagccagctgggcggagacaagaagaagaagctcaagctctag
seqidno:10
化脓性链球菌cas9,具有n-末端和c-末端nls序列(由seqidno:9编码)
mapkkkrkvmdkkysigldigtnsvgwavitdeykvpskkfkvlgntdrhsikknligallfdsgetaeatrlkrtarrrytrrknricylqeifsnemakvddsffhrleesflveedkkherhpifgnivdevayhekyptiyhlrkklvdstdkadlrliylalahmikfrghfliegdlnpdnsdvdklfiqlvqtynqlfeenpinasgvdakailsarlsksrrlenliaqlpgekknglfgnlialslgltpnfksnfdlaedaklqlskdtydddldnllaqigdqyadlflaaknlsdaillsdilrvnteitkaplsasmikrydehhqdltllkalvrqqlpekykeiffdqskngyagyidggasqeefykfikpilekmdgteellvklnredllrkqrtfdngsiphqihlgelhailrrqedfypflkdnrekiekiltfripyyvgplargnsrfawmtrkseetitpwnfeevvdkgasaqsfiermtnfdknlpnekvlpkhsllyeyftvyneltkvkyvtegmrkpaflsgeqkkaivdllfktnrkvtvkqlkedyfkkiecfdsveisgvedrfnaslgtyhdllkiikdkdfldneenediledivltltlfedremieerlktyahlfddkvmkqlkrrrytgwgrlsrklingirdkqsgktildflksdgfanrnfmqlihddsltfkediqkaqvsgqgdslhehianlagspaikkgilqtvkvvdelvkvmgrhkpeniviemarenqttqkgqknsrermkrieegikelgsqilkehpventqlqneklylyylqngrdmyvdqeldinrlsdydvdhivpqsflkddsidnkvltrsdknrgksdnvpseevvkkmknywrqllnaklitqrkfdnltkaergglseldkagfikrqlvetrqitkhvaqildsrmntkydendklirevkvitlksklvsdfrkdfqfykvreinnyhhahdaylnavvgtalikkypklesefvygdykvydvrkmiakseqeigkatakyffysnimnffkteitlangeirkrplietngetgeivwdkgrdfatvrkvlsmpqvnivkktevqtggfskesilpkrnsdkliarkkdwdpkkyggfdsptvaysvlvvakvekgkskklksvkellgitimerssfeknpidfleakgykevkkdliiklpkyslfelengrkrmlasagelqkgnelalpskyvnflylashyeklkgspedneqkqlfveqhkhyldeiieqisefskrviladanldkvlsaynkhrdkpireqaeniihlftltnlgapaafkyfdttidrkrytstkevldatlihqsitglyetridlsqlggdkkkklkl
seqidno:11
全长u6基因启动子序列(不包括转录起始位点)
aaaaaacactagtaagtacttacttatgtattattaactactttagctaacttctgcagtactacctaagaggctaggggtagttttatagcagacttatagctattatttttatttagtaaagtgcttttaaagtaaggtcttttttatagcactttttatttattataatatatattatataataattttaagcctggaatagtaaagaggcttatataataatttatagtaataaaagcttagcagctgtaatataattcctaaagaaacagcatgaaatggtattatgtaagagctatagtctaaaggcactctgctggataaaaatagtggctataagtctgctgcaaaactacccccaacctcgtaggtatataagtactgtttgatggtagtctatc
seqidno:12
截短的/较短的u6基因启动子序列(不包括转录起始位点)
aattcctaaagaaacagcatgaaatggtattatgtaagagctatagtctaaaggcactctgctggataaaaatagtggctataagtctgctgcaaaactacccccaacctcgtaggtatataagtactgtttgatggtagtctatc
seqidno:13
n-末端his6标签/凝血酶/s·tagtm/肠激酶区域多核苷酸序列(具有起始密码子);编码seqidno:18
atgcaccatcatcatcatcattcttctggtctggtgccacgcggttctggtatgaaagaaaccgctgctgctaaattcgaacgccagcacatggacagcccagatctgggtaccgacgacgacgacaaggccatggcc
seqidno:14
sv40nls编码序列(编码seqidno:19)
ccaaaaaagaaacgcaaggtt
seqidno:15
大肠杆菌密码子优化的cas9基因(无终止密码子)
atggataaaaaatacagcattggtctggatatcggaaccaacagcgttgggtgggcagtaataacagatgaatacaaagtgccgtcaaaaaaatttaaggttctggggaatacagatcgccacagcataaaaaagaatctgattggggcattgctgtttgattcgggtgagacagctgaggccacgcgtctgaaacgtacagcaagaagacgttacacacgtcgtaaaaatcgtatttgctacttacaggaaattttttctaacgaaatggccaaggtagatgatagtttcttccatcgtctcgaagaatcttttctggttgaggaagataaaaaacacgaacgtcaccctatctttggcaatatcgtggatgaagtggcctatcatgaaaaataccctacgatttatcatcttcgcaagaagttggttgatagtacggacaaagcggatctgcgtttaatctatcttgcgttagcgcacatgatcaaatttcgtggtcatttcttaattgaaggtgatctgaatcctgataactctgatgtggacaaattgtttatacaattagtgcaaacctataatcagctgttcgaggaaaaccccattaatgcctctggagttgatgccaaagcgattttaagcgcgagactttctaagtcccggcgtctggagaatctgatcgcccagttaccaggggaaaagaaaaatggtctgtttggtaatctgattgccctcagtctggggcttaccccgaacttcaaatccaattttgacctggctgaggacgcaaagctgcagctgagcaaagatacttatgatgatgacctcgacaatctgctcgcccagattggtgaccaatatgcggatctgtttctggcagcgaagaatctttcggatgctatcttgctgtcggatattctgcgtgttaataccgaaatcaccaaagcgcctctgtctgcaagtatgatcaagagatacgacgagcaccaccaggacctgactcttcttaaggcactggtacgccaacagcttccggagaaatacaaagaaatattcttcgaccagtccaagaatggttacgcgggctacatcgatggtggtgcatcacaggaagagttctataaatttattaaaccaatccttgagaaaatggatggcacggaagagttacttgttaaacttaaccgcgaagacttgcttagaaagcaacgtacattcgacaacggctccatcccacaccagattcatttaggtgaacttcacgccatcttgcgcagacaagaagatttctatcccttcttaaaagacaatcgggagaaaatcgagaagatcctgacgttccgcattccctattatgtcggtcccctggcacgtggtaattctcggtttgcctggatgacgcgcaaaagtgaggaaaccatcaccccttggaactttgaagaagtcgtggataaaggtgctagcgcgcagtcttttatagaaagaatgacgaacttcgataaaaacttgcccaacgaaaaagtcctgcccaagcactctcttttatatgagtactttactgtgtacaacgaactgactaaagtgaaatacgttacggaaggtatgcgcaaacctgcctttcttagtggcgagcagaaaaaagcaattgtcgatcttctctttaaaacgaatcgcaaggtaactgtaaaacagctgaaggaagattatttcaaaaagatcgaatgctttgattctgtcgagatctcgggtgtcgaagatcgtttcaacgcttccttagggacctatcatgatttgctgaagataataaaagacaaagactttctcgacaatgaagaaaatgaagatattctggaggatattgttttgaccttgaccttattcgaagatagagagatgatcgaggagcgcttaaaaacctatgcccacctgtttgatgacaaagtcatgaagcaattaaagcgccgcagatatacggggtggggccgcttgagccgcaagttgattaacggtattagagacaagcagagcggaaaaactatcctggatttcctcaaatctgacggatttgcgaaccgcaattttatgcagcttatacatgatgattcgcttacattcaaagaggatattcagaaggctcaggtgtctgggcaaggtgattcactccacgaacatatagcaaatttggccggctctcctgcgattaagaaggggatcctgcaaacagttaaagttgtggatgaacttgtaaaagtaatgggccgccacaagccggagaatatcgtgatagaaatggcgcgcgagaatcaaacgacacaaaaaggtcaaaagaactcaagagagagaatgaagcgcattgaggaggggataaaggaacttggatctcaaattctgaaagaacatccagttgaaaacactcagctgcaaaatgaaaaattgtacctgtactacctgcagaatggaagagacatgtacgtggatcaggaattggatatcaatagactctcggactatgacgtagatcacattgtccctcagagcttcctcaaggatgattctatagataataaagtacttacgagatcggacaaaaatcgcggtaaatcggataacgtcccatcggaggaagtcgttaaaaagatgaaaaactattggcgtcaactgctgaacgccaagctgatcacacagcgtaagtttgataatctgactaaagccgaacgcggtggtcttagtgaactcgataaagcaggatttataaaacggcagttagtagaaacgcgccaaattacgaaacacgtggctcagatcctcgattctagaatgaatacaaagtacgatgaaaacgataaactgatccgtgaagtaaaagtcattaccttaaaatctaaacttgtgtccgatttccgcaaagattttcagttttacaaggtccgggaaatcaataactatcaccatgcacatgatgcatatttaaatgcggttgtaggcacggcccttattaagaaataccctaaactcgaaagtgagtttgtttatggggattataaagtgtatgacgttcgcaaaatgatcgcgaaatcagaacaggaaatcggtaaggctaccgctaaatactttttttattccaacattatgaatttttttaagaccgaaataactctcgcgaatggtgaaatccgtaaacggcctcttatagaaaccaatggtgaaacgggagaaatcgtttgggataaaggtcgtgactttgccaccgttcgtaaagtcctctcaatgccgcaagttaacattgtcaagaagacggaagttcaaacagggggattctccaaagaatctatcctgccgaagcgtaacagtgataaacttattgccagaaaaaaagattgggatccaaaaaaatacggaggctttgattcccctaccgtcgcgtatagtgtgctggtggttgctaaagtcgagaaagggaaaagcaagaaattgaaatcagttaaagaactgctgggtattacaattatggaaagatcgtcctttgagaaaaatccgatcgactttttagaggccaaggggtataaggaagtgaaaaaagatctcatcatcaaattaccgaagtatagtctttttgagctggaaaacggcagaaaaagaatgctggcctccgcgggcgagttacagaagggaaatgagctggcgctgccttccaaatatgttaattttctgtaccttgccagtcattatgagaaactgaagggcagccccgaagataacgaacagaaacaattattcgtggaacagcataagcactatttagatgaaattatagagcaaattagtgaattttctaagcgcgttatcctcgcggatgctaatttagacaaagtactgtcagcttataataaacatcgggataagccgattagagaacaggccgaaaatatcattcatttgtttaccttaaccaaccttggagcaccagctgccttcaaatatttcgataccacaattgatcgtaaacggtatacaagtacaaaagaagtcttggacgcaaccctcattcatcaatctattactggattatatgagacacgcattgatctttcacagctgggcggagac
seqidno:16
blr2核定位信号编码序列(编码seqidno:20)
aagaagaaaaaactgaaactg
seqidno:17
在质粒pet30a-spycas9中的spycas9合成基因的核苷酸序列。编码n-末端his6标签、sv40核定位信号和blr核定位信号的寡核苷酸分别以粗体下划线、斜体下划线和下划线显示。
n-末端his6标签/凝血酶/s·tagtm/肠激酶区域氨基酸序列(具有起始甲硫氨酸)
mhhhhhhssglvprgsgmketaaakferqhmdspdlgtddddkama
seqidno:19
sv40nls
pkkkrkv
seqidno:20
里氏木霉blr2(蓝光调节子2)基因nls
kkkklkl
seqidno:21
从质粒pet30a-spycas9中表达的spycas9蛋白质的氨基酸序列。n-末端his6标签、sv40核定位信号和blr核定位信号分别以粗体下划线、斜体下划线和下划线显示。
底物dna片段的核苷酸序列。utr序列以小写字母显示,而trga基因以大写字母显示。选择的vt结构域,即trga_sth_sgr2以粗体显示,并且用于进一步环出实验的500bp片段以下划线显示。
seqidno:22的正向引物:
5’-gactgtctccaccatgtaatttttc-3’
seqidno:24
seqidno:22的反向引物:
5’-ggcagactacaagtctactagtactac-3’
seqidno:25
trga_sth_sgr2vt结构域
tcctgacttccatccacacc
seqidno:26
用于进一步环出实验的500bp片段
gagcacatgcagtaacgccgactcggcgtcatttcgccacacccaatttggacctgagggatgctggaagctgctgagcagatcccgttaccgattcatggcactactacatccatacgcagcaaacatgggcttgggcttggcttctcaatgcaaaattgcccgcaaaagtcccggcattgtcgatgcagagatgcagatttcagcgggcgattctagggtagggcgactactactactaataccacctagtcagtatgtatctagcaccggaggctaggcggttagtggacgggaacctggtcattccatcgcaaccaggatcccgcacttcgttgcgcttctgcccccacggggcgggagttggcagaggcagaatgcggagcagccccttgtctgccctggccggggcctgttgaagcaagcagacgagagcagagcggttgagaagcggtggttgacgcttgacggtacgaagacgagcgagaatcccgttaagccgaggctgggc
seqidno:27
由t7启动子、cer结构域和vt结构域trga_sth_sgr2组成的用于体外转录的模板序列。vt结构域以大写字母显示,而t7启动子和cer结构域分别以粗体和小写字母显示。
正向
5’-ctttttacggttcctggc-3’
seqidno:29
反向
5’-aaaagcaccgactcgg-3’
seqidno:30
trga敲除盒的核苷酸序列。pyr2启动子、pyr2cds、pyr2终止子和500bp重复序列分别以小写字母、斜体下划线、粗体和下划线显示。
pyr2启动子
ctcgagtttataagtgacaacatgctctcaaagcgctcatggctggcacaagcctggaaagaaccaacacaaagcatactgcagcaaatcagctgaattcgtcaccaattaagtgaacatcaacctgaaggcagagtatgaggccagaagcacatctggatcgcagatcatggattgcccctcttgttgaagatgagaatctagaaagatggcggggtatgagataagagcgatgggggggcacatcatcttccaagacaaacaacctttgcagagtcaggcaatttttcgtataagagcaggaggagggagtccagtcatttcatcagcggtaaaatcactctagacaatcttcaagatgagttctgccttgggtgacttatagccatcatcatacctagacagaagcttgtgggatactaagaccaacgtacaagctcgcactgtacgctttgacttccatgtgaaaactcgatacggcgcgcctctaaattttatagctcaaccactccaatccaacctctgcatccctctcactcgtcctgatctactgttcaaatcagagaataaggacactatccaaatccaacaga
seqidno:32
pyr2cds
atggctaccacctcccagctgcctgcctacaagcaggacttcctcaaatccgccatcgacggcggcgtcctcaagtttggcagcttcgagctcaagtccaagcggatatccccctacttcttcaacgcgggcgaattccacacggcgcgcctcgccggcgccatcgcctccgcctttgcaaagaccatcatcgaggcccaggagaaggccggcctagagttcgacatcgtcttcggcccggcctacaagggcatcccgctgtgctccgccatcaccatcaagctcggcgagctggcgccccagaacctggaccgcgtctcctactcgtttgaccgcaaggaggccaaggaccacggcgagggcggcaacatcgtcggcgcttcgctcaagggcaagagggtcctgattgtcgacgacgtcatcaccgccggcaccgccaagagggacgccattgagaagatcaccaaggagggcggcatcgtcgccggcatcgtcgtggccctggaccgcatggagaagctccccgctgcggatggcgacgactccaagcctggaccgagtgccattggcgagctgaggaaggagtacggcatccccatctttgccatcctcactctggatgacattatcgatggcatgaagggctttgctacccctgaggatatcaagaacacggaggattaccgtgccaagtacaaggcgactgactga
seqidno:33
pyr2终止子
ttgaggcgttcaatgtcagaagggagagaaagactgaaaaggtggaaagaagaggcaaattgttgttattattattattctatctcgaatcttctagatcttgtcgtaaataaacaagcgtaactagctagcctccgtacaactgcttgaatttgatacccgtatggagggcagttattttattttgtttttcaagattttccattcgccgttgaactcgtctcacatcgcgtgtattgcccggttgcccatgtgttctcctactaccccaagtccctcacgggttgtctcactttctttctcctttatcctccctattttttttcaagtcagcgacagagcagtcatatggggatacgtgcaactgggactcacaacaggccatcttatggcctaatagccggcgttggatccactagtca
attg
seqidno:34
500bp重复序列
agcacatgcagtaacgccgactcggcgtcatttcgccacacccaatttggacctgagggatgctggaagctgctgagcagatcccgttaccgattcatggcactactacatccatacgcagcaaacatgggcttgggcttggcttctcaatgcaaaattgcccgcaaaagtcccggcattgtcgatgcagagatgcagatttcagcgggcgattctagggtagggcgactactactactaataccacctagtcagtatgtatctagcaccggaggctaggcggttagtggacgggaacctggtcattccatcgcaaccaggatcccgcacttcgttgcgcttctgcccccacggggcgggagttggcagaggcagaatgcggagcagccccttgtctgccctggccggggcctgttgaagcaagcagacgagagcagagcggttgagaagcggtggttgacgcttgacggtacgaagacgagcgagaatcccgttaagccgaggctgggc
seqidno:35
ggtgtttggtagtagcaatg
seqidno:36
ggcagactacaagtctactagtactac
seqidno:37
环出菌株的pcr产物的预期核苷酸序列。utr序列以小写字母显示,部分trgaorf片段以大写字母显示,并且在环出(重复序列)后保留的500bp片段被加下划线。
ggtgtttggtagtagcaatgtttgcggtggcagtttgagccgagcctcgtcttgggcttctgacccaggcaacgccatctgactagctgcgccgaaggaaggatgattcattgtacgacgccagtcaatggaatcttcaagtaaaagcccgacgaaccgaccatgtcagatatcagaattctcctggctggtggggttggttggagactgcttacggagtcgatgcctcgtgactgtcatggccgcgtccagcctcctgggactctgtccgatattatgacacgagtaaagcctgcatgatgtcagtttgctgcgtctcatgtcgagaacaacacacctggtgctacataggcaatactacctcgtagcttcaaagttgactgttttgctttgatgtctttgatcatgcccatccatcccttgtcttgcagtgcatgtggatctctacgtccagacggggagaaagcttgtctgtgataaagtacgatgatgcattgatgcctgtggctacggcccttttatccccatcgtcatgcatctctatattaatccaggagactctcctcctggcatgggtgagtacaagtgacgaggacatgtagaagcagagccacgcaacgtcttgacatctgtacctattttgggccaaaaatcgagacccaccagctcgtcctaccttacatgtgaagatcttagcccacaatcctactgttttactagtattactgcacagctgtcatcacgagtcctcggttgcttgtgaaacccagctcagctcctgagcacatgcagtaacgccgactcggcgtcatttcgccacacccaatttggacctgagggatgctggaagctgctgagcagatcccgttaccgattcatggcactactacatccatacgcagcaaacatgggcttgggcttggcttctcaatgcaaaattgcccgcaaaagtcccggcattgtcgatgcagagatgcagatttcagcgggcgattctagggtagggcgactactactactaataccacctagtcagtatgtatctagcaccggaggctaggcggttagtggacgggaacctggtcattccatcgcaaccaggatcccgcacttcgttgcgcttctgcccccacggggcgggagttggcagaggcagaatgcggagcagccccttgtctgccctggccggggcctgttgaagcaagcagacgagagcagagcggttgagaagcggtggttgacgcttgacggtacgaagacgagcgagaatcccgttaagccgaggctgggctgacttccatccacaccttcgatcccaaccttggctgtgacgcaggcaccttccagccatgcagtgacaaagcgctctccaacctcaaggttgttgtcgactccttccgctccatctacggcgtgaacaagggcattcctgccggtgctgccgtcgccattggccggtatgcagaggatgtgtactacaacggcaacccttggtatcttgctacatttgctgctgccgagcagctgtacgatgccatctacgtctggaagaagacgggctccatcacggtgaccgccacctccctggccttcttccaggagcttgttcctggcgtgacggccgggacctactccagcagctcttcgacctttaccaacatcatcaacgccgtctcgacatacgccgatggcttcctcagcgaggctgccaagtacgtccccgccgacggttcgctggccgagcagtttgaccgcaacagcggcactccgctgtctgcgcttcacctgacgtggtcgtacgcctcgttcttgacagccacggcccgtcgggctggcatcgtgcccccctcgtgggccaacagcagcgctagcacgatcccctcgacgtgctccggcgcgtccgtggtcggatcctactcgcgtcccaccgccacgtcattccctccgtcgcagacgcccaagcctggcgtgccttccggtactccctacacgcccctgccctgcgcgaccccaacctccgtggccgtcaccttccacgagctcgtgtcgacacagtttggccagacggtcaaggtggcgggcaacgccgcggccctgggcaactggagcacgagcgccgccgtggctctggacgccgtcaactatgccgataaccaccccctgtggattgggacggtcaacctcgaggctggagacgtcgtggagtacaagtacatcaatgtgggccaagatggctccgtgacctgggagagtgatcccaaccacacttacacggttcctgcggtggcttgtgtgacgcaggttgtcaaggaggacacctggcagtcgtaatgaatcggcaaggggtagtactagtagacttgtagtctgcc
seqidno:38
来自seqidno:37的上游utr序列
ggtgtttggtagtagcaatgtttgcggtggcagtttgagccgagcctcgtcttgggcttctgacccaggcaacgccatctgactagctgcgccgaaggaaggatgattcattgtacgacgccagtcaatggaatcttcaagtaaaagcccgacgaaccgaccatgtcagatatcagaattctcctggctggtggggttggttggagactgcttacggagtcgatgcctcgtgactgtcatggccgcgtccagcctcctgggactctgtccgatattatgacacgagtaaagcctgcatgatgtcagtttgctgcgtctcatgtcgagaacaacacacctggtgctacataggcaatactacctcgtagcttcaaagttgactgttttgctttgatgtctttgatcatgcccatccatcccttgtcttgcagtgcatgtggatctctacgtccagacggggagaaagcttgtctgtgataaagtacgatgatgcattgatgcctgtggctacggcccttttatccccatcgtcatgcatctctatattaatccaggagactctcctcctggcatgggtgagtacaagtgacgaggacatgtagaagcagagccacgcaacgtcttgacatctgtacctattttgggccaaaaatcgagacccaccagctcgtcctaccttacatgtgaagatcttagcccacaatcctactgttttactagtattactgcacagctgtcatcacgagtcctcggttgcttgtgaaacccagctcagctcctgagcacatgcagtaacgccgactcggcgtcatttcgccacacccaatttggacctgagggatgctggaagctgctgagcagatcccgttaccgattcatggcactactacatccatacgcagcaaacatgggcttgggcttggcttctcaatgcaaaattgcccgcaaaagtcccggcattgtcgatgcagagatgcagatttcagcgggcgattctagggtagggcgactactactactaataccacctagtcagtatgtatctagcaccggaggctaggcggttagtggacgggaacctggtcattccatcgcaaccaggatcccgcacttcgttgcgcttctgcccccacggggcgggagttggcagaggcagaatgcggagcagccccttgtctgccctggccggggcctgttgaagcaagcagacgagagcagagcggttgagaagcggtggttgacgcttgacggtacgaagacgagcgagaatcccgttaagccgaggctgggc
seqidno:39
下游utr序列
来自seqidno:37的tgaatcggcaaggggtagtactagtagacttgtagtctgcc
seqidno:40
来自seqidno:37的部分trgaorf片段
tgacttccatccacaccttcgatcccaaccttggctgtgacgcaggcaccttccagccatgcagtgacaaagcgctctccaacctcaaggttgttgtcgactccttccgctccatctacggcgtgaacaagggcattcctgccggtgctgccgtcgccattggccggtatgcagaggatgtgtactacaacggcaacccttggtatcttgctacatttgctgctgccgagcagctgtacgatgccatctacgtctggaagaagacgggctccatcacggtgaccgccacctccctggccttcttccaggagcttgttcctggcgtgacggccgggacctactccagcagctcttcgacctttaccaacatcatcaacgccgtctcgacatacgccgatggcttcctcagcgaggctgccaagtacgtccccgccgacggttcgctggccgagcagtttgaccgcaacagcggcactccgctgtctgcgcttcacctgacgtggtcgtacgcctcgttcttgacagccacggcccgtcgggctggcatcgtgcccccctcgtgggccaacagcagcgctagcacgatcccctcgacgtgctccggcgcgtccgtggtcggatcctactcgcgtcccaccgccacgtcattccctccgtcgcagacgcccaagcctggcgtgccttccggtactccctacacgcccctgccctgcgcgaccccaacctccgtggccgtcaccttccacgagctcgtgtcgacacagtttggccagacggtcaaggtggcgggcaacgccgcggccctgggcaactggagcacgagcgccgccgtggctctggacgccgtcaactatgccgataaccaccccctgtggattgggacggtcaacctcgaggctggagacgtcgtggagtacaagtacatcaatgtgggccaagatggctccgtgacctgggagagtgatcccaaccacacttacacggttcctgcggtggcttgtgtgacgcaggttgtcaaggaggacacctggcagtcgtaa
seqidno:41
来自seqidno:37的在环出后保留的500bp片段
agcacatgcagtaacgccgactcggcgtcatttcgccacacccaatttggacctgagggatgctggaagctgctgagcagatcccgttaccgattcatggcactactacatccatacgcagcaaacatgggcttgggcttggcttctcaatgcaaaattgcccgcaaaagtcccggcattgtcgatgcagagatgcagatttcagcgggcgattctagggtagggcgactactactactaataccacctagtcagtatgtatctagcaccggaggctaggcggttagtggacgggaacctggtcattccatcgcaaccaggatcccgcacttcgttgcgcttctgcccccacggggcgggagttggcagaggcagaatgcggagcagccccttgtctgccctggccggggcctgttgaagcaagcagacgagagcagagcggttgagaagcggtggttgacgcttgacggtacgaagacgagcgagaatcccgttaagccgaggctgggc
- 还没有人留言评论。精彩留言会获得点赞!