识别PRAME抗原的TCR的制作方法
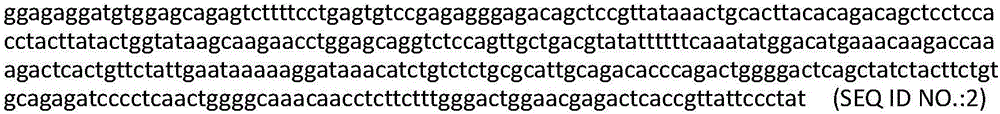
本发明涉及能够识别源自PRAME抗原短肽的TCR,本发明还涉及转导上述TCR来获得的PRAME特异性的T细胞,及他们在预防和治疗PRAME相关疾病中的用途。
背景技术:
PRAME为黑色素瘤特异性抗原(preferentially expressed antigen of melanoma,PRAME),在88%初发和95%转移黑色素瘤中都有表达(Ikeda H,et al.Immunity,1997,6(2):199-208),正常皮肤组织和良性黑素细胞则不表达。PRAME在细胞内生成后被降解成小分子多肽,并与MHC(主组织相容性复合体)分子结合形成复合物,被呈递到细胞表面。GLSNLTHVL是衍生自PRAME抗原的短肽,是PRAME相关疾病治疗的一种靶标。除了黑色素瘤,PRAME还在多种肿瘤表达,包括肺鳞状细胞癌、乳腺癌、肾细胞癌、头颈部肿瘤、霍杰金氏淋巴瘤、肉瘤及成神经管细胞瘤等(van't Veer LJ,et al.Nature,2002,415(6871):530-536;Boon K,et al.Oncogene,2003,22(48):7687-7694)另外,其在白血病中PRAME亦有显著表达,急性淋巴细胞白血病17%~42%,急性粒细胞白血病30%~64%(SteinbachD,et al.Cancer Genet Cytogene,2002,138(1):89-91)。对于上述疾病的治疗,可以采用化疗和放射性治疗等方法,但都会对自身的正常细胞造成损害。
T细胞过继免疫治疗是将对靶细胞抗原具有特异性的反应性T细胞转入病人体内,使其针对靶细胞发挥作用。T细胞受体(TCR)是T细胞表面的一种膜蛋白,其能够识别相应的靶细胞表面的抗原短肽。在免疫系统中,通过抗原短肽特异性的TCR与短肽-主组织相容性复合体(pMHC复合物)的结合引发T细胞与抗原呈递细胞(APC)直接的物理接触,然后T细胞及APC两者的其他细胞膜表面分子就发生相互作用,引起一系列后续的细胞信号传递和其他生理反应,从而使得不同抗原特异性的T细胞对其靶细胞发挥免疫效应。因此,本领域技术人员致力于分离出对NY-ESO-1抗原短肽具有特异性的TCR,以及将该TCR转导T细胞来获得对NY-ESO-1抗原短肽具有特异性的T细胞,从而使他们在细胞免疫治疗中发挥作用。
技术实现要素:
本发明的目的在于提供一种识别PRAME抗原短肽的T细胞受体。
本发明的第一方面,提供了一种T细胞受体(TCR),所述TCR能够与GLSNLTHVL-HLA A0201复合物结合。
在另一优选例中,所述TCR包含TCRα链可变域和TCRβ链可变域,所述TCRα链可变域的CDR3的氨基酸序列为AEIPSTGANNLF(SEQ ID NO:12);和/或所述TCRβ链可变域的CDR3的氨基酸序列为ASSQGGTQY(SEQ ID NO:15)。
在另一优选例中,所述TCRα链可变域的3个互补决定区(CDR)为:
αCDR1-DSSSTY(SEQ ID NO:10)
αCDR2-IFSNMDM(SEQ ID NO:11)
αCDR3-AEIPSTGANNLF(SEQ ID NO:12);和/或
所述TCRβ链可变域的3个互补决定区为:
βCDR1-SGHDN(SEQ ID NO:13)
βCDR2-FVKESK(SEQ ID NO:14)
βCDR3-ASSQGGTQY(SEQ ID NO:15)。
在另一优选例中,所述TCR包含TCRα链可变域和TCRβ链可变域,所述TCRα链可变域为与SEQ ID NO:1具有至少90%序列相同性的氨基酸序列;和/或所述TCRβ链可变域为与SEQ ID NO:5具有至少90%序列相同性的氨基酸序列。
在另一优选例中,所述TCR包含α链可变域氨基酸序列SEQ ID NO:1。
在另一优选例中,所述TCR包含β链可变域氨基酸序列SEQ ID NO:5。
在另一优选例中,所述TCR为αβ异质二聚体,其包含TCRα链恒定区TRAC*01和TCRβ链恒定区TRBC1*01或TRBC2*01。
在另一优选例中,所述TCR的α链氨基酸序列为SEQ ID NO:3和/或所述TCR的β链氨基酸序列为SEQ ID NO:7。
在另一优选例中,所述TCR是可溶的。
在另一优选例中,所述TCR为单链。
在另一优选例中,所述TCR是由α链可变域与β链可变域通过肽连接序列连接而成。
在另一优选例中,所述TCR在α链可变区氨基酸第11、13、19、21、53、76、89、91、或第94位,和/或α链J基因短肽氨基酸倒数第3位、倒数第5位或倒数第7位中具有一个或多个突变;和/或所述TCR在β链可变区氨基酸第11、13、19、21、53、76、89、91、或第94位,和/或β链J基因短肽氨基酸倒数第2位、倒数第4位或倒数第6位中具有一个或多个突变,其中氨基酸位置编号按IMGT(国际免疫遗传学信息系统)中列出的位置编号。
在另一优选例中,所述TCR的α链可变域氨基酸序列包含SEQ ID NO:32和/或所述TCR的β链可变域氨基酸序列包含SEQ ID NO:34。
在另一优选例中,所述TCR的氨基酸序列为SEQ ID NO:30。
在另一优选例中,所述TCR包括(a)除跨膜结构域以外的全部或部分TCRα链;以及(b)除跨膜结构域以外的全部或部分TCRβ链;
并且(a)和(b)各自包含功能性可变结构域,或包含功能性可变结构域和所述TCR链恒定结构域的至少一部分。
在另一优选例中,半胱氨酸残基在所述TCR的α和β链恒定域之间形成人工二硫键。
在另一优选例中,在所述TCR中形成人工二硫键的半胱氨酸残基取代了选自下列的一组或多组位点:
TRAC*01外显子1的Thr48和TRBC1*01或TRBC2*01外显子1的Ser57;
TRAC*01外显子1的Thr45和TRBC1*01或TRBC2*01外显子1的Ser77;
TRAC*01外显子1的Tyr10和TRBC1*01或TRBC2*01外显子1的Ser17;
TRAC*01外显子1的Thr45和TRBC1*01或TRBC2*01外显子1的Asp59;
TRAC*01外显子1的Ser15和TRBC1*01或TRBC2*01外显子1的Glu15;
TRAC*01外显子1的Arg53和TRBC1*01或TRBC2*01外显子1的Ser54;
TRAC*01外显子1的Pro89和TRBC1*01或TRBC2*01外显子1的Ala19;和
TRAC*01外显子1的Tyr10和TRBC1*01或TRBC2*01外显子1的Glu20。
在另一优选例中,所述TCR的α链氨基酸序列为SEQ ID NO:26和/或所述TCR的β链氨基酸序列为SEQ ID NO:28。
在另一优选例中,所述TCR的α链可变区与β链恒定区之间含有人工链间二硫键。
在另一优选例中,其特征在于,在所述TCR中形成人工链间二硫键的半胱氨酸残基取代了选自下列的一组或多组位点:
TRAV的第46位氨基酸和TRBC1*01或TRBC2*01外显子1的第60位氨基酸;
TRAV的第47位氨基酸和TRBC1*01或TRBC2*01外显子1的61位氨基酸;
TRAV的第46位氨基酸和TRBC1*01或TRBC2*01外显子1的第61位氨基酸;或
TRAV的第47位氨基酸和TRBC1*01或TRBC2*01外显子1的第60位氨基酸。
在另一优选例中,所述TCR包含α链可变域和β链可变域以及除跨膜结构域以外的全部或部分β链恒定域,但其不包含α链恒定域,所述TCR的α链可变域与β链形成异质二聚体。
在另一优选例中,所述TCR的α链和/或β链的C-或N-末端结合有偶联物。
在另一优选例中,与所述T细胞受体结合的偶联物为可检测标记物、治疗剂、PK修饰部分或任何这些物质的组合。优选地,所述治疗剂为抗-CD3抗体。
本发明的第二方面,提供了一种多价TCR复合物,其包含至少两个TCR分子,并且其中的至少一个TCR分子为本发明第一方面所述的TCR。
本发明的第三方面,提供了一种核酸分子,所述核酸分子包含编码本发明第一方面所述的TCR分子的核酸序列或其互补序列。
在另一优选例中,所述核酸分子包含编码TCRα链可变域的核苷酸序列SEQ ID NO:2或SEQ ID NO:33。
在另一优选例中,所述的核酸分子包含编码TCRβ链可变域的核苷酸序列SEQ ID NO:6或SEQ ID NO:35。
在另一优选例中,所述核酸分子包含编码TCRα链的核苷酸序列SEQ ID NO:4和/或包含编码TCRβ链的核苷酸序列SEQ ID NO:8。
本发明的第四方面,提供了一种载体,所述的载体含有本发明第三方面所述的核酸分子;优选地,所述的载体为病毒载体;更优选地,所述的载体为慢病毒载体。
本发明的第五方面,提供了一种分离的宿主细胞,所述的宿主细胞中含有本发明第四方面所述的载体或基因组中整合有外源的本发明第三方面所述的核酸分子。
本发明的第六方面,提供了一种细胞,所述细胞转导本发明第三方面所述的核酸分子或本发明第四方面所述的载体;优选地,所述细胞为T细胞或干细胞。
本发明的第七方面,提供了一种药物组合物,所述组合物含有药学上可接受的载体以及本发明第一方面所述的TCR、本发明第二方面所述的TCR复合物、本发明第三方面所述的核酸分子、本发明第四方面所述的载体、或本发明第六方面所述的细胞。
本发明的第八方面,提供了本发明第一方面所述的T细胞受体、或本发明第二方面所述的TCR复合物、本发明第三方面所述的核酸分子、本发明第四方面所述的载体、或本发明第六方面所述的细胞的用途,用于制备治疗肿瘤或自身免疫疾病的药物。
本发明的第九方面,提供了一种治疗疾病的方法,包括给需要治疗的对象施用适量的本发明第一方面所述的T细胞受体、或本发明第二方面所述的TCR复合物、本发明第三方面所述的核酸分子、本发明第四方面所述的载体、或本发明第六方面所述的细胞、或本发明第七方面所述的药物组合物;
优选地,所述的疾病为肿瘤,优选地所述肿瘤包括黑色素瘤、肺鳞状细胞癌、乳腺癌、肾细胞癌、头颈部肿瘤、霍杰金氏淋巴瘤、肉瘤、成神经管细胞瘤、白血病(包括但不限于,急性淋巴细胞白血病,急性粒细胞白血病)、黑色素瘤,以及其他实体肿瘤如胃癌、肺癌、食道癌、膀胱癌、头颈部鳞状细胞癌、前列腺癌、乳腺癌、结肠癌、卵巢癌等。
应理解,在本发明范围内中,本发明的上述各技术特征和在下文(如实施例)中具体描述的各技术特征之间都可以互相组合,从而构成新的或优选的技术方案。限于篇幅,在此不再一一累述。
附图说明
图1a、图1b、图1c、图1d、图1e和图1f分别为TCRα链可变域氨基酸序列、TCRα链可变域核苷酸序列、TCRα链氨基酸序列、TCRα链核苷酸序列、具有前导序列的TCRα链氨基酸序列以及具有前导序列的TCRα链核苷酸序列。
图2a、图2b、图2c、图2d、图2e和图2f分别为TCRβ链可变域氨基酸序列、TCRβ链可变域核苷酸序列、TCRβ链氨基酸序列、TCRβ链核苷酸序列、具有前导序列的TCRβ链氨基酸序列以及具有前导序列的TCRβ链核苷酸序列。
图3为单克隆细胞的CD8+及四聚体-PE双阳性染色结果。
图4a和图4b分别为可溶性TCRα链的氨基酸序列和核苷酸序列。
图5a和图5b分别为可溶性TCRβ链的氨基酸序列和核苷酸序列。
图6为纯化后得到的可溶性TCR的胶图。最左侧泳道为还原胶,中间泳道为分子量标记(marker),最右侧泳道为非还原胶。
图7a和图7b分别为单链TCR的氨基酸序列和核苷酸序列。
图8a和图8b分别为单链TCRα链的氨基酸序列和核苷酸序列。
图9a和图9b分别为单链TCRβ链的氨基酸序列和核苷酸序列。
图10a和图10b分别为单链TCR连接序列(linker)的氨基酸序列和核苷酸序列。
图11为本发明可溶性TCR与GLSNLTHVL-HLA A0201复合物结合的BIAcore动力学图谱。
图12为转导本发明TCR的T细胞的激活实验结果。
具体实施方式
本发明人经过广泛而深入的研究,找到了与PRAME抗原短肽GLSNLTHVL(SEQ ID NO:9)能够特异性结合的TCR,所述抗原短肽GLSNLTHVL可与HLA A0201形成复合物并一起被呈递到细胞表面。本发明还提供了编码所述TCR的核酸分子以及包含所述核酸分子的载体。另外,本发明还提供了转导本发明TCR的细胞。
术语
MHC分子是免疫球蛋白超家族的蛋白质,可以是Ⅰ类或Ⅱ类MHC分子。因此,其对于抗原的呈递具有特异性,不同的个体有不同的MHC,能呈递一种蛋白抗原中不同的短肽到各自的APC细胞表面。人类的MHC通常称为HLA基因或HLA复合体。
T细胞受体(TCR),是呈递在主组织相容性复合体(MHC)上的特异性抗原肽的唯一受体。在免疫系统中,通过抗原特异性的TCR与pMHC复合物的结合引发T细胞与抗原呈递细胞(APC)直接的物理接触,然后T细胞及APC两者的其他细胞膜表面分子就发生相互作用,这就引起了一系列后续的细胞信号传递和其他生理反应,从而使得不同抗原特异性的T细胞对其靶细胞发挥免疫效应。
TCR是由α链/β链或者γ链/δ链以异质二聚体形式存在的细胞膜表面的糖蛋白。在95%的T细胞中TCR异质二聚体由α和β链组成,而5%的T细胞具有由γ和δ链组成的TCR。天然αβ异质二聚TCR具有α链和β链,α链和β链构成αβ异源二聚TCR的亚单位。广义上讲,α和β各链包含可变区、连接区和恒定区,β链通常还在可变区和连接区之间含有短的多变区,但该多变区常视作连接区的一部分。各可变区包含嵌合在框架结构(framework regions)中的3个CDR(互补决定区),CDR1、CDR2和CDR3。CDR区决定了TCR与pMHC复合物的结合,其中CDR3由可变区和连接区重组而成,被称为超变区。TCR的α和β链一般看作各有两个“结构域”即可变域和恒定域,可变域由连接的可变区和连接区构成。TCR恒定域的序列可以在国际免疫遗传学信息系统(IMGT)的公开数据库中找到,如TCR分子α链的恒定域序列为“TRAC*01”,TCR分子β链的恒定域序列为“TRBC1*01”或“TRBC2*01”。此外,TCR的α和β链还包含跨膜区和胞质区,胞质区很短。
在本发明中,术语“本发明多肽”、“本发明的TCR”、“本发明的T细胞受体”可互换使用。
天然链间二硫键与人工链间二硫键
在天然TCR的近膜区Cα与Cβ链间存在一组二硫键,本发明中称为“天然链间二硫键”。在本发明中,将人工引入的,位置与天然链间二硫键的位置不同的链间共价二硫键称为“人工链间二硫键”。
为方便描述二硫键的位置,本发明中TRAC*01与TRBC1*01或TRBC2*01氨基酸序列的位置编号按从N端到C端依次的顺序进行位置编号,如TRBC1*01或TRBC2*01中,按从N端到C端依次的顺序第60个氨基酸为P(脯氨酸),则本发明中可将其描述为TRBC1*01或TRBC2*01外显子1的Pro60,也可将其表述为TRBC1*01或TRBC2*01外显子1的第60位氨基酸,又如TRBC1*01或TRBC2*01中,按从N端到C端依次的顺序第61个氨基酸为Q(谷氨酰胺),则本发明中可将其描述为TRBC1*01或TRBC2*01外显子1的Gln61,也可将其表述为TRBC1*01或TRBC2*01外显子1的第61位氨基酸,其他以此类推。本发明中,可变区TRAV与TRBV的氨基酸序列的位置编号,按照IMGT中列出的位置编号。如TRAV中的某个氨基酸,IMGT中列出的位置编号为46,则本发明中将其描述为TRAV第46位氨基酸,其他以此类推。本发明中,其他氨基酸的序列位置编号有特殊说明的,则按特殊说明。
发明详述
TCR分子
在抗原加工过程中,抗原在细胞内被降解,然后通过MHC分子携带至细胞表面。T细胞受体能够识别抗原呈递细胞表面的肽-MHC复合物。因此,本发明的第一方面提供了一种能够结合GLSNLTHVL-HLA A0201复合物的TCR分子。优选地,所述TCR分子是分离的或纯化的。该TCR的α和β链各具有3个互补决定区(CDR)。
在本发明的一个优选地实施方式中,所述TCR的α链包含具有以下氨基酸序列的CDR:
αCDR1-DSSSTY(SEQ ID NO:10)
αCDR2-IFSNMDM(SEQ ID NO:11)
αCDR3-AEIPSTGANNLF(SEQ ID NO:12);和/或
所述TCRβ链可变域的3个互补决定区为:
βCDR1-SGHDN(SEQ ID NO:13)
βCDR2-FVKESK(SEQ ID NO:14)
βCDR3-ASSQGGTQY(SEQ ID NO:15)。
可以将上述本发明的CDR区氨基酸序列嵌入到任何适合的框架结构中来制备嵌合TCR。只要框架结构与本发明的TCR的CDR区兼容,本领域技术人员根据本发明公开的CDR区就能够设计或合成出具有相应功能的TCR分子。因此,本发明TCR分子是指包含上述α和/或β链CDR区序列及任何适合的框架结构的TCR分子。本发明TCRα链可变域为与SEQ ID NO:1具有至少90%,优选地95%,更优选地98%序列相同性的氨基酸序列;和/或本发明TCRβ链可变域为与SEQ ID NO:5具有至少90%,优选地95%,更优选地98%序列相同性的氨基酸序列。
在本发明的一个优选例中,本发明的TCR分子是由α与β链构成的异质二聚体。具体地,一方面所述异质二聚TCR分子的α链包含可变域和恒定域,所述α链可变域氨基酸序列包含上述α链的CDR1(SEQ ID NO:10)、CDR2(SEQ ID NO:11)和CDR3(SEQ ID NO:12)。优选地,所述TCR分子包含α链可变域氨基酸序列SEQ ID NO:1。更优选地,所述TCR分子的α链可变域氨基酸序列为SEQ ID NO:1。另一方面,所述异质二聚TCR分子的β链包含可变域和恒定域,所述β链可变域氨基酸序列包含上述β链的CDR1(SEQ ID NO:13)、CDR2(SEQ ID NO:14)和CDR3(SEQ ID NO:15)。优选地,所述TCR分子包含β链可变域氨基酸序列SEQ ID NO:5。更优选地,所述TCR分子的β链可变域氨基酸序列为SEQ ID NO:5。
在本发明的一个优选例中,本发明的TCR分子是由α链的部分或全部和/或β链的部分或全部组成的单链TCR分子。有关单链TCR分子的描述可以参考文献Chung et al(1994)Proc.Natl.Acad.Sci.USA 91,12654-12658。根据文献中所述,本领域技术人员能够容易地构建包含本发明CDRs区的单链TCR分子。具体地,所述单链TCR分子包含Vα、Vβ和Cβ,优选地按照从N端到C端的顺序连接。
所述单链TCR分子的α链可变域氨基酸序列包含上述α链的CDR1(SEQ ID NO:10)、CDR2(SEQ ID NO:11)和CDR3(SEQ ID NO:12)。优选地,所述单链TCR分子包含α链可变域氨基酸序列SEQ ID NO:1。更优选地,所述单链TCR分子的α链可变域氨基酸序列为SEQ ID NO:1。所述单链TCR分子的β链可变域氨基酸序列包含上述β链的CDR1(SEQ ID NO:13)、CDR2(SEQ ID NO:14)和CDR3(SEQ ID NO:15)。优选地,所述单链TCR分子包含β链可变域氨基酸序列SEQ ID NO:5。更优选地,所述单链TCR分子的β链可变域氨基酸序列为SEQ ID NO:5。
在本发明的一个优选例中,本发明的TCR分子的恒定域是人的恒定域。本领域技术人员知晓或可以通过查阅相关书籍或IMGT(国际免疫遗传学信息系统)的公开数据库来获得人的恒定域氨基酸序列。例如,本发明TCR分子α链的恒定域序列可以为“TRAC*01”,TCR分子β链的恒定域序列可以为“TRBC1*01”或“TRBC2*01”。IMGT的TRAC*01中给出的氨基酸序列的第53位为Arg,在此表示为:TRAC*01外显子1的Arg53,其他以此类推。优选地,本发明TCR分子α链的氨基酸序列为SEQ ID NO:3,和/或β链的氨基酸序列为SEQ ID NO:7。
天然存在的TCR是一种膜蛋白,通过其跨膜区得以稳定。如同免疫球蛋白(抗体)作为抗原识别分子一样,TCR也可以被开发应用于诊断和治疗,这时需要获得可溶性的TCR分子。可溶性的TCR分子不包括其跨膜区。可溶性TCR有很广泛的用途,它不仅可用于研究TCR与pMHC的相互作用,也可用作检测感染的诊断工具或作为自身免疫病的标志物。类似地,可溶性TCR可以被用来将治疗剂(如细胞毒素化合物或免疫刺激性化合物)输送到呈递特异性抗原的细胞,另外,可溶性TCR还可与其他分子(如,抗-CD3抗体)结合来重新定向T细胞,从而使其靶向呈递特定抗原的细胞。本发明也获得了对PRAME抗原短肽具有特异性的可溶性TCR。
为获得可溶性TCR,一方面,本发明TCR可以是在其α和β链恒定域的残基之间引入人工二硫键的TCR。半胱氨酸残基在所述TCR的α和β链恒定域间形成人工链间二硫键。半胱氨酸残基可以取代在天然TCR中合适位点的其他氨基酸残基以形成人工链间二硫键。例如,取代TRAC*01外显子1的Thr48和取代TRBC1*01或TRBC2*01外显子1的Ser57的半胱氨酸残基来形成二硫键。引入半胱氨酸残基以形成二硫键的其他位点还可以是:TRAC*01外显子1的Thr45和TRBC1*01或TRBC2*01外显子1的Ser77;TRAC*01外显子1的Tyr10和TRBC1*01或TRBC2*01外显子1的Ser17;TRAC*01外显子1的Thr45和TRBC1*01或TRBC2*01外显子1的Asp59;TRAC*01外显子1的Ser15和TRBC1*01或TRBC2*01外显子1的Glu15;TRAC*01外显子1的Arg53和TRBC1*01或TRBC2*01外显子1的Ser54;TRAC*01外显子1的Pro89和TRBC1*01或TRBC2*01外显子1的Ala19;或TRAC*01外显子1的Tyr10和TRBC1*01或TRBC2*01外显子1的Glu20。即半胱氨酸残基取代了上述α与β链恒定域中任一组位点。可在本发明TCR恒定域的一个或多个C末端截短最多50个、或最多30个、或最多15个、或最多10个、或最多8个或更少的氨基酸,以使其不包括半胱氨酸残基来达到缺失天然二硫键的目的,也可通过将形成天然二硫键的半胱氨酸残基突变为另一氨基酸来达到上述目的。
如上所述,本发明的TCR可以包含在其α和β链恒定域的残基间引入的人工二硫键。应注意,恒定域间含或不含上文所述的引入的人工二硫键,本发明的TCR均可含有TRAC恒定域序列和TRBC1或TRBC2恒定域序列。TCR的TRAC恒定域序列和TRBC1或TRBC2恒定域序列可通过存在于TCR中的天然二硫键连接。
为获得可溶性TCR,另一方面,本发明TCR还包括在其疏水芯区域发生突变的TCR,这些疏水芯区域的突变优选为能够使本发明可溶性TCR的稳定性提高的突变,如在公开号为WO2014/206304的专利文献中所述。这样的TCR可在其下列可变域疏水芯位置发生突变:(α和/或β链)可变区氨基酸第11,13,19,21,53,76,89,91,94位,和/或α链J基因(TRAJ)短肽氨基酸位置倒数第3,5,7位,和/或β链J基因(TRBJ)短肽氨基酸位置倒数第2,4,6位,其中氨基酸序列的位置编号按国际免疫遗传学信息系统(IMGT)中列出的位置编号。本领域技术人员知晓上述国际免疫遗传学信息系统,并可根据该数据库得到不同TCR的氨基酸残基在IMGT中的位置编号。
本发明中疏水芯区域发生突变的TCR可以是由一柔性肽链连接TCR的α与β链的可变域而构成的稳定性可溶单链TCR。应注意,本发明中柔性肽链可以是任何适合连接TCRα与β链可变域的肽链。如在本发明实施例4中构建的单链可溶性TCR,其α链可变域氨基酸序列为SEQ ID NO:32,编码的核苷酸序列为SEQ ID NO:33;β链可变域氨基酸序列为SEQ ID NO:34,编码的核苷酸序列为SEQ ID NO:35。
另外,对于稳定性而言,专利文献201510260322.4还公开了在TCR的α链可变区与β链恒定区之间引入人工链间二硫键能够使TCR的稳定性显著提高。因此,本发明的高亲和力TCR的α链可变区与β链恒定区之间还可以含有人工链间二硫键。具体地,在所述TCR的α链可变区与β链恒定区之间形成人工链间二硫键的半胱氨酸残基取代了:TRAV的第46位氨基酸和TRBC1*01或TRBC2*01外显子1的第60位氨基酸;TRAV的第47位氨基酸和TRBC1*01或TRBC2*01外显子1的61位氨基酸;TRAV的第46位氨基酸和TRBC1*01或TRBC2*01外显子1的第61位氨基酸;或TRAV的第47位氨基酸和TRBC1*01或TRBC2*01外显子1的第60位氨基酸。优选地,这样的TCR可以包含(ⅰ)除其跨膜结构域以外的全部或部分TCRα链,和(ⅱ)除其跨膜结构域以外的全部或部分TCRβ链,其中(ⅰ)和(ⅱ)均包含TCR链的可变域和至少一部分恒定域,α链与β链形成异质二聚体。更优选地,这样的TCR可以包含α链可变域和β链可变域以及除跨膜结构域以外的全部或部分β链恒定域,但其不包含α链恒定域,所述TCR的α链可变域与β链形成异质二聚体。
本发明的TCR也可以多价复合体的形式提供。本发明的多价TCR复合体包含两个、三个、四个或更多个本发明TCR相结合而形成的多聚物,如可以用p53的四聚结构域来产生四聚体,或多个本发明TCR与另一分子结合而形成的复合物。本发明的TCR复合物可用于体外或体内追踪或靶向呈递特定抗原的细胞,也可用于产生具有此类应用的其他多价TCR复合物的中间体。
本发明的TCR可以单独使用,也可与偶联物以共价或其他方式结合,优选以共价方式结合。所述偶联物包括可检测标记物(为诊断目的,其中所述TCR用于检测呈递GLSNLTHVL-HLA A0201复合物的细胞的存在)、治疗剂、PK(蛋白激酶)修饰部分或任何以上这些物质的组合结合或偶联。
用于诊断目的的可检测标记物包括但不限于:荧光或发光标记物、放射性标记物、MRI(磁共振成像)或CT(电子计算机X射线断层扫描技术)造影剂、或能够产生可检测产物的酶。
可与本发明TCR结合或偶联的治疗剂包括但不限于:1.放射性核素(Koppe等,2005,癌转移评论(Cancer metastasis reviews)24,539);2.生物毒(Chaudhary等,1989,自然(Nature)339,394;Epel等,2002,癌症免疫学和免疫治疗(Cancer Immunology and Immunotherapy)51,565);3.细胞因子如IL-2等(Gillies等,1992,美国国家科学院院刊(PNAS)89,1428;Card等,2004,癌症免疫学和免疫治疗(Cancer Immunology and Immunotherapy)53,345;Halin等,2003,癌症研究(Cancer Research)63,3202);4.抗体Fc片段(Mosquera等,2005,免疫学杂志(The Journal Of Immunology)174,4381);5.抗体scFv片段(Zhu等,1995,癌症国际期刊(International Journal of Cancer)62,319);6.金纳米颗粒/纳米棒(Lapotko等,2005,癌症通信(Cancer letters)239,36;Huang等,2006,美国化学学会杂志(Journal of the American Chemical Society)128,2115);7.病毒颗粒(Peng等,2004,基因治疗(Gene therapy)11,1234);8.脂质体(Mamot等,2005,癌症研究(Cancer research)65,11631);9.纳米磁粒;10.前药激活酶(例如,DT-心肌黄酶(DTD)或联苯基水解酶-样蛋白质(BPHL));11.化疗剂(例如,顺铂)或任何形式的纳米颗粒等。
另外,本发明的TCR还可以是包含衍生自超过一种物种序列的杂合TCR。例如,有研究显示鼠科TCR在人T细胞中比人TCR能够更有效地表达。因此,本发明TCR可包含人可变域和鼠的恒定域。这一方法的缺陷是可能引发免疫应答。因此,在其用于过继性T细胞治疗时应当有调节方案来进行免疫抑制,以允许表达鼠科的T细胞的植入。
应理解,本文中氨基酸名称采用国际通用的单英文字母或三英文字母表示,氨基酸名称的单英文字母与三英文字母的对应关系如下:Ala(A)、Arg(R)、Asn(N)、Asp(D)、Cys(C)、Gln(Q)、Glu(E)、Gly(G)、His(H)、Ile(I)、Leu(L)、Lys(K)、Met(M)、Phe(F)、Pro(P)、Ser(S)、Thr(T)、Trp(W)、Tyr(Y)、Val(V)。
核酸分子
本发明的第二方面提供了编码本发明第一方面TCR分子或其部分的核酸分子,所述部分可以是一个或多个CDR,α和/或β链的可变域,以及α链和/或β链。
编码本发明第一方面TCR分子α链CDR区的核苷酸序列如下:
αCDR1-gacagctcctccacctac(SEQ ID NO:16)
αCDR2-attttttcaaatatggacatg(SEQ ID NO:17)
αCDR3-gcagagatcccctcaactggggcaaacaacctcttc(SEQ ID NO:18)
编码本发明第一方面TCR分子β链CDR区的核苷酸序列如下:
βCDR1-tctggacatgataat(SEQ ID NO:19)
βCDR2-tttgtgaaagagtctaaa(SEQ ID NO:20)
βCDR3-gccagcagccaaggggggacccagtac(SEQ ID NO:21)
因此,编码本发明TCRα链的本发明核酸分子的核苷酸序列包括SEQ ID NO:16、SEQ ID NO:17和SEQ ID NO:18,和/或编码本发明TCRβ链的本发明核酸分子的核苷酸序列包括SEQ ID NO:19、SEQ ID NO:20和SEQ ID NO:21。
本发明核酸分子的核苷酸序列可以是单链或双链的,该核酸分子可以是RNA或DNA,并且可以包含或不包含内含子。优选地,本发明核酸分子的核苷酸序列不包含内含子但能够编码本发明多肽,例如编码本发明TCRα链可变域的本发明核酸分子的核苷酸序列包括SEQ ID NO:2和/或编码本发明TCRβ链可变域的本发明核酸分子的核苷酸序列包括SEQ ID NO:6。或者,编码本发明TCRα链可变域的本发明核酸分子的核苷酸序列包括SEQ ID NO:33和/或编码本发明TCRβ链可变域的本发明核酸分子的核苷酸序列包括SEQ ID NO:35。更优选地,本发明核酸分子的核苷酸序列包含SEQ ID NO:4和/或SEQ ID NO:8。或者,本发明核酸分子的核苷酸序列为SEQ ID NO:31。
应理解,由于遗传密码的简并,不同的核苷酸序列可以编码相同的多肽。因此,编码本发明TCR的核酸序列可以与本发明附图中所示的核酸序列相同或是简并的变异体。以本发明中的其中一个例子来说明,“简并的变异体”是指编码具有SEQ ID NO:1的蛋白序列,但与SEQ ID NO:2的序列有差别的核酸序列。
核苷酸序列可以是经密码子优化的。不同的细胞在具体密码子的利用上是不同的,可以根据细胞的类型,改变序列中的密码子来增加表达量。哺乳动物细胞以及多种其他生物的密码子选择表是本领域技术人员公知的。
本发明的核酸分子全长序列或其片段通常可以用但不限于PCR扩增法、重组法或人工合成的方法获得。目前,已经可以完全通过化学合成来得到编码本发明TCR(或其片段,或其衍生物)的DNA序列。然后可将该DNA序列引入本领域中已知的各种现有的DNA分子(或如载体)和细胞中。DNA可以是编码链或非编码链。
载体
本发明还涉及包含本发明的核酸分子的载体,包括表达载体,即能够在体内或体外表达的构建体。常用的载体包括细菌质粒、噬菌体和动植物病毒。
病毒递送系统包括但不限于腺病毒载体、腺相关病毒(AAV)载体、疱疹病毒载体、逆转录病毒载体、慢病毒载体、杆状病毒载体。
优选地,载体可以将本发明的核苷酸转移至细胞中,例如T细胞中,使得该细胞表达PRAME抗原特异性的TCR。理想的情况下,该载体应当能够在T细胞中持续高水平地表达。
细胞
本发明还涉及用本发明的载体或编码序列经基因工程产生的宿主细胞。所述宿主细胞中含有本发明的载体或染色体中整合有本发明的核酸分子。宿主细胞选自:原核细胞和真核细胞,例如大肠杆菌、酵母细胞、CHO细胞等。
另外,本发明还包括表达本发明的TCR的分离的细胞,特别是T细胞。该T细胞可衍生自从受试者分离的T细胞,或者可以是从受试者中分离的混合细胞群,诸如外周血淋巴细胞(PBL)群的一部分。如,该细胞可以分离自外周血单核细胞(PBMC),可以是CD4+辅助T细胞或CD8+细胞毒性T细胞。该细胞可在CD4+辅助T细胞/CD8+细胞毒性T细胞的混合群中。一般地,该细胞可以用抗体(如,抗-CD3或抗-CD28的抗体)活化,以便使它们能够更容易接受转染,例如用包含编码本发明TCR分子的核苷酸序列的载体进行转染。
备选地,本发明的细胞还可以是或衍生自干细胞,如造血干细胞(HSC)。将基因转移至HSC不会导致在细胞表面表达TCR,因为干细胞表面不表达CD3分子。然而,当干细胞分化为迁移至胸腺的淋巴前体(lymphoid precursor)时,CD3分子的表达将启动在胸腺细胞的表面表达该引入的TCR分子。
有许多方法适合于用编码本发明TCR的DNA或RNA进行T细胞转染(如,Robbins等.,(2008)J.Immunol.180:6116-6131)。表达本发明TCR的T细胞可以用于过继免疫治疗。本领域技术人员能够知晓进行过继性治疗的许多合适方法(如,Rosenberg等.,(2008)Nat Rev Cancer8(4):299-308)。
PRAME抗原相关疾病
本发明还涉及在受试者中治疗和/或预防与PRAME相关疾病的方法,其包括过继性转移PRAME特异性T细胞至该受试者的步骤。该PRAME特异性T细胞可识别GLSNLTHVL-HLA A0201复合物。
本发明的PRAME特异性的T细胞可用于治疗任何呈递PRAME抗原短肽GLSNLTHVL-HLA A0201复合物的PRAME相关疾病,如肿瘤。所述肿瘤包括但不限于黑色素瘤、肺鳞状细胞癌、乳腺癌、肾细胞癌、头颈部肿瘤、霍杰金氏淋巴瘤、肉瘤、成神经管细胞瘤、白血病(包括但不限于,急性淋巴细胞白血病,急性粒细胞白血病)、胃癌、肺癌、食道癌、膀胱癌、头颈部鳞状细胞癌、前列腺癌、结肠癌、卵巢癌等。
治疗方法
可以通过分离患有与PRAME抗原相关疾病的病人或志愿者的T细胞,并将本发明的TCR导入上述T细胞中,随后将这些基因工程修饰的细胞回输到病人体内来进行治疗。因此,本发明提供了一种治疗PRAME相关疾病的方法,包括将分离的表达本发明TCR的T细胞,优选地,该T细胞来源于病人本身,输入到病人体内。一般地,包括(1)分离病人的T细胞,(2)用本发明核酸分子或能够编码本发明TCR分子的核酸分子体外转导T细胞,(3)将基因工程修饰的T细胞输入到病人体内。分离、转染及回输的细胞的数量可以由医师决定。
本发明的主要优点在于:
(1)本发明的TCR能够与PRAME抗原短肽复合物GLSNLTHVL-HLA A0201结合,同时转导了本发明TCR的细胞能够被特异性激活并且对靶细胞具有很强的杀伤作用。
下面的具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。下列实施例中未注明具体条件的实验方法,通常按照常规条件,例如(Sambrook和Russell等人,分子克隆:实验室手册(Molecular Cloning-A Laboratory Manual)(第三版)(2001)CSHL出版社)中所述的条件,或按照制造厂商所建议的条件。除非另外说明,否则百分比和份数按重量计算。除非另外说明,否则百分比和份数按重量计算。以下实施例中所用的实验材料和试剂如无特别说明均可从市售渠道获得。
实施例1克隆PRAME抗原短肽特异性T细胞
利用合成短肽GLSNLTHVL(SEQ ID NO.:9;北京赛百盛基因技术有限公司)刺激来自于基因型为HLA-A0201的健康志愿者的外周血淋巴细胞(PBL)。将GLSNLTHVL短肽与带有生物素标记的HLA-A0201复性,制备pHLA单倍体。这些单倍体与用PE标记的链霉亲和素(BD公司)组合成PE标记的四聚体,分选该四聚体及抗-CD8-APC双阳性细胞。扩增分选的细胞,并按上述方法进行二次分选,随后用有限稀释法进行单克隆。单克隆细胞用四聚体染色,筛选到的双阳性克隆如图3所示。
实施例2获取PRAME抗原短肽特异性T细胞克隆的TCR基因与载体的构建
用Quick-RNATMMiniPrep(ZYMO research)抽提实施例1中筛选到的抗原短肽GLSNLTHVL特异性、HLA-A0201限制性的T细胞克隆的总RNA。cDNA的合成采用clontech的SMART RACE cDNA扩增试剂盒,采用的引物是设计在人类TCR基因的C端保守区。将序列克隆至T载体(TAKARA)上进行测序。应注意,该序列为互补序列,不包含内含子。经测序,该双阳性克隆表达的TCR的α链和β链序列结构分别如图1和图2所示,图1a、图1b、图1c、图1d、图1e和图1f分别为TCRα链可变域氨基酸序列、TCRα链可变域核苷酸序列、TCRα链氨基酸序列、TCRα链核苷酸序列、具有前导序列的TCRα链氨基酸序列以及具有前导序列的TCRα链核苷酸序列;图2a、图2b、图2c、图2d、图2e和图2f分别为TCRβ链可变域氨基酸序列、TCRβ链可变域核苷酸序列、TCRβ链氨基酸序列、TCRβ链核苷酸序列、具有前导序列的TCRβ链氨基酸序列以及具有前导序列的TCRβ链核苷酸序列。
经鉴定,α链包含具有以下氨基酸序列的CDR:
αCDR1-DSSSTY(SEQ ID NO:10)
αCDR2-IFSNMDM(SEQ ID NO:11)
αCDR3-AEIPSTGANNLF(SEQ ID NO:12)
β链包含具有以下氨基酸序列的CDR:
βCDR1-SGHDN(SEQ ID NO:13)
βCDR2-FVKESK(SEQ ID NO:14)
βCDR3-ASSQGGTQY(SEQ ID NO:15)
通过重叠(overlap)PCR分别将TCRα链和β链的全长基因克隆至慢病毒表达载体pLenti(addgene)。具体为:用overlap PCR将TCRα链和TCRβ链的全长基因进行连接得到TCRα-2A-TCRβ片段。将慢病毒表达载体及TCRα-2A-TCRβ酶切连接得到pLenti-TRA-2A-TRB-IRES-NGFR质粒。作为对照用,同时也构建表达eGFP的慢病毒载体pLenti-eGFP。之后再用293T/17包装假病毒。
实施例3PRAME抗原短肽特异性可溶TCR的表达、重折叠和纯化
为获得可溶的TCR分子,本发明的TCR分子的α和β链可以分别只包含其可变域及部分恒定域,并且α和β链的恒定域中分别引入了一个半胱氨酸残基以形成人工链间二硫键,引入半胱氨酸残基的位置分别为TRAC*01外显子1的Thr48和TRBC2*01外显子1的Ser57;其α链的氨基酸序列与核苷酸序列分别如图4a和图4b所示,其β链的氨基酸序列与核苷酸序列分别如图5a和图5b所示,引入的半胱氨酸残基以加粗和加下划线字母表示。通过《分子克隆实验室手册》(Molecular Cloning a Laboratory Manual)(第三版,Sambrook和Russell)中描述的标准方法将上述TCRα和β链的目的基因序列经合成后分别插入到表达载体pET28a+(Novagene),上下游的克隆位点分别是NcoI和NotI。插入片段经过测序确认无误。
将TCRα和β链的表达载体分别通过化学转化法转化进入表达细菌BL21(DE3),细菌用LB培养液生长,于OD600=0.6时用终浓度0.5mM IPTG诱导,TCR的α和β链表达后形成的包涵体通过BugBuster Mix(Novagene)进行提取,并且经BugBuster溶液反复多次洗涤,包涵体最后溶解于6M盐酸胍,10mM二硫苏糖醇(DTT),10mM乙二胺四乙酸(EDTA),20mM Tris(pH 8.1)中。
溶解后的TCRα和β链以1:1的质量比快速混合于5M尿素,0.4M精氨酸,20mM Tris(pH 8.1),3.7mM cystamine,6.6mMβ-mercapoethylamine(4℃)中,终浓度为60mg/mL。混合后将溶液置于10倍体积的去离子水中透析(4℃),12小时后将去离子水换成缓冲液(20mM Tris,pH 8.0)继续于4℃透析12小时。透析完成后的溶液经0.45μM的滤膜过滤后,通过阴离子交换柱(HiTrap Q HP,5ml,GE Healthcare)纯化。洗脱峰含有复性成功的α和β二聚体的TCR通过SDS-PAGE胶确认。TCR随后通过凝胶过滤层析(HiPrep 16/60,Sephacryl S-100HR,GE Healthcare)进一步纯化。纯化后的TCR纯度经过SDS-PAGE测定大于90%,浓度由BCA法确定。本发明得到的可溶性TCR的SDS-PAGE胶图如图6所示。
实施例4PRAME抗原短肽特异性的可溶性单链TCR的产生
根据专利文献WO2014/206304中所述,利用定点突变的方法将实施例2中TCRα与β链的可变域构建成了一个以柔性短肽(linker)连接的稳定的可溶性单链TCR分子。该单链TCR分子的氨基酸序列及核苷酸序列分别如图7a和图7b所示。其α链可变域的氨基酸序列及核苷酸序列分别如图8a和图8b所示;其β链可变域的氨基酸序列及核苷酸序列分别如图9a和图9b所示;其linker序列的氨基酸序列及核苷酸序列分别如图10a和图10b所示。
将目的基因经NcoⅠ和NotⅠ双酶切,与经过NcoⅠ和NotⅠ双酶切的pET28a载体连接。连接产物转化至E.coli DH5α,涂布含卡那霉素的LB平板,37℃倒置培养过夜,挑取阳性克隆进行PCR筛选,对阳性重组子进行测序,确定序列正确后抽提重组质粒转化至E.coli BL21(DE3),用于表达。
实施例5PRAME抗原短肽特异性的可溶性单链TCR的表达、复性和纯化
将实施例4中制备的含有重组质粒pET28a-模板链的BL21(DE 3)菌落全部接种于含有卡那霉素的LB培养基中,37℃培养至OD600为0.6-0.8,加入IPTG至终浓度为0.5mM,37℃继续培养4h。5000rpm离心15min收获细胞沉淀物,用Bugbuster Master Mix(Merck)裂解细胞沉淀物,6000rpm离心15min回收包涵体,再用Bugbuster(Merck)进行洗涤以除去细胞碎片和膜组分,6000rpm离心15min,收集包涵体。将包涵体溶解在缓冲液(20mM Tris-HCl pH 8.0,8M尿素)中,高速离心去除不溶物,上清液用BCA法定量后进行分装,于-80℃保存备用。
向5mg溶解的单链TCR包涵体蛋白中,加入2.5mL缓冲液(6M Gua-HCl,50mM Tris-HCl pH 8.1,100mM NaCl,10mM EDTA),再加入DTT至终浓度为10mM,37℃处理30min。用注射器向125mL复性缓冲液(100mM Tris-HCl pH 8.1,0.4M L-精氨酸,5M尿素,2mM EDTA,6.5mMβ-mercapthoethylamine,1.87mM Cystamine)中滴加上述处理后的单链TCR,4℃搅拌10min,然后将复性液装入截留量为4kDa的纤维素膜透析袋,透析袋置于1L预冷的水中,4℃缓慢搅拌过夜。17小时后,将透析液换成1L预冷的缓冲液(20mM Tris-HCl pH 8.0),4℃继续透析8h,然后将透析液换成相同的新鲜缓冲液继续透析过夜。17小时后,样品经0.45μm滤膜过滤,真空脱气后通过阴离子交换柱(HiTrap Q HP,GE Healthcare),用20mM Tris-HCl pH 8.0配制的0-1M NaCl线性梯度洗脱液纯化蛋白,收集的洗脱组分进行SDS-PAGE分析,包含单链TCR的组分浓缩后进一步用凝胶过滤柱(Superdex 7510/300,GE Healthcare)进行纯化,目标组分也进行SDS-PAGE分析。
用于BIAcore分析的洗脱组分进一步采用凝胶过滤法测试其纯度。条件为:色谱柱Agilent Bio SEC-3(300A,φ7.8×300mm),流动相为150mM磷酸盐缓冲液,流速0.5mL/min,柱温25℃,紫外检测波长214nm。
本发明获得的可溶性单链TCR的SDS-PAGE胶图如图11所示。
实施例6结合表征
BIAcore分析
本实施例证明了可溶性的本发明TCR分子能够与GLSNLTHVL-HLA A0201复合物特异性结合。
使用BIAcore T200实时分析系统检测实施例3和实施例5中得到的TCR分子与GLSNLTHVL-HLA A0201复合物的结合活性。将抗链霉亲和素的抗体(GenScript)加入偶联缓冲液(10mM醋酸钠缓冲液,pH 4.77),然后将抗体流过预先用EDC和NHS活化过的CM5芯片,使抗体固定在芯片表面,最后用乙醇胺的盐酸溶液封闭未反应的活化表面,完成偶联过程,偶联水平约为15,000RU。
使低浓度的链霉亲和素流过已包被抗体的芯片表面,然后将GLSNLTHVL-HLA A0201复合物流过检测通道,另一通道作为参比通道,再将0.05mM的生物素以10μL/min的流速流过芯片2min,封闭链霉亲和素剩余的结合位点。
上述GLSNLTHVL-HLA A0201复合物的制备过程如下:
a.纯化
收集100ml诱导表达重链或轻链的E.coli菌液,于4℃8000g离心10min后用10ml PBS洗涤菌体一次,之后用5ml BugBuster Master Mix Extraction Reagents(Merck)剧烈震荡重悬菌体,并于室温旋转孵育20min,之后于4℃,6000g离心15min,弃去上清,收集包涵体。
将上述包涵体重悬于5ml BugBuster Master Mix中,室温旋转孵育5min;加30ml稀释10倍的BugBuster,混匀,4℃6000g离心15min;弃去上清,加30ml稀释10倍的BugBuster重悬包涵体,混匀,4℃6000g离心15min,重复两次,加30ml 20mM Tris-HCl pH 8.0重悬包涵体,混匀,4℃6000g离心15min,最后用20mM Tris-HCl 8M尿素溶解包涵体,SDS-PAGE检测包涵体纯度,BCA试剂盒测浓度。
b.复性
将合成的短肽GLSNLTHVL(北京赛百盛基因技术有限公司)溶解于DMSO至20mg/ml的浓度。轻链和重链的包涵体用8M尿素、20mM Tris pH 8.0、10mM DTT来溶解,复性前加入3M盐酸胍、10mM醋酸钠、10mM EDTA进一步变性。将GLSNLTHVL肽以25mg/L(终浓度)加入复性缓冲液(0.4M L-精氨酸、100mM Tris pH 8.3、2mM EDTA、0.5mM氧化性谷胱甘肽、5mM还原型谷胱甘肽、0.2mM PMSF,冷却至4℃),然后依次加入20mg/L的轻链和90mg/L的重链(终浓度,重链分三次加入,8h/次),复性在4℃进行至少3天至完成,SDS-PAGE检测能否复性成功。
c.复性后纯化
用10体积的20mM Tris pH 8.0作透析来更换复性缓冲液,至少更换缓冲液两次来充分降低溶液的离子强度。透析后用0.45μm醋酸纤维素滤膜过滤蛋白质溶液,然后加载到HiTrap Q HP(GE通用电气公司)阴离子交换柱上(5ml床体积)。利用Akta纯化仪(GE通用电气公司),20mM Tris pH 8.0配制的0-400mM NaCl线性梯度液洗脱蛋白,pMHC约在250mM NaCl处洗脱,收集诸峰组分,SDS-PAGE检测纯度。
d.生物素化
用Millipore超滤管将纯化的pMHC分子浓缩,同时将缓冲液置换为20mM Tris pH 8.0,然后加入生物素化试剂0.05M Bicine pH 8.3、10mM ATP、10mM MgOAc、50μM D-Biotin、100μg/ml BirA酶(GST-BirA),室温孵育混合物过夜,SDS-PAGE检测生物素化是否完全。
e.纯化生物素化后的复合物
用Millipore超滤管将生物素化标记后的pMHC分子浓缩至1ml,采用凝胶过滤层析纯化生物素化的pMHC,利用Akta纯化仪(GE通用电气公司),用过滤过的PBS预平衡HiPrepTM16/60S200HR柱(GE通用电气公司),加载1ml浓缩过的生物素化pMHC分子,然后用PBS以1ml/min流速洗脱。生物素化的pMHC分子在约55ml时作为单峰洗脱出现。合并含有蛋白质的组分,用Millipore超滤管浓缩,BCA法(Thermo)测定蛋白质浓度,加入蛋白酶抑制剂cocktail(Roche)将生物素化的pMHC分子分装保存在-80℃。
利用BIAcore Evaluation软件计算动力学参数,得到本发明可溶性的TCR分子与GLSNLTHVL-HLA A0201复合物结合的动力学图谱分别如图11所示。图谱显示,本发明得到的可溶性TCR分子能够与GLSNLTHVL-HLA A0201复合物结合。同时,还利用上述方法检测了本发明可溶性的TCR分子与其他几种无关抗原短肽与HLA复合物的结合活性,结果显示本发明TCR分子与其他无关抗原均无结合。
实施例7PRAME抗原短肽特异性TCR慢病毒包装与原代T细胞转染
(a)通过293T细胞的快速介导瞬时转染(Express-In-mediated transient transfection)制备慢病毒
利用第三代慢病毒包装系统包装含有编码所需TCR的基因的慢病毒。利用快速介导瞬时转染(Express-In-mediated transient transfection)(开放生物系统公司(Open Biosystems)),用4种质粒(含有实施例2所述pLenti-RHAMMTRA-2A-TRB-IRES-NGFR的一种慢病毒载体,以及含有构建传染性但非复制型慢病毒颗粒所必需的其他组分的3种质粒)转染293T细胞。
为进行转染,第0天种细胞,在15厘米培养皿,种上1.7×107个293T细胞,使细胞均匀分布在培养皿上,汇合度略高于50%。第1天转染质粒,包装pLenti-RHAMMTRA-2A-TRB-IRES-NGFR和pLenti-eGFP假病毒,将以上表达质粒与包装质粒pMDLg/pRRE,pRSV-REV和pMD.2G混匀,一个15厘米直径平皿的用量如下:22.5微克:15微克:15微克:7.5微克。转染试剂PEI-MAX与质粒的比例是2:1,每个平皿PEI-MAX的使用量为120微克。具体操作为:把表达质粒与包装质粒加入1800微升OPTI-MEM((吉布可公司(Gibco),目录号31985-070)培养基中混合均匀,室温静置5分钟成为DNA混合液;取相应量PEI与1800微升OPTI-MEM培养基混合均匀,室温静置5分钟成为PEI混合液。把DNA混合液和PEI混合液混合在一起并在室温静置30分钟,再添加3150微升OPTI-MEM培养基,混合均匀后加入到已经转换成11.25毫升OPTI-MEM的293T细胞中,轻轻晃动培养皿,使培养基混合均匀,37℃/5%CO2下培养。转染5-7小时,去除转染培养基,换成含有10%胎牛血清的DMEM((吉布可公司(Gibco),目录号C11995500bt))完全培养基,37℃/5%CO2下培养。第3和第4天收集含有包装的慢病毒的培养基上清。为收获包装的慢病毒,把所收集到的培养上清3000g离心15分钟去除细胞碎片,再经0.22微米过滤器(默克密理博(Merck Millipore),目录号SLGP033RB)过滤,最后用50KD截留量的浓缩管(默克密理博(Merck Millipore),目录号UFC905096)进行浓缩,除去大部分上清液,最后浓缩到1毫升,等分分装后-80℃冻存。取假病毒样品进行病毒滴度测定,步骤参照p24ELISA(Clontech,目录号632200)试剂盒说明书。作为对照用,同时也包转pLenti-eGFP的假病毒。
(b)用含有PRAME抗原短肽特异性的T细胞受体基因的慢病毒转导原代T细胞
从健康志愿者的血液中分离到CD8+T细胞,再用包装的慢病毒转导。计数这些细胞,在48孔板中,在含有50IU/ml IL-2和10ng/ml IL-7的含10%FBS(吉布可公司(Gibco),目录号C10010500BT)的1640(吉布可公司(Gibco),目录号C11875500bt)培养基中以1×106个细胞/毫升(0.5毫升/孔)与预洗涤的抗CD3/CD28抗体-包被小珠(T细胞扩增物,life technologies,目录号11452D)共孵育过夜刺激,细胞:珠=3:1。
刺激过夜后,根据p24ELISA试剂盒所测到的病毒滴度,按MOI=10的比例加入已浓缩的PRAME抗原短肽特异性T细胞受体基因的慢病毒,32℃,900g离心感染1小时。感染完毕后去除慢病毒感染液,用含有50IU/ml IL-2和10ng/ml IL-7的含10%FBS的1640培养基重悬细胞,37℃/5%CO2下培养3天。次日按同样方法进行第二轮感染。第二次转导3天后计数细胞,稀释细胞至0.5×106个细胞/毫升。每两天计数一次细胞,替换或加入含有50IU/ml IL-2和10ng/ml IL-7的新鲜培养基,维持细胞在0.5×106-1×106个细胞/毫升。从第3天开始通过流式细胞术分析细胞,从第5天开始用于功能试验(例如,IFN-γ释放的ELISPOT和非放射性细胞毒性检测)。从第10天开始或在细胞减缓分裂和尺寸变小之时,冷冻储存等分细胞,至少4×106个细胞/管(1×107个细胞/毫升,90%FBS/10%DMSO)。
实施例8转导本发明TCR的T细胞的激活实验
ELISPOT方案
进行以下试验以证明TCR-转导的T细胞对靶细胞特异性的激活反应。利用ELISPOT试验检测的IFN-γ产量作为T细胞激活的读出值。
试剂
试验培养基:10%FBS(吉布可公司(Gibco),目录号16000-044),RPMI1640(吉布可公司(Gibco),目录号C11875500bt)
洗涤缓冲液(PBST):0.01M PBS/0.05%吐温20
PBS(吉布可公司(Gibco),目录号C10010500BT)
PVDF ELISPOT 96孔板(默克密理博(Merck Mill ipore),目录号MSIPS4510)
人IFN-γELISPOT PVDF-酶试剂盒(BD)装有所需的所有其他试剂(捕捉和检测抗体,链霉亲和素-碱性磷酸酶和BCIP/NBT溶液)
方法
靶细胞制备
本实验中所用的靶细胞为T2细胞。在实验培养基中制备靶细胞:靶细胞浓度调至2.0×105个/毫升,每孔取100微升从而得2.0×104个细胞/孔。
效应细胞制备
本实验的效应细胞(T细胞)是实施例7中经流式细胞术分析表达本发明PRAME抗原短肽特异性TCR的CD8+T细胞,并以同一志愿者未转染本发明TCR的CD8+T作为对照组。用抗CD3/CD28包被珠(T细胞扩增物,life technologies)刺激T细胞,用携带PRAME抗原短肽特异性TCR基因的慢病毒转导(依据实施例7),在含有50IU/ml IL-2和10ng/ml IL-7的含10%FBS的1640培养基扩增直至转导后9-12天,然后将这些细胞置于试验培养基中,300g常温离心10分钟进行洗涤。然后将细胞以2×所需终浓度重悬在试验培养基中。同样处理阴性对照效应细胞。
短肽溶液制备
在相应靶细胞(T2)实验组加入对应短肽,使短肽在ELISPOT孔板中的终浓度为1μg/ml。
ELISPOT
按照生产商提供的说明书,如下所述准备孔板:以每块板10毫升无菌PBS按1:200稀释抗人IFN-γ捕捉抗体,然后将100微升的稀释捕捉抗体等分加入各孔。4℃下孵育孔板过夜。孵育后,洗涤孔板以除去多余的捕捉抗体。加入100微升/孔含有10%FBS的RPMI 1640培养基,并在室温下温育孔板2小时以封闭孔板。然后从孔板中洗去培养基,通过在纸上轻弹和轻拍ELISPOT孔板以除去任何残余的洗涤缓冲液。
然后采用以下顺序将试验的诸组分加入ELISPOT孔板:
100微升靶细胞2*105个细胞/毫升(得到总共约2*104个靶细胞/孔)。
100微升效应细胞(1*104个对照效应细胞/孔和PRAME TCR阳性T细胞/孔)。
所有孔一式两份制备添加。
然后温育孔板过夜(37℃/5%CO2)第二天,弃培养基,用双蒸水洗涤孔板2次,再用洗涤缓冲液洗涤3次,在纸巾上轻拍以除去残余的洗涤缓冲液。然后用含有10%FBS的PBS按1:200稀释检测抗体,按100微升/孔加入各孔。室温下温育孔板2小时,再用洗涤缓冲液洗涤3次,在纸巾上轻拍孔板以除去过量的洗涤缓冲液。
用含有10%FBS的PBS按1:100稀释链霉亲和素-碱性磷酸酶,将100微升稀释的链霉亲和素-碱性磷酸酶加入各孔并在室温下温育孔板1小时。然后用洗涤缓冲液洗涤4次PBS洗涤2次,在纸巾上轻拍孔板以除去过量的洗涤缓冲液和PBS。洗涤完毕后加入试剂盒提供的BCIP/NBT溶液100微升/孔进行显影。在显影期间用锡箔纸覆盖孔板避光,静置5-15分钟。在此期间常规检测显影孔板的斑点,确定终止反应的最佳时间。去除BCIP/NBT溶液并用双蒸水冲洗孔板以中止显影反应,甩干,然后将孔板底部去除,在室温下干燥孔板直至每个孔完全干燥,再利用免疫斑点平板计数计(CTL,细胞技术有限公司(Cellular Technology Limited))计数孔板内底膜形成的斑点。
结果
通过ELISPOT实验(如上所述)检验本发明TCR转导的T细胞对负载PRAME抗原短肽GLSNLTHVL的靶细胞起反应的IFN-γ释放。利用graphpad prism6绘制各孔中观察到的ELSPOT斑点数量。
实验结果如图12所示,转导本发明TCR的T细胞对负载其特异的短肽的靶细胞有很好的激活反应,而未转导本发明TCR的T细胞基本没有激活反应。
在本发明提及的所有文献都在本申请中引用作为参考,就如同每一篇文献被单独引用作为参考那样。此外应理解,在阅读了本发明的上述讲授内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
序列表
<110> 广州市香雪制药股份有限公司
<120> 识别PRAME抗原的TCR
<130> P2016-1703
<150> CN201510756448.0
<151> 2015-11-06
<160> 37
<170> PatentIn version 3.5
<210> 1
<211> 113
<212> PRT
<213> 人工序列
<220>
<223> TCRα链可变域
<400> 1
Gly Glu Asp Val Glu Gln Ser Leu Phe Leu Ser Val Arg Glu Gly Asp
1 5 10 15
Ser Ser Val Ile Asn Cys Thr Tyr Thr Asp Ser Ser Ser Thr Tyr Leu
20 25 30
Tyr Trp Tyr Lys Gln Glu Pro Gly Ala Gly Leu Gln Leu Leu Thr Tyr
35 40 45
Ile Phe Ser Asn Met Asp Met Lys Gln Asp Gln Arg Leu Thr Val Leu
50 55 60
Leu Asn Lys Lys Asp Lys His Leu Ser Leu Arg Ile Ala Asp Thr Gln
65 70 75 80
Thr Gly Asp Ser Ala Ile Tyr Phe Cys Ala Glu Ile Pro Ser Thr Gly
85 90 95
Ala Asn Asn Leu Phe Phe Gly Thr Gly Thr Arg Leu Thr Val Ile Pro
100 105 110
Tyr
<210> 2
<211> 339
<212> DNA
<213> 人工序列
<220>
<223> TCRα链可变域
<400> 2
ggagaggatg tggagcagag tcttttcctg agtgtccgag agggagacag ctccgttata 60
aactgcactt acacagacag ctcctccacc tacttatact ggtataagca agaacctgga 120
gcaggtctcc agttgctgac gtatattttt tcaaatatgg acatgaaaca agaccaaaga 180
ctcactgttc tattgaataa aaaggataaa catctgtctc tgcgcattgc agacacccag 240
actggggact cagctatcta cttctgtgca gagatcccct caactggggc aaacaacctc 300
ttctttggga ctggaacgag actcaccgtt attccctat 339
<210> 3
<211> 253
<212> PRT
<213> 人工序列
<220>
<223> TCRα链
<400> 3
Gly Glu Asp Val Glu Gln Ser Leu Phe Leu Ser Val Arg Glu Gly Asp
1 5 10 15
Ser Ser Val Ile Asn Cys Thr Tyr Thr Asp Ser Ser Ser Thr Tyr Leu
20 25 30
Tyr Trp Tyr Lys Gln Glu Pro Gly Ala Gly Leu Gln Leu Leu Thr Tyr
35 40 45
Ile Phe Ser Asn Met Asp Met Lys Gln Asp Gln Arg Leu Thr Val Leu
50 55 60
Leu Asn Lys Lys Asp Lys His Leu Ser Leu Arg Ile Ala Asp Thr Gln
65 70 75 80
Thr Gly Asp Ser Ala Ile Tyr Phe Cys Ala Glu Ile Pro Ser Thr Gly
85 90 95
Ala Asn Asn Leu Phe Phe Gly Thr Gly Thr Arg Leu Thr Val Ile Pro
100 105 110
Tyr Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys
115 120 125
Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr
130 135 140
Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Thr
145 150 155 160
Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala
165 170 175
Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser
180 185 190
Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp
195 200 205
Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe
210 215 220
Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala
225 230 235 240
Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
245 250
<210> 4
<211> 759
<212> DNA
<213> 人工序列
<220>
<223> TCRα链
<400> 4
ggagaggatg tggagcagag tcttttcctg agtgtccgag agggagacag ctccgttata 60
aactgcactt acacagacag ctcctccacc tacttatact ggtataagca agaacctgga 120
gcaggtctcc agttgctgac gtatattttt tcaaatatgg acatgaaaca agaccaaaga 180
ctcactgttc tattgaataa aaaggataaa catctgtctc tgcgcattgc agacacccag 240
actggggact cagctatcta cttctgtgca gagatcccct caactggggc aaacaacctc 300
ttctttggga ctggaacgag actcaccgtt attccctata tccagaaccc cgaccctgcc 360
gtgtaccagc tgagagactc taaatccagt gacaagtctg tctgcctatt caccgatttt 420
gattctcaaa caaatgtgtc acaaagtaag gattctgatg tgtatatcac agacaaaact 480
gtgctagaca tgaggtctat ggacttcaag agcaacagtg ctgtggcctg gagcaacaaa 540
tctgactttg catgtgcaaa cgccttcaac aacagcatta ttccagaaga caccttcttc 600
cccagcccag aaagttcctg tgatgtcaag ctggtcgaga aaagctttga aacagatacg 660
aacctaaact ttcaaaacct gtcagtgatt gggttccgaa tcctcctcct gaaagtggcc 720
gggtttaatc tgctcatgac gctgcggctg tggtccagc 759
<210> 5
<211> 111
<212> PRT
<213> 人工序列
<220>
<223> TCRβ链可变域
<400> 5
Glu Ala Gly Val Thr Gln Phe Pro Ser His Ser Val Ile Glu Lys Gly
1 5 10 15
Gln Thr Val Thr Leu Arg Cys Asp Pro Ile Ser Gly His Asp Asn Leu
20 25 30
Tyr Trp Tyr Arg Arg Val Met Gly Lys Glu Ile Lys Phe Leu Leu His
35 40 45
Phe Val Lys Glu Ser Lys Gln Asp Glu Ser Gly Met Pro Asn Asn Arg
50 55 60
Phe Leu Ala Glu Arg Thr Gly Gly Thr Tyr Ser Thr Leu Lys Val Gln
65 70 75 80
Pro Ala Glu Leu Glu Asp Ser Gly Val Tyr Phe Cys Ala Ser Ser Gln
85 90 95
Gly Gly Thr Gln Tyr Phe Gly Pro Gly Thr Arg Leu Leu Val Leu
100 105 110
<210> 6
<211> 333
<212> DNA
<213> 人工序列
<220>
<223> TCRβ链可变域
<400> 6
gaagctggag ttactcagtt ccccagccac agcgtaatag agaagggcca gactgtgact 60
ctgagatgtg acccaatttc tggacatgat aatctttatt ggtatcgacg tgttatggga 120
aaagaaataa aatttctgtt acattttgtg aaagagtcta aacaggatga gtccggtatg 180
cccaacaatc gattcttagc tgaaaggact ggagggacgt attctactct gaaggtgcag 240
cctgcagaac tggaggattc tggagtttat ttctgtgcca gcagccaagg ggggacccag 300
tacttcgggc caggcacgcg gctcctggtg ctc 333
<210> 7
<211> 290
<212> PRT
<213> 人工序列
<220>
<223> TCRβ链
<400> 7
Glu Ala Gly Val Thr Gln Phe Pro Ser His Ser Val Ile Glu Lys Gly
1 5 10 15
Gln Thr Val Thr Leu Arg Cys Asp Pro Ile Ser Gly His Asp Asn Leu
20 25 30
Tyr Trp Tyr Arg Arg Val Met Gly Lys Glu Ile Lys Phe Leu Leu His
35 40 45
Phe Val Lys Glu Ser Lys Gln Asp Glu Ser Gly Met Pro Asn Asn Arg
50 55 60
Phe Leu Ala Glu Arg Thr Gly Gly Thr Tyr Ser Thr Leu Lys Val Gln
65 70 75 80
Pro Ala Glu Leu Glu Asp Ser Gly Val Tyr Phe Cys Ala Ser Ser Gln
85 90 95
Gly Gly Thr Gln Tyr Phe Gly Pro Gly Thr Arg Leu Leu Val Leu Glu
100 105 110
Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro Ser
115 120 125
Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu Ala
130 135 140
Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp Trp Val Asn Gly
145 150 155 160
Lys Glu Val His Ser Gly Val Ser Thr Asp Pro Gln Pro Leu Lys Glu
165 170 175
Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg Leu Arg
180 185 190
Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg Cys Gln
195 200 205
Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp Arg
210 215 220
Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg Ala
225 230 235 240
Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly Val Leu Ser Ala
245 250 255
Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala Val
260 265 270
Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys Asp Ser
275 280 285
Arg Gly
290
<210> 8
<211> 870
<212> DNA
<213> 人工序列
<220>
<223> TCRβ链
<400> 8
gaagctggag ttactcagtt ccccagccac agcgtaatag agaagggcca gactgtgact 60
ctgagatgtg acccaatttc tggacatgat aatctttatt ggtatcgacg tgttatggga 120
aaagaaataa aatttctgtt acattttgtg aaagagtcta aacaggatga gtccggtatg 180
cccaacaatc gattcttagc tgaaaggact ggagggacgt attctactct gaaggtgcag 240
cctgcagaac tggaggattc tggagtttat ttctgtgcca gcagccaagg ggggacccag 300
tacttcgggc caggcacgcg gctcctggtg ctcgaggacc tgaaaaacgt gttcccaccc 360
gaggtcgctg tgtttgagcc atcagaagca gagatctccc acacccaaaa ggccacactg 420
gtgtgcctgg ccacaggctt ctaccccgac cacgtggagc tgagctggtg ggtgaatggg 480
aaggaggtgc acagtggggt cagcacagac ccgcagcccc tcaaggagca gcccgccctc 540
aatgactcca gatactgcct gagcagccgc ctgagggtct cggccacctt ctggcagaac 600
ccccgcaacc acttccgctg tcaagtccag ttctacgggc tctcggagaa tgacgagtgg 660
acccaggata gggccaaacc tgtcacccag atcgtcagcg ccgaggcctg gggtagagca 720
gactgtggct tcacctccga gtcttaccag caaggggtcc tgtctgccac catcctctat 780
gagatcttgc tagggaaggc caccttgtat gccgtgctgg tcagtgccct cgtgctgatg 840
gccatggtca agagaaagga ttccagaggc 870
<210> 9
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 抗原短肽
<400> 9
Gly Leu Ser Asn Leu Thr His Val Leu
1 5
<210> 10
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> α CDR1
<400> 10
Asp Ser Ser Ser Thr Tyr
1 5
<210> 11
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> α CDR2
<400> 11
Ile Phe Ser Asn Met Asp Met
1 5
<210> 12
<211> 12
<212> PRT
<213> 人工序列
<220>
<223> α CDR3
<400> 12
Ala Glu Ile Pro Ser Thr Gly Ala Asn Asn Leu Phe
1 5 10
<210> 13
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> β CDR1
<400> 13
Ser Gly His Asp Asn
1 5
<210> 14
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> β CDR2
<400> 14
Phe Val Lys Glu Ser Lys
1 5
<210> 15
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> β CDR3
<400> 15
Ala Ser Ser Gln Gly Gly Thr Gln Tyr
1 5
<210> 16
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> α CDR1
<400> 16
gacagctcct ccacctac 18
<210> 17
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> α CDR2
<400> 17
attttttcaa atatggacat g 21
<210> 18
<211> 36
<212> DNA
<213> 人工序列
<220>
<223> α CDR3
<400> 18
gcagagatcc cctcaactgg ggcaaacaac ctcttc 36
<210> 19
<211> 15
<212> DNA
<213> 人工序列
<220>
<223> β CDR1
<400> 19
tctggacatg ataat 15
<210> 20
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> β CDR2
<400> 20
tttgtgaaag agtctaaa 18
<210> 21
<211> 27
<212> DNA
<213> 人工序列
<220>
<223> β CDR3
<400> 21
gccagcagcc aaggggggac ccagtac 27
<210> 22
<211> 274
<212> PRT
<213> 人工序列
<220>
<223> 具有前导序列的TCRα链
<400> 22
Met Lys Thr Phe Ala Gly Phe Ser Phe Leu Phe Leu Trp Leu Gln Leu
1 5 10 15
Asp Cys Met Ser Arg Gly Glu Asp Val Glu Gln Ser Leu Phe Leu Ser
20 25 30
Val Arg Glu Gly Asp Ser Ser Val Ile Asn Cys Thr Tyr Thr Asp Ser
35 40 45
Ser Ser Thr Tyr Leu Tyr Trp Tyr Lys Gln Glu Pro Gly Ala Gly Leu
50 55 60
Gln Leu Leu Thr Tyr Ile Phe Ser Asn Met Asp Met Lys Gln Asp Gln
65 70 75 80
Arg Leu Thr Val Leu Leu Asn Lys Lys Asp Lys His Leu Ser Leu Arg
85 90 95
Ile Ala Asp Thr Gln Thr Gly Asp Ser Ala Ile Tyr Phe Cys Ala Glu
100 105 110
Ile Pro Ser Thr Gly Ala Asn Asn Leu Phe Phe Gly Thr Gly Thr Arg
115 120 125
Leu Thr Val Ile Pro Tyr Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln
130 135 140
Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp
145 150 155 160
Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr
165 170 175
Ile Thr Asp Lys Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser
180 185 190
Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn
195 200 205
Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro
210 215 220
Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp
225 230 235 240
Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu
245 250 255
Leu Leu Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp
260 265 270
Ser Ser
<210> 23
<211> 822
<212> DNA
<213> 人工序列
<220>
<223> 具有前导序列的TCRα链
<400> 23
atgaagacat ttgctggatt ttcgttcctg tttttgtggc tgcagctgga ctgtatgagt 60
agaggagagg atgtggagca gagtcttttc ctgagtgtcc gagagggaga cagctccgtt 120
ataaactgca cttacacaga cagctcctcc acctacttat actggtataa gcaagaacct 180
ggagcaggtc tccagttgct gacgtatatt ttttcaaata tggacatgaa acaagaccaa 240
agactcactg ttctattgaa taaaaaggat aaacatctgt ctctgcgcat tgcagacacc 300
cagactgggg actcagctat ctacttctgt gcagagatcc cctcaactgg ggcaaacaac 360
ctcttctttg ggactggaac gagactcacc gttattccct atatccagaa ccccgaccct 420
gccgtgtacc agctgagaga ctctaaatcc agtgacaagt ctgtctgcct attcaccgat 480
tttgattctc aaacaaatgt gtcacaaagt aaggattctg atgtgtatat cacagacaaa 540
actgtgctag acatgaggtc tatggacttc aagagcaaca gtgctgtggc ctggagcaac 600
aaatctgact ttgcatgtgc aaacgccttc aacaacagca ttattccaga agacaccttc 660
ttccccagcc cagaaagttc ctgtgatgtc aagctggtcg agaaaagctt tgaaacagat 720
acgaacctaa actttcaaaa cctgtcagtg attgggttcc gaatcctcct cctgaaagtg 780
gccgggttta atctgctcat gacgctgcgg ctgtggtcca gc 822
<210> 24
<211> 309
<212> PRT
<213> 人工序列
<220>
<223> 具有前导序列的TCRβ链
<400> 24
Met Val Ser Arg Leu Leu Ser Leu Val Ser Leu Cys Leu Leu Gly Ala
1 5 10 15
Lys His Ile Glu Ala Gly Val Thr Gln Phe Pro Ser His Ser Val Ile
20 25 30
Glu Lys Gly Gln Thr Val Thr Leu Arg Cys Asp Pro Ile Ser Gly His
35 40 45
Asp Asn Leu Tyr Trp Tyr Arg Arg Val Met Gly Lys Glu Ile Lys Phe
50 55 60
Leu Leu His Phe Val Lys Glu Ser Lys Gln Asp Glu Ser Gly Met Pro
65 70 75 80
Asn Asn Arg Phe Leu Ala Glu Arg Thr Gly Gly Thr Tyr Ser Thr Leu
85 90 95
Lys Val Gln Pro Ala Glu Leu Glu Asp Ser Gly Val Tyr Phe Cys Ala
100 105 110
Ser Ser Gln Gly Gly Thr Gln Tyr Phe Gly Pro Gly Thr Arg Leu Leu
115 120 125
Val Leu Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val Phe
130 135 140
Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val
145 150 155 160
Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp Trp
165 170 175
Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro Gln Pro
180 185 190
Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser
195 200 205
Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe
210 215 220
Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr
225 230 235 240
Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp
245 250 255
Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly Val
260 265 270
Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu
275 280 285
Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg
290 295 300
Lys Asp Ser Arg Gly
305
<210> 25
<211> 927
<212> DNA
<213> 人工序列
<220>
<223> 具有前导序列的TCRβ链
<400> 25
atggtttcca ggcttctcag tttagtgtcc ctttgtctcc tgggagcaaa gcacatagaa 60
gctggagtta ctcagttccc cagccacagc gtaatagaga agggccagac tgtgactctg 120
agatgtgacc caatttctgg acatgataat ctttattggt atcgacgtgt tatgggaaaa 180
gaaataaaat ttctgttaca ttttgtgaaa gagtctaaac aggatgagtc cggtatgccc 240
aacaatcgat tcttagctga aaggactgga gggacgtatt ctactctgaa ggtgcagcct 300
gcagaactgg aggattctgg agtttatttc tgtgccagca gccaaggggg gacccagtac 360
ttcgggccag gcacgcggct cctggtgctc gaggacctga aaaacgtgtt cccacccgag 420
gtcgctgtgt ttgagccatc agaagcagag atctcccaca cccaaaaggc cacactggtg 480
tgcctggcca caggcttcta ccccgaccac gtggagctga gctggtgggt gaatgggaag 540
gaggtgcaca gtggggtcag cacagacccg cagcccctca aggagcagcc cgccctcaat 600
gactccagat actgcctgag cagccgcctg agggtctcgg ccaccttctg gcagaacccc 660
cgcaaccact tccgctgtca agtccagttc tacgggctct cggagaatga cgagtggacc 720
caggataggg ccaaacctgt cacccagatc gtcagcgccg aggcctgggg tagagcagac 780
tgtggcttca cctccgagtc ttaccagcaa ggggtcctgt ctgccaccat cctctatgag 840
atcttgctag ggaaggccac cttgtatgcc gtgctggtca gtgccctcgt gctgatggcc 900
atggtcaaga gaaaggattc cagaggc 927
<210> 26
<211> 206
<212> PRT
<213> 人工序列
<220>
<223> 可溶性TCRα链
<400> 26
Gly Glu Asp Val Glu Gln Ser Leu Phe Leu Ser Val Arg Glu Gly Asp
1 5 10 15
Ser Ser Val Ile Asn Cys Thr Tyr Thr Asp Ser Ser Ser Thr Tyr Leu
20 25 30
Tyr Trp Tyr Lys Gln Glu Pro Gly Ala Gly Leu Gln Leu Leu Thr Tyr
35 40 45
Ile Phe Ser Asn Met Asp Met Lys Gln Asp Gln Arg Leu Thr Val Leu
50 55 60
Leu Asn Lys Lys Asp Lys His Leu Ser Leu Arg Ile Ala Asp Thr Gln
65 70 75 80
Thr Gly Asp Ser Ala Ile Tyr Phe Cys Ala Glu Ile Pro Ser Thr Gly
85 90 95
Ala Asn Asn Leu Phe Phe Gly Thr Gly Thr Arg Leu Thr Val Ile Pro
100 105 110
Tyr Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys
115 120 125
Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr
130 135 140
Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Cys
145 150 155 160
Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala
165 170 175
Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser
180 185 190
Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser
195 200 205
<210> 27
<211> 618
<212> DNA
<213> 人工序列
<220>
<223> 可溶性TCRα链
<400> 27
ggtgaagatg ttgaacagag tcttttcctg agtgtccgag agggagacag ctccgttata 60
aactgcactt acacagacag ctcctccacc tacttatact ggtataagca agaacctgga 120
gcaggtctcc agttgctgac gtatattttt tcaaatatgg acatgaaaca agaccaaaga 180
ctcactgttc tattgaataa aaaggataaa catctgtctc tgcgcattgc agacacccag 240
actggggact cagctatcta cttctgtgca gagatcccct caactggggc aaacaacctc 300
ttctttggga ctggaacgag actcaccgtt attccctata tccagaaccc tgaccctgcc 360
gtgtaccagc tgagagactc taagtcgagt gacaagtctg tctgcctatt caccgatttt 420
gattctcaaa caaatgtgtc acaaagtaag gattctgatg tgtatatcac agacaaatgt 480
gtgctagaca tgaggtctat ggacttcaag agcaacagtg ctgtggcctg gagcaacaaa 540
tctgactttg catgtgcaaa cgccttcaac aacagcatta ttccagaaga caccttcttc 600
cccagcccag aaagttcc 618
<210> 28
<211> 241
<212> PRT
<213> 人工序列
<220>
<223> 可溶性TCRβ链
<400> 28
Glu Ala Gly Val Thr Gln Phe Pro Ser His Ser Val Ile Glu Lys Gly
1 5 10 15
Gln Thr Val Thr Leu Arg Cys Asp Pro Ile Ser Gly His Asp Asn Leu
20 25 30
Tyr Trp Tyr Arg Arg Val Met Gly Lys Glu Ile Lys Phe Leu Leu His
35 40 45
Phe Val Lys Glu Ser Lys Gln Asp Glu Ser Gly Met Pro Asn Asn Arg
50 55 60
Phe Leu Ala Glu Arg Thr Gly Gly Thr Tyr Ser Thr Leu Lys Val Gln
65 70 75 80
Pro Ala Glu Leu Glu Asp Ser Gly Val Tyr Phe Cys Ala Ser Ser Gln
85 90 95
Gly Gly Thr Gln Tyr Phe Gly Pro Gly Thr Arg Leu Leu Val Leu Glu
100 105 110
Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro Ser
115 120 125
Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu Ala
130 135 140
Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp Trp Val Asn Gly
145 150 155 160
Lys Glu Val His Ser Gly Val Cys Thr Asp Pro Gln Pro Leu Lys Glu
165 170 175
Gln Pro Ala Leu Asn Asp Ser Arg Tyr Ala Leu Ser Ser Arg Leu Arg
180 185 190
Val Ser Ala Thr Phe Trp Gln Asp Pro Arg Asn His Phe Arg Cys Gln
195 200 205
Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp Arg
210 215 220
Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg Ala
225 230 235 240
Asp
<210> 29
<211> 723
<212> DNA
<213> 人工序列
<220>
<223> 可溶性TCRβ链
<400> 29
gaagcaggtg ttacccagtt ccccagccac agcgtaatag agaagggcca gactgtgact 60
ctgagatgtg acccaatttc tggacatgat aatctttatt ggtatcgacg tgttatggga 120
aaagaaataa aatttctgtt acattttgtg aaagagtcta aacaggatga gtccggtatg 180
cccaacaatc gattcttagc tgaaaggact ggagggacgt attctactct gaaggtgcag 240
cctgcagaac tggaggattc tggagtttat ttctgtgcca gcagccaagg ggggacccag 300
tacttcgggc caggcacgcg gctcctggtg ctcgaggacc tgaaaaacgt gttcccaccc 360
gaggtcgctg tgtttgagcc atcagaagca gagatctccc acacccaaaa ggccacactg 420
gtgtgcctgg ccaccggttt ctaccccgac cacgtggagc tgagctggtg ggtgaatggg 480
aaggaggtgc acagtggggt ctgcacagac ccgcagcccc tcaaggagca gcccgccctc 540
aatgactcca gatacgctct gagcagccgc ctgagggtct cggccacctt ctggcaggac 600
ccccgcaacc acttccgctg tcaagtccag ttctacgggc tctcggagaa tgacgagtgg 660
acccaggata gggccaaacc cgtcacccag atcgtcagcg ccgaggcctg gggtagagca 720
gac 723
<210> 30
<211> 247
<212> PRT
<213> 人工序列
<220>
<223> 单链TCR
<400> 30
Gly Glu Asp Val Glu Gln Ser Leu Phe Leu Ser Val Arg Glu Gly Asp
1 5 10 15
Ser Val Ser Ile Asn Cys Thr Tyr Thr Asp Ser Ser Ser Thr Tyr Leu
20 25 30
Tyr Trp Tyr Lys Gln Glu Pro Gly Ala Gly Leu Gln Leu Leu Thr Tyr
35 40 45
Ile Phe Ser Asn Met Asp Met Lys Gln Asp Gln Arg Leu Thr Val Ser
50 55 60
Leu Asn Lys Lys Asp Lys His Leu Ser Leu Arg Ile Glu Asp Val Gln
65 70 75 80
Pro Gly Asp Ser Ala Ile Tyr Phe Cys Ala Glu Ile Pro Ser Thr Gly
85 90 95
Ala Asn Asn Leu Phe Phe Gly Thr Gly Thr Arg Leu Thr Val Ile Pro
100 105 110
Gly Gly Gly Ser Glu Gly Gly Gly Ser Glu Gly Gly Gly Ser Glu Gly
115 120 125
Gly Gly Ser Glu Gly Gly Thr Gly Glu Ala Gly Val Thr Gln Phe Pro
130 135 140
Ser His Ser Ser Ile Glu Lys Gly Gln Thr Val Thr Leu Arg Cys Asp
145 150 155 160
Pro Ile Ser Gly His Asp Asn Leu Tyr Trp Tyr Arg Arg Val Pro Gly
165 170 175
Lys Glu Ile Lys Phe Leu Leu His Phe Val Lys Glu Ser Lys Gln Asp
180 185 190
Glu Ser Gly Met Pro Asn Asn Arg Phe Asn Ala Glu Arg Thr Gly Gly
195 200 205
Thr Tyr Ser Thr Leu Lys Ile Gln Pro Val Glu Pro Glu Asp Ser Gly
210 215 220
Val Tyr Phe Cys Ala Ser Ser Gln Gly Gly Thr Gln Tyr Phe Gly Pro
225 230 235 240
Gly Thr Arg Leu Thr Val Leu
245
<210> 31
<211> 741
<212> DNA
<213> 人工序列
<220>
<223> 单链TCR
<400> 31
ggtgaagatg ttgaacagtc cctgtttctg tcagtgcgtg aaggcgattc tgttagtatt 60
aactgcacct acacggacag ctctagtacc tatctgtact ggtataaaca ggaaccgggc 120
gcgggtctgc aactgctgac gtacattttt agcaacatgg atatgaaaca ggaccaacgt 180
ctgaccgtct cgctgaataa gaaagataaa cacctgagcc tgcgcatcga agatgtgcag 240
ccgggtgact ctgcgattta cttctgtgcc gaaatcccga gtacgggcgc gaacaacctg 300
tttttcggca ccggtacgcg tctgaccgtc atcccgggcg gtggctcgga aggtggcggt 360
agcgaaggcg gtggctctga aggtggcggt agtgaaggcg gtacgggtga agccggtgtg 420
acccagtttc cgagccattc ctcaattgaa aaaggccaaa ccgttacgct gcgctgcgat 480
ccgatcagcg gtcacgacaa cctgtactgg tatcgtcgcg ttccgggcaa agaaattaaa 540
tttctgctgc atttcgtcaa agaatccaaa caggatgaaa gcggtatgcc gaacaatcgt 600
ttcaatgcag aacgcaccgg cggtacctat tccaccctga aaatccaacc ggtcgaaccg 660
gaagacagtg gcgtgtactt ttgtgcttcg agccagggcg gtacccaata tttcggcccg 720
ggtacgcgcc tgaccgtgct g 741
<210> 32
<211> 112
<212> PRT
<213> 人工序列
<220>
<223> 单链TCRα链
<400> 32
Gly Glu Asp Val Glu Gln Ser Leu Phe Leu Ser Val Arg Glu Gly Asp
1 5 10 15
Ser Val Ser Ile Asn Cys Thr Tyr Thr Asp Ser Ser Ser Thr Tyr Leu
20 25 30
Tyr Trp Tyr Lys Gln Glu Pro Gly Ala Gly Leu Gln Leu Leu Thr Tyr
35 40 45
Ile Phe Ser Asn Met Asp Met Lys Gln Asp Gln Arg Leu Thr Val Ser
50 55 60
Leu Asn Lys Lys Asp Lys His Leu Ser Leu Arg Ile Glu Asp Val Gln
65 70 75 80
Pro Gly Asp Ser Ala Ile Tyr Phe Cys Ala Glu Ile Pro Ser Thr Gly
85 90 95
Ala Asn Asn Leu Phe Phe Gly Thr Gly Thr Arg Leu Thr Val Ile Pro
100 105 110
<210> 33
<211> 336
<212> DNA
<213> 人工序列
<220>
<223> 单链TCRα链
<400> 33
ggtgaagatg ttgaacagtc cctgtttctg tcagtgcgtg aaggcgattc tgttagtatt 60
aactgcacct acacggacag ctctagtacc tatctgtact ggtataaaca ggaaccgggc 120
gcgggtctgc aactgctgac gtacattttt agcaacatgg atatgaaaca ggaccaacgt 180
ctgaccgtct cgctgaataa gaaagataaa cacctgagcc tgcgcatcga agatgtgcag 240
ccgggtgact ctgcgattta cttctgtgcc gaaatcccga gtacgggcgc gaacaacctg 300
tttttcggca ccggtacgcg tctgaccgtc atcccg 336
<210> 34
<211> 111
<212> PRT
<213> 人工序列
<220>
<223> 单链TCRβ链
<400> 34
Glu Ala Gly Val Thr Gln Phe Pro Ser His Ser Ser Ile Glu Lys Gly
1 5 10 15
Gln Thr Val Thr Leu Arg Cys Asp Pro Ile Ser Gly His Asp Asn Leu
20 25 30
Tyr Trp Tyr Arg Arg Val Pro Gly Lys Glu Ile Lys Phe Leu Leu His
35 40 45
Phe Val Lys Glu Ser Lys Gln Asp Glu Ser Gly Met Pro Asn Asn Arg
50 55 60
Phe Asn Ala Glu Arg Thr Gly Gly Thr Tyr Ser Thr Leu Lys Ile Gln
65 70 75 80
Pro Val Glu Pro Glu Asp Ser Gly Val Tyr Phe Cys Ala Ser Ser Gln
85 90 95
Gly Gly Thr Gln Tyr Phe Gly Pro Gly Thr Arg Leu Thr Val Leu
100 105 110
<210> 35
<211> 333
<212> DNA
<213> 人工序列
<220>
<223> 单链TCRβ链
<400> 35
gaagccggtg tgacccagtt tccgagccat tcctcaattg aaaaaggcca aaccgttacg 60
ctgcgctgcg atccgatcag cggtcacgac aacctgtact ggtatcgtcg cgttccgggc 120
aaagaaatta aatttctgct gcatttcgtc aaagaatcca aacaggatga aagcggtatg 180
ccgaacaatc gtttcaatgc agaacgcacc ggcggtacct attccaccct gaaaatccaa 240
ccggtcgaac cggaagacag tggcgtgtac ttttgtgctt cgagccaggg cggtacccaa 300
tatttcggcc cgggtacgcg cctgaccgtg ctg 333
<210> 36
<211> 24
<212> PRT
<213> 人工序列
<220>
<223> 单链TCR连接序列
<400> 36
Gly Gly Gly Ser Glu Gly Gly Gly Ser Glu Gly Gly Gly Ser Glu Gly
1 5 10 15
Gly Gly Ser Glu Gly Gly Thr Gly
20
<210> 37
<211> 72
<212> DNA
<213> 人工序列
<220>
<223> 单链TCR连接序列
<400> 37
ggcggtggct cggaaggtgg cggtagcgaa ggcggtggct ctgaaggtgg cggtagtgaa 60
ggcggtacgg gt 72
- 还没有人留言评论。精彩留言会获得点赞!