锅炉智能燃烧综合优化控制方法与流程
本发明属于火电机组智能控制,具体涉及一种锅炉智能燃烧综合优化控制方法。
背景技术:
大数据和人工智能是国家科技发展的大战略,国内正积极开展智能化电厂的建设,其目标是釆用先进控制策略与技术,实现过程重要参数的精细控制,保证机组安全、经济、环保运行。其中锅炉燃烧优化是智能化电厂建设的重点之一,对火电机组节能减排具有重要意义。
基于大数据和人工智能的锅炉燃烧优化方法,普遍采用了神经网络和遗传算法技术,其应用的关键是如何建立高质量的燃烧优化神经网络模型,这与神经网络训练样本的质量密切相关。提高锅炉效率和降低烟气nox排放是一对矛盾,由于燃烧参数较多,彼此影响关系复杂,如何提供一种有效的手段,方便运行人员根据scr脱硝系统运行状况协调锅炉效率和烟气nox,是锅炉燃烧优化需要解决的问题。另外,火电机组运行的安全性要求很高,燃烧优化算法必须防止优化的参数产生跳变,使机组避免受到热冲击,这是锅炉燃烧优化工程应用必须考虑的问题。目前现有的基于神经网络和遗传算法的锅炉燃烧优化方法没有很好地解决上述问题。
技术实现要素:
发明目的:为了克服现有技术中锅炉智能燃烧控制的优化不足问题,本发明的目的是提供一种锅炉智能燃烧综合优化控制方法,方便运行人员有效平衡锅炉效和烟气nox排放,并尽可能地减小优化燃烧参数的跳变,最终达到提高锅炉效率、降低烟气nox排放的目的。
为了实现上述目的,本发明的技术方案如下:
一种锅炉智能燃烧综合优化控制方法,包括以下步骤:
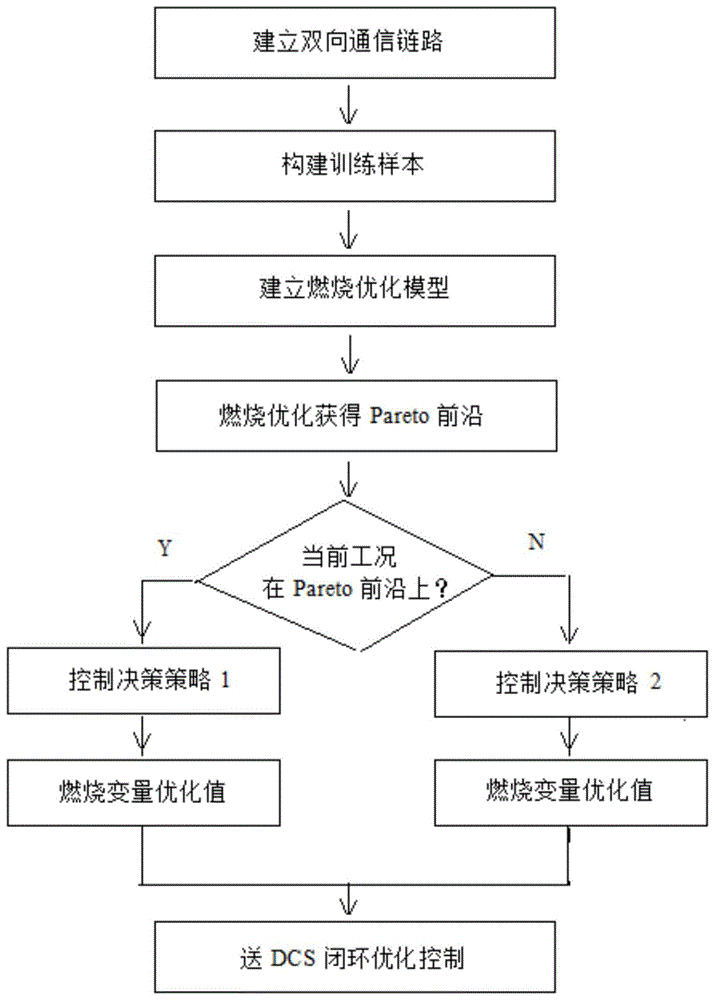
(1)配置优化控制系统,所述优化控制系统包括工作站和plc,将plc的数据通信口与机组dcs数据通信口连接,工作站的通信接口与plc数据通信口连接,建立优化控制系统与机组dcs的双向数据通信链路;
(2)获取机组运行历史数据,构建燃烧优化神经网络训练样本ω,建立燃烧优化神经网络模型m,包括以向量vin=[vc,vo]作为燃烧优化神经网络模型的输入,以向量
(3)基于步骤(2)建立的燃烧优化神经网络模型m,通过多目标遗传算法优化燃烧参数,实现锅炉燃烧闭环优化控制。
进一步的,步骤(1)所述的plc与机组dcs之间采用modbus方式进行数据交换,所述的工作站和plc之间采用opc方式进行数据交换。
步骤(2)包括如下步骤:
(21)从机组dcs历史数据库中获取最近一年的机组运行数据,所述机组运行数据包括工况变量、燃烧参数变量和其他变量,还包括每条数据记录对应的时间;其中工况变量包括机组负荷、入炉煤热值、给水温度和环境温度;燃烧参数变量包括各磨煤机负荷、各磨煤机一次风流量、空预器入口烟气含氧量、二次风门开度、燃尽风门开度;其它变量包括脱硝入口烟气氮氧化合物含量nox,以及用于计算锅炉正平衡炉效的变量;
(22)对步骤(21)获得的历史运行数据进行5分钟滑动平均再采样,并计算每条数据记录对应的锅炉正平衡效率η;用工况变量构成工况变量向量vc,用燃烧参数变量构成燃烧参数变量向量vo,以向量vin=[vc,vo]作为燃烧优化神经网络模型的输入,以向量
(23)从燃烧样本π中获取神经网络训练样本ω,根据神经网络训练样本ω,以vin作为模型输入,vout作为模型输出,采用rbf神经网络学习算法,建立燃烧优化神经网络模型m。
更进一步的,步骤(23)获取神经网络训练样本ω的具体步骤如下:
(231)置神经网络训练样本ω为空;
(232)在燃烧样本π中随机选择一个样本i,其对应的燃烧优化神经网络模型的输入记为
(233)在燃烧样本π中寻找满足如下条件的所有样本j,构成样本集π1:
其中
(234)将
(235)删除燃烧样本π中包含在样本集π1中的样本;删除后,如果样本π为空,则结束,否则,置样本集π1为空,返回步骤(232)。
步骤(3)具体步骤如下:
(31)通过步骤(1)所建立的数据链路,实时采集并计算当前时刻前最近5分钟的滑动平均数据vc、vo和vout;
(32)随机生成n个个体构成初始种群
(33)以最大化锅炉效率η,最小化脱硝入口烟气氮氧化合物含量nox,即使神经网络模型输出最大为优化目标,采用多目标非支配快速排序遗传算法对燃烧参数进行寻优,得到优化的种群
(34)按如下方法进行控制决策,确定最佳燃烧参数值
(35)通过步骤(1)的数据链路将向量
(36)转至步骤(31),重复步骤(31)-步骤(35)。
更进一步的,步骤(34)对于最佳燃烧参数值
(341)从ψ1中选择满足如下条件的所有向量
并构成新的集合
(342)如果ψ2为空集,则转至(346);否则转至下一步;
(343)从φ1中选择与ψ2对应的向量
(344)计算φ2中每一个向量的如下性能指标:
(345)从φ2中选择
min为取小运算;
(346)计算ψ1中每个向量的如下性能指标:
其中
(347)从φ1中选择
max为取大运算;
(348)结束。
有益效果:本发明相比现有技术其显著的效果在于:1、可提高神经网络训练样本的质量,有利于提高燃烧优化模型的质量和建模效率;2、基于遗传算法提出了对于不同运行工况采用不同优化策略的燃烧优化方法,既方便了运行人员有效平衡锅炉效和烟气nox排放,又可保证优化效果,并尽可能地减小了燃烧参数的跳变,避免机组受到热冲击,有利于工程实际应用。
附图说明
图1是本发明锅炉智能燃烧综合优化控制方法步骤框图;
图2是多目标优化得到的pareto前沿曲线图。
具体实施方式
为了详细的说明本发明公开的技术方案,下面结合附图和具体实施例,对本发明做进一步的阐述。
工程应用对象为600mw机组,锅炉为直吹式制粉系统四角切圆燃烧方式,结合图1所示,使用本发明方法的具体步骤如下:
步骤1:优化控制系统配置一台工作站和一个plc,将plc的数据通信口与机组dcs数据通信口连接,采用modbus方式进行数据交换;工作站的通信接口与plc数据通信口连接,采用opc方式进行数据交换,建立优化控制系统与机组dcs的双向数据通信链路;
实际工程应用中,工作站采用了ibm服务器,并采用了西门子的plc,plc通过ts180网关与机组dcs连接,ibm服务器与plc之间采用opc进行数据交换,plc与dcs之间采用modbus方式进行数据交换。
步骤2:获取机组运行历史数据,构建燃烧优化神经网络训练样本ω,建立燃烧优化神经网络模型m,具体方法如下:
(2.1)从机组dcs历史数据库中获取最近一年的机组运行数据,数据包括工况变量、燃烧参数变量、其它变量,以及每条数据记录对应的时间,其中工况变量包括机组负荷、入炉煤热值、给水温度和环境温度;燃烧参数变量包括各磨煤机负荷、各磨煤机一次风流量、空预器入口烟气含氧量、二次风门开度、燃尽风门开度;所述的其它变量包括脱硝入口烟气氮氧化合物含量nox,以及用于计算锅炉正平衡炉效的变量;
(2.2)对(2.1)步获得的历史运行数据进行5分钟滑动平均再采样,并计算每条数据记录对应的锅炉正平衡效率η;用工况变量构成工况变量向量vc,用燃烧参数变量构成燃烧参数变量向量vo,以向量vin=[vc,vo]作为燃烧优化神经网络模型的输入,以向量
(2.3)根据燃烧样本π,采用如下方法构建神经网络训练样本ω:
a1)置神经网络训练样本ω为空;
a2)在燃烧样本π中随机选择一个样本i,其对应的燃烧优化神经网络模型的输入记为
a3)在燃烧样本π中寻找满足如下条件的所有样本j,构成样本集π1:
其中
a4)将
a5)删除燃烧样本π中包含在样本集π1中的样本;删除后,如果样本π为空,则结束,否则,置样本集π1为空,返回步骤a2);
(2.4)根据神经网络训练样本ω,以vin作为模型输入,vout作为模型输出,采用bp神经网络学习算法,建立燃烧优化神经网络模型m;
实际工程实施中,从机组dcs数据库中采集了10个月的机组运行历史数据近432000条记录,按步骤2的方法处理后,得到26800条记录的神经网络训练样本,数据样本涵盖负荷范围为30%到100%额定负荷,涵盖煤质范围为煤种的收到基低位热值14mj/kg到25mj/kg,以此建立的神经网络模型涵盖了机组所有可能出现的运行工况。
选择的工况变量包括:机组负荷、入炉煤热值、给水温度和环境温度,选择的燃烧参数变量包括:6个磨煤机的负荷、6个一次风流量、1个烟气氧量、1个总风量、1个辅助风箱与炉膛差压,6层二次风门开度、1层ofa风门开度、3层sofa风门开度,共计25个变量。以工况变量和燃烧参数变量作为神经网络模型的输入,以锅炉效率η、脱硝入口烟气氮氧化合物含量nox的倒数1/nox作为模型的输出,采用rbf神经网络,建立燃烧优化神经网络模型。
步骤3:基于步骤2建立的燃烧优化神经网络模型m,采用多目标遗传算法优化燃烧参数,实现锅炉燃烧闭环优化控制,达到提高锅炉效率、降低烟气nox排放的目的,具体步骤为:
(3.1)通过步骤1的数据链路,实时采集并计算当前时刻前最近5分钟的滑动平均数据vc、vo和vout;
(3.2)随机生成n个个体构成初始种群φ0=[vop],vop为由燃烧参数变量构成的第p个个体向量,p=1,2,…,n1;以
(3.3)以锅炉效率η最大,脱硝入口烟气氮氧化合物含量nox最小为优化目标,采用多目标非支配快速排序遗传算法(nsga-ii)对燃烧参数进行寻优,得到优化的种群
(3.4)按如下方法进行控制决策,确定最佳燃烧参数值
a1)从ψ1中选择满足如下条件的所有向量
并构成新的集合
a2)如果ψ2为空集,转至a6);否则转至下一步;
a3)从φ1中选择与ψ2对应的向量
a4)计算φ2中每一个向量的如下性能指标:
a5)从φ2中选择
min为取小运算;
a6)计算ψ1中每个向量的如下性能指标:
其中
a7)从φ1中选择
max为取大运算;
a8)结束。
(3.5)通过步骤1的数据链路将向量
(3.6)转至步骤(3.1),重复步骤(3.1)-步骤(3.5)。
步骤3中,vout为实际运行工况点,ψ1为图2中的pareto前沿。当实际运行工况点vout不在pareto前沿曲线上时,ψ2为非空集,即为图2中的pareto前沿ab段,在ab段上任取一工况点,其锅炉效率都比实际运行工况点高,同时nox排放都比实际运行工况点低,为减小燃烧参数的跳变,本发明采用了a5步的优化控制决策策略,以ab段中最接近当前工况的点作为最优解。当实际运行工况点vout在pareto前沿曲线上时,ψ2为空集,本发明采用了a7步的优化控制决策策略,通过优化权重系数实现锅炉效率与nox排放的柔性控制,使运行人员通过调整优化权重系数,方便有效地实现锅炉效率与nox排放的平衡。
工程验收时,由第三方进行了优化前后的锅炉性能对比试验,在满负荷下燃烧优化使锅炉效率提高了约0.53%,nox排放降低了约10%,达到了技术预期的优化目标,表明本发明的方法是有效的。
本发明所述的方法提出了神经网络训练样本的获取方法,既保证了样本尽可能涵盖机组运行的各种工况,又可剔除大量的冗余样本,有利于提高燃烧优化模型的质量和建模效率;本发明同时提出了基于遗传算法的燃烧优化新方法,对于运行于非pareto前沿的当前工况,提出了在pareto前沿上先找出优于该当前工况的区域,并以该区域中最接近当前工况的点作为最优解,将燃烧工况控制到pareto前沿上,不仅保证了燃烧优化的效果,而且可以减小优化燃烧参数的跳变;对于运行于pareto前沿的当前工况,提出了采用nox的优化权重系数λ来综合平衡锅炉效率和烟气nox排放,运行人员可通过优化权重系数λ方便有效地调整平衡锅炉效率和烟气nox排放,有利于工程应用。
- 还没有人留言评论。精彩留言会获得点赞!