使用流动池进行信息存储和检索的系统和方法与流程
使用流动池进行信息存储和检索的系统和方法
1.相关申请
2.本申请要求2019年5月31日提交的名称为“使用合成测序流动池进行信息存储和检索的系统和方法”的美国临时专利申请号62/855,615的优先权,其全部内容通过引用并于本文。本申请还要求2019年5月31日提交的名称为“用于产生多核苷酸的系统和方法”的美国临时专利申请号62/855,653的优先权,其全部内容通过引用并入本文。
背景技术:
3.计算机系统已经使用多种不同的机制来存储数据,包括磁存储、光存储和固态存储。这样的数据存储形式可以读写速度、数据保留的持续时间、功率使用或数据密度的形式存在缺点。
4.正如可以读取天然存在的dna,也可以读取机器写入(machine
‑
written)的dna。预先存在的dna读取技术可以包括基于阵列的循环测序测定(例如合成测序(sbs)),其中dna特征(例如模板核酸)的密集阵列通过酶促操作的迭代循环进行测序。在每个循环之后,可以捕获图像,然后将其与其他图像进行分析,以确定机器写入的dna特征的序列。在另一种生物化学测定中,可以将具有可识别标记(例如荧光标记)的未知分析物暴露于在阵列内具有预先确定地址的已知探针的阵列。观察探针和未知分析物之间发生的化学反应可有助于识别或揭示分析物的特性。
技术实现要素:
5.本文描述了用于使用sbs流动池进行信息存储和检索的系统和方法。
6.根据一个实施方式,提供了一种用于从流动池存储和检索信息的第一方法。所述方法包括将多个寡核苷酸嫁接至流动池,其中每个寡核苷酸是第一测序起始引物或第二测序起始引物。所述方法进一步包括制备包含多核苷酸序列的多核苷酸文库,其中每个多核苷酸序列已被写成包含特定的可检索信息,并且其中每个多核苷酸序列包含与嫁接至所述流动池的所述测序起始引物之一互补的区域。所述方法进一步包括将所述多核苷酸序列的文库结合至嫁接至所述流动池的所述测序起始引物。所述方法进一步包括以允许离散识别所述多核苷酸序列和相对于所述文库中的其他多核苷酸序列其所包含的信息的方式对每个多核苷酸序列进行索引或条形码化。所述方法还包括通过识别和引用与感兴趣的序列相关联的特定索引或条形码来检索所述多核苷酸序列文库中包含的信息。
7.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括以空间预先确定的方式或以随机的方式在所述流动池上定位所述多核苷酸文库中的每个多核苷酸。
8.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括在同一流动池上写入序列信息并从其读取序列信息。
9.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括在将所述多核苷酸结合至所述流动池之前或在将所述多核苷酸结合至所述流动池之后对所述多
核苷酸进行索引或条形码化。
10.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括创建所述索引和所述条形码以包含单独地或与彼此的多种组合的腺嘌呤、胸腺嘧啶、胞嘧啶和鸟嘌呤的多种预先确定序列。
11.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括将分子或纳米颗粒加至每个多核苷酸以创建仅可用已知密钥解密的光学签名或数字签名。
12.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括使用p5/p7作为第一起始引物和第二起始引物和使用p6/p8作为第三起始引物和第四起始引物。
13.根据另一实施方式,提供了另一种用于从流动池存储和检索信息的方法。所述方法包括将多种寡核苷酸嫁接至已适用于合成测序的流动池,其中每个寡核苷酸是第一测序起始引物和第二测序起始引物对的成员或第三测序起始引物和第四测序起始引物对的成员。所述方法进一步包括制备包含多核苷酸序列的多核苷酸文库,其中每个多核苷酸序列已被写成包含特定的可检索信息,和其中每个多核苷酸序列包含与嫁接至所述流动池的所述起始引物之一互补的区域。所述方法进一步包括将多核苷酸序列文库结合至嫁接至所述流动池的所述序列起始引物。所述方法进一步包括以允许离散识别所述多核苷酸序列和相对于所述文库中的其他多核苷酸序列其所包含的信息的方式对每个多核苷酸序列进行索引或条形码化。所述方法进一步包括通过识别和引用与感兴趣的序列相关联的特定索引或条形码来检索所述多核苷酸序列文库中包含的信息。
14.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括以空间预先确定的方式或以随机的方式在所述流动池上定位所述多核苷酸文库中的每个序列。
15.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括在同一流动池上写入序列信息并从其读取序列信息。
16.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括在将所述多核苷酸结合至所述流动池之前或在将所述多核苷酸结合至所述流动池之后对所述多核苷酸进行索引或条形码化。
17.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括创建索引和条形码以包含单独地或与彼此的多种组合的腺嘌呤、胸腺嘧啶、胞嘧啶和鸟嘌呤的多种预先确定序列。
18.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括将分子或纳米颗粒加至每个多核苷酸序列以创建仅可用已知密钥来解密的光学签名或数字dna签名。
19.存在以上实施方式中的任何一个或多个的变型,其中所述流动池包含反应孔和位于所述反应孔之间的间隙空间。
20.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括使用p5/p7作为第一起始引物对和p6/p8作为第二起始引物对,其中p5/p7对被嫁接至所述反应孔,和其中p6/p8对被嫁接至所述间隙空间。
21.在又一实施方式中,提供了另一种用于存储和检索来自流动池的信息的方法。所述方法包括将多种寡核苷酸嫁接至已适用于合成测序的流动池,其中每个寡核苷酸是第一测序起始引物和第二测序起始引物对的成员或第三测序起始引物和第四测序起始引物对
的成员。所述方法进一步包括制备包含多核苷酸序列的多核苷酸文库,其中每个多核苷酸序列已被写成包含特定的可检索信息,和其中每个多核苷酸序列包含与嫁接至所述流动池的测序起始引物之一互补的区域。所述方法进一步包括将多核苷酸序列文库结合至嫁接至所述流动池的所述测序起始引物。所述方法进一步包括以允许离散识别所述多核苷酸序列和相对于所述文库中的其他多核苷酸序列其所包含的信息的方式对每个多核苷酸序列进行索引或条形码化。所述方法进一步包括使用合成测序扩增所述多核苷酸序列。所述方法进一步包括通过识别和引用与多种感兴趣的序列相关联的特定索引或条形码来检索所述多核苷酸序列文库中包含的信息。
22.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括以空间预先确定的方式或以随机的方式在所述流动池上定位所述多核苷酸文库中的每个序列。
23.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括创建所述索引和所述条形码以包含单独地或与彼此的多种组合的腺嘌呤、胸腺嘧啶、胞嘧啶和鸟嘌呤的多种预先确定序列。
24.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括将分子或纳米颗粒加至每个多核苷酸以创建仅可用已知密钥解密的光学签名或数字dna签名。
25.存在以上实施方式中的任何一个或多个的变型,其中所述流动池包含反应孔和位于所述反应孔之间的间隙空间,并且进一步包括使用p5/p7作为第一起始引物对和p6/p8作为第二起始引物对,其中p5/p7对被嫁接至所述反应孔,和其中p6/p8对被嫁接至所述间隙空间。
26.根据另一实施方式,提供了另一种产生多核苷酸的方法。所述方法包括在第一预先确定位置处将包含第一dna序列的第一多核苷酸写至流动池上,其中所述第一多核苷酸包含所述第一dna序列的第一连接序列。所述方法进一步包括在第二预先确定位置处将包含第二dna序列的第二多核苷酸写至所述流动池上,其中所述第二多核苷酸包含所述第二dna序列的第二连接序列,其中所述第二连接序列是所述第一连接序列的反向互补,和其中所述第一连接序列和所述第二连接序列在所述第一多核苷酸和所述第二多核苷酸之间形成第一连接桥。所述方法进一步包括基于连接的第一多核苷酸和第二多核苷酸来延伸所述第一多核苷酸和所述第二多核苷酸中的至少一个以产生包含第三dna序列的第三多核苷酸,所述第三dna序列是所述第一dna序列和所述第二dna序列的组合。所述方法进一步包括在第三预先确定位置处将包含第四dna序列的第四多核苷酸写至所述流动池上,其中所述第四多核苷酸包含所述第四dna序列的第三连接序列,其中所述第三连接序列是包含所述第三dna序列的所述第三多核苷酸的至少一部分的反向互补,并在所述第三多核苷酸和所述第四多核苷酸之间形成第二连接桥。所述方法进一步包括基于连接的第三多核苷酸和第四多核苷酸来延伸所述第三多核苷酸和所述第四多核苷酸中的至少一个以产生包含第五dna序列的第五多核苷酸,所述第五dna序列是所述第一dna序列、所述第二dna序列和所述第三dna序列的组合。
27.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括在所述流动池上提供校准工具以提供关于由所述方法产生的延伸序列的序列完整性的质量保证。
28.存在以上实施方式中的任何一个或多个的变型,其中所述流动池适用于合成测序。
29.存在以上实施方式中的任何一个或多个的变型,其中所述第一引物包含第一引物核苷酸序列和所述第二引物包含第二引物核苷酸序列,所述第一引物核苷酸序列有至少一个核苷酸与所述第二引物核苷酸序列不同。
30.存在以上实施方式中的任何一个或多个的变型,其中所述第一连接序列是第一均聚物和其中所述第二连接序列是与所述第一均聚物反向互补的第二均聚物。
31.存在以上实施方式中的任何一个或多个的变型,其中所述第一连接序列和所述第二连接序列是基因的反向互补组分。
32.存在以上实施方式中的任何一个或多个的变型,其中所述第五多核苷酸具有至少2000个碱基对(bp)。
33.存在以上实施方式中的任何一个或多个的变型,其中第一预先确定距离是至少100nm。
34.根据另一实施方式,提供了用于产生多核苷酸的另一种方法。所述方法包括在第一预先确定位置处将包含第一dna序列的第一多核苷酸写至流动池上,其中所述第一多核苷酸包含所述第一dna序列的第一连接序列,和其中所述流动池适用于合成测序。所述方法进一步包括在第二预先确定位置处将包含第二dna序列的第二多核苷酸写至所述流动池上,其中所述第二多核苷酸包含所述第二dna序列的第二连接序列,其中所述第二连接序列是所述第一连接序列的反向互补,和其中所述第一连接序列和所述第二连接序列在所述第一多核苷酸和所述第二多核苷酸之间形成第一连接桥。所述方法进一步包括基于连接的第一多核苷酸和第二多核苷酸来延伸所述第一多核苷酸和所述第二多核苷酸中的至少一个以产生包含第三dna序列的第三多核苷酸,所述第三dna序列是所述第一dna序列和所述第二dna序列的组合。所述方法进一步包括在第三预先确定位置处将包含第四dna序列的第四多核苷酸写至所述流动池上,其中所述第四多核苷酸包含所述第四dna序列的第三连接序列,其中所述第三连接序列是包含所述第三dna序列的所述第三多核苷酸的至少一部分的反向互补,并在所述第三多核苷酸和所述第四多核苷酸之间形成第二连接桥。所述方法进一步包括基于连接的第三多核苷酸和第四多核苷酸来延伸所述第三多核苷酸和所述第四多核苷酸中的至少一个以产生包含第五dna序列的第五多核苷酸,所述第五dna序列是所述第一dna序列、所述第二dna序列和所述第三dna序列的组合,和其中所述第五多核苷酸具有至少2000个碱基对(bp)。
35.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括在所述流动池上提供校准工具以提供关于由所述方法产生的所述延伸序列的序列完整性的质量保证。
36.存在以上实施方式中的任何一个或多个的变型,其中所述第一引物包含第一引物核苷酸序列和所述第二引物包含第二引物核苷酸序列,所述第一引物核苷酸序列有至少一个核苷酸与所述第二引物核苷酸序列不同。
37.存在以上实施方式中的任何一个或多个的变型,其中所述第一连接序列是第一均聚物和其中所述第二连接序列是与所述第一均聚物反向互补的第二均聚物。
38.存在以上实施方式中的任何一个或多个的变型,其中所述第一连接序列和所述第二连接序列是使用所述方法正在制备的感兴趣的基因的互补组分。
39.存在以上实施方式中的任何一个或多个的变型,其中所述预先确定位置之间的距
离为至少100nm。
40.存在以上实施方式中的任何一个或多个的变型,其中所述第一连接序列和所述第二连接序列是基因的反向互补组分。
41.在又一实施方式中,提供了另一种产生多核苷酸的方法。所述方法包括在第一预先确定位置处将包含第一dna序列的第一多核苷酸写至流动池上,其中所述第一多核苷酸包含所述第一dna序列的第一连接序列,其中所述流动池适用于合成测序,其中所述流动池包含多个单独的像素,和其中所述第一预先确定位置代表第一像素。所述方法进一步包括在第二预先确定位置处将包含第二dna序列的第二多核苷酸写至所述流动池上,其中所述第二多核苷酸包含所述第二dna序列的第二连接序列,其中所述第二连接序列是所述第一连接序列的反向互补,其中所述第一连接序列和所述第二连接序列在所述第一多核苷酸和所述第二多核苷酸之间形成第一连接桥,其中所述流动池适用于合成测序,其中所述流动池包含多个单独的像素,和其中所述第二预先确定位置代表第二像素。所述方法进一步包括基于连接的第一多核苷酸和所述第二多核苷酸来延伸所述第一多核苷酸和所述第二多核苷酸中的至少一个以产生包含第三dna序列的第三多核苷酸,所述第三dna序列是所述第一dna序列和所述第二dna序列的组合。所述方法进一步包括在第三预先确定位置处将包含第四dna序列的第四多核苷酸写至所述流动池上,其中所述第四多核苷酸包含所述第四dna序列的第三连接序列,其中所述第三连接序列是包含所述第三dna序列的所述第三多核苷酸的至少一部分的反向互补,并在所述第三多核苷酸和所述第四多核苷酸之间形成第二连接桥。所述方法进一步包括基于连接的第三多核苷酸和第四多核苷酸来延伸所述第三多核苷酸和所述第四多核苷酸中的至少一个以产生包含第五dna序列的第五多核苷酸,所述第五dna序列是所述第一dna序列、所述第二dna序列和所述第三dna序列的组合,和其中所述第五多核苷酸具有至少2000个碱基对(bp)。
42.存在以上实施方式中的任何一个或多个的变型,其中所述方法进一步包括在所述流动池上提供校准工具以提供关于由所述方法产生的所述延伸序列的序列完整性的质量保证。
43.存在以上实施方式中的任何一个或多个的变型,其中第所述第一引物包含第一引物核苷酸序列和所述第二引物包含第二引物核苷酸序列,所述第一引物核苷酸序列有至少一个核苷酸与所述第二引物核苷酸序列不同。
44.存在以上实施方式中的任何一个或多个的变型,其中所述第一连接序列是第一均聚物和其中所述第二连接序列是与所述第一均聚物反向互补的第二均聚物。
45.存在以上实施方式中的任何一个或多个的变型,其中所述第一连接序列和所述第二连接序列是使用所述方法正在制备的感兴趣的基因的互补组分,和其中所述像素之间的距离是至少100nm。
46.应当理解,前述概念和下文更详细讨论的其他概念的所有组合(假设这样的概念不相互矛盾)被认为是本文公开的发明主题的一部分,并且实现了如本文中所述的益处/优点。特别地,出现在本公开的结尾处的要求保护的主题的所有组合被认为是本文中公开的发明主题的一部分。
附图说明
47.在附图和以下描述中说明了一种或多种实施方式的细节。根据说明书、附图和权利要求书,其他特征、方面和优点将变得显而易见,其中:
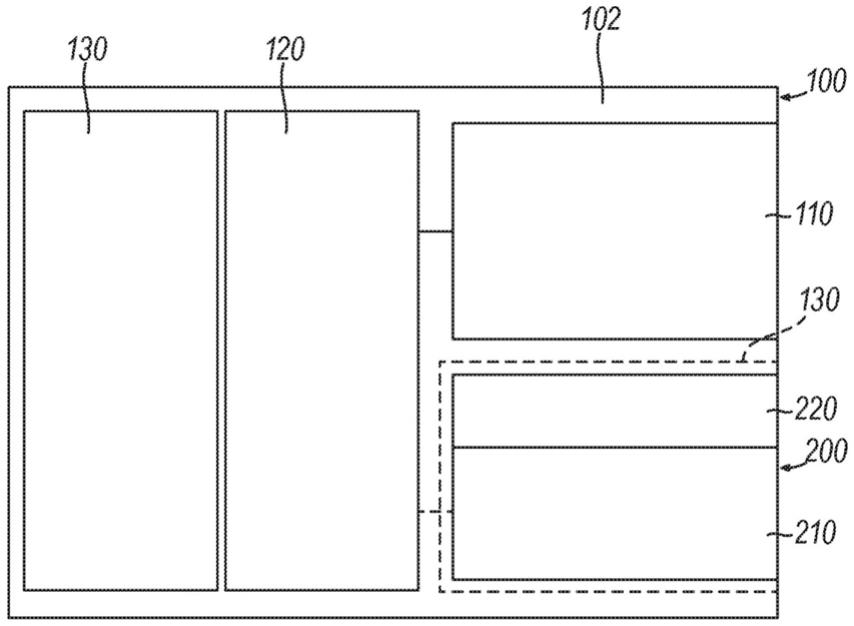
48.图1描绘了可用于进行生化方法的系统的实例的示意性框图;
49.图2描绘了可与图1的系统一起使用的可消耗盒的实例的示意性横截面框图;
50.图3描绘了可以与图1的系统一起使用的流动池的实例的透视图;
51.图4描绘了图3的流动池的通道的放大透视图;
52.图5描绘了可并入图4的通道中的孔的实例的示意性横截面框图;
53.图6描绘了用于读取多核苷酸的方法的实例的流程图;
54.图7描绘了可并入图4的通道中的孔的另一实例的示意性横截面框图;
55.图8描绘了用于写入多核苷酸的方法的实例的流程图;
56.图9描述了电极组件的实例的俯视图;
57.图10描绘了可并入图4的通道中的孔的另一实例的示意性横截面框图;
58.图11描绘了通过在流动池上写入感兴趣的序列而产生的捕获探针;
59.图12描绘了用于在流动池上存储生物学信息的另一种方法,其中以预先确定的空间图案在流动池上布置并写入了独特的或不同的索引或条形码,和其中使用索引或条形码来捕获来自组织样品的不同部分的dna分子;
60.图13描绘了使用某些分子安全措施来保护流动池上存储的数据或信息;
61.图14描绘了使用可变核苷酸序列作为标识符在流动池上进行样品索引的另一种方法;
62.图15描绘了在单个流动池上使用p5/p7引物和p6/p8引物两者的方法;
63.图16描述了在流动池上连接两个相邻接种的dna文库以提供化合物信息的方法;和
64.图17描绘了根据一种实施方式合成的dna分子的示意图,其中均聚物a和互补均聚物t用于将两个相邻的dna片段缝合在一起。
65.将认识到,附图的一些或全部是出于说明目的的示意图。提供附图是出于说明一种或多种实施方式的目的,并且将明确理解的是它们不用于限制权利要求的范围或含义。
具体实施方式
66.在一些方面,本文公开了用于dna存储装置的方法和系统,所述dna存储装置可以是可移除的和便携式的,并且可以用作dna硬盘驱动器模块以用于大小规模的存档目的。机器写入的dna可以替代传统形式的数据存储(例如磁存储、光存储和固态存储)。在其他方面,本文公开了用于合成多核苷酸(例如dna(或其他生物材料))以存储数据或其他信息;和/或读取例如dna(或本文定义的其他生物材料)之类的机器写入多核苷酸以检索机器写入数据或其他信息的方法和系统。机器写入dna可以提供更快的读写速度,更长的数据保留时间,更低的功耗和更高的数据密度。在2015年9月17日公布的名称为“dna中数字信息的高容量存储”的美国公开号2015/0261664中公开了如何在dna中存储数字信息的实例,其全部内容通过引用并入本文中。例如,可使用来自代码理论以增强dna片段中编码消息可恢复性的方法,所述方法包括禁止已知与现有高通量技术中较高错误率相关联的dna均聚物(即多
个相同碱基的运行)。另外,可以将类似于奇偶校验位的错误检测构件集成至代码中的索引信息中。可以在dna存储方案的未来发展中实现更复杂的方案,包括但不限于纠错码,以及实际上在信息学中采用的基本上任何形式的数字数据安全性(例如基于raid的方案)。信息的dna编码可以使用软件来计算。包含每个计算机文件的字节可以通过编码方案由不具有均聚物的dna序列表示,以生成编码文件,所述编码文件将每个字节替换为形成dna序列的五个或六个碱基。
67.尽管可以使用其他编码方案,但是可以构造在编码方案中使用的代码以允许直接编码,该直接编码接近游程受限信道(例如没有重复的核苷酸)的最佳信息容量。所得的计算机硅dna序列可能太长而无法通过标准的寡核苷酸合成而容易地产生,并且可能被分成长度为100个碱基的重叠片段与75个碱基的重叠。为了降低引入任何特定轮碱基的系统合成错误的风险,可以将这些区段的替代区段转换为它们的反向互补,这意味着每个碱基可以“写入”四次,每个方向两次。然后可以用允许确定该区段起源的计算机文件及其在该计算机文件中的位置的索引信息以及简单的错误检测信息来扩展每个区段。该索引信息也可以被编码为非重复的dna核苷酸,并附加到dna区段的信息存储碱基上。将dna区段分成100个碱基的长度与75个碱基的重叠纯粹是任意的和说明性的,并且应当理解,可以使用其他长度和重叠,而不是限制性的。
68.可以使用用于dna片段的其他编码方案,例如以提供增强的纠错特性。可以增加索引信息的数量以允许对更多或更大的文件进行编码。为避免dna区段中的系统模式而对编码方案的一种扩展可以是添加改变信息。一种方式可以使用dna区段中信息的“混洗(shuffling)”,如果知道混洗的模式,则可以在其中检索信息。不同的混洗模式可用于不同的dna区段。进一步的方式是在每个dna区段的信息中增加一定程度的随机性。为此可以使用一系列随机数字,将该系列随机数字与包含编码在dna区段中的信息的数字进行模加。如果知道所使用的一系列随机数字,则可以在解码过程中通过模减检索信息。不同系列的随机数字可用于不同的dna区段。每个字符串的数据编码部分可以包含shannon信息,每个dna碱基5.07位,这接近于每个dna碱基5.05位的理论最佳值(对游程长度限制为一的碱基
‑
4通道而言)。索引的实现可以允许314=4782969唯一数据位置。仅增加2至16个用于指定文件和文件内位置的索引三进制数位(并从而增加碱基)可以得到316=43046721的独特位置,超过了嵌套引物分子记忆(nested primer molecular memory(npmm))方案的实际最大值16.8m。
69.可以在三个不同的运行中合成dna区段设计(将dna区段随机分配给运行)以产生每个dna区段设计的约1.2
×
107拷贝。可以使用亚磷酰胺化学方法,并且可以使用喷墨印刷和原位微阵列合成平台中的流动池反应器技术。在无水室内进行的喷墨打印可以允许将非常少量的亚磷酰胺递送至2d平面表面上的受限偶联区域,从而导致数十万个碱基的并行添加。随后的氧化和去三苯甲基化可在流动池反应器中进行。dna合成完成后,可将寡核苷酸从表面切下并脱保护。
70.然后可以将衔接子添加至dna区段,以使得能够制备dna片段的多个拷贝。不带衔接子的dna区段可能需要其他化学方法,才能通过在dna区段的末端添加其他基团来“启动”化学合成多个拷贝。寡核苷酸可以使用聚合酶链反应(pcr)方法和双末端pcr引物进行扩增,然后进行磁珠纯化和定量。然后可以对寡核苷酸测序以产生104个碱基的读取。然后可
以通过从两端对每个寡核苷酸的中央碱基进行测序、全长寡核苷酸的快速计算以及与设计不一致的序列读取的去除来进行数字信息解码。可以使用完全颠倒编码方法的计算机软件对序列读取进行解码。奇偶校验三进制数位指示错误或可被明确解码或分配给重构计算机文件的序列读取可能会被丢弃。可以在多个不同的测序dna寡核苷酸中检测每个解码文件中的位置,并且可以使用简单多数表决来解决由dna合成或测序错误引起的任何差异。
71.尽管在机器写入的dna的背景下提供了本文的几个实例,但是可以预期的是,本文所述的原理可以应用于其他种类的机器写入的生物材料。
72.如本文所用,术语“机器写入的dna”应被理解为包含由机器产生或由机器修饰的多核苷酸的一条或多条链以存储数据或其他信息。本文的多核苷酸的一个实例是dna。应当注意,尽管在本公开内容中在读取或写入的dna的上下文中使用了术语“dna”,但是该术语仅用作多核苷酸的代表性实例,并且可以涵盖多核苷酸的概念。如本文更详细地描述,如本文中关于“机器写入的”所使用的“机器”可以包括特别设计用于写入dna的仪器或系统。该系统可以是非生物的或生物的。在一个实例中,生物系统可包含或为聚合酶。例如,聚合酶可以是末端脱氧核苷酸转移酶(tdt)。在生物系统中,该方法可以另外由机器硬件(例如处理器)或算法来控制。“机器写入的dna”可以包含具有由机器写入的一个或多个碱基序列的任何多核苷酸。尽管本文以机器写入的dna为例,但是其他多核苷酸链可以代替本文描述的机器写入的dna。“机器写入的dna”可以包括天然碱基和天然碱基的修饰,包括但不限于用甲基化或其他化学标签修饰的碱基、与dna类似的人工合成的聚合物(例如肽核酸(pna))或吗啉dna。“机器写入的dna”还可以包括dna链或其他多核苷酸,这些dna链或其他多核苷酸是由至少一条源自自然界(例如从天然存在的生物中提取)的碱基链形成的,并具有以并行方式或端到端方式固定在其上的机器写入的碱基链。在其他实施方式中。在其他实施方式中,“机器写入的dna”可由代替或除本文所述的dna的非生物系统(例如电极机器)的写入之外的生物系统(例如酶)写入。换句话说,“机器写入的dna”可以由机器直接写成,或由算法和/或机器控制的酶(例如聚合酶)写入。
[0073]“机器写入的dna”可以包括使用已知技术从原始形式(例如照片、文本文档等)转换为二进制代码序列的数据,然后使用已知技术将该二进制代码序列转换为dna碱基序列,然后通过机器以一条或多条dna链或其他多核苷酸的形式产生该dna碱基序列。或者,可以生成“机器写入的dna”以索引或跟踪先前存在的dna,以出于任何合适的目的存储来自任何其他来源的数据或信息,而不需要将原始数据转换为二进制代码的中间步骤。
[0074]
如下文更详细描述的,可以将机器写入的dna写至反应位点和/或从反应位点读取机器写入的dna。如本文所用,术语“反应位点”是可以发生至少一个指定反应的局部区域。反应位点可以包括反应结构或基质的支撑表面,其上可以固定有物质。例如,反应位点可以是空间的离散区域,其中dna链或其他多核苷酸的离散组被写入。反应位点可以允许与相邻反应位点中的反应分离的化学反应。提供dna的机器写入的装置可以包括具有孔的流动池,所述孔具有写入特征(例如电极)和/或读取特征。在一些情况下,反应位点可以包含反应结构的表面(其可以位于流动池的通道中),该表面上已经具有反应组分,例如其上的多核苷酸集落。在一些流动池中,集落中的多核苷酸具有相同的序列,例如单链或双链模板的克隆拷贝。但是,在某些流动池中,反应位点可以仅包含单个多核苷酸分子,例如单链或双链形式。
[0075]
多个反应位点可以沿着流动池的反应结构随机分布,或者可以以预先确定方式排列(例如在矩阵中(例如在微阵列中)并排排列)。反应位点还可以包括反应室、凹口或孔,其至少部分地限定被配置为分隔指定反应的空间区域或体积。如本文所用,术语“反应室”或“反应凹口”包括支撑结构的限定的空间区域(其通常与流动通道流体地偶联)。反应凹口可以与周围环境或其他空间区域至少部分地分开。例如,多个反应凹口可以通过共享的壁彼此分开。作为更具体的实例,反应凹口可以是纳米孔,纳米孔包括凹痕、凹坑、孔、凹槽、腔或凹陷,所述凹痕、凹坑、孔、凹槽、腔或凹陷由检测表面的内表面限定并具有开口或孔隙(即侧面敞开),从而使纳米孔可以与流动通道流体偶联。
[0076]
多个反应位点可以沿着流动池的反应结构随机分布,或者可以以预先确定方式排列(例如在矩阵中(例如在微阵列中)并排排列)。反应位点还可以包括反应室、凹口或孔,其至少部分地限定被配置为分隔指定反应的空间区域或体积。如本文所使用的,术语“反应室”或“反应凹口”包括支撑结构的限定的空间区域(其通常与流动通道流体地偶联)。反应凹口可以与周围环境或其他空间区域至少部分地分开。例如,多个反应凹口可以通过共享的壁彼此分开。作为更具体的实例,反应凹口可以是纳米孔,纳米孔包括凹痕、凹坑、孔、凹槽、腔或凹陷,所述凹痕、凹坑、孔、凹槽、腔或凹陷由检测表面的内表面限定并具有开口或孔隙(即侧面敞开),从而使纳米孔可以与流动通道流体偶联。
[0077]
为了读取机器写入的dna,可以定义反应位点的一个或多个离散的可检测区域。这样的可检测区域可以是可成像区域、电检测区域或其他类型的区域,其可以基于在读取过程中存在的核苷酸的类型而具有可测量的特性变化(或特性变化不存在)。
[0078]
如本文所使用,术语“像素”是指离散的可成像区域。每个可成像区域可包括其中存在多核苷酸的空间的间隔或离散区域。在某些情况下,像素可包括两个或更多个反应位点(例如,两个或更多反应室、两个或更多反应凹口、两个或更多孔等)。在另一些情况下,像素可以仅包括一个反应位点。使用对应的检测装置(例如图像传感器或其他光检测装置)检测每个像素。可以使用集成电路制造工艺来制造光检测装置,例如用于制造电荷偶联器件电路(ccd)或互补金属氧化物半导体(cmos)器件或电路的工艺。因此,光检测装置可以包括例如一种或多种半导体材料,并且可以采取例如cmos光检测装置(例如cmos图像传感器)或ccd图像传感器(另一种图像传感器)的形式。cmos图像传感器可以包括光传感器(例如光电二极管)的阵列。在一种实施方式中,单个图像传感器可以与物镜一起使用以在成像事件期间捕获多个“像素”。在一些其他实施方式中,每个分立的光电二极管或光传感器可以捕获对应的像素。在一些实施方式中,一个或多个检测装置的光传感器(例如光电二极管)可与对应的反应位点相关联。与反应位点相关联的光传感器可以检测来自相关反应位点的光发射。在一些实施方式中,当在相关联的反应位点发生指定的反应时,可以经由至少一个光导来进行光发射的检测。在一些实施方式中,可将多个光传感器(例如光检测或相机装置的几个像素)与单个反应位点相关联。在一些实施方式中,单个光传感器(例如单个像素)可以与单个反应位点或一组反应位点相关联。
[0079]
如本文所用,术语“合成”应被理解为包括其中由机器产生dna以存储数据或其他信息的方法。因此,机器写入的dna可以构成合成的dna。如本文所用,术语“可消耗盒”、“试剂盒”、“可移除盒”和/或“盒”是指相同的盒和/或构成用于盒或盒系统的组件的构件的组合。本文所述的盒可以独立于具有反应位点的元件,例如具有多个孔的流动池。在某些情况
下,可以将流动池可移除地插入盒中,然后将其插入仪器中。在一些其他实施方式中,流动池可以在没有盒的情况下可移除地插入仪器中。如本文所用,术语“生化分析”可以包括生物学分析或化学分析中的至少一种。
[0080]
术语“基于”应被理解为是指某事物至少部分地由指示为“基于”的事物所确定。为了表明某个事物必须由其他事物完全确定,将其描述为完全基于其完全确定的内容。
[0081]
术语“非核苷酸存储器”应被理解为是指能够以不同于可由装置检索和/或处理的核苷酸的形式存储数据或指令的对象、装置或装置组合。“非核苷酸存储器”的实例包括固态存储器、磁存储器、硬盘驱动器、光学驱动器以及前述的组合(例如磁光存储元件)。
[0082]
术语“dna存储装置”应被理解为是指被配置为以多核苷酸序列的形式存储数据或指令的对象、装置或装置的组合,例如机器写入的dna。“dna存储装置”的实例包括具有如本文所述的可寻址孔的流动池、包括多个此类流动池的系统和存储已从其合成表面上切割下来的核苷酸序列的管或其他容器。如本文所用,取决于上下文,应将术语“核苷酸序列”或“多核苷酸序列”理解为包含多核苷酸分子以及该分子的基础序列。多核苷酸的序列可以包含(或编码)指示某些物理特征的信息。
[0083]
本文中说明的实施方式可用于进行指定的反应,以用于可消耗盒的制备和/或生化分析和/或机器写入的dna的合成。
[0084]
i.系统概述
[0085]
图1是被配置为进行生化分析和/或合成的系统100的示意图。系统100可以包括基础仪器102,该基础仪器102被配置为容纳和分别接合可移除盒200和/或具有一个或多个反应位点的构件(component)。基础仪器102和可移除盒200可以被配置为彼此相互作用以将生物材料运输至系统100内的不同位置和/或进行包含生物材料的指定反应,以制备用于随后分析的生物材料(例如通过合成生物材料),并且任选地,以检测生物材料的一个或多个事件。在一些实施方式中,基础仪器102可以被配置为直接在可移除盒200上检测生物材料的一个或多个事件。这些事件可以指示含生物材料的指定反应。可移除盒200可以根据本文描述的任何盒进行构造。
[0086]
尽管下文参考图1所示的基础仪器102和可移除盒200,但是应当理解,基础仪器102和可移除盒200仅示出了系统100的一种实施方式,并且存在其他实施方式。例如,基础仪器102和可移除盒200包括各种构件和特征,其共同执行用于制备生物材料和/或分析生物材料的几种操作。此外,尽管本文所述的可移除盒200包括具有反应位点的元件(例如具有多个孔的流动池),但是其他盒可以独立于具有反应位点的元件,并且具有反应位点的元件可以单独插入至基础仪器102中。也就是说,在某些情况下,流动池可以可移除地插入至可移除盒200中,然后将所述可移除盒200插入至基础仪器102中。在一些其他实施方式中,流动池可以直接可移除地插入基础仪器102中,而没有可移除盒200。在进一步的实施方式中,可直接将流动池插入至可移除盒200中,所述可移除盒200插入至基础仪器102中。
[0087]
在示例的实施方式中,基础仪器102和可移除盒200中的每一个都能够执行某些功能。然而,应当理解,基础仪器102和可移除盒200可以执行不同的功能和/或可以共享这样的功能。例如,基础仪器102被示为包括检测组件(assembly)110(例如成像装置),该检测组件110被配置为检测在可移除盒200处的指定反应。在替代实施方式中,可移除盒200可以包括检测组件,并可通信地偶联至基础仪器102的一个或多个构件。作为另一实例,基础仪器
102是“干”仪器,其不向可移除盒200提供液体,不从其接收液体,不与其交换液体。即,如所示,可移除盒200包括可消耗试剂部分210和流动池接收部分220。可消耗试剂部分210可以容纳在生化分析和/或合成期间使用的试剂。流动池接收部分220可以包括光学透明区域或其他可检测区域,以用于检测组件110对流动池接收部分220内发生的一个或多个事件进行检测。在替代实施方式中,基础仪器102可以向可移除盒200提供例如试剂或其他液体,所述试剂或其他液体随后被可移除盒200消耗(例如用于指定的反应或合成程序)。
[0088]
如本文所用,生物材料可包括一种或多种生物或化学物质,例如核苷、核苷酸、核酸、多核苷酸、寡核苷酸、蛋白质、酶、肽、寡肽、多肽、抗体、抗原、配体、受体、多糖、碳水化合物、多磷酸盐、纳米孔、细胞器、脂质层、细胞,组织、生物和/或生物活性化合物(例如上述物种的类似物或模拟物)。在某些情况下,生物材料可以包括全血、淋巴液、血清、血浆、汗液、眼泪、唾液、痰、脑脊髓液、羊水、精液、阴道排泄物、浆液、滑液、心包液、腹膜液、胸膜液、漏出液、渗出液、囊性液、胆汁、尿液、胃液、肠液、粪便、含有单细胞或多细胞的液体、含有细胞器的液体、液化组织、液化生物、包括病毒病原体的病毒、含有多细胞生物的液体、生物拭子和生物洗涤液。在一些情况下,生物材料可以包括一组合成序列,其包括但不限于机器写入的dna,其可以是固定的(例如附接在盒中的特定孔中)或不固定的(例如存储在管中)。
[0089]
在一些实施方式中,生物材料可以包含添加的材料,例如水、去离子水、盐溶液、酸性溶液、碱性溶液、去污剂溶液和/或ph缓冲剂。所添加的材料还可以包含试剂,该试剂将在指定的测定方案中用于进行生化反应。例如,添加的液体可以包含对生物材料进行多个聚合酶链反应(pcr)循环的材料。在其他方面,添加的材料可以是用于生物材料的载体(例如细胞培养基)或可以允许或保留生物材料的生物学功能的其他缓冲和/或ph调节和/或等渗载体。
[0090]
然而,应当理解,被分析的生物材料可以具有与加载至系统100中或由系统100创建的生物材料不同的形式或状态。例如,加载至系统100中的生物材料可以包括随后对其进行处理(例如通过分离或扩增程序)以提供制备的核酸的全血或唾液或细胞群。然后可以由系统100分析(例如通过pcr定量或通过sbs测序)制备的核酸。因此,当在描述例如pcr的第一操作时使用术语“生物材料”时,并在描述随后的第二操作(例如测序)时再次使用该术语时,应当理解,第二操作中的生物材料可以相对于第一操作之前或期间的生物材料进行修改。例如,可以对由模板核酸产生的扩增子核酸进行测序(例如sbs),所述模板核酸是在先前的扩增(例如pcr)中扩增的。在这种情况下,扩增子是模板的拷贝,并且所述扩增子相比于所述模板的数量以更高的数量存在。
[0091]
在一些实施方式中,系统100可以基于用户提供的物质(例如全血或唾液或细胞群)自动准备用于生化分析的样品。然而,在其他实施方式中,系统100可以分析用户部分地或初步准备用于分析的生物材料。例如,用户可以提供一种溶液,该溶液包含已经从全血中分离和/或扩增的核酸。或者可以提供其中rna或dna序列部分或全部暴露以进行加工的病毒样品。
[0092]
如本文所用,“指定的反应”包括感兴趣的分析物的化学、电、物理或光学特性(或质量)中的至少一种的变化。在特定实施方式中,指定的反应是相关联结合事件(例如将荧光标记的生物分子与感兴趣的分析物的掺入)。指定的反应可以是解离结合事件(例如从感兴趣的分析物释放荧光标记的生物分子)。指定的反应可以是化学转化、化学变化或化学相
互作用。指定的反应也可以是电特性的变化。例如,指定的反应可以是溶液内离子浓度的变化。一些反应包括但不限于化学反应,例如还原、氧化、添加、消除、重排、酯化、酰胺化、醚化、环化或取代;第一化学物质与第二化学物质结合的结合相互作用;两种或多种化学物质彼此分离的解离反应;荧光;发光;生物发光;化学发光;和生物反应(例如核酸复制、核酸扩增、核酸杂交、核酸连接、磷酸化、酶催化、受体结合或配体结合)。指定的反应还可以是质子的添加或去除,例如可作为周围溶液或环境的ph值变化进行检测的反应。另外的指定反应可以是检测跨膜(例如天然或合成双层膜)的离子流。例如,当离子流过膜时,电流被破坏,并且可以检测到破坏。也可以使用带电标签的现场感应;也可以使用热感测和其他合适的分析感测技术。
[0093]
在特定实施方式中,指定的反应包括将荧光标记的分子掺入分析物。分析物可以是寡核苷酸,并且荧光标记的分子可以是核苷酸。当激发光指向具有标记核苷酸的寡核苷酸时,可以检测到指定的反应,并且荧光团发出可检测的荧光信号。在替代实施方式中,检测到的荧光是化学发光和/或生物发光的结果。指定的反应还可以增加荧光(或)共振能量转移(fret),例如,通过使供体荧光团靠近受体荧光团,通过分离供体和受体荧光团来降低fret,通过将淬灭剂与荧光素分离来增加荧光,或通过共置淬灭剂和荧光团来减少荧光。
[0094]
如本文所用,“反应组分”包括可用于获得指定反应的任何物质。例如,反应组分包括试剂、催化剂(例如酶)、用于反应的反应物、样品、反应产物、其他生物分子、盐、金属辅因子、螯合剂和缓冲溶液(例如氢化缓冲液)。反应组分可以单独地以溶液形式或以一种或多种混合物的形式递送至流体网络中的各个位置。例如,可以将反应组分输送至固定有生物材料的反应室中。反应组分可以与生物材料直接或间接相互作用。在一些实施方式中,可移除盒200预加载有参与执行指定的测定方案的一种或多种反应组分。预加载可以在用户接收盒200(例如客户的设施)之前在一个位置处(例如制造设施)进行。例如,可以将一种或多种反应组分或试剂预装载至可消耗试剂部分210中。在一些实施方式中,可移除盒200也可以在流动池接收部分220中预装载有流动池。
[0095]
在一些实施方式中,基础仪器102可以被配置为在每个会话(session)中与一个可移除盒200相互作用。在会话之后,可移除盒200可以被另一可移除盒200替换。在其他实施方式中,基础仪器102可以被配置为在每次会话中与一个以上可移除盒200相互作用。如本文所用,术语“会话”包括进行样品制备和/或生化分析方案中的至少一项。样品制备可包括合成生物材料;和/或分开、分离、修饰和/或扩增生物材料的一种或多种组分以使制备的生物材料适用于分析。在一些实施方式中,会话可以包括连续活动,其中进行多种受控反应直到(a)已经进行了指定数量的反应,(b)已经检测到指定数量的事件,(c)系统时间的指定时间段已过去,(d)信噪比已降至指定阈值,(e)识别了目标组分,(f)已检测到系统失败或故障;和/或(g)用于进行反应的一种或多种资源已经耗尽。或者,会话可以包括暂停系统活动一段时间(例如几分钟、几小时、几天、几周),并随后完成会话,直到发生(a)
‑
(g)中的至少一个。
[0096]
测定方案可以包括用于进行指定反应、检测指定反应和/或分析指定反应的一系列操作。总体上,可移除盒200和基础仪器102可以包括用于执行不同操作的构件。测定方案的操作可以包括流体操作、热控制操作、检测操作和/或机械操作。
[0097]
流体操作包括控制通过系统100的流体(例如流体或气体)的流动,其可以由基础仪器102和/或可移除盒200致动。在一个实例中,流体处于液体形式。例如,流体操作可以包括控制泵以引起生物材料或反应组分流入反应室中。
[0098]
热控制操作可以包括控制系统100的指定部分(例如可移除盒200的一个或多个部分)的温度。举例来说,热控制操作可以包括升高或降低存储包含生物材料的液体的聚合酶链反应(pcr)区域的温度。
[0099]
检测操作可以包括控制检测器的激活或监测检测器的活动以检测生物材料的预先确定特性、质量或特性。作为一个实例,检测操作可以包括捕获包括生物材料的指定区域的图像以检测来自指定区域的荧光发射。检测操作可以包括控制光源以照亮生物材料或控制检测器以观察生物材料。
[0100]
机械操作可以包括控制指定构件的运动或位置。例如,机械操作可以包括控制电动机以使基础仪器102中的阀控制构件移动,该阀控制构件可操作地接合可移除盒200中的可移动阀。在一些情况下,不同操作的组合可以同时发生。例如,当泵控制通过反应室的流体流动时,检测器可以捕获反应室的图像。在某些情况下,针对不同生物材料的不同操作可同时发生。例如,第一生物材料可在第二生物材料正在进行检测时进行扩增(例如pcr)。
[0101]
相似或相同的流体元件(例如通道、端口、储库等)可以被不同地标记以更容易地区分流体元件。例如,端口可以被称为储库端口、供应端口、网络端口、进料端口等。应当理解,两个或更多个被不同标记的流体元件(例如储库通道、样品通道、流动通道、桥通道)不需要流体元件在结构上有所不同。此外,可以对权利要求进行修改以添加这样的标记以更容易地区分权利要求中的这样的流体元件。
[0102]
如本文所用,“液体”是相对不可压缩的物质,并且具有流动并符合容纳该物质的容器或通道的形状的能力。液体可以是基于水的并可包括表现出将液体保持在一起的表面张力的极性分子。液体也可以包括非极性分子,例如在油基或非水物质中。应当理解,在本申请中提及液体可以包含含有两种或更多种液体的组合的液体。例如,分开的试剂溶液可以随后合并以进行指定的反应。
[0103]
一种或多种实施方式可包括将生物材料(例如模板核酸)保留在分析生物材料的指定位置。如本文所用,术语“保留的”当相对于生物材料使用时,包括将生物材料附接至表面或将生物材料限制在指定空间内。如本文所用,术语“固定的”当相对于生物材料使用时,包括将生物材料附接至固体支持物中的表面上或固体支持物上的表面上。固定可以包括将生物材料以分子水平附接至表面上。例如,可以使用包括非共价相互作用(例如静电力、范德华力和疏水性界面的脱水)和共价结合技术(其中官能团或接头有助于将生物材料附接至表面)将生物材料固定于基质的表面。可以基于基质表面的特性、携带生物材料的液体培养基以及生物材料本身的特性来将生物材料固定至基质表面。在某些情况下,可以对基质表面进行功能化(例如化学或物理修饰)以促进将生物材料固定至基质表面。可以首先将基质表面改性为具有结合至表面的官能团。然后,官能团可以结合生物材料以将生物材料固定至其上。在某些情况下,生物材料可以通过凝胶固定至表面。
[0104]
在一些实施方式中,可以将核酸固定至表面并使用桥扩增来扩增。用于扩增表面上的核酸的另一种有用的方法是滚环扩增(rca),例如使用下文进一步详细说明的方法。在一些实施方式中,可将核酸附接至表面并使用一个或多个引物对扩增。例如,一个引物可以
在溶液中,而另一引物可以固定在表面上(例如5'
‑
连接)。举例来说,核酸分子可与表面上的一个引物杂交,然后延伸固定的引物以产生核酸的第一拷贝。然后溶液中的引物与核酸的第一拷贝杂交,该核酸可以使用核酸的第一拷贝作为模板而延伸。任选地,在产生核酸的第一拷贝之后,原始核酸分子可以与表面上的第二固定引物杂交,并且可以同时延伸或在溶液中的引物延伸后延伸。在任何实施方式中,使用固定的引物和溶液中的引物的延伸重复轮次(例如扩增)可用于提供核酸的多个拷贝。在一些实施方式中,可将生物材料限制在含有配置为在生物材料的扩增(例如pcr)期间使用的反应组分的预先确定空间内。
[0105]
本文中说明的一个或多个实施方式可以被配置为执行作为或包括扩增(例如pcr)方案的测定方案。在扩增方案期间,可以改变储库或通道内的生物材料的温度以扩增靶序列或生物材料(例如生物材料的dna)。举例来说,生物材料可经历(1)约95℃的预热阶段约75秒;(2)约95℃的变性阶段约15秒;(3)约59℃的退火
‑
延伸阶段约45秒;(4)约72℃的保温阶段约60秒。实施方式可以执行多个放大循环。注意,以上循环仅描述了一种特定的实施方式,并且替代实施方式可以包括对扩增方案的修改。
[0106]
本文中说明的方法和系统可以使用具有各种密度的特征的阵列,所述密度包括例如至少约10个特征/cm2、约100个特征/cm2、约500个特征/cm2、约1,000个特征/cm2、约5,000个特征/cm2、约10,000个特征/cm2、约50,000个特征/cm2、约100,000个特征/cm2、约1,000,000个特征/cm2、约5,000,000个特征/cm2、或更高。本文中说明的方法和装置可以包括具有至少足以以这些密度中的一个或多个密度解析单个特征的分辨率的检测组件或装置。
[0107]
基础仪器102可以包括用户界面130,该用户界面130被配置为接收用于执行指定的测定方案的用户输入和/或被配置为向用户传达关于该测定的信息。用户界面130可以与基础仪器102整合。例如,用户界面130可以包括触摸屏,该触摸屏附接至基础仪器102的外壳并且被配置为识别来自用户的触摸和所述触摸相对于触摸屏上显示的信息的位置。或者,用户界面130可以位于相对于基础仪器102的远处。
[0108]
ii.盒
[0109]
可移除盒200被配置为在盒室140处可分离地接合或可移除地偶联至基础仪器102。如本文所使用,当术语“可分离地接合”或“可移除地偶联”(或类似术语)用于描述可移除盒200和基础仪器102之间的关系时,该术语旨在表示可移除盒200和基础仪器102之间的连接是可分离的,而不会破坏基础仪器102。对应地,可以电气方式将可移除盒200可分离地接合至基础仪器102,使得基础仪器102的电接触不被破坏。可移除盒200可以以机械方式可分离地接合至基础仪器102,使得保持可移除盒200(例如盒室140)的基础仪器102的特征不被破坏。可移除盒200可以以流体方式可分离地接合至基础仪器102,使得基础仪器102的端口不被破坏。例如,如果仅需要简单地调整构件(例如重新对准)或简单地更换(例如更换喷嘴),则认为基础仪器102没有被“破坏”。当构件可以彼此分离而无需过度的努力或花费大量的时间来分离构件时,构件(例如可移除盒200和基础仪器102)可以容易地分离。在一些实施方式中,可移除盒200和基础仪器102可以容易地分离,而不破坏可移除盒200或基础仪器102。
[0110]
在一些实施方式中,可移除盒200可以在与基础仪器102的会话期间被永久地修改或部分损坏。例如,容纳液体的容器可以包括箔盖,该箔盖被刺穿以允许液体流过系统100。在这样的实施方式中,箔盖可被损坏,使得损坏的容器将被另一个容器替换。在特定实施方
式中,可移除盒200是一次性盒,使得可移除盒200可以在单次使用之后被替换并且任选地被处置。类似地,可移除盒200的流动池可以是单独地可一次性使用,使得流动池可以在一次使用之后被替换并且任选地被处置。
[0111]
在其他实施方式中,可移除盒200可以在与基础仪器102接合的同时使用多于一次,和/或可以从基础仪器102中移出,重新加载试剂,并重新接合至基础仪器102以进行其他指定的反应。因此,在某些情况下,可移除盒200可以被翻新,使得相同的可移除盒200可以与不同的消耗物(例如反应组分和生物材料)一起使用。在盒200已经从位于客户设施处的基础仪器102上移除之后,可以在制造设施处进行翻新。
[0112]
盒室140可包括狭槽、底座、连接器接口和/或任何其他特征,以接收可移除盒200或其一部分以与基础仪器102相互作用。
[0113]
可移除盒200可以包括流体网络,该流体网络可以保持并引导流体(例如液体或气体)通过。流体网络可包括多个互连的流体元件,其能够存储流体和/或允许流体流过其中。流体元件的非限制性实例包括通道、通道的端口、腔、存储装置、存储装置的储库、反应室、废物储库、检测室、用于反应和检测的多用途室等。例如,可消耗试剂部分210可以包括一个或多个存储试剂的试剂孔或腔室,并且可以是流体网络的一部分或偶联至流体网络。流体元件可以以指定的方式彼此流体偶联,使得系统100能够进行样品制备和/或分析。
[0114]
如本文中所使用的,术语“流体地偶联”(或类似术语)是指两个空间区域连接在一起,使得可以在两个空间区域之间引导液体或气体。在某些情况下,流体偶联允许流体在两个空间区域之间来回引导。在其他情况下,流体偶联是单向的,使得在两个空间区域之间仅存在一个流动方向。例如,测定储库可以与通道流体地偶联,使得液体可以从测定储库运输至通道中。然而,在一些实施方式中,不可将通道中的流体引回至测定储库。在特定实施方式中,流体网络可以被配置为接收生物材料并引导生物材料通过样品制备和/或样品分析。流体网络可以将生物材料和其他反应组分引导至废物储库。
[0115]
图2描绘了可消耗盒300的实施方式。可消耗盒可以是组合的可去除盒的一部分(例如图1的可去除盒200的可消耗试剂部分210)或者可以是单独的试剂盒。可消耗盒300可包括壳体302和顶部304。壳体302可包括非导电聚合物或其他材料,并形成以构建一个或多个试剂腔室310、320、330。所述试剂腔室310、320、330的尺寸可以变化以容纳要存储在其中的试剂的不同体积。例如,第一腔室310可大于第二腔室320,第二腔室320可大于第三腔室330。第一腔室310的尺寸可容纳较大体积的特定试剂,例如缓冲试剂。第二腔室320的尺寸可以设置成容纳比第一腔室310小的试剂体积,例如容纳裂解试剂的试剂腔室。第三腔室330的尺寸可设置成容纳比第一腔室310和第二腔室320甚至更小的试剂体积,例如容纳含完全功能的核苷酸的试剂的试剂腔室。
[0116]
在所示的实施方式中,壳体302具有在其中形成腔室310、320、330的多个壳体壁或侧面350。在所示的实施方式中,壳体302形成至少基本上是统一的或整体的结构。在替代实施方式中,壳体302可以由一个或多个子构件构成,这些子构件被组合以形成壳体302,例如腔室310、320和330的独立形成的隔室。
[0117]
一旦将试剂提供至对应的腔室310、320、330中,壳体302可以由顶部304密封。顶部304可以包含导电或非导电材料。例如,顶部304可以是铝箔密封件,该铝箔密封件粘接至壳体302的顶表面以将试剂密封在它们各自的腔室310、320、330内。在其他实施方式中,顶部
304可以是塑料密封件,该塑料密封件粘至壳体302的顶表面以将试剂密封在它们各自的腔室310、320、330内。
[0118]
在一些实施方式中,壳体302还可以包含标识符390。标识符390可以是射频识别(rfid)应答器、条形码、识别芯片和/或其他标识符。在一些实施方式中,标识符390可以被嵌入至壳体302中或附接至外表面。标识符390可以包含用于可消耗盒300的独特标识符的数据和/或用于可消耗盒300的类型的数据。标识符390的数据可以由基础仪器102或被配置用于加热如本文所述的可消耗盒300的单独装置读取。
[0119]
在一些实施方式中,可消耗盒300可以包括其他构件,例如阀、泵、流体管线、端口等。在一些实施方式中,可消耗盒300可以被容纳在另外的外部壳体内。
[0120]
iii.系统控制器
[0121]
基础仪器102还可以包括系统控制器120,该系统控制器120被配置为控制可移除盒200和/或检测组件110中的至少一个的操作。系统控制器120可以利用专用的硬件线路、板、dsp、处理器等的任何组合来实现。或者,系统控制器120可以利用具有单个处理器或多个处理器的现成的pc来实现,其中功能操作分布在处理器之间。作为进一步的选择,可以利用混合配置来实现系统控制器120,在混合配置中,利用专用的硬件来执行某些模块化功能,而利用现成的pc等来执行其余的模块化功能。
[0122]
系统控制器120可以包括多个电路模块,其被配置为控制基础仪器102和/或可移除盒200的某些构件的操作。本文中的术语“模块”可以指被配置为用于执行特定任务的硬件装置。例如,电路模块可以包括流量控制模块,该流量控制模块被配置为控制通过可移除盒200的流体网络的流体的流量。流量控制模块可以可操作地偶联至阀致动器和/或系统泵。流量控制模块可以选择性地激活阀致动器和/或系统泵以引起流体通过一个或多个路径流动和/或阻止流体通过一个或多个路径流动。
[0123]
系统控制器120还可包括热控制模块。热控制模块可以控制热循环仪或其他热组件以从可移除盒200的样品制备区域和/或可移除盒200的任何其他区域提供和/或去除热能。热循环仪可以根据pcr方案增加和/或降低生物材料所经历的温度。
[0124]
系统控制器120还可包括检测模块,该检测模块被配置为控制检测组件110以获得关于生物材料的数据。如果检测组件110是可移除盒200的一部分,则检测模块可以通过直接的有线连接或通过接触阵列来控制检测组件110的操作。检测模块可以控制检测组件110在预先确定时间处或在预先确定时间段内获取数据。举例来说,当生物材料具有附接至其上的荧光团时,检测模块可以控制检测组件110以捕获可移除盒的流动池接收部分220的反应室的图像。在一些实施方式中,可以获得多个图像。
[0125]
任选地,系统控制器120可以包括分析模块,该分析模块被配置为分析数据以向系统100的用户提供至少部分结果。例如,分析模块可以分析由检测组件110提供的成像数据。所述分析可以包括识别生物材料的核酸序列。
[0126]
上述系统控制器120和/或电路模块可以包括一个或多个基于逻辑的装置,包括一个或多个微控制器、处理器、精简指令集计算机(risc)、专用集成电路(asic)、领域可编程门阵列(fpga)、逻辑电路以及能够执行本文所述功能的任何其他电路。在一个实施方式中,系统控制器120和/或电路模块执行存储在计算机或机器可读介质中的一组指令,以执行一个或多个测定方案和/或其他操作。指令集可以以信息源或物理存储器元件的形式存储在
基础仪器102和/或可移除盒200内。由系统100执行的方案可以用于执行例如机器写入dna或合成dna(例如,将二进制数据转换为dna序列,然后合成代表二进制数据的dna链或其他多核苷酸),dna或rna的定量分析,蛋白质分析,dna测序(例如合成测序(sbs)),样品制备和/或用于测序的片段文库的制备。
[0127]
指令集可以包括指示系统100执行特定操作的各种命令,例如在本文中描述的各种实施方式的方法和过程。指令集可以是软件程序的形式。如本文所用,术语“软件”和“固件”是可互换的,并且包括存储在存储器中以供计算机执行的任何计算机程序,包括ram存储器、rom存储器、eprom存储器、eeprom存储器和非易失性ram(nvram)存储器。上述存储器类型仅是实例,因此对于可用于存储计算机程序的存储器类型没有限制。
[0128]
该软件可以是各种形式,例如系统软件或应用软件。此外,该软件可以是单独程序的集合,或较大程序内的程序模块或程序模块的一部分的形式。该软件还可以包括面向对象编程形式的模块化编程。在获得检测数据之后,检测数据可以由系统100自动处理,响应于用户输入进行处理,或者响应于另一处理器做出的请求(例如通过通信链路的远程请求)进行处理。
[0129]
系统控制器120可以经由通信链路连接至系统100的其他构件或子系统,该通信链路可以是硬连线的或无线的。系统控制器120还可以通信地连接到异地系统或服务器。系统控制器120可以从用户界面130接收用户输入或命令。用户界面130可以包括键盘、鼠标、触摸屏面板和/或语音识别系统等。
[0130]
系统控制器120可以用来提供处理能力,例如存储、理解和/或执行软件指令和控制系统100的整体操作。系统控制器120可以被配置和编程为控制各个构件的数据和/或功率方面。尽管系统控制器120在图1中被表示为单个结构,但是应当理解,系统控制器120可以包括多个单独的构件(例如处理器),其分布在整个系统100的不同位置。在一些实施方式中,一个或多个构件可以与基础仪器102集成在一起,并且一个或多个构件可以位于相对于基础仪器102的远处。
[0131]
iv.流动池
[0132]
图3
‑
4示出了可以与系统100一起使用的流动池400的实例。该实例的流动池包括限定了多个延长流动通道410的主体,该多个延长流动通道在主体402的上表面404的下方凹入。流动通道410大体上彼此平行并且基本上沿着主体402的整个长度延伸。虽然示出了五个流动通道410,但是流动池400可以包括任何其他合适数量的流动通道410,包括多于或少于五个流动通道410。该实例的流动池400还包括一组入口端口420和一组出口端口422,其中每个端口420、422与对应的流动通道410相关联。因此,可以利用每个入口端口420来将流体(例如试剂等)连通到对应的通道410;而每个出口端口422可用于连通来自对应流动通道410的流体。
[0133]
在一些版本中,流动池400直接集成至可移除盒200的流动池接收部分220中。在一些其他版本中,流动池400与可移除盒的流动池接收部分220可移除地偶联。在流动池400直接集成至流动池接收部分220或与流动池接收部分220可移除地偶联的版本中,流动池400的流动通道410可以通过入口端口420从可消耗试剂部分210接收流体,入口端口420可以与存储在可消耗试剂部分210中的试剂流体地偶联。当然,流动通道410可以通过端口420、422与各种其他流体源或储库等偶联。作为另一个说明性变型,可消耗盒300的一些版本可以被
配置为可移除地接收或以其他方式集成流动池400。在这样的版本中,流动池400的流动通道410可通过入口端口420从试剂腔室310、320、330接收流体。基于本文的教导,流动池400可被并入系统100的其他合适方式对于本领域技术人员而言将是显而易见的。
[0134]
图4更详细地示出了流动池400的流动通道410。如图所示,流动通道410包括形成在流动通道410的底表面412中的多个孔430。如下文将更详细描述的,每个孔430被配置为包含dna链或其他多核苷酸,例如机器写入的多核苷酸。在一些版本中,每个孔430具有圆柱形构造,具有大致圆形的横截面轮廓。在一些其他版本中,每个孔430具有多边形(例如六边形、八边形等)的横截面轮廓。或者,孔430可以具有任何其他合适的构造。还应当理解,孔430可以以任何合适的图案布置,包括但不限于网格图案。
[0135]
图5示出了流动池500内的通道的一部分,其是流动池400的变型的实例。图5描绘的通道是流动池400的流动通道410的变型。可操作该流动池500以读取多核苷酸链550,多核苷酸链550被固定至流动池500中的孔530的底部534。仅作为实例,固定多核苷酸链550的底部534可以包含用叠氮基封端的共嵌段聚合物。仅作为进一步的实例,这种聚合物可包含根据2015年4月21日公布的名称为“聚合物涂层”的美国专利号9,012,022中的至少某些教导提供的聚(n
‑
(5
‑
叠氮基乙酰胺戊基)丙烯酰胺
‑
共丙烯酰胺)(pazam)涂层,其全部内容通过引用并入本文中。可以将这种聚合物引入本文所述的各种流动池的任何一种中。
[0136]
在本实例中,孔530被由流动池500的底表面512提供的间隙空间514隔开。每个池530具有侧壁532和底部534。可操作本实例中的流动池500以在每个孔530下提供图像传感器540。在一些版本中,每个孔530具有至少一个对应的图像传感器540,图像传感器540固定在相对于孔530的位置。每个图像传感器540可以包括cmos图像传感器、ccd图像传感器或任何其他合适种类的图像传感器。仅作为实例,每个孔530可具有一个相关联的图像传感器540或多个相关联的图像传感器540。作为另一种变型,单个图像传感器540可与两个或更多孔530相关联。在一些版本中,一个或多个图像传感器540相对于孔530移动,使得单个图像传感器540或图像传感器540的单个组可以相对于孔530移动。作为又一变型,流动池500可以相对于可以至少基本上固定在适当的位置的单个图像传感器540或图像传感器540的单个组移动。
[0137]
每个图像传感器540可以直接整合到流动池500中。或者,每个图像传感器540可以直接整合到例如可移除盒200的盒中,其中流动池500集成至流动池中或与所述盒偶联。作为又一说明性变型,每个图像传感器540可以直接整合到基础仪器102中(例如作为上述检测组件110的一部分)。无论图像传感器540位于何处,图像传感器540都可以集成至包括其他构件(例如控制电路等)的印刷电路中。在一个或多个图像传感器540未直接整合到流动池500中的版本中,流动池500可包括允许一个或多个图像传感器540捕获一个或多个荧光团发射的荧光的光学透射特征(例如窗户等)。如下文更详细地描述的,所述一个或多个荧光团与多核苷酸链550相关联并固定至流动池500中的孔530的底部534上。还应该理解,各种光学元件(例如透镜、光波导等)可以置于孔530的底部534和对应的图像传感器540之间。
[0138]
同样如图5所示,可操作光源560以将光562投射至孔530中。在一些版本中,每个孔530具有至少一个对应的光源560,其中光源560固定在相对于孔530的位置。仅作为实例,每个孔530可具有一个相关联的光源560或多个相关联的光源560。作为另一变型,单个光源560可与两个或更多个孔530相关联。在一些其他版本中,一个或多个光源560相对于孔530
移动,使得单个光源560或光源组560可以相对于孔530移动。作为又一变型,流动池500可以相对于单个光源560或单组光源560移动,所述单个光源560或单组光源560可以基本被固定在位置。仅作为实例,每个光源560可以包括一个或多个激光器。在另一实例中,光源560可以包括一个或多个二极管。
[0139]
每个光源560可以直接整合到流动池500中。或者,每个光源560可以直接整合到盒中(例如可移除盒200)中,其中流动池500集成至所述盒中或与所述盒偶联。作为又一说明性变型,每个光源560可以直接整合到基础仪器102中(例如作为上述检测组件110的一部分)。在一个或多个光源560没有直接整合到流动池500中的版本中,流动池500可以包括允许孔530接收由一个或多个光源560发射的光的光学透射特征(例如窗户等),从而使光能够到达固定在孔530底部534上的多核苷酸链550。还应理解,各种光学元件(例如透镜、光波导等)可以在孔530和对应的光源560之间插入。
[0140]
如本文其他部分所述,并且如图6的框590所示,dna读取方法可以开始于在目标孔530中进行测序反应(例如根据2016年9月27日公布的名称为“核酸测序的方法和组合物”的美国专利号9,453,258的至少一些教导(其全部内容通过引用并入本文中))。接下来,如图6的框592中所示,在目标孔530上激活光源560,从而照亮目标孔530。投射的光562可以使与多核苷酸链550相关联的荧光团发荧光。因此,如图6的框594中所示,对应的图像传感器540可以检测从与多核苷酸链550相关联的一个或多个荧光团发射的荧光。基础仪器102的系统控制器120可以驱动光源560以发光。基础仪器102的系统控制器120还可以处理从图像传感器540获得的图像数据,代表孔530中的多核苷酸链550的荧光发射分布。如图6的框596所示,通过使用来自图像传感器540的图像数据,系统控制器120可确定每个多核苷酸链550中的碱基序列。仅作为实例,可以利用该方法和装置来绘制基因组或以其他方式确定与天然存在的生物相关联的生物学信息,其中dna链或其他多核苷酸是从或基于天然存在的生物而获得的。或者,如下文将更详细描述的,可以利用上述方法和装置来获得存储在机器写入的dna中的数据。
[0141]
仅作为进一步的实例,当执行上述图6所示的程序时,时空测序反应可以利用一种或多种化学和成像事件或步骤来区分在测序反应期间掺入至正在生长的核酸链中的多种分析物(例如四个核苷酸)。或者,可以在具有四个不同核苷酸的混合物中检测到少于四种不同的颜色,同时仍然可以确定四个不同的核苷酸(例如在测序反应中)。可以在相同的波长下检测一对核苷酸类型,但是可以根据一对中一个成员相对于另一成员的强度差异,或基于一对中一个成员的变化(导致与检测到的一对的另一成员相比明显的信号出现或消失)(例如通过化学修饰、光化学修饰或物理修饰)来区分。
[0142]
v.机器写入的生物材料
[0143]
在一些实施方式中,系统100(例如图1中所示的系统100)可以被配置为合成生物材料(例如多核苷酸(例如dna))以编码数据,所述数据可以稍后通过进行上述测定来进行检索。在某些实施方式中,这种编码可以通过将值分配给核苷酸碱基(例如,二进制值(例如0或1),三进制值(例如0、1或2等))来进行,其将要编码的数据转换为一串相关值(例如,使用ascii编码方案将文本消息转换为二进制字符串),然后创建一个或多个由碱基的核苷酸组成的多核苷酸,序列与通过转换数据获得的字符串相对应。
[0144]
在一些实施方式中,可使用具有如图7所示配置的孔630的阵列的流动池400的版
本来执行此类多核苷酸的产生。图7示出了流动池600内的通道的一部分,其是流动池400的变型的实例。换言之,图7中描述的通道是流动池400的流动通道410的变型。在该实例中,每个孔630在流动池600的底表面612的下方凹进。因此,孔630通过间隙空间614彼此间隔开。仅作为实例,孔630可以沿流动池600的底表面612以网格或任何其他合适的图案布置。该实例的每个孔630包括侧壁632和底部634。该实例的每个孔630还包括位于孔630的底部634上的对应的电极组件640。在一些版本中,每个电极组件640仅包括单个电极元件。在一些其他版本中,每个电极组件640包括多个电极元件或段。术语“电极”和“电极组件”在本文中应被理解为是可互换的。
[0145]
可操作基础仪器102以独立地激活电极组件640,使得一个或多个电极组件640可以处于激活状态,而一个或多个其他电极组件640不处于激活状态。在一些版本中,cmos装置或其他装置用于控制电极组件640。这样的cmos装置可以直接集成至流动池600中,可以集成至整合流动池600的盒(例如盒200)中,或可直接集成至基础仪器102中。如图7所示,每个电极组件640沿着底部634的整个宽度延伸,终止于对应的孔630的侧壁632。在其他版本中,每个电极组件640可以仅沿着底部634的一部分延伸。例如,一些版本电极组件640可以相对于侧壁632在内部终止。尽管在图5中将电极组件540示意性地描述为单个元件,应当理解,每个电极组件540实际上可以由多个离散的电极形成,而不是仅由单个电极组成。
[0146]
如图7所示,可以通过激活相关孔630的电极组件640以产生特定的多核苷酸链650,以电化学地产生可以使孔630中的多核苷酸链650的端基脱保护的酸。通过举例说明,可以使用在一端具有例如硅烷化学的化学特性并且在另一端具有与dna合成相容的化学特性(例如用于酶结合的短寡核苷酸)的接头来将多核苷酸链650化学地附接至孔630底部的表面。
[0147]
为了促进试剂交换(例如解封剂的传输),在该实例中,每个电极组件640和每个孔630的底部634可包括至少一个开口660。开口660可以与延伸至底部634的下方的孔630下方的流动通道662流体偶联。为了提供穿过电极组件640的这样的开口660,电极组件640可以是环形的,可以放置在象限中,可以放置在孔630的周边或侧壁632上,或者可以其他合适的方式放置或成形以避免干扰试剂交换和/或光的通过(例如可以在涉及荧光发射的检测的测序过程中使用)。在其他实施方式中,可以在没有开口660的情况下将试剂提供至流动池600的流动通道中。应当理解,开口660可以是可选的,并且在某些版本中可以省略。类似地,流动通道662可以是任选的,并且在一些版本中可以省略。
[0148]
图9示出了电极组件640可以采取的形式的实例。在该实例中,电极组件640包括一起限定环形形状的四个离散的电极段642、644、646、648。电极段642、644、646、648因此被配置为环的离散但相邻的象限。每个电极段642、644、646、648可以被配置为提供与特定核苷酸独特地相关联的预先确定电荷。例如,电极段642可以被配置为提供与腺嘌呤独特地相关联的电荷;电极段644可以被配置为提供与胞嘧啶独特地相关联的电荷;电极段646可以被配置为提供与鸟嘌呤独特地相关联的电荷;电极段648可以被配置为提供与胸腺嘧啶独特地相关联的电荷。当这四个核苷酸的混合物流过孔630上方的流动通道时,电极段642、644、646、648的激活可导致来自该流动的对应核苷酸粘附至链650。因此,当电极段642被激活后,其可进行将腺嘌呤写至链650。当电极段644被激活时,它可以进行将胞嘧啶写至至链650;当电极段646被激活时,它可以进行将鸟嘌呤写至链650;当电极段648被激活时,它可
以进行将胸腺嘧啶写至链650。该写入可以通过激活的电极段642、644、646、648与激活的电极段642、644、646、648相关联的像素的酶的抑制剂的杂交来提供。尽管电极段642、644、646、648在图9中被示出为形成环形形状,但是应当理解,可以由电极段642、644、646、648形成任何其他合适的形状。在其他实施方式中,可以将单个电极用于电极组件640,并且可以调节电荷以掺入要写至dna链或其他多核苷酸的多种核苷酸。
[0149]
作为另一个实例,电极组件640可以被激活以提供局部的(例如位于其中布置有电极组件640的孔630内)电化学产生的ph变化;和/或电化学地产生局部的部分(例如还原或氧化试剂)以从核苷酸中除去封闭剂。作为另一种变型,不同的核苷酸可以具有不同的封闭剂。这些封闭剂可以基于传递到孔630的光的波长(例如从光源560投射的光562)进行光切割。作为另一个变型,不同的核苷酸可以具有不同的封闭剂。并且可以基于某些其他条件来切割那些封闭剂。例如,可以基于还原条件加上高局部ph或低局部ph的组合来去除四个封闭剂之一。基于氧化条件加上高局部ph或低局部ph的组合,可以除去四个嵌段中的另一个;根据光线和高局部ph值的组合,可以除去四个嵌段中的另一个。可以根据光线和低局部ph值的组合去除四个嵌段中的另一个。因此,可以同时掺入四个核苷酸,但是使用响应于四组不同的条件而发生的选择性的解封闭。
[0150]
电极组件640进一步在电极段642、644、646、648的布置的中心处限定开口660。如上所述,该开口660可以提供用于流动通道662与孔630之间的流体连通的路径,从而允许流过流动通道662的试剂等到达孔630。如上所注,一些变化可以省略流动通道662,并以其他的一些方式(例如通过被动扩散等)提供试剂等到达孔630中的连通。如本文所述,不管流体是否通过开口660连通,开口660可以提供用于在读取周期期间通过孔630的底部的光传输的路径。在一些版本中,开口660可以是任选的,因此可以省略。在省略了开口660的版本中,流体可以经由在孔630上方或相对于孔630定位的一个或多个流动通道被传送至孔630。此外,可以不需要开口660来提供在读取周期期间通过孔630的底部的光传输的路径。例如,如以下关于流动池601所述,电极组件640可以包含光学透明材料(例如光学透明导电膜(tcf)等),并且流动池600本身可以包含光学透明的材料(例如玻璃),使得电极组件640和形成流动池600的材料可以允许从与机器写入的多核苷酸链650相关联的一个或多个荧光团发出的荧光到达位于孔630下方的图像传感器540。
[0151]
图8示出了可以在流动池600中用于机器写入的多核苷酸或其他核苷酸序列的方法的实例。在该方法的开始,如图8的第一框690所示,核苷酸可以流入流动池600中,经孔630。如图8的下一框692所示,然后可以激活电极组件640以将第一核苷酸写至靶孔630底部的引物。如图8的下一框694所示,然后可以将终止子从刚写在靶孔630中的第一核苷酸上切下。基于本文中的教导,可以将终止子从第一核苷酸上切下的各种合适方式对于本领域技术人员而言是显而易见的。一旦终止子被从第一核苷酸上切下,如图8的下一框696所示,则可以激活电极组件640以将第二核苷酸写至第一核苷酸。虽然在图8中未示出,可以从第二核苷酸上切下终止子,然后可以将第三核苷酸写至第二核苷酸,依此类推,直到已经写成了所需的核苷酸序列为止。
[0152]
在一些实施方式中,可以以其他方式进行经由生物材料(例如dna)的合成的数据编码。例如,在一些实施方式中,流动池600可以完全缺少电极组件640。例如,解封闭剂可以通过开口660从流动通道662选择性地连通至孔630。这可以消除对电极组件640选择性激活
核苷酸的需要。作为另一实例,可以将孔630的阵列暴露于包含可用于编码数据的所有核苷酸碱基的溶液中,然后可以通过使用来自空间光调制器(slm)的光为各个孔630选择性地激活各个核苷酸。作为另一个实例,在某些实施方式中,可以为各个碱基分配组合值(例如,腺嘌呤可用于编码二进制对联(binary couplet)00,鸟嘌呤可用于编码二进制对联01,胞嘧啶可用于编码二进制对联10,胸腺嘧啶可用于编码二进制对联11)以增加所产生的多核苷酸的存储密度。基于本公开,其他实例也是可能的,并且对于本领域技术人员将显而易见。因此,以上对合成生物材料(例如dna)以编码数据的描述应被理解为仅是说明性的且不应被视为限制。
[0153]
vi.阅读机器写入的生物材料
[0154]
在流动池600的一个或多个孔630中已经对多核苷酸链650进行机器写入之后,随后可以读取多核苷酸链650以提取存储在机器写入的多核苷酸链650中的任何数据或其他信息。可以使用例如图5所示和如上所述的布置来执行这种读取方法。换言之,一个或多个光源560可被用于照亮与机器写入的多核苷酸链650相关联的一个或多个荧光团;以及,一个或多个图像传感器540可用于检测由与机器写入的多核苷酸链650相关联的被照亮的一个或多个荧光团发出的荧光。可以处理由与多核苷酸链650相关联的被照亮的一个或多个荧光团发出的光的荧光分布以确定机器写入的多核苷酸链650中的碱基序列。可以处理所述机器写入的多核苷酸链650中的确定的碱基序列以确定存储于所述机器写入的多核苷酸链650中的数据或其他信息。
[0155]
在一些版本中,机器写入的多核苷酸链650在包含孔630的流动池600中保留一段存储时间。当需要读取机器写入的多核苷酸链650时,流动池600可允许直接从流动池读取机器写入的多核苷酸链650。仅作为实例,包含孔630的流动池600可以被接收在盒(例如盒200)或包含光源560和/或图像传感器540的基础仪器102中,使得机器写入的多核苷酸链650是从孔630直接读取的。
[0156]
作为另一说明性实例,包含孔630的流动池可以直接合并光源560或图像传感器540中的一个或两个。图10示出了流动池601的实例,该流动池601包括具有电极组件640的孔630,一个或多个图像传感器540以及控制电路670。与在图5中所描述的流动池500中的一样,可操作该实例的流动池601以接收从光源560投射的光562。该投射光562可以使与机器写入的多核苷酸链650相关联的一个或多个荧光团发荧光;以及,对应的一个或多个图像传感器540可以捕获从与机器写入的多核苷酸链650相关联的一个或多个荧光团发出的荧光。
[0157]
如在上文中流动池500的背景下所注,流动池601的每个孔650可以包括其自己的图像传感器540和/或光源560;或者这些组件可以进行如上所述的其他配置和布置。在本实例中,从与机器写入的多核苷酸链650相关联的一个或多个荧光团发出的荧光可以通过开口660到达图像传感器540。另外地或替代地,电极组件640可以包括光学透明材料(例如光学透明导电膜(tcf)等),并且流动池601本身可以包含光学透明材料(例如玻璃),从而电极组件640和形成流动池601的材料可以允许从与机器写入的多核苷酸链650相关联的一个或多个荧光团发出的荧光到达图像传感器540。此外,各种光学元件(例如透镜、光波导等)可以置于孔650和对应的一个或多个图像传感器之间,以确保图像传感器540仅接收从与机器写入的多核苷酸链650相关联的一个或多个荧光团发出的荧光。
[0158]
在本实例中,控制电路670直接集成至流动池601中。仅作为实例,控制电路670可
以包括cmos芯片和/或其他印刷电路配置/构件。控制电路670可以与图像传感器540、电极组件640和/或光源560通信。在这种情况下,“通信”是指控制电路670与一个或多个图像传感器540、一个或多个电极组件640和/或光源560处于电通信中。例如,可操作控制电路670以接收和处理来自一个或多个图像传感器540的信号,所述信号表示由图像传感器540接收的图像。在此背景下的“通信中”还可包括向图像传感器540、电极组件640和/或光源560提供电力的控制电路670。
[0159]
在一些版本中,每个图像传感器540具有对应的控制电路670。在一些其他版本中,控制电路670与流动池601中的多个(如果不是全部)图像传感器偶联。基于本文的教导,可用于实现其的各种构件和配置对于本领域技术人员将是显而易见的。还应理解,除了集成至流动池601中或代替所述集成地,控制电路670可以全部或部分地集成至盒(例如可移除盒200)和/或基础仪器102中。
[0160]
作为又一个说明性实例,不管是使用如图7的流动池600那样的只写(write
‑
only)流动池还是使用如图10的流动池601那样的读写(read
‑
write)流动池,可以在合成后从孔630转移机器写入的多核苷酸链650。这可以在合成完成之后不久(在读取机器写入的多核苷酸链650之前或在任何其他合适的时间)发生。在这样的版本中,可以将机器写入的多核苷酸链650转移至类似于图5所示的流动池500的只读流动池中;并随后在该只读流动池500中读取。或者,可以使用任何其他合适的装置或方法。
[0161]
在一些实施方式中,通过确定存储合成的感兴趣的链650的孔630,然后使用例如先前描述的那些技术(例如合成测序)对那些链650进行测序,可以实现读取通过生物材料的合成编码的数据。在一些实施方式中,为了促进对存储在核苷酸序列中的数据的读取,当存储数据时,可以用显示孔630的信息来更新索引,其中编码该数据的链650被合成。例如,当使用配置为合成能够存储多达256位数据的链650的系统100的实施方式来存储一个1兆位(1,048,576位)的文件时,系统控制器120可以执行例如以下的步骤:1)将文件分为4,096 256位段;2)在流动池600、601中识别当前未用于存储数据的4,096个孔630的序列;3)将4,096个段写至4,096个孔430、530;4)更新索引以指示从第一个识别出的孔630开始到最后一个识别出的孔630结束的序列正被用于存储文件。随后,当发出读取文件的请求时,可以使用索引来识别包含相关链650的孔630,可以对来自那些孔630的链650进行测序,并且序列可以被组合并转换为适当的编码格式(例如二进制),然后可以将组合和转换后的数据作为对读取请求的响应而返回。
[0162]
在一些实施方式中,可以以其他方式来读取先前经由生物材料的合成而编码的数据。例如,在一些实施方式中,如果要写成对应于4,096个孔630的文件,而不是识别4,096个孔630以将其写成,则控制器可以识别4,096个孔630,然后在那些孔630不形成连续序列的情况下用与所述文件对应的多个位置来更新索引。作为另一实例,在一些实施方式中,系统控制器120可以将孔630分组在一起(例如分成128个孔630的组),而不是识别单个孔630,从而减少与存储位置数据相关联的运营成本(即通过将每个孔630一个地址的寻址要求减少至每组孔630一个地址)。作为另一个实例,在存储反映孔630位置的数据的实施方式(其中dna链或其他多核苷酸已被合成)中,可以以各种方式(例如序列标识符(例如孔1、孔2、孔3等)或坐标(例如阵列中孔位置的x和y坐标))存储该数据。
[0163]
作为另一个实例,在一些实施方式中,可以从其他位置读取链650,而不是从其中
合成了链的孔630中读取链650。例如,链650可以被合成以包括地址,然后从孔630中切下并存储在管中以用于以后的检索,在此期间,所包括的地址信息可以用于识别对应于特定文件的链650。作为另一个说明性实例,可使用聚合酶将链650从表面复制,然后洗脱并存储在管中。或者,可通过使用与dna链或其他多核苷酸杂交的生物素化的寡核苷酸并捕获在分配在孔630中的链霉亲和素珠上的延伸产物来将链650复制至珠子上。基于本公开,其他实例也是可能的并且对于本领域技术人员而言将是显而易见的。因此,以上关于检索通过生物材料的合成编码的数据的描述应被理解为仅是示例性的,不应被视为限制。
[0164]
本文所述的实施方式可将聚合物涂层(例如2015年4月21日公布的名称为“多聚物涂层”的美国专利号9,012,022中所述的多聚物涂层(其全部内容通过引用并入本文))用于流动池的表面。本文所述的实施方式可利用一种或多种具有可检测标记和可切割的接头的标记核苷酸(例如2008年8月19日公布的名称为“标记的核苷酸链”的美国专利号7,414,116中所述的那些(其全部内容通过引用并入本文))。例如,本文所述的实施方式可利用可切割的接头,所述可切割的接头可通过与具有荧光团作为可检测标记的水溶性膦或水溶性含过渡金属的催化剂接触而切割。本文所述的实施方式可使用双通道检测方法来检测多核苷酸的核苷酸,例如2016年9月27日公布的名称为“用于核酸测序的方法和组合物”的美国专利号9,453,258中所述的,其全部内容通过引用并入本文中。例如,本文描述的实施方式可以利用基于荧光的sbs方法,其具有在第一通道中检测到的第一核苷酸类型(例如具有在被第一激发波长激发时在第一通道中检测到的标记物的datp),在第二通道中检测到的第二核苷酸类型(例如具有在被第二激发波长激发时在第二通道中检测到的标记物的dctp),在第一通道和第二通道两者中均检测到的第三核苷酸类型(例如具有在被第一激发波长和/或第二激发波长激发时在两个通道中均检测到的至少一个标记物的dttp),缺少在任一通道中没有检测到或只微弱检测到的标记物的第四核苷酸类型(例如没有标记物的dgtp)。可以根据2014年12月9日公布的名称为“用于生物或化学分析的生物传感器及其系统和方法”的美国专利号8,906,320(其全部内容通过引用并入本文中)、2016年12月6日公布的名为“凝胶图案表面”的美国专利号9,512,422(其全部内容通过引用并入本文中)、2019年4月9日公布的名称为“用于生物或化学分析的生物传感器及其制造方法”的美国专利号10,254,225(其全部内容通过引用并入本文中)和/或2018年5月3日公布的名称为“盒组件”的美国专利号2018/0117587(其全部内容通过引用并入本文中)种描述的一种或多种教导来构建本文所述的盒和/或流动池的实施方式。
[0165]
vii.使用sbs流动池进行信息存储和检索,并使用具有写功能的sbs流动池创建长dna序列
[0166]
因为可用dna来存储各种生物和非生物信息,所以可用sbs系统和工艺来促进至或来自在此类系统和工艺中使用的流动池中的基于dna的信息的写入和读取。因此,使用sbs系统、装置和工艺来分类和存储基于dna的信息并在需要时用其检索这种信息可能是有益的。
[0167]
如前文指出的,可以生成“机器写入的dna”以索引或以其他方式跟踪先前存在的dna,从而以任何合适的目的存储来自任何其他来源的数据或信息,而无需将中间数据转换成二进制代码的中间转换。同样如前文指出的,尽管sbs工艺的某些方面也可以用于将某些索引的、分类的或其他的组织信息写入dna序列或其他多核苷酸序列中,但是一些实施方式
利用合成测序(sbs)来实现读取功能。通常,sbs工艺基于可逆的染料终止子,所述可逆的染料终止子在被引入至合成的多核苷酸中时可以识别单个碱基。sbs可用于全基因组和区域测序、转录组分析、宏基因组学、小rna发现、甲基化分析和全基因组蛋白质
‑
核酸相互作用分析。更具体地,sbs使用四个荧光标记的核苷酸以大规模平行的方式对流动池表面上的数千万个簇进行测序。在每个测序周期中,将单个标记的脱氧核糖核苷三磷酸(dntp)添加至核酸链。核苷酸标记物用作聚合反应的“可逆终止剂”。在掺入dntp后,可通过激光激发和成像等方法识别标记物(例如荧光染料),然后酶切,以进行下一轮掺入。在每个周期内直接从信号强度测量中进行碱基检出(base call)。sbs工作流程/工艺可包括以下内容:(i)样品制备;(ii)簇生成;(iii)测序;(iv)数据分析。
[0168]
在样品(或文库)制备过程中,通过dna或cdna样品的片段化来制备测序文库,然后将其提取并纯化。dna纯化后,该工艺的第一部分是“标签化”,在此过程中,转座酶用于将纯化的dna切成短片段(其被称为插入片段或标签)。然后将衔接子(5'和3')连接至切割点的任一侧,将尚未连接衔接子的多核苷酸洗掉。将衔接子连接至标签后,可使用减少的循环扩增来添加其他基序,例如测序引物结合位点、索引、条形码和与附接至流动池的寡核苷酸互补的区域(末端序列),以及在扩增、测序和分析过程中充当参照点的其他种类的分子修饰。索引和/或条形码是连接至测序文库中片段的独特多核苷酸序列,用于下游计算机分类和识别。在序列分析过程中,计算机将所有具有相同索引的读取分组在一起。索引通常是衔接子或pcr引物的组分,并在测序文库制备阶段被连接至文库片段。这样的索引通常在8
‑
12bp之间。具有独特索引的文库可以汇集在一起,加载至测序流动池的一个泳道中,并在同一运行中进行测序。随后使用生物信息学软件对读取进行识别和分类。该方法称为“多重(multiplex)”。
[0169]
成簇是一个方法,其中每个dna片段以等温方式局部扩增。在簇生成过程中,将片段化的dna文库加载至流动池中,该流动池是载玻片,其中包含一个或多个dna流过的泳道。流动池的每个泳道都可以覆盖两种类型的与文库衔接子互补的表面结合寡核苷酸(例如p5/p7或p6/p8),并且dna库的片段被这些寡核苷酸捕获。通过表面上的两种类型的寡核苷酸中的第一种(例如p5或p6)产生杂交。该寡核苷酸与dna片段之一上的衔接子区域互补,因此结合dna片段。然后将dna聚合酶用于产生杂交dna片段的互补。使新形成的双链dna分子变性,并洗去原始模板。然后通过桥扩增方法克隆扩增剩余的多核苷酸,在此过程中每个多核苷酸折叠并且其衔接子区域与流动池上的第二种类型的寡核苷酸杂交(例如p7或p8)。然后将dna聚合酶用于产生互补链,形成双链桥。然后使该桥变性,从而使分子的两个单链拷贝系链(tethered)在流动池中。然后,该方法反复进行,并针对数百万个簇同时发生,从而导致dna文库中所有片段的克隆扩增。桥扩增后,将反向链切割并洗掉,仅留下正链。然后将这些链的3'端封闭,以防止不必要的引发。成簇过程可发生在自动流动池仪器中或使用测序仪器内的机载簇生成构件。每个簇可以被定义为结合至流动池表面的模板dna的克隆分组。如所述,每个簇由单个模板多核苷酸接种,并通过桥扩增进行克隆扩增,直到簇具有约1000个拷贝。流动池上的每个簇产生单个测序读取。例如,流动池上的10,000个簇可产生10,000个单个读取和20,000个配对的末端读取。簇生成完成后,dna模板即可用于测序。
[0170]
测序从第一测序引物的延伸开始以产生第一读取。在每个循环中,四个核苷酸(dntp)竞争至生长链的添加。四个核苷酸中的一个或多个可以包含要识别的标记物或标
签。根据模板dna的序列,每个多核苷酸一次只能掺入一个dntp。在一些实施方式中,在添加每个核苷酸后,簇被光源激发,并且响应于激发光源,经由标记物发射荧光信号。此方法称为合成测序法或sbs。循环数决定了读取的长度。发射波长以及信号强度决定了碱基检出。对于给定的簇,同时读取所有相同的链。在流动池上以大规模并行方法对亿万个簇进行测序。第一次读取完成后,将读取的产品冲洗掉。在此方法的这一部分中,将索引1(index 1)读取引物引入并杂交至模板。读取以类似于第一次读取的方式生成。在完成索引读取后,将读取的产物洗去并将模板的3’末端去保护。然后,模板折叠并结合流动池上的第二个寡核苷酸。以与索引1相同的方式读取索引2。在此方法的这一部分完成后,将索引2的读取产品冲洗掉。聚合酶延伸第二个流动池寡核苷酸,形成双链桥。该双链dna被线性化并且3’末端被封闭。最初的正向链被切割并洗掉,仅留下反向链。读取二开始于读取二测序引物的引入。与读取一序列一样,重复该方法的测序部分,直到获得所需的读取长度为止。然后将读取的两个产物洗掉。整个过程会产生数百万个读取,代表测序文库中的所有片段。由于测序方法使用基于可逆终止子的方法,该方法可在将单个碱基引入dna模板链时检测单个碱基,并且由于在每个测序周期中均存在所有四个可逆终止子结合的dntp,因此自然竞争可最大程度地降低引入偏差并大大减少原始错误率。结果是高精度的逐个碱基测序,即使在重复序列区域和均聚物中,也几乎消除了序列背景特定的错误。
[0171]
一些实施方式提供了合成长度高达2000个碱基对(bp)或更长的核酸序列的方法。使用本文所述的多核苷酸写入方法和装置的这种合成通过同时平行写入多个较小的多核苷酸链来写入单个长多核苷酸,然后使用平行的较小的多核苷酸的反向互补核苷酸将链偶联在一起。这样的长多核苷酸可用于存储大量数据,合成大基因或其他长多核苷酸。
[0172]
为了允许更长序列的合成,使用了流动池的多个离散点(例如离散反应孔)。为了写入更长的dna链,可以为两个不同的较小的多核苷酸写一个“连接序列”,当一个或两个较小的多核苷酸被延伸时,允许将两个不同的较小的多核苷酸组装成较大的多核苷酸。在一些实施方式中,例如出于数据存储目的,连接序列可以是均聚物(例如单个核苷酸的预先确定序列(例如ttttttt)),并且可以使用对应的反向互补均聚物(例如反向互补核苷酸的预先确定序列(例如aaaaaaa)),而不会影响较小的多核苷酸序列中写入数据的完整性。在不同于感兴趣的dna序列的预先确定序列可能影响所得多核苷酸(例如用于基因合成)的实施方式中,所述连接序列可以是不引入非内源或人工序列的序列(可以与均聚物一起引入)。例如,可以选择连接序列作为待写入的合成多核苷酸的预先确定核苷酸序列。也就是说,例如,如果第一写入的多核苷酸具有对应的atcgtgtgactcga序列,则可以选择该序列的较小子集(例如ctcga)作为连接序列,从而可以将反向互补序列(例如gagct)写入作为第二多核苷酸的序列的一部分,使得连接序列不会将非内源性或人工序列引入较大的合成多核苷酸中。
[0173]
可以将包含第一序列的第一多核苷酸写在流动池的第一孔中或第一预先确定位置处,并将包含第二序列的第二多核苷酸写在流动池的第二孔或第二预先确定位置处。在一些实施方式中,第一多核苷酸和第二多核苷酸可以基本同时、在时间上偏移和/或在不同时间写入。第一多核苷酸和第二多核苷酸可以通过各自的第一连接序列杂交。可以例如通过dna聚合酶延伸杂交的第一多核苷酸和第二多核苷酸以产生与第一多核苷酸和/或第二多核苷酸中的每一个互补的链,从而产生包含第一多核苷酸和第二多核苷酸的第一序列和
第二序列的第三多核苷酸。
[0174]
可将包含第三序列的第四多核苷酸写在流动池的第三孔中或其第三预先确定位置处。在一些实施方式中,第四多核苷酸可与第一多核苷酸和/或第二多核苷酸基本同时、在时间上偏移和/或在不同的时间写入。第四多核苷酸和第三多核苷酸可以通过各自的第二连接序列杂交。可以例如通过dna聚合酶延伸杂交的第四多核苷酸和第三多核苷酸以产生与第四多核苷酸和/或第三多核苷酸中的每一个互补的链,从而产生包含第四多核苷酸和第三多核苷酸的第一序列、第二序列和第三序列的第五多核苷酸。
[0175]
可以重复上述方法作为迭代方法,其中使用两个或更多个相邻的孔来写入多核苷酸序列,使写入的多核苷酸序列杂交,并延伸杂交的序列以构建多达2000个碱基对的或更大的多核苷酸。这些长序列可以代表旨在编码或包含生物学或非生物学信息的长基因、小基因组或其他遗传构建体。为了使多核苷酸在两个或更多个孔之间杂交,孔之间的间隙可以为约100nm。在一些实施方式中,孔之间的间隙可以大于100nm(例如200nm、300nm、400nm、500nm),或者孔之间的间隙可以小于100nm(例如90nm、80nm、70nm、60nm、50nm、40nm、30nm、20nm、10nm)。在本文中,孔是具有特定面积的反应室。在一些实施方式中,孔也可以对应于离散的成像区域,使用于多核苷酸的孔可以用于写入多核苷酸和读取多核苷酸的序列。
[0176]
如下所述,可以通过在杂交之前读取每个多核苷酸来进行质量控制方法。在读取和/或写入的过程中,可能会发生“定相(phasing)”和/或“预定相”,并将错误引入所得的写入多核苷酸或读取序列中。“定相”是指例如通过与尚未从流动池中冲洗掉的残余试剂的相互作用而无意中去除了第一个掺入的核苷酸的可逆终止子,并掺入了第二个核苷酸的情况。在写入过程中,这可能导致为多核苷酸的特定dna序列写入两个核苷酸,而不是单个核苷酸。在读取过程中,这可能导致未检测到与第一个核苷酸相关联的荧光团,从而通过跳过一个核苷酸来偏离(offseting)读取序列。“预定相”是指未引入核苷酸的情况。在写入过程中,这可能导致没有核苷酸被写入多核苷酸的序列中。在读取过程中,这可能导致不会检测到与该序列的核苷酸相关联的荧光团或与先前检测到的核苷酸相关联的荧光团再次被检测到,从而通过滞后或重复读取一个核苷酸来偏离读取序列。由于合成大碱基对多核苷酸(例如那些大于1000个碱基对或大于2000个碱基对的多核苷酸)可能会很耗时,因此在要杂交以形成更大碱基对多核苷酸的较小多核苷酸上实施质量控制方法可在多核苷酸写入过程中更快地检测错误,而不合成可能包含一个或多个错误的完整多核苷酸。在一些实施方式中,第一多核苷酸和/或第二多核苷酸可以在写入之后或在写入过程中进行测序,例如通过使具有一个或多个标记物或标签的dntp流动以对写入的第一多核苷酸和/或第二多核苷酸或其部分进行测序。因此,可以通过合成测序方法来确定在将第一多核苷酸和第二多核苷酸杂交在一起之前,在第一和/或第二多核苷酸的写入过程中是否发生了错误。
[0177]
在数据分析和比对期间,基于在样品制备期间引入的独特索引来分离来自合并的样品文库的序列。对于每个样品,具有相似碱基检出串(stretch)的读取在局部成簇。一次对数百万个簇进行测序,并且如前所述,每个簇具有大约1000个相同的dna插入拷贝。序列“读取”通常是指对应于样品dna或rna的a、t、c和g碱基的数据串。配对正向和反向读取可创建连续序列(称为“重叠群(contig)”),将其与参考基因组比对以进行变体识别。参照基因组是完全测序和组装的基因组,其充当支架,针对该支架对新序列进行比对并比较。配对末端信息用于解决歧义比对。比对后,分析的许多变化(例如单核苷酸多态性(snp)或插入缺
失(indel)识别、rna方法的读取计数、系统发育或宏基因组学分析)都是可能的。
[0178]
在一些实施方式中,其中条形码用于识别或分类文库dna样品或其他样品类型,该条形码可以是空间条形码或非空间条形码。空间条形码的一个实例可以是十个不同的患者生成十个不同的样品。可以离散方式将来自患者1的dna片段条形码标记为1,将来自患者2的dna片段条形码标记为2,依此类推,直至患者10为止。在这种情况下,非空间条形码可能涉及混合10位患者的dna片段,然后将这些片段以随机或超随机格式接种至流动池中(也会从中读取)。空间条形码还可以指文库样品在流动池上的定位,其中来自患者1(或来自相同来源)的每个dna片段都位于流动池上高度局部化的空间预先定义区域(例如通道)上。然后可以使用特定条形码的检索来识别从中检索数据的流动池的特定区域。这种条形码基本上是一种可用于多种目的的分组或编录方法。已知的是,可以使用这种条形码化或索引方法来重新组装先前写入的序列,并且基本上可以以这种方式对任何类型的数据进行空间编码。例如,某些信息的空间条形码或空间写入可用于重建长基因或重建基因组,其中小dna片段的空间排列或位置将驱动基因组的自组装或非常长的基因片段的组装。
[0179]
通常不会从索引或条形码中提取未知信息,而是将索引和条形码用于将标记单向分配给簇的特定池。固定在流动池上的初始引物也可包含条形码序列。例如,引物序列可包含产生独特分子索引的固定条形码或随机序列,该独特分子索引可用于追踪或定位作为序列存储的数据。
[0180]
也可用条形码(索引)来改进对存储数据的检索。例如,当写入数据时,可以分配条形码位置以进行跟踪。可以在写的过程期间在预先确定间隔处插入条形码。例如,在最初的文库接种和扩增后,可以将选定的核苷酸按序引入流动池中以引入用作条形码的非天然序列。该条形码可在读取过程中进一步用于显示dna链“匹配”的位置,并可进行比对以对作为序列存储的数据进行解码。
[0181]
还可以使用实时样品索引将信息写至流动池中或从流动池中读取信息。这种类型的索引包括出于各种组织目的或其他功能,将已知或特定序列写在流动池上。参考图11,通过将感兴趣的序列写在流动池上来创建“捕获探针”。该感兴趣的序列可以代表与特定疾病或特定生物学问题密切相关联的特定外显子或扩增子。在已经嫁接至流动池上的p5引物上,可以添加许多胸腺嘧啶(poly t),这样,流入流动池的具有腺嘌呤(a)尾巴的mrna就会与捕获探针杂交。发生此结合事件后,cdna合成可用于拷贝与流动池结合的特定区域(或目标区域)。可将p7'引物加至每个结合序列的末端以完成样品文库的制备。准备样品文库,捕获感兴趣的文库,然后将衔接子连接到捕获的文库序列上的方法称为“写下(writing down)”序列。衔接子的连接将创建之后簇生成所需的复合物。参考图11,通常将p7'衔接子连接至捕获的文库分子的未结合末端,并且在该过程的该连接部分处,可以将另外的序列数据写至捕获的链上。本质上,此方法在创建样品文库的过程中同时添加了p5和p7两者,从而可以在克隆扩增之前在流动池上操纵文库dna片段,这是sbs方法的重要组成部分。
[0182]
图12描绘了用于在流动池上存储生物学信息的另一种方法。在该图中,在流动池(例如预先分配的像素)上以预先确定的空间图案布置和写成独特的或不同的索引或条形码。所述索引或条形码可以是已知序列,或者它们可以是随机产生的寡核苷酸。每个索引或条形码用于捕获来自组织样品的不同部分的dna分子,每个像素记录一个可以从流动池中读取的非常局部的捕获事件。术语空间转录组学可用于描述此方法,因为在整个组织中存
在不同的表达模式,或者例如,提供了有关细胞功能和存在状态的的不同信息的位于细胞(例如长神经元细胞)不同部分中的rna的位置。
[0183]
参考图13,使用sbs流动池等的数据存储和检索可涉及某些分子安全措施的使用,这在感兴趣的信息包括患者数据时尤其重要。如图13所示,将特定序列锚定至流动池上的特定像素或图块,然后将分子或纳米粒子(例如“魔术墨水”)附接至该序列上以创建仅可用已知密钥解密的光学签名或数字签名。如果没有用于访问数据的签名或特定“密钥”,就无法访问存储在流动池中的数据。
[0184]
图14描绘了在流动池上进行样品索引的另一种方法。在这种方法中,提供了具有p5和p7引物的流动池。p5引物具有以下序列:5'
‑
aatgatacggcgaccga
‑
3',p7引物具有以下序列:5'
‑
caagcagaagacggcatacgagat
‑
3'。该方法的第1轮包括在p5引物上接种文库,延伸文库序列,然后将腺嘌呤(a)写在每个序列的未结合末端上。该方法的第2轮包括将第二批文库接种在引物上,延伸文库序列,然后将胸腺嘧啶(t)写在每个新序列的末端上并将其写至已在之前写入a的每一个序列的末端上。依次使用胞嘧啶(c)和鸟嘌呤(g)继续此方法,直到创建如图所示的完全索引的文库为止。最后,将p7'序列写在每个序列的末端以允许簇的生成。
[0185]
关于p5/p7引物和p6/p8引物的使用,同时操作两种不同类型的引物组允许感兴趣的分子的拷贝数呈指数增加。两种引物组的使用允许创建两个不同的文库,从而在流动池上创建两种不同类型的簇。这种方法允许从单个像素和单个流动池获得更多信息。图15描绘了在单个流动池上使用p5/p7引物和p6/p8引物的方法。在制备流动池时,提供了既具有反应孔又具有孔之间间隙空间的流动池。每个反应孔都包含pazam聚合物,并且间隙空间已被硅烷化或进行了其他预处理。然后,将起始引物接种至硅烷化的间隙区域,然后将p6/p8引物写至其上。接下来,将p5/p7引物嫁接至反应孔中。接下来,将样品文库接种至两组引物对上。将p5/p7序列线性化以读取在反应孔中发生的簇,并且将p6/p8序列线性化以读取在间隙区域中发生的簇,从而允许基于所使用的引物组对数据进行的区分。
[0186]
图16描绘了使用相邻分子的连接在流动池上进行样品索引的另一种方法。在这种方法中,提供了具有p5和p7引物的流动池。该方法的第一部分包括接种p5'文库、扩增序列和将腺嘌呤(a)写在每个序列的未结合末端上。该方法的第二部分包括接种p7'文库、扩增序列和将胸腺嘧啶(t)/腺嘌呤(a)
‑
tatat序列写在每个序列的未结合末端上。在步骤(iii)中,在连接杂交之后,执行amsi延伸。连接两个相邻的文库以形成具有用于成簇的p5
‑
p7'和p7
‑
p5'两者的化合物文库。如果相邻dna分子具有互补序列,则可以使用其他序列。例如,一个序列可以是atgagcta,而反向互补序列可以是tagctcat。
[0187]
图17提供了根据前述方法实施方式合成的多核苷酸,例如dna分子的图。在所示的特定实施方式中,为第一多核苷酸(以p5为根)写入均聚物a的连接序列,为第二多核苷酸(以p7为根)写入均聚物t的反向互补连接序列。然后可以使用连接序列和反向互补连接序列将第一多核苷酸和第二多核苷酸杂交在一起。在一些实施方式中,例如用于多核苷酸中的数据存储,均聚物可以在读出过程中被忽略和/或可以用于检查在读出过程中是否发生了错误。也就是说,例如,如果在均聚物之前写入的多核苷酸具有预先确定长度(例如150个碱基对)并且所得的测序在149个或更少的碱基对之后或151个或更多的碱基对之后遇到均聚物,则可检测到错误,并可实施新的读出方法以重新读取数据和/或以其他方式缓解(例
如通过利用来自备用孔的镜像多核苷酸链)。
[0188]
尽管均聚物可用于数据存储或非内源或人工序列不会影响所得多核苷酸的其他实施方式,但在其他实施方式(例如基因合成)中,此类非内源或人工序列可改变或使所得多核苷酸对预期目的无效。因此,连接序列可以替代地是针对第一多核苷酸和第二多核苷酸两者要被写入的序列的子集。即连接序列将是已经是正被生成的基因的多核苷酸的一部分的互补序列。该实施方式的应用包括:(i)创建长dna片段作为分析或校准工具;(ii)写入一组长数百个碱基的长的捕获全部(catch
‑
all)的寡核苷酸以用于病原体筛查面板(panel),以从血样中检测病原体;(iii)快速制作自定义面板以读取传入的病原体,并使用可用于干扰体内病原体的功能的基于dna的疫苗或自发转化(从dna的的rna复制)创建治疗方案。换句话说,该实施方式可以提供筛查/诊断工具,该筛查/诊断工具也可以成为快速治疗工具。在图17中,p5引物具有以下序列:5'
‑
aatgatacggcgaccga
‑
3',并且p7引物具有以下序列:5'
‑
caagcagaagacggcatacgagat
‑
3'。
[0189]
当进行测序时,例如使用具有光电二极管的cmos测序芯片,或者将物镜与具有光电二极管的图像传感器一起使用,图像校正技术(例如,对不同像素之间的图像光学或光谱串扰进行校正),可以实施物镜的条纹失真、几何失真和/或其他错误。校正方法可能从一个芯片到另一个芯片和/或从一个仪器到另一芯片有所不同。本文描述的多核苷酸合成方法的一种实施方式是产生具有多样性的空间控制的在流动池上的训练数据集,其用于碱基检出训练数据,特别是用于光学系统。即可以将已知多核苷酸序列的流动池上的组写在不同的孔中,使得所得序列均为已知。因此,当执行读取方法时,使用带有光电二极管的cmos芯片或带有物镜的图像传感器,可以对cmos芯片和/或图像传感器产生的原始输出数据进行校准和/或可以根据在不同的孔位置的已知的不同序列确定对应的图像校正。例如,较小节距的流动池可能在每个孔附近具有变形,可以根据流动池上多核苷酸的已知校准序列对其进行校正。所述校正方法可以包括基于在校准流动池上写入多核苷酸的多个预先确定序列的机载质量控制系统。所述方法可以基于已知真值或真值表的创建来提供单独的像素串扰校正和/或成像图块校正。可以将已知序列写在流动池上的预先确定空间处,以同步测序仪和/或可能的随机访问。所述方法还可以允许现场校准(例如,可以在多个孔处写入预先确定序列,然后进行测序,并且可以基于所读出的序列和/或原始数据与已知预先确定序列之间的任何确定的误差来计算校正系数。)。
[0190]
viii.其他
[0191]
所有参考文献,包括专利、专利申请和文章,其全部内容均通过引用并入本文中。
[0192]
提供前述描述以使本领域技术人员能够实施本文描述的各种配置。尽管已经参考各种附图和配置而具体描述了本主题技术,但是应当理解,这些仅是出于说明的目的,而不应被视为对本主题技术范围的限制。
[0193]
本申请中提及的所有申请、专利和公开内容(包括附录)的全部内容均通过引用并入。
[0194]
如本文中所使用的,以单数形式叙述并且以单词“一种/一个(a/an)”开始的元件或步骤应被理解为不排除多个所述元件或步骤,除非明确地指出了相反情况。此外,对“一个实施方式”的引用无意被理解为排除也包含所述特征的其他实施方式的存在。此外,除非有明确的相反说明,否则“包括(comprisng)”或“具有(having)”具有特定属性的一个或多
个元件的实施方式可以包含其他元件,无论它们是否具有该属性。
[0195]
在整个说明书中使用的术语“基本上”和“大约”用于描述和解释小的波动,例如由于处理中的变化而引起的波动。例如,它们可以指小于或等于
±
5%,例如小于或等于
±
2%,例如小于或等于
±
1%,例如小于或等于
±
0.5%,例如小于或等于
±
0.2%,例如小于或等于
±
0.1%,例如小于或等于
±
0.05%。
[0196]
可以有许多其他方式来实现本主题技术。在不脱离本主题技术的范围的情况下,本文所描述的各种功能和元件可以与所示出的功能和元件不同地划分。对这些实施方式的各种修改对于本领域技术人员而言是显而易见的,并且本文中定义的一般原理可以应用于其他实施方式。因此,本领域普通技术人员可以对本技术进行多种改变和修改,而不脱离本技术的范围。例如,可以采用不同数量的给定模块或单元,可以采用不同类型的给定模块或单元,可以添加给定模块或单元,或者可以省略给定模块或单元。
[0197]
带下划线和/或斜体的标题和副标题仅是为了方便起见,不限制主题技术,并且不在解释主题技术时被提及。本领域普通技术人员已知或以后将知晓的贯穿本公开描述的各种实施方式的元件的所有结构和功能等同物均通过引用明确地并入本文中,并且意在被本主题技术涵盖。此外,无论在上文的描述中是否明确叙述了这种公开,本文公开的任何内容都不旨在捐献给公众。
[0198]
应当理解,前述概念和下面更详细讨论的其他概念的所有组合(假设这样的概念不相互矛盾)被认为是本文公开的发明主题的一部分。特别地,出现在本公开的结尾处的要求保护的主题的所有组合被认为是本文公开的发明主题的一部分。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1