车内交流辅助系统的制作方法
1.本发明涉及对基于车内的讲话的交流进行辅助的技术。
背景技术:
2.作为辅助基于车内的讲话的交流的技术,已知有如下技术:利用麦克风对就座于汽车的第一座位上的用户的讲话声音进行拾音,将为了使第二座位上的用户能够清楚地听到而调整了增益后的讲话声音与音频装置输出的音乐等输出音合成,并从扬声器输出(例如,专利文献1)。
3.另外,还已知有如下麦克风阵列的技术:通过将多个麦克风的输出以目标音的相位一致的方式调整延迟时间并进行合成,由此使多个麦克风作为高指向性的麦克风发挥功能,提高目标音的sn比(例如,专利文献2)。
4.此外,还已知有如下技术:使用滤波器将由配置在第一位置的麦克风拾音到的目标音变换为当麦克风配置在第二位置的情况下所拾音的目标音(例如,专利文献3)。
5.在此,在该技术中,事先在第二位置实际配置麦克风,使用自适应滤波器求出配置在第一位置的麦克风的输出与配置在第二位置的麦克风的输出之差为最小的传递函数,并设定为上述滤波器的传递函数。
6.[现有技术文献]
[0007]
[专利文献]
[0008]
[专利文献1]日本特开2002-51392号公报
[0009]
[专利文献2]日本特开平11-234790号公报
[0010]
[专利文献3]日本特开2001-142469号公报
技术实现要素:
[0011]
根据上述的对基于车内的讲话的交流进行辅助的技术,若从扬声器输出的音频装置的输出声音被拾音并被混入到麦克风的输出中,则第一座位的用户的讲话声音的sn比降低,第二座位的用户难以听取讲话声音。另外,由于从扬声器输出蔓延到麦克风的音频装置的输出音的延迟音,所以混响变多,车内整体成为饱和的听觉。
[0012]
这样的问题可以通过使用高指向性的麦克风,以良好的sn比对第一座位的用户的讲话声音进行拾音来减轻。
[0013]
但是,由于高指向性的麦克风一般比较大型且具备特殊的形状,因此产生设计上的限制或向汽车组装上的问题。另一方面,使用麦克风阵列来实现高指向性的麦克风,会产生因麦克风的数量增加而导致的成本增加、处理负荷增大,效率并不高。
[0014]
因此,本发明的技术问题在于,在通过麦克风对用户的讲话声音进行拾音并从扬声器向其他用户输出的车内交流辅助系统中,以比较高效的结构来提高从扬声器输出的讲话声音的sn比。
[0015]
为了实现上述目的,本发明提供一种车内交流辅助系统,该车内交流辅助系统安
装在汽车上,该汽车具有左右排列的座位即第一座位和第二座位、以及与所述第一座位和所述第二座位在前后方向上排列的座位即第三座位,在所述车内交流辅助系统中,设置有:第一麦克风,是配置在所述第一座位附近的麦克风;第二麦克风,是配置在所述第二座位附近的麦克风;扬声器,朝向所述第三座位输出声音;以及信号处理部,使用所述第一麦克风的输出和所述第二麦克风的输出,生成向所述扬声器输出的所述第一座位的用户的讲话声音和所述第二座位的用户的讲话声音。在此,所述信号处理部将以所述第一座位的用户的讲话位置为音源位置的声音作为第一座声音,所述信号处理部具备第一滤波器,该第一滤波器将由所述第二麦克风拾音到的第一座声音变换为由位于比所述第二麦克风更靠近所述第一座位的位置的虚拟的麦克风即第一座虚拟麦克风拾音到的第一座声音并输出,所述信号处理部使用所述第一麦克风的输出和所述第一滤波器的输出,生成由所述第一麦克风和所述第一座虚拟麦克风构成的、虚拟麦克风阵列的输出作为向所述扬声器输出的所述第一座位的用户的讲话声音,所述虚拟麦克风阵列与所述第一麦克风相比,提高了向所述第一座位的用户的讲话位置的指向性。
[0016]
另外,为了实现上述技术问题,本发明提供一种车内交流辅助系统,该车内交流辅助系统安装在汽车上,该汽车具有左右排列的座位即第一座位和第二座位、以及与所述第一座位和所述第二座位在前后方向上排列的座位即第三座位,在车内交流辅助系统中具备:第一麦克风,是配置在所述第一座位附近的麦克风;第二麦克风,是配置在所述第二座位附近的麦克风;扬声器,朝向所述第三座位输出声音;以及信号处理部,使用所述第一麦克风的输出和所述第二麦克风的输出,生成向所述扬声器输出的所述第一座位的用户的讲话声音和所述第二座位的用户的讲话声音。在此,所述信号处理部将以所述第一座位的用户的讲话位置为音源位置的声音作为第一座声音,所述信号处理部具备:第一滤波器,将由所述第二麦克风拾音到的第一座声音变换为由位于比所述第二麦克风更靠近所述第一座位的位置的虚拟的麦克风即第一座虚拟麦克风拾音到的第一座声音并输出;第二滤波器,从所述第一滤波器的输出中提取第一座声音的分量并输出;延迟部,使所述第一麦克风的输出延迟并输出;第三滤波器,从所述延迟部的输出中提取第一座声音的分量并输出;以及加法部,将所述第二滤波器的输出和所述第三滤波器的输出相加,生成向所述扬声器输出的所述第一座位的用户的讲话声音,所述延迟部使所述第一麦克风的输出延迟,以使所述第二滤波器输出的第一座声音的分量与所述第三滤波器输出的第一座声音的分量的延迟时间一致。
[0017]
在此,所述第一滤波器的传递函数例如事先通过如下处理来设定:一边从所述第一座位的用户的讲话位置输出规定的调谐用声音,一边由在所述第一座虚拟麦克风的位置配置的麦克风即第三麦克风进行拾音,将以第二麦克风的输出为输入的第一自适应滤波器的输出与延迟了规定时间后的所述第三麦克风的输出之间的差分作为误差,使该第一自适应滤波器进行自适应动作,并将收敛后的所述第一自适应滤波器的传递函数作为所述第一滤波器的传递函数。
[0018]
另外,所述第二滤波器的传递函数和所述第三滤波器的传递函数例如事先通过如下处理来设定:一边从所述第一座位的用户的讲话位置输出规定的调谐用声音,一边将以所述第一滤波器的输出为输入的第二自适应滤波器的输出与延迟了规定时间后的所述第一麦克风的输出之间的差分作为误差,进行该第二自适应滤波器的自适应动作,并将收敛
后的第二自适应滤波器的传递函数作为第二滤波器的传递函数,将第三自适应滤波器的输出与所述第一滤波器的输出之间的差分作为误差,进行该第三自适应滤波器的自适应动作,并将收敛后的所述第三自适应滤波器的传递函数作为所述第三滤波器的传递函数,所述第三自适应滤波器以延迟了所述规定时间后的所述第一麦克风的输出为输入。
[0019]
另外,以上的车内交流辅助系统也可以将所述第一麦克风配置在从所述第一座位的左右方向的中央向与所述第二座位相反的方向偏离了规定距离的位置,所述第一座虚拟麦克风的位置设为从所述第一座位的左右方向的中央向所述第二座位的方向偏离了所述规定距离的位置。
[0020]
另外,以上的车内交流辅助系统也可以具备朝向所述第三座输出音频内容的声音的音频装置。
[0021]
根据这样的车内交流辅助系统,通过不追加第一座位用的麦克风而利用为了第二座位用而设置的第二麦克风这一高效的结构,能够提高向第一座位的用户的讲话位置方向的指向性,提高从扬声器输出的第一座位的用户的讲话声音的sn比。另外,由于信号处理部的各滤波器的传递函数是固定的,所以处理负荷的增大也得到抑制。
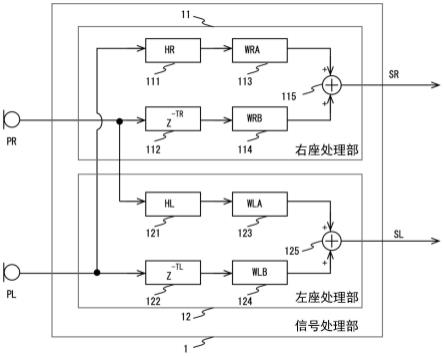
[0022]
发明的效果
[0023]
如上所述,根据本发明,在通过麦克风将用户的讲话声音拾音并从扬声器朝向其他用户输出的车内交流辅助系统中,能够以比较高效的结构提高从扬声器输出的讲话声音的sn比。
附图说明
[0024]
图1是表示本发明的实施方式的车内交流辅助系统的结构的框图。
[0025]
图2是表示本发明的实施方式的车内交流辅助系统的扬声器和麦克风的配置的图。
[0026]
图3是表示本发明的实施方式的信号处理部的结构的框图。
[0027]
图4是表示本发明的实施方式的第一阶段调谐的结构的框图。
[0028]
图5是表示本发明的实施方式的学习用麦克风和学习用扬声器的配置的图。
[0029]
图6是表示本发明的实施方式的第二阶段调谐的结构的框图。
具体实施方式
[0030]
以下,对本发明的实施方式进行说明。
[0031]
图1表示本实施方式的车内交流辅助系统的结构。
[0032]
车内交流辅助系统是搭载在汽车上的系统,如图所示,具有右前座麦克风pr、左前座麦克风pl、信号处理部1、音频装置2、合成处理部3、控制部4、扬声器sp。
[0033]
如图2的a1、a2所示,右前座麦克风pr配置在汽车的右前座的脚踏板(footrest)的右侧,以对就座于右前座的用户的讲话声音进行拾音,左前座麦克风pl配置在汽车的左前座的脚踏板的左侧,以对就座于左前座的用户的讲话声音进行拾音。
[0034]
另外,扬声器sp以朝向就座于后座的用户放射声音的方式配置在后座附近。
[0035]
信号处理部1根据右前座麦克风pr的输出和左前座麦克风pl的输出,生成右前座讲话声音信号sr和左前座讲话声音信号sl,并将所生成的右前座讲话声音信号sr和左前座
讲话声音信号sl输出到合成处理单元3,其中,右前座讲话声音信号sr以高于右前座麦克风pr的sn比来表示右前座的用户的讲话声音,左前座讲话声音信号sl以高于左前座麦克风pl的sn比来表示左前座的用户的讲话声音。
[0036]
合成处理部3在控制部4的控制下将右前座讲话声音信号sr、右前座讲话声音信号sr和表示从音频装置2输出的音乐等的输出声音信号sa合成,并从扬声器sp输出。
[0037]
控制部4根据右前座讲话声音信号sr和左前座讲话声音信号sl,监视右前座的用户的讲话的有无和左前座的用户的讲话的有无。
[0038]
并且,控制部4在右前座的用户讲话中,控制合成处理部3,以将右前座讲话声音信号sr以规定的增益与输出声音信号sa合成后输出到扬声器sp,在右前座的用户没有讲话时,控制合成处理部3以将右前座讲话声音信号sr静音而不与输出声音信号sa合成。另外,控制部4在左前座的用户讲话中,控制合成处理部3,以将左前座讲话声音信号sl以规定的增益与输出声音信号sa合成并输出到扬声器sp,在左前座的用户不讲话时,控制合成处理部3,以将左前座讲话声音信号sl静音而不与输出声音信号sa合成。
[0039]
这里,控制部4也可以在右前座的用户或左前座的用户讲话时,进行使合成处理部3减小输出声音信号sa的增益的控制。
[0040]
接着,图3中示出了信号处理部1的结构。
[0041]
如图所示,信号处理部1具备右座处理器11和左座处理器12,该右座处理器11根据右前座麦克风pr的输出和左前座麦克风pl的输出来生成右前座讲话声音信号sr;左座处理器12根据左前座麦克风pl的输出和右前座麦克风pr的输出来生成左前座讲话声音信号sl。
[0042]
将在右前座的用户的讲话位置产生的声音设为右前座声音,右座处理部11具备:滤波器hr111,将左前座麦克风pl的输出中的右前座声音那样变换为由如图2的b所示那样位于右前座的脚踏板的左侧的虚拟的麦克风即右座虚拟麦克风pvr拾音到的右前座声音;延迟部z-tr
112,将右前座麦克风pr的输出延迟并输出,使该输出中的右前座声音的延迟时间与滤波器hr111的输出中的右前座声音的延迟时间一致;滤波器wra113,提取滤波器hr111的输出中的右前座声音;滤波器wrb114,提取延迟部z-tr
112的输出中的右前座声音;以及右加法器115,将滤波器wra113与滤波器wrb114的输出相加并作为右前座讲话声音信号sr输出。
[0043]
在此,通过右加法器115的加法运算,将右前座麦克风pr的输出中的右前座声音和由位于与右前座麦克风pr不同的位置的右座虚拟麦克风pvr拾音到的右前座声音相加,其他的声音分量被抵消,因此形成使用了右前座麦克风pr和右座虚拟麦克风pvr的、提高了向右前座的用户的讲话位置方向的指向性的虚拟的麦克风阵列,从扬声器输出由虚拟的麦克风阵列输出的右前座讲话声音信号sr,该右前座讲话声音信号sr与右前座麦克风pr的输出相比右前座声音的sn比高。
[0044]
同样,将在左前座的用户的讲话位置产生的声音设为左前座声音,左座位处理部12具备:滤波器hl121,将右前座麦克风pr的输出中的左前座声音变换为由如图2的b所示那样位于左前座的脚踏板的右侧的虚拟的麦克风即左座虚拟麦克风pvl拾音到的左前座声音;延迟部z-tl
122,延迟左前座麦克风pl的输出并输出,使该输出中的左前座声音的延迟时间与滤波器hl121的输出中的左前座声音的延迟时间一致;滤波器wla123,提取滤波器hl121的输出中的左前座声音;滤波器wlb124,提取延迟部z-tl
122的输出中的左前座声音;
以及左加法器125,将滤波器wla123与滤波器wlb124的输出相加并作为左前座讲话声音信号sl输出。
[0045]
在此,通过左加法器125的加法运算,将左前座麦克风pl的输出中的左前座声音和由位于与左前座麦克风pl不同位置的左座虚拟麦克风pvl拾音到的左前座声音相加,其他声音分量被抵消,因此形成使用了左前座麦克风pl和左座虚拟麦克风pvl的、提高了向左前座的用户的讲话位置方向的指向性的虚拟的麦克风阵列,从扬声器输出由虚拟的麦克风阵列输出左前座讲话声音信号sl,该左前座讲话声音信号sl与左前座麦克风pl的输出相比,左前座声音的sn提高。
[0046]
这里,右座处理器11的滤波器hr111、滤波器wra113、滤波器wrb114的传递函数(滤波器系数)的设定,预先通过进行用于计算滤波器hr111的传递函数的第一阶段调谐和用于计算滤波器wra113和滤波器wrb114的传递函数的第二阶段调谐,并且对滤波器hr111、滤波器wra113和滤波器wrb114设定所计算出的传递函数来进行。
[0047]
第一阶段调谐通过图4所示的结构进行。
[0048]
如图所示,该结构具备右前座扬声器tspr、右前座学习用麦克风tpr、左前座麦克风pl、第一延迟部z
-ta
41、第一加法器42、第一自适应滤波器43。另外,第一自适应滤波器43具备第一可变滤波器431、通过nlms等自适应算法来更新第一可变滤波器431的传递函数(滤波器系数)的第一自适应算法执行部432。
[0049]
在此,如图5的a1、a2所示,右前座扬声器tspr是配置在右前座的用户的讲话位置的扬声器,右前座学习用麦克风tpr是配置在右前座的脚踏板的左侧,即右座虚拟麦克风pvr的位置的麦克风。
[0050]
另外,第一阶段调谐在从右前座扬声器tspr输出规定的调谐用声音的同时进行。
[0051]
由左前座麦克风pl拾音到的声音通过第一自适应滤波器43的第一可变滤波器431后被输出到第一加法器42。第一延迟部z
-ta
41将由右前座位学习麦克风tpr拾音到的声音延迟并输出,并使输出中的调谐用声音的延迟时间与左前座麦克风pl的输出中的调谐用声音的延迟时间一致。
[0052]
第一加法器42从第一延迟部z
-ta
41的输出中减去第一可变滤波器431的输出后作为误差e1而被输出到第一自适应滤波器43的第一自适应算法执行部432。
[0053]
第一自适应算法执行部432执行nlms等自适应算法,更新第一可变滤波器431的传递函数,以使误差e1最小。
[0054]
然后,等待第一可变滤波器431的传递函数由于以上的动作而收敛。如果第一可变滤波器431的传递函数收敛,则该传递函数成为如下传递函数:将由左前座麦克风pl拾音到的以右前座的用户的讲话位置为音源位置的声音变换为与由右前座位学习用麦克风tpr拾音到的以右前座的用户的讲话位置为音源位置的声音之间相关尽可能强(尽可能近似)的声音,即,尽可能将以左前座麦克风pl的输出中的右前座的用户的讲话位置为音源位置的声音变换为由右座虚拟麦克风pvl拾音到的以右前座的用户的讲话位置为音源位置的声音,因此将收敛后的可变滤波器的传递函数座位滤波器hr111的传递函数。
[0055]
接着,第二阶段调谐通过图6所示的结构进行。
[0056]
如图所示,该结构具备:右前座扬声器tspr、左前座麦克风pl、右前座麦克风pr、设定了通过第二阶段调谐求出的传递函数的滤波器hr111、第二延迟部z
-tb
61、第二自适应滤
波器62、第三自适应滤波器63、第二加法器64、第三加法器65。
[0057]
另外,第二自适应滤波器62具备第二可变滤波器621和第二自适应算法执行部622,该第二自适应算法执行部622利用lms等自适应算法来更新第二可变滤波器621的传递函数(滤波器系数),第三自适应滤波器63具备第三可变滤波器631和第三自适应算法执行部632,该第三自适应算法执行部632利用lms等自适应算法来更新第三可变滤波器631的传递函数(滤波器系数)。
[0058]
第二阶段调谐在从右前座扬声器tspr输出规定的调谐用声音的同时进行。
[0059]
由左前座麦克风pl拾音到的声音通过滤波器hr111、第二自适应滤波器62的第二可变滤波器621后被输出到第二加法器64。第二延迟部z
-tb
61将由右前座麦克风pr拾音到的声音延迟并输出,并使该输出中的调谐用声音的延迟时间与左前座麦克风pl输出中的调谐用声音的延迟时间一致。并且,第二延迟部z
-tb
61的输出通过第三自适应滤波器63的第三可变滤波器631后被输出到第三加法器65。
[0060]
第二加法器64从第一延迟部z
-tb
61的输出减去第二可变滤波器621的输出后作为误差e2,被输出到第二自适应滤波器62的第二自适应算法执行部622。
[0061]
第二自适应算法执行部622执行lms等自适应算法,更新第二可变滤波器621的传递函数,以使误差e2最小。
[0062]
第三加法器65从滤波器hr111的输出中减去第三可变滤波器631的输出后作为误差e3,被输出到第三自适应滤波器63的第三自适应算法执行部632。
[0063]
第三自适应算法执行部632执行lms等自适应算法,更新第三可变滤波器631的传递函数,以使误差e3最小。
[0064]
然后,等待基于以上动作的第二可变滤波器621的传递函数和第三可变滤波器631的传递函数的收敛,将收敛后的第二可变滤波器621的传递函数作为滤波器wra113的传递函数,将收敛后的第三可变滤波器631的传递函数作为滤波器wrb114的传递函数。
[0065]
这里,在第二可变滤波器621的传递函数和第三可变滤波器631的传递函数收敛的状态下,第二可变滤波器621的传递函数成为从由右座虚拟麦克风pvl拾音到的声音中提取与由右前座麦克风pr拾音到的声音最相关的分量的函数,第三可变滤波器631的传递函数成为从由右前座麦克风pr拾音到的声音中提取与由右座虚拟麦克风pvl拾音到的声音最相关的分量的函数,最相关的分量是以右前座的用户的讲话位置为音源位置的调谐用声音的分量,因此,第二可变滤波器621的传递函数成为从由右座虚拟麦克风pvl拾音到的声音中提取以右前座的用户的讲话位置为音源位置的声音的传递函数,第三可变滤波器631的传递函数成为从由右前座麦克风pr拾音到的声音中提取以右前座位的用户的讲话位置为音源位置的声音的传递函数。
[0066]
接着,左右座处理部的滤波器hl121、滤波器wla123、滤波器wlb124的传递函数(滤波器系数)的设定也同样,预先通过进行计算滤波器hl121的传递函数的第一阶段调谐、以及计算滤波器wla123和滤波器wlb124的传递函数的第二阶段调谐,并且对滤波器hl121、滤波器wla123、滤波器wlb124设定所计算出的各传递函数来进行。
[0067]
计算左座位处理部12的各滤波器的传递函数的第一阶段调谐和第二阶段调谐的内容,是将上述的计算右座处理部11的各滤波器的传递函数的第一阶段调谐和第二阶段调谐的说明中的“左”和“右”置换,并将“r”和“l”置换后的内容。因此,如图5的b1、b2所示,在
左座处理部12的滤波器hl121、滤波器wla123、滤波器wlb124的传递函数的计算中使用的左前座扬声器tspl是配置在左前座的用户的讲话位置的扬声器,左前座学习用麦克风tpl是配置在左前座的脚踏板的右侧,即左座虚拟麦克风pvl的位置的麦克风。
[0068]
以上,对本发明的实施方式进行了说明。
[0069]
如上所述,根据本实施方式,通过不追加各座位用的麦克风而是除了该座位的麦克风之外还利用为了其他座位用而设置的麦克风的高效的结构,能够提高向该座位的用户的讲话位置方向的指向性,提高从扬声器输出的用户的讲话声音的sn比。另外,由于信号处理部1的各滤波器的传递函数是固定的,所以处理负荷的增大也得到抑制。
[0070]
另外,在以上的车内交流辅助系统中,也可以设置使用了回声消除器等自适应滤波器的其他信号处理部,该回声消除器消除由右前座麦克风pr或左前座麦克风pl拾音到的、向扬声器输出的讲话声音的分量。即使这样,由于将信号处理部1的各滤波器的传递函数设为固定,所以其他信号处理部的动作也不会与自适应滤波器发生干扰。
[0071]
[附图标记说明]
[0072]
1:信号处理部;2:音频装置;3:合成处理部;4:控制部;11:右座处理部;12:左座处理部;41:第一延迟部z
-ta
;42:第一加法器;43:第一自适应滤波器;61:第二延迟部z
-tb
;62:第二自适应滤波器;63:第三自适应滤波器;64:第二加法器;65:第三加法器;111:滤波器hr;112:延迟部z
-tr
;113:滤波器wra;114滤波器wrb;115:右加法器;121:滤波器hl;122:延迟部z
-tl
;123:滤波器wla;124:滤波器wlb;125:左加法器;431:第一可变滤波器;432:第一自适应算法执行部;621:第二可变滤波器;622:第二自适应算法执行部;631:第三可变滤波器;632:第三自适应算法执行部;pr:右前座麦克风;pl:左前座麦克风;sp:扬声器;tpr:右前座学习用麦克风;tpl:左前座学习用麦克风;tspl:左前座扬声器。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1