利用人体生物样本评估复杂疾病发病风险的多基因计分分析方法与流程
本发明涉及一种利用人体唾液,血液等生物样本评估复杂疾病发病风险的方法。
背景技术:
许多复杂疾病(包括精神分裂症、双相情感障碍、多动症、冠心病、银屑病、2型糖尿病、多发性硬化、乳腺癌、克罗恩病、溃疡性结肠炎、类风湿性关节炎共11种疾病)具有较大的遗传异质性,且尚无明确的病因,正因如此,对此类复杂疾病的早期预防存在困难。
截止目前,大规模的全基因组关联分析(genomewideassociationanalysis,gwas)已经对大量此类复杂疾病患者的样本进行了研究,并发现了大量与疾病相关的单核苷酸多态性(singlenucleotidepolymorphism,snp)位点。每个单个的snp对疾病发生的影响非常微弱,但是大量与疾病相关的snp的作用累加协同可能对疾病的发生发挥重要作用。
多基因计分(polygenicriskscore,prs)最早于2009年由shaunm.purcell等人提出并发表于《自然》杂志上,他们将多基因计分定义为在某个特定的p值阈值下,与疾病相关的snp位点的基因型与效应值的乘积的总和。他们认为多基因计分能够用于间接评估多个对疾病具有微弱贡献的snp位点对疾病的总的贡献程度。千人基因组工程(the1000genomesproject)的第三期对2504个人类样本进行了全基因组低深度测序,其中包括487个东亚人的样本。针对本发明中涉及到的复杂疾病(包括精神分裂症、双相情感障碍、多动症、冠心病、银屑病、2型糖尿病、多发性硬化、乳腺癌、克罗恩病、溃疡性结肠炎、类风湿性关节炎共11种疾病)相关snp位点,千人基因组工程(the1000genomesproject)中用到的全基因组测序技术有望覆盖大部分snp位点。本发明利用千人基因组工程(the1000genomesproject)中487个东亚人样本的基因型数据,对多种复杂疾病计算多基因计分,用于与测试样本进行对照并对测试样本进行风险评级。
技术实现要素:
本发明旨在克服现有技术的不足,提供一种利用人体生物样本评估复杂疾病发病风险的多基因计分分析方法。
为了达到上述目的,本发明提供的技术方案为:
所述利用人体生物样本评估复杂疾病发病风险的多基因计分分析方法所述方法包括以下步骤:
(1)从人体唾液或血液样本中提取dna;
(2)利用基因芯片技术对与疾病相关的单核苷酸多态性位点进行检测;
(3)编程处理,将所有基因型转化为剂量基因型(dosagegenotype)(野生型:0;杂合子:1;纯合子:2);
(4)针对每一种复杂疾病,对待测样本以及487个东亚正常人样本计算多基因计分,多基因计分的计算公式为:
该公式根据euesden等人的研究进行了修改(2015bioinformatics,euesdenetal.)。对于某一种复杂疾病,针对样本j共有m个单核苷酸多态性位点(gi)可能会影响到该疾病的发生。对于每一个单核苷酸多态性位点(gi),可以基于基因型与表型的相关性计算出该位点的效应值(βi)与p值。以p=0.05作为阈值,将所有p<0.05的单核苷酸多态性位点(gi)的剂量基因型与其效应值(βi)相乘并求和,得到的值即为样本j在该疾病下的多基因计分(prsj);
(5)将待测样本的多基因计分prsj与487个东亚正常人的多基因计分进行比较,并根据样本的多基因计分在对照人群中的分布位置,评定风险等级;具体评定方法为:统计该样本的多基因计分高于人群中的百分比,依据百分比的大小将风险等级分为五级:等级一:0~20%;等级二:20%~40%;等级三:40%~60%;等级四:60%~80%;等级五:80%~100%,等级五为风险最高的等级。每个样本在每种复杂疾病中的风险等级,可以作为评估其发病风险的指标。此风险等级可以作为参考,指导受检者前往正规医疗机构行进一步检查。
其中,所述复杂疾病包括精神分裂症、双相情感障碍、多动症、冠心病、银屑病、2型糖尿病、多发性硬化、乳腺癌、克罗恩病、溃疡性结肠炎和类风湿性关节炎共11中疾病。
所述与疾病相关的单核苷酸多态性位点为通过gwas研究确定的疾病相关snp位点,共包括2754个位点,其中精神分裂症835个、双相情感障碍184个、多动症144个、冠心病208个、银屑病124个、2型糖尿病269个、多发性硬化140个、乳腺癌180个、克罗恩病298个、溃疡性结肠炎202个、类风湿性关节炎170。
本发明从唾液中提取dna,利用基因芯片技术检测基因型,计算多基因计分并与大量正常人群进行比较和分析,其结果具有一定的准确性和较好的参考价值,且具有取样简单、检测费用低等特点,可以用于辅助评估复杂疾病的发病风险。
附图说明
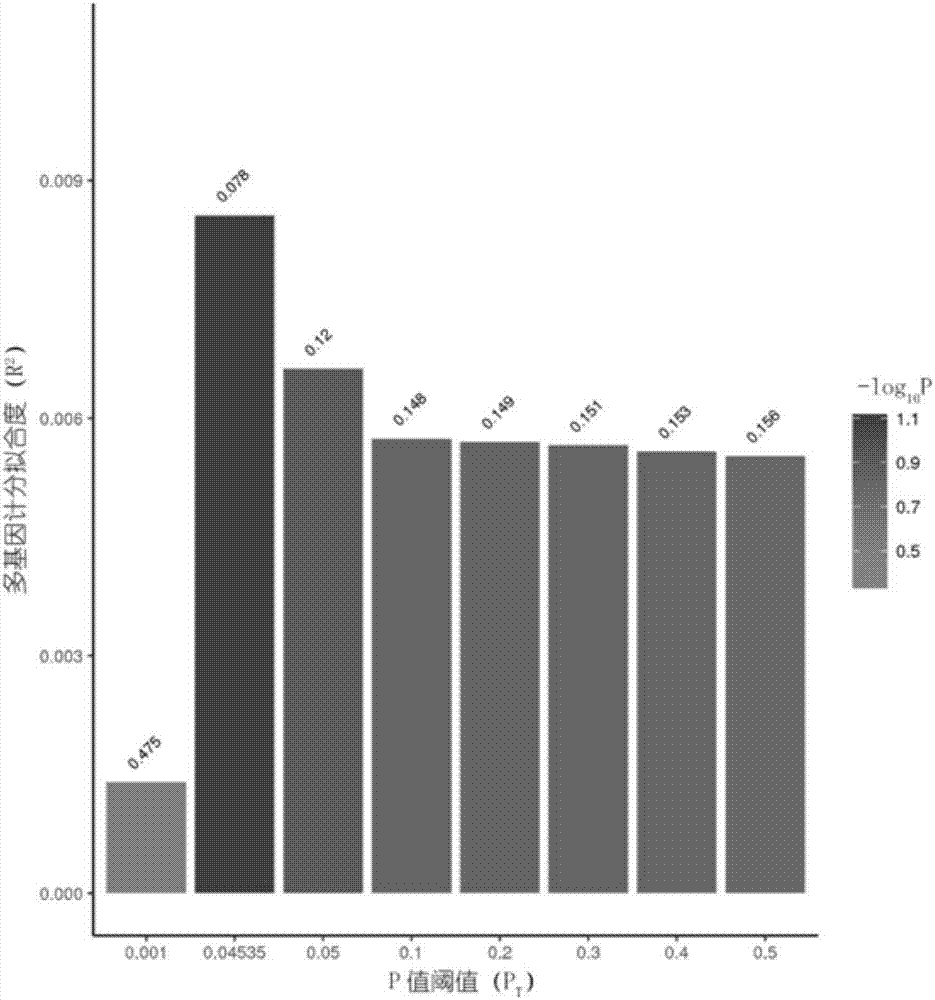
图1为不同p值阈值下487个东亚正常人的精神分裂症多基因计分与疾病表型的相关性(r2)。在pt=0.04535时计算的多基因计分与疾病表型具有最大的相关性;
图2为不同p值阈值下487个东亚正常人的精神分裂症多基因计分与疾病表型的相关性(p值)。
具体实施方式
采集研究对象唾液样本
(1)在提取唾液样本之前的30分钟,请不要饮水、进食、嚼口香糖或者吸烟。
(2)放松脸颊,轻揉脸颊30秒,以促进唾液的产生。
(3)轻轻地向唾液收集器的收集口吐入口腔内的唾液,在收集唾液的时候要尽量注意不要出现过多的泡沫。
(4)收集唾液,直至收集管中的唾液达到2ml的刻度线位置(不包括泡沫)。
(5)将装有保存液的收集器盖子慢慢地扣到收集口上。在扣下的同时,保存液均匀的流入收集管,则表明盖子已扣好。否则,需要重新打开并扣上收集口的盖子,直至保存液均匀流入收集管。操作过程注意动作要尽量轻柔。
(6)轻轻甩动唾液收集器,使保存液更加完全的流入收集管。
(7)确认收集管中液体达到4ml所示的刻度线(不包括上层泡沫)。然后,轻轻地旋下收集管。在旋下收集管的时候,不能使收集管中的唾液贱出或流出。
(8)盖上收集管的盖子并旋紧,上下颠倒摇匀10-15次,使唾液与保存液充分混匀。
(9)轻甩收集管,唾液样本收集完毕。
dna抽提(just-a-tubetm唾液dna提纯试剂盒)
实验之前的准备工作
(1)根据提纯的样品数目制备新鲜的工作结合缓冲液,该缓冲液由结合缓冲液(kb6)与100%异丙醇以1:4体积均匀混合得到。将工作结合缓冲液(kb6)与细胞裂解液按1:1比例混合,剩余的结合缓冲液当天予以丢弃。
(2)qt-275-m试剂盒,加22ml100%乙醇到washingbufferi(wb1)中,充分混匀。qt-275-l试剂盒,加110ml100%乙醇到washingbufferi(wb1),充分混匀。qt-275-s试剂盒,加2.2ml100%乙醇到washingbufferi(wb1),充分混匀。
(3)qt-275-m试剂盒,加72ml100%乙醇到washingbufferii(wb2)中,充分混匀。qt-875-l试剂盒,加360ml100%乙醇到washingbufferii(wb2),充分混匀。qt-875-s试剂盒,加7.2ml100%乙醇到washingbufferii(wb2),充分混匀。
制备裂解液
(1)取20μlrnasea(ra2)到1.5ml或2.0ml离心管中。
(2)将储存在唾液收集瓶中的唾液样品与唾液保存液颠倒和震荡7-8次。静置3-5分钟。
(3)从唾液收集瓶中吸取1ml唾液保存混合物到预先加了rnasea的离心管中,吸头吹打8-9次,或将离心管盖子盖上后颠倒离心管7-8次,混合均匀。(当吸取唾液混合液时,注意不要吸到收集瓶底颗粒状沉淀。)
(4)将离心管置于65℃水浴锅或金属浴中温育10分钟。期间颠倒混合离心管,也可将样品50℃温育过夜。
(5)将离心管以最大转速(13000rpm或16000g)离心2分钟来去除颗粒物质,如食物颗粒,未经消化的死细胞和纤维碎片。
结合程序
(1)转移900ul澄清的唾液裂解液到一个结合管(bt3)中,注意不要吸到离心管底的碎片沉淀。为避免吸到管底的碎片沉淀,吸的时候可以留150-250μl溶液在离心管中。
(2)加900μl含有异丙醇的工作结合缓冲液(kb6)到结合管(bt3)中,充分混匀。
(3)将结合管(bt3)在室温下以最大转速(13000rpm或16000g)离心3分钟来结合dna。在离心过程中,离心管盖朝向转子方向放置,离心后dna大部分聚集在背对管盖的管底一侧。
(4)打开盖子,用吸头吸走结合管底中央的液体,在吸的过程中,吸头不要碰到管壁,因为dna吸附在管壁上。
(5)如果处理超过1ml的唾液保存混合液,重复步骤1-3直到所有的唾液混合物都被利用。加了澄清的唾液裂解液到结合管之后,再次加唾液裂解液时,需将唾液裂解液用吸头吹打5-7次,在加入工作的结合缓冲液(kb6)之前至少温育2分钟。
清洗程序
(1)向每管中加500μl含乙醇的washingbufferi(wb1)。震荡管子4-5次混匀。室温温育1分钟。
(2)在室温以最大转速(≥13000rpm或16000g)离心结合管1分钟。在离心过程中,离心管盖朝向转子方向放置。
(3)用吸头吸走结合管(bt3)管底中央的washingbuffer(wb1),注意在吸的过程中,吸头不要碰到管壁,因为dna吸附在管壁上。
(4)加800μl含乙醇的washingbufferii(wb2)到结合管(bt3)中。震荡管子4-5次或盖上盖子后颠倒离心管7-8次混匀。
(5)在室温以最大转速(≥13000rpm或16000g)离心结合管1分钟。在离心过程中,离心管盖朝向转子方向放置。
(6)用吸头去除结合管(bt3)中washingbuffer(wb2)。
(7)重复步骤4-6,即用washingbuffer(wb2)洗两次。
(8)洗完最后一遍之后,为彻底清除washingbuffer,在移除大部分液体后,可以再次短暂离心结合管(bt3),用200μl吸头吸走管底中间最后一滴液体,将结合管(bt3)在实验室通风橱晾8-10分钟来去除残余的液体。也可以将管子置于62℃水浴锅或金属浴中晾干3-5分钟。
dna的洗脱
(1)吸附在结合管壁的dna至少可以保存六个月。如果dna需要洗脱,可进行下面的程序。
(2)加20μl-100μl洗脱缓冲液(eb2)到每个结合管管壁。如果需要高浓度的dna,加20μl洗脱缓冲液(eb2),选择1或2来洗脱dna。
(3)选择1(涡旋洗脱):盖上离心管的盖子,涡旋离心管30秒,以最大转速短暂离心将所有的液体收集到离心管底部。选择2(震荡洗脱):盖上离心管的盖子,震荡离心管2分钟。选择3(移液枪洗脱):上下吹打溶液8-10次,盖上离心管的盖子,将管子在室温放置2分钟。
(4)洗脱的dna可直接应用于基因芯片检测,或在4℃短期储存或者–20℃长期储存。
基因芯片检测snp
dna样品要求
(1)样品纯度:od260/280值应在1.7~2.0之间,a260/a230>1.5;rna应该去除干净;不含有其它个体或其它物种的dna污染。
(2)样品浓度:dna浓度不低于55ng/μl。
(3)样品总量:每个样品总量不少于2μg。
(4)样品溶剂:溶解在reducedte(10mmtris,ph8.0,0.1mmedta)中。
检测流程
(1)dna片段化:利用dna超声打断仪,将dna打断成100-500bp的片断。
(2)pcr扩增和标记荧光分子:使用通用引物进行pcr扩增,使样品分子标记上可以检测的荧光分子。
(3)杂交:设置合适的条件,使片段化的dna分子与芯片上的探针进行杂交。待杂交完成后,进行洗涤和染色。
(4)数据扫描:打开电脑,连接扫描仪,开始扫描数据。扫描结果为cel文件。
(5)使用r语言将cel信息转为基因型信息。
数据分析
收集疾病相关的snp位点信息
(1)查询已发表的文献及公开的数据库,收集所有通过gwas研究确定的疾病相关snp位点。所有snp位点均有特定疾病对应的or值和p值,表示该snp位点与该疾病的相关性。
(2)针对本发明中所涉及的11种复杂疾病,共收集到2754个snp位点,其中包括精神分裂症835个、双相情感障碍184个、多动症144个、冠心病208个、银屑病:124个、2型糖尿病269个、多发性硬化140个、乳腺癌180个、克罗恩病298个、溃疡性结肠炎202个、类风湿性关节炎170个。
计算多基因计分
(1)针对测试样本的dna,利用基因芯片技术对2754个单核苷酸多态性位点的基因型进行检测。
(2)编程处理,将测试样本的基因型转化为剂量基因型(dosagegenotype)(野生型:0;杂合子:1;纯合子:2)。
(3)同样地,将487个东亚正常人的基因型转化为剂量基因型(dosagegenotype)。这487个东亚正常人来自于千人基因组工程(the1000genomesproject)。
(4)针对每一种复杂疾病,对测试样本以及487个东亚正常人样本分别计算多基因计分。多基因计分的计算公式为:
该公式根据euesden等人的研究进行了修改(2015bioinformatics,euesdenetal.)。对于某一种复杂疾病,针对样本j共有m个单核苷酸多态性位点(gi)可能会影响到该疾病的发生。对于每一个单核苷酸多态性位点(gi),可以基于基因型与表型的相关性计算出该位点的效应值(βi)与p值。以p=0.05作为阈值,将所有p<0.05的单核苷酸多态性位点(gi)的剂量基因型与其效应值(βi)相乘并求和,得到的值即为样本j在该疾病下的多基因计分(prsj)。
结果见图1和图2。
图1:不同p值阈值下487个东亚正常人的精神分裂症多基因计分与疾病表型的相关性(r2)。横坐标是过滤gwas相关snp位点的p值阈值(pt)。纵坐标是多基因计分与疾病表型的拟合度(r2)。颜色深浅表示相关性的p值。在pt=0.04535时计算的多基因计分与疾病表型具有最大的相关性。
图2:不同p值阈值下487个东亚正常人的精神分裂症多基因计分与疾病表型的相关性(p值)。横坐标是过滤gwas相关snp位点的p值阈值(pt)。纵坐标是多基因计分与疾病表型相关性的p值。
评估风险等级
针对每一种复杂疾病,将样本的多基因计分与487个东亚正常人的多基因计分进行比较,并根据样本的多基因计分在对照人群中的分布位置,评定风险等级。具体评定方法为:统计该样本的多基因计分高于人群中的百分比,依据百分比的大小将风险等级分为五级(等级一:0~20%;等级二:20%~40%;等级三:40%~60%;等级四:60%~80%;等级五:80%~100%;),等级五为风险最高的等级。
- 还没有人留言评论。精彩留言会获得点赞!