双端分子标签接头及其用途和带有该接头的测序文库的制作方法
本发明涉及测序
技术领域:
,具体涉及一种双端分子标签接头及其用途和带有该接头的测序文库。
背景技术:
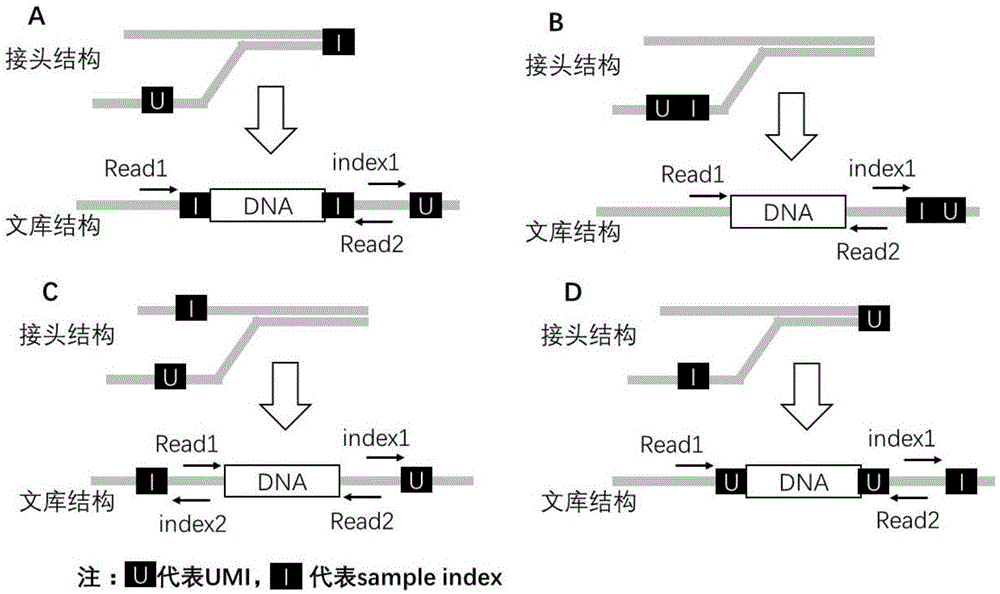
:高通量测序技术由于其高通量、低成本的优势,目前已经成为一种重要的基因检测技术。目前主流的高通量测序技术提供商包括美国的illumina公司、thermofisher公司、pacbio公司、英国的nanopore公司和中国的华大基因(bgi)等。所有这些测序技术在基本原理上都采用测序前的文库构建以及边合成边测序的策略。由于在文库构建和测序过程中存在多个dna扩增环节,每次扩增均有一定的概率引入错误碱基,导致人工突变,产生测序的背景噪音。不同测序技术的错误率不同,大约在0.1%-1%之间。在检测体细胞变异(somaticmutation)时,由于体细胞变异在dna中的频率往往比较低,较多情况下甚至低于0.1%,而高通量测序过程中的背景噪音往往高于0.1%,会堙没真正的低频突变,导致假阴性结果的产生。另一种情况是在rna测序中,往往需要准确区分并定量原始的rna分子的种类和数目,dna扩增导致的重复(duplication)、错误和偏好性能够引起最终rna定性错误或定量失真。第三种测序噪音的来源是生物样本在接触某种化学物质时,会导致dna双链中的某些碱基发生非对称的变异,如石蜡包埋甲醛固定的组织样本(ffpe)会出现很高比例的c>t变异,这种由于体外化学物质导致的非对称的变异也会干扰高通量测序技术对低频突变的检测。分子标签(umi,uniquemolecularidentifiers)的出现能够很好的解决以上问题。通过在建库的最初始阶段,以接头连接的方式引入分子标签,可以标记样本中的每一个原始分子,在随后的测序数据分析过程中可以通过识别分子标签,去除dna扩增导致的重复、错误和偏好性等问题,而双端umi的出现则可以很好的解决非对称变异的问题。目前已经有多种分子标签技术的具体实现方法,纽约大学的jungeuihong对常见的几种分子标签设计方法进行了总结(参考文献pmid:29185922),如图1所示。然而,这几种方法均有不足。具体而言,图1a中单端umi放于原有的样本标签(sampleindex)处会扰乱正常的文库测序,导致测序数据不能正常拆分到每个样本;图1b中单端umi放于样本标签之后,虽然能够实现正常的数据拆分,但是不能实现对非对称变异的有效过滤;图1c中单端umi放于第2个样本标签的位置,不仅不能实现对非对称变异的有效过滤,反而需要额外的一次测序,同时不能兼容双标签(index)测序的模式。图1d中双端umi放于插入片段的两端,虽然可以很好地弥补单端umi的不足,但是目前实现这种双端umi的方法较为繁琐和低效。纽约大学的jungeuihong认为分别合成含有6个n(n代表某个位置可能是a、t、c和g的任一种碱基)的接头,然后直接退火成双链,会导致接头退火的不完全匹配,严重影响连接效率。专利“一种用于检测肿瘤突变的双标签接头序列及检测方法”(申请号201510754103.1)通过在接头umi区的外围引入酶切位点和保护碱基,提高接头退火的效率,然后采用酶切的方法去除部分多余的酶切位点处碱基,整个接头退火纯化过程比较繁琐,回收效率较低。专利“一种分子接头及其应用”(申请号201710240325.0)也采用了类似的酶切纯化的方法。另有专利“一种分子标签的制备方法”(申请号201610496676.3)虽然采用了两步单链延伸的方法避免了酶切,但是也未避免多次的接头反应和纯化过程,操作较为繁琐,接头损失严重。技术实现要素:本发明提供一种双端分子标签接头及其用途和带有该接头的测序文库,能够减少测序读长的浪费,解决碱基不平衡问题,提高测序数据质量。根据第一方面,一种实施例中提供一种双端分子标签接头,包括第一链序列和第二链序列,上述第一链序列的3’端包括2至4个碱基组成的分子标签和至少1个具有碱基平衡作用的碱基位;上述第二链序列的5’端包括2至4个碱基组成的分子标签和至少1个具有碱基平衡作用的碱基位,且上述第一链序列的分子标签与第二链序列的分子标签互补配对,上述第一链序列的具有碱基平衡作用的碱基位与上述第二链序列的具有碱基平衡作用的碱基位互补配对。作为本发明的优选方案,上述分子标签上的每一个碱基各自选自a、t、g、c中的碱基;上述具有碱基平衡作用的碱基位选自g或c或a或没有碱基。作为本发明的优选方案,上述第一链序列和上述第二链序列上的具有碱基平衡作用的碱基位的数量是1个或以上,优选1个或2个,更优选1个。作为本发明的优选方案,上述接头具有选自如下(1)至(3)中任意一种的结构:(1)上述第一链序列具有如下结构:5’-第一链公共接头序列-n1n2n3st-3’,上述第二链序列具有如下结构:5’-psn6n5n4-第二链公共接头序列-3’,其中,p代表磷酸基团,s代表g或c或a或没有碱基,n1至n6分别代表各自选自于a、t、g、c的碱基,且满足如下条件:(a)n1与n4互补配对,n2与n5互补配对,n3与n6互补配对,第一链序列中的s与第二链序列中的s互补配对;(b)当s代表a或没有碱基时,n3和n6分别代表各自选自于g、c的碱基;(c)当s代表g或c时,n3和n6分别代表各自选自于a、t的碱基;(2)上述第一链序列具有如下结构:5’-第一链公共接头序列-n1n2st-3’,上述第二链序列具有如下结构:5’-psn4n3-第二链公共接头序列-3’,其中,p代表磷酸基团,s代表g或c或a或没有碱基,n1至n4分别代表各自选自于a、t、g、c的碱基,且满足如下条件:(a)n1与n3互补配对,n2与n4互补配对,第一链序列中的s与第二链序列中的s互补配对;(b)当s代表a或没有碱基时,n2和n4分别代表各自选自于g、c的碱基;(c)当s代表g或c时,n2和n4分别代表各自选自于a、t的碱基;或(3)上述第一链序列具有如下结构:5’-第一链公共接头序列-n1n2n3n4st-3’,上述第二链序列具有如下结构:5’-psn8n7n6n5-第二链公共接头序列-3’,其中,p代表磷酸基团,s代表g或c或a或没有碱基,n1至n8分别代表各自选自于a、t、g、c的碱基,且满足如下条件:(a)n1与n5互补配对,n2与n6互补配对,n3与n7互补配对,n4与n8互补配对,第一链序列中的s与第二链序列中的s互补配对;(b)当s代表a或没有碱基时,n4和n8分别代表各自选自于g、c的碱基;(c)当s代表g或c时,n4和n8分别代表各自选自于a、t的碱基。作为本发明的优选方案,上述接头具有选自上述(1)所示的结构。作为本发明的优选方案,第一链序列具有如下结构:5’-第一链公共接头序列-n1n2n3st-3’,第二链序列具有如下结构:5’-psn6n5n4-第二链公共接头序列-3’,其中,p代表磷酸基团,s代表g或c或没有碱基,n1至n6分别代表各自选自于a、t、g、c的碱基,且满足如下条件:(a)n1与n4互补配对,n2与n5互补配对,n3与n6互补配对,第一链序列中的s与第二链序列中的s互补配对;(b)当s代表没有碱基时,n3和n6分别代表各自选自于g、c的碱基;(c)当s代表g或c时,n3和n6分别代表各自选自于a、t的碱基。作为本发明的优选方案,上述第一链序列和第二链序列中的公共接头序列选自bgiseq或mgiseq系列测序仪的测序接头序列;优选如下seqidno:1和seqidno:2所示的序列:5’-gaacgacatggctacgatccgactt-3’(seqidno:1);5’-aagtcggaggccaagcggtcttaggaagacaa-3’(seqidno:2)。作为本发明的优选方案,上述第一链序列和第二链序列分别是短链接头序列和长链接头序列,分别具有如下结构:短链接头序列:5’-gaacgacatggctacgatccgacttn1n2n3st-3’(seqidno:3);长链接头序列:5’-psn6n5n4aagtcggaggccaagcggtcttaggaagacaa-3’(seqidno:4);其中,p代表磷酸基团,s代表g或c或没有碱基,n1至n6分别代表各自选自于a、t、g、c的碱基,且满足如下条件:(a)n1与n4互补配对,n2与n5互补配对,n3与n6互补配对,第一链序列中的s与第二链序列中的s互补配对;(b)当s代表没有碱基时,n3和n6分别代表各自选自于g、c的碱基;(c)当s代表g或c时,n3和n6分别代表各自选自于a、t的碱基。作为本发明的优选方案,上述短链接头序列中的n1n2n3st和上述长链接头序列中的psn6n5n4分别具有如下表1所示的序列:表1作为本发明的优选方案,上述第一链序列和第二链序列中至少一个还具有样本标签序列。根据第二方面,一种实施例中提供一种第一方面的双端分子标签接头在制备测序文库中的用途。根据第三方面,一种实施例中提供一种测序文库,该测序文库包括来源于样本的插入片段序列,以及位于上述插入片段序列两端的如第一方面的双端分子标签接头。本发明的双端分子标签接头中双端umi采用尽可能短的umi,既保证了umi的使用效果,又减少了测序读长的浪费;在umi之后采用至少1个碱基位置用来稀释t-a连接产生相同碱基所带来的碱基不平衡问题,提高测序数据质量;本发明的双端分子标签接头制备步骤简单,不存在任何接头损失,每对接头都能够完全配对,达到最佳的连接效率。附图说明图1为现有技术中常见4种umi的设计原理示意图,每个小图中均展示了接头结构和文库结构,并且标注了不同umi接头设计方法的umi和样本标签(sampleindex)的设计位置以及测序方案,其中a图表示单端umi双端样本标签,需要单独进行样本标签的拆分,测序时不能与正常的文库混合上机;b图表示单端umi和单端样本标签在文库的同一侧,需要采用额外的试剂增加标签(样本index)测序的读长;c图表示单端umi和单端样本标签在文库的不同侧,测序时需要进行额外的一次测序(index2),不利于双端标签的接头设计;d图表示双端umi和单端样本标签,对于测序产生的干扰较少,接头的制备较为繁琐。图2为本发明实施例中双端umi的设计原理示意图及几种实现方式,每个小图中均展示了双端umi的一种实现方式,其中umi的设计采用插入dna左右各3个碱基(图中nnn)的形式,共有64种组合形式,为了减弱连接dna时t-a碱基的不平衡,在3个n与t之间选择性地引入1个碱基g或c或不引入任何碱基;其中a图为没有样本标签(sampleindex)的接头结构,b图为单端接头引入1个样本标签;c图和d图均有2个样本标签,d图中样本标签是通过pcr的方式引入的。图3为本发明实施例中64种umi的拆分结果,横坐标显示的是64种不同的umi,纵坐标显示的是每种umi检测到的测序深度,显示umi的分布非常均衡,完全满足umi的使用。具体实施方式下面通过具体实施方式结合附图对本发明作进一步详细说明。在以下的实施方式中,很多细节描述是为了使得本发明能被更好的理解。然而,本领域技术人员可以毫不费力的认识到,其中部分特征在不同情况下是可以省略的,或者可以由其他元件、材料、方法所替代。另外,说明书中所描述的特点、操作或者特征可以以任意适当的方式结合形成各种实施方式。同时,方法描述中的各步骤或者动作也可以按照本领域技术人员所能显而易见的方式进行顺序调换或调整。因此,说明书和附图中的各种顺序只是为了清楚描述某一个实施例,并不意味着是必须的顺序,除非另有说明其中某个顺序是必须遵循的。本发明的一种实施例中提供一种双端分子标签接头,包括第一链序列和第二链序列,上述第一链序列的3’端包括2至4个碱基组成的分子标签和至少1个具有碱基平衡作用的碱基位;上述第二链序列的5’端包括2至4个碱基组成的分子标签和至少1个具有碱基平衡作用的碱基位,且上述第一链序列的分子标签与第二链序列的分子标签互补配对,上述第一链序列的具有碱基平衡作用的碱基位与上述第二链序列的具有碱基平衡作用的碱基位互补配对。本发明中,术语“双端分子标签接头”是指带有双端分子标签(umi,uniquemolecularidentifiers)的接头,可以是测序接头等。所谓“双端分子标签”或“双端umi”,表示在插入片段的两端均有umi。在一个实施例中,双端umi一共有6个碱基,每侧各有3个碱基,优选地,双端umi上的碱基各自选自a、t、g、c中的碱基;为了实现测序时的碱基平衡,3个碱基的umi之后会采用至少1个碱基位置减少t-a连接碱基对测序数据质量的影响。需要说明的是,本发明中具有碱基平衡作用的“碱基位”或“碱基位置”是按照双端分子标签接头的整体设计而言。对于每个具体的双端分子标签接头而言,上述具有碱基平衡作用的“碱基位”或“碱基位置”可能是指1个或以上实际存在的碱基,也可能是指没有碱基存在(碱基数为0)。特别说明的是,即使是在没有碱基存在(碱基数为0)的情况下,也称该处为1个“碱基位”或“碱基位置”。在一个实施例中,双端umi的接头结构如图2所示,图2中每个小图中均展示了双端umi的一种实现方式,其中umi的设计采用插入dna左右各3个碱基(图中nnn)的形式,共有64种组合形式;为了减弱连接dna时t-a碱基的不平衡,在3个n与t之间选择性地引入1个碱基g或c或a或不引入任何碱基(图中s代表的碱基)。其中,a图为没有样本标签(sampleindex)的接头结构,b图为单端接头引入1个样本标签;c图和d图均有2个样本标签,c图中双端接头引入2个样本标签,d图中样本标签是通过pcr的方式引入的。需要说明的是,以上实施例和图2仅是示例性的,在其他实施例中,umi的碱基数采用单侧2个双侧4个碱基或单侧4个双侧8个碱基的设计策略。在其他实施例中,采用2个或更多的具有碱基平衡作用的碱基以达到碱基平衡的目的。此外,接头上样本标签(sampleindex)的数量和存在形式没有限制,无论样本标签的数目是0、1或2个,无论样本标签是直接在接头合成时引入,或通过pcr引物的形式引入,均属于本发明的可行性的技术方式。本发明的双端分子标签的设计和双端分子标签接头的设计方案,广泛地适用于各种测序平台,包括但不限于美国的illumina公司、thermofisher公司、pacbio公司、英国的nanopore公司和中国的华大基因(bgi)的测序平台,在一个实施例中,适用于华大基因的bgiseq或mgiseq系列测序仪。基于本发明的原理,本发明实施例中提出了三种双端分子标签接头,包括第一链序列和第二链序列,分别具有选自如下(1)至(3)中任意一种的结构,优选具有选自上述(1)所示的结构:(1)第一链序列具有如下结构:5’-第一链公共接头序列-n1n2n3st-3’,第二链序列具有如下结构:5’-psn6n5n4-第二链公共接头序列-3’,其中,p代表磷酸基团,s代表g或c或a或没有碱基,n1至n6分别代表各自选自于a、t、g、c的碱基,且满足如下条件:(a)n1与n4互补配对,n2与n5互补配对,n3与n6互补配对,第一链序列中的s与第二链序列中的s互补配对;(b)当s代表a或没有碱基时,n3和n6分别代表各自选自于g、c的碱基;(c)当s代表g或c时,n3和n6分别代表各自选自于a、t的碱基;(2)第一链序列具有如下结构:5’-第一链公共接头序列-n1n2st-3’,第二链序列具有如下结构:5’-psn4n3-第二链公共接头序列-3’,其中,p代表磷酸基团,s代表g或c或a或没有碱基,n1至n4分别代表各自选自于a、t、g、c的碱基,且满足如下条件:(a)n1与n3互补配对,n2与n4互补配对,第一链序列中的s与第二链序列中的s互补配对;(b)当s代表a或没有碱基时,n2和n4分别代表各自选自于g、c的碱基;(c)当s代表g或c时,n2和n4分别代表各自选自于a、t的碱基;或(3)第一链序列具有如下结构:5’-第一链公共接头序列-n1n2n3n4st-3’,第二链序列具有如下结构:5’-psn8n7n6n5-第二链公共接头序列-3’,其中,p代表磷酸基团,s代表g或c或a或没有碱基,n1至n8分别代表各自选自于a、t、g、c的碱基,且满足如下条件:(a)n1与n5互补配对,n2与n6互补配对,n3与n7互补配对,n4与n8互补配对,第一链序列中的s与第二链序列中的s互补配对;(b)当s代表a或没有碱基时,n4和n8分别代表各自选自于g、c的碱基;(c)当s代表g或c时,n4和n8分别代表各自选自于a、t的碱基。在一个实施例中,第一链序列具有如下结构:5’-第一链公共接头序列-n1n2n3st-3’,第二链序列具有如下结构:5’-psn6n5n4-第二链公共接头序列-3’,其中,p代表磷酸基团,s代表g或c或没有碱基,n1至n6分别代表各自选自于a、t、g、c的碱基,且满足如下条件:(a)n1与n4互补配对,n2与n5互补配对,n3与n6互补配对,第一链序列中的s与第二链序列中的s互补配对;(b)当s代表没有碱基时,n3和n6分别代表各自选自于g、c的碱基;(c)当s代表g或c时,n3和n6分别代表各自选自于a、t的碱基。在一个实施例中,测序平台是华大基因(bgi)的测序平台bgiseq或mgiseq系列测序仪,因此,第一链序列和第二链序列中的公共接头序列选自bgiseq或mgiseq系列测序仪的测序接头序列。需要说明的是,各个公司的测序平台的测序接头序列不同,但是其umi的设计原理均相同,并且这些测序平台的测序接头序列是已知序列,因此根据本发明的原理容易设计适用于每一个测序平台的包含本发明的双端分子标签的测序接头序列。在一个实施例中,针对bgiseq或mgiseq系列测序仪,采用如下seqidno:1和seqidno:2所示的序列作为第一链序列和第二链序列中的公共接头序列:5’-gaacgacatggctacgatccgactt-3’(seqidno:1);5’-aagtcggaggccaagcggtcttaggaagacaa-3’(seqidno:2)。需要说明的是,本发明中,第一链序列和第二链序列没有特别限定,在实际应用中,第一链序列可能是测序接头的短链接头序列,也可能是长链接头序列;类似地,第二链序列也可能是测序接头的短链接头序列或长链接头序列。在一个最优选的实施例中,第一链序列和第二链序列分别是短链接头序列和长链接头序列,分别具有如下结构:短链接头序列:5’-gaacgacatggctacgatccgacttn1n2n3st-3’(seqidno:3);长链接头序列:5’-psn6n5n4aagtcggaggccaagcggtcttaggaagacaa-3’(seqidno:4);其中,p代表磷酸基团,s代表g或c或没有碱基,n1至n6分别代表各自选自于a、t、g、c的碱基,且满足如下条件:(a)n1与n4互补配对,n2与n5互补配对,n3与n6互补配对,第一链序列中的s与第二链序列中的s互补配对;(b)当s代表没有碱基时,n3和n6分别代表各自选自于g、c的碱基;(c)当s代表g或c时,n3和n6分别代表各自选自于a、t的碱基。在上述最优选的实施例中,所设计的双端umi采用单侧3个n,双侧共计6个n的设计方案,既保证了umi的使用效果,又尽可能节省了测序读长;在umi之后采用1个碱基的位置稀释t-a连接产生相同碱基的碱基不平衡问题,提高测序数据质量;双端umi接头可以通过穷举合成64对携带有不同umi序列,然后分别退火,等比例混合后使用,接头制备步骤简单,不存在任何接头损失,每对接头都能够完全配对,达到最佳的连接效率。根据测序平台公用接头结构和测序引物的序列,设计seqidno:3所示的短链接头序列和seqidno:4所示的长链接头序列,如表1所示,分别合成尾部带有3-4个碱基不等的分子标签序列的接头序列,共计64对。将合成的接头序列按照对应的序号一一配对退火,形成只含有一种umi的双链接头。按照等物质的量混合64种umi的已退火接头,然后稀释到工作液的浓度进行使用。表1本发明一种实施例中提供本发明上述描述的双端分子标签接头在制备测序文库中的用途。本发明一种实施例中提供一种测序文库,该测序文库包括来源于样本的插入片段序列,以及位于上述插入片段序列两端的如第一方面的双端分子标签接头。这样的测序文库可应用于肿瘤基因检测的测序噪音过滤和低频突变检出,也可能应用于rna相关的测序和微生物相关的测序等领域,涉及的样本类型包括但不限于血浆、ffpe、新鲜组织、粪便、尿液等。以下通过具体实施例详细说明本发明的技术方案和效果,应当理解实施例仅是示例性的,不能理解为对本发明保护范围的限制。实施例1本实施例采用华大基因的bgiseq和mgiseq系列测序仪的常规测序接头进行设计合成双端umi接头,包括:64种短链接头序列:5’-gaacgacatggctacgatccgacttnnnst-3’(seqidno:3),其中umi选自上述表1;64种长链接头序列:5’-psnnnaagtcggaggccaagcggtcttaggaagacaa-3’(seqidno:4),其中umi选自上述表1。上述序列中,p代表磷酸化修饰,s代表g或c或没有碱基。本实施例中上述128条序列通过北京六合华大基因科技有限公司合成,纯化方式为pageplus,订购量为5od。将合成的dna序列干粉进行离心,12000rpm,2min。用te缓冲液将引物稀释到100μm,te配置如表2所示。表2te缓冲液配置试剂名称体积trishcl(1m)500μledta(0.5m)100μl无核酸酶(nf)的水49.4ml合计50ml震荡混匀,瞬时离心,室温静置2h以上。按照如下表3配置25μm的接头,其中短链接头序列和长链接头序列按照表1中umi形成一对一的对应关系。表325μm接头的配置试剂名称体积(μl)长链接头序列(100μm)5短链接头序列(100μm)5trishcl(0.02m)10合计20震荡混匀,瞬时离心,室温静置30min。将64对退火好的接头转移混合到1个1.5ml的ep管中,标记为umi64m,注明浓度为25μm,共计约1280μl。取200μl的umi64m(25μm)与300μl的无核酸酶(nf)的水进行混合,配置成umi64m(10μm)的接头工作液500μl。将uid64m(25μm)和uid64m(10μm)放于-20℃保存,待用。采用kapahyperprepkit建库试剂盒(kapabiosystems,kr0961),10ng的cfdna作为插入片段,采用3μl上述uid64m(10μm)接头进行建库。采用华大智造的mgiseq-2000测序仪,按照pe100的测序模式,测序30g的数据量,对r1端的uid进行拆分。如图3所示,显示64种umi的分布非常均衡,完全满足umi的使用。以上应用了具体个例对本发明进行阐述,只是用于帮助理解本发明,并不用以限制本发明。对于本发明所属
技术领域:
的技术人员,依据本发明的思想,还可以做出若干简单推演、变形或替换。sequencelisting<110>深圳华大基因股份有限公司,深圳华大临床检验中心,广州华大基因医学检验所有限公司<120>双端分子标签接头及其用途和带有该接头的测序文库<130>18i26915<160>4<170>patentinversion3.3<210>1<211>25<212>dna<213>人工序列<400>1gaacgacatggctacgatccgactt25<210>2<211>32<212>dna<213>人工序列<400>2aagtcggaggccaagcggtcttaggaagacaa32<210>3<211>30<212>dna<213>人工序列<220><221>misc_feature<222>(26)..(28)<223>nisa,c,g,ort<400>3gaacgacatggctacgatccgacttnnnst30<210>4<211>36<212>dna<213>人工序列<220><221>misc_feature<222>(2)..(4)<223>nisa,c,g,ort<400>4snnnaagtcggaggccaagcggtcttaggaagacaa36当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1