基于UPLC‑QTOF的植物差异性代谢物快速筛选方法与流程
本发明涉及一种分析样品中所含有的化学成分的方法,尤其涉及一种基于UPLC-QTOF的植物差异性代谢物快速筛选方法。
背景技术:
目前,在中药、香精香料等植物提取物质量控制领域研究中,获取可以表征不同产地、批次等样本组间差异性的方法,并据此对产品质量进行品质调控不仅是工业企业,也是科研单位非常感兴趣的领域。然而,由于植物的提取物品质是植物与生长环境相互作用所产生的代谢产物的整体作用结果,外在宏观品质的差异多是由于其中的一些成分组成与其它组的样本差异所致。在植物分析中如何从更为整体的角度去筛选这些差异性代谢物成为当前研究的一个难点。基于UPLC-QTOF的非靶标代谢轮廓分析技术从整体上对植物中的化学成分进行表征与中药等领域的整体作用思路相一致,在近年来受到更多的关注。
植物样本物质构成复杂性的特点能够充分发挥UPLC-QTOF非靶标代谢论廓技术的优势。通常,每个植物样本的UPLC-QTOF数据中含有上千种的化学成分,如何提取这些成分,并使得样本间的结果具有可比性则成为一个具有挑战性的难题。目前的方法中,仅有少数几个方法能够实现这一分析过程,其中最为著名的方法是XCMS。然而,XCMS方法存在色谱提取不完全的问题。另外,当前的方法中普遍存在假阳性问题,需要人为干预,增加了额外的工作量并且降低了分析效率。
技术实现要素:
针对现有技术的不足,本发明所要解决的技术问题是提供一种基于UPLC-QTOF的植物差异性代谢物快速筛选方法,可以快速筛选出同一种植物不同产地样本间的差异性代谢产物
本发明解决其技术问题所采用的技术方案是:
一种基于UPLC-QTOF的植物差异性代谢物快速筛选方法,分析同一物种不同来源的至少两个样本,包括以下步骤:
时间漂移校正:每一个样本分别得到一个该样本所有色谱峰的高精度质谱表征,选择一个样本作为参比,利用动态规划算法进行其它样本相对参比的时间漂移校正,即对于其它样本的每一个色谱峰,都根据其保留时间和质谱精度与参比相比较进行校正,时间漂移的阈值设定为2min,质谱精度误差设定100ppm,使得不同样本中对应于同一个物质的色谱峰保留时间较为接近,接着使用自适应网络链接算法对不同样本间对应于同一个物质的色谱峰进行注册,最终使得不同样本中属于同一个物质的色谱峰对齐;
方差分析建模:接着利用方差分析分析所有样本中属于同一个物质的色谱峰,筛选不同样本之间具有差异性的指标,利用PLS-DA模型计算各自在建模过程中的VIP值,最终选择VIP大于1,且置信水平小于0.05的变量作为潜在的能够表征样本间差异的差异性代谢物。
最优的,所述时间漂移校正步骤中,使用自适应网络链接算法对不同样本间对应于同一个物质的色谱峰进行注册的具体步骤如下:
寻找侯选峰:选择一个当前色谱峰,将其他样本中与选择的当前色谱峰不在同一个链接线上,且距离最近的色谱峰定义为侯选峰;
链接两个峰:若其他样本中与侯选峰不在同一个链接线上,且距离最近的色谱峰是当前色谱峰,则链接两个峰,即将当前色谱峰和侯选峰可视作不同样本中对应于同一个物质的色谱峰;若其他样本中与侯选峰不在同一个链接线上,且距离最近的色谱峰不是当前色谱峰,则不链接两个峰;链接的过程引入一个约束,即一个样本不能出现两个色谱峰对应同一个物质,且属于同一个物质的质谱精度误差为100ppm。
重复操作:重复寻找侯选峰至链接两个峰步骤,直到链接线无法更新时,停止重复。
最优的,还包括以下步骤:
获得低分辨质谱数据:将UPLC-QTOF中得到的高分辨质谱数据转化为低分辨质谱数据;即每一个样本获得一个Time×m/z的色谱信号矩阵,一个m/z下收集一个色谱信号;
一个m/z下色谱信号中基线的校正:将一个m/z色谱信号中的局部极小值设定为该m/z色谱信号的初始背景噪声的极小值,使用迭代优化算法剔除该初始背景噪声中属于色谱信号中色谱峰的部分,得到该色谱信号真正的背景噪声的极小值,根据该色谱信号真正的背景噪声的极小值在色谱信号中的原始位置,利用线性插值估算出基线漂移,扣除基线漂移后,获得一个m/z下基线校正后色谱信号;
每个样本中所有m/z下色谱信号基线校正:将每一个m/z下的色谱信号都做上述一个m/z色谱信号中基线的校正的处理,得到基线校正后的m/z色谱信号;
色谱信号中有效色谱峰的提取:使用不同尺度高斯平滑卷积运算进行色谱信号平滑,提取每一次平滑后色谱信号中所有的局部极大值,且将所有的局部极大值的位置标记,通过脊线寻优的方法,分别获得每个色谱峰在色谱信号中的原始位置,接着使用色谱信号中非色谱峰部分的仪器噪声波动,计算出仪器噪声水平,剔除色谱信号与仪器噪声之比小于3的色谱峰,剩下的色谱峰为能够准确定量的有效色谱峰,即完成色谱信号中有效色谱峰的提取;
一个色谱峰的高精度质谱表征:根据一个有效色谱峰所位于的低分辨色谱信号的m/z值,查找高分辨率质谱信号中在该m/z±0.5Da范围内的最大的离子,并使用该离子的高精度质谱值标记该有效色谱峰,从而获得一个色谱峰的高精度质谱值;
所有色谱峰的高精度质谱表征:将每一个有效色谱峰均使用上述一个色谱峰的高精度质谱表征的方法处理,最终得到所有色谱峰的高精度质谱表征。
最优的,还包括以下步骤:
离子碎片的聚类:一个分子质量为M的物质在正离子模式下会产生[M+H]+、[M+2H]+、[M+3H]+、[M+H-H2O]+、[M+H-2H2O]+、[M+NH3]+、[M+Na]+、[M-H+Na]+、[M+H+Na]+、[M-H+2Na]+、[M+H+2Na]+或[M+K]+中的至少一个碎片离子峰,将得到的所有色谱峰的高精度质谱表征中时间窗口为0.05min,质谱精度设置为100ppm中属于同一物质的分子离子峰和碎片离子峰进行聚类。
最优的,所述获得低分辨质谱数据步骤具体中,将UPLC-QTOF中得到的高分辨质谱数据转化为精度为1Da步长的低分辨质谱数据。
最优的,所述一个m/z下色谱信号中基线的校正步骤中,使用迭代优化算法的迭代收敛标准为10-6。
最优的,所述色谱信号中有效色谱峰的提取步骤中,其中使用不同尺度高斯平滑卷积运算进行色谱信号平滑,所使用高斯函数标准偏差范围是1~13,且步长0.1。
最优的,还包括以下步骤:
UPLC-QTOF分析:
进行UPLC-QTOF分析的色谱条件为:色谱柱为Agilent C18柱,色谱柱的长度为100mm,色谱柱的直径为4.6mm,色谱柱的粒径为1.7μm,柱温为35℃;流动相A为0.1%甲酸水溶液,流动相B为0.1%甲酸乙腈溶液,色谱分析时,流动相梯度为,初始时流动相A占流动相总体积的95%,流动相B占流动相总体积的5%,接下来的20min内流动相A占流动相总体积的份数降至5%,流动相B占流动相总体积的份数升至95%;
进行UPLC-QTOF分析的质谱条件为:干燥气温度为350℃;干燥气流速为12L/min;喷雾气压力为40psi;保护气温度为350℃;保护气流速为10L/min;电离电压为3500V;质谱扫描范围为50–1500;正离子模式;
UPLC-QTOF分析结束后得到高分辨质谱数据。
最优的,还包括以下步骤:
样本的制备过程:将新鲜收集的样本放入液氮中速冻,在液氮条件下将样本研磨粉碎,将粉碎的样本中加入提取液,涡旋混匀后室温超声处理,然后离心,且取上清液转移至色谱瓶中,待UPLC-QTOF分析。
最优的,所述样本的制备过程步骤中,提取液包括3体积份的乙腈、3体积份的异丙醇和2体积份的水;涡旋1~4分钟,室温超声处理50~80分钟,离心条件为12000r/min离心5min。
由上述技术方案可知,本发明提供的基于UPLC-QTOF的植物差异性代谢物快速筛选方法,该方法利用UPLC-QTOF现代分析技术获得植物中物质化学组分信息,随后利用非靶标代谢轮廓分析技术对物质信息进行提取,采用对色谱峰进行提取和源内裂解分子碎片聚类后,采用动态规划方法进行样本间的时间漂移校正,随后根据自适应网络链接法对样本间的物质进行注册,最后采用统计分析筛选出植物样本间的差异性代谢产物。
附图说明
图1:本发明进行样本间时间漂移校正示例。(A)测样的色谱峰‘2’逐一对齐到不同参比峰的示例。(B)测样中每一个色谱峰对应于每一个参比峰的色谱相似度。‘2’对齐到不同参比色谱峰后的所得相似度用不同背景颜色标出。箭头标记出动态规划算法获得的路径(剪头所指路径上每一个点表示匹配到的色谱峰)。(C)时间漂移校正前和校正后的色谱信号。虚线表示校正前的色谱。经过校正后,测样信号与参比信号中,色谱峰出现的位置相同。
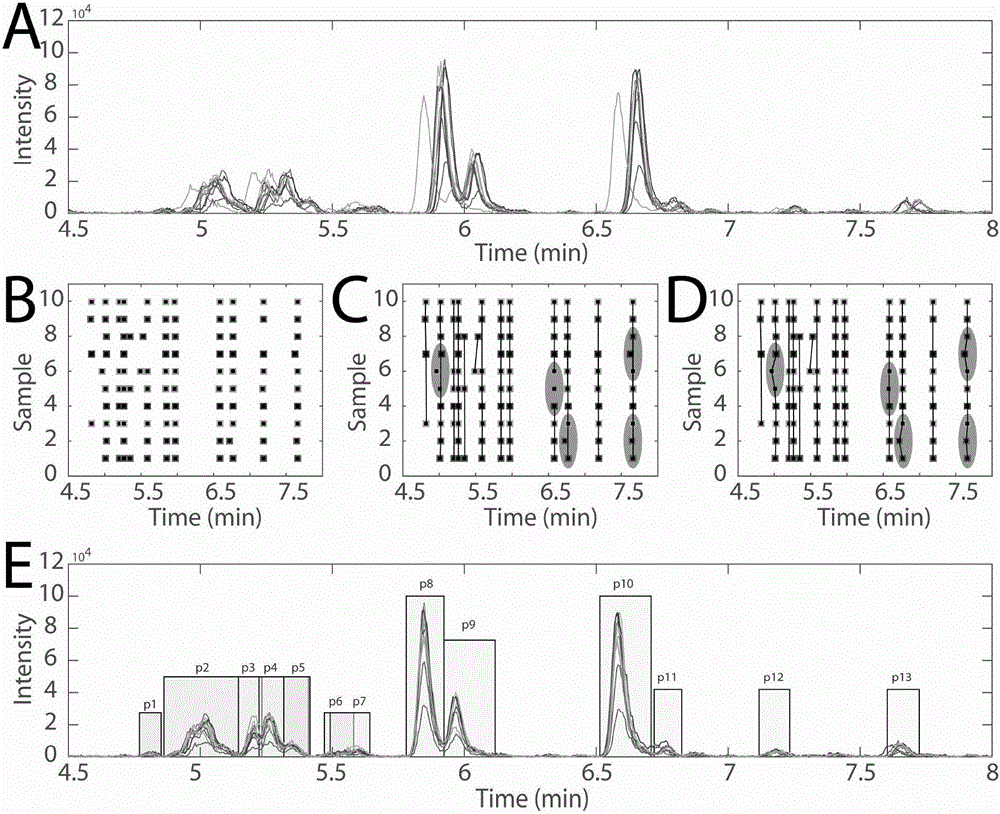
图2:利用自适应网络链接进行色谱峰注册示例图。(A)原始色谱信号,存在时间漂移。(B)经过时间漂移校正后,色谱峰的位置。(C)-(D)本发明自适应网络链接结果示例,其中(C)表示优化过程中的一个暂时性链接结果,其中数个色谱峰未链接到一起,(D)展示了最终获得的链接结果。图(E)给出了最终注册的13个色谱峰,对应于图(D)中的13条链接线。
图3:本发明同经典的XCMS方法进行对比结果。上图:利用XCMS解析不同组别的样本间差异性代谢物进行聚类分析,所得结果。下图:利用本发明解析植物样本后,筛选出来的差异性代谢物(p<0.05)进行聚类分析所得结果,不同组别之间的样本能够获得较好聚类。样本有含有字母g13、g14和g15分别表示了三个不同的组别。
图4:本发明给出的色谱峰提取示例以及同经典方法的对比。左侧一列(A)-(D)为本发明进行色谱分提取原理示意图。右侧一列(E)-(H)是经典基于墨西哥帽小波函数峰提取方法(MassSpecWavelet)示意图。(A)原始色谱信号。图中标注了人为判断出来的5个色谱峰。图(B)不同尺度高斯平滑卷积运算进行色谱信号平滑后的色谱信号。(C)标记出不同平滑尺度下的局部极大值位置,以及通过脊线寻优确定22条脊线(每一个脊线对应一个潜在的色谱峰)。(D)剔除色谱信号与仪器噪声之比小于3的色谱峰后,本发明最终确定的5个有效色谱峰。(E)不同尺度墨西哥小帽小波函数中的系数。(F)不同尺度小波函数下的小波脊线。(G)经典MassSpecWavelet方法筛选出来的潜在的色谱峰。(H)MassSpecWavelet最终提取出来的色谱峰。
具体实施方式
结合本发明的附图,对发明实施例的技术方案做进一步的详细阐述。
样本为同一植物物种,但不同年份的三个组别。分别将所有样本经过如下处理:
基于UPLC-QTOF的植物差异性代谢物快速筛选方法,包括以下步骤:
S1:样品的制备过程:将新鲜收集的茶叶样本放入液氮中速冻,在液氮条件下将样品研磨粉碎,将20mg粉碎的样品中加入2ml提取液,提取液包括3体积份的乙腈、3体积份的异丙醇和2体积份的水,涡旋2分钟后,室温超声处理60分钟,然后12000r/min离心5min,且取1ml上清液转移至色谱瓶中,待UPLC-QTOF分析。
S2:UPLC-QTOF分析:
进行UPLC-QTOF分析的色谱条件为:色谱柱为Agilent C18柱,色谱柱的长度为100mm,色谱柱的直径为4.6mm,色谱柱的粒径为1.7μm,柱温为35℃;流动相A为0.1%甲酸水溶液,流动相B为0.1%甲酸乙腈溶液,色谱分析时,流动相梯度为,初始时流动相A占流动相总体积的95%,流动相B占流动相总体积的5%,接下来的20min内流动相A占流动相总体积的份数降至5%,流动相B占流动相总体积的份数升至95%;
进行UPLC-QTOF分析的质谱条件为:干燥气温度为350℃;干燥气流速为12L/min;喷雾气压力为40psi;保护气温度为350℃;保护气流速为10L/min;电离电压为3500V;质谱扫描范围为50–1500;正离子模式。
S3:获得低分辨质谱数据:将原始数据转化为mzData格式。进入MATLAB环境进行分析。将UPLC-QTOF中得到的高分辨质谱数据转化为精度为1Da步长的低分辨质谱数据;即每一个样本获得一个Time×m/z的色谱信号矩阵,一个m/z下收集一个色谱信号。
S4:一个m/z下色谱信号中基线的校正:将一个m/z色谱信号中的局部极小值设定为该m/z色谱信号的初始背景噪声的极小值,使用迭代优化算法剔除该初始背景噪声中属于色谱信号中色谱峰的部分,且迭代收敛标准为10-6,得到该色谱信号真正的背景噪声的极小值,根据该色谱信号真正的背景噪声的极小值在色谱信号中的原始位置,利用线性插值估算出基线漂移,扣除基线漂移后,获得一个m/z下基线校正后色谱信号。
S5:每个样本中所有m/z下色谱信号基线校正:将每一个m/z下的色谱信号都做上述一个m/z色谱信号中基线的校正的处理,得到基线校正后的m/z色谱信号。
S6:色谱信号中有效色谱峰的提取:使用不同尺度高斯平滑卷积运算进行色谱信号平滑,所使用高斯函数标准偏差范围是1~13,且步长0.1,提取每一次平滑后色谱信号中所有的局部极大值,且将所有的局部极大值的位置标记,通过脊线寻优的方法,分别获得每个色谱峰在色谱信号中的原始位置,接着使用色谱信号中非色谱峰部分的仪器噪声波动,计算出仪器噪声水平,剔除色谱信号与仪器噪声之比小于3的色谱峰,剩下的色谱峰为能够准确定量的有效色谱峰,即完成色谱信号中有效色谱峰的提取。
S7:一个色谱峰的高精度质谱表征:根据一个有效色谱峰所位于的低分辨色谱信号的m/z值,查找高分辨率质谱信号中在该m/z±0.5Da范围内的最大的离子,并使用该离子的高精度质谱值标记该有效色谱峰,从而获得一个色谱峰的高精度质谱值。
S8:所有色谱峰的高精度质谱表征:将每一个有效色谱峰均使用上述一个色谱峰的高精度质谱表征的方法处理,最终得到所有色谱峰的高精度质谱表征。
S9:离子碎片的聚类:一个分子质量为M的物质在正离子模式下会产生[M+H]+、[M+2H]+、[M+3H]+、[M+H-H2O]+、[M+H-2H2O]+、[M+NH3]+、[M+Na]+、[M-H+Na]+、[M+H+Na]+、[M-H+2Na]+、[M+H+2Na]+或[M+K]+中的至少一个碎片离子峰,将得到的所有色谱峰的高精度质谱表征中时间窗口为0.05min,质谱精度设置为100ppm中属于同一物质的分子离子峰和碎片离子峰进行聚类。
S10:时间漂移校正:每一个样本分别得到一个该样本所有色谱峰的高精度质谱表征,选择一个样本作为参比,利用动态规划算法进行其它样本相对参比的时间漂移校正,即对于其它样本的每一个色谱峰,都根据其保留时间和质谱精度与参比相比较进行校正,时间漂移的阈值设定为2min,质谱精度误差设定100ppm,使得不同样本中对应于同一个物质的色谱峰保留时间较为接近。
接着使用自适应网络链接算法对不同样本间对应于同一个物质的色谱峰进行注册,具体步骤为:
S10A:寻找侯选峰:选择一个当前色谱峰,将其他样本中与选择的当前色谱峰不在同一个链接线上,且距离最近的色谱峰定义为侯选峰;
S10B:链接两个峰:若其他样本中与侯选峰不在同一个链接线上,且距离最近的色谱峰是当前色谱峰,则链接两个峰,即将当前色谱峰和侯选峰可视作不同样本中对应于同一个物质的色谱峰;若其他样本中与侯选峰不在同一个链接线上,且距离最近的色谱峰不是当前色谱峰,则不链接两个峰;链接的过程引入一个约束,即一个样本不能出现两个色谱峰对应同一个物质,且属于同一个物质的质谱精度误差为100ppm;
S10C:重复操作:重复寻找侯选峰至链接两个峰步骤,直到链接线无法更新时,停止重复。
最终使得不同样本中属于同一个物质的色谱峰对齐。
S11:方差分析建模:接着利用方差分析分析所有样本中属于同一个物质的色谱峰,筛选不同样本之间具有差异性的指标,利用PLS-DA模型计算各自在建模过程中的VIP值,最终选择VIP大于1,且置信水平小于0.05的变量作为潜在的能够表征样本间差异的差异性代谢物。
时间漂移校正的步骤如附图1所示,本发明进行样本间时间漂移校正示例。(A)测样的色谱峰‘2’逐一对齐到不同参比峰的示例。(B)测样中每一个色谱峰对应于每一个参比峰的色谱相似度。‘2’对齐到不同参比色谱峰后的所得相似度用不同背景颜色标出。箭头标记出动态规划算法获得的路径(剪头所指路径上每一个点表示匹配到的色谱峰)。(C)时间漂移校正前和校正后的色谱信号。虚线表示校正前的色谱。经过校正后,测样信号与参比信号中,不同样本中属于同一个物质的色谱峰出现的位置相同。
其中使用自适应网络链接算法对不同样本间对应于同一个物质的色谱峰进行注册的步骤如附图2所示,利用自适应网络链接进行色谱峰注册示例图。(A)原始色谱信号,存在时间漂移。(B)经过时间漂移校正后,色谱峰的位置。(C)-(D)本发明自适应网络链接结果示例,其中(C)表示优化过程中的一个暂时性链接结果,其中数个色谱峰未链接到一起,(D)展示了最终获得的链接结果。图(E)给出了最终注册的13个色谱峰,对应于图(D)中的13条链接线。结果表明所有的色谱峰能够得到较好的注册。
利用校正后的色谱峰注册表。进行多元统计分析,获得具有差异性的代谢物质。如附图3所示,本发明同经典的XCMS方法进行对比结果。上图:利用XCMS解析不同组别的样本间差异性代谢物进行聚类分析,所得结果。下图:利用本发明解析植物样本后,筛选出来的差异性代谢物(p<0.05)进行聚类分析所得结果,不同组别之间的样本能够获得较好聚类。样本有含有字母g13、g14和g15分别表示了三个不同的组别。可以看出使用XCMS解析不同组别的样本,没有将不同来源的三组样本分离开,结果较为混乱,而本法的方法可以将不同来源的三组样本完全分离来,结果令人十分满意。
如附图4所示,本发明给出的色谱峰提取示例以及同经典方法的对比。左侧一列(A)-(D)为本发明进行色谱分提取原理示意图。右侧一列(E)-(H)是经典基于墨西哥帽小波函数峰提取方法(MassSpecWavelet)示意图。(A)原始色谱信号。图中标注了人为判断出来的5个色谱峰。图(B)不同尺度高斯平滑卷积运算进行色谱信号平滑后的色谱信号。(C)标记出不同平滑尺度下的局部极大值位置,以及通过脊线寻优确定22条脊线(每一个脊线对应一个潜在的色谱峰)。(D)剔除色谱信号与仪器噪声之比小于3的色谱峰后,本发明最终确定的5个有效色谱峰。(E)不同尺度墨西哥小帽小波函数中的系数。(F)不同尺度小波函数下的小波脊线。(G)经典MassSpecWavelet方法筛选出来的潜在的色谱峰。(H)MassSpecWavelet最终提取出来的色谱峰。可以明显看出,使用分发明的方法得到的色谱峰更接近实际情况,而常用的基于墨西哥帽小波函数峰提取方法得到的色谱峰明显少于实际情况,也就是会有很多有用数据被剔除了。
综上所述,可以看出来本发明方法分析得到结果优于现在经常用的XCMS方法的分析结果,可以轻易的将同一植物物种,但来源的三个组别区分开,即可以筛选出组间差异性代谢物,使用效果显著优于现有技术。
- 还没有人留言评论。精彩留言会获得点赞!