一组特异性结合胶霉毒素的核酸适配体及其应用的制作方法
本发明涉及生物技术领域,具体地说,是一组与胶霉毒素特异性结合的高亲和力核酸适配体及其应用。
背景技术:
近年来,随着器官移植术的普及、恶性肿瘤患者的增加,以及广谱抗菌药物、糖皮质激素等的广泛应用,侵袭性曲霉菌的感染率显著增加,在免疫力低下人群中约占15%,病死率可高达90%。引起人类深部感染的曲霉菌主要包括烟曲霉、黄曲霉、构巢曲霉、黑曲霉、土曲霉等。其中,烟曲霉最为常见,约占其中的95%,是引起免疫力低下患者严重深部曲霉感染,甚至是发生侵袭性曲霉病的最主要致病菌。感染患者由于缺乏特征性临床症状,发病隐匿难以区分,其存活主要依赖于早期快速诊断和临床及时治疗。然而,早期诊断一直是临床和实验室面临的最大挑战。
胶霉毒素(gliotoxin)是烟曲霉菌生长过程中产生的毒性最强的代谢物之一,其可直接造成机体损伤,或通过降低机体的免疫功能引起曲霉菌的感染和扩散。尽管真菌毒素的产生一般具有时间依赖性释放特征,但体外培养实验显示,24h时即可检测到胶霉毒素,在48-72h达到高峰。lewis等也发现,在小鼠模型及临床感染患者的血清中均可检测到胶霉毒素。由此可见,感染患者体内特定器官或者血清、尿液中胶霉毒素的检测可以作为侵袭性烟曲霉菌感染早期诊断的一项重要指标。然而,现有的检测方法(如高效液相色谱、薄层色谱等)由于耗时长、样品前制备繁琐、检测灵敏度有限等问题已难以满足早期快速诊断的需求。同时,胶霉毒素是一个非蛋白结构的小分子真菌毒素,其产生识别配体(例如抗体)的能力甚微,从而进一步限制了相应检测方法的发展。因此,目前迫切需要研发与胶霉毒素特异性结合的识别分子,从而为复杂体系中胶霉毒素的分离与去除,体内外胶霉毒素的快速检测与早期诊断,以及相关疾病中胶霉毒素的中和或拮药物的开发和制备等提供有效的工具。
核酸适配体作为一种新型的生物识别分子,能够高特异识别并结合靶分子。它是通过指数富集的配体系统进化技术(systematicevolutionofligandsbyexponentialenrichment,selex)从体外核酸文库中筛选得到的ssdna或者rna分子。核酸适配体由于可化学合成、易于标记和修饰、靶标广泛、批次差异低、不受免疫原性和免疫条件限制等,可用于特定靶分子的捕获、分离和检测,尤其在靶向小分子毒素方面具有良好的应用前景。
技术实现要素:
本发明的目的在于提供一组与胶霉毒素特异性结合的高亲和力核酸适配体。本发明的另一目的在于提供通过截短和突变的方法对核酸适配体进行优化,得到了一条特异性结合胶霉毒素亲和力更高的核酸适配体。本发明的再一目的是提供上述核酸适配体在制备胶霉毒素的分离与去除试剂中、在制备体内外胶霉毒素的检测试剂、试剂盒及诊断方法中、在制备中和或拮抗胶霉毒素的药物中等多方面的应用。
本发明的主要技术方案是:1)通过氧化石墨烯selex技术筛选获得了与胶霉毒素特异性结合的高亲和力核酸适配体;2)通过截短优化获得了该核酸适配体的核心序列;3)通过突变优化进一步改善了该核酸适配体的亲和力、特异性、结构稳定性等性能;为胶霉毒素相关的实验室技术的开发、临床诊断方法的发展和核酸药物的制备提供了一组特异性强、稳定性高、易于生产和修饰的高亲和力生物识别分子。
本发明的第一方面,提供一组与胶霉毒素特异性结合的高亲和力核酸适配体,其序列分别如seqidno.1~seqidno.6(表1)所示。
表1
本发明的第二方面,提供一组如上所述的核酸适配体在制备胶霉毒素检测试剂、试剂盒或传感器中的应用。
进一步的,所述的试剂、试剂盒或传感器可用于快速检测体内外的胶霉毒素。
本发明的第三方面,提供一组如上所述的核酸适配体在制备胶霉毒素分离、识别或捕获制剂中的应用。
进一步的,所述的制剂可以用于复杂体系中胶霉毒素的分离、捕获或去除等。
本发明的第四方面,提供一组如上所述的核酸适配体在开发与胶霉毒素相关临床疾病早期诊断新方法中的应用。
进一步的,所述的胶霉毒素相关临床疾病为侵袭性曲霉菌感染、侵袭性曲霉病等。
本发明的第五方面,提供一组如上所述的核酸适配体在制备中和或拮抗胶霉毒素的药物中的应用。
本发明优点在于:
本发明鉴于胶霉毒素稳定性高,分子量小的结构特点,设计了基于氧化石墨烯selex技术,筛选获得了与胶霉毒素高亲和力、强特异性结合的核酸适配体,并通过截短和突变等优化策略进一步改善了核酸适配体的性能。这些核酸适配体作为与胶霉毒素特异性结合的生物识别分子,具有亲和力高、稳定性好、免疫原性低、易制备、修饰和标记等优势,具有广阔的应用前景,可用于复杂体系中胶霉毒素的分离与去除,体内外胶霉毒素的快速检测与早期诊断,以及在相关疾病中胶霉毒素的中和或拮抗药物的开发与制备等。
因此,本发明的核酸适配体面向实际应用具有巨大的潜力。
附图说明
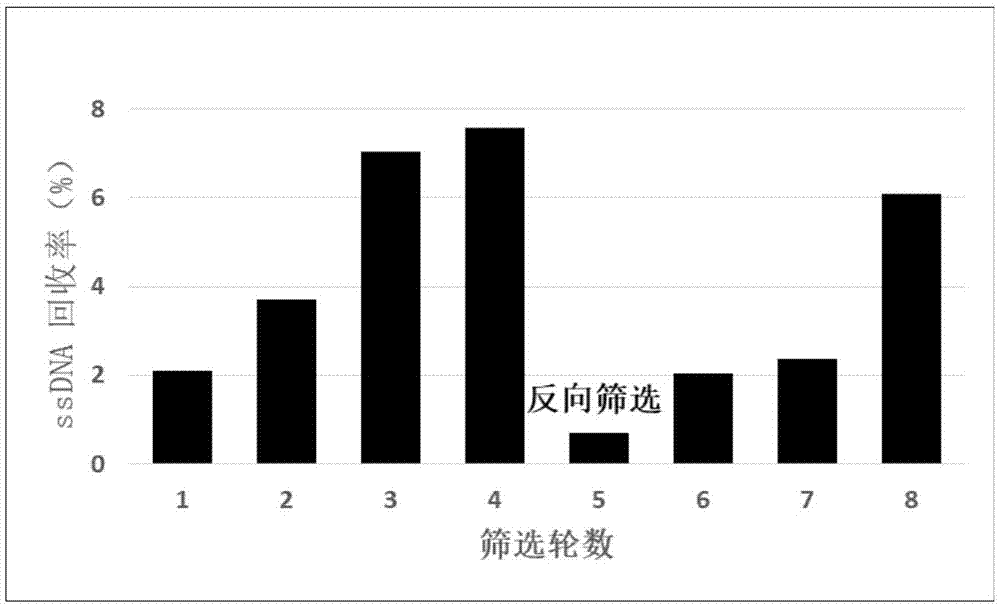
图1.每一轮筛选中结合胶霉毒素的ssdna回收率。
图2.核酸适配体apt8与胶霉毒素的结合解离曲线。
图3.核酸适配体apt8与干扰物结合的相对信号图。
图4.核酸适配体apt16与胶霉毒素的结合解离曲线。
图5.核酸适配体apt16与干扰物结合的相对信号图。
图6.mfold软件预测的核酸适配体的二级结构图。
图7.核酸适配体apt8t1-apt8t3与胶霉毒素的结合解离曲线。
图8.核酸适配体apt8t1m与胶霉毒素的结合解离曲线。
图9.核酸适配体apt8t1m与干扰物结合的相对信号图。
具体实施方式
下面结合实施例对本发明提供的具体实施方式作详细说明。
下列实施例中未注明具体条件的实验方法,通常按照常规条件如sambrook等人,分子克隆:实验室指南(newyork:coldspringharborlaboratorypress,1989)中所述的条件,或按照制造厂商所建议的条件。除非另外说明,否则百分比和份数按重量计算。除非另行定义,文中所使用的所有专业与科学用语与本领域熟练人员所熟悉的意义相同。此外,任何与所记载内容相似或均等的方法及材料皆可应用于本发明中。文中所述的较佳实施方法与材料仅作示范之用。
实施例1.随机ssdna文库及其引物的构建
1.构建长度为80个核苷酸的随机ssdna文库
5′-agcagcacagaggtcagatg-n40-cctatgcgtgctaccgtgaa-3′(seqidno.7);其中,n代表碱基a,t,c,g中任一个,n40代表长度为40个核苷酸的随机序列。
2.引物的构建
上游引物:5′-agcagcacagaggtcagatg-3′(seqidno.8);
下游引物1:5′-ttcacggtagcacgcatagg-3′(seqidno.9);
下游引物2:5′-poly(da20)-spacer18-ttcacggtagcacgcatagg-3′(seqidno.10)。
实施例2.胶霉毒素核酸适配体的筛选
为了获得与胶霉毒素特异性结合的高亲和力核酸适配体,本研究基于氧化石墨烯能够非特异性吸附ssdna的特性共进行了8轮筛选。其中,从第5轮开始引入反向筛选,以进一步提高筛选的效率和特异性。每一轮筛选过程中的核酸适配体与胶霉毒素结合的回收率如图1所示,从而有效的监控筛选的进展。
氧化石墨烯selex技术具体筛选过程为:(1)如表2所示,首先将一定量的ssdna文库溶解于筛选缓冲液中(含5mmmgcl2,5%dmso的d-pbs缓冲液),95℃水浴10min,冰浴猝冷5min,室温放置30min后,加入200pmol的胶霉毒素室温旋转孵育,以促使两者充分碰撞和结合;(2)加入500μl(1mg/ml)的氧化石墨烯溶液和适量的筛选缓冲液,使最终的孵育的体积为1ml。此时,溶液中游离的ssdna通过π-π堆积和疏水作用力被非特异性的吸附在氧化石墨烯表面,而与胶霉毒素特异性结合的核酸适配体序列以结构复合物的形式存在于溶液中。(3)室温旋转孵育结束后,15,000rpm离心3次,将回收的上清进行定量和纯化。(4)将纯化的ssdna作为模板,进行pcr扩增,反应体系为:10μl的hotstartpremix(5x);2.5μl上、下游引物(10μm);5μl的模板;最后加入无菌水至50μl,共40管。扩增条件为:94℃,预变性1min;95℃,变性30s;60℃,退火30s;72℃,延伸30s;最后72℃,再延伸2min;共20个循环;(5)在pcr扩增的文库中加入尿素变性的上样缓冲液,充分混匀后,变复性处理即95℃热变性10min,冰浴猝冷5min,室温放置5min;(6)将处理好的样品加入到12%尿素变性的聚丙烯酰氨凝胶上样孔中,接通电泳仪,300v恒定电压下进行电泳;(7)电泳结束后,在干净的平皿中加入20ml的ddh2o和5μl核酸荧光染料,充分混匀后将凝胶放置其中,在水平摇床上轻轻震荡,染色20min;(7)将聚丙烯酰胺凝胶放置在凝胶成像系统上成像,切胶回收ssdna文库至2ml的试管中,加入1.5ml的ddh2o,沸水煮胶30min后,离心回收上清液。(8)通过
根据上面的筛选方法重复进行下一轮筛选,至第8轮,停止筛选,将富集的文库进行克隆和测序,获得了核酸适配体apt8和apt16。
表2:氧化石墨烯selex技术筛选的协议
实施例3.核酸适配体与胶霉毒素相互作用的测定
本实施例中,通过生物膜干涉技术测定核酸适配体与胶霉毒素的结合亲和力和特异性。
(1)将生物素标记的核酸适配体用筛选缓冲液溶解并稀释至2μm,95℃水浴10min,冰浴猝冷5min,室温放置30min,以促使其重新折叠成稳定的三维结构。
(2)将200μl筛选缓冲液、核酸适配体和胶霉毒素分别加入到96孔板中,链霉亲和素修饰的生物传感器按照仪器设定的程序依次浸入到各反应孔中,经过平衡1.5min,核酸适配体固化5min,漂洗1.5min,结合2.5min和解离2.5min五个步骤。
(3)核酸适配体传感器分别与胶霉毒素和非特异性靶分子β-1,3-glucan,okadaicacid,atp,d-galacto-d-mannan及bsa进行相互作用。结果如图2和图4所示,核酸适配体apt8、apt16与胶霉毒素结合的亲和力常数分别为376nm和381nm。然而,与apt16相比,核酸适配体apt8与其他干扰物几乎不结合(见图3和图5)。因此,优选特异性更强的核酸适配体apt8用于进一步的优化和改造研究。
生物膜干涉技术中采用的缓冲液均为筛选缓冲液。每个试验都设有与缓冲液相互作用的对照传感器,对照传感器的结合解离曲线借助octet数据分析软件cfrpart11version6.x从样品传感器的响应值中扣除,同时采用1:1的结合模式对响应数据进行拟合,得到核酸适配体与靶分子结合的亲和力。
实施例4.核酸适配体优化与鉴定
为了进一步改善核酸适配体的性能,序列截短和位点突变等优化策略分别被引进。基于mfold在线软件的预测,我们发现核酸适配体apt8具有3个颈环结构(图6)。当将颈环1截去后,核酸适配体apt8t1不仅显示出稳定的二级结构,而且与胶霉毒素的结合亲和力增加至196nm(图7)。为了获得该核酸适配体与靶分子更加精准的结合序列,我们将apt8t1进一步截短,获得了序列apt8t2和apt8t3。然而,分子间相互作用的结果显示,apt8t2和apt8t3与胶霉毒素不结合(图7)。这可能是由于当颈环1截去后,颈环2和颈环3折叠成更加稳定的空间结构,导致靶分子的结合位点被充分暴露,引起了两者结合亲和力的增加。因此,通过截短优化的策略,我们获得了与胶霉毒素具有更高结合亲和力的核酸适配体的核心序列apt8t1。
为了进一步提高apt8t1的结构稳定性,我们通过突变优化策略分别在核酸适配体的5'端的颈环处和3'端引入了紧密的小发夹结构(图6)。如图8所示,核酸适配体apt8t1m与胶霉毒素的结合亲和力被显著增加至10.5nm,且具有更高的靶向特异性(图9)。这可能是由于这种增加结构稳定性的方法,使核酸适配体与靶分子胶霉毒素结合更加致密,导致了两者的结合亲和力被进一步的提高。
以上已对本发明创造的较佳实施例进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明创造精神的前提下还可做出种种的等同的变型或替换,这些等同的变型或替换均包含在本申请权利要求所限定的范围内。
sequencelisting
<110>复旦大学附属眼耳鼻喉科医院
上海中医药大学附属龙华医院
<120>一组特异性结合胶霉毒素的核酸适配体及其应用
<130>/
<160>10
<170>patentinversion3.3
<210>1
<211>40
<212>dna
<213>人工序列(artificial)
<400>1
caagggttcatgtgtccacatggaggtgaccttaccctgt40
<210>2
<211>40
<212>dna
<213>人工序列(artificial)
<400>2
acactgggatattggggataaggggattaggggccattcc40
<210>3
<211>24
<212>dna
<213>人工序列(artificial)
<400>3
catgtgtccacatggaggtgacct24
<210>4
<211>14
<212>dna
<213>人工序列(artificial)
<400>4
catgtgtccacatg14
<210>5
<211>9
<212>dna
<213>人工序列(artificial)
<400>5
aggtgacct9
<210>6
<211>24
<212>dna
<213>人工序列(artificial)
<400>6
catgcgtcagcatggaggggacct24
<210>7
<211>80
<212>dna
<213>人工序列(artificial)
<220>
<221>misc_feature
<222>(21)..(60)
<223>nisa,c,g,ort
<400>7
agcagcacagaggtcagatgnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn60
cctatgcgtgctaccgtgaa80
<210>8
<211>20
<212>dna
<213>人工序列(artificial)
<400>8
agcagcacagaggtcagatg20
<210>9
<211>20
<212>dna
<213>人工序列(artificial)
<400>9
ttcacggtagcacgcatagg20
<210>10
<211>20
<212>dna
<213>人工序列(artificial)
<400>10
ttcacggtagcacgcatagg20
- 还没有人留言评论。精彩留言会获得点赞!