DNA集合的归一化迭代条形码和测序的制作方法
本发明涉及dna测序的技术领域。更具体而言,本文所述的组合物和方法用于生成来自多个来源的dna库且用于下一代测序。
背景技术:
在多种不同研究和临床努力中,期望并行获得多个不同样品中所含的核酸序列信息。
通常被称为“sanger测序”的单独样品或单重dna测序的普遍存在的实施方案是使用dna聚合酶以dna模板依赖性方式将荧光双脱氧核苷酸终止子并入一系列嵌套延伸产物中,之后,在耦接到荧光计的毛细管电泳仪器上分离延伸产物来进行,所述荧光计会输出对应于连续核苷酸并入事件的信号。sanger测序当前被视为单独dna读序质量的黄金标准;其尤其在每次从少量dna模板(<100个)获得序列结果时,并且尤其在关注区域的长度处于约数百个与750个碱基对之间时,具有精确性和可靠性。
大规模复用测序(有时被称为下一代测序(ngs)、大规模平行测序(mps)或第二代测序)涵盖数种技术平台,其使得一个样品中的数千到数百万个异质dna分子可以同时得到准备和分析。因此,大型混合物(通常被称为“库”)中的多种核苷酸序列可在单一分析中得到检索。
除了在单一分析中所获得的序列数量方面不同以外,单重(即,sanger)和复用测序还在其如何准许从集合追踪分离样品方面有所不同。在单重测序中,经特定确认的序列的来源或位置一般为明确的,因为模板dna的单一分离样品为分析的输入并且可通过对输出序列数据进行直接追踪来联系。举例来说,可以在电泳之前在其中装载有样品的微量滴定板或毛细管上记录样品位置。在复用/ngs测序中,通过使用输入条形码、标记或索引方案,集合中的特定模板dna的位置或来源可通过将可鉴别的序列标记(即,不同dna序列)并入由特定孔或位置衍生的库片段中来得到确认。然而,对于测序数千个分离或可追踪样品来说,用于独立样品的分子标记的常规输入-索引模式(有时被简单地称为“条形码”)通常过于昂贵。
sanger测序仍为各种情况下,且尤其在需要(1)较长的高质量(低错误率)序列,(2)测序模板或dna克隆的板或位置集合上的位置信息,和/或(3)项目成本、设计、样品数量或与常规ngs方法相关的其它材料约束条件方面的总体实用性的情况下用于进行dna测序的默认方法。举例来说,sanger测序在例如测序筛分(在工程改造肽期间的克隆鉴别的情形下进行)、定制的长扩增子组的全长测序或通过化学基因合成生成的全长产物的测序中仍然是选定方法。
ngs已取代sanger测序,其中通常以数百万或数十亿个碱基读数测量的所获得的原始数据量具有高实用性。举例来说,现在可以在一天之内以足够深度对人类基因组的全部大约60亿碱基进行测序。需要精确计算大量不同核酸的许多其它应用(例如对人类细胞中所表达的mrna进行测序和定量)也极大地受益于现在可以以便宜和简单的方式获得的大量原始序列数据。
尽管现代测序仪器的容量已有所增长,但使用现代仪器的测序容量来同时测序较大数目的不同样品仍然具有相对挑战性。举例来说,通过常规估算,测序一个二倍体人类基因组(60亿个核苷酸)所需的测序容量的量大致与测序一千个大肠杆菌基因组(五百万个核苷酸)所需的容量相当。然而,与由一千个大肠杆菌样品常规制备用于下一代测序的核酸样品库相关的材料和成本将超过单一人类基因组样品的材料和成本至少100倍。这是构成在同时测序大量样品方面的困难的所谓的“库制备瓶颈”的一个实例。
已知用于由核酸样品制备适用于ngs的库的多种方法。代表性方法包括例如美国专利第8,420,319号;第8,728,737号和第9,040,256号中所述的方法。这些方法的统一特征为随机片段由核酸样品(例如,基因组dna样品)产生,并且库是通过添加不对称衔接子,产生可通过多种手段(例如pcr)扩增的适合片段而衍生。利用这些方法,核酸样品的量或浓度也必须通常被定量为指定精确程度以便实现库制备方法的效率、质量或产率。
通过常规方法制造的库的复用通常通过将一种或多种可鉴别的序列标记或条码并入连接到每一衍生库中的片段的衔接子中来实现。可随后通过测量多个库中的每一个的量或浓度并将其混合在一起以制得统一库而将许多此类库以期望比例合并。在一些情况下,这一方法可通过使用机器人技术或能够测量浓度并将单独的库适应性地汇集成一个期望混合库的其它自动化方法来得到自动化。
可使用其它流线型归一化策略来提高库制备方法的并行化的效率。举例来说,可在建库之前使输入核酸样品归一化,或可使用具有有限可逆结合能力的样品容器(例如,赛默飞世尔(thermofisher)
因此所属领域已知的现行方法通常缺乏形成适用于ngs而不需要对输入样品或所得库进行单独调整或并行化归一化的复用化、归一化库的能力。
因此本发明的一个目的在于提供可由多个不同样品形成线性、非选择性扩增的dna分子的统一库的方法,其适用于ngs,同时维持由每一样品产生的dna分子的归一化百分比。
本发明的另一个目标在于提供可用于以并行化和汇集方式由多个不同样品形成线性、非选择性扩增的dna分子的统一库的方法,所述方法不需要明确归一化每一样品中所存在的dna的量,也不需要测量、评定或明确归一化多个不同库来制造统一库。
本发明的另一个目标在于减少将另外与使用当前在所属领域中已知或实践的方法中的任一个由多个不同样品制备dna分子的归一化、统一库相关的困难和时间。
技术实现要素:
本发明尤其提供由多个原始的含核酸的样品制备线性、非选择性扩增的dna片段的统一库的组合物和方法,其中来自多个原始样品中的每一个的片段的比例表述为归一化的(即,片段以大致同等方式展现)并且库是以高度并行化、基于池方式产生。本发明尤其用于制备如下库:其中特定信息经编码而使由所述库的高通量测序衍生的较短测序读序被分析或组合成较长级序列,所述较长级序列在可能的极大型样品集合中完全可追踪到原始含核酸的样品。本发明的组合物涵盖本文所述的多种构筑体,其可与一种或多种用于本发明方法中的另外试剂和使用说明书一起以不同方式封装。
通常,在本发明方法中,首先对多个核酸样品中的每一样品进行样品标记步骤,其中每一样品中的多个核分子经修饰而并入可鉴别的序列标记。用包括唯一、可鉴别的序列标记的构筑体处理(例如在本文所述的条件或分子生物学家已知的常规反应条件下接触)待分析的每一样品以使得一个样品可基于所述标记区别于另一个样品。在优选实施例中,样品标记步骤在将所并入标记的数量限制为远低于每一样品中所存在的可利用的修饰位点的数量的数量(例如样品的核酸分子中所存在的每约1000个核苷酸碱基(例如小于约1,000、900、800、700、600或500个核苷酸碱基)小于一个所并入标记)的反应条件下进行,并且优选地,对于全部多个样品都保持相同。
根据本发明方法,可进行样品标记步骤以使得对于全部多个经处理样品来说,每一样品中所并入的可鉴别的序列标记将大致相等,其与每一样品中所存在的核酸的量或浓度无关。这可以在使用本文所述的指定反应条件,并且更一般来说,其中用于并入可鉴别的序列标记的试剂或构筑体相对于一系列可能的样品核酸浓度保持在一定限度内的至少一些实施例中实现。
在样品标记步骤之后,将多个以可鉴别方式标记的样品随后汇集并且在池标记步骤中进一步加以处理,在所述池标记步骤中,对池中的多个经样品标记的核分子进行修饰以并入鉴别池的其它可鉴别的序列标记(有时在本文中被称为“池标记”)。
在优选实施例中,进行池标记步骤所处的反应条件使得池标记被平均添加到来自池中核酸分子上所存在的任何样品标记的一系列x个核苷酸中。在各个实施例中,x可选择为指定值,例如约100、500或1000个核苷酸。当如某些优选实施例中所规定进行池标记步骤时,所述步骤的一个非显而易见的特征在于池标记的併入与池中所存在的任何核酸分子上所存在的任何样品标记的位置无关,并且也与由先前经历样品标记的任何特定样品产生的核酸分子的相对浓度无关。因此可以说,池中所存在的任何样品标记的x个核苷酸中出现池标记的情况得到归一化。
在池标记步骤之后,池中所存在的核酸分子可在其它实施例中得到扩增。扩增可用杂交到对于全部样品标记、全部池标记或这两者交替常见的序列的区域或子区域的引物由例如pcr来辅助。以此方式,获得由多个原始含核酸的样品产生的线性、非选择性扩增的dna片段的统一、归一化库。
因此,在第一方面中,本发明提供一种由多个样品获得dna片段的迭代标记库的方法。所述方法可包括以下步骤:(a)使多个样品的第一和第二样品中的靶核酸分子分别与均一和限定量的各自包含可鉴别的样品序列标记的第一和第二构筑体接触,其中第一构筑体中的样品序列标记与第二构筑体中的样品序列标记不同,并且接触会进行一定持续时间并在如下条件下进行:其中第一构筑体中的样品序列标记被整合到第一样品中的核酸分子中,并且第二构筑体中的样品序列标记被整合到第二样品中的核酸分子中;(b)汇集第一和第二样品以产生经样品标记的核酸分子的池;(c)使经样品标记的核酸分子的池与包含池标记的第三构筑体接触,其中接触会进行一定持续时间并在如下条件下进行:其中池标记以按照核苷酸的规定频率被整合到池的核酸分子中,由此生成经样品标记的、经池标记的核酸分子的池;以及(d)用寡核苷酸扩增经样品标记的、经池标记的核酸分子,由此生成经扩增核酸分子,所述寡核苷酸包含(i)与经样品标记的、经池标记的核酸分子中的核酸序列互补的核酸序列,和(ii)适用于下一代测序的核酸序列。当如此处和我们本发明描述中的其它处所述进行所述方法时,所述方法会产生dna库,其中与样品对应的每一库中的dna片段的相对丰度得到归一化。在各个实施例中,池标记包括可以按照核苷酸的规定频率(例如,在平均约100-20,000(例如,100-10,000或100-1,000)个核苷酸之间产生池标记的频率)整合到经汇集的、经样品标记的核酸分子中的可鉴别的序列标记,其远离池中的经样品标记的核酸分子上的每一样品序列标记。
多个样品中的至少一个样品可为或可包括基因组dna。另外,多个样品中的至少一个样品可为或可包括cdna、合成性dna或在病毒、细菌、酵母菌、真菌、原虫、昆虫、鱼、禽、哺乳动物或植物中天然存在的dna。不同类型的dna或来自多个来源的dna可存在于任何给定样品中。如所提到,可并行处理多个样品(例如2到约9,600个样品)(例如可并行处理约100个96孔培养盘,其每一孔中都含有样品)。
在本发明方法中,第一和第二构筑体可包括衔接子,所述衔接子随后连接到靶核酸分子;或转座酶或其生物活性变异体,其随后将可鉴别的样品序列标记引入到靶核酸分子中。适合的转座酶可极具活性并且几乎不呈现或不呈现序列偏差。举例来说,用于本发明方法中的构筑体可包括tn3、tn5、tn9、tn10、γ-δ、或mu转座酶、其组合、或其生物活性变异体。
在样品序列标记被整合到靶核酸分子中的条件下,样品序列标记的量可以比随后用于接触经样品标记的核酸分子的池的池标记的量低至少两倍。
转而参看第三构筑体,这一构筑体也可包括随后经连接(例如连接到经样品标记的核酸分子)的衔接子或转座酶(包括上文所列的转座酶中的任一种)或其生物活性变异体,其随后将池标记引入到经样品标记的核酸分子中。第一、第二或第三构筑体中的任一种也可独立地包括特异性结合捕获剂的部分(例如,特异性结合捕获剂中的蛋白质或核酸序列的核酸序列)。举例来说,特异性结合捕获剂的部分可为已被生物素化或洋地黄毒苷化(digoxigenylated)的部分。
在本发明的方法中,可以通过将经样品标记的和/或经池标记的核酸分子群暴露于有限量的捕获剂来使所述群归一化。
上文所述的步骤之后可对dna片段的迭代标记库进行下一代测序。
在另一方面中,本发明提供一个试剂盒,其包含:(a)多个构筑体(例如,2到约9,600个构筑体),其包括可鉴别的样品序列标记,其中多个构筑体的第一构筑体中的可鉴别的样品序列标记不同于第二构筑体中的可鉴别的样品序列标记;和(b)使用说明书。说明书可呈任何形式,包括书写/印刷形式,通过储存于任何合适媒体上的音频或视频录制提供,或通过网站类指导的链接提供。试剂盒可进一步包括池标记试剂(例如如本文所述的构筑体),其用于将可鉴别的序列标记添加到经样品标记的核酸的池中的一种或多种核酸中,和/或用于扩增经样品标记的和/或经池标记的核酸分子的试剂。
附图说明
此处经简要描述的附图意图帮助说明本发明并且并非限制性的。
图1为可用于实施本发明的方案和步骤的代表性实施例的示意性图解。所图示的方法以样品标记开始并且以测序分析结束。
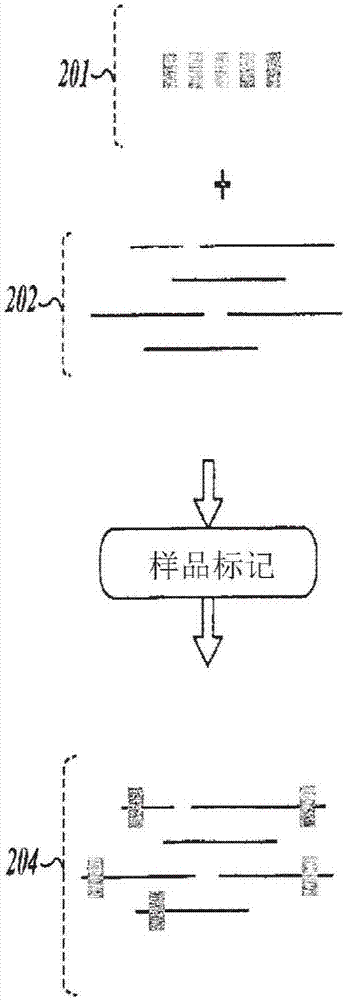
图2图示本发明的一个实施例,其中核酸样品经历样品标记步骤,在所述步骤中,样品的一种或多种核酸标记有可鉴别的序列标记。
图3图示样品标记步骤的归一化方面,其中使用相对固定量的标记试剂将可鉴别的序列标记添加到不同量的dna中。随后将来自多个样品的经标记的产物合并(汇集)。
图4图示池标记步骤;处理经汇集的、经样品标记的核酸以获得序列标记,其鉴别经样品标记的核酸作为池的成员。
图5图示与不同的和可鉴别的池标记一起经历池标记步骤的经样品标记的核酸分子的多个不同池。
图6图示经并行测序以从库中的多个片段中的每一个获得短读序信息的片段的库。对于这些片段中的每一个来说,一组短读序经产生而包含一种或多种样品标记、一种或多种集合标记和每一分子上的一种或多种其它关注区。
图7为展示在对使用本发明方法生成的库进行测序之后所获得的覆盖区的实例的图式(参见实例1中所述的研究)。“多个样品”为由伯克霍尔德菌(burkolderiabacteria)的分离物收集的基因组dna的96孔培养盘中的96个样品。
图8显示如实例2中所示,使用本发明方法由多个千碱基质粒模板获得的组合的连续核苷酸序列的实例。
图9为展示本发明方法的归一化表现的实例的图式,所述效能通过对具有不同原始输入核酸浓度的多个样品进行测序来确定。通过本发明方法实现的归一化作用可与在此处所报告的作用相同(或大致相同)。
具体实施方式
呈现以下描述以使得所属领域的一般技术人员能够进行和使用本发明的各个方面和实例。特定材料、技术和应用的描述仅作为实例而提供。所属领域的一般技术人员将容易明白本文所述的实例的各种修改,并且在不脱离本发明的精神和范围的情况下,本文中所界定的一般原理可以应用于其它实例和应用。因此,本发明并非意图限于所述和所示的实例,而是被赋予与所附权利要求书一致的范围。
在一个方面中,本发明包含由多个原始含核酸样品制备线性、非选择性扩增的dna片段的统一库的方法,其中来自多个原始样品中的每一个的线性片段的比例表述为归一化的。这些方法尤其用于制备dna测序库,其中特定信息经编码而提供通过对待分析或待组合成较长级序列的库进行高通量短读序测序而衍生的测序读序,其在可能的大型样品集合中全部可源于原始分离样品。
在另一个方面中,本发明包含一种或多种试剂盒,其提供用于实现所揭示的本发明方法的试剂和说明书。
除非使用术语的上下文另外明确指明,否则本发明的传授内容利用含义以以下方式解释的术语。
在本文中术语“约”用于表明如下值:其包括用于测定值的装置或方法的内在误差变化;或表明所陈述/参考值±10%,无论哪个更高。
我们使用术语“生物活性变异体”来指与所提及部分(例如“母”分子或模板)相似但并不与其一致,并呈现用于本文所述的方法中的一种或多种的足够活性的部分(例如,代替所提及部分)。在一些情况下,所提及部分为天然存在的,而其生物活性变异体并非天然存在的。举例来说,在所提及部分为天然存在的核酸序列的情况下,其生物活性变异体可包括有限数目的非天然存在的核苷酸;可具有与其天然存在的对应部分不同的核酸序列;或可在其它方面不同于其天然存在的对应部分。举例来说,标记化试剂(tagmentationreagent)可包括“转座酶结合位点”(tbs),其与天然存在的tbs有所不同,但仍然保持很好地结合转座酶以使本发明组合物和方法发挥作用的能力。在所提及部分为天然存在的蛋白质的情况下,其生物活性变异体可包括有限数目的非天然存在的氨基酸;可具有与其天然存在的对应部分不同的肽序列;或可在其他方面不同于其天然存在的对应部分(例如借助于翻译后以不同方式修饰(例如其糖基化模式可有所不同)。
术语“解复用”意指通过数种手段中的任一种分析任何经测序的库片段上存在的可鉴别的序列标记信息,并将指配所述片段的来源的所述信息用于经修饰而并入所述可鉴别的序列标记的特定原始样品。
在一些实施例中,所述衔接子带有简并随机、半随机或非随机“可鉴别的序列标记”的子序列。在各个实施例中,可鉴别的序列标记在突触复合体之间可为相同或不同的。在一些实施例中,可鉴别的序列标记可用于“解复用”(即,计算上分组或分离)来源于单独样品的测序读序(即,经样品标记的读序)和/或来自某些池的测序读序(即,经池标记的读序)。
“试剂盒”是指用于递送进行本发明方法用的材料或试剂的任何递送系统。在分析的情形下,此类递送系统包括允许将反应试剂(合适容器中的例如探针、酶等)和/或支持材料(例如,缓冲液、用于进行分析的书面说明书等)从一个位置储存、传输或递送到另一个位置的系统。举例来说,试剂盒包括一个或多个封装体(例如箱),其含有本发明分析用的相关反应试剂和/或支持材料。此类内含物可共同或分别递送到目标接收者。举例来说,第一个容器可含有用于分析的酶,而第二个容器含有一个或多个探针。
“库”或“片段库”为衍生自一种或多种核酸样品的核酸分子的集合,其中已一般通过并入包含一个或多个引物结合位点和可鉴别的序列标记的末端衔接子序列来修饰核酸片段。
在本发明的上下文中且尤其就归一化来说,术语“有限的”、“有限量”等等用于描述构筑体,如包含活性转座酶的构筑体的量,所述构筑体在广泛范围的目标dna浓度内将不会生成超过期望数量的“标记情况”(即,变位事件)。位点之间的距离暗中控制所产生的可测序片段的尺寸。举例来说,如果位点之间的平均距离为500,那么片段尺寸将平均为500。
当用于本文中时,术语“复用”或“复用化”一般是指多个核酸样品或其所衍生的库分子在一个池、试管或反应中的集合。
术语“归一化”是指一种如下方法:通过所述方法dna样品之间的dna测序读序的变化率大体上降低。尽管归一化通常通过利用样品稀释消耗大量劳动测量和调整每一dna样品在库制备的各个阶段的浓度来实现,但本文中所述的实施例中的归一化是通过标记和汇集技术来实现。类似地,当用于本文中时,术语“归一化的”是指核酸分子或片段的异质混合物的一般期望属性,通过所述属性,由不同原始来源引起的片段丰度的变化率相对于原始来源中的丰度或量已大体上降低。当用于衍生或复用库(例如“归一化库”)的情形下时,术语是指如下属性:通过所述属性,来自多个样品中的每一个的库中的核酸片段的比例量(或百分比表述)小于原始样品的量的变化。尽管归一化通常通过利用样品稀释消耗大量劳动测量和调整每一dna样品在库制备的各个阶段的浓度来实现,但本文中所述的实施例中的归一化是通过标记和汇集技术来实现。
一般以同义使用的“寡核苷酸”或“聚核苷酸”意指一种通过磷酸二酯键或其类似物连接的天然或修饰核苷单体的线性聚合物。术语“寡核苷酸”通常是指较短的聚合物,例如,包含约3到约100个单体的聚合物,并且术语“聚核苷酸”通常是指较长的聚合物,例如,包含约100个单体到数千个单体,例如10,000个单体或更多的聚合物。寡核苷酸包含长度通常在12到60个核苷酸,并且更通常18到40个核苷酸范围内的探针或引物。寡核苷酸和聚核苷酸可为天然或合成的。寡核苷酸和聚核苷酸包括脱氧核糖核苷、核糖核苷和其非天然类似物,如其异头形式;肽核酸(pna)等等,其限制条件为其能够借助于单体与单体相互作用的常规模式特异性结合于靶基因组,如沃森-克里克型碱基配对(watson-cricktypeofbasepairing)、碱基堆积、胡斯坦或反胡斯坦型碱基配对(hoogsteenorreversehoogsteentypesofbasepairing)等等。
核苷单体通常通过磷酸二酯键来连接。只要寡核苷酸由一连串字母,如“atgc……”表示,那么应理解,除非另外指出,否则核苷酸从左到右呈5'到3'顺序,并且“a”表示脱氧腺苷,“c”表示脱氧胞苷,“g”表示脱氧鸟苷,“t”表示脱氧胸苷,并且“u”表示核糖核苷、尿苷。寡核苷酸通常包含四种天然脱氧核苷酸;然而,其还可包含核糖核苷或非天然的核苷酸类似物。一般熟习此项技术者应清楚,当寡核苷酸具有天然或非天然核苷酸时,其可用于本文所述的方法和工艺中。举例来说,在需要通过酶加以处理的情况下,通常需要仅由天然核苷酸组成的寡核苷酸。同样地,在酶具有针对活性的特定寡核苷酸或聚核苷酸基质要求,例如,单链dna、rna/dna双螺旋体等等的情况下,则适于寡核苷酸或聚核苷酸基质的组合物的选择恰在普通技术人员的知识范围内,尤其在论文,如sambrook等人,《分子克隆(molecularcloning)》,第二版(纽约冷泉港实验室(coldspringharborlaboratory,newyork),1989)和类似参考文献的指导下。寡核苷酸和聚核苷酸可为单链或双链的。
寡核苷酸和聚核苷酸可以任选地包括一种或多种非标准核苷酸、核苷酸类似物和/或经修饰的核苷酸。经修饰的核苷酸的实例包括(但不限于)二氨基嘌呤、s2t、5-氟尿嘧啶、5-溴尿嘧啶、5-氯尿嘧啶、5-碘尿嘧啶、次黄嘌呤、黄嘌呤、4-乙酰基胞嘧啶、5-(羧基羟甲基)尿嘧啶、5-羧甲基氨甲基-2-硫代尿苷、5-羧甲基氨甲基尿嘧啶、二氢尿嘧啶、β-d-半乳糖基q核苷、肌苷、n6-异戊烯基腺嘌呤、1-甲基鸟嘌呤、1-甲基肌苷、2,2-二甲基鸟嘌呤、2-甲基腺嘌呤、2-甲基鸟嘌呤、3-甲基胞嘧啶、5-甲基胞嘧啶、n6-腺嘌呤、7-甲基鸟嘌呤、5-甲基氨甲基尿嘧啶、5-甲氧基氨甲基-2-硫尿嘧啶、β-d-甘露糖基q核苷、5'-甲氧基羧甲基尿嘧啶、5-甲氧基尿嘧啶、2-甲硫基-d46-异戊烯基腺嘌呤、尿嘧啶-5-氧基乙酸(v)、丁氧核苷(wybutoxosine)、假尿嘧啶、q核苷、2-硫胞嘧啶、5-甲基-2-硫尿嘧啶、2-硫尿嘧啶、4-硫尿嘧啶、5-甲基尿嘧啶、尿嘧啶-5-氧基乙酸甲酯、尿嘧啶-5-氧基乙酸(v)、5-甲基-2-硫尿嘧啶、3-(3-氨基-3-n-2-羧丙基)尿嘧啶、(acp3)w、2,6-二氨基嘌呤等等。核酸分子亦可在碱基部分(例如在通常可用于形成具有补充核苷酸的氢键的一个或多个原子处和/或在通常不能够形成具有补充核苷酸的氢键的一个或多个原子处)、糖部分或磷酸骨架处得到修饰。
“寡核苷酸标记”、“序列标记”或“标记”意指连接到聚核苷酸的寡核苷酸或其复合物并用于鉴别和/或追踪反应中的聚核苷酸。通常,寡核苷酸标记连接到聚核苷酸的3'端或5'端以形成线性共轭物,所述有时在本文中被称作“标记聚核苷酸”或等效地被称作“经寡核苷酸标记的聚核苷酸共轭物”或“标记-聚核苷酸共轭物”。寡核苷酸标记可在尺寸和组成方面大幅变化;以下参考文献提供对选择适合于具体实施例的寡核苷酸标记组的指导:brenner,美国专利第5,635,400号;brenner等人,《美国国家科学院院刊(proc.natl.acad.sci.)》,97:1665;shoemaker等人,《自然·遗传学(naturegenetics)》,14:450,1996;莫里斯等人,欧洲专利公开案0799897a1;wallace,美国专利第5,981,179号;和类似文献。
“聚合酶链反应(pcr)”是指通过对dna的补充链进行同步引物延伸以使特定dna序列试管内扩增的反应。换句话说,pcr为制得通过引物结合位点侧接的靶核酸的多个拷贝或复制物的反应,此类反应包含重复以下步骤一次或多次:(i)使靶核酸变性,(ii)将引物退火到引物结合位点,和(iii)在三磷酸核苷存在下通过核酸聚合酶延伸引物。通常,反应在热循环仪器中按照针对每一步骤优化的不同温度循环。特定温度、每一步骤的持续时间和步骤之间的变化率取决于本领域普通技术人员熟知的多种因素,例如通过以下参考文献示范的因素:mcpherson等人编,《pcr:实用方法(pcr:apracticalapproach)》和《pcr2:实用方法(pcr2:apracticalapproach)》(irl出版社,牛津(oxford),分别为1991和1995)。举例来说,在使用taqdna聚合酶的常规pcr中,双链靶核酸可在大于90℃的温度下变性,引物在50℃到75℃范围内的温度下退火,并且引物在72℃到78℃范围内的温度下延伸。
pcr涵盖反应的衍生形式,包括(但不限于)rt-pcr、实时pcr、嵌套pcr、定量pcr、复用pcr等等。反应体积在数百纳升(例如200nl)到数百微升(例如200微升)范围内。“逆转录pcr”或“rt-pcr”意指前面是将靶rna转化成补充单链dna的逆转录反应的pcr,其随后扩增,例如tecott等人,美国专利第5,168,038号。“实时pcr”意指随反应进行而监测反应产物,即扩增子的量的pcr。存在实时pcr的多种形式,其主要在用于监测反应产物的检测化学反应方面有所不同例如,gelfand等人,美国专利第5,210,015号(“taqman”);wittwer等人,美国专利第6,174,670号和第6,569,627号(嵌入染料);tyagi等人,美国专利第5,925,517号(分子信标)。实时pcr的检测化学反应在mackay等人,《核酸研究(nucleicacidsresearch)》,30:1292-1305(2002)中得到综述。“嵌套pcr”意指两级pcr,其中第一pcr的扩增子变成使用一组新引物的第二pcr的样品,所述引物中的至少一个结合于第一扩增子的内部位置。如本文所用,关于嵌套扩增反应的“初始引物”意指用于生成第一扩增子的引物,并且“第二引物”意指用于生成第二或嵌套扩增子的一个或多个引物。“复用pcr”意指如下pcr:其中多个靶序列(或单一靶序列和一个或多个参考序列)在同一反应混合物中同时进行(参见例如,bernard等人,《分析生物化学(anal.biochem.)》,273:221-228,1999(双色实时pcr))。通常,针对经扩增的每一序列采用不同引物组。“定量pcr”意指被设计成用于测量样品或试样中的一个或多个特定靶序列的丰度的pcr。定量pcr包括此类靶序列的绝对定量和相对定量。定量pcr的技术对于所述领域的普通技术人员为熟知的,如以下参考文献中所示范:freeman等人(《生物技术(biotechniques)》,26:112-126,1999;becker-andre等人(《核酸研究》,17:9437-9447,1989;zimmerman等人(《生物技术》,21:268-279,1996;diviacco等人(《基因(gene)》,122:3013-3020,1992;becker-andre等人(《核酸研究》,17:9437-9446,1989);和类似文献。
术语“经池标记的”或“经集合标记的”是指由通过多种方法中的任一种将可鉴别的序列标记并入到经样品标记的核酸的池中产生的多个核酸分子。然而,在一些实施例中,所述“池标记”带有不可鉴别的序列标记,并实际上充当用于将核酸添加到经样品标记的核酸上的最小序列衔接子,使得池与特定dna测序平台或扩增策略相容。
“引物”包括天然或合成的寡核苷酸,其能够在形成具有聚核苷酸模板的双螺旋体后充当核酸合成的起始点并从其3'端沿模板延伸以便形成经延伸的双螺旋体。在延伸过程中添加的核苷酸序列通过模板聚核苷酸的序列测定。引物通常通过dna聚合酶延伸。引物的长度通常在3到36个核苷酸、5到24个核苷酸或14到36个核苷酸范围内。在某些方面中,引物为通用引物或非通用引物。引物对可侧接相关序列或相关序列组。引物和探针在序列中可为简并的。在某些方面中,引物结合邻近于靶序列,无论所述序列是否是待捕获用于分析的序列还是待拷贝的标记。
术语“样品标记的”和“经样品标记的”是指将可鉴别的序列标记并入到包含核酸样品的核酸分子中的过程和结果。
术语“鸟枪片段化(shotgunfragmentation)”描述使用机械dna片段化方法(例如,声学、雾化或声处理)或利用
我们使用术语“标记(tagment)”和“标记化(tagmentation)”来描述其中纯化转座酶在人工变位反应用作试剂以制备下一代dna测序(ngs)的库的方法。在标记化中,转座酶首先负载有带有tbs的合成寡核苷酸,随后负载后的转座酶将活跃于分割靶dna并同时所负载的寡核苷酸“标记”和tbs连接到靶dna上的新生成的末端。
现较详细地参考本发明所涵盖的方法,在图1中,我们图示可在实践本发明的一个实施例中实施的步骤(又参见图2-6)。
在图1中,我们展示样品标记步骤100,其中多个样品的核酸样品经修饰而通过所属领域中已知的数种方法中的任一种将可鉴别的序列标记并入到由“鸟枪”片段化和调适产生的dna片段中,吾人还可将所述可鉴别的序列标记称作dna条码。可实施鸟枪片段化和调适,其优于例如,随机剪切、末端修复和衔接子连接,优于转座酶调适(即,标记化),或优于所属领域中已知的或所属领域中后续研发的任何相似方法。
样品标记步骤的关键特征在于添加到每一核酸样品中的可利用的标记的数量保持不变且与每一样品中的可利用的核酸的质量相比相对较低。这一限制条件可替代地例如通过调节时间、浓度或所属领域中已知的其它参数的反应条件来实现,以影响可由物理剪切、核酸酶消化或转座酶类调适获得的片段化,以便生成超过规定长度的片段。在本发明的情况下,规定或期望长度还可表示为样品中所存在的全部核苷酸的每个核苷酸所添加的标记数量。因此,所添加的标记数量可保持限制于每单元质量或摩尔浓度的1000个核苷酸低于一个或其它规定水平。举例来说,在其它实施例中,所添加的标记数量可保持为每单元质量或摩尔浓度的2000、3000、4000、5000或更多个核苷酸小于一个。
如通过各个示范性实施例将清楚,通过使样品中的样品标记率小于规定的每个核苷酸水平施加的限制条件在一些情况下可指示,并非样品中所存在的全部核酸分子都将必须接受样品标记情况。对本文中所主张的发明特别重要且相关的是,如果在相似条件下标记多个样品,并且允许每一样品中的核酸的量有所变化,而标记情况的数量限制在低于规定水平,那么样品之间的标记情况的数量将仍然大致相等。
仍参考图1,在对多个模板样品进行标记步骤100的情况下,将不同或特有聚核苷酸标记序列并入到多个样品中的每一单独样品中将视为有利的。如步骤100中所示,由此经修饰的模板样品随后被称为已‘经样品标记’或被称为具有‘样品标记’。样品标记指示样品集合中样品的特定位置,如微量滴定板上的微孔位置将另外被视为有利的。此外,将不同序列随机化的子区包括在样品标记(长度上有4-20个碱基)内以在后续dna序列分析期间计数或检测由同一母分子衍生的dna序列可为有利的。
仍参考图1,随后显示步骤102,其中已在步骤100中经样品标记的多个样品一起汇集成一种混合物,其随后含有多个经特别标记的模板样品,每一模板样品除了可变长度的另外未知的或部分未知的序列以外还含有多个已知标记序列中的一个,所述未知的序列侧接、邻近或为已知标记序列的上游或下游。
仍参考图1,随后显示步骤104,其中对来自步骤102的经汇集标记的样品进行池标记步骤,以使得包含经汇集的样品的原始核酸分子随机或半随机片段化,通过所属领域的从业者已知的数种方法中的任一种裂解或断裂成较小块,并且随后或同时用已知的单链或双链dna衔接子序列调适,所述衔接子序列在一端或两端上侧接新衍生的片段。可用于步骤102的伴随的片段化方法可包括例如通过各种酶,如dna核酸外切酶以及(或不存在)dna切口酶进行酶促片段化,或通过机械力,如雾化(例如
通过对先前已通过本发明方法样品标记的样品进行池标记而实现的关键特征在于池标记的添加仅视池中所存在的核酸分子的可用质量而定,并且并不取决于经合并而制得池的单独样品分子的相对量,或代表所述同一池中的每一样品的单独核酸分子的所得频率。因此,当进行池标记时,存在使用本发明实施方法中的任一种将池标记添加到处于任何样品标记的规定数量的核苷酸中的位点的相等机率,所述样品标记代表包含池的分子中已经存在的任一原始样品。当使用本发明实施方法进行应用时,包含池的核酸分子的所得特征在于,对于池中任何核酸分子上存在的每一样品标记来说,存在通过池标记步骤添加的池标记中的一个将存在于规定距离的样品标记中的相等机率。
在本发明的各种实施方法中,经池标记的样品中的样品标记和池标记的间距可由调节添加池标记所处的条件来加以控制或限制。举例来说,通过改变时间、浓度或所属领域中已知的其它参数的反应条件来改变样品标记和池标记之间的距离,以影响通过物理剪切、核酸酶消化或转座酶类调适获得的片段化。在将公认为通常有利的是,一些优选的实施条件下,多个样品标记中的每一个和位于同一核酸分子上的相应邻近池标记的距离和相对定向将使得可通过pcr或其它相似手段进行所述同一核酸分子的序列子区域的扩增,所述子区域形成在样品标记和池标记之间。
参考图1的步骤106,通过合适方法扩增和富集步骤104的片段化和池标记。合适方法可包括例如聚合酶链反应(pcr)。所属领域的一般技术人员将认识到使用对并入原始样品标记步骤100中的序列具有特异性,以及对池标记步骤104具有特异性的寡核苷酸引物的扩增可促进对库片段的的扩增和富集,所述库片段除了通过步骤104中所添加的衔接子在一端处侧接的原始模板分子的随机片段以外,在相对端处还含有用于鉴别步骤100的样品的聚核苷酸标记序列。
在其它实施例中,在已由原始多个样品中的每一个产生多个不同池,所述池中的每一个为由所述步骤100、102、104和106产生的经汇集、经片段化、经调适、经扩增和富集的库的情况下,将公认为尤其有利的是,步骤106的扩增和富集中所用的寡核苷酸引物可经修饰而并入一个或多个特别鉴别的聚核苷酸标记序列(即,dna条码或可鉴别的序列标记),其可进一步与由步骤106产生的合适片段的整个池相关。在寡核苷酸引物由此经修饰的情况下,通过使用所述池-标记序列知晓的所得池可用于特别鉴别针对池中的任何样品片段的来源的池。
在其它实施例中,在已由多个多个样品产生多个不同池的情况下,将公认为尤其有利的是,池标记序列作为任何池标记步骤的一部分用于并入一个或多个特别鉴别的池-标记序列(即,dna条码或可鉴别的序列标记),其可进一步与所存在的合适核酸分子的整个池相关。
仍参考图1,随后显示步骤108,其中经扩增和富集的库池(每一库池标记有可鉴别的池标记)经汇集而形成一池标记池,即,经汇集的池。
仍参考图1,随后显示步骤112,其中已根据需要另外经尺寸分级以用于进一步处理的作为所得所得步骤10的统一库,经历大规模平行测序(mps),如
仍参考图1,随后显示步骤114,其中根据来源于样品标记步骤100的聚核苷酸标记序列的组合或池扩增和富集步骤106处的池标记对步骤112中所获得的单独测序读序进行归类或解复用。在一些实施例中,聚核苷酸标记序列的精确组合可用于映射或关联多个单独测序读序,其借助于步骤100处引入的标记针对原始样品集合中的样品的位置具有相同标记,或借助于步骤106处引入的标记针对代表整个集合的片段的池具有相同标记。以此方式,对于展现在多个原始集合中的每一个中的多个原始样品中的每一个来说,可衍生多个单独测序读序,其特别映射或对应于一个原始样品。此外,紧邻的前述多个读序中的单独测序读序中的每一个含有输入到步骤100的原始核酸模板样品的可能未知的区域的其他序列测定。
仍参考图1,随后显示步骤116,其中对由步骤114产生的多个测序读序进行组合、分析或以计算方式处理以衍生对应于原始模板核酸中的区域的组合序列,所述测序读序与模板样品的一个原始集合中的一个特定模板核酸样品相关。组合方法可通过各种现有dna序列组合工具,如velvet、mira、ssake或allpaths以计算方式完成。如果衍生读序的重新组合并非期望的,那么也可使用各种现有dna序列比对工具,如bwa、bowtie、maq等对衍生读序与核苷酸序列参考物进行比较和/或映射。
图2显示图1中所示的样品标记步骤100的代表性实施例。具体言之,示意性图解显示多个核酸分子202标记有固定数量的样品标记201。模板dna202可由线性或圆形dna模板,例如cdna、扩增子或质粒;或较长dna模板,如基因组dna、线粒体dna、细菌人工染色体(bac)或任何任意的相关dna分子以不同方式组成。在不同实施例中,样品标记步骤可包含所属领域中已知的一组方法中的任一种,通过所述方法,核酸样品经修饰或处理而并入特定聚核苷酸标记序列;聚核苷酸标记序列本身可包含一个或多个衔接子区域,引物结合位点或可鉴别的序列标记,其又通常称作dna条码。
仍参考图2,在一些实施例中,在样品标记步骤期间并入的标记204可由同一已知的寡核苷酸序列或不同寡核苷酸序列组成。此外,标记204可由具有相同或不同长度的寡核苷酸序列组成,其中所述长度可在4到10bp、或8到15bp、或10到20bp范围内。
现参考图3,为了强调本发明的归一化方面,显示较详细的过程图,通过所述方法,具有不同原始浓度的样品得到样品标记和汇集。具体言之,显示样品标记反应的三种情况(301、302、303),其中所描绘的每一样品中所存在的核酸(dna)的量由低(例如1ng/μl)向中等(例如10ng/μl)再向高(100ng/μl)变化。对于三种样品标记反应情况中的每一种,使用相对固定和受限的的样品标记条件以使得每一规定单元质量的核酸的标记数量受到限制。所得经样品标记的样品304、305和306由此具有相似数量的样品标记情况,但仍然具有不同量的核酸分子。多个经标记的dna样品经汇集而形成样品池31010,其中通过方法(如图2的方法)制造的多个可能以不同方式标记的dna样品被合并成一种异质混合物。这一池的重要特征在于尽管其包含与每一样品中的核酸分子的质量大致成比例的不同的来自每一样品的核酸分子的质量,但来自池中所存在的每一样品的样品标记情况的数量为固定和归一化的。图3的过程为图1的样品汇集步骤102的实施例。
现参考图4,显示一个方法的实施例,其中通过池标记步骤对由不同样品产生并经汇集而形成经样品标记的池402为池402的多个经样品标记的核酸分子进行汇集标记(标记为403),以衍生多个核酸分子(404),其样品标记、池标记或这两者的不同情况。由于池标记步骤是在经聚集的样品标记的样品上进行,因此池标记的分布为均一的,并且池标记位点产生在样品标记位点的规定距离内的机率与池中的全部不同样品标记相等。
在各个实施例中,如图3和图4中所描绘的池标记可以趋向于形成较大或较小片段的方式,例如通过滴定用于产生所述片段的碎片化酶的量来进行。所述碎片化酶可包括例如dna核酸外切酶i、或sau3ai核酸内切酶、或dsdna
现参看图5,显示一种如下方法:其中由图4中所描绘的方法产生的片段的库可针对保留一端上的样品标记序列和通过鸟枪衔接子侧接的另一端上的一部分潜在未知的序列的片段得到扩增和富集。
现参考图5,显示一个代表性实施例,其中可用不同池标记处理经样品标记的核酸分子的多个不同池,以便获得大量的样品的可能性构型和池标记组合,使得可对更多样品进行并行测序。
现参考图6,显示对由图5中所示的步骤衍生的多个库片段进行测序的绘图,其中每一库片段由样品标记602和一个或多个池标记600和606以及未知的插入区域604组成。由样品标记和池标记获得序列信息使得未知的插入区域的序列与原始培养盘或集合中的样品相关联和/或指配于所述样品。
以下为本发明方法的某些实施例,其通过实例说明方法对特定dna测序任务的应用。
实例
实例1:本实例说明本发明中的方法对来自96孔培养盘中所含的伯克霍尔德菌菌株的基因组dna(gdna)样品的集合的应用。进行以下实验以制造针对每一伯克霍尔德菌属分离株的高质量gdna序列。使用如下文所述的修饰标记化反应设定对每一gdna样品进行样品标记:
seqidno:1
5'-agacgtgtgctcttccgatctcaacccgaaccgagtctcgtgggctcggagatgtgtataagagacag-3'
seqidno:2:5'-tcgtcggcagcgtcagatgtgtataagagacag-3'
全部96个反应都接受同一通用反向引物(seqidno:2)/用同一通用反向引物(seqidno:2)进行,并且每一反应还接受不同的样品标记正向引物/用不同的样品标记正向引物进行(即,96种特有的样品标记引物之一,其实例显示在seqidno:1中)。使用热循环仪在同一反应中进行标记化和利用pcr的样品标记,所述热循环仪编程如下:
完成pcr后,将来自96孔pcr培养盘的每一孔的10μl经样品标记的pcr产物(样品标记有可鉴别的测序标记)汇集到单一1.5ml微量离心试管(
使用伴随picogreendsdna分析试剂盒
将反应聚集在8孔pcr条管的0.2ml孔中,并用塑料盖加以密封。使用
第二标记化之后,使用池-标记引物对产物进行pcr扩增,其使用以下反应条件:
seqidno:3:5'-caagcagaagacggcatacgagattcgccttagtgact
ggagttcagacgtgtgctcttccgatc-3'
seqidno:4:5'-aatgatacggcgaccaccgagatctacactagatcgc
tcgtcggcagcgtcagatgtgtataagagacag-3'
对于每一pcr反应,我们使用池标记正向引物和索引反向引物(indexreverseprimer)的不同组合。将pcr反应集中在先前用于标记化步骤的相同8孔pcr条管中,并随后循环如下:
扩增之后,随后将样品混合并汇集到一个1.5ml微量离心试管中以形成池。使用制造商所建议的结合和洗涤方案用60μl
随后将经纯化的、经大小选择的集合池稀释10,000倍并使用
读序的解复用:使用定制处理脚本,分析由
产生序列的孔的%的评估:图7显示由测序数据衍生的读序的相对百分率(占总体的%),所述指数可指配于使用所述方法处理的原始培养盘上的96个伯克霍尔德菌属样品中的每一个。
实例2
本实例说明本发明方法供用于由质粒克隆的集合衍生长组合读序的用途,所述质粒克隆衍生自非洲爪蟾属开放阅读框(orf)集合。质粒克隆的十(10)个96孔培养盘处理如下。
使用这些反应设定条件来进行样品鸟枪调适:
使用不同的经样品标记的正向引物(例如seqidno:1)将反应集中于96孔pcr培养盘的每一孔中,但在所有96个反应中相同通用反向引物。随后在如下的热循环仪中使反应保温:
完成热循环后,将来自pcr培养盘的每一孔的10μl经样品标记的pcr产物汇集到单一1.5ml微量离心试管(
使用伴随picogreendsdna分析试剂盒
随后使用以下反应设定条件对所纯化的经样品标记的pcr产物进行第二标记化:
将反应聚集在8孔pcr条管的0.2ml孔中,并用塑料盖加以密封。使用
随后使用以下pcr反应设定条件使用经池标记的引物对第二标记化反应的产物进行扩增:
为了由第二标记化的产物形成十(10)个经池标记的子库,使用来自克隆非洲爪蟾属orf的不同的96孔培养盘的96种经样品标记的dna的池作为模板来设定每一反应,并随后每一反应接受经池标记的正向和反向引物的特有组合以明确地指配每一96孔培养盘的测序读序。将这些十(10)个pcr反应聚集在如用于第二标记化步骤的相同的8孔pcr条管中,并在密封之后,使反应循环如下:
扩增之后,将十(10)个反应(现表示不同的经池标记的子库)汇集到单一1.5ml微量离心试管中以形成单一经池标记的库(即,所汇集的样品的池)。使用制造商所建议的结合和洗涤方案用60μl
将经纯化的、经大小选择的、经池标记的库稀释10,000倍并使用
读序的解复用:使用定制处理脚本,分析由
读序组合:随后使用软件程序
实例3
本实例通过对由96个dna标准物(全部具有相等dna质量)生成的dna测序读序的数量与由同一标准dna的两倍稀释系列产生的读序的数量进行比较来说明本发明的归一化特性。
如picelli等人(《基因组研究(genomeresearch)》15:2033-2040,2014)所述,将极具活性的tn5转座酶的储备浓度纯化为35μm。
制备两个dna标准物的96孔培养盘(2-logdna梯度0.1-10.0kb,newengland
将以下组分添加到每一96孔pcr培养盘的每一孔中以单独地标记每一样品:
seqidno:5:5'-caagcagaagacggcatacgagatactaactggtctcgtgggctcggagatgtgtataagagacag-3'
seqidno:6:5'-磷酸-ctgtctcttatacacatct-3'
用粘性箔密封培养盘之后,通过标记化将序列标记直接添加到样品中。使用
随后,每孔添加2μl的60单位/毫升蛋白酶k溶液
在完成蛋白酶k反应之后,将来自培养盘a(dna对照物)的全部经样品标记的产物汇集于单一微量离心试管中;并且将来自培养盘b(dna稀释系列)的全部经样品标记的产物汇集于分开的微量离心试管中。随后根据作业说明书如下分开纯化来自培养盘a和来自培养盘b的所汇集的经样品标记的产物:将相等体积的magwisetm顺磁纯化珠粒(seqwelltm)添加到每一样品中并在磁性分离之前结合5分钟;随后,用80%乙醇洗涤珠粒两次,并随后再悬浮于10mmtris-hcl,ph8.0中以洗脱所纯化的dna。最后,在保温5分钟以以磁性方式从悬浮液去除珠粒之后,将约30μl的洗脱后的每一dna转移到干净的1.5ml微量离心试管(
在纯化两个经样品标记的产物之后,将全部体积的每一洗脱液(30μl)转移到8孔pcr条管中的单独孔,并添加以下组分以设定第二标记化:
seqidno:7:5'-aatgatacggcgaccaccgagatctacactagatcgctcgtcggcagcgtcagatgtgtataagagacag-3'
seqidno:8:5-磷酸-ctgtctcttatacacatct-3
用粘性箔密封8孔pcr条管之后,将经池标记的反应如下保温于热循环仪中:
随后将12μl终止溶液添加到每一池标记反应中。重新密封之后,使8孔pcr条管返回到热循环仪,并保温如下:
将相等体积的magwisetm顺磁纯化珠粒(seqwelltm)添加到每一样品中,并在磁性分离之前保温5分钟。随后,根据操作说明书用80%乙醇洗涤珠粒两次,并随后再悬浮于10mmtris-hcl中以洗脱所纯化的dna。最后,在保温5分钟以以磁性方式从悬浮液去除珠粒之后,将约30μl的洗脱后的每一dna转移到干净的1.5ml微量离心试管(
如下文所述设定两种衔接子填充反应以延伸标记化之后残留在dna片段上的内嵌式3'-突出端。填充反应集中于8孔pcr条管中。
在密封8孔pcr条管之后,将反应保温于热循环仪中处于72℃下10分钟。随后在衔接子填充之后立即将以下引物直接添加到反应中以使用pcr开始进行库扩增:
seqidno:9:5'-aatgatacggcgaccaccga-3'
seqidno:10:5'-caagcagaagacggcatacga-3'
重新密封8孔pcr条管,随后使其返回到热循环仪以使用以下pcr循环条件进行库扩增:
在pcr扩增之后,使两种库(对应于来自对照物和稀释系列的样品)各与0.75×体积的magwisetm顺磁纯化珠粒(seqwelltm)混合以对每一库进行大小选择,并在磁性分离之前保温5分钟。随后,根据制造商的操作说明书用80%乙醇洗涤珠粒两次,并随后再悬浮于10mmtris-hcl中以洗脱所纯化的dna。最后,在保温5分钟以以磁性方式从悬浮液去除珠粒之后,将约30μl的每一纯化后的库转移到两个干净的1.5ml微量离心试管(
随后将所纯化的、经大小选择的库稀释10,000倍并使用
读序的解复用:使用定制处理脚本,分析由
评定归一化结果:将来自每一经稀释的dna样品的解复用测序读序的数量与由固定量的对照dna(设定为100%)产生的读序的平均数目进行比较。这一分析的输出结果显示在图9中。平均读序数量相对于大于60倍的一系列dna输入质量(2ng到128ng的dna输入)属于窄1.4倍范围内。实例3中的结果突显出可使用本发明方法实现显著归一化作用。
- 还没有人留言评论。精彩留言会获得点赞!