一种用户识别方法与装置以及具有用户识别功能的健康秤与流程
本发明涉及一种用户识别方法与装置,特别是涉及一种用于电子健康秤的用户识别方法与装置。
背景技术:
具备脂肪分析功能或带bmi功能的健康秤,一般需要要根据用户的身高、年龄、性别、目标重量等用户信息,计算各成份含量及重量变化。为方便用户使用,现有的脂肪秤,在首次设定完用户资料且测量后,在以后使用的过程中,都可以通过简单的重量识别来确认当前测量用户。
一般重量识别方法是:用户的当前测量重量(currentweight)与上一次测量重量(lastweigth)相减的绝对值,如果在一定的变化范围(range)内,则认为识别到了用户。即满足:
|currentweight-lastweigth|≤range。
其中range越大,识别范围越广,但识别准确度越差。range越小,识别范围越小,但识别成功率越低。在一个家庭环境中,使用如上功能识别,往往会出现识别出多个用户的情况,或者无法识别出用户。比如家里的父亲和儿子,在体重接近的情况下,往往是无法准确识别出当前测量用户的。或者在range较小的情况下,一个用户吃一顿饭,或者因出差而引起的重量变化,现有的秤也无法识别出来。
因此,需要一种新的用户识别方法与装置,以便有效解决因同一个用户重量变化,或者存在多个重量接近用户时,无法准确识别当前测量用户的问题。
技术实现要素:
本发明的目的是为了克服现有技术存在的缺陷,提供一种用户识别方法与装置。为了实现这一目的,本发明所采取的技术方案如下。
按照本发明实施例的第一方面,提供一种用于健康秤的用户识别方法,包括选择步骤,用于选择下述识别方法中的至少一种,直至识别出具体用户:重量识别法,测量时间识别法,上秤时长识别法,使用习惯识别法,左右平衡度识别法,阻抗识别法,以及通信识别法。
按照一个实施例,所述的用于健康秤的用户识别方法还包括学习步骤,用于通过用户手动设定用户号,并且记录该次设定结果以及与该用户相关的特征数据。
按照再一个实施例,所述的用于健康秤的用户识别方法还包括分析步骤,通过统计分析各识别方法的成功率,并按照识别成功率确定选择各识别方法的优先顺序。
按照另一个实施例,所述的用于健康秤的用户识别方法还包括交互步骤,用于将测量数据及特征数据发送给远程服务器,并通过该服务器进行用户识别处理。
按照又一个实施例,所述的用于健康秤的用户识别方法还包括确认步骤,用于将识别结果推送至用户终端,并由该用户确认或再分配测量数据。
按照再又一个实施例,所述的用于健康秤的用户识别方法还包括更新步骤,用于更新识别成功后的用户特征数据。
按照本发明实施例的第二方面,提供一种具有用户识别功能的健康秤,包括处理器,此外,还包括:重量识别模块,测量时间识别模块,上秤时长识别模块,使用习惯识别模块,左右平衡度识别模块,阻抗识别模块,以及通信识别模块;其中所述处理器配置成启用上述识别模块中的至少一种,直至识别出具体用户。
按照一个实施例,所述的具有用户识别功能的健康秤还包括学习模块,用于通过用户手动设定用户号,并且记录该次设定结果以及与该用户相关的特征数据。
按照再一个实施例,所述的具有用户识别功能的健康秤还包括分析模块,用于通过统计分析各识别模块的识别成功率,以便按照识别成功率确定启用各识别模块的优先顺序。
按照又一个实施例,所述的具有用户识别功能的健康秤还包括交互模块,用于将测量数据及特征数据发送给远程服务器,并通过该服务器进行用户识别处理。
按照另一个实施例,所述的具有用户识别功能的健康秤还包括确认模块,用于将识别结果推送至用户终端,并由该用户确认或再分配测量数据。
按照再另一个实施例,所述的具有用户识别功能的健康秤还包括更新模块,用于更新识别成功后的用户特征数据。
按照本发明实施例的第三方面,提供一种用于健康秤的用户识别方法,包括下述识别方法中的一种:测量时间识别法,根据不同用户在不同时间的测量习惯来识别不同用户;上秤时长识别法,根据称量过程中秤体锁定重量后至用户下秤的时间长度来识别不同用户;使用习惯识别法,根据用户上秤使用左右脚习惯不同来识别不同用户;左右平衡度识别法,根据用户站在秤上时,左右脚两边的重量差异来识别不同用户;以及阻抗识别法,根据不同用户在不同时间左右脚之间的阻抗不同来识别不同用户。
按照本发明实施例的第四方面,提供一种用于健康秤的用户识别装置,包括下述识别模块中的一种:测量时间识别模块,用于根据不同用户在不同时间的测量习惯来识别不同用户;上秤时长识别模块,用于根据称量过程中秤体锁定重量后至用户下秤的时间长度来识别不同用户;使用习惯识别模块,用于根据用户上秤使用左右脚习惯不同来识别不同用户;左右平衡度识别模块,用于根据用户站在秤上时,左右脚两边的重量差异来识别不同用户;以及阻抗识别模块,用于根据不同用户在不同时间左右脚之间的阻抗不同来识别不同用户。
按照本发明实施例的用户识别方法与装置以及具有用户识别功能的健康秤,可通过多个特征来实现用户识别,使用户识别更为准确和高效。
下面将结合附图并通过实施例对本发明进行具体说明,其中相同或基本相同的部件采用相同的附图标记指示。
附图说明
图1是按照本发明一个实施例的用于健康秤的用户识别方法的示意性流程图;
图2是按照本发明一个实施例的单秤体的示意性识别流程图;
图3是按照本发明一个实施例的包括利用网络服务器进行用户识别在内的总体过程的示意性流程图;
图4是按照本发明一个实施例的具有用户识别功能的健康秤的示意性结构框图。
具体实施方式
下面先分别描述按照本发明实施例的各种不同的用户识别方法。
(1)通过测量时间来识别用户
不同用户习惯性的测量时间点往往存在差异,有可能用户1习惯在早上测量,用户2习惯在下午测量。但用户1与用户2的体重是接近的,通过重量无法判断出来。但在基于重量的基础上,通过不同用户的不同测量时间点可以判断出来。利用秤体处理器或服务器对不同用户以往测量时间进行统计,以及对下次测量时间与过往测量时间进行对比,即可作为进行用户识别的特征数据之一。
健康秤处理器可配置成将一天的24小时分为若干个时间段,例如按照一个实施例分为六个时间段:0:00-4:00,4:00-8:00,…,以及20:00-0:00,该时间分段也可根据处理器的统计结果确定。如果用户a每天都在8:00-12:00测量重量,而用户b每天在16:00-20:00测量,如果用户a与用户b重量接近,但如果测量时间在9:00则可判断该次测量为用户a。
(2)通过上秤时长来识别用户
不同用户在称量体重时,踩在秤上的时间一般是不一样的。秤体处理器可配置成在开机状态下可以判断用户是站在秤上,还是已下秤。若用户a在重量锁定显示(即重量显示不再变化,称重完成)后,很快就下秤,例如通过计时器确定锁定后呆在秤上的时间为3秒左右;而用户b是一直站在秤上,直到关机,例如通过计时器确定站在秤上的时间为10秒钟左右。此时,假设用户a与b重量接近,则可通过该方式识别用户a与用户b。
如果以前的测量记录表明a用户在测量完成显示锁定就下秤(重量锁定后,下秤时间小于5秒),而该次的用户测量在重量锁定后,5秒以内下秤,若通过该特征数据能识别出单个用户,则认为识别成功。
(3)通过使用习惯来识别用户
有些用户,习惯左脚上秤,有些则习惯右脚上秤。使用双桥传感器的秤可感知是左脚先上秤还是右脚先上秤。若用户a测量时,先是左脚上秤,而用户b测量时,都是右脚先踩上去。假定有一次测量,在通过其它特征无法区分出用户时,若该次测量用户是右脚先上秤,而右脚先上秤的所有已知用户里面只有该用户,则可以从多个用户里面识别出单一用户。也就是依据使用习惯这一特征数据可进行用户识别。
(4)通过左右平衡度来识别用户
不同用户,左右脚两边的重量会存在差异,要么左边偏重,要么右边偏重,或者左右脚两边的重量均等,此时差异为零。使用双桥传感器的秤可感知左桥的承载的重量与右桥承载的重量。通过计算左桥和右桥的重量差值,并通过左右两边的重量差值,可做为用户识别的特征数据。在识别中,若通过其它特征无法区分用户a与用户b,假定之前记录中表明,用户a的左边比右边重1kg,而用户b左右两边基本相等。如果在该次测量中,测得该用户左右脚两边基本相等,即左右基本平衡,则可表明该用户为用户b。
(5)通过阻抗来识别用户
在每天的同一时间段内,用户双脚间的阻抗是基本恒定的。不同用户,该阻抗存在一定差异。在识别出多个用户的情况下,可通过该特征数据获取当前用户。
例如,在之前的记录表明8:00-12:00时间段内用户a测量的阻抗值为600欧姆,用户b在该时间段内测量的阻抗测量为500欧姆。若当前测量用户在8:00-12:00时间段内的测量值为610欧姆,在无法识别出具体用户的情况下,若通过该特征数据可唯一识别出用户,则识别成功。
(6)通过学习来识别用户
秤体在最初使用时会因为无参考资料,或者因为后期使用过程中的特征数据变化而无法识别出用户。此时,用户可手动选择用户号。该次选择的结果,可被秤体记录,在下一次出现类似特征数据时,即可将其识别为上一次选择的用户。
(7)通过通信来识别用户
对于具有通信功能的健康秤,利用用户的通信终端设备,通过配对功能(即绑定)与秤建立连接后,该秤可产生一个随机数分配给当前用户。在下一次测量时,用户通信终端连接上后,秤体通过对比该随机数,可识别当前用户是谁。通过该方式,可准确识别用户。
如图1所示,是按照本发明一个实施例的用于健康秤的用户识别方法的示意性流程图,主要包括:选择步骤102;在另一个实施例中,对于用户初次使用的情况,还可包括学习步骤100;在其他实施例中,还可选地包括:分析步骤104,交互步骤106,确认步骤108,以及更新步骤110。
其中选择步骤102用于选择下述识别方法中的至少一种,直至识别出具体用户:重量识别法,测量时间识别法,上秤时长识别法,使用习惯识别法,左右平衡度识别法,阻抗识别法,以及通信识别法。在学习步骤100中,对初次使用的用户会因为无参考数据,或者因为后期使用过程中的特征数据变化,用户可手动选择用户号,并且秤体处理器可记录该次选择的结果以及与该用户相关的特征数据,用于下一次出现类似特征数据时,进行用户识别。在分析步骤104中,通过统计分析各识别方法的识别成功率,并按照识别成功率确定选择各识别方法的优先顺序,也就是优先选用识别成功率高的识别方法。
按照又一个实施例,在交互步骤106中,可将测量数据及特征数据发送给远程服务器,并通过该服务器进行用户识别处理。也就是说,通过互联网服务器进行统计识别,具体如下所述:
对于大多数的普通秤,能保存的用户数据有限,而且用户数也有限,样本不足。因此,一般只能以前一笔数据做为依据对比,无法统计出每项特征识别成功概率。也无法调整用户特征识别的优先顺序(即,先通过时间点判断,还是先通过左右平衡来判断,或者阻抗判断等)。而通过服务器识别,可统计大量识别成功的样本。
如用户a在一年内测量了600多次,成功识别500次。通过服务器可以计算出如下的一些特征数据:
测量时间点:可统计出该用户测量时间的概率分布,用以做为测量时间点特征的识别依据。
上秤时长:可统计出该用户在测量完成,重量锁定后,站在秤上的平均时长,用以做为识别依据,相比单秤体识别,可提升识别成功概率。
上秤习惯:可统计该用户出左脚或右脚上秤的概率,例如,左脚上秤概率=左脚上秤次数/总测量次数*100%。
左右平衡度:统计出左右平衡的差值,平均左右重量差值=总样本数的差值和/样本数。
统计各测量时间点的阻抗值:通过测量时间点分时段,求出各时间段的不同用户阻抗值的平均值。
上述特征数据可做为今后用户识别的依据,样比于单秤体识别,该方式可获得更高的识别概率,数据也更具备参考性。当然,在其他实施例中,通过适当设置秤体的配置,也可在单秤体中实现上述通过统计分析的识别过程。
在确认步骤108中,可将用户识别结果(例如通过服务器)推送至用户终端,并且该用户数据可再被分配,即在分配错误的情况下,用户手动识别该笔重量。在更新步骤110中,更新识别成功后的用户特征数据,作为下次用户识别的依据。
服务器在识别流程中,可以知道是通过哪一个步骤识别成功。比如,在之前特征都无法识别的时候,服务器通过阻抗识别出了用户,再将数据分配给用户。如果用户未对数据再分配,则表明识别成功;如果用户对数据再进行了分配,即用户认为该笔数据不属于他,则认为识别失败。
通过服务器统计,利用阻抗识别出用户的总次数,及识别成功的总次数,可计算出通过阻抗识别成功的概率(请注意:该处的统计可以是所有接入服务器的用户统计,而非单用户统计)。
其它特征也可通过该方法统计得出,可以通过其统计结果,重新调整识别优先顺序,让识别成功率更高。
通过学习识别,也是通过用户选择来实现。在用户选择的过程中,服务器可获取本次的识别结果,用于调整服务器的识别流程。
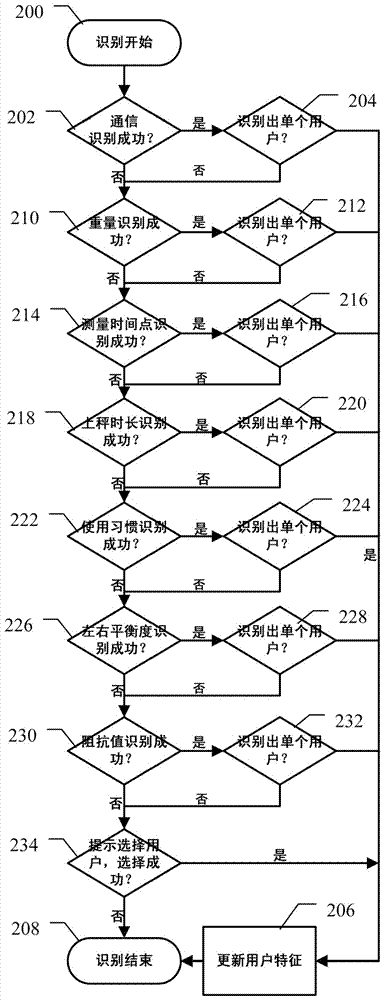
如图2所示,是按照本发明一个实施例的单秤体示意性识别流程图。识别开始后(框200),先进行通信识别,确认是否能识别成功(框202),如果识别出单个用户(框204),则更新用户特征数据(框206),并结束识别(框208)。如果通信识别不成功或者在框204中识别不出单个用户,则进行重量识别,确认是否能识别成功(框210),如果识别出单个用户(框212),则更新用户特征数据(框206),并结束识别(框208)。如果重量识别不成功或者在框212中识别不出单个用户,则进行测量时间识别(框214),如果识别出单个用户(框216),则更新用户特征(框206),并结束识别(框208)。如果测量时间识别不成功或者在框216中识别不出单个用户,则进行上秤时长识别(框218),如果识别出单个用户(框220),则更新用户特征数据(框206),并结束识别(框208)。如果上秤时长识别不成功或者在框220中识别不出单个用户,则进行使用习惯识别(框222),如果识别出单个用户(框224),则更新用户特征数据(框206),并结束识别(框208)。如果使用习惯识别不成功或者在框224中识别不出单个用户,则进行左右平衡度识别(框226),如果识别出单个用户(框228),则更新用户特征数据(框206),并结束识别(框208)。如果左右平衡度识别不成功或者在框228中识别不出单个用户,则进行阻抗识别(框230),如果识别出单个用户(框232),则更新用户特征数据(框206),并结束识别(框208)。如果阻抗识别不成功或者在框232中识别不出单个用户,则提示选择(或设定)用户(框234),如果选择(或设定)用户成功,则更新用户特征数据(框206),并结束识别(框208);如果选择(或设定)用户不成功,则结束识别(框208)。上述各种识别方法的选择可以是随机的,但是,优选旳是,在另一个实施例中,通过统计分析各识别方法的成功率,可按成功率从高到低的顺序选择识别方法。
如图3所示,是按照本发明一个实施例的包括利用网络服务器进行用户识别在内的总体过程的流程图。测量开始后(框300),记录测量数据及各特征值(即特征数据)(框302);随后,确定是否具备通信功能(框304),如果判断为是,则将测量数据及各特征值发送至通信终端(框306),通信终端计算统计结果或者发送至服务器计算统计分析结果(框308);然后,根据特征值或统计值识别用户(框310),识别出单个用户后,结束识别(框312)。如果在框304确定不具备通信功能,则直接根据特征值或统计值识别用户(框310)。
如图4所示,是按照本发明一个实施例的具有用户识别功能的健康秤400的示意性结构框图,主要包括:处理器402,重量识别模块404,测量时间识别模块406,上秤时长识别模块408,使用习惯识别模块410,左右平衡度识别模块412,阻抗识别模块414,以及通信识别模块416;其中所述处理器配置成启用上述识别模块中的至少一种,直至识别出具体用户。在其他实施例中,还可选地包括:学习模块418,分析模块420,交互模块422,确认模424,和/或更新模块426;学习模块418用于通过用户手动设定用户号,并且记录该次设定结果以及与该用户相关的特征数据;分析模块420用于通过统计分析各识别模块的成功率,并按照识别成功率确定启用各识别模块的优先顺序;交互模块422用于将测量数据及特征数据发送给远程服务器,并通过该服务器进行用户识别处理;确认模块424用于将识别结果推送至用户终端,并由该用户确认或再分配测量数据;更新你看426用于更新识别成功后的用户特征数据。
上述处理器402包括但不限于cpu、dsp、plc、mcu、单片机等等,上述模块可以通过软件、硬件、固件或者其他组合来实现,在此不做详述。
上述通信识别模块416包括但不限于蓝牙、wifi、ant、rf、红外、usb、声波等等。
以上通过具体的实施例对本发明进行了说明,但本发明并不限于这些具体的实施例。本领域技术人员应该明白,还可以对本发明做各种修改、等同替换、变化等等,例如将上述实施例中的一个步骤或模块分为两个或更多个步骤或模块来实现,或者相反,将上述实施例中的多个步骤或模块的功能放在一个步骤或模块中来实现。但是,这些变换只要未背离本发明的精神,都应在本发明的保护范围之内。另外,本申请说明书和权利要求书所使用的一些术语,并不是限制,仅仅是为了便于描述。此外,以上多处所述的“一个实施例”、“另一个实施例”等等表示不同的实施例,当然也可以将其全部或部分结合在一个实施例中。
- 还没有人留言评论。精彩留言会获得点赞!