基于有限层次状态机和深度强化学习的自动驾驶决策方法
本发明属于无人驾驶汽车,涉及基于有限层次状态机和深度强化学习的自动驾驶决策方法。
背景技术:
1、驾驶行为决策是智能车辆研究领域的关键问题之一,也是自动驾驶系统智能化水平的重要体现。在实际道路交通环境中,智能车辆所面临的驾驶环境和交通状况存在多样性、随机性和不准确性等特征,而人们对车辆自动驾驶的安全性和实时性要求不断提高,这对驾驶行为决策系统提出了巨大挑战。不管是城市道路还是高速公路,自动驾驶车辆都要能够根据不同的现场环境选择合理的驾驶行为。自动驾驶的终极目标,是能够像人类一样产生合理的驾驶行为。
2、随着环境感知及智能控制技术的不断发展,移动机器人相关研究取得了飞跃式进展并涌现出了许多行为决策方法,包括有限状态机决策方法、神经网络决策方法、马尔科夫决策方法、贝叶斯网络决策方法以及深度学习决策方法等,但每种方法都存在一定的缺陷。有限状态机决策法需要穷举所有可能存在的状态,但道路环境变化万千,有限的状态集合很难覆盖复杂多变的环境,对于未知的状态,错误的决策将导致车辆异常的行为。神经网络算法、马尔科夫法算法、深度学习算法等,都需要根据大量的数据进行自我学习迭代,巨大的数据量将给硬件带来沉重的负担,这必然将导致硬件成本增加。总之现有的自动驾驶技术还难以兼顾道路适应性广和算法效率高的要求。
技术实现思路
1、本发明的目的是提供基于有限层次状态机和深度强化学习的自动驾驶决策方法,用于解决现有技术中难以兼顾道路适应性广和算法效率高,如果进行深度学习对数据量要求较高的问题。
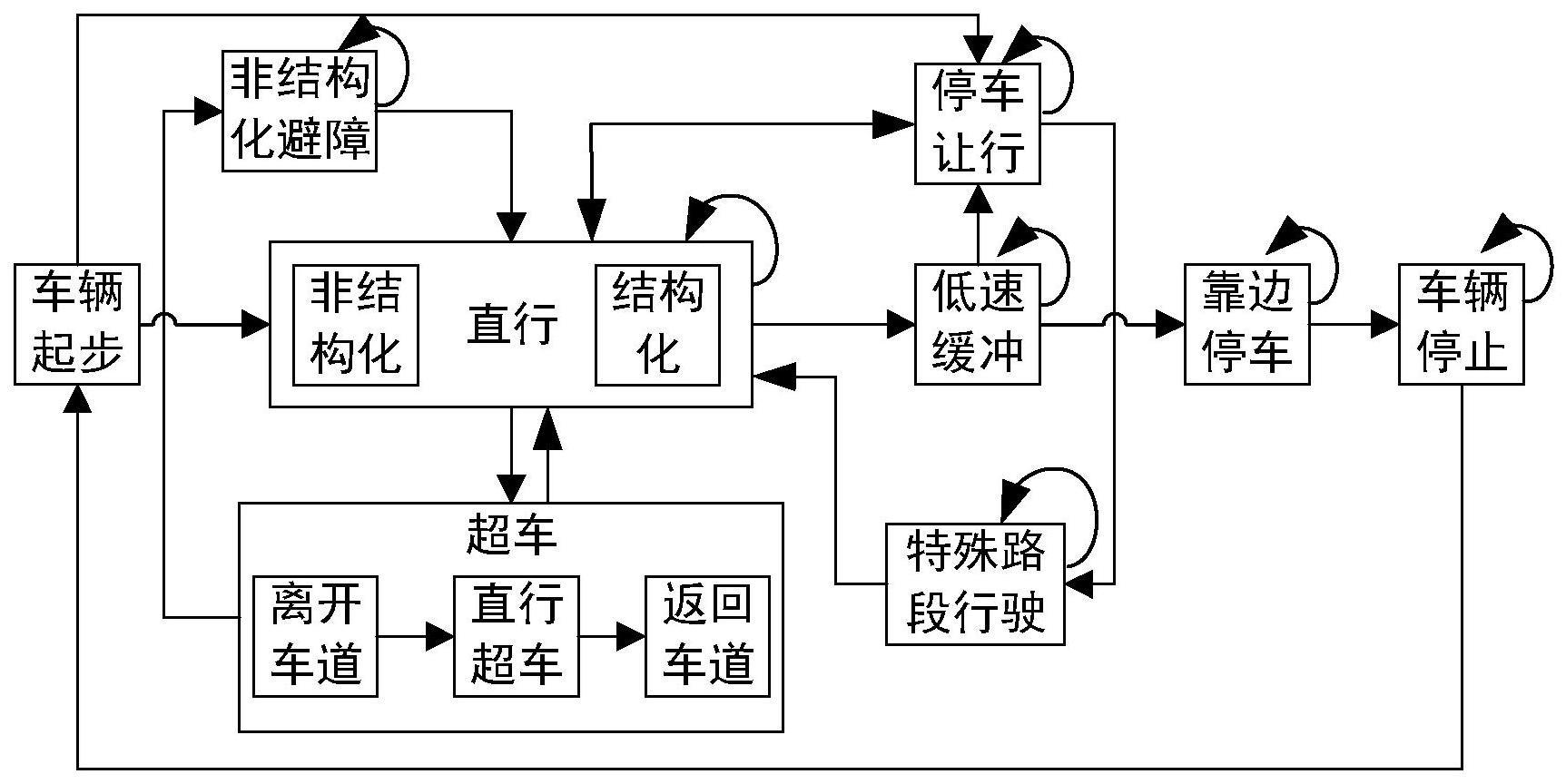
2、所述的基于有限层次状态机和深度强化学习的自动驾驶决策方法,包括下列步骤:
3、s1、实现环境感知与融合,并完成坐标的统一与转换;
4、s2、基于统一坐标后的信息进行场景分析;
5、s3、基于场景分析的结果进行顶层状态转移输出;
6、s4、进行基于深度强化学习算法的底层决策,结合顶层状态转移结果和当前环境状态,通过深度强化学习进行训练操作,当训练次数达到设定阈值时,需要验证训练结果是否符合驾驶员的操作意图;当训练结果符合操作意图时,保存深度强化学习的训练结果;当训练结果不符合操作意图时,需要重新进行训练操作,直到训练结果符合要求为止;
7、训练时需要根据不同顶层状态,分别进行深度学习的训练,将深度学习符合要求的训练结果存储为“训练参数-顶层状态”的映射列表,在车辆域控制器中运行时,只需要根据顶层状态查找对应深度学习参数进行决策;
8、s5、输出决策结果。
9、优选的,所述步骤s3中,根据场景分类、环境状态及车辆主动指令,进行顶层状态的转移输出,状态转移的过程由状态转移函数确定,状态转移函数主要考虑环境中自车周围障碍物的信息,考虑内容包括动态障碍物与静态障碍物,状态转移函数包括:道路风险值函数、障碍物风险值函数、车辆碰撞时间函数。
10、优选的,所述道路风险值函数表示偏离道路中心的危险程度,道路风险值的计算方法为:
11、其中,lw表示道路宽度,a(x)表示道路危险势能幅值随道路宽度的变化参数,a(x)的计算式为:
12、
13、其中,xz和xc分别为主车道和超车道中心线的横向坐标,x为车辆的横向坐标,sgn()是阶跃函数,pm表示车道中心线处的危险度,越接近车道中心线,危险度越低;
14、障碍物风险值函数主要描述为可行轨迹与障碍物垂直最小距离的倒数,障碍物风险值的计算方法为:
15、
16、其中,discollision为可行轨迹与障碍物垂直最小距离,ε为表示极小的正数,防止出现分母为0的情况;
17、车辆与障碍物的碰撞时间函数考虑了位置和速度,车辆碰撞时间ttc的计算方法为:
18、
19、其中,discar2obs表示车辆到障碍物的距离,正数时:障碍物在车辆前面;负数时:障碍物在车辆后面;△v表示车辆速度vcar与障碍物速度vobs的差,正数时:车速大于障碍物速度;负数时,车速小于障碍物速度。
20、优选的,所述步骤s4采用ddpg算法进行决策,结合强化学习问题的基本要素,依次建立车辆的状态与动作、驾驶回报、值函数及策略函数;然后结合强化学习中演员-评论员机制的思想,通过迭代更新值函数和策略函数以求解最优策略,完成车辆行为决策方法。
21、优选的,所述步骤s4中,建立当前时刻车辆状态矩阵为:s=[c0,c1,c2,...,cn],其中c0为表征目标车辆的状态向量,ci(i=1,2,...,n)为表征环境车辆i的状态向量,n为状态矩阵中环境车辆的数目,车辆状态矩阵反映了目标车辆在行为决策时考虑到的其周围最近的环境车辆的数目;车辆i的状态向量应包含车辆的位置及速度信息,从x方向和y方向刻画位置及速度,则有:
22、c0=[x0,y0,v0x,v0y]t
23、ci=[△xi,δyi,vix,viy]t
24、其中,x0,y0为目标车辆的坐标,包含横向坐标x0和纵向坐标y0,v0x,v0y分别表示目标车辆的横向速度和纵向速度;δxi,△yi,vix,viy分别表示环境车辆i的横向坐标、纵向坐标、横向速度和纵向速度。
25、优选的,所述步骤s4中,驾驶回报包括:
26、行车安全,需要根据目标车辆及环境车辆在每个时刻的位置来计算它们之间的距离,并与安全车距进行比较;其计算方法为:
27、x0′=x0+vox′·△t
28、y0′=y0+voy′·△t
29、
30、其中,di表示目标车辆和环境车辆的车距。若目标车辆与环境车辆距离过近,则二者可能发生碰撞,不满足行车安全性。vox′和voy′分别时间间隔δt中目标车辆的平均横向速度和平均纵向速度,x0′和y0′表示时间间隔δt后目标车辆的横向坐标和纵向坐标。xi′和yi′表示时间间隔δt后环境车辆i的横向坐标和纵向坐标;
31、车辆驾驶平稳性,综合考虑目标车辆下一时刻与当前时刻在x和y两个方向上的速度变化量来衡量车辆驾驶平稳性,车辆驾驶平稳性的计算方法为:
32、
33、其中,v0x′和v0y′分别时间间隔δt后目标车辆的横向速度和纵向速度,v0x和v0y分别时间间隔δt后目标车辆的横向速度和纵向速度;
34、行车效率,应当描述为当其单位时间段内的有效行驶距离越大,说明该时间段内的驾驶越高效,在某一时间间隔δt内,目标车辆的有效行驶距离△s的计算方法为:其中,表示初始速度。
35、优选的,所述步骤s4中,通过向量线性组合的方式来辅助表达强化学习模型中的值函数与策略函数,设值函数的权重向量为w,状态矩阵s对应的特征向量为x(s),则值函数可以表示为:
36、v(s)=wtx(s)
37、其中x(s)的形式可以由多种方法决定,在本实施例中,选择用线性形式构建特征向量,x(s)为行向量x(s)=[c0,c1,c2,…,cn]t。那么,w应为与x(s)维度相同的行向量。
38、优选的,所述步骤s2中,根据当前环境状态,通过模糊算法,对障碍物、车道线、道路等特征分析,通过模糊规则及隶属度确定当前环境所属的场景类别,分析内容包括:结构化道路与非结构化道路的分类、障碍物稀疏与密集程度的分析、单车道与多车道的分类、道路弯曲程度的分析。
39、优选的,所述步骤s1中,从车辆感知系统中,实时获取车辆的周围环境信息,再通过环境感知与融合模块进行数据融合;采集周围环境信息的同时,还对车辆进行融合定位,获取车辆的定位坐标,另一方面也同时采集车身信息;融合后的数据进行坐标系统一与变换,世界坐标系到车辆坐标系的变换关系为:
40、
41、其中,世界坐标系到车辆坐标系的旋转矩阵由横滚角(roll)、俯仰角(pitch)、偏航角(yaw)计算;世界坐标系到车辆坐标系的的平移矩阵由车辆定位坐标car(x,y,z)计算;世界坐标系到车辆坐标系的的齐次变换矩阵。
42、本发明具有以下优点:
43、1、在底层决策规划阶段使用深度强化学习,对顶层转移状态分别进行训练学习,不仅能降低各种状态的耦合程度,而且在每种状态进行深度学习时所要求的数据量都将降低,提高了强化学习的算法效率。
44、2、在顶层决策规划阶段使用有限状态机,引入模糊规则与隶属度,对有限状态进行分类,最大程度地覆盖了所有场景,弥补有限状态机场景覆盖率低的问题。
45、3、底层决策规划阶段,通过对不同状态建立“训练参数-状态”映射列表,在车辆域控制器算力有限的条件下,强化学习算法直接调用训练结果进行决策计算,保证了算法的实时性。
46、4、有限状态机做顶层决策规划,深度强化学习做底层决策规划,结合层次状态机与深度强化学习的优点,决策规划结果更符合驾驶员的行车意图,车辆行驶过程更加合理。
- 还没有人留言评论。精彩留言会获得点赞!