一种高通量测序污染检测用分子标签组及其应用的制作方法
本发明涉及生物信息学和生物
技术领域:
,特别是涉及一种高通量测序污染检测用分子标签组及其应用。
背景技术:
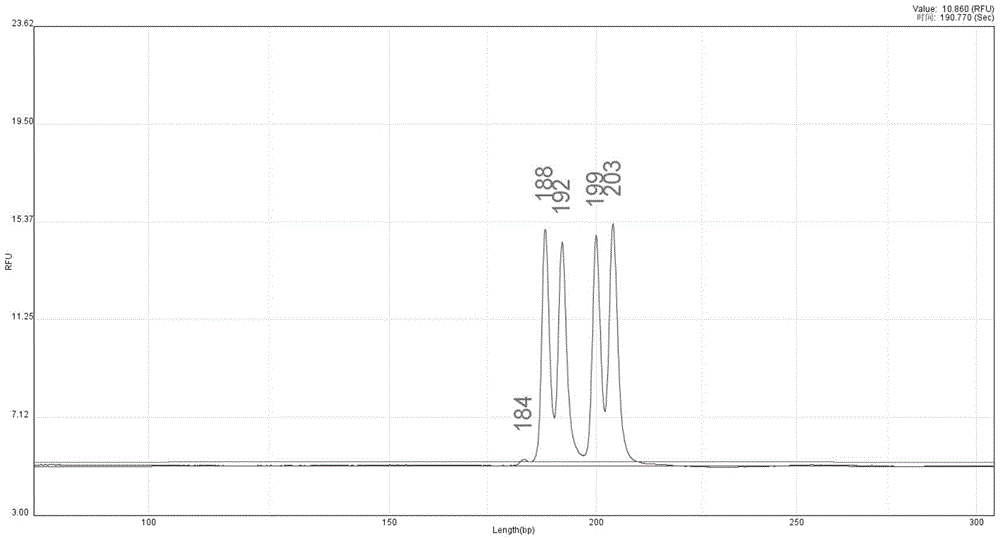
:二代测序与一代测序、pcr等检测手段相比,检测周期相对较长,检测过程也更为复杂,一个检测周期包括样本预处理、核酸提取、文库构建、测序、数据分析等步骤。整个检测周期,从样本到数据,经历多个检测环节和多个检测人员,一旦发生了样本混淆、样本相互污染等情况,将产生错误的数据分析结果。因此,样本溯源和污染识别,是产生正确的二代测序结果的前提和保证。二代测序中常用的样本溯源方法,是给不同样本加上不同的标签,得以在数据中识别并拆分。具体的说,二代测序在文库构建过程中,会在文库两端加上测序平台通用接头,以使得文库可以在测序平台上被测序。通用接头包含了一段用于在测序下机数据中识别区分样本的标签序列,同一次测序反应中,不同文库会加上不同的标签序列,使得数据分析人员得以在下机数据中,将不同样本文库的数据拆分开,单独进行后续分析。如果实验过程中,不同文库之间的标签序列发生了交叉污染,将导致数据拆分时,一个样本中错误地混入另一个样本的数据。如果无法识别这种交叉污染,也会得出错误的分析结果。还有一种用于二代测序中样本溯源的方法,即选择一些snp位点,用更简单快速的方法检测样本dna中的这些snp位点,与最终数据中这些snp分型对比,以此判断样本是否属于同一来源。这种方法需要在常规的检测流程基础上增加一个额外的snp检测,对人力物力时间成本的消耗也相应的增加。还有一些实验室通过样本采集管多处注明、建立样本信息追踪单、设置实验评选重复以及不同处理条件下的标志物等方法来规避样本混淆,这些操作不仅复杂也不适用于临床检测。技术实现要素:鉴于以上所述现有技术的缺点,本发明的目的在于提供一种高通量测序污染检测用分子标签组及其应用。本发明第一方面提供一种高通量测序污染检测用分子标签组,所述分子标签组中包括若干不同的分子标签;不同的分子标签长度不同;所述分子标签为核酸片段。本发明第二方面提供一种高通量测序污染的检测方法,所述方法至少包括如下步骤:在每个样本中引入选自前述的分子标签组中的一个或多个分子标签,其中,各样本引入的分子标签中,至少包括一个特有分子标签,所述特有分子标签是指与其他样本引入的分子标签均不同的分子标签。本发明第三方面提供一种高通量测序污染的样本区分方法,所述方法至少包括如下步骤:在每个样本中引入选自前述的分子标签组中的一个或多个分子标签,其中,各样本引入的分子标签中,至少包括一个特有分子标签,所述特有分子标签是指与其他样本引入的分子标签均不同的分子标签。本发明第三方面提供高通量测序污染检测用分子标签组,或前述的高通量测序污染的检测方法或前述高通量测序的样本区分方法在基因测序中的用途。如上所述,本发明的一种高通量测序污染检测用分子标签组及其应用,具有以下有益效果:利用本发明所述的分子标签组进行样本检测时,在样本预处理前,将适量拷贝的分子标签混入样本中,样本类型包括但不限于血液、唾液、血浆、dna等。混入有分子标签的样本进行核酸提取、文库构建、多重pcr、杂交捕获等环节,最终通过特异性地扩增文库中包含的分子标签,并利用片段分析仪器检测扩增产物长度分布,快速简单地判断样本是否发生混淆或交叉污染并确定污染源;所述方法还可以用于样本的区分。附图说明图1:样本a扩增产物片段分析结果。图2:样本b扩增产物片段分析结果。图3:样本d扩增产物片段分析结果。具体实施方式以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。在进一步描述本发明具体实施方式之前,应理解,本发明的保护范围不局限于下述特定的具体实施方案;还应当理解,本发明实施例中使用的术语是为了描述特定的具体实施方案,而不是为了限制本发明的保护范围;在本发明说明书和权利要求书中,除非文中另外明确指出,单数形式“一个”、“一”和“这个”包括复数形式。当实施例给出数值范围时,应理解,除非本发明另有说明,每个数值范围的两个端点以及两个端点之间任何一个数值均可选用。除非另外定义,本发明中使用的所有技术和科学术语与本
技术领域:
技术人员通常理解的意义相同。除实施例中使用的具体方法、设备、材料外,如本
技术领域:
的技术人员对现有技术的掌握及本发明的记载,还可以使用与本发明实施例中所述的方法、设备、材料相似或等同的现有技术的任何方法、设备和材料来实现本发明。除非另外说明,本发明中所公开的实验方法、检测方法、制备方法均采用本
技术领域:
常规的分子生物学、生物化学、染色质结构和分析、分析化学、细胞培养、重组dna技术及相关领域的常规技术。本发明一实施例的高通量测序污染检测用分子标签组,所述分子标签组中包括若干不同的分子标签;不同的分子标签长度不同;所述分子标签为核酸片段。所述分子标签组包括两个以上长度不同的分子标签。所述分子标签组内的分子标签数量可灵活运用。例如可以为3个以上,4个以上,5个以上,6个以上,7个以上,10个以上,15个以上,17个以上,等等。有几个分子标签,就可以同时检测几个样本有无相互污染。分子标签的上限可不受限制。数量少的话,可用的组合就少;数量多的话,前期分子标签制备就会工作量大。进一步的,一个样本对应的分子标签组中,至少有一个分子标签的长度与待检测的其他样本的分子标签的长度不同。进一步的,所述分子标签的序列与样本同源性低。优选的,所述同源性低于90%。所述同源性采用序列比对的方法获得。具体的,使用ncbi数据库的核酸比对(nucleotideblast)功能,将分子标签序列与检测样本物种基因组进行比对,比对结果中的per.ident即代表分子标签序列与样本物种基因组序列某一段区域的同源比例。可选的,所述分子标签与样本不同源;防止对样本结果造成干扰。进一步的,所述分子标签包括相同段和长度特异性段,所述相同段的长度相同,碱基排列顺序相同。长度特异性段是指该段序列的长度不同。所述分子标签可来源于不同的分子标签源。所述分子标签可以通过基因合成,分子克隆或pcr扩增等手段制备。在一种实施方式中,所述分子标签组中各分子标签可均来源于同一分子标签源片段。方便进行扩增。所述分子标签源片段可来自病毒基因组序列。在一种实施方式中,所述分子标签源片段来源于病毒phix174的基因组序列。优选的,所述分子标签源片段的序列如seqidno:18所示。在一种实施方式中,所述分子标签序列选自以下seqidno:1~17中的一个或多个。进一步的,所述分子标签长度为100bp-20kb。在一种实施方式中,测序样本为片段化dna时,所述分子标签为短片段分子标签,所述短片段分子标签的长度为100-300bp;测序样本为gdna时,所述分子标签为长片段分子标签,所述长片段分子标签的长度为1kb~20kb。所述长片段分子标签可以通过短片段分子标签插入载体中获得。所述载体可以为质粒载体。例如pesi-t载体、bluescribe载体、pbluescript载体、pgem载体、puc19载体等常规分子克隆载体。长片段分子的标签的优势在于,在提取基因组dna的过程中分子标签不易损失。一般的基因组dna提取试剂盒采用磁珠法或柱离心法,通过磁珠或硅胶膜等载体吸附基因组dna,这种吸附通常具有选择性,倾向于吸附1kb以上的dna片段,丢失掉大部分1kb以下的小片段。若使用短片段分子标签,提取到的dna中,分子标签的回收率非常低,该dna构建的文库中也有可能难以扩增富集到相应的分子标签。对于血浆游离dna,其本身片段较短(160bp左右),提取游离dna的试剂盒中核酸吸附载体倾向于吸附小片段核酸,因此,对于血浆样本,使用短片段分子标签即可。本发明一实施例的高通量测序污染的检测方法,至少包括如下步骤:在每个样本中引入选自前述的分子标签组中的一个或多个分子标签,其中,各样本引入的分子标签中,至少包括一个特有分子标签,所述特有分子标签是指与其他样本引入的分子标签均不同的分子标签。在一种实施方式中,所述方法至少包括如下步骤:(1)在每个样本中引入选自前述的分子标签组的分子标签;(2)获取每个样本中的核酸片段,将核酸片段和接头进行连接,进行基因文库构建;(3)利用分子标签的通用引物扩增步骤(2)获得的产物;(4)分析步骤(3)获得的扩增产物的片段长度,若样本m中出现n样本的特有分子标签的长度峰,则m样本被n样本污染;若m样本中没有其他样本特有分子标签的长度峰出现,则m样本没有被污染。所述分子标签的通用引物是指与分子标签的相同段互补的引物,可以对所有的分子标签进行扩增富集,得到分子标签。在一种实施方式中,所述方法还包括以下步骤:(21)将步骤(2)中获得的基因文库,与杂交探针进行杂交捕获,获得捕获文库;所述杂交探针包括分子标签特异性探针和样本探针。所述分子标签特异性探针用于特异性捕获一个样本中所有分子标签。进一步的,所述分子标签特异性探针为一个样本中所有分子标签相同段中的一部分。可以同时捕获一个样本中所有分子标签。所述样本探针序列根据样本的不同及实验目的的不同进行选择。杂交捕获方法是为了捕获样本基因组文库中的目标区域,样本探针指的就是捕获样本目标区域的探针。目标区域是根据整个实验检测的目的而定的,比如要检测遗传病,样本探针就覆盖遗传病相关基因区域。本发明还可以提供一种高通量测序的样本区分方法,所述方法至少包括如下步骤:在每个样本中引入选自前述的分子标签组中的一个或多个分子标签,其中,各样本引入的分子标签中,至少包括一个特有分子标签,所述特有分子标签是指与其他样本引入的分子标签均不同的分子标签。所述方法至少包括如下步骤:(1)在每个样本中引入选自权利要求1-7中任一项所述的分子标签组的分子标签;(2)获取每个样本中的核酸片段,将核酸片段和接头进行连接,进行基因文库构建;(3)利用分子标签的通用引物扩增步骤(2)获得的产物;(4)分析步骤(3)获得的扩增产物的片段长度,根据样本中特有分子标签对样本进行区分。由于各个样本中添加的分子标签组已知、不同且特异性对应,例如样本m与分子标签组m对应,样本n与分子标签组n对应,样本p与分子标签组p对应。分析步骤(3)获得的扩增产物的片段长度时,若一个样本中只出现分子标签组m的长度峰,则可知该样本为样本m;若一个样本中只出现分子标签组n的长度峰,则可知该样本为样本n;若一个样本中只出现分子标签组p的长度峰,则可知该样本为样本p。在一种实施方式中,所述方法还包括以下步骤:(21)将步骤(2)中获得的基因文库,与杂交探针进行杂交捕获,获得捕获文库;所述杂交探针包括分子标签特异性探针和样本探针。所述分子标签特异性探针用于特异性捕获一个样本中所有分子标签。进一步的,所述分子标签特异性探针为一个样本中所有分子标签相同段中的一部分。可以同时捕获一个样本中所有分子标签。所述样本探针序列根据样本的不同及实验目的的不同进行选择。杂交捕获方法是为了捕获样本基因组文库中的目标区域,样本探针指的就是捕获样本目标区域的探针。目标区域是根据整个实验检测的目的而定的,比如要检测遗传病,样本探针就覆盖遗传病相关基因区域。前述的高通量测序污染检测用分子标签组,或前述高通量测序污染的检测方法或高通量测序的样本区分方法可用于基因测序。实施例1分子标签制备本发明选择了病毒phix174的基因组序列作为分子标签来源,将phix174的seqidno:18所示的序列作为分子标签源,扩增得到短片段分子标签,可用于片段化dna样本质控。将短片段分子标签连接到质粒载体上,得到长片段分子标签,可用于基因组dna样本质控。具体的,seqidno:18:tccatgcggtgcactttatgcggacacttcctacaggtagcgttgaccctaattttggtcgtcgggtacgcaatcgccgccagttaaatagcttgcaaaatacgtggccttatggttacagtatgcccatcgcagttcgctacacgcaggacgctttttcacgttctggttggttgtggc。同时,针对分子标签源片段设计了扩增引物,扩增引物length-primer-f序列为gagttttatcgctxxxxxxxxxxxxxxxx,其中xxxxxxxxxxxxxxxx为分子标签长度特异性序列,此序列通过结合于phix174基因组上不同位置扩增出不同长度的序列,扩增引物length-primer-r序列为aagcggctcacctttagcatcaacag(seqidno:19)。扩增分子标签具体引物如下:(这里仅列出17个分子标签的扩增引物,实际应用中可以不止17条)使用以上引物对phix174基因组dna(neb,cat#n3021)进行扩增,扩增体系如下:试剂体积(μl)2×taqmastermix(vazyme)25引物1phix174gdna1nucleasefreewater23总体积50扩增程序如下:得到的扩增产物即短片段分子标签序列如下表1所示:表1使用零背景topo-ta克隆试剂盒(翊圣生物,10908es20),根据产品说明书中的操作步骤,将扩增产物连接至载体pesi-t(该载体为上述克隆试剂盒内包含)上,获得长度约为2kb的长片段分子标签。实施例2在全血样本中混入短片段分子标签分别在全血样本a和b中混入表1分子标签组的短片段分子标签,其中,在10ml全血样本a中混入length-2、length-3、length-5和length-6这几个短片段分子标签,每个短片段分子标签混入108个拷贝,10ml全血样本b中混入length-1、length-2、length-4和length-6这几个短片段分子标签,每个短片段分子标签混入108个拷贝。将两个全血样本分别进行梯度离心,分离出4-5ml血浆,并提取血浆中的cfdna。分别对两个全血样本中的cfdna进行基因文库构建和杂交捕获。过程如下:2.1末端修复和加a2.1.1反应体系如下:试剂名称体积(μl)cfdna20nuclease-freewater12endrepair&abuffer15endrepair&aenzyme3总体积502.1.2将反应体系置于pcr仪上,运行如下程序:2.2连接接头2.2.1连接体系如下:试剂名称体积(μl)ligatebuffer20ligaseenzyme5nuclease-freewater13接头2末端修复加a产物50总体积902.2.2连接接头反应程序如下:反应温度反应时间4℃hold22℃60min4℃hold2.3片段筛选向步骤2.2.2获得的产物中加入100μl磁珠,混匀;室温静置5min后,置于磁力架上,待溶液澄清,吸弃全部上清。用75%乙醇清洗磁珠两次。然后用100μlnuclease-freewater悬浮磁珠,室温静置2min后,加入100μlpeg/nacl溶液至上清液中,混匀,室温静置5min。再次置于磁力架上,待溶液澄清,吸弃全部上清。用75%乙醇清洗磁珠两次。加入23μlnuclease-freewater,吹打混匀,室温静置2min,获得片段筛选产物。2.4进行扩增,构建基因文库2.4.1扩增程序如下:2.4.2扩增体系如下:试剂名称体积(μl)2xkapahifihotstartpcrreadymix25接头引物2片段筛选产物23总体积50扩增体系置于pcr上,运行程序,分别获得样本a和b的基因文库。2.5基因文库纯化向样本a和b的基因文库中分别加入50μl磁珠,混匀;室温静置5min后,置于磁力架上,待溶液澄清,吸弃全部上清。用75%乙醇清洗磁珠两次。然后用30μlnuclease-freewater悬浮磁珠,室温静置2min后,将上清吸取至新的1.5ml离心管内。2.6杂交2.6.1将分子标签特异性探针与原本杂交捕获的探针(分别用于捕获样本a和样本b的探针)混合,获得捕获探针组;每条探针每个杂交反应加入2fmol,所述分子标签特异性探针序列为:gtagcgttgaccctaattttggtcgtcgggtacgcaatcgccgccagttaaatagcttgcaaaatacgtggccttatggttacagtatgcccatcgcagt(seqidno:37)。2.6.2将样本a和b的两个基因文库分别加入4μl2.61中的捕获探针组、8μluniversalblockers和5μlblockersolution,混匀并浓缩至完全干燥,用20μlfasthybridizationmix将其溶解,再加入30μlhybridizationenhancer。于pcr仪上运行如下程序,杂交时间为16h。温度时间95℃∞95℃5min60℃∞2.7捕获2.7.1将100μl链霉亲和素磁珠用200μlfastbindingbuffer清洗3次,再加入200μlfastbindingbuffer悬浮磁珠。2.7.2杂交结束后,将杂交体系快速转移到链霉亲和素磁珠管内,混匀后室温孵育30min后,离心后置于磁力架上静置1min,待溶液澄清后,吸弃上清。2.7.3用200μl已预热至70℃的fastwashbuffer1清洗两次后,用200μl48℃预热的washbuffer2悬浮磁珠,48℃孵育5min后,置于磁力架上静置1min,待溶液澄清后,吸弃上清。2.7.4重复上一步两次,然后完全除去残留上清,加入22.5μlnuclease-freewater,混匀,转移至0.2mlpcr管中,获得捕获产物。2.8进行扩增,获得样本a和样本b的捕获文库扩增程序如下:扩增体系如下:试剂名称体积(μl)kapahifihotstartreadymix25接头引物2.5捕获产物22.5总体积502.9文库纯化向步骤2.8获得的捕获文库中加入90μl磁珠,混匀;室温静置5min后,置于磁力架上,待溶液澄清,吸弃全部上清。用75%乙醇清洗磁珠两次。然后用30μlnuclease-freewater悬浮磁珠,室温静置2min后,将上清吸取至新的1.5ml离心管内,获得纯化后的捕获文库。2.10分子标签通用引物扩增捕获文库2.10.1用分子标签通用引物分别扩增样本a和b纯化后的捕获文库,通用引物f序列为acacgacgctcttccgatctgagttttatcgct(seqidno:38),r序列为ccttggcacccgagaattccaaagcggctcaccttta(seqidno:39)。2.10.2扩增体系为:2.10.3扩增程序为:2.11扩增产物用片段分析仪qsep100进行片段分析将步骤2.10获得的样本a和样本b文库扩增产物用片段分析仪qsep100进行片段分析,片段分析结果如图1和图2所示。其中,样本a混入的短片段分子标签分别为length-2、length-3、length-5和length-6,理论上通用引物扩增后得到产物长度应为188bp、192bp、200bp和204bp,实际扩增产物qsep检测长度为188bp、192bp、199bph和203bp。样本b混入的分子标签分别为length-1、length-2、length-4和length-6,理论上通用引物扩增后得到产物长度应为184bp、188bp、196bp和204bp,实际扩增产物qsep检测长度为185bp、188bp、196bp和204bp。两个样本最初加入的分子标签长度,与所得文库扩增产物的片段分布是一一对应的,并且没有其他样本对应短片段分子标签长度的峰出现。可判断两个样本没有发生混淆或交叉污染。实施例3在全血样本中混入长片段分子标签分别在全血样本c和d中混入根据表1的短片段分子标签制得的长片段分子标签,其中,在2ml全血样本c中混入的分子标签包括length-7、length-9和length-13这几个短片段分子标签对应的长片段分子标签,每个长片段分子标签混入108个拷贝,在2ml全血样本d中混入包括length-9、length-13和length-17这几个短片段分子标签对应的长片段分子标签,每个长片段分子标签混入108个拷贝。从c样本中取200μl混入d样本中,人为制造样本污染。将样本d进行基因组dna提取,并构建样本d的基因组文库。构建过程如下:3.1片段化、末端修复和加a取100ngd样本的基因组dna,补nuclease-freewater至50μl,加入10μlsmearasemix,混匀后置于冰上。pcr仪设置如下程序:温度时间4℃1min30℃20min72℃20min4℃∞待程序运行开始运行4℃时,将反应体系放入pcr仪。3.2连接接头,获得连接产物3.2.1根据下表配制连接体系:试剂名称体积(μl)5xfast-paceligationbuffer20fast-pacet4dnaligase5接头1.5nuclease-freewater13.5步骤3.1产物60总体积1003.2.2设置如下pcr程序并运行:温度时间20℃15min4℃∞3.3片段筛选向步骤3.2获得的连接产物中加入100μl磁珠,混匀;室温静置5min后,置于磁力架上,待溶液澄清,吸弃全部上清。用75%乙醇清洗磁珠两次。然后用100μlnuclease-freewater悬浮磁珠,室温静置2min后,加入65μl磁珠上清液,混匀,室温静置5min;再置于磁力架上,待溶液澄清,吸取160μl上清至新的离心管,加入20μl磁珠至上清液中,混匀,室温静置5min;置于磁力架上,待溶液澄清,吸弃全部上清。用75%乙醇清洗磁珠两次。加入24μlnuclease-freewater,吹打混匀,室温静置2min。3.4进行扩增,构建样本d的基因组文库反应体系如下:溶液体积(μl)2xkapahifihotstartpcrreadymix25dna24接头引物1total50扩增程序如下:3.5基因组文库纯化向扩增产物即样本d的基因组文库中加入50μl磁珠,混匀;室温静置5min后,置于磁力架上,待溶液澄清,吸弃全部上清。用75%乙醇清洗磁珠两次。然后用30μlnuclease-freewater悬浮磁珠,室温静置2min后,将上清吸取至新的1.5ml离心管内。3.6通用引物扩增样本d的基因组文库3.6.1用分子标签通用引物扩增样本d的基因组文库,通用引物f序列为acacgacgctcttccgatctgagttttatcgct(seqidno:38),r序列为ccttggcacccgagaattccaaagcggctcaccttta(seqidno:39)。3.6.2扩增体系为:试剂体积/μl2×taqmastermix(vazyme)25通用引物1样本d的基因组文库1nucleasefreewater23总体积503.6.3扩增程序为:3.7扩增产物用片段分析仪qsep100进行片段分析将步骤3.6获得的样本d的基因组文库扩增产物用片段分析仪qsep100进行片段分析,片段分析结果如图3所示,样本c混入的长片段分子标签对应的短片段分子标签分别为length-7、length-9和length-13,理论上通用引物扩增后得到产物长度应为208bp、216bp和232bp;样本d混入的长片段分子标签对应的短片段分子标签分别为length-9、length-13和length-17,理论上通用引物扩增后得到产物长度应为216bp、232bp和248bp。样本d被样本c污染,分子标签扩增产物中应有样本c对应的分子标签长度的峰。样本d实际扩增产物qsep检测长度为209bp、215bp、230bp和247bp,其中长度为209bp的峰来自于样本c中的分子标签,由此可判断样本d样本被c样本污染。以上的实施例是为了说明本发明公开的实施方案,并不能理解为对本发明的限制。此外,本文所列出的各种修改以及发明中方法、组合物的变化,在不脱离本发明的范围和精神的前提下对本领域内的技术人员来说是显而易见的。虽然已结合本发明的多种具体优选实施例对本发明进行了具体的描述,但应当理解,本发明不应仅限于这些具体实施例。事实上,各种如上所述的对本领域内的技术人员来说显而易见的修改来获取发明都应包括在本发明的范围内。序列表<110>上海韦翰斯生物医药科技有限公司<120>一种高通量测序污染检测用分子标签组及其应用<160>39<170>siposequencelisting1.0<210>1<211>143<212>dna<213>人工序列(artificialsequence)<400>1gagttttatcgctacaggtagcgttgaccctaattttggtcgtcgggtacgcaatcgccg60ccagttaaatagcttgcaaaatacgtggccttatggttacagtatgcccatcgcagtctg120ttgatgctaaaggtgagccgctt143<210>2<211>147<212>dna<213>人工序列(artificialsequence)<400>2gagttttatcgcttcctacaggtagcgttgaccctaattttggtcgtcgggtacgcaatc60gccgccagttaaatagcttgcaaaatacgtggccttatggttacagtatgcccatcgcag120tctgttgatgctaaaggtgagccgctt147<210>3<211>151<212>dna<213>人工序列(artificialsequence)<400>3gagttttatcgctcacttcctacaggtagcgttgaccctaattttggtcgtcgggtacgc60aatcgccgccagttaaatagcttgcaaaatacgtggccttatggttacagtatgcccatc120gcagtctgttgatgctaaaggtgagccgctt151<210>4<211>155<212>dna<213>人工序列(artificialsequence)<400>4gagttttatcgctcggacacttcctacaggtagcgttgaccctaattttggtcgtcgggt60acgcaatcgccgccagttaaatagcttgcaaaatacgtggccttatggttacagtatgcc120catcgcagtctgttgatgctaaaggtgagccgctt155<210>5<211>159<212>dna<213>人工序列(artificialsequence)<400>5gagttttatcgcttatgcggacacttcctacaggtagcgttgaccctaattttggtcgtc60gggtacgcaatcgccgccagttaaatagcttgcaaaatacgtggccttatggttacagta120tgcccatcgcagtctgttgatgctaaaggtgagccgctt159<210>6<211>163<212>dna<213>人工序列(artificialsequence)<400>6gagttttatcgctactttatgcggacacttcctacaggtagcgttgaccctaattttggt60cgtcgggtacgcaatcgccgccagttaaatagcttgcaaaatacgtggccttatggttac120agtatgcccatcgcagtctgttgatgctaaaggtgagccgctt163<210>7<211>167<212>dna<213>人工序列(artificialsequence)<400>7gagttttatcgctgtgcactttatgcggacacttcctacaggtagcgttgaccctaattt60tggtcgtcgggtacgcaatcgccgccagttaaatagcttgcaaaatacgtggccttatgg120ttacagtatgcccatcgcagtctgttgatgctaaaggtgagccgctt167<210>8<211>171<212>dna<213>人工序列(artificialsequence)<400>8gagttttatcgcttgcggtgcactttatgcggacacttcctacaggtagcgttgacccta60attttggtcgtcgggtacgcaatcgccgccagttaaatagcttgcaaaatacgtggcctt120atggttacagtatgcccatcgcagtctgttgatgctaaaggtgagccgctt171<210>9<211>175<212>dna<213>人工序列(artificialsequence)<400>9gagttttatcgcttccatgcggtgcactttatgcggacacttcctacaggtagcgttgac60cctaattttggtcgtcgggtacgcaatcgccgccagttaaatagcttgcaaaatacgtgg120ccttatggttacagtatgcccatcgcagtctgttgatgctaaaggtgagccgctt175<210>10<211>179<212>dna<213>人工序列(artificialsequence)<400>10gagttttatcgctcatttccatgcggtgcactttatgcggacacttcctacaggtagcgt60tgaccctaattttggtcgtcgggtacgcaatcgccgccagttaaatagcttgcaaaatac120gtggccttatggttacagtatgcccatcgcagtctgttgatgctaaaggtgagccgctt179<210>11<211>183<212>dna<213>人工序列(artificialsequence)<400>11gagttttatcgcttcttcatttccatgcggtgcactttatgcggacacttcctacaggta60gcgttgaccctaattttggtcgtcgggtacgcaatcgccgccagttaaatagcttgcaaa120atacgtggccttatggttacagtatgcccatcgcagtctgttgatgctaaaggtgagccg180ctt183<210>12<211>187<212>dna<213>人工序列(artificialsequence)<400>12gagttttatcgctgccgtcttcatttccatgcggtgcactttatgcggacacttcctaca60ggtagcgttgaccctaattttggtcgtcgggtacgcaatcgccgccagttaaatagcttg120caaaatacgtggccttatggttacagtatgcccatcgcagtctgttgatgctaaaggtga180gccgctt187<210>13<211>191<212>dna<213>人工序列(artificialsequence)<400>13gagttttatcgctaatggccgtcttcatttccatgcggtgcactttatgcggacacttcc60tacaggtagcgttgaccctaattttggtcgtcgggtacgcaatcgccgccagttaaatag120cttgcaaaatacgtggccttatggttacagtatgcccatcgcagtctgttgatgctaaag180gtgagccgctt191<210>14<211>195<212>dna<213>人工序列(artificialsequence)<400>14gagttttatcgctagctaatggccgtcttcatttccatgcggtgcactttatgcggacac60ttcctacaggtagcgttgaccctaattttggtcgtcgggtacgcaatcgccgccagttaa120atagcttgcaaaatacgtggccttatggttacagtatgcccatcgcagtctgttgatgct180aaaggtgagccgctt195<210>15<211>199<212>dna<213>人工序列(artificialsequence)<400>15gagttttatcgctgtacagctaatggccgtcttcatttccatgcggtgcactttatgcgg60acacttcctacaggtagcgttgaccctaattttggtcgtcgggtacgcaatcgccgccag120ttaaatagcttgcaaaatacgtggccttatggttacagtatgcccatcgcagtctgttga180tgctaaaggtgagccgctt199<210>16<211>203<212>dna<213>人工序列(artificialsequence)<400>16gagttttatcgcttatggtacagctaatggccgtcttcatttccatgcggtgcactttat60gcggacacttcctacaggtagcgttgaccctaattttggtcgtcgggtacgcaatcgccg120ccagttaaatagcttgcaaaatacgtggccttatggttacagtatgcccatcgcagtctg180ttgatgctaaaggtgagccgctt203<210>17<211>207<212>dna<213>人工序列(artificialsequence)<400>17gagttttatcgcttgagtatggtacagctaatggccgtcttcatttccatgcggtgcact60ttatgcggacacttcctacaggtagcgttgaccctaattttggtcgtcgggtacgcaatc120gccgccagttaaatagcttgcaaaatacgtggccttatggttacagtatgcccatcgcag180tctgttgatgctaaaggtgagccgctt207<210>18<211>180<212>dna<213>人工序列(artificialsequence)<400>18tccatgcggtgcactttatgcggacacttcctacaggtagcgttgaccctaattttggtc60gtcgggtacgcaatcgccgccagttaaatagcttgcaaaatacgtggccttatggttaca120gtatgcccatcgcagttcgctacacgcaggacgctttttcacgttctggttggttgtggc180<210>19<211>26<212>dna<213>人工序列(artificialsequence)<400>19aagcggctcacctttagcatcaacag26<210>20<211>29<212>dna<213>人工序列(artificialsequence)<400>20gagttttatcgctgtagcgttgaccctaa29<210>21<211>29<212>dna<213>人工序列(artificialsequence)<400>21gagttttatcgctacaggtagcgttgacc29<210>22<211>29<212>dna<213>人工序列(artificialsequence)<400>22gagttttatcgcttcctacaggtagcgtt29<210>23<211>29<212>dna<213>人工序列(artificialsequence)<400>23gagttttatcgctcacttcctacaggtag29<210>24<211>29<212>dna<213>人工序列(artificialsequence)<400>24gagttttatcgctcggacacttcctacag29<210>25<211>29<212>dna<213>人工序列(artificialsequence)<400>25gagttttatcgcttatgcggacacttcct29<210>26<211>29<212>dna<213>人工序列(artificialsequence)<400>26gagttttatcgctactttatgcggacact29<210>27<211>29<212>dna<213>人工序列(artificialsequence)<400>27gagttttatcgctgtgcactttatgcgga29<210>28<211>29<212>dna<213>人工序列(artificialsequence)<400>28gagttttatcgcttgcggtgcactttatg29<210>29<211>29<212>dna<213>人工序列(artificialsequence)<400>29gagttttatcgcttccatgcggtgcactt29<210>30<211>29<212>dna<213>人工序列(artificialsequence)<400>30gagttttatcgcttcttcatttccatgcg29<210>31<211>29<212>dna<213>人工序列(artificialsequence)<400>31gagttttatcgctgccgtcttcatttcca29<210>32<211>29<212>dna<213>人工序列(artificialsequence)<400>32gagttttatcgctaatggccgtcttcatt29<210>33<211>29<212>dna<213>人工序列(artificialsequence)<400>33gagttttatcgctagctaatggccgtctt29<210>34<211>29<212>dna<213>人工序列(artificialsequence)<400>34gagttttatcgctgtacagctaatggccg29<210>35<211>29<212>dna<213>人工序列(artificialsequence)<400>35gagttttatcgcttatggtacagctaatg29<210>36<211>29<212>dna<213>人工序列(artificialsequence)<400>36gagttttatcgcttgagtatggtacagct29<210>37<211>100<212>dna<213>人工序列(artificialsequence)<400>37gtagcgttgaccctaattttggtcgtcgggtacgcaatcgccgccagttaaatagcttgc60aaaatacgtggccttatggttacagtatgcccatcgcagt100<210>38<211>33<212>dna<213>人工序列(artificialsequence)<400>38acacgacgctcttccgatctgagttttatcgct33<210>39<211>37<212>dna<213>人工序列(artificialsequence)<400>39ccttggcacccgagaattccaaagcggctcaccttta37当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1