一种提升痤疮杆菌耐药突变及耐药基因检测准确性和效率的方法及其配套试剂盒与流程
本发明属于痤疮杆菌耐药检测
技术领域:
,具体涉及一种提升痤疮杆菌耐药突变及耐药基因检测准确性和效率的方法及其配套试剂盒。
背景技术:
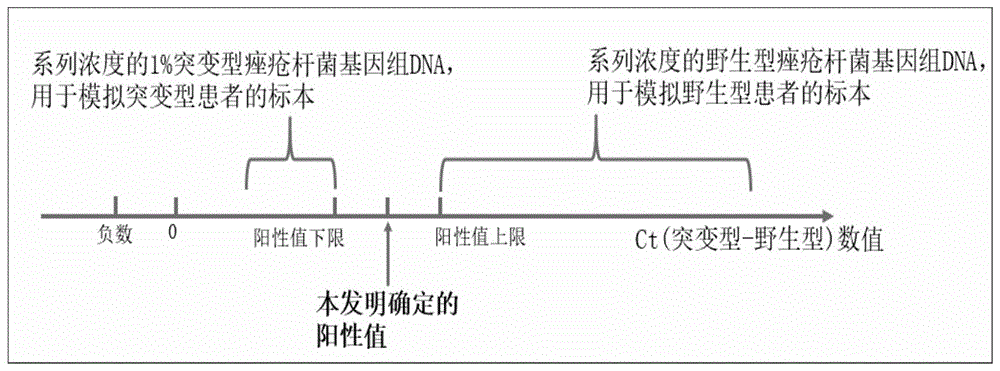
:寻常痤疮(青春痘)是世界上最常见的皮肤病之一。在全球范围内,痤疮的患病率居于所有疾病的第8位,主要累及青少年人群及20~30岁的成年人,影响超过十亿人。在中国,国内多个省市开展的流行病学调查报道了在10~22岁范围内的不同人群中,患病率波动于36.4~54.9%之间。面部痤疮的发生,影响了患者的面部容貌,不仅给患者带来严重的心理负担,影响患者的社交、就业与生活质量,还可能导致自卑、抑郁。《中国痤疮治疗指南(2014)》指出,痤疮对青少年的心理和社交影响已经超过了哮喘和癫痫。国外研究也指出,痤疮患者更易焦虑、抑郁,失业率甚至自杀率也比同龄的非痤疮患者更高。目前公认,痤疮杆菌在皮肤毛囊中的大量繁殖与痤疮有密切关系。在中国,皮肤科医生主要对痤疮患者使用大环内酯类抗生素,抑制痤疮杆菌的生长。长期使用抗生素会产生耐药性痤疮杆菌。因此,在科学研究中,确定痤疮杆菌对大环内酯类抗生素的耐药性具有重要意义。使用现有的细菌学方法,可以对痤疮杆菌的耐药性进行检测。但是,痤疮杆菌属于厌氧菌,需要苛刻的培养条件与昂贵设备(厌氧手套箱或产气袋),且生长缓慢。取得患者标本后,常需等待一周时间才能给出检测结果。并且由于操作上的繁琐,痤疮杆菌耐药性的检测费用昂贵、自动化程度极低,需要进行大量实验操作,不仅难以开展,对于进行相关研究的单位来说也成为一种负担。更重要的是,此前一直认为:一个病人面部痤疮杆菌群落的状态只有两种,一种是只携带耐药痤疮杆菌,另一种是只携带野生型(即不耐药)痤疮杆菌。但在实验中,我们发现大部分病人处于既携带野生型痤疮杆菌、又携带耐药痤疮杆菌的中间状态,只是耐药痤疮杆菌所占比例不同,在检测中即体现为δct不同。而由于缺乏检测手段,这一现象并没有被描述过,属于本发明首次证实。从这个角度来看,现有方法(分离纯化后进行pcr-测序或药敏实验)存在固有缺陷:如果某患者的面部痤疮杆菌种群中,耐药型痤疮杆菌比例较少,常规的分离纯化方法将无法将其分离、获得,从而出现假阴性的错误结果。由此导致医院检验科和研究者不愿、也不可能常规开展此菌的分离培养与耐药检测项目。因此,目前在世界范围内,科学界尚没有对大量痤疮患者进行耐药检测的实践,更没有一种准确性更高,效率更高的检测方法和配套产品提出。痤疮杆菌的耐药主要由两种机制引起:基因组中携带ermx基因或携带23srrna基因的点突变a2058t、a2058g、a2059g,这四个指标有任何一个阳性,该痤疮杆菌即对大环内酯类抗生素药物(红霉素、阿奇霉素、克拉霉素等)和/或林可霉素类抗生素耐药。痤疮杆菌的23srrna基因的2058位点由野生型a突变为g或t,2059位点由野生型a突变为g,均可产生耐药性。其机制是,23srrna中肽酰转移酶的结构域v的碱基序列改变,使其与大环内酯类抗生素药物的结合能力减弱甚至无法结合。ermx基因编码一种甲基转移酶,将药物结合位点甲基化,能够使痤疮杆菌产生对大环内酯类抗生素的耐药性,该基因序列见ncbi数据库。我们提出,以上述三个检测对象,出现任何一个突变,即可判断为痤疮杆菌对大环内酯类抗生素耐药。其余位点因出现频率过低、且未得到科学界的充分验证,不列入本发明检测范围。注:为避免混淆,下文中凡涉及到痤疮杆菌耐药突变位点本身,及本发明的检测结果和痤疮杆菌的基因型,都称之为野生型(不带有3种耐药突变中的任何一种)、a2058t、a2058g、a2059g;凡涉及到arms引物的名称,都称之为58a、58t、58g、59a、59g;凡涉及到使用arms引物进行qpcr,产生的ct值都称之为ct(ermx)、ct(16s)、ct(58a)、ct(58t)、ct(58g)、ct(59a)、ct(59g);凡涉及到将两个ct值相减,以判断某个标本中的痤疮杆菌是否携带ermx基因或耐药突变,所得的ct值的差值都称之为ct(ermx-16s)、ct(58t-58a)、ct(58g-58a)、ct(59g-59a)。技术实现要素:本发明的首要目的是提供一种提升痤疮杆菌耐药突变及耐药基因检测准确性和效率的方法,第二个目的是建立一种能够直接利用患者的痤疮内容物、快速检测其中痤疮杆菌耐药性的产品。本发明是全球首个痤疮杆菌耐药检测的科学研究解决方案。仅需两小时即可给出痤疮杆菌对大环内酯类抗生素耐药性的准确检测结果。在目前阶段,经过试用,就已经受到皮肤科医生及患者的热烈欢迎。本发明的目的是通过以下方式实现的。一种提升痤疮杆菌耐药突变及耐药基因检测准确性和效率的方法,包括以下步骤:(1)以待测痤疮内容物皮脂粒或者痤疮皮肤拭子标本的总dna作为模板;(2)进行arms-qpcr:建立6个反应体系如下:第1个:扩增2058位点的基因型为a的痤疮杆菌23srrna基因片段;第2个:扩增2058位点的基因型为t的痤疮杆菌23srrna基因片段;第3个:扩增2058位点的基因型为g的痤疮杆菌23srrna基因片段;第4个:扩增2059位点的基因型为a的痤疮杆菌23srrna基因片段;第5个:扩增2059位点的基因型为g的痤疮杆菌23srrna基因片段;第6个:扩增ermx基因片段和痤疮杆菌16srrna基因片段;优选:还在第1-5个反应体系中均同时扩增痤疮杆菌16srrna基因片段,作为内对照;(3)结合ct值结果,得出痤疮杆菌耐药突变及耐药基因检测结果。本发明检测的痤疮杆菌耐药突变及耐药基因是针对大环内酯类(包括红霉素、阿奇霉素、克拉霉素等),林可霉素等的耐药。进一步的,本发明优选还设置第7和第8个反应体系。第7个反应体系:阳性对照;设置此对照的目的是确保反应体系不含有pcr抑制剂、引物和探针没有因为降解而失效,以防止假阴性结果。此体系除加入与第1个反应体系或者第4个反应体系相同的试剂外,另加入基因型为携带2058a、2059a,不携带ermx基因的痤疮杆菌基因组dna,优选加入量为10ng。第8个反应体系:阴性对照;设置此对照的目的是确保反应体系在没有添加痤疮杆菌dna时,没有受到其他痤疮杆菌dna的污染,以保证结果的可靠。此体系加入除加入与第1个反应体系或者第4个反应体系相同的试剂外,另加入ermx的引物和探针(fam)。进一步的,上述的方法,第1-5个反应体系,每个反应体系中除加入各自需要扩增23srrna基因片段的正反引物外,还需要加入扩增23srrna基因的探针、步骤(1)的模板,第6个反应体系中加入扩增ermx基因的正反引物、扩增ermx基因的探针以及扩增痤疮杆菌16srrna基因片段的正反引物和扩增16srrna基因的探针,步骤(1)的模板;优选还在第1-5个反应体系中加入扩增痤疮杆菌16srrna基因片段的正反引物和扩增16srrna基因的探针。进一步的,上述的方法,第1-5每个反应体系中,需要扩增23srrna基因片段的正反引物为arms正向通用引物和负责分型的arms反向引物;优选在设计2058位点扩增引物时3’端的第二个碱基使用兼并碱基,使2058和2059两个相邻位点的检测互不干扰。进一步的,上述的方法,各引物和探针设计优选,但不限于以下序列:需要扩增23srrna基因片段的正反引物包括:arms正向通用引物arms-e-f:ggggacctgagctgtc,见seqidno.1。负责分型的arms反向引物58a:ctatagtaaaggtcccggggtcgyt;见seqidno.2,58t:ctatagtaaaggtcccggggtcgya;见seqidno.3。58g:ctatagtaaaggtcccggggtcgyc;见seqidno.4y为兼并碱基,可与a或g互补配对。59a:ctatagtaaaggtcccggggtcat;见seqidno.5。59g:ctatagtaaaggtcccggggtcac;见seqidno.6。扩增23srrna基因探针,简称为23s探针,下同:fam-catctttactcgtaatgcaatttcacc-bhq1,见seqidno.7。扩增ermx基因的引物:ermx-f:gatgatgacggctcagtggt;见seqidno.8;ermx-r:tttgcgctgctctatcggaa;见seqidno.9。扩增ermx基因的探针,简称为ermx探针:fam-ttcacatttcacctgggttctcgggtaccaa-bhq1,见seqidno.10。作为内对照扩增16srrna基因引物:435-f:accgctttcgcctgtgac;见seqidno.11,579-r:agccccaagattacacttccgac见seqidno.12。扩增16srrna基因的探针,简称16s探针或内对照探针:vic-aagcgtgagtgacggtaatgggtaaagaagcacc-bhq1,见seqidno.13。上述的方法,每一反应体系配制优选如下:扩增痤疮杆菌16s基因片段的正、反引物和探针的用量均为0.05ul,且它们在体系中的终浓度均为0.01-2.5μm,优选0.05μm。扩增2058位点基因片段的正、反引物和探针的用量均为0.125ul,且它们在体系中的终浓度均为0.01-2.5μm,优选0.125μm。扩增2059位点基因片段的正、反引物和探针的用量均为0.175ul,且它们在体系中的终浓度均为0.01-2.5μm,优选0.175μm。扩增ermx基因片段的正、反引物和探针的用量均为0.1ul,且它们在体系中的终浓度均为0.01-2.5μm,优选0.1μm。扩增2058或2059位点基因片段的模板用量优选1ul,扩增ermx基因片段的模板用量优选0.5ul,每一反应体系中均优选加入premix10ul,每一反应体系总体积优选加水到20ul。第7个反应体系:阳性对照,除加入与第1个反应体系或者第4个反应体系相同的试剂外,另加入基因型为携带2058a、2059a,不携带ermx基因的痤疮杆菌基因组dna,优选加入量为10ng。第8个反应体系:阴性对照,此体系加入除加入与第1个反应体系或者第4个反应体系相同的试剂外,另加入扩增ermx基因的引物和探针(fam)。第7,8反应体系中引物,探针,模板等的用量参考第1-6反应体系。本发明的反应体系主要包括正反arms引物、23s探针、正反16s引物、16s探针、模板和其余反应成分。经过系列实验,我们尝试了各种引物和探针浓度,结果如下:1.由于模板添加量对反应性能没有影响,出于减小孔间移液误差的考虑,将其确定优选为每个反应孔添加0.5或1ul,浓度不必定量。2.经过预实验,我们发现vic通道的扩增痤疮杆菌16srrna基因的qpcr反应性能极佳,出于避免其消耗过多dntp等反应体系内资源的考虑,将正反16s引物、16s探针的添加量确定为每个反应孔优选添加0.05μm。3.正反arms引物浓度对分型与qpcr反应性能影响最大。因此,我们尝试了五种添加量,分别为0.1,0.125,0.15,0.175,0.2μm。选择的依据为,对于某一给定的模板,无论突变型痤疮杆菌在其中所占的比例,其qpcr结果中,野生型与突变型的δct均应达到最大。这样的选择标准是为了保证,当检测任何模板时,均可以有最大的δct值,从而使产品尽可能灵敏。上述的方法,反应循环如下:1.95℃,2分钟;2.95℃,15秒3.60℃,30秒4.重复2-3步,39个循环。本发明所述的提升痤疮杆菌耐药突变及耐药基因检测准确性和效率的方法的结果判断规则包括:痤疮杆菌23srrna的2058位点由野生型a突变为g或t、2059位点由野生型a突变为g,以及携带ermx基因三种情况中至少出现一个,即判断为痤疮杆菌耐药。进一步的,具体包括以下步骤:1)当判断标本中的痤疮杆菌是否携带ermx基因时,通过ct(ermx-16s),即ermx探针扩增的ct值与16s探针扩增的ct值的差值大小进行判断;如果该差值小于等于阳性值,就判断为阳性,即标本中的痤疮杆菌携带ermx基因;如果该数值大于阳性值,就判断为阴性,标本中的痤疮杆菌不携带ermx基因;对于判断是否携带ermx基因时,使用公认的roc曲线法确定阳性值;2)当判断标本中的痤疮杆菌是否携带23srrna的2058位点和2059位点突变时,通过各自位点突变型的ct值与野生型的ct值的差值大小进行判断;如果该差值小于等于阳性值,就判断为阳性,即标本中的痤疮杆菌携带对应位点的突变;如果该差值大于阳性值,则判断为阴性,即标本中的痤疮杆菌不携带对应位点的突变;首先判断是否带有a2058t突变,再来判断a2059g突变,最后判断a2058g突变;步骤2)所述阳性值的确定过程如下:a,分为阳性值上限确定和阳性值下限确定两个部分,具体如下:对于阳性值上限的确定:分别使用基因型为2058a和2059a的野生型的痤疮杆菌基因组dna,根据标本检测极限范围梯度稀释(可根据需求进行设置,如本发明实施例中的标本检测极限范围为50ng至50pg),各梯度进行检测(除了模板按照这里的梯度设计,其余采用本发明方法,包括试剂、引物、探针、步骤等),并计算各个梯度的ct(突变型-野生型)数值,选取每种突变型最小的ct(突变型-野生型)数值,即为对应突变型的阳性值上限;对于阳性值下限的确定:分为三组进行,按照标本中突变最低检测极限百分比在野生型中分别掺杂a2058t、a2058g、a2059g的单突变型痤疮杆菌基因组dna,根据野生型标本检测极限范围梯度稀释,(突变最低检测极限百分比可根据需求进行设置,如本发明实施例中标本中单突变最低检测极限百分比为1%,标本的检测极限范围为50ng至50pg),各梯度进行检测(除了模板按照这里的梯度设计,其余采用本发明方法,包括试剂、引物、探针、步骤等),并计算ct(突变型-野生型)数值;选取每种突变型最大的ct(突变型-野生型)数值,即为对应突变型的阳性值下限;每个突变位点的阳性值可以选取上下限中的任一个数值;b,当带有a2058t突变,不再利用步骤a中确定的a2059g的阳性值来判断是否存在a2059g,需要重新确定a2059g的阳性值,确定过程如下:以纯a2058t突变型痤疮杆菌基因组dna(2059野生型),根据标本检测极限范围梯度稀释(可根据需求进行设置,如本发明实施例中的标本检测极限范围为3.1ng至50ng),各梯度进行检测(除了模板按照这里的梯度设计,其余采用本发明方法,包括试剂、引物、探针、步骤等),并计算ct(59g-59a)数值,选取ct(59g-59a)中的最小值进行下浮调整,下浮标准为0.5以内的任意数值;调整之后的数值即为阳性值。c,当不带有a2058t突变(2058野生型),带有a2059g突变时,不再利用步骤a中确定的a2058g的阳性值来判断是否存在a2058g,需要重新确定a2058g的阳性值,确定过程如下:以纯a2059g突变型痤疮杆菌基因组dna,根据标本检测极限范围梯度稀释(可根据需求进行设置,如本发明实施例中的标本检测极限范围为3.1ng至50ng),各梯度进行检测(除了模板按照这里的梯度设计,其余采用本发明方法,包括试剂、引物、探针、步骤等),并计算ct(58g-58a)数值,选取ct(58g-58a)中的最小值进行下浮调整,下浮标准为0.5以内的任意数值;调整之后的数值即为阳性值。进一步的,确定标本中是否带有突变型痤疮杆菌的具体步骤如下:步骤一:如果ct(ermx–16s)≤6.10,即判定为标本中的痤疮杆菌携带ermx基因,即对大环内酯内抗生素耐药;如果ct(ermx–16s)>6.10,即判定为标本中的痤疮杆菌不携带ermx基因;步骤二:如果同时满足ct(58t-58a)>10.50且ct(59g-59a)>9.5且ct(58g-59a)>8.0,该标本的基因型为2058-2059aa;如果同时满足ct(58t-58a)>10.50且ct(59g-59a)≤9.5且ct(58g-59a)>5.0,该标本的基因型为2058-2059ag;步骤三:如果同时满足ct(58t-58a)≤10.50且ct(59g-59a)>6.5,该标本的基因型为2058-2059ta;如果同时满足ct(58t-58a)≤10.50且ct(59g-59a)≤6.5,该标本的基因型为2058-2059tg;步骤四:如果同时满足ct(58t-58a)>10.50且ct(59g-59a)>9.5且ct(58g-59a)≤8.0,该标本的基因型为2058-2059ga;如果同时满足ct(58t-58a)>10.50且ct(59g-59a)≤9.5且ct(59g-59a)≤5.0,该标本的基因型为2058-2059gg;步骤一判断标本面部的痤疮杆菌是否携带ermx基因;步骤二、三、四判断标本面部的痤疮杆菌23srrna基因2058、2059位点的基因型。本发明采用天根生化科技(北京)有限公司tianexactgenotypingqpcrpremix(fp211),以及bioradc1000touchcfx96实时荧光定量pcr仪。本发明的一种提升痤疮杆菌耐药突变及耐药基因检测准确性和效率的方法和配套的试剂盒,排除直接以疾病诊断为目的的方面的应用,但可以用于痤疮杆菌耐药位点或者基因突变机理的研究或者如何提高检测方法效率和准确性方面的研究。本发明还提供了一种与上述方法配套使用的痤疮杆菌耐药突变及耐药基因检测试剂盒,包括:配制6个反应体系所需的试剂:第1个:扩增2058位点的基因型为a的痤疮杆菌23srrna基因片段;第2个:扩增2058位点的基因型为t的痤疮杆菌23srrna基因片段;第3个:扩增2058位点的基因型为g的痤疮杆菌23srrna基因片段;第4个:扩增2059位点的基因型为a的痤疮杆菌23srrna基因片段;第5个:扩增2059位点的基因型为g的痤疮杆菌23srrna基因片段;第6个:扩增ermx基因片段和痤疮杆菌16srrna基因片段;优选:还在第1-5个反应体系中均同时扩增痤疮杆菌16srrna基因片段,作为内对照;进行arms-qpcr所需的试剂。所述的试剂盒,还包括:第1-5个反应体系中需要扩增23srrna基因片段的正反引物:arms正向通用引物和负责分型的arms反向引物,扩增23srrna基因的探针,扩增ermx基因的正反引物、扩增ermx基因的探针,扩增痤疮丙酸杆菌16srrna基因片段的正反引物和扩增16srrna基因的探针,负责分型的arms反向引物中扩增2058位点的引物,优选使用兼并碱基。所述的试剂盒,还包括:需要扩增23srrna基因片段的正反引物包括:arms正向通用引物arms-e-f:ggggacctgagctgtc;负责分型的arms反向引物58a:ctatagtaaaggtcccggggtcgyt;58t:ctatagtaaaggtcccggggtcgya;58g:ctatagtaaaggtcccggggtcgyc;y为兼并碱基,能与a或g互补配对;59a:ctatagtaaaggtcccggggtcat;59g:ctatagtaaaggtcccggggtcac;扩增23srrna基因的探针:fam-catctttactcgtaatgcaatttcacc-bhq1;扩增ermx基因的引物:ermx-f:gatgatgacggctcagtggt;ermx-r:tttgcgctgctctatcggaa;扩增ermx基因的探针:fam-ttcacatttcacctgggttctcgggtaccaa-bhq1;作为内对照扩增16srrna基因引物:435-f:accgctttcgcctgtgac;579-r:agccccaagattacacttccgac;扩增16srrna基因的探针:vic-aagcgtgagtgacggtaatgggtaaagaagcacc-bhq1。本发明的试剂盒产品还可以包括:标本dna提取试液、装有40目玻璃珠的1.5ml离心管(玻璃珠占体积0.2ml)、2个空的1.5ml离心管、dna硅胶吸附柱、预填充有qpcr反应液(arms正反引物和探针、内对照正反引物和探针、premix预混液、水)的白色0.1ml八连管(带光学平盖)等部分构成。其中,标本dna提取试液包括:a液:2.5%ctab/0.5mnacl水溶液;b液:10%sds水溶液;c液:10mg/ml蛋白酶k溶液;d液:无水乙醇;e液:50%异丙醇水溶液;f液:75%乙醇水溶液;g液:核酸洗脱液(5mmtris,0.5mmedta,ph8.0)。其中,预填充有arms-qpcr反应液的白色0.1ml八连管的具体用途如下:第1个孔:扩增2058位点基因型为a的痤疮杆菌23srrna基因片段(fam);第2个孔:扩增2058位点基因型为t的痤疮杆菌23srrna基因片段(fam);第3个孔:扩增2058位点基因型为g的痤疮杆菌23srrna基因片段(fam);第4个孔:扩增2059位点基因型为a的痤疮杆菌23srrna基因片段(fam);第5个孔:扩增2059位点基因型为g的痤疮杆菌23srrna基因片段(fam);第6个孔:扩增ermx基因片段(fam);第7个孔:阳性对照(确保反应体系不含有pcr抑制剂、引物和探针没有因为降解而失效,以防止假阴性结果);第8个孔:阴性对照(确保反应体系在没有添加痤疮杆菌dna时,没有受到其他痤疮杆菌dna的污染,以保证结果的可靠);第1-6个孔同时扩增痤疮杆菌16srrna基因片段(vic),作为内对照,以排除操作者疏忽而忘记往某个孔中加样造成的假阴性。本发明试剂盒产品使用流程如下:1.消毒面部皮肤,使用清洁的粉刺针将痤疮内的皮脂粒挤出;2.将皮脂粒转移至装有275μl2.5%ctab/0.5mnacl溶液(a液)的装有40目玻璃珠的1.5ml离心管,而后将离心管置于组织破碎仪,4000rpm10min以充分打碎皮脂粒,释放出痤疮杆菌,并破碎细菌细胞壁。3.加入蛋白酶k(c液)20μl,涡旋15秒以混匀。58℃处理10min以水解蛋白。再加入10%sds溶液(b液)125μl,涡旋15秒混匀,70℃处理10min以变性蛋白。之后将样液全部转入一个新的1.5ml离心管中。加入无水乙醇(d液)500μl以沉淀dna,涡旋15秒混匀。将液体全部转入吸附柱中,12000rpm离心1min,倒弃收集管中液体。4.加入50%异丙醇溶液(e液)500μl以除去残留的蛋白,12000rpm离心1min,倒弃收集管内液体。5.加入75%乙醇溶液(f液)600μl以除去异丙醇,12000rpm离心1min,倒弃收集管内液体。6.重复步骤5一次。7.14000rpm离心3min甩干残液。拿出吸附柱,打开管盖,置于58℃干燥3min以烘干残余乙醇。将吸附柱插入第二个1.5ml离心管中。吸附柱中加入核酸洗脱液(g液)100μl,置于室温下5min使其充分浸润。14000rpm离心3min,在收集管中得到模板(标本dna溶液)。8.打开八连管的盖子。在八连管的前五个孔中各加入1μl模板。在第六个孔中加入0.5μl模板。关闭管盖并涡旋10秒混匀。离心10秒以将液体甩到管底并去除气泡。之后将八连管放入实时荧光定量pcr仪,运行反应程序。完成后进行结果判读。本发明还提供了用于检测痤疮杆菌23srrna基因的2058和2059位点的引物,序列如下:负责分型的arms反向引物58a:ctatagtaaaggtcccggggtcgyt;58t:ctatagtaaaggtcccggggtcgya;58g:ctatagtaaaggtcccggggtcgyc;y为兼并碱基,能与a或g互补配对;59a:ctatagtaaaggtcccggggtcat;59g:ctatagtaaaggtcccggggtcac。本发明还提供一种检测痤疮杆菌耐药基因ermx的试剂,含有扩增ermx基因片段和痤疮杆菌16srrna基因片段所需的试剂,具体包括:扩增ermx基因的引物、探针;扩增16srrna基因引物、探针,所述的试剂当判断标本中的痤疮杆菌是否携带ermx基因时,通过ct(ermx-16s),即ermx探针扩增的ct值与16s探针扩增的ct值的差值大小进行判断;如果该差值小于等于阳性值,就判断为阳性,即标本中的痤疮杆菌携带ermx基因;如果该数值大于阳性值,就判断为阴性,标本中的痤疮杆菌不携带ermx基因;对于判断是否携带ermx基因时,使用公认的roc曲线法确定阳性值。通过ct(ermx-16s)进行是否携带耐药基因的判断是本发明首次提出。本发明创新点:1、通过突变位点筛选,并结合了中国人群的痤疮杆菌耐药突变携带情况,将各突变位点组合为一整套耐药检测试剂盒,包括四个耐药位点的检测,可以一次性读取所有突变位点的结果。准确性上,准确度可达100%,特异度可达96%;使用实验周期上,能在两小时内报告检测结果。2、由于待检测的2058与2059位点相邻,因此2058引物必然覆盖待检测的2059位点。而2059位点有a,g两种可能的基因型。如果按现有arms引物设计方法,必然导致2058位点的检测结果依赖于对2059位点基因型的判断,可靠性欠佳。我们创新性地在2058引物中,结合2059位点的碱基位置(2058位点的3’端第二位碱基)使用一个简并碱基(或称兼并碱基)y,可与a或g互补配对,有效解决了这一问题,比普通arms引物设计方法更新颖。3、此前有过报道的所有arms检测引物,均没有考虑到多种细菌共同存在时,干扰检测结果的问题。此前见于报道的arms引物,包括乙肝病毒耐药、结核耐药等,标本成分极其简单,没有亲缘关系相近的物种干扰检测。本产品为了临床上实施的便利,首次提出:痤疮内容物中的皮脂粒可以直接作为检材,并且通过创新的引物设计,克服了此标本中细菌种类极其复杂、亲缘关系近、干扰检测的困难。因为,只有痤疮杆菌的抗生素耐药性才对医生有参考价值,因此产品必须做到只扩增痤疮杆菌,而不受同科、甚至同属不同种的细菌的干扰。我们通过仔细设计通用引物序列(5条arms反向引物共用1条正向通用引物),在23srrna基因序列上寻找特异性区域,最终做到了极好的扩增特异性,形成了正向通用引物负责确保检测的特异性、反向arms引物负责分型的范式,可以扩展应用到其他临床复杂标本。总之,通过创新的设计,扩增所需的通用正向引物特异性极好,在临床样品中可以做到只扩增痤疮杆菌dna。负责特异性的正向通用引物与负责分型的arms反向引物互相配合,保证了产品检测结果的准确性,比普通arms引物设计方法更创新。4、通过前述的三个位点的组合来检测痤疮杆菌耐药性,是由我们最先提出并应用于本产品,可以达到极高准确率。此前见于文献报道的痤疮杆菌耐药确定方法,都需要将该种细菌分离出来,做药敏试验,方可确定。药敏试验一直被认为是痤疮杆菌耐药性检测的金标准。此前没有报道过通过这三个位点的检测,直接以极高的准确率,得出细菌耐药性信息的方法。并且,经典的药敏试验方法,依赖于从标本中分离出一株或几株痤疮杆菌,再进行药敏试验。然而,由于突变可在没有抗生素存在的情况下自发产生,有极大的可能,病人既携带大量的不耐药野生型痤疮杆菌,又携带少量的耐药突变痤疮杆菌。而由于耐药的突变型痤疮杆菌所占比例少,经典方法必然会无法检出,得出患者对抗生素敏感的结论。此时使用抗生素,敏感的痤疮杆菌被杀死,少量的耐药痤疮杆菌繁殖壮大,病人不会有好转。而本方法检测的是标本中所有痤疮杆菌的相关位点,可先天地克服这一问题。arms法检测耐药突变的这一优势,此前未见报道。总之,目前临床通行的药敏试验只能分离出临床标本中有限的细菌,无法得知菌群耐药突变情况的全貌。本方法能掌握标本中耐药突变的比例,有效避免了假阴性。5、痤疮杆菌是痤疮皮脂粒中含量最丰富的细菌,相对丰度为30%~90%,其中绝大部分患者都>90%。但是,有少部分患者痤疮杆菌含量较低,因此即使痤疮杆菌携带ermx基因,拷贝数也较低,可能出现假阴性。ermx基因不仅存在于痤疮杆菌,也广泛存在于其他细菌中,甚至环境中。因此,如果患者携带的痤疮杆菌以外的细菌也携带ermx,且此种细菌相对丰度较高,可能造成假阳性。因此我们创新地将特异性扩增痤疮杆菌的内对照,与特异性扩增ermx基因的引物进行结合,只有当ct(ermx–16s)≤6.10时才判断为阳性,有效解决了以上问题。现有的试剂盒产品中,内对照的用途都是排除因为忘记加入样品而造成的假阴性。而对耐药基因的扩增,都选取某个菌种中特异性存在的基因进行检测。由于临床样品的复杂性,我们提出的阳性判断标准将靶基因ermx与内对照(即痤疮杆菌的16srrna基因)结合,富有创新性,并且能平移到其他类似的复杂标本中。总之,有效解决了不同病人标本中:(1)痤疮杆菌含量较少造成的假阴性结果;(2)除痤疮杆菌以外的其他细菌含有的ermx基因造成的假阳性结果。6、基于我们的最新发现,大部分病人处于既携带野生型痤疮杆菌、又携带耐药痤疮杆菌的中间状态,只是耐药痤疮杆菌所占比例不同的理论,在检测中即体现为ct(突变型-野生型)不同,并据此总结出一套全新的精细准确判定突变的准则,不仅显著提升痤疮杆菌耐药突变及耐药基因检测准确性和效率,经过与经典方法比较,已经确认本发明方法的可行性、准确性与特异性。本发明具有高特异性、高准确度、操作简便等优点,检测结果准确可靠,具体有益效果如下:1、本方法不仅能进行大样本痤疮突变位点调查、为诊疗标准的制定提供证据、促进国民健康,更比目前临床主流的“分离纯化细菌+药敏试验”方法准确,因为本方法获得的检测结果是患者标本中所有痤疮杆菌的相关位点基因型的总和,不是单个细菌的检测结果,有效避免了因耐药型细菌在标本所有细菌中比例低而无法被分离出、进而无法检出的问题。2、23srrna基因通用引物及16srrna基因引物有意回避了亲缘关系相近的细菌的相同序列,避免了非特异性扩增,可以做到只扩增痤疮杆菌dna,具有特异性强的优点。3、ermx基因引物回避了erm基因家族的其他基因,能做到只扩增ermx靶基因。通过与ct(16s)结合进行判读,有效避免了假阴性与假阳性,性能优越。4、引入的额外碱基错配兼并碱基,提高了引物对单碱基突变的识别能力,使引物能有效识别一个碱基的差异,不影响相邻两个突变位点的检测,提高了检测准确性和可靠性。5、本发明技术方案确定的引物-探针组合,性能优越,检测范围宽,最低检测浓度极限范围低,模板用量少。模板使用痤疮杆菌基因组dna时,模板加入量在50pg-50ng之间,引物对突变的分辨能力没有显著变化。6、本产品可以在50pg至50ng的动态范围内,实现野生型标本的准确判别,并可以实现标本中含有1%突变型痤疮杆菌的准确判别。通过与金标准(传统方法)进行对比,敏感度为100%,特异度为96.4%。7、检测方法简单,仅需要一台实时荧光定量pcr仪就能完成。操作快速便捷。且检测用时比大多数医院内的检测项目都短,可在2小时内完成分型工作并出具报告。以下文字叙述本发明结果判读所需的阳性值的确定方法。这套结果判读方法,以及其所需的阳性值确定方法是由本发明首次提出,与本发明的原理与目的密切相关,具有很强的创新性。首先叙述ermx基因阳性值的确定过程,其次叙述2058和2059位点突变型阳性值的确定过程。ermx基因阳性值的确定过程如下:在患者的痤疮皮脂粒标本中,既有痤疮杆菌,也有许多其他细菌。研究表明,许多种细菌都可能携带ermx基因。因此,如果只在标本中检测ermx基因,就无法确定其是否来源于痤疮杆菌,因此无法对痤疮杆菌的耐药性做出判断。本发明采用以下方法,巧妙地解决这个难题。在八连管的第6个反应管中,fam标记的探针检测标本中ermx基因的含量,vic标记的探针检测痤疮杆菌16srrna基因的含量。将两个反应的ct值相减,就得到ermx基因与痤疮杆菌在标本中的含量关系。具体的,本发明通过ct(ermx-16s),即ermx的ct值减去16s的ct值的数值大小进行判断。如果该数值≤阳性值,判断为阳性,即标本中的痤疮杆菌携带ermx基因;如果该数值>阳性值,判断为阴性,即标本中的痤疮杆菌不携带ermx基因。我们在ncbi数据库中统计了痤疮杆菌16srrna基因的拷贝数,见表1。ncbi数据库中共有痤疮杆菌基因组数据20个,其中15个痤疮杆菌的16srrna基因有3个拷贝,3个痤疮杆菌的16srrna基因有2个拷贝。这说明痤疮杆菌中16srrna基因的数量较为恒定,可以作为内对照,用来指示标本中痤疮杆菌的相对数量。表1ncbi数据库中痤疮杆菌基因组中16srrna基因的拷贝数菌株名称基因组大小/mb16srrna基因拷贝数atcc69192.4953atcc11828,defendens2.492typeia2p.acn17,acnes2.5233typeia2p.acn31,acnes2.4993typeia2p.acn33,acnes2.4903sk1372.4953pa_12_1_l12.493pa_12_1_r12.472pa_15_1_r12.493pa_15_2_l12.543pa_21_1_l12.563pa_30_2_l12.533fdaargos_5772.4953kpa1712022.563hl202pa12.481kcom13152.563kcom18612.526p62.522j1392.481j1652.503至于ermx基因阳性值的确定,本发明采用roc曲线法。即,将同一份标本分为两部分,一部分用本发明进行检测,另一部分用传统方法(金标准)检测:分离出痤疮杆菌,提取其基因组dna,并进行ermx基因的pcr扩增,根据pcr扩增结果进行标本的阳性/阴性判断。将许多个标本的阳性或阴性结果,与对应的ct(ermx-16s)值对应起来,再使用spss22软件进行roc曲线分析,得出敏感度与特异度均最高的一个值,即为阳性值。从患者标本中分离纯化出的细菌,需鉴定其是否为痤疮杆菌。首先16srrna基因片段扩增(使用takara公司的primestarmaxpolymerasepremix,退火温度53.4℃,反应程序及反应体系按厂家说明书进行)。扩增后,对扩增产物进行sanger测序。序列经ncbiblast分析确定是否为痤疮杆菌。鉴定痤疮杆菌的引物序列为:16s-f,pcr:agagtttgatcmtggctcag,见seqidno.14;16s-r,pcr:tacggttaccttgttacgac,见seqidno.15。ermx的pcr扩增方法如下:使用天根生化科技有限公司的2×taqpcrmastermix(kt201),退火温度62℃,反应程序及反应体系按厂家说明书进行。目标条带在300-400bp之间。引物序列为:ermx-f,pcr:gtctgcatacggacacgg,见seqidno.16ermx-r,pcr:cgagcgacttcccactgc,见seqidno.17。以下表2、表3分别给出了经金标准确定为ermx阳性和阴性的标本。由这两个表格及roc曲线,可以确定ct(ermx-16s)≤6.10为阳性。表2经金标准确定为ermx阳性的标本的ermx基因检测结果注:本发明规定ct(ermx-16s)≤6.10为ermx阳性。表3经金标准确定为ermx阴性的标本的ermx基因检测结果本发明规定ct(ermx-16s)>6.10为ermx阴性,表中数据显示,本发明判断ermx阴性与pcr检测ermx阴性基本全部吻合,只有5例不吻合。表2及表3中,共有真阳性43例,真阴性52例,假阳性5例,假阴性0例。敏感度为100%,特异度为91.23%。以上数据说明,本发明根据ct(ermx-16s)≤6.10来判断标本中的痤疮杆菌是否携带ermx基因是准确的。2058和2059位点突变型阳性值的确定过程:要使本发明检测准确,需考虑标本中的三方面干扰因素:(1)不同患者的野生型与突变型痤疮杆菌的比例不同;(2)不同患者的标本量、标本内痤疮杆菌数量存在差异;(3)如果标本中携带两种突变,会互相干扰检测结果。以下分别叙述本发明的解决方案。表4标本内野生型与突变型痤疮杆菌比例对检测结果的影响注:表中ct(野生型)是ct(58a)和ct(59a)的统称,ct(突变型)是ct(58t)、ct(58g)和ct(59g)的统称。进行比较时,仅对同一个位点的ct值进行比较。对于第一方面:基因突变在痤疮杆菌中自然随机发生。痤疮杆菌的耐药基因突变发生后,如果该名患者使用了抗生素,那么经过抗生素的筛选,该患者面部的痤疮杆菌群落中就会仅存突变型痤疮杆菌。这种情况下,产品检测结果将会体现为ct(突变型)<ct(野生型)。但是,如果该患者未使用抗生素,就没有环境对耐药痤疮杆菌的筛选,该患者面部将会同时存在野生型与突变型痤疮杆菌。此时,产品检测结果将会体现为ct(野生型)<ct(突变型)。表5-12的试验均是采用本发明实施例2的方法进行,除了模板用量按照各表设计。由下表5可知:只要2059a标本中含有a2059g突变型痤疮杆菌,就会使δct减小,而且突变型比例越大,对δct的影响越大,当2058a标本中含有a2058t或者a2058g突变型痤疮杆菌,也具有相同的变化趋势。因此将δct作为确定标本中是否含有突变型痤疮杆菌的指标是可靠、灵敏的。表5痤疮杆菌dna总量为20ng,改变野生型与突变型比例后的实验结果2059a模板a2059g模板突变型比例%ct(59a)ct(59g)ct(59g-59a)20.0ng0ng015.3525.410.0519.9ng0.1ng0.5%16.0923.297.219ng1ng5%15.921.635.7315ng5ng25%16.2319.793.5610ng10ng50%17.2618.110.855ng15ng75%17.4918.120.630ng20ng100%28.1916.49-11.7不同患者的标本量、标本内痤疮杆菌数量存在差异,最终体现为标本中痤疮杆菌基因组dna浓度的差异。因此本发明所称阳性值的确定过程如下:使用基因型为野生型2058a,2059a的痤疮杆菌基因组dna,梯度稀释至50pg至50ng/ul,各浓度均取1ul进行检测,观察在dna量变化时,野生型痤疮杆菌检测结果的变化情况,作为确定阳性值的参考,使最终确定的阳性值能够满足投入50pg至50ng痤疮杆菌基因组dna时,检测结果均准确可靠。表6含量为50pg至50ng时,野生型痤疮杆菌基因组dna的实验结果注:表6实验结果表明,野生型标本的ct(58t-58a)、ct(58g-58a)、ct(59g-59a)均在一定范围内波动。但是ct(58t-58a)均≥12.52,ct(58g-58a)均≥8.02,ct(59g-59a)均≥9.53。为了观察在dna加入量变化时,ct的变化情况,为阳性值的制定提供参考,痤疮杆菌野生型基因组dna梯度稀释至50pg/ul至50ng/ul,然后每个梯度均以1%的比例加入基因型分别为a2058t,a2058g,a2059g的突变型痤疮杆菌基因组dna。各梯度均进行检测,流程图如图10。具体方法如下:使用微量紫外分光光度计进行野生型dna浓度测定后,稀释至约50ng/ul并分装于3个1.5毫升微量离心管,每个梯度分别以1%的比例加入基因型分别为a2058t,a2058g,a2059g的突变型痤疮杆菌基因组dna,即:99ul浓度为50ng/ul的野生型痤疮杆菌基因组dna+1ul浓度为50ng/ul的单突变型痤疮杆菌基因组。继续梯度稀释至每ul含dna约10ng、1ng、500pg、100pg、50pg,各梯度均取1ul使用本发明进行检测。表7加入模板50pg至50ng时,1%a2058t痤疮杆菌基因组dna实验结果注:表7实验结果表明,a2058t单突变型标本的ct(58t-58a)均≤10.32。表8加入模板50pg至50ng时,1%a2058g痤疮杆菌基因组dna实验结果注:表8实验结果表明,a2058g单突变型标本的ct(58g-58a)均≤7.93。表9加入模板50pg至50ng时,1%a2059g痤疮杆菌基因组dna实验结果注:表9实验结果表明,a2059g单突变型标本的ct(59g-58a)均≤9.37。由表6、表7、表8、表9中的数据,制定出本发明中标本的阳性值:ct(58t-58a)>10.50(在12.52与10.32之间)为2058位点野生型,ct(59g-59a)>9.5(在9.53与9.37之间)为2059位点野生型,ct(58g-58a)>8.00(在7.93与8.02之间)为2058位点野生型。本发明发现:某些情况下,某一个突变的存在会影响其他突变位点的检测。因此,需根据实验确定新判断标准。(纯突变样本代表了不同位点之间相互影响的最大程度,因此本发明选择使用纯突变样本进行实验。)下表10为纯a2058t突变型(2059野生型)痤疮杆菌基因组dna的实验结果。由此表可见,即使2059位点是野生型,ct(59g-59a)也变小。且此时ct(58g-58a)已失去意义。表10.不同痤疮杆菌基因组dna加入量下,纯a2058t突变型的实验结果a2058t模板量ct(58a)ct(58t)ct(58g)ct(59a)ct(59g)ct(59g-59a)50ng22.4914.9123.2214.6521.516.8625ng26.9516.1023.3615.2823.428.1412.5ng27.5717.0124.6216.2924.187.896.25ng26.7017.3925.1517.3524.987.633.1ng29.2718.5326.3218.4225.677.25由此表可得:对于携带a2058t的突变型标本,其携带a2059g的判断标准为:ct(59g-59a)<6.5。(上表10中ct(59g-59a)最小值为6.86,确定阳性值时,为了避免误差,将6.86进行下浮调整,下浮标准为0.5以内的任意数值,这里选定了6.5)下表11为纯a2059g突变型(2058野生型)的实验结果。可见,即使2058位点是野生型,ct(58g-58a)也变小,但ct(58t-58a)不受影响。表11不同痤疮杆菌基因组dna加入量下,纯a2059g突变型的实验结果由此表可得:对于不携带a2058t,但携带a2059g的突变型标本,其携带a2058g的判断标准为:ct(58g-58a)<5.00。(上表11中ct(58g-58a)最小值为5.22,确定阳性值时,为了避免误差,将5.22进行下浮调整,下浮标准为0.5以内的任意数值,这里选定了5.0)下表12为纯a2058g突变型(2059野生型)的实验结果。可见,2058g突变对ct(59g-59a)没有影响。表12不同痤疮杆菌基因组dna加入量下,纯a2058g突变型的实验结果a2058g模板量ct(58a)ct(58t)ct(58g)ct(59a)ct(59g)ct(59g-59a)50ng27.9030.4319.0018.2929.210.9125ng28.6734.1220.3219.4229.369.9412.5ng28.8035.4121.4120.4530.7410.296.25ng29.9536.0122.2821.5131.9910.483.1ng30.4736.6522.9222.5832.6110.03简而言之,如果某个标本含有a2058t突变型痤疮杆菌,将会影响a2058g、a2059g的判断;如果某个标本含有a2059g突变型痤疮杆菌,将影响a2058g的判断。为了避免干扰检测结果,在痤疮杆菌基因型的判断中,要严格按照本发明规定的顺序进行。即:首先判断是否带有a2058t突变,再来判断a2059g突变,最后判断a2058g突变。下表即总结的最终判断规则:表13.标本内痤疮杆菌是否携带ermx基因和23srrna2058、2059位点基因型的判断标准附图说明图1为突变位点阳性值确定示意图。图2为本发明检测示意图。图3为各位点测序谱图arms引物扩增示意图。图4为arms通用引物(扩增痤疮杆菌23srrna基因)序列比对图。图5为内对照正向引物(扩增痤疮杆菌16srrna基因)序列比对图。图6为ermx基因正反引物与erm基因家族其他基因的同源序列对比图。图7为ermx的pcr扩增实验部分结果电泳图。图8为本发明pcr反应程序。图9为641#患者样本各突变位点pcr扩增结果。图10为本发明灵敏度实验流程图。具体实施方式以下结合具体实施方式旨在进一步说明本发明,而非限制本发明。实施例1以下叙述2058和2059两个位点的arms引物筛选。2059位点共筛选6条引物,序列如下表14。表142059位点的6条候选引物序列通过将mu引物和wt引物任意两两组合后,分别使用野生型痤疮杆菌基因组dna和a2059g型痤疮杆菌基因组dna为模板进行qpcr,发现wt-1/mu-1的鉴别效果最佳。判断根据是:综合考虑表15、表16,mu引物扩增野生型、突变型的ct差值,和wt引物扩增野生型、突变型的ct差值都较大,且不产生引物二聚体扩增。以下表15、表16是所有候选引物的ct值:表152059位点的6条候选引物使用野生型模板2059a实验结果wt/mu引物组合wt引物的ct值mu引物的ct值δctwt-1/mu-116.5625.819.25wt-2/mu-222.7528.796.04wt-3/mu-312.5921.659.06wt-1/mu-216.5628.7912.23wt-1/mu-316.5621.655.09wt-2/mu-322.7521.651.10wt-2/mu-122.7525.813.06表162059位点的6条候选引物使用突变型模板a2059g实验结果wt/mu引物组合wt引物的ct值mu引物的ct值δctwt-1/mu-123.5914.159.44wt-2/mu-225.318.037.27wt-3/mu-317.5313.54.03wt-1/mu-223.5918.035.56wt-1/mu-323.5913.510.09wt-2/mu-325.313.511.8wt-2/mu-125.314.1511.15由以上数据挑选出wt-1/mu-1引物对。2058位点需进行a、t、g的鉴别:筛选9条引物(序列如下表17),标准与2059引物筛选相同。表172058位点的9条候选引物序列引物名称引物序列a1ctatagtaaaggtcccggggtcayt见seqidno.24a2ctatagtaaaggtcccggggtccyt见seqidno.25a3ctatagtaaaggtcccggggtcgyt见seqidno.26g1ctatagtaaaggtcccggggtcayc见seqidno.27g2ctatagtaaaggtcccggggtccyc见seqidno.28g3ctatagtaaaggtcccggggtcgyc见seqidno.29t1ctatagtaaaggtcccggggtcaya见seqidno.30t2ctatagtaaaggtcccggggtccya见seqidno.31t3ctatagtaaaggtcccggggtcgya见seqidno.32上表中y为兼并碱基,能与a或g互补配对;下表18、表19分别使用野生型模板2058a和突变型模板a2058t,对引物a1、a2、a3、t1、t2、t3进行扩增、筛选。表18使用野生型模板2058a的实验结果表19使用突变型模板a2058t的实验结果基于以上数据,从待选引物a1,a2,a3,t1,t2,t3中选出a3和t3。下表20、表21对g1、g2、g3三条引物进行筛选:表20使用野生型模板2058a的实验结果表21使用突变型模板a2058g的实验结果模板为a2058g时,g3引物并非最优,但模板为2058a时,g1、g2性能明显劣于g3,故选择g3。实施例2(1)提取新鲜痤疮内容物(皮脂粒)样品或皮肤表面拭子的总dna,作为检测模板。(2)建立20ul反应体系如下:扩增痤疮杆菌16s基因片段的正、反引物和探针的用量均为0.05ul,且它们在体系中的终浓度均为0.05μm,扩增2058位点基因片段的正、反引物和探针的用量均为0.125ul,且它们在体系中的终浓度均为0.125μm,扩增2059位点基因片段的正、反引物和探针的用量均为0.175ul,且它们在体系中的终浓度均为0.175μm,扩增ermx基因片段的正、反引物和探针的用量均为0.1ul,且它们在体系中的终浓度均为0.1μm,扩增2058或2059位点基因片段的模板用量1ul,扩增ermx基因片段的模板用量0.5ul,每一孔中均加入premix10ul,每一孔反应体系总体积加水到20ul。第7个孔:除加入与第1个孔或者第4个孔相同的试剂外,另加入基因型为携带2058a、2059a且不携带ermx基因的痤疮杆菌基因组dna,加入量为10ng。第8个孔:除加入与第1个孔或者第4个孔相同的试剂外,另加入ermx的引物和探针(fam)。第7,8孔中引物,探针,模板等的用量参考第1-6孔。总体积也均为20ul。上述涉及的引物和探针序列如下表:表22序列表(4)将反应管放入实时荧光定量pcr仪,运行程序。(5)结合阴性对照(不应出现扩增)、阳性对照(ct值应小于20)、内对照结果(ct值应小于35),得出耐药性检测结果。下表选取641#患者样本,展示本发明的检测结果。表23641#患者样本的检测结果结果报告:2058位点:a(野生型);2059位点:a(野生型);携带ermx基因。患者携带的痤疮杆菌对大环内酯类抗生素耐药。实施例3使用传统方法(或称“金标准”)验证本产品的准确性本发明试剂盒产品属于全世界首次提出,没有类似功能的同类产品。根据国家药品监督管理局的指导意见,为了验证本产品的准确性,应将产品的检测结果与金标准进行对比。对于2058/2059突变检测,适用的金标准为:从标本中分离出痤疮杆菌后进行基因测序。对于ermx耐药基因检测,适用的金标准为从标本中分离出痤疮杆菌后进行ermx基因的pcr扩增、琼脂糖凝胶电泳。从2018年6月29日起,我们从湘雅医院皮肤科门诊收集了62例痤疮患者的皮脂粒,使用本产品进行了检测,并将结果与金标准进行了比对,证明本产品的检测结果与金标准完全吻合(除1例外),见表24。可见本发明的结果和金标准一致,可信度极高。表24.检测结果与金标准的比对结果注:表中药敏试验结果表示为mic值,单位为ug/ml。金标准是:首先从标本中分离纯化出痤疮杆菌,然后进行ermx基因pcr与23srrna基因测序,金标准的结果中“+”表示携带ermx基因,“-”表示不携带ermx基因,大写字母代表2058和2059位点的基因型。本发明方法结果中基因型判断“+”表示携带ermx基因,“-”表示不携带ermx基因,大写字母代表2058和2059位点的基因型,加*号的患者标本为:金标准检测时分离出不止一种痤疮杆菌基因型的患者。序列表<110>中南大学<120>一种提升痤疮杆菌耐药突变及耐药基因检测准确性和效率的方法及其配套试剂盒<160>32<170>siposequencelisting1.0<210>1<211>16<212>dna<213>人工序列(artificialsequence)<400>1ggggacctgagctgtc16<210>2<211>25<212>dna<213>人工序列(artificialsequence)<220><221>misc_feature<222>(24)..(24)<223>y与a或g互补配对<400>2ctatagtaaaggtcccggggtcgyt25<210>3<211>25<212>dna<213>人工序列(artificialsequence)<220><221>misc_feature<222>(24)..(24)<223>y与a或g互补配对<400>3ctatagtaaaggtcccggggtcgya25<210>4<211>25<212>dna<213>人工序列(artificialsequence)<220><221>misc_feature<222>(24)..(24)<223>y与a或g互补配对<400>4ctatagtaaaggtcccggggtcgyc25<210>5<211>24<212>dna<213>人工序列(artificialsequence)<400>5ctatagtaaaggtcccggggtcat24<210>6<211>24<212>dna<213>人工序列(artificialsequence)<400>6ctatagtaaaggtcccggggtcac24<210>7<211>27<212>dna<213>人工序列(artificialsequence)<400>7catctttactcgtaatgcaatttcacc27<210>8<211>20<212>dna<213>人工序列(artificialsequence)<400>8gatgatgacggctcagtggt20<210>9<211>20<212>dna<213>人工序列(artificialsequence)<400>9tttgcgctgctctatcggaa20<210>10<211>31<212>dna<213>人工序列(artificialsequence)<400>10ttcacatttcacctgggttctcgggtaccaa31<210>11<211>18<212>dna<213>人工序列(artificialsequence)<400>11accgctttcgcctgtgac18<210>12<211>23<212>dna<213>人工序列(artificialsequence)<400>12agccccaagattacacttccgac23<210>13<211>34<212>dna<213>人工序列(artificialsequence)<400>13aagcgtgagtgacggtaatgggtaaagaagcacc34<210>14<211>20<212>dna<213>人工序列(artificialsequence)<400>14agagtttgatcmtggctcag20<210>15<211>20<212>dna<213>人工序列(artificialsequence)<400>15tacggttaccttgttacgac20<210>16<211>18<212>dna<213>人工序列(artificialsequence)<400>16gtctgcatacggacacgg18<210>17<211>18<212>dna<213>人工序列(artificialsequence)<400>17cgagcgacttcccactgc18<210>18<211>24<212>dna<213>人工序列(artificialsequence)<400>18ctatagtaaaggtcccggggtcat24<210>19<211>24<212>dna<213>人工序列(artificialsequence)<400>19ctatagtaaaggtcccggggtcgt24<210>20<211>24<212>dna<213>人工序列(artificialsequence)<400>20ctatagtaaaggtcccggggtcct24<210>21<211>24<212>dna<213>人工序列(artificialsequence)<400>21ctatagtaaaggtcccggggtcac24<210>22<211>24<212>dna<213>人工序列(artificialsequence)<400>22ctatagtaaaggtcccggggtcgc24<210>23<211>24<212>dna<213>人工序列(artificialsequence)<400>23ctatagtaaaggtcccggggtccc24<210>24<211>25<212>dna<213>人工序列(artificialsequence)<220><221>misc_feature<222>(24)..(24)<223>y与a或g互补配对<400>24ctatagtaaaggtcccggggtcayt25<210>25<211>25<212>dna<213>人工序列(artificialsequence)<220><221>misc_feature<222>(24)..(24)<223>y与a或g互补配对<400>25ctatagtaaaggtcccggggtccyt25<210>26<211>25<212>dna<213>人工序列(artificialsequence)<220><221>misc_feature<222>(24)..(24)<223>y与a或g互补配对<400>26ctatagtaaaggtcccggggtcgyt25<210>27<211>25<212>dna<213>人工序列(artificialsequence)<220><221>misc_feature<222>(24)..(24)<223>y与a或g互补配对<400>27ctatagtaaaggtcccggggtcayc25<210>28<211>25<212>dna<213>人工序列(artificialsequence)<220><221>misc_feature<222>(24)..(24)<223>y与a或g互补配对<400>28ctatagtaaaggtcccggggtccyc25<210>29<211>25<212>dna<213>人工序列(artificialsequence)<220><221>misc_feature<222>(24)..(24)<223>y与a或g互补配对<400>29ctatagtaaaggtcccggggtcgyc25<210>30<211>25<212>dna<213>人工序列(artificialsequence)<220><221>misc_feature<222>(24)..(24)<223>y与a或g互补配对<400>30ctatagtaaaggtcccggggtcaya25<210>31<211>25<212>dna<213>人工序列(artificialsequence)<220><221>misc_feature<222>(24)..(24)<223>y与a或g互补配对<400>31ctatagtaaaggtcccggggtccya25<210>32<211>25<212>dna<213>人工序列(artificialsequence)<220><221>misc_feature<222>(24)..(24)<223>y与a或g互补配对<400>32ctatagtaaaggtcccggggtcgya25当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1