一种针对血清特性分析与建模方法与流程
本发明涉及医疗科学领域,具体而言,涉及血清光谱分析检测的方法。
背景技术:
随着社会的发展,科学技术也相应地不断提高,人们的生活饮食习惯也发生了很大的改变,这导致社会上高血糖、高血脂等疾病的病人俞渐增多,而且还呈现着逐年增高的趋势,这就需要现在的医疗机构能够快速准确地诊断出血清中的有关生理指标,而这也是当今生命科学领域急需解决的问题。现在比较成熟的检测技术还是停留在化学检测方面,需要对样本进行多次处理,容易导致血清中所含的生命物质活性降低,使检测过程所需要的时间大大延长,更大问题是检测时间的延长影响了检测结果准确性。现如今国内外医学领域,很少涉足血清光谱特性的研究,所相关的论文或者科学技术甚少,这就严重制约了这方面研究的发展。
技术实现要素:
为了解决快速而又准确地检测分析血清成分,本发明提出了一种能够利用三维荧光光谱技术去检测分析血清的方法,并提出采用采用遗传算法和bp算法进行预测分析。
一种针对血清三维光谱分析的方法,包括如下步骤:
步骤1,受试者清晨空腹静脉抽取的方法获得人体血清样本,再用纯净水混合稀释得到血清的样本,让光源的光透过激发光单色器生成激发光波长,样品血清中的荧光物质被激发后产生荧光;
步骤2,激发光与发射光探头呈直角排列,让荧光通过发射光单色器作用于检测器上,得到相应的电信号,经放大后记录下来,如附图1所示。再以曲线或者数字的形式显示出来,利用插值法去除三维荧光光谱中的瑞利散射光,保留荧光光谱中有用的荧光信息;
步骤3,利用s-g多项式平滑法对处理后的三维光谱曲面数据预处理,将二维s-g平滑法移动窗口内的数据向量矩阵扩展为数据矩阵,通过窗体内的非中心点来;
步骤4,利用平行因子算法(parafac)构建三维模型,然后基于相关系数分析的局部回归方法,提取三维光谱中的相关系数分析,采用ga-bp建模的方法,进行分析预测
更进一步的,使用瑞利散射山峰两侧的数据点来拟合散射带的数据点。
具体首先是确定散射的区域,散射区域一般分布在发射波长等于1倍或者2倍激发波长处及其邻近区域(±10~15nm)。确定了散射区域后,将这两个山峰带区域的荧光数据置零,根据散射带两侧的数据来拟合出散射带的荧光光谱数据。其中处理三维荧光光谱数据时选用低次且足够光滑的样条插值,
更进一步的,处理光谱数据时,会在光谱的待处理点前后选取一段数据,连续奇数个点构成一个窗口,并且使点处理点位于窗口中心,用这奇数个点去拟合窗口的中心点,将窗口从前往后依次移动一位,重复上述过程。
其具体的方法是在三维荧光光谱中选取一个矩阵平滑窗口,使得窗口包含(2p+1)×(2q+1)个数据点,其窗口的数据点可以表示为:
(a-p,b-q,x(a-p,b-q,))…(a-p,b0,x(a-p,b0,)),…,(a-p,bq,x(a-p,bq,))
.....
(a0,b-q,x(a0,b-q,))…(a0,b0,x(a0,b0,)),…,(a0,bq,x(a0,bq,))
.....
(ap,b-q,x(ap,b-q,))…(ap,b0,x(ap,b0,)),…,(ap,bq,x(qp,bq,))
其中am(m=-p,...,p)为第m个发射光谱波长,bn(n=-q,...,q)为第n个激发光谱波长,x(am,bn)(m=-p,...,p,n=-q,...,q)为数据点(am,bn)的荧光强度。
更进一步的,将激发发射的荧光矩阵与化学计量学二阶校正方法相结合,充分利用二阶校正方法的二阶优势,用“数学分离”代替“化学分离”,能够快速并且简单的得到准确的定量结果,得到三线性模型的矩阵形式:
然后通过平行因子模型的典型的迭代过程,得到相对矩阵a和已知标准浓度矩阵y之间线性浓度关系:y=aβ+e,以及对未知血清样本浓度估计:ynew=anewβ。
更进一步的,采用遗传算法和bp算法(ga-bp)轮流对三维模型模型训练,选取其中220-240nm的波段代入遗传算法模型进项建模,直到看到网络收敛。
抽取方法为:先将所有血清样本按照浓度从小到大的顺序排列,然后从1号开始,间隔5抽取一个样本,对于荧光吸收光谱,预测集为:1-6-11-16-21-26-31-36,共8个样本,余下32个样本作为训练集。
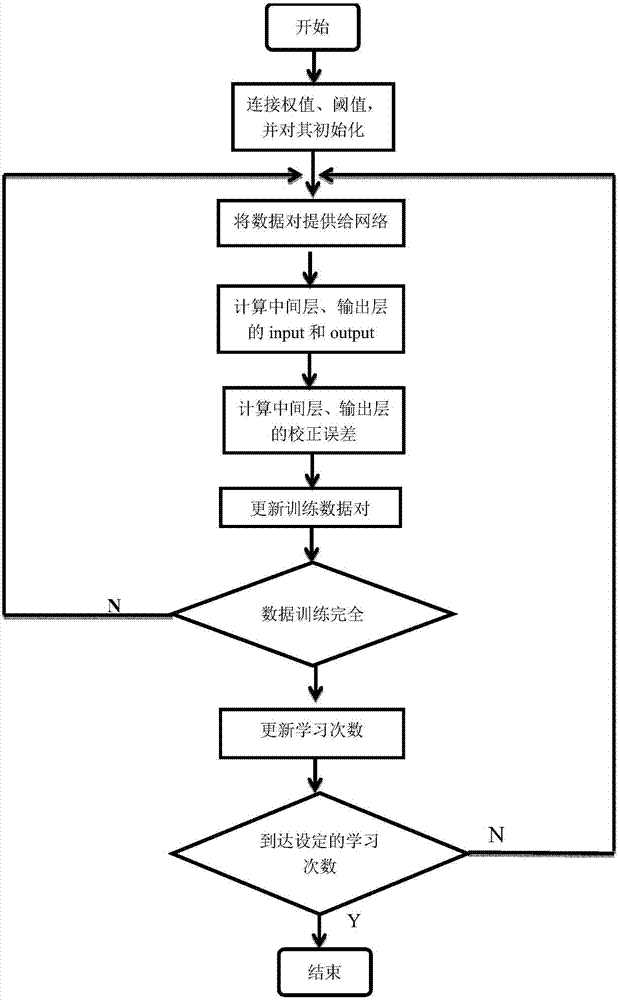
其中bp网络学习流程如图2所示,选择3蹭bp网络的拓扑结构,其输入层神经元选取荧光光谱图像的像素,然后网络化输入归一化样本数据,参照预测样本的仿真效果,当预测值均方根误差达到一定指标就提前停止训练,直接输出训练好的bp网络模型,如图3所示。
附图说明
图1为荧光光谱测量原理图
图2为bp网络学习流程图
图3为ga-bp建模过程图
具体实施方式
本发明提出了一种血清成分快速准确分析的数据分析方法,为医院提供更加详尽且准确的临床诊断技术。这种方法所采用的三维建模的方法,有效的避免因将三维数据平铺城二维过程中丢失有效信息,能更加全面分析样品的信息。而荧光光谱数据分析具有分析速度快、无接触、无破坏和结果稳定等优点。为医生可以准确诊断和治疗提供了决策依据和技术支撑。
为达到上述目的,本发明的实施采用了以下技术方案:
步骤1,受试者清晨空腹静脉抽取的方法获得人体血清样本,再用纯净水混合稀释得到血清的样本,让光源的光透过激发光单色器生成激发光波长,样品血清中的荧光物质被激发后产生荧光;
步骤2,激发光与发射光探头呈直角排列,让荧光通过发射光单色器作用于检测器上,得到相应的电信号,经放大后记录下来,如附图1所示。再以曲线或者数字的形式显示出来,利用插值法去除三维荧光光谱中的瑞利散射光,保留荧光光谱中有用的荧光信息;
步骤3,利用s-g多项式平滑法对处理后的三维光谱曲面数据预处理,将二维s-g平滑法移动窗口内的数据向量矩阵扩展为数据矩阵,通过窗体内的非中心点来;
步骤4,利用平行因子算法(parafac)构建三维模型,然后基于相关系数分析的局部回归方法,提取三维光谱中的相关系数分析,采用ga-bp建模的方法,进行分析预测
其中插值法去除三维荧光光谱中的瑞利散射光,包括使用瑞利散射山峰两侧的数据点来拟合散射带的数据点。
具体步骤如下
步骤1:确定散射的区域,散射区域一般分布在发射波长等于1倍或者2倍激发波长处及其邻近区域(±10~15nm)。
步骤2:确定了散射区域后,将这两个山峰带区域的荧光数据置零,根据散射带两侧的数据来拟合出散射带的荧光光谱数据。
步骤3:依据已知的数据点找到一组拟合多项式进行拟合,选用低次且足够光滑的样条插值处理三维荧光光谱数据,样条插值函数使用分段多项式进行插值,其中插值函数既是低阶分段函数,又是光滑函数。
处理光谱数据时,会在光谱的待处理点前后选取一段数据,连续奇数个点构成一个窗口,并且使点处理点位于窗口中心,用这奇数个点去拟合窗口的中心点,将窗口从前往后依次移动一位,重复上述过程。
其具体的方法是:
步骤1:在三维荧光光谱中选取一个矩阵平滑窗口,使得窗口包含(2p+1)×(2q+1)个数据点,其窗口的数据点可以表示为:
(a-p,b-q,x(a-p,b-q,))…(a-p,b0,x(a-p,b0,)),…,(a-p,bq,x(a-p,bq,))
.....
(a0,b-q,x(a0,b-q,))…(a0,b0,x(a0,b0,)),…,(a0,bq,x(a0,bq,))
.....
(ap,b-q,x(ap,b-q,))…(ap,b0,x(ap,b0,)),…,(ap,bq,x(aq,bq,))
其中am(m=-p,...,p)为第m个发射光谱波长,bn(n=-q,...,q)为第n个激发光谱波长,x(am,bn)(m=-p,...,p,n=-q,...,q)为数据点(am,bn)的荧光强度。
步骤2,在拟合窗口中建立一个新的坐标,以窗口数据的中心点(a0,b0,x(a0,b0,))为坐标系的原点,发射波长a的方向为横坐标,激发波长b的方向为纵坐标,
选取savizky-golay多项式拟合的二元h次多项式曲面为:
其中d为系数矩阵,平滑窗口有(2p+1)×(2q+1)个数据点,将数据点代入到上式得到方程组
其中m=-p,-p+1,...,0,p-1,p;n=-q,-q+1,...,o,q-1,q构建新的矩阵a:
利用最小二乘算法求解d的最优值:
计算窗口内各点的平滑值:
其中,将激发发射的荧光矩阵与化学计量学二阶校正方法相结合,充分利用二阶校正方法的二阶优势,用“数学分离”代替“化学分离”,能够快速并且简单的得到准确的定量结果
第一步,将n个血清样本的f个成分的荧光数据的三线性模型表示为:
其中xijk为第i个血清样本在发射波长j、激发波长k处的应该强度,f代表组分数;aif为第i个血清样本中第f个成分的相对浓度值;bjf为第f个组分在波长j处的相对发射光谱值;ckf为第f个组分在波长k处的相对激发光谱值。
第二步,通过平行因子模型的典型的迭代过程确定组分数f的值,并初始化载荷矩阵b和c,
第三步,利用x,b和c,按照
at(i)=(btb,ctc)-1diag(btxi..c)式子,估计矩阵a;
然后根据x、a和c,利用
然后根据x、a和b,利用
第四步就是反复第三步,直到
目标函数
最后,得到相对矩阵a和已知标准浓度矩阵y之间线性浓度关系:y=aβ+e,以及对未知血清样本浓度估计:ynew=anewβ。
并且,采用遗传算法和bp算法(ga-bp)轮流对三维模型模型训练,选取其中220-240nm的波段代入遗传算法模型进项建模,直到看到网络收敛。
抽取方法为:先将所有血清样本按照浓度从小到大的顺序排列,然后从1号开始,间隔5抽取一个样本,对于荧光吸收光谱,预测集为:1-6-11-16-21-26-31-36,共8个样本,余下32个样本作为训练集。
其中bp网络学习流程如图2所示,选择3蹭bp网络的拓扑结构,其输入层神经元选取荧光光谱图像的像素,然后网络化输入归一化样本数据,参照预测样本的仿真效果,当预测值均方根误差达到一定指标就提前停止训练,直接输出训练好的bp网络模型,如图3所示。
- 还没有人留言评论。精彩留言会获得点赞!