一种利用近红外光谱技术鉴别金银花产地的方法与流程
本发明涉及一种利用近红外光谱技术鉴别金银花产地的方法,涉及近红外分析检测领域。
背景技术:
金银花为忍冬科植物忍冬(lonicerajaponicathunb)的干燥花蕾或带初开的花。夏初花开放前采收、干燥。金银花自古被誉为清热解毒的良药,常用复方制剂如清热解毒口服液、双黄连口服液、双黄连注射液、痰热清口服液等一般规定以金银花入药。金银花的种植区域主要集中在山东、河南、河北、重庆、陕西、湖北等地。其中,山东省临沂市平邑县为金银花的主产区,种植面积最大,野生品种居多,历史悠久,是农业部命名的“中国金银花之乡”。解世全等用hplc和uv法测定14个产地中绿原酸和木犀草含量、总酚酸和总黄酮含量,均以山东临沂产地最高,综合评价以山东临沂平邑产地金银花的质量最佳。随着近年来金银花价格的持续上涨,平邑金银花作为地理标志产品和道地产地的药材在市场上经常遭遇造假现象,必须建立一种方便快捷的鉴别金银花产地方法。
目前,对金银花产地溯源的研究技术主要有傅里叶变换红外光谱、dna指纹分析技术、矿物元素指纹分析技术、稳定同位素分析等。dna指纹分析、矿物元素指纹分析、稳定同位素分析的分析时间较长、成本高且需要对金银花样品进行前处理,不能对金银花进行无损处理;傅里叶变换红外光谱也需要对样品进行前处理,不能对金银花进行无损处理。
技术实现要素:
本发明克服了上述现有技术的不足,提供一种利用近红外光谱技术鉴别金银花产地的方法。本发明利用近红外光谱技术采集不同地区的金银花原始光谱,采用数学方法减弱或是消除干扰因素对光谱的影响,提取有用信息,建立模型,鉴别金银花产地。
一种利用近红外光谱技术鉴别金银花产地的方法,包括如下步骤:
1)原始光谱采集:在中国金银花主产区采集金银花样品,将金银花样品平铺放置,厚度大于5mm,将光谱仪光斑区域紧贴晾干的金银花样品采集样品的原始光谱;
2)原始光谱的预处理:将步骤1)获得的原始光谱数据剔除异常数据后,采用ks方法将剔除后的光谱数据分为校正集和验证集,以二阶导数和snv的方法共同对校正集和验证集的近红外光谱数据进行处理,获得优化后的校正集样品和验证集样品的光谱数据;
3)最佳主成分数的选择:使用步骤1)中获得原始光谱的数据建立金银花样品的定性分析模型获得最佳主成分数;
4)构建pls-da判别模型:利用步骤2)中获得的校正集样品的光谱数据并选用步骤3)中获得的主成分数来建立pls-da判别模型,并使用验证集样品的光谱数据来验证模型有效性;
5)将待鉴别的金银花样品进行近红外光谱的采集和特征波长的提取,通过二阶导数和snv的方法共同对待鉴别的金银花样品的近红外光谱进行预处理,再通过导入到经过有效性验证过的模型中即可鉴别金银花产地。
进一步的,步骤1)中所述的原始光谱采集使用的是便携式近红外光谱仪micronir1700(美国jdsu公司),以聚四氟乙烯白板为参比,将光谱仪光斑区域紧贴白板采集参比光谱。
进一步的,步骤2)中所述光谱采集的波长范围为908-1676nm,光谱采集重复扫描次数为50次,单次积分时间为8000μs,每个样品采集5次,计算平均光谱作为该样品的近红外光谱。
进一步的,步骤2)中所述剔除异常数据指对步骤1)中获得的原始光谱数据进行主成分分析,剔除不在95%置信区间内的异常样本。
进一步的,所述步骤3)中所述最佳主成分数指的是在定性分析模型中误差值最小时所对应的主成分数。
进一步的,步骤4)中所述验证模型有效性指将pls-da判别模型的阈值设置为0.5,验证集中样本的预测值与实际值之差的绝对值小于0.5,则模型的判别正确,正确率越高模型有效性越高。
有益效果:
(1)近红外光谱具有快速、高效、无损、成本低、适用范围广等特点,特别是不需要对金银花进行前处理步骤,在不破坏金银花结构的情况下就可以进行产地溯源,实现无损化处理。
(2)本发明建立的金银花的判别模型相对于其他需要实验室检测的产地溯源方法能够更快的获得鉴别结果(小于1分钟),可以通过理化方法验证充分证明该鉴别结果的有效性,操作简单,提高鉴别效率。
附图说明
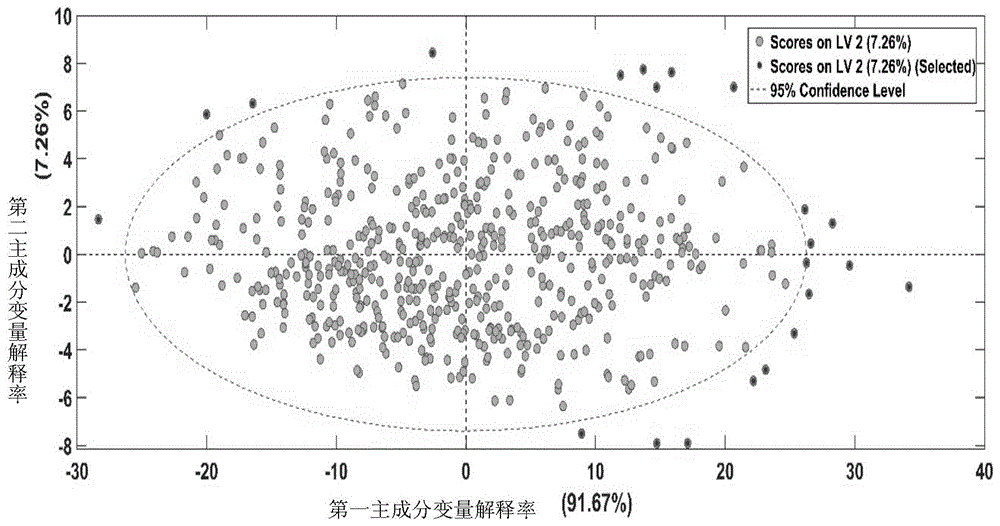
图1金银花样品的主成分得分图。
图2a原始光谱图;b:二阶导数和snv预处理后的光谱图。
图3金银花定性分析模型的rmsecv-lv图。
图4验证集中金银花样品的pls-da模型的判别结果。
具体实施方式
实施例1筛选最佳光谱预处理方案
1材料方法
1.1样品
于收获季节(5-9月份)在中国金银花主产区(河南、山东、河北、重庆)采集金银花样品,每个地区均覆盖多个县乡,共采集金银花近红外光谱数据501个。剔除异常数据后,采用ks(kennard.stone)方法对样品集进行划分,即通过计算平均光谱和每一条光谱间的欧氏距离进行校正集的选择,将光谱差异较大的样品选入校正集,以保证所建立的模型能够具有足够的代表性,并在一定程度上避免建模集样品分布不均。
1.2试验仪器及光谱采集
本研究采用便携式近红外光谱仪micronir1700(美国jdsu公司)以聚四氟乙烯白板为参比,将光谱仪光斑区域紧贴白板采集参比光谱;将晾干的金银花样品平铺放置,厚度不少于5mm,将光谱仪光斑区域紧贴金银花样品采集样品光谱。光谱采集的波长范围为908–1676nm,每次光谱采集重复扫描次数为50次,单次积分时间为8000μs。每次光谱扫描后,移动光谱仪光斑区,重新采集一次,每个样本采集5次,计算平均光谱作为该样品的近红外光谱。
1.3光谱预处理及建模方法
近红外原始光谱不但包含许多与结构相关的信息,还包含许多无关信息和噪声,这些无关信息和噪声将影响模型建立的效果。光谱预处理就是采用数学方法减弱或是消除干扰因素对光谱的影响,提取有用信息,以提高模型分析的准确性和可靠性。在本研究中,对几种常用的预处理方法进行了比较,得到了最优的结果。包括平滑算法(smoothing),导数算法(derivative),标准正态变量(snv)等。
2、结果与分析
2.1金银花的原始光谱和异常样品剔除
对金银花样品的光谱数据进行主成分分析(principalcomponentanalysis,pca),由(图1)可知,前两个主成分的变量解释率分别为91.67%,7.26%。代表了98.93%的变量信息。深色的样本不在95%置信限以内,偏离样本集,为异常样本,所以将这12个样本从建模数据中剔除。
应用ks分类法,将剔除异常值后的489个数据按照3:1的比例划分为校正集和验证集。校正集样品和验证集样品的具体分类信息如表1所示。
表1金银花样品分类信息
2.2光谱预处理结果
按照pls-da判别方法的流程,首先对不同产地金银花校正集样本的分类变量进行赋值,以河南省为例,河南样本赋值1,其他地区赋值0。赋值之后运用回归方法对校正集样本的光谱与样本对应的分类变量进行回归分析,建立光谱特征与分类变量间的pls模型对预处理后的校正集图谱进行回归分析,比较多种光谱预处理方法,根据最优校正模型的主要性能参数,筛选出最佳处理组合,表2为不同光谱预处理方法对不同产地校正集和验证集的验证结果。其中,模型的主成分数是通过press值结合f检验来确定。原始光谱和经二阶导数和snv共同处理后的光谱比较如图2所示。
表2不同预处理方法下构建的pls-da模型的校正及预测结果
3、结论
由表2所示,二阶导数和snv共同使用对光谱矩阵进行预处理,此时模型校正集和验证集的识别率以及拒绝率均达到100%,由图2可以看出,经过二阶导数和snv处理后的光谱差异化更显著,可以看出明显的光谱差异,更有利于样品之间的识别,因此将二阶导数和snv作为最佳预处理方法。
实施例2利用近红外光谱技术鉴别金银花产地
1.1样品
于收获季节(5-9月份)在中国金银花主产区(河南、山东、河北、重庆)采集金银花样品,每个地区均覆盖多个县乡,共采集金银花近红外光谱数据501个。采用ks(kennard.stone)方法对样品集进行划分,即通过计算平均光谱和每一条光谱间的欧氏距离进行校正集的选择,将光谱差异较大的样品选入校正集,以保证所建立的模型能够具有足够的代表性,并在一定程度上避免建模集样品分布不均。
1.2试验仪器及光谱采集
本研究采用便携式近红外光谱仪micronir1700(美国jdsu公司)以聚四氟乙烯白板为参比,将光谱仪光斑区域紧贴白板采集参比光谱;将晾干的金银花样品平铺放置,厚度不少于5mm,将光谱仪光斑区域紧贴金银花样品采集样品光谱。光谱采集的波长范围为908–1676nm,每次光谱采集重复扫描次数为50次,单次积分时间为8000us。每次光谱扫描后,移动光谱仪光斑区,重新采集一次,每个样本采集5次,计算平均光谱作为该样品的近红外光谱。
1.3光谱预处理及建模方法
在本研究中将二阶导数和snv作为光谱预处理方法。
pls-da算法是基于pls回归的判别分析方法,回归模型得到的样本的预测值不是整数,需要设置阈值以判断样本的归属。pls-da以二进制码组来表示样品类属,样品有几类,二进制码组就有几位,每一位称为一个节点,每位节点以“1”表示属于该类,以“0”表示属于其他类。本文中阈值设置为0.5,即预测值与实际值之差的绝对值小于0.5,则判别正确,反之,则判别错误。模型性能的优劣以对验证集样本的准确判别率为标准,正确判别率越高,说明模型性能越好。本研究中光谱的预处理和模型的建立使用matlab2015a和plstoolbox。
2.1金银花的原始光谱和异常样品剔除
对金银花样品的光谱数据进行主成分分析(principalcomponentanalysis,pca),由(图1)可知,前两个主成分的变量解释率分别为91.67%,7.26%。代表了98.93%的变量信息。深色的样本不在95%置信限以内,偏离样本集,为异常样本,所以将这12个样本从建模数据中剔除。
应用ks分类法,将剔除异常值后的489个数据按照3:1的比例划分为校正集和验证集。校正集样品和验证集样品的具体分类信息如表1所示。
2.2光谱预处理
使用二阶导数和snv进行光谱预处理获得校正集图谱(如图2)。
2.3最佳主成分数的选择
金银花样品的定性分析模型结果随着主成分数的变化情况如图3,由图3可知,在建模过程中,模型的误差随着主成分数的增大逐渐变小,当主成分数为4的时候,误差值达到最小,因此选择4作为最佳主成分数。
2.4pls-da判别模型的建立与验证
将采集到的金银花近红外光谱,剔除异常值后,采用ks方法将样品分类,以二阶导数和snv的预处理方法对样品近红外光谱数据进行预处理,主成分选为4,建立pls-da定性分析模型。由图4可以看出,pls-da模型可以将四个产地的金银花样品完全分开。图4中(a)部分为验证集样本中河南样本特征的预测结果,其中验证集中所有的河南样本的分类变量的预测值都接近于1,而其他3个产地的金银花样本分类变量的预测值在0.5以下,偏差均小于0.5。根据pls-da方法的判别准则可知,验证集中所有河南样本均被正确识别,而其他3个产地的样本不具有河南产地样本的特征,说明pls-da判别模型对河南产地样本的判别准确率为100%。图4中(b)、(c)、(d)部分分别为采用上述已建立山东、河北和重庆pls-da判别模型对验证集中相应的金银花样本特征的预测结果。模型对验证集中的山东、河北和重庆样本的判别准确率均为100%。
2.5鉴别金银花产地
将待鉴别的金银花样品进行近红外光谱的采集和特征波长的提取,通过二阶导数和snv的方法共同对近红外光谱的预处理,再通过导入到经过有效性验证过的模型中即可鉴别金银花产地。
3结论
采用近红外光谱技术鉴别河南、山东、河北、重庆地区金银花的产地,使用二阶导数算法和snv算法共同对提取出的光谱数据进行去噪处理,并基于全谱建立pls-da判别模型取得了比较好的识别效果,可以准确判断金银花产地。
本研究所用的便携式近红外光谱仪采集的光谱仪易于操作,适合现场检测,通过适当的光谱预处理方法能够准确识别出四个金银花的产地,,因此具有很大的推广应用价值。
- 还没有人留言评论。精彩留言会获得点赞!