用于诊断和治疗监测的生物学指标的鉴定和用途的制作方法
本专利一般涉及健康状况的诊断和治疗。在一些特定的实施例中,本专利涉及将生物学指标与健康分类、健康状态、治疗效果、健康改善或偏差等关联起来的新系统和方法。
背景技术:
对医疗保健界来说,及时诊断和治疗健康状况非常重要。诊断和治疗健康状况的传统方法在准确度和精确度方面存在不足。特别是对于从生物样本中获取的质谱进行解析的传统方法容易受到人为误差的干扰。人为输入经常会出现偏差,这些偏差可能会影响质谱解析的结论。有必要通过新的系统和方法在智能环境下进行无偏差且连续验证有效的决策,从而提高质谱解析的可靠性、准确度和精确度。
附图说明
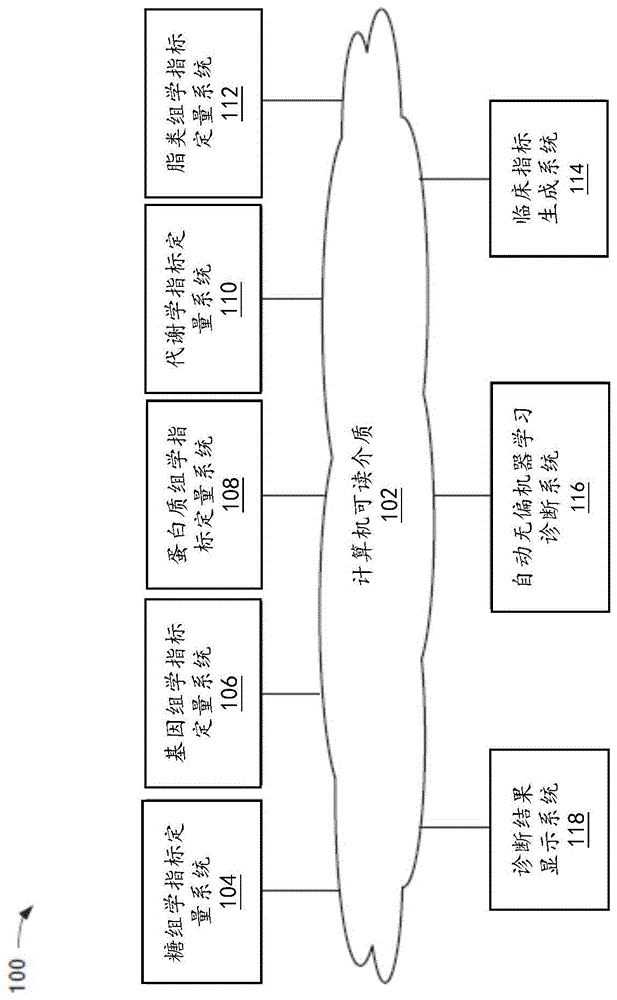
图1a是示例系统的示意图,根据本专利的一个或多个实施例,该示例系统能够鉴定与一个或多个健康分类相关的一种或多种生物学指标,并基于该生物学指标预测性地诊断一个或多个受试者的一个或多个健康状态。
图1b是示例系统的示意图,该示例系统能够使用峰积分平台对生物学指标进行定量,鉴定与一个或多个健康分类相关的一种或多种生物学指标,并基于该生物学指标预测性地诊断一个或多个受试者的一个或多个健康状态。
图1c是可分析生物样本的质谱示意图。
图1d是一个基于可分析的生物样本的质谱生成的峰值波形示意图。
图1e示出了图1d中所示峰值波形的积分。
图2是确定一种或多种生物学指标作为一种或多种生物标记物的示例方法流程图。
图3是示例系统示意图,该示例系统能够执行一个或多个自动无偏深度学习操作,以确定生物标记物。
图4是执行自动无偏深度学习操作以确定生物标记物的示例方法的流程图。
图5是基于生物标记物对受试者进行疾病诊断的示例系统图。
图6是乳腺癌患者的血浆样本相对于对照组的血浆样本中免疫球蛋白g(igg)糖肽比率的示例性变化的示意图。
图7示出了原发性硬化性胆管炎(psc)和原发性胆汁性肝硬化(pbc)患者的血浆样本相对于健康供体血浆样本中igg糖肽比率的变化。
图8a-8c分别示出了psc和pbc样本的血浆样本相对于健康供体的血浆样本中igg、iga和igm糖肽的单独判别分析数据。
图9示出了psc和pbc患者的血浆样本相对于健康供体的血浆样本中igg、iga和igm糖肽的组合判别分析数据。
详细说明
定义
在本说明书中,除非上下文另有说明,下列词语和短语通常具有以下含义。
词语“生物样本”是指任何生物体液、细胞、组织、器官或上述一种或多种的任意部分,或前述任何一种或多种的任意组合。例如,“生物样本”可以包括一种或多种通过活检获取的组织切片;正在进行或适合组织培养的细胞;唾液、眼泪、痰、汗液、粘液、粪便、胃液、腹腔液、羊水、囊肿液、腹膜液、脊髓液、尿液、滑液、全血、血清、血浆、胰液、母乳、肺灌洗液、骨髓、胃酸、胆汁、滑液、精液、脓液、水状液、渗出液等样本;或任何其他生物学物质、或上述任何一种或多种的任意部分或其组合。
词语“生物标记物”是指一种或多种过程、事件、状况或其任意组合的独特的生物学或来自生物学的指标。通常,生物学指标和来自生物学的指标是可检测、可定量的和/或可测量的。例如,生物标记物可以包含一种或多种可测量的分子或物质,这些分子或物质产生于受试者、与受试者相关或从受试者得到,其存在提示另一种特性(quality),例如一个或多个过程、事件、状况或上述各项的任意组合。生物标记物可以包括任何一种或多种生物分子(单独或组合),或任何一种或多种生物分子的片段(单独或组合),其被检测到的存在、数量(绝对量、成比例的量、相对量或其他形式)、度量,或者一种或多种此类的存在、数量或度量的变化,与一种或多种特定的健康状态相关。例如,生物标记物包括但不限于一种或多种生物分子:核苷酸、氨基酸、脂肪酸、类固醇、抗体、激素、肽、蛋白质、碳水化合物和类似物。其他实例还包括一种或多种糖基化的肽片段、脂蛋白等。生物标记物可以提示健康状况,例如一种或多种疾病、感染、综合症、症状或其他状态的存在、发作、阶段或状态,也包括对一种或多种疾病、感染、综合症或症状有风险。
词语“聚糖”指糖复合物例如糖肽、糖蛋白、糖脂或蛋白聚糖中的碳水化合物部分。
词语“糖型”是指附着有特定结构聚糖的蛋白质的独特的一级、二级、三级和四级结构。
词语“糖基化的肽片段”是指通过一种或多种蛋白酶对糖基化肽进行酶解而得的糖基化肽(或糖肽),其氨基酸序列与所述糖基化肽部分相同但不完全相同。
词语“多反应监测质谱法(mrm-ms)”是指对生物样本中的蛋白质/肽进行的高灵敏度、高选择性的靶向定量方法。与传统质谱法不同,mrm-ms具有高度选择性(靶向性),研究人员可以微调仪器以寻找特定目标肽/蛋白质片段。mrm的灵敏度更高、特异性更高、分析速度更快、且定量限更大,可用于检测特定肽/蛋白质片段,例如潜在的生物标记物。mrm-ms包括三重四极杆(qqq)质谱仪或四极杆飞行时间(qtof)质谱仪。
词语“蛋白酶”是指能够将蛋白质进行蛋白水解或分解成较小的多肽或氨基酸的酶。蛋白酶的实例包括但不限于丝氨酸蛋白酶、苏氨酸蛋白酶、半胱氨酸蛋白酶、天冬氨酸蛋白酶、谷氨酸蛋白酶、金属蛋白酶、天冬酰胺肽裂解酶中的一种或多种及其任意组合。
词语“受试者”是指哺乳动物。哺乳动物的非限制性实例包括人、非人灵长类、小鼠、大鼠、狗、猫、马或牛等。除人类以外的哺乳动物作为代表动物病时、病前或病前状态的动物模型的受试者比较有优势。受试者可以是雄性或雌性。受试者可以是先前已被确定患有某种疾病或症状,也可以是已经或正在接受某种疾病或症状的治疗干预。作为可供选择的方案,受试者也可以先前未被诊断出患有疾病或症状。例如,受试者可以表现出一种或多种疾病或症状的危险因素,或者不表现出疾病危险因素,或者是对疾病或症状无表现。受试者也可以正患有疾病或症状或处于患有疾病或症状的风险中。
词语“治疗措施”或“治疗”是指对受试者如哺乳动物的疾病或症状的任何处理,包括:(1)预防所述疾病或症状,即使临床症状不再发展;(2)抑制疾病或症状,即阻止或抑制临床症状的发展;和/或(3)缓解疾病或症状,即使临床症状消退。
本说明书使用的单数名词“一”、“一个/种”和“该”、“所述”包括复数,除非上下文另有明确说明。
系统
图1a描述了一个示例系统的图,该系统能够鉴定出与健康分类相关的生物学指标,并基于该生物学指标预测性地诊断受试者的健康状态。如图所示,系统100包括计算机可读介质102、糖组学指标定量系统104、基因组学指标定量系统106、蛋白质组学指标定量系统108、代谢学指标定量系统110、脂类组学指标定量系统112、临床指标生成系统114、自动无偏机器学习诊断系统116和诊断结果派送系统118。
计算机可读介质102指代各种可适用的技术。例如,计算机可读介质102可以用于形成网络或网络的一部分。当两个组件同时位于设备上时,计算机可读介质102可以包括总线或其他数据通道或平面(plane)。在第一组件位于一个设备上并且第二组件位于不同设备上的情况下,计算机可读介质102可以包括无线或有线后台网络或lan。如果适用,计算机可读介质102也可以包含wan或其他网络的相关部分。
如本说明书中所使用的,“计算机可读介质”包括所有法定的(例如,依照美国35usc101的规定)全部介质;如果对于包括计算机可读介质的权利要求的有效性所必需的话,特别不包括性质上非法定的全部介质。已知的法定计算机可读介质包括硬件(仅举几例,例如寄存器、随机存取存储器(ram)、非易失性(nv)存储设备),可以限于也可以不限于硬件。
本说明书中所述的计算机可读介质102或其中的一部分,以及其他系统、接口、引擎、数据存储库和其他设备,可作为一个计算机系统、多个计算机系统或一个计算机系统或多个计算机系统中的一部分来实施。通常,计算机系统包括处理器、存储器、非易失性存储器和接口。典型的计算机系统通常至少包括处理器、存储器以及将存储器连接到处理器的设备(例如总线)。处理器可以是例如微处理器等通用中央处理单元(cpu),或者例如微控制器等专用处理器。
存储器的非限制性实例可以包括例如动态ram(dram)和静态ram(sram)等的随机存取存储器(ram)。所述存储器可以是本地、远程或分散式的。总线还可以将处理器连接到非易失性存储器。非易失性存储器通常是软盘或硬盘,磁光盘,光盘,例如cd-rom、eprom或eeprom等只读存储器(rom),磁卡或光卡,或者其它形式的用于大量数据的存储器。该数据中的某些数据通常在计算机系统执行软件期间通过直接存储器访问程序写入到存储器中。非易失性存储器可以是本地的、远程的或者分散式的。因为可以使用存储器中全部可用数据来创建系统,所以非易失性存储器是可选的。
软件通常存储在非易失性存储器中。实际上,对于大型程序而言,可能无法将整个程序存储在存储器中。但是,应该理解的是,要运行软件,必要时可将其移动到适于处理的计算机可读位置;出于说明的目的,所述位置在本说明书中称为存储器。即使将软件移至存储器中执行,处理器也通常会使用硬件寄存器存储与软件相关的值,理想情况下,可使用本地缓存加速执行。在本说明书中,当软件程序被称为“在计算机可读存储介质中应用”时,假定所述软件程序存储在可用的已知或方便的位置(从非易失性存储器到硬件寄存器)。当与程序相关的至少一个值存储在可由处理器读取的寄存器中时,该处理器被视为是“能够执行程序”。
在一个操作示例中,计算机系统可以由操作系统软件控制,该操作系统软件是包括例如磁盘操作系统的文件管理系统软件程序。具有相关文件管理系统软件的操作系统软件的一个示例是来自华盛顿州雷德蒙德市微软公司的
总线还能够将处理器连接至接口。所述接口可以包括一个或多个输入和/或输出(i/o)设备。i/o设备的非限制性实例可以包括键盘、鼠标或者其它定点设备、磁盘驱动器、打印机、扫描仪及其它i/o设备,也包括显示设备。所述显示设备的非限制性实例可以包括阴极射线管(crt)、液晶显示器(lcd)或者其它一些可用的已知或方便的显示设备。所述接口可以包括一个或多个调制解调器或者网络接口。应当理解,调制解调器或者网络接口可以被认为是计算机系统的一部分。所述接口可以包括模拟调制解调器、isdn调制解调器、电缆调制解调器、令牌环接口、卫星传输接口(例如,“卫星直播因特网”)或者其它用于将计算机系统连接至其它计算机系统的接口。接口使计算机系统与其它设备能够在网络中连接在一起。
计算机系统可以与基于云的计算系统兼容、或作为基于云的计算系统的一部分、或通过基于云的计算系统来实现。如本说明书中所使用的,基于云的计算系统是向客户端设备提供虚拟化的计算资源、软件和/或信息的系统。通过维护集中式服务和资源使计算资源、软件和/或信息虚拟化,所述集中式服务和资源可由边界设备通过网络等通信接口访问。“云”可能是营销术语,出于说明目的,本说明书中它可以包括所述的任何网络。基于云的计算系统可以涉及服务订阅或者使用公用事业定价模型。用户可以通过位于其客户端设备上的web浏览器或其它容器应用来访问基于云的计算系统协议。
计算机系统可被实现为引擎、引擎的一部分或可以经由多个引擎来实现。本说明书中所说的引擎包括至少两个组件:(1)专用或共享处理器;以及(2)处理器所执行的硬件、固件和/或软件模块。基于特定实现方式或其它考虑,引擎可以为集中式或者其功能为分散式。引擎可以包括计算机可读介质中的专用硬件、固件或软件,以供处理器执行。如图所示,处理器使用已实现的数据结构和方法来将数据转换为新数据。
本文所述的引擎或者通过其可以实现本文所述的系统和设备的引擎可以是基于云的引擎。本文中所述的基于云的引擎,是可以使用基于云的计算系统来运行应用程序和/或功能的引擎。这些应用程序和/或功能的全部或一部分可以分散在多个计算设备之间,不局限于唯一的计算设备上。在一些实施例中,基于云的引擎可以执行最终用户经web浏览器或容器应用程序进行访问的功能和/或模块,而无需将这些功能和/或模块本地安装在最终用户的计算设备上。
本文中所述的数据存储库,包括具有任何可用的数据组织的资源库,其中该数据组织包括表、逗号分隔值(csv)文件、传统数据库(例如sql)或者其它适用的已知或方便管理的格式。例如,数据存储库可以实现为软件,所述软件体现在通用或专用机器上的物理计算机可读介质中、在固件中、在硬件中、在它们的组合中、或者在可用的已知或方便的设备或系统中。尽管数据存储库相关组件的物理位置和其它特性对于理解本文所述的技术而言并不重要,但诸如数据库接口等的数据存储库相关组件可被视为数据存储库的“一部分”、其它系统组件的一部分或它们的组合。
数据存储库可以包括数据结构。本文中所述的数据结构与在计算机中储存和组织数据的特定方式相关,这使得在特定情况下可以高效使用该数据结构。数据结构一般基于计算机在其存储器内的任何位置,在指定地址(即本身可以储存在存储器中并且由程序操纵的位字符串)提取和储存数据的能力。因此,一些数据结构基于利用算术运算来计算数据项的地址;而其它数据结构基于将数据项的地址存储在结构本身中。许多数据结构使用这两种原理,有时以有意义的方式组合使用。数据结构的实现通常需要编写一组程序来创建和操控该结构实例。本文中所描述的数据存储库可以是基于云的数据存储库。基于云的数据存储库是与基于云的计算系统和引擎兼容的数据存储库。
再次参考图1a的例子,糖组学指标定量系统104连接到计算机可读介质102。糖组学指标定量系统104表示一种可以对生物样本的糖组学指标进行定量的系统,该系统同时可以向计算机可读介质102提供糖组学指标定量结果的信息。为了对生物样本中的糖组学指标进行定量,糖组学指标定量系统104可以由收集生物样本的实体(例如医院)控制,也可以不由其控制。糖组学指标可以包括生物样本中糖基化蛋白的数量和数量的变化、由糖基化蛋白酶解的糖基化的肽片段的类型的数量和数量的变化,以及生物学样本的来源。在一个实施例中,糖组学指标定量系统104连续运行,使得无论何时获取的新的生物样本,都可以获取其定量结果。
在一些实施例中,生物学样本来自先前的一项或多项研究,时间跨度为1至50年甚至更长。在一些实施例中,所述研究同时包括其他各种临床指标和先前已知的信息,例如受试者的年龄、身高、体重、种族、病史等。这种附加信息可用于将所述受试者与某种疾病或症状关联起来。在一些实施例中,所述生物样本是从所述受试者预先收集的一种或多种临床样本。
在一个实施例中,从所述受试者分离出的生物学样本是身体组织、唾液、眼泪、痰、脊髓液、尿液、滑液、全血、血清或血浆。在另一实施例中,从所述受试者分离出的生物样本是全血、血清或血浆。在另一些实施例中,所述受试者是哺乳动物。在其他一些实施例中,所述受试者是人类。
在一个实施例中,用于定量糖组学指标的糖基化蛋白是是下列中的一种或多种:α-1-酸糖蛋白、α-1-抗胰蛋白酶、α-1b-糖蛋白、α-2-hs-糖蛋白、α-2-巨球蛋白抗凝血酶-iii、载脂蛋白b-100、载脂蛋白d、载脂蛋白f、β-2-糖蛋白-1、铜蓝蛋白、胎球蛋白、纤维蛋白原、免疫球蛋白(ig)a、igg、igm、触珠蛋白、血红素、富含组氨酸的糖蛋白、激肽原-1、血清转铁蛋白、转铁蛋白、玻连蛋白和锌-α-2-糖蛋白。
在一个实施例中,用于定量糖组学指标的糖基化的肽片段是o-糖基化和n-糖基化中的一种或多种。在另一个实施例中,用于定量糖组学指标的糖基化的肽片段具有5至50个氨基酸残基的平均长度。在另一个实施例中,糖基化的肽片段的平均长度为约5至约45、或约5至约40、或约5至约35、或约5至约30、或约5至约25、或约5至约20、或约5至约15、或约5至约10,或约10至约50、或约10至约45、或约10至约40、或约10至约35、或约10至约30、或约10至约25、或约10至约20、或约10至约15,或约15至约45、或约15至约40、或约15至约35、或约15至约30、或约15至约25、或约15至约20个氨基酸残基。在一个实施例中,所述糖基化的肽片段的平均长度约为15个氨基酸残基。在另一实施例中,所述糖基化的肽片段的平均长度约为10个氨基酸残基。在另一实施例中,所述糖基化的肽片段的平均长度约为5个氨基酸残基。
在一个实施例中,使用一种或多种蛋白酶对糖基化蛋白进行酶解。在一个实施例中,所述一种或多种蛋白酶包括丝氨酸蛋白酶、苏氨酸蛋白酶、半胱氨酸蛋白酶、天冬氨酸蛋白酶、谷氨酸蛋白酶、金属蛋白酶、天冬酰胺肽裂解酶或其组合。蛋白酶的一些代表性实例包括但不限于胰蛋白酶、胰凝乳蛋白酶、内切蛋白酶、asp-n、arg-c、glu-c、lys-c、胃蛋白酶、嗜热菌素、酯酶、木瓜蛋白酶、蛋白酶k、枯草杆菌蛋白酶、梭菌蛋白酶、羧肽酶等。在另一实施例中,本专利提供的如上所述的方法中,所述一种或多种蛋白酶至少包括两种蛋白酶。在另一个实施例中,糖基化蛋白的酶解和定量使用与多反应监测质谱法(mrm-ms)相结合的液相色谱-质谱(lc-ms)技术,在单次lc/mrm-ms分析中可以定量数百个糖基化片段(及其母体蛋白)。本专利的高级质谱技术提供了有效的离子源、更高的分辨率、更快的分离速度和具有更高动态范围的检测器,在保留靶向测量的好处的同时,可以支持宽范围的非靶向测量。
本专利所述的质谱法每次可以分析多个糖基化蛋白质。例如,使用质谱仪每次至少可以分析大于50、或至少大于60或至少大于70、或至少大于80、或至少大于90、或至少大于100、或至少大于110或120个以上的糖基化蛋白质。
在一个实施例中,本专利的质谱法使用qqq或qtof质谱仪。在另一实施例中,本专利的质谱法提供的数据具有10ppm或更高、或5ppm或更高、或2ppm或更高、或1ppm或更高、或0.5ppm或更高、或0.2ppm或更高、或0.1ppm或更高的质量精度,分辨力在5,000或更高、或10,000或更高、或25,000或更高、或50,000或更高、或100,000或更高。
在图1a的示例中,基因组学指标定量系统106连接到计算机可读介质102。基因组学指标定量系统106表示的是用于对生物样本的基因组学指标进行定量的系统,该系统还可以向计算机可读介质102提供基因组学指标定量结果的信息。为了对生物样本的基因组学指标进行定量,基因组学指标定量系统106可以由收集生物样本的实体(例如,医院)控制,也可以不由其控制。在实施中,基因组学指标可以包括从生物样本中提取的dna或rna的基因组序列。dna(rna)测序的方法没有特别限制,在实施中,所述方法可以包括maxam-gilbert测序、链终止方法、大规模平行签名测序(mpss)、聚合酶克隆测序、454焦磷酸测序、光照测序、solid测序、离子洪流半导体测序、dna纳米球测序、直升机显微镜单分子测序、单分子实时(smrt)测序、纳米孔dna测序、隧道电流dna测序、杂交测序、质谱测序、微流体sanger测序、rnap测序和体外病毒高通量测序。在实施中,与糖组学指标定量系统104相似,基因组学指标定量系统106连续运行,以更新数据。
在图1a的示例中,蛋白质组学指标定量系统108连接到计算机可读介质102。蛋白质组学指标定量系统108表示用于对生物样本的蛋白质组学指标进行定量的系统,该系统还可以向计算机可读介质102提供蛋白质组学指标的定量结果的相关信息。为了从生物样本中定量蛋白质组学指标,蛋白质组学指标定量系统108可以由收集生物样本的实体(例如,医院)控制,也可以不由其控制。在实施中,蛋白质组学指标可以包括生物样本中的各种蛋白质的数量和数量的变化,以及所述生物样本的来源。检测和/或定量蛋白质的方法没有特别限制,在实施中,所述方法可以包括酶联免疫吸附测定(elisa)、蛋白质印迹法,埃德曼降解、基质辅助激光解吸/电离(maldi)、电喷雾电离(esi)、质谱免疫分析(msia)和抗多肽抗体捕捉稳定同位素标准法(siscapa)。在实施中,与糖组学指标定量系统104相似,蛋白质组学指标定量系统108连续运行,以更新数据。
在图1a的示例中,代谢学指标定量系统110连接至计算机可读介质102。代谢学指标定量系统110表示定量生物样本的代谢指标的系统,该系统还可以向计算机可读介质102提供代谢学指标定量结果的相关信息。为了从生物样本中定量代谢学指标,代谢学指标定量系统110可由收集生物样本的实体(例如医院)控制,也可以不由其控制。在实施中,代谢学指标可包括受试者的代谢产物和/或副产物(包括糖、核苷酸和氨基酸)的数量和数量的变化、由代谢导致的受试者的生物学状态,以及生物样本的来源等。可以通过任何已知的方法定量代谢学指标,例如使用多反应监测质谱法(mrm-ms)的液相色谱-质谱法(lc-ms)技术等。在实施中,与糖组学指标定量系统104相似,代谢学指标定向系统110以连续方式运行,以更新数据。
在图1a的示例中,脂类组学指标定量系统112连接到计算机可读介质102。脂类组学指标定量系统112表示定量生物样本的脂类组学指标的系统,该系统还可以向计算机可读介质102提供脂类组学的定量结果的相关信息。为了从生物样本中定量脂类组学指标,脂类组学指标定量系统112可由收集生物样本的实体(例如医院)控制,也可以不由其控制。在实施中,脂类组学指标可包括任何脂类的数量和数量的变化,例如甘油酯(acyglycerol)、蜡、神经酰胺、磷脂、鞘磷脂、甘油磷脂、鞘糖脂、甘油糖脂、脂蛋白、硫脂、脂肪酸、萜类、类固醇和类胡萝卜素,以及获取到脂类的生物样本的来源等。在实施中,与糖组学指标定量系统104相似,脂类组学指标定量系统112以连续的方式运行,以更新数据。
在图1a的示例中,临床指标生成系统114连接至计算机可读介质102。临床指标生成系统114表示生成生物样本的临床指标,并向计算机可读介质102提供临床指标的相关信息的系统。为了生成受试者的临床指标,临床指标生成系统114可由收集受试者的临床数据的实体(例如医院)控制,也可以不由其控制。在实施中,临床指标可以包括通过检查受试者而获取的任何可定量和/或不可定量的数据(例如心率、血压、血型、体温、肤色、眼睛颜色、血糖浓度、体重、身高、当前感知的健康分类状态等),以及通过询问受试者或从病历获取的任何数据(例如生活习惯,包括食物、睡眠和唤醒时间、运动量和运动频率、吸烟量和吸烟频率、酒精消耗量以及饮酒频率、过敏、服用的药物、疾病史、种族、疼痛和疼痛的起因等)。在实施中,与糖组学指标定量系统104相似,临床指标生成系统114以连续的方式运行,以更新数据。
具体的实施方式虽然包括在临床和实验室生态系统中,但是应该理解,从社交媒体获取受试者数据的社交媒体指标生成系统、从各种来源中获取在线活动数据的行为主义指标生成系统、从政府网站获取公开可用数据的政府记录指标生成系统等其他指标生成系统也可使用。数据样本量越大,能被纳入到健康分类指标中的不同数据越多。
在图1a的示例中,自动无偏机器学习诊断系统116连接到计算机可读介质102。自动无偏机器学习诊断系统116表示由实体(例如医院)控制的系统,该系统负责鉴定与特定健康分类相关的一种或多种生物学指标。所述实体与控制糖组学指标定量系统104、基因组学指标定量系统106、蛋白质组学指标定量系统108、代谢学指标定量系统110、脂类组学指标定量系统112和临床指标生成系统114的实体可以是同一实体,也可以不是同一实体。
在一种具体实施方式中,自动无偏机器学习诊断系统116能够自动测定一种或多种可定量生物学指标的丰度或缺失,作为与特定健康分类相关的生物标记物,和/或自动测定一种或多种不可定量的生物学指标的存在或缺失,作为与特定健康分类相关的生物标记物。根据具体实施方式或其他方面的考虑,确定为生物标记物的生物学指标可以是生物学指标的标量值或取值范围,或者是两种或多种生物学指标的组合(例如,两种生物学指标的比率和两种或多种生物学指标的矢量)。例如,指示健康状况的代谢产物的某个范围(例如高于某个阈值或在较低阈值和较高阈值之间)。在另一个实例中,某种类型的糖肽与某种类型脂类的数量的特定比率或比率范围可以指示健康状况。在另一个实例中,一些超过一定阈值的可定量生物学指标和阳性不可定量指标的组合(例如非吸烟者)可以作为生物标记物。
在一个具体实施方式中,自动无偏机器学习诊断系统116禁止或限制用户对其用于特定数据计算过程的指标设置进行更改,以确保机器自动计算没有人工干预(例如无人为偏差)。这是因为,在观察者(例如科研人员)来看,一些生物标记物看似无关,这种人为偏差会导致更难找到健康分类的生物标记物。例如,在自动无偏机器学习诊断系统116中,至少在计算的初始阶段,纳入自动无偏机器学习诊断系统116的每种生物学指标具有相等的权重。换言之,在计算的初始阶段,自动无偏机器学习诊断系统116不会忽略任何生物学指标。随着计算过程的进行,自动无偏机器学习诊断系统116越来越关注与特定健康分类相关的生物学指标的第一子集,而较少关注与特定健康分类无关的生物学指标的第二子集(例如噪音成分)。根据具体实施方式或其他考虑,可通过用户身份验证系统保护机器学习操作的指标设置的更改,以确保操作无偏。根据具体实施方式或其他考虑,机器学习是深度学习、神经网络、线性判别分析、二次判别分析、支持向量机、随机树,最近邻或它们的组合。
在一个具体实施方式中,自动无偏机器学习诊断系统116将确定的与健康分类相关的生物标记物的丰度或缺失与从受试者获取的相应生物学指标的定量结果进行比较,以诊断受试者健康分类的状态(阳性或阴性)。例如,当从受试者获取的生物学指标的定量结果落入生物标记物的特定范围内时,可以确定受试者患有某种疾病。
在一个具体实施方式中,自动无偏机器学习诊断系统116通过比较从患有疾病但未接受治疗的受试者、患有所述疾病且接受治疗的受试者、以及未患所述疾病(也未接受治疗)的健康受试者获取的生物标记物的定量结果,来确定所述疾病的医学治疗效果。在此,医学治疗方案可以包括但不限于,对诊断或鉴定健康状况的受试者适用的运动疗法、饮食补充、减肥、手术干预、设备植入以及治疗性或预防性的方案。例如,当从接受治疗的受试者获取的生物标记物的定量结果与未接受治疗的受试者获取的生物标记物的定量结果相比,是否更接近于从健康受试者获取的生物标记物的定量结果时,可以确定医疗措施对健康状况的治疗是否具有医学上的有益效果。在一个具体的实施方式中,通过比较从具有某种健康分类但未接受治疗的受试者、具有该健康分类且接受治疗的受试者以及不属于该健康分类(且未接受治疗)的受试者获取的生物学指标的定量结果,自动无偏机器学习诊断系统116还能够确定医疗措施的进度。例如,当从接受治疗的受试者获取的生物标记物的定量结果与从健康受试者获取的生物标记物的定量结果大致匹配时,可以确定能够终止治疗。在一个具体的实施方式中,自动无偏机器学习诊断系统116还能够以与确定治疗进度相似的方式来确定健康分类的进度。在一个具体的实施方式中,自动无偏机器学习诊断系统116还能够通过比较测定到的各种可能治疗措施的进度,从多种可能的治疗方式中确定或选择出有效的治疗方式。
在图1a的示例中,诊断结果显示系统118连接到计算机可读介质102。诊断结果显示系统118表示由带有平台的实体(例如网络服务提供商)控制的系统,该平台能够显示自动无偏机器学习诊断系统116测定的生物学指标,和/或由自动无偏机器学习诊断系统116生成的诊断结果。所述实体可以与控制糖组学指标定量系统104、基因组学指标定量系统106、蛋白质组学指标定量系统108、代谢学定量系统110、脂类组学定量系统112、临床指标生成系统114和/或自动无偏机器学习诊断系统116的实体相同,也可以不同。
可用的平台的非限制性实例包括但不限于网页(例如,可以将测定到的生物学指标和/或诊断结果作为消息显示在个人网页上,例如医院的个人网页)、电子消息(例如电子邮件、文本消息、语音消息)、平面媒体(例如信件)以及其他适用于向受试者提供内容的平台。
图1a示出了利用所述系统测定用于特定健康分类的生物学指标,并基于生物学指标对受试者进行诊断的具体操作实例,下文将对此进行说明。糖组学指标定量系统104定量生物样本(例如血液样本)中的糖组学指标(例如n-聚糖),并向自动无偏机器学习诊断系统116提供糖组学指标定量结果的相关信息。与糖组学指标定量系统104类似,基因组学指标定量系统106、蛋白质组学指标定量系统108、代谢学指标定量系统110和脂类组学指标定量系统112分别定量生物样本中的相应生物学指标,向自动无偏机器学习诊断系统116提供定量结果的相关信息。临床指标生成系统114生成生物样本的临床指标(例如,对每个受试者的问卷作出的阳性/阴性评价),并向自动无偏机器学习诊断系统116提供临床指标的相关信息。
基于从糖组学指标定量系统104接收的糖组学指标、从基因组学指标定量系统106接收的基因组学指标、从蛋白质组学指标定量系统108接收的蛋白质组学指标、从代谢学指标定量系统110接收的代谢学指标、从脂类组学指标定量系统112接收的脂类组学指标中的至少一个定量结果,和/或基于从临床指标生成系统114接收的临床指标的定量和/或非定量结果,自动无偏机器学习诊断系统116可确定与一个或多个健康分类相关的一种或多种生物学指标。其优势在于,自动无偏机器学习诊断系统116可基于来自糖组学指标定量系统104、基因组学指标定量系统106、蛋白质组学指标定量系统108、代谢学指标定量系统110、脂类组学指标定量系统112和临床指标生成系统114中的两个或多个的数据组合,确定一种或多种生物学指标作为生物标记物,从而提高作为生物标记物的生物学指标的准确性。
在一个具体的实施方式中,自动无偏机器学习诊断系统116基于生物学指标与测量值或受试者的检查状态的对比情况来诊断受试者。诊断结果显示系统118用于显示(例如生成gui)自动无偏机器学习诊断系统116测定的生物学指标和/或自动无偏机器学习诊断系统116生成的诊断结果(例如阳性或阴性)。
为了分别定量生物学指标(例如糖组学指标、基因组学指标、蛋白质组学指标、代谢学指标、脂类组学指标),系统100可以对采用本专利特定实施例中使用的质谱技术获取的univerise质谱数据,执行一个或多个定量操作。在一些实施例中,例如,可以利用一个或多个峰值拾取工具和相关的积分方法来定量生物样本集或单个生物样本的一种或多种相应的生物学指标。在一些实施例中,本专利中的诸如系统100等系统可以配备子系统或平台,在执行定量操作时,系统104-112中的一个或多个可以使用所述子系统或平台。图1b所示为这种实施例的示例性实施方式。
图1b为示例系统的示图,根据本专利的一个或多个实施例,所述系统使用峰积分平台对生物学指标进行定量,鉴定与一个或多个健康分类相关的一种或多种生物学指标,并基于生物学指标预测性地诊断一个或多个受试者的一个或多个健康状态。
如图1b所示,系统120可以包括图1a中提及的部件102-118中一个或多个,它们与峰积分平台130、样本数据存储库122、过渡列表存储库(transitionlistrepository)124和糖蛋白组学universe存储库126之间能够进行有效的通信。如图所示,峰积分平台可以配备一个或多个采集组件132、特征提取组件134、共识/集成(consensus/ensemble)组件136和峰积分组件138。
采集组件132可以从数据源(例如样本数据存储库122)获取质谱数据集,并允许系统120的一个或多个其他组件/部件访问所述质谱数据集信息,包括例如一个或多个峰积分平台130,如特征提取组件134、共识/集成组件136和峰积分组件138。采集组件132还可以将获取的数据集的副本存储在与之连接的一个或多个其他数据存储库中。采集组件132可以响应用户发出的指令命令获取数据,或自动触发获取数据(例如,在特定时间从特定数据源进行预设或周期性的数据提取),或者连续获取数据。例如,采集组件132可以接收用户指令(例如用户经由计算设备进行选择),所述用户期望加载与来自被研究的受试者的新生物样本相关的特定质谱数据集。采集组件132还可以使一个或多个组件顺序地、同时地(即并行地)、根据预设顺序,或者以基于预设标准的另一种排列,来获取数据集。采集组件132可以是便于以专用方式下载质谱数据集信息的独立应用程序,或者它可以与另一应用程序协同运行以实现相同功能。
特征提取组件134能够从采集组件132接收质谱数据(例如与来自一个或多个受试者的一种或多种生物样本相关),并提取(即鉴定)数据内有代表性的一种或多种蛋白质组学特征。为了实现特征提取,特征提取组件能够从原始质谱数据或预处理质谱数据中提取肽诱导信号(即波峰)。与来自受试者的生物样本相关的质谱数据集可以包含与许多不同分子种类(例如不同分子)相关的从数十条到数千条的图谱(对应于与同位素对应的许多不同质量通道的强度信息)。特征提取组件134能够分析质谱数据集,以确定在数据集中观察到的任何谱图(例如观察到的同位素分布、峰等)与已知或未知但是统计学上重要/明显的分子种类是否对应。可以将与已知分子种类对应的已知谱图和/或同位素分布存储在过渡列表存储库124中,特征提取组件134可以在作业期间对其进行访问。例如,过渡列表存储库124可以包括已知的与波峰和波谷之间的过渡相关而且与某种特征相关的信息。过渡列表存储库124还可以包括具有预设积分起点和终点的预设峰值波形(起点和终点通常对应于与已知特征相关的波峰的任一侧的波谷)。因为质谱数据通常混杂有重叠的同位素图样和大量干扰信息,所以特征提取组件134有必要能够鉴定出相互重叠的各波峰形成的组合,并滤出或以其他方式减少数据集中的化学和/或检测器干扰信息。
特征提取组件134采用本领域中已知的峰值拾取工具,诸如nitpick,skyline,openms,dia-umpire,pecan,xcms,multiplierz,mzmine,t-bioinfo,mass++,msinspect,massspecwavelet,maldiquant,eigenms,prepms,lc-ims-ms-feature-finder,mmass,imtbx(离子迁移工具箱),grppr(grouper),mzdesktop,cromwell,mapquant,pparse,mzjava,happytools,mass-up,limpic,spicehit,proteinpilot,process,gagfinder,intactmass,jumbo,maltcms,spectrodive,envipick,findmf,pnnlpreprocessor,msxpertsuite,lcms-2d或siren(sparseisotoperegressionn)。特征提取组件134可以仅应用或启用前述的任何一个或多个的无偏特征,从而禁止在峰值拾取过程中发生人为干预。
在一些实施例中,特征提取组件可以对某一数据集进行两次或多次峰值拾取操作(例如并行地),以获取所述数据集的两个或多个特征提取结果集。共识/集成组件136从特征提取组件134的数据集获取多组特征提取数据,并在多组特征提取结果之间或者在多组特征提取结果的各部分之间鉴定出共识或非共识。可以在整个数据集中以特征为基础考虑共识,也可以在其他期望标准的基础考虑共识。在一些实施例中,对于特定提取特征(即对于给定的波峰(和过渡相关))的共识,可以通过在该数据集中鉴定该波峰所得到的、所应用的峰值拾取操作的预设值、百分比或比率来实现。
在一些实施例中,共识/集成组件136可以生成共识数据集,所述共识数据集包括一组特征提取结果,所述特征提取结果包含特征提取数据;基于这些特征提取数据,通过多个峰值拾取操作获取到共识。在一些实施例中,对提取到的特征进行多次峰值拾取操作,结果具有实质性相似,共识/集成组件136可以生成集成数据集,所述集成数据集包括能够代表提取特征的一组特征提取结果。在一些实施例中,通过统计操作来定义波峰的一种或多种特征(例如波谷、过渡、峰尖、波形上某点的峰值波形的斜率等),将多个提取特征结果的集合(例如基于特定特征)中的特征提取结果进行合并,由共识/集成组件136生成集合数据集。这种统计操作可以包括平均值、中位数,加权组合或任何其他组合中的一种或多种。
峰积分组件(peakintegrationcomponent)138能够从一个或多个特征提取组件134和共识/集成组件136(或系统120的其他组件或元件)获取一个或多个特征提取结果,并进行积分以确定强度曲线下的面积,该曲线定义了与给定提取特征(例如给定的分子)相关的峰。峰积分组件138可以采用任何类型的积分方法,例如梯形积分、矩形积分等。给定特征(甚至是无单位面积)强度曲线下的面积,与生物样本中考虑范围内的特征相关的分子的数量相对应。本专利的系统虽然不需要生成图谱、峰值波形或任何其他数据的曲线图或图形表即可进行操作,图1c、1d和1f对这些概念提供了示例图,对此作出了说明。
图1c示出了由采集组件132获取的质谱数据的示例。特征提取组件134可以将这些谱图鉴定为与不同特征相关。例如,特征提取组件134可以确定通常由数字141标记的图谱(具有基本相似的质荷比)与第一特征(例如第一峰)相关;特征提取组件134可以确定通常由数字142标记的图谱(具有基本相似的质荷比)与第二特征(例如第二峰)相关;特征提取组件134可以确定通常由数字143标记的图谱(具有基本相似的质荷比)与第三特征(例如第三峰)相关;特征提取组件134可以确定大体上由数字144标记的图谱(具有基本相似的质荷比)与第四特征(例如第四峰)相关;特征提取组件134可以确定通常由数字145标记的图谱(具有基本相似的质荷比)与第五特征(例如第五峰)相关。
从图1c可以看出,第四峰144的图谱与第五峰145的图谱重叠。峰144的图谱用虚线表示,以示与第五峰145图谱的区别。如上所述,特征提取组件134能够区分这两种波形,并将其鉴定为表示两种不同特征的图谱,并非表示同一种特征。出于说明的目的,虽然在图1c中仅示出了两种特征,应当理解,特征提取组件能够和/或被训练为能够区分两个以上的重叠峰,尤其是能够确定或以其他方式鉴定出和不同特征相关的各波峰和波谷之间的过渡点(为后续积分鉴定起点和终点)。
图1d示出了由图1c中所示的质谱数据中提取的特征相关的第一峰、第二峰、第三峰、第四峰和第五峰的示例性峰值波形。如图所示,图1d中的第一峰值波形151对应图1c中第一峰141;类似地,图1d中数字标记依次为152、153、154、155的第二峰、第三峰、第四峰和第五峰值波形,分别对应图1c中数字标记依次为142、143、144、145的第二峰、第三峰、第四和第五峰。
图1e示出了图1d中所示的示例峰值波形。把峰值波形曲线下方的区域阴影化,以象征性地示出由峰积分组件138完成的积分示例。如图所示,图1b中的系统120沿水平轴方向确定积分的起点和终点。例如,系统120可以确定水平轴上与154a对应的过渡点,作为对峰值波形154进行积分的起点,水平轴上与154b对应的过渡点应作为对峰值波形154进行积分的终点。类似地,如图所示,系统120可以确定水平轴上与155a对应的过渡点作为对峰值波形155进行积分的起点,水平轴上与155b对应的过渡点作为对峰值波形155进行积分的终点。
图2描绘了示例方法的流程图200,所述方法确定一种或多种生物学指标作为与一个或多个健康分类相关的一种或多种生物标记物,并基于所确定的生物标记物对受试者进行诊断。本说明书中的流程图200和其他流程图均以一系列模块的形式进行说明。应该理解的是,如果有必要的话,可以改变模块的顺序并且可以重新排列模块以进行串行或并行的处理。
如图2所示,流程图200始于模块202:至少获取一种生物学指标的定量结果。在一个具体的实施方式中,通过分析生物样本获取生物学指标。生物学指标可以包括例如糖组学指标、基因组学指标、蛋白质组学指标、代谢学指标和脂类组学指标。
如图2所示,流程图200接下来到模块204:获取临床指标的定量和/或非定量结果。在一个具体的实施方式中,通过检查和询问受试者来获取所述结果和指标。
如图2所示,流程图200接下来到模块206:执行自动无偏机器学习操作,以确定一种或多种生物学指标作为健康分类的一种或多种生物标记物。在实施过程中,自动无偏机器学习操作从对生物学和临床指标的平等处理开始,消除科学上的偏见,且没有为用户配置手动更改机器学习操作的计算设置。
如图2所示,流程图200接下来到模块208:基于从受试者的生物样本获取的生物学指标与所确定的生物标记物的比较来诊断受试者的健康分类状态(例如阳性或者阴性)。例如,当从血清获取的n-聚糖和免疫球蛋白g(igg)的丰度(例如高于阈值)被确定是卵巢癌的生物标记物时,通过从受试者的血清中获取的相应的生物学指标(即n-聚糖和igg)的丰度是否足够(例如高于阈值)来进行确定。模块208是可选模块。
如图2所示,流程图200在模块210处结束:如果通过模块208获取到确定的生物标记物和/或诊断结果,则予以显示。在一种实施方式中,诊断结果的显示方式是通过网页显示结果、通过电子邮件通知结果和/或在医疗设备上现场显示结果的邀请。
图3示出了系统的示例图300,所述系统用于执行自动无偏深度学习操作以确定生物学指标,所述生物学指标可以预测受试者分类,作为可供选择的方案,也可以基于候选生物学指标来预测分类。图300包括定量结果数据存储库301、数据分类引擎302、训练数据组数据存储库303、测试数据组数据存储库304、无偏深度学习引擎305、内部验证引擎306、新结果输入引擎307以及外部验证引擎308。
如图3所示,定量结果数据存储库301表示通过生物样本数字化获取的定量结果,无论采用何种格式,都要与后续处理流程相兼容,以确定生物标记物的候选生物学指标。更具体而言,例如,当对糖组学指标进行定量时,定量结果的数据单元与生物样本(或受试者)的唯一标识符相关,并且包括不同种类的糖基化肽片段(例如已知肽片段和/或未知肽片段)的定量结果,所述糖基化肽片段的指标与代表每个受试者具有或不具有的一个或多个健康分类的健康分类状态(例如积极的/否定的)相关。
如图3所示,数据分类引擎302连接至定量结果数据存储库301。数据分类引擎302表示专用的硬件和软件,所述硬件及软件将定量结果数据存储区301中的定量结果分为两个不同的数据组,即训练数据组和测试数据组;所述训练数据组用于通过自动无偏深度学习确定候选生物学指标,所述测试数据组用于验证确定的候选生物学指标。将各个数据单元分类到训练和测试数据组之一的方式,以及训练数据组相对于测试数据组的比例(训练组与测试组的比率),没有特别限制,并且根据算法可以采用多种数据分类方案。
如图3所示,训练数据组数据存储库303连接到数据分类引擎302。训练数据组数据存储库303表示由数据分类引擎302分类为训练数据组的数据单元。训练数据组数据存储库303与定量结果数据存储库301中的数据单元的数据格式可能相同,也可能不同。在实施中,定量结果数据组数据存储库301中的数据单元可以是非结构化数据格式,训练数据组数据存储区303中的数据单元可以是结构化数据格式。
如图3所示,测试数据组数据存储库304连接到数据分类引擎302。测试数据组数据存储库304表示由数据分类引擎302分类为测试数据组的数据单元。与训练数据组数据存储库303类似,测试数据组数据存储库304中数据单元与定量结果数据存储库301中数据单元的数据格式可能相同,也可能不同。在实施中,定量结果数据存储库301中的数据单元可以是非结构化数据格式,测试数据组数据存储库304中的数据单元可以是结构化数据格式。
如图3所示,无偏深度学习引擎305连接到训练数据组数据存储库303。无偏深度学习引擎305表示专用的硬件和软件,所述硬件和软件根据算法执行无偏深度学习过程,以确定一种或多种生物学指标,作为指示受试者的分类(例如疾病状态)的一种或多种候选生物标记物。
在实施中,无偏深度学习引擎305形成人工神经网络(ann),所述人工神经网络包括输入层、输出层以及在输入层和输出层之间形成的一个或多个隐藏层。输入层包括多个人工神经元,对于输入层的每个人工神经元,输入部分或全部类型的糖基化肽片段的一个定量结果;作为可供选择的方案,还可以输入的一种或多种表示受试者状态的指标。类似地,一个或多个隐藏层中的每个隐藏层包含多个人工神经元,并且对一个或多个隐藏层中的每个隐藏层的每个人工神经元,输入其直接相邻前一层(例如输入层或隐藏层之一)的一个或多个人工神经元的输出。在一个或多个隐藏层的每个人工神经元中,根据算法以一定的权重接收其直接相邻前一层的输入,并且执行特定的计算(例如xor)。一个或多个隐藏层中的最后一个隐藏层的人工神经元的输出,被输入到输出层的一个或多个人工神经元,输出层输出一种或多种生物学指标作为候选生物标记物,以预测分类(例如疾病状态)。根据具体实施方式或其他考虑,无偏深度学习引擎305的人工神经网络可以包括神经网络,例如各层之间的连接不形成循环的前馈神经网络,或各层之间的连接形成定向循环的递归神经网络(rnn)。根据具体实施方式或其他考虑,无偏深度学习引擎305的单一单元可以针对多个目标健康分类执行深度学习过程。在替代性方案中,无偏深度学习引擎305提供独立的单元,用于目标健康分类。
如图3所示,内部验证引擎306连接到无偏深度学习引擎305和测试数据组数据存储库304。内部验证引擎306的输出还连接到数据分类引擎302和无偏深度学习引擎305。内部验证引擎306表示专用的硬件和软件,所述硬件和软件通过将候选生物学指标与测试数据组(测试数据组数据存储库304中)的数据单元进行匹配,来验证由无偏深度学习引擎305确定的一种或多种候选生物学指标,并输出有效的候选生物学指标作为与健康分类相关的生物标记物。在一个具体的实施方式中,针对一种或多种候选生物学指标中的每一种生物学指标,内部验证引擎306用于确定从测试数据组中的阳性受试者(即具有某种健康分类的受试者)获取的候选生物学指标的定量结果与训练数据组的数据单元确定的候选生物学指标的丰度(或缺失)是否匹配,及确定从测试数据组的阴性受试者(即不具有某种健康分类的受试者)获取的候选生物学指标的定量结果与从训练数据组中的数据单元确定的候选生物学指标的缺失(或丰度)是否匹配。
在具体实施中,将内部验证引擎306获取的匹配结果反馈给数据分类引擎302,并基于所述匹配结果,数据分类引擎302将对把定量结果分类为训练数据组和测试数据组的方式进行维持或修改。在具体实施中,把内部验证引擎306获取的匹配结果反馈到无偏深度学习引擎305;基于所述匹配结果,无偏深度学习引擎305对人工神经网络中应用的每个人工神经元的权重进行维持或修改。
如图3所示,新结果输入引擎307连接到定量结果数据存储库301。新结果输入引擎307表示专用的硬件和软件,所述硬件和软件专用于把一个或多个新受试者(或新生物样本)的生物学指标的定量结果输入系统。新受试者包括:例如有待于基于生物标记物进行健康分类的预测性诊断的受试者,和/或已经被诊断为具有或没有某种健康分类的受试者。将新受试者的定量结果输入到定量结果数据存储库301作为新受试者的附加数据单元,并输入到外部验证引擎308,基于所述新受试者的定量结果,对所述新受试者进行预测性诊断或对生物标记物进行扩展验证。
如图3所示,外部验证引擎308连接到内部验证引擎306和新结果输入引擎307。外部验证引擎308的输出也连接到数据分类引擎302和无偏深度学习引擎305。在具体实施中,外部验证引擎308表示的专用硬件和软件,所述硬件和软件基于由内部验证引擎306验证的一种或多种生物标记物,来执行预测性诊断;和/或通过将有效的生物标记物与从新结果输入引擎307输入的新受试者的数据单元进行匹配,对一种或多种生物标记物进行扩展验证。在具体实施中,出于预测性诊断的目的,针对一种或多种生物标记物中的每一个,外部验证引擎308确定从阳性受试者获取的相应生物学指标的定量结果与所述生物标记物的丰度或缺失是否匹配。在另一具体实施中,出于扩展验证的目的,针对一种或多种生物标记物中的每一个,外部验证引擎308确定从新受试者中的阳性受试者(即具有某种健康分类的受试者)获取的生物学指标的定量结果与生物标记物丰度或缺失是否匹配,以及从新受试者中的阴性受试者(即没有某种健康分类的受试者)获取的相应生物学指标的定量结果与所述生物标记物的缺失度是否匹配。然后,出于显示目的,外部验证引擎308输出有效的生物标记物。
在一个具体的实施方式中,与内部验证引擎306类似,将外部验证引擎308获取的匹配结果反馈给数据分类引擎302;基于所述匹配结果,数据分类引擎302将对定量结果分为训练数据组和测试数据组的方式,和/或训练与测试的比率进行维持或修改。此外,外部验证引擎308把获取的匹配结果反馈到无偏深度学习引擎305,并且基于所述匹配结果,无偏深度学习引擎305对人工神经网络应用的每个人工神经元的权重,和/或深度学习的其他可操作指标进行维持或修改,以提高确定所述健康分类的准确性。
图4的示例流程图400,描绘了通过执行自动无偏深度学习操作,来确定用于预测受试者分类的生物标记物,以及基于所确定的生物标记物来预测分类的方法。流程图400始于模块402,即将通过生物样本数字化而获取的定量结果分类为训练数据组和测试数据组。
如图4所示,流程图400继续进行到模块404:针对训练数据组执行无偏深度学习过程,以确定一种或多种生物学指标,作为预测健康分类的一种或多种候选生物标记物。
如图4所示,流程图400继续进行到模块406:根据测试数据组来验证已确定的候选生物学指标。在具体实施方式中,验证包括确定某种健康分类的阳性受试者是否具有与已确定的候选生物学指标的丰度或缺失相匹配的一种或多种生物学指标的定量结果,以及确定该健康分类的阴性受试者是否具有与已确定的候选生物学指标的丰度或缺失不匹配的定量结果。
如图4所示,流程图400继续进行到判定点408,即确定一种或多种候选生物标记物中的每一种是否都有效。如果存在无效的候选生物标记物(408-n),流程图400将进行到模块410,将候选生物标记物的验证结果反馈到通过模块402执行的定量结果分类和/或在模块404进行的深度学习,流程图400结束。如果候选生物标记物有效(408-y),流程图进行到模块412,对模块402执行的定量结果分类和/或在模块404执行的深度学习过程进行反馈。在具体的实施方式中,对于无效的候选生物标记物,可以削弱两个人工神经元之间的神经联系,例如可以降低无效的候选生物标记物的权重;对于有效的候选生物标记物,可以增强两个人工神经元之间的神经联系,例如可以提高有效的候选生物标记物的权重。
如图4所示,流程图400继续进行到判定点414:确定是否对新受试者进行健康分类的预测性诊断。如果确定对新受试者进行健康分类的预测性诊断(414-y),即如果新受试者的健康分类状态未知,则流程图400继续进行到模块416,基于(在模块406中验证)有效的生物标记物的丰度或缺失与从所述新受试者的生物样本获取的相应生物学指标的定量结果之间的比较,对新受试者进行预测性地诊断,流程图400结束。例如,当某种糖基化肽片段的丰度超过预设阈值提示健康分类状态为阳性的话,则当从新受试者的生物样本获取的所述糖基化肽片段的定量结果,则确定所述新受试者的健康分类状态为阳性。在具体的实施方式中,(在模块406中被验证无效)无效的生物标记物不用于模块416中的预测诊断。
另一方面,如果确定不对新受试者进行健康分类的预测性诊断(414-n),例如已知所述新受试者的健康分类状态的话,则流程图400继续进行到模块418,根据所述新受试者的定量结果对有效的生物标记物进行扩展验证。在具体的实施方式中,扩展验证包括确定阳性健康分类受试者是否具有与有效的生物标记物的丰度或缺失匹配的一种或多种对应的生物学指标的定量结果,及确定阴性健康分类受试者是否具有与有效的生物标记物的丰度或缺失不匹配的一种或多种相应的生物学指标的定量结果。
如图4所示,流程图400继续进行至判定点420,确定一种或多种生物标记物中的每一种均通过扩展验证。如果有无效的生物标记物(420-n),则流程图400返回至模块410,并如前所述继续进行。如果有通过扩展验证的生物标记物(420-y),流程图400继续进行至模块422,以与模块412类似的方式,对在模块402执行的定量结果分类和/或模块404执行的深度学习过程进行反馈,流程图400结束。在具体实施方式中,对于无效的生物标记物,可以减弱两个人工神经元之间的神经联系,例如降低无效的生物标记物的权重。对于经扩展验证的生物标记物,可以增强两个人工神经元之间的神经联系,例如可以进一步增加经过扩展验证的生物标记物的权重。
图5为示例性的系统图500,所述系统基于机器学习过程及从受试者的生物样本获取的所述受试者的对应生物学指标的定量结果,对所述受试者的健康状况进行诊断。图500包括标准生物标记物数据存储库501、定量结果数据存储库502、生物标记物诊断引擎503和诊断结果数据存储库504。
如图5所示,标准生物标记物数据存储库501表示通过自动无偏机器学习过程确定的生物标记物的详细信息,所述详细信息可从例如图3所示的内部验证引擎306和/或外部验证引擎308获取。所述生物标记物的详细信息包括,例如高于第一阈值的从血清获取的n-聚糖和高于第二阈值的igg,指示卵巢癌为阳性状态。在另一个例子中,所述生物标记物的详细信息包括一种高于某个阈值的糖基化的肽片段且血糖水平低于某个阈值,指示癌症为阳性状态。如上文所述,任何单种生物学指标或两种及多种生物学指标的组合都可以作为生物标记物。
如图5所示,定量结果数据存储库502表示来自受试者的生物样本的、可定量的生物学指标的定量结果和不可定量的生物学指标的数据。在实施中,定量结果和数据来自如图1a所示的糖组学指标定量系统104、基因组学指标定量系统106、蛋白质组学指标定量系统108、代谢学指标定量系统110、脂类组学指标定量系统112、临床指标生成系统114中的一个或多个系统。
如图5所示,生物标记物诊断引擎503连接到标准生物标记物数据存储库501和定量结果数据存储库502。在具体的实施方式中,生物标记物诊断引擎503表示专用的硬件和软件,所述硬件和软件根据一种或多种生物标记物对受试者进行诊断,并将诊断结果存储在诊断结果数据存储库504中。在具体的实施方式中,生物标记物诊断引擎503基于生物标记物确定从受试者的生物样本获取的生物学指标的定量结果是否在特定范围内,和/或从受试者获取的不可定量的指标的非定量数据与生物标记物的标准是否匹配,从而确定受试者是否具有某种健康分类。
在一个具体的实施方式中,根据生物标记物的详细信息,生物标记物诊断引擎503确定从受试者的生物样本获取的生物学指标的定量结果是否接近与健康状态对应的某一特定范围,或者所述定量结果是否偏离与健康分类状态相对应的另一特定范围,通过与受试者接受治疗之前的定量结果进行对比,从而能够确定应用于受试者的治疗措施是否有效。
在一个具体的实施方式中,根据生物标记物的详细信息显示,生物标记物诊断引擎503通过确定从受试者的生物样本获取的生物学指标的定量结果在与健康分类状态相关的某一特定范围内是增加还是减少,以及所述定量结果是否偏离与健康状态相关的另一特定范围,并且通过对比该受试者在诊断为具有该健康分类之后的在先定量结果,以此确定该受试者客观的健康分类进度。例如,在诊断出受试者患有心脏病之后,根据生物标记物的水平,客观地确定心脏病的阶段。
在具体的实施方式中,生物标记物诊断引擎503基于存储在诊断结果数据存储库504中的诊断结果、特别是治疗有效性结果,来确定(或选择)适用于具有某种健康分类的受试者治疗方法。例如,基于受试者的定量结果和生物标记物,生物标记物诊断引擎503从诊断结果数据库504中检索已应用于具有该健康分类的受试者的多种不同治疗方法的治疗效果,并从多种治疗方法中选择最佳的治疗方法。
疾病
本专利方法适用于可以通过分析从受试者的生物样本获取的生物学指标来检测的任何疾病或症状。在一些实施例中,所述疾病或症状是癌症。在其他实施例中,所述癌症是急性淋巴细胞白血病(all)、急性髓细胞性白血病(aml)、肾上腺皮质癌、肛门癌、膀胱癌、血液癌、骨癌、脑瘤、乳腺癌、女性生殖系统癌、男性生殖系统癌、中枢神经系统淋巴瘤、宫颈癌、儿童横纹肌肉瘤、儿童肉瘤、慢性淋巴细胞性白血病(cll)、慢性髓细胞性白血病(cml)、结肠和直肠癌、结肠癌、子宫内膜癌、子宫内膜肉瘤、食道癌、眼癌、胆囊癌、胃癌、胃肠道癌、毛细胞白血病、头颈癌、肝细胞癌、霍奇金病、下咽癌、卡波济肉瘤、肾癌、喉癌、白血病、肝癌、肺癌、恶性肿瘤纤维组织细胞瘤、恶性胸腺瘤、黑色素瘤、间皮瘤、多发性骨髓瘤、骨髓瘤、鼻腔和鼻旁窦癌、鼻咽癌、神经系统癌、神经母细胞瘤、非霍奇金淋巴瘤、口腔癌、口咽癌、骨肉瘤、卵巢癌、胰腺癌、甲状旁腺癌、阴茎癌、咽喉癌、垂体瘤、浆细胞瘤、原发性中枢神经系统淋巴瘤、前列腺癌、直肠癌、呼吸系统癌、视网膜母细胞瘤、唾液腺癌、皮肤癌、小肠癌、软组织肉瘤、胃癌、睾丸癌、甲状腺癌、泌尿系统癌、子宫肉瘤、阴道癌、血管系统、巨球蛋白血症、wilms肿瘤等。在另一实施例中,所述癌症是乳腺癌、宫颈癌或卵巢癌。
在另一实施例中,所述疾病是自身免疫疾病。在另一实施例中,所述自身免疫疾病是急性播散性脑脊髓炎、阿迪森氏病、无球蛋白血症、年龄相关性黄斑变性、斑秃、肌萎缩性侧索硬化、强直性脊柱炎、抗磷脂综合征、抗合成酶综合征、特应性过敏、特应性皮炎、自身免疫性自身免疫性疾病心肌病、自身免疫性肠病、自身免疫性溶血性贫血、自身免疫性肝炎、自身免疫性内耳疾病、自身免疫性淋巴增生性综合征、自身免疫性周围神经病、自身免疫性胰腺炎、自身免疫性多内分泌综合征、自身免疫性孕激素性皮炎、自身免疫性血小板减少性紫癜、自身免疫性荨麻疹同心性硬化症、贝塞特氏病、伯杰氏病、比克斯塔夫氏脑炎、布劳综合征、大疱性天疱疮、癌症、卡斯曼病、腹腔疾病、恰加斯病、慢性炎性脱髓鞘性多发性神经病、慢性反复发作局灶性骨髓炎、慢性阻塞性肺疾病、变应性肉芽肿性血管炎、瘢痕性天疱疮、科干综合征、冷凝集素病、补体成分2缺乏症、接触性皮炎、颅动脉炎、crest综合征、克罗恩病、库欣综合征、皮肤白细胞性血管炎、德戈氏病皮肤病、疱疹样皮炎、皮肌炎、i型糖尿病、弥漫性皮肤全身性硬化症、德勒综合症、药物性狼疮、盘状红斑狼疮、湿疹、子宫内膜异位、与炎性炎相关的关节炎、嗜酸性筋膜炎、嗜酸性肠炎、嗜酸性粒细胞增多症结节、胎儿成纤维细胞增多症、必要的混合性冷球蛋白血症、伊文氏综合症、进行性骨增生性纤维增生、纤维化性肺炎、胃炎、胃肠道天疱疮、肾小球肾炎、古德帕斯综合征、格雷夫斯病、吉兰-巴雷综合征、桥本脑病、桥本甲状腺炎、过敏性紫癜、艾滋病毒、妊娠天疱疮、化脓性汗腺炎、休斯史托文综合征、低球蛋白血症、特发性炎症性脱髓鞘疾病、特发性肺纤维化、特发性血小板减少性紫癜性慢性、iga肾病、包涵体肌炎、关节炎、川崎病、兰伯特-伊顿肌无力综合征、白细胞碎裂性血管炎、扁平苔藓、扁平苔藓、线性iga病、红斑狼疮、majeed综合征、美尼尔氏病、显微多发性血管炎、混合性结缔组织病、硬斑病、多发性曼氏病、重症肌无力、肌炎、发作性睡病、视神经脊髓炎、神经性肌强直、眼球瘢痕性天疱疮、视神经支配性肌阵挛综合征、奥德甲状腺炎、回旋风湿病、与链球菌相关的小儿自身免疫性神经精神疾病、副交感神经变性、阵发性夜间血红蛋白尿、帕里·罗姆伯格综合征、帕森纳格·特纳综合征、帕尔斯平炎、寻常性天疱疮、恶性贫血、静脉性脑脊髓炎、poems综合征、结节性多发性动脉炎、多肌痛风湿病、多发性肌炎、原发性胆汁性胆汁性硬化症、原发性胆囊炎、银屑病关节炎、坏疽性脓皮病、纯红细胞发育不良、拉斯穆森氏脑炎、雷诺综合征、复发性软骨炎、赖特氏综合征、躁动性腿综合征、腹膜后纤维化、类风湿性关节炎、风湿热、结节病、精神分裂症、施密特综合征、施尼茨勒综合征、巩膜炎、硬皮病、血清病、干燥综合征、脊椎关节炎、僵人综合征、亚急性细菌性心内膜炎、susac综合征、急性发热性嗜中性皮病、交感性眼炎、takayasu动脉炎、颞动脉炎、血小板减少症、痛性眼肌麻痹综合征、横贯性脊髓炎、溃疡性结肠炎、未分化的结缔组织病、荨麻疹性血管炎、脉管炎、白癜风和韦格纳氏病等。在另一实施例中,所述自身免疫疾病是艾滋病、原发性硬化性胆管炎、原发性胆汁性肝硬化或牛皮癣。
实施例
实施例1:igg糖肽作为乳腺癌生物标记物的定量
图6显示了乳腺癌患者的血浆样品相对于对照组的血浆样品中igg1、igg0和igg2糖肽变化的定量结果。分析不同癌症阶段的乳腺癌患者的血浆样品相对于年龄对应的对照组的血浆样品中的igg1、igg0和igg2糖肽,并比较它们的比例变化。具体而言,在qqq质谱仪上对处于原位癌阶段的20个样品、ec1阶段的50个样品、ec2阶段的138个样品、ec3阶段的25个样品、ec4阶段的9个样品以及73个年龄相符的对照样品进行mrm定量分析。定量结果如图6所示,在本实验研究的乳腺癌的各个阶段中,与对照组相比,某些igg1糖肽的水平升高了,某些igg1糖肽的水平降低了。举例来说,在本实验研究的乳腺癌的各个阶段中,监测了igg1糖肽中的al-a11;与对照组相比,发现糖肽a1和a2的水平升高了,糖肽a8、a9和a10的水平降低了。因此,糖肽a1、a2、a8、a9和a10可确认为乳腺癌的生物标记物。可以看到,与对照组相比,a5的水平虽然升幅较小,但有所升高;与对照组相比,a6的水平虽然降幅较小,但有所降低。因此,如果认为“小幅”变动是足够的话,a5和a6也可以确认为生物标记物。
实施例2:igg糖肽作为psc和pbc的潜在生物标记物的定量分析
实施例2显示了原发性胆汁性肝硬化(pbc)、原发性硬化性胆管炎(psc)患者和健康供体(没有患pbs或psc)的血浆样品中igg、igm和iga糖肽变化情况的定量结果,如图7所示。
在实施例2中,分析了psc患者、pbc患者的血浆样品以及健康供体的血浆样品中的igg1和igg2糖肽,并比较了它们的糖肽比例的变化。具体而言,将100个pbc血浆样品、76个psc血浆样品和49个健康供体的血浆样品在qqq质谱仪上进行mrm定量分析。从图7的定量结果可以看出,在pbc和psc患者的血浆样品中,与健康供体相比,某些igg1糖肽升高了,而某些igg1糖肽降低了。举例来说,与健康供体相比,pbc和psc患者血浆样品中的糖肽a升高了,糖肽h、i和j降低了。因此,可以将糖肽a、h、i和j确认为pbc和psc的生物标记物。
此外,图8a-8c和图9示出了单独和组合判别分析结果(使用k均值聚类算法),表明在组合判别分析中预测疾病状态的准确性为88%。对pbc患者和psc患者的血浆样品中的iga和igm糖蛋白进行了类似的分析。判别分析结果如图8a-c所示,表明根据igg、igm和iga的单项数据预测的准确率分别为59%、69%和74%。然而,如图9所示,将所有igg、igm和iga的结果进行组合后,判别分析的准确率约为88%。
本说明书提供的这些实例和其他实例旨在说明而不是限制所述的实施方式。例如,本说明书所使用的词语“实施/实施方式”是指用于通过非限制性实例说明的实施方式。可根据需要将前述文字和附图中所述的技术进行混合和搭配,以产生其他替代性的实施方式。
- 还没有人留言评论。精彩留言会获得点赞!