基于M-RVM融合动态加权AdaBoost的变压器故障诊断方法与流程
本发明属于变压器故障在线监测技术领域,具体涉及一种基于m-rvm融合动态加权adaboost的变压器故障诊断方法。
背景技术:
随着智能电网的发展与持续增长用电量的需求,电力系统规模与变压器容量不断扩增,致使变压器故障给国民经济造成的损失也在日益增加,因此对变压器的运行状态进行准确地诊断对电力系统的安全运行具有重要意义。目前大多利用油中溶解气体分析(dga)实现电力变压器的内部故障诊断,但这些方法如iec三比值法、罗杰斯比值法存在比值边界过于绝对、编码不全等问题,可能造成故障的误诊断。近几十年来,随着人工智能的发展,人工神经网络、支持向量机等算法在这一领域得到了广泛的应用,但故障诊断准确率较低,究其原因如下:(1)算法层面:神经网络训练速度慢、易陷入局部最小;svm存在稀疏性不强、核函数计算量大等问题;(2)变压器的故障具有多样性、复杂性等特点,运用单一的智能故障诊断方法存在推理能力不足、参数依靠经验选取等问题,导致故障诊断准确率不高。
技术实现要素:
本发明的目的是提供一种基于m-rvm融合动态加权adaboost的变压器故障诊断方法,解决了现有技术中存在的变压器故障诊断准确率低的问题。
本发明所采用的技术方案是,一种基于m-rvm融合动态加权adaboost的变压器故障诊断方法,具体按照以下步骤实施:
步骤1、首先对所采集的油浸式变压器带有类标签的样本集s={(x1,t1),(x2,t2),…,(xi,ti)}进行分类,i属于正整数,每一类按3:1比例分为训练样本l和待测样本u,其中xi=xi1,xi2,xi3,xi4,xi5代表样本属性,xi1~xi5分别对应氢气、甲烷、乙烷、乙烯、乙炔五种属性,
步骤2、对训练样本l和待测样本u分别进行归一化,然后建立m-rvm分类器模型,测试每个训练样本l经m-rvm分类后输出的后验概率,并结合后验概率计算信息熵对训练样本l进行筛选;
步骤3、利用筛选出的训练样本训练多个基于adaboost方法的m-rvm分类器a-mrvm;
步骤4、设x为待测样本中的一个样本,即x∈u,对x进行检测,并在满足条件的情况下动态调整基分类器加权系数,最终利用集成加权强分类器得到待测样本的最终诊断结果。
本发明的特点还在于,
步骤2具体按照以下步骤实施:
步骤2.1、建立m-rvm分类模型:
步骤2.1.1、输入训练样本集l={(x1,t1),(x2,t2)…,(xj,tj)…,(xl,tl)…,(xz,tz)},其中,j=1,2,…z,l=1,2,…z,j≠l,z表示训练样本集l的样本数量,xz为训练样本集l中的最后一个样本,训练样本集满足如下关系:
tj=y(xj,ω)+τj(1)
式中,xj为训练样本集l中的一个样本,在此也表示训练输入向量,tj为训练样本集l中xj对应的输出标签,在此也表示目标值即期望输出值,ω=ω0,ω1,…ωj,…ωz为模型训练权值分布,y为相关向量机预测函数,τj为样本噪声,服从均值为0,方差为σ2的高斯分布,即τj~n(0,σ2);
步骤2.1.2、rvm的输出模型表示为:
式(2)中,ωj∈ω为第j个模型的权值,k(xl,xj)为核函数,xl为训练样本集l中的一个样本,在此也表示训练输入向量;
步骤2.1.3、通过不断迭代求取模型训练权值分布ω;
步骤2.1.4、采用二叉树的分类方法,使用训练样本集建立m-rvm模型;
步骤2.2、利用步骤2.1.4建立的m-rvm模型对训练样本进行测试,计算每个训练样本经过m-rvm测试后输出的后验概率,并根据后验概率计算样本的信息熵并设定样本筛选的信息熵阈值对训练样本进行筛选。
步骤2.1.2中k(xl,xj)采用rbf核函数,其具体形式如下:
式(3)中,φ表示核函数的高度参数,|xl-xj|表示两个输入向量之间的距离。
步骤2.1.3具体按照以下步骤实施:
步骤a、计算整个训练样本集的似然函数p(t|ω):
式(4)中,t=(t1,t2,…,tj,…,tz)t,tz为训练样本集l中xz对应的输出标签,σ(y)=1/(1+e-y)为sigmoid连接函数;
步骤b、假设使公式(2)中ωj服从均值为0,方差为α-1高斯分布,则:
式(5)中,α表示n+1维超参数向量,α=(α0,α1,…,αj,…αz)t,n()表示正态分布函数;
步骤c、利用似然函数式(4)与先验分布函数式(5),得到权值ωj的后验分布函数:
p(ω|t,ασ2)=n(ω|μ,σ)(6)
式(6)中,σ=(σ2φtφ+a)-1表示后验协方差,μ=μ1,μ2,…,μj,…,μz=σ-2σφtφt表示后验均值,φ=[k(xj,x1),k(xj,x2),…,k(xj,xj),…,k(xj,xz)],a=diag(α0,α1,…,αj,…,αz);
步骤d、利用最大边缘化似然函数p(t|α,σ2)对超参数α,σ进行优化,得到ω的最大后验分布:
对式(7)中的α,σ分别求偏导并令其导数为0得到式(8)(9),得到α,σ的迭代公式,从而得到ω的分布:
式(7)(8)(9)中,i为单位矩阵,σjj为σ的第j个对角元素,μj∈μ,αj∈α,
步骤2.1.4具体为:
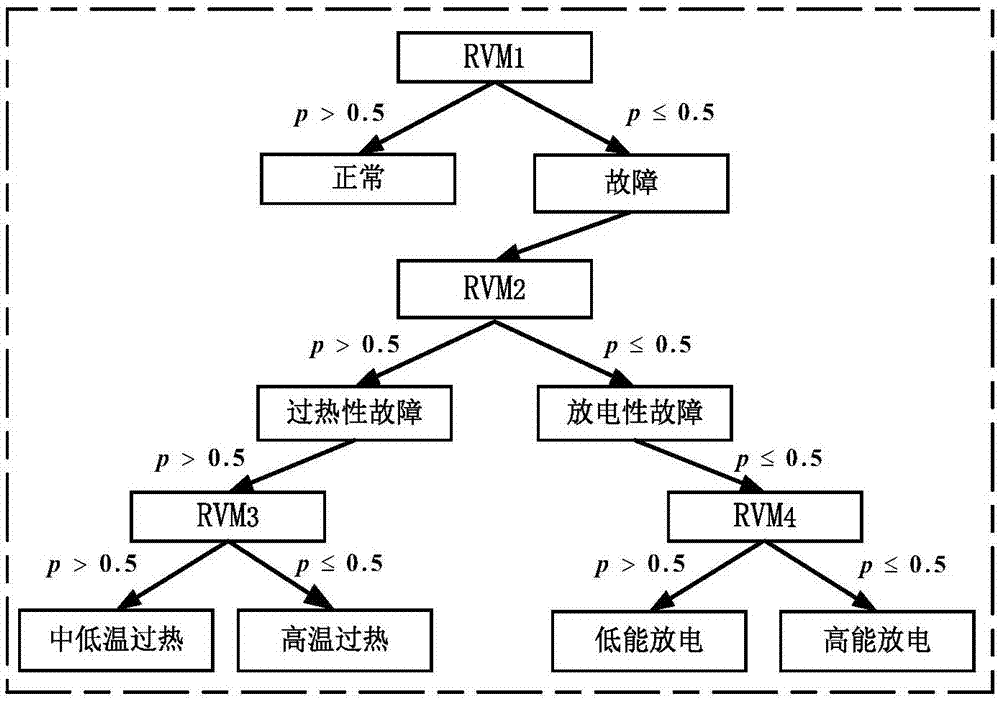
设rvm1分类器用来进行正常状态与故障状态的识别,若rvm1分类器的输出概率大于0.5,则辨识为正常状态,否则为故障状态;rvm2分类器用来进行过热性故障与放电性故障的识别,若rvm2分类器的输出概率大于0.5,则辨识为过热性故障,否则为放电性故障;rvm3分类器用来进行中低温过热与高温过热的识别,若rvm3分类器的输出概率大于0.5,则辨识为中低温过热,否则为高温放电;rvm4分类器用来进行低能放电与高能放电的识别,若rvm4分类器的输出概率大于0.5,则辨识为低能放电,否则为高能放电。
步骤2.2具体为:
步骤2.2.1、计算样本信息熵h(j):
循环z次,计算每个训练样本的信息熵
式中,pjk表示第j个样本分到第k类的概率,k为5个类别标签中的某一类;
步骤2.2.2、计算分类器m-rvm对样本的训练错误率λ,选取总数据的2λ作为信息量富足的数据,定义ω=2λ,对训练样本的信息熵按照从大到小的顺序进行排序,取信息熵前ω的训练样本作为下一阶段adaboost方法的训练集,两种数据的分界点的信息熵即为阈值,记hω。
步骤3具体为:
步骤3.1、输入筛选出的训练样本集d={(x1,t1),(x2,t2),…,(xd,td)},输入基分类器m-rvm,样本权重分布,h=h1,h2,…,hm,…,hm,初始化h1=1/d,其中,d为筛选出的训练样本集d的样本个数;设循环条件为m=1,…,m,m为当前循环轮数,m为最大循环次数;
步骤3.2、根据样本分布h,结合adaboost算法对步骤2中所建立的m-rvm进行m次重复迭代训练,得到m个a-mrvm分类器a-mrvm1,a-mrvm2,…,a-mrvmm,…,a-mrvmm,其中a-mrvmm是第m轮迭代后得到的a-mrvm分类器;
步骤3.3、设dm为第m轮迭代时根据hm得到的训练样本集,hm∈h,在第m轮基分类器的迭代训练过程中,判断所有训练集样本dm中,每一类中分类正确的样本权值之和是否大于分到其他任意类样本的权值之和,若满足,训练下一个基分类器,若不满足,重新开始训练本轮基分类器。
步骤4具体为:
步骤4.1、利用步骤2训练的m-rvm分类器对待测样本x进行分类,并计算信息熵,将计算出来的信息熵与信息熵阈值hω进行比较,若小于信息熵阈值则以m-rvm分类器分类的结果作为最终分类结果,反之则下一步;
步骤4.2、使用多个a-mrvm基分类器对x继续分类,通过计算各分类器对待测样本x的分错率,不断调整每个基分类器的权重系数,最终将所有基分类器加权投票得到最终强分类器进行故障诊断,得到最终诊断结果。
步骤4.2具体为:
步骤4.2.1、利用训练完成的m个基分类器分别对待测样本x进行分类,x∈u,分类结果为e={a-mrvm1(x),a-mrvm2(x),…,a-mrvmm(x)};设定阈值δ,其中,0<δ≤1,统计e中分到各类的数量,如果分到某一类的个数大于m*δ,那么直接把这一类别作为待测样本的最终分类结果,否则,继续下一步;
步骤4.2.2、设定样本的相似度阈值θ,测量样本x与其他样本之间的距离,确定x的相似样本;
步骤4.2.3、采用样本相似度计算待测样本之间的距离:输入样本(x,χ),样本x与χ之间的距离为
步骤4.2.4、判断d(x,χ)与阈值θ之间的大小关系:若d(x,χ)≥θ,判定χ是x的相似样本,否则判定χ是无关样本;
步骤4.2.5、计算每个基分类器对待测样本x的相似样本的分类错误率εm,更新基分类器的权重:αdm=lb((1-εm)/εm);
步骤4.2.6、利用更新权重后的基分类器构成最终强分类器,对待测样本x进行故障诊断,得到最终诊断结果。
本发明的有益效果是,一种基于m-rvm融合动态加权adaboost的变压器故障诊断方法,利用adaboost对m-rvm进行集成,可提高m-rvm的分类性能,结构简单,不易过拟合;根据m-rvm输出的后验概率来定义样本的信息熵从而对样本进行筛选,改善了adaboost对于强分类器的提升效果不明显,甚至会降低分类器的性能的缺陷;针对不同的测试样本,利用每个基分类器对待测样本的分类结果,计算其相似样本,并求得分类错误率,进而调整每个基分类器的权值,可进一步提高故障诊断结果的准确率。
附图说明
图1是本发明基于m-rvm融合动态加权adaboost的变压器故障诊断方法中的m-rvm基分类器框架图;
图2是本发明基于m-rvm融合动态加权adaboost的变压器故障诊断方法中的a-mrvm基分类器训练流程图;
图3是本发明基于m-rvm融合动态加权adaboost的变压器故障诊断方法中的m-rvm融合动态加权adaboost诊断流程图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明一种基于m-rvm融合动态加权adaboost的变压器故障诊断方法,流程图如图3所示,具体按照以下步骤实施:
步骤1、首先对所采集的油浸式变压器带有类标签的样本集s={(x1,t1),(x2,t2),…,(xi,ti)}进行分类,i属于正整数,每一类按3:1比例分为训练样本l和待测样本u,其中xi=xi1,xi2,xi3,xi4,xi5代表样本属性,xi1~xi5分别对应氢气、甲烷、乙烷、乙烯、乙炔五种属性,
步骤2、对训练样本l和待测样本u分别进行归一化,然后建立m-rvm分类器模型,测试每个训练样本l经m-rvm分类后输出的后验概率,并结合后验概率计算信息熵对训练样本l进行筛选,具体按照以下步骤实施:
步骤2.1、建立m-rvm分类模型,如图1所示:
步骤2.1.1、输入训练样本集l={(x1,t1),(x2,t2)…,(xj,tj)…,(xl,tl)…,(xz,tz)},其中,j=1,2,…z,l=1,2,…z,j≠l,z表示训练样本集l的样本数量,xz为训练样本集l中的最后一个样本,训练样本集满足如下关系:
tj=y(xj,ω)+τj(1)
式中,xj为训练样本集l中的一个样本,在此也表示训练输入向量,tj为训练样本集l中xj对应的输出标签,在此也表示目标值即期望输出值,ω=ω0,ω1,…ωj,…ωz为模型训练权值分布,y为相关向量机预测函数,τj为样本噪声,服从均值为0,方差为σ2的高斯分布,即τj~n(0,σ2);
步骤2.1.2、rvm的输出模型表示为:
式(2)中,ωj∈ω为第j个模型的权值,k(xl,xj)为核函数,xl为训练样本集l中的一个样本,在此也表示训练输入向量;
步骤2.1.3、通过不断迭代求取模型训练权值分布ω;
步骤2.1.4、采用二叉树的分类方法,使用训练样本集建立m-rvm模型;
步骤2.2、利用步骤2.1.4建立的m-rvm模型对训练样本进行测试,计算每个训练样本经过m-rvm测试后输出的后验概率,并根据后验概率计算样本的信息熵并设定样本筛选的信息熵阈值对训练样本进行筛选;
步骤2.1.2中k(xl,xj)采用rbf核函数,其具体形式如下:
式(3)中,φ表示核函数的高度参数,|xl-xj|表示两个输入向量之间的距离;
步骤2.1.3具体按照以下步骤实施:
步骤a、计算整个训练样本集的似然函数p(t|ω):
式(4)中,t=(t1,t2,…,tj,…,tz),tz)t,tz为训练样本集l中xz对应的输出标签,σ(y)=1/(1+e-y)为sigmoid连接函数;
步骤b、假设使公式(2)中ωj服从均值为0,方差为α-1高斯分布,则:
式(5)中,α表示n+1维超参数向量,α=(α0,α1,…,αj,…αz)t,n()表示正态分布函数;
步骤c、利用似然函数式(4)与先验分布函数式(5),得到权值ωj的后验分布函数:
p(ω|t,ασ2)=n(ω|μ,σ)(6)
式(6)中,σ=(σ2φtφ+a)-1表示后验协方差,μ=μ1,μ2,…,μj,…,μz=σ-2σφtφt表示后验均值,φ=[k(xj,x1),k(xj,x2),…,k(xj,xj),…,k(xj,xz)],a=diag(α0,α1,…,αj,…,αz);
步骤d、利用最大边缘化似然函数p(t|α,σ2)对超参数α,σ进行优化,得到ω的最大后验分布:
对式(7)中的α,σ分别求偏导并令其导数为0得到式(8)(9),得到α,σ的迭代公式,从而得到ω的分布:
式(7)(8)(9)中,i为单位矩阵,σjj为σ的第j个对角元素,μj∈μ,αj∈α,
步骤2.1.4具体为:
设rvm1分类器用来进行正常状态与故障状态的识别,若rvm1分类器的输出概率大于0.5,则辨识为正常状态,否则为故障状态;rvm2分类器用来进行过热性故障与放电性故障的识别,若rvm2分类器的输出概率大于0.5,则辨识为过热性故障,否则为放电性故障;rvm3分类器用来进行中低温过热与高温过热的识别,若rvm3分类器的输出概率大于0.5,则辨识为中低温过热,否则为高温放电;rvm4分类器用来进行低能放电与高能放电的识别,若rvm4分类器的输出概率大于0.5,则辨识为低能放电,否则为高能放电;
步骤2.2具体为:
步骤2.2.1、计算样本信息熵h(j):
循环z次,计算每个训练样本的信息熵
式中,pjk表示第j个样本分到第k类的概率,k为5个类别标签中的某一类;
步骤2.2.2、计算分类器m-rvm对样本的训练错误率λ,选取总数据的2λ作为信息量富足的数据,定义ω=2λ,对训练样本的信息熵按照从大到小的顺序进行排序,取信息熵前ω的训练样本作为下一阶段adaboost方法的训练集,两种数据的分界点的信息熵即为阈值,记hω;
步骤3、利用筛选出的训练样本训练多个基于adaboost方法的m-rvm分类器a-mrvm,如图2所示,具体为:
步骤3.1、输入筛选出的训练样本集d={(x1,t1),(x2,t2),…,(xd,td)},输入基分类器m-rvm,样本权重分布,h=h1,h2,…,hm,…,hm,初始化h1=1/d,其中,d为筛选出的训练样本集d的样本个数;设循环条件为m=1,…,m,m为当前循环轮数,m为最大循环次数;
步骤3.2、根据样本分布h,结合adaboost算法对步骤2中所建立的m-rvm进行m次重复迭代训练,得到m个a-mrvm分类器a-mrvm1,a-mrvm2,…,a-mrvmm,…,a-mrvmm,其中a-mrvmm是第m轮迭代后得到的a-mrvm分类器;
步骤3.3、设dm为第m轮迭代时根据hm得到的训练样本集,hm∈h,在第m轮基分类器的迭代训练过程中,判断所有训练集样本dm中,每一类中分类正确的样本权值之和是否大于分到其他任意类样本的权值之和,若满足,训练下一个基分类器,若不满足,重新开始训练本轮基分类器;
步骤4、设x为待测样本中的一个样本,即x∈u,对x进行检测,并在满足条件的情况下动态调整基分类器加权系数,最终利用集成加权强分类器得到待测样本的最终诊断结果,具体为:
步骤4.1、利用步骤2训练的m-rvm分类器对待测样本x进行分类,并计算信息熵,将计算出来的信息熵与信息熵阈值hω进行比较,若小于信息熵阈值则以m-rvm分类器分类的结果作为最终分类结果,反之则下一步;
步骤4.2、使用多个a-mrvm基分类器对x继续分类,通过计算各分类器对待测样本x的分错率,不断调整每个基分类器的权重系数,最终将所有基分类器加权投票得到最终强分类器进行故障诊断,得到最终诊断结果,具体为:
步骤4.2.1、利用训练完成的m个基分类器分别对待测样本x进行分类,x∈u,分类结果为e={a-mrvm1(x),a-mrvm2(x),…,a-mrvmm(x)};设定阈值δ,其中,0<δ≤1,统计e中分到各类的数量,如果分到某一类的个数大于m*δ,那么直接把这一类别作为待测样本的最终分类结果,否则,继续下一步;
步骤4.2.2、设定样本的相似度阈值θ,测量样本x与其他样本之间的距离,确定x的相似样本;
步骤4.2.3、采用样本相似度计算待测样本之间的距离:输入样本(x,χ),样本x与χ之间的距离为
步骤4.2.4、判断d(x,χ)与阈值θ之间的大小关系:若d(x,χ)≥θ,判定χ是x的相似样本,否则判定χ是无关样本;
步骤4.2.5、计算每个基分类器对待测样本x的相似样本的分类错误率εm,更新基分类器的权重:αdm=lb((1-εm)/εm);
步骤4.2.6、利用更新权重后的基分类器构成最终强分类器,对待测样本x进行故障诊断,得到最终诊断结果。
本发明一种基于m-rvm融合动态加权adaboost的变压器故障诊断方法,rvm是根据稀疏贝叶斯框架理论所提出的一种强学习算法,该算法不仅具备svm所有优点,还克服了svm所存在的稀疏性不强、核函数计算量大、核函数必须满足mercer条件等缺点,本发明采用二叉树的分类方法,将rvm扩展到多分类,以适应变压器故障多类别的特点。m-rvm融合动态加权adaboost的变压器故障诊断算法,使用多分类相关向量机(m-rvm)作为adaboost的基分类器,首先训练m-rvm分类模型,并测试每个训练样本经过m-rvm分类输出的后验概率,以后验概率来计算样本的信息熵从而设定信息熵阈值,对样本进行筛选;然后利用筛选出的训练样本训练多个基于adaboost算法的m-rvm分类器a-mrvm,未筛选出的样本直接使用m-rvm分类器分类的结果作为最终输出结果;最后在对待测样本进行分类时,首先通过m-rvm分类器进行分类并计算信息熵,将信息熵与信息熵阈值进行比较,若小于阈值则m-rvm分类器分类的结果作为输出,反之则再使用多个a-mrvm基分类器对其继续分类,通过结合每个a-mrvm基分类器对待测样本的分类情况,不断调整基分类器的加权系数,进而加权集成最终强分类器,提升整个算法的诊断准确率。
- 还没有人留言评论。精彩留言会获得点赞!