用于检测基因突变的方法和系统与流程
相关申请的交叉引用本申请要求2014年9月26日提交的美国临时申请号62/056,314的根据35u.s.c.§119(e)的权益,出于所有目的将其通过引用全文并入本文。本文提供了基因分析的方法和系统。更具体地,本文提供了使用组织样品检测基因突变的方法和系统。
背景技术:
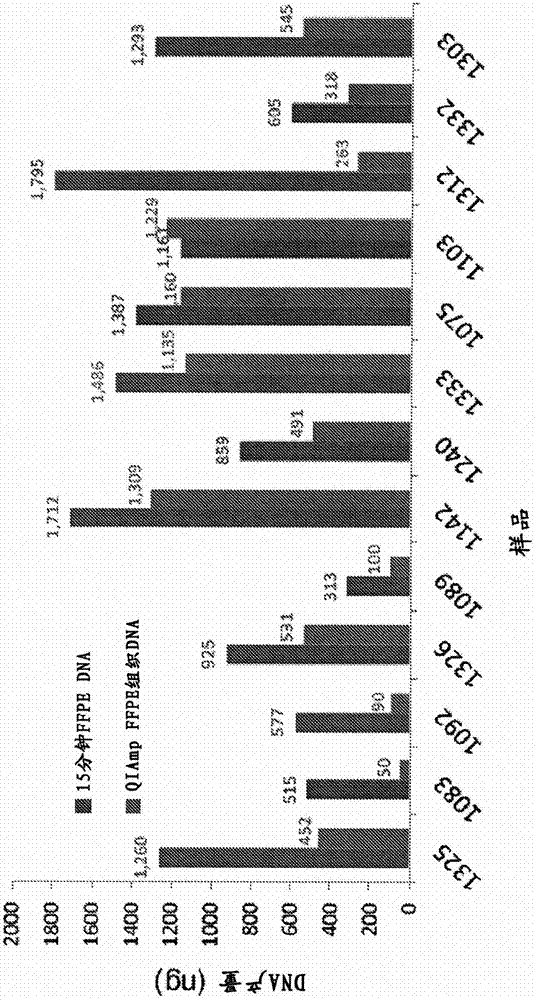
:最近,人类疾病的治疗策略症快速地进入个性化医疗,如对人类癌症的靶向治疗。例如,吉非替尼和埃罗替尼是良好使用的靶向肺癌患者中的egfr突变的受体酪氨酸激酶(rtk)抑制剂。而且,具有eml4-alk融合的肺癌患者对克唑替尼(一种met-alk抑制剂)有响应是已知的。市场上的或研发中的许多抗癌药物是靶向特异性药物。因此,通过使用更快和更稳健的技术加快临床标本的基因分析是非常重要的。福尔马林固定的石蜡包埋(ffpe)组织是临床基因分析中最常用的样品类型。来自ffpe组织的基因组dna高度降解并且具有低质量是已知的。这限制了提取自ffpe组织的基因组dna在临床基因分析中的应用。此外,通过商业可用的方法从ffpe标本提取dna是昂贵和耗时的过程。通常,这些过程涉及有毒化学物质如苯酚或氯仿,其延误了患者样品的稳健性处理。因此,需要开发快速、简单、稳健和节省成本的方法,由ffpe样品制备基因组dna用于基因分析。下一代测序(ngs)的出现已经改变了在许多医学领域和生命科学领域中基因和基因组研究的范例。ngs已经使人类、动物、微生物和农学基因组(agrogenomic)样品的测序应用革命化和最大化。之前的基因技术如桑格测序主要覆盖单个基因的小区域,而ngs测序可以覆盖全外显子组(基因组的所有外显子),甚至覆盖全基因组。ngs应用的全基因组覆盖使得能够拓宽疾病的基因和基因组研究的范围。因为许多人类疾病如癌症主要是由在关键驱动子或主要途径调节因子中的基因改变的累积所导致的,高度期待的是使用ngs会发现新的治疗靶点和诊断标记物。已经有许多鉴定之前未报道的基因改变(例如,突变、多态性、扩增、染色体重排和基因融合)的ngs项目,所述基因改变可以用于人类疾病如癌症的治疗靶点或诊断标记物。虽然全基因组或外显子组测序仍然广泛地用于许多研究,但ngs的趋势目前正快速移向靶向测序。聚焦于小但是重要的基因集或基因区的靶向测序是筛选疾病相关的关键基因的非常有效的方法。目前,用于患者(例如,癌症患者)筛选的大多数ngs应用是通过靶向ngs而不是外显子组或全基因组测序来进行的。成本和实验时间的快速降低和靶向测序的可用性促进了ngs用于许多基因应用的用途。虽然ngs是有前途的并且在许多生命科学应用中变得更加流行,数种因素如复杂的样品制备、高成本和耗时的数据分析阻止其应用在临床和研究环境中更常规地使用。因此,改善当前的方法或开发更快、更稳健和精确的ngs应用的新方法是关键的。此外,在使用ngs中,ngs数据分析也呈现了障碍。因此,需要开发使ngs应用在许多生物领域和临床领域中更普遍和必要的新的、容易的且稳健的ngs数据分析工具。虽然靶向测序在人类疾病的基因测序中正在变得更具优势和更流行,但是数据分析主要由针对全外显子组或基因组测序而开发的程序或算法执行。因此,开发稳健的靶向测序分析工具对于许多靶向测序的应用(例如,癌症诊断、个性化医疗和产前筛选)将是非常重要的。技术实现要素:本文提供了用于确定来自组织样品(例如保存的组织样品)的靶核酸中存在突变(例如于疾病风险相关的突变)的方法和系统。在第一个方面,本文提供了用于从保存的组织样品中提取核酸的方法。所述方法包括以下步骤:a)温育保存的组织样品与组织消化溶液以形成组织消化混合物;b)在80~110℃下加热组织消化混合物1~30分钟;c)将包含蛋白酶(proteinase)的蛋白酶(protease)溶液添加至组织消化混合物中以形成蛋白降解混合物;d)在50~70℃下温育蛋白降解混合物1~30分钟;和e)在80~110℃下温育蛋白降解混合物1~30分钟;由此,从保存的组织样品中提取核酸。在一些实施方式中,组织消化溶液选自i)组织消化溶液,其包含浓度为10mm~140mm的nacl、浓度为0.5mm~10mm的na2hpo4、浓度为0.1mm~5mm的kh2po4以及吐温20;ii)组织消化溶液,其包含浓度为10mm~140mm的nacl、浓度为0.5mm~10mm的na2hpo4、浓度为0.1mm~5mm的kh2po4以及triton-x100;iii)组织消化溶液,其包含浓度为10mm~140mm的nacl、浓度为0.5mm~10mm的na2hpo4以及浓度为0.1mm~5mm的kh2po4;iv)组织消化溶液,其包含浓度为0.5mm~25mm的taps钠盐、浓度为0.05mm~5mm的dtt以及浓度为0.2mm~200mm的kcl;v)组织消化溶液,其包含浓度为1mm~100mm的hepes缓冲液;vi)组织消化溶液,其包含浓度为1mm~100mm的hepes缓冲液以及triton-x100;vii)组织消化溶液,其包含浓度为1mm~100mm的hepes缓冲液以及吐温20;viii)组织消化溶液,其包含浓度为0.5mm~25mm的taps钠盐、浓度为0.05mm~5mm的dtt、浓度为0.2mm~200mm的kcl以及triton-x100;ix)组织消化溶液,其包含浓度为0.5mm~25mm的taps钠盐、浓度为0.05mm~5mm的dtt、浓度为0.2mm~200mm的kcl以及吐温20;和x)组织消化溶液,其包含浓度为0.5mm~25mm的taps钠盐、浓度为0.2mm~200mm的kcl、浓度为0.1mm~1mm的β-巯基乙醇以及tritonx-100。在某些实施方式中,蛋白酶溶液选自由以下组成的组:a)蛋白酶溶液,其包含浓度为5mg/ml~60mg/ml的蛋白酶k、浓度为1mm~50mm的tris-hcl以及浓度为0.1~10mm的edta;b)蛋白酶溶液,其包含浓度为5mg/ml~60mg/ml的蛋白酶k;c)蛋白酶溶液,其包含浓度为5mg/ml~60mg/ml的蛋白酶k以及浓度为1mm~50mm的tris-hcl;d)蛋白酶溶液,其包含浓度为5mg/ml~60mg/ml的蛋白酶k以及浓度为0.1mm~10mm的edta;e)蛋白酶溶液,其包含浓度为5mg/ml~60mg/ml的蛋白酶k、浓度为0.2mm~50mm的tris-hcl、浓度为0.1mm~10mm的cacl2以及浓度为20%~70%的甘油。在一些实施方式中,加热(b)是在99℃下进行5~30分钟。在某些实施方式中,温育蛋白降解混合物(c)是在60℃下进行5~30分钟。在一些实施方式中,温育蛋白降解混合物(d)是在99℃下进行5~30分钟。在另一个方面,本文提供了由组织样品制备靶核酸扩增子文库的方法,所述方法包括以下步骤:a)扩增从组织样品中提取的核酸,扩增步骤使用靶向感兴趣的核酸的5’磷酸化寡核苷酸;和b)将包括衔接头核酸和条形码核酸的寡核苷酸直接连接于每种扩增的靶核酸,由此制备靶核酸扩增子文库。在某些实施方式中,所述方法进一步包括在直接连接寡核苷酸(b)之前纯化扩增的靶核酸(a)的步骤。在另一个方面,本文提供了检测组织样品靶核酸序列中的突变而无需预处理序列数据的方法,所述方法包括以下步骤:(a)获得组织样品靶核酸序列数据和数据库靶核酸序列数据,其中所述数据库靶核酸序列数据位于突变数据库中;(b)比较组织样品靶核酸序列数据与数据库靶核酸序列数据以确定样品靶核酸序列数据是否含有来自突变数据库的登记的突变;(c)通过确定突变数据库中登记的突变的突变等位基因频率来确定突变数据库中登记的突变的可靠性;以及(d)生成关于组织样品靶核酸序列数据是否含有突变的结果,由此检测突变。在另一个方面,本文提供了包括以下的计算系统:一个或多个处理器;存储器;以及一个或多个程序。计算系统的一个或多个程序存储于存储器中,并且被配置为通过用于检测组织样品靶核酸序列中的突变的一个或多个处理器来执行。所述一个或多个程序包括检测组织样品靶核酸序列中的突变的指令,所述指令包括:(a)获得组织样品靶核酸序列数据和数据库靶核酸序列数据,其中所述数据库靶核酸序列数据位于突变数据库中;(b)比较组织样品靶核酸序列数据与数据库靶核酸序列数据以确定样品靶核酸序列数据是否含有来自突变数据库的登记的突变;(c)通过确定突变数据库中登记的突变的突变等位基因频率来确定突变数据库中登记的突变的可靠性;和(d)生成关于组织样品靶核酸序列数据是否含有突变的结果,由此检测突变。在另一个方面,本文提供了用于检测来自保存的组织样品的核酸是否具有突变的方法,所述方法包括以下步骤:a)温育保存的组织样品与组织消化溶液以形成组织消化混合物;b)在80~110℃下加热组织消化混合物1~30分钟;c)将包含蛋白酶(proteinase)的蛋白酶(protease)溶液添加至组织消化混合物中以形成蛋白降解混合物;d)在37~70℃下温育蛋白降解混合物1~30分钟;e)在80~110℃下温育蛋白降解混合物1~30分钟;由此,从保存的组织样品中提取核酸;f)扩增从组织样品中提取的核酸,扩增步骤使用靶向感兴趣的核酸的5’磷酸化寡核苷酸;g)将包括衔接头核酸和条形码核酸的寡核苷酸直接连接于每种扩增的靶核酸,由此制备包含组织样品靶核酸的靶向的核酸扩增子文库;h)对文库测序;i)获得组织样品靶核酸序列数据和数据库靶核酸序列数据,其中所述数据库靶核酸序列数据位于突变数据库中;j)比较组织样品靶核酸序列数据与数据库靶核酸序列数据以确定样品靶核酸序列数据是否含有来自突变数据库的登记的突变;k)通过确定突变数据库中登记的突变的突变等位基因频率来确定突变数据库中登记的突变的可靠性;以及1)生成关于组织样品靶核酸序列数据是否含有突变的结果,由此检测突变。在一些实施方式中,组织消化溶液选自i)组织消化溶液,其包含浓度为10mm~140mm的nacl、浓度为0.5mm~10mm的na2hpo4、浓度为0.1mm~5mm的kh2po4以及吐温20;ii)组织消化溶液,其包含浓度为10mm~140mm的nacl、浓度为0.5mm~10mm的na2hpo4、浓度为0.1mm~5mm的kh2po4以及triton-x100;iii)组织消化溶液,其包含浓度为10mm~140mm的nacl、浓度为0.5mm~10mm的na2hpo4以及浓度为0.1mm~5mm的kh2po4;iv)组织消化溶液,其包含浓度为0.5mm~25mm的taps钠盐、浓度为0.05mm~5mm的dtt以及浓度为0.2mm~200mm的kcl;v)组织消化溶液,其包含浓度为1mm~100mm的hepes缓冲液;vi)组织消化溶液,其包含浓度为1mm~100mm的hepes缓冲液以及triton-x100;vii)组织消化溶液,其包含浓度为1mm~100mm的hepes缓冲液以及吐温20;viii)组织消化溶液,其包含浓度为0.5mm~25mm的taps钠盐、浓度为0.05mm~5mm的dtt、浓度为0.2mm~200mm的kcl以及triton-x100;ix)组织消化溶液,其包含浓度为0.5mm~25mm的taps钠盐、浓度为0.05mm~5mm的dtt、浓度为0.2mm~200mm的kcl以及吐温20;和x)组织消化溶液,其包含浓度为0.5mm~25mm的taps钠盐、浓度为0.2mm~200mm的kcl、浓度为0.1mm~1mm的β-巯基乙醇以及tritonx-100。附图说明图1显示了本文提供的核酸提取步骤的工作流程。该方法使得以快速、有效和节省成本的方式由ffpe组织制备基因组dna。一些其他核酸提取方法不同,本文描述的方法不涉及柱也不涉及有毒化学物质。对于整个过程仅需要加热块(heatblock)或常规热循环仪(pcr仪)。提取的dna不需要进一步的纯化或步骤,并且准备好进行之后的实验或基因分析(即pcr、qpcr、桑格测序、ngs等)。图2a和图2b显示了与qiagendnaffpe组织试剂盒(picogreen定量)相比,本文提供的核酸提取方法(“15分钟ffpedna”方法)产生更高量的基因组dna。来自13名肺腺癌患者的一种ffpe载玻片切片(5μm厚)用于dna提取。通过方法对2μl分离的dna一式三份地定量,用于比较通过15分钟ffpedna方法和qiagendnaffpe组织试剂盒制备的dna的产量。红色柱表示来自15分钟ffpedna方法的基因组dna的产量,蓝色柱表示dnaffpe组织试剂盒的基因组dna的产量(a)。与dnaffpe组织试剂盒相比,15分钟ffpedna试剂盒方法产生了更高量的基因组dna(平均值-提高至3.19倍,中值-提高至2.13倍)(b)。图3显示了对主题核酸提取方法(“15分钟ffpedna”方法)和dnaffpe组织试剂盒的实时定量pcr(qpcr)数据比较。使用等量的ffpe组织分离基因组dna,并且以相同的体积洗脱。来自肺腺癌ffpe样品的2μl分离的dna(图2a中所示的)用于qpcr分析(qpcr探针-rna酶偏好基因)。通过15分钟ffpedna方法获得的ct(循环阈值)为21~24个循环,而获得自dnaffpe组织试剂盒的ct为27~29个循环。这显示了在qpcr分析中,来自15分钟ffpedna方法的dna更有效地扩增。该结果显示了主题核酸提取方法对以非常低量的组织或少量的细胞检测(challenging)生物标本会是更适当和理想的。图4显示了主题直接扩增和连接(次日测序(nextdayseq))扩增子样品文库制备的工作流程。使用5’磷酸化寡核苷酸扩增10ngdna并纯化。将条形码和通用衔接头直接连接于5’磷酸化寡核苷酸末端。最终纯化步骤提供了准备好用于模板制备和测序的靶向的扩增子文库。扩增子文库制备需要约2.5小时。图5a和图5b显示完整的“次日测序”过程的流程图。其显示了完整的“次日测序”流程,包括:ffpedna提取、用5’磷酸化探针制备样品文库以及最终的测序和数据分析。从dna提取到最终数据分析的完整过程在36小时内进行。请注意,第一个dna提取步骤用主题核酸提取方法(“15分钟ffpedna”方法)进行,最后的数据分析步骤通过用于检测如本文提供的靶核酸中的突变的主题方法(“danpa”)进行。图6显示了用于检测靶核酸(数据库关联的无预处理分析(danpa))中的突变以从ngs测序数据筛选体细胞突变的主题方法的通用工作流程。该图显示了用于从ngs数据检测体细胞突变的danap的通用工作流程。danpa跳过了几乎所有已知的ngs预处理/处理后步骤(未绘制的序列重排、重复删除(dedupping)、插入缺失重排(indelrealignment)、碱基质量评分复校、变体评分复校和功能性注释),但是通过直接搜索突变数据库中的靶序列检测突变。一旦靶序列(即癌症患者dna序列)在突变数据库中匹配,danpa考虑数据库中登记的突变的稳定性(即报告的时间和同聚物区)和从总读数中检查突变等位基因频率(突变等位基因频率的计算)。在用>300的覆盖深度(coverage-depth)进行靶向测序的情况下,具有3%突变等位基因频率的体细胞突变可以稳健地被danpa检测到。图7显示了danpa工作流程的详细算法。该工作流程显示了danpa如何比较患者(或靶dna)的序列和指定的数据库(例如cosmic)中的登记的突变。如果患者的序列与任何登记的突变匹配,danpa计算等位基因频率(突变读数/总读数)并检查突变呼叫(mutationcall)的统计学显著性。通常对靶向测序面板的所有扩增子重复该步骤,无论突变的类型或复杂性,danpa都提供了快速和可靠的体细胞突变数据。图8显示了用于肺癌患者的体细胞突变检测的danpa和激流套件(torrentsuite)之间的比较。显示了两名肺癌患者的体细胞突变分析结果。(a)虽然通过两种方法都检测到两个点突变(以红色显示的pdgfra和egfr),但是egfr基因的缺失突变仅通过danpa检测到(蓝色)。在60名肺癌患者的筛选中,通过激流套件没有检测到单个缺失或插入突变,而通过danpa检测到所有突变。注意,通过激流套件检测到了假阳性(fp)呼叫。(b)虽然通过danpa和激流套件两者均检测到四个点突变时(以红色显示),但仅通过danpa检测到具有低等位基因频率(约3%)的一个突变(kit),而通过激流套件则未能检测到。图9是用于检测靶核酸序列中的突变的电子网络的方框图。图10是根据一些实施方式的图9中所示的主题设备存储器的方框图。图11是根据一些实施方式的用于检测靶核酸序列中的突变的方法的流程图。具体实施方式本文提供了用于检测组织样品(例如,保存的组织样品)中的基因突变的方法和系统。在一些实施方式,所述方法包括以下步骤:a)从保存的组织样品中提取核酸;b)由提取的核酸制备靶向的核酸扩增子文库;c)对靶核酸扩增子文库测序以产生组织样品靶核酸序列数据;和d)确定靶核酸序列数据是否含有突变(例如,与特定疾病的风险有关的突变)。本文描述的方法可以有利地从提取a)到确定d)在少于48小时内进行。在某些实施方式中,所述方法可以在少于45、44、43、42、41、40、39、38、37、36、35、34、33、32、31、30、29、28、27、26或25小时内进行。在某些实施方式中,所述方法可以在少于36小时内进行。以下详细地讨论本文提供的方法和系统的方面。核酸提取在第一个方面,本文提供了用于从组织样品中提取核酸的方法。在某些实施方式中,所述方法包括以下步骤:(a)温育组织样品与组织消化溶液以形成组织消化混合物;(b)在80~110℃下加热组织消化混合物1~30分钟;(c)将包含蛋白酶的蛋白酶溶液添加至组织消化混合物中以形成蛋白降解混合物并在50~70℃下温育蛋白降解混合物1~30分钟;和(d)在80~110℃下温育蛋白降解混合物1~30分钟;由此,从保存的组织样品中提取核酸。本文提供的核酸提取方法提供了从组织样品中提取核酸的快速和有效的方法。在一些实施方式中,核酸是脱氧核糖核酸(dna)。在其他实施方式中,核酸是核糖核酸(rna)。在一些实施方式中,dna是基因组dna。在其他实施方式中,dna是线粒体dna。根据主题方法,可以使用的组织样品包括但不限于结缔组织、肌肉组织(例如,平滑肌、骨骼肌和心肌)、神经组织和上皮组织(例如,鳞状上皮、立方上皮、柱状上皮、腺上皮和纤毛上皮)。根据主题方法,可以使用的组织样品包括冷冻组织样品或新鲜组织样品。在某些实施方式中,样品是保存的组织样品。如本文使用的“保存的组织样品”是分离自受试者的组织样品,该组织样品经过了用于保存样品的组织和/或大分子(例如,核酸如dna和rna)的完整性的一种或多种过程。用于组织保存的技术包括但不限于福尔马林固定和深度冷冻。在一些实施方式中,保存的组织样品是福尔马林固定的石蜡包埋(ffpe)组织样品。在与主题方法使用之前可以使用任意适合的技术将ffpe组织样品脱石蜡,所述适合的技术例如使用二甲苯或溶解石蜡的有机溶剂的技术(见例如美国专利号6,632,598和8,574,868)。在某些实施方式中,在组织消化溶液中温育(a)之前使保存的组织样品脱石蜡。在具体实施方式中,在组织消化溶液中温育(a)之前在二甲苯中使保存的组织样品脱石蜡。在一些实施方式中,保存的组织样品是1μm、2μm、3μm、4μm、5μm、6μm、7μm、8μm、9μm、10μm厚的ffpe。在某些实施方式中,核酸提取方法可以在90分钟或更少、60分钟或更少、55分钟或更少、50分钟或更少、45分钟或更少、40分钟或更少、35分钟或更少、30分钟或更少、25分钟或更少、20分钟或更少、15分钟或更少、14分钟或更少、13分钟或更少、12分钟或更少、11分钟或更少、10分钟或更少、9分钟或更少、8分钟或更少、7分钟或更少、6分钟或更少或5分钟或更少内进行。在某些实施方式中,核酸提取方法可以在15分钟或更少内进行。在某些实施方式中,本文提供的核酸提取方法包括第一步:温育保存的组织样品与组织消化溶液以形成组织消化混合物。组织消化溶液包括盐和/或清洁剂。可以在主题核酸提取方法中使用的盐包括但不限于nacl、na2hpo4、kh2po4、kcl和taps钠盐。在某些实施方式中,消化溶液包括浓度为10mm~140mm的nacl。在某些实施方式中,消化溶液包括浓度为0.5mm~10mm的na2hpo4。在一些实施方式中,消化溶液包括浓度为0.1mm~5mm的kh2po4。在一些实施方式中,消化溶液包括浓度为0.2mm~200mm的kcl。在某些实施方式中,消化溶液包括浓度为0.5mm~25mm的taps钠盐。在某些实施方式中,组织消化溶液包括清洁剂。任何适当的清洁剂可以用于组织消化溶液中。可以使用的示例性清洁剂包括但不限于triton-x100和吐温20。在某些实施方式中,组织消化溶液包含浓度为10mm~140mm的nacl、浓度为0.5mm~10mm的na2hpo4、浓度为0.1mm~5mm的kh2po4和吐温20。在一些实施方式中,组织消化溶液包含浓度为10mm~140mm的nacl、浓度为0.5mm~10mm的na2hpo4、浓度为0.1mm~5mm的kh2po4和triton-x100。在一些实施方式中,组织消化溶液包含浓度为10mm~140mm的nacl、浓度为0.5mm~10mm的na2hpo4和浓度为0.1mm~5mm的kh2po4。在一些实施方式中,组织消化溶液包含浓度为0.5mm~25mm的taps钠盐、浓度为0.05mm~5mm的dtt和浓度为0.2mm~200mm的kcl。在其他实施方式中,组织消化溶液包含浓度为1mm~100mm的hepes缓冲液。在一些实施方式中,组织消化溶液包含浓度为1mm~100mm的hepes缓冲液和triton-x100。在其他实施方式中,组织消化溶液包含浓度为1mm~100mm的hepes缓冲液和吐温20。在其他实施方式中,组织消化溶液包含浓度为0.5mm~25mm的taps钠盐、浓度为0.05mm~5mm的dtt、浓度为0.2mm~200mm的kcl和triton-x100。在其他实施方式中,组织消化溶液包含浓度为0.5mm~25mm的taps钠盐、浓度为0.05mm~5mm的dtt、浓度为0.2mm~200mm的kcl和吐温20。在又其他实施方式中,组织消化溶液包含浓度为0.5mm~25mm的taps钠盐、浓度为0.2mm~200mm的kcl、浓度为0.1mm~1mm的β-巯基乙醇和triton-x100。在某些实施方式中,在促进组织样品消化的最佳的温度和最佳的时间量下温育组织消化混合物。在某些实施方式中,组织消化混合物在60℃、65℃、70℃、75℃、80℃、85℃、90℃、95℃、100℃、105℃、110℃、115℃或120℃的温度下温育。在一些实施方式中,组织消化混合物在60℃~65℃、65℃~70℃、70℃~75℃、75℃~80℃、80℃~85℃、85℃~90℃、90℃~95℃、95℃~100℃、100℃~105℃、105℃~110℃、110℃~115℃或115℃~120℃的温度下温育。在一些实施方式中,组织消化混合物在60℃~80℃、65℃~85℃、70℃~90℃、75℃~85℃、80℃~90℃、85℃~95℃、90℃~100℃、95℃~105℃、100℃~110℃、105℃~115℃或110℃~120℃的温度下温育。在某些实施方式中,组织消化混合物在60℃~90℃、70℃~100℃、80℃~110℃或90℃~120℃的温度下温育。在某些实施方式中,组织消化混合物在80℃~110℃的温度下温育。在某些实施方式中,组织消化混合物在90℃、91℃、92℃、93℃、94℃、95℃、96℃、97℃、98℃、99℃、100℃、101℃、102℃、103℃、104℃、105℃、106℃、107℃、108℃、109℃、110℃下温育。在具体的实施方式中,组织消化混合物在99℃下温育。在一些实施方式中,组织消化混合物温育0.5、1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、20、25、30、45或60分钟。在某些实施方式中,组织消化混合物温育1~3、2~4、3~5、4~6、5~7、6~8、7~9或8~10分钟。在某些实施方式中,组织消化混合物温育1~10分钟、5~15分钟、10~20分钟、15~25分钟、20~30分钟、35~45分钟、40~50分钟、45~55分钟或50~60分钟。在具体的实施方式中,组织消化混合物温育5分钟。在一些实施方式中,组织消化混合物在80℃~110℃下温育1~30分钟。在一些实施方式中,组织消化混合物在95℃~105℃下温育4~6分钟。在某些实施方式中,组织消化混合物在99℃下温育5分钟。温育组织消化混合物后,将含有蛋白酶的蛋白酶溶液添加至组织消化混合物以形成蛋白降解混合物。在促进蛋白降解的预定的时间和温度下温育蛋白降解混合物。主题核酸提取方法的蛋白酶溶液中可以包括帮助消化蛋白的任意蛋白酶。可以使用的示例性蛋白酶包括但不限于丝氨酸蛋白酶、苏氨酸蛋白酶、半胱氨酸蛋白酶、天冬氨酸蛋白酶、谷氨酸蛋白酶、金属蛋白酶或其组合。在某些实施方式中,蛋白酶溶液包括丝氨酸蛋白酶。丝氨酸蛋白酶是切割蛋白中的肽键的酶,其中丝氨酸充当酶活性位点的亲核氨基酸。丝氨酸蛋白酶包括例如胰蛋白酶样蛋白酶、胰凝乳蛋白酶样蛋白酶、弹性蛋白酶样蛋白酶和枯草杆菌蛋白酶样蛋白酶。示例性丝氨酸蛋白酶包括但不限于胰凝乳蛋白酶a、二肽酶e、枯草杆菌蛋白酶、核孔蛋白、乳铁蛋白、菱形蛋白1(rhomboid1)和蛋白酶k。在一些实施方式中,丝氨酸蛋白酶是蛋白酶k。蛋白酶k的主要切割位点是与具有封闭的α-氨基基团的脂肪族氨基酸和芳香族氨基酸的羧基相邻的肽键。在某些实施方式中,蛋白酶k以1~100mg/ml、2~90mg/ml、3~80mg/ml、4~70mg/ml或5~60mg/ml的浓度存在于蛋白酶溶液中。在具体的实施方式中,蛋白酶k以5~60mg/ml的浓度存在于蛋白酶溶液中。在某些实施方式中,蛋白酶溶液进一步包括缓冲液(例如,tris-hcl)和/或蛋白变性剂(例如,edta、urea或sds)。在一些实施方式中,蛋白酶溶液包括浓度为5mg/ml~60mg/ml的蛋白酶k、浓度为1mm~50mm的tris-hcl和浓度为0.1~10mm的edta。在一些实施方式中,蛋白酶包括浓度为5mg/ml~60mg/ml的蛋白酶k和浓度为1mm~50mm的tris-hcl。在某些实施方式中,蛋白酶包括浓度为5mg/ml~60mg/ml的蛋白酶k和浓度为0.1mm~10mm的edta。在某些实施方式中,tris-hcl的ph为8.0。在某些实施方式中,蛋白降解混合物在30℃、35℃、40℃、45℃、50℃、55℃、60℃、65℃、70℃、75℃、80℃、85℃或90℃下温育。在一些实施方式中,蛋白降解混合物在30℃~90℃、40℃~80℃或50℃~70℃的温度下温育。在一些实施方式中,蛋白降解混合物在30℃~35℃、35℃~40℃、45℃~50℃、55℃~60℃、60℃~65℃、65℃~70℃、70℃~75℃、75℃~80℃、80℃~85℃或85℃~90℃下温育。在具体的实施方式中,蛋白降解混合物在50℃~70℃下温育。在某些实施方式中,蛋白降解混合物在60℃下温育。在一些实施方式中,蛋白降解混合物温育至少0.5、1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、20、25、30、45或60分钟。在某些实施方式中,蛋白降解混合物温育1~3、2~4、3~5、4~6、5~7、6~8、7~9或8~10分钟。在某些实施方式中,蛋白降解混合物温育1~10分钟、5~15分钟、10~20分钟、15~25分钟、20~30分钟、35~45分钟、40~50分钟、45~55分钟或50~60分钟。在具体的实施方式中,蛋白降解混合物温育5分钟。在某些实施方式中,蛋白降解混合物在50℃~70℃下温育1~10分钟。在某些实施方式中,蛋白降解混合物在60℃下温育5分钟。在促进蛋白降解的温度下温育蛋白降解混合物后,将蛋白降解混合物加热以灭活蛋白降解混合物中的蛋白酶,由此从保存的组织样品中提取核酸。在某些实施方式中,将蛋白降解混合物加热到60℃、65℃、70℃、75℃、80℃、85℃、90℃、95℃、100℃、105℃、110℃、115℃或120℃的温度以灭活蛋白酶。在一些实施方式中,将蛋白降解混合物加热到60℃~65℃、65℃~70℃、70℃~75℃、75℃~80℃、80℃~85℃、85℃~90℃、90℃~95℃、95℃~100℃、100℃~105℃、105℃~110℃、110℃~115℃或115℃~120℃的温度以灭活蛋白酶。在一些实施方式中,将蛋白降解混合物加热到60℃~80℃、65℃~85℃、70℃~90℃、75℃~85℃、80℃~90℃、85℃~95℃、90℃~100℃、95℃~105℃、100℃~110℃、105℃~115℃或110℃~120℃的温度以灭活蛋白酶。在某些实施方式中,将蛋白降解混合物加热到60℃~90℃、70℃~100℃、80℃~110℃或90℃~120℃的温度以灭活蛋白酶。在某些实施方式中,将蛋白降解混合物加热到80℃~110℃的温度以灭活蛋白酶。在某些实施方式中,将蛋白降解混合物加热到90℃、91℃、92℃、93℃、94℃、95℃、96℃、97℃、98℃、99℃、100℃、101℃、102℃、103℃、104℃、105℃、106℃、107℃、108℃、109℃、110℃的温度以灭活蛋白酶。在具体的实施方式中,将蛋白降解混合物加热到99℃的温度。在一些实施方式中,蛋白降解混合物温育1、2、3、4、5、6、7、8、9或10分钟。在一些实施方式中,蛋白降解混合物温育1~10分钟、5~15分钟或10-20分钟。在具体的实施方式中,蛋白降解混合物温育1~10分钟。在某些实施方式中,蛋白降解混合物温育5分钟。在某些实施方式中,蛋白降解混合物在80℃~110℃下温育5分钟。在具体的实施方式中,蛋白降解混合物在99℃下温育5分钟。在加热蛋白降解混合物以使蛋白酶变性并提取核酸后,提取的核酸可以直接从蛋白降解混合物使用,或可以进一步通过本领域已知的任何适当的方法分离和纯化,例如,通过离心或沉淀(例如,乙醇沉淀)方法。使用主题方法提取的核酸可以用于各种应用。在某些实施方式中,提取的核酸是可以直接用于(即蛋白酶变性后无需进一步纯化)聚合酶链式反应(pcr)扩增的dna。尤其,使用主题方法制备的dna可以有利地用于生产大于900bp的pcr扩增子。在一些实施方式中,本文提供的主题核酸提取方法产生可以产生大于900bp的pcr扩增子的dna。可以使用这样的大pcr扩增子,例如,生成扩增子文库,如下文所描述的。靶核酸扩增子文库在另一个方面,本文提供了用于制备靶向的核酸扩增子文库的方法。如本文使用的,“靶向的核酸扩增子文库”是指含有一种或多种已经由样品扩增的靶核酸(例如来自使用主题提取方法从组织中提取的核酸)的多种核酸,并且其可以用于测序(例如,高通量测序如下一代测序(ngs))。在一些实施方式中,靶核酸含有与疾病(例如癌症)风险相关的一个或多个突变基因座。在一些实施方式中,所述方法包括(a)使用靶向感兴趣的核酸(例如,包括一个或多个与疾病如癌症的风险有关的突变基因座的核酸)的寡核苷酸引物对扩增从组织样品中提取的核酸,以产生靶向的核酸扩增子和(b)将包括衔接头核酸和/或条形码核酸的寡核苷酸直接连接至每种靶向的核酸扩增子来制备靶向的核酸扩增子文库。本文描述的主题靶向的核酸扩增子文库方法有利地提供了用于靶向的核酸扩增子文库构建的快速方法。具体地,主题靶核酸扩增子文库可以由从组织样品中提取的核酸在少于4小时内、少于3.5小时内、少于3小时内、少于2.5小时内或少于2小时内构建。在某些实施方式中,靶核酸扩增子文库可以在少于2.5小时内制备。在一些实施方式中,所述方法包括第一步:使用靶向感兴趣的核酸的寡核苷酸引物对扩增从组织样品中提取的核酸来产生靶核酸扩增子。可以使用任何适当的技术从组织样品中提取核酸,所述技术包括但不限于sds-蛋白酶k、酚-氯仿、盐析、基于色谱的技术、基于磁珠的技术、基于树状分子的技术或基质研磨器核酸提取技术。在某些实施方式中,使用本文描述的主题核酸提取方法从组织样品中提取核酸。可以靶向任意靶核酸来用于本文描述的主题靶核酸扩增子文库生产方法。在一些实施方式中,靶核酸大于50bp、大于100bp、大于150bp、大于200bp、大于250bp、大于300bp、大于350bp、大于400bp、大于450bp、大于500bp、大于550bp、大于600bp、大于650bp、大于700bp、大于750bp、大于800bp、大于850bp、大于900bp、大于950bp或大于1000bp的长度。在一些实施方式中,扩增(a)包括扩增1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、150、200、250、300、350、400、450、500、550、600、650、700、750、800、850、900、950、1000、2000、3000、4000、5000或更多种感兴趣的靶核酸。在某些实施方式中,感兴趣的靶核酸包括与疾病风险相关的一个或多个基因座。在一些实施方式中,靶核酸包括与癌症风险相关的一个或多个基因座。癌症靶核酸包括但不限于与膀胱癌、脑癌、乳腺癌、结肠癌、肝癌、卵巢癌、肾(kidney)癌、肺癌、肾(renal)癌、结肠直肠癌、胰腺癌和前列腺癌,以及血液的癌症(例如,白血病)相关的靶核酸。在某些实施方式中,靶核酸是肺癌、结肠直肠癌和/或泛癌(即多种癌症的集合或组合)的靶核酸。靶核酸可能包括与一个或多个基因座相关的但不限于以下疾病:软骨发育不全,肾上腺脑白质营养不良,x连锁性无丙种球蛋白血症,x连锁性阿拉吉耶(alagille)综合征,α-地中海贫血x连锁性精神发育迟缓综合征,阿尔茨海默病,阿尔茨海默病,早发家族性肌萎缩性侧索硬化症(early-onsetfamilial,amyotrophiclateralsclerosisoverview),雄性激素不敏感综合征,安格曼(angelman)综合征,共济失调症(ataxiaoverview),遗传性共济失调-毛细血管扩张症,贝克肌营养不良(beckermusculardystrophy)(也称为肌营养不良症),贝威二氏综合征(beckwith-wiedemannsyndrome),β-地中海贫血,生物素酶缺乏症,腮耳肾综合征,brca1和brca2遗传性cadasil,卡纳万病(canavandisease),癌症,腓骨肌萎缩性遗传性神经病(charcot-marie-toothhereditaryneuropathy),1型腓骨肌萎缩性神经病(charcot-marie-toothneuropathytype1)、2型腓骨肌萎缩性神经病(charcot-marie-toothneuropathytype2),4型腓骨肌萎缩性神经病(charcot-marie-toothneuropathytype4),x型腓骨肌萎缩性神经病(charcot-marie-toothneuropathytypex)、科凯恩综合征(cockaynesyndrome),挛缩性蜘蛛指(趾)综合征、先天性颅缝早闭综合征(fgfr相关的),囊性纤维化,胱氨酸病,耳聋和遗传性听力损失,drpla(齿状核红核苍白球丘脑下部核萎缩),戴乔治综合征(digeorgesyndrome)(也称为22q11缺失综合征),扩张型心肌病,x连锁性唐氏综合征(21三体),杜氏肌营养不良(也称为肌营养不良症),肌张力障碍,早发性原发(dyt1)肌营养不良症,ehlers-danlos综合征,kyphoscoliotic形式,埃-当综合征(ehlers-danlossyndrome),血管型单纯大疱性表皮松解(vasculartype,epidermolysisbullosasimplex),外生骨疣,遗传性多发性面肩胛肱型肌营养不良症(hereditarymultiple,facioscapulohumeralmusculardystrophy),莱登第五因子易栓症(factorvleidenthrombophilia),家族性腺瘤性息肉病(fap),家族性地中海热,脆性x综合征,弗里德赖希共济失调(friedreichataxia),额颞叶痴呆伴随帕金森综合征-17,半乳糖血症,戈谢病(gaucherdisease),血色素沉着症,遗传性血友病a,血友病b,出血性微血管扩张症,遗传性听力损失和耳聋,非综合征性dfna(连接蛋白26),听力损失和耳聋,非综合征性dfnb1(连接蛋白26),遗传性痉挛性截瘫,赫曼斯基-普德拉克综合征(hermansky-pudlaksyndrome),六氨基酸a缺乏症(也称为家族黑蒙性白痴病(tay-sachs)),亨廷顿病,软骨发育不良,鱼鳞病,先天性常染色体隐性遗传性色素沉着症,肯尼迪病(也称为脊髓和延髓肌肉萎缩),克拉伯病,莱伯遗传性视神经病,莱斯特-尼汉综合征白血病,李弗莱门综合征(li-fraumenisyndrome),肢带型肌营养不良症,脂蛋白脂肪酶缺乏症,家族性无脑回马凡综合征,melas(线粒体性脑肌病,乳酸性酸中毒和中风样发作),单体性2型多发性内分泌肿瘤,多发性外生骨疣,遗传性肌营养不良,先天性肌强直性营养不良,肾源性尿崩症,神经纤维瘤病1,神经纤维瘤病2,神经病变伴随压力麻痹倾向,遗传性c型尼曼氏病(niemann-pickdiseasetypec),奈梅根破裂综合征诺里病(nijmegenbreakagesyndromenorriedisease),1型眼皮肤白化病,眼咽肌营养不良,帕利斯特霍尔综合征(pallister-hallsyndrome),帕金型青少年帕金森病,佩利措伊斯梅茨巴赫病(pelizaeus-merzbacherdisease),彭德莱综合征(pendredsyndrome),黑斑息肉综合征(peutz-jegherssyndrome)苯丙氨酸羟化酶缺乏,普瑞德威利综合征(prader-willisyndrome),prop1相关的垂体激素缺乏症(combinedpituitaryhormonedeficiency,cphd),色素性视网膜炎,视网膜母细胞瘤,罗斯曼-汤姆森综合征(rothmund-thomsonsyndrome),史密斯-莱姆-奥维茨综合征(smith-lemli-opitzsyndrome),痉挛性截瘫,遗传性脊髓和延髓肌萎缩(也称为肯尼迪病),脊髓性肌萎缩,1型脊髓小脑共济失调,2型脊髓小脑共济失调,3型脊髓小脑共济失调,6型脊髓小脑共济失调,7型脊髓小脑性共济失调,粘液综合征(sticklersyndrome)(遗传性关节与眼病(hereditaryarthroophthalmopathy)),家族黑蒙性白痴病(tay-sachs)(也称gm2神经节苷脂沉积症),三体结节性硬化综合征,i型尤赛氏综合征(ushersyndrometypei),ii型尤赛氏综合征,软腭心面综合征(velocardiofacialsyndrome)(也称为22q11缺失综合征),冯希伯-佩尔林道综合征(vonhippel-lindausyndrome),威廉氏综合征,威尔森氏病,x连锁性肾上腺脑白质营养不良,x连锁无丙种球蛋白血症、x连锁扩张型心肌病(也是肌营养不良症),和x连锁低张性精神发育迟滞综合征。在一些实施方式中,靶核酸包括与癌症风险相关的一个或多个基因座。癌症靶核酸包括但不限于与膀胱癌、脑癌、乳腺癌、结肠癌、肝癌、肾(kidney)癌、肺癌、肾(renal)癌、结肠直肠癌、胰腺癌和前列腺癌,以及血液的癌症(例如,白血病)相关的靶核酸。在某些实施方式中,靶核酸是肺癌或结肠直肠癌或泛癌的靶核酸。在一些实施方式中,使用以下表1、表2或表3中公开的一种或多种寡核苷酸引物对进行提取自组织样品的核酸的扩增。表1、表2和表3提供了用于制备靶核酸的扩增子文库的引物对实验对象小组(panel),所述靶核酸含有分别与肺癌、结肠直肠癌和多于一种类型的癌症(即“泛癌”实验对象小组)相关的基因座。在某些实施方式中,每种寡核苷酸引物对的寡核苷酸包括磷酸化的5’端。具有磷酸化的5’端的寡核苷酸引物对有利地使寡核苷酸直接连接于靶向的核酸扩增子、条形码寡核苷酸、衔接头寡核苷酸或其组合。可以连接于靶向的核酸扩增子的5’端的示例性寡核苷酸包括以下寡核苷酸:该寡核苷酸包括促进靶向的核酸扩增子测序的元件或更多元件(例如条形码和通用衔接头)。在某些实施方式中,用于制备靶核酸扩增子文库的主题方法包括在寡核苷酸连接于每种靶核酸扩增子的磷酸化的5’端之前纯化扩增的靶核酸扩增子的步骤。可以用于纯化扩增的靶核酸扩增子的任何适当的技术包括乙醇/异丙醇沉淀和过滤/亲和柱技术。在一些实施方式中,所述方法进一步包括将包括衔接头核酸和/或条形码核酸的寡核苷酸直接连接于扩增的靶核酸的每个磷酸化的5’端,由此制备靶核酸扩增子文库的步骤。如本文使用的,“直接连接(directlyligate)”和“直接连接(directligation)”等是指在不存在酶的情况下连接寡核苷酸的过程或制备用于连接的扩增的靶核酸的5’末端(例如,削平)的过程。在某些实施方式中,直接连接的步骤包括将包括衔接头核酸的寡核苷酸连接于扩增的靶核酸的每个磷酸化的5’端。如本文使用的,“衔接头核酸”是含有允许特定靶核酸扩增子克隆扩增(例如,通过乳液pcr)的核酸序列的寡核苷酸。在某些实施方式中,衔接头序列与连接到乳液pcr中使用的磁珠的寡核苷酸的序列互补。在某些实施方式中,衔接头序列的长度为3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、25、30、35、40个核苷酸。在其他实施方式中,直接连接的步骤包括将包括条形码核酸的寡核苷酸连接于扩增的靶核酸的每个磷酸化的5’端。如本文使用的,“条形码序列”是在合并的靶核酸扩增子文库的测序(例如多路测序,见例如smith等人.nucleicacidsres.,38(13):e142(2010))期间使来自不同样品(例如不同的组织样品)的靶核酸彼此相互区别的核酸序列。在某些实施方式中,条形码序列的长度为3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、25、30、35、40个核苷酸。在又其他实施方式中,直接连接的步骤包括将包括衔接头核酸和条形码核酸的寡核苷酸连接于扩增的靶核酸的每个磷酸化的5’端。在构建靶核酸扩增子文库之后,可以使用本领域已知的任何方法对文库测序来产生靶核酸序列数据。在某些实施方式中,使用本领域已知的下一代测序(ngs)方法对靶核酸扩增子文库测序。ngs测序方法包括但不限于单分子实时测序(例如,pacificbio)、离子半导体方法(离子激流测序)、焦磷酸测序(例如,454lifesciences)、通过合成测序(例如,illumina测序和单分子实时(例如,smrt)测序)、通过连接测序(例如,solid测序)、链终止测序(例如,桑格测序)、基于珠的测序(例如,大规模平行签名测序(massivelyparallelsignaturesequencing,mpss))、聚合酶克隆测序(polonysequencing)、dna纳米球测序、heliscope单分子测序(例如,heilscopebiosciences)。基因突变分析对靶核酸扩增子文库测序之后,可以使靶核酸经历用于检测基因突变的分析。在另一个方面,本文提供了用于检测组织样品靶核酸序列中的突变的方法,所述方法包括:a)获得组织样品靶核酸序列数据和数据库靶核酸序列数据,其中所述数据库靶核酸序列数据位于突变数据库中;b)比较组织样品靶核酸序列数据与数据库靶核酸序列数据,以确定样品靶核酸序列数据是否含有来自突变数据库的登记的突变;c)通过确定突变数据库中登记的突变的突变等位基因频率来确定突变数据库中登记的突变的可靠性;和d)生成关于组织样品靶核酸序列数据是否含有突变的结果,由此检测突变。用于检测突变的主题方法可以用于确定任何类型的基因突变。在某些实施方式中,所述方法用于检测基因突变数据库中登记的点突变、缺失、插入、扩增或任何其他突变。在一些实施方式中,所述方法用于检测在癌症的体细胞突变目录(cosmic,http://cancer.sanger.ac.uk/cancergenome/projects/cosmic/)、clinvar(http://www.ncbi.nlm.nih.gov/clinvar/)和/或在线人类孟德尔遗传(omim,http://www.omim.org)和/或任何变异(突变)的数据库中登记的基因突变。在某些实施方式中,主题方法中使用的用于检测的组织样品靶核酸序列数据是尚未被预处理的数据。如本文使用的“预处理的数据”是指已经经历未绘制序列重排、数据处理的重复删除、插入缺失重排、碱基质量评分校正、变体评分复校和/或功能性标注的数据。在某些实施方式中,使用尚未被预处理的组织样品靶核酸序列数据来进行比较b)。在某些实施方式中,主题方法允许在以下时间内检测组织样品靶核酸序列中的突变:少于2天、1天、12小时、6小时、5小时、少于4小时、少于3小时、少于2小时、少于1小时或少于30分钟。在具体的实施方式中,主题方法允许在少于1小时的时间内检测组织样品靶核酸序列中的突变。在另一个方面,本文提供了计算系统,所述计算系统包括:一个或多个处理器、存储器以及一个或多个程序,其中一个或多个程序存储于存储器中,并且被配置为通过用于检测组织样品靶核酸序列中的突变的一个或多个处理器来执行,其中一个或多个程序包括用于检测组织样品靶核酸序列中的突变的指令,所述指令包括:a)获得组织样品靶核酸序列数据和数据库靶核酸序列数据,其中所述数据库靶核酸序列数据位于突变数据库中;b)比较组织样品靶核酸序列数据与数据库靶核酸序列数据以确定样品靶核酸序列数据是否含有来自突变数据库的登记的突变;c)通过确定突变数据库中登记的突变的突变等位基因频率来确定突变数据库中登记的突变的可靠性;和d)生成关于组织样品靶核酸序列数据是否含有突变的结果,由此检测突变。图9是一些实施方式中用于检测基因突变的电子网络100的图解视图。电子网络100包括通过通信路径相互连接的一系列点或节点。电子网络100可以与其他网络相互连接,可以包含子网络,并且可以通过局域网(lan)、城域网(man)、广域网(wan)或全球网络(互联网)的方式体现。另外,电子网络100可以通过其使用的协议类型表征,如wap(无线应用协议)、tcp/ip(传输控制协议/互联网协议)、netbeui(netbios扩展用户接口)或ipx/spx(网间分组交换/顺序数据包交换)。另外,电子网络100可以通过其是否携带声音、数据或这两种类型的信号表征;通过可以使用电子网络100的人表征(其是公共的或私人的);以及通过其连接的一般性质表征(例如,拨号连接、专用连接、转换连接、非转换连接或虚拟连接)。电子网络100使多个用户设备110连接于至少一个基因突变分析服务器102。通过可以包括内联网、无线网络、蜂窝数据网络或优选包括互联网的通信或电子网络106来进行该连接。通过可以是例如同轴电缆、铜线(包括但不限于pstn、isdn和dsl)、光纤、无线电、微波或卫星链路的通信连接108来进行连接。设备和服务器之间的通信优选通过互联网协议(ip)或任选地安全同步协议来发生,但也可选地通过电子邮件(email)来发生。基因突变分析服务器102示于图9中,并且如下描述为区别于用户设备110。基因突变分析服务器102包括至少一个数据处理器或中央处理单元(cpu)212、服务器存储器220、(任选的)用户接口设备218、通信接口电路216和至少一条使这些元件相互连接的总线214。服务器存储器220包括存储用于通信的指令、处理数据、访问数据、存储数据、搜索数据等的操作系统222。服务器存储器220还包括远程访问模块224和突变数据库226。在一些实施方式中,远程访问模块224用于在基因突变分析服务器102和通信网络106之间通信(传送和接收)数据。在一些实施方式中,突变数据库226用于存储包括登记的基因突变并可以通过本文提供的计算系统的一个或多个程序(例如,用于检测基因突变的程序)使用的突变数据库靶核酸序列数据。在一些实施方式中,突变数据库226包括含有登记的与特定疾病相关的基因突变的突变数据库靶核酸序列数据。在一些实施方式中,基因突变数据库包括登记在癌症的体细胞突变目录(cosmic)、clinvar和/或omim和/或任何变异(突变)数据库中的基因突变。在一些实施方式中,用户设备110是由确定靶核酸是否具有突变(例如与疾病相关的突变)的用户使用的设备。用户设备110通过远程客户端计算设备如台式电脑、便携式电脑、笔记本电脑、手持式电脑、平板电脑或智能手机等访问通信网络106。在一些实施方式中,与基因突变分析服务器102有关的描述的设备类似,用户设备110包括数据处理器或中央处理单元、用户接口设备、通信接口电路和总线。如下描述的,主题设备110还包括存储器120。存储器220和120可以包括易失性存储器如随机访问存储器(ram),和非易失性存储器如硬盘或闪速存储器。图10是根据一些实施方式的图9中显示的用户设备存储器120的方框图。主题设备存储器120包括与服务器存储器220(图1)中的远程访问模块224(图1)兼容的操作系统122和远程访问模块124。在一些实施方式中,用户设备存储器120包括基因突变分析模块126。如下详细说明的,基因突变分析模块126包括用于检测靶核酸序列中的基因突变的指令。在一些实施方式中,基因突变分析模块126包括用于检测靶核酸序列中的基因突变的一个或多个模块。例如,在一些实施方式中,用户设备存储器120中包括的基因突变分析模块126包括获取模块128、比较模块130、确定模块132和生成模块134。在一些实施方式中,用户设备存储器120还包括突变数据库140。在某些实施方式中,突变数据库140包括含有登记的基因突变的突变数据库靶核酸序列数据,所述登记的基因突变与特定的疾病相关并且用于如下描述的计算系统的检测的方法。在一些实施方式中,基因突变数据库包括在癌症的体细胞突变目录(cosmic)、clinvar和/或omim和/或任何变异(突变)数据库中登记的基因突变。在一些实施方式中,用户设备存储器120还包括样品靶核酸序列数据库142。在一些实施方式中,样品靶核酸序列数据库包含使用本文描述的主题方法从保存的组织样品获得的靶核酸序列数据。应该注意的是,上文描述的各种数据库具有以使得它们的目录可以容易地被访问、管理和更新的形式组织的它们的数据。数据库可以包括例如平面文件数据库(采用表格形式的数据库,其中仅一个表格可以用于每个数据库)、关系数据库(表格式数据库,其中数据被定义为使得其可以以多种不同方式重组和访问)或面向对象的数据库(适合于以对象类和子类定义的数据的数据库)。数据库可以托管在单个服务器上或分布在多个服务器上。在一些实施方式中,存在突变数据库226但是不存在突变数据库140。图11是说明了根据主题计算系统的一些实施方式,用于检测靶核酸(例如,使用本文描述的方法从保存的组织样品获得和扩增的靶核酸)中的突变的方法300的流程图。在一些实施方式中,所述方法通过本文描述的主题计算机系统的一个或多个程序进行。在一些实施方式中,所述方法包括:(a)获得样品靶核酸序列数据和突变数据库靶核酸序列数据300;(b)比较组织样品靶核酸序列数据与突变数据库靶核酸序列数据以确定样品靶核酸序列数据是否含有登记的突变310;(c)通过确定突变数据库中登记的突变的突变等位基因频率来确定突变数据库中登记的突变的可靠性320;和(d)生成关于组织样品靶核酸序列数据是否含有突变的结果,由此检测突变330。在一些实施方式中,用于检测靶核酸中的突变的方法包括:获得样品靶核酸序列数据和突变数据库靶核酸序列数据300。在本文提供的计算系统的某些实施方式中,根据包括在用户设备110的用户设备存储器120中存储的获取模块128中的指令,进行获得(a)。在某些实施方式中,突变数据库靶核酸序列数据获得自基因突变分析服务器102的服务器存储器220中存储的突变数据库226。在某些实施方式中,突变数据库靶核酸序列数据获得自用户设备110的用户设备存储器120中存储的突变数据库140。如本文使用的,“突变数据库靶核酸序列数据”是指与突变数据库中存储的特定靶核酸相关的任意核酸序列数据。示例性突变数据库包括但不限于:癌症的体细胞突变目录(cosmic)、clinvar和在线人类孟德尔遗传(omim,http://www.omim.org)。在某些实施方式中,突变数据库140或226包含与特定疾病相关的突变。在一些实施方式中,基因突变数据库包括在癌症的体细胞突变目录(cosmic)中登记的基因突变。在某些实施方式中,样品靶核酸序列数据尚未经过未绘制序列重排、重复删除、插入缺失重排、碱基质量评分校正、变体评分复校和/或功能性标注(即尚未经过预处理)。在某些实施方式中,在获得(a)300之后,所述方法包括比较组织样品靶核酸序列数据与突变数据库靶核酸序列数据以确定样品靶核酸序列数据是否包含登记的突变310。在本文提供的计算系统的某些实施方式中,根据用户设备110的用户设备存储器120中存储的比较模块130中包括的指令进行比较(b)。在一些实施方式中,组织样品靶核酸序列数据与基因突变数据库140或226中的10或更多个、20或更多个、30或更多个、40或更多个、50或更多个、60或更多个、70或更多个、80或更多个、90或更多个、100或更多个、150或更多个、200或更多个、250或更多个、300或更多个、350或更多个、400或更多个、450或更多个、500或更多个、600或更多个、700或更多个、800或更多个、900或更多个单独的突变数据库靶核酸序列“读数”比较,以确定样品靶核酸序列数据是否含有基因突变数据库140或226中登记的突变。如果样品靶核酸序列数据被认为含有基因突变数据库140或226中登记的突变,进一步确定登记的突变的可靠性。在某些实施方式中,所述方法包括(c):通过确定突变数据库中登记的突变的突变等位基因频率来确定突变数据库中登记的突变的可靠性320。在本文提供的计算系统的某些实施方式中,根据用户设备110的用户设备存储器120中存储的确定模块132中包括的指令进行确定(c)。在某些实施方式中,如果登记的突变呈现了高于阈值突变等位基因频率,则确定登记的突变是可靠的。在一些实施方式中,如果登记的突变呈现了高于比较(b)310中的总突变数据库靶核酸序列“读数”的阈值百分比,那么确定登记的突变是可靠的。在一些实施方式中,如果登记的突变呈现了高于比较(b)中的总突变数据库靶核酸序列“读数”的1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%或70%,那么确定登记的突变是可靠的。在某些实施方式中,确定模块132通过计数包含登记的突变的突变数据库靶核酸序列“读数”的数量,选择统计模式(staticmodels)中的算法、确定p值和筛选结果来确定登记的突变是否是可靠的。在某些实施方式中,所述方法包括(d)生成关于组织样品靶核酸序列数据是否含有突变的结果,并且由此在确定(c)之后检测突变330。在本文提供的计算系统的某些实施方式中,根据用户设备110的用户设备存储器120中存储的生成模块134中包括的指令,进行生成(d)。实施例实施例1:核酸提取方法为了使最低量的ffpe组织的核酸产量和质量最大化,开发了快速和简单的核酸(尤其是dna)的提取方法。特别地,核酸提取方法允许在15分钟或更短时间内提取核酸(“15分钟ffpedna试剂盒”)。此外,与大多数其他商业ffpe核酸提取方法不同,除了两种溶液(溶液a和b)以外,新方法既不使用柱也不使用专门的材料。如图1中的通用流程图中所示的,该方法可以用于装备有简单加热块或常规热循环仪的任何实验室或设施。将脱石蜡的ffpe组织切片与溶液a在99℃下温育5分钟,然后与溶液b在60℃下温育另外5分钟。在99℃下最终温育5分钟产生了高产量和高质量的dna。图2显示了与市场上主导的qiagendnaffpe组织试剂盒相比,提供的核酸提取方法产生高量的dna。来自13名肺腺癌患者的每一种ffpe载玻片切片(5μm厚)用于dna提取。方法用于定量通过“15分钟ffpedna试剂盒”和qiagendnaffpe组织试剂盒制备的dna。红色柱表示来自“15分钟ffpedna试剂盒”的基因组dna的产量,蓝色柱表示dnaffpe组织试剂盒的基因组dna的产量(a)。与qiagendnaffpe组织试剂盒相比,“15分钟ffpedna试剂盒”产生了更高量的基因组dna(平均值-提高至3.19倍,中值-提高至2.13倍)(b)。图3说明了由15分钟ffpedna试剂盒提取的核酸可以用于任何基于pcr(即定量pcr(qpcr)、桑格测序和下一代测序)的分析或基因分析。使用等量的ffpe组织分离基因组dna,并且以相同的体积洗脱。来自肺腺癌ffpe样品的2μl分离的dna(图2a中所示的)用于qpcr分析(qpcr探针-rna酶偏好基因)。通过15分钟ffpedna试剂盒获得的ct(循环阈值)为21~24个循环,而通过dnaffpe组织试剂盒获得的ct为27~29个循环。这显示了在qpcr分析中,来自15分钟ffpedna试剂盒的dna更有效地被扩增。对于仅5μm厚的ffpe切片,可以获得高达2μg的dna。该方法对qpcr和大尺寸pcr(大于1kb)分析也是非常有效的。不像大多数其他已知的和商业的方法,“15分钟ffpedna试剂盒”使得能够进行大扩增子分析,这使得ffpe样品分析在临床基因分析中更灵活和更可适用。实施例2:核酸扩增子制备方法为了能够在样品到达的次日内获得靶向深度测序数据,开发了称为“次日测序(nextdayseq)”的简单的和稳健的样品扩增子制备方法。简言之,研究人员和医生可以在36小时内获得测序数据,即从给定的样品(即福尔马林固定的石蜡包埋的(ffpe)组织样品)开始dna提取、文库制备、测序和数据分析。在此,通过使用5’磷酸化寡核苷酸,伴随靶基因或扩增子的多路扩增的直接连接方法(图4和图5)。该方案不需要靶区域的酶消化或水解(hybridization)。为了在本文描述的直接扩增和连接方法中使用,开发了靶ngs实验对象小组,设计了靶向作为人肺癌(表1)、结肠直肠癌(表2)和泛癌中的治疗病灶的一般突变基因的探针序列。进一步地,这样的扩增子制备方法可以通过修饰靶向感兴趣的基因的探针序列来应用于任何癌症或基因实验对象小组(panel)。表1.用于肺癌实验对象小组的5′磷酸化寡核苷酸序列表2.用于结肠直肠癌实验对象小组的5′磷酸化寡核苷酸序列表3.用于泛癌实验对象小组的5′磷酸化寡核苷酸序列结论为了尽快地向临床医生和研究人员提供来自患者的标本的关键突变数据,已经开发了新的稳健的靶向ngs方法。这可以帮助这样的临床医生和研究人员决定哪种治疗选项(个性化医疗)或生物应用对于治疗具有特定突变的患者是最佳的。例如,该应用可以是筛选肺癌标本以检测egfr基因中的肿瘤驱动的和药物敏感性的突变,这可以使患者得益于酪氨酸激酶抑制剂(tki,即吉非替尼或埃罗替尼)治疗。通过使dna提取试剂盒和用于本文描述的突变分析的计算系统结合,扩增子制备方法将能够为患者、医生和研究人员在36小时内(次日)提供关键的突变数据。实施例3:下一代测序(ngs)的数据库关联的无预处理分析(danpa)方法/主要发现:称为danpa的新数据分析工具提供快速、准确和稳健的ngs数据分析。开发danpa主要用于靶向测序分析,虽然其也可以用于全外显子组或基因组测序数据分析。danpa检测数据库中登记的任何类型的报告的突变,所述数据库如癌症的体细胞突变目录(cosmic),其是最大的和稳健的癌症突变数据库(图6和图7)。cosmic中存在超过150万个登记的突变,任何另外的数据库可以连接于danpa以筛选突变(图6)。因此,假设这些数据库中没有登记的任何基因变异或突变是具有非常有限的临床或生物作用的非病原性的或极其稀少的突变。如果需要,可以容易地将另外的或新的突变(很可能后来证明其在某些疾病中的生物或临床作用)添加至突变数据库。经典ngs数据分析步骤包括称为ngs数据分析的“预处理”的数个步骤(未绘制序列重排、重复删除、插入缺失重排和碱基质量评分复校)。存在主要开发用于大规模ngs数据分析的数种ngs数据分析工具(即samtools、gatk、picard和激流套件/报告者(torrentsuite/reporter))。虽然这些程序针对每个预处理步骤使用不同算法,但是它们通常根据以下步骤工作:未绘制序列重排、重复删除、插入缺失重排和碱基质量评分复校。danpa跳过了这些预处理步骤并且连接用于检测突变的指定的数据库。因此,通过danpa可以稳健地检测到任何类型的登记的突变。最佳的例子是egfr基因的外显子19缺失。该基因的正确的突变信息对于癌症患者的临床决策是重要和基本的。具有egfr突变如外显子19缺失或l858r突变的肺癌患者对酪氨酸激酶抑制剂(tki)吉非替尼或埃罗替尼响应。然而,外显子19缺失倾向于是通过其他ngs分析程序是非常难以检测到的多于15bp的缺失或甚至缺失和插入两者的组合(indel)。此外,离子激流系统(iontorrentsystem)(两种主要的商业测序平台之一)在检测(复杂)插入和缺失如egfr外显子19突变时具有严重问题。然而,在danpa应用于离子激流数据中,只要这些类型的复杂突变登记在数据库中,检测这些类型的复杂突变就不存在问题。使用danpa和激流套件(离子激流支持的官方数据分析程序)的比较数据示于图8。danpa在检测突变中的另一个巨大优势是当其仅选择数据库登记的突变时假阳性呼叫或测序错误的大幅度减少。ngs在同聚物区中具有高的假阳性率是已知的。因为danpa通过与指定的截止水平(cut-offlevel)(等位基因频率:即3%的突变等位基因)直接连接的数据库,去除了大多数的这些假阳性突变呼叫并且仅检测到明显的体细胞突变。表4和表5总结了利用主题“次日测序”直接扩增和连接扩增子样品文库制备,然后进行下一代测序和使用如本文描述的danpa进行数据分析的另一项实验。表4提供了实验中使用的临床样品和生物样品的总结,表5提供了由实验中使用的866ffpe样品揭示的突变的总结。表4样品类型样品数目ffpe866新鲜冷冻的组织431质粒114细胞系18其他401表5结论:开发了新的ngs数据分析程序danpa,其直接连接于突变数据库。该工具可以在1小时内从ngs数据处理突变分析,而其他程序无疑需要多于1天。因为跳过了其他ngs分析程序中常规使用的几乎所有预处理步骤,可得到快速的数据分析。danpa的准确性也是测试的程序(gatk、激流套件和报告者和samtools)中最佳的。另外,danpa解决了与ngs应用(尤其是离子激流测序程序)相关的两个问题:假阴性(即egfr基因的插入缺失重排和长bp缺失)和假阳性(即在同聚物区域中的缺失或插入)。这种最快速、最简单和最准确的ngs分析程序会帮助临床医生和研究人员鉴别人类疾病中或任何生命科学领域中有意义的临床标记物和基因机制。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1