基于Bayesian数据驱动的风机健康状态监测方法与流程
本发明涉及异常状态诊断技术技术领域,具体为基于bayesian数据驱动的风机健康状态监测方法。
背景技术:
伴随着过去十年全球风电装机容量的迅速扩大,全球安装了大量风力发电机组,2015年约有433gw中的370台已经老化并超出保修范围。由于风力涡轮机分布在偏远的野外并暴露在恶劣的工作环境中,因此它们经常出现故障和意外停机。之前的研究报告说,运营和维护(o&m)实践的改进可以使海上和内陆风电场的生命周期成本降低21%和11%。此外,参考文献中提到了到2023年全球运营和维护市场将达到206亿美元的预期。风力发电异常状态诊断方法一直是业内的重要研究领域,设想通过故障诊断系统对已上线风力发电机进行预测性诊断,提前发现风力发电机的亚健康状态,优化安排维护保养策略,提高维保人员的工作效率,在避免出现重大安全事故发生的同时,最大化风电场的在线率并保证风机的安全高效运行。
在国内,相关领域专家学者也对风电故障诊断和维护进行了研究。例如张晓波,张新燕等采用小波分析的方法来判定风机发电中电力电子的故障王斌,董兴辉等研究了基于故障树的专家系统在风电齿轮箱上的应用李辉,郑海起等进行了基于和功率谱的齿轮故障诊断研究。这些研究内容主要是针对风力发电机的一个部件进行故障诊断,极少是从大数据层面出发来对风力发电机进行全面系统的故障诊断。
现有技术主要存在以下缺点:
1.实用价值受到限制,例如要求以高频率采样的特定信号,例如变速箱振动,这在商业风电场中是不可用的;
2.现有故障诊断算法极少有做到真正从大数据层面出发,融入机器学习理论,保证诊断模型的持续有效。并且风能行业对使用当前可用数据(例如由监督控制和数据采集(scada)系统收集的数据)的有效故障诊断方法具有很高的好奇心。
基于此,本发明设计了基于bayesian数据驱动的风机健康状态监测方法,以解决上述提到的问题。
技术实现要素:
本发明的目的在于提供基于bayesian数据驱动的风机健康状态监测方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:基于bayesian数据驱动的风机健康状态监测方法,具体包括以下步骤:
s1:收集风力涡轮机scada数据集并对数据集进行预处理;
s2:结合风力涡轮机实际存在健康状态,标注每个时间状态下已知风力涡轮机健康状态,将其代码存入scada数据库;
s3:采用基于bin方法、基于多元正态分布的方法和基于copula关联函数的bayesian分类模型建立风力涡轮机异常状态诊断模型;
s4:利用scada数据集对风力涡轮机异常状态诊断模型进行训练、拟合优化;
s5:实时采集的风力涡轮机运行数据传送至本异常状态诊断系统进行实施诊断,并输出诊断结果;
s6:赋予诊断结果对应的标签,用户可在此基础上对风机进行实际健康状态确认,根据确认结果对诊断结果标签进行修正并储入历史数据库;
s7:按照需求定期对诊断模型重新拟合,优化异常状态诊断模型。
优选的,所述健康状态为二元健康状态,包括正常和非正常状态。
优选的,所述基于copula的方法可选用不同边际累积分布函数和不同copula模型的组合。
优选的,所述步骤s4中,利用scada数据集对风力涡轮机异常状态诊断模型进行训练、拟合优化具体步骤如下:
s4.1:导入scada历史数据,根据对风力涡轮机健康状态影响的重要程度确定用于建立风力涡轮机异常状态诊断模型的参数:风速、输出功率、发动机转速;
s4.2:采用基于bin方法、基于多元正态分布的方法和基于copula关联函数的bayesian分类模型求取上述各参数组合的异常状态诊断条件概率密度,同时统计历史数据的涡轮机故障先验概率密度,并代入计算公式计算后验条件概率,并通过五折交叉验证的方式提高概率计算的准确性;
s4.3:将风力涡轮机故障发生的后验条件概率与风力涡轮机处于正常状态的后验条件概率比较并进行迭代运算,选择最优异常状态诊断模型;
s4.4:将最优风机异常状态诊断模型存入数据库,以备调用。
优选的,所述步骤s5中,风力涡轮机异常状态诊断模型,具体步骤如下:
s5.1:选择经过预处理、标注完成风力涡轮机健康状态的数据库;
s5.2:导入历史数据库中的历史数据,根据对风力涡轮机健康状态影响的重要程度确定用于建立风电发力机异常状态诊断模型相应的参数;
s5.3:采用交叉验证的方式,依数据量大小合理选择,分别使用基于bin方法、基于多元正态分布的方法和基于copula关联函数的bayesian分类模型进行故障先验概率计算、条件概率密度计算,其中所述条件概率密度计算为选择上述影响风力涡轮机运行的参数维度不同组合的概率密度计算;
s5.4:将异常状态发生的后验概率与正常状态的后验概率比较并进行迭代运算;
s5.5:根据四个度量指标综合评分选择不同设备相应的最优诊断模型;
s5.6:予以存储,以备调用。
优选的,所述四个度量指标分别为:
1、缺失率=正常状态数据被错划分为非正常状态数据的数量/正常状态数据总量;
2、特异性=非正常状态数据正确划分为非正常状态的数量/非正常状态数据总量;
3、错误率=(正常状态数据被错分为非正常状态数据的数量+非正常状态数据被错误划分为正常状态数据的数量)/数据总量;
4、正确率=(非正常状态数据正确划分为非正常状态的数量+正常状态数据正确划分为正常状态数据的数量)/数据总量。
优选的,在所述步骤s6中,实时诊断结果确认为诊断正确的,将其直接录入历史数据库用于风机故障诊断模型优化实时诊断结果为误判诊断的,修改故障标签后录入历史数据库用于风机故障诊断模型优化。
与现有技术相比,本发明的有益效果是:该方法引入bayesian框架来探索仅基于scada数据的风机异常状态辨识算法,在基于scada数据的bayesian框架开发中,使用bin方法、基于多元法线的方法和基于copula的方法开发了三种类型的贝叶斯分类模型,随着数据量的积累,风机异常状态诊断模型不断优化,实现最大化风电场的在线率并保证风机的安全高效运行。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
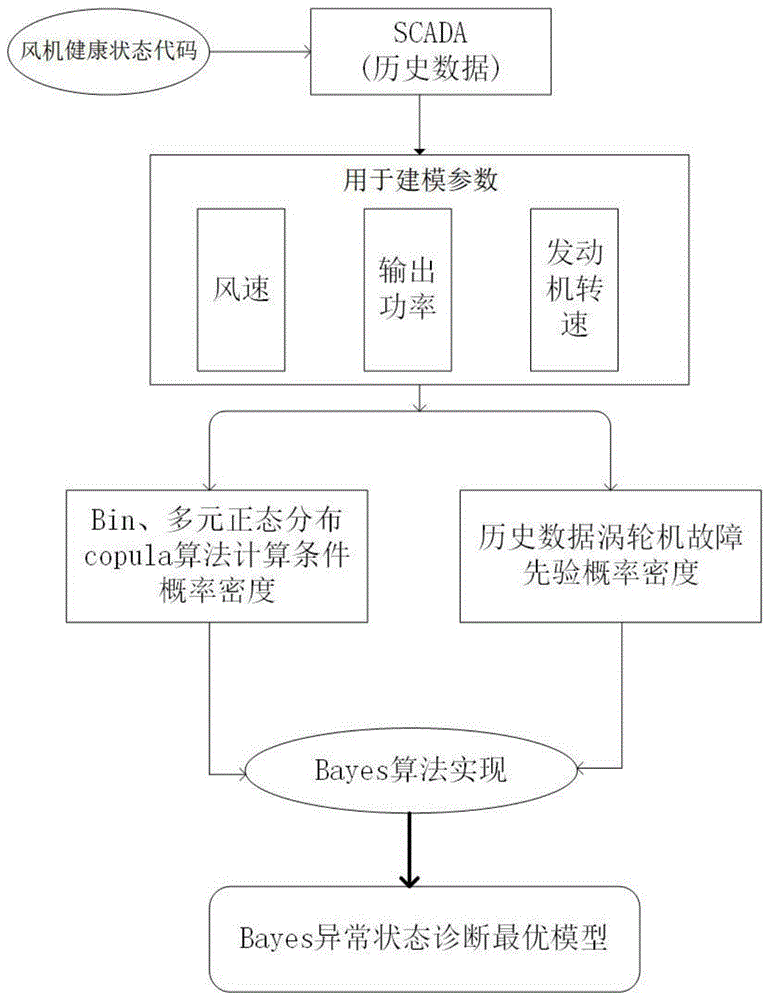
图1为本发明实施例中风力涡轮机异常状态预测性诊断方法的具体流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
实施例1
请参阅图1,本发明提供一种技术方案:基于bayesian数据驱动的风机健康状态监测方法,具体包括以下步骤:
s1:收集风力涡轮机scada数据集并对数据集进行预处理;
s2:结合风力涡轮机实际存在健康状态,健康状态为二元健康状态,包括正常和非正常状态,标注每个时间状态下已知风力涡轮机健康状态,将其代码存入scada数据库;
s3:采用基于bin方法、基于多元正态分布的方法和基于copula关联函数的bayesian分类模型建立风力涡轮机异常状态诊断模型,基于copula的方法可选用不同边际累积分布函数和不同copula模型的组合;
s4:利用scada数据集对风力涡轮机异常状态诊断模型进行训练、拟合优化;
步骤s4中,利用scada数据集对风力涡轮机异常状态诊断模型进行训练、拟合优化具体步骤如下:
s4.1:导入scada历史数据,根据对风力涡轮机健康状态影响的重要程度确定用于建立风力涡轮机异常状态诊断模型的参数:风速、输出功率、发动机转速;
s4.2:采用基于bin方法、基于多元正态分布的方法和基于copula关联函数的bayesian分类模型求取上述各参数组合的异常状态诊断条件概率密度,同时统计历史数据的涡轮机故障先验概率密度,并代入计算公式计算后验条件概率,并通过五折交叉验证的方式提高概率计算的准确性;
s4.3:将风力涡轮机故障发生的后验条件概率与风力涡轮机处于正常状态的后验条件概率比较并进行迭代运算,选择最优异常状态诊断模型;
s4.4:将最优风机异常状态诊断模型存入数据库,以备调用。
s5:实时采集的风力涡轮机运行数据传送至本异常状态诊断系统进行实施诊断,并输出诊断结果;
步骤s5中,风力涡轮机异常状态诊断模型,具体步骤如下:
s5.1:选择经过预处理、标注完成风力涡轮机健康状态的数据库;
s5.2:导入历史数据库中的历史数据,根据对风力涡轮机健康状态影响的重要程度确定用于建立风电发力机异常状态诊断模型相应的参数;
s5.3:采用交叉验证的方式,依数据量大小合理选择,分别使用基于bin方法、基于多元正态分布的方法和基于copula关联函数的bayesian分类模型进行故障先验概率计算、条件概率密度计算,其中所述条件概率密度计算为选择上述影响风力涡轮机运行的参数维度不同组合的概率密度计算;
s5.4:将异常状态发生的后验概率与正常状态的后验概率比较并进行迭代运算;
s5.5:根据四个度量指标综合评分选择不同设备相应的最优诊断模型;
四个度量指标分别为:
1、缺失率=正常状态数据被错划分为非正常状态数据的数量/正常状态数据总量;
2、特异性=非正常状态数据正确划分为非正常状态的数量/非正常状态数据总量;
3、错误率=(正常状态数据被错分为非正常状态数据的数量+非正常状态数据被错误划分为正常状态数据的数量)/数据总量;
4、正确率=(非正常状态数据正确划分为非正常状态的数量+正常状态数据正确划分为正常状态数据的数量)/数据总量。
s5.6:予以存储,以备调用。
s6:赋予诊断结果对应的标签,用户可在此基础上对风机进行实际健康状态确认,根据确认结果对诊断结果标签进行修正并储入历史数据库,实时诊断结果确认为诊断正确的,将其直接录入历史数据库用于风机故障诊断模型优化实时诊断结果为误判诊断的,修改故障标签后录入历史数据库用于风机故障诊断模型优化;
s7:按照需求定期对诊断模型重新拟合,优化异常状态诊断模型。
在本说明书的描述中,参考术语“一个实施例”、“示例”、“具体示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
- 还没有人留言评论。精彩留言会获得点赞!