一种基于边云协同机制的变压器智能故障诊断方法与流程
本发明涉及变压器故障诊断技术,深度学习技术,信息技术领域,具体涉及一种基于边云协同机制的变压器智能故障诊断方法。
背景技术:
变压器是电力系统中成本最高的设备,它能否安全运行不仅关系到电力企业的安全生产和经济利益,而且对社会的影响也无法估量。因此,对变压器故障诊断进行深入研究是十分重要的。
变压器的故障情况一般表现为:由于接点故障、短路等出现油温升高,内部短路故障、高温高热等致使变压器出现喷油,或者出现三相电压不平衡等情况。目前,检测变压器故障方法中的主流方法为溶解气体分析法。但是仅仅根据变压器油中溶解的气体成分来检测变压器内部故障的性质(过热性或放电性)也存在一些不足。例如:通过油中溶解气体法的分析发现的变压器故障多处于变压器已出现明显异常后,但此时变压器故障往往已比较严重;如果溶解的气体含量异常不明显,则无法准确的判断变压器的绝缘状况,还可能延误故障变压器的检修,导致发生更加严重的故障。目前很多算法不能应用多种参数值来全面监测变压器故障导致变压器故障检测实时性低,故障诊断的正确率差强人意。
北京立思辰新技术有限公司与杭州谷逸网络科技有限公司何小明等人发明了一种应用于电力系统变压器的云服务器监测管理方法(公开号:cn106787210a),该方法利用部署在变压器的监测终端实时采集变压器状态数据、并且通过加密通道传送到云服务器,通过该服务器的大数据分析和评估实现变压器的集中智能监测、分析和相关指标的评估和预测,并对异常数据产生实时报警信息,以此实现对变压器故障的检测。该方法保证了数据的加密传输,但对变压器状态进行监测以及异常情况的诊断和告警上没有利用边缘计算和云计算融合技术,增加了云计算中心的计算负担,加大了网络带宽的压力,在系统的实时性上也大打折扣。
边缘端一般部署在终端的物理位置附近。在长期运行周期下,边缘端中算法与周边环境的适应性的维护主要依赖人工定时检修优化为主、自动化手段为辅。这不仅会耗费大量人力物力资源,还会降低变压器故障诊断系统的运行效率,具体的解决方案仍然存在一定欠缺。
技术实现要素:
本发明是为了解决上述背景技术中的存在的问题,提出一种基于边云协同机制的变压器智能故障诊断方法,以期采用多种参数值全面监测变压器故障并利用中心云一边缘端一终端的三层架构协同实现变压器的故障诊断,同时解决边缘端长周期运行下的维护问题,从而提高变压器故障状态诊断的正确率,满足快速化准确化的实际需求,并保证系统的运行效率。
本发明为解决技术问题采用如下技术方案:
本发明一种基于边云协同机制的变压器智能故障诊断方法的特点是应用于由云端、边缘端、各类传感器所组成的网络环境中,并按如下步骤进行:
步骤1、在云端中进行神经网络的训练:
步骤1.1、resnet-18网络和resnet-50网络的训练:
步骤1.1.1、获取包含变压器运行时产生不同故障类型以及正常状态的l个时间段;将所述l个时间段中任意第l个时间段记为tl,将所述第l个时间段tl划分为n个等间隔时刻;在任意第n个等间隔时刻内采集油浸式变压器的m个油中溶解气体含量并作为主要故障特征变量,记为
步骤1.1.2、设定滑动窗口大小为m×m,步长为δ,对所述归一化操作后的变压器故障特征矩阵的前m行进行横向滑动取值,得到n×l-m+1个m×m的矩阵作为第一训练集tres,1;更改滑动窗口大小为(m+k)×(m+k),用相同方式进行取值,从而得到第二训练集tres,2;
步骤1.1.3、定义resnet-18网络,令输入层的节点个数为m×m,输出层的节点个数为q×1;所述云端中采用两个resnet-50残差网络结构,包括:输入层的节点个数为(m+k)×(m+k),输出层的个数节点为q×1,命名为resnet-50-1的网络,以及输入层的节点个数为(m+k)×(m+k),输出层的节点个数为(q+1)×1,命名为resnet-50-2的网络;
步骤1.1.4、定义resnet-18网络的迭代次数为μ0,学习率为λ0,初始化权重为w0,偏置为b0;定义resnet-50-网络和resnet-50-2网络的迭代次数分别为μ1,μ2,学习率分别为λ1,λ2,初始化权重分别为w1,w2,偏置分别为b1,b2;基于第一训练集tres,1,利用梯度下降的反向传播算法迭代更新所述resnet-18网络,从而更新网络的权重和偏置,并得到训练好的resnet-18网络后保存;基于第二训练集tres,2,利用梯度下降的反向传播算法分别迭代更新所述resnet-50-1网络和resnet-50-2网络的权重和偏置,并得到训练好的resnet-50-1网络和resnet-50-2网络后保存;
步骤1.1.5、云端将训练好的resnet-18网络发送至边缘端;
步骤1.2、lstm网络的训练:
步骤1.2.1、获取变压器在工作状态下的连续g个时间段,其中,第g个时间段记为tg,将所述第g个时间段tg划分为n个等间隔时刻;在任意第n个等间隔时刻内采集油浸式变压器的m个油中溶解气体含量并作为主要特征变量,记为
步骤1.2.2、设定滑动窗口大小为(m+k)×(m+k),对所述归一化操作后的变压器特征矩阵按照步长为δ′进行p次横向滑动,得到p×(m+k)×(m+k)的数据作为一个样本,从而得到样本集tlstm;
步骤1.2.3、定义lstm网络,令输入层的节点个数为(m+k)×(m+k)×p,输出层的节点个数(m+k)×(m+k);
步骤1.2.4、定义lstm网络的迭代次数为μ3,学习率分别为λ3,初始化权重分别为w3,偏置分别为b3;基于样本集tlstm并利用梯度下降的反向传播法迭代更新lstm网络的权重和偏置,从而得到训练后的lstm网络并保存;
步骤2、初始化:
步骤2.1、在边云协同机制下,定义边缘端的resnet-18网络的更新时间间隔为t0,云端中resnet-18网络的更新时间间隔为t1;
步骤2.2、在边云协同机制下,在云端设定第一数据缓存区q1和第二数据缓存区q2;所述第一数据缓存区q1只存储当前时间段的上传数据,存储大小为(m+k)×(m+k);所述第二数据缓存区q2存储p个连续时间段的上传数据,存储大小为(m+k)×(m+k)×p;
步骤3、传感器针对故障特征变量采集数据;获取当前变压器在工作状态下第i个时间段,将所述第i个时间段划分为n个等间隔时刻;在任意第n个等间隔时刻内采集油浸式变压器的m个油中溶解气体含量以及k个次要特征变量,从而构成行数为m+k,列数为n的运行数据;
步骤4、对所述运行数据进行归一化操作,得到运行矩阵;利用大小为m×m的滑动窗口对所述运行矩阵进行横向滑动,并取第n-m+1个矩阵,得到大小为m×m的第一故障特征矩阵;同样利用大小为(m+k)×(m+k)的滑动窗口对所述运行矩阵进行横向滑动,并取第n-(m+k)+1个矩阵,得到大小为(m+k)×(m+k)的第二故障特征矩阵;
步骤5、所述边缘端将所述第二故障特征矩阵通过tcp/ip网络上传云端进行储存;
步骤6、所述云端判断网络传输过程中的第二故障特征矩阵是否需要进行丢包补偿:
步骤6.1、云端不断扫描数据缓存区q1并读取由边缘端上传的第二故障特征矩阵;
步骤6.2、定义接收数据的最大延时tmax;
步骤6.3、判断tmax时间内是否读取到数据缓存区q1中的第二故障特征矩阵;若读取到第二故障特征矩阵,则判断为未发生丢包,并将第i个时间段的第二故障特征矩阵保存到数据缓存区q2后,执行步骤7;若在数据缓存区q1中未读取到第二故障特征矩阵,则判断为第i个时间段的第二故障特征矩阵产生丢包,并执行步骤6.4;
步骤6.4、触发lstm网络,并输入数据缓存区q2中的(m+k)×(m+k)×p个数据,从而利用lstm网络预测出当前第i个时间段丢失的第二故障特征矩阵并存入缓存区q1;
步骤7、云端截取所述第二故障特征矩阵中右上角的m行m列,并将所截取的矩阵扩充到所述第一训练集tres,1中,将第二故障特征矩阵扩充到所述第二训练集tres,2;
步骤8、云端判断resnet-18残差网络是否需要更新:
步骤8.1、定义云端当前更新次数为第j次更新,并初始化j=1,则第j-1次更新后的网络为所述步骤1.1.4中的resnet-18网络;定义云端相邻两次更新之间的resnet-18网络的运行计时参数为tcloud,并初始化为“0”;
步骤8.2、对tcloud进行计时;判断tcloud<t1是否成立,若成立,则表示所述云端resnet-18网络不用更新,并执行步骤9;否则,执行步骤8.3;
步骤8.3、基于所述步骤7中扩充后的第一训练集tres,1,训练第j-1次更新后的resnet-18网络,从而得到第j次更新后的网络参数并保存至云端;
步骤8.4、将j+1赋值给j,并对tcloud清零后,重新执行步骤8.2;
步骤9、所述边缘端判断resnet-18残差网络是否需要更新:
步骤9.1、定义边缘端当前更新次数为第γ次更新,初始化γ=1,则第γ-1次更新后的网络为所述步骤1.1.5中的resnet-18网络;定义边缘端相邻两次更新之间的resnet-18网络的运行计时参数为tedge,并初始化为“0”;
步骤9.2、对tedge进行计时;判断tedge<t0是否成立,若成立,则表示边缘端不更新网络,并执行步骤10;否则,执行步骤9.3;
步骤9.3、所述边缘端通过tcp/ip网络从云端中获取最新一次resnet-18网络更新训练后的网络参数,并更新到边缘端的resnet-18网络中;
步骤9.4、将γ+1赋值给γ,并对tedge清零后,重新执行步骤9.2;
步骤10、将所述步骤4中大小为m×m的第一故障特征矩阵输入边缘端的resnet-18网络中,经过全连接层的分类层,输出发生故障状态类型或正常状态;
步骤11、定义第i个时间段边缘端resnet-18网络的输出概率为pi={pi,1,pi,2…pi,q};其中,假定第一个输出为正常状态,即pi,1为正常状态的输出概率,则pi,2,pi,3......pi,q分别为故障类型1至故障类型q-1的输出概率;定义第i个时间段边缘端的resnet-18网络中第α个输出的输出概率pi,α与第β个输出的输出概率pi,β之间差值绝对值的最大值为δpi,α=max{|pi,α-pi,β|},α,β∈1,2...q且α≠β;定义边缘端resnet-18网络输出概率相差阈值为δ;
步骤12、所述边缘端判断maxpi=pi,1和δpi,1>δ是否同时成立,若同时成立,则表示所述边缘端中的resnet-18网络输出正常状态,并执行步骤19,否则,执行步骤13;
步骤13、所述边缘端判断maxpi=pi,η和δpi,η>δ是否同时成立;若成立,则判断为产生已知故障类型η,并执行步骤14;否则,判断为产生未知故障类型,并转至执行步骤16,其中,η∈1,2...q且η≠1;
步骤14、所述云端将大小为(m+k)×(m+k)的第二故障特征矩阵输入所述云端中已训练好的resnet-50-1网络中;
步骤15、所述云端判断resnet-50-1网络输出是否也为故障类型η;若是,则表示所述边缘端判别的变压器故障类型准确,并执行步骤19,否则,则所述云端产生报警信号,并执行步骤19;
步骤16、所述云端将大小为(m+k)×(m+k)的第二故障特征矩阵输入云端中已训练好的resnet-50-2网络中,将输出得到的新故障类型结果下发至边缘端;
步骤17、所述云端将resnet-50-2网络替换为resnet-50-1网络;
步骤18、重新构建云端中的resnet-18网络,输入节点个数不变,输出层节点增加为(q+1)×1;基于所述步骤7的第一训练集tres,1训练重构的resnet-18网络,并将已训练好的重构的resnet-18网络替换所述边缘端原有的resnet-18网络;重新构建云端中的resnet-50-2网络,输入节点个数不变,输出层节点增加为(q+2)×1,基于所述步骤7的第二训练集tres,2训练重构后的resnet-50-2网络并保存;
步骤19、将i+1赋值给i后,返回步骤3。
与已有技术相比,本发明的有益效果体现在:
1、本发明基于边云协同机制进行故障诊断,边缘端利用主要变量作为轻量级神经网络的输入,对变压器进行故障诊断。当发生故障时,将主要变量和次要变量的数据上传云端中的复杂神经网络进行协同判断。当结果一致,则边缘端直接给出决策方案,当结果不一致,云端提供报警信息,从而显著提高了变压器故障状态诊断准确率。
2、本发明通过边云协同机制定时更新网络参数,云端根据存储历史数据不断定时训练与边缘端保持相同结构的神经网络的参数。在边缘端到达更新预设时间时,边缘端可从云端数据库中读取已训练的与边缘端保持相同网络结构的最新网络参数,解决了边缘端算法长周期维护的问题,保证了系统的可靠性和运行效率。
3、本发明包含边云协同机制下产生丢包的补偿方法,此方法应用于边缘端向云端传输数据过程。若在边缘端向云端传输数据过程中产生数据丢包,采用云端预存长短期记忆网络,利用存储历史数据对丢失的数据进行预测,从而保证了数据的完整性和系统的可靠性。
附图说明
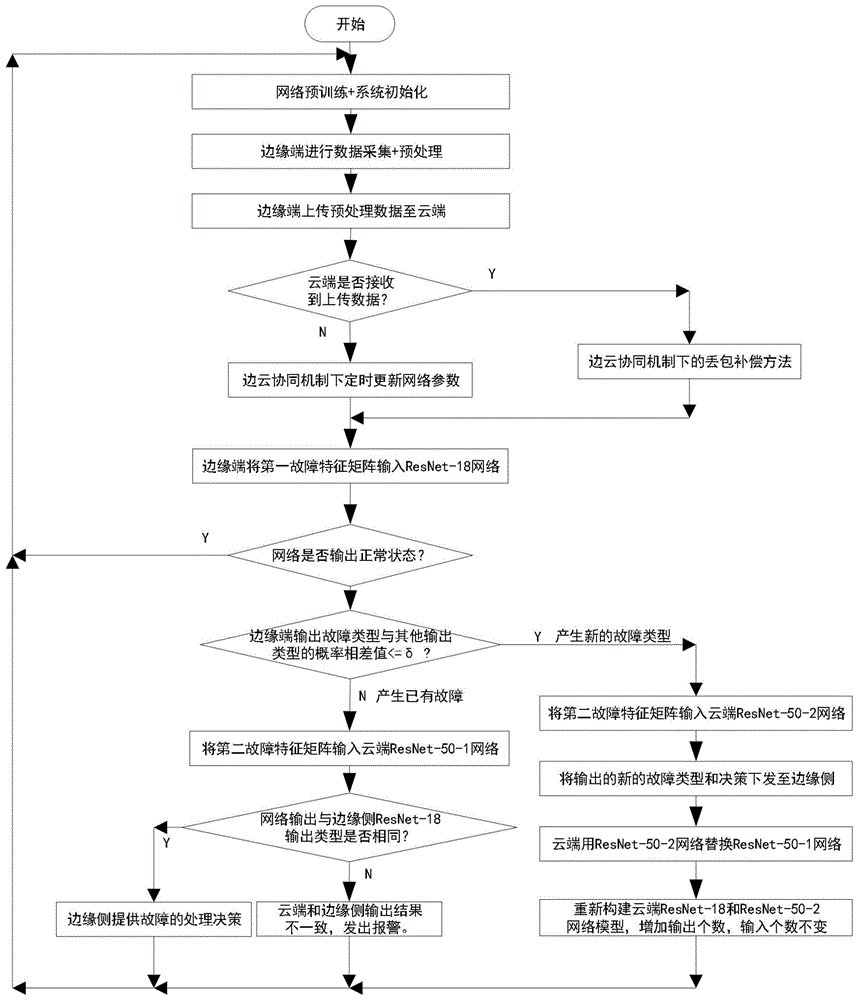
图1为基于边云协同机制的变压器智能故障诊断方法的流程图;
图2为基于边云协同机制下的数据丢包补偿方法的流程图;
图3为边云协同机制下定时更新网络参数的流程图。
具体实施方式
本实施例中,参照图1,一种基于边云协同机制的变压器智能故障诊断方法,是应用于由云端、边缘端、各类传感器所组成的网络环境中,并按如下步骤进行:
步骤1、在云端中进行神经网络的训练:
步骤1.1、resnet-18网络和resnet-50网络的训练:
步骤1.1.1、获取包含变压器运行时产生不同故障类型以及正常状态的l个时间段;将l个时间段中任意第l个时间段记为tl,将第l个时间段tl划分为n个等间隔时刻;在任意第n个等间隔时刻内采集油浸式变压器的m个油中溶解气体含量并作为主要故障特征变量,记为
步骤1.1.2、设定滑动窗口大小为7×7,步长为δ=1,对归一化操作后的变压器故障特征矩阵的前7行进行横向滑动取值,得到9594个7×7的矩阵作为第一训练集tres,1;更改滑动窗口大小为13×13,用相同方式进行取值,从而得到9588个13×13的矩阵作为第二训练集tres,2;
步骤1.1.3、定义resnet-18网络,令输入层的节点个数为7×7,输出层的节点个数为q×1;云端中采用两个resnet-50残差网络结构,包括:输入层的节点个数为13×13,输出层的个数节点为q×1,命名为resnet-50-1的网络,以及输入层的节点个数为13×13,输出层的节点个数为(q+1)×1,命名为resnet-50-2的网络;具体实施中,q=6,即resnet-18的输出包含五个故障类型和一个正常状态;resnet-50-1和resnet-50-2网络的输出包含resnet-18的输出类型和一个新的变压器故障类型;
步骤1.1.4、定义resnet-18网络的迭代次数为μ0,学习率为λ0,初始化权重为w0,偏置为b0;定义resnet-50-网络和resnet-50-2网络的迭代次数分别为μ1,μ2,学习率分别为λ1,λ2,初始化权重分别为w1,w2,偏置分别为b1,b2;基于第一训练集tres,1,利用梯度下降的反向传播算法迭代更新resnet-18网络,从而更新网络的权重和偏置,并得到训练好的resnet-18网络后保存;基于第二训练集tres,2,利用梯度下降的反向传播算法分别迭代更新resnet-50-1网络和resnet-50-2网络的权重和偏置,并得到训练好的resnet-50-1网络和resnet-50-2网络后保存;
步骤1.1.5、云端将训练好的resnet-18网络发送至边缘端;
步骤1.2、lstm网络的训练:
步骤1.2.1、获取变压器在工作状态下的连续g个时间段,其中,第g个时间段记为tg,将第g个时间段tg划分为n个等间隔时刻;在任意第n个等间隔时刻内采集油浸式变压器的m个油中溶解气体含量并作为主要特征变量,记为
步骤1.2.2、设定滑动窗口大小为13×13,对归一化操作后的变压器特征矩阵按照步长为δ′进行p(p=5)次横向滑动,得到13×13×5的数据作为一个样本,从而得到样本集tlstm;其含义是将云端五个连续时间接收的变压器特征矩阵作为一次训练样本来训练网络;当发生丢包时,利用云端lstm网络和数据缓存区中的最新五个连续时间的变压器特征矩阵作为lstm网络输入,预测出当前时间段丢失的变压器特征矩阵;
步骤1.2.3、定义lstm网络,令输入层的节点个数为13×13×5,输出层的节点个数13×13;
步骤1.2.4、定义lstm网络的迭代次数为μ3,学习率分别为λ3,初始化权重分别为w3,偏置分别为b3;基于样本集tlstm并利用梯度下降的反向传播法迭代更新lstm网络的权重和偏置,从而得到训练后的lstm网络并保存;
步骤2、初始化:
步骤2.1、在边云协同机制下,定义边缘端的resnet-18网络的更新时间间隔为t0,云端中resnet-18网络的更新时间间隔为t1;具体事例中,t0>t1,即云端的更新周期要短于边缘侧的更新周期;
步骤2.2、在边云协同机制下,在云端设定第一数据缓存区q1和第二数据缓存区q2;第一数据缓存区q1只存储当前时间段的上传数据,存储大小为13×13;第二数据缓存区q2存储5个连续时间段的上传数据,存储大小为13×13×5;
步骤3、传感器针对故障特征变量采集数据;获取当前变压器在工作状态下第i个时间段,将第i个时间段划分为n个等间隔时刻;在任意第n个等间隔时刻内采集油浸式变压器的m个油中溶解气体含量以及k个次要特征变量,从而构成行数为m+k,列数为n的运行数据;其中,n=96,m=7,k=6;可得到行数为13,列数为96的运行数据;
步骤4、对运行数据进行归一化操作,得到运行矩阵;利用大小为7×7的滑动窗口对运行矩阵进行横向滑动,并取第90个矩阵,得到大小为7×7的第一故障特征矩阵;同样利用大小为13×13的滑动窗口对运行矩阵进行横向滑动,并取第84个矩阵,得到大小为13×13的第二故障特征矩阵;
步骤5、边缘端将第二故障特征矩阵通过tcp/ip网络上传云端进行储存;
步骤6、云端判断网络传输过程中的第二故障特征矩阵是否需要进行丢包补偿,边云协同机制下的数据丢包补偿方法具体如图2所示:
步骤6.1、云端不断扫描数据缓存区q1并读取由边缘端上传的第二故障特征矩阵;
步骤6.2、定义接收数据的最大延时tmax=2;
步骤6.3、判断2s时间内是否读取到数据缓存区q1中的第二故障特征矩阵;若读取到第二故障特征矩阵,则判断为未发生丢包,并将第i个时间段的第二故障特征矩阵保存到数据缓存区q2后,执行步骤7;若在数据缓存区q1中未读取到第二故障特征矩阵,则判断为第i个时间段的第二故障特征矩阵产生丢包,并执行步骤6.4;
步骤6.4、触发lstm网络,并输入数据缓存区q2中的13×13×5个数据,从而利用lstm网络预测出当前第i个时间段丢失的第二故障特征矩阵并存入缓存区q1;
步骤7、云端截取第二故障特征矩阵中右上角的7行7列,并将所截取的矩阵扩充到第一训练集tres,1中,将第二故障特征矩阵扩充到第二训练集tres,2;
步骤8、云端判断resnet-18残差网络是否需要更新,边云协同机制下的云端网络定时更新过程具体如图3所示:
步骤8.1、定义云端当前更新次数为第j次更新,并初始化j=1,则第j-1次更新后的网络为步骤1.1.4中的resnet-18网络;定义云端相邻两次更新之间的resnet-18网络的运行计时参数为tcloud,并初始化为“0”;
步骤8.2、对tcloud进行计时;判断tcloud<t1是否成立,若成立,则表示云端resnet-18网络不用更新,并执行步骤9;否则,执行步骤8.3;
步骤8.3、基于步骤7中扩充后的第一训练集tres,1,训练第j-1次更新后的resnet-18网络,从而得到第j次更新后的网络参数并保存至云端;
步骤8.4、将j+1赋值给j,并对tcloud清零后,重新执行步骤8.2;
步骤9、边缘端判断resnet-18残差网络是否需要更新,边云协同机制下的边缘端网络定时更新过程具体如图3所示:
步骤9.1、定义边缘端当前更新次数为第γ次更新,初始化γ=1,则第γ-1次更新后的网络为步骤1.1.5中的resnet-18网络;定义边缘端相邻两次更新之间的resnet-18网络的运行计时参数为tedge,并初始化为“0”;
步骤9.2、对tedge进行计时;判断tedge<t0是否成立,若成立,则表示边缘端不更新网络,并执行步骤10;否则,执行步骤9.3;
步骤9.3、边缘端通过tcp/ip网络从云端中获取最新一次resnet-18网络更新训练后的网络参数,并更新到边缘端的resnet-18网络中;
步骤9.4、将γ+1赋值给γ,并对tedge清零后,重新执行步骤9.2;
步骤10、将步骤4中大小为7×7的第一故障特征矩阵输入边缘端的resnet-18网络中,经过全连接层的分类层,输出发生故障状态类型或正常状态;
步骤11、定义第i个时间段边缘端resnet-18网络的输出概率为pi={pi,1,pi,2…pi,q};其中,假定第一个输出为正常状态,即pi,1为正常状态的输出概率,则pi,2,pi,3......pi,q分别为故障类型1至故障类型q-1的输出概率;定义第i个时间段边缘端的resnet-18网络中第α个输出的输出概率pi,α与第β个输出的输出概率pi,β之间差值绝对值的最大值为δpi,α=max{|pi,α-pi,β|},α,β∈1,2...q且α≠β;定义边缘端resnet-18网络输出概率相差阈值为δ=0.3;
步骤12、边缘端判断maxpi=pi,1和δpi,1>δ是否同时成立,若同时成立,则表示边缘端中的resnet-18网络输出正常状态,并执行步骤19,否则,执行步骤13;
步骤13、边缘端判断maxpi=pi,η和δpi,η>δ是否同时成立;若成立,则判断为产生已知故障类型η,并执行步骤14;否则,判断为产生未知故障类型,并转至执行步骤16,其中,η∈1,2...q且η≠1;
本实施例中,表一给出了五组不同时间段下,边缘端resnet-18网络的输出类型的概率,并根据步骤11-步骤13的方法,判定输出故障类型。
表一不同时间段下resnet-18网络输出类别概率
步骤14、云端将大小为13×13的第二故障特征矩阵输入云端中已训练好的resnet-50-1网络中;
步骤15、云端判断resnet-50-1网络输出是否也为故障类型η;若是,则表示边缘端判别的变压器故障类型准确,并执行步骤19,否则,则云端产生报警信号,并执行步骤19;
步骤16、云端将大小为13×13的第二故障特征矩阵输入云端中已训练好的resnet-50-2网络中,将输出得到的新故障类型结果下发至边缘端;
步骤17、云端将resnet-50-2网络替换为resnet-50-1网络;
步骤18、重新构建云端中的resnet-18网络,输入节点个数不变,输出层节点增加为7×1;基于步骤7的第一训练集tres,1训练重构的resnet-18网络,并将已训练好的重构的resnet-18网络替换边缘端原有的resnet-18网络;重新构建云端中的resnet-50-2网络,输入节点个数不变,输出层节点增加为8×1,基于步骤7的第二训练集tres,2训练重构后的resnet-50-2网络并保存;
步骤19、将i+1赋值给i后,返回步骤3。
- 还没有人留言评论。精彩留言会获得点赞!