鉴定高含油率油茶的方法与流程
本发明涉及生物技术领域,属于油茶分子生物学及遗传育种技术领域,具体涉及一种油茶种子含油率筛选的多态性位点分子标记,同时还涉及该分子标记在油茶种子高含油率育种中的应用。
背景技术:
油茶(Camellia oleifera Abel.),隶属山茶科(Theaceae)山茶属(Camellia L.),是我国特有的木本油料树种,也是我国南方重要的木本食用油料物种。油茶籽油营养保健价值较高,其品质可与橄榄油相媲美,是一种优质的食用油,其不饱和脂肪酸含量达90%以上,以油酸(80%以上)和亚油酸(约8%)为主,且具有抗肿瘤、降血脂等功效。近十年来,在国家政策引导和扶持下,我国油茶产业得到了长足发展,全国种植面积已达6000多万亩,年产油60多万吨。根据《全国油茶产业发展规划(2009~2020)》,至2020年,我国油茶种植面积将达到9300万亩,因此油茶良种苗木需求量很大。目前,油茶育种以选择和杂交育种为主要手段、以产果量为主要育种目的,并已取得了重要进展,但以提高油茶籽含油率为目的育种研究开展较少。同时,由于油茶童期长的生物特性导致油茶育种年限较长,新品种选育缓慢,良种选育速度还不能满足产业发展的需求,已成为阻碍油茶产业发展的重要因素之一。应用分子标记辅助(MAS)育种手段可从苗期开始选择,大幅缩短育种的进程,对以果实为主要目的的经济林育种优势尤其明显。因此,开展油茶高含油率的MAS育种将有效缩短油茶育种周期,且具有巨大的应用潜力。
油茶的分子标记辅助育种研究已有几十年的历史,包括RAPD、ISSR、SRAP等多种分子标记技术,取得了一定的成果。但这些技术均表现出一定的弊端,所获得的多态性标记位点很难真正用于油茶辅助育种。主要弊端包括:1、这些标记均属于显性标记,无法准确的体现多态性位点的基因型;2、这些标记技术对实验操作人员及环境要求较高,实验结果不稳定;3、这些标记技术均是对整个基因组序列进行分析,工作量大,无法将多态性位点精准定位,亦很难筛选到与目的性状紧密连锁的标记;4、传统的数量性状位点(quantitative trait loci,QTL)作图需要具有亲缘关系的作图群体,油茶童期长的生物特性,使得创建大规模的油茶杂交作图群体耗时长,难度大且需占用大面积林地。因此,以自然群体为研究对象,采用共显性SNPs标记,通过连锁不平衡作图开发与油茶种子含油率关联的多态性位点,筛选可稳定用于早期辅助选择的标记,成为油茶有效的分子标记辅助育种策略。
技术实现要素:
本发明的第一个目的在于提供与油茶种子含油率相关的SNP分子标记。
本发明的第二个目的是提供检测该SNP分子标记的方法。
本发明的第三个目的是提供一种鉴定高含油率油茶的方法。
本发明的目的是通过以下技术方案实现的:
(1)在油茶全分布区内广泛收集油茶种质资源,建立种子含油率广泛分离的油茶自然群体。
(2)采用KAC法(TaKaRa试剂盒Code No.9768)提取自然群体500个单株的嫩叶总DNA,并用0.8%~1%的琼脂糖凝胶电泳及核酸测定仪测定提取DNA的质量,要求DNA无降解,无蛋白质、多糖等杂质污染,浓度达100ng/μL以上。
(3)采集关联群体500份油茶种质的完全成熟种子,用索氏抽提法测定种子含油率。
(4)根据油茶Cofad2-2基因(林萍,周长富,姚小华,曹永庆,普通油茶两个Δ-12脂肪酸脱氢酶基因序列特征及表达模式研究,林业科学研究,2016,29(5):743-751)序列,合成引物P1:5’-ATGGGTGCAGGTGGCCGAATGT-3’(SEQ ID NO.1)和P2:5’-TCGTGAAATTGATACCGACA-3’(SEQ ID NO.2),并对样本DNA进行PCR扩增,该扩增产物长度为1385±3bp。扩增产物琼脂糖凝胶回收后,采用一代测序技术测定核苷酸序列。过程中用到软件包primer5(http://www.Premier5BioSoft.com)是免费公开的;主要试剂包括Taq酶、dNTP、琼脂糖、AxyPrep DNA凝胶回收试剂盒。
(5)采用多序列比对法,依据最少基因型频率≥5%的原则,筛选序列内的SNP位点,分析测序峰图确定SNP位点基因型。
(6)将群体的基因型数据输入Structure2.3.4(http://pritchardlab.stanford.edu/structure.html)软件,进行群体遗传结构分析。
(7)将群体的基因型数据、遗传结构数据、种子含油率的表型数据以及Kinship矩阵数据输入TASSEL5.0(http://www.maizegenetics.net/tassel)软件中,采用统一混合模型方法(MLM)分析SNPs标记和油茶种子含油率性状的连锁不平衡性,检测到SNP02778位点与油茶种子含油率极显著关联(采用Bonferroni多重检验校正,P<2.75×10-4),对表型变异的贡献率为8.02%。
利用上述技术措施,本发明最终获得了与油茶种子含油率极显著关联的分子标记SNP02778,该标记位于油茶Cofad2-2基因开放阅读框778bp处,碱基为C/C或C/A。针对油茶种子含油率性状,若假设C/A基因型的基因效应为0,C/C的基因效应为8.70642。
具体地,本发明提供的一种与油茶种子含油率相关的SNP分子标记,位于油茶Cofad2-2基因开放阅读框778bp处,该位点基因型为C/A。
进一步地,本发明的与油茶种子含油率相关的SNP分子标记可以由核苷酸序列如SEQ ID NO.1-2所示的引物对以油茶基因组DNA为模板经PCR扩增获得。
本发明的与油茶种子含油率相关的SNP分子标记通过核苷酸序列如SEQ ID NO.1-2所示的引物对以油茶基因组DNA为模板经PCR扩增获得,扩增产物含有位于油茶Cofad2-2基因开放阅读框778bp处的碱基,其多态性为C/A。
本发明提供了上述SNP分子标记在鉴定油茶种子含油率表型中的应用,若SNP分子标记的基因型为C/C时,待鉴定油茶为高含油率,若SNP分子标记的基因型为C/A,则待鉴定油茶为低含油率或候选低含油率。
具体方法为:(1)将待鉴定油茶材料嫩叶提取基因组DNA,采用P1和P2引物对(SEQ ID NO.1-2)进行PCR扩增,通过琼脂糖凝胶电泳检测并回收所得到的PCR产物;
(2)测定PCR产物的碱基序列,并鉴定SNP02778位点的基因型,若该位点的基因型为C/C,则待鉴定油茶为高含油率油茶或候选高含油率油茶;若该位点的基因型为C/A,则待鉴定油茶为低含油率油茶或候选低含油率油茶。
所述待鉴定油茶可以为任何育种材料,包括自然群体个体和有性群体个体。
上述方法中,提取油茶基因组DNA采用KAC法(TaKaRa试剂盒Code NO.9768)。
上述方法中,所述PCR程序为:95℃,3min,1个循环预变性;95℃,15s变性,68℃,45s延伸,40个循环;68℃,5min,1个循环彻底延伸。
所述琼脂糖凝胶电泳中,琼脂糖凝聚的浓度为1.2%。胶回收使用AxyPrep DNA凝胶回收试剂盒。上述方法测定PCR产物的碱基序列,以P1和P2为测序引物,采用一代测序技术。
本发明提供了上述SNP分子标记在油茶种质资源改良中的应用。
本发明提供了上述SNP分子标记在油茶种子含油率早期预测中的应用。
本发明提供了上述SNP分子标记在筛选高含油率油茶中的应用。
本发明提供了用于检测上述SNP分子标记的基因型的引物对,其核苷酸序列分别如SEQ ID NO.1-2所示。
含有SEQ ID NO.1-2所示引物对的试剂盒属于本发明的保护范围。
本发明提供了SEQ ID NO.1-2所示的引物对或含有该引物对的试剂盒在鉴定高含油率油茶中的应用。
上述应用是采用PCR检测待测油茶基因组DNA,扩增产物(扩增产物核苷酸序列如SEQ ID NO.3所示)的第778位碱基,若基因型为C/C时,则待鉴定油茶为高含油率油茶。
上述应用中,PCR的反应程序为:95℃3min;95℃15s,68℃45s,共40个循环;68℃5min,1个循环彻底延伸。
本发明的有益效果在于:本发明首次开发了一个与油茶含油率高度关联的SNP位点,可以解释8.02%的含油率表型方差。利用该标记对有性油茶群体进行了辅助选择,结果表明,该位点为G/G的单株中,65.64%的个体其种子含油率高于群体种子含油率平均值,该位点为C/A的单株中,68.42%的个体其种子含油率低于群体平均值。这表明该标记用于辅助选择是切实有效的。与油茶种子含油率关联位点的开发方法,其原理是油茶是典型的异交物种,连锁不平衡(LD)通常在一个基因范围内迅速消减,因此可以开展重要性状关键基因内的LD作图。调控油茶不饱和脂肪酸含量的关键基因已经被分离,作为本发明标记开发的主要区域。在具备产生了大量明显的遗传变异的油茶自然群体的前提下,可有效开展与油茶含油率、脂肪酸成分含量等经济性状变异显著相关的标记开发。
在油茶常规选择育种中,种子含油率性状的鉴定需要幼苗造林5-6年才能鉴定,费时费力。本发明中的SNP位点位置明确,检测方法方便快速,不受环境影响,目的性更强,工作量小,效率更高,成本低。因此,通过检测该SNP位点,可在苗期进行鉴定和辅助筛选,大大节约生产成本和提高选择效率。在油茶育种中,可选择本发明的分子标记及检测其的方法鉴定出高含油率油茶进行育种,可提高油茶育种的选择效率,加快育种进程。
附图说明
图1油茶自然群体种子含油率的样本数量分布图(横坐标表示油茶种子含油率%,纵坐标表示样品个体数),结果表明油茶种子含油率表型呈正态分布,属于数量性状。
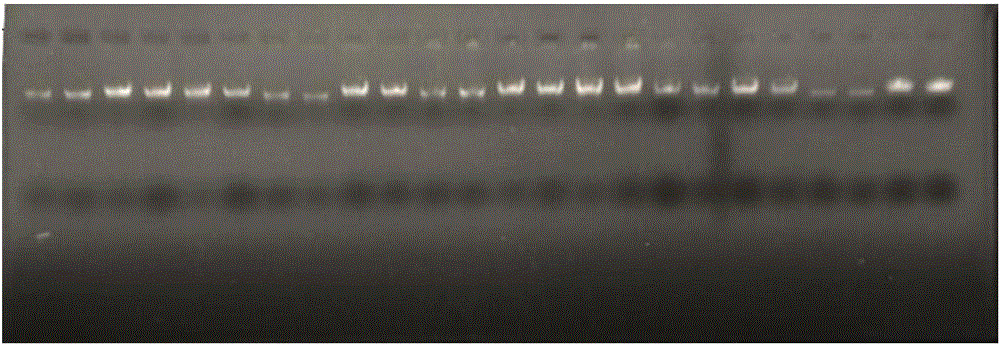
图2提取嫩叶DNA电泳图,每个泳道为一个样品,可见所提取的DNA样品无降解,无蛋白质、多糖等杂质污染,质量较高,可用于后续实验。
图3扩增产物测序峰图,由于油茶属于异交物种,杂合度较高,很多位点属于杂合位点,本发明中检测到的SNP位点亦为杂合位点。虚线框内部分即为检测位点,左图为C/A基因型(杂合位点),右图为C/C基因型。
图4样本亚群群体结构效应示意图。结果表明本发明所用自然群体所有个体,根据其核苷酸多态性可分为4个亚群。
具体实施方式
以下实施例进一步说明本发明的内容,但不应理解为对本发明的限制。在不背离本发明精神和实质的情况下,对本发明方法、步骤或条件所作的修改或替换,均属于本发明的范围。
本研究中所用的自然群体材料500份单株,均由中国林业科学研究院亚热带林业研究所木本油料研究组收集、评价,并保存于浙江金华婺城区东方红林场种质资源圃。
若未特别指明,实施例中所用的技术手段为本领域技术人员所熟知的常规手段。
实施例1 油茶种子含油率分离群体的构建及性状测定
本实施例中使用普通油茶资源收集圃内500份种质资源的自然群体,其起源地涵盖我国油茶主产区的大部分,包括浙江省、湖南省、江西省、广西区、福建省、广东省等。500个体待果实完全成熟后(5%果实开裂),采集种子,采用索氏抽提法测定种子含油率。其操作步骤如下:
(1)制备中速滤纸包,并放入铝盒内,105℃烘至恒质量,记录铝盒和滤纸包质量(W1)。
(2)适量油茶种子剥去硬种皮,105℃烘至恒质量,用粉碎机粉碎后,装入滤纸包内包扎好,记下铝盒、滤纸包和试样的总质量(W2)。
(3)采用瑞士Buchi索氏提取仪B-811LSV,将称好质量的试样滤纸包放入浸提瓶中,加入约100ml乙醚,提取6h,回收乙醚,将滤纸包(内有残渣)放入铝盒内于105℃烘至恒质量,记下铝盒、滤纸包和残渣的质量(W3)。
干籽含油率=[(W2-W3)/(W2-W1)]×100%
油茶种子含油率测定结果表明:自然群体种子含油率呈正态分布(见图1),说明该性状具有数量性状特点。
实施例2 Cofad2-2基因片段扩增
1、叶片总DNA提取:
利用TaKaRa MiniBEST Plant Genomic DNA Extraction Kit中富含多糖、多酚及油脂植物材料裂解系统提取叶片总DNA,具体步骤如下:
(1)首先在1.5ml离心管中加入500μl的Buffer HSⅡ。取0.1g新鲜叶片加入液氮充分研磨,迅速将研磨好的叶片粉末加入到离心管中充分混匀,然后加入10μl的RNaseA(10mg/ml),充分振荡混匀,于56℃水浴温浴10分钟;
(2)加入62.5μl的Buffer KAC,充分混匀。冰上放置5分钟,12000rpm离心5分钟。取上清,加入与上清液等体积的Buffer GB,充分混匀。
(3)将Spin Column安置于收集管上,溶液移至Spin Column中(溶液过多,可分两次过柱,每次过柱的体积量不要超过700μl),12000rpm离心1分钟,弃滤液。
(4)将500μl的Buffer WA加入至Spin Column中,12000rpm离心1分钟,弃滤液。
(5)将700μl的Buffer WB加入至Spin Column中,12000rpm离心1分钟,弃滤液。
(6)重复操作步骤(5)。
(7)将Spin Column安置于收集管上,12000rpm离心2分钟。
(8)将Spin Column放置于新的1.5ml的离心管上,在SpinColumn膜的中央处加入30~50μl的Elution Buffer,室温静置5分钟,12000rpm离心2分钟洗脱DNA。用紫外分光光度计测定DNA浓度,于-20℃冰箱中保存备用(图2)。
2、引物的开发和合成:
所用引物是根据申请人已克隆的油茶Cofad2-2基因的cDNA序列设计的。具体的开发方法是根据该基因的cDNA序列利用Primer5软件(http://www.Premier5BioSoft.com)在起始密码子和3’非编码区分别设计引物P1:5’-ATGGGTGCAGGTGGCCGAATGT-3’(SEQ ID NO.1)和P2:5’-TCGTGAAATTGATACCGACA-3’(SEQ ID NO.2)并交由公司合成。
3、Cofad2-2基因片段扩增,其流程如下:
以提取的所有个体DNA为模板,P1和P2为扩增引物,进行PCR扩增,反应体系:
PCR扩增程序为:
4、扩增片段的凝胶检测和纯化回收并测序、基因分型,按照AxyPrep DNA凝胶回收试剂盒说明书进行,其流程如下:
(1)配制1.2%的琼脂糖凝胶,将50μl扩增产物全部上样,电泳电压为5V/cm,电泳约20分钟至上样缓冲液中二甲苯青达到距离凝胶前端1cm处时停止电泳。
(2)在紫外灯下切下含有目的DNA的琼脂糖凝胶,用纸巾吸尽凝胶表面的液体并切碎。计算凝胶重量,该重量作为一个凝胶体积(例如100mg=100μl体积)。
(3)加入3个凝胶体积的Buffer DE-A,混合均匀后于75℃加热,每2~3分钟间断混合,直至凝胶块完全熔化。
(4)加入0.5个Buffer DE-A体积的Buffer DE-B,混合均匀。
(5)将上述溶液转移到DNA制备管中,12000rpm离心1分钟,弃滤液。
(6)加入500μl Buffer W1,12000rpm离心30秒,弃滤液。
(7)加入700μl Buffer W2,12000rpm离心30秒,弃滤液。以同样的方法再用700μl Buffer W2洗涤一次,12000rpm离心1分钟,弃滤液。
(8)将制备管放回离心管中,12000rpm离心1分钟。
(9)将制备管置于洁净的1.5ml离心管中,在制备膜中央加25~30μl去离子水,室温静置1分钟。12000rpm离心1分钟洗脱DNA。
(10)凝胶回收DNA,以P1和P2为测序引物,采用一代测序测定扩增产物核苷酸序列。用Chromas软件判读测序峰图上每个SNP位点的基因型(图3)。
实施例3 与油茶种子含油率相关的SNP位点的筛选
群体结构分析和连锁不平衡分析,其步骤如下:
(1)将所有样本的SNPs位点数据导入Structure2.3.4软件中,设置K=2~9,每K值运行5次,burnin5000次,重复50000次。当LnP(D)和α值均保持稳定,且α<0.2时,确定群体结构的K值(图4),本发明中K=4,并确定各个样本的K(4)个亚群效应值(表1)。
表1 自然群体部分个体的4个亚群效应值
(2)将所有样本的SNPs位点数据、K个亚群效应值数据、表型数据(见实施例1)及Kinship矩阵数据导入TASSEL5.0软件中,采用MLM法分析SNPs与含油率性状的连锁不平衡性,筛选与种子含油率显著关联的分子标记,采用Bonferroni多重检验校正,检测到了一个跟含油率存在极显著关联的位点SNP02778,其基因型为C/C或C/A,该标记与含油率关联F检验的P值为1.18×10-5,对含油率差异的贡献率为8.02%。
实施例4 分子标记SNP02778在油茶种子高油育种中的应用
(1)选择一个油茶杂交F1代家系群体为材料,采集嫩叶提取总DNA(见实施例2)。
(2)利用P1和P2引物对总DNA进行PCR扩增(见实施例2)。
(3)PCR扩增产物进行凝胶回收纯化和测序分析(见实施例2)。
(4)鉴定所有个体SNP02778位点的基因型。若该SNP位点的基因型为C/C,则油茶个体为高含油油茶或候选高含油油茶;若该位点的基因型为C/A,则油茶个体为低含油油茶或候选低含油油茶。
(5)采集所有F1代个体完全成熟种子,测定其种子的含油率(见实施例1)。结果表明,该位点为C/C的单株中,65.64%的个体其种子含油率高于群体种子含油率平均值(36.20%),该位点为C/A的单株中,68.42%的个体其种子含油率低于群体平均值(36.20%)(表2)。这表明该标记用于辅助选择是切实有效的,可用于早期鉴别或辅助鉴别,可大大节约生产成本,提高选择效率,加快油茶高油育种进程。
表2 利用SNP02778位点辅助选择得到的F1单株的种子含油率数据
虽然,上文已经用一般性说明、具体实施方式及试验,对本发明作了详尽的描述,但在本发明基础上,可以对之做出一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
SEQUENCE LISTING
<110> 中国林业科学研究院亚热带林业研究所
<120> 鉴定高含油率油茶的方法
<130> KHP171110817.7
<160> 3
<170> PatentIn version 3.5
<210> 1
<211> 22
<212> DNA
<213> 人工序列
<400> 1
atgggtgcag gtggccgaat gt 22
<210> 2
<211> 20
<212> DNA
<213> 人工序列
<400> 2
tcgtgaaatt gataccgaca 20
<210> 3
<211> 1385
<212> DNA
<213> 油茶
<400> 3
atgggtgcag gtggccgaat gtctgttcct cctgagggaa agaagtcaga ccgtgatgtc 60
atccggcgag ttccttactc aaaacctcca ttcacagttg gcgagatcaa gaaggccata 120
ccaccccatt gttttcgtcg atctgttctc cactcattct cctacgttgt ttatgacttg 180
atcatagcct tcctgttcta ctatctcgcc accaattaca tccacctcct tcctcaacct 240
ctctcgtacc ttgcctggct ggtttactgg atctgtcaag gttgtgtcct aaccggtgtt 300
tgggtcgtag cccatgagtg tggccatcat gccttcagtg actaccaatg gcttgatgac 360
acagtcggtc tcgtccttca ctctgctctc cttgttcctt acttctcttg gaaatatagc 420
catcgccgcc accattccaa cacggcttct ctagagcgcg atgaggtgtt tgttcccaaa 480
cttaagtcca gcgttggatg gtattccaaa tatcttaaca acccacctgg ccgaattctc 540
acagtcgtca tcacactgac tctaggctgg ccgctatacc taatgttcaa cgtttcaggc 600
cgacattatg atcgttttgc atgccactat gacccttatg gccctattta ctcagatcgc 660
gagcgccttc aaatttacct ctctgatgct ggtgttcttg gagtgagtta tgtgctttat 720
cggtttgcac tagtaaaagg actagcttgg gtactctgtc tttatggtgg tcctcttctc 780
atcgtgaatg ggtttcttgt gctgatcacg tggttgcagc acactcaccc tgcattgcca 840
cactacgatt catctgagtg ggactggttg agaggagctc tagctacatg tgaccgagat 900
tatggaattc taaacaaggt attccataat atcactgata ctcatgtagc ccaccatttg 960
ttctcaacaa tgccacatta ccatgcaatg gaagccacaa aagcaataaa gccgattttg 1020
ggagattatt atcagtgtga tgcgactccg gttttgaggg caatatggag ggaagcaaag 1080
gagtgcattt atgtggagaa tgacgaaagt gaccaaacca aaggtgtttt ctggtacaaa 1140
aacaagcttt gaatggcgga agaaattgca ggcggggaag ttttggtttc ttgttaggga 1200
ctaaactccc atttcctggt aaaagttagg ttgtttttgt tgtttttgta ctgaatctct 1260
aattttagat taattatttt tgttgttcac tacatgcttg gaacattgca aactggtgaa 1320
gtttgaagga cctctgttgg gttttgattt tttgatattt tcaaatgtcg gtatcaattt 1380
cacga 1385
- 还没有人留言评论。精彩留言会获得点赞!